
Abstract
Domain adaptation is a method to classify the new domain accurately by using the marked image of the old domain. It shows a good but a challenging application prospect in computer vision. In this article, we propose a unified and optimized problem modeling method, which is called as Geodesic Kernel embedding Distribution Alignment (GKDA). Specifically, GKDA aims to reduce the domain differences. GKDA avoids degenerated feature transformation by using geodesic kernel mapping feature, and then adjusts the weight of cross-domain instances in the process of dimensionality reduction in principle, finally, constructs a new feature to represent the difference of distribution and unrelated instances. The experiment result shows that GKDA has obvious superiority in cross-domain image recognition.
Introduction
Human can enhance their abilities continuously by learning knowledge. In the past, machine start learning mostly from zero and machine can neither refer to the knowledge they learned nor improve the knowledge they learned, which limit the ability of machine learning significantly. The traditional machine learning is based on statistical learning, which shows a good learning effect within its ability. However, statistical learning requires the knowledge it learns and the problems it applies have the same statistical characteristics since it is based on mathematical statistics. Thus, in general, statistical learning can only solve the same problem in the same field. As long as learning and application scenarios transfers, the statistical characteristics will change accordingly, which affects the effect of statistical learning significantly. However, people do not learn the knowledge in the same field. For instance, when we study physics, we can use the mathematical foundation we have built up in the past. So, when humans learn, they can transfer the knowledge among different fields and different problems, which is the ability that machine learning is lacking by now. The ability to transfer knowledge among different situations is defined as “transfer learning”.
With the development of big data, the key issue in machine learning is how to use tagged relevant data to learn the knowledge in a new area. Obviously, it is inefficient to completely abandon the relevant annotation data and reconstruct the training data from the beginning. To solve this problem, a new method of transfer learning has been developed which is called as “domain adaptation”. The purpose of this study is to solve the problems as follows: when the training data is not identical with the test data, how to achieve better results by using the training data to train the optimal classifier for the test data.
Traditional machine learning algorithms requires the two datasets in the same space, which means that the two datasets have the same feature distribution. Then the researchers design the corresponding model and criterion to classify or predict the test data. However, it is different between the probability distribution of training samples and the one of test samples in many learning scenarios. For instance, the actual input image are different in the classification or recognition system by some extent, such as the shooting Angle, posture, expression, illumination, image quality and other problems in the image recognition. Under this background, researchers proposed the concept of “transfer learning”. The purpose of transfer learning is to use the knowledge learned from old domain to finish the learning tasks in the new domain effectively. Then domain adaptation(DA) is proposed as a special transfer learning, which is used to solve the learning problems in target domain by using the training data in sources domain [1]. Therefore, the main calculation of DA is how to reduce the difference of the sampled probability distributions between two different domains.
According to the literature review [1, 2], the method of domain adaptation by now has been divided into two categories: i) Feature matching, which exploits the subspace geometrical structure in both source domain and target domain [13, 15, 28], or narrows the marginal or conditional distribution gap between two different datasets [23, 17]. ii) Instance reweighting [9, 27], the weights of samples are selected in the source domain though a certain weighting technique is better to classify the models.
In this study, we propose a method which is based on Transfer Joint Matching (TJM) [24] and Geodesic Flow Kernel (GFK) [15]. To be specific, the method can realize the common feature representation in domains through the manifold feature embedded and achieve the effect of domain adaptive learning. Or more specifically about this method, firstly, it maps the source and target datasets in GFK kernel space. Secondly, it employs the mapped source domain and target domain to domain adaptation. Thirdly, it reweights the instances. We name it as Geodesic Kernel Embedding Distribution Alignment (GKDA), which is an unsupervised transfer learning algorithm. The GKDA is capable of addressing three challenges: avoid distortion, namely joint feature transformation and avoid negative transfer. We test our method on 6 datasets, which we will introduce specifically in the following Section 4. According to these datasets, we compared this method to several advanced traditional methods. As a result, GKDA can improve average accuracy by at least 1.1% than other methods with the same classifier (1NN) except D-GFK [30]. Next, we introduce DA’s related work in the Section 2. In Section 3, we describe the detail of GKDA about how to combine GFK and TJM. Lastly, we discuss the experiments and result in the Section 4.
Related work
According to the information above, feature matching and instance reweighting are the two major methods for feature transferring. The goal of the feature matching method is to reduce the distribution difference through feature transformation or feature representation. The feature representations by now are almost the three main methods as follows: I) extracting the potential factors of domain invariance [15, 18, 30]; II) minimizing appropriate distance measures [19, 20, 14, 29]; III) adjusting the weights of relevant features based on sparse regularization [3, 17, 9]. In addition, a paper [32] proposed an ‘EasyTL’ algorithm, getting the mapping through Intra-domain alignment, which is a non-parameter algorithm with good results. The purpose of the instance reweighting method is to reduce the distribution differences and reduce negative transfer [11, 7, 4, 5, 31] through reweighting the source and target instances according to their correlation. Other papers [2, 23, 25, 30] have estimated the soft label in the target domain by many different methods that makes the pseudo labels more accurate via iteration, improving the domain adaptation and optimizing the distribution distance of domains. However, all of the approaches used in those papers are independent to each other, which is not good enough for DA. In this study, we combine the two methods [15, 24], which involve geometric subspace learning, joint feature matching, and instance reweighting. In this process we use the manifold feature maps and the infinite RKHS to match these features more effectively.
Geodesic Kernel embedding Distribution Alignment (GKDA)
Problem definition
There is a labeled source domain
Main idea (Geodesic Kernel embedding Distribution Alignment)
This study proposes to use various domains by feature transformation
In fact, it is materially impossible that the most of data is distributed in Euclidean space. Therefore, it is difficult for the measurement of traditional Euclidean space to be applied to the non-linear data in the real world. So we need introduce a new hypothesis to the data distribution. Manifold is a kind of locally Euclidean space, which includes various latitude curves and surfaces, such as spheres and curved planes. The local and Euclidean Spaces of manifolds which include different dimensions of curves and surfaces are isomorphic. As same as general dimensional reduction, manifold learning reduces the data from a high dimensional space to a low dimensional space. To be different from previous methods, there is an assumption in manifold learning that the processed data are sampled on a potential manifold space or there is a potential manifold space for this dataset.
The main idea of GFK.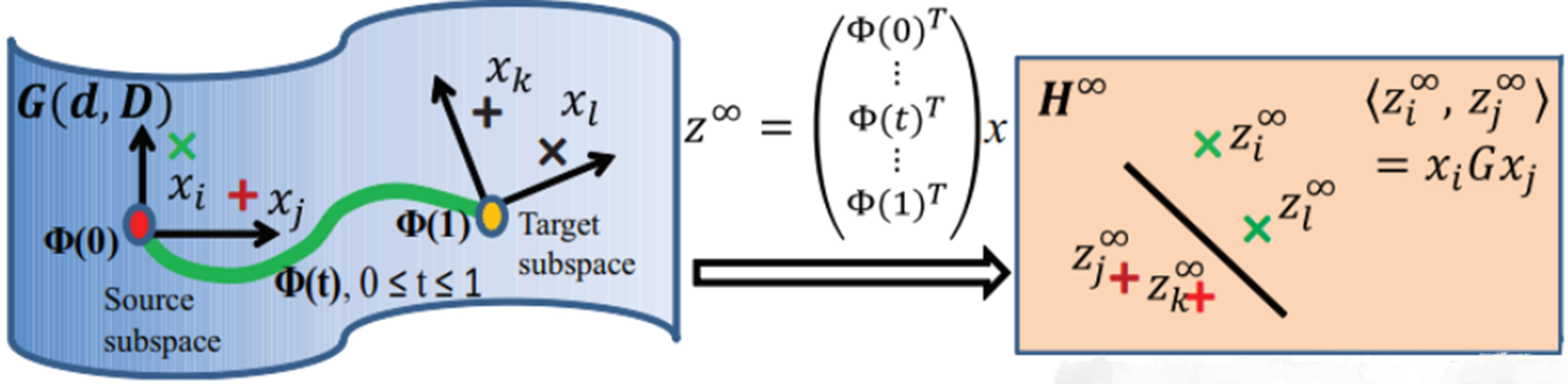
Gong et al. [15] proposed an unsupervised DA algorithm on the basis of manifold theory, which is called Geodesic Flow Kernel (GFK). The innovation of this algorithm is that it proposes a new kernel function “GFK”, which is based on the research of Gopalan et al. [8]. This domain adaptive learning method is defined as “Sampling Geodesic Flows” (SGF). SGF assumes that the target domain and the source domain are two points in a special Grassmann manifold space, and then SGF structures several points which are in the middle of the two domains to establish a geodesic line by connecting several point between the two domains to get corresponding subspace. Finally, the two domains are projected onto the manifold subspace, and the formation of new features is used in the train classification. The main idea of GFK algorithm (Fig. 1) is very similar to SGF algorithm, which can be regarded as an extension of SGF algorithm. The unique feature of GFK algorithm is that it employs geodesics to establish an infinite dimensional feature space, combines all information of source domain, targets domain and virtual intermediate domain between them. Therefore, the inner product on this space can be represented by an efficient closed kernel function so that the algorithm is finally presented in the form of kernel function. The first two steps of the algorithm of GFK are exactly identical to the SGF algorithm. In particular, firstly, the two domains are embedded into two d-dimensional subspaces which are regarded as two points on the Glassman manifold. Then it structures a geodesic line
There are two original datasets
From [15], their geodesic flow can be expressed as:
where
The kernel matrix can be computed in a closed-form
where
Algorithm 1 summarizes the complete procedure.
As mentioned before, most of the data are non-linear, so we cannot use the traditional linear dimensionality reduction. In this paper, we employ kernel-PCA (KPCA) method and calculate KPCA in Reproducing Kernel Hilbert Space (RKHS). In mathematics, Hilbert space is an extension of Euclidean space, which is an unlimited dimensional space. As same as Euclidean space, Hilbert space is a complete inner product space. It is called as ‘infinite dimensional Euclidean space’ which means that the limit operation in the space cannot run out of the space and infinite dimensions can be permitted. The work of PCA is to project the data set from high dimension to low dimension so as to cover most data set information with few features. The essential principle of PCA is that the greater the variance of the data distributed along a feature, the more information the feature contains. So there are
where
KPCA: To work in the RKHS, consider kernel function
where
Now we just reduce the dimension of the manifold mapping data to k-dimensional representation. However, since we assume that their distributions are different, the main problem of the domain adaptive is to minimize the distance between two domains. In this study, we proposed that the distance between
For minimizing MMD between the two domains in the RKHS, the MMD distance adopts k-dimensional embeddings extracted by KPCA.
where
As TCA, to maximize Eq. (4), and to minimize Eq. (5), the first- and high-order statistics of feature distributions are matched under feature
Nevertheless, just joint matching feature is not good enough when the two domains are significantly different. There are always some source samples that are independent of the target domain. Accordingly, you should work with the TCA instance revaluation process to handle this difficult setup. According to study of TJM [9] proposes to impose
where
With the increase (decrease) weight in the new representation, according to difference between the instances, it reweighted the source instances by minimizing Eq. (7), so that Eq. (4) is maximized. Features are now reweighted in joint feature learning with their relevance. Otherwise, the regularizer is often used in machine models to solve the problem of model complexity and over-fitting.
In this paper, we focus on using MMD distance to reduce different domains’ feature distributions and use regularizer to reweight the source instances. By solving Eqs (5) and (7) into Eq. (4), we can obtain the GKDA optimization problem:
where
According to the constrained optimization theory,
Setting
Algorithm 2 summarizes the complete procedure.
The performance of GKDA is assessed by extensive experiments on six datasets which are publicly used in DA tests.
Data preparation
We assess domain adaptation algorithms through six widely-used datasets, the detail of datasets is as below.1
The performance of GKDA is compared with that of 10 advanced traditional methods for visual image classification.
1NN, SVM, and PCA Transfer Component Analysis (TCA) [20] Geodesic Flow Kernel (GFK) [15] Joint distribution alignment (JDA) [23] Transfer Joint Matching (TJM) [24] Adaptation Regularization (ARTL) [22] CORAL relation Alignment (CORA ) [21] Scatter Component Analysis (SCA ) [18] Transfer Independently Together (TIT) [29] Discriminative Geodesic Flow Kernel (D-GFK) [30] Optimal Transport (OT-GL) [31]
GKDA has the closest relation to TJM, and GKDA is different from TJM by
From [6, 20], this study employs the same method to evaluate the model. Firstly, we obtain the new representation of source and target data. Next, we use adaptive source data to train a classifier (1NN). Finally, we use the trained classifier to classify the unlabeled target data. Because of difference distributions, it cannot use cross validation to optimize the optimal parameters. So in this study we choose 1NN classifier. Accordingly, this study assesses GKDA through an empirical search of the parameter space and obtains the optimal parameter settings with the highest average accuracy over all data sets, and reports the best results for GKDA. Other results of the base methods are from paper [12]. For manifold kernel learning, we set dimension
Classification Accuracy on test data is widely used in literature [20, 6, 16].
Accuracy (%) on Office+Caltech10 datasets using SURF features
Accuracy (%) on Office+Caltech10 datasets using SURF features
Accuracy (%) on USPS(U)
Tables 1 and 2 show the accuracy of GKDA classification (recognition) which obtains the 14 baseline methods test result with 16 cross domain datasets. And we also make a figure (Fig. 2) to explain the results more intuitively. The Fig. 2 shows that GKDA performs better than the 11 out of the 14 baseline methods in the most of 16 datasets. The average classification accuracy of GKDA on 16 datasets is 48.88%. The GKDA has 1.1% improvement over OT-GL which is better than other baseline methods except CORAL and TIT. Although CORAL and TIT are unsupervised transfer learning algorithm, it needs to be trained by SVM classifier which requires manual selection of the appropriate classifier parameters. In this study we use 1NN as the base classifier because 1NN does not need cross-validation parameters. In the test result, SVM shows about 10% more accurate than 1NN, which proves that SVM is more powerful than 1NN as a classifier. Although the result of the baseline method of TIT is better than our method, it still cannot prove that TIT itself is better than our method.
JDA is the supervised transfer learning which uses the source domain labels to predict the target domain pseudo labels. But GKDA is the unsupervised transfer learning algorithm without source domain labels. What we need to pay attention to is that the adaptive varies of the 16 datasets are significantly difficult, and the average classification accuracy of the standard 1NN classifier is only 31.4%, which is poor in the large number of datasets.
The basic method of GKDA is to map the source domain and target domain with the geodesic kernel of GFK, and align the distribution of the two domains. GKDA mainly uses the method in GFK and TJM. However, Table 2 shows that the accuracy of GKDA is 5.73% and 2.54%, which is respectively higher than GFK and TJM. So even though the approach of GKDA is based on GFK and TJM, GKDA is still considered as a good method. Also we can show the superiority over GFK and TJM as follows.
Recognition accuracy (%) on Office 
Firstly, as shown in the figure above, the results of GKDA is better than TJM in almost every item, and it is just slightly not good enough compared to the best method. It proves that GKDA can represent feature more successfully in the way to solve the different domains problems.
Secondly, as shown in Fig. 2, the performance of TCA, JDA, ARTL, and TJM, which are based on distribution alignment methods, are worse than GKDA. The reason for this is that some ranges of feature distortion happen in the process of dimension reduction; the performance of GFK, CORAL, and SCA, which are based on subspace learning methods, are worse than GKDA. The reason is that these kinds of methods above cannot solve the problem of two domains’ distribution alignment, which reveals the weaknesses of the methods above in the way of coping with the degenerated feature transformation. Although the performance of ARTL is better than GKDA on the digit datasets, it is worse than GKDA on the object datasets. However, the domain is significantly complex, and image datasets are more complex than digit datasets, so we consider that GKDA is better than ARTL. Other studies [25, 26] have proved that manifold learning can reduce feature degradation in the original space in the way that the features represent to special geometric structure in the manifold space. Therefore, ARTL methods can perform better only on the digit datasets. Accordingly, it proves that manifold structure learning is also significantly effective and robust in domain adaptation in the case of large difference visual domains. The method of D-GFK and GKDA is as same as the one of GFK in the first step. To be specific, in the first step, D-GFK maps two domains into two n-dimensional subspaces, and regards the two subspaces as two points on the Glassman manifold. In the second step, D-GFK predicts the soft labels by “label propagation”, and then obtains the accurate soft label though several iterations. Finally, D-GFK trains it by the labeled domains. Although D-GFK has 1.4% improvement over GKDA, as shown in Table 1, GKDA is still better than D-GFK in 4 parts. Therefore we still consider that GKDA is a powerful algorithm.
Thirdly, GKDA is obviously better than TJM, especially on the object dataset, which means that the more different the domain is, the better the performance of GKDA can show. Therefore, GKDA is a better way to solve domain adaptation problem in the case of the significantly different domain. GKDA has solved degenerated feature transformation problem of TJM.
TJM refers to distribution alignment and instances reweight learning in the source domain, which is similar to GKDA. GKDA locates manifold space learning to geodesic kernel mapping, obtains the new source domain through geodesic kernel remapping and target domain, and aligns marginal distribution and instance reweight. For the above reasons, we primarily analysed the difference between GKDA and TJM.
Compares TJM and GJKM with different regularization parameter.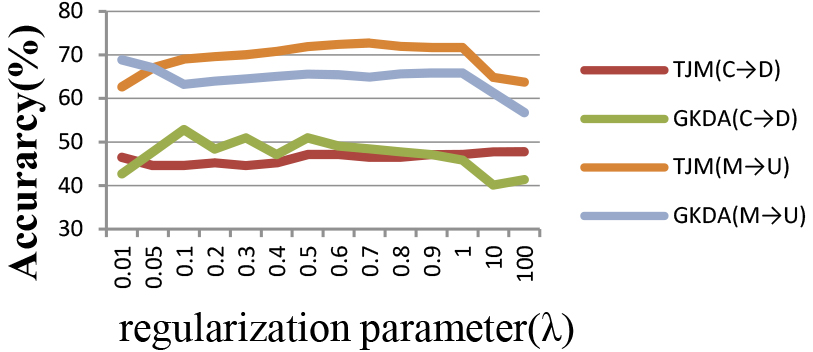
In the Fig. 3, If the parameter
Accuracy (%) w.r.t. #iterations.
MMD distance w.r.t. #iterations.
As shown in Fig. 4, GKDA and TJM usually converge within T
Figures 6 and 7 shows the two dimension results of GKDA, respectively. (Fig. 6
The convergence of GKDA is empirically examined in Fig. 4, which shows that with the increase of iterations the classification accuracy will converge in only 10 iterations.
Running time (s) of GKDA and some other methods
Running time (s) of GKDA and some other methods
Accuracy (%) w.r.t. Geodesic kernel dimensionality (d).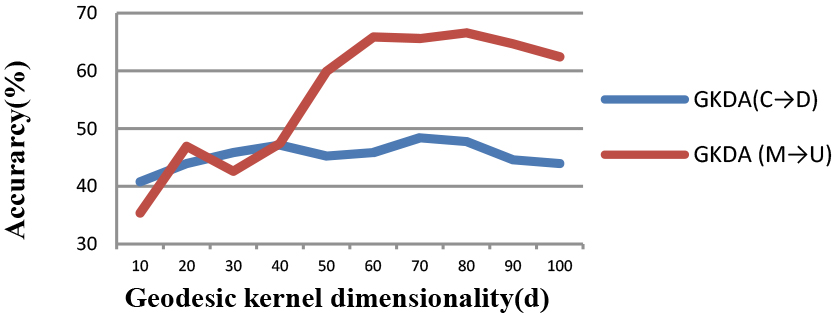
Accuracy (%) w.r.t. subspace dimensionality (k).
Time complexity is assessed on dataset C
We proposed a new transfer joint matching method for domain adaptation. The goal of GKDA is to reduce the feature distribution distance among different domains. And GKDA combines the advantage of TJM and GFK. The superiority of GKDA is that it solved the problem of both distributed differences and unrelated instances. From the overall experimental results, GKDA is effective to solve various cross-domain problems, and obviously outperforms the existing adaptation approaches even if the domain is remarkably different. The final aim of transfer learning is to narrow the gap between the two different domains. However, some samples in the source domain will always cause a lot of negative transfer, which is extremely worse for reducing the distance between domains. In the future studies, we will try to change or reduce the samples though some rules in the source domain, so as to avoid the negative transfer and make a better performance in distribution alignment.
Footnotes
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.