
Abstract
In the communication of RFID system, it is easy to cause collision during data exchange between the tag and the reader, thus tags may not be identified. On the basis of researching binary algorithm, bit positions of collision are locked through setting different statuses of the order during collision, and then samples of the locked positions are recorded to select the remaining collision positions during the paging process to the descending order. Compared with traditional binary collision algorithm, significant improvements have been made in analyzing the algorithm’s indexes like searching times, amount of communication and throughput, improving efficiency of the system.
Introduction
RFID (Radio Frequency Identification), a data acquisition technology that is automatically available without contact, relies on electromagnetic waves as a transmission medium for bidirectional communication and automatic identification purposes [1], and is widely used in medical, smart card, attendance system and project tracking attributable to its advantages such as strong automatic identification, fast response, low hardware cost and long service life.
RFID is mainly composed of readers, tags and processing systems, and works depending on the bidirectional communication between wireless network and tag after the ID with unique identification enters the electromagnetic field of the reader, which enables data collection of tags, data processing and resource sharing. However, one obvious disadvantage is that multiple tags entering the scope of the reader at the same time will cause communication collisions with the reader, which will lead to the failure of tag recognition. At present, the common tag anti-collision algorithms are time-division multipath based non-deterministic algorithm and deterministic algorithm [2]. The former is mainly represented by ALOHA algorithm [3], which is simple and easy to implement, can meet basic requirements and occasions, and read-only tags [4]. The latter is mainly represented by binary search algorithm [5], which requires multiple searches, has a large amount of identifying data and a low throughput. Scholars at home and abroad have put forward different solutions to this problem. An improved RFID tag anti-collision algorithm was proposed, and a new RFID technology module was established to improve the identification efficiency of the RFID system [6]. An optimized anti-collision algorithm was presented, which uses two-digit arbitration collision for bit-by-bit recognition by constructing a new request-building method, greatly reducing the number of corresponding tags in collision detection, thus reducing the bit collision probability [7]. The uniqueness of tag sequence number and the feature of Manchester encoding to identify tag collision locations are presented, and binary optimal encoding is used to optimize and shorten the length of sending characters [8].
In this paper, on the basis of researching binary algorithm [9], bit positions of collision are locked through setting different statuses of the order during collision, and then samples of the locked positions are recorded to select the remaining collision positions during the paging process in descending order [10]. Finally, good results have been achieved. Compared with traditional binary collision algorithm, significant improvements have been made in analyzing the algorithm’s indexes like searching times, amount of communication and throughput, improving efficiency of the system.
Basic binary anti-collision search algorithm
Algorithm process
In the binary search anti-collision algorithm, the bit conflict detection protocol is mainly used as the anti-collision scheme, in which the reader is required to accurately obtain the bit location of the collision. Therefore, Manchester codes are generally used to identify collision locations in bits when multiple tags respond simultaneously, and to search for tags again according to certain rules based on the collision locations. Basically, in the binary search algorithm, the reader sends a certain length of serial number to compare with each tag’s ID. If there are tags less than or equal to the serial number, the reader sends its ID to the reader, otherwise the response is not triggered. Assuming the tag ID number is
Initialization. First the reader sends the command with the sequence number of all 1, then all the tags send their IDs to the reader so that it can detect the ID number and find the conflicting bit location (assuming it is in the Each tag compares its ID number with the reader’s new serial number in step 1, and the tag is sent back to the reader if less than or equal to the serial number, otherwise nothing is done. Step 2 is repeated until the process where only one tag responds ends, the tag is identified, then it is de-selected, and step 1 is executed until all tags are identified.
The length of command request sent in the reader is mainly the length of its own code, the length of the relevant parameters and the length of the data of the tag response command. Therefore, the number of times the binary algorithm receives feedback command is as follows. The number of times the basic binary search algorithm searches the first tag to issue command is as follows:
In the equation above,
After the first tag is deselected, it is searched again from the beginning. At this time, the tag waiting for recognition is
So the number of times needed to search for all the tags is:
Therefore, it is found that the efficiency of binary collision algorithm is mainly the response times of electronic tags. The longer the response times, the more times to complete all tags, which will reduce the efficiency of the algorithm and occupy more communication time.
Raise of problem
Assuming that all the tags in the reader’s working area are responding to replies, if there is a conflict of tags at
Related instructions of improved binary algorithm
The specific meanings of each instruction are as follows:
ID represents the sequence number obtained after the reader sends the first instruction sequence. After the reader judges the exact bit position of data collision, the information of multiple collision positions is extracted and set to 1 at one time, and the other non collision positions are set to 0, forming a new sequence number. In response, the tag compares the data bits in its ID with the serial number issued in the reader, and locks the bit positions in the corresponding tag set to 1 back to the reader.
SELECT(ID): The reader sends the serial number as a parameter to the electronic tag. A tag with the same serial number executes an answer command, while a tag with another serial number only responds to the REQUEST command.
READ: Selected tags send data to the reader.
UNSELECT: The tag is set to be silent and does not respond to the received REQUEST command.
Steps for the improved binary algorithm
Initialize settings for reader commands and related parameters. The reader sends a REQUEST ( The reader keeps searching for signals sent by surrounding tags. If the tag does not respond, go to step 2 and the reader keeps sending commands; Otherwise, go to step 4. The reader decodes the response signal of the reply tag and compares the decoding results to determine whether a collision has occurred. If no collision occurs, send SELECT and READ commands for read and write operations, and then issue UNSELECT commands to make the tag secure. Otherwise, a collision occurs, and the location of the collision will be recorded using a set of samples.
Algorithm implementation process. How to find the specific collision location as soon as possible after the collision in step 4 is the key to improve the algorithm in this paper. Set the tags for the response to be in three states: wait, sleep, and exposure, and set a status counter. The value of the status counter equal to 0 indicates that the tag is in a waiting state, greater than 0 indicates that it is sleep, and the exposure state indicates that the reader has recognized the tag and no longer responds to the signal from the reader. When the reader detects the collision, it first detects the collision position. Assuming that the collision is at the Identify all tag locations and finish processing.

The description of the entire algorithm flow is shown in Fig. 1(a), in order to explaining the model clearly, you can take a look Fig. 1(b) which described by N-S chart. The further examples illustrated in Fig. 2.
Algorithm implementation process described by N-S chart.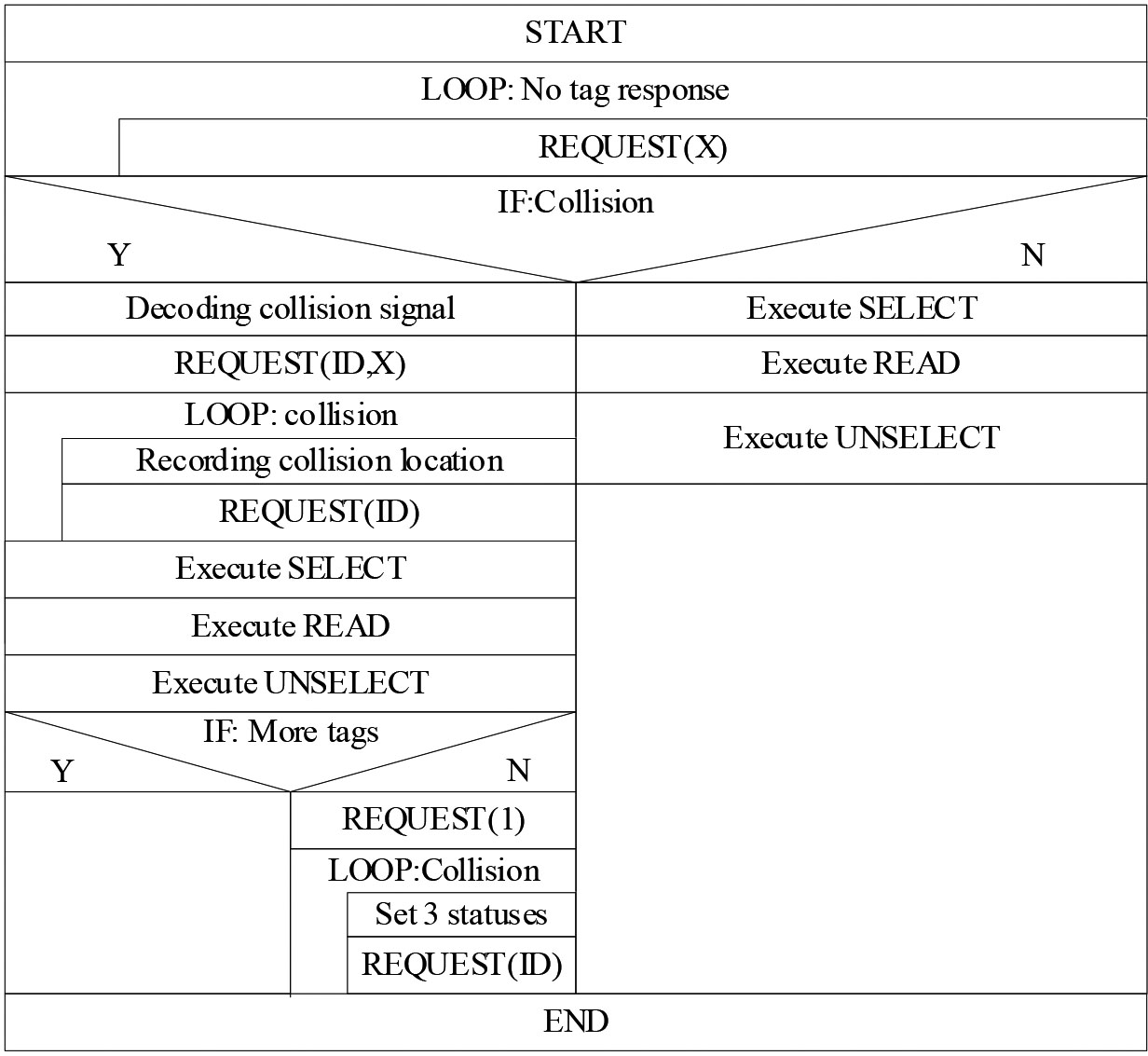
Illustrated examples of the implementation process.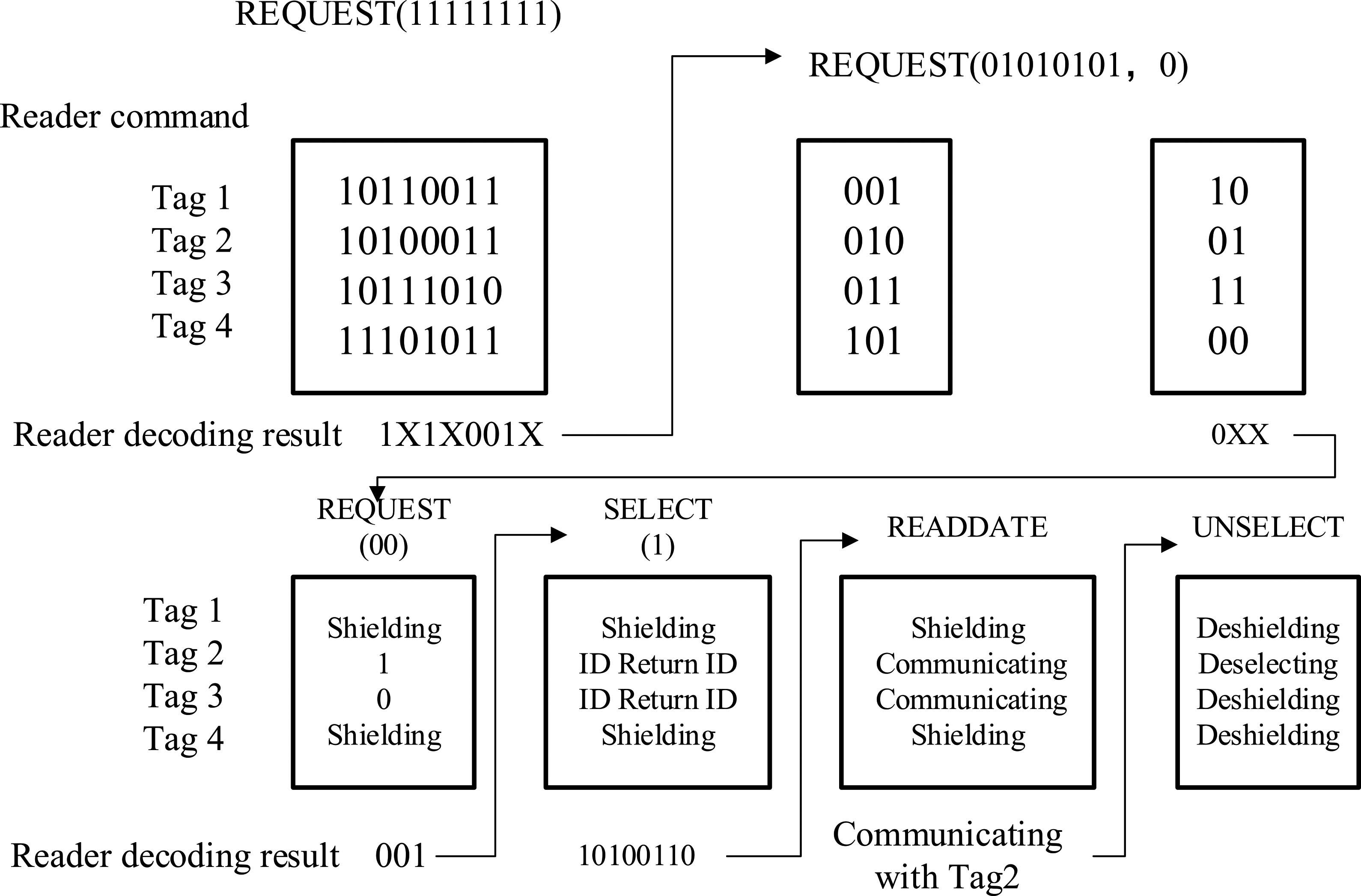
Relationship between searching times and collision.
Here are the main steps about the examples:
First, send the request code ‘11111111’ to the 4tags (10110011, 10100011, 10111010, 11101011). Second, according to the decoding is ‘1x1x001x’, so send out the request code ‘01010101,0’. The result is (001, 010,011,101), (10,01,11,00). Then, set the decoding ‘0xx’, and send out request code ‘00’, we can get the target tag2. So, the communicating can be done between the reader and the tag. When finished, deselecting the tag, and reading for the next step.
The performance of RFID anti-collision algorithm is mainly measured from the search times, communication and throughput, by comparison with representative algorithms, BS (Binary search) algorithm and DBS (Dynamic Binary Search) algorithm of binary collision algorithm.
Search times
Set the number of E-tag xxx as N, when the collision occurs at the
Communication bit amount of three algorithm readers
Relationship between data transmission and communication bit amount and collision times.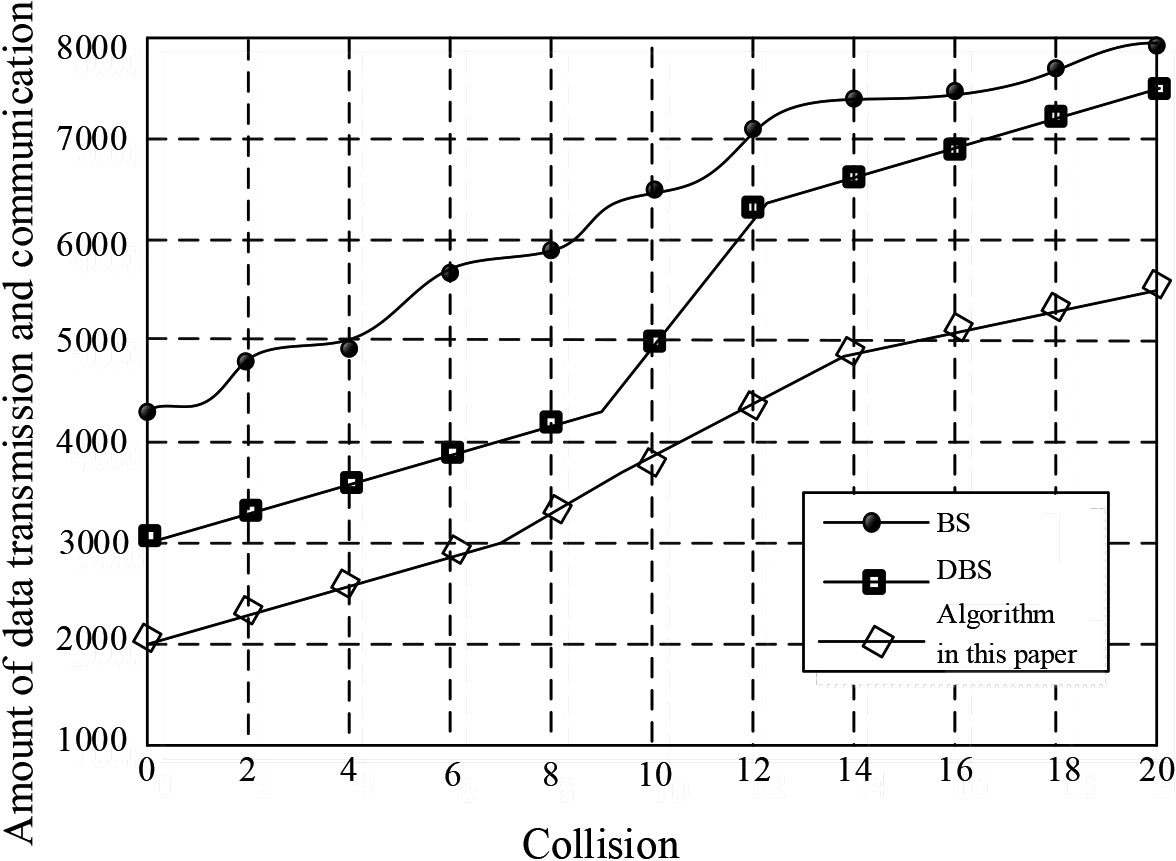
Figure 3 shows that compared with BS and DBS algorithm, the algorithm in this paper has a significant reduction in search times, and the more collision positions are, the more obvious the effect is. When the collision occurs at 14 bits, the effect is obvious.
To further illustrate the superiority of this algorithm, only the number of communication data bits of the reader is studied in this paper, mainly because the number of communication data bits sent by the reader is equal to the length of communication data returned by the tag. The tag serial number length is set to
In Eq. (9), M1&M2 mean the minimum and the maximum length in the tags.
Figure 4 and Table 1 shows that the communication data consumed by BS and DBS algorithm is larger with more tags, but the consumption of this algorithm is relatively small and stable, which shows that this algorithm is stable.
Throughput is related to the data efficiency in the process of data identification and transmission. If
Comparison of relationship between throughput and collision times for different algorithms.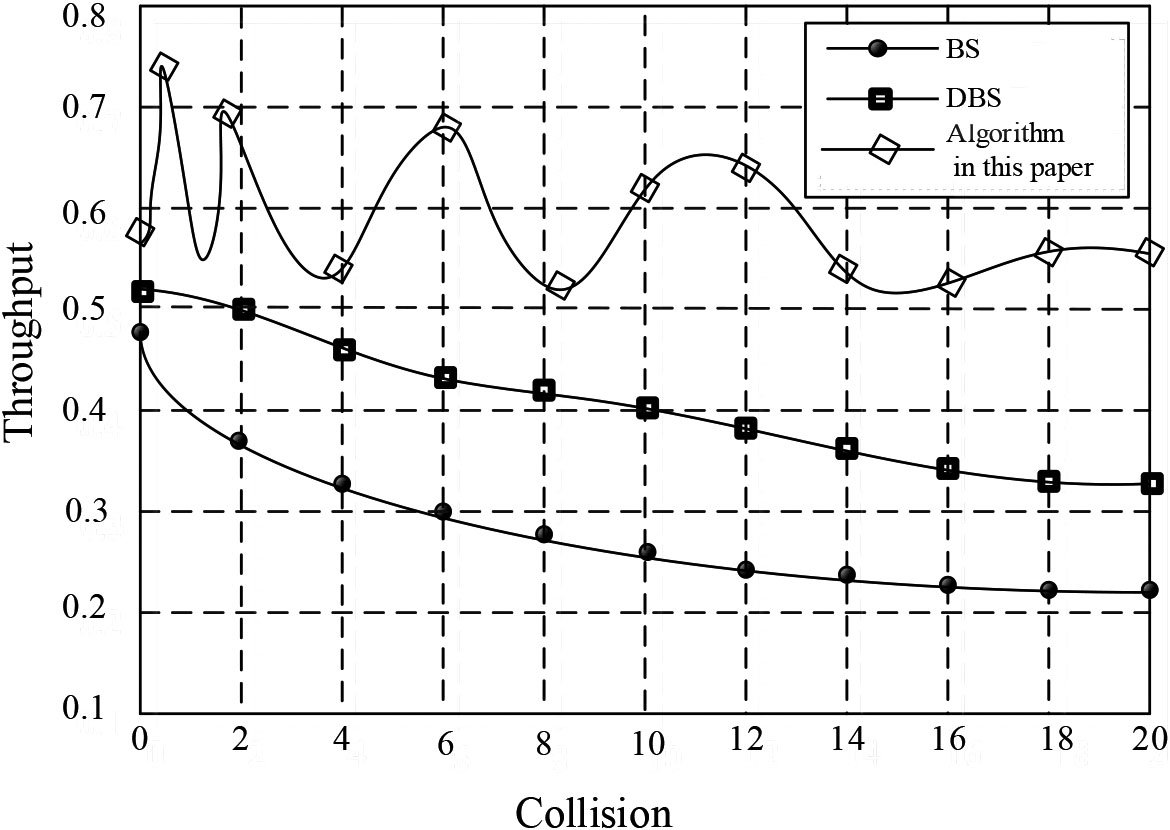
Figure 5 shows that the throughput of this algorithm is wavy, and most of it is always better than that of BS algorithm and DBS algorithm, especially when the number of tags is increasing, the superiority of this algorithm is more obvious.
In this paper, firstly, the characteristics of binary search anti-collision algorithm are analyzed. On this basis, the collision bits are locked by setting different statuses in the process of collision, and the locked positions are recorded as samples. Then, in the process of paging, the remaining collision bits in the sample set are selected in descending order, and good results are achieved. The algorithm analysis shows that this algorithm has obvious improvement compared with the traditional binary collision algorithm and improves the efficiency of the system.
Footnotes
Acknowledgments
The work was financially supported by Science and Technology Research Project of Chongqing Municipal Commission of Education (KJQN201803105).