
Abstract
Private set intersection and related functionalities are among the most prominent real-world applications of secure multiparty computation. While such protocols have attracted significant attention from the research community, other functionalities are often required to support a PSI application in practice. For example, in order for two parties to run a PSI over the unique users contained in their databases, they might first invoke a support functionality to agree on the primary keys to represent their users.
This paper studies a secure approach to agreeing on primary keys. We introduce and realize a functionality that computes a common set of identifiers based on incomplete information held by two parties, which we refer to as private identity agreement, and we prove the security of our protocol in the honest-but-curious model. We explain the subtleties in designing such a functionality that arise from privacy requirements when intending to compose securely with PSI protocols. We also argue that the cost of invoking this functionality can be amortized over a large number of PSI sessions, and that for applications that require many repeated PSI executions, this represents an improvement over a PSI protocol that directly uses incomplete or fuzzy matches.
Introduction
In recent years Private Set Intersection (PSI) and related two-party protocols have been deployed in real-world applications [21]. In the simplest setting of PSI, each party has a set
Owing to its importance in real-world applications, PSI has been the topic of a significant body of research. Common PSI paradigms include DDH-style protocols [1,10,19,22,31], approaches based on oblivious transfer [12,26,29,30] or oblivious polynomial evaluation [9,14], and approaches based on garbled circuits [18,26,27]. Performance improvements have been dramatic, especially the computational overhead of PSI.
State-of-the-art PSI protocols require exact matches to compute the intersection; in other words, the intersection is based on bitwise equality. In real-world application scenarios the parties may not have inputs that match exactly. As an example, consider the case of two centralized electronic medical record (EMR) providers, which supply and aggregate medical records for medical practitioners, who wish to conduct a study about the number of patients who develop a particular disease after their recent medical histories indicate at-risk status. The EMR providers could use a PSI protocol to count the total number of unique diagnoses among their collective patients. Unfortunately, the EMR providers may not have the same set of information about each patient in their databases; for example, one might identify Alice by her street address and phone number, while the other might use her phone number and email address. Further complicating matters, Bob could use “bob@email.com” for one provider, but “BobDoe123@university.edu” for another.
It may appear that naively applying PSI to each column in two parties’ databases would allow them to realize their desired functionality, but such an approach has many flaws. For example, in the case that individuals use different identifying information for the different services, this approach could incur false negatives. To remedy this issue, there has been previous research on the private record linkage problem, in which “fuzzy matches” between records are permitted [16,33]. In this problem, two rows from different parties’ databases can be said to match if they satisfy some closeness relation, for example by matching approximately on t out of n columns. However, fuzzy matching PSI protocols are not as performant as exact-matching protocols.
As a design goal, we consider applications in which two parties would like to run PSI many times over respective databases. In our EMR example, the rows comprising users change slowly as new patients enter the system and some are expunged. However, auxiliary medical data could change frequently, at least daily. If the EMR providers wish to continuously update their medical models or run multiple analyses, they may run many PSI instances with auxiliary data [21].
In general, for many applications it is desirable for two parties to run PSI-style protocols many times over their respective data sets, and in this work we assume the parties will perform many joint queries. It is therefore advantageous for the parties to first to establish a new column for their databases, containing a single key for each row that can be used for the most performant exact-match PSI protocols.
As a second design goal, we relax an assumption that is standard for the private record linkage problem. We believe that it is not always realistic in practice to assume or to ensure that each participant’s database uniquely maps its rows to identities. For example, one EMR provider may unknowingly have multiple records about the same person in its database, as a result of that person providing different identifying information to different medical providers. As part of a correct protocol, some preprocessing phase must identify records that belong to the same individual – using both parties’ records – and group them accordingly. This is especially important for PSI applications that compute aggregate statistics.
This correctness requirement introduces an additional privacy concern. Consider the case in which party A has a single row in its database that matches more than one row in party B’s database. Naively running a protocol to produce primary keys which link records would inevitably reveal some information to one of the parties. Either party A would learn that the party B is unaware that its rows could be merged, or party B would learn that it has several rows that correspond to a single person. Either way, one party will learn more about the other party’s input than it should.
This work focuses on resolving the apparent trade-offs in privacy and performance between state-of-the-art exact-matching and fuzzy-matching PSI protocols. Our approach is to design a new two-party protocol that computes a new identifier for every row in both databases that will give exact matches. To avoid the additional leakage problem described above, our protocol outputs either (a) shares of the new identifiers, or (b) encryptions of the new identifiers for a generic CPA-secure encryption scheme with XOR homomorphism, which can be decrypted with a key held by the other party. (Our protocol can also output both share and encryptions, and we in fact prove security in the case that it outputs both.) The regime of PSI protocols that can be composed with our protocol is limited to those that can combine shares or decrypt online without revealing the plaintext to either party. However, the flexibility we provide in producing outputs offers flexibility to the design of PSI protocols which can be composed with ours. Additionally, although our identifier-agreement protocol is computationally intensive compared to the subsequent PSI protocol, we argue that this is a one-time cost that can be amortized over many PSI computations.
Our contributions
This work addresses two problems: (1) The performance and accuracy tradeoffs between exact matching PSI and fuzzy matching PSI protocols. (2) The correctness and privacy problems introduced to PSI by the possibility of poorly defined rows. We address both of these problems in one shot by defining a functionality that computes shared primary keys for two parties’ databases, such that the keys can be used multiple times as inputs to successive efficient PSI protocols, without revealing the keys to the parties. We refer to our stated problem as the private identity agreement functionality, and define it formally. We additionally discuss the security implications of composing our identity agreement functionality and subsequent PSI functionalities. We note that identity agreement is substantially more complex than private set intersection and private record linkage because of the concerns introduced by producing an intermediate output of a larger functionality.
After defining the identity agreement problem, we present a novel two-party protocol that solves the problem in the honest-but-curious model. We additionally describe a modification to our protocol that allows the outputs to naturally compose with DDH-style PSI protocols. Finally we present performance of a prototype implementation.
Technical overview
Agreement with record linkage
Imagine there exists a universe
The naive approach is simply to perform a PSI protocol to discover all the elements in
However, this does not suffice for our problem, precisely due to the issue of linking records. It may be the case that some party has two pieces of information in its database which belong to the same identity, but that it does not know that they belong to the same identity; however, there may be information in the other party’s database that can be used to link the two pieces of information. For example, Alice’s database may have two separate rows (john@email.com, 888-867-5309) and (john@university.edu, 123 First Street), while Bob’s database has a single row (john@email.com, 123 First Street) that links the two rows from Alice’s database (under the assumption that every piece of identifying information belongs to only a single identity). Therefore, although PSI suffices for identifying the elements in both databases, and it is possible to generate random labels for items not in the intersection, we must additionally perform some computation that groups pieces of information that belong to the same identity, without revealing to either party whether this has happened.
Approach
We model the id agreement problem as a graph problem, as follows. For the universe
We explain in Section 4.2 that assigning a unique label to each component in
Next, we use PSI to identify the vertices in the intersection of the two parties’ graphs. (Correspondingly, we perform PSI to identify the elements in the intersection of the two parties’ databases, and assign common labels to those elements.) We then perform computations on the graph structure in order to “fix” the vertices so that every vertex in the same component of
Our challenge is to perform the “fixing” step obliviously. Our approach requires a black-box operator that allows us to perform conditional updates on the labels that we assign to each vertex. For this, we turn to garbled circuits. At a high level, we design a garbled circuit that iteratively performs a two step process. First, the circuit performs PSI (borrowing a garbled-circuit PSI subroutine from [18]) to assigns matching labels to all vertices in the intersection of two parties’ graphs. The garbled circuit then performs conditional updates on the labels of every vertex in the parties’ graphs to ensure that vertices in the same component of
Related work
Private set intersection with “fuzzy” matches has been considered in previous research. An early work by Freedman, Nissim, and Pinkas on PSI included a proposed fuzzy matching protocol based on oblivious polynomial evaluation [14]. Unfortunately that protocol had a subtle flaw identified by Chmielewski and Hoepman, who proposed solutions based on OPE, secret sharing, and private Hamming distance [7].
Concurrently with our work, Buddhavarapu et al. [6] presented private matching for compute, which addresses the problem of producing intermediate identifiers for repeated private set functionalities. They use different techniques and parallelize their implementation, which yields very good performance. However, they do not address the issues incurred by linking records between data sets, which is the most technically challenging and expensive aspect of the problem we consider.
Wen and Dong presented a protocol solving the private record linkage problem, which is similar to the common identifiers problem in this work [33]. In that setting the goal is to determine which records in several databases correspond to the same person, and to then reveal those records. Wen and Dong present two approaches, one for exact matches using the garbled bloom filter technique from previous work on PSI [12] and one for fuzzy matches that uses locality-sensitive hash functions [20] to build the bloom filter. One important difference between the PRL setting and ours is that our privacy goal requires the matches and non-matches to remain secret from both parties. We also assign a label to each record, with the property that when two records match they are assigned the same label.
Huang, Evans, and Katz compared the performance of custom PSI protocols to approaches based on garbled circuits [18]. One of their constructions, which they call sort-compare-shuffle, is a repeated subroutine in our construction. Unlike their constructions, our output is not a set intersection.
Problem definition
Our setting assumes two parties, each holding some database, who wish to engage in inner-join style queries on their two databases, which we refer to as the private joint-database query functionality

Query functionality

ID agreement functionality
We consider a scenario in which it is advantageous for the parties to first establish a new database column containing keys for each record. We refer to this as the private identity agreement functionality, denoted
Importantly, the newly established keys should not be revealed to either party, as this could also reveal information about the other party’s input. This makes it impossible to separate the protocol for
We denote the set of possible identifiers that either party may hold by
It is possible to establish
For each party
The goal of the identity agreement functionality
We define the privacy goals of
We present the two-party component labeling functionality
The functionality a CPA-secure encryption of a one-time pad of
In Sections 4 and 5, respectively, we present a protocol to realize

Two-party component labeling functionality
Garbled circuits
Garbled circuits were proposed by Andrew Yao [34] as a means to a generic two-party computation protocol. Yao’s protocol consists of two subprotocols: a garbling scheme [5] and an oblivious transfer. Most of the CPU work of a garbled circuit protocol involves symmetric primitives, and as Bellare et al. show, garbling schemes can use a block cipher with a fixed key, further improving performance [5]. A drawback of garbled circuits is that they require as much communication as computation, but this can be mitigated by using garbled circuits to implement efficient subprotocols of a larger protocol.
Our construction makes use of garbled circuits to realize secure function evaluation. The functionality

2-party secure function evaluation
In this section we give the description of a CPA-secure encryption scheme with XOR-homomorphism. In our construction we use a modification of the ElGamal encryption scheme [15]. We describe the additional homomorphism provided by ElGamal below.
(Xor-Homomorphic CPA-Secure Encryption Scheme).
A CPA-Secure encryption scheme with XOR-homomorphism is a tuple of probabilistic polynomial-time algorithms Given a security parameter λ, Given the public key Given the secret key Given a ciphertext c which encrypts message m and an additional plaintext message
El-Gamal encryption. Our construction uses the ElGamal encryption scheme as an implementation of a CPA-Secure scheme in order to compose gracefully with a specific class of protocols. When specifically using ElGamal rather than a generic CPA-secure scheme, we use the notation
The ElGamal encryption scheme is CPA-secure under the DDH assumption, and supports homomorphic group operations. If the plaintext space is small, addition in the exponent can also be supported, but decryption in this case requires computing a discrete logarithm. Using the identity element of the group, the homomorphism can be used to re-randomize a ciphertext.
We include the description of the homomorphism as an algorithm of the ElGamal encryption scheme:
Given the public key
In Section 4.4.2, we describe how to use
Secure ID agreement as secure two-party component labeling
In this section, we define a graph problem that we call Two-Party Component Labeling, and provide a reduction between ID agreement and Two-Party Component Labeling. We then describe an algorithm to compute component labeling and a two-party protocol that securely implements it.
Two-party component labeling
In the two-party component labeling problem, each party
More precisely, consider parties
Reducing ID agreement to two-party component labeling
We reduce the two-party identity agreement problem to two-party component labeling. Each party
The component labeling of two graphs
Intuitively, the reduction works because the two parties compute ID agreement over their databases by computing a union of their graphs. If the two parties’ graphs contain the same vertex v (meaning both databases contain the same piece of identifying information), then the components containing v in
An algorithm for two-party component labeling
In this section, we present a component labeling algorithm without explicitly addressing privacy concerns. In Section 4.4, we present a protocol to implement the algorithm while preserving privacy. We illustrate an execution of our percolate-and-match algorithm in Fig. 5 and provide pseudo-code in Fig. 6.
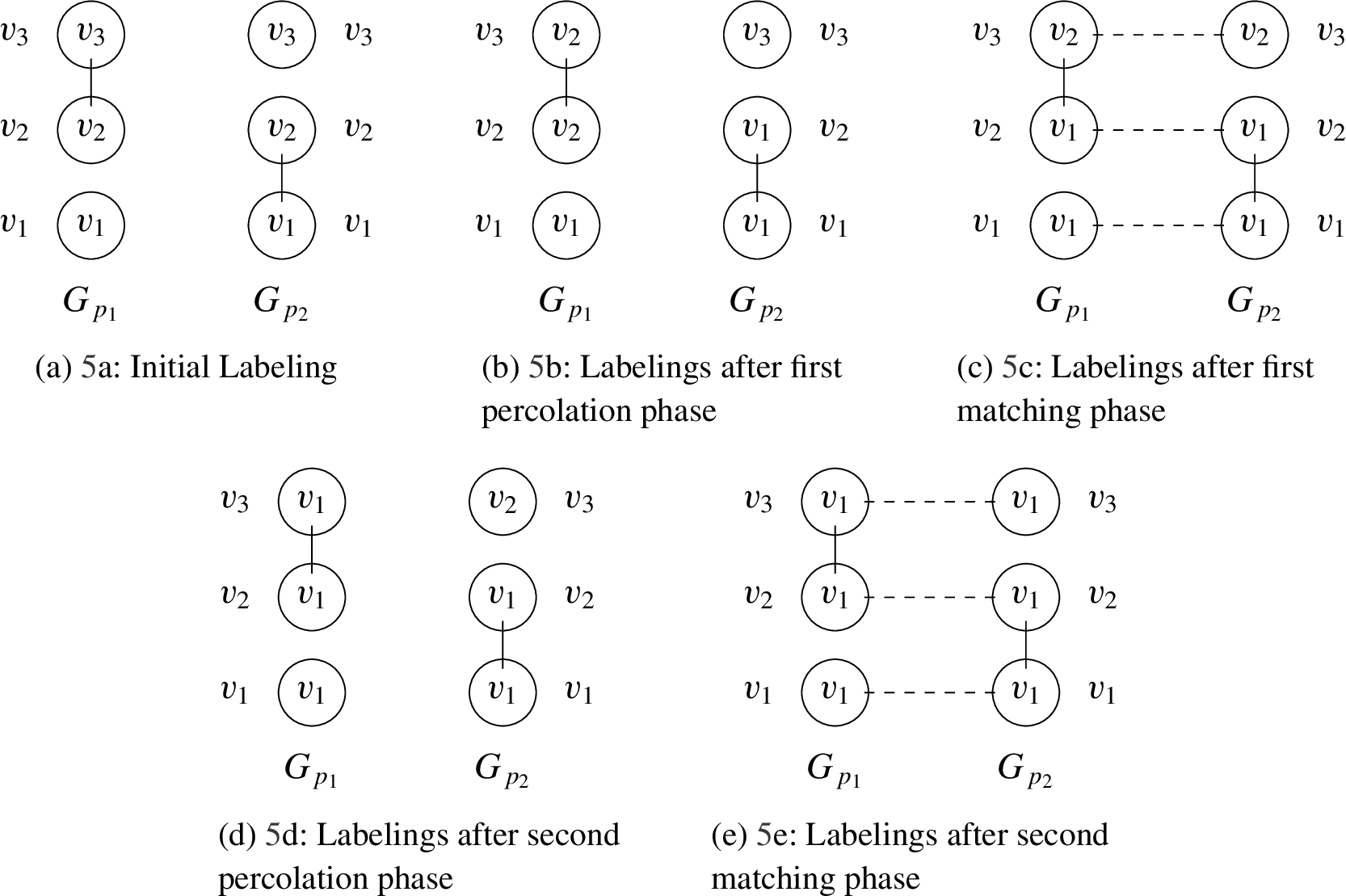
Depiction of the percolate-and-match algorithm for component labeling.
Our component labeling algorithm is an iterative procedure in which the two parties assign labels to every vertex in their respective graphs and then progressively update their vertices’ labels. To initialize the procedure, each party
In an application, the label would be the data that the vertex represents. Additionally, if the parties agree on an encoding scheme beforehand, types (address, zip, phone) can be encoded as part of a label at the cost of only a few bits.
By the end of the iterative procedure, two properties of the labelings must be met. First, within each component of a party’s graph, all vertices must have the same label. Second, if any vertex is in both parties’ graphs, then the vertex has the same label in both parties’ labelings. Together, these two requirements enforce that every two vertices within a component of
Each step in our iterative procedure is a two phase process. The first phase operates on each party’s graph independently. It enforces the property that for each component in a party’s graph, every vertex in the component has the same label. In this phase, the algorithm assigns to every vertex
In the second phase, the algorithm operates on the vertices which are common to both parties’ graphs. It ensures that every vertex v which is common to both parties’ graphs has been assigned the same label in the two parties’ labelings. If one party’s label for v differs from the other party’s label for v, then both labels are updated to the minimum of two labels that have been assigned to v. We call this a matching phase because vertices which are common to both graphs are assigned matching labels in the two labelings.
If some vertex’s label is updated in a matching phase, then its label may differ from the labels of the other vertices in its component. Therefore, the iterative procedure repeats until labelings stabilize. During percolation, each vertex’s label is set to the minimum label of all vertices in its component. If some vertex’s label changes during a matching phase, its new label must be “smaller” than its previous label. During the next percolation phase, the change is propagated by again updating the label of each vertex in the component is to the minimum label in the component. In Section 4.5, we prove that if m denotes the maximum size of a component in

Pseudocode for component labeling algorithm.
We now provide a protocol which implements the component labeling algorithm described in Section 4.3 while preserving privacy. The ideal functionality
Approach
The challenge of securely implementing the percolate-and-match algorithm arises from the fact that percolate-and-match performs two operations: (1) comparisons on vertices, and (2) updates on vertex labels. However, if either party knew the output of any such operation on its vertices, then it would learn information about the other party’s graph. Consider that if a participant learns that its vertex’s label changed during the any matching phase or during a percolation phase, it learns that one of the vertices in its graph has a matching vertex in the other party’s graph. Similarly, if a party learns that its vertex’s label isn’t updated during the first matching or percolation phase, it learns its vertex isn’t in the other party’s graph.
Our approach is to perform both vertex comparisons and label updates without revealing the output of any comparison or update, and to encrypt all intermediate and output labels so that no information is leaked about the computation. Naively adapting state-of-the-art PSI protocols in order to perform our matching phase does not work for this approach, because in addition to finding the common vertices in the two parties’ graphs, we must also perform updates on matching labels; state of the art PSI protocols do not provide easy ways to modify auxiliary data without revealing information.
To implement comparisons and updates, we use garbled circuits. Importantly, garbled circuits must implement oblivious algorithms, whose operation is independent of the input data. Notably, for any branch in the execution tree of an oblivious algorithm, we must perform operations for both possible paths, replacing the untaken path with dummy operations. Additionally, random accesses to an array (i.e. those for which the index being read is input-dependent) must either scan over the entire array, incurring a
Matching via garbled circuits. To perform our matching phase obliviously, we adapt a technique described by Huang, Evans, and Katz for PSI [18]. In their scheme, called Sort-Compare-Shuffle, each party sorts its elements, then provides its sorted list to a garbled circuit which merges the two lists. If two parties submit the same element, then the two copies of the element land in adjacent indices in the merged list. The circuit iterates through the list, comparing elements at adjacent indices in order to identify common elements. After comparing, their circuit shuffles the sorted list before revealing elements in the intersection.
Our construction adapts the sort-compare-shuffle technique to efficiently perform our matching phase with label updates as follows. Each party submits a sorted list of vertices to a garbled circuit, including auxiliary information for each vertex that represents the vertex’s currently assigned label. To perform matching, we merge the two parties’ lists of vertices into one sorted list
Percolation via garbled circuits. To percolate labels within a component, a party can submit all of the vertices in one of its components to a garbled circuit along with each vertex’s current label. The circuit computes the minimum of the labels and assigns the minimum label to each vertex in the component.
Stitching percolation and matching together. The remaining question is how to efficiently stitch together percolation phases and matching phases without revealing intermediate labels of any vertices.We perform percolation and matching in the same circuit. To transition between percolation and matching phases, we permute the list of vertices. We define a permutation π which is hidden from both parties, and apply π and
Our garbled circuit begins by merging the two parties’ sorted lists into one large list
We remark that permuting
Graph structure. There is one additional caveat. Revealing the indices of the vertices of each component in
Outputs. Each party receives as output XOR-shares of both parties’ labels and their own labels encrypted under a key held by the other party.
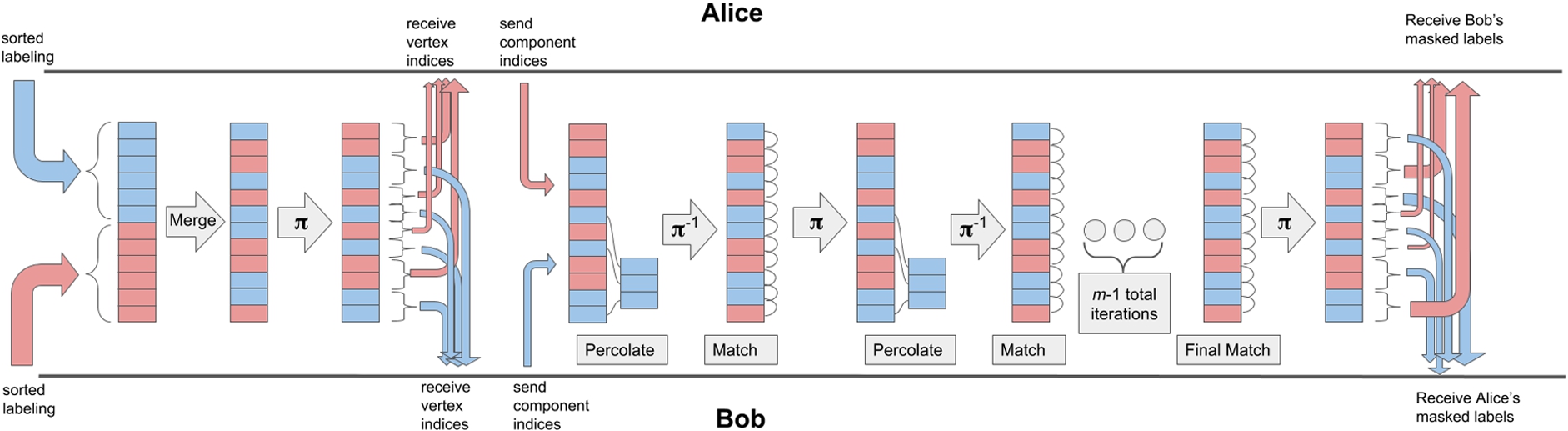
Illustration of the percolate-and-match garbled circuit approach.
We now describe how to privately implement our percolate-and-match algorithm. Figure 7 illustrates our approach, Fig. 8 contains the full protocol, and Fig. 9 describes our garbled circuits.

Full protocol for secure component labeling.

Garbled circuit for secure component labeling. The subcircuits
Protocol inputs. As input, each party
In addition, each party
Initial labelings. Each party represents the current labeling of its graph as a list of vertex descriptors. A descriptor
We refer to
Garbled circuit part 1: Merge, permute, and reveal order. After the parties set up their inputs, they invoke a garbled circuit that merges their descriptors into a combined labeling
Next, the circuit reveals to each party the indices of its own vertices in
Given the indices of each of its vertices in
Garbled circuit part 2: Percolate and match. In the second subcircuit, the parties perform percolation and matching. The parties use the information revealed about their components’ indices in
Given a circuit with the parties’ descriptors arranged as
If not using equality to compare the descriptors, then one could substitute any other comparison circuit to evaluate matching between two elements.
The circuit iterates between percolation and matching
Encrypting vertex labels. At the end of the protocol, each party must receive its vertex labels encrypted under a key known only to the other party. We show how to move encryption outside of the garbled circuit in order to save the cost of online encryption at the expense of a few extra rounds of communication.
For a generic CPA-secure encryption scheme, we use the following technique. Consider a message m, computed within a circuit, that needs to be encrypted under a key k known only to
The garbled circuit produces outputs to the parties as follows. Let
Interfacing with DDH-style PSI protocols. We present our technique for ElGamal encrypting vertex labels. As we show below, DDH-style PSI protocols can be modified to accept ElGamal-encrypted inputs.
First, the parties agree on ℓ group elements
We represent a label m using these group elements by letting each pair of group elements
Suppose m is the label of one of
Recall that DDH-style PSI protocols proceed as follows:
We note that the exponentiations of each party’s input elements can actually be performed using
We require that our El-Gamal transformation maintains uniqueness of labels. This is to say that there should be no two labels m,
Recall that we represent a label m group elements by letting a pair of group elements
To maintain uniqueness of labels under the transformation, we require that for all
More simply, we can define the event of a label collision as one in which two distinct labels are assigned the same group element. For labels m,
In any multiplicative group G of prime order q, there are only two unique elements
We note that the size of the group must already be large enough that computing discrete logarithms is hard, and that the probability of guessing correctly is negligible in the security parameter. Our upperbound on the probability of a collision is a factor of
Protocol outputs. Each party outputs two sets of encrypted labels. First, each party outputs the other party’s masked labels, which it receives from the garbled circuit. Second it output its own vertices’ encrypted labels.
Parties associate their encrypted labels with their vertices based on the order in which they receive their encrypted labels. In the earlier reveal phase, the parties learn the indices of their own vertices in the permuted list. They sort their vertices based on their indices in that list, and then associate the sorted vertices in order with the encrypted labels they receive. To choose a component label, a party arbitrarily selects any label assigned to a vertex in the component.
Given two parties’ graphs,
(Termination of Percolate-and-Match).
Let V be a set of vertices, let
We show that vertex labels stabilize after
Consider any component
If in any percolation phase,
Worst case example for the number of iterations until labels stabilize. 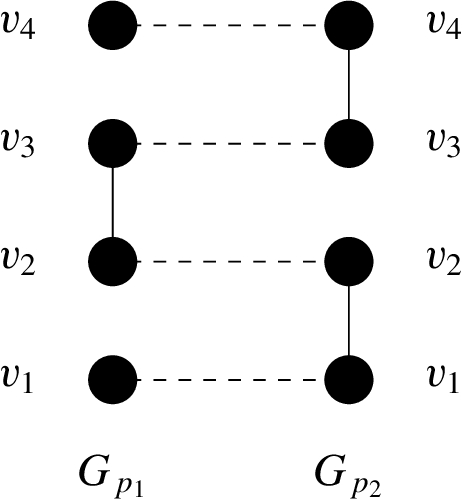
In Fig. 10, we provide an example of a graph in which
Our protocol for component labeling achieves security in the honest-but-curious model. We write the proof in a hybrid model in which the parties have access to a functionality
We denote by
Let
In the
We describe how Intuitively, the strategy works for The description of We proceed to compare the distributions of messages that In To satisfy the definition of security, we must also show that the view generated by Therefore, the message that the garbled circuit inputs that are implied by This is the case, since We proceed with the full proof of security in presence of a corrupt This is the viewproduced by a simulator This identical to To better discuss the order in which labels are output, we define an n-ordering to be a list containing an n-sized subset of Observe that the indices of This is identical to We divide our analysis of The set of strings corresponding to For all the indices for which This is identical to there are no collisions of vertex images (preserving correctness) the labeling function applied by This is identical to (Security with respect to honest-but-curious adversaries).
We note that the outputs space of the hash function is subject to the birthday bound, in the best case when it is well-balanced. However, the output space can be chosen to be large enough that the probability of a collision is a negligible function of the security parameter. Second, we require that
Asymptotic analysis
The offline cost of the protocol is dominated by setup and encryption phases. In the setup, sorting a list of N of vertices offline requires
The garbled circuit performs the following computations for the percolate-and-match algorithm. Merging two sorted lists of size N requires
The total cost of the protocol is dominated by the garbled circuit. The circuit size depends on the output length ℓ of the hash function H because each comparison is performed over ℓ-bit values. The total cost of the circuit is therefore
Experiments
We implemented our protocol using Obliv-C [35] and Absentminded Crypto Kit [11]. We modified to Obliv-C to send batches of 500 gates at a time, rather than sending each gate as soon as it is ready; from this optimization we observed a 50% speedup. Our tests were performed in parallel on Google Compute Platform (GCP) on n1-highmem-32 (32 vCPUs with 208 GB memory) machines between pairs of machines in the same datacenter. El-Gamal operations were performed over elliptic curve secp256r1.
For each problem size, we ran our tests for three label lengths, each length corresponding to a parameterization of the correctness error, as explained in Section 6.3; specifically, we ran tests for parameters that bound the correctness error probability at
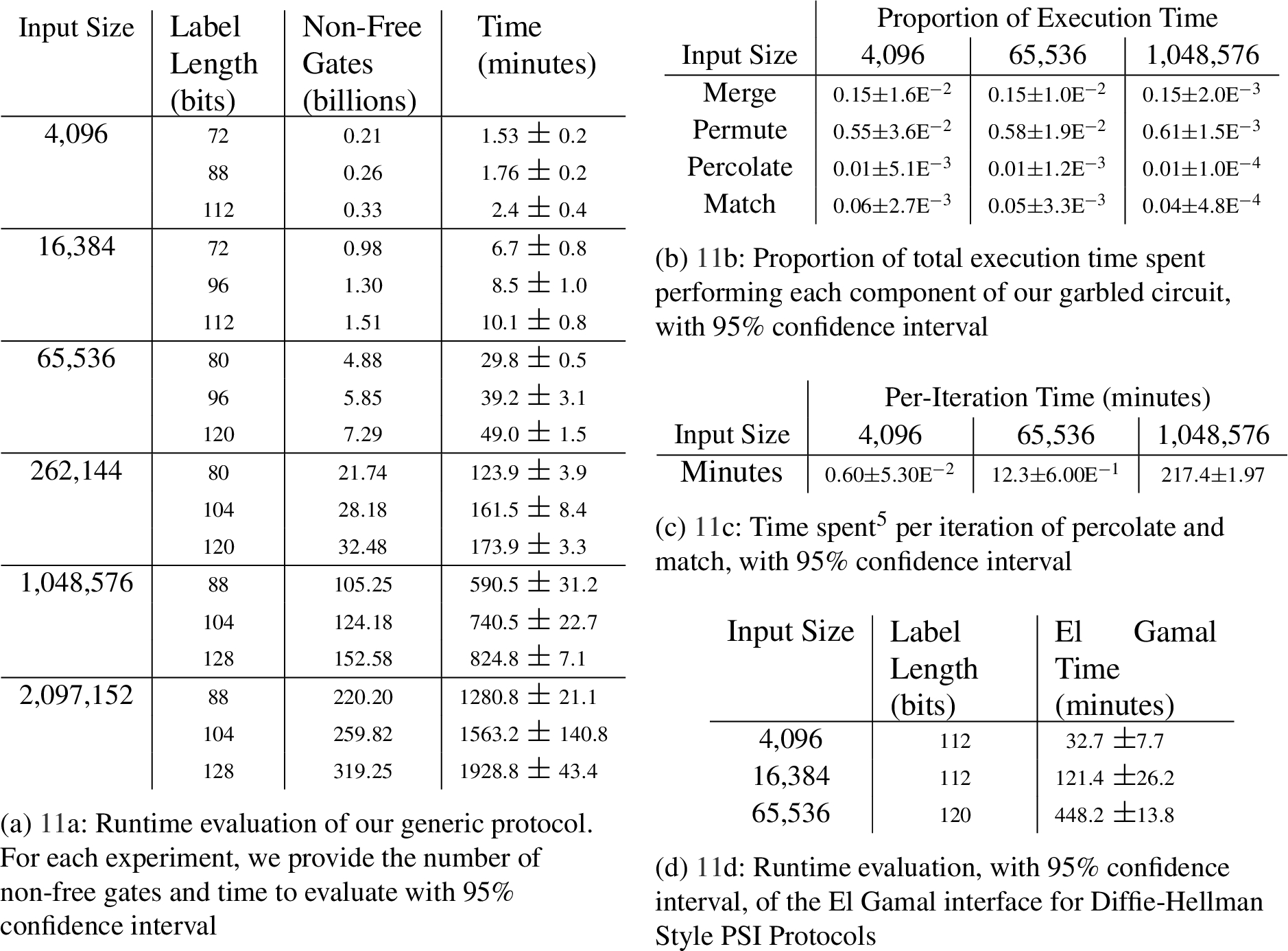
Evaluation of our prototype implementation. We tested three different label lengths per input size; with lengths corresponding to correctness parameters (which upperbound the error probability) of
We measured the iteration time twice per experiment and take the average as the iteration time for that experiment.
We summarize our experimental results in Figs 11(a), 11(b), 11(c) and 11(d). We evaluated the performance of our generic the garbled circuit protocol (including outputting of masked labels), and present the results in Figs 11(a), Fig. 11(b), and Fig. 11(c). In the generic protocol, encryptions of output labels were computed using AES in CTR mode. Each test was performed with
Importantly, our prototype implementation was not parallelized. We believe performance could be improved substantially by parallelizing, in particular because parts of the garbled circuit and the vast majority of the El-Gamal phase are embarrassingly parallel.
We observe that if an application that allows us to tune the correctness probability, we adapt the protocol to allow error with some tolerable probability ε in order to improve efficiency. Specifically, we show that we can set the bit length ℓ of the labels assigned to vertices as a function of ε. Reducing bit length of the labels directly improves the cost of the protocol, as the number of gates in the garbled circuit is linear in the bit length of the labels.
Recall that correctness of our protocol requires that for every pair of vertices u, v in
Our analysis is an application of the birthday bound. Recall that each party has a graph of size N, and consider that H is a random oracle. Let
Therefore, it is possible to achieve correctness with probability
Discussion and future work
We have presented a two-party protocol that can be used as a setup for subsequent PSI-style computations. Our ID-agreement protocol was designed for use with DDH-style PSI protocols. In particular, we rely on the fact that in DDH-style protocols it is straightforward to work with ElGamal encryptions by taking advantage of the homomorphism over the group operation. We believe similar techniques can be applied to other PSI paradigms, which we leave for future work.
In a real-world application it is possible that the parties will update their respective databases and require new encrypted labels for their modified rows. One approach to computing the updated labels would be to run the entire protocol again, but this would be expensive if the updates occur frequently. More efficiently updating labels without scaning over bother parties’ entire inputs is an interesting future direction.
Subsequent to the initial publication of this work, Heath and Kolesnikov [17] introduced further garbled circuit optimizations that we believe would substantially improve the performance of our garbled circuit implementation. To improve the construction further, we consider the fact that more than half of the time spent in our experiments was spent on permuting the list of vertices in our circuit. An anonymous reviewer pointed out that there are more efficient ways obliviously permute lists, such as the work by Mohassel and Sadeghian [25], and that a technique such as this could reduce the complexity of the permutation step by an order of the security parameter. However, it is not trivial to perform oblivious updates on the label associated with each vertex by composing better shuffling techniques with garbled circuits for black-box updates. We consider this a direction for future research with many potential applications.
Footnotes
Acknowledgments
We would like thank Samee Zahur for his assistance with the Obliv-C compiler and Jack Doerner for his assistance with Absentminded Crypto Kit.