
Abstract
In this paper, we study the privacy breach caused by unsafe correlations in transactional data where individuals have multiple tuples in a dataset. We provide two safety constraints to guarantee safe correlation of the data: (1) the safe grouping constraint to ensure that quasi-identifier and sensitive partitions are bounded by l-diversity and (2) the schema decomposition constraint to eliminate non-arbitrary correlations between non-sensitive and sensitive values to protect privacy and at the same time increase the aggregate analysis. In our technique, values are grouped together in unique partitions that enforce l-diversity at the level of individuals. We also propose an association preserving technique to increase the ability to learn/analyze from the anonymized data. To evaluate our approach, we conduct a set of experiments to determine the privacy breach and investigate the anonymization cost of safe grouping and preserving associations.
Introduction
Data outsourcing is on the rise, and the emergence of cloud computing provides additional benefits to outsourcing. Privacy regulations pose a challenge to outsourcing, as the very flexibility provided makes it difficult to prevent against trans-border data flows, protection and separation of clients, and other constraints that may be required to outsource data. An alternative is encrypting the data [5]; while this protects privacy, it also prevents beneficial use of the data such as value-added services by the cloud provider (e.g., address normalization), or aggregate analysis of the data (and use/sale of the analysis) that can reduce the cost of outsourcing. Generalization-based data anonymization [9,12,18,19] provides a way to protect privacy while allowing aggregate analysis, but does not make sense in an outsourcing environment where the client wants to be able to retrieve the original data values.
An alternative is to use bucketization, as in the anatomy [24], fragmentation [4], or slicing [11] models. Such a database system has been developed [15,16]. The key idea is that identifying and sensitive information are stored in separate tables, with the join key encrypted. To support analysis at the server, data items are grouped into buckets; the mapping between buckets (but not between items in the bucket) is exposed to the server. An example is given in Table 1 where attribute DrugName is sensitive: Table 1(b) is an anatomized version of table prescription with attributes separated into
Prescription anonymized
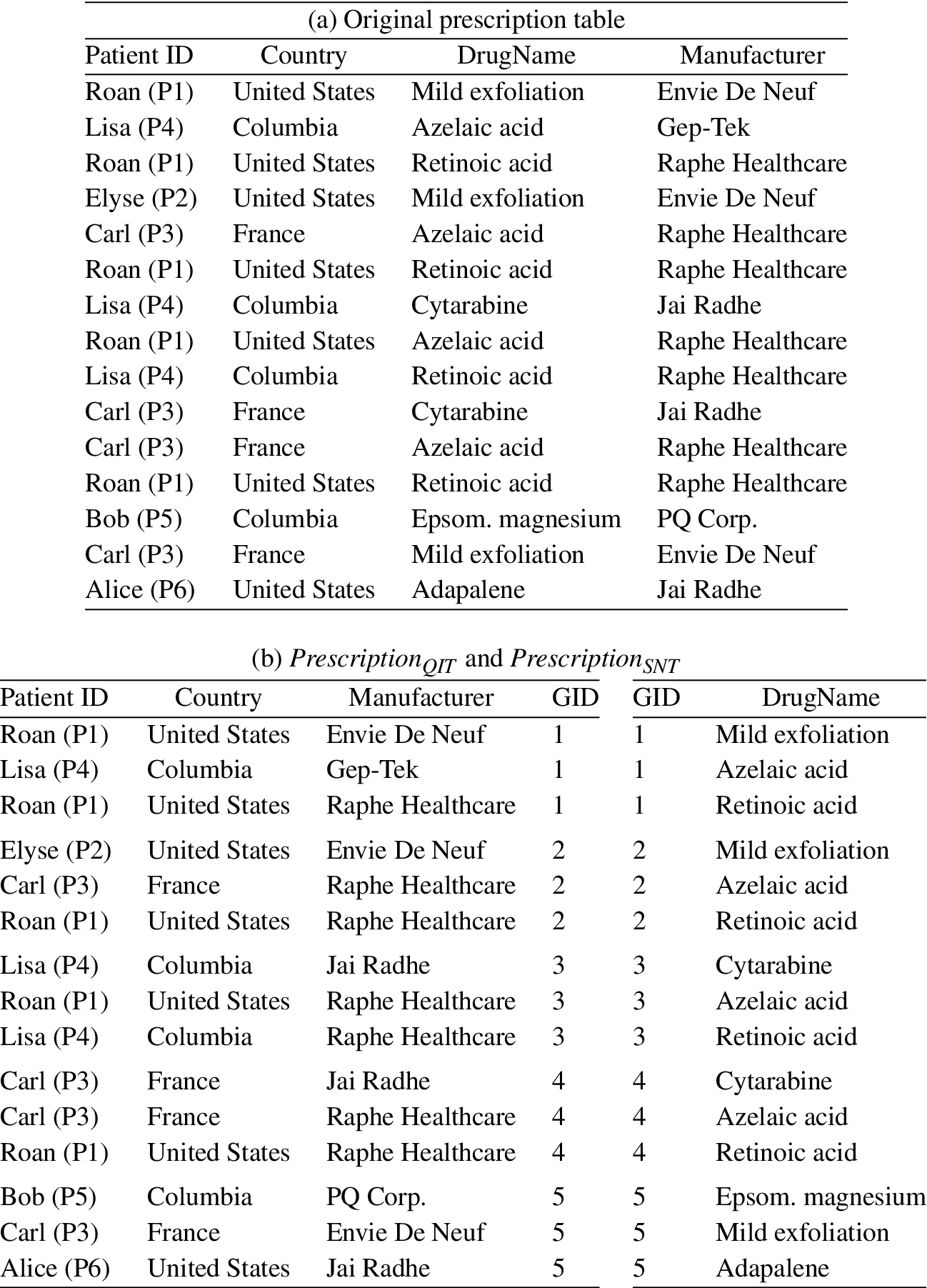
Prescription anonymized
The bucket size and grouping of tuples into buckets ensures that privacy constraints (such as k-anonymity [18,19] or l-diversity [12]) are satisfied.
Complications arise when extending this approach to transactional datasets. Even with generalization-based approaches, it has been shown that transactions introduce new challenges. Approaches such as
We give examples of this based on Table 1(b). The anonymized table satisfies the
Inter-group dependencies occur when an adversary knows certain facts about drug use, e.g., Retinoic acid is a maintenance drug taken over a long period of time. As P1 is the only individual who appears in all groups where Retinoic acid appears, it is likely that P1 is taking this drug. Note that this fact can either be background knowledge, or learned from the data.
Intra-group dependencies occur where the number of transactions for a single individual within a group results in an inherent violation of l-diversity (this would most obviously occur if all transactions in a group were for the same individual). By considering this separately for transactional data, rather than simply looking at all tuples for an individual as a single “data instance”, we gain some flexibility.
Another privacy breach might occur when an adversary can use the (anatomized) data to link sensitive information to the non-sensitive attribute (neither (quasi)-identifying, nor sensitive). Such correlation between attributes can then be used to link the sensitive values to the identifying information. For instance, let us assume a (publicly known) correlation between Manufacturer and DrugName; e.g., only Raphe Healthcare makes Retinoic acid. This enables the adversary to determine a drug taken by the individual. More subtle is the case where the dependency occurs in the other direction, e.g., a manufacturer might produces only one drug (as shown with Envie de Neuf). To cope with such cases, anatomy must produces two sensitive tables as in [6] (one for each sensitive attribute), which alternatively inhibits the ability to learn such correlations from the data.
In this paper, we present a method to counter such privacy violations while preserving data utility. Our contributions can be summarized as follows:
An in-depth study of privacy violation due to correlation of individuals’ related tuples in bucketization techniques.
A safe grouping technique to eliminate privacy violation due to the transactional nature of the data. Our safe grouping technique ensures that quasi-identifier and sensitive partitions respect the l-diversity privacy constraint.
A schema decomposition technique to eliminate non-arbitrary correlations between non-sensitive and sensitive values. We consider that safely decomposing the table can be used to expose the correlation of non-identifying information to sensitive values in a way that protects privacy while allowing analysis of data.
The approach is based on knowing (or learning) the correlations, and forming buckets with a common antecedent to the correlation. This protects against inter-group dependencies. Identifiers are then suppressed where necessary (in an outsourcing model, this corresponds to encrypting just the portion of the tuple in the identifier table) to ensure the privacy constraint is met (including protection against intra-group correlation).
In the next section, we present our adversary model. Section 3 gives further background on prior work and its limitations in dealing with this problem. In Section 4, we define the basic notations and key concepts used in the rest of the paper. A definition of correlation-based privacy violation in transactional datasets is given in Section 5. In Section 6, we present our a safety constraints; safe grouping and safe decomposition that form the basis of our anonymization method. Section 7 gives our safe grouping and preserving associations algorithms. A set of experiments to evaluate both the practical efficiency and the loss of data utility (suppression/encryption) is given in Section 8. We conclude with a discussion of next steps to move this work toward practical use.
In our adversary model, we assume that the adversary has knowledge of the transactional nature of the dataset. We also assume that he/she has outside information on correlations between sensitive data items that leads to a high probability that certain sets of items would belong to the same individual. This is illustrated in the Introduction (example 1) where the fact that the drug Retinoic acid is known to be taken for a long period of time makes it possible to link it to patient P1.
We do not care about the source of such background information; it may be public knowledge, or it may be learned from the anatomized data itself. (We view learning such knowledge from the data as beneficial aggregate analysis of the data.)
We explicitly distinguish between identifying information (which in bucketization can be both explicitly identifiers such as name and quasi-identifiers such as address that can be linked to identity using public information); non-identifying, non-sensitive information (such as the manufacturer of a medication), and sensitive information (such as the name of the medication being taken). We assume that the adversary does not have prior knowledge of the link between non-sensitive, non-identifying attribute values and specific individuals, beyond what can be inferred from general knowledge about frequency of attributes – if an adversary could have such knowledge, these become identifying information. This same assumption is made with generalization methods such as l-diversity or k-anonymity, where such knowledge weakens the privacy provided. Our method deals with potential information disclosure from correlation between identifying or non-sensitive attributes and sensitive attributes.
Related work
In [23], the authors consider that any transaction known by the adversary could reveal additional information that might be used to uncover a sensitive linking between a quasi-identifier and a sensitive value. They define
In [11] the authors propose a slicing technique to provide effective protection against membership disclosure. It is similar to how we approach the association between non-sensitive and sensitive attributes where separating the data cannot be done in a trivial matter without considering the correlations. However, the slicing technique as proposed (i.e., grouping quasi-identifier and sensitive attributes based on their correlation threshold) remains vulnerable to identity disclosure. This is due to adversary’s knowledge of the transactional nature of the dataset where he/she may still be able to associate an individual identifier with correlated sensitive values.
The authors in [6] discuss privacy violations in the anatomy privacy model [24] due to functional dependencies (FDs). In their approach, they propose to create QI-groups on the basis of a FD tree while grouping tuples based on the sensitive attribute to form l-diverse groups. Unfortunately, dealing with FDs’ is not sufficient, as less strict dependencies can still pose a threat.
In [3], the authors consider correlation as foreground knowledge that can be mined from anonymized data. They use the possible worlds model to compute the probability of associating an individual to a sensitive value based on a global distribution. In [8], a naïve Bayesian model is used to compute association probability. They used exchangeability [1] and De Finetti’s theorem [17] to model and compute patterns from the anonymized data. In [10], the authors deal with background knowledge that can be mined from the data. In their paper they focus mainly on what we consider as negative correlations limiting by that the ability to handle positive and exposed correlations. These papers address correlation in its general form where the authors show how an adversary can violate l-diversity privacy constraint through an estimation of such correlations in the anonymized data. As it is a separate matter, we consider that correlations due to transactions where multiple tuples are related to the same individual ensure that particular sensitive values can be linked to a particular individual when correlated in the same group (i.e., bucket). We go beyond this, addressing any correlation (either learned from the data or otherwise known) that explicitly violates the targeted privacy goal.
Formalization
Given a table T with a set of attributes
Identifier (
Sensitive attribute (
Non-sensitive attribute (
(Equivalence class/QI-group [18]).
A quasi-identifier group (QI-group) is defined as a subset of tuples of
Note that for our purposes, this can include direct identifiers as well as quasi-identifiers; we stick with the QI-group terminology for compatibility with the broader anonymization literature.
(l-diversity [13]).
A table T is said to be l-diverse if each of the QI-groups m is the total number of QI-groups in T,
(Anatomy).
Given a table T, we say that T is anatomized if it is separated into a quasi-identifier table (
To express correlation in transactional data we use the following notation
Notations
Notations
Next, we present a formal description of the privacy violation that can be caused due to such correlations.
In this section, we formally define the privacy violation that might occur due to correlation.
Correlation between identifying and sensitive values
Inter-group correlation occurs when transactions for a single individual are placed in multiple QI-groups (as with P1, P3 and P4 in Table 1(a)). The problem arises when the values in different groups are related (as would happen with association rules); this leads to an implication that the values belong to the same individual. Formally:
(Inter QI-group correlation).
Given a correlation dependency of the form
The example shown in Table 1, explains how an adversary with prior knowledge of the correlation, in this case that Retinoic acid must be taken multiple times, is able to associate the drug with the patient Roan (P1) due to their correlation in several QI-groups.
An intra-group violation can arise if several correlated values are contained in the same QI-group. Here the problem is that this gives a count of tuples that likely belong to the same individual, which may limit it to a particular individual in the group. Table 3 is an example of intra QI-group correlation in which the number of tuples associated with patient Roan (P1) in
Intra QI-group correlation
Intra QI-group correlation
Given a QI-group
u is the individual who has the most frequent tuples in
Let r be the number of remaining sensitive values in
It would be nice if this lemma was “if and only if”, giving criteria where a privacy violation would NOT occur. Unfortunately, this requires making assumptions about the background knowledge available to an adversary (e.g., if an adversary knows that one individual is taking a certain medication, they may be able to narrow the possibilities for other individuals). This is an assumption made by all k-anonymity based approaches, but it becomes harder to state when dealing with transactional data.
Let us go back to Table 3, an adversary is able to associate both drugs (Retinoic acid and Azelaic acid) with patient Roan (P1) due to the correlation of their related tuples in the same QI-group.
Eliminating the threat related to the correlation of non-sensitive and sensitive attribute values can be done using naïve anatomization where multiple sensitive attributes are separated to preserve individual’s privacy. This is somehow inevitable under anatomy even if these attributes are not sensitive by their nature (e.g., the attribute manufacturer is an example of such attributes). This leads to a loss of utility as explained by the following two points:
Loss of correlation: Given the correlation between a non-sensitive and sensitive attributes It refers to the association of a value in
Loss of association: Consider a correlation between attributes
As we have shown in the previous section, bucketization techniques do not cope well with correlation, which is due to transactional data where an individual might be represented by several tuples that could lead to identifying his/her sensitive values and/or due to the ability to link sensitive to non-sensitive attribute values. In order to guarantee safety, this section presents our two safety constraints; safe grouping and safe decomposition.
(Safe grouping).
Given a correlation dependency in the form of
Safe grouping ensures that individual tuples are grouped in one and only one QI-group that is at the same time l-diverse, respects a minimum diversity for identity attribute values, and all subsets
Prescription respecting our safety constraints
Prescription respecting our safety constraints
Table 4 describes a quasi identifier group (
Let
Consider an individual u in
Given an anonymized table
Safe grouping guarantees that individual’s u related tuples
We can estimate,2
In the following, we present a schema decomposition safety constraint that recognizes and deals with correlation between non-sensitive and sensitive attributes.
Given a table T, let
The safe decomposition constraint ensures that non-sensitive attributes related by correlation to sensitive ones are removed from
Given the non-sensitive attribute
As defined in our adversary model.
Consider a table T formed by m QI-groups under a grouping by correlation where the sensitive table holds the sensitive attribute
Summarizing, if a non-sensitive attribute is correlated with an identifying attribute, we can place it in
We note that a benefit of the safe decomposition constraint is that it exposes the correlations, improving the utility of the data for aggregate analysis. This is shown using the following preserving associations definition.
Let
Preserving associations deals with the case where a non-sensitive attribute is correlated with both identifying and sensitive attributes. Again, this is done through making the correlation explicit in the data – both improving utility, and ensuring that the knowledge of the correlation does not give the adversary additional capabilities. The way we do this is by forming the anatomy groups so that the non-sensitive
Table 5 shows an example on how it is possible to preserve the association between the attributes patient and manufacturer.
Preserving association between patient and manufacturer
Preserving association between patient and manufacturer
Let
Let us assume that
We note that using the safety constraints described above, we do not intend to replace anatomy. In fact, we divide the table as described in the original anatomy model by separating it into two subtables (
In this section, we provide mechanisms to enforce the safe correlation safety constraint when anonymizing data. We start with safe grouping algorithm that guarantees the safe grouping safety constraint. We also present the associations preserving algorithm used to create QI-groups under the safe decomposition constraint.
Safe grouping algorithm
Algorithm 1 guaranties the safe grouping of a table T based on an identity attribute correlation dependency

SafeGrouping
The main idea behind the algorithm is to create k buckets based on the attribute (
The safe grouping algorithm takes a table T, a correlation dependency
If l-diversity for the QI-group in question is not met, the algorithm enforces it by anonymizing tuples related to the most frequent sensitive value in the QI-group. After the l-diversity enforcement process, the algorithms verifies whether the group contains k buckets, and if not anonymizes (which could mean generalizing, suppressing, or encrypting the values, depending on the target model).
From Steps 19–26 the algorithm anatomizes the tables based on the QI-groups created. It stores random non-sensitive and sensitive attribute values in the

Preserving associations
While safe grouping provides safety, its ability to preserve data utility is limited to the number of distinct values of
We now present our preserving associations algorithm (Algorithm 2) that groups attributes to preserve the associations between individuals and non-sensitive attribute values while still guaranteeing the requirements needed to ensure a safe correlation.
The preserving associations algorithm’s main priority is to create QI-groups with common values of non-sensitive attribute. The algorithm takes a table T, a non-sensitive attribute
In Step 10, the algorithm ensures that the remaining buckets are anonymized. We do not specify the anonymization technique to be used. However, both safe grouping and anatomy can be adopted, as desired to meet privacy constraints.
In Steps 11–18, the algorithm stores QI-groups in the decomposed tables
The example in Table 5 shows how to preserve associations. As you can notice, the main objective is to create QI-groups with common Manufacturer values as is the case for
Experiments
We now present a set of experiments to evaluate the efficiency of our approach, both in terms of computation and more importantly, loss of data utility. We implemented our algorithms in Java based on the Anonymization Toolbox [7], and conducted experiments with an Intel XEON 2.4 GHz PC with 2 GB RAM.
Evaluation dataset
In keeping with much work on anonymization, we use the Adult Dataset from the UCI Machine Learning Repository [2]. To simulate real identifiers, we made use of a U.S. state voter registration list containing the attributes Birthyear, Gender, Firstname and Lastname. We combined the adult dataset with the voter’s list such that every individual in the voters list is associated with multiple tuples from the adult dataset, simulating a longitudinal dataset from multiple census years. We have constructed this dataset to have a correlation dependency of the following form
We say that an individual is likely to stay in the same occupation across multiple censuses. Note that this is not an exact longitudinal dataset; n varies between individuals (simulating a dataset where some individuals move into or out of the census area). The generated dataset is of size 48,836 tuples with 21,201 distinct individuals.
In the next section, we present and discuss results from running our safe grouping algorithm.
Evaluation results
We elaborated a set of measurements to evaluate the efficiency of safe grouping. These measurements can be summarized as follows:
evaluating privacy breach in a naive anatomization. We note that the same test could be performed on the slicing technique [11] as the authors in their approach do not deal with identity disclosure, determining anonymization cost represented by the loss metric to capture the fraction of tuples that must be (partially or totally) generalized, suppressed, or encrypted in order to satisfy the safe grouping, comparing the computational cost of our safe grouping algorithm to anatomy [24], and evaluating the utility of preserving associations compared to a basic anatomization.
Evaluating privacy
After naïve anatomization over the generated dataset, we have identified 5 explicit violations due to intra QI-group correlations where values of
Significance is measured in this case based on the support of
After we applied the above test to the anatomized dataset, we have identified for
We evaluate our proposed anonymization algorithms to determine the loss metric (
(Loss metric (
)).
Let
Table 4 shows a anonymized version of table prescription where grouping is safe and has a loss metric equal to
We investigate the anonymization cost for a correlation dependency

Safe grouping evaluation in transactional datasets (a)–(c). (a) % of tuples anonymized to ensure the safety constraint and l-diversity for
From Fig. 1, we can see that the
We now give the processing time to perform safe grouping compared to anatomy. Figure 1(d) shows the computation time of both safe grouping and anatomy over a non-transactional dataset with different k values. Theoretically, a worst case of safe grouping could be much higher; but in practice, for a small values of l the safe grouping has better performance than anatomy. Furthermore, as k increases the safe grouping computation time decreases due to reduced I/O access needed to test QI-groups’ l-diversity.
Utility of associations preserving algorithm
We now evaluate the utility of preserving associations given the correlation dependencies. We investigate the amount of associations preserved between individuals and the attribute Hours-per-week in the dataset. To do so, we compute a quality metric
(Association metric
).
Let
We compute
Conclusion
In this paper, we proposed a safe grouping and safe decomposition constraints to cope with defects of bucketization techniques in handling correlated values in transactional dataset. Our safe grouping algorithm creates partitions with an individual’s related tuples stored in one and only one group, eliminating these privacy violations. We also provided a preserving associations technique to make the associations between individuals and non-sensitive attribute values explicit, thus increasing the ability to analyze the anonymized data.
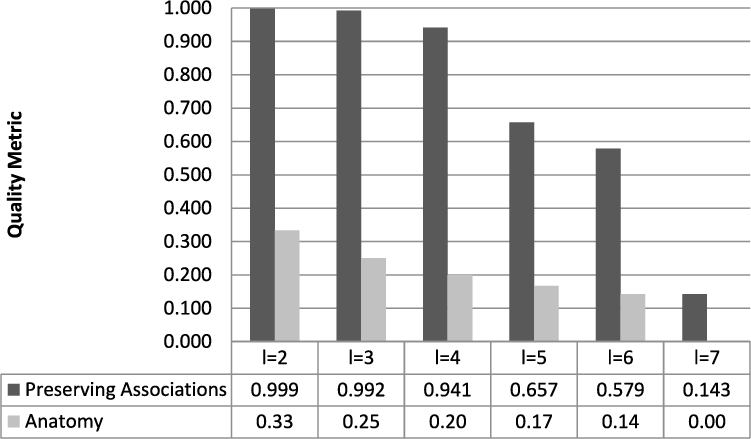
Quality of preserving associations.
We showed, using a set of experiments, that there is a trade-off to be made between privacy and utility. This trade-off is quantified based on the number of tuples to be anonymized using the safe grouping algorithm. We investigated the computation time of safe grouping and showed that despite the exponential growth of safe grouping, for a small range of values of l, safe grouping outperforms anatomy while providing stronger privacy guarantees. Finally, we showed that our associations preserving technique clearly gives additional learning abilities compared to the traditional anatomy.
Footnotes
Acknowledgments
This publication was made possible by NPRP grant 09-256-1-046 from the Qatar National Research Fund. The statements made herein are solely the responsibility of the authors.