
Abstract
This paper promoted the development of new media art and film and television culture creation through multi-modal information fusion and analysis, and discussed the existing problems of new media art and film and television culture creation at present, including piracy, management problems and lack of innovation ability. The network structure of RNN neural network can cycle information among neurons, retain the memory of previous user information in the progressive learning sequence, analyze user behavior data through previous memory, accurately recommend users, and provide artists with a basis for user preferences. The viewing experience scores for works 1 to 5 created using traditional creative methods were 6.23, 6.02, 6.56, 6.64, and 6.88, respectively. The viewing experience scores for works 1 to 5 created through multi-modal information fusion and analysis were 9.41, 9.08, 9.11, 9.61, and 8.44, respectively. Movies created through multi-modal information fusion and analysis had higher viewing experience ratings. The results of this article emphasize that multi-modal information fusion and analysis can overcome the limitations of traditional single creative methods, provide rich and diverse expressions, and enable creators to more flexibly respond to complex creative needs, thereby achieving better creative effects.
Keywords
Introduction
With the continuous development and popularization of information technology, new media art and film and television cultural creation are receiving increasing attention in today’s society. Especially in the digital era, the expression forms of art and film and television works have shifted from a single media form to multi-media and cross platform expression, and people’s requirements for works are also increasing. They hope that works can be more diversified and enriched. With the help of digital technology, creators of new media art and film and television culture can use digital media technology more innovatively, integrating richer, three-dimensional, and multi-level creative elements into their works, thereby enhancing the expressiveness and artistry of the works, and enabling audiences to enjoy a richer and more diverse artistic experience. Therefore, how to integrate and analyze information based on multi-modal information to create more excellent new media art and film and television cultural works has become an important research direction in this field.
With the development of new media technology and digital media, the traditional film and television industry is facing opportunities for transformation and innovation. Newsinger Jack analyzed the diversity policies of the contemporary film and television industry, and studied the explicit and implicit operations of these policies, and how they affect the outcomes of film and television diversity. He provided a more detailed conceptualization of diversity policies and their outcomes [1]. Cepeda RAG proposed that with the passage of time and the development of digital technology, more and more new media art works are facing challenges. Many new media artworks rely on certain technologies, and when these technologies are replaced or no longer available, measures should be taken to make old artworks compatible with the new technologies that replace them [2]. Coleman ER aimed to explore the connection between the structural organization of the television industry and the well-being of ordinary people involved in its production. He conducted in-depth interviews with documentary writers and producers, seeking their experiences in television production, with a focus on developments related to work practices, marketing strategies, and broader media [3]. With the popularization of new media technology, the threshold for using some tools and software has been lowered, and the creative ideas of artists may also be restricted. This requires artists to focus on innovation, try new creative methods and forms of expression, and constantly overcome their own thinking and technological limitations.
Deep learning methods have developed voice recognition, image recognition and natural language processing. Each of these tasks involves a single mode of its input signal. It is of wide interest to study more complex modeling and learning problems across multiple modes. Zhang Chao provided technical analysis multimodality of existing models and learning methods. The combination of vision and natural language modality has become an important topic in the research field of computer vision and natural language processing. In film and television creation, multimodality can be used for image-to-text caption generation, text-to-image generation, and visual question and answer (Q&A), which could promote the development of related fields [4]. Pajkovic Niko found that as the streaming media war continues to heat up, recommendation systems become a key competitive feature for top tier video streaming media. Therefore, film and television production and consumption could increasingly be mastered in semi-autonomous algorithm technology [5]. Ming-Hao Yang proposed that in multi-modal human-machine dialogue, nonverbal channels such as facial expressions, postures, and gestures, combined with oral information, are important in the conversation process. Currently, despite the excellent computational performance of single channel behavior, accurately understanding users’ intentions from their multi-channel behavior remains a significant challenge. He reviewed data fusion methods in multi-modal human-machine dialogue and discussed important breakthroughs that data fusion methods may make in future multi-modal human-machine interaction applications [6]. In the creation of new media art and film and television culture, multi-modal information fusion and analysis can help creators gain a more comprehensive and in-depth understanding of works, and enhance their artistic value and market influence.
The application of new technologies and the rise of new media platforms have provided more innovative space and ways of expression for film and television creators, which can provide them with more possibilities for innovation. At the same time, the emergence of new media platforms has also provided creators with a wider audience and market space, enabling innovative works to receive more attention and support. With the continuous development of new media technology, multi-modal information processing has become an important research direction. Multi-modal information fusion and analysis is a research field that comprehensively analyzes various types of information, aiming to improve the accuracy and robustness of the system by integrating multi-source data information. In the field of new media art and film and television cultural creation, multi-modal information fusion and analysis have become a very important application field. In this field, different algorithms and models can be studied to achieve the synthesis, analysis, and mining of multimedia information, thus laying a solid foundation for new media art and film and television cultural creation.
Current situation and problems of new media art and film and television culture creation
Challenges of new media art and film and television cultural creation
New media art and film and television culture have become a rapidly developing huge industry in today’s society. The content of film and television cultural creation is rich and colorful, including movies, television dramas, animations, documentaries, and online videos. The creation in this field is very artistic and also a highly commercial industry [7, 8]. In the field of film and television cultural creation, the emergence of new media technology has brought new opportunities and challenges to creation, continuously promoting the development of film and television cultural creation. Film and television cultural creation is a comprehensive creation that integrates culture, art, commerce, and technology. It is a form of creation that expresses and conveys people’s perception, thinking, and response to life from multiple perspectives such as images, music, and text.
Film and television cultural creation is a high-end art form that can convey emotional experiences and express deep emotions and thoughts through various expressive techniques such as images and music. Creators in the field of film and television culture not only need to have artistic talent, but also need to consider market demand and commercial interests. With the continuous development of technology, new technological means are increasingly used in film and television cultural creation. The application of new technologies can present film and television cultural creation more vividly and realistically, and can also increase the expressive power and artistic value of creation. Film and television cultural creation can be disseminated through various channels, including television, cinemas, the internet, and other forms. Its dissemination scope often has a large coverage and can convey more ideas and values.
(1) Piracy issues
The most direct problem faced by film and television art creation in the era of new media is piracy. Currently, many content in Chinese video websites’ film and television programs is in a non-copyright state [9, 10]. Piracy often appears online immediately after a film or television work is aired. Currently, Chinese people have weak copyright awareness and do not have particularly effective and strong enforcement management measures. Film and television cultural creation is a highly sensitive industry, and the content in works often involves political, cultural, moral and other issues. Lack of regulatory links can lead to the emergence of some negative works, affecting the healthy development of society.
This article selects 200 works each from movies, music, art, and photography, and the piracy situation of different types of works is shown in Table 1.
Piracy of different types of works
Piracy of different types of works
As shown in Table 1, 31 out of 50 film works were pirated; 29 out of 50 music works were pirated; 37 out of 50 art works were pirated; 40 out of 50 photography works were pirated. It can be found that piracy is a common problem in the market, which can cause serious damage to the rights and interests of creators and producers, and bring great trouble to artists and the creative industry.
The investment and production costs of film and television cultural creation are relatively high, but there are still many low-quality film and television works that often lack exploration and thinking, follow a commercialized model, and lack artistry. The film and television art in the new media era could face more serious piracy problems in the old media era. With the introduction of a series of relevant policies and the purification and self-discipline of several major video websites to combat online video piracy, the piracy problem in the new media era remains severe.
(2) Management issues and innovation capabilities
In the fields of new media art and film and television culture, market regulation and norms are relatively weak, and the capacity and resources of regulatory entities and institutions are limited. This leads to weak market management, allowing some non-compliant and unhealthy business behaviors to exist and develop. This article selects 1000 creators for investigation, and the relationship between market regulatory measures and mechanisms and innovation capability is shown in Fig. 1 (Fig. 1a represents the severity of market regulatory measures and mechanisms, and Fig. 1b represents the innovation capability of creators).
Market regulatory measures, mechanisms, and innovation capabilities. (a) Severity of market regulation measures and mechanisms. (b) Innovation capability situation.
As shown in Fig. 1, in the market management survey of the field of new media art and film and television culture, Fig. 1a found that only 7.90% of creators believed that market regulatory measures and mechanisms were very strict; 8.60% of creators believed that market regulatory measures and mechanisms were relatively strict; 68.20% of creators believed that market regulatory measures and mechanisms were not strict; 15.30% of creators indicated that the market has not established regulatory measures and mechanisms.
In Fig. 1b, only 5.50% of creators had very strong innovation abilities; only 6.10% of creators had relatively strong innovation abilities; 53.80% of creators had very weak innovation abilities.
From Fig. 1, it can be observed that the market regulatory measures and mechanisms in the fields of new media art and film and television culture are not strict enough, and the innovation ability of creators is not high.
(1) Interactive art creation
Multi-modal information fusion and analysis refers to the integration and analysis of information from different modalities (such as vision, audio, text, etc.) to obtain more comprehensive and accurate data [11]. The basic principle of multi-modal information fusion and analysis is to combine information from multiple sources, and supplement, modify, and enhance each other, in order to achieve better results.
Multi-modal information fusion can achieve more diverse artistic creation methods, such as integrating different art forms to achieve interactive and participatory artistic creation [12]. Interactive imaging refers to the real-time interaction between humans and computers, allowing the content of the image to change with user actions or other operations. This kind of image form needs to combine a variety of media elements, such as vision, sound, interaction, etc., in order to present a richer and more diversified image effect, and to realize seamless connection and synergistic interaction between different media elements, so as to achieve a higher interactive effect and artistic experience. The interactive art scene is shown in Fig. 2.
Interactive art scene.
Multi-modal information fusion can integrate multiple sensory elements such as vision, hearing, and touch, creating a richer and more diverse artistic experience. In visual art, virtual reality technology and projection technology can be combined to create works that are immersive and have a strong sense of depth. In music art, elements such as light, shadow, and dance can be combined to create more expressive and infectious music video works. Through various sensory stimuli and interactions, art works can better convey emotions and ideas.
(2) Analysis of work content
Multi-modal information fusion can integrate different media elements into film and television works, thereby creating more diverse and personalized film and television works. By combining movie images with three-dimensional (3D) technology, more realistic and three-dimensional effects can be created, or elements such as movies, games, and virtual reality (VR) can be integrated to create a new audio-visual experience.
Through multi-modal information analysis and fusion technology, more efficient and accurate film and television editing and production can be achieved, synchronizing audio and video content to achieve better audio and video consistency. Film and television production requires the integration of multiple media elements, and multi-modal information fusion can enable the integration and coordination of different media elements, thereby achieving a richer artistic effect in film and television works. For example, the combination of music, sound effects, and subtitles can make the plot of the film more vivid and infectious, in order to achieve higher artistic effects.
(3) User interest recommendation
Multi-modal information fusion combines users’ viewing history, ratings, and preferences, and analyzes relevant videos based on multi-modal information fusion. Facial recognition technology, scene recognition, and other modalities can be used to understand users’ preferences and features. Based on these features, recommendation algorithms are used to recommend video works that meet users’ interests. By utilizing multi-modal information fusion technology, users’ preferences for images and music are analyzed, and features such as image content and emotional colors are matched with the rhythm and style of music to recommend music that matches their favorite images.
By utilizing information from different modalities such as images, text, and audio, a comprehensive analysis of art works is conducted. Based on users’ personal preferences and interests, a multi-modal information fusion recommendation algorithm is used to recommend art works that meet their taste, such as painting, photography, etc. The user’s preference for episodes and the characteristics of their tastes are analyzed. By combining different modalities of information such as images, audio, and text in film and television works, this paper recommends movies, dramas, or novels that meet users’ interests.
(4) Speech recognition and text analysis
Film and television works are no longer a single visual medium. With the entry of sound and other media, film and television works have become more comprehensive and richer, which requires the support of multi-modal information fusion. By integrating visual, sound, and other elements, audiences can have a more comprehensive audio-visual experience while watching film and television works, thereby improving audience engagement and the artistic value of film and television works [13, 14]. Through multi-modal information fusion, more accurate and comprehensive speech recognition and text analysis can be achieved, integrating speech and text content to achieve better accuracy in speech conversion and speech recognition [15].
There are various technical models for multi-modal information fusion, including neural networks, support vector machines, decision trees, etc. They can fuse various forms of data, such as images, text, videos, etc., for intelligent analysis and processing, thereby making the work more diverse [16].
User interest recommendation based on RNN neural network
In the creation of new media art and film and television culture, user interest recommendation through RNN can provide personalized content recommendation and enhance user experience. RNN analyzes user behavior data on the platform, such as viewing history, likes, comments, etc., captures long-term dependencies in user interest areas, and predicts potential interest preferences based on user historical behavior, providing personalized recommendation content for users. RNN can also be used to generate content such as film and television scripts, music, or images, and learn a large amount of text, audio, or image data through training models to generate art works with certain coherence and creativity. The application of recurrent neural network can be used for the creation of new media art to provide inspiration and creative support for artists.
RNN has been widely used in the recommendation field due to its network structure that allows for information circulation between neurons, which has a natural advantage in extracting hidden features from sequence information. While gradually learning new information in the sequence, it also preserves the memory of previous information.
For the input interest point check-in sequence data, the memory unit at time
In the formula,
Users view historical sequences and input them into RNN to learn their viewing habits and preferences. Based on this, this paper recommends works that users may be interested in. RNN captures the temporal correlation between users, providing more accurate recommendation results. The output of the memory cell at moment
The reason why RNN can achieve the effect of memorizing the previous information is because the structure of its internal hidden layer is related before and after. Therefore, when the hidden layer performs calculations, each input data includes not only the current input information state, but also the data information output after the previous state extraction. It is precisely this structure that fuses all input sequence information and establishes corresponding relationships. For time
In the formula,
RNN connects nodes between hidden layers in the network to each other. This structure can also obtain the processing results of previous times when processing current data, and combine the two to obtain the current output. That is to say, RNN memorizes the previously processed information, and correlates the data before and after, and the current output is co-determination determined by the current input and the output of the previous period. RNN, which can associate the front and rear data, has been widely used in speech recognition, machine translation and other fields where data has sequence characteristics.
Speech recognition converts people’s oral content into textual form, providing convenience for script creation. Artists or screenwriters can use voice input devices to dictate the plot, lines, and scene descriptions of a script, and then use RNN for voice recognition to convert them into editable and modifiable text form, thereby improving the efficiency of script creation [17, 18]. The RNN is recursive in the sequence evolution direction and chains all the loop cell nodes. The forward computation process of RNN is as follows:
When performing speech recognition, a new speech signal is input, and after preprocessing and feature extraction, a feature sequence is obtained. Then, the trained RNN model is used to predict the feature sequence and output the corresponding label sequence.
In film and television works, adding subtitles can help audiences with poor listening comprehension understand dialogue content, or provide translation services for audiences in different languages. Through RNN for voice recognition, the voice content in the video can be automatically converted into text subtitles, providing a better viewing experience. In some cases, artists may need to re-dub movies or videos, such as providing voice dubbing for audiences in other languages during international distribution. Through RNN for speech recognition, the original speech content can be converted into text, and it is convenient for artists or voice actors to voice record, thus achieving multilingual release of movies. Speech recognition can also be used for intelligent sound effect creation. By identifying the characteristics and emotions of sound, as well as the content and tone of dialogue, RNN can generate or select sound effects that match it, thereby increasing the immersion and emotional expression of film and television works.
As an important art form, film and television requires the processing of a large amount of audio and video information during its creative process. Traditional film and television production often requires the cooperation of multiple professionals, such as audiologists, editors, visual effects artists, etc., to handle different information modalities separately. With the development of multi-modal information fusion and analysis technology, audio and video information in film and television production can be more efficiently integrated and analyzed, thereby achieving more complex and exquisite film special effects and sound effects.
In film and television production, the fusion of audio and video information is very important. Multi-modal information fusion can be used to synchronize audio and video information for processing, achieving more accurate sound effect design. At the same time, different information modalities can be cross analyzed to obtain more exquisite visual effects and sound effects. In film and television, multiple audio tracks need to be mixed to achieve ideal balance and effect among different audio elements (such as music, dialogue, ambient sound, etc.) in the final audio heard by the audience. The mixing formula is used to adjust the gain and balance of the audio signal. The output signal after mixing is:
Among them,
By adjusting the gain coefficients of different audio signals, the relative volume and balance of each sound element in the final mixed signal can be controlled. Video overlay technology can combine multiple video layers to achieve special effects, scene synthesis, etc. Transparency is an important parameter used to control the visibility of each video layer, thus achieving layer overlay:
Among them,
Multi-modal information analysis technology can also provide better decision-making support for directors and production personnel in film and television production. In terms of predicting the box office of a movie, a wide range of information such as audio, video and text from the movie can be used to analyze the preferences of the audience group, so that better market positioning and promotion strategies can be developed.
Digital art is an innovative art form, which organically combines new media technology with traditional art forms, presenting a richer and more diversified artistic creation. By utilizing multi-modal information fusion and analysis, the atmosphere and emotions in movies can be better expressed. Audio and video present different emotions and scenes, enhancing the audience’s perception and emotional experience of the movie atmosphere. For example, in tense and suspenseful scenes, the design of audio effects and video editing can enhance the sense of pressure and tension in the atmosphere, making the audience more immersed in the plot.
RNN neural network extracts features from audio and image, and fuses them to provide more abundant and diversified creation possibilities for digital art creation. Feature extraction is performed on audio and image inputs separately. Hidden states are output in the final layer or feature representations of audio and image are obtained through global average pooling. These two features can then be fused to obtain the overall multi-modal features:
RNN uses multi-modal features that integrate audio and image information to generate digital art creation, input multi-modal features into the network, and generate output that conforms to artistic creation style:
In addition, multi-modal information fusion and analysis technology can also realize the creation of interactive media in digital art, and use user feedback information for analysis to continuously improve the creation and performance of works.
VR is a new scientific and technological field, which applies computer graphics, 3D modeling, multimedia and other technologies to human-computer interaction and simulation of real environment. The relationship between VR and multi-modal information fusion is that in virtual reality creation, a large amount of image, audio, and interactive information needs to be processed. Multi-modal information fusion and analysis technology can achieve efficient fusion and analysis of this information, thereby achieving a more realistic and three-dimensional virtual reality experience.
Multi-modal information fusion provides strong support for VR and augmented reality. By integrating virtual scenes or objects with the real world, artists can create realistic and vivid art works. In virtual reality art, the audience can immerse themselves in a new art space through the head-mounted display and interact with virtual elements. In augmented reality art, the audience can combine virtual art content with the real environment through mobile phones, tablets and other devices. The application of head-mounted display is shown in Fig. 3.
Application of head-mounted display.
As shown in Fig. 3, Fig. 3a is a head-mounted display, and Fig. 3b is the viewing effect of a head-mounted display. The virtual dinosaurs are lifelike.
Multi-modal information fusion can also be applied to the field of data and information visualization and artistic expression. By fusing and transforming different types of data, such as text, audio, image, video, etc., artists can create works of art with rich information and diverse forms. Through cross-border integration and innovation, artistic works can better meet the diverse needs of audiences, while also promoting artistic innovation between different fields. The application of multi-modal information fusion and analysis technology in new media art and film and television cultural creation is becoming increasingly widespread, providing more diverse and diverse ways of expression for artistic creation. In the future, with the further development of new media technology, multi-modal information fusion and analysis technology could also be more widely applied and developed.
Comparative evaluation of algorithms
(1) Speech recognition comparison
Five works of new media art and film and television culture were selected to have Chinese, English, and Japanese speech recognition. This article used traditional artificial neural networks and RNN neural networks for speech recognition of the works in Chinese, English, and Japanese. The recognition accuracy of the two methods is shown in Fig. 4 (the horizontal axis in Fig. 4 represents different languages, including Chinese, English, and Japanese, while the vertical axis represents accuracy).
Recognition accuracy of two methods. (a) Recognition accuracy of traditional artificial neural networks. (b) RNN neural network recognition accuracy.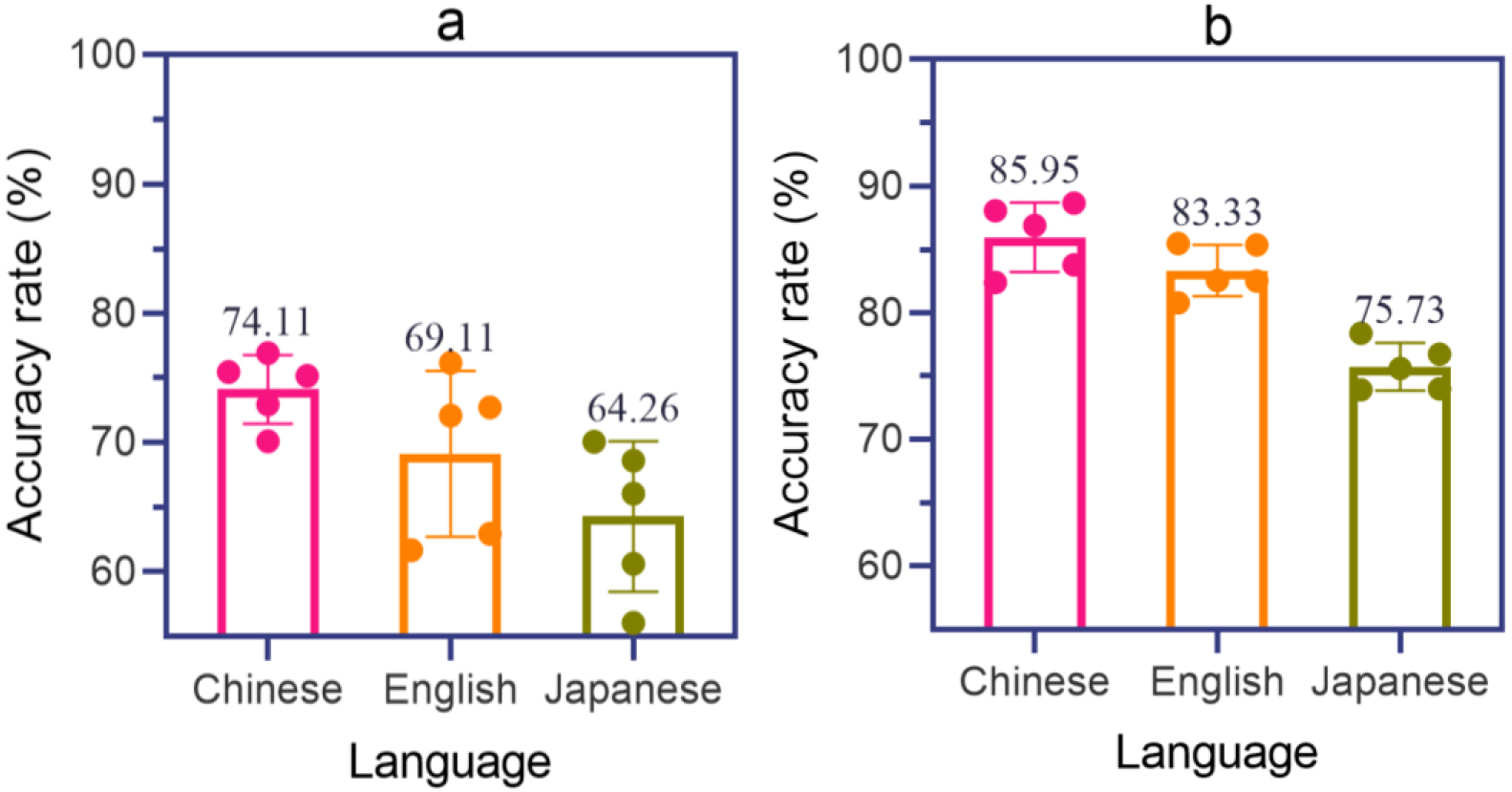
As shown in Fig. 4, in Fig. 4a, the average Chinese recognition accuracy for works 1 to 5 using traditional artificial neural networks was 74.11%; the average English recognition accuracy for works 1 to 5 was 69.11%; the average Japanese recognition accuracy for works 1 to 5 was 64.26%.
Figure 4b shows an average Chinese recognition accuracy of 85.95% for works 1 to 5 using RNN neural networks, an average English recognition accuracy of 83.33% for works 1 to 5, and an average Japanese recognition accuracy of 75.73% for works 1 to 5.
Compared to traditional artificial neural networks, RNN has advantages in speech recognition in new media art and film and television cultural creation, and can achieve better recognition results.
(2) Comparison of recommendation accuracy
User recommendation refers to recommending relevant content or products to users based on their interests and behavioral data. In the creation of new media art and film and television culture, user recommendation can be used to provide personalized recommendations for art, movies, music, and photography to enhance the user experience and meet their needs. This article selected 20 users and recommended them. The recommendation accuracy of traditional artificial neural networks and RNN neural networks is shown in Fig. 5 (the abscissa represents the user and the ordinate represents the accuracy).
Recommended accuracy of two methods. (a) Recommendation accuracy of traditional artificial neural networks. (b) RNN neural network recommendation accuracy.
As shown in Fig. 5, Fig. 5a shows that the overall recommendation accuracy of movies, music, art, and photography for users 1 to 20 through traditional artificial neural networks was below 80%.
Figure 5b shows that the accuracy of recommending movies, music, art, and photography to user 1 through the RNN neural network was 83.49%, 84.46%, 83.81%, and 78.34%, respectively.
The accuracy of recommending to most users through RNN neural networks is higher than that through traditional artificial neural networks. In the creation of new media art and film and television culture, RNN can be applied to user recommendations to improve accuracy.
(1) Creation cost
Multi-modal information fusion integrates and analyzes information from different media forms, making it easier to collect, process, and annotate multi-modal data through the use of modern technologies and tools. Compared to traditional creative methods, automated processing can significantly reduce the cost of data processing. Films, music, art and photography created by traditional methods and films, music, art and photography created by multi-modal information fusion and analysis were selected separately to count their creation costs.
The cost of creating works using traditional creative methods is shown in Table 2.
Cost of traditional creation methods for creating works (10000 yuan)
Cost of traditional creation methods for creating works (10000 yuan)
As shown in Table 2, the cost of traditional creative methods for creating films, music, art, and photography works 1 was 8.389 million yuan, 12600 yuan, 38600 yuan, and 10600 yuan, respectively; the cost of creating films, music, art, and photography works using traditional creative methods was 9.5748 million yuan, 11700 yuan, 39000 yuan, and 9700 yuan, respectively.
The cost of creating works through multi-modal information fusion is shown in Table 3.
Cost of multi-modal information fusion creation works (10000 yuan)
As shown in Table 3, the cost of creating works 1 for film, music, art, and photography through multi-modal information fusion was 5.041400 yuan, 5300 yuan, 29700 yuan, and 4100 yuan, respectively; the cost of creating films, music, art, and photography works through multi-modal information fusion was 5.5556 million yuan, 8500 yuan, 23900 yuan, and 4500 yuan, respectively.
Compared to traditional creative methods, applying multi-modal information fusion to the creation of new media art and film and television culture can to some extent reduce costs.
Multi-modal information fusion and analysis technology can help artists capture creative inspiration and intentions. By analyzing multi-modal data, it is possible to discover the connections and potential creative elements between different media, providing creators with more creative inspiration and direction. Such tools and technologies can reduce the time and energy consumption of artists in finding inspiration and ideas. Multi-modal information fusion and analysis can also be used to automate the generation and synthesis of multimedia content, which is beneficial for reducing manual production and post processing costs in traditional creations and improving creative efficiency.
(2) Creative quality
With the development of technology and scientific progress, new creative methods and tools are gradually being introduced into the creation of new media art and film and television culture. These new methods and tools, such as multi-modal information fusion and analysis, can provide creators with more inspiration and creative possibilities, further improving the quality of their creations.
A relevant artist rated the quality of works 1 to 5 created using traditional methods and multi-modal information fusion and analysis. The comparison of work quality ratings between traditional methods and multi-modal information fusion creation is shown in Fig. 6 (the horizontal axis represents the work, and the vertical axis represents the rating, with a maximum score of 10 points. The higher the score, the better the quality).
As shown in Fig. 6, according to the edge of the area plot in Fig. 6a, it can be seen that the quality ratings of artists for different types of traditional creative methods (film, music, art, and photography), such as work 1, work 2, work 3, work 4, and work 5, were all below 8 points. In Fig. 6b, it was found that artists rated the quality of different types (film, music, fine art, and photography) of works 1, 2, 3, 4, and 5 created by multi-modal information fusion and analysis at a score of 8 or higher.
The quality rating of works created through multi-modal information fusion and analysis is higher than that of works created through traditional creative methods. Works created through multi-modal information fusion and analysis can improve the quality of creation and artistic expression.
Rating of viewing experience for works created by traditional creation methods
Comparison of work quality ratings between traditional methods and multi-modal information fusion creation. (a) Quality rating of works created using traditional methods. (b) Work quality rating for multi-modal information fusion creation.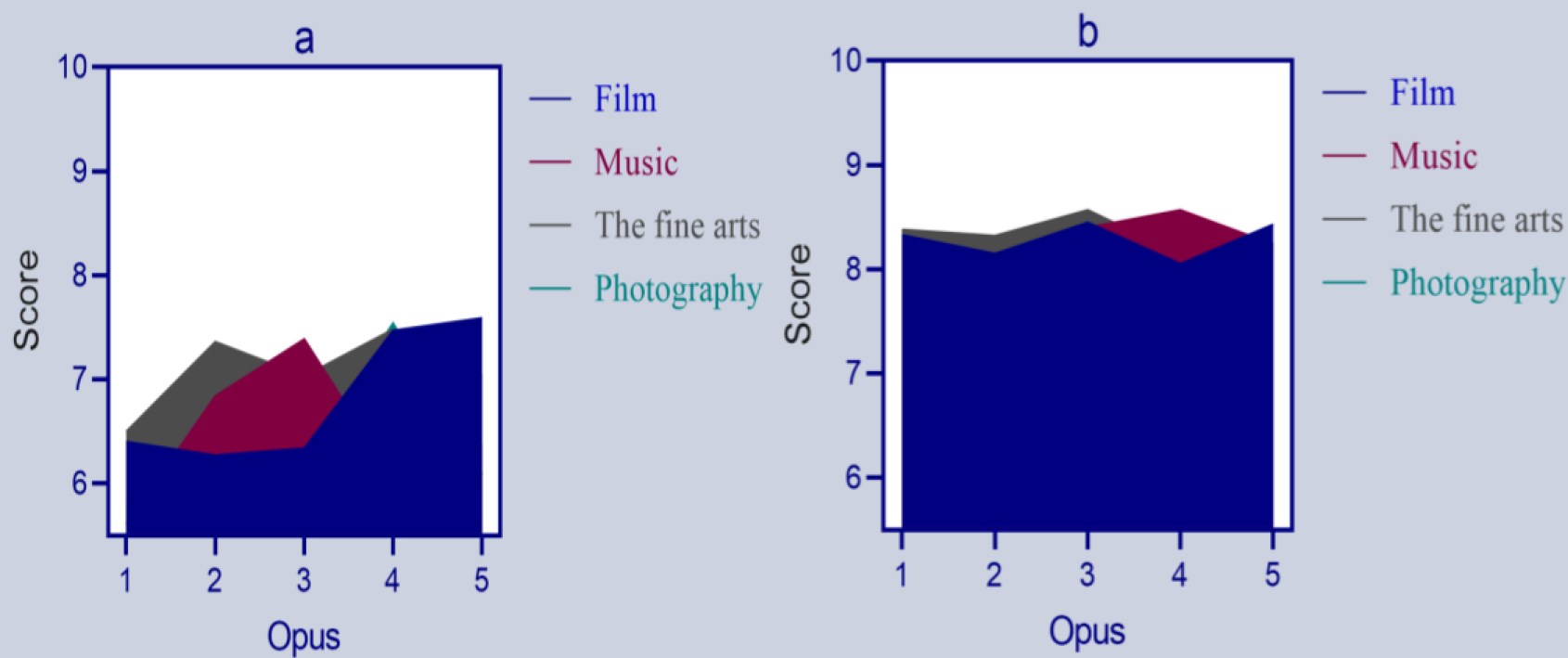
(3) Experience in watching film and television works
Five viewers were selected to rate the viewing experience of films, music, art, and photography created using traditional creative methods, with a maximum score of 10. The viewing experience rating of works created using traditional creative methods is shown in Table 4.
As shown in Table 4, the viewing experience scores for works 1 to 5 created using traditional creative methods were 6.23 points, 6.02 points, 6.56 points, 6.64 points, and 6.88 points, respectively. The overall viewing experience scores were all below 7 points.
The ratings of 5 viewers on the viewing experience of movies, music, art, and photography created through multi-modal information fusion and analysis are shown in Table 5.
Rating of the viewing experience of works created through multi-modal information fusion and analysis
As shown in Table 5, the viewing experience scores for works 1 to 5 created through multi-modal information fusion and analysis were 9.41 points, 9.08 points, 9.11 points, 9.61 points, and 8.44 points, respectively. The overall viewing experience scores were all above 8 points.
Combining Tables 4 and 5, it can be found that the viewing experience rating of works created through multi-modal information fusion and analysis was higher than that of works created through traditional creative methods.
(4) Interactivity
In order to avoid repetition of the experiment, this article selected another 6 viewers to rate the interactivity of the work. The interactivity rating of the work created by traditional methods and multi-modal information fusion is shown in Fig. 7 (the horizontal axis of Fig. 7 represents movies, music, art, and photography, and the vertical axis represents the rating, with a maximum score of 100 points. The higher the score, the better the interactivity).
Interactive rating of works created using traditional methods and multi-modal information fusion. (a) Interactive rating of works created using traditional methods. (b) Interactive rating of works created through multi-modal information fusion.
As shown in Figure, from the distribution of violins in Fig. 7a, it can be seen that the six viewers rated the interactivity of films, music, art, and photography created using traditional creative methods below 70 points.
From the distribution of violins in Fig. 7b, it can be seen that the six viewers rated the interactivity of movies, music, art, and photography created using multi-modal information fusion and analysis creative methods above 70 points.
From Fig. 7, it can be observed that overall, the interactivity score of works created by multi-modal information fusion was higher than that of works created by traditional methods, because multi-modal information fusion and analysis can achieve interaction between creators and audiences through data feedback and communication with the audience.
Figure 1 shows that there are problems in the field of new media art and film and television culture, such as insufficient market regulatory measures and mechanisms, and insufficient innovation capabilities of creators. Commercial interests are often one of the dominant factors, and producers, investors, and others tend to be guided by commercial interests and pursue huge economic returns. This makes market management more focused on commercial success and profitability, while neglecting considerations of artistic creation, cultural heritage, and social responsibility. Market management requires a set of industry standards and rules to guide the healthy development of the market. However, the current lack of normative guidance in market management has led to significant confusion and uncertainty in artistic creation and market operation. The traditional film and television industry has relatively rigid systems and mechanisms, and the creative process is subject to various norms and restrictions, such as script review and distribution mechanisms. These limitations may limit the creative thinking and expression of creators, leading to a lack of freshness and innovation in film and television works.
Figure 4 shows that compared to traditional artificial neural networks, RNN has better performance in speech recognition in new media art and film and television cultural creation. RNN can capture the dependencies of time series, has memory function, and can perform efficient speech recognition through end-to-end training. It has a memory function that can remember previously processed information, which is very important for speech recognition, as speech signals typically have longer time-domain persistence features and rely on contextual information for accurate recognition. RNN improves the accuracy of speech recognition by internalizing the previous state and passing it on to the next time step, allowing the model to take into account the previous contextual information when processing the current step.
Figure 5 shows that the RNN neural network has a higher recommendation accuracy for most users. Compared to traditional artificial neural networks, RNN has certain advantages in processing sequence data, as it can preserve and utilize previous information to better understand the current input. RNN can model the user’s historical behavior in sequence, thereby better understanding the user’s interests and preferences. In user recommendations, RNN can generate recommendation results based on the user’s historical behavior and current context, thereby improving the accuracy of recommendations.
Figure 6 shows that the quality ratings of different types of works created through multi-modal information fusion and analysis are generally higher. By integrating and analyzing different media and information, creators can discover the correlation and potential creative inspiration between different media. Especially, RNN neural networks can automatically generate new creative content by learning a large number of art works and film and television clips. With RNN’s automated creative assistance, artists and creators can generate inspiration more quickly and improve creative efficiency.
Figure 7 shows that works created through multi-modal information fusion have higher interactive ratings. The combination of multi-modal information fusion and analysis with interactive technology enables the audience to actively participate in the creation. In virtual reality or augmented reality creation, the audience can interact with the work through gestures, voice, touch, and other methods to change the display and interpretation of the work. This interactive experience enhances the audience’s sense of participation and immersion, and enhances interactivity. Multi-modal information fusion and analysis: By analyzing audience feedback and behavioral data, creators can understand audience reactions and opinions towards the work, and further adjust and improve the work. This type of data feedback and communication promotes interaction and communication between creators and audiences. By utilizing multi-modal information fusion and analysis, film and television production can provide users with personalized interactive experiences. By analyzing users’ audio and video inputs, movie versions that meet their specific needs can be automatically generated based on their preferences and emotional states. Based on the user’s emotional expression and preferences, the audio and video presentation is automatically adjusted to create a movie viewing experience that matches the user’s personality.
Conclusions
With the rapid development of new media technology, the application of multi-modal information fusion and analysis in the creation of new media art and film and television culture is becoming increasingly widespread. These technologies can simultaneously process multiple modalities of information, including audio, video, images, text, etc., thus achieving more comprehensive, accurate, and diverse artistic creations. A multi-modal information analysis model refers to the process of comprehensively analyzing and modeling information from different modalities or data sources. In the creation of new media art and film and television culture, multi-modal information analysis models can help people gain a deeper understanding and analysis of artistic works and film and television content. Multi-modal information fusion and analysis technology has become a common technical means in the field of new media art and film and television cultural creation. It can integrate and analyze information from different perceptual modalities, thereby helping artists and film and television producers better understand and express their creativity.