
Abstract
Attention mechanisms are widely used on NLP tasks and show strong performance in modeling local/global dependencies. Directional self-attention network shows the competitive performance on various datasets, but it not considers the reverse information of a sentence. In this paper, we propose the Multiway Dynamic Mask attention Network (MDMAN). The model has two modules: a dynamic mask selector and a multi-attention encoder. The dynamic mask selector chooses high-quality reverse information with reinforcement learning and feeds reverse information to multi-attention encoder, the multi-attention encoder uses four attention functions to match the word in the same sentence at different token level, then combine the information from all functions to obtain the final representation. Our experiments performed on two publicly available NLI datasets show that MDMAN achieves significant improvement over DSAN.
Keywords
Introduction
Natural language inference (NLI) or recognizing textual entailment (RTE) play a significant role in the field of natural language processing. Given a pair of sentences (premise and hypothesis), the purpose of natural language inference is to determine whether the hypothetical sentence can be reasonably inferred from the given premise sentence [1]. There are three types of relation in NLI, Entailment (the hypothesis can be inferred), Contradiction (the hypothesis cannot be true), and Neutral (irrelevant). A few examples are illustrated in Table 1. Recently, a substantial amount of annotated data such as SNLI [2] and MultiNLI [3] make it possible to use deep learning methods to solve the NLI task. Deep learning methods applied in NLI can be roughly divided into two ways. The first methods are sentence encoding-based models where each sentence is encoded to a fixed-sized vector in a completely independent manner and the two vectors for the corresponding sentences are used in predicting the degree of matching, such as Bi-LSTM max-pooling network in Conneau et al. [4] or Stack-augmented Parser-Interpreter Neural Network (SPINN) in Bowman et al. [5]. The latter methods which allow utilizing interactive features between two sentences to directly model the relation between two sentences, such as the densely-connected co-attentive recurrent Model (ESIM) in Kim et al. or the enhancing sequential inference model (BiMPM) in Chen et al.
Recent works have found that models with attention mechanisms have shown state-of-the-art performance in natural language inference [8], question answering [9], sentiment analysis. Recently, Tay et al. proposed a multicast attention network for natural language processing, which the attention mechanisms are imagined as a feature extractor [13]. The model uses multiple attention to extract different word-level features at different granularity. Thus, the model can obtain better hidden features of a sentence.
Examples of relations between a premise and a hypothesis, where E for entailment, C for contradiction, N for neutral, P for premise and H for hypothesis
Examples of relations between a premise and a hypothesis, where E for entailment, C for contradiction, N for neutral, P for premise and H for hypothesis
In parallel, some neural networks composing only of attention, especially self-attention, outperform traditional convolutional [10] or recurrent neural networks [11] on NLP tasks due to its highly parallelized computations, such as transformer [14] and DISAN [15], which further shows the effective in attention mechanisms in capturing contextual dependencies. Lately, Shen et al. presented an attention-based model, which provides strong results for various tasks [15]. In particular, they achieve the state-of-the-art result in SNLI. In the model, the sentence can be temporal order encoded by the forward mask and backward mask. However, the reverse information of the sentence was not considered at all when the model encodes sentence by direction mask, which will inevitably lead to the lack of information. Moreover, it is only a simple concatenation of the sentence information of multiple attention. As a result, it bloats subsequent layers with a high dimensional vector. It is hence increasing the parameter cost of subsequent layers.
In this paper, to tackle this limitation, we propose multiway dynamic mask attention networks consisting of two modules: a dynamic mask selector and multi-attention encoder. However, it also brings an additional problem. We don’t have explicit supervision for the dynamic mask selector, and the mask in the dynamic mask selector is a discrete variable, which leads to a non-differentiable objective function. Since the dynamic mask selector has the following two properties: first, trial-and-error search, the dynamic mask selector attempts to adjust the mask to obtain the feedback (or reward) of the selected mask; Second, we can only obtain feedback from multi-attention encoder when we complete the typically delayed mask selection process. Therefore, We address this challenge by casting the dynamic mask selector task as a reinforcement learning problem. The dynamic mask selector uses the current sentence feature to adjust mask based on the direction mask. This allows the multi-attention encoder to obtain effective reverse information when use masks to encode temporal order information. As shown in the example in the table, two men on bicycles competing in a race and people are riding bikes. The relation of these two sentences is entailment. The relation between two men on bicycles competing in a race and men are riding bicycles on the streets is contradictory. These vectors are very similar, which makes it difficult to distinguish between them using a single attention mechanism. In order to address the issue, we combine two different self-attention with the dynamic mask generated by the dynamic mask selector to generate four different attention to obtain information at different token level. And then use the attention fusion layer to solve the problem of consequently incurs parameter costs on the subsequent network layer due to the increase in the number of attention, the attention fusion layer also retains useful information.
Our contributions in this work are as follows:
We propose a multiway dynamic mask attention network, which consists of a dynamic mask selector and a multi-attention encoder. This formalization allows our model to utilize different word-level features to obtain better sentence information. We formulate the dynamic mask selector as a reinforcement learning problem. The model performs the selection of the mask without ground truth labels but just with a weak supervision signal from the multi-attention encoder.
Recently, the development of large-scale annotated datasets [2] and deep learning algorithms have made significant achievements in modeling sentences. Researchers have studied the essential representations techniques of NLP on the SNLI, such as attention [16], memory [17], and grammatical structures [18]. In the conventional methods, these models use a sentence encoder to encode sentences into a sentence representation and then determine the relationship based on these independent sentence representations through a neural network classifier [19]. These sentence-encoding-based methods make it easy to extract sentence representations and can be used in transfer learning to other natural language tasks [20]. Wang and Jiang proposed match-LSTM for natural language inference, trying to match the current word in the hypothesis with the representation of the premise through the attention mechanism [21]. Wang et al. proposed BiMPM, which achieves the significant results in recognizing textual entailment and answer sentence selection by matching two sentences by bilateral matching with attention mechanisms in multiple perspectives [22]. Tan et al. used the representations obtained by different attention to enhance the feature representation, avoiding the problem of simply using max-pooling and mean-pooling to cause information loss [23].
Recently, attention mechanisms are successfully applied on the natural language processing. Seo et al. proposed a Bi-Directional Attention Flow (BIDAF) model [24]. It uses bi-directional attention mechanism to obtain a context representation. Vaswani et al. proposed a multi-head attention model. The multi-head attention model uses multi-head dot-product attention to represent each word in the sentence. Shen et al. constructed a fully attention-based sentence coder, which proposed a multi-dimensional self-attention mechanism that uses the attention model to calculate the attention of each dimension [15]. Shen et al. constructed a fully attention-based sentence coder, which proposed a multi-dimensional self-attention mechanism that uses the attention model to calculate the attention of each dimension and adds a directional mask to the logit of attention, words in a specific direction in the sentence were masked to avoid attention. The extent to which attention results are ultimately reflected was determined through fusion gate. In our study, we constructed a model based on multi-dimensional self-attention mechanism, which uses dynamic masks to obtain reverse information and uses multiple attentions to focus on different features at the sentence level.
Background
Self-Attention is a special case of the attention mechanism. It can generate the dependencies between tokens from the same sequence. Recently, various self-attention mechanisms have been developed and applied in different tasks. In this paper, we use Directional self-attention [15] and Directional dot attention (dot attention [25] with mask). the dependency of
where
The final output of attention S is the expectation of sampling the token according to the categorical distribution. i.e.,
The overall architecture of our model is shown in Fig. 1. Our model consists of two key modules: a dynamic mask selector and a multi-attention encoder. The dynamic mask selector dynamically generates an effective mask based on the current sentence feature to boost the ability of the multi-attention encoder to obtain useful information. The multi-attention encoder is mainly composed of two independent components, a sentence encoder and a classifier. In the multi-attention encoder, we follow the conventional neural network structure in natural language reasoning [26], First, the input sentences, premise and hypothesis, are encoded as vectors, u and v, without using any other sentence information, through multi-attention encoder, and then a probability for each of the 3-class is generated through the classifier.
Overall architecture. The dynamic mask selector generates an effective mask according to a policy function, and then The mask are used to train a better multi-attention encoder. The dynamic mask selector updates the parameters with a reward calculated from the multi-attention encoder.
The overall process of the dynamic mask: (1) initialize the forward and backward masks; (2) the mask generated by the dynamic mask selector based on the sentence features, and (3) the final forward and backward masks.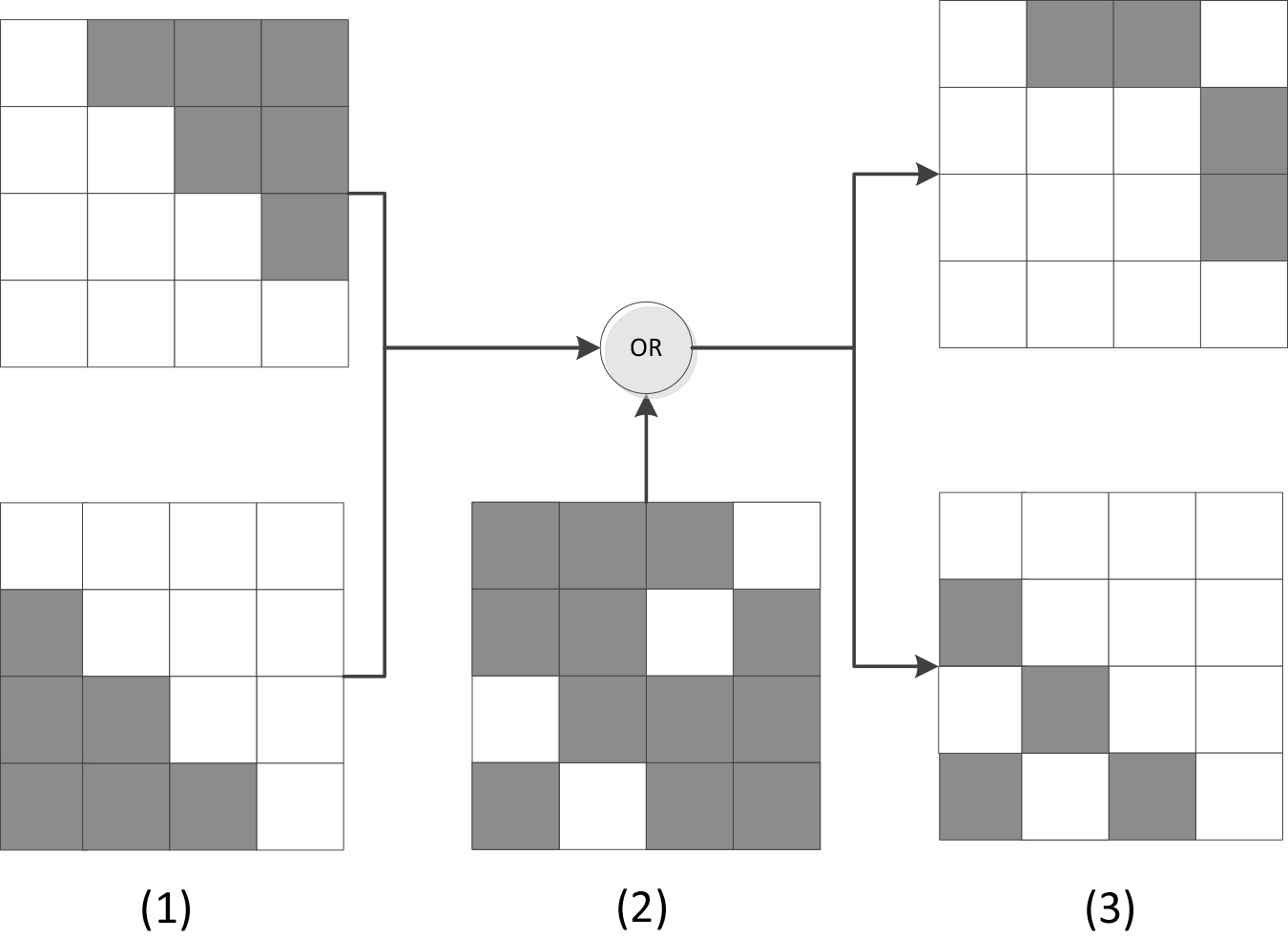
Directional Self Attention Network utilizes the forward mask and the backward mask to temporal order encodes the sentences based solely on the attention mechanism. The model achieved very significant results. However, its mask is fixed. The model can only encode sentences in a specific direction, and can not dynamically generate a more effective mask based on the sentence feature. In this paper, the dynamic mask selector uses the current sentence feature to dynamically select its important reverse information based on the direction mask.
For the training of the dynamic mask selector, there are no truth labels to indicate whether the token should be selected and the mask is a discrete random variable, which is leads to a non-differentiable objective function. As a result, we address the issue by using the policy gradient method of reinforcement learning. The dynamic mask selector follows a policy to decide which action (selecting the token or not) at each state (consisting of
In the dynamic mask selector, the forward mask and the backward mask are first initialized according to Eqs (3) and (4). The mask after initialization is shown in Fig. 2(1).
The state
In the current sentence
where
Then, we use the action function a to generate two equal-length sequences vectors
Finally, the resulting mask
Sentence Encoder. The sentence encoder is mainly composed of the word embedding layer, the dynamic mask multi-attention layer, the attention fusion layer, and the classifier. The overall structure is shown in Fig. 3.
The overall structure of the sentence encoder.
Word Embedding Layer. In the word embedding layer, the input sentences (premise and hypothesis) are transformed into dense representations
where
Dynamic Mask Multi-Attention Layer. In the dynamic mask multi-attention layer, we design multiple attention functions to obtain information at different token level. We combine self-attention and dot attention with a dynamic mask to generate four different attention mechanisms, forward dynamic self-attention, backward dynamic self-attention, forward dynamic dot attention, and backward dynamic dot attention. They use their own calculation method to calculate the score of each feature of each token. We first generate vector representations
where
Forward dynamic self-attention:
backward dynamic self-attention:
forward dynamic dot attention:
backward dynamic dot attention
Where is
Then, we combine the attention-generated s and the input sentence vector
where,
Attention Fusion Layer. In the attention fusion layer, we aggregate the matching information from Dynamic Mask Multi-Attention functions to generate the resulting representation.
We follow the standard procedure [5]. For the output encoding u (premise) and v (hypothesis), the representation of the relation between the two sentences is generated by the concatenation of u, v, u – v, u
Experiments
In this section, we conduct experiments on the NLI task with two datasets, SNLI and MultiNLI. Experimental results show that our model outperforms our baseline and other competing approaches.
Training details
We implement our model with Tensorflow [28] framework and train out model on single Nvidia TITAN X. We use the 300D GloVe 6B pre-trained vectors to initialize the word embedding without any finetuning. The out-of-vocabulary words are randomly initialized with uniform distribution. All weight matrices are initialized using Glorot [29], and the biases are initialized with 0. We set the dropout to 0.73, the initial learning rate is set to 0.5, and the decay rate is 0.999, the batch size is set to 64. We use Adam as optimizer. Hidden units number
In the classification setting, we use cross-entropy loss plus L2 regularization penalty as the loss, i.e.,
where,
In the dynamic mask selector, there is no label indicating whether a token should be selected. As a result, we use the policy gradient method to train our dynamic mask selector. Since the overall goal of the dynamic mask selector is to obtain an efficient reverse mask and the number of the reverse positions selected is as small as possible. We can obtain a loss value from the multi-attention encoder, which can be regarded as the delayed reward to train the dynamic mask selector and a penalty limiting the number of selected reverse positions is included in the reward
Where
Experimental results for different methods on SNLI
For thorough comparison, in addition to the neural networks proposed in the previous NLI work, we implement two extra neural network baselines to compare with MDMAN. These neural networks help us to analyze the improvement contributed by each part of MDMAN.
Dynamic Mask self-attention Network: DISAN with Dynamic Mask.
Directional Multiway attention Network: Applying a directional mask on a multi-attention mechanism.
Table 2 shows the results on SNLI. The results show that our model outperforms our baseline model DiSAN. The model achieves better performance on the SNLI dataset. Comparing the two additional baseline models, we demonstrate that adding dynamic masks can improve the accuracy of the model, and using multiple attention with dynamic masks can further improve accuracy.
MultiNLI results
The results of applying our model to the MultiNLI data dataset without additional parameter tuning were compared with the baseline model and other models. The results are shown in Table 3. We obtained our matched-test accuracy and mismatched-test accuracy by submitting our test results to Kaggle open evaluation platforms. The results show that our matched-test accuracy and mismatched-test accuracy are greater than 3.7% and 1.9% when compared to the Directional Self-Attention Network, respectively. Our model achieves better accuracy in MultiNLI and is a significant improvement over our baseline model.
Experimental results for different methods on MultiNLI
Experimental results for different methods on MultiNLI
To gain a closer view of what dependencies in a sentence can be captured by MDMAN, we visualize the attention probability or alignment score by heatmaps. In order to compare with our baseline model, we will focus on dynamic forward and backward self-attention (Eqs (4.2) and (4.2)) and forward/backward fusion gates F (Eq. (4.2)). Note that we only explain its dependencies at the word level.
We select a sentence from SNLI test set as an example and visualize its result value. The sentence is “A girl playing a violin along with a group of people”.
Attention probability in dynamic forward/backward self-attention.
As shown in Fig. 4, similar to directed self-attention, semantically important words, such as nouns and verbs, usually get a lot of attention in dynamic mask attention, but for stop words (am, is, are, etc.), there will get less attention. For globally important words, e.g., girl, violin, get large attention from these words. Unlike directed self-attention, dynamic self-attention focuses on reverse semantically important words and usually ignores semantically unimportant words, such as stop words. As a result, dynamic attention can obtain important reverse information.
As shown in Fig. 5, we show the value of the fusion gate F (Eq. (4.2)). This fusion gate combines the input h and the output of dynamic masked self-attention to generate a sentence vector. If the weight of F is very small, it usually tends to select the output of dynamic masked self-attention instead of the input h. This shows that the gate values for words that are meaningless, such as stop words, tend to be very small. Because meaningless words themselves cannot contribute important information, at this time, we add their semantic relations with other words to make it more meaningful. Compared with the fusion gate value F generated by the directed self-attention, we have a smaller gate value for the meaningless word than the directed self-attention gate value. For semantically important words, the value of the fusion gate is larger than the value of the fusion gate of the directed self-attention, which indicates that we can better utilize the characteristics of the context. It may help to understand the sentence better.
(a) and (b) is the fusion gate F in dynamic forward/backward self-attention, (c) and (d) is the fusion gate F in directional forward/backward self-attention.
In this paper, we propose a multi-path dynamic mask model. On the basis of DISAN, we use dynamic mask to obtain its important reverse information and use a variety of attention methods to pay attention to the different granularity of sentences at the word level. Using the attention fusion layer instead of the simple vector connection, we can get a better sentence vector while reducing the burden of the subsequent network layer, thus improving our experimental results.
In future research, we will further study attention-based models and achieve better performance in other more challenging tasks such as QA, reading comprehension.
Footnotes
Acknowledgments
This work is supported by the Zhejiang Province Technology Project (No. 2020C03105).