
Abstract
Recommender systems have been very important components to prevent people from dwelling in the overwhelming information. In this paper we analyze the difference between item-based recommendation algorithms and SVR-based collaborative filtering algorithms, and it can be found that item-based method performs much better while the data is not sparse significantly, and SVR-based method performs better while the data is dense and small. On this premise we propose a method that can combine the advantages of these two methods by predicting a small part of ratings using SVR method firstly and then predicting the rest of ratings using the item-based algorithm, which can solve the problem of data sparsity to certain extend. Finally, we evaluate our results compared with the benchmark on different datasets and prove our method’s advantages.
Introduction
For decades, the data for recommend systems to work are usually based on users and items, which are typically displayed as U-I matrices [1]. There are two major benchmarks to realize collaborative filtering (CF) so to explore the relationship between users and items [2] basically. One is the memory-based method [3, 4] including user-based CF and item-based CF. Wang et al. [5] presented a schedule-based user recommendation system with improved K-means algorithm. Their results show that the system improves the recall and precision compared to traditional one. Dixit and Jain [6] introduced another novel framework for real life recommender systems, utilizing k-prototype clustering technique in grouping contextually similar users to get a reduced set and find the contribution of different context features to control data sparsity problem. Gupta and Dixit [7] presented a scalable and optimized recommender system for e-commerce web sites, where similarity measures were used along with efficient rough set leader clustering algorithm, which helped in making accurate and fast recommendations. These methods often calculate the similarity function between users or items to predict the particular users’ unknown or unpaid items rates.
Another way of collaborative filtering is the model-based [8] method, which directly constructs a map between input rates and the predicting rates. Yu et al. [9] proposed a novel robust recommendation method based on kernel matrix factorization, therefore enhance the power of the model, and realize the robust estimation of user feature matrix and item feature matrix. Liu et al. [10] presented a method of kernelizing matrix factorization for collaborative filtering, which applied multiple kernel learning method to capture the non-linear relationships in the rating data for improving the prediction accuracy. Xian et al. [11] used Singular Value Decomposition (SVD) for recommender systems, and it was claimed that the proposed method not only protected privacy information in the raw data but also ensured the accuracy of recommendations. García-Floriano et al. [12] analyzed the prediction accuracy of SVR when applied to predict software enhancement effort. The results shown that the polynomial kernel
However, most of memory-based algorithms suffer from the data sparsity [14, 15] since the majority of datasets lack more than 90% of the data. It means even with the best prediction algorithms, we can’t get a convincing result due to the principle of statistics.
In this paper we utilize a recommend algorithm that combines the KNN item-based CF and the support vector regression (SVR) model, and it can solve the problem of data sparsity. First, we record the majority part of rated items and users and use SVR model [16] to predict a pre-filled U-I matrix, and then, we use the item-based CF algorithm to predict the rest ratings according to the above pre-filled U-I matrix. Therefore, we can get a part of comparable accurate data rather than empty data to deal with the sparse data.
In Section 2, the related work and the proposed model are introduced and in Section 3, we present the evaluation methodology and the performance of the method. Lastly, Section 4 provides the readers with some method conclusions and plans for the future work.
Proposed approach
The idea of the proposed method is originated from the fact that item-based CF method always meets the problem of data sparsity. At the same time, SVR-based method performs well when the data is dense and small. For the above mentioned reasons, the proposed method can combine the advantages of these two methods by using SVR to predict a small part of ratings firstly, and then using the item-based CF algorithm to predict the rest of ratings with pre-filled and rated data, which is not significantly sparse any more.
Notation
The number of users is denoted by
Motivation
Item-based collaborative filtering looks into the set of items that the active user has rated and computes how similar they are to the active item
where “
For each item
The SVR model treats collaborative filtering as a regression problem using Support Vector Machine (SVM) by three ways. One way, the two-dimensional data [user, movie] associated with a rating is treated as a
Both the item-based collaborative filtering and the SVR-based algorithm have their own advantages and particular restrictions, so a method is present which can combine the advantages of both algorithms while prevent the sparsity problem. An item-based method can predict rating fast and has the good scalability, but using one similarity function to evaluate the whole dataset might be not precise especially when the dataset is sparse extremely. When it comes to SVR-based method, we can use the precise power of SVM to classify data or do regression to predict a small amount of missing values, where the time cost of training process and the probability of over-fitting make this method lack of flexibility when the data is large.
a. Dataset with different densities; b. Predicted values from the dense part using SVR model; c. Predict the rest part of U-I matrix using item-based CF.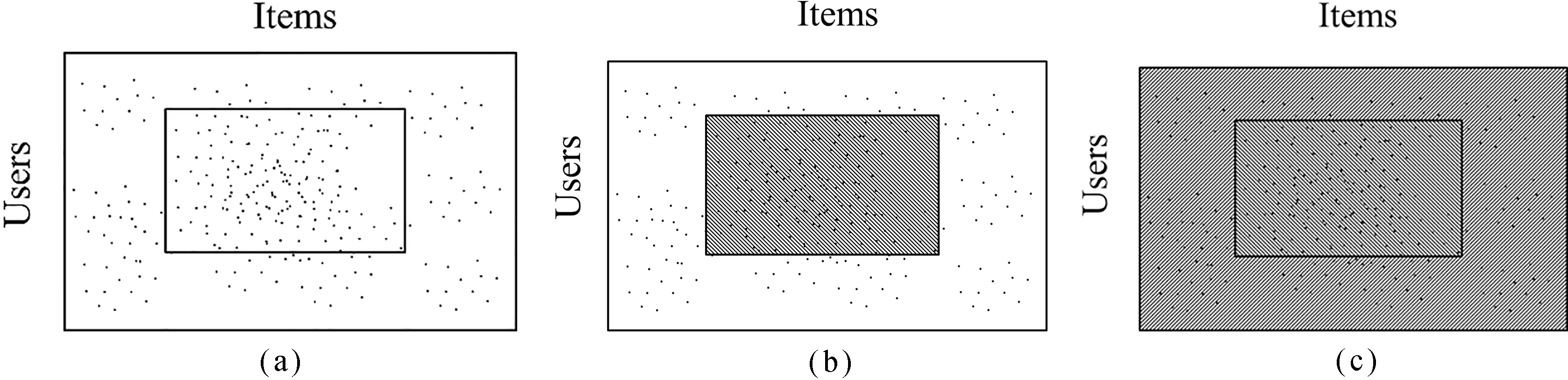
After observing the data, we found the data was composed by comparably dense part and sparse part. The previous prediction method often pre-fill the missing value, as average rating of the same item rated by users or the average rating of the user, to predict the U-I matrix. In this paper, at the first step, SVR model is used to predict the missing values of the dense part, and at the second step, item-based model is used to predict the missing values of the sparse part. The simplified process is denoted in Fig. 1.
In this part, we present our method SVR-based Collaborative Filtering (SVR-based CF), which pre-fills the comparable dense part of the U-I matrix using SVR model and then predicts the rest of missing values in the U-I matrix using KNN item-based algorithm.
The prediction process of the dense part of U-I matrix. a. Select the dense part of U-I matrix corresponding to the red rectangular area, and the sparse part corresponds to the other area; b. Pre-fill the missing values of U-I matrix with the average rating of the corresponding item rated by all users; c. Train SVR model according to the dense part of U-I matrix which has been pre-filled; d. Update each pre-filled missing value with the rating predicted by SVR model; e. Output the predicted dense part of U-I matrix, the red rectangular area.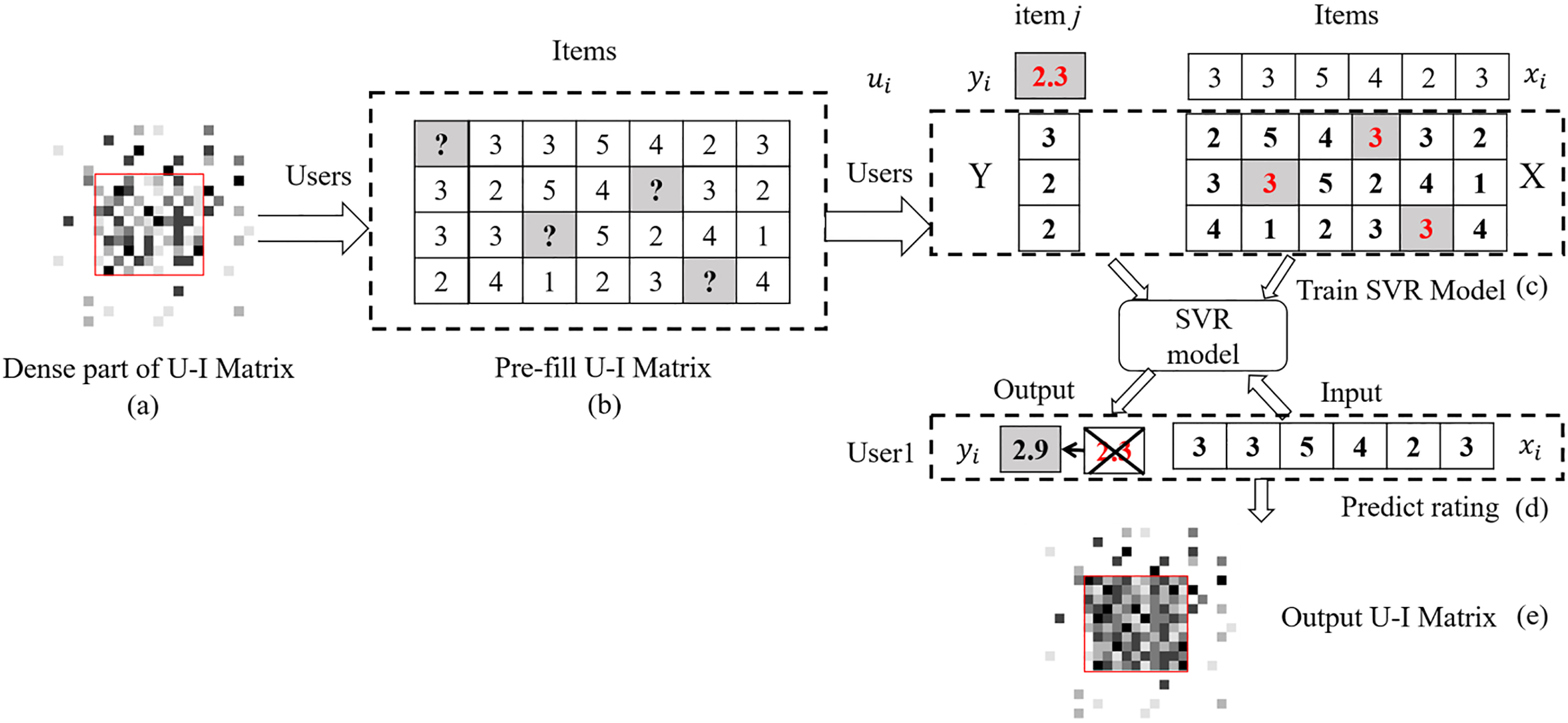
The first step, we need to choose the dense part of a dataset, i.e. the red rectangular area shown in Fig. 2a. We calculate the rated number for each user denoted as
The algorithm of SVR-based collaborative filtering
Dataset attributes
Finally, given the number of missing values
Datasets
We evaluate the results of the proposed method with different datasets, of which attributes are shown in Table 2. The sparsity value means the number of missing values divided by the U-I matrix size, i.e.
where
The MovieLens [21] and ML-latestaremovie datasets [22], which represent movie ratings, range from 1 to 5 as discrete integers. The jester dataset [23] is an online joke recommender system with ratings range from
In the experiments, we use five-fold cross-validation to evaluate the performance of the presented algorithm. Moreover, we measure the performance by computing the MAE values of different methods,
where
The MovieLens dataset’s MAE values of KNN Item-based method and the proposed SVR-based CF can be seen in Fig. 3. The horizontal axis means different
MAE values for different datasets
MAE values for different datasets
MAE values of MovieLens dataset using KNN item-based CF and SVR-based CF.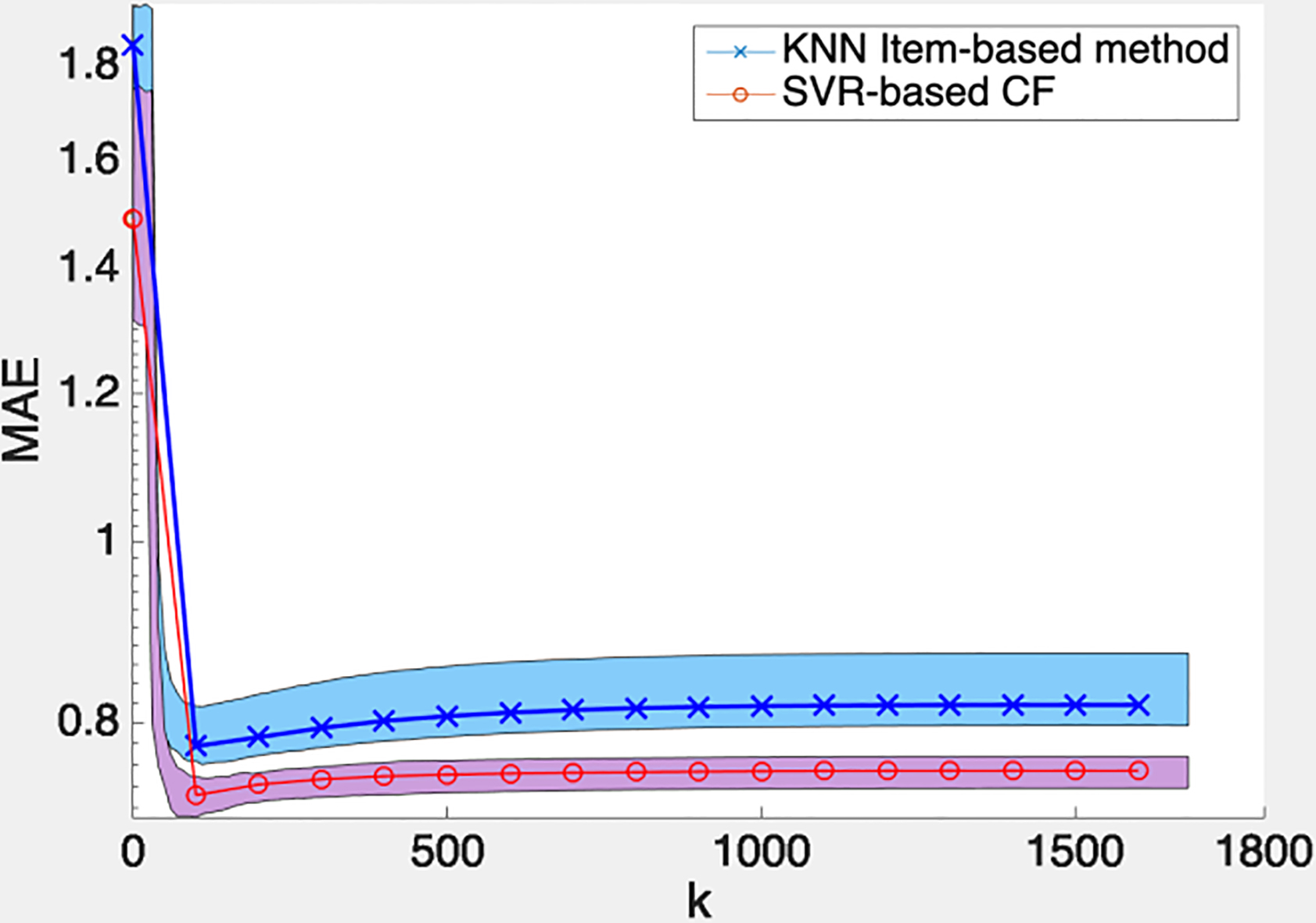
Furthermore, as shown in Fig. 3, the MAE value of the prediction is reduced first, and then prediction error is rising. The reason is that the prediction process selects more similar neighbors, the more accurate. However, when the number of neighbors exceeds a certain degree, the items that the general public likes are included in the calculation for many times, and the error will increase inevitably. Therefore, the experiments on different datasets will change the number of neighbors according to the number of projects owned by the dataset, which better reflects the change of the MAE value generated by the algorithm when the value changes.
In addition, the MAE comparisons of the proposed method SVR-based CF and the traditional KNN item-based method on different datasets are shown in Table 3. It can be found that the method proposed in this paper performs better on most of the above datasets, each of which the sparsity is very high. By predicting the SVR model iteratively and extending the trusted data reasonably, it can avoid the problem that the sparsity of the data set is higher than 90%, which makes it difficult for different algorithms and supports the shortcomings of statistical significance [26, 27]. However, when the sparsity of the Jester dataset is not very high, as shown in Table 2, it means that the missing values in the U-I matrix account for the proportion of the entire matrix size, and the missing score is less than 90%. Therefore, traditional algorithms still stand out in predicting the missing values of such data sets.
Calculation time
Calculation time
The other advantage of the proposed method is that with SVR model, we make it better to utilize the tag information and timing information, and the other data attributes as vectors for SVR to do regression works. In this way, we don’t need analyze the semantics of the attributes anymore and just treat them as special vectors in the training process.
Moreover, the time cost comparisons are shown in Table 4. With more accurate results, the proposed method using the iteratively predicted SVR locally increases the time consuming which is not too large. Meanwhile, it is evidently that using SVR locally is time-saving than using SVR globally.
Although the proposed method achieves better results than KNN item-based method in most cases, it also has some shortcomings. When facing different datasets, we need to choose different amounts of data to train the SVR model because different attributes result in different vector dimension. The SVR model has the possibility of over fitting, so we should choose the number of items as vector number and the user number as data quantity properly, which is also the next work in the future.
In this paper, we present a method to improve the traditional KNN item-based recommendation algorithm. It divides the prediction into two steps of predicting the dense part and the sparse part of a dataset, and combining the precise prediction of SVR and the scalability, time-saving prediction of the item-based algorithm. The proposed method enriches the data in a reasonable way to solve the data sparsity problem, even though the pre-predicted data from SVR-based method are not a hundred percent precise. The experiment results indicate that the pre-prediction of the data to enrich the sparse information are mostly better than lacking information especially when the data is extremely sparse as more than 90% lack of information, with the characteristic of small sample, high dimension and nonlinear. However, the presented method is too agility to decide which part of data should be called dense and which part should be called sparse. In order to make the algorithm better, we need to select the dense part of dataset adaptively rather than manually. In the future, we can calculate each single missing value from the most dense part gradually to the global area of U-I matrix. Another way is to utilize the context information as new vector features, and the SVR model doesn’t need to analyze the semantics of added features so the features will be easily added.
Footnotes
Acknowledgments
This work was supported by the Fundamental Research Funds for the Central Universities of China (Grant No. 3122015C021).