
Abstract
During the long-term operation of the photovoltaic (PV) system, occlusion will reduce the solar radiation energy received by the PV module, as well as the photoelectric conversion efficiency and economy. However, the occlusion detection of the PV power station has the defects of low efficiency, poor accuracy, and untimely detection, which will cause unknown system losses. Based on the deep learning algorithm, this paper conducts research on PV module occlusion detection. In order to accurately obtain the occlusion area and position information of the PV panel, a PV module occlusion detection model based on the Segment-You Only Look Once (Seg-YOLO) algorithm is established. Based on the YOLOv5 algorithm, the loss function is modified, the Segment Head detection module is introduced, and the convolutional block attention module (CBAM) attention mechanism is added to achieve the accurate detection of small targets by the algorithm model and the fast detection of the PV module occlusion area identify. The model performance research is carried out on three types of occlusion datasets: leaf, bird dropping, and shadow. According to the experimental results, the proposed model has better recognition accuracy and speed than SSD, Faster-Rcnn, YOLOv4, and U-Net. The precision rate, recall rate, and recognition speed can reach 90.52%, 92.41%, and 92.3 FPS, respectively. This model can lay a theoretical foundation for the intelligent operation and maintenance of PV systems.
Introduction
Energy is the foundation and driving source for the economic and social development. With the growing global awareness of environmental protection, green energy has gradually become a form of energy pursued by people. Compared to conventional fossil energy, it is infinitely renewable and effective in reducing the impacts of environmental pollution and climate change. As a kind of safe, clean and pollution-free energy with large reserves, solar energy has broad development prospects. Photovoltaic (PV) power generation, owing to its inherent diversity and flexibility, has emerged as a highly effective method for harnessing solar energy [1].
Partial or total shading of PV modules affects the efficiency of PV power systems, resulting in loss of generated power and economic benefits [2, 3]. After shading of a PV module, the product of local module current and voltage may increase, causing local temperature rise of the module to form the hot spot effect [4]. If the shadow exists for a long time and the hot spot effect reaches a certain degree, it may lead to the damage of PV module, which not only seriously affects the module service life, but also seriously affects the power generation of PV system to reduce its power generation income [5]. Research has shown that shading affects the effective solar radiation intensity and temperature of PV cells, as well as the light transmittance performance of their surface protective glass [6]. An experimental study by Hishikawa et al. [7] demonstrated that a maximum power loss of 2% would be caused when the PV module was shaded by bird droppings. Belhaouas et al. [8] found that the influence of partial masking effect was not limited to reducing the power output of PV generators. Meanwhile, multiple peaks appeared on the PV characteristic curve, which though might be the primary cause of hot spot phenomenon. In a series of comparative experiments, Enaganti et al. [9] observed that the surface transmittance of solar photovoltaic (PV) panels decreased by approximately 48.7% to 13.14% after being exposed to shading conditions for a duration of 17 days. Local shadow shading leads to the reverse bias of shaded solar cell. At this time, the solar cell becomes an energy loading and consuming other solar cells, thereby reducing the output power of PV module, and even resulting in hot spots [10, 11]. Akram et al. [12] employed two deep learning frameworks, an isolated deep learning algorithm and a transfer learning algorithm, for realizing automated detection of defects in photovoltaic panels within infrared images. Ali et al. [13] proposed the use of machine learning algorithm SVM for classifying the obtained PV panel thermograms into three categories: healthy, non-fault and fault hot spots. By comparing various machine learning algorithms and datasets, the superiority of the proposed model and hybrid feature dataset was verified. Premkumar et al. [14] analyzed and evaluated interconnected PV modules under various conditions and modes of shading. The partial shading conditions attributable to various factors reduced the power output of PV array, whose characteristics displayed multiple peaks due to the mismatched losses between PV panels. PV shading has a serious impact on the generated power, and long-term shading causes formation of hot spots on the PV panel, eventually leading to the PV module breakdown. However, due to the complex background at the PV module location, directly finding the shading location is difficult. Thus, shading is a challenging problem for the PV modules.
Currently, methods for shading recognition have low accuracy and speed, which can hardly identify small shading targets [15], and thus become a major problem in the research of PV shading recognition. Hence, this study constructs a simple and effective network, with a view to providing a tool for intelligent operation and maintenance. Deep learning has gained broad scholarly attention in recent years, which can be applied to the scenario of PV module surface shading to detect the shading statuses of various parts on the PV surface. Cavieres et al. [16] proposed an artificial neural network tool, which independently predicted the performance of each module using the visible spectrum RGB images and environmental data of multiple solar panels, thereby estimating the shading status of PV panel surface. Basne et al. [17] put forward a PNN-based intelligent fault detection model for PV arrays, which achieved accurate classification of fault types. In case the fault state was hardly distinguishable from the normal state, their method could predict the result accurately. Li et al. [18] systematically explored the application of artificial neural network and hybrid artificial neural network model into the PV fault detection and diagnosis. Demirci et al. [19] proposed a novel framework for automatic detection and classification of solar cell defects, where the image features extracted by deep neural network were classified by such machine learning methods as SVM, decision tree, random forest and naive Bayes. Li et al. [20] proposed a double-iterative algorithm, which could extract the ODM feature parameters of PV modules accurately and intuitively. Through careful modeling of PV module I-V characteristics, the PV array prediction was achievable, where the simulation curve and estimated parameters could serve as appropriate references for monitoring and diagnosing the PV module status under actual operating conditions. A monitoring system was developed by Lazzaretti et al. [21] to measure electrical and environmental variables, so that instantaneous and historical data could be generated for estimating the parameters related to power plant efficiency. While using the monitoring system, they proposed a recursive linear model to detect faults in the system, where the irradiance and temperature on PV panel were simultaneously used as input signals and the power was used as output. How to detect the type and location of shaded pollutants has become the current research focus. Detection of PV module shading pollutants is a standard problem of small target detection in deep learning. Plenty of target detection networks for small targets have been proposed by prior researchers. Although target detection models have attained satisfactory results in various tasks, it remains a challenge for detection of small targets. Generally, long-distance targets share the characteristics of small targets like fewer pixels and unclear features, whose detection efficiency and accuracy are thus lower compared to large targets.
Conclusively, a Seg-YOLO algorithm is proposed in this study. On the basis of YOLOv5 algorithm, it improves the accuracy of small target detection by modifying the loss function, introducing the Segment Head detection module and increasing the CBAM attention mechanism, thereby achieving fast recognition of PV module shading areas. The algorithm model performance is explored on 3 shading datasets: leaves, bird droppings and shadows. Finally, the Seg-YOLO algorithm is compared with conventional target recognition algorithm to obtain its detection performance indicators like accuracy rate, recall rate and recognition speed. It effectively addresses the untimely detection and inaccurate localization of PV panel foreign body shading, as well as the difficulty of shading area detection. Besides, it also effectively improves the generation efficiency of PV plants, and more economically and intelligently arranges the cleaning plan, thereby achieving the economic, safe and stable operation of the PV plants.
Model
Seg-YOLO
The network structure of Seg-YOLO consists of four modules, including input module, backbone module, head module and prediction module. Before the image enters the network, the input module needs to scale it to the size required by the network, as well as pre-processing such as normalization and channel sorting. This paper takes a 640*640 size picture as an example. After the image is processed, it will be input to the Backbone network for feature extraction. After operations such as convolutional layers and pooling layers, a series of feature maps of different sizes are obtained. In contrast, low-level feature maps pay more attention to image texture and edge information, while high-level feature maps pay more attention to image semantic information. In order to obtain more comprehensive language information and more diverse feature information, the Neck network fuses the feature maps of different levels generated by the backbone network. This feature fusion method helps the algorithm better understand and identify objects in the image. After feature fusion, each grid cell is regarded as a candidate object frame. Then, each object frame is subjected to object prediction. The Seg-YOLO structure is shown in Fig. 1.
Seg-YOLO algorithm structure diagram.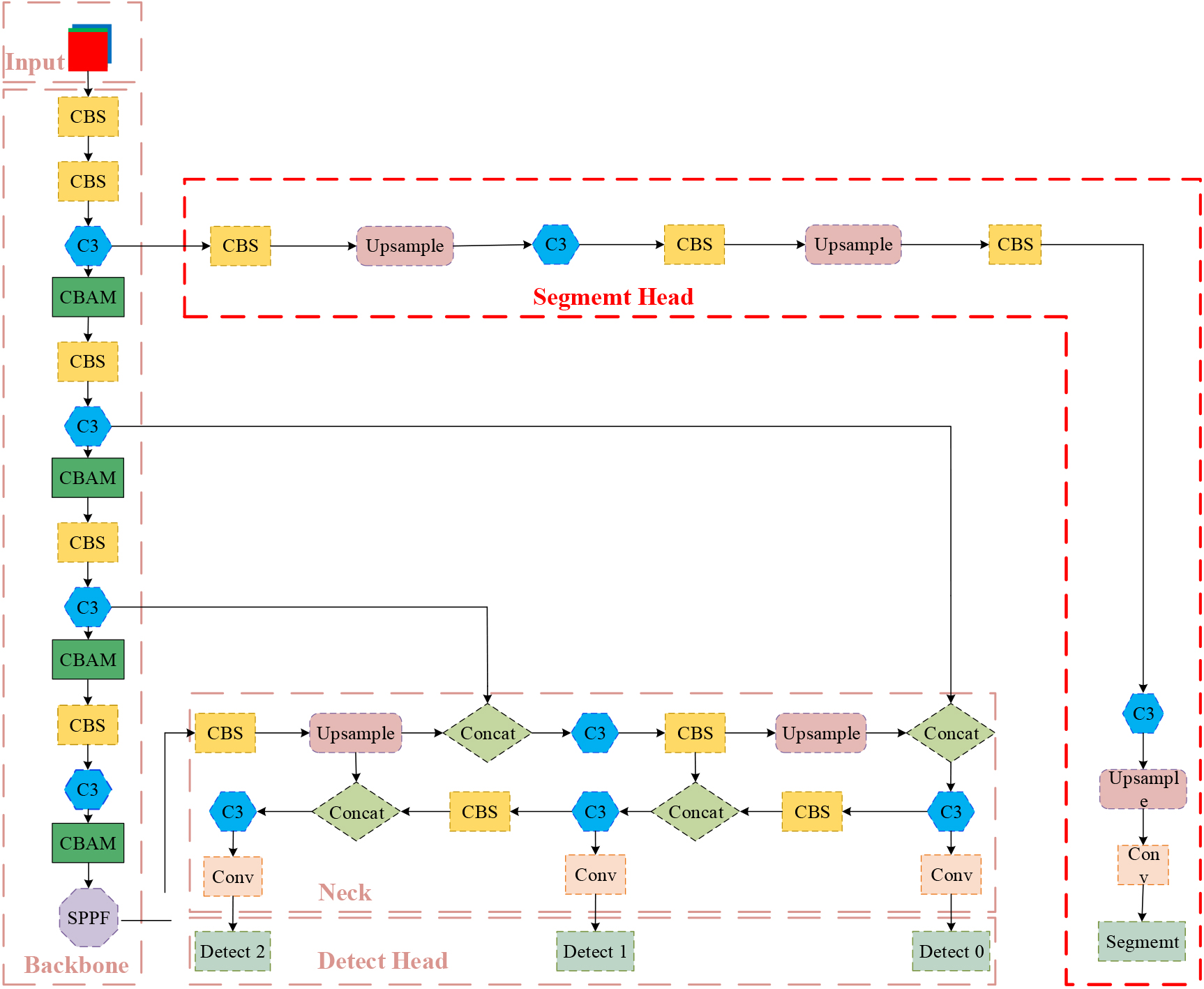
In order to improve the detection precision of the self-built PV module abnormal occlusion dataset, the identification accuracy of the occlusion area, the detection performance of small targets, and reduce the omission rate, the EIOU loss function is adopted. The Segment Head detection layer is added to perform semantic segmentation and identify the occlusion area of the PV module. By referring to the CBAM attention mechanism, the inference time of the algorithm is shortened.
The loss function is a vital part of the training model, which can measure the accuracy of the model’s prediction of the result and judge the gap between the model and the actual data. Therefore, it is necessary to choose an appropriate loss function, which is crucial to obtain a better model and speed up the convergence of the training process. This paper uses the EIOU loss function.
EIOU loss function not only introduces the concept of area intersection, but also considers the influence of length-width ratio on error. EIOU introduces the concept of area intersection on the basis of GIOU to quantify the intersection of prediction frame and realistic frame, which can more accurately measure the degree of overlap between the two. EIOU loss function can more accurately handle the inclusion relationship between the prediction frame and the realistic frame, and avoid the problem that the GIOU loss function cannot determine the positional relationship. Considering the impact of the length-width ratio of the prediction frame and the realistic frame on the error, EIOU loss function increases the fairness of the target detection results by adjusting the length-width ratio factor. EIOU loss function is simpler in mathematical form, which reduces the complexity of model training and improves the stability and robustness of the model. EIOU loss function can improve the detection accuracy, recall rate, and target detection stability of small targets to a certain extent. The primary advantage of the EIOU loss is its ability to encourage more precise bounding box predictions, which can reduce localization errors and improve the overall stability of object detection models. By considering both the intersection and the union of the predicted and ground truth bounding boxes, the EIOU loss provides a more robust optimization objective.
In order to increase the detection ability of YOLO, semantic segmentation detection is introduced into the YOLOv5 algorithm, as shown in Fig. 2. The segment detection layer can separate the recognized objects from the background. The function of the segment head detection layer is to segment the image and separate the target in the image from the background. This method can locate the target more accurately while avoiding the influence of the background on the target. The bottom layer of the FPN is fed into the segmentation branch with size (w/8, H/8, 256). Splitting branches is very simple. After three upsampling processes, the output feature map is restored to a size of (W, H, 2), which represents the probability of each pixel in the input image in the target detection object and the background. Due to the shared SPPF in the neck network, an extra SPP module is not added to split the branches as usual. Moreover, the upsampling layer uses nearest interpolation to reduce computational cost instead of deconvolution. Therefore, the segmented encoder of this algorithm has high-precision output and fast inference. The main advantage of the segment head detection layer is to improve the detection precision and robustness of the YOLO model.
Segment head branch.
The attention mechanism is widely used in image recognition, natural language processing and other tasks in the field of machine learning, which can improve algorithm performance and accuracy. CBAM attention mechanism module improves the expressiveness and accuracy of the model by adaptively learning the importance of each channel and weighting the spatial information. The structure of CBAM attention mechanism module is shown in Fig. 3.
CBAM module structure diagram.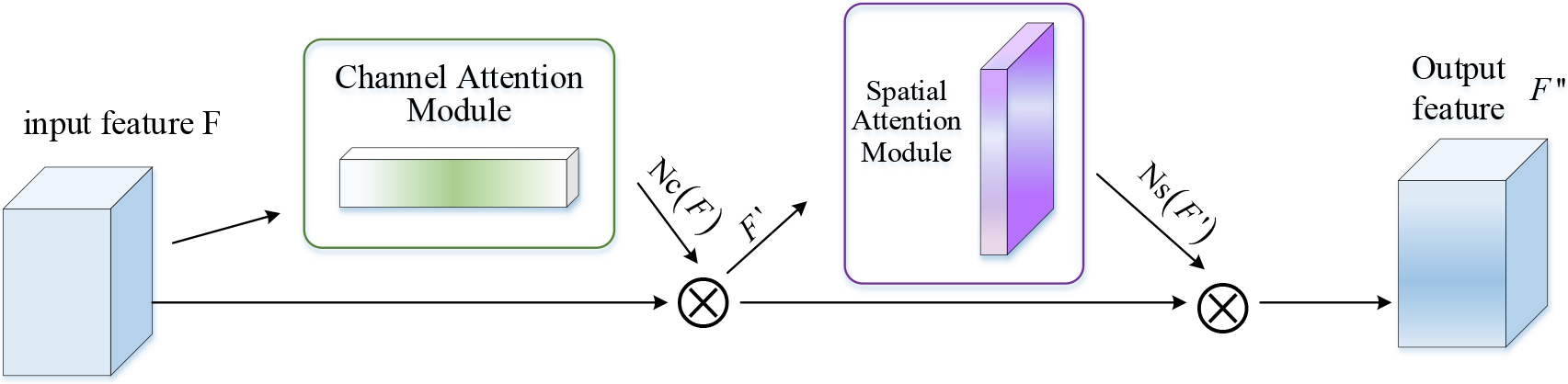
Compared with the traditional convolutional network, the addition of the CBAM module is conducive to better focusing on important features in the image, reducing the interference of redundant information, and improving the generalization ability of the model. The CBAM module is applicable to different levels of the model, which can improve the overall performance of the model. The computational load of this module is relatively small, which does not significantly increase the computational complexity of the model. The application of the CBAM module in the PV module occlusion target detection task can effectively enhance the detection precision of small targets, reduce the risk of missed detection and false detection, and improve the practicability and reliability of the algorithm. The attention mechanism can enhance the representational power of the network and highlight the characteristics of objects that need to be recognized. Channel attention module and space attention module have their own advantages and limitations. The channel attention module can accurately evaluate the importance of each channel, but cannot capture the information inside each channel. The channel attention module is shown in Fig. 4. The space attention module can capture the information of each spatial location, but cannot distinguish the importance of different channels. The space attention module is shown in Fig. 5.
Channel attention module.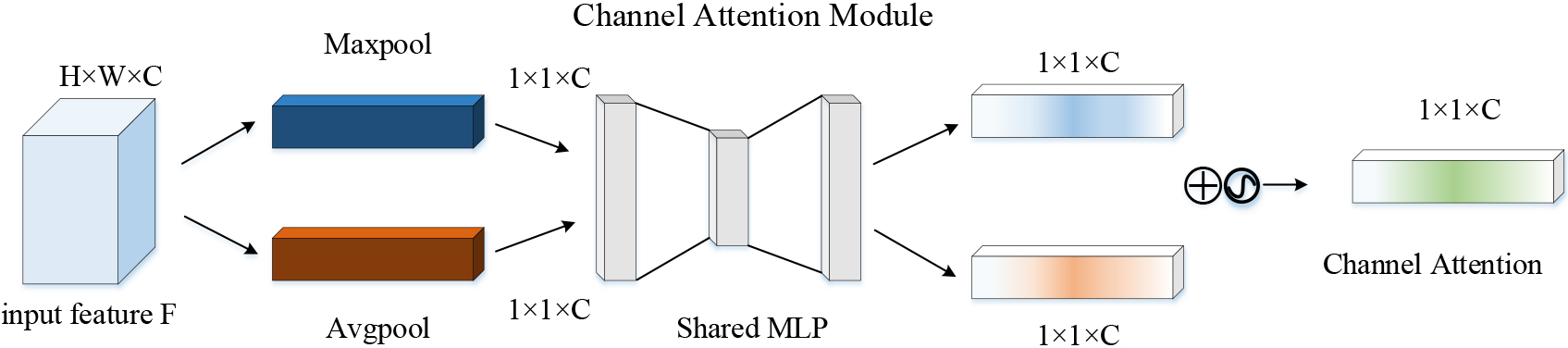
Space attention module.
The space attention module can capture the information of each spatial location, but cannot distinguish the importance of different channels. The space attention module is shown in Fig. 5.
Therefore, the combination of the two attention mechanisms can give full play to their respective advantages and improve the performance of the model. By fusing the feature maps recalibrated by the attention mechanism, richer and more accurate feature representations can be generated. In SAM, the feature map is input from the input, and then two results are obtained after maximum pooling and average pooling. Dimensions changed from H
Common occlusions in PV panel
The occlusions on the surface of the PV module will cause faults and abnormalities [22]. For common PV occlusions, bird dropping, leaf and shadow are selected as the target detection and recognition objects of PV module occlusion. Table 1 shows the visible light images of occlusion pollutants, the causes of occlusion, and the hazards of occlusion. It should be noted that the selected ones are common abnormal occlusions in the PV module, with a certain representativeness.
Occlusion characteristics
Occlusion characteristics
Bird dropping is the main type of abnormal occlusion in large PV power stations. Since bird dropping is difficult to prepare in the laboratory, the bird dropping occlusion dataset in this project uses PV array pictures taken by drone from a PV power station in Jilin Province. The on-site pictures and aerial pictures taken by drone are shown in Fig. 6.
Existing public datasets lack pictures of PV power station sites. A dataset augmentation approach is adopted. This dataset contains image data of PV power station abnormal occlusion. After the dataset expansion program, and subsequent labeling according to their respective labels, the labeled dataset consists of numbers such as 1180, 720, and 500 for labels like leaf occlusion, bird dropping occlusion, and shadow occlusion. This dataset exhibits a degree of randomness. The dimensions of the dataset images are unified to 640
Datasets and number of labels
Datasets and number of labels
The bird dropping occlusion diagram of the PV power station on-site drone aerial photography.
The software and hardware tools and hyper parameter settings involved in the model training and testing experiments of this project are shown below. The Windows 10 operating system is adopted. The operating environment includes Intel(R) Xeon(R) CPU E5-2620 v4, NVIDIA 3070 Ti GPU, 16 GB memory capacity, and CUDA10.2 library files. The development language is Python, and the deep learning framework is PyTorch. During the experiment, the input image size is set to 640
Hyperparameter setting
Hyperparameter setting
In order to verify the accuracy of the model, precision rate, precision rate and mean accuracy value are used as evaluation criteria to verify its performance.
TP (True Positive) is the target that is accurately predicted as the true category. FP (False Positive) is the object that is incorrectly predicted as the true category. FN (False Negative) is the object that is incorrectly predicted as the non-true category. TN (True Negative) is the object that is accurately predicted as the non-real category.
mAP is to use P as the ordinate and R as the abscissa to obtain the P-R curve. The area enclosed by the P-R curve and the coordinate axis is the value of AP. The calculation method of AP is shown in Eq. (1). mAP represents the average AP of all classes in the entire dataset. The calculation method of mAP is shown in Eq. (2). Typically, the threshold is set to 0.5. The prediction frame with IoU greater than 0.5 is valid, which is represented by mAP@0.5. mAP@0.5:0.95 means that the IoU is taken from 0.5 to 0.95, and the mAP value is calculated every 0.05, and finally the average value of all mAPs is calculated.
Recognition performance
The training results using the Seg-YOLO network structure proposed in this paper under the self-made PV shading dataset are shown in Fig. 7. Precision measures how many of the model’s predictions are correct, while recall measures how many true positives the model is able to detect. The box loss typically represents the position and size of the target object in an image. YOLO uses the objectness score to filter out bounding boxes that contain the target object, thereby improving detection accuracy. YOLO is commonly used for multi-class object detection, so the prediction results for each bounding box also include a class label representing the category of the target. The target loss, classification loss, and detection frame loss tend to stabilize around 200 rounds. The precision rate and recall rate tend to be stable around round 50 and finally greater than 0.8. The recognition accuracy of leaf, shadow and bird dropping three kinds of occlusions reached 91.29, 95.67 and 89.43 respectively. In addition, the detection speed reaches 92.3 FPS.
Comparison performance results of five algorithms
Comparison performance results of five algorithms
The training results of Seg-YOLO.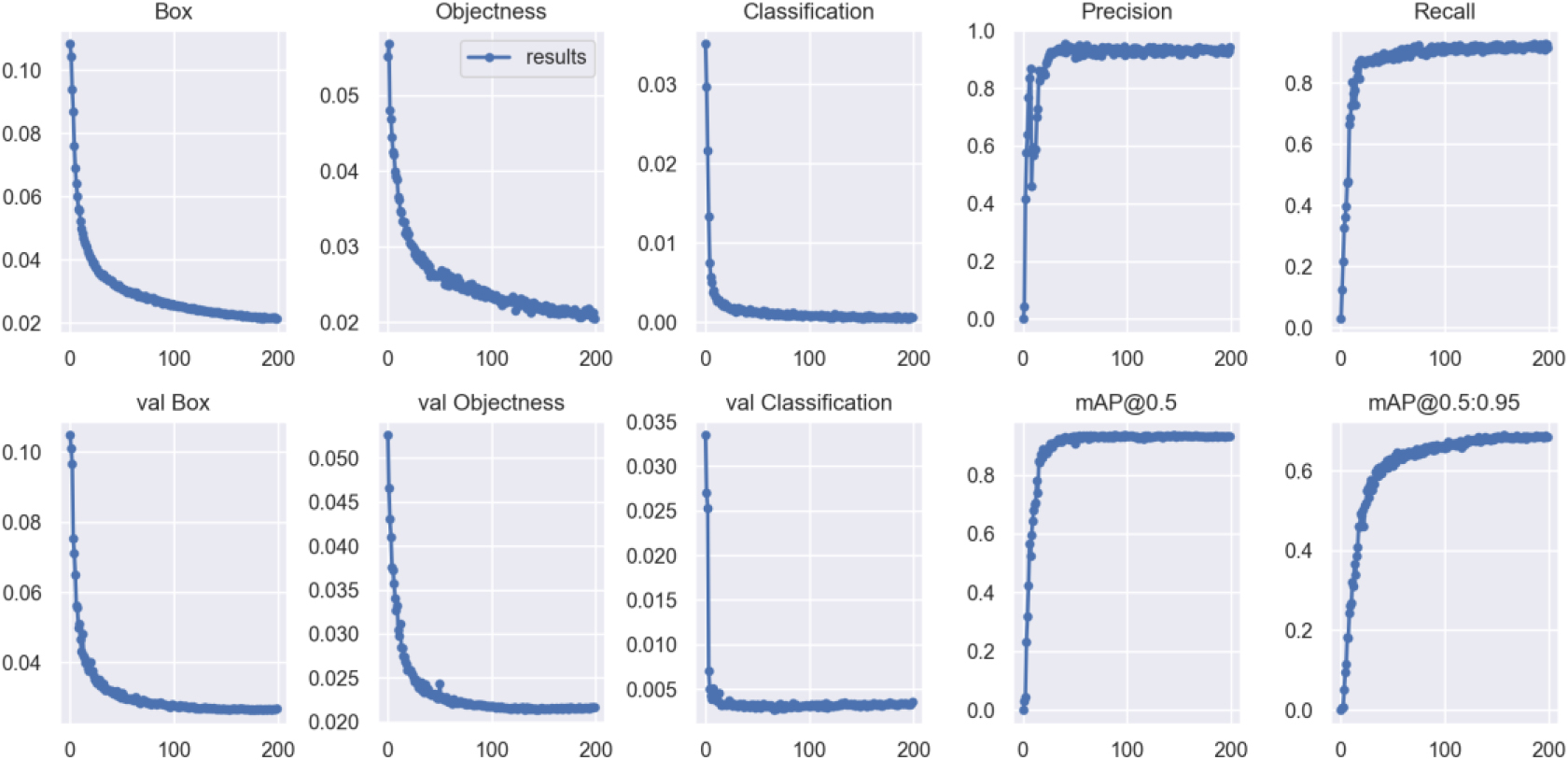
In order to further verify the superiority of the improved algorithm in this paper, the current mainstream algorithm is compared with the proposed algorithm, including the selection of SSD, and the Faster-Rcnn, YOLOv4, and U-Net algorithms of the same series as YOLO. The above algorithms are trained on the same PV module occlusion dataset. The results of data set image processing and analysis are shown in Table 4.
In order to verify the effect of the improved loss function and the increased attention mechanism on the original YOLOv5, four sets of experiments were set up. Among them, Experiment 1 uses the original YOLOv5 algorithm. On the basis of Experiment 1, Experiment 2 changes the GIOU loss function of the original YOLOv5 to EIOU loss function. Experiment 3 increases the CBAM attention mechanism on the basis of Experiment 2. Experiment 4 adds a Segment Head detection layer based on Experiment 3, which is the Seg-YOLO detection algorithm.
Comparison of mAP before and after algorithm improvement.
According to the results of Experiment 2, when the loss function was changed from GIOU to EIOU, the mAP increases by 5.65%, the accuracy improvement effect is not obvious, and the recall rate is improved. Experiment 3 introduces the CBAM attention mechanism, which has significantly improved the algorithm, because the introduction of CBAM has greatly improved the effect of small target detection. Experiment 4, which combines the three methods, improves both precision rate and recall rate. Therefore, it can be concluded that the three improved methods are better than the unimproved previous ones.
Comparison of precision rate and recall rate before and after algorithm improvement.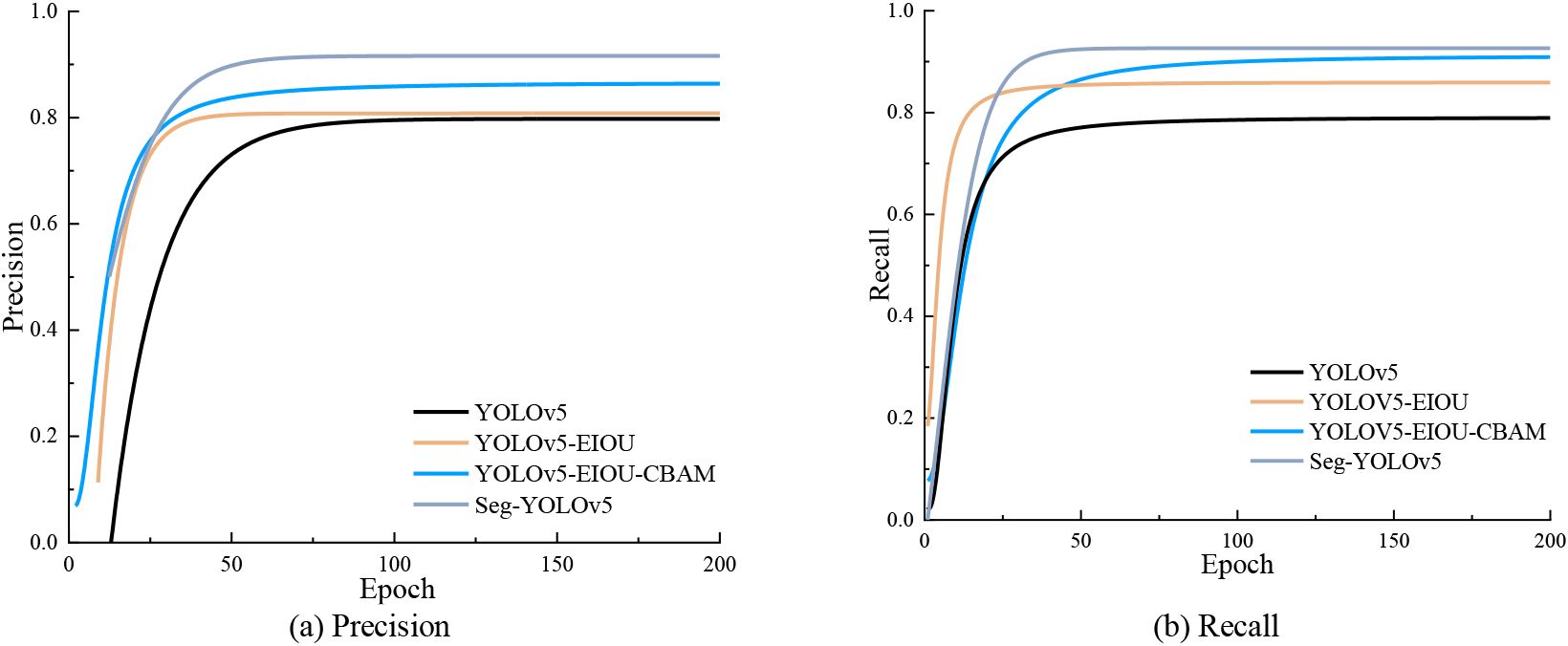
Figure 10 shows the detection results of different target detection algorithms in the same data set. In the data set pictures detected by SSD, Faster-Rcnn, YOLOv4, U-Net, and Seg-YOLO algorithms, the PV module has a complex background, including a large number of distractors, which poses a huge challenge to the target detection algorithm. In this case, the YOLO series of networks showed good detection and recognition results for occluded targets, with relatively high detection precision and speed. However, when the U-net network handles this complex image segmentation task, due to the large number of parameters, it requires a lot of computing resources and training time, and is prone to false detection.
Comparison of algorithm performance parameters.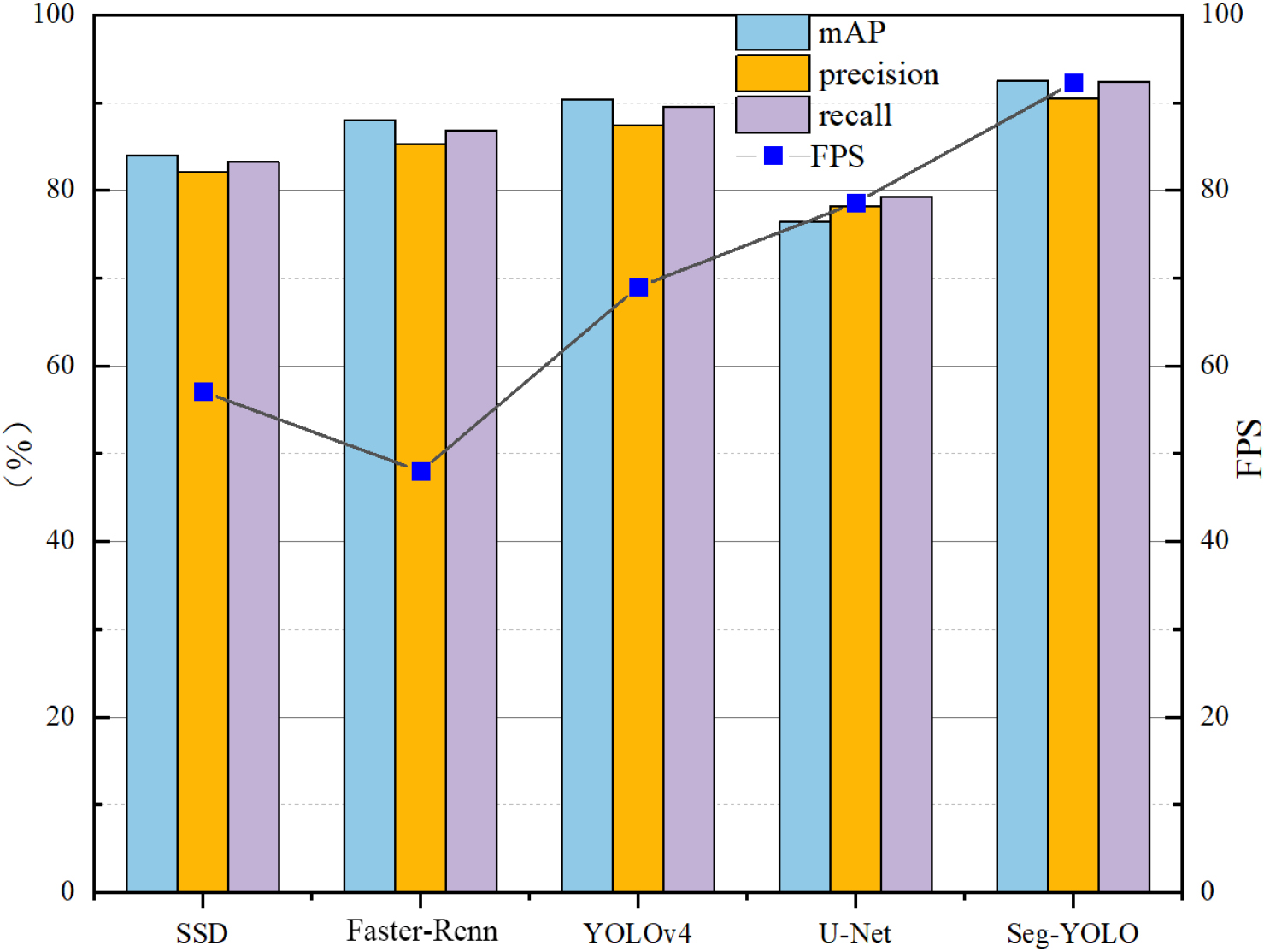
Four networks, YOLOv5, YOLOv5-EIOU, YOLOv5-EIOU-CBAM and Seg-YOLO, are used for occlusion detection of the PV module. It can be seen from Fig. 11 that using EIOU instead of IOU can improve the generalization ability and detection precision of the model, and improve the confidence in the detection results. The CBAM attention mechanism introduced in the backbone can effectively improve the detection rate of the algorithm for small target occluders, and detect bird dropping, which cannot be detected by YOLOv5 and YOLOv5-EIOU. Seg-YOLO takes into account the above advantages, including improving the detection precision rate and recall rate, and reducing the network omission rate.
Field recognition results.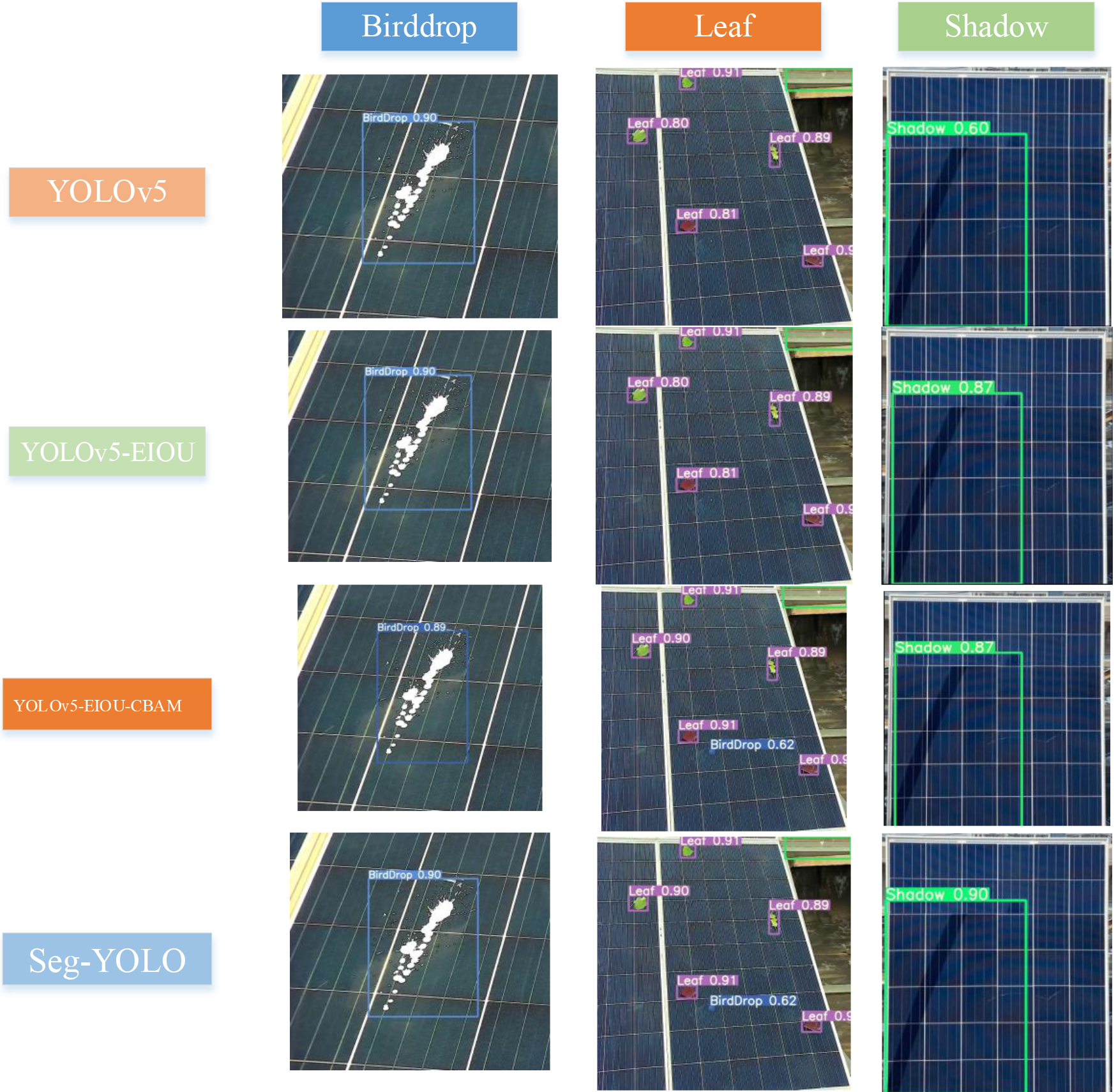
Field recognition results of different algorithms.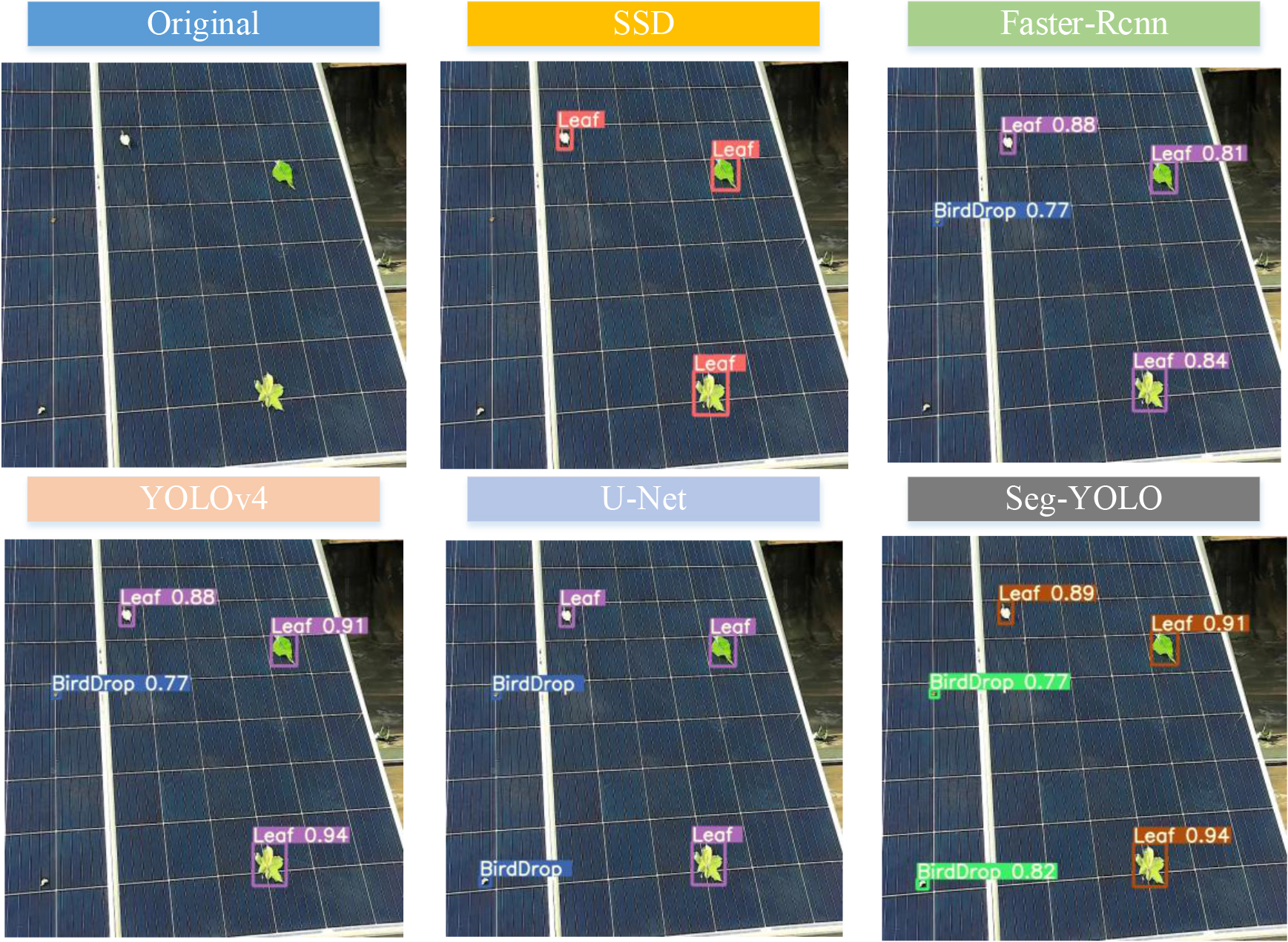
For leaf occlusion images, the intensity of the light source is high, and the gray value between the PV module and the background is very close. Therefore, the original algorithm of the YOLO series has missed detection. The Seg-YOLO algorithm introduced into the CBAM module can effectively improve the detection effect of small targets.
The YOLOv5-EIOU-CBAM algorithm with CBAM can detect bird dropping in leaf occlusion, thus showing better performance. This shows that the model developed in this paper has strong robustness, which can achieve better results in different scenarios.
For the same PV module surface occlusion image, five networks including SSD, Faster-Rcnn, YOLOv4, U-Net, and Seg-YOLO are used for detection. According to the original image, this image contains leaf occlusion and bird dropping occlusion. The SSD algorithm misses detection of bird dropping. The YOLO algorithm has a good performance. The Faster-Rcnn and YOLOv4 algorithms can identify leaf occlusion, with confidence levels above 0.8. Seg-YOLO can identify all occlusions in the PV module, and its confidence is higher than other algorithms.
In order to improve the speed and accuracy of photovoltaic panel occlusion detection, this paper proposes the target detection algorithm Seg-YOLO, introduces EIOU loss function, and combines CBAM attention mechanism. The performance of the improved algorithm in small target detection has been greatly improved. It provides a simple, portable and low-cost new method for the operation and maintenance of photovoltaic power stations. SSD, Faster-Rcnn, YOLOv4, U-Net, and the improved Seg-YOLO detection algorithm are used to train and validate the dataset. Through comparative experiments and verification, the improved Seg-YOLO detection algorithm is better than other algorithms in performance indicators such as precision rate and recall rate. While increasing the precision rate, the detection speed of the algorithm is not affected, and the FPS is increased to 92.3.
Footnotes
Funding
This work was supported by Science and Technology Development Plan Project of Jilin Province Grant. 20210203049SF.