
Abstract
Considering the scarcity of Uyghur sentiment resources, in this paper proposed a new combined unsupervised sentiment classification method for Uyghur text without any labeled corpora. In the first part, a Uyghur sentiment dictionary, UYSentiDict, was adopted to classify the sentences. For the sentiment vocabulary matching, both the matching of the original word and the stem were considered, and the influence of sentence patterns, negation words, and degree adverbs were further considered as well. Based on different thresholds, the sentences with higher sentiment values were selected from the lexicon-based classification results as a pseudo-labeled dataset. In the second part, different sentiment characteristics were learned from the pseudo-labeled dataset by the machine learning classifier, and the remaining categorical data were further classified. It can be concluded that the method proposed in this paper has good classification efficiency in Uyghur sentiment corpora in four different fields, and some results were performed better than the classification results of machine learning classifier. Moreover, this method is not restricted by the field of data and does not need to be marked in advance with good training corpus, and can solve the resource shortage problem in the field of Uyghur sentiment classification effectively.
Keywords
Introduction
Text sentiment analysis has become an active research topic in the field of NLP. Among the classifiers available, the positive and negative sentiment classification of network data has attracted researchers’ attention. For the first time in 2002, Pang [1] used the machine learning classifier to classify the sentiment of documents. Since then, supervised machine learning classification method has been widely applied. Supervised machine learning classification uses artificially labeled datasets for training, and when there are sufficient and correctly labeled training data in a field, this method can achieve satisfactory classification results.
Network data covers a wide range of fields. Ensuring sufficient annotated corpora are available in certain fields to meet various classification requirements can be challenging. Although the lexicon-based sentiment classification method is domain independent and does not require an annotated corpus, some sentiment vocabularies express different sentiment polarities in different fields or different contexts.
Domestic and foreign researchers have conducted in-depth research on the sentiment classification of English and Chinese. A large-scale sentiment corpus and sentiment dictionaries have been created [2, 3, 4, 5]. Many satisfactory sentiment classification models and algorithms have emerged, and have been cited in some practical applications.
Compared with the study of English and Chinese sentiment classification, the research on Uyghur text sentiment classification has relatively lagged. No lexical resources or labeled corpus publicly available for researchers to use for Uyghur language sentiment classification. For languages lacking sentiment resources, some researchers combined dictionaries and machine learning classifiers. Li [6] and Melville et al. [7] combined dictionaries and small amount of annotated texts to train classifiers. He [8] and Qiu et al. [9] used the sentiment dictionary to complete initial judgments on the tendency of the text, used this result to generate a new classifier, and then revised the initial results. Such methods do not rely on a large amount of annotated data and can be used in sentiment classification tasks in any field. Therefore, these methods are suitable for the sentiment classification of resource-poor languages, such as Uyghur.
Inspired by previous work [8, 9], in this paper, first calculated the sentence’s sentiment score based on the Uyghur sentiment dictionary (UYSentiDict).1
Code and data for the first step are available at
Code and data for the second step are available at
For the code, corpus and experimental results of the final step are available at
The method applied in this paper involved training the machine learning classifier based on the sentiment classification results of the lexicon-based classifier. Therefore, the result of the lexicon-based classifier directly affects the classification result of the subsequent machine learning classifier. In the process of classification based on sentiment lexicon, degree adverbs, negation words, and sentence patterns are the key factors that influence the tendency of sentences. Although some of these factors were also considered in the literature related to Uyghur sentiment classification, they were all assessed on the corpus of a certain area. However, the overall impact on different corpus has not been systematically studied. Therefore, taking into account the above factors that affect the classification results, research aimed to improve the classification efficiency as much as possible, based on the lexicon classifier.
The main contributions of this article are as follows:
We systematically studied the influence of modifiers, such as turning conjunctions, progressive conjunctions, degree adverbs, and negation words, on the sentiment polarity of Uyghur sentences. We propose some optimization algorithms. To classify a sentence, we first determined the sentence pattern, and then found the sentiment word and the additional modifiers, such as degree adverbs and negation words, within a certain window size before and after the sentiment word. The sentiment polarity of sentences was graded according to different weight rules. The traditional dictionary scoring method was obtained by directly summing up the sentimental values of the positive and negative words in the sentence. Although this method is simple, it resulted in lower accuracy. Uyghur is a rich morphological adhesive language. Words are composed of stems and affixes. Some sentiment vocabularies are the words themselves, and some are their stems. Therefore, to standardize the scoring algorithm, we set weight factors for word stems determined through comparison experiments. In the process of sentence sentiment scoring, we considered the original word as well as the stem. The method proposed in this paper is universal for the sentiment classification of resource-poor languages and is domain independent. First, by using the domain independence feature of the dictionary method, the pseudo-annotated data of the target domain was obtained, and then the domain knowledge was learned from the pseudo-annotated data by a machine learning classifier. Finally, the remaining data that cannot be classified by the dictionary method was classified, thereby combining the strengths of above two methods. This method does not need to annotate the corpus in the target area in advance, so it effectively solves the resources shortage problem in the sentiment classification work of minor languages such as Uyghur.
Sentiment classification methods are divided into two general methods: machine learning [1] and lexicon-based methods [10, 11]. At present, machine learning methods are the most common method for sentiment classification. When a sufficient amount of labelled training corpora is available, this method can achieve better classification efficiency. However, this method has a serious “domain-dependent” problem [12]. That is, classifiers trained on annotated sample sets in a certain domain can only perform well on test sets in the same field. However, when switching to other fields, especially if the distribution between the target domain and the source domain is large, the performance of the algorithm will be greatly reduced. This problem can be solved by labelling a sufficiently-sized domain dataset.
With the rapid development of the Internet, a large amount of text data must be processed every day. Quickly labelling this data is a challenging task. Data labelling is a laborious task, and labelling costs are high. In reality, the number of unlabelled data are always more than the amount of labelled data. Therefore, the research on sentiment classification has been focusing on semi-supervised learning with unlabelled samples and unsupervised learning methods without labelled samples. Dasgupta and Ng [13] first selected the easy-to-categorize review text based on the spectral clustering method, and then applied the active learning method to tag the indistinguishable texts, and finally built an entire semi-supervised learning system by means of transfer learning. Goldberg and Zhu [14] solved the problem of predicting the polarity scores of comments based on the semi-supervised learning model of a graph. Li et al. [15] started with a personal view of the evaluation text and used a cooperative training method to perform semi-supervised sentiment classification. Xue et al. [16] proposed a semi-supervised sentiment classification method that integrates social network knowledge.
For the unsupervised sentiment classification method, Turney’s work [11] was the pioneer work. First, the phrase in the document according to a certain pattern is extracted, then the sentimental tendency of the phrase is calculated based on the PMI (Pointwise Mutual Information) value between the phrase and the seed words. Finally, the polarity of the document is calculated. Subsequent studies [17, 18, 19] used sentiment lexicon to perform unsupervised sentiment classification. This domain-independent method does not require any tagged corpora, and based on a small amount of seed words, can achieve better classification results. However, this method also has some shortcomings. Although the sentiment lexicon is not related to the domain as a whole, some sentiment words may express different sentiment polarities in different fields or different contexts. For example, “unpredictable” expresses positive feelings when used in the field of movie reviews, and expresses negative feelings when used in the automotive field to evaluate automotive performance. In the field of digital cameras, “long” is used to express the positive tendency in the phrase “long power supply time”, and in the phrase “long focusing time” the tendency of “long” is negative.
Considering the performance limitations of unsupervised classification methods based on sentiment lexicon, another group of scholars proposed an unsupervised sentiment classification algorithm that combines sentiment lexicon and machine learning classifier. Some of these algorithms combine lexicon-based methods with machine learning methods that are trained on a small number of labelled data [6, 7, 20]. This method was proven to effectively improve the classification results obtained by either the machine learning classifier and the lexicon-based classifier used in isolation. Ten et al. [21, 22] divided the sentiment classification process into two steps: first, the sentiment dictionary is used to make initial judgments on the tendencies of the review text, then this result is used to generate a new classifier. Finally, the statistical properties of the corpora in the domain are used to accomplish the classification task [8, 9, 21, 22].
In the field of Uyghur text sentiment classification, some researchers have explored sentiment classification based on sentiment lexicon [23, 24, 25]. In Yusuf and Hamdulla [23], the sentiment words and phrases were manually extracted from sentences based on the sentiment characteristics of Uyghur sentences, and a Uyghur sentiment lexicon containing 379 words was constructed. Then, the keywords matching algorithm performed four categories of sentiment classification on Uyghur sentiment corpora containing 873 sentences. The literature [24] proposed a Uyghur sentiment word set based on automatic annotation, and completed eight categories of sentiment classification for sentences. During the classification process, the influence of turning conjunctions and negations on the sentiment tendency of sentences was analysed. The method of shielding the first half of the sentence was adopted for turning conjunctions. The treatment of negation words reversed the tendency of the sentence as long as a negation word appeared in the sentence. Nian et al. [25] translated the HowNet (Chinese sentiment dictionary), NTUSD (National Taiwan University School of Dentistry), and the dictionary published by the Dalian University of Technology into Uyghur, and expanded it with the Uyghur Synonymous Dictionary, constructing a Uyghur sentiment lexicon containing 9342 words. With the help of negation words, degree adverbs, transition adjuncts, and other modifiers, sentiment classification on the self-built sentiment corpus was accomplished. However, prior studies did not describe how to address these modifiers in detail.
Unsupervised sentiment classification method combined with lexicon and machine learning
The unsupervised sentiment classification method in this paper is divided into two phases. The first phase involves selecting the pseudo-labelled training data. In this stage, the sentiment scores of each sentence in the dataset to be classified are calculated using a sentiment dictionary, and then the part of the classification data with a higher confidence level is selected as a pseudo-labelled data set. The second stage is the classifier learning phase, in which a classifier is trained using the pseudo-labelled dataset obtained in the previous stage. The remaining first-stage datasets with lower confidence are classified to obtain the final classification result. The classification framework is shown in Fig. 1.
Process diagram of the classification framework.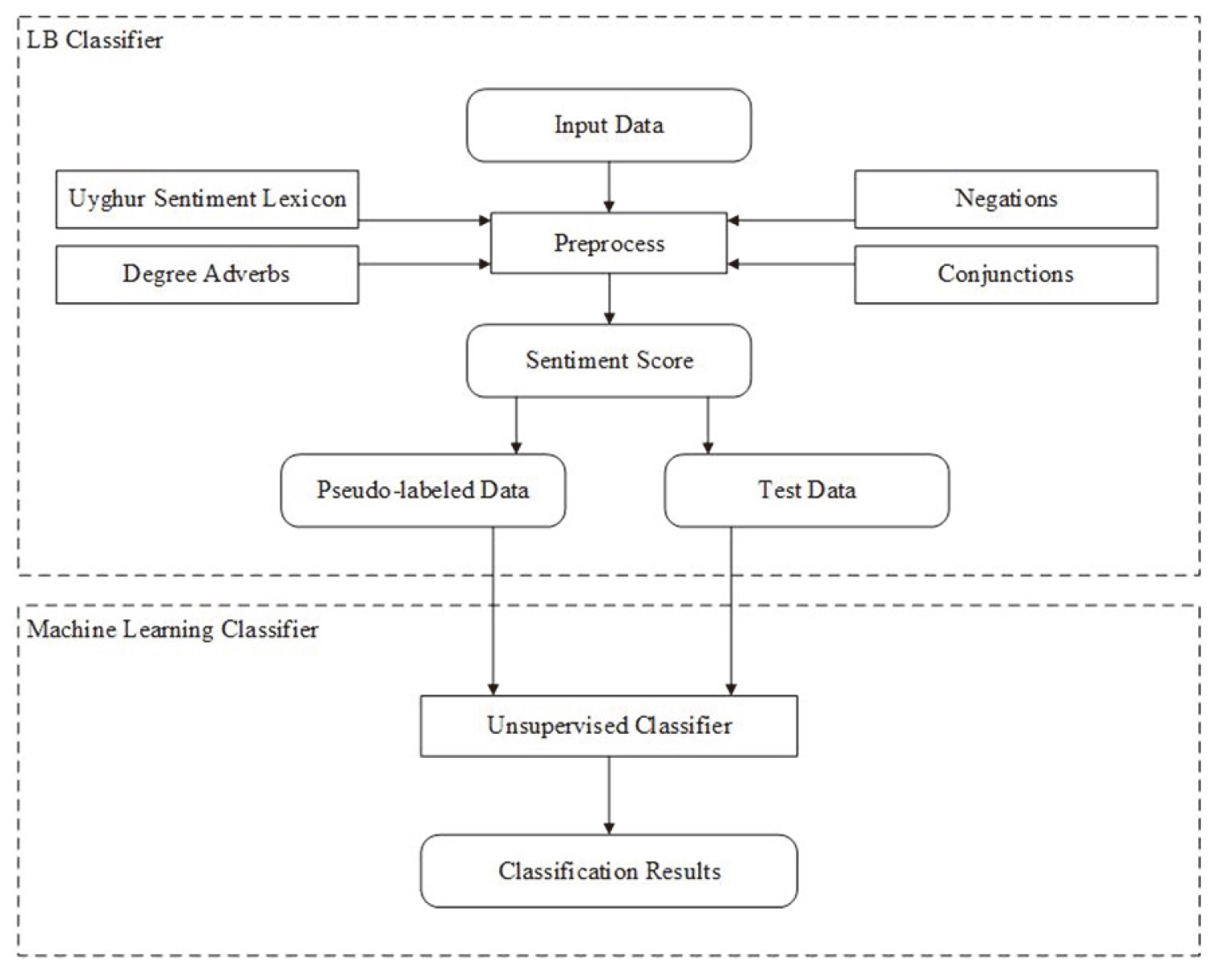
Construction of uyghur sentiment lexicon
Lexicon-based sentiment classification methods need a cross-domain sentiment dictionary with wide coverage. No public sentiment dictionaries are available in Uyghur.
To quickly create a Uyghur sentiment lexicon, we followed previously established methods [26, 27] to translate selected positive and negative sentiment words and positive and negative evaluative words from two widely used Chinese dictionaries, HowNet [5] and NTUSD [28], which were collected and compiled by Taiwan University into Uyghur by the machine translation tool called the Tilmach Chinese-Uyghur Bilingual Dictionary (Provided by multilingual information technology laboratory of Xinjiang). Then, we created a basic Uyghur sentiment lexicon using the translated words after manual filtering. The vocabulary obtained by the translation retained the original sentimental tendencies. Some words that lost or changed their sentiment tendencies were removed from the translated words list.
To further expand the Uyghur sentiment lexicon, adjectives, interjections, modal words, verbs, and nouns were extracted from the Practical Dictionary of Uyghur and Chinese [29] as a candidate sentiment vocabulary. The sentiment polarity of the words was annotated by two professional students, and inconsistent annotations were determined through negotiation, and they were added to the vocabulary list of the basic sentiment lexicon. The final constructed Uyghur sentiment lexicon was named as UYSentiDict. UYSentiDict also includes vocabulary such as phrases, idioms, negation words, degree adverbs, and conjunctions, as shown in Table 1.
Uyghur sentiment lexicon glossary
Uyghur sentiment lexicon glossary
The first step was to calculate the sentiment score of each sentence in the dataset to be classified according to the sentiment lexicon. If the sentiment score of the sentence was greater than zero, then the sentence was positive; if it was less than zero, it was negative. If the score was equal to zero, then the sentence type could not be determined. During the classification process, based on the grammatical characteristics of the Uyghur language, the impact to the sentence sentiment of conjunctions, degree adverbs, and negations was comprehensively considered.
3.1.2.1. Sentiment vocabulary
In most cases, the sentiment tendencies expressed in texts are reflected by sentiment words, so sentiment words are one of the important bases of sentiment tendency judgment.
Uyghur is a morphologically rich language; Uyghur words are made up of stems and suffixes. The sentiment tendencies of some words are expressed by its stem, and some sentiments are expressed after the stem plus some suffixes. Through the “Uyghur lexical analyser” (Provided by multilingual information technology laboratory of Xinjiang) This paper conducted word segmentation and stemming on the sentiment corpus. This paper first checked the sentiment words from the original word sequence of each sentence. If the sentiment could not be determined from the original words sequence, then the stem of each word in the sentence was checked. The following is the sentence processed by the Uyghur lexical analyser.
“
where “
In Nian et al. [25] and Wiegand et al. [30], the sentiment value of positive words was designed to be 1, and that of negative words was
where
3.1.2.2. Special sentence pattern
In Uyghur, for a sentence containing turning conjunctions, the clauses behind the turning conjunction often express the true sentiment of the speaker, and the preceding clause of the turning conjunction is not the true intention of the speaker and can be ignored. Such as:
“u naxayiti chirayliq, lékin bek hurun”. (Translation: She is beautiful, but very lazy).
Although the positive term “chirayliq” appeared in the first half of the sentence, the turning conjunctive “lékin” was used, emphasizing the negative term “hurun” in the latter half of the sentence. This article summarizes a total of seven Uyghur textual turning conjunctions from the book “The reference grammar of modern Uygur Language” [32], as follows:
“biraq, lékin, emma, halbuki, epsuski, epsus, shughinisi” (Translation: but, however, yet, unfortunately)
By analyzing the sentiment corpus in this paper, found that colloquial turning conjunctions such as “emmaze lékinze” were also in the corpus. Therefore, we expanded the dictionary of turning conjunctions into a dictionary containing the above nine turning conjunctions. In this paper, through the in-depth analysis of Uyghur sentiment corpora, we improved the turning conjunction processing methods used in the literature [24]. Sentence sentiment score calculation rules with turning conjunctions are summarized in Table 2. This calculation rule uses the turning conjunction as the center and divides the sentence
Sentence sentiment score calculation rules with turning conjunctions
The sentiment scoring process and the value adjusting process of the sentence containing turning conjunctions are shown as Algorithms 1 and 2, respectively.
In Algorithm 1, if the sentiment tendency of the latter half of sentence
In Algorithm 2, if the sentiment tendency of
Sentences that contain progressive conjunctions affect the sentiment of the sentence. For example, the sentence “He is not only good at learning, but also very friendly”. The sentence contains two positive words “good” and “friendly”, but the sentence in the latter part of the sentence is even stronger. Such progressive sentences are also found in Uyghur texts. The two most commonly used progressive conjunctions in Uyghur are:
“…la qlmastin …/…belki …”, “…qalmay …/…yene …” (Translation: Not only …but also …)
For example, there are two sentences in the corpus:
“siz yaxshi fotugraf bolupla qalmastin yene usta shair ikensiz jumu”. (Translation: You are not only a good photographer, but a good poet.) “ular eneniwiy naxshilarni orunlapla qalmastin belki yene gheripning nurghun muzikilirini orundaydu”. (Translation: They not only played traditional music but also played a lot of Western music.)
Both sentences express positive sentiments. If a sentence like this does not take into account the progressive sentence, then the progressive conjunctions “la qlmastin” will be regarded as a negative word because it contains the negation suffix “ma”. The first half of the sentence will change into a negative sentiment. Then, the sentiment tendency of the entire sentence becomes 0, so it would be impossible to determine its category. As shown in the following examples:
According to the stipulations in Liu et al. [33], progressive conjunctions were used as the segmentation point of the sentence to divide the sentence into two parts. The first half of the sentence’s sentiment weight was designed to be 1, and the latter half of the sentence’s sentiment weight was designed to be 1.5.
3.1.2.3. Degree adverbs
Degree adverbs play an important role in the process of sentiment analysis. For verbs and adjectives, degree adverbs are modifiers that strengthen or weaken the meaning of words. The combination of degree adverbs and sentiment words can more clearly express the degree of sentiment in the text. When degree adverbs modify sentiment words, the intensity of the sentiment tendencies of the sentiment words changes, which become stronger or weaker than prior modification. For example:
⟀ bu shéxir neqeder güzel he. (This is such a beautiful poem.) ⟁ ademni héjep bizar qildi. (It’s so annoying.) ⟂ bügün sel hérip qaptimen. (Today I’m a bit tired.)
In ⟀ and ⟁ above, the degree adverbs “neqeder” and “héjep” modify the positive term “güzel” and the negative term “bizar”, respectively, expressing a more intense sentiment. In example ⟂, “sel” modifies the negative term “hérip” and weakens the original sentiment. Relevant literature expressed strengths and weaknesses according to different weight values.
We learned from the definition of the weights of Uyghur degree adverbs previously proposed [25, 30], and combined the weights with the definition of the Uyghur adverbs in the literature [32], dividing the degree adverbs into three levels: high, medium, and low. We also defined the weight of each level. Table 3 shows the 129 Uyghur degree adverbs and the corresponding weights collected in this paper.
Examples of Uyghur degree adverbs
The degree adverbs in Uyghur are usually present in front of the modified words. The method proposed in this paper is a sliding window with a length of three for degree adverbs, to find degree adverbs from the three vocabularies in front of the sentiment vocabulary. The optimal window size was determined by contrast experiments. If a degree adverb was present, the sentiment score of the sentiment word modified by the degree adverb was multiplied by the corresponding weight value.
3.1.2.4. Negations
Negations are common linguistic phenomena that affect sentiment tendencies. When a negation word modifies a positive sentiment word, the original positive sentiment expressed will be transformed into negative, and vice versa. The negation category of modern Uyghur consists of simple negation words, derived negation words, and negation configuration morphemes [34].
Simple Negation Words. The simple negation words in modern Uyghur texts include “yaq”, “emes”, “yoq”, and so on, which in turn signify the meaning of “no”, “not”, and “none”. Among them, “yaq” is generally a negative response to a non-questionable sentence. “yoq” indicates that the state of things does not exist or disappear. They do not have the ability to reverse the sentiment information expressed in sentences. “emes” is generally used to negate some of the qualitative states represented by adjectives, and in most cases reverses the tendency of the sentiment words that preceded negation words.
Derived Negation Words. Adding the prefix “bet …bi …na …” before the partial nouns, adjectives, and verb roots, or appending the suffix “siz” after the roots constitutes a negative derivative that is opposite to the meaning of the original word. We did not address derived negation words in this paper, and since such words are limited in Uyghur, we incorporated all derived negation words selected from the Uyghur Detailed Explanation Dictionary from the 1999 edition of Xinjiang People’s Publishing House, into the Uyghur text sentiment dictionary we created.
Negation Morpheme. Uyghur’s negation form of morpheme is “ma/me”. When the vowel weakens into a “mi” suffix, it is added at the end of the stem of the verb to indicate negation, such as: “yaz
In Uyghur, the negation word appears after the word to be modified. In short, the negation component that can constitute a negation sentence in Uyghur is only the shape-denying component “ma/me” and the negation component “emes” [35]. Therefore, we only considered the influence of these two negation components on the sentiment tendency of sentences.
We designed a sliding window with a length of five for the negation words by comparing the optimum window size determined by experiment, and looked at whether the negation components appeared in the sentiment vocabulary and the following four words after the sentiment vocabulary. Then the following steps were used to address negation components that modify the sentiment tendency of sentences.
Step 1. View the part of speech tag of sentiment vocabulary. If it is a verb and the negation morpheme suffix “ma/me/mi” is connected, the sentiment score of the sentiment word is multiplied by Step 2. Check whether the negation word “emes” or words connecting the negation morpheme suffix “ma/me/mi” in the four words behind the sentiment word are present. If so, then the sentiment score of this word is multiplied by
If the negation word “emes” is connected to the suffix “mu” to become “emesmu”, then it has no reversal effect on the sentimental tendency of sentences. Therefore, the stem “emes” of “emesmu” is not treated as a negation word. For example:
Bu shéirmu xéli qamliship qaptu emesmu. (This poem is not bad.) If the four words behind the sentiment vocabulary have negation morphological suffixes such as “ma/me/mi”, the vocabulary is judged as a negation vocabulary, but the following suffixes containing “ma/me/mi” should be excluded: “men, miz, midu, maq, mek, miki, mamdu, memdu, mamsen, memsen, tima, miken, ptime, mighay, migey, misi, ghiymidi, migey, masmidi”. Step 3. If two consecutive negation words occur before and after a sentiment word in a sentence, then the sentiment of the sentence is not modified. Step 4. If no sentiment vocabulary is present in the sentence, but there are multiple negation words, then the sentence is more likely to express a negative sentiment. Therefore, in this paper, when more than three negation words were present in a sentence, the sentences were directly judged as negative sentences, and the sentiment score assigned was
To evaluate the influence of the above modified components on the sentence sentiment classification results, the following four lexicon-based (LB) sentiment classifiers were designed.
Classifier LB Classifier LB Classifier LB Classifier LB
Table 4 summarizes the attributes of the different LB classifiers.
Attributes of different lexicon-based (LB) classifiers
The LB
The basic steps of this algorithm are as follows:
Step 1. Load the basic resources: Uyghur sentiment dictionary, degree adverb dictionary, negative dictionary, and transitional dictionary; Step 2. Use the Uyghur lexical analyzer to cut each sentence Step 3. If a turning conjunction is in the sentence, then the sentence is divided into two parts, Step 4. Calculate the score
According to the sentiment dictionaries PosDic and NegDic, each word According to the degree adverb dictionary IntensifierDic, check whether there are degree adverbs among the three words in front of the sentiment word Check whether a verb occurs in the sentiment word The Step 5. Return the sentiment score
The sentence
where
The basic aim of creating an unsupervised classifier based on sentiment lexicon proposed in this paper was to construct a domain-independent and powerful Uyghur lexicon-based classifier. We then wanted to train a machine classifier based on the corpora marked by Uyghur lexicon-based classifier. To achieve a better classification effect with the machine classifier, the lexicon-based classifier ensures the accuracy of the tagged corpus. The experiment was divided into two steps. The first step was a classification module based on a sentiment dictionary. The data marked by the step was divided into two groups. The first group included pseudo labeled data, in which the sentiment score of every sentence was higher than the specified threshold value. The second group included classified data that consisted of the sentences with lower sentiment scores or sentences whose tendency could not be defined. The second step used the pseudo labeled data obtained in the first step to train the machine learning classifier and then using the classified data as test data to evaluate the classification effect.
Since BNB (Bernoulli Naive Bayes) and SVM (Support Vector Machine) classifiers perform well in the field of text classification and sentiment classification [1], the above two classifiers were selected for the second step machine learning classifier. After, the basic features, such as Unigrams, Bigrams, DictWords, and PBPs (Part-of-Speech based phrases) [36, 37], the combined features of Unigrams and Bigrams, and the combined features of Unigrams and PBPs, were selected from the pseudo labeled data. Based on the feature selection method MI (Mutual Information) and the feature weighting method Tf-Idf (Term frequency-Inverse document frequency), the most relevant features and the most differentiated features were selected. Next, the two classifiers NB and SVM finished the classification of the data classified in the first step.
Experiments and analysis
Experimental dataset
In order to verify the effectiveness of the proposed method in this paper, design sentiment classification experiments on corpus from four different fields. The description of the four different fields of sentiment dataset used in this paper is shown in Table 5.
Overview of datasets
Overview of datasets
Influence of stem weights on the classification results in LB
Influence of stem weights on the classification results in LB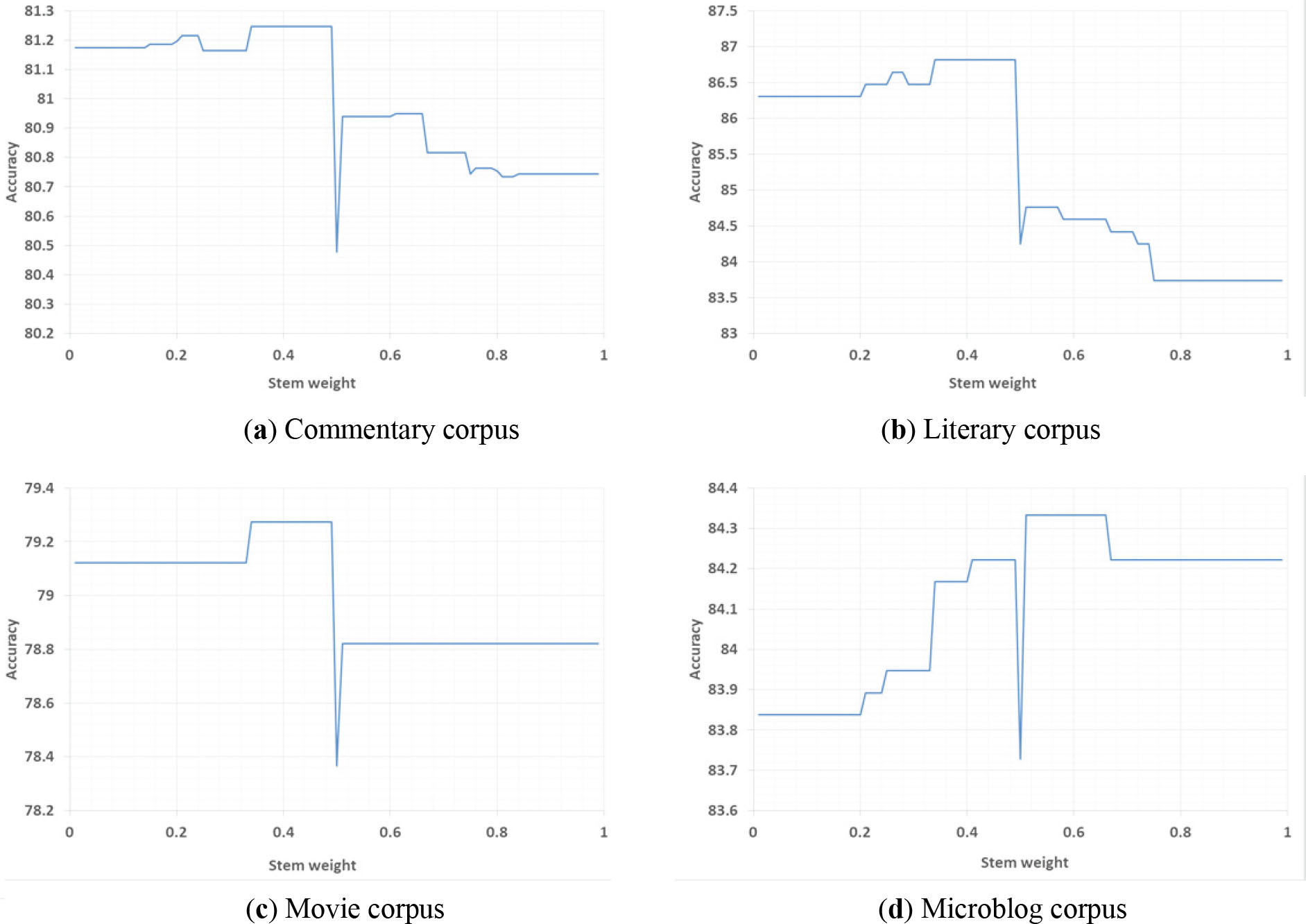
Influence of stem weight factor, sliding window size of degree adverb, and negation word on classification results
Uyghur is a morphologically complex language; stems connect different suffixes to produce different words. In this paper, when looking for a sentiment word from a sentence that matched the sentiment dictionary, we first looked at the original words. If a match was not found, we looked for the stems of each word in the sentence. In this paper, sentiment values of 1 and
In Uyghur, degree adverbs generally appear in front of modified words, and negation words appear behind modified words. To determine the maximum influence range of this kind of vocabulary on the sentimental tendency of sentences, we designed a sliding window size with a length of three for degree adverbs, and found the degree adverbs from the three vocabularies in front of sentiment words. We designed a sliding window with a size of five for the negation words, meaning we looked for negation elements in the sentiment vocabulary itself and the four words that followed.
Figures 2–5 describe the effect of stem weight factors (from 0.01 to 0.99), degree adverb sliding window size, and negation word sliding window size on sentiment classification results on different corpus and in different LB classifiers. In Figs 2 and 3, only the effect of stem weight factor
In Fig. 4, the best weight factor range and degree adverb window size were determined by 99 (stem weight factor)
In Fig. 5, the best weight factor range, degree adverb, and negation word window size were determined by 99 (stem weight factor)
Influence of stem weight and degree adverb window size on the classification result in LB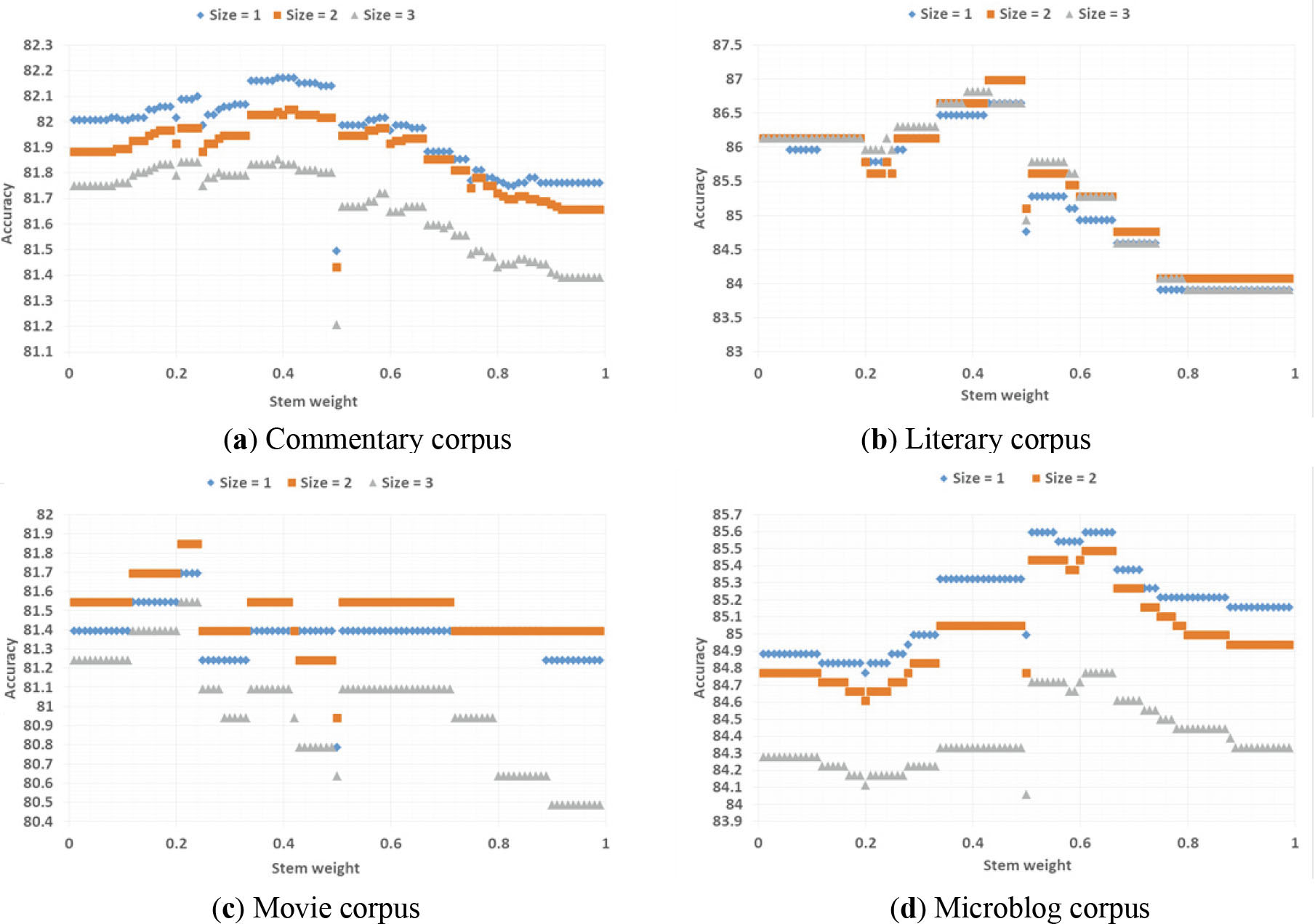
Optimal values for different parameters
Influence of stem weights and negation word window sizes on the classification results in LB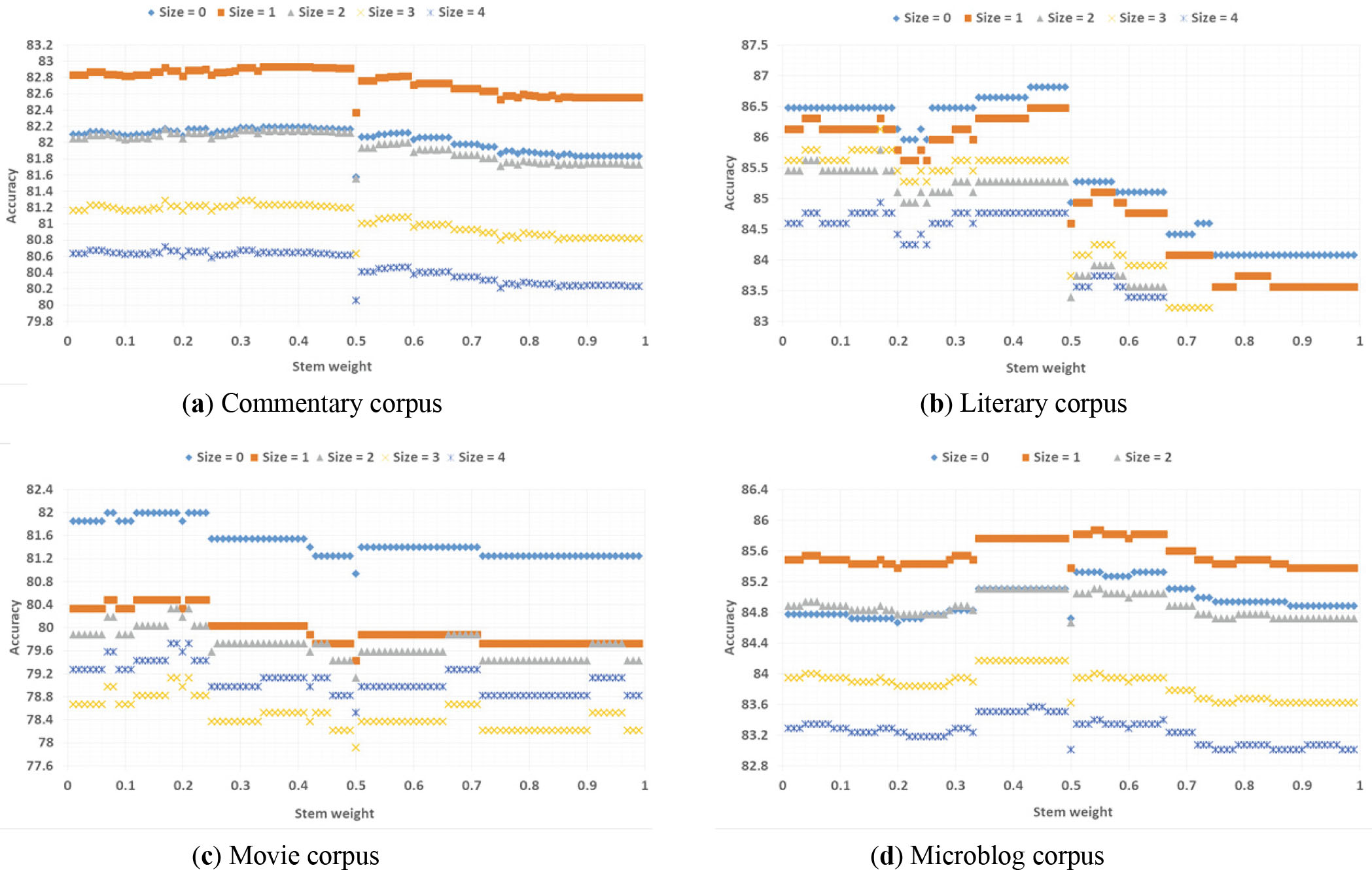
Based on the above experimental results, the optimal weight factor range
From the experimental results in Table 6, stemming weight factors have a common point of 0.43 for different LB classifiers and different corpus, in addition to the partial results on the Microblog corpus and Movie corpus. Therefore, was set to 0.43 in the following experiments. In the Commentary corpus and Microblog corpus, when both the degree adverb window size and the negation window size were set to one, LB
To compare the effect of different sentiment word matching methods on the classification results of the LB classifier, we used the above four LB classifiers to perform classification experiments on different corpus. Tables 7–10 provide the classification results. In the four tables, the second column finds the sentiment vocabulary only from the original word, the third column finds the sentiment vocabulary from the stem, and the fourth column finds the sentiment vocabulary from the original word first, then from the stem. At this time, the weights of the positive and negative stem are the same as the original word, at 1 and
Classification accuracy of different LB classifiers on Commentary corpus
Classification accuracy of different LB classifiers on Commentary corpus
Classification accuracy of different LB classifiers on Movie corpus
Classification accuracy of different LB classifiers on Microblog corpus
From the above experimental results, for different LB classifiers, the sentiment word matching method of Original and Stem
Classification results of machine learning classifiers on pseudo-labeled datasets of different scales
The greater the value of the sentence’s sentiment score, the stronger the sentiment bias of the sentence and the more accurate the classification result. In this paper, the second step machine classifier was trained on the pseudo-labeled data obtained from the first step LB classifier. To obtain a more correct training corpus, different sentiment thresholds were designed, and pseudo-labeled data were selected according to the classification accuracy under different thresholds and the coverage of correct sentences. From the above experimental results (Tables 7–10), LB
Classification accuracy of different LB classifiers on Literary corpus
Classification accuracy of different LB classifiers on Literary corpus
Figure 6 displays a line chart of the ratio of the classification accuracy of the LB
Classification accuracy and correct sentence coverage under different sentiment thresholds in the LB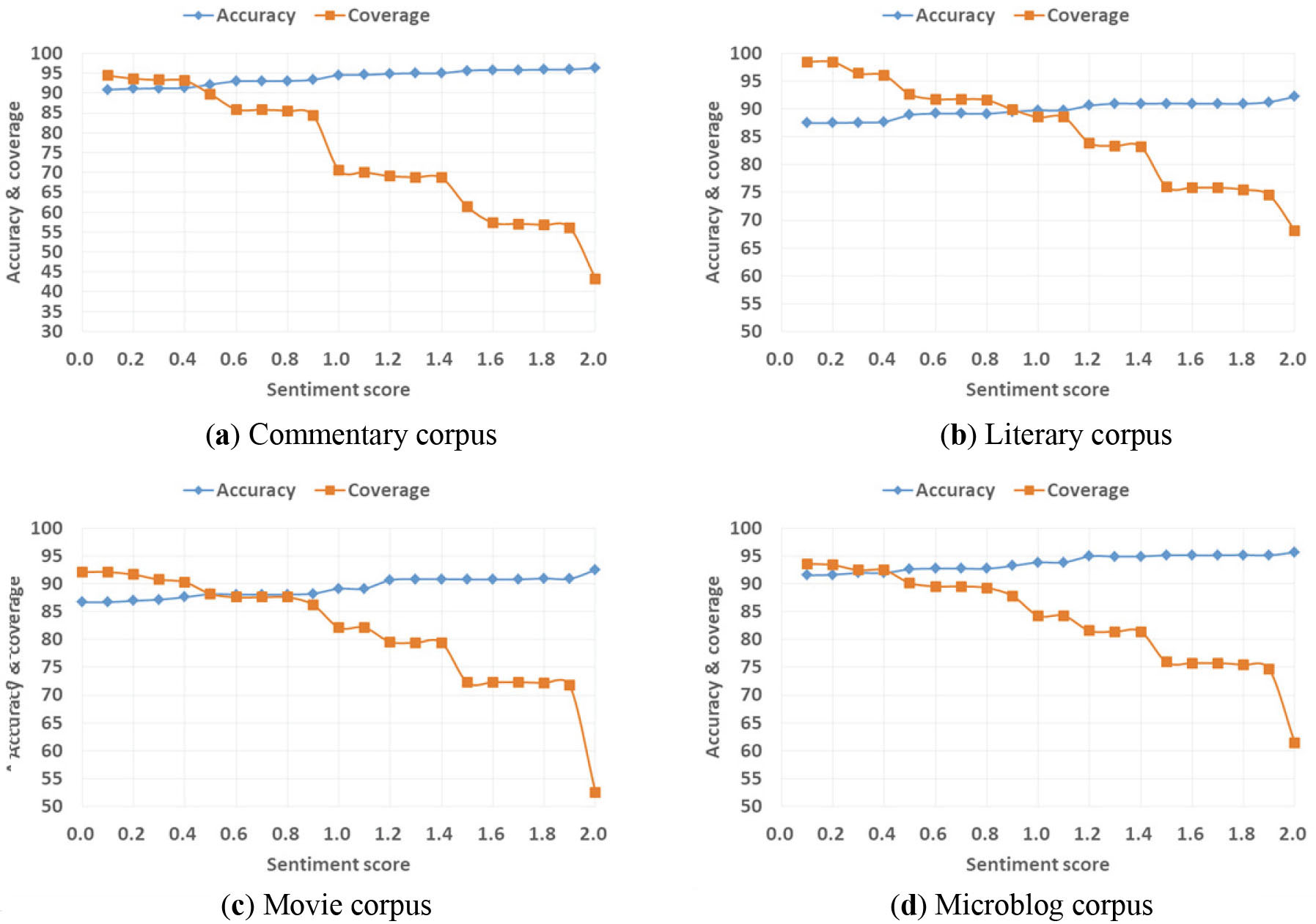
Classification results when the training set uses different pseudo-labeled data scales on the Commentary corpus
Classification results when the training set uses different pseudo-labeled data scales on the Literary corpus
Classification results when the training set uses different pseudo-labeled data scales on the Movie corpus
Classification results when the training set uses different pseudo-labeled data scales on the Microblog corpus
From Fig. 6, with the increase in sentence sentiment scores, the classification accuracy slowly increased. However, the proportion of correctly classified sentences in the total corpora gradually decreased. For example, in the Commentary corpus, when the sentiment score was greater than the threshold of 1.2, the classification accuracy was close to 95%, and 82% of the total corpus were correctly classified sentences. To obtain higher classification efficiency and accuracy, the scale of the pseudo-labeled data needs to be as great as possible. To determine the best pseudo-labeled data limit, we chose the same number of positive and negative corpus as the pseudo-annotated data of the training classifier in the classification results under different sentiment score thresholds. Based on the BNB and SVM classifiers, basic features, such as Unigrams, Bigrams, DictWords, and PBPs, and the combination of Unigram and Bigram features, and the combination of Unigram and PBPs, were used to train the classifier. Then, we classified the remaining data with a sentiment score less than the specified threshold. Tables 11–14 provide the classification results when using different scale pseudo-labeled datasets on different corpus. The threshold refers to the absolute value of the sentence trend value, i.e., the absolute value of the positive sentence is greater than or equal to the specified threshold, and the absolute value of the negative sentence is less than or equal to the specified threshold. The “
From the experimental results (Tables 11–14), for some features and some thresholds, the final classification result improved considerably after combining the LB classifier and the machine learning classifier Without any labeled corpora, a high-quality training corpus was obtained using a LB classification method. On this basis, we trained the machine learning classifier and obtained a higher classification accuracy than the LB classifier.
Table 15 describes the results of the supervised learning methods such as SVM BNB, CNN (Convolutional Neural Networks), RNN (Recurrent Neural Network) and RNN
Code for neural network experiment can be download from here
Comparison of the experimental results for the four corpora on the supervised classifiers, the LB classifier, and the unsupervised classifier proposed in this article
From the Table 15, on the Commentary corpus, the best classification accuracy of the combined method proposed in this paper was 83.60%, 0.67% higher than the lexicon-based method, but not as good as the machine learning based method. On the other three corpora, the classification results of the proposed method were better than those based on LB classifiers and machine learning classifiers. This shows that, based on the classification results, the lexicon-based classifiers used to train the machine learning classifier had better classification accuracy than the lexicon-based classification method. On a smaller corpus, the classification efficiency of combining methods was even better than machine learning methods. In general, the combination method is very suitable for use in the sentiment classification task of resource-poor languages such as the Uyghur language
Considering the difficulties for achieving tagged samples, this paper improves the existing Lexicon-Based classification method and combines it with the machine learning classifier. Firstly, classify the Uyghur sentiment corpus take using of “UYSentiDict”, in the matching process of emotional vocabulary, the object is extended from the word prototype to the stem, and the influence of the language grammar rules (turning conjunctions, progressive conjunctions, degree adverbs, negation words) on the emotional tendency of the sentences is fully considered. Then the machine learning classifier trained on the pseudo-annotated data sets that selected from the results of lexicon based classifier, and the remaining corpora are classified by extracting some optimal features. Thanks to the proposed method not be constrained by domain, also not need to use pre-tagged training data, therefore our approach can deal with the resource scarcity problem of Uyghur sentiment classification.
In this paper, we discussed an unsupervised sentiment classification method. In the process of classification, only considered two kinds of emotion tendencies, positive and negative, while emotional texts contain many kinds of emotion changes, such as happy, sad, surprised, frightened …, etc. Therefore, in the later work, we will study more emotional tendencies in Uyghur texts.
Nowadays, in the field of sentiment classification, researchers use deep learning method to get satisfactory classification results. The prominent advantage of sentiment classification method based on deep learning is that it does not need a large number of labeled corpus, and does not need human participation in feature selection. However, there is a common problem in deep learning method that constructs word vectors according to the context of vocabulary without considering the emotional information, that resulting in similar word vectors trained by words with similar context but opposite emotional polarity. In the later work, we will deeply study the sentiment classification method based on deep learning, and combine the advantages of traditional machine learning methods into the classification process of deep learning method, so as to further improve the classification efficiency of Uyghur text sentiment classification.
Footnotes
Acknowledgments
This work was supported by Foundation of National Program on Key Basic Research Project of China (2014CB340506); National Natural Science Foundation of China (61363063, 61662076).