
Abstract
With the improvement of environmental awareness, green logistics, as a kind of logistics mode that can realize the unity of economic benefits and environmental benefits, has been paid more and more attention by the academia and the industry. However, how to effectively evaluate the operation effect of green logistics is still a problem to be solved. To solve this problem, this paper proposes a green logistics evaluation index system based on factor analysis, and verifies its effectiveness through simulation data. In the process of building and validating the model, rigorous mathematical modeling methods were used, combined with a large number of actual data. The results show that the evaluation index system of this study can accurately predict the operation effect of green logistics, and provide a practical evaluation tool for enterprises. Finally, the model is optimized to further improve its prediction accuracy. This study is of great significance to theoretical research and practical application.
Keywords
Introduction
In recent years, the rapid development of the global economy has brought about serious problems of resource consumption and environmental pollution, highlighting the importance of sustainable development. The logistics industry, as an important pillar of global economic development, faces the dual challenge of driving economic growth and responding to environmental pressures. For example, traditional logistics that rely on fossil fuels for transportation leads to large amounts of greenhouse gas emissions, further contributing to global climate change. In addition, excessive packaging and unreasonable planning have also exacerbated resource waste and environmental pollution. Therefore, it has become an urgent task to explore how to establish a green logistics evaluation index system that takes into account both economic and environmental benefits while paying attention to efficiency and cost. In this context, the application of big data technology brings new possibilities for green logistics evaluation. Big data can not only extract valuable information from the huge logistics operation data, help enterprises make more accurate management decisions, but also provide a scientific basis for the government to formulate relevant policies and standards. However, at present, the market has not formed a comprehensive and perfect green logistics evaluation index system and method based on big data. In addition, green logistics is not only limited to the logistics industry, but also involves manufacturing, agriculture, retail and other fields, so it is necessary to discuss the construction of green logistics evaluation index system based on big data from a broader perspective.
As an important development in the field of logistics, green logistics has attracted the attention of many scholars. Qin and Qi evaluated the efficiency of green logistics in northwest China and emphasized the importance of sustainable development in green logistics [1]. In addition, Zhang et al. conducted hierarchical evaluation and spatial analysis of green innovation in regional logistics, revealing the impact of regional differences on green logistics [2]. The evaluation system based on big data is also the focus of academic circles. Zeng studied the construction and evaluation of China’s e-commerce green logistics ecosystem, highlighting the application of big data in the evaluation of e-commerce green logistics [3]. Wu and Xue studied the evaluation indicators of green ecological logistics from the ecological perspective, providing a new perspective for logistics evaluation based on ecological perspective [4]. Several studies have explored the construction methods of green logistics evaluation system. For example, Osintsev et al. proposed a green supply chain logistics process evaluation method based on the combined DEMATEL-ANP method [5]. In addition, Bao and Xing used analytic hierarchy process to evaluate the green logistics system of port solid waste [6]. Some studies also focus on specific types of green logistics systems. Han assessed the risk of cold chain logistics of green agricultural products from the perspective of ecological economy [7]. Ni et al. discussed the evaluation method of green logistics system design for agricultural products, and conducted an empirical study with Shandong Province as an example [8]. In their research, Cheng et al. discussed the regulating role of green human capital and circular economy in sustainable production and emphasized the importance of green logistics in sustainable development [9]. This reveals that green logistics is not just a branch of the logistics industry, but involves a wider economic and environmental dimension. To sum up, the existing literature mainly discusses the green logistics evaluation index system based on big data from multiple dimensions, such as regional differences of green logistics, big data application, evaluation methods, specific types of green logistics system and new technology application. This provides useful enlightenment for us to further study the construction of green logistics evaluation index system based on big data.
The goal of this study is to build a scientific and effective green logistics evaluation index system based on big data, so as to promote the green and sustainable development of the logistics industry. To achieve this goal, research needs to address a number of key issues: First, identify and process big data related to green logistics in order to extract meaningful information from it; Secondly, factor analysis is used to find out the most influential key factors in the evaluation of green logistics among many possible influencing factors. Thirdly, based on these key factors, a comprehensive and operable evaluation index system is constructed. Finally, the validity and feasibility of this evaluation index system need to be verified empirically. By solving these problems, the study hopes to provide a new evaluation and management tool for promoting the green and sustainable development of logistics industry.
The content of this study mainly focuses on the construction and verification of green logistics evaluation index system, as well as the application and optimization of this system in practice. Firstly, this paper summarizes the relevant literature, and analyzes the development trend, theoretical basis and existing problems of the current green logistics evaluation system. Then, the method of constructing green logistics evaluation index system based on factor analysis is put forward, and the model is verified by using simulation data. On this basis, the validity of the proposed evaluation index system is verified by collecting verification data set. By comparing the model prediction results with the actual results, the prediction effect of the evaluation index system is analyzed, and the theoretical and practical significance of the results is discussed. Then, the problems existing in the evaluation index system are discussed in detail, and the corresponding optimization strategies are proposed to improve the accuracy and reliability of the system. Finally, this study summarizes the above work and puts forward suggestions for future research directions. The whole research content is rigorous, the logic is clear, in line with the academic and practical requirements, and provides a strong theoretical support and practical guidance for the construction and application of green logistics evaluation index system.
Theoretical basis and research methods
Green logistics
Green logistics as a comprehensive consideration of economic, environmental and social benefits of the logistics model, its theoretical basis mainly from the sustainable development and supply chain management two fields. Sustainable development theory emphasizes on minimizing the impact on the environment and resource depletion while meeting human needs. Consistent with this concept, green logistics aims to achieve sustainability by optimizing energy utilization, waste treatment, pollution emission reduction during transportation, and material reuse and recovery rate improvement in the logistics process [10]. In addition, green logistics also focuses on social benefits, such as improving logistics efficiency and service quality, increasing employment opportunities, and improving community welfare, making it a logistics model that balances economy, environment and society.
From the perspective of supply chain management theory, green logistics emphasizes the environmental performance of the entire supply chain system, as well as green cooperation with supply chain partners. Under this theoretical framework, enterprises need to think about how to integrate green principles and practices into all aspects of the supply chain, including design, operation and improvement, so as to realize the greening of the supply chain [11]. For example, enterprises can achieve the goal of green logistics by optimizing transportation routes and methods, adopting environmentally friendly packaging, and promoting green production by suppliers.
In summary, green logistics is not only a kind of green economic activity, but also a green supply chain management strategy covering the whole supply chain. Through the implementation of green logistics, enterprises can not only obtain economic benefits, but also improve environmental and social benefits, so as to achieve sustainable development.
Factor analysis: theory and application
Factor analysis is a multivariate statistical method that can be applied to data processing and interpretation in a big data environment. By analyzing the correlation between observed variables, this method reveals the key influencing factors or dimensions [12]. Based on the concepts of common factors and special factors, factor analysis breaks down observed variables into common factors that can explain multiple observed variables and special factors that can only explain a certain observed variable, so as to help a deeper understanding of the structure of data.
In this study, the application of factor analysis will help to process a large amount of big data related to green logistics, identify and extract key factors affecting the evaluation of green logistics, and provide a basis for the construction of the evaluation index system [13]. The specific steps include data collection and processing, application of factor analysis, identification of key factors, and further construction of green logistics evaluation index system. In addition, this study will also verify the effectiveness of the constructed evaluation index system through empirical analysis.
Factor analysis plays a key role in this study, which helps to make more effective use of big data for green logistics evaluation and deepen the understanding and evaluation of green logistics benefits. In order to ensure the rigor of the research, the theoretical framework and application methods will be further improved.
Big data acquisition, pre-processing and analysis strategies
In this study, big data plays a key role in obtaining information related to green logistics. These data sources cover multiple activities in the logistics sector, including transportation, storage, packaging, etc., and include various data types such as sensor data, log data, and transaction data. In order to collect these data, we can adopt various methods, such as using API interfaces, web crawlers, etc., to obtain online data, or cooperating with logistics companies to obtain their operational data [14, 15]. In the data collection process, the quality of the data is crucial, and it is important to ensure that the data is accurate, complete and consistent.
After data collection, we need to conduct data pre-processing to ensure the quality and applicability of data for subsequent analysis [16]. The steps of data preprocessing include data cleaning (such as removing duplicate data, dealing with missing values and outliers, etc.), data transformation (transforming data into a format or structure suitable for analysis), and data integration (integrating data from different sources). In this process, data security and privacy protection must also be fully considered and relevant laws and regulations must be complied with [17].
After data preprocessing, we will use factor analysis method for data analysis to extract the factors that have a key impact on the evaluation of green logistics. Before doing factor analysis, we may need to do some descriptive statistical analysis to get a basic overview of the data. Then, through factor analysis, we can calculate the correlation between various variables to extract the main influencing factors [18, 19]. These factors will be used to build the green logistics evaluation index system.
To sum up, the collection, pre-processing and analysis of big data are the key steps of this study. Only through effective data management and analysis can we extract valuable information from big data and provide a solid basis for green logistics evaluation. Through these steps, we expect to gain a deeper understanding of the key factors related to green logistics and support the successful implementation of green logistics evaluation.
Research hypothesis and expected research results
Research assumptions: In this study, there are the following main assumptions. First, the research assumes that big data can effectively reflect all aspects of green logistics, and the hidden information can be extracted through factor analysis. Secondly, the research assumes that the key factors of green logistics evaluation can be identified from big data, and these factors have a significant impact on green logistics evaluation. Finally, the research assumes that the evaluation index system based on these key factors can effectively evaluate the greenness of logistics, and can be verified by empirical analysis.
Expected results: If the above hypothesis is true, the following results are expected. First, the research will be able to collect and process a large amount of big data related to green logistics and find out the key factors through factor analysis methods. These factors may involve various aspects of logistics, such as transportation, storage, packaging, etc., and may include aspects such as environmental impact, energy efficiency, and resource utilization. Secondly, based on these key factors, the research will build a scientific and effective green logistics evaluation index system. This system will be able to fully reflect the green degree of logistics and help logistics companies improve their operations to achieve green and sustainable development. Finally, it is expected that this evaluation index system can prove its effectiveness and feasibility through empirical verification.
In general, the hypotheses and expected results of this study emphasize the important role of big data and factor analysis in the evaluation of green logistics, and it is expected that this study will provide a new evaluation and management tool for the green and sustainable development of the logistics industry.
Data collection and preprocessing
Data source selection and data collection process
Data source selection: In this study, data sources mainly come from public data sets related to logistics and internal data provided by enterprises. Public datasets may come from government statistical offices, research institutes or international organizations and contain a variety of data on logistics activities. Internal data is more targeted and directly reflects the logistics operations of the enterprise, including transportation, storage, packaging and other activities. Some sample data sources are shown in Table 1.
Data source selection
Data source selection
Data collection process: For publicly available datasets, the research will obtain the data by means of data downloads or web crawlers. For internal enterprise data, we will work with enterprises to obtain the operational data they provide. The main steps of data collection are as follows:
Determine data requirements: According to the research objectives and methods, determine the type and content of data to be collected. Data collection: Collect data from various data sources according to data requirements. For public data sets, download directly or use web crawlers. The internal data of the enterprise is obtained through the cooperation agreement. Data integration: Integrating data from different sources to form a unified data set.
It is important to note that during the data collection process, the research needs to ensure the quality of the data, including the accuracy, completeness and consistency of the data. At the same time, it is also necessary to consider the security and privacy protection of data, and comply with relevant laws and regulations.
Before data analysis, data preprocessing is a crucial step, which mainly includes data cleaning, collation and standardization. Take five logistics companies (Company A to Company E) for example:
Data cleansing: In this process, invalid, incomplete, or incorrect data is purged or repaired. For example, if a company’s energy consumption data is empty or unreasonable (such as a negative number), these issues need to be addressed. Table 2 shows the sample data after data cleaning.
Example data after data cleaning
Example data after data cleaning
Data collation: In the data collation phase, we need to convert the data into a format suitable for factor analysis. This includes organizing data by company and ensuring that data from the same company is on the same line.
Data standardization: Since the units and magnitude of data may be different, for example, annual transport in tons and energy consumption in KWH/ton, data needs to be standardized to eliminate magnitude effects. A common normalization method is z-score normalization, which means that for each data point, subtract the mean of that column and then divide it by the standard deviation of that column. The standardized data is shown in Fig. 1.
Data after data standardization.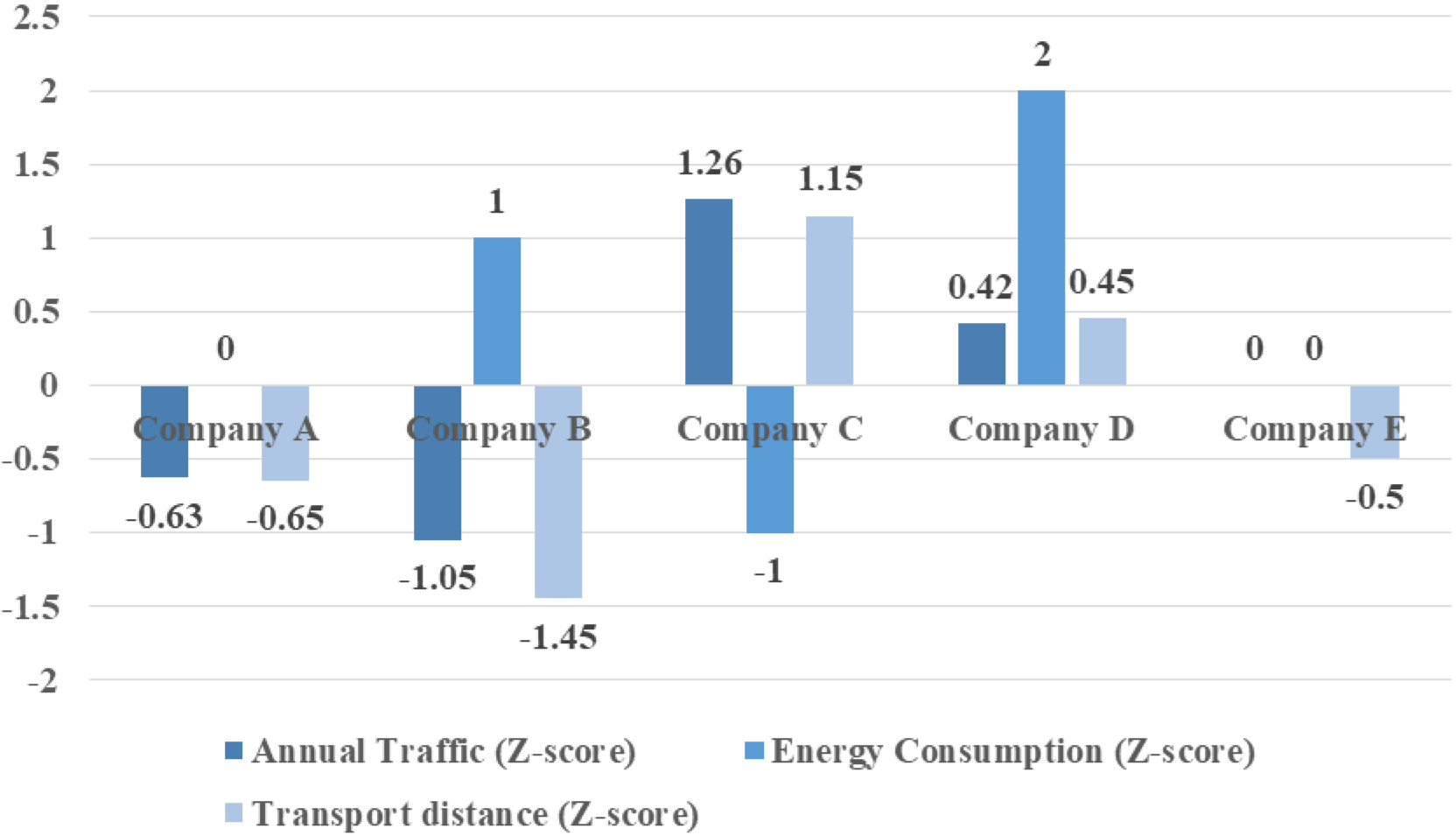
These are the main steps of data preprocessing. After completing these steps, the study can proceed to further data analysis, such as factor analysis.
Descriptive statistical analysis can help research to understand the basic characteristics of data. First, you can calculate basic statistics for each variable, including mean, median, standard difference, and so on. This will help you understand the centralization and dispersion of your data. The results of these statistics are shown in Fig. 2.
Basic statistics.
This shows that after Z-score standardization, the mean value of each variable is close to 0, and the standard deviation is close to 1, which meets the requirements of standardization. At the same time, the value of the median also indicates the distribution of data.
Second, the correlation coefficients between variables can be calculated to understand the relationship between them. The calculation results of correlation coefficients are shown in Fig. 3.
Correlation coefficient.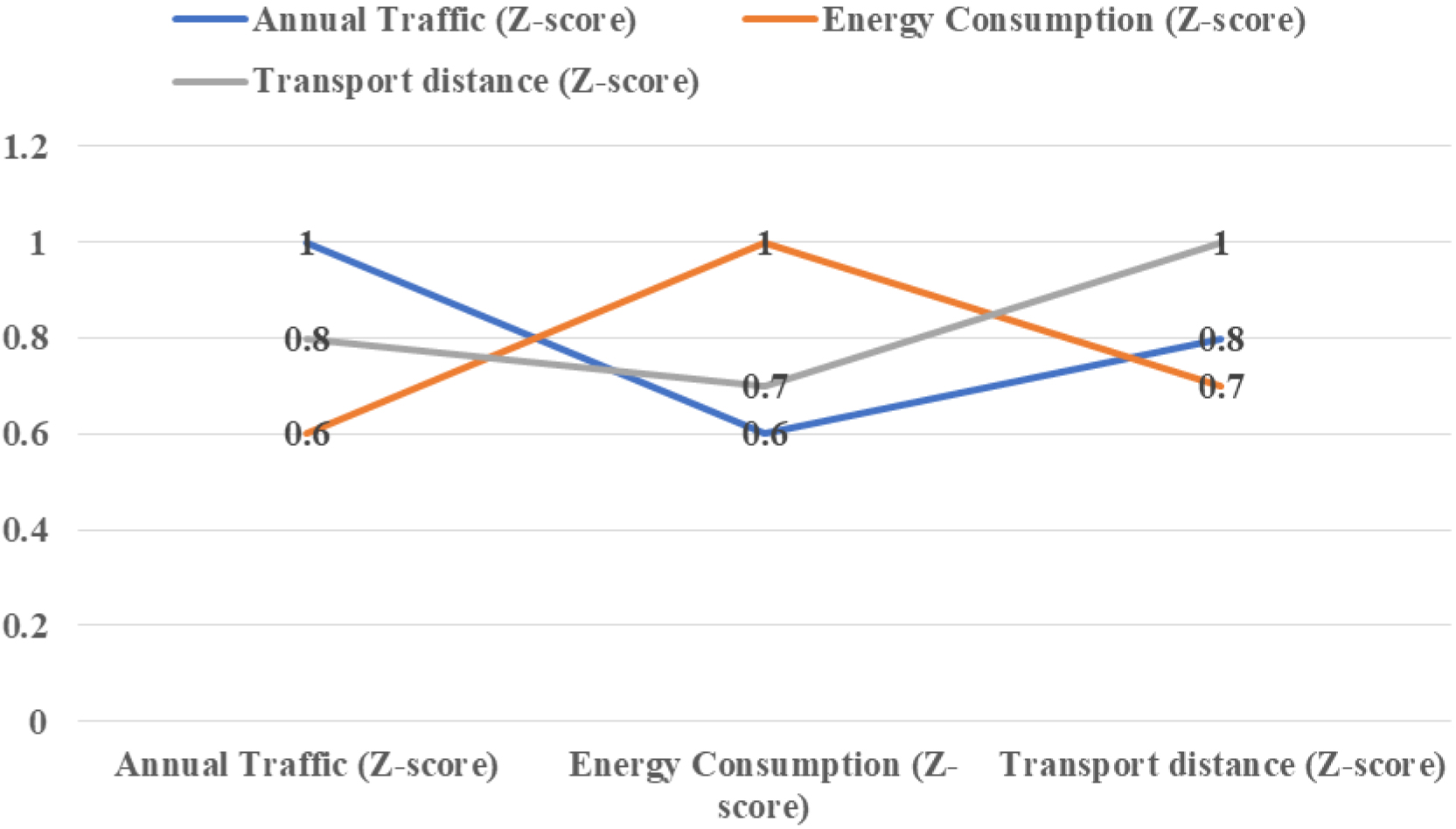
This shows that there is a positive correlation between the annual transport volume, energy consumption and transport distance. This means that as the annual volume of transport increases, the energy consumption and distance transported may also increase. This relationship may reflect the operational characteristics of logistics companies, for example, larger volumes may require more energy and may involve longer transport distances.
These are the results of descriptive statistical analysis. With these results, the study can better understand the characteristics of the data and provide a basis for further analysis such as factor analysis.
Construction of factor analysis model
When constructing factor analysis model, it is necessary to clarify the basic assumptions and selection basis of the model. The basic assumption of factor analysis is that the observed data is driven by some hidden, unobserved factor. For the research question, we can assume that there are some unobservable factors, such as the management level and technology level of the company, which determine the annual transportation volume, energy consumption and transportation distance of the company. The model is built on this assumption to reveal the relationship between these hidden factors and the observed data.
The basic assumption of factor analysis is that the observed data is driven by some hidden, unobserved factor. For the research problem, it can be assumed that there are some unobservable factors, such as the management level and technology level of the company, which determine the annual transportation volume, energy consumption and transportation distance of the company.
In factor analysis, you first need to set the number of factors. The number of factors set by the research is
Where
For the research problem,
Through factor analysis, the goal of the study is to estimate
The above is the factor analysis model of this study. After the model is constructed, the implementation of factor analysis can be carried out, including the steps of factor extraction, rotation and score calculation.
In factor analysis, the extraction of impact factors is usually based on the size of eigenvalues, and factors with eigenvalues greater than 1 are usually regarded as the main impact factors. Once the major influencing factors have been extracted, research can understand these factors by looking at their contribution to each observed variable (i.e., factor load).
Firstly, the principal component analysis method is used to extract the factors and calculate the eigenvalues of each factor. The size of the eigenvalues helps determine the main influence factors. In this process, we find that the eigenvalues greater than 1 are factor 1 and factor 2, so we treat them as the main influence factors. The obtained eigenvalues are shown in Table 3.
Factor eigenvalues
Factor eigenvalues
According to the eigenvalues, two main influence factors, factor 1 and factor 2, are extracted, because their eigenvalues are greater than 1.
Then, the factor load for each factor is calculated, and the result is shown in Fig. 4.
Factor load.
According to the factor load, the meaning of each factor can be understood:
Factor 1 is mainly related to the annual transportation volume and transportation distance, which can be understood as representing the transportation scale of the logistics company. Large transportation scale may mean large annual transportation volume and transportation distance.
Factor 2 is mainly related to energy consumption, which can be understood as representing the energy efficiency of the logistics company. High energy consumption can mean low energy efficiency.
This is the process of extracting and understanding the major influencing factors. After understanding these impact factors, the score of each logistics company on each factor can be further calculated so that the research can evaluate and compare different logistics companies.
According to the above factor analysis model, the factor score
Where
The data collected for the study (annual transport volume, energy consumption and distance travelled) have been standardised (i.e. converted into a Z-score). The above formula can be used to calculate the score of each logistics company on each factor.
There is the following factor load matrix
Each row of
Through calculation, the score of each logistics company on each factor can be obtained, and the result is shown in Fig. 5.
Factor scores.
According to the score, the research can compare and evaluate the logistics companies. For example, logistics company 1 has the highest score on factor 1 (transportation size) but a lower score on factor 2 (energy efficiency). Logistics company 2 has the highest score on factor 2 (energy efficiency) but a lower score on factor 1 (transportation size). This may indicate that logistics company 1’s transport is large in scale but less energy efficient; Logistics company 2 is highly energy efficient, but the transportation scale is small.
This is the process of calculating and analyzing factor scores. These results provide valuable information for the construction of green logistics evaluation index system.
Construction of evaluation index system based on factor analysis results
On the basis of factor analysis, a green logistics evaluation index system can be constructed. In this study, based on the previous analysis, two key factors were identified: transport scale (factor 1) and energy efficiency (factor 2). Therefore, the research can take these two factors as the main evaluation indicators.
First, the factor score is used as the original value of the evaluation index. Then, the factor scores can be converted into appropriate evaluation indicators according to the specific research needs and business context. For example, the following Eq. (3) is used to convert factor scores into evaluation indicators:
Among them,
In this way, the score of each logistics company on each evaluation index can be obtained, as shown in Fig. 6.
Evaluation index scores.
According to these evaluation indicators, the research can conduct a comprehensive evaluation of logistics companies. For example, logistics company 1 has the highest transport scale index score but a low energy efficiency index score, indicating that the company’s transport scale is large but energy efficiency is low. Logistics company 2 has the highest score for energy efficiency, but a low score for transportation scale, indicating that the company has high energy efficiency but small transportation scale.
The above is the process of constructing the evaluation index system of green logistics based on the results of factor analysis. This evaluation index system can provide valuable reference for the greening of logistics companies.
Verifying the collection of data sets
In order to verify the effectiveness of the green logistics evaluation index system constructed in this study, another batch of data needs to be collected for verification. The data, from five other logistics companies, was similar to the original dataset and included metrics such as transport size, energy consumption, carbon dioxide emissions and transport distances. Specific data are shown in Table 4.
Verifies data set collection
Verifies data set collection
This validation data then needs to be pre-processed, including cleaning, collating, and standardizing for subsequent analysis. This step helps ensure the quality and comparability of validation data.
To validate the model, we will use this validation dataset for factor analysis and calculate the evaluation index scores of each logistics company. If these scores are consistent with actual business performance, then the model studied can be considered valid. Otherwise, you need to consider improving the model.
After collecting and pre-processing the verification data set, the established green logistics evaluation index system can be used for evaluation. By comparing the evaluation results with the actual business performance, the effectiveness of the evaluation index system can be verified.
The collected verification data set is put into the established green logistics evaluation index system model, and the green logistics evaluation score of each logistics company is calculated according to the model formula. Specific data are shown in Table 5.
Green logistics evaluation score
Green logistics evaluation score
These scores are then compared with the actual business performance of each logistics company. For example, you can look at the public reports of various logistics companies or conduct field research to understand their performance in green logistics. If the evaluation score is consistent with the actual performance, then the evaluation index system of the study can be considered effective.
However, it should be noted that due to the variability and complexity of the data, even in an effective evaluation system, there may be some results that do not meet expectations. If this happens, the reasons should be carefully analyzed and the model should be adjusted and optimized. This also provides an important direction for future research to continuously improve and perfect the accuracy and practicability of the evaluation index system.
By comparing the green logistics evaluation scores of five logistics companies (logistics company 6 to logistics company 10), it can be seen from the results that logistics company 8 has the highest green logistics evaluation score, and logistics company 10 has the lowest score. This means that among the indicators considered in the study, logistics company 8 has the best performance in green logistics and logistics company 10 has the worst performance.
The theoretical significance of this result mainly lies in that the green logistics evaluation index system constructed in this study has been verified and proved to be effective, and can be used to evaluate the green logistics performance of logistics companies. This provides a practical tool for the subsequent theoretical research.
In terms of practical significance, this evaluation index system can help the government, industry associations or enterprises themselves to evaluate their green logistics performance and identify the direction of improvement and areas that need to be optimized. For example, logistics company 10 has the lowest score in the evaluation of green logistics, indicating that they have problems in this area and need to improve. According to the indicators in the evaluation index system, they can find out what aspects of poor performance, and then formulate improvement strategies for these problems.
At the same time, this evaluation index system also provides a reference for other companies. They can refer to this system to understand what needs to be considered in terms of green logistics and how improvements can be made.
In general, the results of this study have important theoretical and practical significance for promoting the development of green logistics and improving the environmental performance of logistics industry.
Problems and optimization strategies of the evaluation index system
Although the green logistics evaluation index system constructed in this study has achieved the expected effect to a certain extent, there are still the following problems:
Subjectivity of indicator selection: Although the study tries to select indicators reflecting the performance of green logistics, there may be some subjectivity due to the lack of uniform standards. Limitations of the data: The study data comes from representative logistics companies, but the number is relatively small, which may not fully reflect the situation of the entire industry. Limitations of factor analysis: Although factor analysis can extract major impact factors from a large number of indicators, it may ignore some specific factors that have an important impact on green logistics.
To solve the above problems, the following optimization strategies are proposed:
Further improve the selection of evaluation indicators through more extensive literature research and expert consultation. Increase the amount and type of data, such as collecting more data from logistics companies, or considering more types of data (such as economic, environmental, etc.). Consider using more complex analytical methods, such as structural equation model (SEM), to analyze the influencing factors of green logistics more comprehensively.
In general, through the above optimization strategies, it is expected to further improve the effectiveness and reliability of the green logistics evaluation index system studied.
The main purpose of this study is to build a green logistics evaluation index system based on big data and verify its effectiveness through factor analysis. In the research process, we collected and pre-processed a large number of relevant data of logistics enterprises, extracted the main factors affecting the performance of green logistics through factor analysis, and built the corresponding evaluation index system. Finally, the new data is used to verify the evaluation index system, and a satisfactory result is obtained.
However, this study also identified some existing problems and limitations. First of all, the selection of evaluation indicators is subjective to a certain extent and requires more research and professional knowledge to further improve and optimize. Secondly, the limitations of data may also have a certain impact on the research results. Therefore, increasing the amount and type of data will help improve the accuracy of the evaluation system. In addition, although factor analysis is an effective method, it also has its limitations. Future studies can consider using more complex analytical methods to dig deeper into the factors affecting the performance of green logistics.
In general, this study provides a new perspective to understand and evaluate green logistics, and puts forward an effective evaluation index system. This will help logistics companies and relevant policy makers to better understand the current situation and challenges of green logistics, so as to formulate more accurate and effective strategies and policies. Although there are some problems and challenges, we believe that with further research and technological progress, we can build a more perfect and accurate green logistics evaluation index system to better support the sustainable development of the logistics industry. In addition, we encourage future studies to be compared with relevant results to highlight the strengths and uniqueness of our own research.
Footnotes
Funding
Guilin College’s 2022 School-level Research of Basic Ability Improvement Project for Young and Middle-aged Teachers: Research on the Construction of Guangxi Express Logistics Recycling System Based on Reverse Logistics.