Unsupervised domain adaptation (UDA) aims to build a classifier for the unlabeled target domain by transferring knowledge from a well-labeled source domain. Recently deep domain adaptation methods can not effectively integrate discriminability with transferability of features, and these methods can only reduce, but not remove, the cross-domain discrepancy. To this end, this paper proposes a new domain adaptation method called Joint Category-Level and Discriminative Feature Learning Network (CDN). CDN not only achieves domain adaptation by minimizing category-level distribution discrepancy between domains but also learns discriminative feature representations via maximizing inter-category distance and selecting transferability samples simultaneously. Moreover, we develop a Transferability Weighting Module (TWM), which is based on a constructed classifier, to further strengthen the discriminability of sample’s features. The experimental results demonstrate that CDN can significantly decrease the cross-domain distribution inconsistency and further promote the classification performance.
Pattern recognition methods have attracted much attention in many applications [1–13]. Especially deep learning method has achieved huge success in computer vision [10, 11] and natural language processing [12, 13]. However, training a deep neural network requires a large amount of labeled samples, which is not easy to obtain. Especially in many real-world applications, it is difficult to collect training data that have the same distribution as testing data. Therefore, to address the scarcity of labeled data on some target tasks, it is a strong motivation to leverage labeled samples of the auxiliary domain (i.e., source domain) to improve classifier’s performance in the unlabeled domain (i.e., target domain) [14, 15]. Unfortunately, the training data and test data are drawn from different distributions, which is also known as domain shift [16–19]. For example, the models trained with the simulated images do not generalize well in realistic domains. In these cases, domain shift is a major obstacle of knowledge transfer between domains.
Unsupervised domain adaptation reaps huge fruits [14, 20–24] in reducing the distribution discrepancy between a well-labeled source data (domain) and a related unlabeled target data (domain). Many of them attempt to align the distributions of source and target domains by minimizing the maximum mean discrepancy (MMD) [25] distance to obtain the domain invariant feature [26–29] or reweighting the samples of source domain to select transferable samples[30, 31].
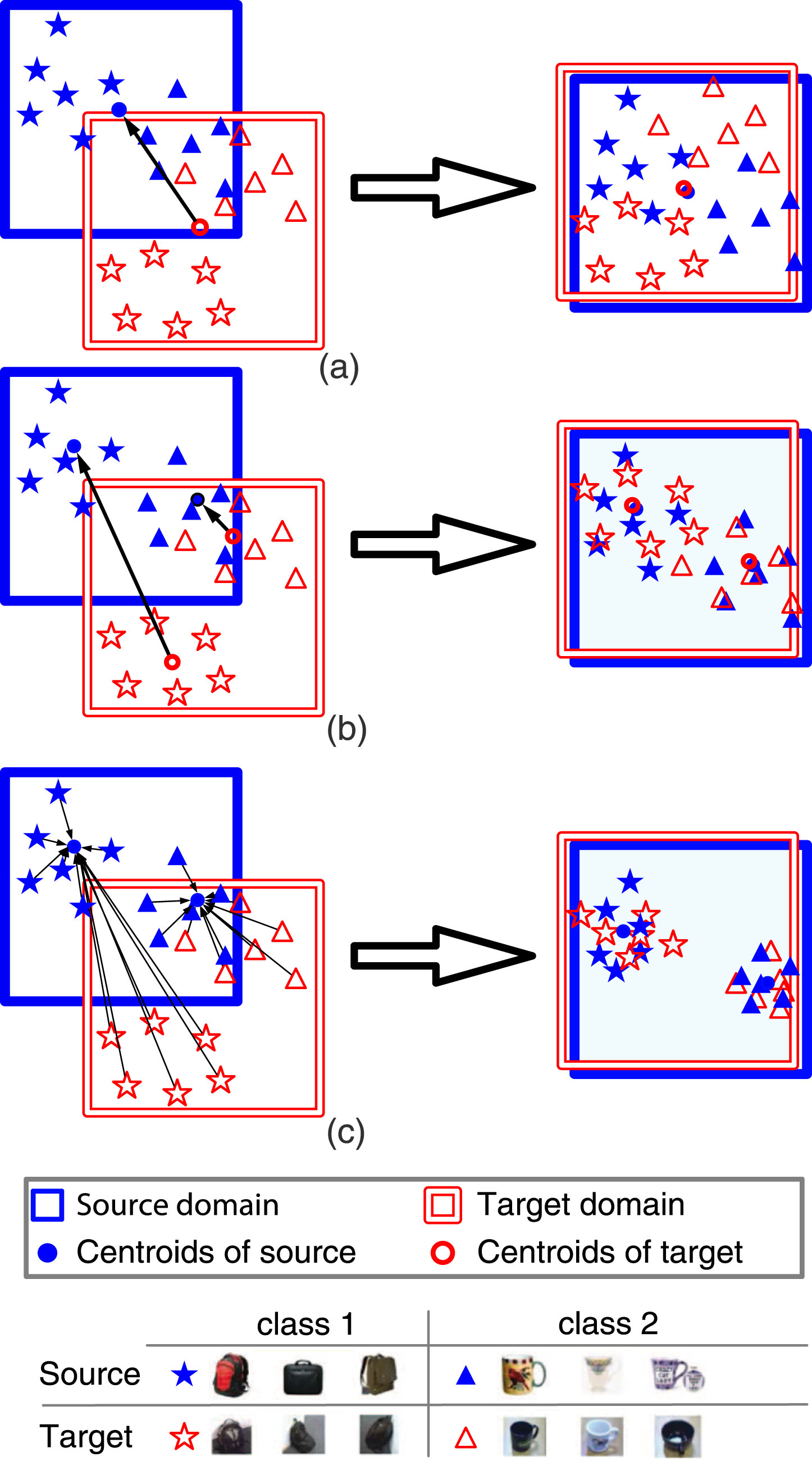
Recent advances show that deep networks can learn abstract feature representations, i.e., deep adaptation networks [32, 33] matches the different domain distributions by learning hidden representations of all task-specific layers in a reproducing kernel Hilbert space. However, most of them [26, 33–36] only conduct the global adaptation and do not consider local adaptation. As illustrated in Fig. 1, the global adaptation reduces the marginal distribution discrepancy between domains while the local adaptation minimizes conditional distribution between domains. A possible consequence of such global adaptation is that some originally well aligned categories between the source and target are incorrectly mapped (negative transfer [14]), which leads to worse classification results in the target domain. On the other hand, even if the local distribution of the source data and the target data are well aligned, there are still many samples that are easy to be misclassified on the classification plane, which weakens the transferability from the source data to the target data.
(Best viewed in color.) The figure shows some toy examples. (a) Global adaptation aligns marginal distribution by drawing centroids of all data between domains closer. (b) Local adaptation aligns conditional distribution by drawing closer the category centroids between domains. (c) The proposed method in this paper. We encourage the networks to pull the source or target data close to the category centroids of source data.
In summary, most of domain adaptation methods [26, 33–36] still are constrained by two bottlenecks. First, global adaptation may fail to solve the domain shift. Second, reducing the distribution discrepancy can not ensure discriminative feature learning, which is important to obtain a more accurate model [37–39]. Note that this risk cannot be tackled by existing local adaptation methods [40], and we propose joint Category-Level and Discriminative Feature Learning Networks (CDN) in this paper to adapt the distribution of domains. Specifically, the reduction of the intra-category variance aims to reduce the intra-category distance between the source and target domain. Hence it can promise the domain adaptation and lessen the domain shift. We further propose to learn discriminative feature by means of increasing inter-category distance and selecting transferability samples. The main contributions of this paper are listed as follows.
Firstly, this paper considers pulling the source or target data closer to the category centroids of source data which enhances the transferability of the source data to the target data. Due to the reduction of intra-category variance, the category-level adaptation mitigate the domain shift.
We propose to maximize inter-category distance and select transferable samples simultaneously to obtain discriminative feature representation, which can lead to obtaining a more accurate and robust classifier.
Extensive experiments on image datasets demonstrate that the category-level and discriminative feature representation will further mitigate the negative transfer and benefit the classification, which would significantly enhance the performance of unsupervised domain adaptation.
The rest of the paper is organized as follows. Section 2 is the review of the related works about domain adaptation. The formal definitions for the problem and the framework are presented in Section 3. In Section 4, comprehensive experiments on benchmark data set verify the effectiveness and efficiency of the proposed methods. Finally, we conclude our work in Section 5.
Related works
According to the difference in feature representation, domain adaptation method can be roughly divided into shallow learning methods and deep learning methods.
Shallow learning methods: Transfer component analysis method [26] looks for domain feature invariants by reducing the cross-domain marginal distribution discrepancy in the reproducing kernel Hilbert space while joint distribution adaptation method [28] also considers the class conditional distribution adaptation. Geodesic flow kernel method [41] regards two subspaces as two points on Grassmann manifold, and bridges source and target subspaces via seeking the smooth geodesic path. Subspace alignment method seeks a domain adaptation solution by learning a projection function to aligns the source subspace with the target one [42]. Transfer joint matching method [43] reduces the domain difference by jointly matching the features and re-weighting the instances across domains. Joint geometrical and statistical alignment method [29] considers preserving the source discriminative information and aligns the distributions by two coupled projections. EasyTL learns both non-parametric transfer features and classifiers by exploiting intra-domain structures[44].
Deep learning methods: Recent advances show that deep networks can learn abstract feature representations. The feature transferability drops significantly in higher layers with increasing domain discrepancy [34]. Hence, the adaptation of higher layers is the key to avoid the negative transfer. Deep domain confusion [34] introduces an adaptation layer and an additional domain confusion loss to learn a representation that is both semantically meaningful and domain invariant. Deep adaptation networks [32, 33] matches the different domain distributions by learning hidden representations of all task-specific layers in a reproducing kernel Hilbert space. Joint adaptation networks [40] aligns the joint distributions of multiple domain-specific layers across domains basing on a joint maximum mean discrepancy criterion. Residual transfer networks [35] jointly learn adaptive classifiers and transferable features from labeled data in the source domain and unlabeled data in the target domain.
To illustrate the difference between the proposed method and the previous works, Table 1 shows a basic overview of the properties of the CDN and some of the most advanced methods. On the one hand, inter-class variance minimization and intra-class distance maximization decrease not only model learning errors but also distribution discrepancy. On the other hand, reducing the weights of outlier source samples further promote the reduction of distribution discrepancy.
Given nS labeled source samples with visual features xSi ∈ Rd and corresponding labels ySi ∈ RK, transfer learning aims to recognize nT unknown visual samples xTj ∈ Rd, which has same label space but follows a different distribution.
The frequently used notations are listed in Table 2, and the concepts about domain adaptation will be described in this part.
Notations and corresponding descriptions
Notation
Description
Notation
Description
xS and yS
Source samples/Labels
Centroid of kth category
xT and yT
Target samples / Labels
K
Number of categories
and
Source / Target domain
Pseudo labels
and
Feature /Label space
w
Sample weight
λ and β
Penalty pameters
Probability distributions
Task: Transfer learning aims to improve the performance of models in the target domain through relevant labeled source data.
Domain: A domain contains feature space , label space , and corresponding classifier . This paper considers the problem of homogeneous domain adaptation, that is, the feature space and category space of source data and target data are consistent, i.e., and , but the distributions are generally different.
Local Adaptation: The conditional distribution adaptation can effectively achieve local adaptation [45]. Unfortunately, it is nontrivial to match the conditional distributions since there is no labeled data in the target domain. Therefore, the pseudo target labels [30, 45–48] are adopted to measure the conditional distribution discrepancy.
Maximum mean discrepancy is an effective distance measure for conditional distribution [25, 40]. With pseudo target labels , the conditional distribution discrepancy can be calculated as:
where nk and mk denote the numbers of kth class samples in the source domain and target domain, respectively. In other words, conditional distribution adaptation tries to draw the centroid of same category closer. [45] has verified that conditional distribution adaptation plays a crucial role in both adaptation and classification. Therefore, we adopt conditional distribution adaptation to achieve the goal of UDA.
Motivation
Existing deep domain adaptation methods may not effectively integrate discriminability with transferability of features since the transferable representations and the discriminative representations of the source and target domains mainly linger in thedifferent high-level feature layers(i.e., the last pooling layer and the fully connected layer) respectively. We believe that learning both category-level and discriminative feature representations is important since it can promote the robustness of networks. This paper explores how to effectively transfer a learning model from the source domain to the target domain via the category-level feature representations in high-order statistics. It is important to increase inter-category distance and select transferability samples simultaneously in order to obtain a discriminative feature representation.
Domain adaptation via variance reduction
It is essential for domain adaptation to learn the category-level feature representation between source and target domain. Intuitively, the minimization of intra-category variance contributes to category-level feature learning, which is beneficial to the adaptation of category centroids. Therefore, in order to avoid negative transfer during domain adaptation, the source domain should learn the robust category-level feature representation through the intra-category variance reduction.
In unsupervised domain adaptation problems, however, the distributions of the source domain and target domain usually embody complex structures, which reflects the category boundaries [49]. With the label information of the source domain, the intra-category variance reduction of the source can be formulated as:
where is the centroid of kth category, and it is defined as:
where nk denotes the number of kth class samples in the source domain. With minimizing the formulation of the equation 3, the distance between samples of the same category in the source domain is significantly reduced.
Unfortunately, the adaptation of conditional distribution is nontrivial, since there is no labeled data in the target domain. Target pseudo labels have achieved significant results in practice of conditional distribution adaptation [30, 45–48]. Since the target domain has no labels, we also use the pseudo labels from source classifier trained on the well-labeled xS. Therefore, with the source labels and pseudo target labels, the intra-category variance between and can be defined as:
where mk denotes the number of kth class samples in the target domain. We minimize the intra-category variance of between and to reduce the conditional distribution discrepancy.
The above goal can be rewritten as:
The centroids of the source data and the target data are well aligned via optimizing equation 6, and the alignment of centroids achieves the adaptation of source and target domain. To improve the performance of the transfer task, the discriminability of the features is also indispensable. We will describe this in the next part in detail.
Discriminative features learning
Increase Inter-Category Distance: To further improveing the classification performance during variance reduction, it is essential to ensure the discriminative feature learning. However, only reducing the distribution discrepancy does not attain this goal. Intuitively, if the distances between different categories are as large as possible, the discriminativeness of the learned feature representation will be improved. Hence, we suggest to let the distance among each category’s centroid with non-matching labels yi to be as large as possible. Take the source domain as an example, we can calculate the distance between data in different categories. In order to attain this goal, the inter-category distance of source domain should be increased, which is defined as:
And the inter-category distance should be increased, which is defined as:
Since only source data are labeled, we propose to let the distance between source centroid category k with non-matching target pseudo labels to be as large as possible. Considering the above objectives,
Through maximizing , the different centroid will be pulled away, which can encourage discriminative feature learning.
Transferability Weighting Module: The source instance which is irrelevant to the target instance can make the domain adaptation difficult. We believe it is important to explore strategies for identifying the most relevant source instances to learn discriminative features. So we select source domain instance that is closer to the target domain and adjusts the source domain distribution by transferability weighting. Because the domain classification can quantify the similarity between the source sample and the target sample, we pre-trained domain classifier Gd to distinguish the representations of the source domain from that the target domain,
Gd is only used to select the instances with high transferability, and its gradient does not back-propagated for updating f. The output of the Gd gives the probability of whether a sample belongs to the source domain through a softmax activations. The smaller the probability value of Gd (xsi), the closer the source instance is to the target instance. Hence, the domain classification probability from the domain classifier Gd can be defined as the weight of source instance. Based on information theory, the entropy function is an uncertainty measure defined as H (p) = - ∑jpj · log(pj) that can properly quantify the sample transferability. Therefore, we utilize the entropy criterion to generate the transferability weighting value for each sample of the source domain as:
In this way, the instance with higher transferability will be weighted by a larger value.
In summary, this paper considers increasing inter-category distance and selecting transferability samples simultaneously in order to obtain discriminative feature representation.
Network structure
In the task of extracting features of data such as images and videos, deep learning can extract more transferability features representations. The transferability of features has been proven effective in many deep transfer learning methods. However, the high level features of source domain learned by the last few layers are not transferable to the target domain due to the domain shift [50], which hinders the improvement of classification performance. Therefore, we extended the deep residual network ResNet [51] to implement CDN as shown in Fig. 2, which contains 50 convolution-pooling layers conv1-pool5 as share feature extractor f for source domain and target domain, and fully connected layer fc as the task classifier Gy. We design the domain adaptation layer at the fully connected layers fc and the pooling layers pl via joint category-level and discriminative features representations learning. In addition, we design a transferability weighting module (TWM) basing on the domain classifier Gd used for calculation of w (xsi). The empirical error of CDN classifier Gy on source domain labeled data is
where is the cross-entropy loss function. Due to the existence of cross-domain discrepancy, when training by (12) directly, the classification performance for the target domain task will be poor. Meanwhile, the transferability of features and classifiers decreases when cross-domain discrepancy increases. Therefore, it is very important to explicitly reduce the distribution difference. The transferable representations of the source and target domains and mainly linger in the Pooling layer (pl) while the discriminative representations and mainly remain in Fully connected layer (fc). Such limitations may cause the failure to capture discriminability and transferability of feature representation simultaneously. Our network bridges the gap of these layers by variance reduction and discriminative feature learning. Therefore, the domain adaptation layer completes the category-level feature alignment by minimizing (6). In addition (9) and transferability weighting module(TWM) make the network learn more discriminative features which can further improve classification performance during training. We have the following training objective for a CDN:
where λ and β is a trade-off parameter, denotes the weight of each source sample xsi. It is worth noting that the centroid of the same category () needs to update as the parameters of the deep learning network change. In the CDN optimization process, the centroid of the same category is updated based on mini-batch in each training iteration that can reduce the computational cost and adjust the centroid in time. At the same time, γ as optimization learning rate of centroid, can reduce the interference caused by few mislabelled samples. The update equation of is defined as:
where w (xsj) denotes the transferability of source sample. The larger the w (xsj) value, the higher the transferability of the source data, so it is important to stabilize the adaptation process and learn discriminative features.
The overall architecture of our proposed CDN which is based on ResNet-50 [51]. The network consist of three modules: 1) the feature extractor f composed of convolutional layers; 2) the domain adaptation layer composed of pooling layers and fully connected layers, which is used to complete the adaptive task with minimization and maximizing; 3) the transferability weighting module(TWM) for outputing transferability weighting w for source domain based on a domain classifier Gd(the gradient of Gd will not be back-propagated for updating f).
Experiments
We conduct experiments to evaluate the CDN compared with state-of-the-art unsupervised domain adaptation methods.
Comparison Methods: We compare CDN with shallow domain adaptation and the state-of-the-art deep domain adaptation methods: Transfer Component Analysis (TCA) [26], Geodesic Flow Kernel (GFK) [41], ResNet Deep Domain Confusion (DDC) [34], Residual Transfer Network (RTN) [35], Reverse Gradient (DANN) [36], Adversarial Discriminative Domain Adaptation (ADDA) [48], Deep Adaptation Network (DAN) [32, 33], Easy Transfer Learning(EasyTL) [44],Joint Adaptation Networks (JAN) [40]. We follow standard experimental setting for all unsupervised domain adaptation tasks [33, 36]: fully labeled samples of the source domain and unlabeled samples of target domain are used for domain adaptation training.
Datasets
Office-31 dataset [52] is a standard open benchmark dataset for domain adaptation, comprising 4,652 images and 31 categories collected from three subsets: Amazon (A), which contains images downloaded from amazon.com, Webcam (W) and DSLR (D), which contain images respectively taken by web camera and digital single-lens reflex camera under different settings in office environment. Each subset is an independent domain, and their distribution is different. Hence, we evaluate all methods on six unsupervised domain adaptation tasks A → W, D → W, W → D, A → D, D → A and W → A following the common evaluation protocol as [32].
ImageCLEF-DA dataset [53] is a standard benchmark dataset for ImageCLEF 2014 domain adaptation task,which contains three subsets: Caltech-256(C), ImageNet ILSVRC 2012(I) and PascalVOC 2012(P). There are 600 images in each subset with12 categories and 50 images per category. Because three subsets in ImageCLEF-DA are of equal size, it is a good complement to Office-31 where images from different subsets have different sizes. We evaluate all six unsupervised domain adaptation tasks: I → P, P → I, I → C, C → I, C → P, and P → C.
In detail, we follow standard evaluation protocols for unsupervised domain adaptation: all labeled source data and all unlabeled target data are used for training, and only the target data is used for testing (the label of target data is only used for testing stage). Moreover, we show some samples of the datasets in Fig. 3.
Some selected sample images of object datasets.
Evaluation Protocols: Our CDN and all comparative domain adaptation methods are based on models from ResNet(50-layer) [51] which are the base framework for learning deep transferable features. Specifically, the deep representations output by the layer pool5 of ResNet50 is used as features for domain adaption. We follow standard evaluation protocols for unsupervised domain adaptation [33, 52], and we compare the classification accuracy and the standard error of all domain adaptation task through three random experiments.
We implement our CDN basing on the PyTorch framework. The base architecture ResNet(50-layer) [51] is pre-trained on the ImageNet dataset [54]. We fine-tune the shared feature extractor f and train a classifier Gy by end-to-end back propagation. We adopt mini-batch stochastic gradient descent (SGD) with the momentum of 0.9 for all parameters updated. The learning rate annealing follows the strategy DANN [36]: the learning rate is adjusted during SGD by , where p is the training progress of epochs linearly changing from 0 to 1 for promoting convergence and reducing error on the source domain. Since the classifier is retrained, we set its learning rate to be ten times of the other layers. In the domain adaptation layer, the centroid of the same source category is updated by standard mini-batch stochastic gradient descent (SGD). The hyper parameter λ and β dominates the penalty of , , respectively. γ controls the learning rate of centroid in source domain. We conducted three experiments on office-31 tasks A → W to study the sensitivity of the three parameters, which are shown in Fig. 5(c), (d) and (e).
Results and discussion
Results on Office-31 and ImageCLEF-DA: The classification performance of unsupervised domain adaptation is shown in Tables 3 and 4. For fair comparison, we cite the published results from their original papers or directly from [40]. In most domain adaptation tasks, our proposed CDN model outperforms others for all comparison methods. We gain several interesting observations from the experimental results. First of all, compared to traditional shallow transfer learning methods and standard deep learning methods, deep transfer learning methods achieve better performance. Some recent works such as DDC [34], DAN [32, 33], DANN [36], RTN [35] and JAN [40], have validated that the reduction of domain discrepancy plays an important role in the extraction of migratable features. Secondly, in order to study the influence of our method on transferable feature learning, we conduct ablation experiments on the Office-31 dataset. The study evaluate several variants of CDN: CDN(w/o DR), which denotes that Increase Inter-Category Distance and Transferability Weighting Module are not used in the training process; CDN(w/o R), which denotes training completely without the Transferability Weighting Module. The results in Table 5 prove that the motivation of this paper is correct. (a) CDN(w/o DR) achieves better results than JAN. This validates that the variance reduction plays an important role in domain adaptation. (b) CDN(w/o R) works better than CDN(w/o DR), but worse than full CDN. This validates that transferability weighting module makes more transferable source domain features and form dense clusters. This demonstrates that TWN stabilizes the adaptation process. By comparing the result of CDN(w/o DR) with CDN(w/o R), it can be observed that the increase of inter-category distance makes centroid of different categories more discrete which promotes the network to learn more discriminative features and further improve the classification performance of the target domain. (c) The full CDN model achieves the best results whose domain adaptation layer consists of category-level and discriminative features learning. It suggests that domain adaptation of the same category samples reduces distribution discrepancy, while samples of different categories are more discrete, making the features more discriminative. Finally, in the domain adaptation layer of CDN, the network can fully utilize the conditional distribution information of the source domain. Based on the deep learning and domain adaptation layer, the distribution of source and target domains can be well adapted. Thus the CDN model gains the state-of-the-art performance on the Office31 and ImageCLEF-DA.
Classification accuracy (%) on Office-31 dataset
Method
A → W
D → W
W → D
A → D
D → A
W → A
Avg
ResNet
68.4 ± 0.2
96.7 ± 0.1
99.3 ± 0.1
68.9 ± 0.2
62.5 ± 0.3
60.7 ± 0.3
76.1
GFK
72.8 ± 0.0
95.0 ± 0.0
98.2 ± 0.0
74.5 ± 0.0
63.4 ± 0.0
61.0 ± 0.0
77.5
TCA
72.7 ± 0.0
96.7 ± 0.0
99.6 ± 0.0
74.1 ± 0.0
61.7 ± 0.0
60.9 ± 0.0
77.6
DDC
75.6 ± 0.2
96.0 ± 0.2
98.2 ± 0.1
76.5 ± 0.3
62.2 ± 0.4
61.5 ± 0.5
78.3
RTN
84.5 ± 0.2
96.8 ± 0.1
99.4 ± 0.1
77.5 ± 0.3
66.2 ± 0.2
64.8 ± 0.3
81.6
EasyTL
81.8 ± 0.0
85.7 ± 0.0
67.6 ± 0.0
96.3 ± 0.0
93.8 ± 0.0
67.2 ± 0.0
82.1
DANN
82.0 ± 0.4
96.9 ± 0.2
99.1 ± 0.1
79.7 ± 0.4
68.2 ± 0.4
67.4 ± 0.5
82.2
ADDA
86.2 ± 0.5
96.2 ± 0.3
98.4 ± 0.3
77.8 ± 0.3
69.5 ± 0.4
68.9 ± 0.5
82.9
DAN
86.3 ± 0.3
97.2 ± 0.2
99.6 ± 0.1
82.1 ± 0.3
64.6 ± 0.4
65.2 ± 0.3
82.5
JAN
85.4 ± 0.3
97.4 ± 0.2
99.8 ± 0.2
84.7 ± 0.3
68.6 ± 0.3
70.0 ± 0.4
84.3
CDN
90.6 ± 0.3
99.0 ± 0.0
100.0 ± 0.0
89.7 ± 0.6
66.1 ± 0.6
66.4 ± 0.1
85.3
Classification accuracy (%) on ImageCLEF-DA dataset
Method
I → P
P → I
I → C
C → I
C → P
P → C
Avg
ResNet
74.8 ± 0.3
83.9 ± 0.1
91.5 ± 0.3
78.0 ± 0.2
65.5 ± 0.3
91.2 ± 0.3
80.7
GFK
73.5 ± 0.0
74.8 ± 0.0
91.2 ± 0.0
84.8 ± 0.0
70.0 ± 0.0
82.3 ± 0.0
79.4
TCA
75.0 ± 0.3
78.3 ± 0.0
91.5 ± 0.0
83.7 ± 0.0
71.7 ± 0.0
84.0 ± 0.0
80.7
DAN
74.8 ± 0.3
83.9 ± 0.1
91.5 ± 0.3
78.0 ± 0.2
65.5 ± 0.3
91.2 ± 0.3
80.7
RTN
74.6 ± 0.3
85.8 ± 0.1
94.3 ± 0.1
85.9 ± 0.3
71.7 ± 0.3
91.2 ± 0.4
83.9
DANN
75.0 ± 0.6
86.0 ± 0.3
96.2 ± 0.4
87.0 ± 0.5
74.3 ± 0.5
91.5 ± 0.6
85.0
EasyTL
78.5 ± 0.0
83.9 ± 0.0
93.3 ± 0.0
85.5 ± 0.0
72.0 ± 0.0
95.0 ± 0.0
85.6
JAN
76.8 ± 0.4
88.0 ± 0.2
94.7 ± 0.2
89.5 ± 0.3
74.2 ± 0.3
91.7 ± 0.3
85.8
CDN
78.8 ± 0.4
92.0 ± 0.2
95.9 ± 0.1
91.0 ± 0.3
75.7 ± 0.3
95.2 ± 0.4
88.1
Ablation experiments on the Office-31 dataset
Method
A → W
D → W
W → D
A → D
D → A
W → A
Avg
ResNet
68.4 ± 0.2
96.7 ± 0.1
99.3 ± 0.1
68.9 ± 0.2
62.5 ± 0.3
60.7 ± 0.3
76.1
CDN(w/o DR)
89.0 ± 0.4
98.8 ± 0.1
100.0 ± 0.0
87.3 ± 0.8
65.2 ± 0.1
64.6 ± 0.4
84.1
CDN(w/o R)
89.6 ± 0.3
98.9 ± 0.1
100.0 ± 0.0
89.0 ± 0.2
65.7 ± 0.5
66.1 ± 0.0
84.9
CDN
90.6 ± 0.3
99.0 ± 0.0
100.0 ± 0.0
89.7 ± 0.6
66.1 ± 0.6
66.4 ± 0.1
85.3
Conditional Distribution Discrepancy: The theory result of domain adaptation shows that cross-domain discrepancy is a key to solve the domain shift problem [22, 55]. For the Office-31 dataset, the distribution of domains W and D are similar, but they are not similar to A. The results are shown in Table 3, and the tasks on (W → D and D → W) with similar domain distribution differences gain better accuracy than on A → W and A → D which well validates the above theory. For the transfer task A → W and A → D which have the larger distribution discrepancy of domains, CDN model is even more accurate. However, the difficulty to transfer increases for asymmetric domain adaptation tasks from a small number of samples to a large number of samples (D → A and W → A). Different to Office-31, the three domains of ImageCLEF-DA are more symmetric. With these domain adaptation tasks, we expect to verify whether the performance improves with the same subset size. The classification results based on ResNet-50 [51] are shown in Table 4. The CDN models gain better performance on most domain adaptation tasks than other comparison methods. This also verifies the completeness of our theory.
Analysis
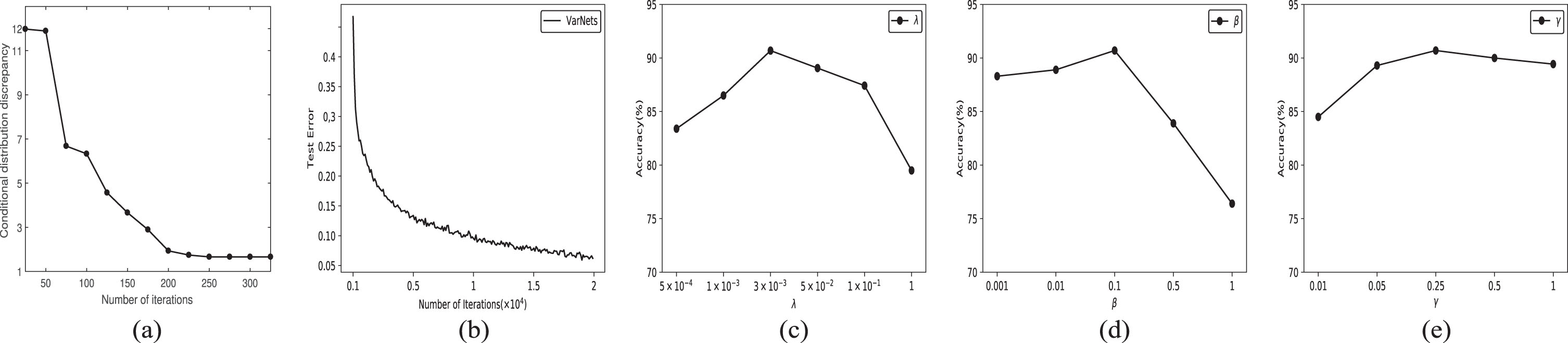
Feature Visualization: We visualize the network activations for feature extractors of ResNet, DAN [33], CDN(w/o DR), CDN(w/o R) and full CDN on the adaptation task A → W by t-SNE [56] in Fig. 4. For the feature of ResNet, the clusters of the source domain is not compact enough, and samples of the target domain are not well aligned with the centroid of the cluster. It is noted that DAN only aligns the marginal distributions, thus this global adaptation strategy does not consider the category-level distribution adaptation as illustrated in Fig. 4(b). As a result, the source and target are not aligned well with global adaptation i.e., DAN, better aligned with ResNet but categories are not discriminated well. Figure 5(a) shows the conditional distribution discrepancy of learned features during the training phase, which are calculated with Equation (2). The conditional distribution discrepancy can be reduced by our method after several iterations. It can be observed that the distribution divergence become smaller during the optimization iterations. In other words, our approach can effectively achieve domain adaptation. For the features of CDN(w/o DR), the source domain forms compact clusters, and samples of the target domain are well aligned with the centroid of the same category in source domain. However, some features of the source and target domains have not been well identified. For the features of CDN(w/o R), the clusters of the source and target domain are more discrete. For the features of our CDN, the source and target domain further form more dense clusters, and the shared categories across domains are perfectly aligned while different categories are well distinguished. The effectiveness of CDN is verified intuitively.
The t-SNE visualization of feature representations learned by (a) ResNet (trained by source data), (b) DAN, (c) CDN(woDC/R), (d) CDN(woR) and (e) CDN. Note that the ▵ are samples from the source domain Amazon (A), and the are samples from the target domain Webcam (W) respectively. The same color represents the same category of data. Especially, global adaptation (DAN) does not guarantee category-level adaptation as illustrated in Fig. 2(b).
Parameter Sensitivity: We check the sensitivity of CDN hyper-parameter λ, β, and γ which controls the learning rate of the centralization of clusters in the adaptation layer. Figure 5 demonstrates the parameter sensitivity of CDN on task A → W. When testing CDN penalty λ, we fix γ = 0.25, β = 0.1 and vary λ ∈ {0.0005, 0.001, 0.003, 0.005, 0.01, 1}. When testing β, we fix λ = 0.003, γ = 0.25 and vary β ∈ {0.01, 0.1, 0.5, 1}. The results are shown in Fig. 5(c) and (d). Theoretically, larger values of λ and β can make shrinkage regularization more important in CDN. When λ→ ∞ or β→ ∞, the optimization problem is ill-defined. When λ → 0 or β → 0, distribution adaptation is not performed, and CDN cannot construct robust representation. When testing γ, we fix λ = 0.003 β = 0.1 and vary λ ∈ {0.01, 0.05, 0.25, 0.5, 1}. The verification accuracies are illustrated in Fig. 5(e), the verification performance of our model remains mostly stable across a wide range of γ.
(a) Conditional distribution discrepancy. It is worth noting that the reduction of variances decreases the discrepancy of the conditional distribution, (b) Convergence performance on the adaptation task of A → W by our CDN, (c)-(e) Sensitivity of λ, β and γ.
Convergence Performance: We also empirically check the convergence performances of CDN. Figure 5(b) shows the test errors of CDN on the adaptation task A → W, which suggests that classification accuracy (distribution distance) increases (decreases) steadily with more iterations.
Conclusion
In this paper, we have introduced a novel unsupervised domain adaptation approach, which focuses on category-level and discriminative feature representations learning. In this paper, we consider the category-level distribution adaptation by variances reduction between source and target. Comprehensive experimental evidence on image classification datasets verifies the effectiveness and efficiency of the proposed approach over several state-of-the-art methods.
Most of the recent work has focused on cross-domain image classification tasks. In real-world applications, unsupervised domain adaptation is gaining more and more attention. We will explore the application of unsupervised domain adaptation in other areas, such as cross-domain image segmentation or object detection tasks.
Footnotes
Acknowledgment
The work is supported by National Key R&D Program of China (2018YFC0309400), National Natural Science Foundation of China (61871188), Guangzhou city science and technology research projects(201902020008).
References
1.
Fathollahi-FardA.M., Hajiaghaei-KeshteliM. and MirjaliliS., Multi-objective stochastic closed-loop supply chain network design with social considerations, Applied Soft Computing, 2018, 505–25.
2.
Fathollahi-FardA.M., Hajiaghaei-KeshteliM. and MirjaliliS., A bi-objective green home health care routing problem, Journal of Cleaner Production, 2018, 423–43.
3.
Hajiaghaei-KeshteliM. and Fathollahi-FardA.M., A set of efficient heuristics and metaheuristics to solve a two-stage stochastic bi-level decision-making model for the distribution network problem, Computers & Industrial Engineering, 2018, 378–95.
4.
FuY., TianG., Fathollahi-FardA.M., AhmadiA. and ZhangC., Stochastic multi-objective modelling and optimization of an energy-conscious distributed permutation flow shop scheduling problem with the total tardiness constraint, Journal of cleaner production, 2019, 515–25.
5.
FardA.M. and Hajiaghaei-KeshteliM., A bi-objective partial interdiction problem considering different defensive systems with capacity expansion of facilities under imminent attacks, Applied Soft Computing, 2018, 343–59.
6.
Fathollahi-FardA.M., Hajiaghaei-KeshteliM. and MirjaliliS., A set of efficient heuristics for a home healthcare problem, Computing and Applications, 2019, 1–21.
7.
Bahadori-ChinibelaghS., Fathollahi-FardA.M. and Hajiaghaei-KeshteliM., Two Constructive Algorithms to Address a Multi-Depot Home Healthcare Routing Problem, IETE Journal of Research, 2019, 1–7.
8.
AbdiA., AbdiA., Fathollahi-FardA.M. and Hajiaghaei-KeshteliM., A set of calibrated metaheuristics to address a closed-loop supply chain network design problem under uncertainty, International Journal of Systems Science: Operations & Logistics, 2019, 1–8.
9.
SafaeianM., Fathollahi-FardA.M., TianG., LiZ. and KeH., A multi-objective supplier selection and order allocation through incremental discount in a fuzzy environment, Journal of Intelligent & Fuzzy Systems, 2019, 1435–1455.
10.
ElsayedG., ShankarS., CheungB., PapernotN., KurakinA., GoodfellowI. and Sohl-DicksteinJ., Adversarial examples that fool both computer vision and time-limited humans, Advances in Neural Information Processing Systems, 2018, 3910–3920.
11.
VoulodimosA., DoulamisN., DoulamisA. and ProtopapadakisE., Deep learning for computer vision: A brief review, Computational intelligence and neuroscience, 2018.
12.
YoungT., HazarikaD., PoriaS. and CambriaE., Recent trends in deep learning based natural language processing, IEEE Computational intelligenCe magazine13(3) (2018), 55–75.
13.
BeckerM., KasperS., BöckmannB., JöckelK.H. and VirchowI., Natural language processing of german clinical colorectal cancer notes for guideline-based treatment evaluation, International journal of medical informatics127 (2019), 141–146.
14.
PanS.J. and YangQ., A survey on transfer learning, IEEE Transactions on knowledge and data engineering20(10) (2009), 1345–1359.
15.
DuanL., XuD. and TsangI.W.H., Domain adaptation from multiple sources: A domain-dependent regularization approach, IEEE Transactions on Neural Networks and Learning Systems23(3) (2012), 504–518.
16.
TorralbaA. and EfrosA.A., Unbiased look at dataset bias, CVPR1(2) (2011), 7.
17.
DaiW., YangQ., XueG.R. and YuY., Boosting for regression transfer, Proceedings of the 24th international conference on Machine learning, ACM, 2007, 193–200.
18.
PardoeD. and StoneP., Boosting for regression transfer, Proceedings of the 27th International Conference on International Conference on Machine Learning, Omnipress, 2010, 863–870.
19.
LuoY., ZhengL., GuanT., YuJ. and YangY., Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation, arXiv preprint arXiv:1809.09478, 2018.
20.
BlitzerJ., DredzeM. and PereiraF., Biographies, Bollywood, Boom-boxes and Blenders: Domain adaptation for sentiment classification, Proceedings of the 45th annual meeting of the association of computational linguistics, 2007, 440–447.
21.
ZhouJ.T., TsangI.W., PanS.J. and TanM., Heterogeneous domain adaptation for multiple classes, Artificial Intelligence and Statistics, 2014, 1095–1103.
22.
Ben-DavidS., BlitzerJ., CrammerK., KuleszaA., PereiraF. and VaughanJ.W., A theory of learning from different domains, Machine learning79(1-2) (2010), 151–175.
23.
HuangJ., GrettonA., BorgwardtK., SchölkopfB. and SmolaA.J., Correcting sample selection bias by unlabeled data, Advances in neural information processing systems, 2007, 601–608.
24.
WangW., WangH., ZhangC. and GaoY., Cross-domain metric and multiple kernel learning based on information theory, Neural computation30(3) (2018), 820–855.
25.
GrettonA., BorgwardtK.M., RaschM.J., SchölkopfB. and SmolaA., A kernel two-sample test, Journal of Machine Learning Research13(Mar) (2012), 723–773.
26.
PanS.J., TsangI.W., KwokJ.T. and YangQ., Domain adaptation via transfer component analysis, IEEE Transactions on Neural Networks22(2) (2010), 199–210.
27.
BaktashmotlaghM., HarandiM.T., LovellB.C. and SalzmannM., Unsupervised domain adaptation by domain invariant projection, Proceedings of the IEEE International Conference on Computer Vision, 2013, 769–776.
28.
LongM., WangJ., DingG., SunJ. and YuP.S., Transfer feature learning with joint distribution adaptation, Proceedings of the IEEE international conference on computer vision, 2013, 2200–2207.
29.
ZhangJ., LiW. and OgunbonaP., Joint geometrical and statistical alignment for visual domain adaptation, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, 1859–1867.
30.
SunQ., ChattopadhyayR., PanchanathanS. and YeJ., A two-stage weighting framework for multi-source domain adaptation, Advances in neural information processing systems, 2011, 505–513.
31.
GongB., GraumanK. and ShaF., Connecting the dots with landmarks: Discriminatively learning domain-invariant features for unsupervised domain adaptation, February, International Conference on Machine Learning, 2013, 222–230.
32.
LongM., CaoY., CaoZ., WangJ. and JordanM.I., Transferable representation learning with deep adaptation networks, IEEE transactions on pattern analysis and machine intelligence, 2018.
33.
LongM., CaoY., WangJ. and JordanM.I., Learning transferable features with deep adaptation networks, arXiv preprint arXiv:1502.02791, 2015.
34.
TzengE., HoffmanJ., ZhangN., SaenkoK. and DarrellT., Deep domain confusion: Maximizing for domain invariance, arXiv preprint arXiv:1412.3474, 2014.
35.
LongM., ZhuH., WangJ. and JordanM.I., Unsupervised domain adaptation with residual transfer networks, Advances in Neural Information Processing Systems, 2016, 136–144.
36.
GaninY. and LempitskyV., Unsupervised domain adaptation by backpropagation, International Conference onMachine Learning (ICML), 2015, 1180–1189.
37.
DosovitskiyA., SpringenbergJ.T., RiedmillerM. and BroxT., Discriminative unsupervised feature learning with convolutional neural networks, Advances in neural information processing systems, 2014, 766–774.
38.
WenY., ZhangK., LiZ. and QiaoY., A discriminative feature learning approach for deep face recognition, European conference on computer vision, SpringerCham, 2016, 499–515.
39.
WangH., WangY., ZhouZ., JiX., GongD., ZhouJ. and LiuW., Cosface: Large margin cosine loss for deep face recognition, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, 5265–5274.
40.
LongM., ZhuH., WangJ. and JordanM.I., Deep transfer learning with joint adaptation networks, Proceedings of the 34th International Conference on Machine Learning Learning-Volume 70, JMLR, org, 2017, 2208–2217.
41.
GongB., ShiY., ShaF. and GraumanK., Geodesic flow kernel for unsupervised domain adaptation, 2012 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2012, 2066–2073.
42.
FernandoB., HabrardA., SebbanM. and TuytelaarsT., Unsupervised visual domain adaptation using subspace alignment, Proceedings of the IEEE international conference on computer vision, 2013, 2960–2967.
43.
LongM., WangJ., DingG., SunJ. and YuP.S., Transfer joint matching for unsupervised domain adaptation, Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, 1410–1417.
44.
WangJ., ChenY., YuH., HuangM. and YangQ., Easy Transfer Learning By Exploiting Intra-domain Structures, arXiv preprint arXiv:1904.01376, 2019.
45.
LongM., WangJ., DingG., PanS.J. and PhilipS.Y., Adaptation regularization: A general framework for transfer learning, IEEE Transactions on Knowledge and Data Engineering26(5) (2013), 1076–1089.
46.
WangJ., ChenY., HuL., PengX. and PhilipS.Y., Stratified transfer learning for cross-domain activity recognition, IEEE International Conference on Pervasive Computing and Communications (PerCom), IEEE, 2018, 1–10.
47.
QuanzB., HuanJ. and MishraM., Knowledge transfer with low-quality data: A feature extraction issue, IEEE Transactions on Knowledge and Data Engineering24(10) (2012), 1789–1802.
48.
TzengE., HoffmanJ., SaenkoK. and DarrellT., Adversarial discriminative domain adaptation, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, 7167–7176.
49.
PeiZ., CaoZ., LongM. and WangJ., Multi-adversarial domain adaptation, Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
50.
YosinskiJ., CluneJ., BengioY. and LipsonH., How transferable are features in deep neural networks?Advances in neural information processing systems, 2014, 3320–3328.
51.
HeK., ZhangX., RenS. and SunJ., Deep residual learning for image recognition, Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, 770–778.
52.
SaenkoK., KulisB., FritzM. and DarrellT., Adapting visual category models to new domains, European conference on computer vision, Springer, Berlin, Heidelberg, 2010, 213–226.