
Abstract
This work aims to advance the security management of complex networks to better align with evolving societal needs. The work employs the Ant Colony Optimization algorithm in conjunction with Long Short-Term Memory neural networks to reconstruct and optimize task networks derived from time series data. Additionally, a trend-based noise smoothing scheme is introduced to mitigate data noise effectively. The approach entails a thorough analysis of historical data, followed by applying trend-based noise smoothing, rendering the processed data more scientifically robust. Subsequently, the network reconstruction problem for time series data originating from one-dimensional dynamic equations is addressed using an algorithm based on the principles of Stochastic Gradient Descent (SGD). This algorithm decomposes time series data into smaller samples and yields optimal learning outcomes in conjunction with an adaptive learning rate SGD approach. Experimental results corroborate the remarkable fidelity of the weight matrix reconstructed by this algorithm to the true weight matrix. Moreover, the algorithm exhibits efficient convergence with increasing data volume, manifesting shorter time requirements per iteration while ensuring the attainment of optimal solutions. When the sample size remains constant, the algorithm’s execution time is directly proportional to the square of the number of nodes. Conversely, as the sample size scales, the SGD algorithm capitalizes on the availability of more information, resulting in improved learning outcomes. Notably, when the noise standard deviation is 0.01, models predicated on SGD and the Least-Squares Method (LSM) demonstrate reduced errors compared to instances with a noise standard deviation of 0.1, highlighting the sensitivity of LSM to noise. The proposed methodology offers valuable insights for advancing research in complex network studies.
Keywords
Introduction
Recent advancements in science and technology have ushered in an era where the Internet and big data technology find application across diverse social domains, fundamentally reshaping the way people interact with the world, spanning areas like work, consumption, and travel. Broadly, the Internet has the capacity to model complex systems-ranging from logistics and power systems to biological networks-by representing them as network topologies (Graphs), where nodes and edges symbolize system elements and their relationships. This empowers the study of complex systems, often characterized by intricate structures and dynamic behaviors [1, 2]. Complex networks, an interdisciplinary field encompassing Graph Theory, statistics, and physics, rely heavily on computer technology to simulate large-scale datasets, real-world phenomena, and practical applications. The resultant analyses unravel network structures, functions, and robustness, enabling the optimization of complex system performance. Notably, network topology serves as the foundation for the functional exploration of Complex networks, with different topologies offering unique insights into the network’s dynamic behavior [3, 4, 5]. Furthermore, network topology analysis can inform routing strategies tailored to specific network structures, while network routing strategies, in turn, reflect the network’s topology. This symbiotic relationship underscores the practical and research significance of delving into a network’s topological characteristics and routing strategies. Such insights enhance our understanding of network structures, ultimately paving the way for optimized routing strategies.
The study of complex networks offers invaluable insights into the characteristics and topologies of intricate systems. However, the inherent complexity of real-world networks often results in incomplete information, rendering certain network topologies wholly or partially unknown. This predicament persists due to several challenges: (1) Many network connections manifest as signals rather than explicit entities, as seen in social relationship networks; (2) Network structures undergo evolution, exemplified by dynamic friend and communication networks, necessitating significant investments in resources and time for timely topology descriptions; (3) The direct detection of entity connections between nodes, such as functional brain networks, remains technologically challenging. In light of these challenges, this work reviews recent contributions in the field. Liu et al. [6] introduced the reconfigurable modular network topology PSNet. Kwayu et al. [7] explored the universality and interactivity of topics in Traffic Accident narratives through structured topic modeling and network topology analysis. Yedidsion et al. [8] investigated data acquisition in Wireless Ad hoc Sensor Networks by employing mobile entities to minimize data loss and determine the optimal communication tree layout. Safaei et al. [9] recognized that real-time complex networks posed challenges due to their size and complexity while exhibiting small-world, scale-free, and self-similar features. A reconnection mechanism rooted in Shannon entropy was proposed to simplify network structures and enhance network elasticity. Meng et al. [10] highlighted the perpetual significance of complex network reconstruction and presented a reconstruction network method employing the Spearman correlation coefficient. In summary, while the study of complex networks greatly aids in unraveling their characteristics and topologies, real-life networks often contain incomplete information, posing challenges in their comprehensive analysis and understanding.
This work explores critical issues identified in the current landscape of complex systems research through an innovative approach. By integrating genetic algorithms into heuristic algorithms, this work optimizes the initial weights and thresholds of Long Short-Term Memory (LSTM) neural networks. The study delves into the analysis of time series data, one-dimensional (1D) dynamic equations, and the Stochastic Gradient Descent (SGD) algorithm. Specifically, the SGD algorithm is harnessed to tackle network problems rooted in 1D dynamic equations and time series data. Additionally, the work scrutinizes the selection mechanism of objective functions and adaptive learning rates. The proposed algorithm is rigorously evaluated through a series of comprehensive experiments, shedding light on its efficacy and potential implications.
Previous research has underscored the significance of investigating complex networks to unveil the characteristics and topological structures inherent in complex systems. However, real-world networks frequently exhibit incomplete information, as is the case with neural networks, gene regulatory networks, and metabolic networks. This incompleteness poses a challenge for comprehensive connection detection. Consequently, this work distinguishes itself from prior research by addressing the intricate task of handling networks with partially or entirely absent topological information. The primary objective is to devise efficacious methodologies for reconstructing the topological frameworks of these intricate networks, thereby facilitating improved comprehension and analysis of their attributes. In the contemporary technological landscape, persistent challenges revolve around the detection of all network connections, encompassing signal transmission in social networks, networks characterized by dynamic evolving structures, and connections between entities that defy direct measurement, such as functional brain networks. Therefore, this work endeavors to bridge this research lacuna by presenting innovative approaches tailored to contend with incomplete topological information in network analysis. These approaches are designed to adapt to the complexity and informational gaps encountered in real-world complex networks. This work initiates the discussion by introducing the feature-enhanced LSTM network, a novel architectural modification that augments the LSTM’s capacity to assimilate information across varying time scales. This enhancement effectively addresses the computational demands entailed by exceedingly lengthy time series data. The second contribution is the introduction of a trend-based noise smoothing scheme, a data preprocessing technique that leverages trend analysis to mitigate the impact of noise on the data. Finally, the paper delineates a decomposition-based network reconstruction method, elucidating its procedural intricacies, including the stepwise reconstruction of individual nodes culminating in the reconstruction of the entire network. Key technical demonstrations are provided to facilitate a lucid comprehension of the methodologies advanced in this paper. These demonstrations encompass specific instances of the noise smoothing scheme’s application and illustrate how these methods are practically employed in analyzing real-world data.
Methodology
Data preprocessing
This work presents an innovative approach to data noise processing, addressing a critical challenge in data analysis. While previous studies have employed Gaussian filters, K-Nearest Neighbor smoothing filters, Kalman filters, and mixed-weight movements [11, 12], these methods are often overly complex and fail to account for data trends [13, 14]. In contrast, this work defines data trends as the incremental change in data relative to historical data and introduces a trend-based noise smoothing scheme that incorporates considerations of traffic flow data periodicity and uncertainty [15, 16]. In this scheme, the current data value
This work presents an innovative method for calculating the offset
This work introduces an advanced data smoothing technique designed to improve data quality by effectively addressing noise points. In particular, the method focuses on smoothing the data
Additionally, this work introduces an advanced data smoothing technique designed to improve data quality by effectively addressing noise points. In particular, the method focuses on smoothing the data associated with the last noise point in a series of continuous noise data points. The smoothing process is mathematically represented by Eq. (3). By applying this sophisticated data smoothing process to the last noise point, the proposed method significantly reduces data irregularities and enhances data accuracy, particularly in scenarios involving consecutive noise data points.
Within the architecture of the LSTM neural network model, each LSTM neuron boasts a cell state and is equipped with three essential gate mechanisms. These gate mechanisms serve as the backbone of the LSTM model, tasked with the vital responsibility of preserving and governing the cell state [17, 18, 19]. The output gate in Recurrent Neural Networks plays a crucial role in managing information flow. When provided with an input time series data sequence (
where the symbols
The concept of the attention mechanism gained prominence in 2017, following a significant breakthrough by Google in the field of natural language processing (NLP). This innovative approach encouraged researchers to pay closer attention to crucial details within their environments. Subsequently, the attention mechanism has found widespread application across various domains, including image captioning, machine translation, speech recognition, and the prediction of time series data. Building upon this foundation, this work introduces a feature-enhanced LSTM model designed to address the limitations of LSTM’s ability to handle long sequences. Figure 1 illustrates the relationship between the attention mechanism and LSTM. In Fig. 1a, the attention mechanism (
The model’s weight and bias parameters can be obtained by minimizing the function
Equation (11) represents the weight before the
In Eqs (12)–Eq. (16),
Attention mechanism and LSTM a. Attention mechanism; b. LSTM.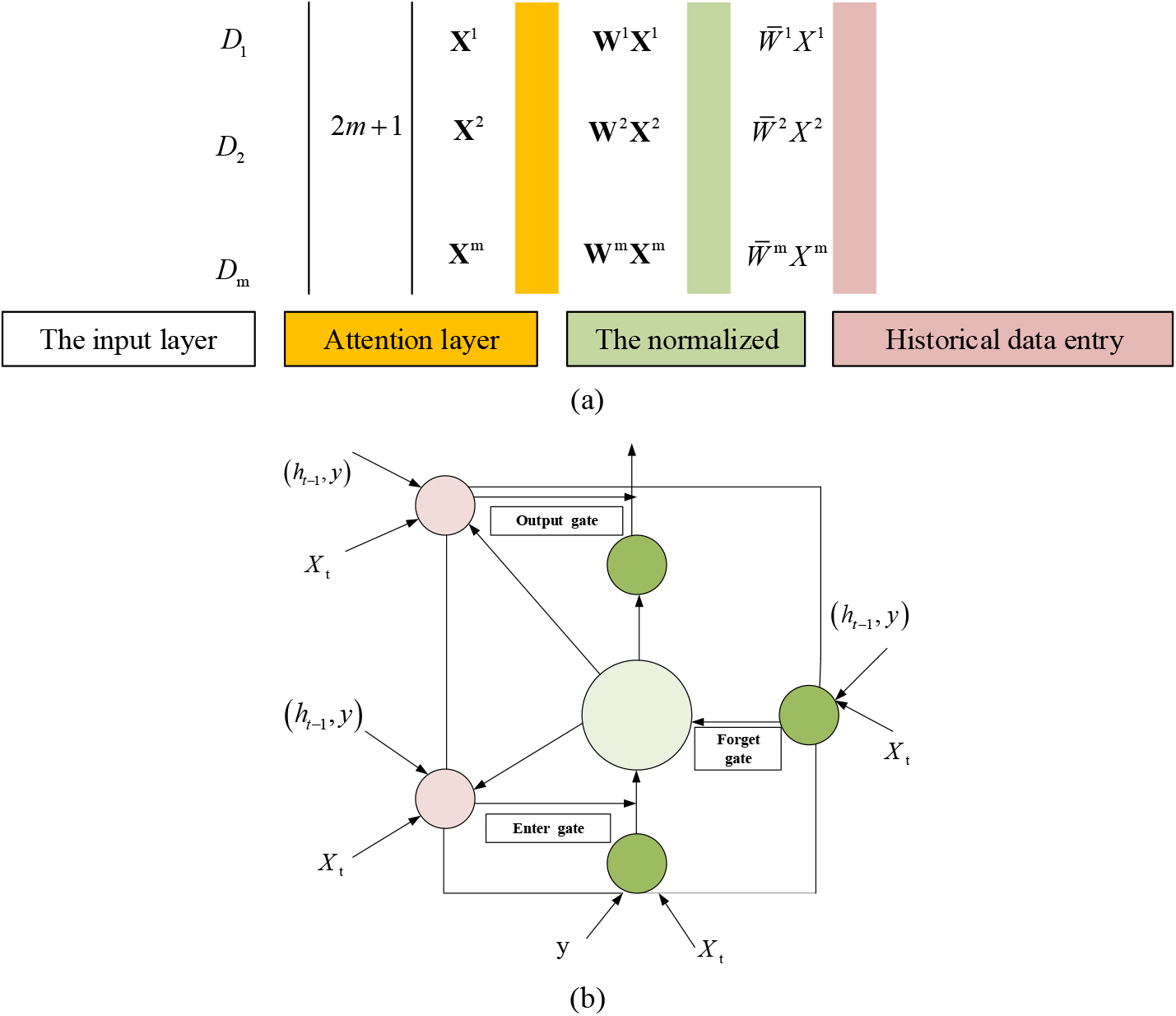
Heuristic algorithms aim to find feasible solutions for combinatorial optimizations within reasonable time and space constraints, providing near-optimal solutions while not guaranteeing feasibility or optimality [23, 24]. These algorithms fall into categories such as traditional, metaheuristic, and super heuristic algorithms. Metaheuristic algorithms, in particular, encompass genetic algorithms, Ant Colony Optimization, and variable neighborhood search algorithms, and they find applications in combinatorial optimizations across various domains [25]. For instance, Hou et al. introduced a model for Building Information Modeling-based big data storage and management [26].
The genetic algorithm belongs to the family of evolutionary algorithms and operates as a metaheuristic natural selection process [27, 28]. Its operation involves several key steps: 1) Coding: Initially, the genetic algorithm requires the determination of the objective function and variables. Subsequently, these variables are encoded, often employing a binary-decimal decoding process, as follows:
In Eq. (17), the notation (
2) The fitness function serves as a metric to assess the fitness of each individual within the population. In this context, the objective function is equivalent to the fitness function [29, 30].
3) The evolutionary process comprises a sequence of fitness-driven genetic operations applied to each individual, a concept known as the “Survival of the Fittest.” These operations encompass selection, crossover, and mutation [31]. To elaborate, selection and crossover fulfill the search function [32, 33, 34], while mutation bolsters the searchability for optimal solutions. Figure 2 depicts the R language code of the classic genetic algorithm.
R language code of the classic genetic algorithm.
Addressing the challenges of optimizing task-oriented network reconstruction methods in LSTM neural networks, this section employs a genetic algorithm to optimize the initial weights and thresholds of LSTM neural networks. This optimization aims to mitigate limitations, reduce prediction errors, and enhance prediction accuracy. Building upon the preceding discussions, this work delves into the application of the genetic algorithm to optimize LSTM models. The optimization process is outlined in the following steps: 1. Random generation of the initial population. 2. Initialization of the LSTM neural networks. 3. Training of the LSTM neural networks to calculate its total error. 4. Inclusion of the total error in the total fitness function to compute the fitness for each individual. 5. Execution of genetic operations on the current population to generate a new population. 6. If the maximum evolutionary generation is not reached, the current population is used to establish a new LSTM neural network, and Steps 3, 4, and 5 are repeated. 7. Calculation of fitness for all individuals in the current population. 8. Utilization of the remaining data to train the network with the optimal initial weights and thresholds to calculate the network output error. 9. Algorithm termination when the termination conditions are met. The flowchart illustrating the improved LSTM neural networks algorithm is depicted in Fig. 3. This section draws inspiration from the theory of word vectorization (embeddings) in NLP. It involves concatenating the load into vector representations using relevant features to generate new time series data. The Point-In-Time (PIT) historical load is represented through its associated features. Subsequently, the sliding window generates the feature map from the input time series data sequentially. To facilitate subsequent network calculations, the sliding window is configured as follows: width
Flowchart of improved LSTM neural networks algorithm.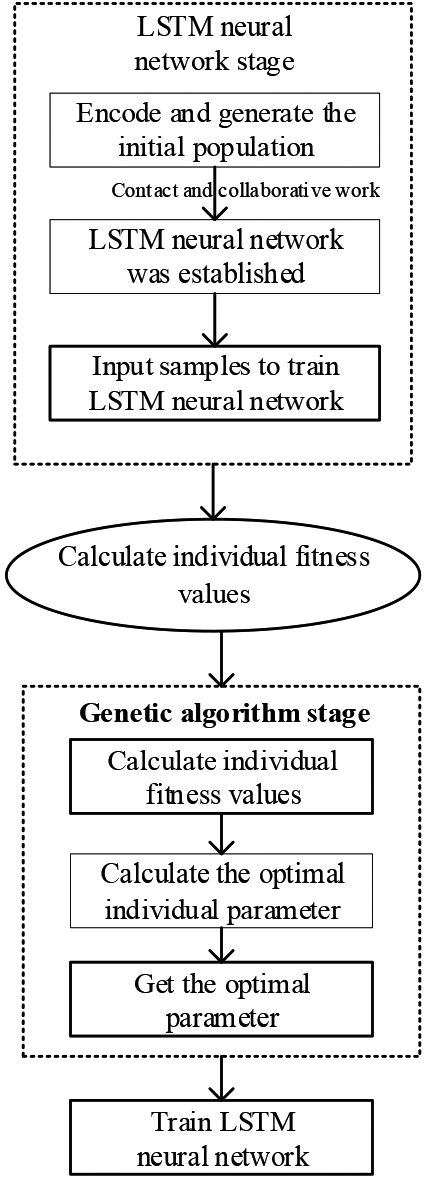
Complex systems are often abstracted into complex networks for study. The operation of complex systems typically adheres to specific laws or rules that govern interactions among individual units within the system. When these systems are abstracted into complex networks, the dynamic equation becomes a governing law. A directed graph with
In Eq. (18),
In Eq. (19),
The statuses of network nodes evolve over time due to interactions among them. Time series data can be acquired by recording the states of each node at regularly spaced time intervals to capture the dynamics of the network [35, 36].
In a complex network, every node operates under a time-varying dynamic state and continuously engages with other nodes. As a result, a new time series dataset can be generated by recording the individual node states at uniform time intervals. Specifically,
In Eq. (20),
Next, the LSTM neural network generates simulated time series data based on the input real-time series data at the next PIT through continuous learning of the weight matrix. At the same PIT, the states of the simulated time series data should align with those of the real-time series data, resulting in a learned weight matrix that closely approximates the actual network topology. Subsequently, an objective function is devised to quantify the disparity between the simulated time series data and the real-time series data. Typically, objective functions hinge on the variance between the simulated value and the actual values at
The proposed SGD algorithm operates by systematically scanning the entire training set and updating the parameters based on each individual sample. After several iterative scans, the algorithm converges, and the training samples are shuffled to prevent redundant iterations. Additionally, the proposed SGD algorithm employs an adaptive learning rate to effectively handle noisy samples, thereby ensuring algorithm convergence.
To evaluate the effectiveness of the proposed algorithm, experiments are conducted using GRNs and Social Networks, each containing network nodes ranging from 120 to 200. A typical GRN consists of nodes connected by directed edges with weights falling within the range [
As depicted in Fig. 4, each gene’s state is depicted by a specific numerical value, and the network nodes are interconnected by weighted edges. Consequently, the states of these nodes evolve over time due to interactions through these edges, leading to the generation of dynamic time series data.
The GRN and social network datasets are both generated based on the dynamic equation, reflecting the unique characteristics of dynamic systems. These network structures find widespread use in various industries. In social networks, edges are typically undirected, with the presence and absence of edges represented by 1 and 0, respectively, in the adjacency matrix. To accommodate the algorithm’s capacity to reconstruct weighted networks, all undirected edges are substituted with two reverse-directed edges, each pair of which is assigned randomly generated weights. Table 1 provides an overview of the dataset’s fundamental information.
Experimental data sets
Experimental data sets
Typical GRN.
In this context, the model error serves as a metric for quantifying the disparity between the actual weight matrix of the network and the weight matrix acquired through time series data learning. The model error index is computed using Eq. (23).
In Eq. (23),
Subsequently, with a learning rate set to 1.2 and a maximum iteration of 1,000, the experimental results, including the model’s error, accuracy, and execution time, are recorded at intervals of 10, 100, 500, 700, and 1,000 iterations. Subsequently, the SGD and the LSM are applied to analyze noisy time series data. Furthermore, a comparative analysis of the reconstruction results obtained by SGD and LSM using a dataset comprising three 50-node networks is conducted, summarizing the strengths and weaknesses of both algorithms.
Model error test results
Figure 5 displays the model error index obtained from the proposed algorithm across all datasets.
Test results of algorithm model error (
Figure 5 confirms that the proposed algorithm exhibits favorable convergence characteristics across the test datasets. As the number of iterations increases continuously, from 10 to 1,000, the model error exhibits a gradual decrease. However, when dealing with limited time series data, the reduction in model error is more gradual. For instance, in cases where the node count is 50 and the time series data volume is 1*10, the model error remains above 0.2. This indicates that with smaller time series data volumes, the reduction in model error is slower, resulting in a notable disparity between the learned weight matrix and the actual weight matrix. Conversely, when the time series data volume is substantial, the model error diminishes rapidly. The proposed algorithm can reach its minimum error after approximately 50 iterations under these conditions. At this point, the reconstructed weight matrix closely resembles the actual weight matrix, and the algorithm attains convergence swiftly, yielding the optimal solution. Moreover, the model error decreases progressively with increasing iterations. In the case of a Small-World Network, the model error tends to become negligible as the time series data volume surpasses a certain threshold. Additionally, larger networks initially exhibit significant model errors, but these errors can be reduced to nearly zero by augmenting the time series data volume. These experimental results affirm that the model error is challenging to minimize when dealing with limited time series data, resulting in slow error reduction and a noticeable disparity between the learned and actual weight matrices. Conversely, increased time series data volumes enable the algorithm to achieve rapid and effective error reduction, bringing the model error closer to zero. This work explores the intricacies of scaling up networks and the associated challenges in achieving optimal performance. Specifically, when transitioning from a 10-node network to a 100-node network, it is observed that the latter may exhibit increased error rates by the 1000th iteration. This phenomenon can be attributed to incomplete convergence within the specified iteration limit or susceptibility to overfitting issues.
Figure 6a illustrates the relationship between network node count and algorithm complexity, while Fig. 6b depicts the correlation between network node count and time series data volume.
Algorithm complexity analysis (x is the number of EXP).
Figure 6a illustrates the relationship between the network node count (100) and algorithm complexity. The execution time of the proposed algorithm increases with the growing time series data volume until it reaches the point of minimum model error. Subsequently, the execution time of the proposed algorithm decreases as the time series data volume continues to rise. Figure 6b depicts the relationship between the network node count and algorithm execution time under the same time series data volume. Notably, the execution time of the proposed algorithm exhibits a linear correlation with the square of the node count. To be specific, the execution time of the algorithm depends on several variables, including the node count, time series data volume, and the number of PITs in each time series data. When the number of samples is fixed, the algorithm’s execution time is positively associated with the square of the node count.
The preceding analysis confirms that the algorithm’s execution time exhibits a linear relationship with the square of the node count. The complexity analysis of the algorithm indicates that its execution time is influenced by several variables, including the number of nodes (
Figure 7a compares the SGD algorithm and the LSM when the noise Standard Deviation (SD) is set to 0.01, while Fig. 7b illustrates the performance of the SGD algorithm and the LSM when the noise SD is increased to 0.1. In both figures, the x-axis represents the time series data volume, and the y-axis denotes the mean model error.
Performance comparison between SGD and LSM under the same noise.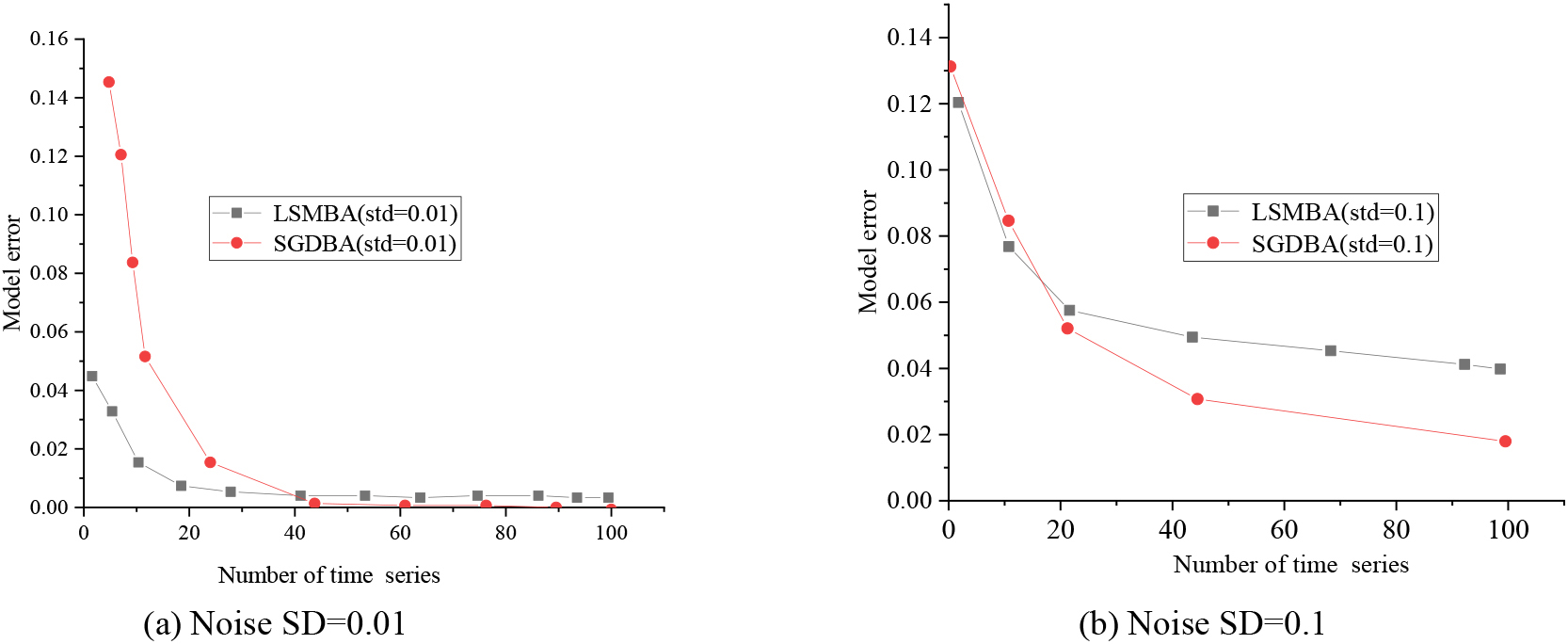
Figure 7 demonstrates an inverse relationship between model error and time series data volume for both the SGD and the LSM. Specifically, when the time series data volume is small, the LSM exhibits a lower error compared to the SGD, but as the time series data volume increases, the LSM’s error surpasses that of the SGD. This analysis indicates that the SGD algorithm benefits from more extensive sample sizes, allowing it to gather more valuable information and adapt its learning rate for improved results. In contrast, the LSM optimizes its performance based on the overall error across the entire sample set, which can sometimes lead to suboptimal results, especially when dealing with significant sample noise. Additionally, the LSM’s performance does not significantly improve with an increased number of samples, making it advantageous for smaller sample sizes.
Figure 8 presents a comparison of the SGD-based and LSM-based models on the same network structure dataset under various noise levels.
Performance comparison of SGD algorithm and LSM under different noise conditions.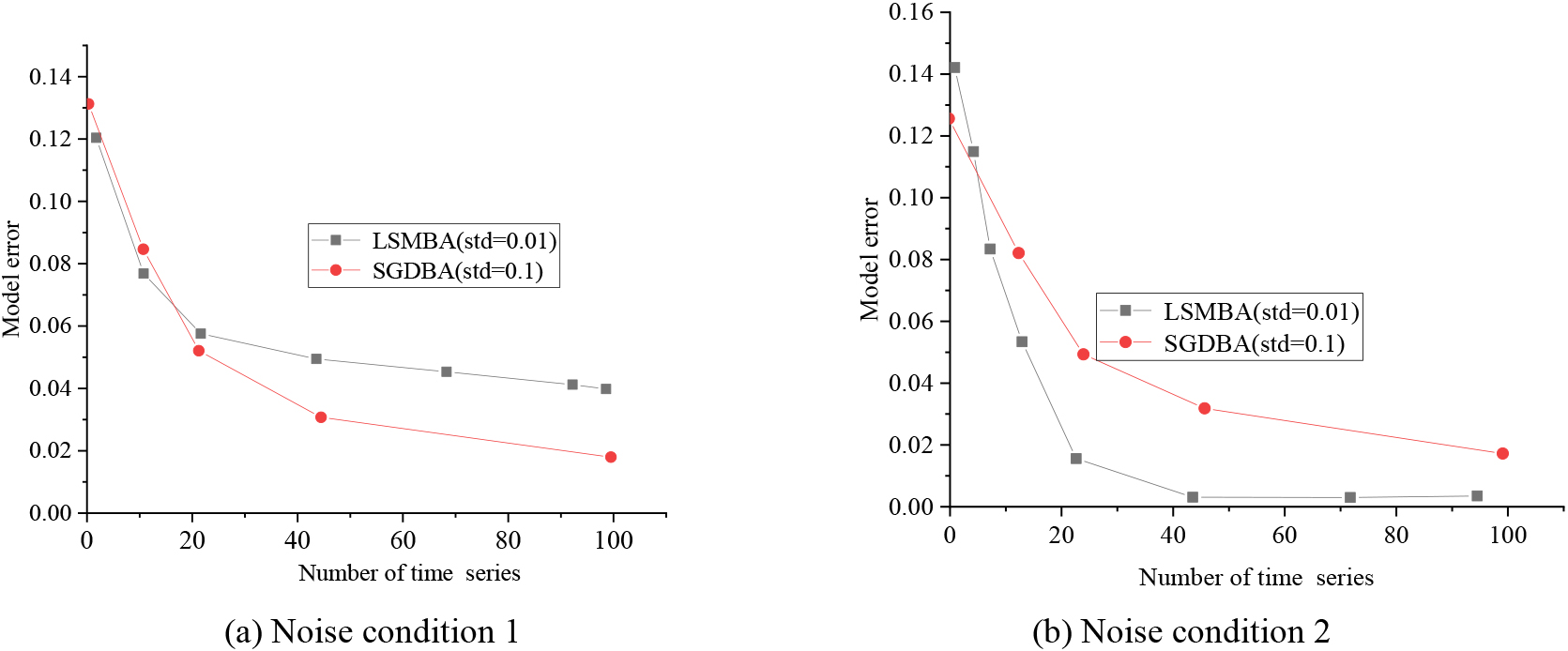
Figure 8 illustrates that both the SGD-based and LSM-based models exhibit a reduction in error as the time series data volume increases. Additionally, Fig. 8a and b reveal that both the SGD-based and LSM-based models display smaller errors when the noise SD is 0.01 compared to when it is 0.1. This sensitivity to noise indicates that the LSM is more susceptible to noise disturbances.
Empirical results demonstrate that SGD outperforms LSM when handling large-sample datasets, showcasing its ability to acquire extensive, high-quality learning information and adaptively adjust learning rates for improved outcomes. However, SGD may exhibit reduced sensitivity to noise, potentially affecting its performance in high-noise environments. In contrast, LSM excels with small-sample datasets by considering overall performance holistically. Nevertheless, its efficacy diminishes with larger datasets as it cannot optimize individual samples. Moreover, as the sample size grows, SGD leverages additional learning information to enhance model generalization. Consequently, LSM typically yields lower errors in scenarios involving small-sample datasets and minimal noise. In comparison, SGD tends to achieve lower errors in situations with large-sample datasets and higher noise levels. These findings underscore the significance of selecting an appropriate optimization algorithm tailored to the data’s characteristics in diverse contexts.
This work thoroughly evaluates an optimization model across various datasets, showcasing its remarkable performance and rapid convergence. However, the model’s runtime demonstrates the correlation with data scale and noise levels. Specifically, in scenarios featuring shorter time series and lower noise levels, the Least-Squares Method proves effective in minimizing model errors. Conversely, as time series length and noise levels escalate, SGD emerges as the more advantageous choice. Consequently, the selection of an optimization algorithm should be guided by a reasonable trade-off between performance and computational complexity, contingent on specific contextual factors.
Conclusion
As big data technology continues to advance, complex network theory can now be applied to define increasingly complex systems, including but not limited to GRN, financial systems, ecosystems, and social systems. In practical applications, complex network technology finds utility in various interdisciplinary contexts. The study of complex networks is essential for comprehending the diverse dynamic behaviors exhibited by complex systems and understanding the implications and significance of these network dynamics. This work is pivotal for enhancing our ability to manage complex systems and leveraging networks for the betterment of humanity. Consequently, investigating the underlying complex network models of complex systems through big data technology has become fundamental in the study of dynamic behaviors within these systems. This work focuses on two main aspects: Firstly, it enhances the structure of LSTM neural networks using genetic algorithms within a heuristic framework. This improvement results in the development of a feature-enhanced LSTM network designed for predicting traffic flow data. Additionally, the work addresses data noise by proposing a trend-based noise smoothing scheme. This scheme identifies noise by analyzing historical data and subsequently employs data trends to smooth noisy data. Compared to traditional methods, the smoothed data produced by this scheme is more scientifically sound and reasonable. Besides, the research investigates the challenge of network reconstruction using time series data generated by a one-dimensional dynamic equation. The primary approach involves decomposing time series data into smaller samples and combining adaptive learning rates with the SGD method to optimize the learning process. Model error and the Area Under the Curve are employed to assess the accuracy of the reconstructed network. Experimental results demonstrate that, with proper parameter settings, this algorithm achieves high accuracy and efficiency, making it suitable for reconstructing large-scale networks.
Nonetheless, certain limitations persist in this work. Firstly, the investigation into network reconstruction based on time series data predominantly considers edge weights within the [
Footnotes
Funding
This work was supported in part by the Research Projects of Shaanxi Province in Social Development field of Specialized Industrial Innovation Chain under Grant No. 2023-YBSF-397.