
Abstract
Reading Comprehension models have achieved superhuman performance on mainstream public datasets. However, many studies have shown that the models are likely to take advantage of biases in the datasets, which makes it difficult to efficiently reasoning when generalizing to out-of-distribution datasets with non-directional bias, resulting in serious accuracy loss. Therefore, this paper proposes a pre-trained language model based de-biasing framework with positional generalization and hierarchical combination. In this work, generalized positional embedding is proposed to replace the original word embedding to initially weaken the over-dependence of the model on answer distribution information. Secondly, in order to make up for the influence of regularization randomness on training stability, KL divergence term is introduced into the loss function to constrain the distribution difference between the two sub models. Finally, a hierarchical combination method is used to obtain classification outputs that fuse text features from different encoding layers, so as to comprehensively consider the semantic features at the multidimensional level. Experimental results show that PLM-PGHC helps learn a more robust QA model and effectively restores the F1 value on the biased distribution from 37.51% to 81.78%.
Keywords
Introduction
Machine Reading Comprehension (MRC) is a hot topic in a wide range of Natural Language Processing (NLP) tasks, which aims to train the model to predict correct answers based on given paragraphs, and can be further applied to intelligent question answering scenarios [3]. With the rapid development of deep networks, the research task on MRC has gradually shifted from cloze-style [11], multiple-choice [17] to span extraction [24] and free-form prediction [10]. Span extraction is the focus of this study: after reading the passage and the question, it extracts a continuous text that best matches the question as the answer.
Early QA models were mostly based on end-to-end neural networks: the input texts were represented as fixed word vectors, sent to CNN or RNN network architecture for encoding, and then the information between contexts and questions was captured with attention or self-attention mechanism, and finally two classifiers were trained to predict answer positions. Over the past few years, with the emergence of Transformer [28], the paradigm of pre-training and fine-tuning has gradually become the mainstream method in NLP tasks. The BERT pre-trained model [8] proposed by Google innovatively added two pre-trained tasks, masked language model (MLM) and next sentence prediction (NSP), to better capture semantic information, and showed state-of-the-art performance on various NLP downstream tasks. It is worth mentioning that its performance on SQuAD1.1 based on evaluation metrics even surpasses that of human baselines, and since then has opened up a new era of pre-trained language models (PLMs).
Nevertheless, it is questionable whether the pattern of predict answer position for span is robust. In this regard, Ko et al. [16] trained on a biased training set where the answer always lie in the first sentence of the paragraph, and found that the prediction results may be severely biased. As shown in Fig. 1, QA model tends to make predictions according to the shortcut: false clues of the position distribution of answers, rather than real learning of the context. Although existing models have achieved superhuman accuracy on several standard test sets, the prediction results of them may drop significantly on samples that have been specially processed or contain small perturbations, which seems to hinder the development of learning proper reading ability by existing networks. If the model is only built in the text world without establishing a connection with the real world, the model can only learn “form”, but not “meaning” [6]. To this end, how to help the model optimize its generalization ability to out-of-domain or adversarial settings has become a significant challenge in this field. Building on recent research on robustness in QA tasks, this paper focuses on the aforementioned position bias problem, and attempts to develop an effective de-biasing framework to learn generalizable solutions when training on datasets with unintentional bias.

A sample of position bias in reading comprehension.
Recently, several different types of approaches have been proposed to tackle this problem, especially focusing on their performance on BERT. A more direct approach is to disturb the position of the input sequence, avoiding learning the direct correlation between word positions and answers [16]. However, the disruption of a specific encoding structure may have a negative impact on the stability of the model, resulting in significant sacrifice to the in-distribution (ID) performance. Moreover, the integration strategy achieves encouraging results by combining the probability distribution of the start/end positions from the target model and the bias model, but there are also some defects: the lack of robust optimization at the target model level.
Motivated by the above work, this paper introduce a pre-trained model based optimized framework on positional generalization and hierarchical encoding combination for relieving position bias problem in QA. Specifically, regularized technology is used into embedding layer of the model, which helps weaken the over capture of position information. Besides, a hierarchical feature fusion architecture is constructed to comprehensively consider the semantic features at multidimensional level. The detailed experiments has been conducted to demonstrate the advantages of our framework. In summary, the major contributions of this study are recapitulated as follows: To solve the bias problem in QA, we design a positional generalization embedding to reduce the over capture of position information by the model, and further introduce an additional distributed differential loss term to maintain in-distribution performance To further promote the text understanding of the model, we proposed the hierarchical encoding fusion structure to optimize the capture of multidimensional features. Detailed experiments were conducted based on the combinatorial de-biasing framework, which confirmed that it could help the model to make more efficient reasoning in the face of non-oriented bias distributions.
The remaining of the paper is organized as follows: Section 2 reviews the related works on extractive QA and de-biasing methods. Section 3 introduces our proposed framework PLM-PGHC; Section 4 presents the experimental results, and Section 5 concludes the paper and suggests future research potential.
Extractive QA
MRC tasks based on multi-step synthesis and reasoning have always been a hot topic in the field of Natural Language Understanding (NLU). With the continuous iteration of QA models, the construction of artificial intelligence question answering systems has gradually emerged, leading to the birth of a series of human-like open-domain chatbots [14], which have been successfully applied to realistic scenarios such as medicine and finance [22]. In this work, we will delve into the robust optimization based on extractive QA to promote high-quality semantic understanding of the model.
The formation of the span extraction task of MRC originates from the first large-scale extractive MRC dataset SQuAD1.1 [25], which is in the form of “context-query-answer” triples. Considering that the form of the answer for this task is a continuous span, Wang et al. [30] proposed the first end-to-end neural network model tested on SQuAD, using the pointer network [29] to predict the start and end position of the answer. Since then, QA models based on this mainstream pattern, such as R-Net [31] and QANet [34], have emerged, and integrated technologies like attention mechanism [2] to highly specialized design text modeling and semantic interaction module for performance benefits. Moreover, the rapid iteration of pre-trained models also constantly refreshes the list of MRC datasets. So far, most researchers have continued to focus on experimenting and improving pre-trained models and their variants, extending to multiple tracks such as knowledge graphs [19], pre-trained tasks [15], and parameter compression [9].
Despite the mature performance of extractive QA, some researchers have found that existing models may be fragile. Sugawara et al. [27] firstly pointed out that the current MRC models do not actually reason the answer in the way we expected, and they are tend to learn shortcuts, or some obvious laws. Lai et al. [18] designed two synthetic datasets and quantitatively analyzed the learning mechanism of the model under different training settings, indicating that models tend to solve shortcut problems due to small computing resource requirements. In addition, existing language models are more susceptible to the interference of adversarial samples [6]: for example, by introducing subtle noise disturbances such as synonym substitution and text addition into normal text, the model can generate incorrect prediction. With the existence of shortcuts, how to better enable models to learn real ability of reading comprehension and maintain robustness to the noise introduced into the datasets is a topic worthy of research.
De-biasing methods
Since position bias is the focus of this paper, we focus on some existing excellent de-biasing work for inspiration. Along with the introduction of position bias problem, Ko et al. [16] propose an ensemble-based de-biasing method, which uses a product of expert [12] to combine a predefined bias model and the log-likelihood of the target model, where the bias model is defined as pre-calculated answer priors. In order to enable the model to perform well in both ID (in-distribution) and OOD (out-of-distribution), Niu et al. [21] fuse the knowledge of two teacher models that specifically capture ID and OOD bias, and distill a student model to accomplish this balance. Zhu et al. propose Counterfactual QA [35], which captures the answer position bias as the direct causal effect of paragraphs on answers, and subtracts the direct causal effect from the total causal effect to remove the position bias.
Taking the above ideas into account, researchers tend to stack external modules and ignore conducting de-biasing experiments through robust optimization of biased target model. With the highly evolution of neural networks over the past years, optimization techniques [1] dominated by gradient descent have been widely demonstrated to be effective methods for solving the optimal value of the objective functions. In addition, the latest intelligent search algorithms such as meta heuristic algorithms [20] have further expanded the limitations of traditional gradients and numerical computing, achieving great performance in fields like sentiment analysis [13] and clustering of texts [4]. Therefore, this paper considers starting from the point of biased model itself, and constructs an optimization objective based on generalized position information and stable performance to achieve the purpose of de-biasing. Compared with the previous work, our method is more easy and effective, compatible to the BERT based structure, and can be integrated with existing strategies to achieve considerable performance.
Model
The proposed framework mainly consists of four parts as shown in Fig. 2. The whole architecture is described in details in the following sections:
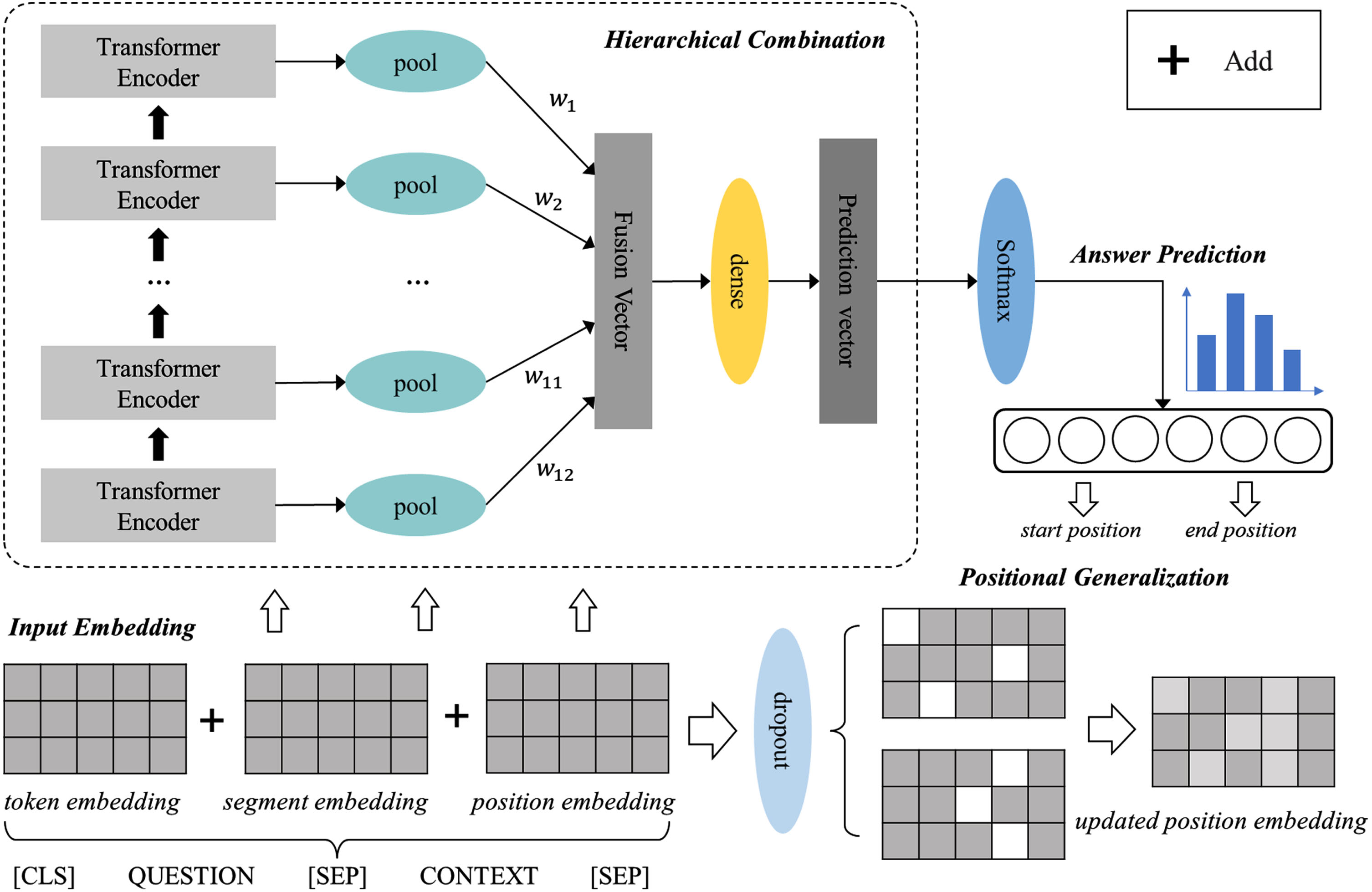
Architecture of the proposed framework PLM-PGHC.
In this paper, the pre-trained model BERT is used as the basic encoding architecture to extract text features. As shown in Fig. 2, as the sentence pairs composed of paragraph C and question Q are sent into the model, the token [CLS] for obtaining classification information and the token [SEP] for separating questions and contexts are added into them for firstly text pre-processing. Then, the input sentence [CLS]+C+[SEP]+Q+[SEP] is processed by word segmentation to form the text representation
Where, e
token
, e
seg
,
It should be noted that BERT uses absolute position embedding, which firstly initializes the embedding according to specified sequence length, and then put it into the pre-trained process to train the word vector of each position. However, for reading comprehension tasks, while training the position vector with the task of predicting answer start position of answers, it is easy for the model to learn the direct correlation between the word position and the predicted answers. This false shortcuts greatly affect the prediction accuracy when there is serious bias in the datasets. Therefore, this paper introduces dropout technology to preliminarily regularize the position embedding and generalize the direct capture of distribution information. More specifically, the elements in the d-dimension position embedding will be randomly set to 0 with probability p, so as to obtain the updated word embedding as equation (2):
The position embedding through dropout will be more robust and can learn more useful features instead of focusing on false shortcuts. The updated embedding is fed into the encoding layer as input to get the final prediction result.
In the previous section, by integrating the regularization technology into position embedding representation, the excessive dependence of the model on answer distribution information during training process has been preliminarily alleviated. However, concerns have been raised that dropout may lead to some side effects: on the one hand, the lack of some feature elements affects the integrity of the embedded structure, which may lead to the loss of in-distribution training performance; on the other hand, studies have shown that the introduction of dropout may cause a non-negligible differentiation to models between the training and inference phases. Therefore, inspired by the work of Wu et al. [32], the generalized positional embedding here should be further optimized.
As the process of positional generalization shown in Fig. 3, instead of the the direct composition of the word embedding E described in Section 3.1, the initial position embedding e pos will first generate two different generalized position embedding through the dropout module, which enables the same input to get two different distributions with the same model. The two path networks here are approximately regarded as two different model networks, and the different distributions generated by them can be represented as P1 (y|e pos ) and P2 (y|e pos ).
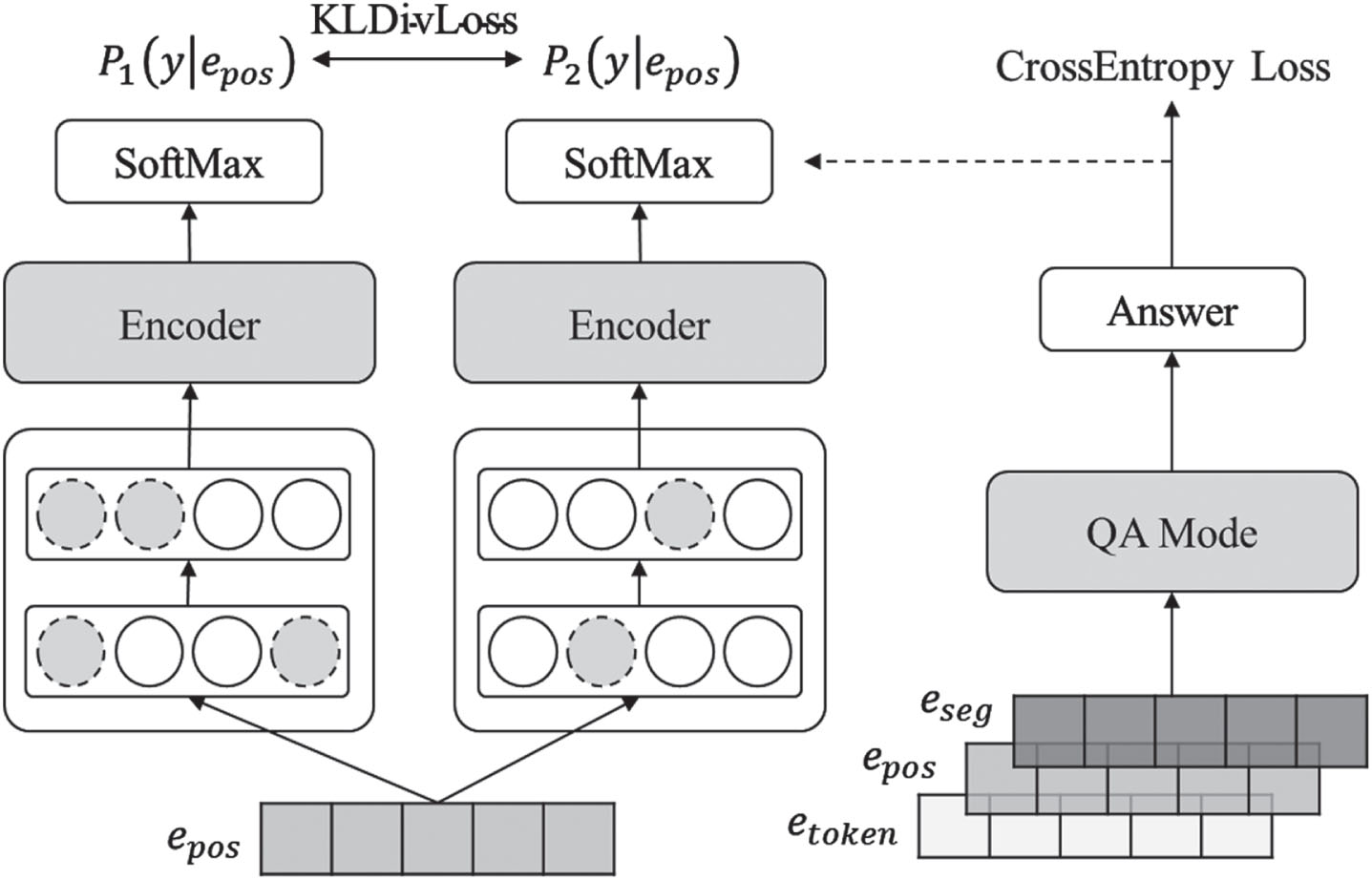
The illustration of regularized positional generalization.
In order to evaluate the differences between the output distributions of two different sub models, the Kullback Leibler (KL) divergence is adopted to measure the degree of difference between two probability distributions. When the KL divergence value is 0, it represents that the two distributions are completely the same. Then the distribution difference can be calculated as equation (3):
Where, i represents the i-th input sample, and D KL (·) presents the calculation of KL divergence.
Due to the inherent asymmetry of divergence, it is necessary to further exchange the positions of these two distributions to finally get the average processed KL divergence, which can be calculated as follows:
In order to make the outputs of the two different sub models as consistent as possible, the output consistency of the two random sub models caused by dropout will be restricted by continuously lowering
In addition, with the full account of the secondary update of e
pos
, the initial position embedding in the BERT model will be replaced by the average position embedding
Finally, the updated word embedding E* can be represented as equation (7):
In summary, the idea of positional generalization, combined with the regularity of encoding and the constraint of distribution difference, is conducive to solving the reasoning defects led by information of answer distribution while maintaining in-distribution performance.
The original BERT adopts a stacked encoding architecture based on Transformer encoding blocks, and uses the output vectors of the last layer for classification prediction. However, considering that QA tasks require a high degree of summarization and abstraction of text content while retaining different granularity semantic attributes, the inherent single-layer feature extraction pattern cannot fully represent the input sequence. Therefore, in order to enable the model to learn the semantic knowledge contained in multi-layer structures more comprehensively, this paper adopts a hierarchical combination encoding module to fuse feature vectors of each hidden layer, and the parameters are fine-tuned during the training process by combining multi-dimensional features to obtain richer text information.
For PLM-PGHC, the input of the first encoding layer will be updated to the positional generalization word embedding E* as defined in section 3.2. The feature vectors obtained from each hidden layer are the output of the corresponding encoding block, and the output vectors of each hidden layer are obtained as shown in equation (8):
Where,
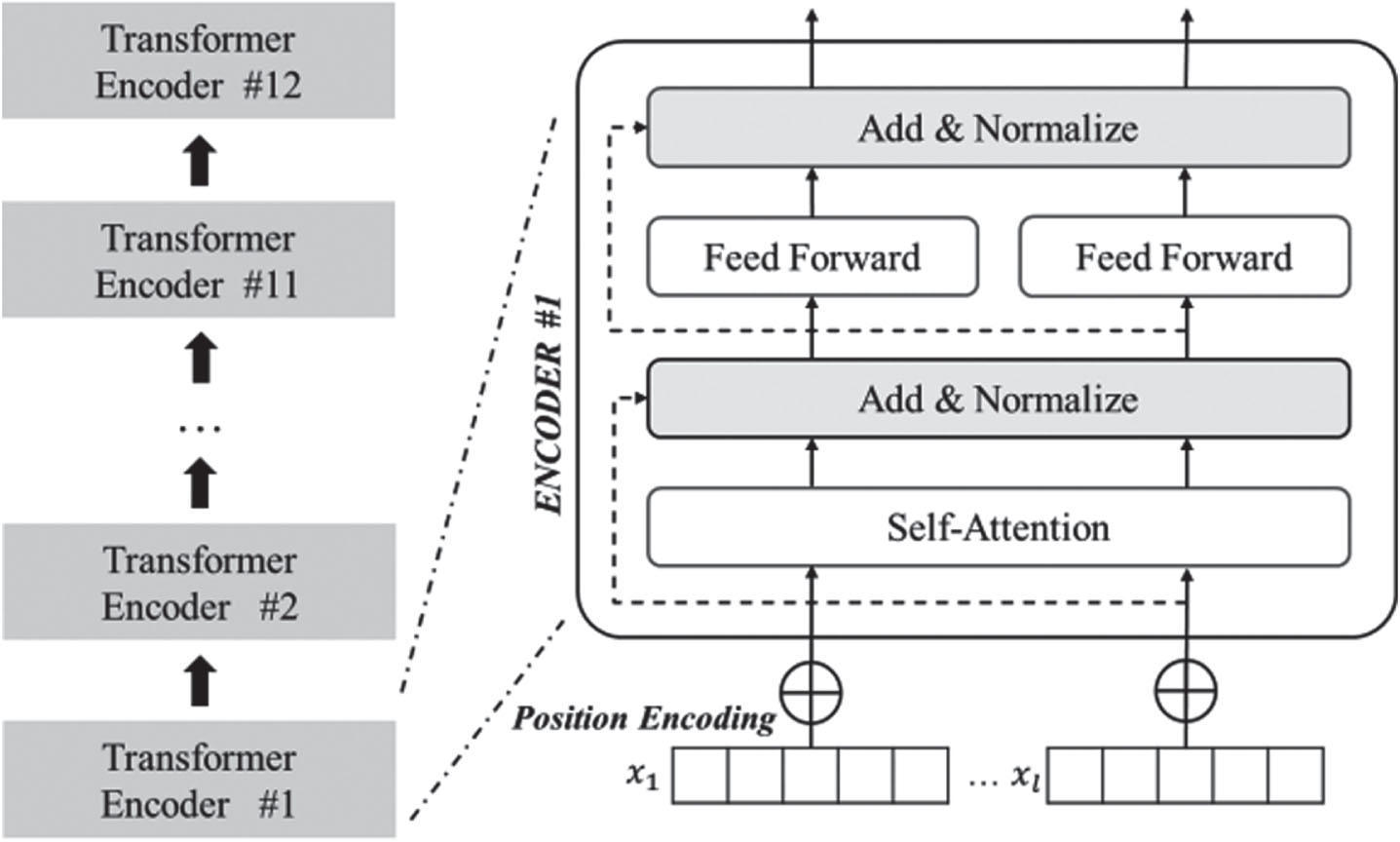
Structure of the Transformer encoding module.
To obtain the fusion representation information of each hidden layer, we introduce a pooling module to preprocess the output of each hidden layer. Specifically, we extract the first token corresponding to each hidden layer representation, i.e. the feature vector
In order to make full use of the information of each hidden layer, the nonlinear activation function is further introduced to dynamically assign weight to output feather of each layer. Based on the numerical normalization characteristic of sigmoid activation function, the input real number field representation values of each layer are mapped to weight value between 0 and 1, as shown in Equation (10):
Then, the combination vector that integrates text features at different levels is obtained by weighted combination, and is connected to the full connection layer for dimensional transformation, so as to obtain prediction vectors of corresponding classification vector dimensions, which can be represented as follows:
In summary, the hierarchical combination module enhances the original BERT architecture by enabling the model to grasp semantic knowledge contained in multi-lay structures more comprehensively. This updated architecture not only improves the model’s ability to summarize and abstract text content but also retains different granularity semantic attributes crucial for QA tasks.
The task of extractive QA is to find the correct starting position of the answer from a paragraph to correctly answer the given question. Specifically, after the input sequence is processed by the BERT encoding layer, the feature vector of the last coding layer M ={ m1, . . . , m
L
} is retained, where L is expressed as the maximum length of the input sequence. Then, M is transformed through the fully connected layer and softmax, and the predicted start and end probabilities is obtained, that is:
The loss function of answer span prediction adopts the traditional cross entropy, which is defined as minimizing the negative logarithm of answer score and taking the average value on all training samples:
Where, N represents the number of samples,
In order to further regularize the random instability brought by dropout, the KL loss obtained by twice position embedding dropout is added to cross entropy, that is, on the basis of inherent training loss, a regularized term to strengthen the robustness of the model will be additionally introduced. Thus the final loss function can be represented as:
Where, α is the adjustable super parameter that controls the ratio of L CE to L KL .
In the training process, our method constrains the parameter space by constraining the outputs between the random sub models generated by dropout, so as to keep different outputs as consistent as possible, effectively solve the inconsistency between training and testing, and better optimize the way of generalized positional embedding.
Datasets description
The experimental part is mainly based on SQuAD to train and evaluate our method. It is one of the most classic QA datasets collected through crowd-sourcing. More than 10 W question-answer pairs are extracted from 536 articles on Wikipedia. These answers are in the form of a continuous span to the corresponding paragraph. The typical length of the paragraphs is around 250 and the question is of 10 tokens except for some particularly long cases.
In order to explore the effect of our method on alleviating position bias in QA, SQuAD is divided into five sub data sets according to the position of the answer located in the paragraph. Specifically, k is used to represent the k-th sentence in the paragraph, which can take 1, 2, 3, 4 and k ⩾ 5, corresponding to sub data sets SQuAD_k1, SQuAD_k2, SQuAD_k3, SQuAD_k and SQuAD_k5, respectively. Table 1 lists the specific number of samples in each sets. Among them, SQuAD_k1 has the largest number of samples, exceeding 30% of the total, which has the best verification conditions. Therefore, the de-biasing experiments and results analysis in this paper will mainly carry out on SQuAD_k1.
Statistical details of SQuAD and its sub sets
Statistical details of SQuAD and its sub sets
In this paper, all experiments are performed training using Windows 10 64bit operating system, accelerated by NVIDIA GeForce RTX 3060 graphics card. The network is implemented on the Pytorch framework. The parameter setting work mostly follows the BERT-base model settings. The initial learning rate of the Adam optimizer is set to 3e-5 and the number of training epoch is 2 with batch sizes 12. For the input, the maximum value of tokens for sequence and questions are limited to 512 and 64 respectively. The previous setting that sampling 384 indices for BERT is kept when the baseline strategy of random position is conducted. The performance of the model will be evaluated by comparing the predicted answers with the true answers, specifically using Exact Match (EM) and F1 scores as the main metrics.
Note that our de-biasing framework has introduced two additional parameters, dropout rate p for positional generalization and ratio α for loss weight, we will conduct parameter analysis in the subsequent experiments for the best performance. Compared with traditional training, the implementation of our method has doubled the amount of data in batch processing, and leads to a certain increase in computing cost. But it is worth affirming that the average training time of model with PLM-PGHC is almost similar to the original one, and the final performance is significantly better than the baseline.
Baseline models
In this section, experiments are mainly conducted on sub sets of SQuAD to evaluate how each component of the proposed method contributes to the final de-biasing performance. To verify the performance of the proposed method, the following baseline models and integration strategies are applied for comparative analysis:
BiDAF [26]: An end-to-end model based on bidirectional attention flow to represent context.
XLNet [33]: An auto-regressive pre-trained model for bidirectional context learning.
BERT [8]: A pre-trained model with bidirectional encoder representation from Transformers.
Random Position (RP) [16]: A de-biasing method by perturbing input positions and randomly sampling indices to generate position embeddings.
Bias Product (BP) [12]: A de-biasing method by combining the probability distributions of start/end position from the target model and the bias model.
Learned Mixin (LM) [7]: An improved BP by adding an affine transformation on hidden representations before the softmax layer.
Results
Baseline comparison
For an overall analysis of the proposed framework, the experiment is firstly conducted on SQuAD and SQuAD_k1 with three different baseline models.
As can be seen from Table 2, the training accuracy of the three baselines under the biased distribution is significantly decreased compared with the original performance on SQuAD, indicating that the position bias has a serious impact on the model performance. By comparing the accuracy loss of these models, it is found that XLNet has relatively minimal accuracy decrease due to its special embedding structure of relative position representation. However, the BERT model has shown a serious decline trend in accuracy under the premise of good performance on unbiased data, which is the most suitable baseline for further improvement based on its model universality and performance loss ratio.
Comparison results of baseline models
Comparison results of baseline models
Table 3 provides the comparison of training results of different de-biasing methods and the proposed framework on biased sets SQuAD_k1. Among them, +PGHC represents the integration of the de-biasing framework proposed in this paper. The performance of each strategy is mainly evaluated by evaluate metrics EM and F1 value on validation set SQuADdev, and further evaluated based on the performance on biased validation sets
Comparison results of different de-biasing models on SQuAD_k1
From Table 3, it is clear to observe that different baseline methods have a certain improvement in accuracy compared to initial BERT on SQuAD_k1. On this basis, BP achieved the maximum accuracy gain after integrating the PGHC, increasing the F1 value by 5.94%. For the LM baseline strategy based on dynamic deviation integration, our framework achieved a relatively optimal improvement of 0.81% in F1 value, which is lower than the accuracy gain of other baselines. However, the advantage is that the introduction of PGHC did not sacrifice performance of BERT on
Overall, the learning framework based on position generalization and hierarchical combination can effectively alleviate the position bias problem in QA. With the optimal combination of LM and PGHC, the predictive performance of BERT model is improved from 31.21% EM and 37.51% F1 to 73.37% EM and 81.78% F1, effectively restoring the reasoning ability of the model.
Since the de-biasing framework proposed in this paper is mainly based on two parts of structural optimization, that is, positional generalization (PG) and hierarchical combination (HC), in order to verify their effectiveness, the two optimization modules are integrated into baseline method RP, BP and LM for ablation experiments. And the specific experimental results are shown in Table 4.
Comparison results of optimizations for different de-biasing modules on SQuAD_k1
Comparison results of optimizations for different de-biasing modules on SQuAD_k1
According to the results of these two optimization modules performed on each baseline method in Table 4, it can be seen that both of the updated word representation module and encoding module have a certain improvement compared with baseline model. In the case of only introducing PG, the model has achieved a significant gain of 41.82% EM and 44.2% F1, indicating that the correction of position information is highly influential. In conclusion, this experiment has proved that generalization of position embedding is beneficial for the model to weaken irrelevant position clues, promote deep understanding and mining of input texts. Moreover, the integration of hierarchical encoding representation promotes the combinatorial learning of multi-dimensional semantic information and further enhances the comprehensive attention of the QA model to multi-dimensional representation.
In order to conduct a more comprehensive study of the bias problem, it is not sufficient to focus solely on the sub sets whose answers are biased to the first sentence of the paragraph. Therefore, supplementary experiments are also conducted on sub sets with different position distributions of answers. Figure 4 shows the comparison of the results on different sub sets after integrating PGHC with RP.
As can be seen from Fig. 5, it can be observed that with different bias distributions, the introduction of PGHC always achieved the optimal de-biasing effect, and the F1 value of the model on each sub set are respectively improved by 6.58%, 2.17%, 5.28%, and 1.66% compared to the best results. Among them, the improvement on SQuAD_k5 is relatively small, due to the fact that the sub set contains samples that are mixed with the later answer distribution, and there is no significant bias problem compared to SQuAD_k1 and SQuAD_k2, which limits the ability of the integrated model to capture and optimize bias.
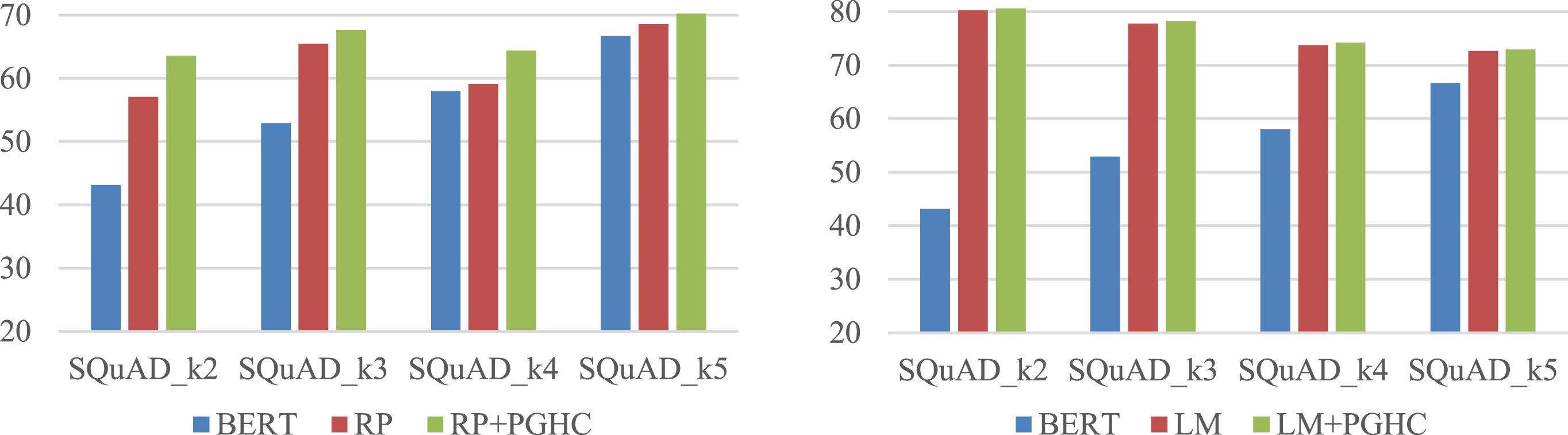
Comparison of F1 values based on RP (left) and LM (right) on each sub set.
Figure 6 shows the comparison of results on each sub set after integrating PGHC into LM. It can be seen that the framework in this article achieved a relative improvement in F1 values of 0.29%, 0.38%, 0.45%, and 0.27% compared to the current best results on SQuAD_k2, SQuAD_k3, SQuAD_k4 and SQuAD_k5, respectively. The accuracy gain on this baseline is not significant compared to that on PR, but the optimization performance is still stable, verifying that the applicability of this framework to different biased distributions.
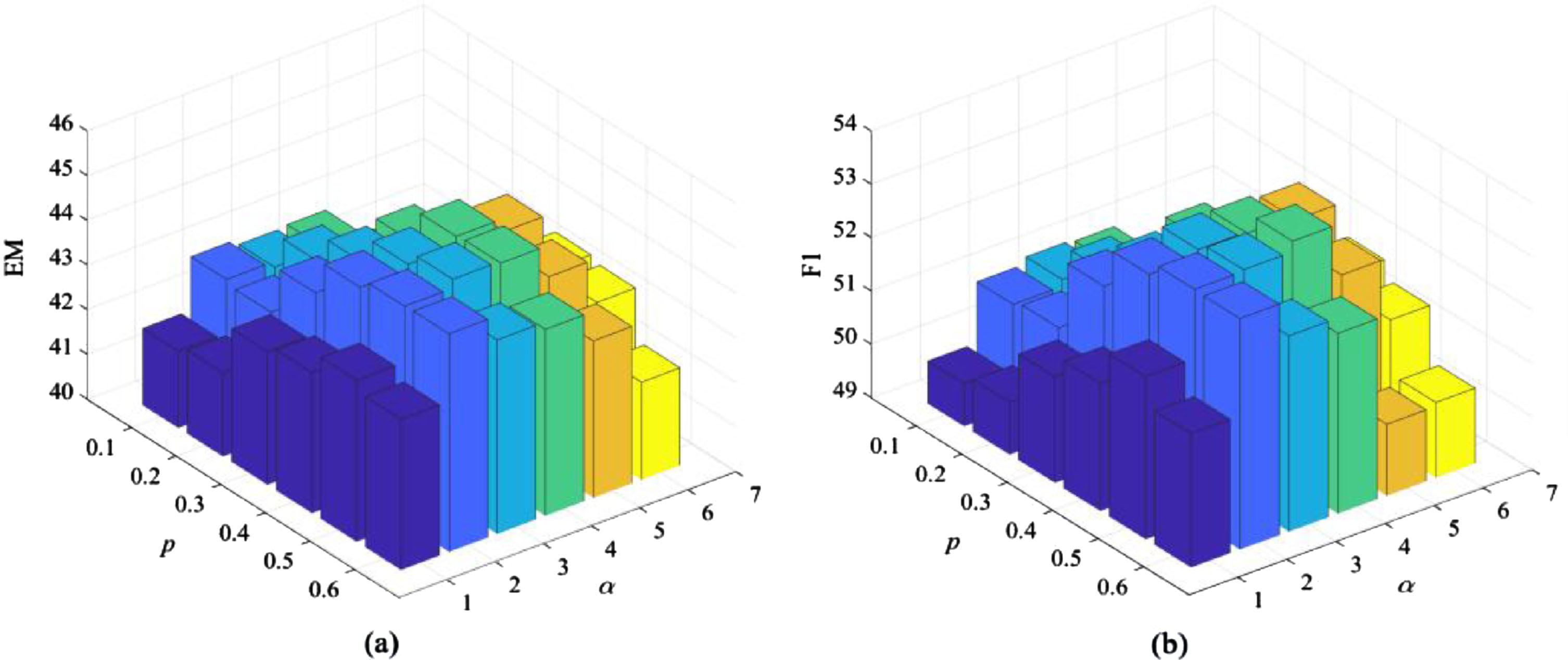
Comparison of F1 values with parameter p and α based on RP.
It should be noted that, while effectively improving the prediction performance of out-of-distribution data, the de-biasing strategy should also maintain the in-distribution performance to ensure the stability of the model. In this paper, it refers to the accuracy of the de-biasing strategy under the unbiased distribution. Therefore, Table 6 provides a comparison of training effects of different ensemble de-biasing models on the complete SQuAD data set.
It can be seen from Table 5 that the addition of our framework PGHC achieves better performance than a series of baseline methods, and achieves an accuracy gain of 0.17% F1 when integrating PGHC with BERT. The optimal results are obtained when introducing PGHC into LM, which are higher than the original BERT of 0.25% F1 value. From above analysis, the proposed framework is of great effectiveness on unbiased distribution as well as alleviating the bias problem of QA sets, thereby promoting the inference learning ability of the model under non-oriented bias distributions and effectively enhance its robustness.
Comparison results of different de-biasing models on complete datasets
Comparison results of different de-biasing models on complete datasets
There are two new adjustable hyperparameters in the proposed framework: dropout rate p and the loss ratio α. The parameter p controls how many elements are zeroed in the positional vector. And the parameter α determines the ratio of the cross entropy loss to the divergence term. Therefore, in order to confirm the influence of the adjustable parameters on the model performance, we conduct quantitative experiments for further parameter analysis. The results of PGHC based on RP and LM under different settings of p and α are summarized in Figs. 6 and 7 respectively. To reduce the impact of dropout on model performance, we set p between 0.1 and 0.6, so as to maintain the model performance. Considering both the loss bias and appropriate proportion, we set the loss ratio α between 1 and 6.
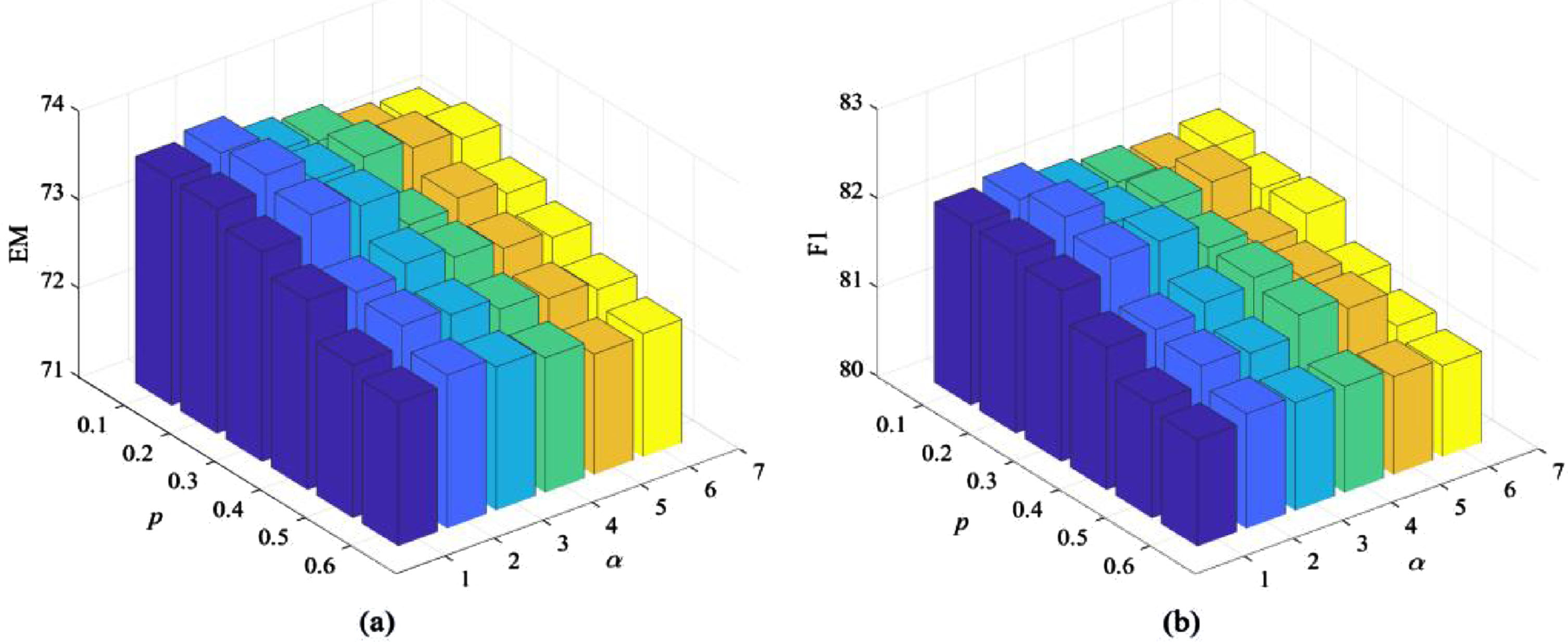
Comparison of F1 values with parameter p and α based on LM.
It can be seen from Fig. 6 that for the combination of RP PGHC, there is a significant fluctuation on EM and F1 value with the variation of adjustable parameters, with a difference of 4.92% between the maximum and minimum F1 values. This may be related to the superposition of two partial randomness algorithms. When p = 0.4 and α = 4, the optimal results of 54.90% F1 values can be obtained, and a higher rate of p has a certain adaptability to RP.
In contrast, for the combination of LM and PGHC, the accuracy change of the model is relatively stable, with a difference of only 1.18% for F1 value. When p = 0.2 and α = 2, the optimal results are obtained, which corresponds to 73.37% EM and 81.78% F1. From p = 0.2, with the increase of dropout rate, both EM and F1 have a general downward trend, and even get some results that are lower than the baseline result of LM, which indicates that an excessively large parameter p may affect the performance of the model, thereby damaging the ideal de-biasing effect. In summary, the experiment further reflects that both the dropout rate and the loss ratio have a certain influence on the model effect.
Several recent studies have found that training on biased datasets may allow QA models to obtain answers through false position clues. In order to safely alleviate bias problem without degradation of in-distribution performance, this paper proposes a novel de-biasing framework named PLM-PGHC, which promotes the learning of multi-dimensional text features through positional generalization and hierarchical combination encoding representation module. Experimental results prove that our method effectively restore the model performance on biased distribution. In addition, the optimized architecture in this paper has no obvious defects in training time and effectively enhances the training robustness of the model.
We hope that this study could help inspire further research in several possible directions. Firstly, PLM-PGHC focuses on robustness enhancement based on model structure optimization. Considering the role of feature extraction in text semantic understanding, advanced strategies such as feature extraction module or data augment can be further introduced in future work to enrich the diversity of semantic information extraction. Secondly, due to the limitations of the de-biasing research focusing on the problem of position bias on the generalization effect of the model, the robustness of this method to other shortcut problems in QA tasks should be further expanded.
Footnotes
Acknowledgments
This research was supported by National Natural Science Foundation of China (No.61977039).