
Abstract
Security APIs, key servers and protocols that need to keep the status of transactions, require to maintain a global, non-monotonic state, e.g., in the form of a database or register. However, most existing automated verification tools do not support the analysis of such stateful security protocols – sometimes because of fundamental reasons, such as the encoding of the protocol as Horn clauses, which are inherently monotonic. A notable exception is the recent tamarin prover which allows specifying protocols as multiset rewrite (msr) rules, a formalism expressive enough to encode state. As multiset rewriting is a “low-level” specification language with no direct support for concurrent message passing, encoding protocols correctly is a difficult and error-prone process.
We propose a process calculus which is a variant of the applied pi calculus with constructs for manipulation of a global state by processes running in parallel. We show that this language can be translated to msr rules whilst preserving all security properties expressible in a dedicated first-order logic for security properties. The translation has been implemented in a prototype tool which uses the tamarin prover as a backend. We apply the tool to several case studies among which a simplified fragment of PKCS#11, the Yubikey security token, and an optimistic contract signing protocol.
Introduction
Automated analysis of security protocols has been extremely successful. Using automated tools, flaws have been for instance discovered in the Google Single Sign On Protocol [5], in commercial security tokens implementing the PKCS#11 standard [10], and one may also recall Lowe’s attack [25] on the Needham-Schroeder public key protocol 17 years after its publication. While efficient tools such as ProVerif [7], AVISPA [4] or Maude-NPA [14] exist, these tools are generally not suitable to analyze protocols that require non-monotonic global state, i.e., some database, register or memory location that can be read and altered by different parallel threads. The input language of the AVISPA tool offers support for this kind of state but only supports a bounded number of sessions. This is particularly restrictive when analysing security APIs where attacks typically require several keys and API calls, which are difficult to bound a priori. ProVerif, one of the most efficient and widely used protocol analysis tools for an unbounded number of sessions, relies on an abstraction that encodes protocols in first-order Horn clauses. This abstraction is well suited for the monotonic knowledge of an attacker (who never forgets), makes the tool extremely efficient for verifying an unbounded number of protocol sessions and allows to build on existing techniques for Horn clause resolution. However, Horn clauses are inherently monotonic: once a fact is true it cannot be set to false anymore. As a result, even though ProVerif’s input language, a variant of the applied pi calculus [2], allows a priori encodings of a global memory, the abstractions performed by ProVerif introduce false attacks. In the ProVerif user manual [8, Section 6.3.3] such an encoding of memory cells and its limitations are indeed explicitly discussed: “Due to the abstractions performed by ProVerif, such a cell is treated in an approximate way: all values written in the cell are considered as a set, and when one reads the cell, ProVerif just guarantees that the obtained value is one of the written values (not necessarily the last one, and not necessarily one written before the read).”
A prominent example where non-monotonic global state appears are security APIs, such as the RSA PKCS#11 standard [27], IBM’s CCA [11] or the trusted platform module (TPM) [35]. They have been known to be vulnerable to logical attacks for some time [9,24] and formal analysis has shown to be a valuable tool to identify attacks and find secure configurations. One promising paradigm for analyzing security APIs is to regard them as a participant in a protocol and use existing analysis tools. However, Herzog [18] already identified not accounting for mutable global state as a major barrier to the application of security protocol analysis tools to verify security APIs. Apart from security APIs many other protocols need to maintain databases: key servers need to store the status of keys, in optimistic contract signing protocols a trusted party maintains the status of a contract, RFID protocols maintain the status of tags and more generally websites may need to store the current status of transactions.
Our contributions. We propose a tool for analyzing protocols that may involve non-monotonic global state, relying on Schmidt et al.’s tamarin tool [30,31] as a backend. We designed a new process calculus that extends the applied pi calculus by defining, in addition to the usual constructs for specifying concurrent processes, constructs for explicitly manipulating global state. This calculus serves as the tool’s input language. The heart of our tool is a translation from this extended applied pi calculus to a set of multiset rewrite rules that can then be analyzed by tamarin which we use as a backend. We prove the correctness of this translation and show that it preserves all properties expressible in a dedicated first order logic for expressing security properties. As a result, relying on the tamarin prover, we can analyze protocols without bounding the number of sessions, nor making any abstractions. Moreover it allows to model a wide range of cryptographic primitives by the means of equational theories. As the underlying verification problem is undecidable, tamarin may not terminate. However, it offers an interactive mode with a GUI which allows to manually guide the tool in its proof. Our specification language includes support for private channels, global state and locking mechanisms (which are crucial to write meaningful programs in which concurrent threads manipulate a common memory). The translation has been carefully engineered in order to favor termination by tamarin, including a goal ranking method tailored to the output of the translation. Several case studies illustrate the tool’s capability: a simple security API in the style of PKCS#11, a complex case study of the Yubikey security token, as well as several examples analyzed by other tools that aim at analyzing stateful protocols. In all of these case studies we were able to avoid restrictions that were necessary in previous works.
Related work. The most closely related work is the StatVerif tool by Arapinis et al. [3]. They propose an extension of the applied pi calculus, similar to ours, which is translated to Horn clauses and analyzed by the ProVerif tool. Their translation is sound but allows for false attacks, limiting the scope of protocols that can be analyzed. Moreover, StatVerif can only handle a finite number of memory cells: when analyzing an optimistic contract signing protocol this appeared to be a limitation and only the status of a single contract was modeled, providing a manual proof to justify the correctness of this abstraction. In important case studies, e.g. key-management APIs like PKCS#11 or the Yubikey, an unbounded amount of memory is required to avoid artificially bounding the number of keys or Yubikey devices. Finally, StatVerif is limited to the verification of secrecy properties. As illustrated by the Yubikey case study, our work is more general and we are able to analyze complex injective correspondence properties.
Mödersheim [26] proposed a language with support for sets together with an abstraction where all objects that belong to the same sets are identified. His language, which is an extension of the low level AVISPA intermediate format, is compiled into Horn clauses that are then analyzed, e.g., using ProVerif. His approach is tightly linked to this particular abstraction, limiting the scope of applicability, e.g., when keys may be compromised (all keys with the same attributes are abstracted to one and the same, thus either all are revealed, or none) or when the set of states a key or value is not bounded a priori (as in the Yubikey case study). Mödersheim also discusses the need for a more high-level specification level which we provide in this work.
There has also been work tailored to particular applications. In [13], Delaune et al. show by a dedicated hand proof that for analyzing PKCS#11 one may bound the message size. Their analysis still requires to artificially bound the number of keys. Similarly in spirit, Delaune et al. [12] give a dedicated result for analyzing protocols based on the TPM and its registers. However, the number of reboots (which reinitialize registers) needs to be limited.
Guttman [17] also extended the strand space model by adding support for state. While the protocol execution is modeled using the classical strand spaces model, state is modeled by a multiset of facts, and manipulated by multiset rewrite rules. The extended model has been used for analyzing by hand an optimistic contract signing protocol. In a more recent paper Ramsdell et al. [28] propose another approach also based on the strand space model. Using the CPSA tool they obtain a symbolic representation (called skeletons) of all possible attacks. However, as their model analyzed by CPSA encodes the state in a message passing style, the tool may consider false attacks. They therefore import the CPSA result, as an axiom, in the theorem prover PVS and, based on a more precise model of the possible state transitions, refine their analysis to exclude the false attacks. The approach has been applied to the so-called envelope protocol, which was also analysed (in a slightly more restrictive model) in [12].
In the goal of relating different approaches for protocol analysis Bistarelli et al. [6] also proposed a translation from a process algebra to multiset rewriting: they do however not consider private channels, have no support for global state and assume that processes have a particular structure. These limitations significantly simplify the translation and its correctness proof. Moreover their work does not include any tool support for automated verification.
Obviously any protocol that we are able to analyze can be directly analyzed by the tamarin prover [30,31] as the rules produced by our translation could have been given directly as an input to tamarin. Indeed, tamarin has already been used for analyzing a model of the Yubikey device [23], the case studies presented with Mödersheim’s abstraction, as well as those presented with StatVerif. It is furthermore able to reproduce the aforementioned results on PKCS#11 [13] and the TPM [12] – moreover, it does so without bounding the number of keys, security devices, reboots, etc. Contrary to ProVerif, tamarin sometimes requires additional typing lemmas which are used to guide the proof. These lemmas need to be written by hand (but are proved automatically). In our case studies we also needed to provide a few such lemmas manually. In our opinion, an important disadvantage of tamarin is that protocols are modeled as a set of multiset rewrite rules. This representations is very low level and far away from actual protocol implementations, making it very difficult to model a protocol adequately. Encoding private channels, nested replications and locking mechanisms directly as multiset rewrite rules is a tricky and error prone task. As a result we observed that, in practice, the protocol models tend to be simplified. For instance, locking mechanisms are often omitted, modeling protocol steps as a single rule and making them effectively atomic. Such more abstract models may obscure issues in concurrent protocol steps and increase the risk of implicitly excluding attacks in the model that are well possible in a real implementation, e.g., race conditions. Using a more high-level specification language, such as our process calculus, arguably eases protocol specification and overcomes some of these risks. Examples in which the explicit modelling of locking mechanisms in SAPIC improved the protocol and/or the analysis include the Yubikey case study presented in Section 7. In our modelling of the Yubikey the server can handle several requests from different devices in parallel, which was not possible in the direct modelling in [23]. Another example is the model of the enhanced authorization mechanism introduced in the TPM 2.0 specification by Shao et al. [33]. In this work, a model of the TPM that executes API commands sequentially is compared to one that executes them in parallel, finding flaws in the parallel version. The TPM model in the tamarin example files models TPM commands as atomic steps. While an explicit modelling of locking steps is possible in tamarin, judging from existing models, it is not widely used, although protocols and analysis could benefit from it.
Since the first prototype of this translation was presented [21], subsequent work has demonstrated and extended its scope. The present calculus and verification method have been used to verify a configuration of the key-management API PKCS#11 [22] and was extended with loops to allow for the analysis of the streaming protocol TESLA [19]. In [33], Shao et al. used our tool to analyse the enhanced authorization mechanism introduced in the TPM 2.0 specification.
Preliminaries
Terms and equational theories. As usual in symbolic protocol analysis we model messages by abstract terms. Therefore we define an order-sorted term algebra with the sort
We equip the term algebra with an equational theory E, that is a finite set of equations of the form
Symmetric encryption can be modelled using a signature
For the remainder of the article we assume that E refers to some fixed equational theory and that the signature and equational theory always contain symbols and equations for pairing and projection, i.e.,
We suppose the usual notion of positions for terms. A position p is a sequence of positive integers and
Facts. We also assume an unsorted signature
Predicates. We assume an unsorted signature
Suppose
Substitutions. A substitution σ is a partial function from variables to terms. We suppose that substitutions are well-typed, i.e., they only map variables of sort s to terms of sort s, or of a subsort of s. We denote by
Sets, sequences and multisets. We write
Syntax and informal semantics
Our calculus, dubbed SAPiC (Stateful Applied Pi calculus) is a variant of the applied pi calculus [2]. In addition to the usual operators for concurrency, replication, communication and name creation, it offers several constructs for reading and updating an explicit global state. The grammar for processes is described in Fig. 1.

Syntax, where
0 denotes the terminal process.
The remaining constructs are used for manipulating state and are new compared to the applied pi calculus. The construct insert M,N binds the value N to a key M. Successive inserts allow changing this binding. We emphasise that we have only one value bound to a key, and that successive inserts update the binding. The delete M operation simply “undefines” the mapping for the key M. The lookup M as x in P else Q allows for retrieving the value associated to M, binding it to the variable x in P. If the mapping is undefined for M the process behaves as Q. The lock and unlock constructs are used to gain or waive exclusive access to a resource M, in the style of Djkstra’s binary semaphores: if a term M has been locked, any subsequent attempt to lock M will be blocked until M has been unlocked. This is essential for writing protocols where parallel processes may read and update a common memory.
In the following example, which will serve as our running example, we model a security API that, even though much simplified, illustrates the most salient issues that occur in the analysis of security APIs such as PKCS#11 [10,13,15].
We consider a security device that allows the creation of keys in its secure memory. The user can access the device via an API. If he creates a key, he obtains a handle, which he can use to let the device perform operations on his behalf. For each handle the device also stores an attribute which defines what operations are permitted for this handle. The goal is that the user can never gain knowledge of the key, as the user’s machine might be compromised. We model the device by the following process (we use 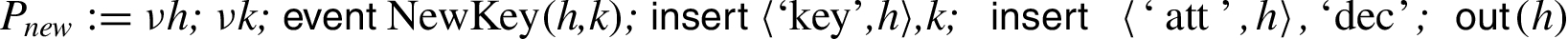
In the first line, the device creates a new handle h and a key k and, by the means of the event NewKey
allows the attacker to change the attribute of a key from the initial value 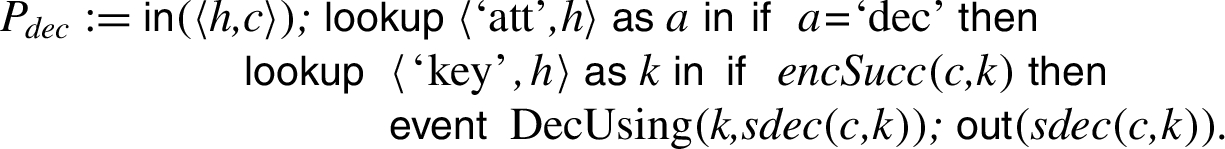
The first lookup stores the value associated to
If a key has the 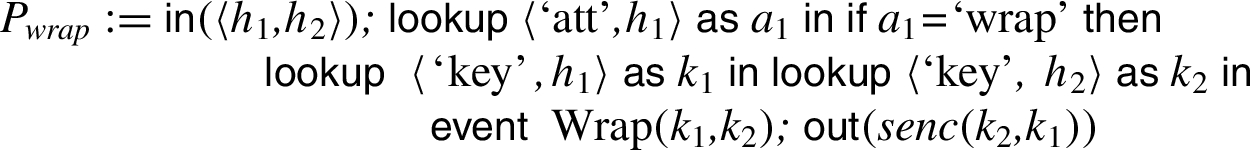
The bound names of a process are those that are bound by
A process is ground if it does not contain any free variables. We denote by
Frames and deduction. Before giving the formal semantics of SAPiC we introduce the notions of frame and deduction. A frame consists of a set of fresh names
(Deduction).
We define the deduction relation

Deduction rules.

Proof tree witnessing that
If one key is used to wrap a second key, then, if the intruder learns the first key, he can deduce the second. For
Operational semantics. We can now define the operational semantics of our calculus. The semantics is defined by a labelled transition relation between process configurations. A process configuration is a 5-tuple
σ is a ground substitution modeling the messages output to the environment;
The transition relation is defined by the rules described in Fig. 4. Transitions are labelled by sets of ground facts. For readability we omit empty sets and brackets around singletons, i.e., we write → for
Given a ground process P we define the set of traces of P as

Operational semantics.
In Fig. 5 we display the transitions corresponding to the creation of a key on the security device in our running example and witness that

Example of transitions modelling the creation of a key on a PKCS#11-like device.
We now recall the syntax and semantics of labelled multiset rewriting rules, which constitute the input language of the tamarin tool [30].
(Multiset rewrite rule).
A labelled multiset rewrite rule
(Labelled multiset rewriting system).
A labelled multiset rewriting system is a set of labelled multiset rewrite rules R, such that each rule r does not contain for each
A labelled multiset rewriting system is called well-formed, if additionally
We define one distinguished rule
The semantics of the rules is defined by a labelled transition relation.
(Labelled transition relation).
Given a multiset rewriting system R we define the labeled transition relation
(Executions).
Given a multiset rewriting system R we define its set of executions as
The set of executions consists of transition sequences that respect freshness, i.e., for a given name a the fact
(Traces).
The set of traces is defined as
Note that both for processes and multiset rewrite rules the set of traces is a sequence of sets of facts.
Security properties
In the tamarin tool [30] security properties are described in an expressive two-sorted first-order logic. The sort
(Trace formulas).
A trace atom is either false ⊥, a term equality
As we will see in our case studies this logic is expressive enough to analyze a variety of security properties, including complex injective correspondence properties.
To define the semantics, let each sort s have a domain
(Satisfaction relation).
The satisfaction relation
For readability, we define 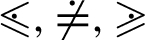 ) as expected. We also use classical notational shortcuts such as
) as expected. We also use classical notational shortcuts such as
(Validity, satisfiability).
Let
A trace formula φ is said to be satisfiable for
Note that The following trace formula expresses secrecy of keys generated on the security API, which we introduced in Section 3.
In this section we define a translation from a process P into a set of multiset rewrite rules
Definition of the translation of processes
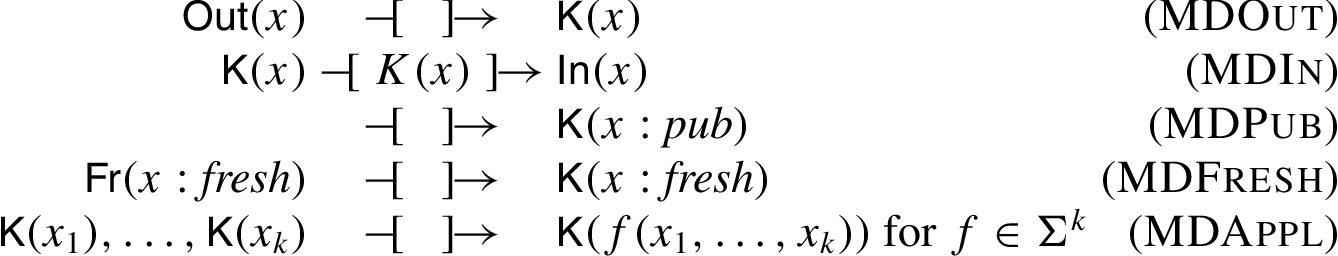
The set of rules
To model the adversary’s message deduction capabilities, we introduce the set of rules
The set of reserved variables is defined as the set containing the elements
For our translation to be sound, we require that for each process, there exists an injective mapping assigning to every ”In every branch of the syntax tree, every lock must be followed by precisely one corresponding unlock. In Given a ground process P we define the annotated ground process (Process annotation).
(Well-formed).
A ground process P is well-formed if
no reserved variable nor reserved fact appears in P, any bound name and variable in P cannot be rebound, i.e., if u is bound in P then u is not under the scope of a previous binder, and
A trace formula φ is well-formed if no reserved variable nor reserved fact appear in φ.
The two first restrictions of well-formed processes can be assumed without loss of generality as processes and formulas can be consistently renamed to avoid reserved variables and α-converted to avoid binding names or variables several times. Also note that the second condition is not necessarily preserved during an execution, e.g. when unfolding a replication,
The annotation of locks restricts the set of protocols we can translate, but allows us to obtain better verification results, since we can predict which
Given a well-formed ground process P we define the labelled multiset rewriting system
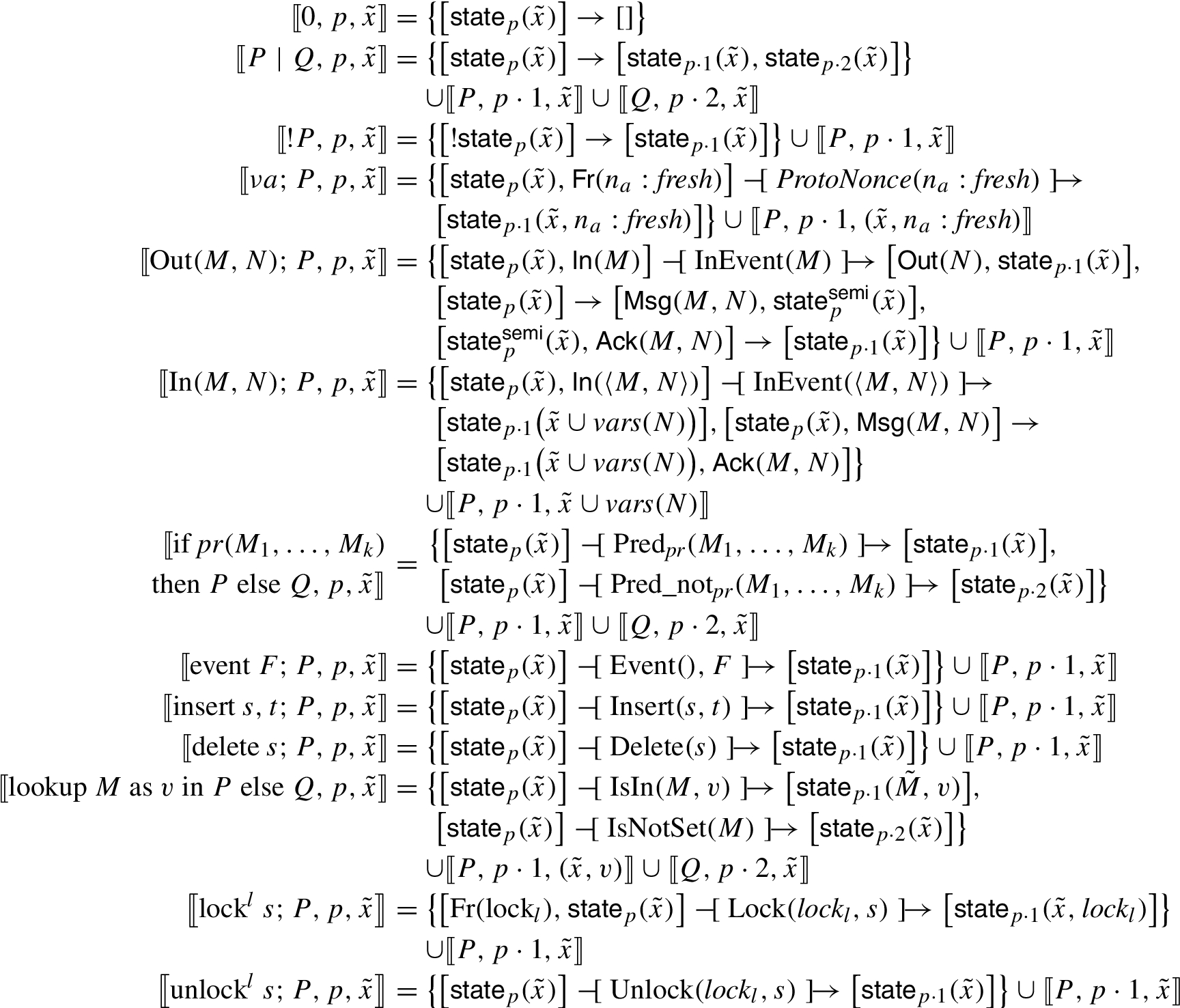
Translation of processes: definition of
In the definition of

The set of multiset rewrite rules
Figure 8 illustrates the above translation by presenting the set of msr rules
A graph representation of an example trace, similar to the one generated by the tamarin tool, is depicted in Fig. 9. Every node stands for the application of a multiset rewrite rule, where the premises are at the top, the conclusions at the bottom, and the actions (if any) annotate the node. Every premise needs to have a matching conclusion, visualized by the arrows, to ensure the graph depicts a valid msr execution. (This is a simplification of the dependency graph representation tamarin uses to perform backward-induction [30,31].) We also note that in the current example
Example trace for the translation of 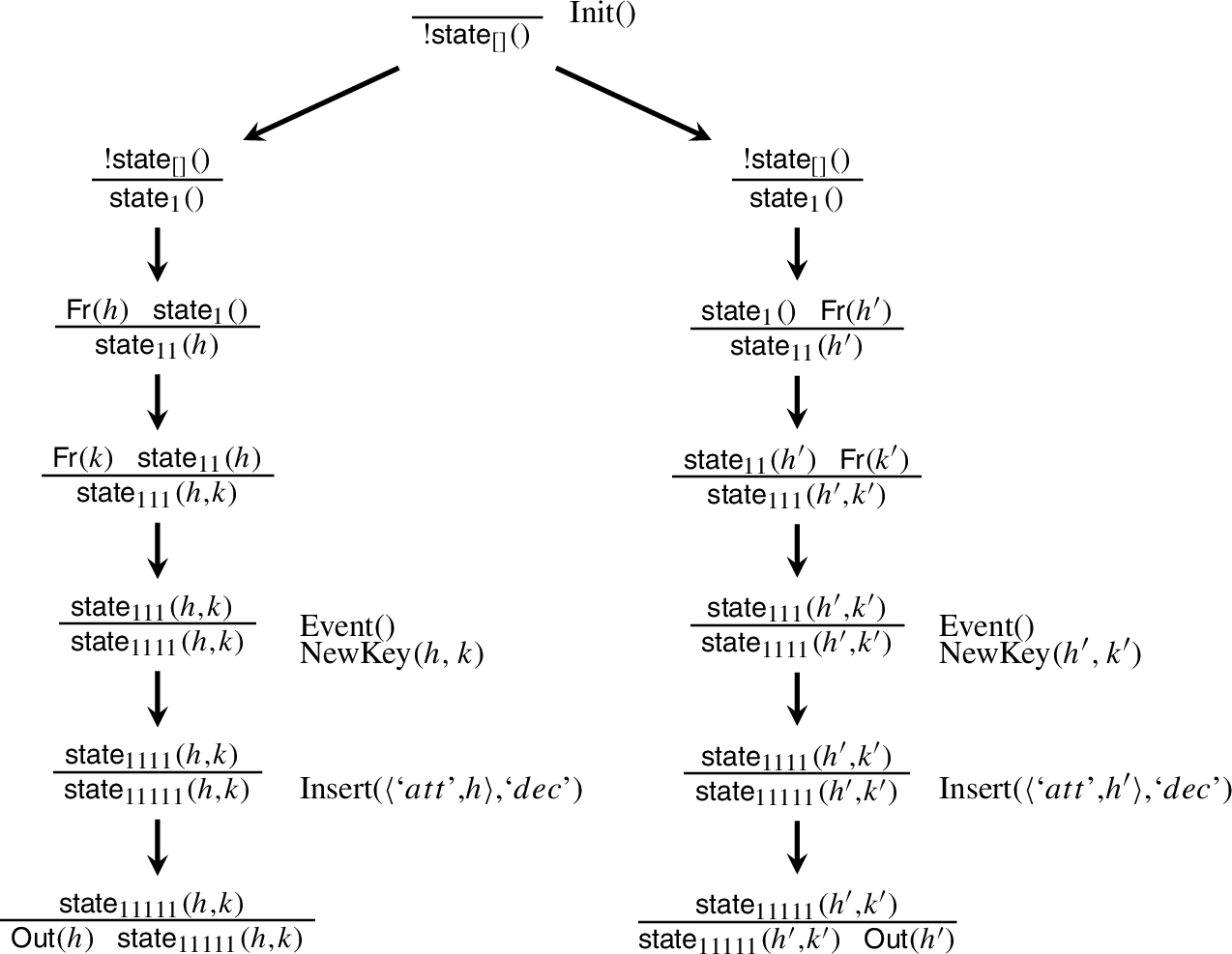
One may note that, while for all other operators, the translation produces well-formed multiset rewriting rules (as long as the process is well-formed itself), this is not the case for the translation of the
We can now define the translation for formulas.
Given a well-formed trace formula φ we define

Definition of α.
The formula α uses the actions of the generated rules to filter out executions that we wish to discard:
We also note that
There exist certainly other ways of correctly translating our calculus into msr rules. Most of our choices were guided by the way tamarin internally works. To better appreciate our choices we will give a high-level overview of the procedure implemented in tamarin. A detailed review of the procedure is however out of scope of this paper and we refer the reader to [30] for a detailed description.
A short overview of tamarin. Tamarin basically applies a backward reasoning approach to try to find a trace which satisfies a given formula. (Validity claims are first translated to satisfiability claims.) This is reminiscent to the reasoning when proving protocol correctness in the strand space model [20]. More precisely, rather than reasoning about traces, tamarin reasons about dependency graphs, an enriched representation of traces. Dependency graphs are DAGs, where each node corresponds to a ground instance of an msr rule and the edges represent the causal dependencies among these rules. For every premise of a rule there is an incoming edge from another rule with a conclusion that matches the premise. Moreover, linear facts may have at most one outgoing edge and fresh rules are unique. Every topological ordering then corresponds to a trace.
Tamarin’s backward search is formalised by a constrained solving algorithm. The solutions of a constraint system are the dependency graphs whose traces satisfy the constraints. The initial constraint system is simply the formula to be satisfied. The procedure then applies simplification rules which preserve all solutions. If the constraint system reaches ⊥ the formula is unsatisfiable. In case no more rules can be applied the system is solved, and the dependency graphs that are the solutions of the constraint system can be directly constructed.
Slightly simplifying, a typical rule in the constraint solving algorithm would state that if the formula is of the form
The constraint simplification procedure may of course enter a loop and not terminate. This is natural given that the underlying problem is undecidable. The algorithm can nevertheless be guided by heuristics to avoid some of these loops and use previously proven lemmas and axioms to prune otherwise infinite branches.
Design choices. The axioms in the translation of the formula are designed to work hand in hand with the translation of the process into rules. They express the correctness of traces with respect to our calculus’ semantics, but are also meant to guide tamarin’s constraint solving algorithm. The use of axioms, rather than other possible encodings, often helps the algorithm to enforce termination as they can be used to cut branches that are not consistent with the axioms. We will discuss the axioms related to state manipulation.
Let us first consider the axioms related to lock actions. A naïve axiomatization would postulate that “every lock is preceded by an unlock and no lock or unlock in between, unless it is the first lock.” This would however cause tamarin to loop, as we will see below. We will first illustrate how the axiom
Consider the constraint solving procedure for the following process
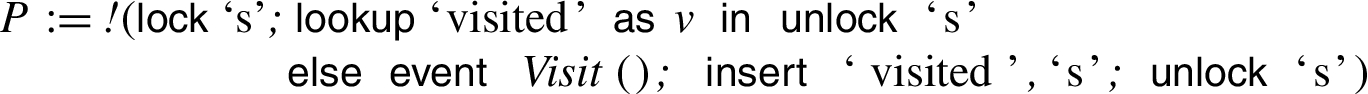
and the trace formula

Translation of process P.
Tamarin shows validity of the trace formula by showing that its negation
Constraint system resulting from the negation of All 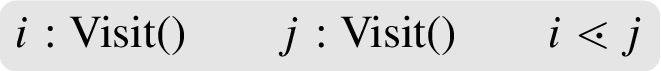
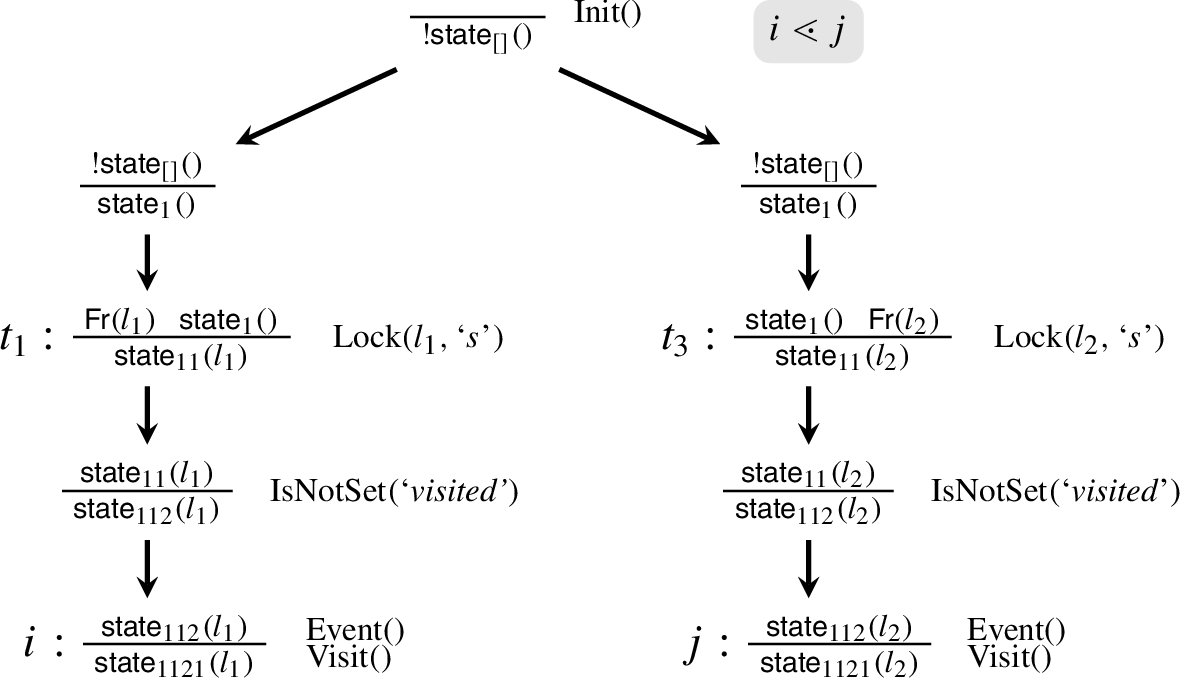
As all
By 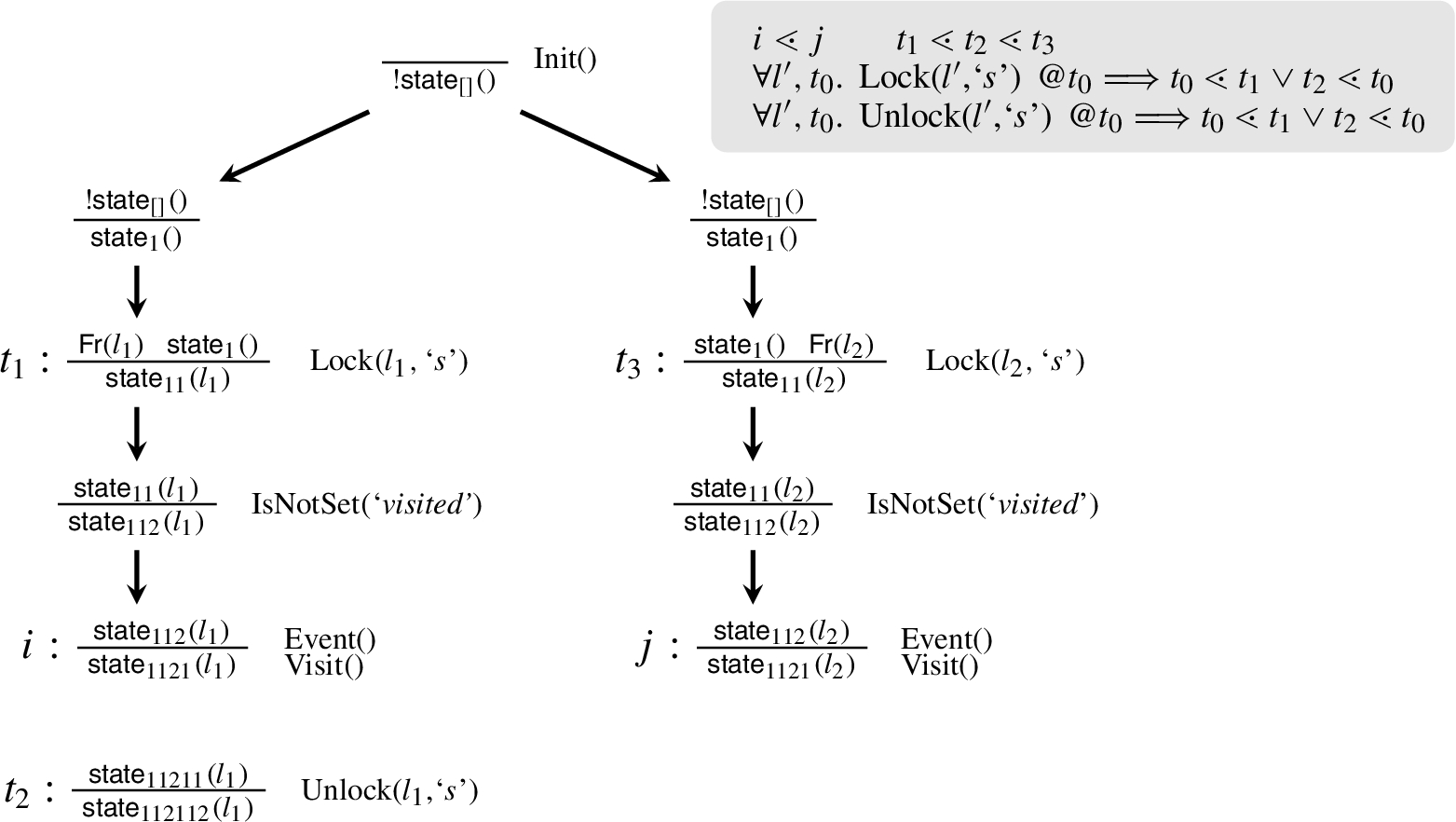
Now
Due to the annotation, the fact
Because of the common premise
If we would not annotate locks with fresh names, these two subgraphs would not be merged, as they could be different. In fact, the axion
Because of the identical premise 
We have achieved a total ordering on all rule instantiations that appear in the constrain system. Now
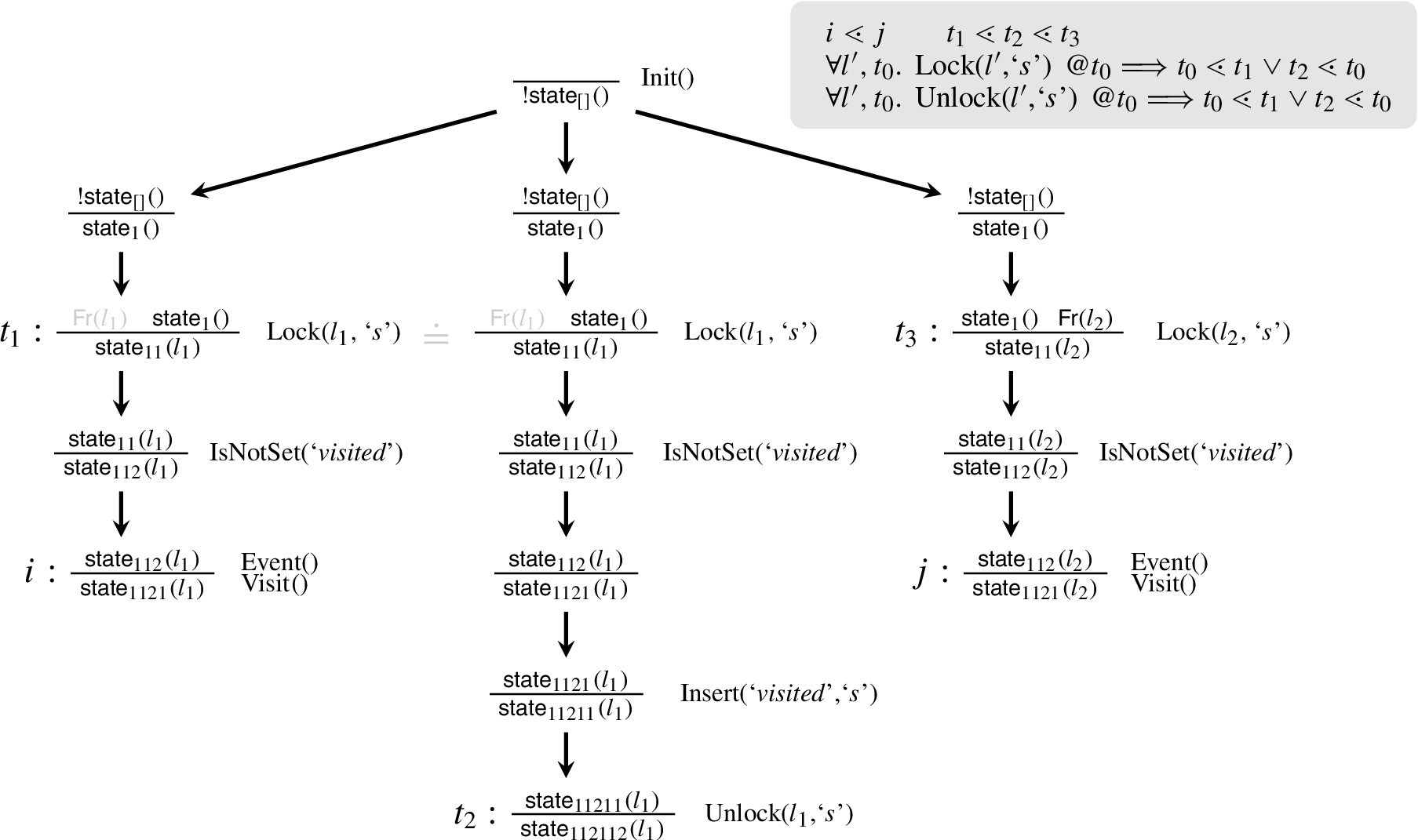
In contrast, consider now the naïve formulation of
Even if annotations are employed, this would easily provoke a loop: applied after the second step, to the Lock-node at

The naïve formulation
In summary, a careful formulation of this axiom was necessary to avoid loops. The annotation helps distinguishing which unlock is expected between two locks, vastly improving the speed of the backward search. This optimisation, however, required us to put restrictions on the locks. The axiom is formulated in a way that links the lock with the corresponding unlock by means of this annotation. The equivalence between
Similarly, the axioms
The correctness of our translation is stated by the following theorem.
Given a well-formed ground process P and a well-formed trace formula φ we have that
We here give an overview of the main propositions and lemmas needed to prove Theorem 1. To show the result we need two additional definitions. We first define an operation that allows to restrict a set of traces to those that satisfy the trace formula α as defined in Definition 15.
Let α be the trace formula as defined in Definition 15 and
The following proposition states that if a set of traces satisfies the translated formula then the filtered traces satisfy the original formula.
Let
We first show the two directions for the case
Next we define the hiding operation which removes all reserved facts from a trace.
Given a trace
As expected well-formed formulas that do not contain reserved facts evaluate the same whether reserved facts are hidden or not.
Let
We start with the case
If
If
From the above statements we easily have that
We can now state our main lemma which is relating the set of traces of a process P and the set of traces of its translation into multiset rewrite rules.
Let P be a well-formed ground process. We have that
The proof is given in Appendix B. Our main theorem can now be proven by applying Lemma 1, Proposition 2 and Proposition 1.
□
In the following we will briefly overview some case studies we performed. These case studies include a simple security API similar to PKCS#11 [27], the Yubikey security token, the optimistic contract signing protocol by Garay, Jakobsson and MacKenzie (GJM) [16] and a few other examples discussed in Arapinis et al. [3] and Mödersheim [26]. We do not detail all the formal models of the protocols and properties that we studied, and sometimes present slightly simplified versions. All files of our prototype implementation and our case studies are available at
In addition to the syntax of the calculus described in Section 3 our tool also allows the user to fall back to labelled msr rules inside of processes. The treatment of this extension is described in the conference version [21]. Having an access to the underlying formalism may sometimes be convenient, but as we do not use it in the examples described in this paper we chose to omit this feature to clarify the presentation.
Related work complements these case studies with an analysis of a more complete model of PKCS#11 [22], and the enhanced authorisation mechanism in the TPM 2.0 [33], as well as an extension of SAPIC that allows for the analysis of stream protocols such as TESLA [19].
We will also discuss a dedicated heuristics we developed that favours termination of tamarin on msr systems produced by our tool. The results are summarized in Table 1. For each case study we provide the number of typing lemmas that were needed by the tamarin prover and whether manual guidance of the tool was required. In case no manual guidance is required we also give execution times.
Case studies
Case studies
Running times on Intel i7-4770 CPU 3.40 GHz (8 Cores) and 8 GB RAM.
This example illustrates how our modelling might be useful for the analysis of Security APIs in the style of the PKCS#11 standard [27]. Indeed, Künnemann [22] used our tool to perform an automated analysis of PKCS#11 v2.20. In addition to the processes presented in the running example in Section 3 the actual case study models the following two operations: (i) encryption: given a handle and a plain-text, the user can request an encryption under the key the handle points to. (ii) unwrap: given a ciphertext
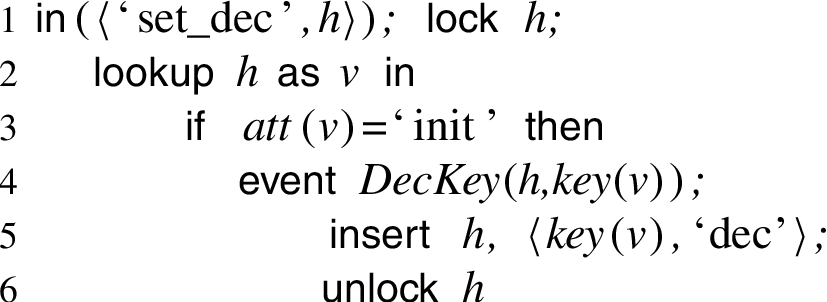
Note that, in contrast to the running example, it is necessary to encapsulate the state changes between lock and unlock. Otherwise an adversary can stop the execution after line 3, set the attribute to ‘wrap’ in a concurrent process and produce a wrapping. After resuming operation at line 4, he can set the key’s attribute to ‘dec’, even though the attribute is set to ‘wrap’. Hence, the attacker is allowed to decrypt the wrapping he has produced and can obtain the key. Such subtleties can produce attacks that our modeling allows to detect. If locking is handled correctly, we show secrecy of keys produced on the device, proving the property introduced in Example 5. If locks are removed the attack described before is found. The conference version [21] mistakenly reported that the verification of this example was fully automated, but the verified model contained a typo, where
Yubikey
The Yubikey [34] is a small hardware device designed to authenticate a user against network-based services. Manufactured by Yubico, a Swedish company, the Yubikey itself is a low cost ($25), thumb-sized USB device. In its typical configuration, it generates one-time passwords based on encryptions of a secret value, a running counter and some random values using a unique AES-128 key contained in the device. The Yubikey authentication server accepts a one-time password only if it decrypts under the correct AES key to a valid secret value containing a counter larger than the last counter accepted. The counter is thus a means to prevent replay attacks. To date, over a million Yubikeys have been shipped to more than 50,000 customers including governments, universities and enterprises, e.g. Google, Microsoft and Facebook [36].
The following process

Here, the processes

The one-time password

Note that, in our modelling, the server keeps one lock per public id, which means that it is possible to have several active instances of the server thread in parallel as long as all requests concern different Yubikeys.
We model the counter as a multiset only consisting of the symbols “one” and “zero”. The multiplicity of ‘one’ in the multiset is the value of the counter. A counter value is considered smaller than another one, if the first multiset is included in the second, therefore
The process we analyse models a single authentication server (that may run arbitrarily many threads) and an arbitrary number of Yubikeys, i.e.,
Our analysis makes three simplifications: First, in
A similar analysis has already been performed by Künnemann and Steel, using tamarin’s multiset rewriting calculus [23]. However, the model in our new calculus is more fine-grained and we believe more readable. Security-relevant operations like locking and tests on state are written out in detail, resulting in a model that is closer to the real-life operation of such a device. The modeling of the Yubikey takes approximately 38 lines in our calculus, which translates to 49 multiset rewrite rules. The model of [23] contains only four rules, but they are quite complicated, resulting in 23 lines of code. More importantly, the gap between their model and the actual Yubikey protocol is larger – in our calculus, it becomes clear that the server can treat multiple authentication requests in parallel, as long as they do not claim to stem from the same Yubikey. An implementation on the basis of the model from Künnemann and Steel would need to implement a global lock accessible to the authentication server and all Yubikeys. This is however unrealistic, since the Yubikeys may be used at different places around the world, making it unlikely that there exist means of direct communication between them. While a server-side global lock might be conceivable (albeit impractical for performance reasons), a real global lock could not be implemented for the Yubikey as deployed.
The GJM contract signing protocol [16]
A contract signing protocol allows two parties to sign a contract in a fair way: none of the participants should be bound to the contract without the other participant being bound as well. A straightforward solution is to use a trusted party that collects both signatures on the contract and then sends the signed contracts to each of the participants. Optimistic protocols have been designed to avoid the use of a trusted party whenever possible (optimizing efficiency, and avoiding the potential cost of a trusted party). In these protocols the parties first try to simply exchange the signed contracts; in case of failure, or cheating behavior of one of the parties, the trusted party can be contacted. Depending on the situation, the trusted party may either abort the contract, or resolve it. In case of an abort decision the protocol ensures that none of the parties obtains a signed contract, while in case of a resolve the protocol ensures that both participants obtain the signed contract. For this the trusted party needs to maintain a database with the current status of all contracts (aborted, resolved, or no decision has been taken). In our calculus the status information is naturally modelled using our insert and lookup constructs. The use of locks is also crucial here to avoid the status to be changed between a lookup and an insert.
This protocol was also studied by Arapinis et al. [3]. They showed the crucial property that a same contract can never be both aborted and resolved. However, due to the fact that StatVerif only supports a finite number of memory cells, they have shown this property for a single contract and provide a manual proof to lift the result to an unbounded number of contracts. We directly prove this property for an unbounded number of contracts.
Further case studies
We investigated the case study presented by Mödersheim [26], a key-server example, as well as a simple security device which served as an example for StatVerif [3]: the device is initialized once, either to left or right. Later on, it accepts pairs of encryptions and decrypts either the left component of the pair or the right component, but not both. As the input language of StatVerif is very similar to ours their model could be easily adapted to our tool. In fact, we were able to remove the restriction to a single security device. Finally, we also illustrate the tool’s ability to analyze classical security protocols by analyzing the Needham Schroeder Lowe protocol [25].
Heuristics
In order to improve our results on the case studies presented in the conference version [21], we have altered the heuristics of the tamarin-prover. We make use of the a priori knowledge that the msr system is an output of our translation. These heuristics can be switched on using the command line switch
The main goal is to avoid a loop in the resolution procedure, so our approach is conservative in that we only prioritize goals that do not cause other prioritized goals to appear, unless the protocol has been annotated to do that. The heuristic alters tamarin’s standard “smart” heuristic in the following way:
Proof effort
A comparison between the effort needed to derive a proof for a protocol in our calculus and a protocol modelled via multiset rewrite rules is only sound when both model the same thing. Whenever the direct encoding is simplified, e.g., in the Yubikey model, the proof is obviously simpler, but on the other hand, as we have already discussed in Section 7.2, it may be oversimplified. Whenever models were relatively close, our experiments suggested that the same kind of lemmas are needed. In particular for the GJM contract signing protocol, the simple security device and the Needham–Schroeder–Lowe protocol, the lemmas were literally the same. This suggests that these helping lemmas prove properties beyond the level of representation, i.e., properties of the protocol itself.
Our dedicated heuristics discussed in the previous section also improve termination. One may note that tamarin also includes several heuristics that can be chosen from and combined in several ways to help termination. Some of the case studies, e.g., the group protocols analysed in [32], also required the development of dedicated heuristics. Our heuristics benefit from the fact that the msr rules are generated and, therefore, are more restricted than the arbitrary msr rules that may be given to tamarin using a direct msr rule modelling.
When these heuristics fail, or the user wishes to inspect the proof, tamarin’s interactive mode allow manual inspection and selection of the proof goals that are chosen at each step. To make use of this, in addition to the working of the tamarin interactive mode, a basic understanding of our translation (but not of the correctness proof) is necessary. A tight integration of SAPIC into tamarin would surely aid in this regard, but requires significant engineering effort. Such an integration could additionally provide information given by the process description. Relations between locks, lookup and inserts could be highlighted and protocol roles (often defined as abbreviations by protocol designers) distinguished.
For protocols which have complicated control flow or structure (e.g. group protocols [32]), a direct encoding may actually be better suited. We provide a mechanism for embedding labelled msr rules directly inside processes (described in the conference version [21]), which may useful is some circumstances, and such a mixed model might sometimes give the user “the best of the two approaches”.
Conclusion
We present a process calculus which extends the applied pi calculus with constructs for accessing a global, shared memory together with an encoding of this calculus in labelled msr rules which enables automated verification using the tamarin prover as a backend. Our prototype verification tool, automating this translation, has been successfully used to analyze several case studies. As future work we plan to increase the degree of automation of the tool by automatically generating helping lemmas. To achieve this goal we can exploit the fact that we generate the msr rules, and hence control their form. We also plan to use the tool for more complex case studies, specifically contract signing protocols.
Footnotes
Acknowledgments
This work has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement No 645865-SPOOC), and from the German Federal Ministry of Education and Research (BMBF) within EC SPRIDE.