
Abstract
Initial results of neural architecture search (NAS) in natural language processing (NLP) have been achieved, but the search space of most NAS methods is based on the simplest recurrent cell and thus does not consider the modeling of long sequences. The remote information tends to disappear gradually when the input sequence is long, resulting in poor model performance. In this paper, we present an approach based on dual cells to search for a better-performing network architecture. We construct a search space that is more compatible with language modeling tasks by adding an information storage cell inside the search cell, so that we can make better use of the remote information of the sequence and improve the performance of the model. The language model searched by our method achieves better results than those of the baseline method on the Penn Treebank data set and WikiText-2 data set.
Introduction
Since the emergence of deep learning technology [1], great strides have been made in many fields, such as the ResNet [2] in computer vision (CV) and the recurrent neural network (RNN) [3] in natural language processing (NLP). However, their success largely depends on researchers spending considerable time and energy designing a good network structure for specific applications. The success of the transformer model [4] in NLP is an example. Two problems of this scientific research model exist: 1. The network structure depends on the application field, and different fields require different structures. 2. The cost of manual research is too high, and designing a good architecture requires even the best domain experts to spend several years. From the seq2seq model [5] in 2014 to the transformer model in 2017, the world’s best team required 3 years to carry out the design. Neural architecture search (NAS) has emerged in response to these two problems.
NAS is a branch of automated machine learning (Auto-ML). By defining a search space, machines can automatically search for an excellent neural network structure that matches the current task without manual intervention under a specific task and corresponding data set. MetaQNN [6], which continuously explores excellent structures in an extremely large discrete space based on reinforcement learning (RL), is the earliest NAS method. The evolutionary algorithm (EVO) [7] also searches in a discrete space, and it continues to evolve and update the initial network to obtain a network structure with superior performance. Recently, a method based on gradient optimization [8, 16] has gradually become popular. This type of method changes the search space from discrete to continuous and uses gradient descent to optimize the network structure. Compared with RL and EVO, the methods based on gradients are orders of magnitude faster in search speed.
Although experts have proposed many excellent NAS methods, most focus on the search strategy and search speed, and the search space is designed manually. To reduce the search space, the existing methods do not search the entire RNN but search only the internal structure of the cell. They set the connection mode between the internal cells of the RNN and require all cells to use the same structure. The network formed by the cell searched out in this way cannot match the current task the most. The most popular NAS method, DARTS [9], is such a search form. It defines the inside of the cell as a directed acyclic graph (as shown in Fig. 1, top), uses gradient optimization to learn the internal structure of the cell and cyclically connects the learned cell to form the final model. The model based on recurrent cells can handle certain short-term dependence of the sequence, but when the sequence is long, the gradient at the far end of the sequence struggles to propagate back to the current sequence, which causes gradient disappearance and leads poor model performance.

The internal structure of the search cell in DARTS (top), and the internal structure of the search cell in our method (bottom).
To solve this problem, we propose a search space based on a dual cell that more closely matches the language modeling tasks. We choose DARTS as our basic method because it is based on gradient optimization and has lower experimental hardware requirements and a more efficient search speed. We improve the search space of DARTS by adding an information storage cell (cellct) inside the complete cell. Cellct receives the input of the first five moments to effectively save previous information of the sequence and then transfers the saved sequence information to the information processing cell (cellht), as shown in Fig. 1, bottom, so that the current output can be better predicted. The increase in the number of information storage cells also directly expands the search space and improves the probability of searching for an excellent network structure.
We test our method on language modeling tasks. The data sets used are Penn Treebank (PTB) and WikiText-2 (WT2). PTB is currently the most widely used data set when training language models. WT2 is a subset of WikiText-103, and its number of words is 3.3 times that of the PTB data set. Each word also retains the original article that produced the word, which is especially suitable for testing scenarios where natural language modeling is required for a long time. On the PTB and WT2 data sets, our method achieves 55.3 and 69.4 test perplexity (ppl, where the lower the perplexity is, the better), which is better than the baseline test perplexity of 55.7 and 69.6. These results prove that our method can alleviate the problem of disappearing gradients in long sequences to a certain extent.
NAS, as a branch of Auto-ML, has attracted widespread attention and research. An increasing number of scholars are devoted to NAS research, and various methods have emerged. These methods are mainly divided into three categories: 1. RL-based [6, 10–13], 2. EVO-based [7, 14], and 3. gradient-optimization-based [8, 16] methods.
NAS [10], which uses an RNN controller to guide network generation based on RL and was proposed by Google in 2016, is a pioneering work of NAS. The RNN controller first samples a network structure with a probability, then trains the sampled network, and finally updates the RNN controller with the network accuracy obtained by training. An excellent network structure can be obtained by cyclic sampling and updating. It is also an RL method. MIT proposed MetaQNN [6] based on the Q-learning algorithm in the same year. MetaQNN defines the state and action. With the convolutional neural network (CNN) as an example, the state is the operation of the current layer, and the action is the operation of the next layer. Calculating the reward (the accuracy of the network) after the current state takes a specific action, and the network is composed of high actions. The RL-based method has served as a prelude to NAS research, but ordinary researchers cannot reproduce the experiment because of the high hardware requirements.
The EVO-based method encodes the network structure, converts it into a sequence similar to a gene, and then changes this sequence to obtain a new network structure. EVO [7], proposed by Real et al, is the first evolution method. It first creates a population that contains a certain number of the simplest initial networks with accuracy and then randomly selects two networks in the population for comparison. The lower one is eliminated, the higher one evolves into the parent network to obtain the child network, and then the parent network and the child network are added to the population. After a certain number of cycles, the network with the highest accuracy in the population is selected as the optimal network structure. EVO does not consider the potential of the initial network, that is, a network with poor performance in the early stage may be greatly improved after several evolutions; thus, the author further improved the method and proposed AmoebaNet [14]. AmoebaNet does not eliminate networks with poor performance during comparison but does remove the oldest network in the population after a period of time to avoid the prematurely stifling network potential in EVO.
Recently, the NAS method based on gradient optimization has gradually become popular, as it solves the hardware requirement and search time problems. RL and EVO usually treat structural optimization as a discrete optimization problem to solve, while gradient-based methods treat it as a continuous optimization problem. Gradient optimization is represented by NAO [8] and DARTS [9]. NAO includes an encoder, predictor and decoder. The encoder is responsible for mapping the structure of a cell into a continuous space, the predictor optimizes the performance of the network with increasing gradient, and the decoder obtains an optimized structure from the continuous space. DARTS constructs a directed acyclic graph containing several nodes and places all the operations that can be taken between each node to change the network structure from a discrete state to a continuous state. When the secondary optimization problem is solved, the operation between each node is obtained.
Although DARTS achieves excellent performance, most researches have verified that it tends to crash because it contains too many skip connections. To solve this problem, Chen et al. proposed PDARTS [17], which restricted the search space, tailored skip connections by setting the dropout rate, and artificially limited the number of skip connections. Zela et al. [18] designed multiple search spaces and proved that skip connections are the main cause of the collapse of DARTS. To enhance the stability of the search process, they proposed to supervise the verification loss of the model, but this added additional calculations. Chu et al. [19] proposed relaxing the search space to avoid exclusive competition. By using the sigmoid function to imitate the coding, each operation has an independent architectural weight, and the softmax restriction between DARTS nodes is cancelled, which expands the search space. Zhang et al. [20] solved the skip connection problem by adding unbiased and small variance noise in the training process. Dong et al. [21] used the Gumbel-Max trick to trans-form the search space into continuous, and found an excellent structure in four hours. These improved DARTS methods have achieved great success in the field of computer vision, and even achieved state-of-the-art results on individual tasks.
In contrast to the field of computer vision, there are relatively few studies on NAS in the field of NLP, and the Transformer model [4] remains the state of the art. Since the models in NLP are often more complex and larger in scale, the existing NAS methods are insufficient to design such a complex and huge network structure from scratch. On top-level tasks such as machine translation, NAS uses a seed model as the basis for searching, and on low-level tasks such as language models, a complete search can be performed. Le et al. [22] used evolutionary algorithms for machine translation tasks. They used NAS for feedforward models for the first time, using Transformer as the seed network, and successfully searched for a better-performing Evolved Transformer network. Wang et al. 0proposed a coordinated NAS method based on Transformer, which achieved better results than the original model by adding LSTM or other layers. In the 2019 International Machine Translation Competition [24], the Microsoft team used its own gradient optimization-based NAO [8] method for the Transformer model. It encodes and embeds the model structure into a continuous vector space and then finds and decodes a structure with better performance through gradient optimization. Jiang et al. [25] used the NAS method for the first time in low-level tasks other than language model tasks. They pointed out the limitations of softmax in the DARTS algorithm and achieved success in language model and named entity recognition tasks.
Method
We introduced the extended search space based on dual cells in Section A. Different from the existing search space, our method sets two subcells in the search cell at each moment of the RNN: the information storage cell cellct and the information processing cell cellht. Each subcell is composed of a directed acyclic graph, and the search strategy DARTS in Section B is used to guide the search of the entire neural network structure. The information storage cell and the information processing cell are respectively defined as c t = f (. , .) and h t = g (. , .). The input is a set of sequence vectors {x1, x2, … x t }, the output of cellct is {c1, c2, … c t } and the output of Cellht is {h1, h2, … h t }, where t is the time step. The purpose of NAS is to automatically search for two good unit functions f (. , .) and g (. , .).
Dual-cell expansion space
Designing the search space is the first step of NAS and is very important. The large framework of the entire search space follows the setting in DARTS. We search for a cell and then connect it to form the final RNN. Different from DARTS, we set up two subcells inside each search cell: the information storage cell cellct and the information processing cell Cellht. Each cell is a directed acyclic graph with several nodes. The input of cellct is the input of the first five moments in the sequence xt-1, xt-2, xt-3, xt-4, xt-5. The very first intermediate node of cellct is obtained by linearly transforming the five inputs, adding up the results and then passing them through a tanh activation function. The input of cellht is the current input xt of the sequence, the hidden state ht-1 at the previous time and the output ct of cellct. The input of the first node and the output of the cell are processed in the same way as in the information storage cell.
Search algorithm
In terms of the search algorithm, we use DARTS as a guiding strategy. Both the RL and evolutionary algorithms require a sufficiently large GPU group to search, but the hardware requirements of DARTS are much lower than those of the previous two methods, and its search speed is more efficient. Hence, DARTS is our first choice. The search process of DARTS includes four main steps: 1. Construct a directed acyclic graph containing several nodes, where the input of the large node is the output of all the small nodes. 2. Put all the actions that can be taken between every two nodes to make the discrete network structure continuous. 3. Alternately optimize the structure weight α and the network weight w, and find the operation corresponding to the largest structure weight α. 4. Fix the network structure according to the learned structure weight α, initialize all network weights w, and perform the final training. We consider a set of ordered nodes node(1), node(1), …, node(n), o(i,j) (i < j)represents the action taken by node i to node j, and the input of node j is obtained after all the previous nodes are operated, which is specifically expressed as:
Operation o(i,j) is usually selected from a set of alternative operations, such as some activation functions in an RNN. For each set of operations o(i,j), we define a set of coefficients α ={ α(i,j) }. In the search training process, we use a hybrid operation
The entire cyclic neural network has two sets of parameters to be trained: one is the network’s structural parameter α, and the other is the network’s weight parameter w. The two sets of parameters undergo an alternating optimization process. We randomly initialize the structure parameter α to obtain the initialization network. The network weight w is trained on the training set and updated by reducing the loss on the training set, and the network structure parameter α is updated based on the loss on the validation set. The optimal network structure is obtained through this alternating optimization, and the search phase of the NAS ends. Next, we fix the network structure according to the structural parameter α obtained in the search stage, initialize all weights of the network at random, and then train on the training set again to obtain the final network.
Experiments
We verified our method on the language modeling task. The data set selected was the standard PTB data set (containing 10,000 words) and the WT2 data set (containing 33,000 words), and the GPU selected was NVIDIA 2080Ti. The experimental process consists of two stages: the search stage of the cell structure and the evaluation stage of the complete network. The search stage involves searching the cell structure on the training set and continuously optimizing it based on the loss on the validation set. The cell structure with the smallest loss is the optimal structure. In the evaluation stage, we use the optimal cell structure searched in the search stage to build a complete RNN, randomly initialize all network weights w, and complete the validation on the test set after sufficient training on the training set.
Search stage
The entire search stage is performed on the PTB data set, and most of the experimental parameters in this part follow the settings in DARTS. The RNN is one layer, the word embedding size and hidden layer size are both 300, and the batch size is 256. Each cell is equipped with an information storage cell cellct and an information processing cell Cellht. Cellct contains 3 nodes, and cellct contains 8 nodes. Four operations can be taken on the edge between nodes: tanh, ReLU, sigmoid and identity. For the two optimization stages, we use different algorithms for optimization. The network weight w is optimized by the SGD algorithm, the learning rate is 20, and the weight attenuation is 5e-7. The structural weight α is optimized by the Adam algorithm, the initial learning rate is 3e-3, and the weight decay is 1e-3. The entire search phase lasts 50 epochs.
Since the structure search is sensitive to the initial structure, we randomly initialize the structure weight α to obtain five different initial cell structures. We start the search from five different initial structures, select the structure with the least loss on the validation set during the search process as a candidate cell structure, and then select the optimal structure from the five candidate cell structures in the evaluation stage.
Evaluation stage
In the evaluation stage, we expand the word embedding size and hidden layer size of the model to 850, the batch size is 64, the ASGD algorithm is used as the optimizer of the weight w, the initial learning rate is 20, and the weight decay is 8e-7. In the language modeling task, we evaluate the five candidate cell structures searched in the last stage for a short time to obtain the optimal cell structure. The weight w of each cell structure to be selected is randomly initialized and trained on the training set for 300 epochs, and the structure with the lowest validation ppl at this time is selected as the optimal structure. Figure 2 shows the perplexity when the five candidate structures are trained for 300 epochs. The lowest perplexity is 61.79, and the cell structure corresponding to this perplexity is shown in Fig. 3. After obtaining the optimal cell structure, we initialize the network weight w again randomly and train for a longer time on the training set until it converges. Table 1 shows a comparison between the perplexity of our method and that of the baseline method and other methods. Compared with that of the baseline model, the perplexity of our model on the validation set increases by 0.6 points, and the perplexity on the test set increases by 0.4 points.
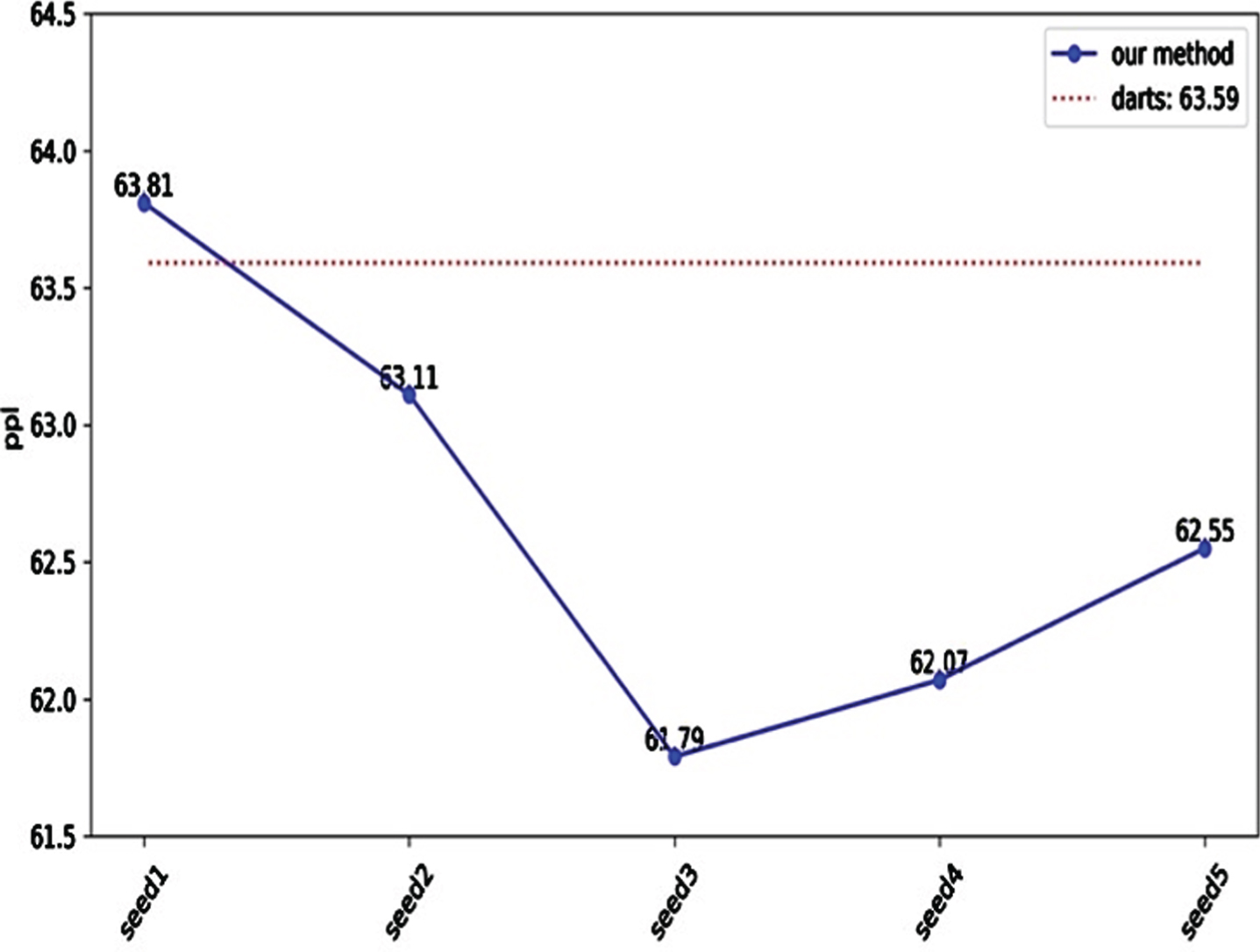
The blue line is the perplexity when 300 epochs are trained for the structure searched by our method. seed1 to seed5 represent the structure searched according to 5 different initial structures. The red line is the perplexity on the validation set when training 300 epochs for the optimal structure searched by DARTS. The less ppl, the better.
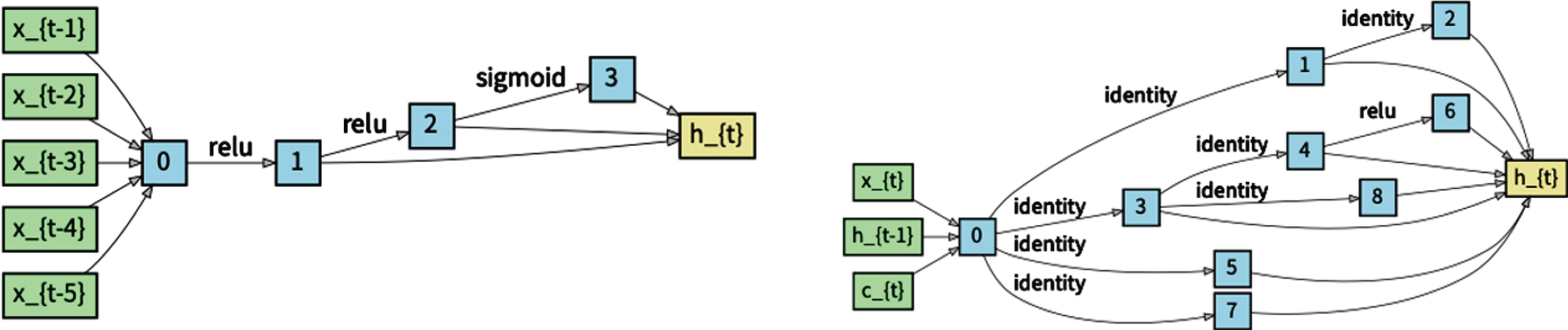
The information storage cell (left) and the information processing cell (right) searched on the PTB data set by our method.
Results on PTB data set
Comparison of the perplexity between the method in this paper and other methods on the PTB data set. The second line presents the manually designed network results, the third line presents the results of other NAS methods, and the fourth line presents the results of the baseline DARTS and our method.
To verify the transferability of the structure searched by our method, we transfer the optimal cell structure searched on the PTB data set directly to the WT2 data set for evaluation. The size of the embedded layer and the hidden layer is set to 700 for both, and the weight decay is 5e-7. Table 2 shows the results of the structure transfer to the WT2 dataset. After full training on the test set, compared with that of the baseline model, the perplexity of our model on the test set increases by 0.2 points.
Results on WT2 data-set
Results on WT2 data-set
The result of transferring the structure searched on the PTB data set to the WT2 data set. The second line presents the manually designed network results, the third line presents the results of other NAS methods, and the last line corresponds to the baseline method and our method.
We analyze the match between the search space constructed in this paper and the task by verifying the perplexity of sentences of different lengths. Specifically, we perform statistics and groupings on the test set, as shown in Table 3. The test set has a total of 3761 sentences. The minimum number of words in the sentence is one, and the maximum is 77. We divide the test set into eight groups according to the number of words, and test the perplexity of the model under these eight groups of data. The results are shown in the Fig. 4.
Test set size and grouping of PTB data set
Test set size and grouping of PTB data set
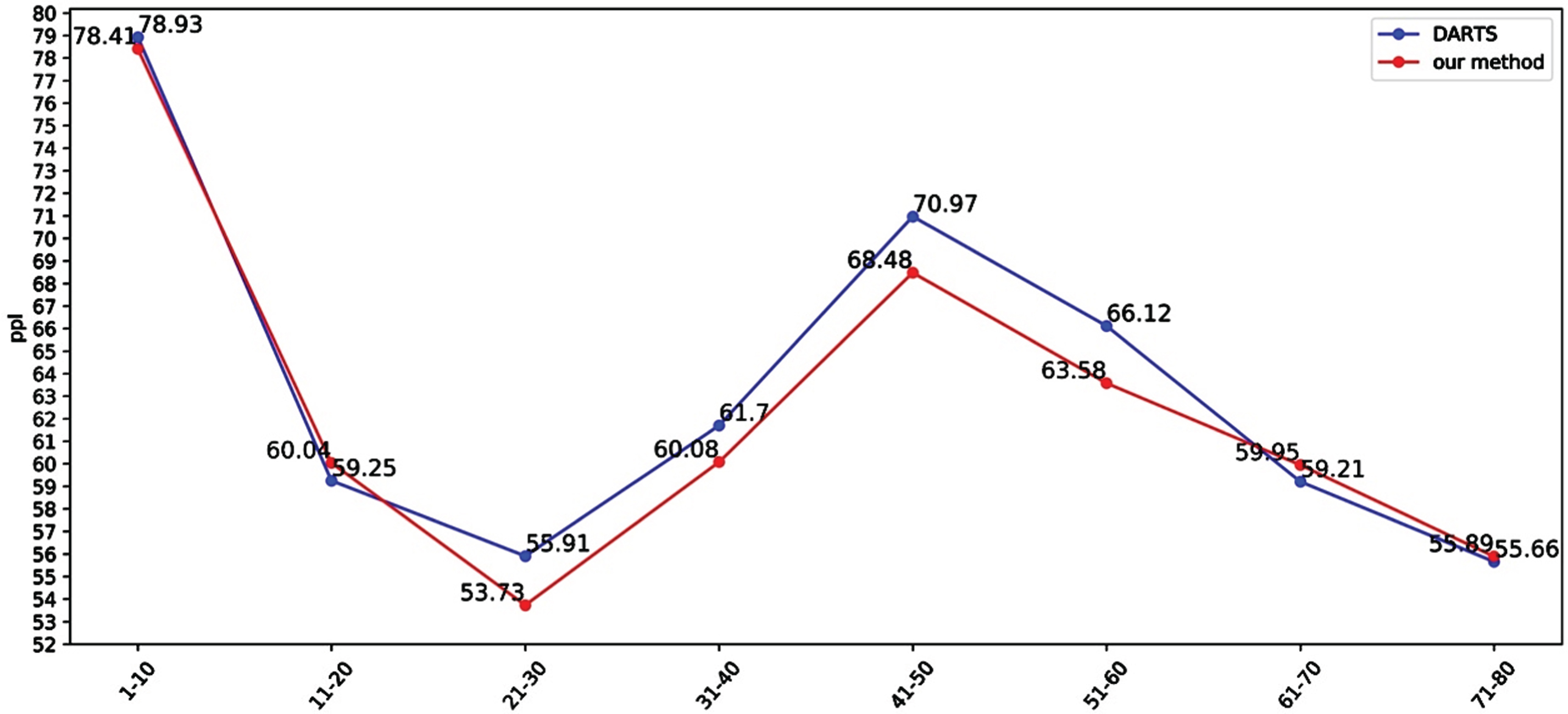
The model perplexity result of grouped data, the blue line is the result of the baseline method, and the red line is the result of our method.
We have proved the transferability of the method in this paper, the transferbility of the network structure, and the matching of the dual-cell search space with the task through three sets of experiments. First, on the PTB data set, the language model searched by the method presented in this paper achieved a test perplexity of 55.3, which is 0.4 points higher than the baseline, which proves the effectiveness of our method. Then, we directly migrated the structure searched on the PTB data set to the WT2 data set for training, and achieved a test perplexity of 69.4, which is 0.2 points higher than the baseline. Since the manual network structure is designed directly on the WT2 data set, and our network is migrated from the PTB data set, there is still a gap in performance, but it is a relatively competitive result. Finally, in order to prove that the search space proposed in this paper is more compatible with the language model task, we grouped the test set and conducted experiments. Figure 4 shows that when the sentence length is short (1–20) or very long (61–80), the difference in perplexity between our method and the baseline method is within 1, which shows that the two methods have similar modeling capabilities for short sequences and ultralong sequences. However, in terms of long-sentence (20–60) modeling ability, our method is significantly better than the baseline method, which proves that the dual-unit search space proposed in this paper has better modeling ability for long sequences and is more compatible with the task.
Conclusions
We propose an NAS method based on the dual-cell expansion space and construct a dual-cell search space that more closely matches the language model task. An information storage cell is added inside the cyclic neural network cell to effectively save the front-end information of the sequence, thereby improving the model’s ability to model long sequences. At the same time, an increase in the number of cells directly expands the search space and increases the probability that we can search for a better network structure. We prove the effectiveness of our method through experiments on the language modeling task, where the perplexity on the PTB data set is increased by 0.4 points compared with that of the baseline method. The transferability of the model is also verified on the WT2 data set.
Footnotes
Acknowledgments
This study was supported by the project of the National Key Research and Development Program of China (2018YFC0830100), National Natural Science Foundation of China (61762056, 61866020), Natural Science Foundation project of the Yunnan Science and Technology Department (2019FB082), Yunnan provincial major science and technology special plan projects: Digitization research and application demonstration of Yunnan characteristic industry, under Grant: 202002AD080001, and Personal Training Project of the Yunnan Science and Technology Department (KKSY201703015).