
Abstract
Event extraction, as one of the difficult tasks of information extraction, can quickly obtain valuable information from the massive information on the Internet. This paper proposes a joint event extraction model based on RoBERTa-wwm-ext and gating mechanism for document-level long text data, which not only uses the prior knowledge from event types and pre-trained language models, but also uses gated fusion module to aggregate information in the event argument extraction tasks to enhance entity representation and splices entity type embedding, thereby enhancing the correlation among events, arguments and argument roles in the text, and improving the recognition accuracy of the arguments of each event in the document. Finally, the effectiveness of the model is verified on the public dataset.
Introduction
Unstructured information, such as financial news and company announcements, is generated in cyberspace on a daily basis. These unstructured texts make it challenging for people to fully understand and digest professional knowledge, and how to capture valuable and specific information quickly and efficiently from a vast amount of information is one of the current research hotspots.
Event extraction, as a branch of information extraction, allows event information and knowledge to be automatically extracted from unstructured natural language texts and presented as structured data. Event extraction technology can help us efficiently screen out the knowledge of events of interest to assist in the construction of the event evolutionary graph, the information retrieval and the generation of event context. This paper is based on the authoritative Automatic Context Extraction (ACE) conference in the field of event extraction, and the following concepts involved in event extraction need to be clarified:
Event: A change in the status of some roles in a certain way at a particular time and place. Event type: The category to which the event belongs. Entity mention: Entities mentioned in the document, such as time, place, financial product, person, organization, stock value, etc. Event argument: The entity involved in the occurrence of an event. Event argument role: The part an event argument plays in the event is known as the event argument role.
At present, the majority of the event extraction methods concentrate on the sentence level, but in actual announcements or news, an event is usually expressed by multiple sentences, with the event arguments distributed in different sentences. Figure 1 illustrates a case of document-level event extraction, where unstructured natural language is used to describe an equity underweight event. In S2, “China Orient Asset Management Corporation”, “1,903,356 shares”, “October 29, 2008” and “February 10, 2009” play the following four different event argument roles in this event: ‘EquityHolder’, ‘TradeShares’, ‘StartData’ and ‘EndData’. However, these are only some of the event arguments of the event, and event argument “6,843,683” corresponding to the role of ‘LaterHoldingShares’ is supplemented in S3. The event arguments extracted from sentences S2 and S3 and their roles in that event together constitute a complete equity underweight event.
Example of document-level event extraction.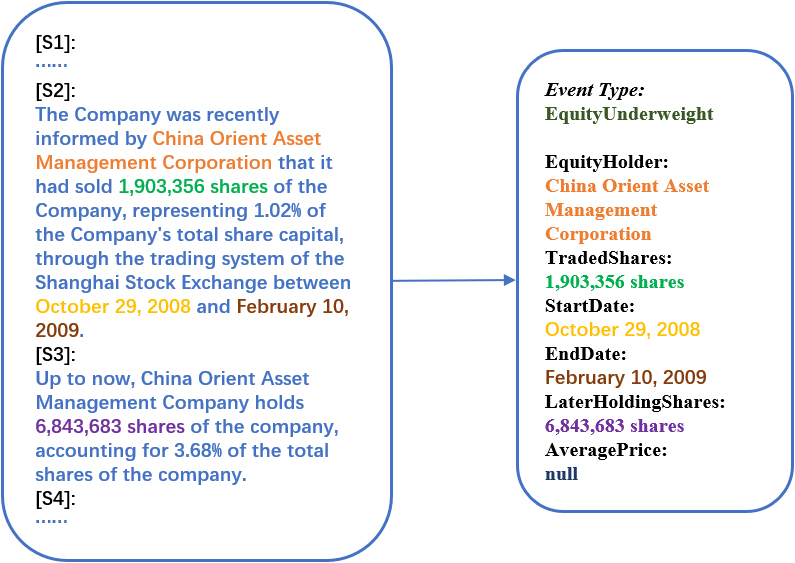
Currently, there are still several challenges in event extraction: (1) The granularity of extraction is limited to the sentence level due to the difficulty of event extraction itself. However, news texts are mostly document-level, and event arguments may be scattered in different sentences. (2) In one news text, there may be multiple events of the same or different types, that is, a multi-event problem.
In view of the above difficulties, this paper focuses on the following two aspects:
In this study, an end-to-end event extraction model at the document level is constructed, which is subjected to the joint training in three parts: event type detection, event argument extraction and event record generation, and whose effectiveness is demonstrated through experiments on the public dataset.
A document-level joint event extraction model based on the RoBERTa-wwm-ext pre-trained language model [1] is proposed, which uses the event types obtained from event type detection in event argument extraction and introduces a gated fusion module to aggregate information to enhance entity representation, thereby improving the recognition accuracy of the arguments of each event in the case of documents with scattered arguments and multiple events.
The evolution of event extraction technology can be divided into three stages: pattern matching-based, traditional machine learning-based, and deep learning-based.
Pattern matching-based method
In the early pattern matching-based event extraction method, it is necessary to first find rules in corpus and construct templates, and then match against the templates in the text to be extracted. Lexico-semantic patterns were employed by Borsje et al. [2] to extract financial events from RSS news sources. This method can achieve relatively good results in specific domains, but the construction of the pattern needs the guidance of a large number of domain experts and high labor costs.
Traditional machine learning-based method
Traditional machine learning-based methods are built on statistical models, which alleviate the difficulty of manually constructing patterns. Li et al. [3] unified the outputs of the three information extraction tasks including entity mention, relationship and event into information network representation, which was extracted using a joint model based on structured prediction. Using a hidden variable semi-Markov conditional random field, Lu et al. [4] established a model for sequence annotation that accepted coarse mention and type information and predicted the roles of parameters in an event template. Although this method is more broad, it requires a sizable annotated corpus, and the quality of the machine learning outcomes depends on the choice of features.
Deep learning-based method
With the improvement of deep learning technology, deep learning-based event extraction methods have gradually become the current research hotspot. Convolutional neural networks were used by Chen et al. [5] to collect sentence-level information and introduced a word representation model to capture relevant lexical-semantic norms. Nguyen et al. [6] extracted events through a joint framework of bidirectional recurrent neural networks. The sequence-to-structure generation paradigm TEXT2EVENT was proposed by Lu et al. [7] and can directly extract events from text in an end-to-end way. Liu et al. [8] proposed a novel multi-event extraction framework, which extracted multiple trigger words and event arguments by introducing an attention-based graph convolutional neural network. Liu et al. [9] proposed to define the event extraction as machine reading comprehension, converting the event pattern into a group of natural questions, asking and answering questions based on BERT [10], and taking the retrieval results as the results of event extraction. The DE-PPN model was proposed by Yang et al. [11]. It used a multi-granularity non-autoregressive decoder to extract structured events from documents concurrently after first introducing a document-level encoder to obtain a document-aware representation. In order to capture the interdependence between events, Xu et al. [12] first built a heterogeneous graph interaction network to track the extracted events. They then incorporated a tracker model to follow the extracted events.
Event extraction can be separated into sentence-level event extraction and document-level event extraction from the standpoint of text granularity. Sentence-level event extraction focuses on extracting the important contents from the sentence and only makes use of features that have been obtained within a single sentence. A type-aware biased neural network architecture with an attention mechanism was introduced by Liu et al. [13], which encoded the representation of sentences according to the type of target events, and explored the detection of events in the absence of trigger words. Document-level event extraction additionally uses cross-sentence or cross-document features to assist in the implementation of extraction tasks. Du et al. [14] dynamically fused information of different granularity in documents, and paid attention to the context at both sentence level and document level. For most event extraction, a pipeline method is adopted, which identifies the event type and argument first, and then determines the role of the event argument. Yang et al. [15] first used a sequence annotation model to automatically extract sentence-level events, and proposed a key event detection model and an element filling strategy to extract events from the entire document. Huang et al. [16] proposed a multi-layer event extraction architecture with a model including a document type classifier for identifying event types, two types of sentence classifiers, and a noun phrase classifier for filling argument roles. The pipeline-based event extraction method has an inevitable problem of error transmission.
In 2019, Zheng et al. [17] proposed the Doc2EDAG model, which first extracted entities as candidate event arguments, then used binary classification to judge whether a document triggered a certain event type, and generated a directed acyclic graph to fill the candidate event arguments into the event record table. The PTPCG model proposed by Zhu et al. [18] in 2022 can be used to combine event-argument extraction on the pruned complete graph produced under the guidance of automatically chosen pseudo-trigger words, which is effective for event extraction under conditions of single events, but is less effective under the conditions of scattered event arguments and multiple events. In order to address the aforementioned issues, based on the existing research on document-level event extraction, this study proposes a document-level joint event extraction model based on RoBERTa-wwm-ext pre-trained language model.
Our model
The goal of document-level event extraction is to determine the different sorts of events that are present in documents, the arguments that take part in the event, and the roles that the arguments play. The model in this paper consists of four parts, as shown in Fig. 2, including input encoding layer, event type detection, event argument extraction and event record generation.
Event extraction model architecture.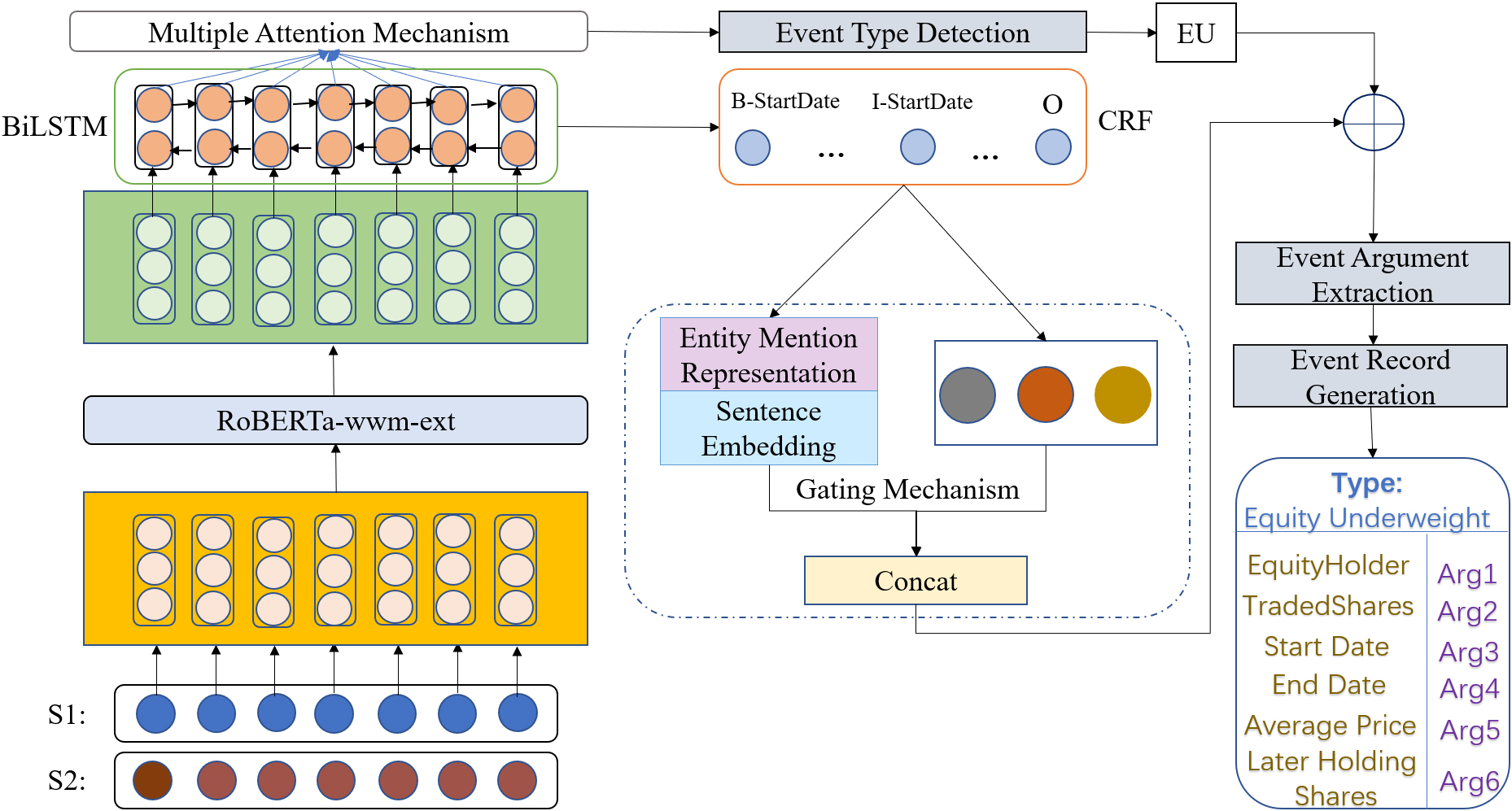
In this paper, the RoBERTa-wwm-ext is adopted as the pre-trained language model. It is an open-source model of Harbin Institute of Technology, which consists of 12 layers of Transformers and combines Whole Word Masking (WWM) with RoBERTa model [19]. It has shown more prominent experimental results in a variety of natural language processing tasks. The basic structure of RoBERTa-wwm-ext is basically the same as the BERT model, and the improvement is more from the perspective of training set and training strategy. First of all, RoBERTa-wwm-ext eliminates the next sentence prediction task, which improves the efficiency. It also uses a large amount of text for data training, including Chinese Wikipedia, news, community Q&A, etc. At the same time, the WWM strategy is adopted. If some characters in the word are masked, then other parts of the same word will be masked. Based on this, RoBERTa-wwm-ext can learn information better at the word level. Compared with BERT’s static mask mechanism and the traditionally unidirectional language model for shallow splicing training, RoBERTa-wwm-ext adopts a dynamic mask mechanism, which generates a new mask every time a sequence is input to the model mode. This approach improves the randomness of the model input, enabling the model to gradually adapt to different mask strategies, while generating deep bidirectional language representations that can capture deeper contextual and semantic information from text.
Each document
Event type detection
Event type detection is an important task in event extraction, which aims to detect the occurrence of events from a given text and classify them by type. Since there may be multiple events in a given text, we model event type detection as a multi-label classification task. An event query based on the multi-headed attention mechanism is used on the obtained sequence of sentence vectors to perform binary classification of each event type.
The sequence representation
among
We take the sentence vectors in the document in turn as the input of the fully connected layer
All pre-defined event types are classified separately using a Sigmoid classifier. The Eq. (6) below gives the calculation for predicting a certain event type.
Finally, the cross-entropy is used for event type detection as the loss function, as shown in Eq. (7).
In Eq. (7),
Event argument extraction includes event argument detection and argument role classification. Event argument detection requires the identification of all entities involved in an event in a sentence, which is modeled in this paper as a sequence annotation task. Argument role classification requires the role classification of the identified argument corresponding to the event type.
Through Bi-LSTM feature extraction, the scores of text sequence corresponding to each tag are output, and conditional random fields (CRFs) [20] are used to constrain tags to reduce incorrect prediction sequences. CRFs output the optimal predicted tag corresponding to the entity in the sentence, and uses the BIO tag to directly mark the scope and type of the entity, so as to obtain the entity mention representation.
In order to strengthen the correlation among events, arguments and argument roles in the document and to enhance the recognition accuracy of the arguments of each event in the document, this paper proposes a gating mechanism to enhance the entity mention representation in the document by doing a gated fusion of the entity mention representation obtained from the following two parts to facilitate the interaction between the sentence and event arguments. One is to introduce sentence-level embedding information to each entity mention in sentence
The event type obtained by event type detection is used as the prior information of event argument extraction, and the entity type encoding
For event argument extraction, the negative log-likelihood loss function is used to calculate the loss
The goal of the event record generation module is to find words belonging to a specific event type, and its extraction contents include time, place, person and behavior. In event extraction tasks, the trigger word can be regarded as an argument role of the event, so that the presence or absence of the trigger word in the training set is equivalent to adding or subtracting one argument. Before generating event records, we first selected a set of pseudo-trigger words for each type of event. The pseudo-trigger words have been proved to be effective in the event extraction tasks. Following the work of Zhu et al. [18], we calculate the existence and distinguishability of a set of argument roles of each type of event and select the argument role with the highest importance score as the pseudo-trigger word of that event type.
For event classification, the selected pseudo-trigger words are combined with other common arguments of that event type and corresponding roles, and then these combinations are filled into the event table.
For event record generation, the binary cross entropy is used for the loss function to calculate the loss
Model traing
We train the event type detection, event argument extraction and event record generation at the same time, and calculate the loss
Dataset
In our paper, we use two datasets, ChFinAnn [17] and DuEE-fin [21], to carry out experiments to verify the compatibility and effectiveness of the model while obtaining experimental results.
ChFinAnn is a Chinese document-level financial event dataset published by Zheng et al. Constructed by remote supervision without trigger word annotation, the dataset contains a large number of real financial announcements from 2008 to 2018, making it the largest document-level event extraction dataset to date. ChFinAnn divides financial events into five types: Equity Freeze (EF), Equity Repurchase (ER), Equity Underweight (EU), Equity Overweight (EO) and Equity Pledge (EP). The dataset has a total of 32,040 documents, 29% of which contain multiple records, and 98% of the records contain arguments that are scattered in different sentences. Statistics on the number of documents in the dataset ChFinAnn are shown in Table 1 below.
DuEE-fin is a document level event extraction dataset in the financial field released by Baidu, which contains 11,700 documents, among which 13 event types and their corresponding 92 argument role categories are defined. Event types come from common financial events, and documents in the dataset come from news and announcements in the financial field.
Statistics on the number of documents in ChFinAnn
Statistics on the number of documents in ChFinAnn
The hyperparameter settings are shown in Table 2. Hyperparameters were set for better comparison with the baseline model PTPCG. Therefore, most of the hyperparameters were set to be the parameters of the baseline model, except for Batch_size. Due to the hardware equipment, we used a smaller Batch_size for training.
Hyperparameter settings
Hyperparameter settings
In this paper, the evaluation criteria in PTPCG [18] is used. The final result of model evaluation is the result of the test set with the highest F1 value of the validation set among all training rounds. For each predicted event, the results obtained using the event extraction model are directly compared with the real values for the evaluation of effectiveness, using the precision (P), recall (R) and F1-measure (F1) as evaluation metrics, which are defined as follows.
We compare the model proposed in this paper with the following models:
The DCFEE model, a key event detection model, extracts events from the entire document using an argument filling method. While DCFEE-M can extract multiple events from a single document, DCFEE-O can only extract single events.
The baseline GreedyDec of Doc2EDAG greedily populates only one event table entry by using the identified entity roles.
Doc2EDAG model populates the event table based on the entire path expansion, and uses a directed acyclic graph to achieve document-level event extraction.
The GIT model uses a tracker to determine whether each entity conforms to the role position under the current path by judging whether the entity conforms to the role position under the path according to the sequence of defined event roles, so as to achieve event extraction PTPCG model implements event extraction by constructing a pruned complete graph to fill the event table.
Analysis of results
The final results of document-level event extraction are shown in Table 3. It can be seen that the document-level joint event extraction model proposed in this paper has achieved the best event extraction effect on the two event types in the ChFinANN dataset. Specifically, in EF, ER, EU, EO and EP event types, the F1 scores are improved by 1.1, 0.1, 3.7, 2.9 and 0.4 respectively compared with those of the baseline PTPCG model.
Evaluation results of document-level event extraction on various event types
Evaluation results of document-level event extraction on various event types
In order to demonstrate the difficulty in document-level event extraction when scattered arguments meet multiple events, experiments are conducted in both single-event (where the document contains only one event) and multi-event (where the document contains multiple events) scenarios. Table 4 shows the F1 scores and average scores for single-event and multi-event sets of each event type. As can be seen, the multi-event scores are significantly lower than the single-event scores. However, compared with PTPCG, the model in this paper still improves the multi-event F1 score by 3 and the average F1 score by 1.7, which is similar to the GIT model.
F1 scores for all event types and the averaged ones (Avg.) on single-event (S.) and multi-event (M.) sets
Table 5 shows the comparison between the number of GPUs consumed and the runtime. Although the results of the proposed model on the ChiFinAnn dataset is not so different from that of the GIT model, it only needs to run with a single GPU for 4.9 days, which is very superior to GIT’s runtime of 6.6 days for eight GPUs. In terms of resource consumption and runtime, the model is better than GIT.
Runtime comparison
To further demonstrate the superiority of the model, we conduct experiments on DuEE-fin dataset, and the results are shown in Table 6. The model presented in this paper achieves the best F1 score in online evaluation, with an improvement of 4.0 compared with PTPCG
Experimental results in DuEE-fin
In this section, we remove the RoBERTa-wwm-ext and gating mechanism to see whether the key part of the model plays a positive role in event extraction tasks. The experimental results are shown in Fig. 3, from which it can be seen that both RoBERTa-wwm-ext and gating mechanism are useful.
Ablation experiences of event extraction on ChFinANN.
The document-level joint event extraction model proposed in this paper uses the pre-trained language model RoBERTa-wwm-ext to encode sentences in the input document and uses a masked language model to generate deep bidirectional language representations that combine semantic and contextual information. This method based on pre-trained language model is compared with DCFEE model which uses Word2vec to transform words into vectors, GreedyDec and Doc2EDAG model which uses Transformer to encode input text, and PTPCG model which uses Bi-LSTM to encode sentences. The method of integrating prior knowledge into the model can improve the effect of event extraction and make the results of the model more accurate in the sub-task of event argument extraction.
The gating module can weight information from different places and effectively adjust the weights according to their contribution to the task, so that the events, arguments and argument roles in the document are more closely related, thus improving the recognition accuracy of the arguments of events in the document.
This paper proposes a document-level joint event extraction model based on RoBERTa-wwm-ext, which consists of three parts: event type detection, event argument extraction and event record generation. The model not only uses the prior knowledge from event types and the pre-trained language models, but also uses gated fusion to enhance the entity representations and splice the entity type embedding, so as to enhance the association of events, arguments and argument roles in the text. The model does not depend on real trigger words, which addresses the situation where no trigger words exist in the application scenario. Through the joint training of the three modules, the error transmission of the pipeline method is avoided. Finally, the effectiveness and compatibility of the model is verified on the public dataset ChFinANN and DuEE-fin.
This paper focuses on document-level dataset in the financial domain, and no comparative experiments have been conducted in other domains. In addition, multiple events are still a major difficulty in the event extraction tasks. How to improve the effect of multiple event extraction is the goal of our further studies.
Footnotes
Acknowledgments
This work was supported by the National Defense Science and Technology Industrial Technology Research Project (Civil aviation 2020-682) and Basic Research Project of Liaoning Department of Education LJKMZ20220536.