
Abstract
Community discovery in complex networks has become a core issue in multidisciplinary cross-disciplinary research and has been successfully applied in many areas, such as social network analysis, protein network analysis, and link prediction. This paper proposes a genetic algorithm based on adaptive cross mutation operator for complex network community mining. The population is generated by establishing fitness value calibration and adaptive cross mutation operator, and a good individual is selected from it. An improved adaptive cross mutation operator is proposed to ensure the convergence of genetic algorithm and accelerate the generation of optimal solution while maintaining the diversity of population. Finally, experiments were carried out in multiple real networks to verify the stability and efficiency of the algorithm.
Introduction
At present, many complex systems in the real world can be expressed in the form of complex networks by their connection modes. The components in a system can be regarded as the vertices in a complex network, and the connection relationships between components represent, for example, connected by many computers. Data exchange, internet, social networks of people connected by some kind of social interaction [1], the metabolic network formed by the chemical reactions connected with the consumption of chemical substances [2]. It can be said that mankind has lived in a world full of various complex networks. This kind of network of human society brings great convenience to people’s lives and also brings great negative impacts on human life, such as contagion. The rapid spread of disease, the rapid spread of rumors in the Internet and so on. Therefore, only by fully understanding the structural characteristics of various complex networks can mankind be able to fully grasp the operating mechanism in complex systems. All along, the research on complex networks has attracted scholars from different disciplines to explore and produce a large number of academic achievements. With the deepening of research on complex networks, people find that small networks are commonly found in complex networks [3], that is, the shorter average path length of both existing networks and the higher clustering coefficient of regular networks; Scale-free features, that is, the node degree distribution in the network conforms to the basic statistical characteristics such as the power distribution characteristics. The characteristics of community structure involved in this paper are another important characteristic of complex networks. Community can be understood as a set of nodes with similar functions or with the same ownership. Usually, there are nodes in a community that are closely connected and nodes in a community are connected Loose features.
The complex network community identification method studied in this paper is to reveal the real community structure in complex network. It is of great significance for analysing the characteristics of network topology, finding the hidden rules in the network and mastering the operating mechanism in complex systems. Researchers in various fields have conducted a comprehensive study of community identification in complex networks and related algorithms are emerging [4, 5, 6, 7, 8, 9]. The Tasgin algorithm initializes the population by randomly assigning community identifiers to each node, proposes a single-way crossover strategy for individual cross-operation, uses a random mutation strategy to complete the mutation operation, and selects the modularity function as the objective function to complete the community identification. task. The complex network community discovery algorithm based on clustering fusion genetic algorithm introduces the idea of cluster fusion in crossover operator and improves the traditional crossover operator of simple interchange gene. Large Complex Network Community Discovery Algorithm is based on Genetic Algorithm. The algorithm uses individuals in the population based on the coding of loci to reduce the complexity of discovering community structures and greatly reduce the search space. Social Network Community Discovery Algorithm is based on Genetic Algorithm. The algorithm identifies the connection-intensive node group and the sparse connection node group by optimizing the fitness function. The mutation operator in this method only considers the modification of the correlation between the actual nodes only. Because the existing community discovery algorithm based on genetic algorithm has some defects, such as large computation, high time complexity, slow convergence, and weak search ability. Therefore, it is not suitable for community mining of large-scale complex networks. Therefore, in view of these defects, this paper has improved the existing genetic algorithms in order to achieve fast and efficient community mining on large-scale complex networks.
Genetic algorithm based on adaptive cross mutation operator
In order to solve the problem of complex time complexity and slow convergence in complex network community mining methods, a genetic algorithm based on adaptive crossover operator is proposed to mine complex network communities. According to the improved adaptive crossover mutation rate, the good individuals can be selected from the group according to fitness value calibration and adaptive crossover mutation, and the convergence of genetic algorithm is guaranteed while keeping the population diversity. In addition it also helps to accelerate the generation of the optimal solution and improve the search efficiency of the algorithm.
Encoding
Due to the fact that community mining of complex networks can not be directly processed by genetic algorithms, we have to translate the solution of the problem into chromosomes or individuals in the genetic algorithm through coding operations. Coding operation is the basis of genetic algorithm to deal with the problem, is an individual phenotype conversion to genotype process, which determines the individual’s genotype through which decoding mode conversion to phenotype, while the subsequent crossover, mutation and other genetic operations. The choice also has important implications. In complex networks, an individual’s code is an array or string of bits used to represent some sort of result, also called chromosomes. The position of a gene in a chromosome is called a locus or a gene and it also means that one of the complex networks Node, chromosome corresponds to a division of the complex network, the chromosome solution space corresponding to all possible methods of division, from the resulting solution space corresponding to the chromosome called coding. The mapping of chromosomes into the solution space is called decoding. Currently, the coding methods used in community mining algorithms based on genetic algorithms are based on string-based coding [14] and on the basis of genetic code [15]. In this paper, we use a coding method based on the position of a gene to represent an individual in a population composed of several network communities, that is, an individual code represents the result of dividing an online community.
Initialize the population
When initializing a population, any one of the individuals in the individual selects one of its neighbors as an individual of their alleles to generate a population, which can greatly reduce the search space for community partitioning while allowing the initial solution space to be constant. To the optimal solution space close to speed up the evolutionary process.
Fitness function and selection operator
The evolutionary search process of genetic algorithm has its own unique advantages. It only needs to evaluate the candidate solution according to the fitness function, and does not depend on too much other information, and only determines the subsequent genetic operation according to the fitness function value. The fitness of an individual reflects the advantages and disadvantages of the community partitioning result it represents and can reasonably evaluate the partition of the community structure obtained by the algorithm. In order to quantitatively describe the structure of the network community structure is good or bad, this article uses the widely accepted network modularity function (Q function) as a fitness function of individuals in the group. Although the modularity function has some drawbacks, if the network size is relatively small and only contains some non-hierarchical, non-overlapping modular structures, the extreme degradation problem is not so serious, and the modular optimization method also performs well. If the appropriate weights are assigned to links in complex networks, the resolution limitations and extreme degradation caused by model optimization can be alleviated. The Q function is defined as the difference between the proportion of the actual number of connections in the network in the community and the proportion of the expected number of connections in the community in the network in the case of random connections. The calculation of the
Given an undirected right-of-freedom network
Where
Under normal circumstances, the initial population may exist special individuals fitness value is very large. In order to prevent it from controlling the whole group and misleading the development direction of the group, the algorithm converges to the local optimal solution and its reproduction needs to be restricted. As the genetic algorithm converges gradually near the end of the computation, it is difficult to continue optimizing the selection because the fitness values of individual individuals in the population are relatively close, resulting in the swinging around the optimal solution. In this case, the individual fitness value should be enlarged to improve the selection Capacity, called the fitness value of the calibration, this paper proposes the use of Eq. (2) to calculate fitness values, which can be expressed as:
Calibration of fitness values.
The selection operator is a global search operator in the genetic algorithm. In order to keep the best individual in each generation and accelerate the convergence of the algorithm, the
The choice of crossover probability
The adaptive genetic algorithm can guarantee the convergence of the genetic algorithm while maintaining the population diversity. The Eqs (3) and (4) can be used to dynamically adjust the probability of cross-mutation of individuals, which can be expressed as:
Among them,
Adaptive genetic algorithm fitness value adjustment process has three cases. First, when the fitness value is lower than the average fitness value, it indicates that the individual is a poor performance individual, which can adopt a larger crossover rate and mutation rate. If the fitness value is higher than the average fitness value, it indicates that the individual has excellent performance and can obtain the corresponding crossover rate and mutation rate according to its fitness value. Second, when the fitness value is closer to the maximum fitness value, the crossover rate and mutation rate are smaller. Thirdly, when the fitness value is equal to the maximum fitness value, the value of the crossover rate and mutation rate is zero. These three methods of adjustment are more suitable for the group to be in the late evolutionary stage, but unfavorable to the early stage of evolution because the better individuals in the early stage of evolution are almost in a state of no change, while the fine individuals in this case are not necessarily the optimal ones. The optimal solution, which easily increases the possibility of evolution toward a local optimal solution. To this end, the crossover and mutation probability made further improvements, so that the maximum fitness of the population worth individuals cross rate and mutation rate is not zero, respectively, to
From the above analysis found that adaptive genetic algorithm to maintain population diversity, while ensuring the convergence of genetic algorithms.
In the genetic algorithm, a good strategy of population selection is essential in order to retain good individuals. The good individuals produced by fitness value calibration and adaptive crossover mutation proposed in this paper can be selected from the group. According to the improved adaptive cross-mutation rate, this paper presents IGACD algorithm. Specific algorithm IGACD described as follows:
In the IGACD algorithm, the initial population is first generated and then the network community structure is probed by iteratively performing adaptive crossover and
Experimental results
To verify the validity of the proposed algorithm in this chapter, the IGACD algorithm is now tested on a real network dataset. In these networks, due to the real community structure of Karate, Dolphins, Polbooks and Football, in these four data sets, based on the split GN algorithm [10], FN algorithm based on local modularity optimization [11]. The LPA algorithm [12] for label propagation and the GANET algorithm [13] based on genetic algorithm are compared and analyzed in the aspects of NMI [16], which is the evaluation index of community identification precision and Q. Because the genetic algorithm needs to set the relevant parameters when it is running, the IGACD algorithm also needs to set the general parameters of the genetic algorithm. This chapter draws on the literature and after analysis, given IGACD algorithm parameter settings, which IGACD algorithm population size P is 100, the crossover rate of
Real network data set
Real network data set
Comparisons of NMI accuracy of each algorithm on real network
Table 1 shows the real network data set. Table 2 shows that the community recognition accuracy of each algorithm on four known community structure datasets. It can be seen that in the four networks, IGACD is only in the Dolphins network, its recognition accuracy is slightly lower than that of the GANET algorithm. In other networks, the IGACD algorithm has significantly higher community recognition accuracy than other comparison algorithms. Table 3 shows the intra-community connection tightness of each algorithm on four known community structure datasets. Comparing the IGACD algorithm with other comparison algorithms, it can be seen that the GN algorithm needs to be analyzed globally to obtain the edge medium, and then to complete the community identification through splitting, so the efficiency of the algorithm is relatively low. Due to the strong randomness of LPA algorithm, the recognition quality of its community is affected. The Q value corresponding to the community structure identified by the FN algorithm is superior to the IGACD algorithm, but overall, the IGACD algorithm is superior to the FN algorithm. The GANET algorithm based on genetic algorithm, because of its destructive crossover strategy and mutation strategy with strong randomness in the process of identifying communities, the overall quality of GANET algorithm is not high. According to the comparative analysis of Q value of four real networks through each algorithm, IGACD algorithm has better community recognition ability. Since the population size and the number of iterations are constant, the complex network is usually a sparse network, so the time complexity of the IGACD algorithm is close to O(cn), where
The algorithm compares the Q values of 4 real networks
To further illustrate the effectiveness of the IGACD algorithm, IGACD is now analyzed against the community structures identified by the four real networks. Karate is a network of karate clubs in a university in the United States built around a two-year observation and analysis of an American college karate club. There are 34 members in the club as nodes and the friendship between the members as the edge connecting 2 nodes. Due to disagreements, the club is divided into two new clubs centered on the principal (34 nodes) and coach (1 node). For the Karate network, the NMI value obtained by IGACD is close to 1, and the corresponding community structure is shown in Fig. 2. It can be seen that the IGACD algorithm accurately decomposes the Karate network into two communities.
The community structure identified by IGACD for the Karate Network.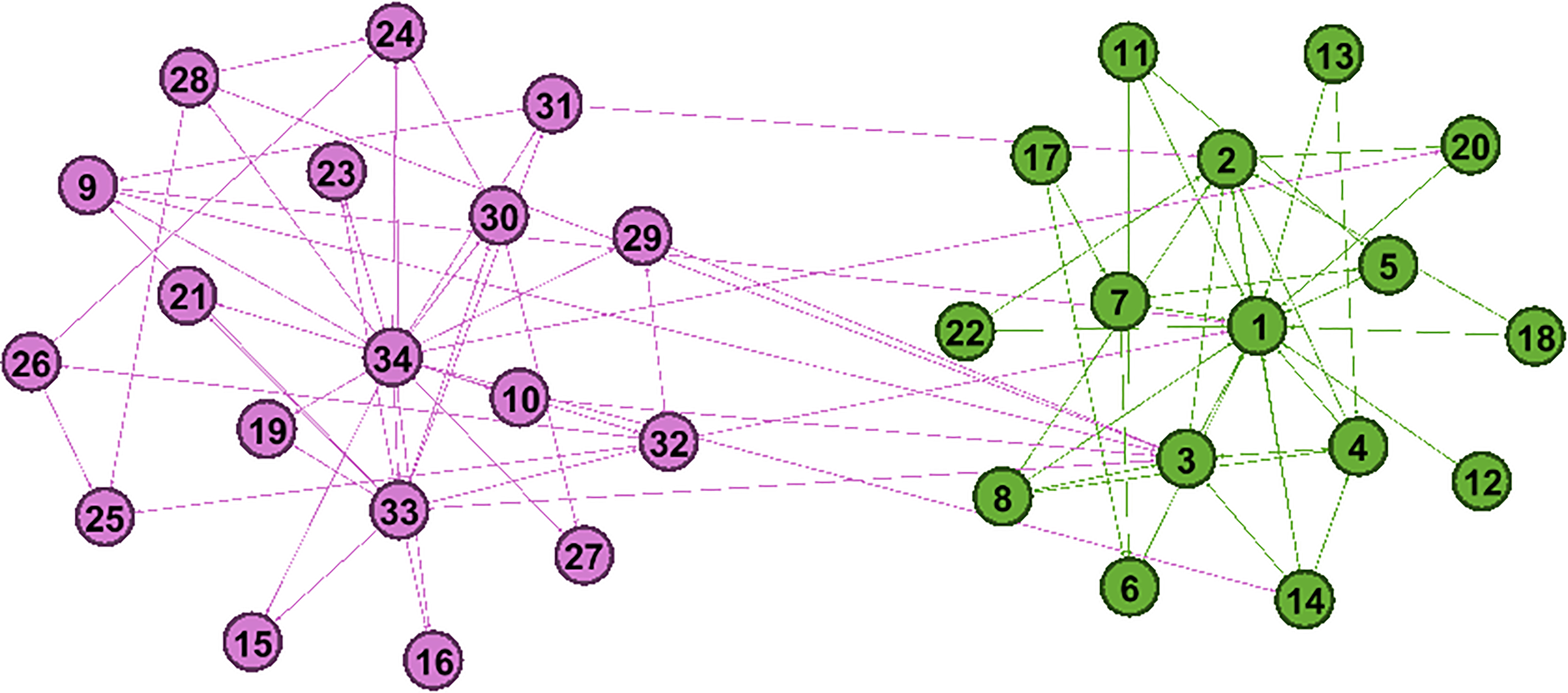
Through experiments on real networks, we can see that the NMI and Q values obtained by IGACD are all excellent, and the community structures obtained by IGACD for Karate, Dolphins, Polbooks and Football networks are also more reasonable. Therefore, it is verified that IGACD The rationality and feasibility of the algorithm. The size of the community in a large-scale real network is generally much smaller than the size of the entire network, so for a large-scale real network, the efficiency of the IGACD algorithm proposed in this paper is very high.
For the problem that the genetic algorithm community identification method is not strong, this paper proposes a genetic algorithm based on adaptive cross mutation operator for complex network community mining. According to the improved adaptive cross mutation operator, the convergence of the genetic algorithm is guaranteed while maintaining the diversity of the population. The accuracy of the node’s belonging community is further ensured, thereby improving the quality of community identification. In each stage of finding the optimal community structure, the IGACD algorithm strives to reduce the randomness of the algorithm and ensure the quality of the community. Finally, the experimental test is carried out in the real network, and compared with many classical algorithms. The experimental results show that the IGACD algorithm is stable, effective and feasible.
Footnotes
Acknowledgments
The study was supported by the Science and Technology Innovation Project of Shanxi Higher Education Institution (No. 201804011).