
Abstract
This paper aims to improve the level of social credit system and the accuracy and efficiency of bank users’ credit scoring by using business intelligence technology based on deep neural network (DNN). Firstly, based on the theory of personal credit evaluation factors, a comprehensive credit evaluation factor system is constructed, taking into account social and economic background, consumption habits, behavior patterns and other factors. Meanwhile, back propagation neural network (BPNN) theory is introduced as the core method of modeling to cope with the nonlinear relationship in the credit scoring task and the demand of large-scale data processing. Secondly, by analyzing the operation process of BPNN in detail, the specific application in credit scoring model is emphasized. Finally, on the basis of theory and operation, this paper implements a credit scoring model for bank users based on BPNN theory. The experimental results show that the model realized in this paper can automatically discover the key attributes and internal rules in the sampled data, and adjust the weight and threshold of the network by modifying the parameters and network structure to meet the expected requirements. The accuracy of the credit score of the predicted sample data reaches 99.5%, and the prediction error is very small, which has a good prediction effect. This paper provides a feasible solution for business intelligence and DNN in the field of credit scoring, and also provides strong empirical support for improving the level of social credit system.
Introduction
The Bank of China’s personal credit assessment business has been flourishing in credit operations and credit institutions due to the rapid development of the Chinese economy. Because of high profit margins and risk diversification, credit activities have become an important part of the development process of commercial banks. However, with the rapid increase in workload of bank, personal credit problems, especially credit risk control, become increasingly difficult [1]. The World Bank points out that credit risk is the main reason for bank bankruptcy. Today, through the comprehensive management of commercial bank risks, credit risk is still the main factor leading to bank operation problems [2]. The global banking sector has achieved significant advancements and advances in risk assessment technology as a result of the new Basel Capital Accord, which is progressive and forward-looking in the field of risk management [3]. However, at present, there are many problems in reviewing and approving the personal loans of national commercial banks, such as the difficulty of the authenticity of the credit data of bank loan applicants, and the lack of objective and fair evaluation of the credit status of individual customers [4]. Therefore, China needs a scientific, effective, and practical personnel of the credit rating system of the banking industry to provide strong support. The decision makers in loan and the personnel promoting the credit expansion of commercial banks should evaluate the credit conditions of bank users objectively and fairly.
In the paper, a bank user credit scoring model based on BP neural network (BPNN) is implemented according to related theories of BPNN, and prediction and classification are made on the credit of the collected samples. The purpose of the paper is to provide some referencing value for bank credit scoring. Specifically, the research method can be divided into the following steps: firstly, this paper introduces the theory of personal credit evaluation factors and the theory of BPNN. Personal credit evaluation factors include personal basic information, loan information, performance ability, etc. These factors can be used to build a credit scoring model. BPNN is a machine learning algorithm based on neural network, which has strong pattern recognition and data mining capabilities. Secondly, this paper analyzes the application of BPNN in the credit score of bank users, and focuses on the operation process of BPNN. In order to automatically identify the important characteristics and internal rules in the data and create an accurate credit scoring model, BPNN continuously iteratively learns by adjusting the network weights and thresholds. A credit scoring model of bank users based on BPNN theory is implemented, and the collected user information is distributed to neural networks. The distribution results are standardized to facilitate the training and prediction of the model. Finally, in this paper, the BPNN model is used to classify the standardized data, and the prediction results of the model are verified by experiments and analyzed. The experimental results show that the model can automatically discover the key attributes and internal rules in the data, and the prediction accuracy is as high as 99.5%, which has a good prediction effect. Generally speaking, this paper uses BPNN technology to build a credit scoring model for bank users, which can help improve the level of social credit system and promote the harmonious and stable development of society. The model of this paper can automatically discover the key attributes and internal rules in the data, and the prediction accuracy is as high as 99.5%, which can effectively improve the accuracy and efficiency of bank users’ credit scoring. The BPNN technology and method adopted in this paper can provide reference for data mining research in other fields. Being a neural network-based machine learning technique, BPNN is extensively utilized across multiple domains and possesses robust pattern identification and data mining capabilities. The BPNN model utilized here has been effectively implemented and validated in the domain of credit scoring for bank users, offering insights and inspiration for data mining investigations in various fields.
This paper is divided into five sections. Section 1 is the introduction, which mainly describes the current credit status of bank users and the difficulties in user credit scoring, puts forward the research methods of this paper, and explains the research contribution and article structure of this paper. Section 2 is the literature review, which mainly reviews the research on the user credit scoring model and the application of deep learning in bank credit evaluation, analyzes the defects of previous research, and expounds the research motivation of this paper. Section 3 is the experimental method, which mainly explains the construction process of bank user credit scoring model based on BPNN theory. Section 4 is the experimental results, which mainly classifies and analyzes the standardized data by the constructed BPNN model. Section 5 is the conclusion, which mainly explains the research results of this paper and looks forward to the future research work.
Related work
Personal credit rating model is widely used in foreign credit management. It uses advanced statistical methods to analyze large amounts of data, such as demographic characteristics, behavior of historical credit records, ability to assess and individuals to comply with their commitments and credit levels to determine the credit rating and credit lines [5]. As the foundation for credit rating classification, Wang et al.’s research on the application of blockchain to bank financial services indicated that the credit scoring system significantly reduces the time and cost of credit evaluation, improves the accuracy of credit decision-making, and plays an important role in providing lending services to clients who extend loans and generate unignorable profits [6]. The practical experience showed that the loan provided by using personal credit rating standards and consistently processing applications was characterized by fast, low-cost, and a therapeutic goal, which played an important role in risk management of consumer credit.
With regard to the application of deep learning in bank credit evaluation, Gunnarsson et al. considered the applicability of deep learning algorithm to credit scoring, and constructed a credit scoring framework of multi-layer perceptron network and deep belief network. The research found that XGBoost was superior to random forest in credit scoring [7]. Munkhdalai et al. made an empirical comparison on the credit evaluation of bank customers by using machine learning method. They found that the expected credit loss of Fair Isaac Corporation (FICO) credit scoring model based on machine learning would be lower and more sustainable [8]. Huang et al. investigated the literature on the application of deep learning model in the fields of finance and banking to provide a systematic evaluation of model pretreatment, input data, and model evaluation [9]. It was found that Neural Network (NN) was suitable for processing cross-sectional data. Sharma et al. thought that machine learning and deep neural learning could be further analyzed and implemented in various applications [10]. Teles et al. compared and analyzed Bayesian network and Artificial Neural Network (ANN) to predict the recovery value in credit operation, and found that ANN was more effective than Bayesian network [11]. Bücker et al. put forward a credit scoring model and a framework to make the “black box” machine learning model transparent, auditable, and interpretable [12].
There is currently no unified personal credit rating system in China due to the fact that the credit evaluation system is relatively late, the relevant social credit system is not perfect, and there is a lack of relevant data regarding personal credit evaluation in China as well as professional research scholars and evaluation institutions [13]. Personal credit rating model is widely used in foreign credit management, and advanced statistical methods are used to analyze a large number of data to determine credit rating and credit limit. Credit scoring system significantly reduces the time and cost of credit evaluation and improves the accuracy of credit decision. Meanwhile, the deep learning algorithm has also achieved certain results in bank credit evaluation. But there are still some problems and defects. For example, Gunnarsson et al. only considered the credit scoring architecture of multi-layer perceptron network and deep belief network, but did not explore more deep learning algorithms. Munkhdalai et al. used machine learning method to make an empirical comparison of bank customer credit evaluation, but did not involve the application of deep learning algorithm. In addition, although the deep learning algorithm has high prediction accuracy, it is difficult to explain and audit its results because of its “black box” nature. The purpose of this paper is to offer a deep learning-based business intelligence model that is highly interpretable and accurate, and that has been better applied to the credit score of bank customers.
The proposed optimal model
Concepts of personal credit and theories of BPNN
Evaluation of personal credit
Evaluation of personal credit refers to with the scientific and rigorous analysis methods to comprehensively judge and evaluate the subjective and objective impacts of internal and external factors of individuals and families and their ability to fulfill economic commitments [14]. The connotation of personal credit assessment mainly includes the following three aspects: Firstly, the scale of the survey. A comprehensive and full list of factors should be considered, going beyond economic metrics that simply reflect the objective external environment, including asset status and personal income level. Bank users’ credit levels, as evidenced by their credit records, can also be reflected in macro indicators such as economic and environmental indicators and internal credit level. Secondly, evaluation of personal credit is conducted mainly through scientific analysis methods to obtain intuitive evaluation results [15]. Thirdly, personal credit assessment evaluates the degree of realization of personal economic commitment, and provides corresponding evaluation results for different credit responders. Therefore, from the view of the loan applicants, credit evaluation is a comprehensive evaluation of the ability and credibility of individuals to participate in market economy transactions, execute capital projects, finance, contracts and access to certain services.
Basic principle of BPNN
The principle of BPNN is to divide the learning process into two processes: signal forward transmission and error signal backward transmission. Each neuron in the entry layer receives external input information and passes it to each neuron in the hidden layer [16]. This layer is responsible for internal information processing and information conversion. According to the requirements of information change, it is designed with one or more hidden layer structure. After processing each hidden layer, the information is transmitted to the output layer, which is a process of outward transmission [17]. When the actual output of the output layer does not match the expected output, it enters the error feedback stage. During the experiment, the error is transmitted and assigned to the hidden layer and the input layer of the output layer, so each neuron of the error signal can be used as a basis to correct the reconnection of each layer [18]. The signal circulates forward and backward errors during transmission and the weight of each layer is adjusted until the output error of the artificial neural network is reduced to an acceptable threshold or until the number reaches the previous definition. The calculation expressions from the input layer to the hidden layer in the forward propagation of three-layer BPNN are shown in Eqs (1) and (2):
It is not necessary to provide an equation for each of these reflection connections beforehand because the error feedback algorithm is able to learn and remember a wide range of reflection relationships between input and output modes [19]. Learning rules use the fastest descent method and feedback transmission to continuously adjust the weight and threshold of the network to generate the sum of squares of the minimum network error. BPNN consists of three neural layers: input layer, output layer and hidden layer. There is only one input layer and one output layer. The hidden layer is manually defined and can be one or more layers. Among them, the most extensive and simplest application is BP network, which only contains one hidden layer [20]. In this network model, each layer contains one or more nodes, and the comprehensive interconnection is made among all layers, so that each node comprehensively connects the upper nodes of each layer. But connection does not exist among nodes which belong to the same layer, that is, there is no feedback among nodes.
Figure 1 shows three-layer BPNN. It is the most common, and from left to right is the input layer, hidden layer and output layer of the three-layer BPNN. The data is entered from the leftmost input layer and then output from the rightmost output layer, fully connected among layers. BPNN is actually a nonlinear input-output reflection. The network input value is considered as the independent variable of the nonlinear function, and the output prediction value of network is considered as the dependent variable of the nonlinear function. When the input and output nodes are a, b, respectively, BPNN represents reflection relationship of a-b function.
To sum up, the training process of BPNN algorithm is shown in Table 1.
The training process of BPNN algorithm
Structure of BPNN.
Due to its unique advantages, BPNN is widely used in information, automation and other fields. In recent years, many researchers who study BPNN begin to apply it to the economic field, especially credit evaluation [21]. In order to evaluate the credit degree of bank users, it is feasible to use BPNN, which can be introduced from the following aspects. First, BPNN has high information processing speed. Credit evaluation of bank users is extremely complex, but BPNN model can accurately deal with measurement information because there are many neurons in the system. The results of the evaluation are different from those of the most basic credit evaluation model that cannot deal with these complex relationships [22]. Second, BPNN is good at handling suspicious information. There are many factors being used to evaluate credit risk, and some factors themselves are constantly changing, but with the advantages of BPNN in information processing it can well adapt to this change [23]. Because this model has many neurons and a lot of information storage space, it can handle the changing information well. Third, the nonlinear advantage of BP network is that actually it is a nonlinear processing unit. In this regard, it is unlike the computer we usually contact [24]. Different from the traditional linear processing method, it can be more effectively applied to credit evaluation and effectively deal with a large amount of information.
In this paper, a credit scoring model based on deep learning and business intelligence technology is adopted. At the core of this model is a deep BPNN, which is a kind of multilayer feedforward neural network, and can predict the credit score of bank users by learning the complex mapping relationship between input and output. In the aspect of model structure, several types of neural network layers are used to construct the deep learning model. The first is the input layer, which receives the user data after preprocessing and feature engineering. Then there are several hidden layers, which are composed of a large number of neurons and are used to capture nonlinear relationships and complex patterns in data. The hidden layers used in the paper mainly include Dense layers, and each neuron in these layers is connected with each neuron in the previous layer. The number of hidden layers and the number of neurons in each layer are optimized according to experiments to ensure the performance optimization of the model. In the selection of activation function, Rectified Linear Unit (ReLU) activation function is adopted, because it has fewer gradient vanishing problems and high computational efficiency in deep neural network (DNN). ReLU function is shown in Eq. (9):
Equation (9) can provide nonlinear mapping, while maintaining the stability of neural network in backward propagation. In order to train the neural network, Adaptive Moment Estimation (Adam) is adopted as the optimization algorithm. Adam combines the advantages of Momentum and RMSprop, and can calculate the adaptive learning rate of each parameter. This enables the model to converge stably and quickly in the training process. The business intelligence technology in this paper also includes the steps of data preprocessing and feature selection to ensure that the data input into the neural network is accurate and efficient. In addition, in order to better understand and analyze user data, data visualization technology is applied to show the relationship between user characteristics and credit distribution.
Selection and valuation of index parameters of credit evaluation for bank users
Firstly, the scientific selection and establishment of personal credit evaluation indicators are carried out. Personal credit evaluation includes leading elements which are different from enterprise credit risk assessment [25]. Most of the parameters of the personal credit index are non-digital, which is different from the factors that affect corporate credit ratings. So firstly, under different evaluation factors, these non-digital data need to be transformed and weighted, and then they need to be used as experimental data.
According to the method of credit rating evaluation and the evaluation criteria of the banking industry, 10 credit rating factors are selected from the aspects of credit data of bank users, basic information of bank users and identification information of bank users. In the design process, three-layer neural network is used to simulate the credit rating, and the number of nodes is 10 in the input layer.
Subdivision and valuation of parameters
(1) Evaluation factors and valuation of basic information of users
In the basic information evaluation of the credit scoring model, seven key factors are selected: gender, education, marital status and children’s situation, age, occupation, employment and professional title, and working years in the current company. In the experimental process of these factors, it is necessary to standardize each evaluation factor and make a specific score according to the characteristics of the input values [26]. For gender, credit risk of male is higher than that of female. The score of female credit is 10. The score of male credit is 5. For education, the bank users are classified according to the level of education received, including P on behalf of primary school education, J on behalf of junior high school education, H on behalf of high school education, S on behalf of specialized college education, U on behalf of university education, M on behalf of master degree, D on behalf of doctor degree. Table 2 shows the corresponding credit assignment. For the wedlock and whether there is a child or not of bank users, the classification and assignment are as follows: the valuation is 0 of that after the divorce of husband and wife, there is no child; the valuation is 3 of that after the divorce, there is a child; the valuation is 5 of that after the divorce of husband and wife, there is a child; the valuation is 8 of that after the marriage, there is no child; the valuation is 10 of that after the marriage, there is a child.
Valuation of credit according to education degree
Valuation of credit according to education degree
According to the income and job stability, bank users are classified into different age groups. The specific credit valuation is 7 for the age of 18 to 25, 8 for the age of 25 to 30, 9 for the age of 30 to 35, 10 for the age of 35 to 40, 9 for the age of 40 to 45, 8 for the age of 45 to 50, 7 for the age of 50 to 55, 6 for the age of 45 to 60. In terms of industry, the specific credit valuation is 1 for national units and institutions; 8 for health and social welfare units; 6 for tourism, geology, transportation and so on; 1 for businessmen, catering, intermediary and other units; 8 for soldiers, doctors and nurses, network operations, mobile telecommunications and so on; 4 for barbers, hairdressers, designers; 1 for other occupations; 0 for non-occupations. In the course of the experiment, bank users are divided according to their positions in companies, as Table 3. There are many types of occupation can refer to the above classification and valuation. In employment and title, bank users in national institutions are divided according to the level of division, durance in the current company. According to the durance, 1 more score is added to the total scores with 1 more year, until the total valuation achieves 10 scores.
Valuation of credit of title and occupation
In Table 3, S represents the “Si Ji” (Leading roles of departments or equivalents), of which the valuation is 10; C represents the “Chu Ji” (Leading roles of divisions or equivalents), of which the valuation is 8; K represents the “Ke Ji” (Leading roles of sections or equivalents), of which the valuation is 5; J represents the “Ke Yuan” (Staff members), of which the valuation is 2; Q represents other levels, of which the valuation is 1. F represents the company legal person, of which the valuation is 10; Z represents the person in charge, of which the valuation is 8; B represents the department head, of which the valuation is 5; G represents the individual enterprise owner, of which the valuation is 3; Y represents the employee, of which the valuation is 0.
(2) Evaluation factors and valuation of personal assets
Core indexes to determine the debt situation and bank debt solvency of bank users are the evaluation indexes of assets and liabilities for personal mainly include three indicators: family per capita annual income, housing mode and bank deposits. On the situation of family per capita annual income, under the condition of not more than 10 000, the credit valuation is 0; The credit valuation is 1 of the family with per capita annual income between 10 000 and 30 000. The credit valuation is 6 of the family with per capita annual income between 50 000 and 100 000. The credit valuation is 8 of the family with per capita annual income between 10 and 150 000. And the credit valuation is 10 of the family with per capita annual income more than 150 000. In the case of personal bank deposits, the credit valuation is 0 of individual with per capita annual income less than 10 000. The credit valuation is 1 of individual with per capita annual income between 10 000 and 50 000. The credit valuation is 4 of individual with per capita annual income between 50 000 and 150 000. The credit valuation is 6 of individual with per capita annual income between 150 000 and 250 000. The credit valuation is 8 of individual with per capita annual income between 250 000 and 450 000. And the credit valuation is 10 of individual with per capita annual income more than 450 000. The first criterion that can most accurately represent each unique asset is housing mode, as shown in Table 4.
Housing mode and its valuation of credit
Among them, CMH represents commercial mortgage house purchase, PFMH represents provident fund mortgage house purchase, PMH represents portfolio mortgage house purchase, PH represents private housing, RH represents rental housing, and O represents other ways.
(3) Credit scoring of bank users
The credit status of bank users can be determined according to the total score of individual credit value, namely, credit scoring. According to the actual situation of each credit scoring at present stage, Table 5 shows the credit scoring categories.
Personal credit scoring of bank users
In the specific circumstances, bank users with excellent credit level have a better degree of credit, which means that they will enjoy higher treatment and higher credit in the bank service. While those with excellent credit can also benefit from certain special treatment, their credit is handled less favorably than that of the former. People with poor credit cannot be treated the same as people with higher credit levels, nor can their credit level be a reflection of their reliability or responsiveness [27].
The establishment of bank credit scoring model requires the selection of scoring factors, accurate personal information collection and the implementation of bank internal policies, for example, samples for training and inspection [28]. However, due to the confidentiality of user data of Bank of China, it is difficult to obtain user data and information. Although the evaluation index system of customer credit established is complete and systematic, only some personal credit evaluation factors can be selected due to the limitations of data [29]. Generally speaking, only some indicators are selected, so that the credit evaluation system does not produce a verification, and its ideological strengths should conform to the views proposed here, and it has a relatively high similarity evaluation index of comprehensiveness and portability [30]. Therefore, the model implemented can also apply in where there are enough user credit evaluation factor data.
The overall sample is 750 normal credit bank users and 350 non-credit bank users, with a total of 1100 samples. The sample information includes basic information of users (gender, education, marital status and children’s status, age, occupation, employment and title, and working time in the current company) and personal asset information (per capita annual income, housing mode and bank deposit). In the actual training and test division, 500 normal users are used as the training set, and the remaining 500 samples (250 normal users and 150 users without credit) are used as the test set. The ratio of training set to test set is 1:1. The remaining 150 non-credit users are used as the verification set. In the training process, the training data sets are standardized according to the standardized formula, and then the standardized data are input into the BPNN model for learning.
Process of algorithm
First, the data are input. Then, the data are preprocessed and initialized to determine the parameters of the network. The weights and thresholds of the network are initialized, and the initial values are coded. Next, the absolute value of the error obtained by BPNN is used as the fitness value. Afterwards, the selection operation, crossover operation, and mutation operation are carried out to calculate the fitness value. If the end condition is satisfied, the optimal weights and thresholds are obtained, and the errors are calculated. The weights and thresholds are updated to meet the conditions and output results. If the end condition is not satisfied, the return selection operation starts again [31].
Experimental environment and deployment
In this paper, the DNN model is deployed on a Dell PowerEdge R940 server to ensure that the model can run efficiently when dealing with complex computing tasks. The server is specially equipped with four Intel Xeon Platinum processors, each with multiple cores and threads, providing powerful computing power. In addition, the server is equipped with NVIDIA Tesla V100 GPU accelerator, which supports CUDA to accelerate computing and provides additional computing performance for the DNN model. Meanwhile, the Dell PowerEdge R940 server has a large capacity of memory, with 256 GB of memory configured to ensure that the model can run efficiently when dealing with large-scale data. In addition, the server hard disk adopts high-speed solid-state hard disk, which provides fast data reading and writing speed and helps to improve the performance of the model. In the aspect of operating system, Ubuntu Server is selected, and Python is used as the main development language, combined with PyTorch deep learning framework for model development and training. Through such a combination of hardware and software, IT is ensured that the model can run stably in a high-performance environment after deployment and realize seamless integration with the existing IT system of the bank.
In the aspect of integration, API is designed to make the model communicate with the existing system of the bank. When the new customer data is input into the banking system, the system will automatically call our model API, transmit the necessary customer information and obtain the corresponding credit score results. This integration method not only realizes efficient information transmission, but also reduces the burden on the banking system. The research process pays special attention to the security of data, and protects the privacy of data transmission by using encrypted channels. In addition, in order to further ensure the privacy of customer information, this model does not store any personal information in the calculation and prediction process, but only makes immediate calculation and prediction.
In the design process of the model, it pays attention to the expansibility, so that it can adapt to the data of different scales and needs. The model can handle data from thousands to millions of users, and with the increase of data volume, the prediction accuracy of the model will be further improved. In addition, the model supports concurrent requests, which can handle multiple users’ credit scoring requests at the same time, and ensuring high performance under high load.
Moral considerations and safeguard measures in credit scoring
The use of business intelligence and DNN for credit scoring should not only focus on innovation and performance, but also pay attention to dealing with potential moral problems. This comprehensive solution revolves around privacy, fairness and prejudice, ensuring that the credit scoring model of this paper follows the highest ethical standards while serving users.
Secret protection
Data transmission security: Encrypted channel is adopted to ensure the security of user information in transmission. Temporary data storage: User information is only used for credit score calculation, and will not be permanently stored after calculation. Desensitization: When sensitive data is desensitized, even if it is intercepted during data transmission, it is impossible to identify the personal identity. Access control: By strict access control and authentication, only authorized personnel can access relevant data. Fairness and prejudice management
Bias detection and correction: The potential historical biases in datasets are detected and correct to ensure the balance of data. Feature selection: The features directly related to personal credit behavior are given priority to and unnecessary deviation is reduced. Fairness correction: The fairness constraints or correction algorithms are applied to ensure that the model has equal accuracy for all user groups. Systematic deviation analysis: A detailed analysis of the prediction results of different groups is made to prevent systematic deviation. Multidisciplinary team supervision:
Interdisciplinary cooperation: A multidisciplinary team including data scientists, sociologists and ethical experts is established. Continuous monitoring of the model: The team continuously monitors and evaluates the model to find and correct potential problems in time. User service responsibility: The credit scoring model serves all users efficiently and responsibly is ensured.
This comprehensive solution aims to ensure that our credit scoring model performs well in dealing with potential ethical issues such as privacy, fairness and prejudice to build more responsible business intelligence and DNN applications.
Training results of model of BPNN
First, the data should be standardized, and experiments should be carried out according to the above description. Figure 2 shows the specific training process of BPNN.
Learning process of model of BPNN.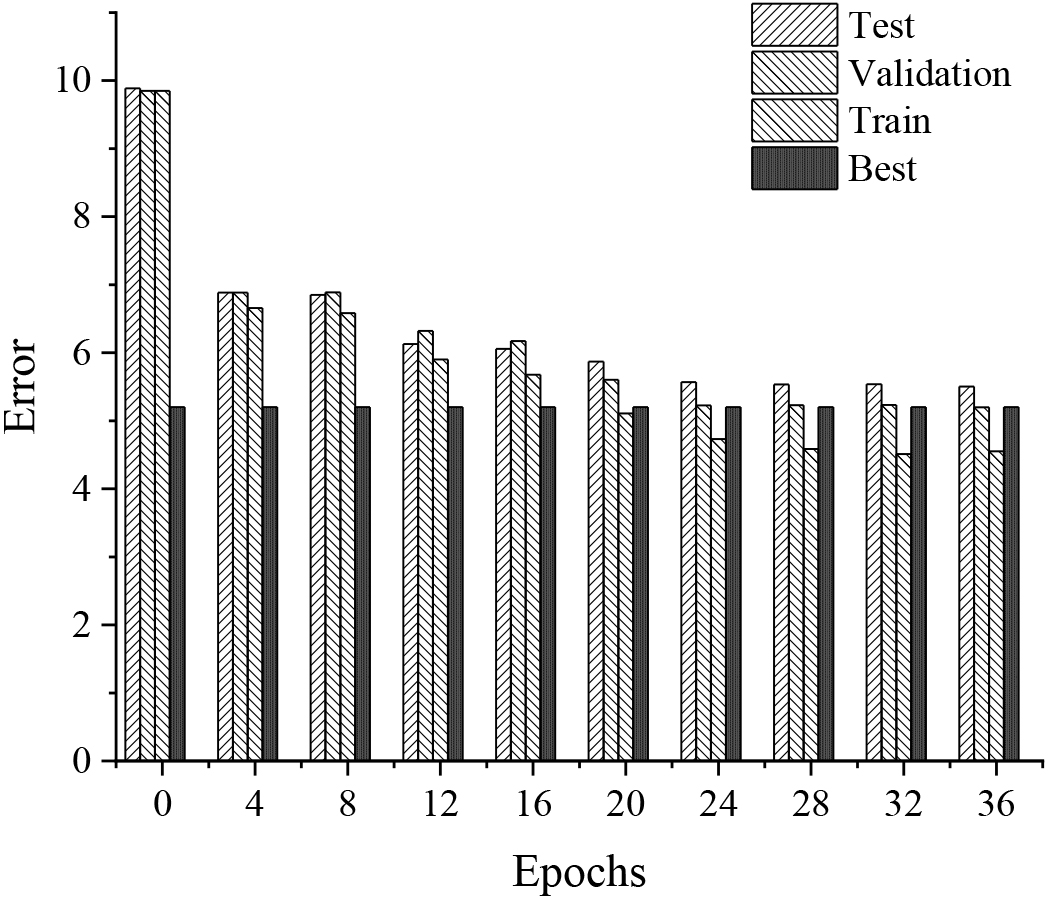
Classification results of model of BPNN.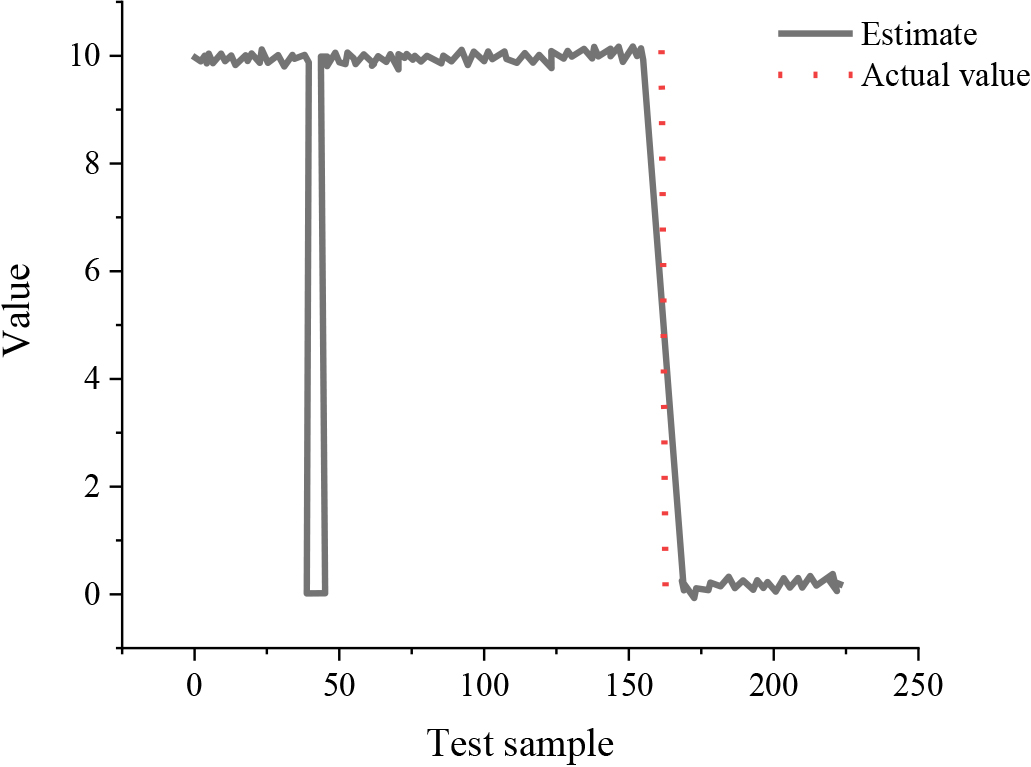
Credit classification error and test time of first model.
Figure 2 is the formation process of model of BPNN. The vertical axis represents the square error, and the horizontal axis represents the times of iterations. “Train” represents the training square error, and “Validation” represents the square error calibration. “Test” represents the average error test, and “Best” represents the minimum error of the average square error after multiple iterations.
Before the test, the datasets should be standardized, and the obtained model should be used to predict the credit score of bank users. Figure 3 shows classification results of model of BPNN.
Figure 3 reflects that the vertical axis represents the credit category of each user, the horizontal axis represents the dataset, and the red in Fig. 3 represents the actual credit category. But there are wrong data, errors of which are represented as the black vertical line in Fig. 3. Figure 3 suggests that there are two errors, that is, dishonest bank users are predicted as normal bank users, and in turn, normal users are predicted as dishonest users.
Two experiments are carried out, and two errors occur in each experiment, in the same position. The running time increases with the increase in the number of samples. Figures 4 and 5 show the specific error of the model for bank user credit classification.
Error of second simulated credit classification.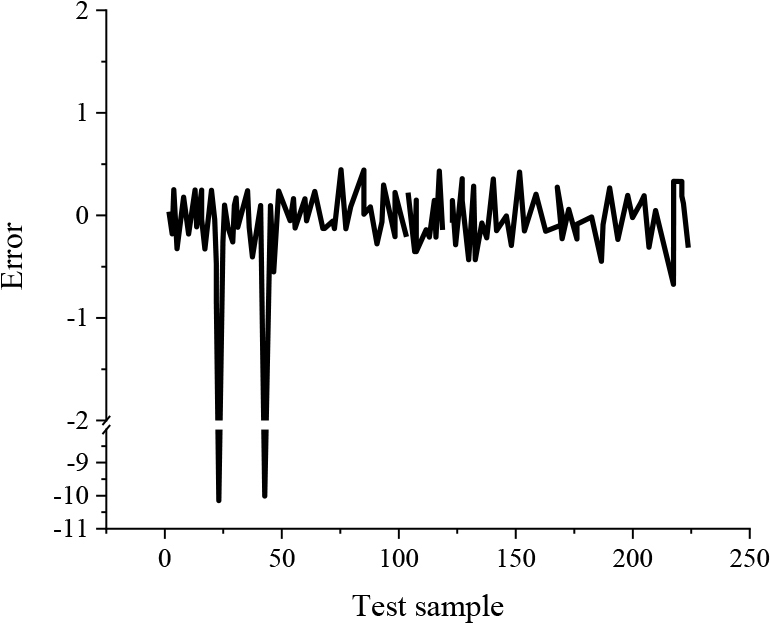
In summary, this experiment uses prediction model of BPNN to classify and predict 400 data. Finally, the accuracy rate is 99.5% of bank user credit classification. In general, this model has high accuracy for user credit classification. Meanwhile, it also shows that the model is feasible and stable.
In this paper, the number of customers is used to evaluate the user’s credit rating. The relationship between the number of users and credit rating reflects a quantitative credit evaluation logic. Specifically, different number intervals are set to correspond to different credit ratings to reflect the credit status of users more accurately. According to the proposed user’s credit rating, from high to low: the number of customers is greater than or equal to 5, and the credit rating is 1. This shows that the large number of bank users is regarded as a positive credit factor. Secondly, as the number of users gradually decreases, the credit rating gradually decreases. When the number of users is between 4 and 5, the credit rating is 2, which reflects a certain degree of good credit. The credit rating of 4
BPNN model to evaluate the credit score results of bank users.
As shown in Fig. 6, the credit rating of most bank users is about 2, the output value of BPNN model is [0.163985, 0.846153], and the model error is [0.000086, 0.000106]. Figure 7 shows the credit evaluation results of bank users with different DNNs.
The credit evaluation results of bank users with different DNNs ((a) Training time; (b) Model effect).
As shown in Fig. 7, in the three cross-validation, the training time of logistic regression, random forest and XGboost is longer, while the average training time of BPNN is 0.97. The auc value of logistic regression cross-validation is 0.679, that of random forest cross-validation is 0.744, that of XGboost cross-validation is 0.758, and that of this model cross-validation is 0.805. Therefore, based on the above research results, the training result of BPNN is the best.
Cross-validation results of this model
Cross-validation results of this model
In order to analyze the model differences between the personal credit evaluation sample data information used in this paper and other independent dataset. In this paper, Lending Club Loan Data, German Credit Data Set and statlog (Australian credit approval) dataset are used to test the performance of this model. The performance results of this model under different datasets are shown in Table 7. Judging from the prediction accuracy, this model performs well on the sample data of personal credit evaluation, reaching 99.50%. It also performs well on other independent datasets, especially on Lending Club Loan Data, with an accuracy of 97.90%. This shows that the model in this paper has high generalization ability on different datasets and can adapt to credit scoring tasks in different fields.
Performance results of this model under different datasets
In order to ensure the robustness of the verification results, the model comparison method is adopted to compare the performance with other scholars’ credit scoring models. The performance results of different models in the same dataset are shown in Table 8. This model outperforms other models in accuracy, recall and F1 score, showing better performance. This shows that this model has a competitive advantage over other models in the credit scoring task, and is more suitable for practical application.
Performance results of different models in the same dataset
The results of this paper show that the BPNN model has achieved remarkable advantages in credit scoring. Chatterjee et al. focused on traditional statistical models, including logistic regression and decision tree, for the application of credit scoring. This method usually relies on manual selection and engineering features rather than automatic learning [33]. Compared with the DNN method in this paper, the traditional model may have some limitations in dealing with nonlinear relations and large-scale data. Ampountolas et al. paid attention to the application of machine learning methods in credit scoring, including random forest and XGboost [34]. Compared with the DNN adopted in this paper, these machine learning methods may be easier to explain and understand in some cases. However, they cannot capture complex nonlinear relationships well, especially on large-scale datasets. Bücker et al. paid attention to the application of Explainable AI (XAI) in credit scoring [35]. This method focused on providing transparency and interpretability of model decisions to meet regulatory and business needs. However, compared with DNN, XAI method performed poorly in dealing with large-scale data and complex relationships. Kriebel et al. focused on ensemble learning and model fusion to improve the accuracy of credit scoring [36]. These methods combined the prediction results of multiple models to achieve better overall performance. Compared with the DNN used in this paper, the integration method may be more robust in some cases, but its computational complexity may be higher. By comparing the research of the above scholars, compared with the traditional statistical model, the DNN can better capture the nonlinear relationship and improve the accuracy and efficiency of credit scoring. Compared with machine learning method, BPNN model can automatically discover the key attributes and internal rules in sample data, and meet the expected requirements by adjusting the weights and thresholds of network parameters and structures. This ability of automatic learning and adjustment is the advantage of this model, especially in large-scale and complex datasets. Compared with interpretable AI, DNN may be superior in prediction performance, but it may be poor in transparency and interpretability. Compared with the integration method, the DNN can automatically discover key attributes and internal rules in the learning process, avoiding the complexity of manual selection and adjustment, and improving the accuracy. Generally speaking, the credit scoring model based on DNN proposed in this paper performs well in the experimental results, which has obvious advantages in improving the level of social credit system and the accuracy and efficiency of bank users’ credit scoring.
Conclusion
Personal credit evaluation is an important practical problem that needs to be solved urgently in the financial field, and it is also an important problem faced by the comprehensive development of bank work. The application of model of BPNN is introduced in the background of the user credit evaluation system of Bank of China. BPNN model is applied to the credit evaluation of retail customers of Chinese commercial banks. The research results show that the credit scoring model based on business intelligence and DNN has achieved remarkable success in two experiments. By introducing the number of users as an additional evaluation factor, a new dimension is added to the credit rating, which improves the discrimination of the model. Among many models, BPNN model performs best in cross-validation, which not only has short training time, but also has high generalization ability and adapts to credit scoring tasks in different fields. In the face of potential moral problems, multi-level privacy and fairness protection measures are taken to ensure the credibility and responsibility of the model. Through the verification of other independent datasets and comparison with other models, the model in this paper performs well in practical application. This paper provides a feasible scheme for the application of business intelligence and DNN in the field of credit scoring, and also contributes to the strong empirical support for improving the level of social credit system.
Although the accuracy and efficiency of bank users’ credit score have been successfully improved by using BPNN model, there are still some research defects. First, the BPNN model used in this paper may face certain computational complexity and computational resource requirements when dealing with large-scale data. The training and tuning of DNNs usually require a lot of computing resources and time, which may limit the efficiency of the model in practical large-scale application. Secondly, the research is limited to the use of personal credit evaluation factor theory and BPNN theory, but does not fully consider other important factors that may affect the credit score. Personal credit is influenced by many factors, including social and economic background, consumption habits, behavior patterns, etc. The neglect of these factors may make the model have some shortcomings in fully grasping the individual credit situation. In addition, according to the specific scale and representativeness of the dataset used in the paper, it is difficult to judge the generalization ability of the model in a wider population. The quality and diversity of datasets are very important for the practicality of the model, which may affect the practical application effect of the model. Finally, although the experimental results show that the model has high accuracy in sample data, it is still necessary to be cautious about the popularization of this result. The performance of the model on a specific dataset does not always translate into robustness in the real scene, and may be affected by unknown environment and changes. Therefore, when applying this model, researchers and decision makers need to fully consider these limitations to ensure that the scope of application and potential limitations of the model are fully understood in practical application.
The future research direction can focus on further promoting the development of business intelligence and DNN in the field of credit scoring to better meet the actual needs of banking and finance. First, the computational complexity of BPNN model in dealing with large-scale data can be solved by optimizing computational resources and improving algorithm efficiency. The new computing technologies and algorithms, such as distributed computing and model compression, is introduced and studied to ensure the efficiency and stability of the model in large-scale applications. Secondly, the paper can expand the scope of credit evaluation factors and deeply explore the influence of social and economic background, consumption habits, behavior patterns and other factors on personal credit. With more abundant and comprehensive data, a more detailed credit evaluation model can be established and the accuracy of the model on individual credit status can be improved. In addition, considering the continuous development of financial technology, the integration of more non-traditional data sources, such as social media activities and online behaviors, can be explored to obtain more global user information. In terms of datasets, future research can pay more attention to the quality and diversity of datasets to ensure that the datasets are more representative and can better reflect the credit status of different groups of people. This may involve establishing a closer data sharing relationship with financial institutions and other partners to obtain more extensive and true user information. In addition, future research can also improve the prediction performance of credit evaluation model by introducing more advanced models and algorithms. For example, other network structures or ensemble learning methods in deep learning can be considered to improve the robustness and generalization ability of the model while maintaining high accuracy. In order to better understand the performance of the model in the actual scene, future research can strengthen the verification of the model in the real environment. This includes field testing in more financial institutions, verifying the applicability of the model in different business scenarios, and further evaluating the reliability and robustness of the model. This will help to improve the practical application of the research results and provide more reliable credit evaluation tools for banks and financial institutions. Generally speaking, the future research direction should aim at improving the practicability, reliability and adaptability of business intelligence and DNN credit scoring model, and provide more advanced and comprehensive solutions for credit evaluation of financial industry. Such efforts will further promote the development of financial technology and help build a smarter and more efficient credit evaluation system.
Footnotes
Fundings
This research is the result of the integrated education model of industry, academia, and research, in collaboration between banks and universities.funded by the Education Department of Hainan Province (Hnjg2021-96), and the exploration and practice of interdisciplinary and multi-disciplinary integration in the cultivation of financial science and technology talents (Hnjg2022-98).