
Abstract
The influence maximization problem is one of the hot research topics in the field of complex networks in recent years. The so-called influence maximization problem is how to select the seed set that propagates the largest amount of information on a given network. In practical applications, networks are often exposed to complicated environments, and both link-specific and node-specific attacks can have a significant impact on the network’s propagation performance. Several pilot studies have revealed the crux of the robust influence maximization problem, but the current work available is not comprehensive. On the one hand, existing studies only consider the case that the network structure is stable or under link-specific attacks, and few researches have concentrated on the case when the network structure is under node-specific attacks. On the other hand, the current algorithm fails to combine the information of the search process well to solve the robust influence maximization problem. Aiming at these deficiencies, in this paper, a metric for evaluating the robust influence performance of seeds under node-specific attacks is developed. Guided by this, a genetic algorithm (GA) maintaining the principle of diversity concern (DC) to solve the Robust Influence Maximization (RIM) problem is designed, called DC-GA-RIM. DC-GA-RIM contains several problem-orientated operators and fully considers diverse information in the optimization process, which significantly improves the search ability of the algorithm. The effectiveness of DC-GA-RIM in solving the RIM problem is demonstrated on a variety of networks. The superiority of this algorithm over other approaches is shown.
Introduction
Numerous complex systems found in the natural world can be effectively characterized through the lens of network theory. A prototypical network is comprised of numerous nodes interconnected by edges, with each node representing distinct entities within a real-world system, and the edges symbolizing the relationships between these entities. Typically, a specific relationship exists between any two nodes. For instance, the nervous system can be conceptualized as a network [1], with neural fibers forming connections via various nerves [1]. Similarly, computer networks are composed of autonomous components such as optical cables, twisted pairs, and coaxial cables, akin to electrical networks [2]. Social relational networks [1, 4], traffic networks [5], and scheduling networks [6] are also commonplace in our daily lives. With the advancement of technology, network systems have become an indispensable facet of human society, prompting an increasing number of scholars to immerse themselves in the study of large complex systems using complex network theory. In recent years, complex network research has concentrated on critical topics such as the influence maximization problem [7], robustness [8], graph neural networks [9], community discovery [10], and network dynamics [11].
With the popularity and rapid development of the Internet in recent years, social network services such as WeChat, Facebook, and Twitter have entered people’s vision. These platforms have greatly enriched human socialization and even become a crucial part of human society. With the growing user scale, social networking platforms have become an important channel for people to express their opinions and communicate. At the same time, the characteristics of efficient information dissemination and a large number of users make online marketing an efficient manner for business. Due to financial and other constraints, it is not possible for businesses to promote their products to every user, they thus often target a small number of “seed” users to generate considerable influence This process is called “viral marketing” or “word-of-mouth marketing”. Therefore, how to select the most influential “seed” users becomes a key problem, and this problem can be modeled as the influence maximization problem [7].
Several well-developed models for information propagation in network systems have been proposed, including the Independent Cascade model (IC model) [11], the Weight Cascade model (WC model) [12], and the Linear Threshold model (LT model) [13]. Kempe et al. [11] transformed the influence maximization problem into a discrete combinatorial optimization problem, demonstrating its NP-hard nature. In recent years, various methods have emerged to address the influence maximization problem. For example, heuristic-based method [14], community-based method [15], and population search-based method [16], all of which provide alternatives that can be referred to for seed selection.
Networks often encounter complex application environments; at times, node and link functions may fail or fluctuate due to various internal or external factors. It is crucial for a network to possess the capability to withstand such failures and fluctuations, demonstrating robustness. The robustness of a network holds significant importance in ensuring the security of network systems, such as social networks, the World Wide Web, and transportation networks. Previous studies have established a close relationship between network structure and its overall performance [1]. Additionally, in the context of a social network, alterations in its network structure can also impact the interactive behavior of its members [17]. These changes in interactive behavior are likely to have a cascading effect on the process of information or influence propagation, as evidenced by several preliminary studies [7]. In summary, the assessment and optimization of the robustness of network systems have emerged as prominent research topics in the realm of complex networks in recent years.
Nevertheless, challenges persist in the current landscape of influence maximization problems. On one hand, as previously mentioned, practical applications often encounter unforeseeable attacks on the network structure, targeting either nodes [8] or links [18]. These attacks can result in significant structural damage and compromise the network’s functionality. Existing research either neglects the scenario of network structure alterations or solely addresses link-specific attacks, which represents a limitation. On the other hand, genetic algorithms have proven effective in addressing the influence maximization problem. However, traditional genetic algorithms often struggle to leverage population information effectively during the search process, leading to issues such as poor population diversity. In extreme cases, this can result in slow convergence and a tendency to converge to local optima. In genetic algorithms, the diversity within the population plays a crucial role in achieving optimal results and computational efficiency. To attain the global optimal solution, it is essential to disperse the population widely within the solution space. Moreover, some cutting-edge studies have begun to explore the selection of seed nodes that satisfy both robustness and influence maximization. However, these investigations are generally limited to scenarios where system parameters, such as node influence propagation probability [19] and propagation model [20], are uncertain. As of now, the challenge of effectively evaluating seed performance under the conditions of node-specific network attacks and designing a proven scheme for seed optimization selection remains unresolved in current research.
To address the limitations and shortcomings of current research, this paper systematically analyzes and studies how to solve the influence maximization problem from the perspective of network impairment, and the condition that the network under node-specific attack is considered. First, combined with the influence evaluation factor proposed in [21], this paper designs a comprehensive influence performance metric that can evaluate the influence performance of seeds under node-specific attacks. Further, an optimization algorithm based on a genetic algorithm and diversity concern principle is designed to find the most influential seed set in the network, which is denoted as DC-GA-RIM. DC-GA-RIM contains an initialization operator, crossover operator, mutation operator, local search operator, and selection operator, and fully considers diversity information in these operators, which effectively solves the problem of insufficient diversity of traditional genetic algorithms. It is demonstrated that the seed set obtained under the guidance of the designed metrics can achieve better influence propagation in the process of network damage.
Contributions of this paper are summarized as follows.
In terms of the complex network field, existing research has predominantly centered on link-based attacks, while neglecting the prevalent presence of node-based attacks in real-world scenarios. Building upon previous studies, this research introduces an innovative indicator to evaluate the robustness and influence of seeds under node-based attacks. This novel indicator fills a critical void in the investigation of maximizing robust influence, contributing significantly to the advancement of knowledge in the field of complex networks.
In terms of the computational intelligence field, to tackle the challenge of maximizing robust influence, a genetic algorithm was developed. This algorithm incorporates various operators that consider diversity information, effectively addressing the issue of limited diversity in traditional genetic algorithms and significantly enhancing convergence performance. The proposed method’s effectiveness was validated on multiple artificial synthetic networks and real networks. The results demonstrate that, guided by the proposed evaluation indicators, the algorithm-generated seed set achieves superior impact propagation during node failure. Valuable candidates can be generated for decision-makers to solve practical diffusion dilemmas.
The paper is structured as follows, Section II briefly describes the influence propagation model and the associated performance evaluation methods in influence maximization problems, as well as background work on related network structure robustness metrics. Section III gives an evaluation metric of seeds’ robust influence performance. Section IV gives the flowchart of the DC-GA-RIM algorithm and the details of the operator. Section V shows the corresponding experimental results. Finally, the full-text summary are given in Section VI.
Background
The social network structure can be represented by a graph G: G = (V, E); Here, V = {1, 2, . . . , N} is the set of N users in the network, and each node v ∈ V represents a user in the social network; M is the interactive links between different users in the network, and each edge (i, j) represents the influence relationship from node i to node j. The description of the network in this paper also follows the definition as above.
Influence maximization problem and related work
The so-called influence maximization problem is to select K nodes from a given network as the seed set S = {s1, s2, . . . , s K }, and the seed set S carries out influence propagation in the whole network, and the maximum value of its final influence propagation range is recorded as σ (S).
Numerous methods are available for informing and addressing the influence maximization problem. The classical genetic algorithm (GA) involves several stages, including initialization, crossover, mutation, and selection. While it has demonstrated flexibility and effectiveness, it does not fully leverage the information in the search process. Some structural-property-based methods, such as Degree, PageRank, and Betweenness, offer criteria for assessing the structural significance of nodes. These methods efficiently allocate resources for identifying influential seeds but may not adequately address the issue of influence redundancy.
A Monte Carlo method was introduced in [11] to tackle the influence maximization problem. However, this algorithm is impractical for large networks due to its prohibitive computational cost. Additionally, a simulated annealing-based approach proposed in [8] can also address the influence maximization problem. It combines the probabilistic burst-hopping property with randomly selected solutions under the objective function. Nevertheless, controlling its parameters can be challenging.
Gong et al. [15] introduced a novel algorithm for influence maximization in social networks, known as CMA-IM. They employ a dynamic programming approach to identify communities with the most significant propagation increments. The algorithm is then applied to identify the most influential nodes within these selected communities. Population-based search methods, such as the discrete particle swarm optimization (DPSO) algorithm [14], have also demonstrated superior results.
Wang et al. [16] considered the network structure in the context of link-specific attacks and proposed a genetic algorithm to address the influence maximization problem when the network structure is compromised. These methods offer valuable solutions for addressing the influence maximization problem and can serve as references for researchers in the field.
Influence propagation model
In the process of seeds trying to spread influence outward, the propagation model defines the rules of information propagation. Generally speaking, there are several common propagation models: independent cascade model (IC model), weight cascade model (WC model), and linear threshold model (LT model). A brief introduction is given as follows. First, these models are based on the following rules: the nodes in the network have two states: active and inactive, if the node is activated, it means it has received the information and become a spreader; if it is inactive, it means it has not received the information. Each active node has a certain probability of activating the connected inactive nodes; the activation state of the node can only change from the inactive state to the active state, but not vice versa.
The propagation process of the IC model is as follows. In the initial state (t = 0), there are and only the nodes in the seed set are configured as the active state, that is, S0 = S. When t = k, each node n in the active node set S k attempts to affect all its inactive neighbor nodes m at a certain probability. If this attempt is successful, the node activated in step k will be saved in Act k , and then the active node set Sk+1 = S k ∪ Act k will be updated. When multiple active nodes intend to activate an inactive node, their propagation processes do not affect each other. When no nodes are activated in the whole network at a certain time (that is, when the Actk′ obtained in a step k′ is an empty set), the propagation process ends. Finally, σ (S) (the maximum influence propagation range of the seed set S) is determined by the number of the size of activated node sets ∥S T ∥. The difference between the propagation rule of WC model and IC model is that in IC model, the propagation probability p mn is generally set as a constant (usually 0.1 or 0.01, which can be determined according to different network characteristics). The propagation probability in WC model needs to be determined according to the weight information in the network. In the LT model, each directed edge E has a weight w (u, v) ∈ [0, 1], which reflects the importance proportion of the influence of node u in the middle of all incoming neighbors of node v; each node v has an affected threshold θ v ∈ [0, 1], which indicates the difficulty of its activation. Only when the inactive node receives influence which is not less than its own affected threshold, can this node become an active node. Similar to the IC model, when a step k′ gets Actk′ empty set, the propagation process ends. Considering that the IC model exhibits a broader theoretical value and has received more attention in previous studies [14, 21–23], this work chooses the IC model as the influence propagation model to study the influence maximization problem.
Influence performance evaluation methods
In general, when provided with an initial seed set S comprising active nodes within a network, the Monte Carlo process can be employed to assess its influence level, denoted as σ (S). However, it is worth noting that this approach can be exceedingly time-consuming and may not be well-suited for extensive networks. In contrast to the Monte Carlo process, the Reverse Influence Sampling (RIS) method [24–26] offers an alternative that eliminates the need for subsequent iterative traversal computations in the solution process. However, a challenging question remains imperfectly answered: how many nodes should be included in the generation of the reverse reachable set during its sampling phase.
In a related paper [21], a rapid approximation of influence levels is proposed based on the 2-hop neighbors of the seed nodes. This method, however, does not encompass all nodes within the network; instead, it confines the influence coverage of nodes to a 2-hop radius, as defined below.
Here, H
s
is the 1-hop neighbor of node s, p (s, c) is the propagation probability from activated node s to inactive node c, and
Realistic network systems are often exposed to complicated application environments, and may even suffer from malicious attacks that cause nodes or links failed. To address these issues, it is necessary to consider the robustness of the seeds in the determination process. The literature [8] proposes an evaluation factor R that considers the network robustness performance under structural attacks, and the evaluation process is as follows: each node is ranked according to the degree value first, the node with the maximum degree for each attack is selected, this node together with all connected neighbors is removed; and then the maximum connected cluster at this time step is calculated. The above steps are repeated until a given termination condition is reached, and finally the final robustness performance evaluation metric is obtained by a normalized summation. The specific definition is as follows.
Here, S (Q) is the maximum connected cluster of the network after removing Q nodes, N is the total number of nodes in the network, and 1/N is the normalization factor to ensure that the different networks can be compared fairly with each other. It is shown that the robustness is positively correlated with the R value, and this evaluation factor achieves considerable results for network robustness optimization problems.
For the influence maximization problem, previous work has ignored the impact of potential network structure disruption on the information dissemination capability of selected seeds. In practical applications, decision makers often tend to select nodes with dramatic influence and robust performance. To address the shortcomings of previous literature that do not consider potential network structure damage or only consider network structure damage under link-specific attacks when selecting seeds, a robust influence performance evaluation metric is proposed considering under node-specific attacks on networks.
Evaluation method for robustness influence performance
In reality, many networks exhibit the scale-free feature [1], where only a small number of users or nodes in the network show significant importance. This feature lead to extreme sensitivity to node-specific attacks. Social networks are a typical scale-free network. When hackers attack social networks, they usually steal a user’s social account and cut off the connection attached to this user. Once more influential users are attacked, it would inevitably cause significant disruptions and damages to the function of the whole social network together with the influence spreading task. Most of previous studies are limited to the case when the network structure is not changed or only consider the case when the network structure is attacked by links, and little attention has been paid to the aforementioned case when the network node-specific attack. In this work, a new seeds robust influence evaluation metric is developed based on Equation (2) from the perspective of node-specific attacks.
It has been demonstrated [8, 27] that malicious attacks can cause distinct damage on the network system over random attacks. The malicious attack here means that the importance of all nodes in the current network is first estimated based on a specific importance evaluation metric, and the attacker ranks the nodes according to their importance and removes the most important node at each round. The purpose is to cause a quick destruction on the network structure. In general, there are several metrics to evaluate the importance of nodes in the network: Degree, PageRank, Betweenness, etc. Considering that Degree can reflect the importance of nodes in the network accurately at a low cost, Degree is chosen here as the evaluation metric to measure the importance of nodes.
Next, we describe our evaluation method in detail. In the process of seeds propagating their influence outward, we re-evaluate the influence of the seed set S after each suffered attack. Since the propagation processes under suffered node attacks are uncorrelated with each other, the summation and normalization operations in Equation (2) can be adopted to obtain the combined influence performance of the seed set S under node-specific attacks. According to the mechanism as above, this paper defines the robust influence performance evaluation metric of the seed set S as follows.
Here, similar to Equation (2), N denotes the number of nodes in the current network, and
In this paper, the evaluation metric R S is designed considering the influence level of the seed set under the node-specific attack. Following the network performance evaluation in Equation (2), a normalization operation is considered to ensure the comparability of the values under different network sizes. In addition, the quick evaluation method of influence level in Equation (1) is introduced to reduce the computational cost, thus providing a more reliable guideline for the selection of the seed set.
In practice, depending on the preference of intruder attacks, network systems sometimes suffer from attacks against nodes and sometimes suffer from attacks against links. For the influence maximization problem, we can flexibly choose different robust influence evaluation metrics according to different types of network attacks. Wang et al. [16] proposed a robust influence evaluation metric, which can be used for influence evaluation of seeds under link-specific attacks. It is defined as follows.
Here, M is the total number of links in the current network, Per is the number of links attacked by the attacker as a fraction of M, and
For the influence maximization problem, the choice of different evaluation metrics tends to bring different preferences on the selection of seeds, and the robustness and influence performance of the resulting seeds would also differ. By analyzing the differences in the information of the selected seeds under the two indicators, we can flexibly choose different robustness influence evaluation metrics to cope with the complex external environment in reality. In addition, these analyses are helpful and informative for subsequent optimization algorithm design. In this section, we select seeds and compare them under the guidance of two metrics. Specifically, we choose the classical genetic algorithm (GA) to select seeds under the guidance of R
S
(Equation (3)) and
Information of the seeds selected by GA guided by
Information of the seeds selected by GA guided by R S .
The results are shown in these tables. First, as
In addition, structure-based metrics such as Degree, PageRank, Betweenness, Closeness, and Clustering are also important metrics for evaluating node centrality and influence performance. Degree indicates the number of its connected links or neighbors, and is the most direct assess of node centrality in network analysis. PageRank is an algorithm used by the Google search engine to evaluate the importance of web pages in the network. Betweenness evaluates the extent to which a point lies in the middle of other point pairs in the graph, reflecting the importance of the node in the network. Closeness reflects the proximity of a node to other nodes in the network. Clustering is a coefficient that describes the degree of clustering between points in a network, and is used to assess the degree of interconnection between neighbors of a node, which can reflect the importance of a node to some extent. Similar to
In this section, we describe details of the proposed DC-GA-RIM algorithm to solve the robust influence maximization problem. The algorithm starts from the principle of diversity concern and aims at maximizing the influence evaluation metrics R S proposed in Equation (3). First, the overall framework of the DC-GA-RIM algorithm is introduced, and then the initialization operator, the crossover operator, the mutation operator, the local search operator, and the selection operator are presented.
Algorithm framework
The procedure of DC-GA-RIM is as follows. First, an initialization operator relying on the combination of three strategies of Degree-first, PageRank-first, and Clustering-first is executed to generate a series of seeds to initialize the population (the size is InitialSize.). Then, the crossover operator is applied, combining uniform crossover strategy, two-point crossover strategy, and single-point crossover strategy for genetic information exchange, expanding the population size to PopSize. Subsequently, the population undergoes a mutation operator to increase population diversity and help escape local optima. The mutation probability of the mutation operator designed in this paper relies on the fitness value of the individuals themselves, and the smaller the fitness, the higher the probability of mutation. In addition, the algorithm needs to execute a local search operator for Pop g , which combines three strategies, namely 2-hop neighborhood search, random search, and influence value-first search, to improve the fitness level of the whole population. Finally, the selection operator is executed, and the elite strategy is implemented to update the optimal solution obtained in each iteration. The above steps are repeatedly executed until the pre-defined termination condition is satisfied. Finally, the optimal solution that has appeared during the evolution process is taken as the output. Here, R S (Equation (3)) is used as the fitness value. The procedure of the DC-GA-RIM algorithm is summarized in Algorithm 1.
The DC-GA-RIM can be mainly divided into the following parts: (1) Initialization operator, which initializes InitialSize individuals with a complexity of O(InitialSize) and is executed only once; (2) Crossover operator, which requires expanding the population size to PopSize, resulting in a complexity of O(MaxGen)*(PopSize - InitialSize) throughout the entire iteration; (3) Mutation operator, executed up to PopSize times per iteration, resulting in a complexity of O(PopSize * MaxGen) over the entire iteration; (4) Local search operator, each iteration is executed at most PopSize times, and the complexity required for each execution is O(K * < k > * < k > +0.1 * N + 0.1 * N), the complexity of this operator during the whole iteration is O(PopSize * MaxGen * K * < k > * < k > +PopSize * MaxGen * K * N); (5) Selection operator, which selects InitialSize individuals to enter the next generation, resulting in a complexity of O(MaxGen * InitialSize) over the entire iteration.
The overall time complexity of the DC-GA-RIM algorithm is thus O(PopSize * MaxGen * K * < k > * < k > +PopSize * MaxGen * K * N).
Initialization operator
The search process of the DC-GA-RIM algorithm originates from the initialization operator, which is aimed at generating possible candidates considering the structural information of the inputted network. To address the shortcomings of the previous methods, the initialization operator designed in this paper follows the principle of individual diversity and combines three strategies of Degree-first, PageRank-first, and Clustering-first to initialize the population. Specifically, the initialization of the first 1/3, middle 1/3, and remaining 1/3 individuals of the population performs the three strategies respectively. Finally, a population Pop g of size InitialSize is generated. The initialization operator based on the importance information of Degree, PageRank, and Clustering is used as indicators for assessing the importance. A given number of nodes are selected as the genes of individuals using the roulette wheel method. Therefore, the larger the Degree, PageRank, and Clustering of nodes are, the higher the likelihood they have to be selected, ensuring the performance of the initial seeds. At the same time, some nodes with smaller importance still can be selected, guaranteeing the diversity of the distribution of seeds in the solution space.
Crossover operator
Similar to the reproduction phenomenon in biology, the crossover operator can enrich the diversity of the population and generate more individuals. In this work, a crossover operator that follows the principle of genetic diversity is adopted, which combines three strategies: uniform crossover, two-point crossover, and single-point crossover to expand the size of Pop g to PopSize. It should be noted that if there are duplicate nodes within an individual after conducting the operator, a correction operation should be performed on the individual. The correction operation is as follows: a node in the network is randomly selected to replace the duplicate node in the individual until there are no duplicate nodes in this individual.
Mutation operator
The mutation operator in genetic algorithms refers to conducting a random change of a gene at a locus in the chromosome of an individual to form a new individual. Its purpose is to improve the search capability and enrich genetic information to prevent premature maturation. The mutation operator designed in this paper follows the principle of probability diversity, i.e., dynamic adjustment mutation probability according to the fitness value of the individuals. The details are as follows: first, according to R S (Equation (3)), the fitness value of all individuals in the population is evaluated, and the sum of the fitness of all individuals is obtained. Then, for each individual in the population, the mutation operator is executed at the probability of p m * β (β = 1 –the fitness value of this individual/the fitness value of all individuals in the population), and a random gene in the individual is replaced with another node. Note that the mutation process also follows the principle of no duplicate nodes within the individual. If there are duplicate nodes, the correction operation mentioned above is performed.
Local search operator
The local search operator is a process of generating new feasible solutions based on a set of feasible solutions by performing searching procedures in the current population. The incorporation of local search operator can greatly enhance the optimization capability of the algorithm. The local search operator designed in this paper follows the search space diversity principle and extends the search scope from local areas to global areas. Specifically, the local search operator of DC-GA-RIM is designed into three parts. The first part is the 2-hop neighborhood search, whose search space is the 2-hop neighborhood of the current seed node. Nodes are considered to be randomly replaced by their neighbors in the 2-hop area. The second part is the influence value first search, whose search space is the set of nodes in the top 10% of the network in terms of robust influence value R S ; again, considering replacing the existing node with one of these top nodes. The third part is random search, whose search space is the set of randomly selected nodes (10% of the network size) from the network, and consider replacing the existing node with one of these candidate nodes. The local search operator dynamically adopts different search methods for each individual (possible seed set) in population according to the genetic process, and intends to replace part of the nodes in the individual to achieve better fitness value. If the replaced individual gets an increased performance and there are no duplicate nodes, the replacement operation is accepted.
Unlike the crossover operator and mutation operator, the local search operator of DC-GA-RIM uses the robust influence evaluation metric R S as the guidance and only retains new individuals that perform better for influence propagation. Such a search, although maintaining a relatively high time complexity, can directly improve the fitness level of the whole population and promote the convergence of the optimization process. The specific procedure of the local search operator is given in Algorithm 2.
Selection operator
Inspired by the survival of the fittest in nature, the role of the selection operator in genetic algorithms is to select the vigorous individuals in the population to generate a child population. At the end of each genetic iteration, the DC-GA-RIM algorithm employs the roulette wheel selection method to choose better individuals from population Pop g , and incorporate them into the offspring population (the size is InitialSize). Here some individuals with poor performance also have chances to be selected, which can enhance the diversity of the population to some extent. In addition, the first individual of the child population is saved as the global optimal solution found by the current search process, which is used to prevent the degradation of the population fitness. Such a selection mechanism also contributes to avoiding local optima.
Experiments
The performance analysis on synthetic networks
First, in order to combine the validity of the designed evaluation metric R S (Equation (3)) and the performance of DC-GA-RIM, we implement DC-GA-RIM and other methods for seeds selection and analyze their robust influence propagation performance R S . The experimental results are taken as the mean value of each node in the seed node, and the following experiments follow this rule. In detail, under the guidance of R S , we use DC-GA-RIM, genetic algorithm (GA), Degree based (Deg), PageRank based (Pag), Betweenness based (Bet), Closeness based (Clo) and Clustering based (Clu) methods to select seeds from the given network, and the performance is compared. Parameters of DC-GA-RIM are set as Table 3. Similarly, the parameters of GA are set as follows: MaxGen is set to 150, p c is set to 0.5, p m is set to 0.05, InitialSize is set to 20, and PopSize is set to 40. Here, we conduct experiments on three synthetic networks, scale-free network [1] (SF network) which is with power-law degree distribution, ER network, and small-world network [29] (WS network) which is with shorter average path lengths and larger clustering coefficient. The average degree < k>of these networks is 4, and set the size of seeds as K = 5, K = 10 and K = 20.
Parameter settings for DC-GA-RIM
Parameter settings for DC-GA-RIM
The experimental results are illustrated in Fig. 1. It is evident that the seed set obtained through DC-GA-RIM exhibits a notably higher R S compared to other methods. This observation signifies that these seeds demonstrate superior performance in propagating influence within a network characterized by structural impairments. Furthermore, the results underscore the inherent challenges in selecting seeds with optimal information dissemination capabilities and robustness when relying solely on network structural properties such as degree, PageRank, and betweenness, especially in the presence of structural impairments. The utilization of the traditional genetic algorithm (GA) exhibits only marginal improvements when compared to the network-structural-property-based approach, falling short of the effectiveness achieved by DC-GA-RIM. When the value of K is small, even simple approaches based on network structural information or traditional GA can yield seeds with robust influence performance. However, as K gradually increases, the limited number of crucial nodes in the network becomes insufficient to meet the seed set’s size requirements. Moreover, the overlapping influence regions among seeds cannot be disregarded, thereby increasing the complexity of seed selection. Existing methods neglect to account for the potential disruption in network structure’s impact on the influence propagation capacity of seeds. Furthermore, their centrality information fails to meet the criteria for ensuring robust performance. The population-based approach employed by GA, which includes information exchange among different individuals (via crossover operators) and individual mutations (via mutation operators), partially addresses these challenges. However, the effectiveness of this approach still falls short of expectations.
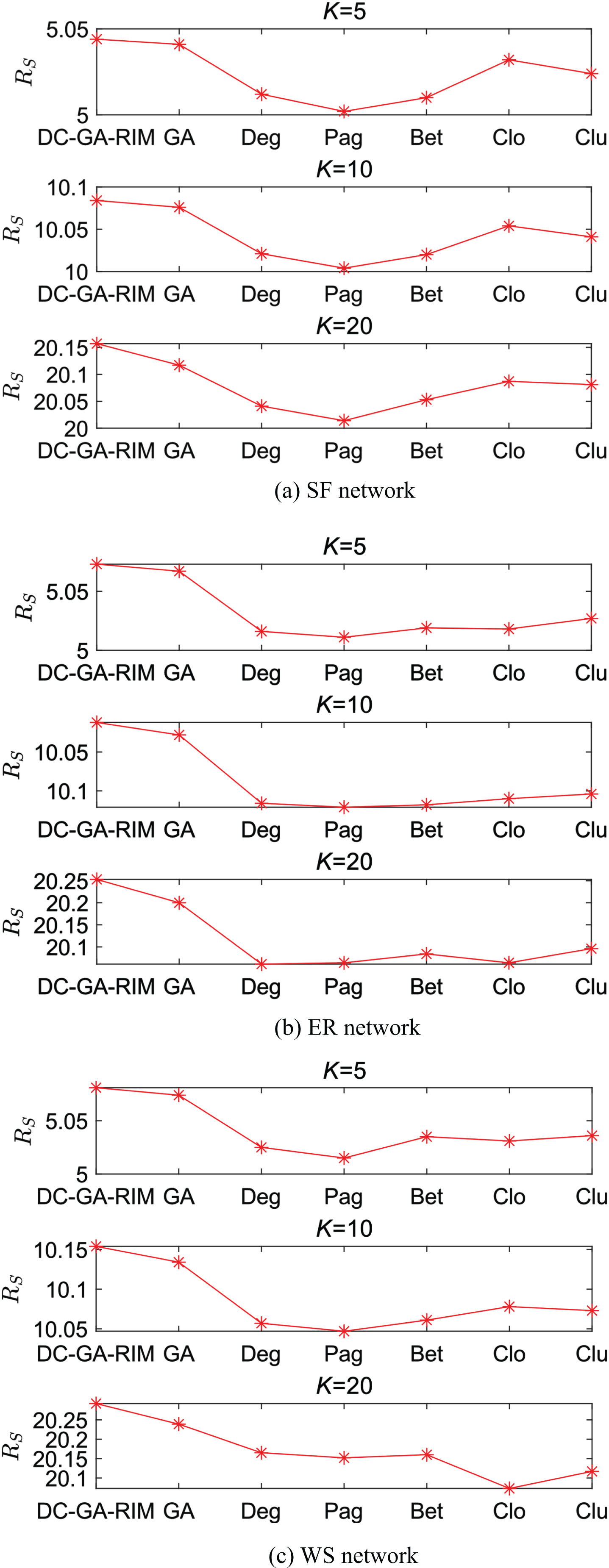
The robust influence performance R S comparison of selected seeds on three synthetic networks.
The DC-GA-RIM algorithm, based on a genetic algorithm and employing R
S
as the fitness value, demonstrates its efficacy in solving the aforementioned problems. Firstly, DC-GA-RIM utilizes a genetic algorithm as its foundation, employing a population-based search strategy that enhances the propagation ability of the searched seeds. Secondly, DC-GA-RIM is guided by R
S
, incorporating the 2-hop influence propagation estimator
In Table 4, this paper also compares the influence performance of different seed sets in the network using DC-GA-RIM and GA using R S as the optimization metric and other network structural-property-based methods for selecting seeds. The experiments were conducted under three synthetic networks with 200 nodes, SF, ER, and WS, with K = 20. Here, a t-test with a significance level of 0.02 is also performed on the results obtained by DC-GA-RIM to verify whether there is a significant performance difference between algorithms.
Comparison of the
The experimental results presented in this study lead us to observe that the seed nodes generated by DC-GA-RIM do not achieve the highest performance in terms of influence propagation when using R S as the evaluation metric. This observation suggests the existence of a trade-off between seed node robustness and influence propagation performance. Given the diverse and complex environments in which networks operate, decision-makers often prioritize the selection of robust seeds over those with optimal influence propagation capabilities. With the guidance of R S , DC-GA-RIM can significantly enhance the robustness of the selected seed nodes, albeit at the cost of some influence, resulting in a seed set that is more practical and meaningful for real-world applications.
By integrating the findings presented in Fig. 1 and Table 4, we can draw the conclusion that, when the network structure is compromised, seeds selected by DC-GA-RIM with R S guidance exhibit superior robustness compared to traditional genetic algorithms and other methods based on network structural properties. The concurrent results displayed in Table 4 further substantiate the validity of R S as a metric and affirm its capacity to offer a dependable assessment of seed performance in terms of robust information propagation.
Further, in order to verify the effectiveness of DC-GA-RIM on large-scale networks, the performance of R
S
and
Comparison of R
S
and
In order to verify the effectiveness of the diversity concern strategy and the local search operator included in DC-GA-RIM, the convergence process of DC-GA-RIM and GA is analyzed. The experiment is conducted on a SF synthetic network with node size of 200. The result is shown in Fig. 2. It can be seen that both the two population-based algorithms can converge gradually, but DC-GA-RIM is significantly better than GA in terms of convergence speed and performance of the optimal solution. As mentioned in Section I, the convergence ability of genetic algorithm is positively correlated with population diversity, and the diversity concern strategy incorporated in DC-GA-RIM dramatically enhances the population diversity, and its unique local search operator incorporating multiple search ranges also strengthens the search ability of DC-GA-RIM. DC-GA-RIM takes R S as the optimization target, and its strong search ability can select the seed set with better propagation ability. The seed set with high R S value not only can better accomplish the information dissemination task in the original network, but also can ensure the completion of the information dissemination task when the network is under attack and the connectivity is impaired. Therefore, the seed selection scheme proposed in this paper can more comprehensively cope with the social network influence propagation problem such as those proposed in the literature [14, 30–32].

Trends in R S of DC-GA-RIM and GA selected seeds on SF networks.
In addition to the synthetic networks mentioned above, the effectiveness and practicality of R S and the DC-GA-RIM are verified on two real networks (Frid and Robot). Detailed information is given in Table 6.
Parameters of the real network
Parameters of the real network
Frid network is a regional logistics and transportation network in Berlin given in the literature [33], each node representing a different freight station, and each link representing a different transportation route. Robot network is a robot communication network given in the database of Sun Yat-sen University, each node representing different robots, and each link representing the communication interactions between different robots.
The seed selection is performed for DC-GA-RIM and other algorithms guided by R
S
with size of K = 5, K = 10 and K = 20, and their robust influence propagation performance R
S
and 2-hop influence propagation level
The findings presented in this study offer valuable insights for decision-makers grappling with real-world challenges. In the context of the Frid network, nodes exhibiting robust information dissemination capabilities can serve as viable alternatives to traditional logistics transit centers. These influential nodes have the potential to rapidly impact the connectivity of transportation nodes, ultimately leading to enhanced system efficiency [20, 33]. Moreover, these selected seeds possess remarkable resilience, enabling them to continue their information dissemination functions even in the face of potential attacks. Turning our attention to the Robot network, the chosen seeds typically represent pivotal figures within the system. They facilitate swift execution of tasks such as disseminating control commands and facilitating information exchange among robots. Consequently, this bolsters the manager’s overall control over the entire system. It’s worth noting that robotic networks frequently operate in sensitive military contexts where resilience is of utmost importance. The robot nodes selected using the DC-GA-RIM algorithm are likely to maintain significant information dissemination capabilities, even in scenarios involving potential enemy intrusion. In summary, the algorithm outlined in this paper offers effective solutions for addressing the challenge of maximizing robust influence in various networks, including common synthetic artificial networks like SF, ER, and WS, characterized by distinct degree distribution patterns, as well as real-world networks.
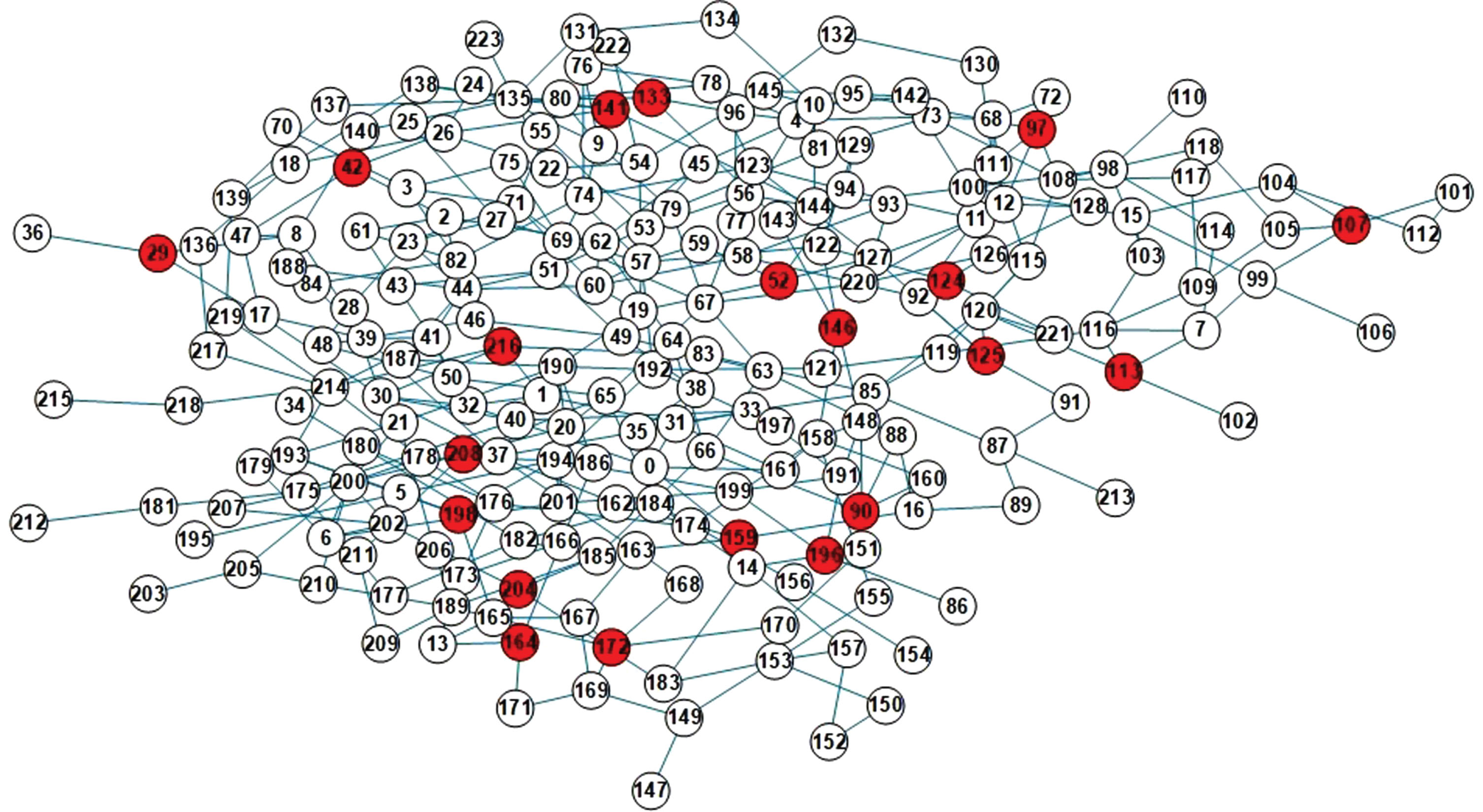
Distribution of seeds in the Frid network with K = 20.
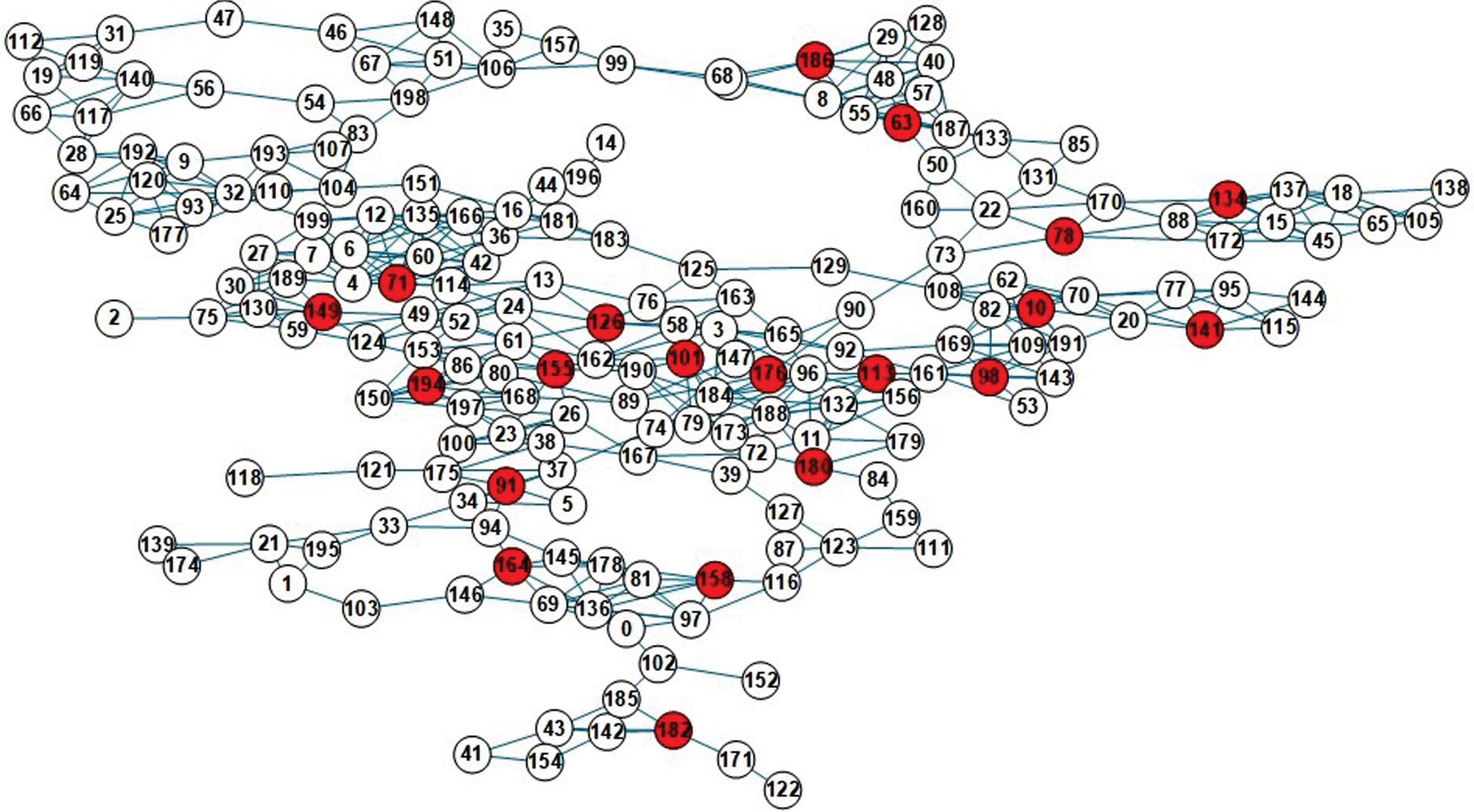
Distribution of seeds in the Robot network with K = 20.
Results obtained for each scenario with different K settings on the Frid network
Results obtained for each scenario with different K settings on the Robot network
Aiming at determining influential nodes from networked systems, this paper introduces the concept of robustness into this problem based on the deficiencies of existing research. For scenarios where the network structure is destroyed, the target is to select nodes with both robust and influential performances. Based on existing work, an evaluation metric has been proposed to comprehensively evaluate the robustness and influence performance of seeds when the network structure is under node-specific attacks. And for the shortcomings of existing algorithms, DC-MA-RIM with attention on the diversity information is proposed on the basis of the evolutionary optimization paradigm. The algorithm fully considers the information of the entire population and includes an effective local search operator. DC-MA-RIM shows good performance in experiments on artificial and real networks, and provides a reliable reference solution to the robust influence maximization problem.
Footnotes
Acknowledgments
This work was supported in part by the Shenzhen Science and Technology Program under Grant JCYJ20220818102012024, in part by National Natural Science Foundation of China under Grant 62203477, in part by Guangdong Basic and Applied Basic Research Foundation under Grant 2021A1515110543, and in part by Fundamental Research Funds for the Central Universities, Sun Yat-sen University under Grant 23qnpy72.