
Abstract
To enhance the precision of the music recommendation environment system, a novel design approach has been introduced, utilizing multi-label propagation and hierarchical clustering analysis for a dual music recommendation environment. First of all, the process model of music recommendation environmental system is built based on music recognition system, which is composed of music signal preprocessing module, music model, sound model and music recognizer; second, on the basis of further study on the clustering validity, a new clustering validity function is established by describing the intra-class compactness and inter-class separation of clustering through fuzzy similarity relation; finally, the validity of the proposed music double recommendation environmental system using multi-label propagation hierarchical clustering analysis is verified by simulation experiment. The results show that the recommendation method based on comprehensive evaluation of user characteristics is suitable for single-category users, while the recommendation method based on multi-category evaluation is suitable for multi-category users. This approach offers an effective and precise means to enhance the accuracy and customization of music recommendation systems, thereby increasing user satisfaction.
Keywords
Introduction
Music recommendation system is an important part of internet music service platform, which can provide personalized music recommendation for users to meet their needs and interests. However, the traditional music recommendation system can only consider a single label or a specific attribute, and it is difficult to meet the needs of users for diversification and personalization [1]. Classed as one form of multi-media information, music is now met with not only an increasing amount of data on itself, but also a constantly increasing demand from the consumers, which poses a more demanding requirement on the research into music recommendation algorithms. Therefore, the music double recommendation system based on multi-tag propagation has become a research hotspot.
To address this feedback, it is important for the authors to enrich the introduction section to align with the theme of service automation and data-driven decision analytics, as highlighted in this special issue. This enhancement can be achieved by incorporating a dedicated paragraph or section emphasizing the significance of digital transformation and service automation. In this added section, the authors should discuss how digital transformation is reshaping industries by integrating advanced technologies like AI, machine learning, and big data analytics into various services. The focus should be on how these technologies contribute to automating services, improving efficiency, and enabling more informed decision-making through data analysis. Furthermore, the section should elucidate the relevance of service automation in the current digital era, highlighting its benefits such as increased operational efficiency, enhanced customer experience, and the creation of new business opportunities. The authors could also touch upon the challenges and considerations in implementing such transformations. By incorporating these aspects, the introduction will provide a comprehensive backdrop to the study, setting the stage for the research’s contribution to the fields of service automation and digital transformation.
In this paper, the topic is focused on CNN-based piano music recommendation algorithm, to conduct research into how frequency spectrum is generated and how musical notes are identified for piano music. The CNN classification model is established and trained. The classification is optimized and the users’ characteristics are calculated. Thus, the recommendations to users are achieved with an experimental comparison drawn. In this paper, an improvement is made to the algorithm for identifying the musical notes of piano music. The characteristics of musical notes are combined with frequency spectrum to derive the frequency spectrum of musical notes, with the accuracy rate of CNN classification improved. The algorithm combines the characteristics of notes with the frequency spectrum to obtain the frequency spectrum of notes, thus improving the accuracy of CNN classification. Specifically, it is to use CNN model to classify and identify piano music, and meanwhile consider the characteristics of users to realize personalized recommendation. By optimizing the algorithm and model, the accuracy and efficiency of the recommendation system can be further improved to enhance users’ trust and satisfaction with the recommendation system, thus promoting the development and application of the piano music recommendation system and improving its frequency and viscosity of using the music recommendation system.
In order to get a more accurate music recommendation model. Firstly, this paper sorts out and summarize the research results in China and other countries. Secondly, the music recommendation process and probability index model for multi-label communication are established to realize a variety of accurate matching of music performance. Next, the hierarchical clustering analysis algorithm is designed to further improve the accuracy and personalization of the recommendation system. By analyzing the characteristics of songs, songs can be divided into different clusters to better understand the relationship between songs. Then, the performance of the model and algorithm is verified. Finally, it is concluded that the hierarchical clustering algorithm of music double recommendation system based on multi-tag propagation has obvious advantages and credibility, and can achieve the goal of improving user satisfaction and stickiness to the greatest extent.
Introduction to Ensemble Learning and Active Learning: Begin by providing a basic understanding of what ensemble learning and active learning are, highlighting their significance in the field of machine learning and data analysis.
Discuss the complexity and challenges associated with processing heterogeneous data, which often involves diverse data types and sources, requiring sophisticated handling and analysis. Delve into how the novel ensemble approach effectively harnesses the strengths of both ensemble and active learning techniques to address these challenges. Explain how this combination enhances the model’s ability to learn from diverse datasets more efficiently and with better accuracy. Provide a comprehensive description of the proposed ensemble approach. This should include the algorithms used, how they are integrated, the role of active learning in this context, and any innovative strategies employed to optimize performance. Highlight the advantages of this approach, such as improved predictive accuracy, better handling of data variability, and enhanced model robustness. Discuss potential applications in various fields like healthcare, finance, or environmental studies, where heterogeneous data is common.
If available, include case studies or experimental results that demonstrate the efficacy of the novel ensemble approach in real-world scenarios or through simulations. Conclude with thoughts on how this approach could evolve and its implications for future research in data science and machine learning. Incorporating this section will provide the readers with a thorough understanding of how the novel ensemble approach can be effectively applied to heterogeneous data, highlighting its potential to revolutionize data analysis methodologies.
Literature review
Meng et al. introduced a multi-label music recommendation method based on label graph propagation. This method used tag graph to describe the relationship between songs and tags, and used propagation algorithm to calculate the similarity between songs [2]. Additionally, the authors have proposed a hierarchical clustering-based recommendation technique, utilizing clustering trees to categorize songs and employing a single-chain clustering method for making recommendations. Experimental data indicate that this approach yields superior recommendation results. By analyzing user behavior and music data characteristics, this algorithm can anticipate user preferences and autonomously recommend music. Over time, it has resolved numerous practical issues, evolving from a method focused on user behavior preferences to one that emphasizes associative recommendations among users. In recent years, it has further explored potential user preferences. Generally speaking, music recommendation algorithms have become more and more capable of making recommendations. A paper by Huang introduced a music recommendation method based on collaborative filtering and hierarchical clustering [3]. This method used collaborative filtering algorithm to calculate the similarity between users, and used hierarchical clustering algorithm to divide songs into different groups. Huang also proposed a recommendation method based on multi-tags, which used the tag information of songs to determine the similarity between songs. The experimental results showed that this method could obtain better recommendation effect.
However, Han believed that in an era characterized by big data, the recommendation method facing massive music data faced some new challenges and opportunities. On the one hand, the processing of massive data was very complicated, and the original recommendation algorithm needed to be updated. On the other hand, it was urgent to solve the problems existing in the original recommendation algorithm, such as the cold start problem in collaborative filtering recommendation [4]. From another perspective, innovative computer technologies were constantly emerging, such as big data processing technology and deep learning, all of which could help design new recommendation algorithms with stronger processing power and higher accuracy. Wu et al. introduced a music recommendation method based on hierarchical clustering in their paper [5]. This method used spectral clustering algorithm to calculate the similarity between songs, and used hierarchical clustering algorithm to divide songs into different groups. They also proposed a recommendation method based on users’ preferences, which used users’ historical records of listening to songs to determine the types of songs that users like, and used hierarchical clustering algorithm to recommend songs for users. The experimental results showed that this method could obtain better recommendation effect.
As revealed by the research results of MIR in recent years, there are two main methods of music recommendation: content-based recommendation and context-based recommendation. The former focuses on the analysis of audio data, while the latter focuses on music-related data, such as labels, categories, authors, comments and ratings. Here are several commonly used music recommendation algorithms. As for content-based recommendation, the data comes from the characteristics displayed by the audio signal of music, so the classification and recommendation of music are objective, and it has nothing to do with users’ preferences. However, it is difficult to extract and analyze the complex features of audio signals, which makes the music description impossible to be accurate, thus affecting the recommendation results. For collaborative filtering recommendation, the data comes from the user’s preference for music, which allows mining the user’s potential preference. However, this method has many problems, such as cold start, sparsity and scalability. Some mainstream music websites continue to take this approach. Zhang et al. applied this recommendation method for graph-based models, and the data came from graph models composed of users and music [6]. Nodes in this model were classified as users or music, and the connecting lined between nodes represented their association. This method had high accuracy, but the graphic structure was relatively complex and difficult to generate. As for hybrid recommendation, the data came from the comprehensive application of data sources of all the above methods. This method represented the combination of different recommendation strategies to give full play to their respective advantages. Although the accuracy was high, it involved a complex strategy combination process.
Method
The procedure of music recommendation for multi-label dissemination
The procedure of music recommendation.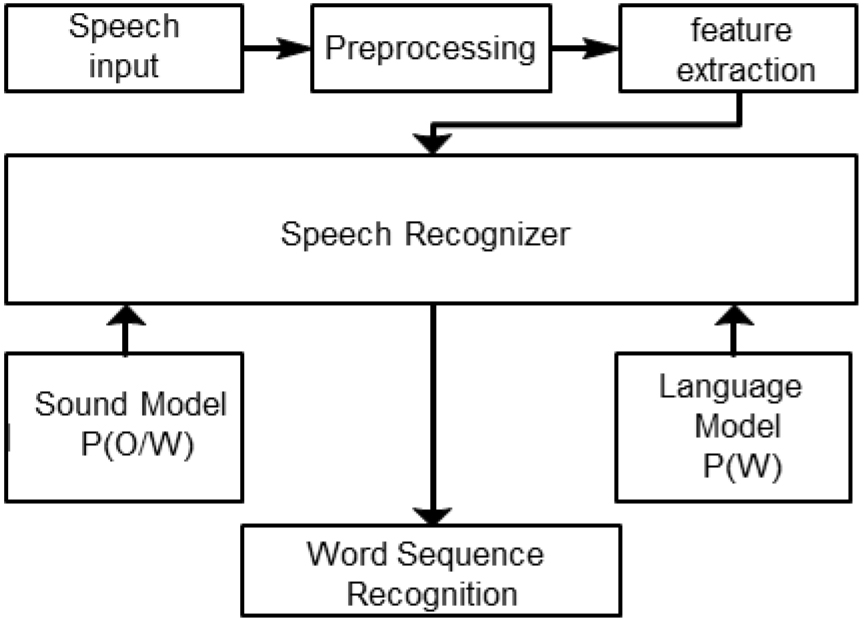
Figure 1 shows a framework of music identification algorithm, from which it can be seen that, this framework is comprised of four component parts, namely musical signal pre-processing module, music module, audio module as well as music identifier. Firstly, the continuous frames as input are divided in the pre-processing module. Secondly, in the module for extraction of characteristics, the feature vector of each frame is extracted to represent the audio information, based on which a diffused feature vector sequence derives.
Subsequently, the music identifier is applied to make word identification based on certain criteria. In order to apply the optimal algorithm to the music recognition system, the Markov model was suggested by some scholars for the music recognition system. By using search algorithms featuring a commonly-used Viterbi algorithm and combining audio model with music model as output to maximize
The all-search recognition process subsequent to feature extraction represents a core part of the algorithm and this process is also known as music identifier, which is based on the acoustic and musical knowledge demonstrated by the music model
The musical model indicator is,
Thus, the music recognition process can be represented by the maximized indicator as follows
The pseudo code is as follows:
1 Start 2 Input:
Equation (5) represents a probability index model. From a procedural perspective, the optimal algorithm could be applied to derive a maximum solution, further with which the optimal parameters derive for music recognition to be achieved. In the space to search for music, the categories that match the unknown sample are explored to derive the sequence of output words. In fact, however, this probability index model is incapable of a direct application of EA algorithm to the search for optimization.
As shown in Fig. 1, it is the whole process of music recommendation. First, after voice input, the system preprocesses the input information and captures features, and then processes the heard templates and voice templates through a voice recognizer. Finally, the keyword recommendation is completed, and the whole music recommendation process is carried out according to the characteristics, with high accuracy.
Hierarchical clustering analysis algorithm is also known as tree clustering algorithm. Firstly, a similarity matrix
Hierarchical clustering algorithm is considered quite effective as iteration continues only until all data belongs to a single cluster. Meanwhile, there are several downsides to it, such as high spatial complexity, low efficiency in clustering and significant error [7, 8].
Definition of the algorithm
In dictionary, a cluster is defined as a combination of many similar or identical items. Such a definition has double implications. Firstly, all the samples of the same category exhibit similar or identical attributes [9, 10]. That’s to say, the value of compactness measure for clustering is supposed to be minimized. Otherwise, in case that the samples of different attributes are classified into the same category, the value of compactness measure for this category would be significant [11, 12]. Secondly, the separateness among different categories for an ideal clustering shall be excellent. If the samples supposed to be of the same category are classified into different categories, category overlapping would be significant, which suggests that there is supposed to be a significant discreteness among the categories derived from an excellent clustering result. In this paper, the similarity measure among the samples is applied to define both the in-category compactness measure and inter-category discreteness [13, 14, 15].
It’s assumed that the similarity matrix which is derived from the similarity measure of sample set
Category represents a set of the samples with similar attributes. Of the same category, the variations in similarity among different samples tend to be comparatively insignificant. It means that the similarity of each sample to other samples and the in-category average similarity vector would be relatively insignificant. Therefore, the definitions as follows are derived.
Definition 1 of in-category compactness measure.
A specific layer in the dendrogram of hierarchical clustering for the sample set
In order to achieve a desirable inter-category discreteness, the variations between the average similarity vector of all categories and that of sample set are definite to be significant. So, in this paper, the inter-category discreteness measure is defined by the distance between the in-category average similarity vector and the average similarity vector of sample set.
Definition 2 of inter-category compactness measure.
A specific layer in the dendrogram of hierarchical clustering for the sample set
As for an excellent category, the more similar the samples within the same category are, the better. In comparison, the less similar the samples of different categories are, the better. Thus, a lower value of in-category compactness measure and higher value of inter-category discreteness measure would be more desirable [18, 19, 20].
Definition 3 of new effectiveness indicator.
The new effectiveness indicator is established as follows.
A higher
The training samples are sourced from both www.hqgq.com and Neteast Cloud Music, with 4 standard categories involved, namely Blues, Classical, Jazz and Pop [21, 22]. For each category, 100 pieces are included, all of which are pure piano performance in mp3 format. The compression of frequency is classed into 128 classes, corresponding to the longitudinal coordinate on the image of frequency spectrum. The data on frequency within one second is mapped into 50 pixels, corresponding to the horizontal coordinate on the image of frequency spectrum. After splitting, the pixel of frequency spectrum is 128
The distribution of maximum proportion for the predicted classification of testing samples.
As revealed in Fig. 2, the 400 samples with a maximum proportional value in exceed of 0.9 account for 92.7%. Except for sample 12, the maximum proportional value of all the remaining samples exceeds 0.5, suggesting that most of the errors stem from the error in predicted classification, with only a fraction of them as statistical error. In review of the classification results for sample 12, it is discovered that the corresponding classification to the second largest proportional value happen to be the label classification of this sample, indicating that the sample is likely to fall into multiple categories. That is to say, the classification results for sample 12 stem from data error.
The distribution of maximum proportion for testing samples on music.
In this paper, besides, the statistics on classification of the frequency spectrum samples for 10 pieces of music are involved. Figure 3 shows how the maximum proportion is distributed for the 10 pieces of sample music, with every 100 continuous samples representing a piece of music. Figure 2 presents a similar classification to Fig. 3. Errors arise in classification from wrongly-labeled samples with the maximum proportional value approaching 0.5, which is despite that this sort of samples makes up only a tiny proportion and has no impact on the overall classification. It indicates that even a fragment that lasts 2.56 s is possible to signal the type of an entire piece of music. As to what is represented by the range from 600 to 700, the part with discrete proportion shall not be discounted straightaway as it has a potential to represent multiple categories as a sort of effective data.
In order to highlight the advantages of the dual-system music recommendation algorithm based on multi-tag propagation, 20 users are randomly selected and their Mean Absolute Error (MAE) values with the traditional algorithm is compared, as shown in Fig. 4.
Comparison of MAE values of sampled users.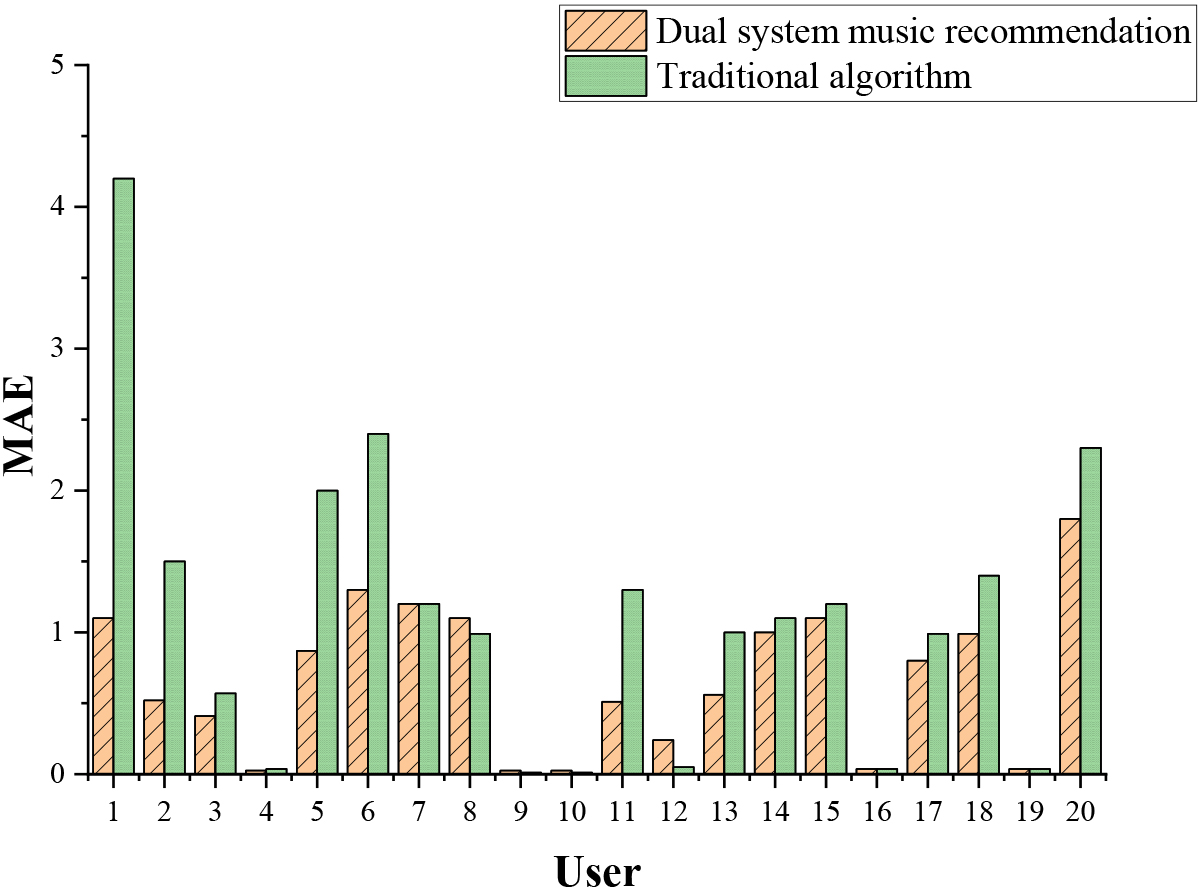
Comparison of hit ratio between traditional algorithm and dual-system music recommendation algorithm.
As shown in Fig. 4, the MAE value of the dual-system recommendation algorithm adopted in this paper is smaller than that of the traditional algorithm, which shows that the working accuracy and implementation of the dual-system music algorithm are better than that of the traditional algorithm. Figure 5 shows the hit rate of music recommendation by the dual-system music recommendation algorithm and the traditional algorithm.
As shown in Fig. 5, for all users to recommend music with traditional algorithm and dual-system music recommendation algorithm, it is obvious that the average hit rate of the dual-system music recommendation algorithm based on multi-tag propagation designed in this paper is higher than that of the traditional algorithm. It fully demonstrates the rationality and availability of designed algorithm and provides a feasible scheme for improving user experience.
Experimental comparison between varying proportion of user ratings.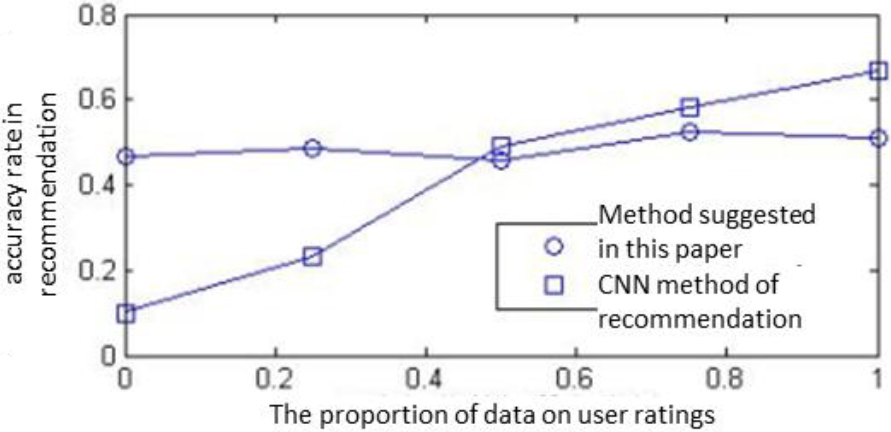
The horizontal coordinate in Fig. 6 signifies the proportion of user ratings in all user data, which is a music list. The data on ratings is the ratings given by the users to music. In this paper, two separate methods are experimented with, respectively, for the accuracy rate in recommendation when the data on user ratings accounts for 0%, 25%, 50%, 75% and 100%, respectively. As revealed by the results, the CNN recommendation algorithm reliant on data of user ratings produces a low accuracy rate during cold start, and the rate improves when the data on user ratings are introduced. In comparison, the method suggested in this paper has no dependence on user ratings, for which the accuracy rate of recommendation varies little. Therefore, this method is useful to some extent in the absence of user ratings for making recommendation.
In this paper, the statistical analysis led to a discovery that the classification results are met with data errors as well as classification errors, further with which the threshold model was raised for optimization. The refined results from post-optimization can serve as a feature vector to delineate the classification attributes of music. By integrating these with user preferences, it becomes possible to calculate individual preference profiles [23, 24]. The study proposes two distinct recommendation strategies for empirical comparison: one that utilizes a holistic evaluation of user characteristics, and another that employs a multi-dimensional assessment of these traits. The experimental findings suggest that the holistic assessment method is more appropriate for users with single-category preferences, while the multi-dimensional approach is better suited for users with diverse, multi-category interests. Overall, the result from a comprehensive assessment is superior to that from a multi-category assessment [25, 26]. Building on the existing research, it’s feasible to enhance the music recommendation system’s accuracy and user experience by incorporating additional data sources alongside the music’s own labels. This could include leveraging information such as users’ interests and hobbies from social networks, as well as their location data, to create a more tailored and effective dual music recommendation system.
Data availability
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Funding
This work was supported by General Project of Philosophy and Social Sciences in Hunan Province in 2020 “Research on the Communication of Hunan Red Music Culture in the New Era” (No. 20YBA041).
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent was obtained from all individual participants included in the study.
Footnotes
Acknowledgments
The authors acknowledge the help from the university colleagues.
Conflict of interest
All Authors declare that they have no conflict of interest.