
Abstract
Garbled circuits provide a powerful tool for jointly evaluating functions while preserving the privacy of each user’s inputs. While recent research has made the use of this primitive more practical, such solutions generally assume that participants are symmetrically provisioned with massive computing resources. In reality, most people on the planet only have access to the comparatively sparse computational resources associated with their mobile phones, and those willing and able to pay for access to public cloud computing infrastructure cannot be assured that their data will remain unexposed. We address this problem by creating a new SFE protocol that allows mobile devices to securely outsource the majority of computation required to evaluate a garbled circuit. Our protocol, which builds on the most efficient garbled circuit evaluation techniques, includes a new outsourced oblivious transfer primitive that requires significantly less bandwidth and computation than standard OT primitives and outsourced input validation techniques that force the cloud to prove that it is executing all protocols correctly. After showing that our extensions are secure in the malicious model, we conduct an extensive performance evaluation for a number of standard SFE test applications as well as a privacy-preserving navigation application designed specifically for the mobile use-case. Our system reduces execution time by 98.92% and bandwidth by 99.95% for the edit distance problem of size 128 compared to non-outsourced evaluation. These results show that even the least capable devices are capable of using large garbled circuits for secure computation.
Introduction
Secure Function Evaluation (SFE) allows two or more parties to compute the result of a function without any party having to expose their potentially sensitive inputs to the others. While considered a generally theoretical curiosity even after the discovery of Yao’s garbled circuit [63], recent advances in this space have made such computation increasingly practical. Today, functions as complex as AES-128 and approaching one billion gates in size are possible at reasonable throughputs, even in the presence of a malicious adversary.
While recent research has made the constructions in this space appreciably more performant, the majority of related work makes a crucial assumption – that both parties are symmetrically provisioned with massive computing resources. For instance, Kreuter et al. [37] rely on the Ranger cluster at the Texas Advanced Computing Center to compute their results using 512 cores. In reality, the extent of a user’s computing power may be their mobile phone, which has many orders of magnitude less computational ability. In the increasingly common setting where a mobile device performs some computation with an application server, there is an asymmetry of computational ability that makes current SFE techniques highly impractical. Moreover, even if the mobile device is given access to a public compute cloud such as Amazon EC2 or Windows Azure, the sensitive nature of the user’s data and the history of data leakage from cloud services [58,61] prevent the direct porting of known SFE techniques.
In this paper, we develop mechanisms for the secure outsourcing of SFE computation from constrained devices to more capable infrastructure. Our protocol maintains the privacy of both the mobile user’s and the application server’s inputs and outputs while significantly reducing the computation and network overhead required by the mobile device for garbled circuit evaluation. We develop a number of extensions to allow the mobile device to check for malicious behavior from the circuit generator or the cloud and a novel Outsourced Oblivious Transfer (OOT) for sending garbled input data to the cloud. We then implement the new protocol on a commodity mobile device and reasonably provisioned servers and demonstrate significant performance improvements over evaluating garbled circuits directly on the mobile device.
We make the following contributions:
Outsourced oblivious transfer and outsourced consistency checks: Instead of blindly trusting the cloud with sensitive inputs, we develop a highly efficient Outsourced Oblivious Transfer primitive that allows mobile devices to securely delegate the majority of computation associated with oblivious transfers. We also provide mechanisms to outsource consistency checks to prevent a malicious circuit generator from providing corrupt garbled values. These checks are designed in such a way that the computational load is almost exclusively on the cloud, but cannot be forged by a malicious or “lazy” cloud. We demonstrate that both of our additions are secure in the malicious model as defined by Kamara et al. [31].
Performance analysis: Extending upon the implementation by Kreuter et al. [37], we conduct an extensive performance analysis against a number of simple applications (e.g., edit distance) and cryptographic benchmarks (e.g., AES-128). Our results show that outsourcing SFE provides improvements to both execution time and bandwidth overhead. For the edit distance problem of size 128, we reduce execution time by 98.92% and bandwidth by 99.95% compared to direct execution without outsourcing on the mobile device.
Privacy preserving navigation app: To demonstrate the practical need for our techniques, we design and implement an outsourced version of Dijkstra’s shortest path algorithm as part of a Navigation mobile app. Our app provides directions for a Presidential motorcade without exposing its location, destination, or known hazards that should be avoided (but remain secret should the mobile device be compromised). The optimized circuits generated for this app are among the largest circuits evaluated to date. Without our outsourcing techniques, such an application is far too processor, memory and bandwidth intensive for any mobile phone.
While this work is similar in function and provides equivalent security guarantees to the Salus protocols recently developed by Kamara et al. [31], our approach is dramatically different. The authors of the Salus protocol state that their protocol is optimized for outsourcing work from low-computation devices with high communication bandwidth. With provider-imposed bandwidth caps and relatively slow and unreliable cellular data connections, this is not a realistic assumption when developing solutions in the mobile environment. Thus, the optimization goals for our work are to reduce the computation and communication overhead required at the mobile device. Moreover, rather than providing a proof-of-concept work demonstrating that offloading computation is possible, this work seeks to develop and thoroughly demonstrate the practical potential for applying large garbled circuits to secure mobile applications.
The remainder of this work is organized as follows: Section 2 presents important related work and discusses how this paper differs from Salus; Section 3 provides cryptographic assumptions and definitions; Section 4 formally describes our protocols; Section 5 provides informal security discussion; Section 6 provides full proofs of security; Section 7 shows the results of our extensive performance analysis; Section 8 presents our privacy preserving navigation application for mobile phones; and Section 9 provides concluding remarks.
Related work
Three general categories of techniques have been developed to perform two-party SFE. The first, using homomorphic encryption, has yielded several special-purpose protocols using partially homomorphic encryption [4,5,7,15,56]. Other more generalizable protocols combine partially homomorphic encryption with garbled circuit constructions [20]. However, these schemes are manually optimized for specific functions. While protocols using fully homomorphic encryption (FHE) promise more generalizable results [16], these cryptosystems are currently too inefficient to be used practically, even on server-class machines. A second technique for secure function evaluation uses only the Oblivious Transfer (OT) primitive to compute certain functions [11,51,54,59]. While recent advances have made OT-based schemes more practical, their performance is only optimal for evaluating specific functions. Because of this, we focus this work on the most studied and widely applied technique, the Yao garbled circuit [63]. With the Fairplay implementation [46], garbled circuits were shown to have significant promise in terms of efficiency.
Beginning with Fairplay [46], several secure two-party computation implementations and applications have been developed using various circuit representations in the semi-honest adversarial model [24,27,29,38,41,45,55]. However, a malicious party using corrupted inputs or circuits can learn more information about the other party’s inputs in these constructions [33]. To resolve these issues, new protocols have been developed to achieve security in the malicious model, using cut-and-choose constructions [40,43,46,48,60,62], input commitments [60], and other various techniques [25,32,48]. To improve the performance of these schemes in both the malicious and semi-honest adversarial models, a number of optimization techniques have also been developed to reduce the cost of generating and evaluating circuits [12,18,26,35,40,50]. Kreuter et al. [36,37] combined several of these techniques into a general garbled circuit protocol that is secure in the malicious model and can efficiently evaluate circuits on the order of billions of gates using parallelized server-class machines. This SFE protocol is among the most efficient implementations to date that are fully secure in the malicious model.
Garbled circuit protocols rely on oblivious transfer schemes to exchange certain private values. While several OT schemes of various efficiencies have been developed [2,43,52,57], Ishai et al. demonstrated that any of these schemes can be extended to reduce
Currently, the performance of garbled circuit protocols executed directly on mobile devices has been shown to be feasible only for small circuits in the semi-honest adversarial model [7,22]. While outsourcing general computation to the cloud has been widely considered for improving the efficiency of applications running on mobile devices, the concept has yet to be applied in practice to cryptographic constructions. Beginning in the 1980s with the outsourced RSA signature scheme by Matsumoto et al. [47], several theoretical schemes have been developed in the area of server-aided cryptography. However, most of these protocols were either broken or never implemented for practical purposes. Green et al. explored this idea further by outsourcing the costly decryption of ABE ciphertexts to server-class machines while still maintaining data privacy [19]. Naor et al. [53] develop an oblivious transfer technique that sends the chooser’s private selections to a third party, termed a Proxy Oblivious Transfer. While this idea is applied to a limited application in their work, it could be leveraged more generally into existing garbled circuit protocols. In the field of SFE, López-Alt et al. developed a theoretical construction for outsourcing multiparty computation using FHE [44]. When considering more practical SFE techniques, the costs of exchanging inputs and evaluating garbled circuits securely would make an outsourcing technique extremely useful in allowing limited capability devices to execute SFE protocols. Our work extends the Proxy Oblivious Transfer by combining it with the OT extension of Ishai et al. [28] allowing us to construct a garbled circuit evaluation protocol that securely outsources computation to the cloud.
In work performed concurrently and independently from our technique, Kamara et al. recently developed two protocols for outsourcing secure multiparty computation to the cloud in their Salus system [30,31]. While their work achieves similar functionality to ours, we distinguish our work in the following ways: first, their protocol is constructed with the assumption that they are outsourcing work from devices with low-computation but high-bandwidth capabilities. With cellular providers imposing bandwidth caps on customers and cellular data networks providing highly limited data transmission speed, we construct our protocol without this assumption using completely different cryptographic constructions. Second, their work focuses on demonstrating outsourced SFE as a proof-of-concept. Our work offers a rigorous performance analysis on mobile devices, and outlines a practical application that allows a mobile device to participate in the evaluation of garbled circuits that are orders of magnitude larger than those evaluated in the Salus system. Finally, their protocol that is secure in the malicious model requires that all parties share a secret key, which must be generated in a secure fashion before the protocol can be executed. Our protocol does not require any shared information prior to running the protocol, reducing the overhead of performing a multiparty fair coin tossing protocol a priori. While our work currently considers only the two-party model, by not requiring a preliminary multiparty fair coin toss, expanding our protocol to more parties will not incur the same expense as scaling such a protocol to a large number of participants. To properly compare security guarantees, we apply their security definitions in our analysis.
Assumptions and definitions
To construct a secure scheme for outsourcing garbled circuit evaluation, some new assumptions must be considered in addition to the standard security measures taken in a two-party secure computation. In this section, we discuss the intuition and practicality of assuming a non-colluding cloud, and we outline our extensions on standard techniques for preventing malicious behavior when evaluating garbled circuits. Finally, we conclude the section with formal definitions of security.
Non-collusion with the cloud
Throughout our protocol, we assume that none of the parties involved will ever collude with the cloud. This requirement is based in theoretical bounds on the efficiency of garbled circuit evaluation and represents a realistic adversarial model. The fact that theoretical limitations exist when considering collusion in secure multiparty computation has been known and studied for many years [3,10,39], and other schemes considering secure computation with multiple parties require similar restrictions on who and how many parties may collude while preserving security [6,13,14,30,31]. Kamara et al. [31] observe that if an outsourcing protocol is secure when both the party generating the circuit and the cloud evaluating the circuit are malicious and colluding, this implies a secure two-party scheme where one party has sub-linear work with respect to the size of the circuit, which is currently only possible with fully homomorphic encryption. However, making the assumption that the cloud will not collude with the participating parties makes outsourcing securely a possibility in practice. In reality, many cloud providers such as Amazon or Microsoft would not allow outside parties to control or affect computation within their cloud system for reasons of trust and to preserve a professional reputation. In spite of this assumption, we cannot assume the cloud will always be semi-honest. For example, our protocol requires a number of consistency checks to be performed by the cloud that ensure the participants are not behaving maliciously. Without mechanisms to force the cloud to make these checks, a “lazy” cloud provider could save resources by simply returning that all checks verified without actually performing them. Thus, our adversarial model encompasses a non-colluding but potentially malicious cloud provider that is hosting the outsourced computation.
Kamara et al. [30] define this property formally as a non-cooperative adversary. An adversary
When running garbled circuit based secure multiparty computation in the malicious model, a number of well-documented attacks exist. We address here how our system counters each.
Malicious circuit generation: In the original Yao garbled circuit construction, a malicious generator can garble a circuit to evaluate a function Selective failure attack: If, when the generator is sending the evaluator’s garbled inputs during the oblivious transfer, he lets the evaluator choose between a valid garbled input bit and a corrupted garbled input, the evaluator’s ability to complete the circuit evaluation will reveal to the generator which input bit was used. To prevent this attack, we use the input encoding technique from Lindell and Pinkas [42], which lets the evaluator encode her input in such a way that a selective failure of the circuit reveals nothing about the actual input value. To prevent the generator from swapping garbled wire values, we use a commitment technique employed by Kreuter et al. [37]. Input consistency: Since multiple circuits are evaluated to ensure that a majority of circuits are correct, it is possible for either party to input different inputs to different evaluation circuits, which could reveal information about the other party’s inputs. To keep the evaluator’s inputs consistent, we again use the technique from Lindell and Pinkas [42], which sends all garbled inputs for every evaluation circuit in one oblivious transfer execution. To keep the generator’s inputs consistent, we use the malleable claw-free collection construction of shelat and Shen [60]. This technique is described in further detail in Section 3.3. Output consistency: When evaluating a two-output function, we ensure that outputs of both parties are kept private from the cloud using an extension of the technique developed by Kiraz and Schoenmakers [33]. The outputs of both parties are XORed with random strings within the garbled circuit, and the cloud uses a witness-indistinguishable zero-knowledge proof as in the implementation by Kreuter et al. [37]. This allows the cloud to choose a majority output value without learning either party’s output or undetectably tampering with the output. At the same time, the witness-indistinguishable proofs prevent Alice and Bob from learning the index of the majority circuit. This prevents Bob from learning anything by knowing which circuit evaluated to the majority output value.
Malleable claw-free collections
To prevent the generating party from providing different inputs for each evaluation circuit, we implement the malleable claw-free collections technique developed by shelat and Shen [60]. Their construction essentially allows the generating party to prove that all of the garbled input values were generated by exactly one function in a function pair, while the ability to find an element that is generated by both functions implies that the generator can find a claw.
Goldreich and Kahan define a claw-free collection as a three-tuple of algorithms [17]. The index sampling algorithm, G, takes a security parameter
(Claw-free collections [17,60]).
A three-tuple of algorithms Easy to evaluate: Both the index selecting algorithm G and the domain sampling algorithm D are probabilistic polynomial-time, while the evaluating algorithm F is deterministic polynomial-time. Identical range distribution: Let Hard to form claws: For every non-uniform probabilistic polynomial-time algorithm A, every polynomial
Given this definition, shelat and Shen build their scheme on a modified construction which adds in a malleability property, and focuses on a special case where
(Malleable claw-free collection [60]).
A four-tuple of algorithms A subset of claw-fee collections: Uniform domain sampling: For any I in the range of G, random variable Malleability:
Our implementation of a malleable claw-free collection uses the same construction as Kreuter et al. [37], built on the discrete logarithm assumption.
Model and definitions
The work of Kamara et al. [31] presents a definition of security based on the ideal-model/real-model security definitions common in secure multiparty computation. Because their definition formalizes the idea of a non-colluding cloud, we apply their definitions to our protocol for the two-party case in particular. We summarize their definitions below.
Real-model execution. The protocol takes place between two parties
Ideal-model execution. In the ideal model, the setup of participants is the same except that all parties are interacting with a trusted party that evaluates the function. All parties are provided inputs A protocol securely computes a function f if there exists a set of probabilistic polynomial-time (PPT) simulators
Participants
Our protocols reference three different entities:
The evaluating party, called Alice, is assumed to be a mobile device that is participating in a secure two-party computation.
The party generating the garbled circuit, called Bob, is an application- or web-server that is the second party participating with Alice in the secure computation.
The proxy, called Cloud, is a third party that is performing heavy computation on behalf of Alice, but is not trusted to know her input or the function output.
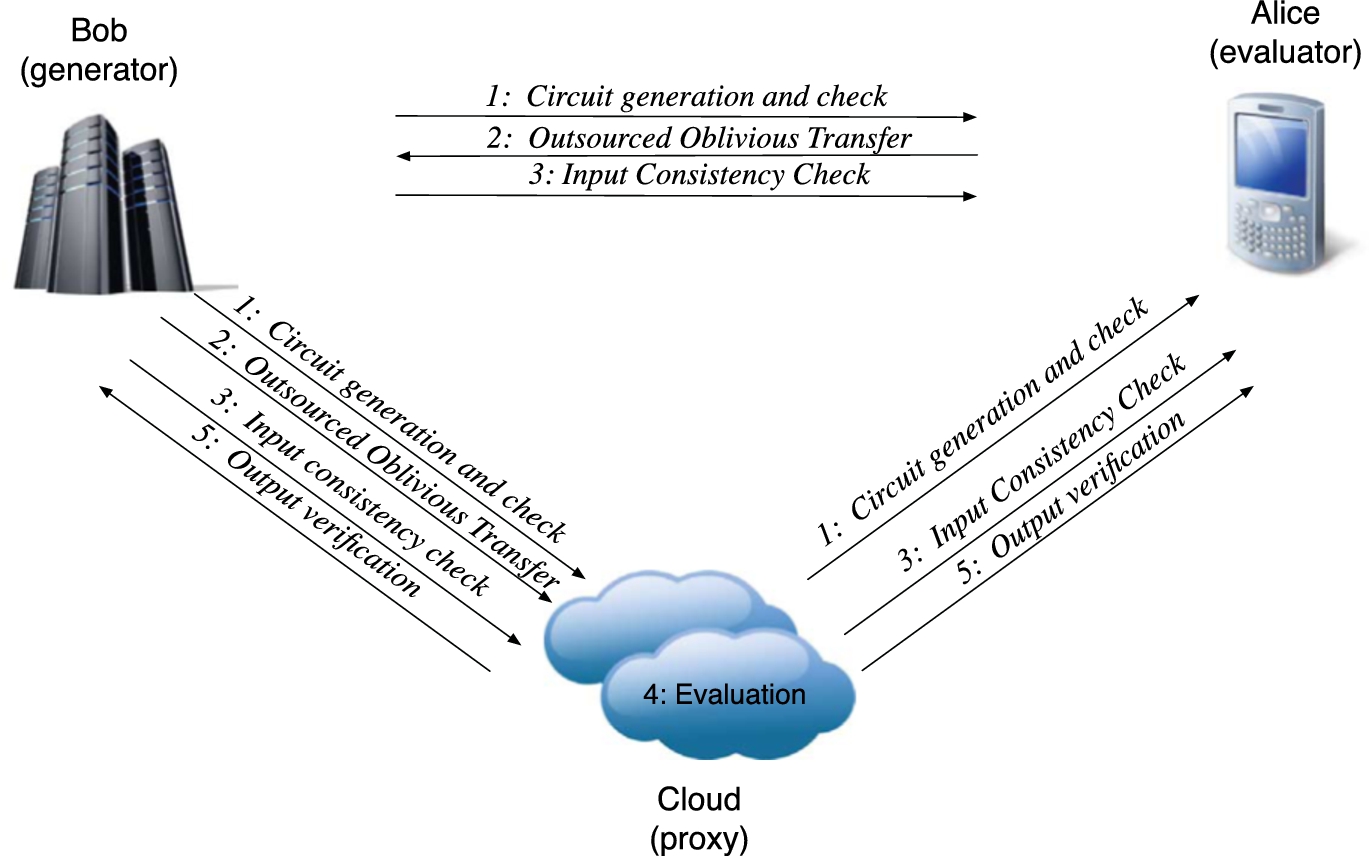
The complete outsourced SFE protocol.
Our protocol can be divided into five phases, illustrated in Fig. 1. Given a circuit generator Bob, and an evaluating mobile device Alice, the protocol can be summarized as follows:
Phase 1: Bob generates a number of garbled circuits, some of which will be checked, others will be evaluated. After Bob commits to the circuits, Alice and Bob use a fair coin toss protocol to select which circuits will be checked or evaluated. For the check circuits, Bob sends the random seeds used to generate the circuits to the Cloud and the hashes of each circuit to Alice. These are checked to ensure that Bob has not constructed a circuit that is corrupted or deviates from the agreed-upon function. Phase 2: Alice sends her inputs to Bob via an outsourced oblivious transfer. Bob then sends the corresponding garbled inputs to the Cloud. This allows the Cloud to receive Alice’s garbled inputs without Bob or the Cloud ever learning her true inputs. Phase 3: Bob sends his garbled inputs to the Cloud, which verifies that they are consistent for each evaluation circuit. This prevents Bob from providing different inputs to different evaluation circuits. Phase 4: The Cloud evaluates the circuit given Alice and Bob’s garbled inputs. Since the Cloud only sees garbled values during the evaluation of the circuit, it never learns anything about either party’s input or output. Since both output values are blinded with one-time pads, they remain private even when the Cloud takes a majority vote. Phase 5: The Cloud sends the encrypted output values to Alice and Bob, who are guaranteed its authenticity through the use of commitments and zero-knowledge proofs.
Outsourced protocol
Common inputs: a function
Private inputs: The generating party Bob provides his input to the function b and a random string of bits
Output: The protocol outputs separate private values
(Circuit generation and checking).
Circuit preparation: Before beginning the protocol, both parties agree upon a circuit representation of the function Additional XOR gates must be added such that Bob’s output is set to For each of Alice’s input bits, the input wire Circuit garbling: Bob first selects and malleable claw-free collection as index Circuit commitment: Bob generates commitments for all circuits by hashing Input label commitment: Bob commits to Alice’s garbled input wires as follows: for each generated circuit In the same fashion, Bob commits to his own input wires: for each circuit Cut and choose: Alice and Bob then run a fair coin toss protocol to agree on a set of circuits that will be evaluated, while the remaining circuits will be checked. The coin toss generates a set of indices each commitment the value the value for every bit value b and input wire j, the values committed in
If any of these checks fail, the Cloud immediately aborts. Otherwise, it sends the hash values

The outsourced oblivious transfer protocol.
Input encoding: For every bit OT setup: Alice initializes an Primitive OT operations: With Alice as the sender and Bob as the chooser, the parties initiate k 1-out-of-2 oblivious transfers. Alice’s input to the ith instance of the OT is the pair Permuting the selections: Alice generates a random bit string p of length Encrypting the commitment keys: Bob generates a matrix of keys that will open the committed garbled input values and proofs of consistency as follows: for Alice’s jth input bit, Bob creates a pair Receiving Alice’s garbled inputs: Alice blinds her input as Verifying consistency across Alice’s inputs: Given the decommitted values
(Generator input consistency check).
Delivering inputs: Bob decommits the hash seeds for each of his garbled input values by sending Check consistency: Alice then checks that all the hash seeds were generated by the same function by checking if:
(Circuit evaluation).
Evaluating the circuit: For each evaluation circuit, the Cloud evaluates Checking the evaluation circuits: Once these output have been computed, the Cloud hashes each evaluation circuit as
(Output check and delivery).
Committing the outputs: The Cloud then generates random commitment keys Selection of majority output: Bob opens the commitments Proof of output consistency: Using the OR-proofs as described by Kiraz and Schoenmakers [33], the Cloud proves to Bob that Output release: The Cloud then decommits Output decryption: Alice recovers her output
Asymptotic evaluation
When considering the performance of our outsourcing scheme, our goal is to optimize the workload on the mobile device. Because this device will always be more limited in computing capability than the Cloud, we need to minimize the overhead at this bottleneck. The dominating operations on the mobile device can be summarized in three categories: the OOT protocol, which requires k oblivious transfers and
Asymptotic analysis of the operations required on the mobile device for each outsourcing protocol
Asymptotic analysis of the operations required on the mobile device for each outsourcing protocol
Notes: Here, SYM is symmetric cryptographic operations, GROUP is group algebraic operations, and OT is oblivious transfers. Recall that k is the security parameter, λ is the number of circuits generated, a is the mobile device’s input, and b is the application server’s input.
In this section, we provide a summary of the security mechanisms used in our protocol and an informal discussion of the security guarantees of our outsourced oblivious transfer construction. While all of the basic consistency checks already exist in previous work, our protocol demonstrates how these checks can be modified to allow for secure computation in the outsourced model. In combination with our novel outsourced oblivious transfer protocol, this construction provides a significant step towards practical SFE on mobile devices that is secure against malicious adversaries.
Recall from Section 3 that there are generally four security concerns when evaluating garbled circuits in the malicious setting. To solve the problem of malicious circuit generation, we apply the random seed check variety of cut-and-choose developed by Goyal et al. [18]. To solve the problem of selective failure attacks, we employ the input encoding technique developed by Lindell and Pinkas [42]. To prevent an adversary from using inconsistent inputs across evaluation circuits, we employ the witness-indistinguishable proofs from shelat and Shen [60]. Finally, to ensure the majority output value is selected and not tampered with, we use the XOR-and-prove technique from Kiraz and Schoenmakers [33] as implemented by Kreuter et al. [37]. In combination with the standard semi-honest security guarantees of Yao garbled circuits, these security extensions secure our scheme in the malicious security model.
Garbled circuit generation
To ensure the evaluated circuits are generated honestly, we require two properties. First, we limit the generator Bob’s ability to trick Alice into evaluating a corrupted circuit using a cut-and-choose technique similar to a typical, two-party garbled circuit evaluation. Second, we ensure that a lazy Cloud attempting to conserve system resources cannot bypass the circuit checking step without being discovered. We call this the Cloud’s “proof-of-work”.
(Security).
Assuming that the hash function
shelat and Shen [60] perform a rigorous analysis of the optimal cut-and-choose strategy for evaluating garbled circuits in the malicious setting. Given that the generator prepares λ circuits before the cut-and-choose, their protocol sets the number of check circuits to
(Proof-of-work).
Assuming the hash function H is one-way and collision resistant
As previously stated, before the circuit check begins the generator Bob sends the evaluator Alice λ hashed circuit values
Validity of evaluator inputs
To assure that the generator cannot learn anything about the evaluator’s inputs by corrupting the garbled values sent during the OT, we employ the random input encoding technique by Lindell and Pinkas [42], which is built into the implementation by Kreuter et al. [37]. This technique allows the evaluator to encode each input bit as the XOR of a set of input bits. Thus, if the generator corrupts one of those input bits as in a selective failure attack, it reveals essentially nothing about the evaluator’s true input. Additionally, we use the commitment technique employed by Kreuter et al. [37] to ensure that Bob cannot swap garbled input wire labels between the zero and one value. To accomplish this, the generator commits to the wire labels before the cut-and-choose. During the cut and choose, the input labels for the check circuits are opened to ensure that they correspond to only one value across all circuits. Then, during the OOT, the commitment keys for the labels that will be evaluated are sent instead of the wire labels themselves. Because our protocol implements this technique directly from the literature, we do not make any additional claims of security.
Input consistency
The security of our input consistency check is based on two schemes, one for the evaluator’s input and one for the generator’s input. To assure the evaluator’s inputs are consistent across circuits, we use the approach from Lindell and Pinkas [42], which is built into the implementation of Kreuter et al. [37]. Since the evaluator only performs one oblivious transfer for all the evaluation circuits, her received garbled inputs will all represent her input to the OT.
To assure that the generator’s inputs are consistent, we employ the malleable claw-free collection approach from shelat and Shen [60]. However, we modify the zero-knowledge proof to provide some guarantee that the Cloud server actually possesses well-formed inputs:
Assuming the witness-indistinguishable proof used in the malleable claw-free collection input check catches inconsistent inputs except for a negligible probability
During the witness-indistinguishable proof, the generator sends the modified pre-image values to the mobile device, while the Cloud server sends the garbled input values of each evaluation circuit to the mobile device. The device then checks that all input values for each individual input wire were generated by the same function in the malleable claw-free pair. Based on the assumption that the generator and the Cloud will not collude, the probability of a malicious generator providing inconsistent modified pre-image values that match the garbled inputs possessed by the Cloud server is negligible in the security parameter of the malleable claw-free pair.
To ensure that the Cloud cannot learn either party’s output or tamper with either party’s output from the garbled circuit, we implement the technique of blinding and proving the garbled output values from the protocol by Kiraz and Schoenmakers [33]. The privacy and correctness of the generator’s output is guaranteed based on the security of this construction in Kiraz’s two-party secure function evaluation protocol. By the same proof for the generator’s output remaining secure, we argue that the evaluator’s output is also secure and correct. By using the same construction for both parties’ outputs, we guarantee output privacy and consistency, even in the presence of a malicious Cloud. Note that to maintain security, this construction only provides Bob and Alice with the output of computation, not the index of the majority evaluation circuit.
Outsourced oblivious transfer
Our outsourced oblivious transfer is an extension of a technique developed by Naor et al. [53] that allows the chooser to select entries that are forwarded to a third party rather than returned to the chooser. By combining their concept of a proxy oblivious transfer with the semi-honest OT extension by Ishai et al. [28], our outsourced oblivious transfer provides a secure OT in the malicious model. We achieve this result for four reasons:
First, since Alice never sees the outputs of the OT protocol, she cannot learn anything about the garbled values held by the generator. This saves us from having to implement Ishai’s extension to prevent the chooser from behaving maliciously. Since the Cloud sees only random garbled values and Alice’s input blinded by a one-time pad, the Cloud learns nothing about Alice’s true inputs. Since Bob’s view of the protocol is almost identical to his view in Ishai’s standard extension, the same security guarantees hold (i.e., security against a malicious sender). Finally, if Alice does behave maliciously and uses inconsistent inputs to the primitive OT phase, there is a negligible probability that those values will hash to the correct one-time pad keys for recovering either commitment key, which will prevent the Cloud from de-committing the garbled input values.
It is important to note that this particular application of the OOT allows for this efficiency gain since the evaluation of the garbled circuit will fail if Alice behaves maliciously. By applying the maliciously secure extension by Ishai et al. [28], this primitive could be applied generally as an oblivious transfer primitive that is secure in the malicious model. Further discussion and analysis of this general application is outside the scope of this work.
Proof of security
We formally prove the security of our protocol with the following theorem, which gives security guarantees identical to the Salus protocol by Kamara et al. [31].
The outsourced two-party SFE protocol securely computes a function
To demonstrate that:
In this scenario, both Bob and Cloud participate honestly in the protocol. Note that during the protocol execution, Alice only exchanges messages with the other participants at five points: the coin-flip during the cut-and-choose, the primitive oblivious transfer, sending decryption information at the end of the OOT, checking Bob’s input consistency, and receiving the proof of validity and output from the garbled circuit. Thus, our simulator needs only ensure that these sections of the protocol are indistinguishable to the adversary
Simulating the coin-flip (Phase 1):
Based on the security of the fair coin toss protocol, we know that there exists a simulator
Simulating the primitive OT (Phase 2):
Based on the malicious security of the OT primitive, we know that there exists a simulator
Checking the output of OOT (Phase 2):
Consider that in
Simulating consistency check and substituting inputs (Phase 3):
Here we cite Lemma 5 from the proof of shelat and Shen’s scheme [60]. Since the messages sent in our scheme are identical to theirs in content, we simply change the entity sending the message in the experiment and the lemma still holds. □
Simulating the output proof (Phase 5):
Based on the security of the garbled circuit construction being used, the trusted third party output and the circuit output will be indistinguishable when provided with
Since
In this scenario, both Alice and Cloud participate honestly in the protocol. Note that in the protocol, the generator exchanges messages with both parties at five critical points: circuit cut-and-choose, the primitive OT, the OOT result delivery, the input consistency check, and the output proof of integrity and delivery. Consider the following hybrid experiments and lemmas.
Simulating the cut-and-choose (Phase 1):
Here we cite Lemma 8 from shelat and Shen’s protocol proof [60]. The idea in their proof is that if
Checking input consistency and recovering inputs (Phase 3):
Based on the security of shelat and Shen’s claw-free collections technique for checking the consistency of
Simulating the output proof (Phase 5):
Based on the security of the garbled circuit construction being used, the trusted third party output and the circuit output will be indistinguishable when provided with
Simulating the primitive OT (Phase 2):
Based on the security of the primitive OT scheme, we know that the simulator
Checking the output of OOT (Phase 2):
Recall that in
Since all of the steps in the protocol run in expected polynomial time, the only step that must be verified is the rewinding phase. Based on Lemma 14 from shelat and Shen’s proof [60], the total time for the rewinds is also polynomial in k. Thus, the composition of all steps runs in polynomial time. □
In this scenario, both Alice and Bob participate honestly in the protocol. Note that in the protocol, the Cloud participates in checking the circuits during the cut-and-choose, decrypting Alice’s inputs in the OOT, forwarding Bob’s inputs for consistency checking, evaluating the circuit, and proving and delivering the final output of computation. Consider the following hybrid experiments and lemmas.
Replacing inputs for the OOT (Phase 2):
In a real execution,
Replacing inputs for the consistency check (Phase 3):
In this hybrid,
Checking the output of the circuit (Phase 5):
In
Since the protocol itself requires only polynomially many steps, the time to run
Given the simulators
We now characterize how garbled circuits perform in the constrained-mobile environment with and without outsourcing. Two of the most important constraints for mobile devices are computation and bandwidth, and we show that order of magnitude improvements for both factors are possible with outsourced evaluation. We begin by describing our implementation framework and testbed before discussing results in detail. These results extend the experimental work performed by Carter et al. [9].
Framework and testbed
Our framework is based on the system designed by Kreuter et al. [37], hereafter referred to as KSS for brevity. We selected this system as our foundation and as our benchmarking comparison because it was the most efficient implementation of a two-party garbled circuit protocol at the time of our original publication. We contacted the authors of the Salus protocol [31] and requested the source code for their framework to compare the actual performance of their scheme with ours, but they were unable to release their code. Thus, an asymptotic comparison was the only fair comparison we could make to the only other existing outsourced scheme. Recent work has shown that using different underlying garbled circuit protocol can yield similar or better performance gains to our work [8,49]. However, these works also require a completely new outsourcing protocol and proofs of security, which is outside the scope of this work. For comparison between our protocol and these newer protocols, we refer the reader to [8,49].
Using KSS as a foundation, we implemented our outsourced protocol and performed modifications to allow for the use of the mobile device in the computation. Notably, KSS uses the Message Passing Interface (MPI), for communication between the multiple nodes of the multi-core machines relied on for circuit evaluation. Our solution replaces MPI calls on the mobile device with sockets that communicate directly with the Generator and Proxy. To provide a consistent comparison, we revised the KSS codebase to allow for direct evaluation between the mobile device (the Evaluator) and the cloud-based Generator. The modifications required included removing the MPI library from the phone client and functions, which did not exist on the phone. The largest difficulty was changing the Intel specific instructions to generic instruction, which would work on the ARM processor of the mobile device.
We also informed the original authors of KSS of several problems we noticed. They in turn fixed the problems necessary for our trials. We found the following problems: generator’s input consistency check was missing from one of the possible run environments, arrays did not work correctly in some cases, nested if statements did not work correctly, and for loops inside of if statements did not work correctly. We thank those authors for their assistance.
Our deployment platform consists of two Dell R610 servers, each containing dual 6-core Xeon processors with 32 GB of RAM and 300 GB 10K RPM hard drives, running the Linux 3.4 kernel and connected as a VLAN on an internal 1 Gbps switch. These machines perform the roles of the Generator and Proxy, respectively, as described in Section 4.1. The mobile device acts as the Evaluator. We use a Samsung Galaxy Nexus phone with a 1.2 GHz dual-core ARM Cortex-A9 processor and 1 GB of RAM, running the Android 4.0 “Ice Cream Sandwich” operating system. We connect an Apple Airport Express wireless access point to the switch. The Galaxy Nexus communicates to the Airport Express over an 802.11n 54 Mbps WiFi connection in an isolated environment to minimize co-channel interference. All tests are run 10 times with error bars on figures representing 95% confidence intervals.
We also ran tests using a 64-core server with 1 TB of memory where the phone was connected over a standard local network, which included additional traffic other than just our tests. This platform performed the roles of both the Generator and the Proxy. We experienced small but noticeable time differences depending upon what other tasks were being performed on the LAN.
When we use our 12-core servers both Bob and the Cloud each have their own 12-core server. In contrast, both parties are run on the same 64-core server. Each circuit can use two processes on our 64-core server or 1 process on each of our smaller 12-core servers. We ran our tests with the same security parameters as KSS for 80-bit security, although we vary the amount of circuits in our tests.
Execution time
Our tests evaluated the following problems:
Millionaires: This problem models the comparison of two parties comparing their net worth to determine who has more money without disclosing the actual values. We perform the test on input values ranging in size from 4 to 8192 bits. In our circuit two comparisons are performed, one for Bob and one for Alice. There is one bit of output for each party.
Edit (Levenshtein) distance: This is a string comparison algorithm that compares the number of modifications required to covert one string into another. We performed the comparison based on the circuit generated by Jha et al. [29] for strings sized between 4 and 128 bits. There are eight bits of output per party.
Set intersection: This problem matches elements between the private sets of two parties without learning anything beyond the intersecting elements. We base our implementation on the SCS-WN protocol proposed by Huang et al. [23], and evaluate for sets of size 2 to 128. Each element in the set is 8 bits for 16 to 1024 bits of input per party. Each party receives
AES: We compute an AES encrypt operation with a 128-bit key length, based on a circuit evaluated by Kreuter et al. [37]. One party enters in the key, 128 bits, and other party enters in text to encrypt, which is also 128 bits.
Since our protocol specifies all outputs must be under blinds, we also need to input output blinds, each of our circuits also inputs a blind for each party. The size of the blind corresponds to the size of the party’s output.

Execution time for the Edit Distance program of varying input sizes, with 2 circuits evaluated. On 12 core servers.

Execution time for significant stages of garbled circuit computation for outsourced and non-outsourced evaluation. The Edit Distance program is evaluated with variable input sizes for the two-circuit case. On 12 core servers.
Figure 3 shows the result of the edit distance computation for input sizes of 2 to 128 with two circuits evaluated. This comparison represents worst-case operation due to the cost of setup for a small number of small circuits – with input size 2, the circuit is only 122 total gates in size. For larger input sizes, however, outsourced computation becomes significantly faster. Note that the graph is logarithmic such that by the time strings of size 32 are evaluated, the outsourced execution is over 6 times faster than non-outsourced execution, while for strings of size 128 (comprising over 3.4 million total gates), outsourced computation is over 16 times faster.
The reason for this becomes apparent when we examine Fig. 4. There are three primary operations that occur during the SFE transaction: the oblivious transfer (OT) of participant inputs, the circuit commit (including the circuit consistency check), and the circuit evaluation. As shown in the figure, the OT phase takes 292 ms for input size 2, but takes 467 ms for input size 128. By contrast, in the non-outsourced execution, the OT phase takes 307 ms for input size 2, but increases to 1860 ms for input size 128. The overwhelming factor, however, is the circuit evaluation phase. It increases from 34 ms (input size 2) when the evaluation is complete by the time the checks finish on the phone to 7320 ms (input size 128) for the outsourced evaluation, a 215 factor increase. For non-outsourced execution however, this phase increases from 108 ms (input size 2) to 98,800 ms (input size 128), a factor of 914 increase.
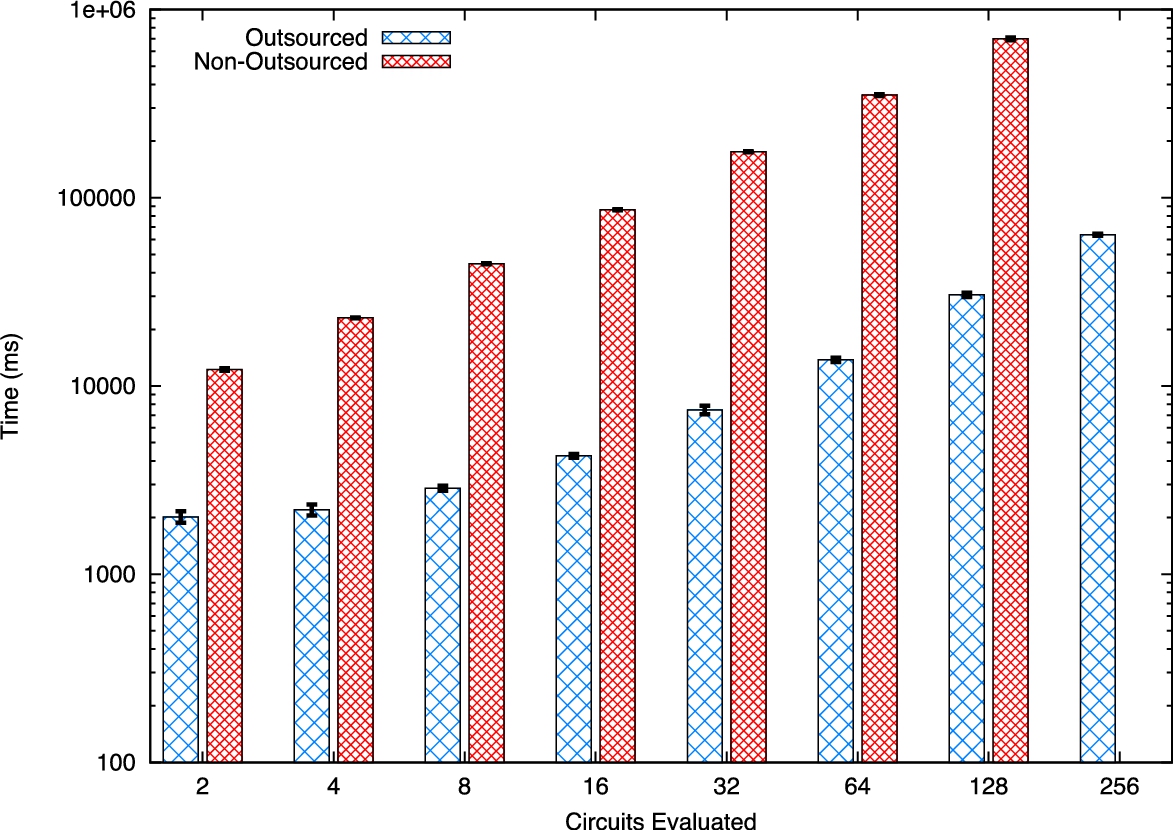
Execution time for the Edit Distance problem of size 32, with between 2 and 256 circuits evaluated. In the non-outsourced evaluation scheme, the mobile phone runs out of memory evaluating 256 circuits. On 12 core servers.
The security parameter for the garbled circuit check is
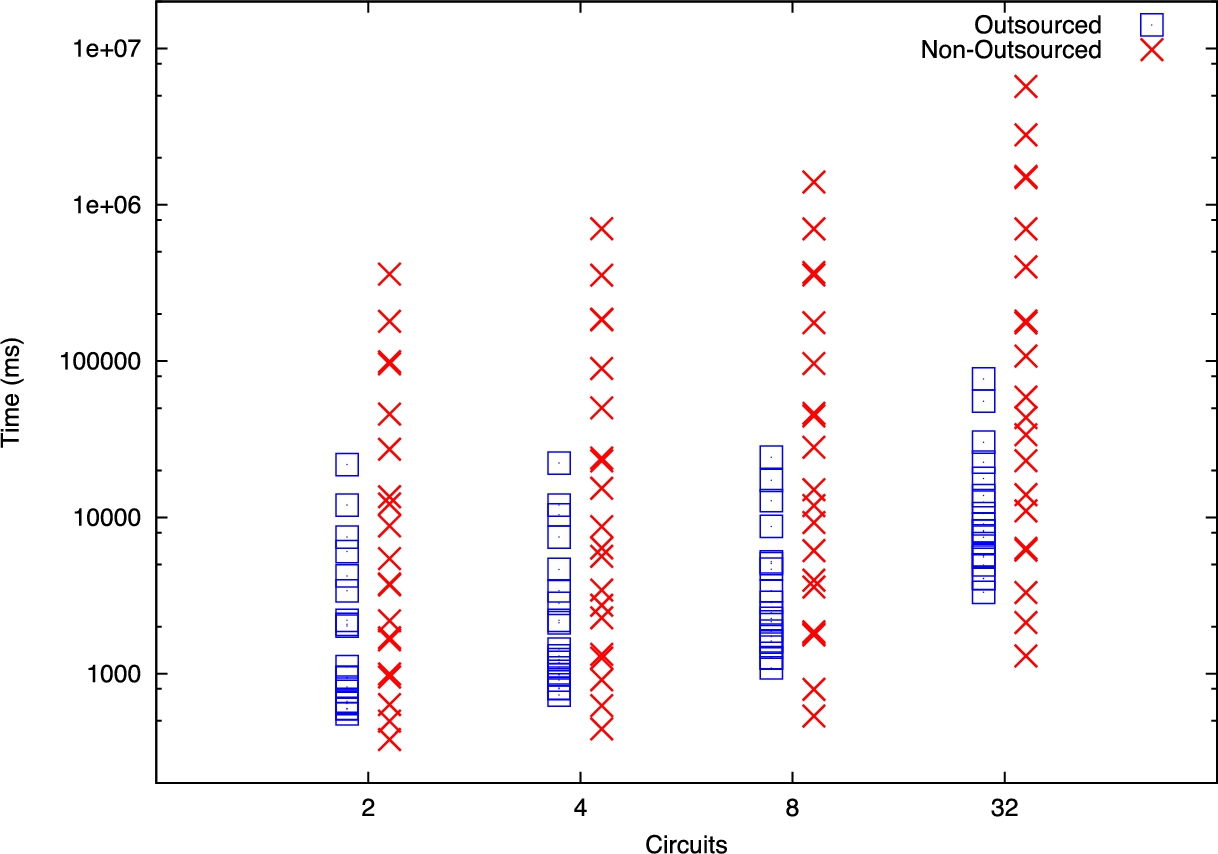
Execution time for all problems tested, with between 2 and 64 circuits evaluated. In the non-outsourced evaluation scheme, the mobile phone runs out of memory evaluating 128 and 256 circuits. Observed that with the exception of a few programs with small input sizes, the execution times of the non-outsourced test programs cluster higher than the outsourced programs. This shows an overall execution time reduction achieved through outsourcing. On 12 core servers.
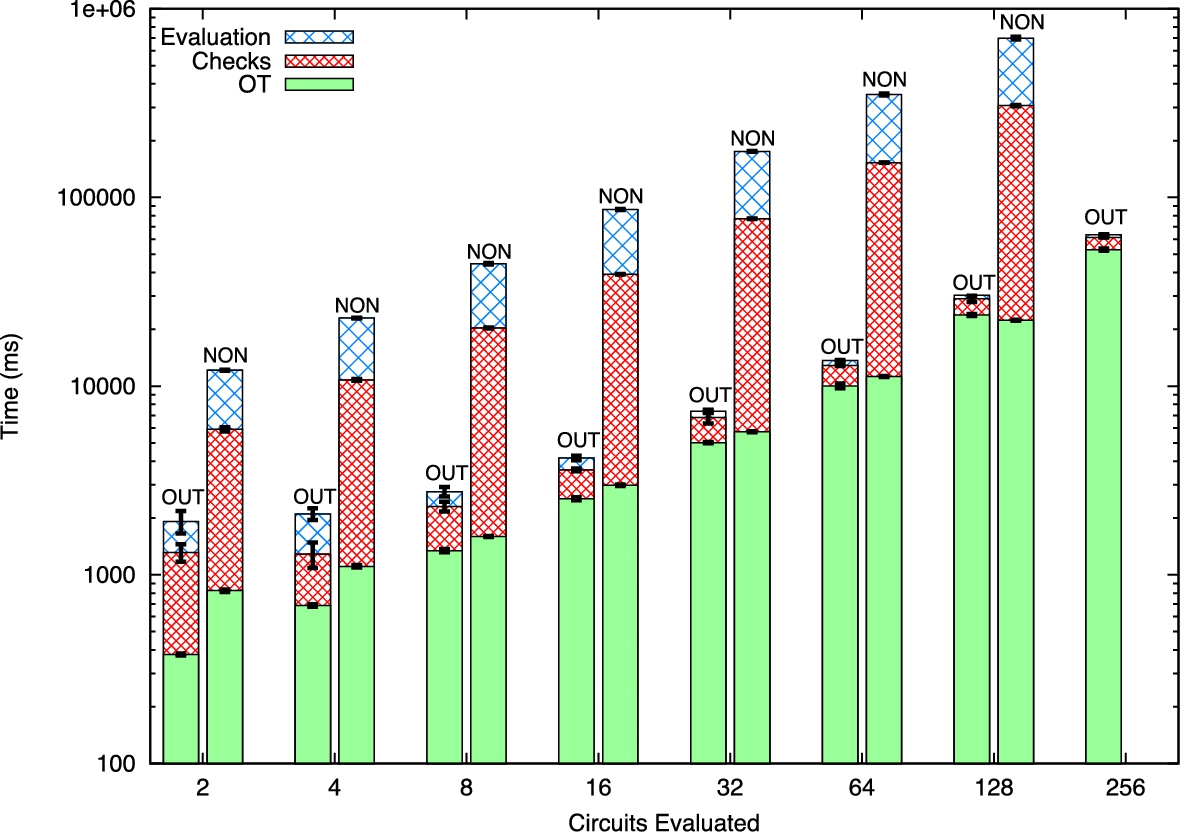
Microbenchmarks of execution time for Edit Distance with input size 32, evaluating from 2 to 256 circuits. Note that the y-axis is log-scale; consequently, the vast majority of execution time is in the check and evaluation phases for non-outsourced evaluation. On 12 core servers.
Note as well that in the non-outsourced scheme, there are no reported values for 256 circuits, as the Galaxy Nexus phone ran out of memory before the execution completed. We observe that a single process on the phone is capable of allocating 512 MB of RAM before the phone would report an out of memory error, providing insight into how much intermediate state is required for non-outsourced evaluation. Thus, to handle circuits of any meaningful size with enough check circuits for a strong security parameter, the only way to be able to perform these operations is through outsourcing.
We present our complete performance results in the Appendix. Our experiments span circuits from small to large input size, and from 8 circuits evaluated to the 256 circuits required for a
Multicore circuit evaluation. We briefly note the effects of multicore servers for circuit evaluation. The servers in our evaluation each contain dual 6-core CPUs, providing 12 total cores of computation. The computation process is largely CPU-bound: while circuits on the servers are being evaluated, each core was reporting approximately 100% utilization. This is evidenced by regression analysis when evaluating between 2 and 12 circuit copies; we find that execution time
The results above show that as many-way servers are deployed in the cloud, it becomes easier to provide optimal efficiency computing outsourced circuits. A 256-core machine would be able to evaluate 256 circuits in parallel to provide the accepted standard
Different programs have different bottlenecks that affect the performance. When the bottleneck of the execution is on the mobile device, the speed of the computation cannot benefit by having more cores. Our analysis of the results revealed this occurs when a circuit has a high amount of inputs, relatively few gates in the circuit, and uses many cores working in parallel. In the aforementioned cases the gate execution completes before the mobile device completes the generator’s input consistency. At 32 circuits the bottleneck is the input when we use our 12-core servers for AES, all millionaires programs, all set intersection programs other than size 128, edit distance 2, 4, and 8. On our 64-core test server input is the bottleneck at 32 circuits for AES, all millionaires programs, all set intersection programs other than size 128, and edit distance 2, 4, 8, and 16.
In our tests we used the standard KSS implementation in our phone client for our non-outsourced tests. If we had used a more memory efficient implementation like PCF [36] and combined it with other memory optimizations we would have been able to evaluate all of our programs directly on a mobile phone. However, if this were the case our results would show further improvements in time and bandwidth our system saves over the mobile KSS client.
For a mobile device, the costs of transmitting data are intrinsically linked to power consumption, as excess data transmission and reception reduces battery life. Bandwidth is thus a critical resource constraint. In addition, because of potentially uncertain communication channels, transmitting an excess of information can be a rate-limiting factor for circuit evaluation. Figure 8 shows the bandwidth measurement between the phone and remote parties for the edit distance problem with 2 circuits. When we compared execution time for this problem in Fig. 3, we found that trivially small circuits could execute in less time without outsourcing. Note, however, that there are no cases where the non-outsourced scheme consumes less bandwidth than with outsourcing. Our other test programs showed similar results (see Fig. 9), with the non-outsourced execution trending exclusively higher in bandwidth use than the outsourced protocol.

Bandwidth measurements from the phone to remote parties for the Edit Distance problem with varying input sizes, executing two circuits. On 12 core servers.
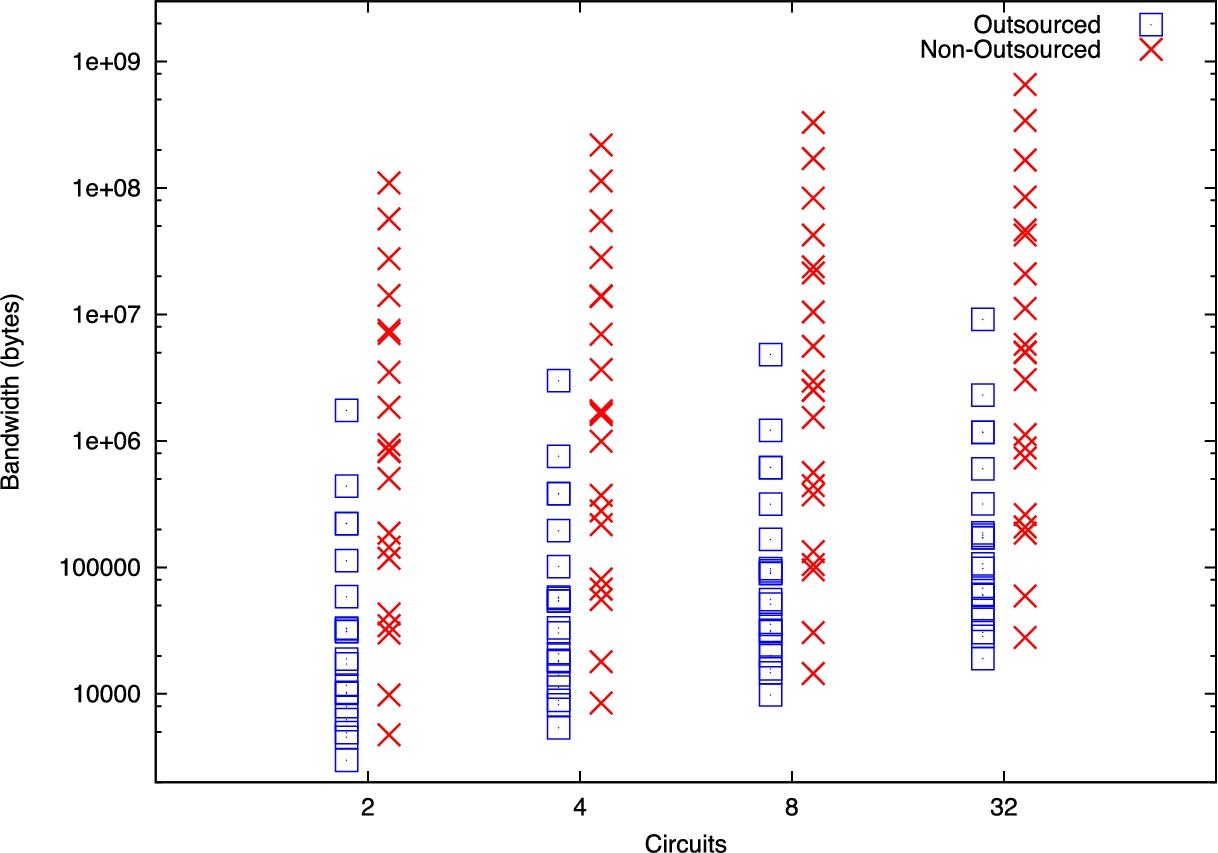
Bandwidth measurements from the phone to remote parties for all problems with varying input sizes, executing between 2 and 64 circuits. Note that the non-outsourced measurements cluster higher than the outsourced measurements, indicating that outsourcing the computation consistently saves bandwidth across the tested applications. On 12 core servers.
This is a result of the significant improvements garnered by using our outsourced oblivious transfer (OOT) construction described in Section 4. Recall that with the OOT protocol, the mobile device sends inputs for evaluation to the generator; however, after this occurs, all further evaluation until the final output verification from the cloud proxy occurs between the generator and the proxy, ensuring that further communication is not required by the mobile device. Figure 8 shows that the amount of data transferred increases only nominally compared to the non-outsourced protocol. Apart from the initial set of inputs transmitted to the generator, data demands are largely constant. This is further reflected in Tables 7 and 8 in the Appendix, which shows the vast bandwidth savings over the 32-circuit evaluation of our representative programs. In particular, for large, complex circuits, the savings are vast: outsourced AES-128 requires 96.3% less bandwidth, while set intersection of size 128 requires 99.7% less bandwidth than in the non-outsourced evaluation. Remarkably, the edit distance 128 problem requires 99.95%, over 1900 times less bandwidth, for outsourced execution.
We performed an analytical analysis of what affects the amount of bandwidth. We determined input size is the only aspect of a program, which affects the amount of bandwidth used by the mobile device. The amount of gates in a circuit does not affect the amount of bandwidth used by the mobile device. The Alice’s input (OTs) and Bob’s input (consistency checks) both use bandwidth.
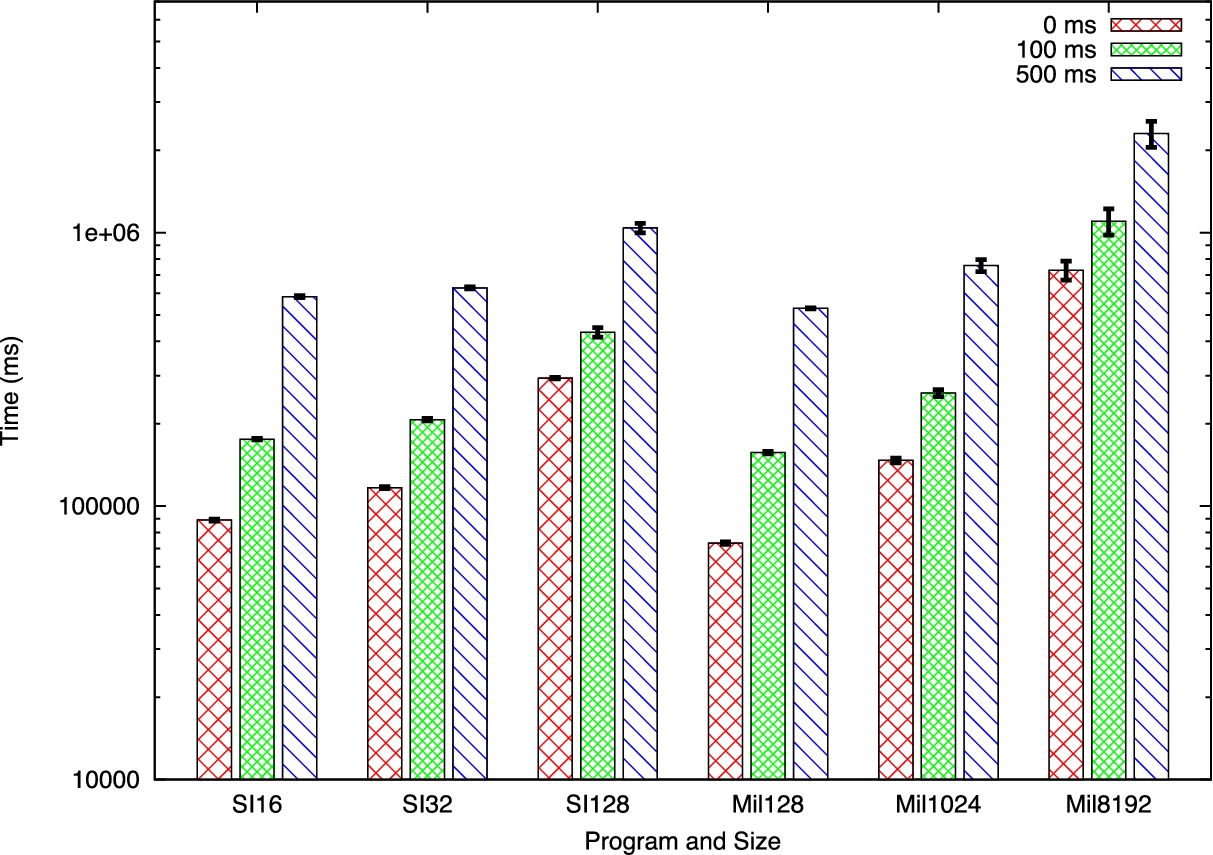
Execution time over varying network latency for the Edit Distance problem with varying input sizes, executing between 256 circuits. On 12 core servers.
As network latency is a limiting factor on mobile phones, we wanted to see how our outsourced system performed in an environment with latency. We performed trials of our execution system with two different amounts of latency added, 100 ms and 500 ms. We used Linux’s tc command to emulate different latency amounts. It was found by Huang [21] that the median ping latency to a landserver on a 3G connection was between 180 ms to 250 ms.
In Fig. 10 we present the results of our latency tests. The slowdown of added latency is not uniform across all of our tests. With the Millionaires 8192, we observed a slowdown of about 1.9× to 1.2× from 0 latency to 100 ms latency, depending on the amount of circuits executed. Whereas Set Intersection 16 had a slowdown of 2.8× to 2× when we added 100 ms of latency. Making the transition from 0 latency to 500 ms makes the differences more apparent. We observed a slowdown of 3.7× to 2.8× for Millionaires 8192. Correspondingly, the Set Intersection 16 had an observed slowdown between 9.7× to 6.4×.
The reason for the difference in the slowdown is due to the different bottlenecks different programs have in our system. For some programs the bottleneck will be at the phases necessary for input for the different parties, the oblivious transfer (large mobile input) and consistency check (large generator input). For other programs the bottleneck will be the garbled circuit generation and evaluation. A future goal is to improve the performance of our system in high latency environments.
Evaluating large circuits
Beyond the standard benchmarks for comparing garbled circuit execution schemes, we aimed to provide compelling applications that exploit the mobile platform with large circuits that would be used in real-world scenarios. Based on our initial testing, these circuits are too large to evaluate directly on the mobile device using KSS due to the significant memory requirements. These experiments highlight the main practical contribution of our protocol, that we can now evaluate circuits that are orders of magnitude larger than was possible using previously existing techniques.
We discuss public-key cryptography and the Dijkstra shortest path algorithm, then describe how the latter can be used to implement a privacy-preserving navigation application for mobile phones.
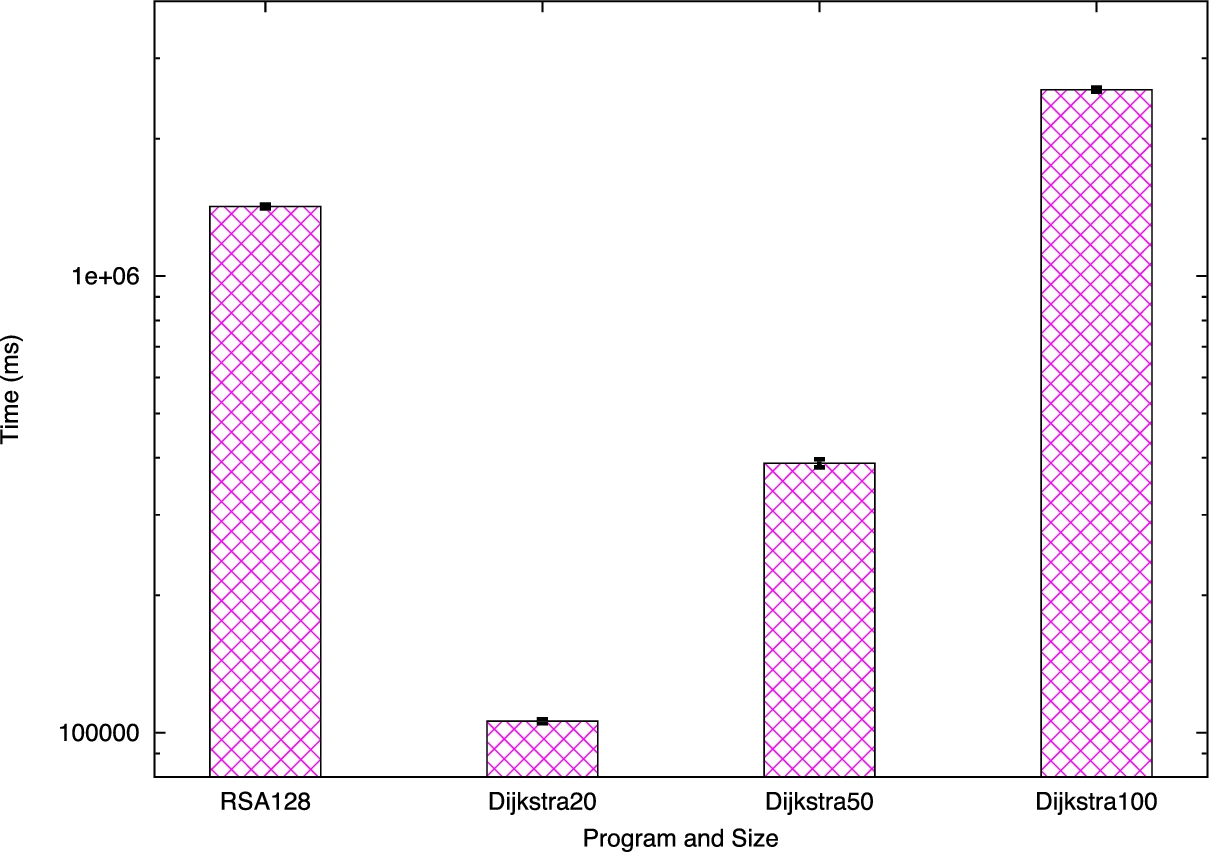
Execution time for the large circuit test applications with varying input sizes, executing 128 circuits. On 64 core servers.
Figure 11 shows the execution time required for a blinded RSA circuit of input size of 128. For these tests we used our more powerful 64-core server. As described in Section 7, larger testbeds capable of executing 128 or 256 cores in parallel would be able to provide similar results for executing the 256 circuits necessary for a
The RSA circuit inputs 128 bits each both parties as well the necessary output blinds. Both parties receive output 130 bits. The RSA circuit is the same circuit used in KSS12, which principally calculates a single modular exponentiation.
We only report the outsourced execution results, as the circuits are far too large to evaluate directly on the phone. As with the larger circuits described in Section 7, the phone runs out of memory from merely trying to store a representation of the circuit. Prior to optimization, the blinded RSA circuit is 192,537,834 gates and afterward, comprises 116,083,727 gates, or 774 MB in size.
Our Dijkstra’s circuit assumes each node has a maximum degree of 4. Each edge weight is represented internally with 16 bits. Each node is internally represented with 8 bits. The program performs
The implementation of Dijkstra’s shortest-path algorithm results in very large circuits. The pre-optimized size of the shortest path circuit for 20 vertices is 20,288,444 gates and after optimization is 1,653,542 gates. The 100-node graph is even larger, with 168,422,382 gates post optimization, 1124 MB in size. This final example is among the largest publicly evaluated circuit to date (see the Appendix for complete results). While it may be possible for existing protocols to evaluate circuits of similar size, it is significant that we are evaluating comparably massive circuits from a resource-constrained mobile device. Table 2 gives the amount of bandwidth these larger programs use.
Bandwidth of 128-bit RSA and Dijkstra 20, 50, and 100
Bandwidth of 128-bit RSA and Dijkstra 20, 50, and 100
Note: All entries are in Bytes.
Mapping and navigation are some of the most popular uses of a smartphone. Consider how directions may be given using a mobile device and an application such as Google Maps, without revealing the user’s current location, their ultimate destination, or the route that they are following. That is, the navigation server should remain oblivious of these details to ensure their mutual privacy and to prevent giving away potentially sensitive details if the phone is compromised. Specifically, consider planning of the motorcade route for the recent Presidential inauguration. In this case, the route is generally known in advance but is potentially subject to change if sudden threats emerge. A field agent along the route wants to receive directions without providing the navigation service any additional details, and without sensitive information about the route loaded to the phone. Moreover, because the threats may be classified, the navigation service does not want the holder of the phone to be given this information directly.
To model this scenario, we overlay a graph topology on a map of downtown Washington DC, encoding intersections as vertices. Edge weights are a function of their distance and heuristics such as potential risks along a graph edge. Figure 12 shows graphs generated based on vertices of 20, 50, and 100 nodes, respectively. Note that the 100-node graph (Fig. 12(c)) encompasses a larger area and provides finer-grained resolution of individual intersections than the 20-node graph (Fig. 12(a)).

Map of potential presidential motorcade routes through Washington, DC. As the circuit size increases, a larger area can be represented at a finer granularity. (a) 20 identified intersections; (b) 50 identified intersections; (c) 100 identified intersections.
There is a trade-off between detail and execution time, however; as shown in Fig. 11, a 20-vertex graph can be evaluated in 1 min 46 s, while a 100-vertex graph requires almost 43 min with 128 circuits in our 64-core server testbed. We anticipate that based on the role a particular agent might have on a route, they will be able to generate a route that covers their particular geographical jurisdiction and thus have an appropriately-sized route, with only certain users requiring the highest-resolution output. Additionally, as described in Section 7.3, servers with more parallel cores can simultaneously evaluate more circuits, giving faster results.
Figure 13 reflects two routes. The first, overlaid with a dashed line, is the shortest path under optimal conditions that is output by our directions service, based on origin and destination points close to the historical start and end points of the past six presidential inaugural motorcades. Now consider that incidents have happened along the route, shown in the figure as a car icon in a hazard zone inside a red circle. The agent recalculates the optimal route, which has been updated by the navigation service to assign severe penalties to those corresponding graph edges. The updated route returned by the navigation service is shown in the figure as a path with a dotted line. In the 50-vertex graph in Fig. 12, the updated directions would be available in just over 135 s for 32-circuit evaluation, and 196 and a half seconds for 64-circuit evaluation.
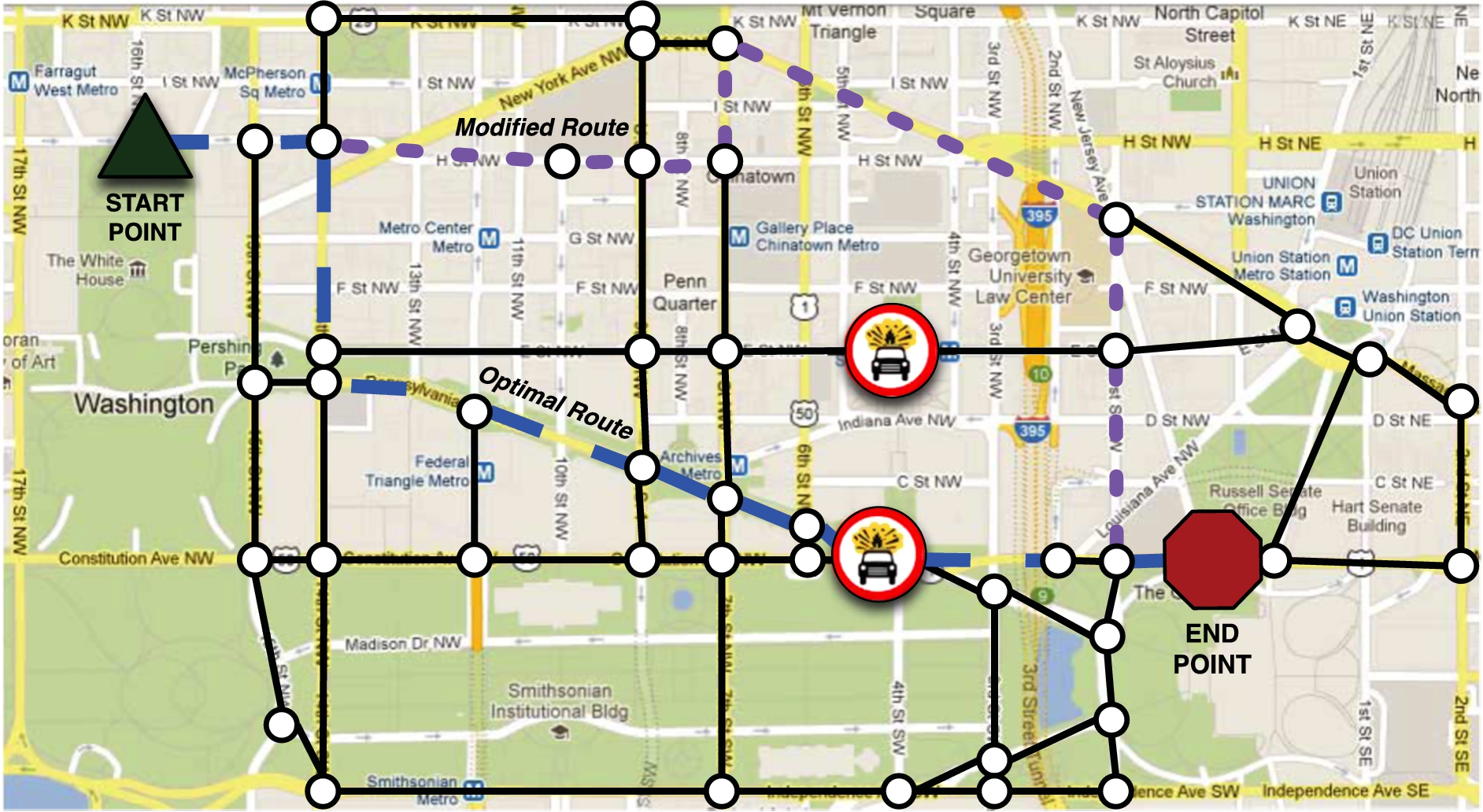
Motorcade route with hazards along the route. The dashed line represents the optimal route, while the dotted line represents the modified route that takes hazards into account.
While garbled circuits offer a powerful tool for secure function evaluation, they typically assume participants with massive computing resources. Our work solves this problem by presenting a protocol for outsourcing garbled circuit evaluation from a resource-constrained mobile device to a cloud provider in the malicious setting. By extending existing garbled circuit evaluation techniques, our protocol significantly reduces both computational and network overhead on the mobile device while still maintaining the necessary checks for malicious or lazy behavior from all parties. Our outsourced oblivious transfer construction significantly reduces the communication load on the mobile device and can easily accommodate more efficient OT primitives as they are developed. The performance evaluation of our protocol shows dramatic decreases in required computation and bandwidth. For the edit distance problem of size 128 with 32 circuits, computation is reduced by 98.92% and bandwidth overhead reduced by 99.95% compared to non-outsourced execution. These savings are illustrated in our privacy-preserving navigation application, which allows a mobile device to efficiently evaluate a massive garbled circuit securely through outsourcing. These results demonstrate that the recent improvements in garbled circuit efficiency can be applied in practical privacy-preserving mobile applications on even the most resource-constrained devices.
Footnotes
Acknowledgments
This material is based on research sponsored by the U.S. National Science Foundation under grant numbers CNS-1464088, CNS-1526718, CNS-1540217, and CNS-1540218 and DARPA under agreement number FA8750-11-2-0211. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of DARPA or the U.S. Government. We would like to thank Adam Bates for his help with figures for this paper; Daniel Ellsworth for his help with setting up our testbed; Benjamin Kreuter, abhi shelat, and Chih-hao Shen for working with us on their garbled circuit compiler and evaluation framework; Chris Peikert for providing helpful feedback on our proofs of security; Thomas DuBuisson and Galois for their assistance in the performance evaluation; and Ian Goldberg for his guidance in shepherding the conference version of this work.
Experimental results
Execution time for evaluating a 128-bit blinded RSA circuit and Dijkstra shortest path solvers over graphs with 20, 50, and 100 vertices
| 32 circuits time (ms) | 64 circuits (ms) | 128 circuits (ms) | Optimized gates | Unoptimized gates | Size (MB) | |
| RSA128 | 505,000.0 ± 2% | 734,000.0 ± 4% | 1,420,000.0 ± 1% | 116,083,727 | 192,537,834 | 774 |
| Dijkstra20 | 25,800.0 ± 2% | 49,400.0 ± 1% | 106,000.0 ± 1% | 1,653,542 | 20,288,444 | 11 |
| Dijkstra50 | 135,000.0 ± 1% | 197,000.0 ± 3% | 389,000.0 ± 2% | 22,109,732 | 301,846,263 | 147 |
| Dijkstra100 | 892,000.0 ± 2% | 1,300,000.0 ± 2% | 2,560,000.0 ± 1% | 168,422,382 | 2,376,377,302 | 1124 |
Notes: All numbers are for outsourced evaluation, as the circuits are too large to be computed without outsourcing to a proxy.