
Abstract
Aiming at the problem of complex method and low efficiency of fuzzy numbers in classification processing, a parallel Fuzzy CMeans (FCM) clustering method based on cut set is proposed. Firstly, according to the decomposition theorem, the fuzzy numbers are divided horizontally into the form of the union of interval numbers, and then the interval numbers are transformed into the determined “real” data, and the parallel FCM clustering algorithm is used to classify the fuzzy numbers. The theoretical analysis and application show that the method has good classification accuracy and efficiency for fuzzy data clustering.
Introduction
Fuzzy number is a kind of special data widely existing in the information world. It expresses inaccurate and uncertain description of transaction, so it can truly reflect the characteristics of objective transaction, such as meteorological observation data, and language data such as “about or almost” generated in people’s communication. At present, the analysis and processing of this kind of data has gradually attracted the interest of researchers, and many local research results have been obtained [1, 2, 3, 4]. However, due to the complexity of fuzzy number itself, much of the work is still preliminary [5]. At this stage, relevant methods and technologies need to be further improved. They includes: for the problem of fuzzy number expression and conversion, Auephanwiriyakuk et al. [6] expressed the fuzzy number as
In 1973, Bezdek proposed Fuzzy C-Means (FCM) clustering algorithm based on objective function according to fuzzy theory and fuzzy relation. Since then, the research of FCM algorithm has been carried out continuously, and its application is very extensive. For the details of FCM algorithm, please refer to the relevant literature, which is not detailed here. Based on the comprehensive analysis of the fuzzy number processing methods proposed by scholars at home and abroad, and inspired by the interval number clustering given in literature [8], a parallel FCM clustering algorithm based on cut set is proposed, and the implementation of the algorithm is given for the one-dimensional bell fuzzy number of normal distribution and the triangular fuzzy number of multi-dimensional attributes. The method has a clear design idea and sufficient theoretical basis. Experiments show that it has high clustering accuracy and has certain reference value for the analysis and processing of uncertain data in the information world.
Transforming fuzzy number into interval number
The relationship between fuzzy number and interval number
Fuzzy number is a basic concept in fuzzy set theory. It is a kind of special uncertain data defined on the data set. Common fuzzy numbers include normal fuzzy numbers, triangular fuzzy number, trapezoidal fuzzy number, etc. According to the principle of expansion in fuzzy mathematics, it is intuitive and natural to extend ordinary algebra operation to fuzzy number, but in actual operation, the method is difficult to implement. In addition, there is an inevitable connection between fuzzy number and interval number. The calculation of interval number is relatively simple. Therefore, before clustering fuzzy numbers, we can convert them to interval numbers and then cluster them based on interval numbers to achieve fuzzy clustering analysis.
Let
Among them,
In this way, the fuzzy number
The relationship between fuzzy number and interval number was given earlier. The following two kinds of fuzzy numbers (multi-attribute index triangle fuzzy number, normal distribution fuzzy number) are used to design their representation methods, and other representations such as trapezoidal fuzzy number can be used for reference.
Multi-attribute index triangular fuzzy number: Let
According to the principle that cut set of the normalized fuzzy number is an interval number, the
In addition, the data set
Therefore, the two-dimensional number composed of the interval median and the interval size after the transformation is:
Normal distribution fuzzy number: Suppose that an observation sample set
Interval number conversion into real data
The interval number is also a special type of uncertain data. For this type of data, the interval number can be transformed into real data, and then the traditional FCM algorithm is called for clustering. For the interval number
Where
Replaced Eq. (5) with the interval median
It can be seen from Eq. (6) that
After defining the relationship between fuzzy number and interval number and the method of converting interval number into real data, a parallel FCM clustering method based on interval value of fuzzy number is proposed. Suppose the observation sample set
In the above formula, the fuzzy weighted index
Fuzzy number clustering algorithm based on interval value parallel FCM.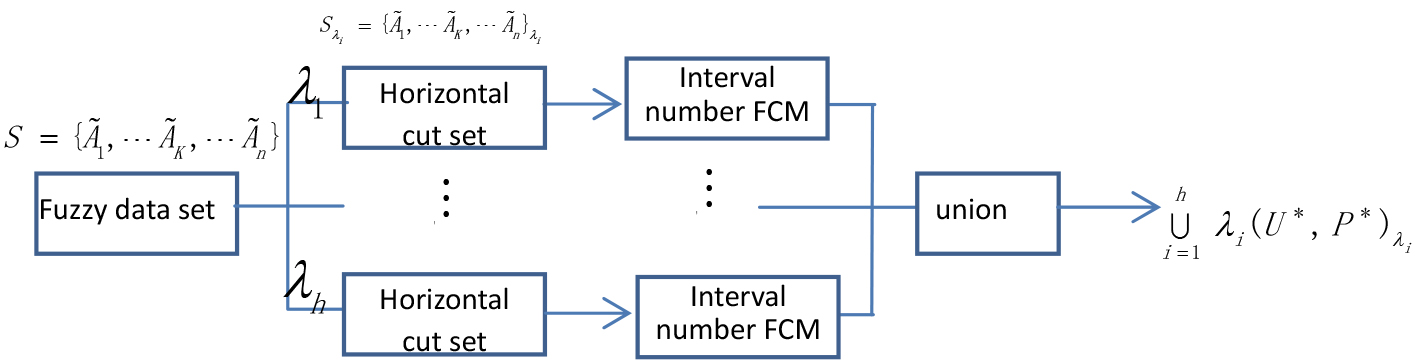
It can be seen from Fig. 1 that the FCM algorithm for fuzzy number can be implemented by the interval number FCM algorithm. The algorithm structure is parallel and the accuracy of the algorithm can be adjusted by the value of
With the method of converting interval number into real data, combined with Fig. 1, the implementation of parallel FCM clustering based on fuzzy number composed interval value is as follows:
Set an For each interval number obtained in step1, transform it into ordinary real data according to Eq. (4). In the process, a reasonable value of the influence factor Initialize the FCM clustering of eachreal data set, set the iteration termination threshold Inverse transform, restore the clustering center obtained in step3 to obtain the left and right endpoint values of the interval of clustering center
After each computing node completes its assigned clustering task, according to Fig. 1, the union of clustering results of each interval is taken to obtain the clustering result of the fuzzy number set.
In order to verify the effectiveness of the fuzzy number parallel FCM clustering algorithm proposed in this paper, we use multiple fuzzy data sets for repeated experiments, including artificial data set, standard test data set, and real data set with the prior categories and data set without prior knowledge. Due to space limitations, this section only analyzes the experimental process and experimental results of two fuzzy data sets. One is an artificially constructed one – dimensional fuzzy data set, and the other is from the literature [1], the triangular fuzzy data set of the multi – dimensional attribute index formed by the tea grade evaluation in a certain place in Taiwan. Experimental environment: computer hardware configuration includes i7 CPU, 4G memory, programming implementation tool is matlab2014a. In the experimental process, all clustering processes are completed on the same machine. Because the algorithm is executed in parallel, the order of interval number clustering generated by
Experiment 1 Artificial data set
This experiment constructs 100 fuzzy numbers belonging to 2 classes in a one – dimensional space. The membership of each fuzzy number is a bell function with a normal distribution. The central values of bell function are generated by Gauss random numbers of N (0.25, 0.1) and N (0.75, 0.1) respectively, and the variance of bell function is generated with random numbers what uniformly distributed between [0, 0.02]. Use the cut – set fuzzy number parallel FCM clustering algorithm proposed in this paper to perform experiment. The
It can be seen from Table 1, with the increase of
The clustering center, accuracy and running time of bell function fuzzy number under different
The clustering center, accuracy and running time of bell function fuzzy number under different
This is a data set of tea classification in Taiwan. It contains 69 types of tea, each of which has 4 attributes of appearance, color, soup color and fragrance. The 4 attributes of each tea were evaluated by 10 experts; all tea is divided into five levels: perfect, good, medium, poor and bad, and then the experts express the evaluation language value with triangular fuzzy numbers, as shown in Table 2. Among the triangular fuzzy numbers of each attribute, the first value represents the central evaluation value (equivalent to the maximum membership value of triangular fuzzy number), the second value represents the maximum offset of evaluation, and the third represents the minimum offset, The detailed evaluation scheme and the fuzzy data set for evaluation are shown in the literature [1].
Expert evaluation data set for 69 types of tea
Expert evaluation data set for 69 types of tea
Membership of 2 cluster centers obtained by parallel FCM clustering.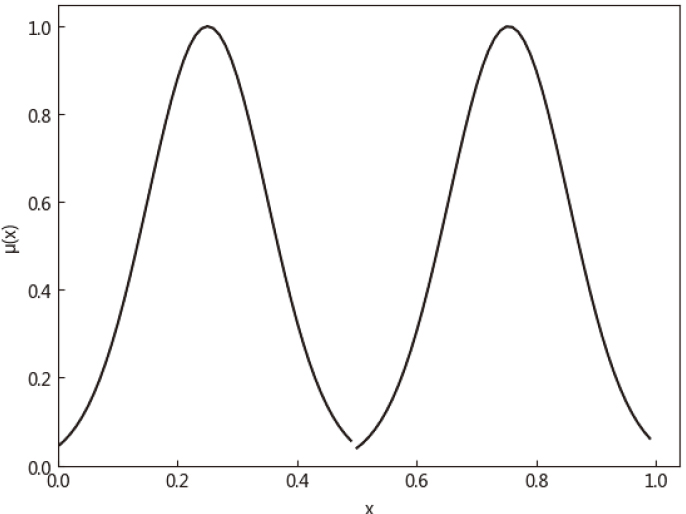
Firstly, the cut set parallel FCM algorithm (CPFCM for short) proposed in this paper is used to carry out tea classification experiments. The experimental environment is the same as experiment 1. Through experiment 1, we know that when the
Classification results of 69 kinds of tea
In addition, in order to verify the robustness of the algorithm to the noise samples and the time efficiency of the parallel algorithm, one of the best-quality teas which named “white tip” is added to the above tea varieties, which form a data set of 70 triangular fuzzy numbers. The serial number of this kind of tea is 70, and the triangle fuzzy numbers of its 4 attributes are (0.9120, 0.1362, 0.2230), (0.9260, 0.1284, 0.2640), (0.8765, 0.1834, 0.2650) and (0.8354, 0.2109, 0.2210), respectively. The experiments are performed using the CPFCM algorithm, the AFCN algorithm proposed in [1] and the FCN algorithm proposed in [15]. Among them, Yang M. S. first proposed a classical fuzzy clustering algorithm based on fuzzy number in reference [15], and then improved it to propose an adaptive fuzzy number clustering algorithm in reference [1]. Both algorithms have been successfully applied in fuzzy number clustering, so it is feasible to use them for experimental comparison. The experimental classification results are shown in Table 4.
Classification results of 70 kinds of tea by 3 algorithms
It can be seen from Table 4 that after adding exceptional noise with tea of “white tip”, the experimental results of the algorithm proposed in this paper is consistent with the results in Table 3, and the clustering accuracy rate is still 100%, that is, the noise sample (tea No. 70) is not divided into any category, although the AFCN algorithm does not classify the noise sample of tea No. 70 into any of the categories, the classification results are inconsistent with the classification results of no noise samples, thus indicating that the algorithm in this paper is very robust to noise. However, the FCN algorithm separates the noise samples into the first category, but the other 69 kinds of tea are only divided into 4 class levels, which are inconsistent with the actual classification, indicating that the algorithm is sensitive to noise. Of course, from the perspective of the experiment completion time, compared to the FCN algorithm and the AFCN algorithm, the parallel FCM algorithm proposed in this paper takes longer to complete the classification, but it is worthwhile to sacrifice the computer’s time overhead properly under the condition of ensuring the classification accuracy. In addition, you can also reduce the time overhead by setting up multiple computing nodes to run in parallel, of course, at the expense of multiple computing node resources that is, computing space is exchanged for computing time.
Fuzzy number is an important part of the data field in the information world. In this paper, a clustering method based on cut-set parallel FCM is proposed for the clustering of fuzzy numbers. The validity of the method is verified by clustering analysis of artificial data set and tea evaluation experiments. There are two innovations in this paper. One is the method of converting interval number into real data, including the design of the interval size influence factor, the relationship between triangular fuzzy numbers and three-parameter interval numbers, and the conversion rules of three-parameter interval numbers and real data. The second is the implementation mechanism of fuzzy number parallel FCM clustering. It should be noted that in the process of parallel FCM clustering of fuzzy numbers, since interval clustering of multiple cut-sets is to be performed, and as the number of cut-sets increases (that is,
Footnotes
Acknowledgments
This paper supported by the Industrial Support Project of Xinyu Science and Technology Bureau, Jiangxi Province: Research on Reliability Control Technology for Train Communication Network Transmission System (2019).