
Abstract
When the traditional C4.5 algorithm deals with the big data with a large number of multidimensional continuous attribute values, it may cause the issue of low classification accuracy with the related discretization method. This paper proposes a novel method to discretize continuous data based on the k-means algorithm. The method generates data clusters by combining continuous, unfeatured data with corresponding class labels, and then takes the approximate boundary points of the cluster as the candidate splitting-points of the continuous attribute. Based on this, the information gain ratio is calculated. Experimental results show that, the proposed K-C4.5 algorithm improves the classification accuracy of the decision tree in comparison with the traditional one.
Introduction
With the rapid development of big data and artificial intelligence technology, more and more industry fields need to use machine learning technology for data mining, such as smart medical, to obtain valuable information from big data. The data complexity is increasing, and the data amount is getting bigger and bigger. Those data involved in the analysis work are no longer just discrete data with clear feature information and limited sample types. On the contrary, a large number of them are continuous data, which results in the difficulty of classification. Moreover, the unit definition of the data attributes is numerous, and the attribute values are not countable.
There are many kinds of machine learning algorithms under different application scenarios. Among them, the C4.5 algorithm has been widely used in the clinical diagnosis [1], behavior analysis [2] and meteorological prediction [3], which thanks for its simple classification rules and clear traceable classification process. The C4.5 algorithm is a decision tree algorithm proposed by Quinlan [4] in 1993, which is an improvement and extension of ID3 algorithm [5] proposed by Quinlan. The C4.5 algorithm uses the information gain ratio instead of the information gain in the ID3 algorithm, which improves the multi-value tendency problem of the ID3 algorithm and improves the classification accuracy of the decision tree. On the other hand, C4.5 algorithm transforms continuous feature attributes into discrete feature attributes, which makes up for the insufficiency of ID3 algorithm in the continuous data processing.
However, the C4.5 algorithm suffers from several performance issues in the face of large-scale data sets with continuous data. One is that the traditional discretization method in C4.5 may require a long execution time. And it is difficult to get the expected classification result quickly. Consequently, this makes data analysis without any timeliness. The other is that, the discretization method may cause the lack of information when calculating the continuous values without features, which makes the final classification accuracy insufficient.
This paper makes some positive contributions to the current discretization method. It proposes two novel continuous-attribute-discretization mechanisms, K-C4.5 and TD-C4.5 to address the issues mentioned above.
The main contribution, K-C4.5 consists of a new discretization method based on the k-means clustering algorithm [6]. The discretization method of K-C4.5 combines the continuous attribute with the category information, which makes the selection of candidate splitting-point more reasonable. Thereby, it improves the classification accuracy. K-C4.5 generates a new data set that contains the continuous attributes and related class labels from original data set. Then, several clusters are constructed based on the k-means clustering algorithm. After that, it is calculated that of the information gain ratio of approximate boundary points between each cluster. The optimal splitting-point of C4.5 algorithm is found to construct the decision tree.
TD-C4.5 (short for Ten-Decile-group-based C4.5) decreases the execution time and improves the classification efficiency in comparisons with the tradition C4.5 algorithm. TD-C4.5 calculates the information gain ratio at 10 equal points after sorting the continuous attribute values.
Extensive experiments have been conducted. The experimental results show that the accuracy of the proposed K-C4.5 algorithm is better than any of traditional C4.5 algorithm and TD-C4.5 algorithm in the scenarios of the data mining which contain plentiful continuous attributes. Also, in classification the data with high-dimensional continuous condition attributes, K-C4.5 improves the accuracy of the algorithm stably.
The rest of this paper is organized as follows. The related literature is reviewed in Section 2, and the traditional C4.5 algorithm and k-means algorithm is introduced in Section 3. Improved C4.5 discretization method is then presented in Section 4, followed by experimental results and analysis. Conclusions are drawn in the last section.
Related work
Aiming at the inefficiency of C4.5 algorithm in processing continuous attribute values, many scholars have improved the discretization method of continuous data of C4.5 algorithm.
The researchers [7] proposed a discretization method based on CAIM criterion to deal with continuous attributes, in this way, the information loss of numerical data in the process of discretization is reduced. This method improves the classification accuracy of C4.5.
The authors [8] utilized the boundary value theorem to obtain the possible splitting-points; the optimal splitting-point was then selected by calculating the information gain ratio and Bayes probability of each point, which improves the efficiency of continuous attribute discretization.
To solve the problems of low efficiency and low classification accuracy of C4.5 algorithm in processing continuous data, the literature [9] proposed an improved C4.5 decision tree algorithm based on splitting criterion, several criterion are formed by randomly extracting training data which has been put back several times, and the optimal classification features of C4.5 decision tree are extracted by multiple splitting criterion, which improves the execution speed of the algorithm for large-scale training data.
However, the optimal classification rule in literature [9] comes from the local optimal solution, which aggravates the “overfitting” phenomenon of C4.5 algorithm. To solve this problem, literature [10] based on Occam’s razor principle, uses substitution estimation to reduce the scale of the C4.5 decision tree, thus reducing the fit of the decision tree to the training data. The author also discretizes the continuous data by using the boundary theorem and replaces the logarithm calculation of information entropy of the original C4.5 algorithm with Gini index, which improves the efficiency of the algorithm.
From the perspective of exploring the relevance of conditional attributes, literature [11] optimizes the C4.5 decision tree algorithm by calculating the average information entropy of one attribute and other attributes to represent the redundancy of this attribute and other attributes, combined with the information gain ratio as the split information of the decision tree, the classification accuracy of the C4.5 decision tree algorithm is improved.
In literature [12], the conditional attributes are merged by using the correlation between attributes, and proposed an improved C4.5 decision tree algorithm based on cosine similarity. Calculate the cosine similarity of two attributes with small difference in information entropy, merge the two attributes whose similarity is within the threshold range, recalculate the information gain ratio of the merged “new attribute”, and participate in the next split calculation, this way effectively reduce the scale of the decision tree and improve the execution efficiency and classification accuracy of C4.5 algorithm.
Literature [13] used Kendall coefficient of concordance to estimate the correlation of conditional attributes, classified conditional attributes according to the rating method, and introduced coefficient to improve the calculation formula of information gain. Experimental results show that the improved algorithm has higher execution efficiency and classification accuracy.
Table 1 summaries the literature reviewed above from the aspects of the effect of key way, technical methods and capabilities.
A summary of literature
A summary of literature
Traditional C4.5 algorithm
C4.5 algorithm is a decision tree algorithm commonly used in data mining. Decision tree algorithm [14] is a classification algorithm, it establishes a tree structure algorithm with classification process by learning and summarizing a group of training data with class labels. Each node on the tree (non-leaf node) represents an attribute, and each branch represents the split path on the attribute. The leaf node at the end of the tree stores the class label of the training data set, which represents the final classification result by layer and layer splitting. By recursively traversing all attributes of the training data set, a decision tree model with classification ability can be established. Figure 1 is a simple application of the decision tree model in medical field.
Simple decision tree model [15].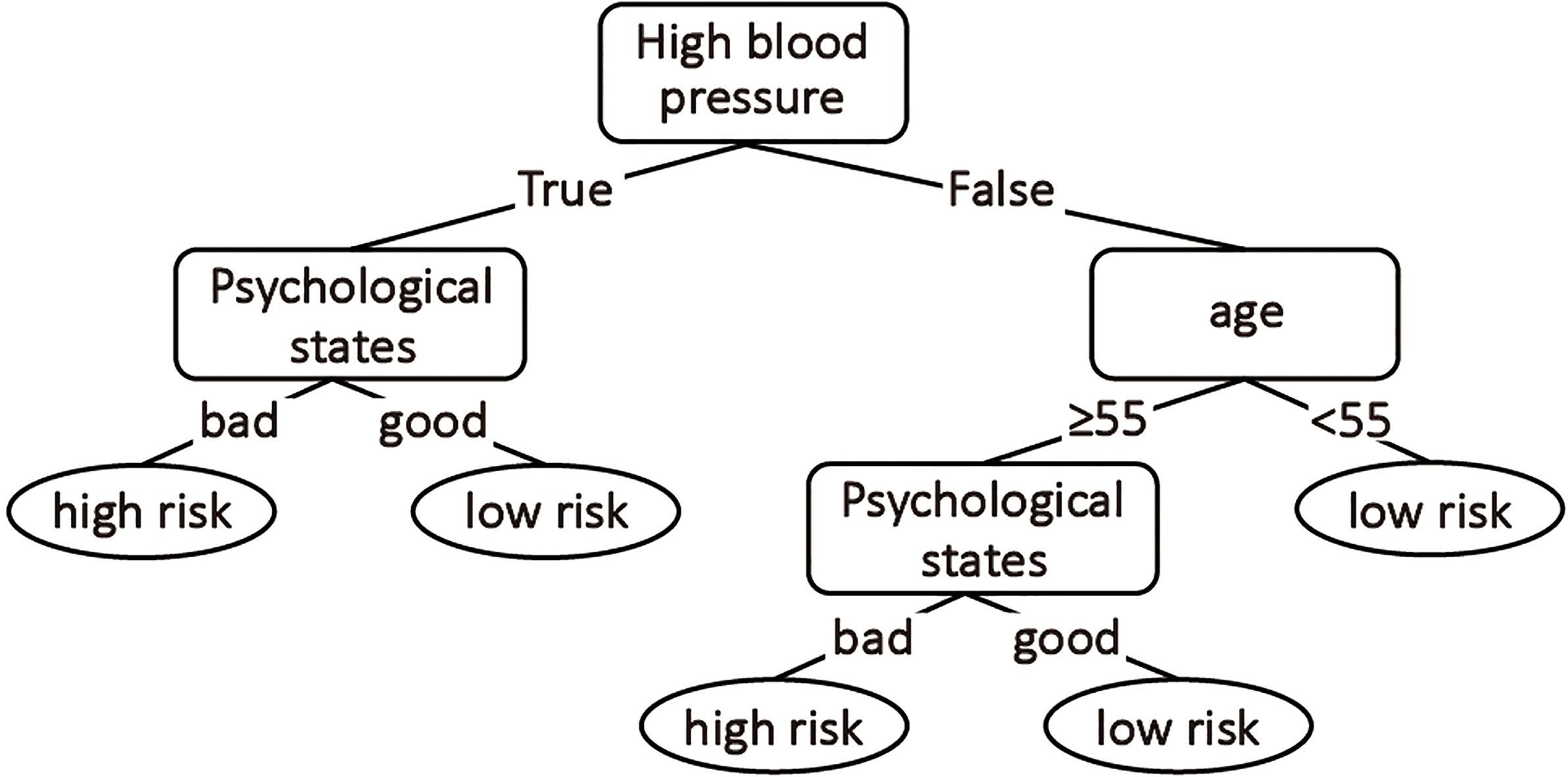
In the decision tree model, the attribute selection measures (splitting criterion) are used to decide which attribute and which type of attribute value to split. C4.5 algorithm uses the information gain ratio as the splitting criterion to evaluate each attribute of the training data set.
Let the training data set
where
Then, the information entropy of data set
Let this training data set have a total of
The smaller the
The split information of the
Let
The information gain ratio of the partition on the
At this point, we choose the attribute with the highest information gain ratio as the split attribute of the decision tree node, the corresponding tuple as the splitting-point, and set the splitting-point as the split node
K-means clustering algorithm is one of the classical clustering algorithms. The core idea is to divide the data objects with similar Euclidean distances into the same cluster by iterative calculation, so that the scattered data points are as close as possible, and the clusters are as independent as possible from the other clusters. K-means algorithm first randomly selects
The original training dataset
The sum of squared errors
Discretization of continuous attributes of C4.5 algorithm
In the calculation of attribute information entropy, if the attribute to be split is discrete, it will be calculated according to the number of values of the attribute itself. If the attribute
Different critical value in TD-C4.5
Different critical value in TD-C4.5
In order to address the issues of the continuous attribute discretization method arisen in traditional C4.5 algorithm, this paper proposes an improved C4.5 algorithm TD-C4.5, which is based on the decile group method. TD-C4.5 is presented in Algorithm 1.
TD-C4.5 algorithm takes digit 100 as a critical value to determine whether an attribute is with continuous values. The basic idea is to decrease execution time together with to ensure the classification accuracy. Experiments have been performed to check the impacts of the value selection on accuracy and run time on large-scale data set cod-rna [16], which has 59535 data of 2 categories. Experimental results in Table 2 show that, there is no significant difference in classification accuracy. However, the higher the critical value, the longer the time consumed. From a rational point of view, for an attribute, if the number of different values is too small, various discrete data may be mistaken as continuous data. If the number is too large, the data sets with a small sample size will lose the significance of discretization. Also, it may prolong the execution time of the algorithm. Thus, digit 100 is selected as critical value in TD-C4.5.
K-C4.5 discretization flow chart.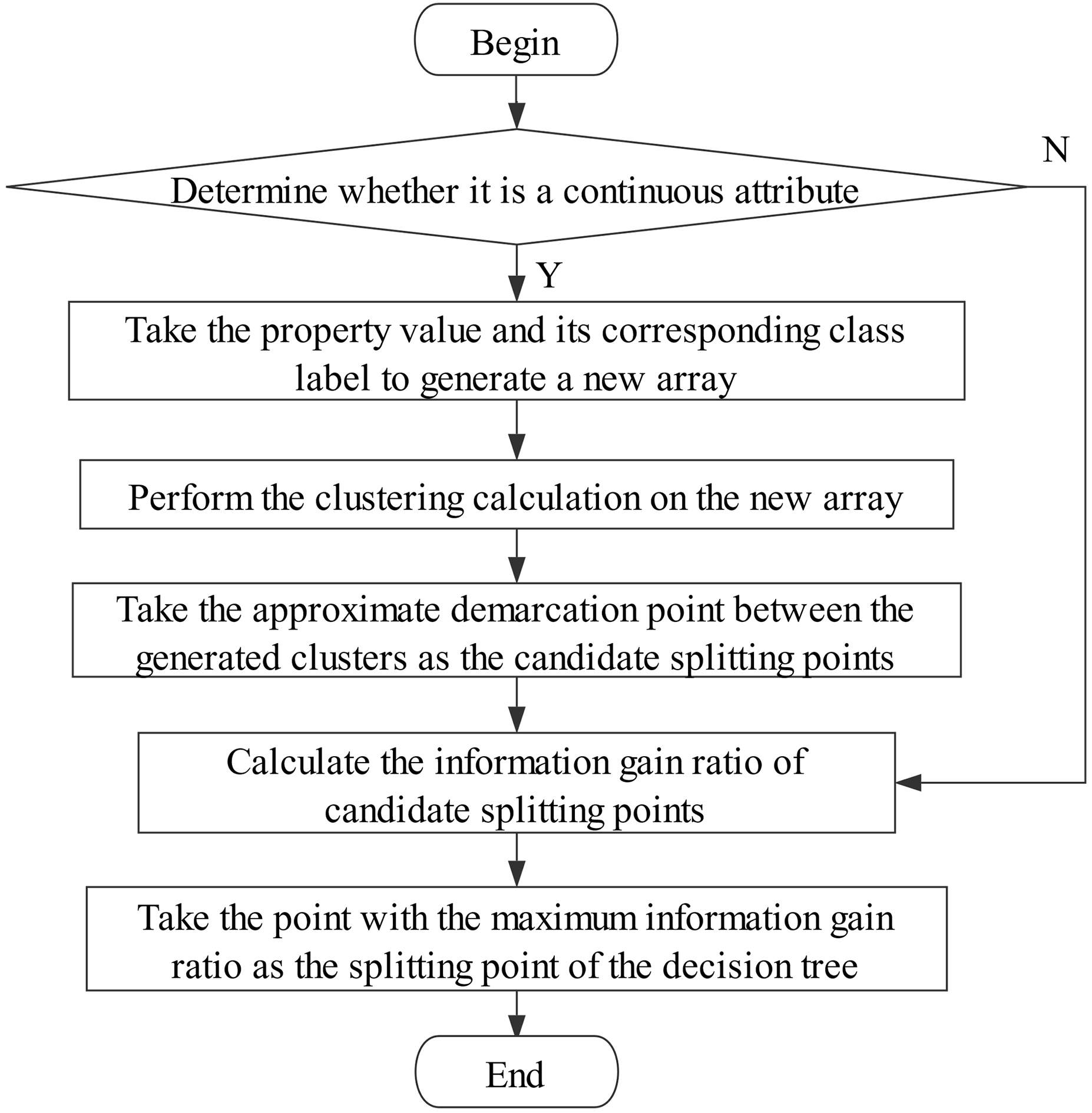
In the traditional C4.5 algorithm, when calculating the continuous attribute information gain ratio, numerical attribute values without classification features are substituted into Eq. (2) as discrete eigenvalues for probability calculation, as a result, features of continuous data are missing and the selected points with the best information gain ratio are not accurate enough. However, k-means algorithm is suitable for processing continuous data. By “characterizing” the data, k-means algorithm improves the rationality of the selection of splitting-points and the accuracy of final classification. K-C4.5 discretization process is shown in Fig. 2.
The idea of K-C4.5 discretization method is as follows: After inputting the training data set, if the attribute value is continuous, a new two-dimensional data set
Experimental results and analysis
Experimental platform and data sets
The computer used in this experiment is Intel Core i7, 8 GB RAM, Windows 10 operating system. The proposed algorithms K-C4.5 and TD-C4.5 and traditional C4.5 are all implemented in Python language.
Since this paper focuses on a large number of continuous data discretization problems, from the perspective of control variables, we select two-class and multi-dimensional continuous attribute data sets for algorithm performance comparison. The test data includes Svmguide3 [17], and three data sets in UCI (UCI Machine Learning Repository: Data Sets) database [18], which are sensor_reading1 (subset of Wall-Following-Robot-Navigation Data), and HIGGS2 (a subset of HIGGS Data data set) and ionosphere data sets.
In the experiment, 70% of each candidate data set was selected as the training data set
Data sets
Data sets
Classification accuracy is an important indicator to evaluate the performance of classification algorithms. The calculation method of classification accuracy is described as below.
In order to check the classification results, the Data set validation method [19] is used. As described above, the validation set
This section compares the classification accuracy of the proposed algorithms K-C4.5, TD-C4.5 with traditional C4.5 algorithms. In order to test the performance of K-C4.5 algorithm under different
Comparison of classification accuracy of three algorithms when 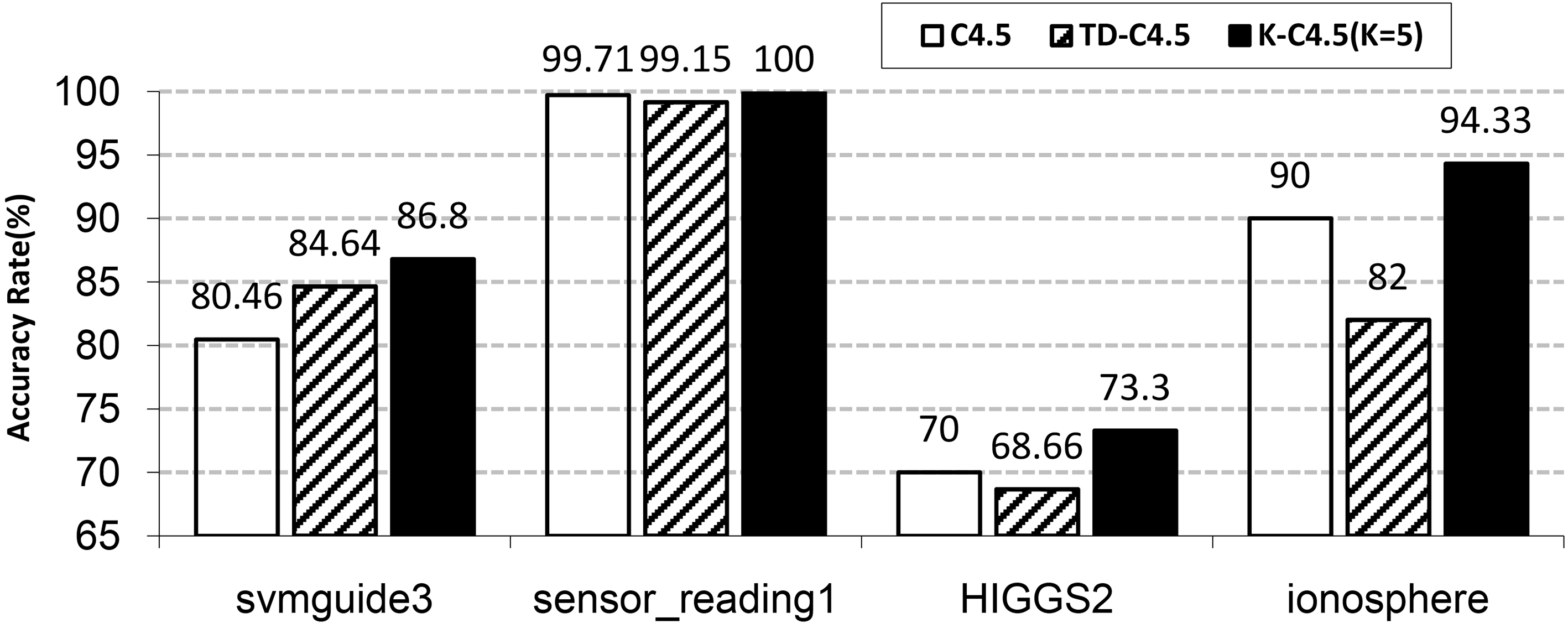
It can be seen from Fig. 3 that when the parameter
Comparison of classification accuracy of three algorithms when 
It can be observed in Fig. 4 that the classification accuracy of the K-C4.5 algorithm on the four data sets is higher than traditional C4.5 and TD-C4.5 when the parameter
Figure 5 depicts that the classification accuracy of the K-C4.5 algorithm on the four data sets is higher than traditional C4.5 and TD-C4.5 algorithms when the parameter
From Figs 3–5, it can be seen that compared with traditional C4.5 and TD-C4.5 algorithms, when the conditional attribute dimension of the data set is small, the accuracy of TD-C4.5 algorithm is better than traditional C4.5 algorithm about 4.18%; when the conditional attributes of the data set are similar, the classification accuracy of TD-C4.5 algorithm and traditional C4.5 algorithm are not much different, only improved by 0.56% to 1.34%; when the conditional attribute dimension of the data set is high, the accuracy of the TD-C4.5 algorithm is lower than that of the traditional C4.5 algorithm, which is 8% lower. It can be seen that the comparison between TD-C4.5 algorithm and C4.5 algorithm, the classification accuracy is related to data set dimension.
In summary, after the TD-C45 algorithm discretizes the continuous attribute of a single column, the calculation scale of the information gain ratio is reduced, and the classification accuracy depends on data set dimension. The K-C4.5 algorithm has higher classification accuracy than traditional C4.5 and TD-C4.5, even if the parameter
The traditional C4.5 discretization method directly calculates the gain rate without taking other related attributes into account. However, K-C4.5 algorithm first extracts the continuous attribute value and its corresponding class label to form a new temporary array, so that every attribute value has its own category information. In the two-dimensional coordinate system, these points have their own positions. K-C4.5 clusters the scattered data and integrates them into several stable groups. After that, approximate boundary points between every two groups are found, these points can be considered as candidate splitting-points to participate in computation of information gain rate. By using the data points that are closer to each other in space, the internal relations of them can be found. Thereby, the better splitting-points can be achieved. As a result, the performance of K-C4.5 is better than the tradition C4.5 with respect to the classification accuracy.
The execution time of the algorithm is another important indicator to measure the performance of the algorithm. This paper further compares K-C4.5 and TD-C4.5, as well as traditional C4.5’s execution time. The experimental results are shown in Table 4.
Comparison of execution time of three algorithms
Comparison of execution time of three algorithms
Comparison of classification accuracy of three algorithms when 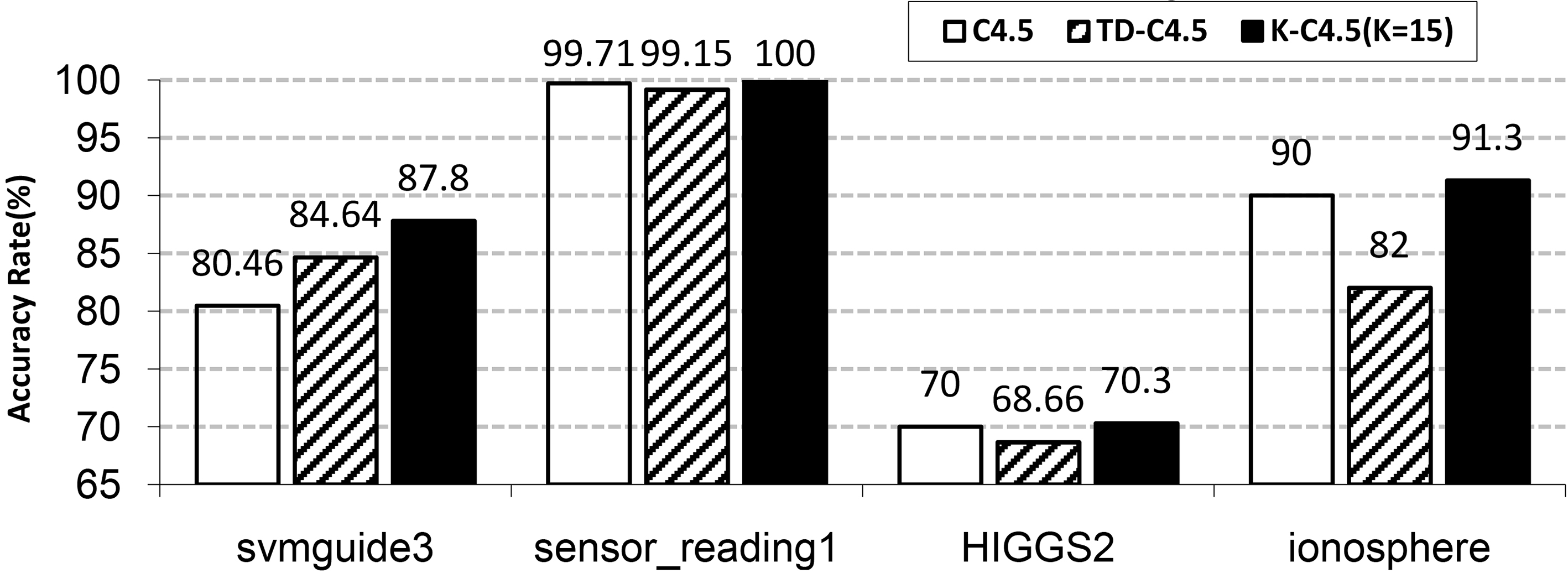
Table 4 shows that the execution time of TD-C4.5 algorithm on data set svmguide3 is 7 seconds less than that of traditional C4.5 algorithm; On sensor_reading1, TD-C4.5 is 1.876 seconds less than C4.5; On HIGGS2, TD-C4.5 is 7.199 seconds less than C4.5; On ionosphere, the execution time of the two algorithms is not much different. It can be seen that TD-C4.5 algorithm reduces the calculation scale of continuous attributes and improves the execution efficiency of traditional C4.5 algorithm. The main reasons for this result are described below.
The traditional C4.5 algorithm needs to calculate the information gain ratio about
However, K-C4.5 algorithm needs to repeat clustering to get the candidate splitting-point before calculating the information gain ratio, then the execution time of the algorithm will increase correspondingly compared with the other two algorithms. Table 2 also shows that the execution time of K-C4.5 algorithm is 34
K-means algorithm is employed in K-C4.5 to deal with discretization of large high-dimensional data with continuous attributes. To understand how the value selection of parameter
Classification accuracy comparison of different 
First, on the dataset svmguide3, as shown in Fig. 6, When
There are two possible reasons for the fact that the classification accuracy is not linearly correlated with the increase value of
On the data set sensor_recording1, as shown in Fig. 6, when
On data set HIGGS2, as shown in Fig. 6, when
As shown in Fig. 6, on the data set ionosphere, when
Due to the different selection of
The traditional C4.5 algorithm suffers from the low classification efficiency and low classification accuracy when dealing with data set with a large number of multi-dimensional continuous values. In order to address this issue, this paper proposes two continuous-attribute-discretization mechanisms, K-C4.5 and TD-C4.5. In comparison with the traditional C4.5 algorithm, K-C4.5 greatly improves the classification accuracy through combination with
Footnotes
Acknowledgments
This work was financial supported in part by Natural Science Foundation of China (grant no. 6136 3016), and Natural Science Foundation of Inner Mongolia Autonomous Region (grant no. 2015MS0605 and no. 2015MS0626).