
Abstract
In the deep learning-based video action recognitio, the function of the neural network is to acquire spatial information, motion information, and the associated information of the above two kinds of information over an uneven time span. This paper puts forward a network extracting video sequence semantic information based on deep integration of local Spatial-Temporal information. The network uses 2D Convolutional Neural Network (2DCNN) and Multi Spatial-Temporal scale 3D Convolutional Neural Network (MST_3DCNN) respectively to extract spatial information and motion information. Spatial information and motion information of the same time quantum receive 3D convolutional integration to generate the temporary Spatial-Temporal information of a certain moment. Then, the Spatial-Temporal information of multiple single moments enters Temporal Pyramid Net (TPN) to generate the local Spatial-Temporal information of multiple time scales. Finally, bidirectional recurrent neutral network is used to act on the Spatial-Temporal information of all parts so as to acquire the context information spanning the length of the entire video, which endows the network with video context information extraction capability. Through the experiments on the three video action recognitio common experimental data sets UCF101, UCF11, UCFSports, the Spatial-Temporal information deep fusion network proposed in this paper has a high correct recognition rate in the task of video action recognitio.
Introduction
In the deep learning based video action recognitio, the design of the neural network structure mainly focuses on how to obtain spatial information, motion information, and the association of the above two kinds of information over an uneven time span. Only by fully obtaining enough spatial information and motion information in the time dimension can the neural network better recognize the action. For example, when performing a motion recognition such as a swing in golf and a bicycle, the difference in spatial background information will be good classification identification information because in a swing of golf, the golf club and golf ball are significantly recognized and most of the green background can be regarded as information of action recognition. However, relying solely on spatial information is difficult to recognize actions with similar backgrounds, such as the golf swing action and the hitting action of the croquet sport. Because the backgrounds of these two actions are very similar, in the case of such a situation, the motion information clearly better recognizes the above two actions.
Recently, many researchers have had many outstanding achievements in such research: Let single or multiple video frames enter single channel CNN to learn local Spatial-Temporal information [1, 2]. The CNN-acquired spatial information is merged with the motion information extracted by the traditional optical flow method through the CNN [3, 4]. The CNN combines with the Long-Short Term Memory Network (LSTM) to obtain video stream context information [5]. A method of fusing features extracted by single-channel CNN learning with traditional artificially defined features (such as HOF [6]) [7].
Among the above methods, there are still some defects, mainly for the following reasons: (1) The training data set for action recognition is relatively lacking. Different from image classification, there are large data sets like ImageNet (1000 samples per category) that can be used for training, but the data set for action recognition UCF101 has only 100 samples per action category. (2) The method of the multi-video frame simultaneously entering CNN to extract Spatial-Temporal information solves the problem of local Spatial-Temporal information fusion. However, because CNN does not get good information about video streams over time, such methods cannot solve the problem of full acquisition of temporal information. In addition, the dual-stream architecture method [8, 9] based on spatial CNN network spatial features and temporal CNN network optical flow characteristics in fully-connected layers fusion cannot obtain two important clues in video understanding: (i) spatial location where motion occurs (ii) spatial information and changes in motion information over time. (3) In the method of combining CNN and LSTM, the first fully-connected layer of CNN is connected to LSTM. LSTM network is used as a tool for temporal information extraction. Because the fully-connected layer of the CNN network only has semantic information, the temporal clue of the spatial information is not obtained. And the lack of temporal clues makes the regional attention mechanism of video frames impossible.
Based on the defects mentioned above, this paper puts forward a neutral network architecture with video context information extraction mechanism that can not only fully integrate local spatial information and motion information, but also acquire local Spatial-Temporal information of multiple time scales
Related work
In the recent research on CNN forvideo action recognitio, the main problem is how to obtain the spatial information of video frames and the information over time. In the method proposed in Ref. [10], 16 consecutive frames in a finite time were entered into a CNN network (3DCNN) having a three-dimensional convolution kernel with a parameter of 3×3×3. This method works because the convolution kernel acts on both the spatial dimension and the time dimension. Therefore, compared with which only has a 2D convolution kernel acting on the spatial dimension methods, the network architecture achieves better performance, but the network depth and parameters will be deeper and more. For 3DCNN, as in Ref. [11], the authors decomposed the 3D volume integration into 2D spatial convolution and 1D time convolution. The 1D time convolution was a characteristic channel in which 2D spatial was convolved in time, and it was embedded only at the upper layers of the network. As shown in Fig. 1, Paper [12] proposed a two-stream structure model based on CNN, which used spatial CNN stream to extract spatial information of single video frame and used time stream CNN to extract motion information of multi-optical stream frame. Then, the extracted spatial information and the motion information were fused on the fully-connected layers in the dual stream structure. There are two methods of fusion: 1)fused the softmax scores using averaging, 2)SVM-based fusion of softmax scores. And have corresponding conclusions: SVM-based fusion of softmax scores outperforms fusion by averaging.

Two-stream architecture for video action recognition.
In the method of combining CNN and LSTM, the image features were first extracted using CNN, and the features extracted by CNN were sent to LSTM. For example, C. Zhu et al. [13] proposed the use of hyper-column features for facial analysis. This so-called hyper-column feature not only extracted the feature map of the last layer of the CNN as a feature of entering the LSTM, but also extracted the features of the previous CNN layer and the late CNN layer into the LSTM. In Ref. [14], the authors made CNN’s fully-connected layers features into LSTM for time-dependent semantic information extraction. Among such methods, the feature map extracted by the previous CNN is rich in spatial features but lacks semantic information. In video action recognitio, the most important thing is to extract a feature that is independent of position and rotation, but the feature information extracted by the previous CNN is not related to position and rotation. On the contrary, in the features extracted by the late CNN fully-connected layers, the semantic information is rich, but lacks spatial information.
In Ref. [15, 16], the authors proposed an LSTM-based attention model that added a mechanism to where actional classification of video frames should be addressed. In Ref. [15], the authors used a soft focus mechanism—using the back propagation training method to dynamically change the region of interest of each frame in the video. This method of training focus coefficient weights using a backpropagation algorithm is a very resource intensive task, and the classification fails if there is an error in the area of interest. In addition, Karpathy et al. [17] proposed a multi-resolution method with a fixed focus on the central portion of the video frame.
Compared with all the existing methods, the Spatial-Temporal information integration network with global expression mechanism possesses not only spatial information and motion information integration mechanism, but also video context information extraction capability.
In our work, the pre-trained convolutional neural network(CNN) is used to extract video frame spatial information, and the multi-spatialtemporal scale 3D convolution network is used to extract motion information. The features from the spatial and temporal stream CNN are fused at the pixel level and then enter the temporal pyramid sub-network for local Spatial-Temporal information extraction. Finally, the semantic information features of the video series are extracted using a bidirectional cyclic network with time series expression capability. The selection of CNN will be discussed in Section 3.1 of this paper. Section 3.2 discusses the fusion method of dual-stream CNN feature pixel level. Section 3.3 discusses the Method of video’s context information extraction. Section 3.4 introduces the Long Short Term Memory network with layer normalization function adopted by this paper; Section 3.5 gives the overall network architecture. Section 3.6 introduces the specific implementation details of the network –network hyper-parameter settings.
Convolutional Neural Network (CNN) migration learning implementation
For the training problem of limited data sets, Motivated by [18] and in order to overcome the problem of limited training, this paper uses the method of migration learning. As shown in Ref. [18], transfer learning: Ability of a system to recognize and apply knowledge and skills learned in previous domains tasks to novel domains tasks. I use pre-trained models to implement transfer learning. Step 1: Select the source model. A pre-trained source model is selected from the available models. Many research institutions have published models based on very large data sets, which can be used as candidates for source models. Step 2: Reuse the model. The selected pre-trained model can be used as a starting point for learning the model for the second task. As described below about the structure of the CNN network, here we take part of the method using pre-trained models. Step 3: Adjust the model. The model can selectively fine-tune the input-output pairs in the target dataset to make it adapt to the target task; The paper’s CNN network that has the same network layer original state as VGG-16 [18] is Model VGG-16 pre-trained with ImageNet data set. The specific model structure of the Temporal stream network for extracting motion features is shown in Fig. 2. The front 9 convolutional layers are consistent with the convolutional layers of Model VGG-16 while the back 4 convolutional layers are 3D convolutional layers (the specific realization method is shown in the Fig. 3). The representation form of the convolutional layer in Fig. 2 is conv < receptive_field_size> <number_of_channels>. Introduction of 3D convolutional layers (3DCNN) helps acquire local motion information, but increases network parameters and calculated amount. To save computing resources, this paper decomposes the 3D convolution into spatial 2D convolution and temporal 1D convolution. The corresponding convolution kernel is decomposed as follows:
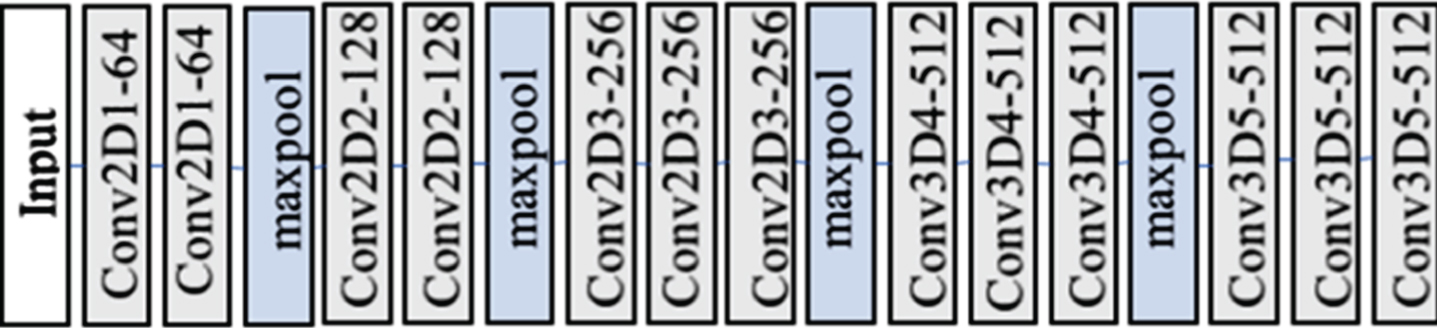
Multi Spatial–temporal scale three-dimensional convolutional neural network (MST_3DCNN).

3D convolutional layer used for acquiring motion information of multiple spatial and temporal scales.
Conv [3 × 3 ×3] represents a three-dimensional convolution with a convolution kernel tensor of the form [3 × 3 ×3], and the corresponding computational complexity is: O (n) = n3. SimilarConv [3 × 3 ×1] + Conv [1 × 1 ×3] represents a three-dimensional convolution with convolution kernel tensor forms of [3 × 3 ×1] and [1 × 1 ×3], and the calculation complexity is: O (n) = n2 + n, that is, the computational complexity is reduced by an exponential level compared to the left side of the equation. Because the [3 × 3 ×1] convolution kernel actually spans 1 in the third dimension, we consider the [3×3×1] convolution as a 2D convolution. [1 × 1 ×3] convolution only has a span of more than 1 in the third dimension, so we call it 1D convolution.
In addition, to acquire motion information of multiple spatial and temporal scales, the 3D convolutional layer of Temporal stream CNN is achieved by combining convolution kernels of different time scales and convolution kernels of different spatial scales. The specific network structure is shown in Fig. 3. In Fig. 3, the values of all time scales are respectively: t1 = 3, t2 = 3, t3 = 5.
There are two main drawbacks in the dual-stream fusion structure proposed in Ref. [12]: (i) Because fusion is only performed at the categorizable layer (FC layer), it is impossible to obtain information about the spatial and temporal characteristics at the pixel level through training. (ii) In the spatial information and Temporal information extraction operation, the spatial CNN stream only works with a limited number of video frames, and the Temporal CNN stream acts on a limited and fixed length video optical stream frame, which makes it difficult for the model to distinguish the action over time.
Spatial feature fusion method
When distinguishing actions such as brushing the teeth and combing hair, the Temporal stream CNN can recognize such motion because the hand has a periodic motion back and forth in space. The spatial stream CNN can recognize the position information of the motion (located in the teeth or hair), so the fusion of the two streams can identify whether to brush or comb the hair. For this reason, when the dual-stream network is fused, the fusion of the feature maps on each channel should be the corresponding fusion between pixels in the same position.
If the spatial stream CNN and the Temporal stream CNN have the same network structure in the dual stream structure, the fusion method of the same spatial position on the feature map is very easy to implement, for example, it can be simply covered or stacked in the same location. However, each network (spatial network CNN, Temporal network CNN) has multiple channels in the fusion layer. How to determine the channel correspondence between different networks is a key issue. We assume that different channels on the spatial network are responsible for extracting features from different regions of the space, while a channel in the Temporal network is responsible for extracting motion features from different regions. Therefore, after the channels of the dual stream network are stacked on the fusion layer, the method of fusion must enable subsequent sub-networks to learn the ability to obtain a correspondence between one channel of one network and a channel of another network, so as to better distinguish between different categories.
Based on the above considerations, we have chosen a spatial information fusion method based on convolution operations [8]. The mapping relationship of feature fusion is
First, we make the feature maps of each channel on the fusion layer of the two networks in series, that is, have the following feature mapping relationship: y
cat
= f
cat
(x
a
, x
b
), the specific stacking method is as follows:
In the above formula, f is a set of filters, and
In the dual-stream network structure, another key issue in feature fusion is the feature fusion at the given level. As shown in Fig. 4, the method of fusion has many forms. The multi-layer fusion method used in the right diagram of Fig. 4 is not only fusion in the spatially rich convolutional layer, but also in the fully connected layer with rich semantic information. This fusion method has the pixel-level fusion of spatial information and motion information, and the complexity of semantic information is further improved, which enhances the robustness of network classification. However, the main parameters of the network come from the fully-connected layers, so this fusion method greatly increases the number of network parameters. In this paper, the fusion method shown on the left side of Fig. 4 is used. This method only fuses in the convolutional layer with rich spatial information, so it does not increase the parameter amount of the network. Through post-validation, this fusion method can achieve a good action recognition accuracy rate when combined with the network design method introduced in the following chapters.

Spatial information and motion information fusion method.
Since RNN (Recurrent Neural Network) performs well in acquiring the context of sequence objects, we obtain the video context information extraction capability through the local Spatial-Temporal characteristics of RNN aggregated videos. But for processing of long sequences, introduction of multi-step RNN will lead to fold increase of the demand for computing resources. To save computing resources and increase the timeliness of recognition processing, we adopt Temporal Pyramid Net (TPN) [19] as is shown in Fig. 5 to integrate the Temporal-spatial characteristics of adjacent single frames at multiple time scales. TPN is different from time dimension attention network. The latter is for selecting key frames that make prominent contributions to video action recognitio while the former can distortionlessly acquire complete local Spatial-Temporal information apart from redcing sequence length. Assuming that the Spatial-Temporal characteristics of adjaceng single frames are

Temporal Pyramid Net(TPN).
In the 3 formulas above, Function ψ is a mean value function. After pooling of TPN, local Spatial-Temporal information is obtained:

Bi_Directional_LSTM Network(Thanks to Colah for providing the original figure [30].
The backward calculation achieving integration between future information and current information is:
Current predicted output is:
Among the Bi_Directional_LSTM used by this paper, the recurrent neutral units are all Layer normalization LSTM cells described in Section 3.4.
The “cell” structure of the traditional LSTM cycle network is shown in Fig. 7. To acquire richer Temporal information characteristics, we use Bi_Directional_LSTM network to act on the local Spatial-Temporal information of video frame acquired by TPN. And end-to-end training method is applied to Bi_Directional_LSTM sub-network combined with TPN sub-network and CNN sub-network. Therefore, the depth of the network proposed in this paper is relatively deep, and the LSTM input gate i
t
, the forgetting gate f
t
, the activation function of the output gate o
t
are all sigmoid functions. In order to ensure the convergence of the training, the LSTM cyclic network with layer normalization function is used in the network. That is, the parameters of each input sigmoid function are subjected to the following normalization process:

LN_LSTM(Layer normalization LSTM) cyclic neural network “cell” structure.
In the above four formulas, m is the number of samples used in single training, x i is the i-th sample value in a single training sample, and y i is the sample value of the input sigmoid activation function after normalization.
As described in Sections 3.1, 3.2, 3.3, and 3.4, we will present our proposed network architecture as shown in architecture as shown in Fig. 8. The spatial network and the Temporal network perform 3D convolution fusion on the last layer of convolutional layer (after ReLU output), and the fused feature are input into TPN to shorten the time sequences of time dimension information and obtain complete local Spatial-Temporal information of multiple time scales. Finally, the bi_directional Long Short-Term Memory (Bi_Directional_LSTM) is used to extract the context information of the sequence local features output by the TPN network, thereby obtaining the contexts information of the video. The last layer of the network is soft-max classification layer. In order to classify the video sequences, T frames are acquired in each video and enter the spatial network. The sampling time of the video frames shown in Fig. 8 is t, t + τ, t + 2τ … , t + Tτ (t is the first frame acquisition time point, τ is the acquisition interval time, T is the total number of acquisition frames), respectively. In addition, the input information of the network is centered on the information collection time of the spatial network, and the Temporal characteristics are collected in the range of the center point time L/2 (L is the number of video frames). That is, the collected optical flow frame is collected centering on the captured video image frame. For example, if L = 4, a total of the optical image of the T × 4 (L) frame is collected into the Temporal network. In addition, if τ ⩾ L, the collection of optical flow frames will overlap.

Spatial-Temporal information deep fusion network with video context information Expression mechanism.
The spatial convolutional neural network we use is VGG-16 network models. The VCC-16 model consists of 13 layers of convolutional layers and 3 layers of fully-connected layers. In the network structure of Fig. 8, the initial state of each convolutional layer of the spatial network is the pre-trained VGG-16 model of the ImageNet data set. The input of the spatial network is the video frame image. If we select the training data set and the video with the smallest number of video frames with T frames, we set the number of sampling frames per video as T. Temporal convolutional neural network is a variant of VGG-16. The back 4 convolution layers are cross use of MST_3DCNN and 3DCNN. The parameters of the 4 convolutional neural networks are initialized at random. MST_3DCNN extracts motion information at multiple Spatial–temporal scales while 3DCNN achieves extraction of richer motion information and dimensionality reduction of the features output by MST_3DCNN at the last layer. The tensor pattern for the output and input of MST_3DCNN is d × h × w × c (d for Temporal depth, this paper takes 24. In the data set, the frames of different videos are different, the smallest is 22 frames. If the number of video frames is less than 24 frames, the last frame of the video is read repeatedly; h for height of feature map; w for width of feature map; c for number of channels). In this paper, the specific input tensor of MST_3DCNN is d × h × w × 512, and the output tensor is d × h × w × 1536. The specific input tensor of 3DCNN is d × h × w × 1536, and the output tensor is d × h × w × 512. The initial input of the Temporal convolutional neural network is a multi-frame stack of video optical flow images. The number of stacked frames we use is L = 4. Before training, we will process the optical flow image of the video in advance, which can further shorten the training time. Because the number of channels in the first layer of the Temporal convolutional network is equal to the number of stacked optical images, the initialization of the first convolutional layer of the Temporal stream network is random initialization and the initial state of other convolutional layers is consistent with the initialization process of the spatial stream convolutional neural network, which is pre-trained VGG-16 model for the ImageNet dataset. The size of the video frame image and the optical stream image of the input network are both 224×224.
As with the fusion structure described in Section 3.2 of this paper, the dimensionality of the 3D convolution kernel f used in Spatial-Temporal information fusion is 3 × 3 ×3 × 1024 × 512, where the dimension of the Spatial–temporal filter is H″ × W″ × T″ = 3 ×3 × 3. D = 1024 is the number of channels after the feature map is stacked in the last convolutional layer (after the ReLU output) of the spatial convolutional neural network and the Temporal convolutional neural network. D′ = 512 is equal to the number of input channels of the next layer network (TPN). In the Bi_LSTM network used by this paper, the hidden states of the LN_LSTM unit networks all have a number of dimensions of 101. In Fig. 8, the tensor patterns in TPN sub-networks are respectively 8 × 7 ×7 × 512. TPN output is one-dimensional characteristic vector, and the number of dimensions is 1756167 * 7 *7 * 512.
The computer used for network training is configured with two E5-2620 V4 processors and one NVIDIA GTX1080TI GPU. The computer system is a 64-bit UBUNTU system, and the software development environment is tensorflow. This paper simultaneously trains spatial network, temporal network, temporal pyramid network as well as Bi_Directional_LSTM. In the training, the dropout ratios for the connection between TPN and Bi_Directional_LSTM are 0.5. the dropout ratios for the output of LN_LSTM in Bi_Directional_LSTM are 0.25. The learning rate of the first training in network learning is 10-5. When the network training converges and reaches a fixed classification accuracy rate, the training will stop. The second training uses the result of the first training as the initial state, which is the same as the subsequent training, and from the second training session, the initial learning rate is further reduced to 10-6. According to the above method, it takes 3 days to train the network model for the first time to stabilize the network parameters. The second training takes only 1 day to stabilize the network parameters. As mentioned above, the initial state of the second training is the result of the first training, and the learning rate of the second training is an order of magnitude lower than the first training, so the second training time is reduced. That is, the second training converges faster.
In order to strengthen the network generalization ability, the following random image frame acquisition process is added. That is, in the selected T frame image, in the case where the T frame can be acquired, the initial acquisition frame is randomly generated, and the acquisition interval τ is randomly sampled in the range of [2, 10].
Experiment
We use three public data sets to train and validate our network: UCF101 [20], UCF11 (YouTube action dataset), and UCFSports [21]. The above three data sets are very challenging for the recognition task of video content because the lighting conditions of each video are inconsistent. Moreover, in some video imaging processes, the camera does not move continuously, while in some video imaging, the camera does not move, and the background complexity of each video is different.
Datasets
(1) UCF101, UCF101 video dataset has 13320 videos, including 101 categories. (2) UCF11, UCF11 video dataset has 1600 videos, including 11 video categories: Ball-shooting, cycling, diving, golf swings, horseback riding, football kicking, swinging, tapping tennis, trampoline, volleyball smashing, and dog walks. (3) UCFSports, UCFSports video dataset with 150 videos, including 10 different video categories: Diving, golf swing, kicking, weightlifting, horseback riding, running, skateboarding, swing bench, swing side, and walking. The video with the smallest number of frames in the data set has 22 frames.
Experimental procedure
Among the videos of each data set, the video of the minimum number of frames has an inconsistent number of video frames. For each data set, the minimum number of video frames T is selected as the number of frames of each video sample. Assuming that N is the total number of frames of a video sequence, the acquisition interval t is:
In this paper, the total video frames T sampled by the three data sets are all 24 frames. The experiment uses a cross-validation method(in each traning epoch), that is, each training data set is randomly divided into a training set and a verification set. The training set is used to train the network model, and the verification set is used for the training correctness rate test verification after training. The ratio of the training set and the verification set is 7 : 3.
Figure 9 is a graph showing the relationship between the ‘epoch loss function’(The ‘epoch loss function’ here is not a loss function used to optimize the network, but an average value of the batch loss function. That is, in the figure:

The relationship between the loss function and thenumber of training obtained by performing training verification on the UCF101 video data set.
Comparison of our results to the state-of-the-arts on action recognition datasets UCF101
The UCF101 datasets are classified using existing methods, and the experimental results of each method are shown in Table 1.
The LRCN [22] method caused the first fully-connected layers and the second fully-connected layers of the convolutional neural network to be sent to the LSTM for Temporal information extraction, which lacked time change information extraction of spatial in formation. Dense Trajectories [23] was a traditional dense trajectory method. The Composite LSTM Model [24] method used the video sequence frame as a sequence information with context semantics and used LSTM to implement sequence-to-sequence mapping for video characterization. This method does not use volume and neural network (CNN) to extract spatial information. Soft attention [15] had a frame attention mechanism, but it lacks the spatial information fusion between the motion information and the spatial information pixel level, and lacks the effective expression ability of the overall spatial information, thus leading to errors in the classification of ball-shooting, juggle, and spiking. C3D [25] and Two-Stream ConvNet [12] have the disadvantage of limited time dimension information. The Snippets method [26] implemented CNN to extract spatial features as a keyframe extraction tool and used the following SVM to classify keyframes. Such methods lack complete time dimension information.
Figures 10 and 11 are graphs showing the relationship between the ‘epoch loss function’ (The ‘epoch loss function’ here is not a loss function used to optimize the network, but an average value of the batch loss function. That is, in the figure:
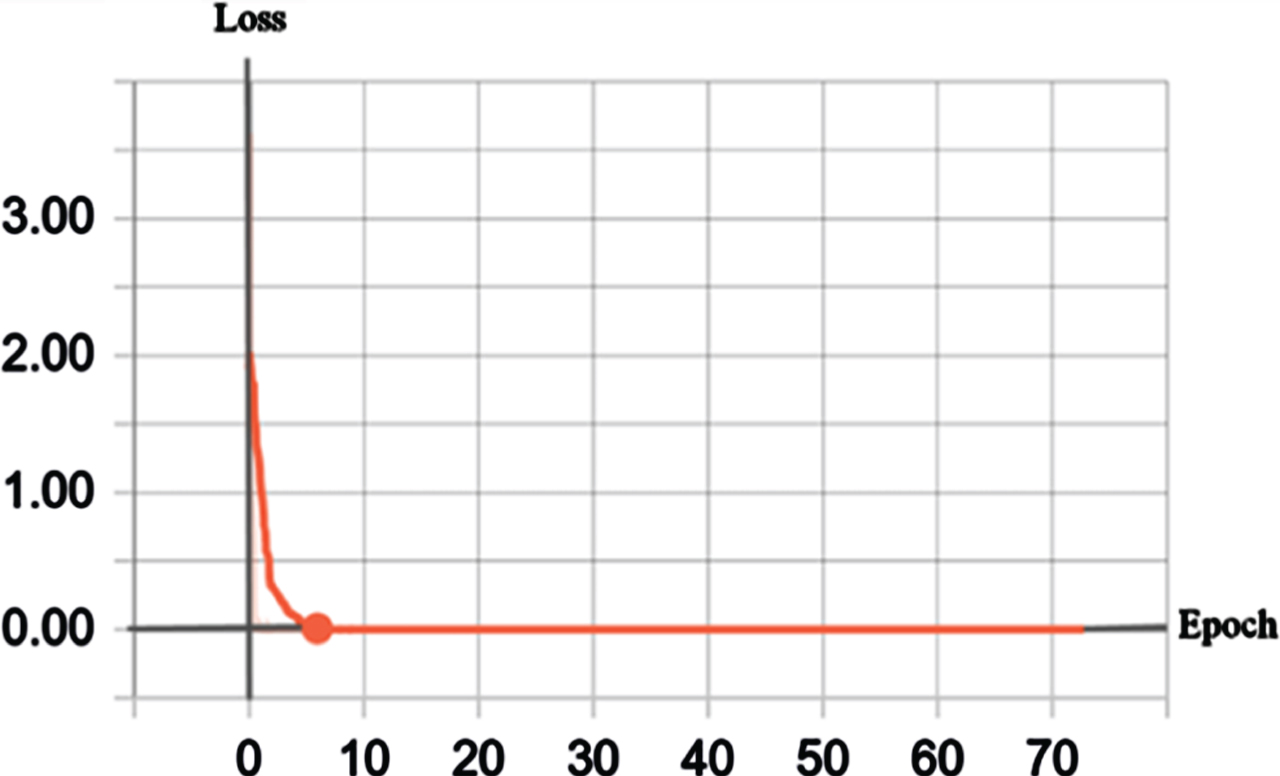
The relationship between the loss function and the number of training obtained by performing training verification on the UCF11 video data set.
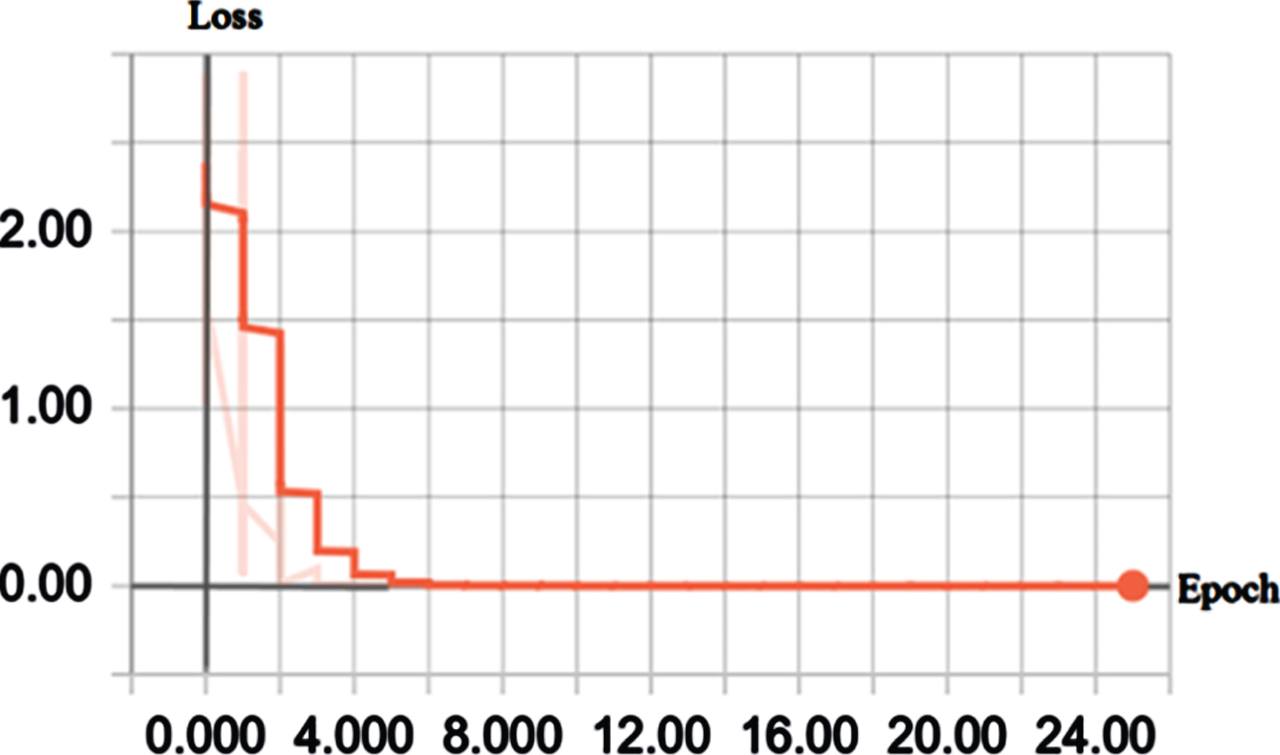
The relationship between the loss function and the number of training obtained by performing training verification on the UCF_SPORT video data set.
The UCF11 and UCF Sport dataset datasets are classified using existing methods, and the experimental results of each method are shown in Table 2, in the case of limited training samples and verification sets, the correct rate is 98%, which makes it possible to judge that our network has a good generalization ability.
Comparison of our results to the state-of-the-arts on action recognition datasets UCF11 and UCF Sport
Cho et al. [27] used traditional multi-core sparse representation to express video local motion features and global motion features. This method requires learning the dictionary to express local motion features and is limited by the dictionary’s expressive ability. Weinzaepfel et al. [28] first used spatial CNN and Temporal CNN to obtain multi-target candidate regions of frame images, racked regions with higher classification scores, and then evaluated the scores. Finally, the action was timed and classified using the form of a sliding window on the time dimension. Such methods lack the effective integration of spatial information and Temporal information, so the classification results are improved with the relative traditional methods, but there are still many areas for improvement. SGSH [29] first detected the video frame containing the target and the target in the corresponding frame image, extracted the frame containing the target, and described the global characteristics of the video sequence with HOOF features. Meanwhile, the frame image target area was extracted, and the 3D-SIFT feature was used to describe the local target feature. Finally, the HOOF and 3D-SIFT features entered the multi-class SVM for class classification. This method is the best performing method in traditional non-deep learning methods because of the fusion of local features and global features. However, it is well known that no matter what kind of artificially designed video global features and local features, it is impossible to contain more effective information than the neural network itself obtained through learning.
As mentioned in Tables 1 and 2 above, Compared with the previous method, our proposed 3D conv-TPN-Bi_Directional_LSTM network has better performance, which proves that the network we designed has improved various drawbacks of the existing methods. For example, Soft attention [15] lacks the fusion of motion information and spatial information pixel level, and lacks the effective expression ability of the overall Spatial-Temporal information, thus leading to errors in the classification of ball-shooting, juggle, and spiking. After the different initialization methods are trained, the verification accuracy rate for UCF11 is 98%, so there is no problem with the above Soft attention method.
When the UCF11 data set is used for network training, the first training is based on the VGG-16 model pre-trained by the ImageNet data set to initialize the network part layer. The trained network performs multiple classification verifications on the UCF11 dataset. The classification results are shown in Table 3.
The correct rate of classification of various types of video in the UCF11 data set (initialization of the network part layer by the VGG-16 model parameters pre-trained by the ImageNet data set)
As shown in Table 3, the shooting class will be partially misidentified as juggle class or spiking. This is because, as shown in Fig. 12:

Classification of shooting videos that are prone to errors.
In the shooting video, there is a lack of shooting background information for some video content (basketball court and basketball), and it is similar to the juggle class or spiking frame content. In the first training, because the network with random initialization occupies a certain ratio, the network parameters fall into the local optimal solution, which leads to a higher recognition error probability of the shooting class recognition accuracy rate. If the second training initializes the network with the parameters obtained by the first training, the final implementation is as shown in Fig. 10 and Table 2: A near-zero ‘epoch loss function’ and a near 100% (97.7%) correct recognition rate on the UCF11 dataset. This indicates that initializing the network with the parameters obtained from the previous training can make the training of the network closer to the global optimal solution. Combining the characteristics of the above methods and comparing the action recognition network architecture proposed by our analysis, we can conclude that the network architecture designed in this paper can achieve the fusion of Spatial-Temporal information and the ability to express global features and local features. The experimental results also demonstrate the effectiveness of our method.
Disadvantages of our method: when the video action recognitio is performed on the computer used in the network training, the specific prediction speed is slower –one video takes 800ms. In addition, when we train and verify the effectiveness of the neural network, the data sets used are all human sports data sets, and finally prove that the network we designed is a good classification effect for such data sets. However, there is no relevant experimental verification for the data sets of human daily life like children crossing the road, supermarket robbery, group riots, etc. Therefore, whether the network we design is suitable for human daily behavior classification needs further experimental verification. In addition, the accuracy rate we give is that when the network acts on the test data set, a certain category is classified more than 1,000 times, and the classification results are calculated (as shown in Table 3). Because in Figs. 9–11,
We put forward a network applied in video action recognitio: The method of transfer learning is adopted. Under the situation where training samples are limited, pre-trained CNN network is used to fully acquire the spatial information of video frames and the corresponding local motion information. Meanwhile, we deeply integrate the spatial information and motion information of a certain moment so as to obtain pixel-level Spatial-Temporal information. Later, TPN is used to acquire the local Spatial-Temporal information at multiple time-space scales. Finally, Bi_RNN is used to correlate the local Spatial-Temporal information to achieve the video context information. Through experimental comparison with three action recognition data set(UCF101/UCF11/UCF Sport), our method is proved to have enhanced recognition accuracy, which evidences the effectiveness of the three mechanisms in the network architecture put forward by us: (1) integration between single-frame spatial information and motion information; (2) TPN acquires local Spatial-Temporal information; (3) the fore and after local Spatial-Temporal information is correlated to realize the video context information extraction.
Footnotes
Acknowledgments
Thanks to Professor Lianwen Jin from the School of Electronics and Information, South China University of Technology for his guidance and support for research funding.