
Abstract
Web applications written in JavaScript are regularly used for dealing with sensitive or personal data. Consequently, reasoning about their security properties has become an important problem, which is made very difficult by the highly dynamic nature of the language, particularly its support for runtime code generation via eval. In order to deal with this, we propose to investigate security analyses for languages with more principled forms of dynamic code generation.
To this end, we present a static information flow analysis for a dynamically typed functional language with prototype-based inheritance and staged metaprogramming. We prove its soundness, implement it and test it on various examples designed to show its relevance to proving security properties, such as noninterference, in JavaScript. To demonstrate the applicability of the analysis, we also present a general method for transforming a program using eval into one using staged metaprogramming.
To our knowledge, this is the first fully static information flow analysis for a language with staged metaprogramming, and the first formal soundness proof of a CFA-based information flow analysis for a functional programming language.
Introduction
An information flow analysis determines which values in a program can influence which parts of the result of the program. Using an information flow analysis, we can, for instance, prove that program inputs that are deemed high security do not influence low security outputs; this important security property is known as noninterference [15].
Early work on noninterference focused mainly on applications in a military or government setting, where there might be strict rules about security clearance and classification of documents. More recently, there has been increased interest in information security (and hence its analysis) for Web applications, particularly for Web 2.0 applications written in JavaScript. Analysis of JavaScript programs is hindered by its many dynamic features, in particular
We have developed a static information flow analysis for a dynamically typed, pure, functional language with stage-based metaprogramming [26]; we call the language SLamJS (Staged Lambda JS) because it exhibits a number of JavaScript’s interesting features in an idealised, lambda calculus-based setting [18]. The analysis is based on the idea of extending a constraint-based formulation of the analysis 0CFA [47] with constraints to track information flow. We believe that the idea could be extended to other CFA-style analyses (such as CFA2 [50]) for improved precision. We have formally proved the correctness of our analysis; we have also implemented it and tested it on a number of examples. Finally, in order to demonstrate the applicability of the analysis to programs using string-based
Our work stems from the observation that, while programmers may pass arbitrary strings to
Next, we seek a way to transform
Supporting material, which includes mechanisations of our key results in the theorem prover Coq and an implementation of our analysis in OCaml, is available online [30]. The presentation of the analysis in this paper extends that in CSF 2013 [28]. The details of the transformation are novel, but we outlined its key ideas in previous work [29].
The structure of the remainder of the paper is as follows. In Section 2, we present SLamJS: we begin with an explanation of why we believe our chosen combination of language features is relevant to information security in Web applications. Next, we present the semantics of SLamJS and explain, using an augmented semantics, what information flow means in this language. Section 3 explains how the analysis works and how we proved its correctness. We discuss our implementation and some examples on which we have tested the analysis in Section 4. Then, in Section 5, we describe how to apply the analysis to
The language SLamJS
Motivation
The new arena of Web applications presents many interesting challenges for information flow analysis. While there is an extensive body of research on information flow in statically typed languages [40], there is comparatively little tackling dynamically typed languages. The semantics of JavaScript are complex and poorly understood [33], which makes any formal analysis difficult. Web applications frequently comprise code from multiple sources (including libraries and adverts), written by multiple authors in an ad-hoc style. They are often interactive (so cannot be viewed as a single execution with inputs and outputs) and it might not be known in advance which code will be loaded.
The
We have developed a simplified language called SLamJS, which we use to present our ideas. This allows us to work reasonably formally without being distracted by the complexities of full JavaScript. The language is heavily influenced by
Staged metaprogramming versus eval
The
In JavaScript, as in most languages, strings can be joined together using concatenation. Thus, if a string encodes a piece of program code, string concatenation can be used to splice together code templates. Consider, for example:
This program constructs the code template
For several years, authors of static analyses for JavaScript argued that they could ignore it because it was rarely used or used only in trivial ways [16]. Their real reason was probably that analysis of such a powerful construct seemed utterly hopeless, particularly when considering the language’s lack of protection mechanisms, as it allows arbitrary behaviours to result from an unstructured data value.
In contrast, the language Lisp allows programs to construct code templates as data values, splice them together and run the resulting code. We refer to these features collectively as staged metaprogramming. Following Kim et al. [26], we can add these features to a programming language with three constructs:
The values in a program using these constructs and the steps in its execution can be stratified into numbered stages. Programs that do not use these constructs execute entirely at stage 0. The contents of a
The constructs
Our goal is to produce an information flow analysis for a JavaScript-like language extended with these constructs, then show how to transform an example like the former into the latter, so that we may apply our analysis to the former.
Roughly speaking,
Syntax and semantics of SLamJS
Syntax

Syntax of SLamJS.
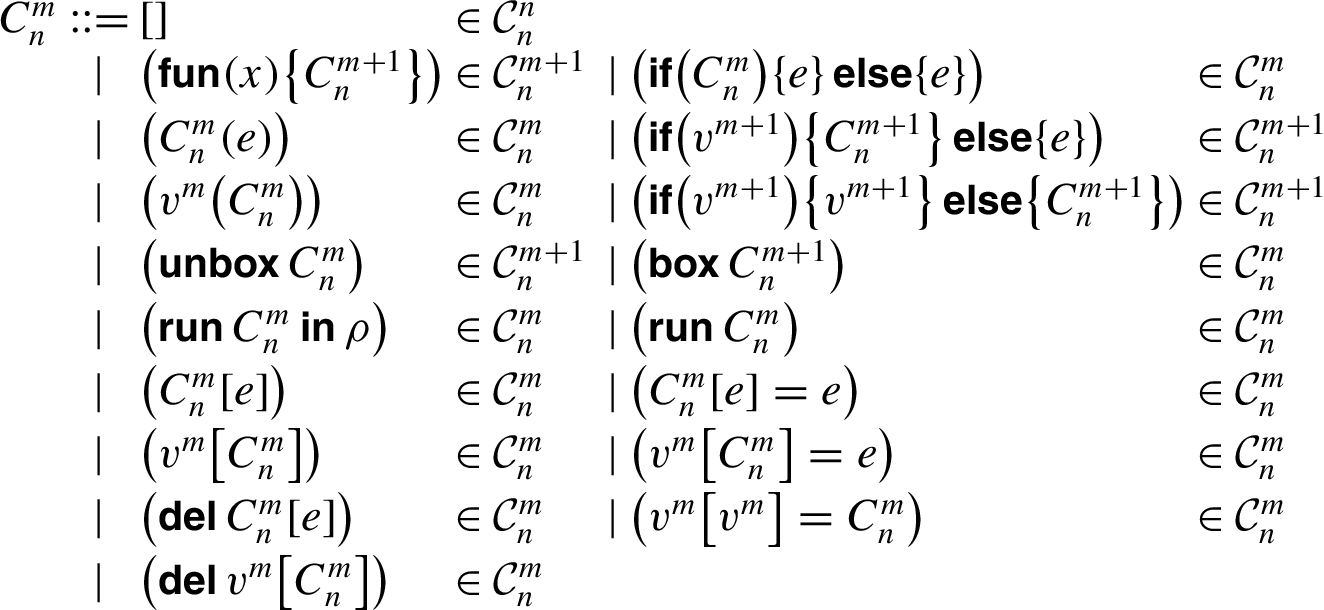
Evaluation contexts.
SLamJS is a functional language with atomic constants, records, branching, first-class functions and staged metaprogramming; the syntax is given in Fig. 1.
The language has five types of atomic constant: booleans, strings, numbers and two special values (
Branching on boolean values is enabled by the
Staged metaprogramming is supported through use of the
Expressions of the form
Values exist at all stages. Constants, records with constant fields and constant code quotations are values
We give a small-step operational semantics with evaluation contexts and explicit substitutions for SLamJS. There are two reduction relations,
Evaluation contexts In a staged setting, evaluation contexts may straddle stage boundaries, hence they are annotated with stage subscripts and superscripts. A context
Reduction rules Top-level reduction rules fall into two categories: environment propagation rules for pushing explicit substitutions inwards (Fig. 3), and proper reduction rules (Fig. 4). Almost all the proper reductions occur only at stage 0. The exception is
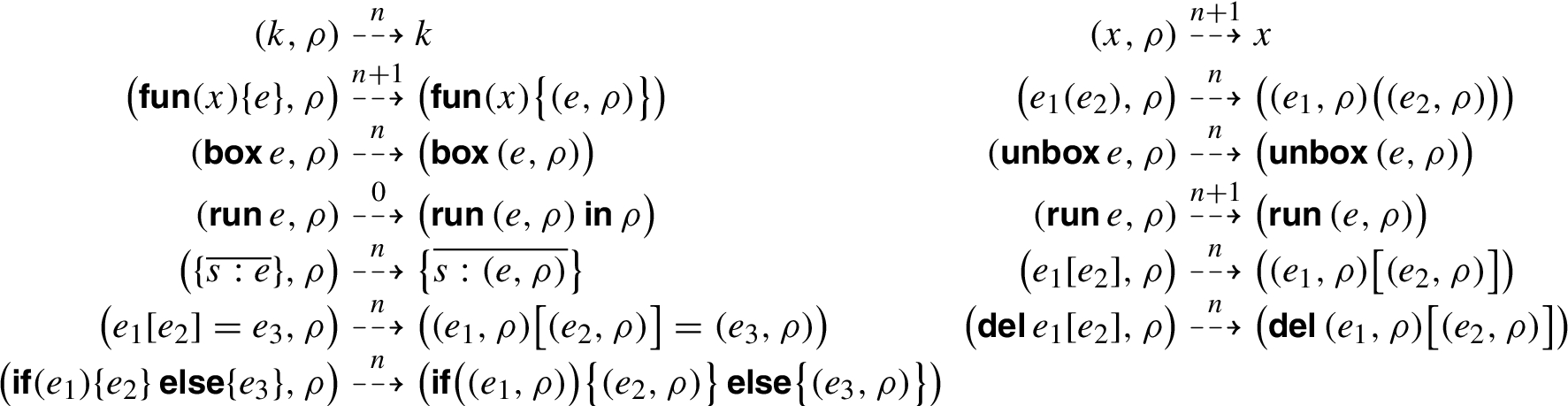
Environment propagation rules.
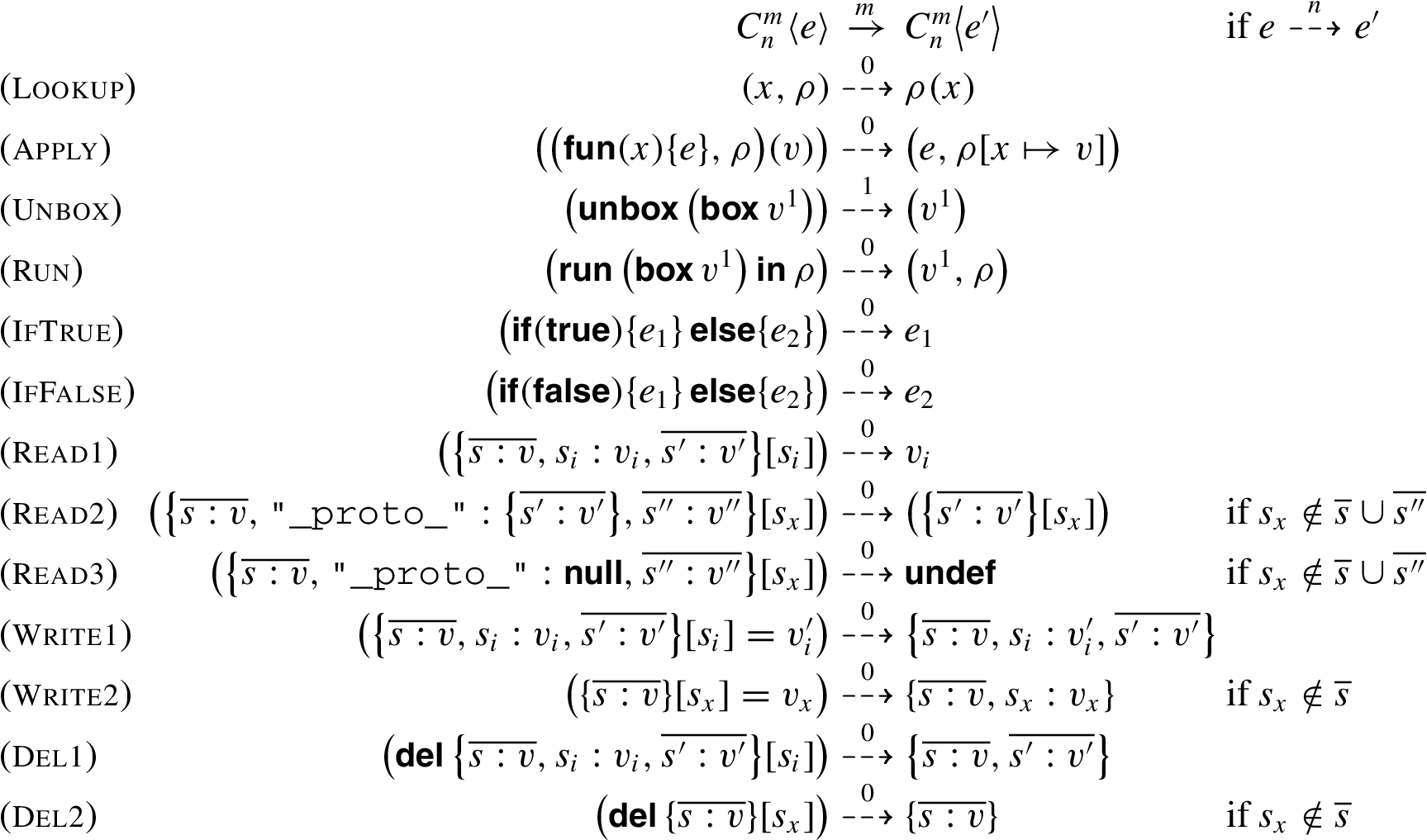
Evaluation under a context and proper reduction rules.
The environment propagation reductions control variable scoping within the language. Note that explicit substitutions only apply at stage 0, hence
The proper reduction rules are also quite standard [7], except for the field access rules, which are designed to be similar to JavaScript semantics.
In particular, every record is expected to have a
There is only a single rule for
Here is an evaluation trace of a simple
The staging constructs in SLamJS allow fragments of code to be treated as values and spliced together or evaluated at run-time, as shown in this evaluation trace.
Our staging constructs allow variables to be captured by code values originating outside their scope. Here, the code value
However, the power comes at a price: the usual alpha equivalence property of λ-calculus does not hold in SLamJS [26], which makes reasoning about programs harder.
The result of a program can depend on its component values in essentially two different ways. Consider programs operating on two variables l and h. The program
In order to track the dependency of a result on its component subexpressions, we augment the language with explicit dependency markers [1,39]. We also introduce new rules for lifting markers into their parent expressions to avoid losing information about dependencies. As an expression is executed according to the augmented semantics, these markers accumulate around the result, recording its dependencies. However, the augmented semantics is not intended for use in the execution of programs; rather, we use it for analysing and reasoning about dependencies in the original language. We begin by adding markers to the syntax:

Semantic rules for lifts.
In Fig. 5 we introduce lifts to maintain a record of indirect flows. Lifts are not needed to record direct flows, as markers are part of values, so the markers will move wherever the values do. For example, in a record assignment
Recall Example 1. Suppose we add markers to each of the components of the
Here is an example of marked evaluation with functions:
Simulation
Consider a function
The marked semantics introduces some nondeterminism, but only in the order of application of lift rules for records, where if both a record and its field selector are marked, then a lift rule may be applied on either first. However, this only affects the order in which markers accumulate around an expression during evaluation, not the identity of the markers or the value of the result.
Overview
Before we can define an information flow analysis, we need to define what information flow is. Following Pottier and Conchon [39], we use the idea that if information does not flow from a marked expression into a value resulting from evaluation, then erasing that marked expression or replacing it with a dummy value should not affect the result of evaluation. (We use only their proof technique; their type-based analysis is not applicable to our language.) We begin in Section 3.2 by defining erasure and establishing some results about its behaviour.
Our information flow analysis is built on top of a 0CFA-style analysis capable of handling our staging constructs. Two variants of such an analysis are explained in Section 3.3; mechanised correctness proofs in Coq are available online [30].
In Section 3.4, we present the information flow analysis itself. A key idea in CFA is that control flow influences data flow and vice versa. Information flow depends on control and data flow, but the reverse is not true. Therefore it is possible to treat information flow analysis as an addition to CFA, rather than a completely new combined analysis. We have two versions of the CFA, each of which yields an information flow analysis. We sketch a correctness proof of the simpler analysis; complete mechanised proofs of both are available online [30].
Finally, in Section 3.5, we prove soundness of the information flow analysis. We also discuss its relationship with termination-insensitive noninterference.
Erasure and stability
Erasure and prefixes
We extend the language with a “hole” that behaves like an unbound variable:
Now for
Prefixing and monotonicity
We say that
Evaluation is monotonic with respect to prefixing: if
If
By induction over the rules defining
Consider an expression
Consider any Base case: Inductive step: If it is such a lift, then let Otherwise, apply the Step Stability Lemma to get Recall that in Example 5, the result depended on (Step Stability).
We use a context-insensitive, flow-insensitive control flow analysis (0CFA [47]) to approximate statically the set of values to which individual expressions in a program may evaluate at runtime. As far as 0CFA is concerned, the only non-standard feature of SLamJS is its staging constructs. We present two variants of 0CFA for SLamJS: a simple, but somewhat imprecise formulation that does not distinguish like-named variables bound by different abstractions, and a more complicated one that does.
Simple analysis
Following Nielson, Nielson and Hankin [36], we formalise our analysis by means of an acceptability judgement of the form
More precisely, we assume that all expressions in the program are labelled with labels drawn from a set

Some details of the simple analysis.
Our domain of abstract values (Fig. 6, top) is mostly standard, with, e.g., an abstract value
The acceptability judgement is now defined using syntax-directed rules, some of which are shown in Fig. 6 (middle). The remaining rules, which are standard, are given in Appendix B.
We write
The rule for
The rule for
Finally, we show the rule for
To show this acceptability judgement makes sense, we prove its coherence with evaluation:
If
The proof of this theorem is fairly technical and is elided here. A full formalisation in Coq is available online in our supporting material [30]. As an overview, the first step is to prove that if
Owing to its syntax-directed nature, the definition of the acceptability relation can quite easily be recast as constraint rules; by generating and solving all constraints for a given program, an acceptable flow analysis can be derived.
Note that, while there may be infinitely many abstract values of the form
Recall again Example 5. Our implementation of the analysis labels the expression as follows:

Some details of the improved analysis.
The analysis presented so far is not very precise, since abstract environments do not distinguish identically named parameters of different functions. Ordinarily, this is not a problem, as one can rename them apart, but this is not possible for SLamJS, which does not enjoy alpha conversion.
To restore analysis precision in the absence of alpha conversion, we introduce an abstract context Ξ that keeps track of name bindings (Fig. 7, top) and various operations on it (Fig. 7, middle). In a single-staged language, such an abstract context would simply map a name x to the innermost enclosing function abstraction whose parameter is x. In a multi-staged setting, we need to distinguish between bindings at different stages, hence the abstract context maintains one such mapping per stage. Thus Ξ is a stack of abstract frames Λ, one for each stage; a frame maps each variable name to the label of its binding context.
For instance, the two uses of x in the SLamJS expression
The height of an abstract context is the level of its topmost abstract frame; that is, one less than the total number of frames in the context.
Having enhanced the analysis by recording where variables are bound, we can use this information to improve the precision of our abstract environment ϱ, which is now a binary function. For a label ℓ labelling the body of a function abstraction with parameter x,
The acceptability judgement for the improved analysis is now of the form
If
Once again, a full formalisation in Coq is available in the online supporting material.
Consider the following expression, in which the variable x is bound twice:
Assume we have already analysed a program using 0CFA and found environments
By recursing over the structure of an expression, we generate constraints on a relation ↝:
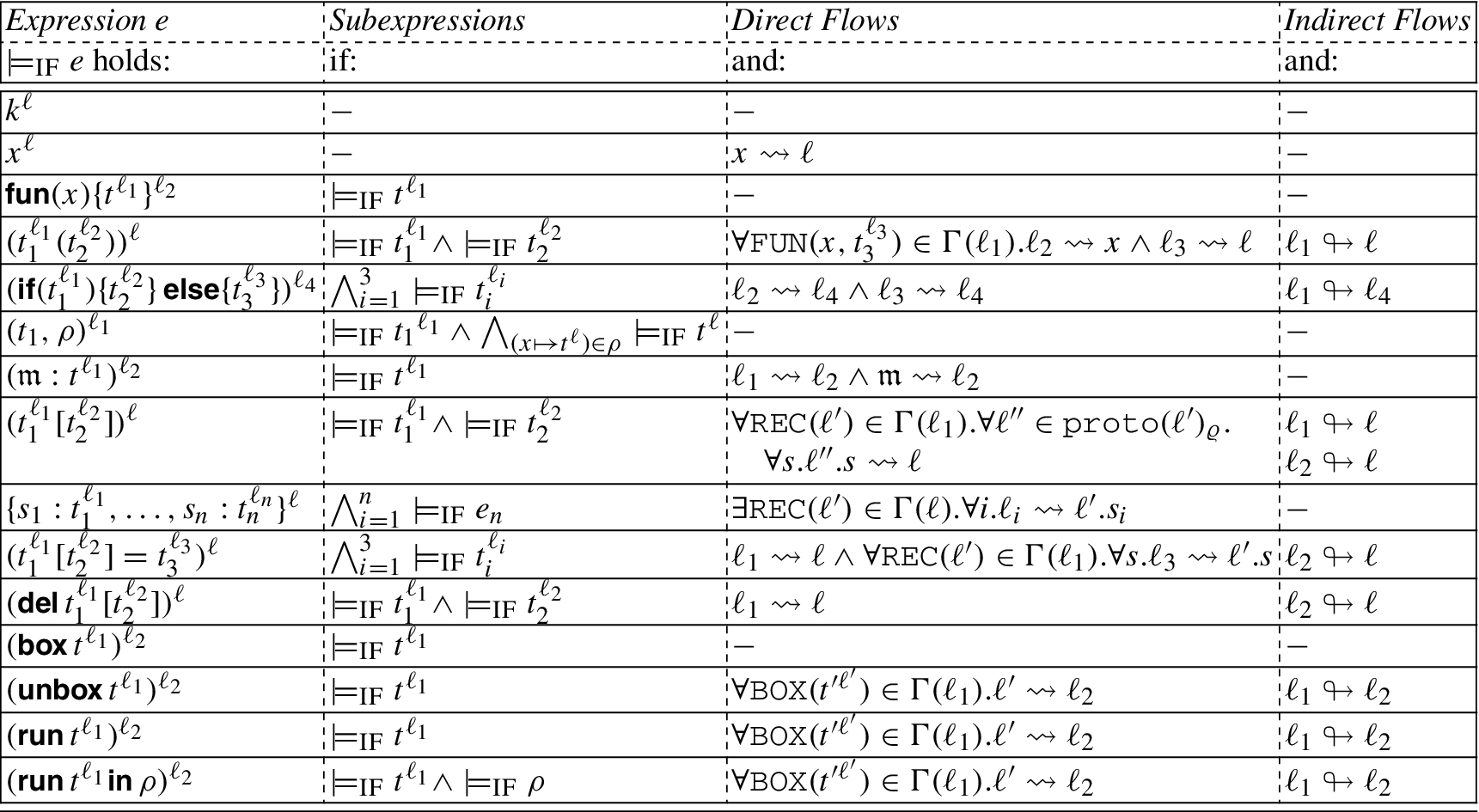
Rules for the judgment
The constraints on ↝ between labels, variable names and markers are split into direct flows (written
We say that
We now prove the coherence of our information flow analysis with evaluation. Like the corresponding proof for our 0CFA, this is lengthy and technical, so we only sketch it here. A mechanisation of the proof is available online [30].
If we have
By case analysis on the rules defining
If we have
Sketch: Unfolding the definition of
Observe that
The claim that
Note that, while the 0CFA and information flow analysis phases are conceptually distinct, correctness of the latter depends on correctness of the former. Therefore, for the sake of simplicity, our mechanisation of the proof concerns a combined formulation of the analyses in which both phases are performed simultaneously.
Recall once more Example 5. Using the results of 0CFA, our implementation generates the relations ⇝ and ↬ as depicted in Fig. 9.
Setting
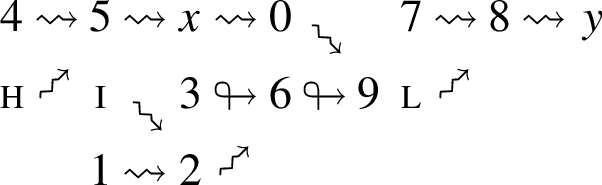
Information flow constraints for Example 5.
The information flow relation ↝ expresses which flows might occur (locally) during a single step of execution of an expression. We now show how this relates to the flows that might occur (globally) over a sequence of execution steps that terminates in a value.
Suppose
(We argue using the judgment for the simple analysis, but the same argument holds for the improved analysis.) First show that Base case: Inductive step: Assume that Now we have But v is a value composed only of markers and constants, so for every marker (Information Flow Soundness).
Relationship with noninterference
Our information flow analysis can be used to verify the classical security property termination-insensitive noninterference. Noninterference asserts that the values of any “high-security” inputs must not affect the values of any “low-security” outputs. In order for this assertion to be meaningful, we must have notions of input, output and high- and low-security levels.
For example, assume elements of
Say that expression
By the condition on
The conditions on
Note that, as our information flow relation ↝ expresses all local information flows within a program, its applications need not be restricted to transitive noninterference. It could also be used to reason about intransitive noninterference policies [42,49], in which some flows from
We have implemented our analysis in OCaml and tested it on a range of examples. The most expensive part of the analysis computationally is 0CFA, which runs in time
For each example, we list the markers on which our simple analysis says the result may depend. Where the improved analysis gives a more precise result, we list that too. To improve readability, we write
Depends on:
Depends on:
Depends on:
f and g are bound to functions; x is set to a code value of either f or g; a function argument is added to the code value and the result executed. In this example, both f and g ignore their argument
Depends on:
Depends on:
Depends on:
which may arise when using
Depends on:
Depends on:
Depends on:
Depends on:
Depends on:

Control flow in the Boxing Algorithm.
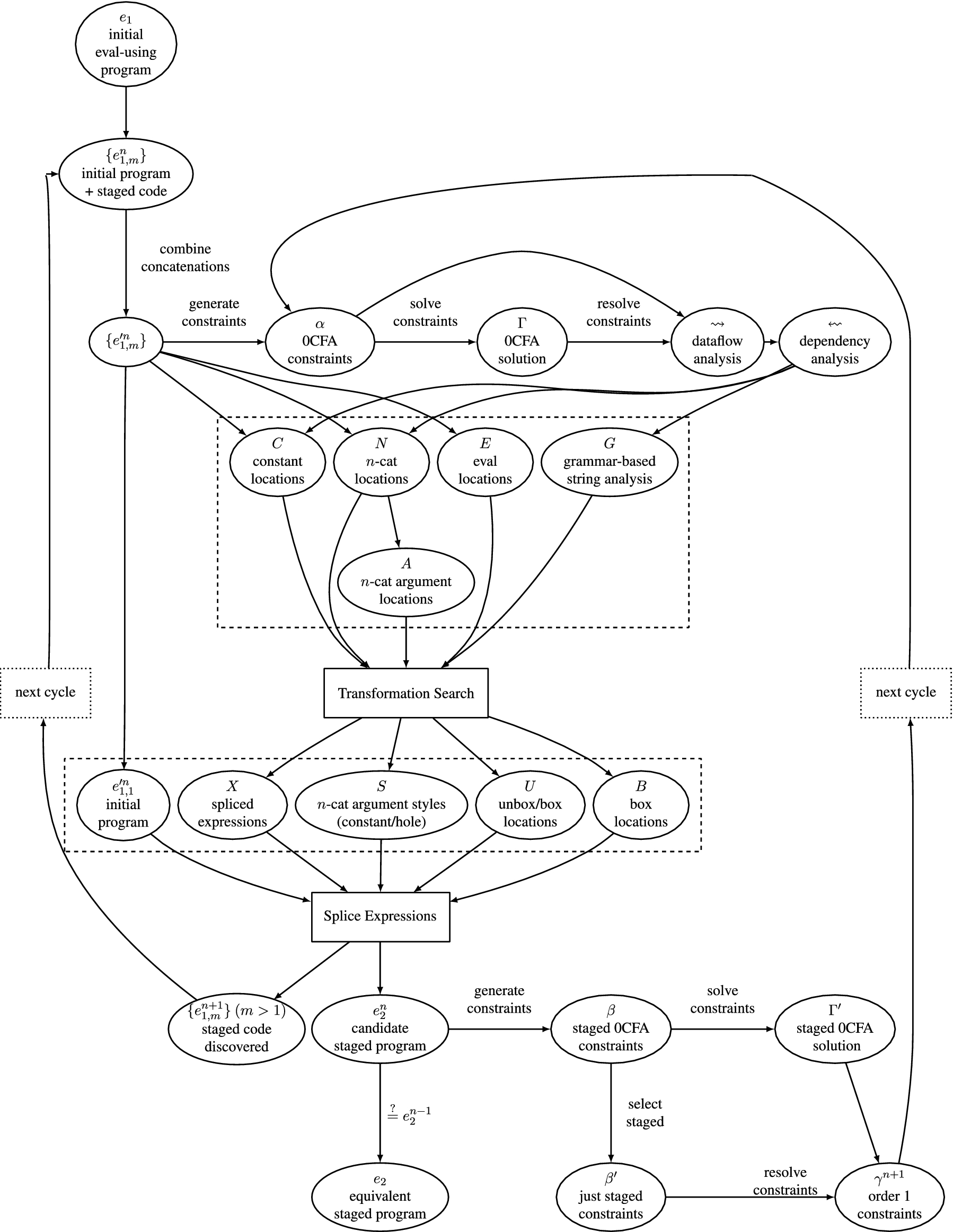
Data flow in the Boxing Algorithm.
Overview
In order to demonstrate the applicability of the information flow analysis, we now describe the Boxing Algorithm, an algorithm for transforming a program that uses string-based
Given a program
The transformation is based on the assumption that an
Key ideas
Prerequisites
The basic idea is that the algorithm will transform:
code constants into concatenation of code strings into splicing using we need a sound dataflow analysis for the target language, including metaprogramming constructs; we need a string analysis for the target language that will produce a sound over-approximation of the string values that may occur at different program points or be bound to different variables; the language must be parseable using
We have already seen how to apply 0CFA to SLamJS, so we reuse that analysis to satisfy condition (1). As 0CFA over-approximates the flow control of a program with a regular graph, it is easy to extract a grammar-based string analysis from the results; that satisfies condition (2), although there are many techniques that could improve upon this [6]. The lexer and parser for SLamJS are implemented using OCamlLex and OCamlYacc, which satisfies condition (3). (INRIA’s Prosecco has produced such an unambiguous grammar for JavaScript, so it meets the criteria for our algorithm to be applied.)
Building a sequence of program approximations
In most static analyses, the goal is to construct an over-approximation of the behaviours of a program. In contrast, the goal of the Boxing Algorithm is to produce a staged program that exactly captures the behaviours of the original
In particular, any information supplied by the analysis about the program’s behaviour prior to the first execution of
We cannot simply analyse individual code strings, as there may be infinitely many possible such strings arising over all executions of the program. Fortunately, the staged metaprogramming analysis allows us to analyse the behaviour of possibly infinite sets of code values built using staged metaprogramming.
The approximation produced in the nth cycle of the fixed point process, if run, would behave the same as the original program up to the nth execution of
Parsing expressions out-of-order
The Boxing Algorithm relies on using the existing parser for a language for part of the transformation; this makes the technique easily applicable to other languages. Typically, languages are parsed in two phases. The first phase, lexical analysis, splits the program text into a sequence of lexemes and transforms these into a sequence of tokens; the tool
Normally, the lexer processes the characters in the program text in order from beginning to end. Similarly, the parser processes the token sequence in order from left to right (hence the second L in LALR). The Boxing Algorithm abuses these tools to process
Parsing. In order to build an approximate analysis of an
For example, consider a language (unlike SLamJS) with conventional arithmetic expressions. Using the usual precedence of arithmetic operators, the expression
The problem arises because without the rules of precedence, the grammar of expressions in the language is ambiguous. The proposed transformation corresponds to one possible parsing of
If the language we wish to analyse is parseable using a deterministic context free grammar, we can parse fragments of program code out-of-order without changing the resulting expression. Hence we can safely transform a sequence of concatenations into the splicing of an expression into a template.
This is not an onerous requirement as, while
Disambiguation in grammar specifications is often achieved by adding extra syntactic classes of expression. In the case of arithmetic expressions, there might be a class that represents only bracketed expressions or those free from addition, with multiplication only being permitted between expressions in this class. The example above might not be transformable in this case, as while x and y should clearly encode valid expressions, it is no longer permissible to multiply arbitrary expressions. In this case, replacing the final concatenation with
We can easily modify the
Consider again the second example at the start of Section 5.2.1. Having added
Lexing. A further complication in parsing expressions out-of-order is that concatenation of code strings may change the boundaries and types of tokens produced during their lexical analysis.
This is unlikely to cause problems in SLamJS because the grammar is quite restrictive, but suppose we allowed function application to be written as juxtaposition of expressions without brackets, as in a typical functional language, and consider the following:
The problem in this case is that the use of the hole has changed the lexeme boundaries within the string and hence its tokenisation. Conceptually, we can view the lexer as a deterministic finite state transducer T that reads the string and emits tokens on lexeme boundaries. In order to avoid changing the tokenisation of code strings, we need to check that, whenever code strings x and y are concatenated, it is true that
This hides some details of the problem, as in practice tokens that are identical in the automaton model often carry some data that distinguishes them (as with
Our solution is to look at the finite state transducer produced by the lexer generator in combination with the string analysis. Whenever we wish to treat a concatenation argument as a hole, we compute (an over-approximation to): the final states of the lexer having processed the last character of the hole string; and all possible first characters of the following argument. We then require that, for each possible final state: either it is one that emits a token (and hence the following character is irrelevant in how the hole string is lexed); or, for all possible following characters, the lexer immediately emits the same token. That is, each final state must correspond to a lexeme boundary. If the check fails, then the argument may not safely be treated as a hole.
Constraint solution and resolution
Recall that the staged metaprogramming analysis for SLamJS is formulated as a system of constraints. The constraints describe the abstract values that may arise when evaluating a particular subexpression of a program. Solution of the constraints yields a function Γ such that
The majority of constraints are “order 0” constraints of the form
It is possible (although not most efficient [37]) to find the smallest solution to these constraints iteratively using a fixed point computation: initialise each
Note that, for a fixed Γ, an order 2 constraint can be expressed as a set of order 1 constraints and an order 1 constraint can be expressed as a set of order 0 constraints. Obviously, when solving the constraints iteratively, Γ is not fixed, but this observation that higher order constraints can be resolved to lower order ones becomes important when considering how to use staged constraints in an
Combining concatenations
The main premise of the Boxing Algorithm is that the syntactic structure of concatenation in reasonable
The solution is to replace syntactically adjacent instances of binary concatenation in an expression with a single n-ary concatenation (or n-cat). This will not change the behaviour of the program in SLamJS, as concatenation is associative, although in other languages (such as full JavaScript) there may be subtleties arising from implicit string conversion or other peculiarities.
Cycle description
Let us now consider the steps in a single cycle of the fixed point process that produces a transformation. Each cycle operates on the original program (plus, in later cycles, fragments of staged code and associated constraints).
We begin by combining adjacent concatenations in the original program to get
We also use the dataflow graph to produce a naive, grammar-based string analysis G. Essentially, we associate a non-terminal with every program point and introduce a production for every edge in the dependency graph. For string constant expressions, we add a production to the corresponding constants; concatenation operations are translated directly into concatenation in the grammar. This approach is outlined and developed further by Christensen et al. [8], considering in particular how to produce a reasonably precise but regular over-approximation to the strings generated at a program point in the presence of loops in the graph. But for the purposes of this transformation, we need only to determine whether a program point ℓ yields a constant string (and if so, what it is).
We are now able to determine which program points are candidates for transformation:
E – all occurrences of C – all constant strings on which an argument of an N – all n-cats on which the argument of an A – all arguments to n-cats in N.
E is determined syntactically from
For every path from an
A code concatenation expression will consist of several subexpressions joined together. For each of these subexpressions, we must choose whether to treat it as a constant (which is obviously only possible if the subexpression is indeed constant, as determined by G), or to treat it as a hole. If we treat it as a constant, it becomes part of the code template, which we parse to produce the
Hence the process of choosing what and how to transform can be viewed as a depth-first search rooted at the occurrences of
B – a set of program points where we may transform string constants into
U – a set of program points where we may transform string concatenations into
A more formal description on the conditions that B, U, X and S must satisfy is given in Fig. 12. (In addition, every template must satisfy the lexing check described in Section 5.2.3.) As the conditions are described in a syntax-directed way, it is usually fairly straightforward to find values that satisfy the requirements using a search algorithm, if they exist. Some worked examples are given in Appendix D.

Conditions on B, U, X and S in a cycle of the Boxing Algorithm.
It is possible that we are unable to find B, U, X and S satisfying these conditions, in which case the analysis fails. Otherwise, we transform
In order to make explicit the relationship between the original and transformed subexpressions, we must maintain the labels on the program points. That is, the label on a subexpression being spliced in must match the label on the subexpression it replaces. For example, in transforming
We can now analyse our approximation
What we would like to do is augment the constraints generated in the analysis of
However, observing that the staged constraints are order 2 constraints, after solving β in our analysis
As the staged constraints generated in cycle n express the interaction between the unstaged parts of
So when we repeat the transformation cycle, we consider not just the original program
We repeat the process until (hopefully) we reach a fixed point; that is, until the transformed expression is identical in two consecutive cycles. The rationale is that in cycle n, the transformed expression accurately models the behaviour of
It is not clear that the fixed point computation will terminate. In the case of 0CFA on a purely staged program, termination is guaranteed because we need only consider finitely many program points and finitely many abstract code values (representative of infinitely many possible constructed code values). However, both of these conditions are violated when we introduce new transformed code. That said, it seems unlikely that this would ever occur; it is more likely that the increasing density of constraints in the original program would lead to a cycle where no transformation was possible, so the algorithm would fail.
It seems unlikely that a useful, realistic program will feature a pathological sequence of extracted constant code values, although it may be possible to construct one in a similar style to a Quine (self-replicating program) [21]. For example, if a program constructs and
If possible non-termination is an issue, the algorithm can simply be set to terminate after a fixed number of cycles. In fact, in the vast majority of examples, where the first cycle of analysis of
Soundness
We now sketch a proof of the soundness of the transformation produced by the Boxing Algorithm. It would be desirable to give a detailed proof of the correctness of the algorithm, perhaps even going as far as the mechanised proof of the information flow analysis in the previous section. However, as discussed earlier, the algorithm tackles an unusually broad range of concerns. Correspondingly, a more formal and detailed proof would need to invoke many results about the behaviours of the dataflow analysis, the string analysis and lexical analysis and parsing. Furthermore, a significant amount of technical machinery would have to be introduced to track the interaction between these concerns. In particular, it would require: a reformulation of the semantics of SLamJS in terms of a graph model (rather than the current term tree model) in order to track the correspondence between the initial expression and its staged approximations; and a modified proof of the information flow analysis to take account of the meaning of the resolved staged constraints and the staged code fragments. This would be a significant undertaking, but would be unlikely to aid significantly in the understanding of the algorithm or the clarity of its exposition, so we leave it for future work.
The transformation is developed through a sequence of approximations. So in order to argue about the correctness of the final result, we must argue about the correctness of the intermediate steps.
The input to the algorithm is an expression
In cycle n of the Boxing Algorithm:
the candidate
the fragments of staged code
the constraints
See Appendix C. □
Consider a program
If the algorithm terminates, then (Boxing Cycle Soundness).
We now consider some example programs on which our implementation of the transformation works and some on which it does not. As we are not immediately concerned with information flow analysis, but rather on turning
This example illustrates the basic concept that we turn constant strings (in this case, representing the numbers 0 and 1) into
Although this is a seemingly reasonably program, in this case, the transformation fails because the concatenation does not match the syntactic structure of the language. As
Where possible, the transformation prefers to use
Note how, as
A similar concern applies if we wish to extend the transformation to handle a language with side effects, especially as they may affect which code strings are constructed. Suppose our original program contains an expression e that yields a code string s, but also has some side effects, such as incrementing a mutable variable used as a loop counter elsewhere in the source program. If we wish to transform e to a code value
All of the examples so far reach a fixed point in a single cycle of the algorithm, although a second cycle is required in order to check that a fixed point has been reached. This program requires two cycles to reach a fixed point: the first finds that the string in y is a code string for
This is a functional implementation of a motivating example of Choi et al. [7]. It builds the arithmetic expression
The staged power function is a staple of literature on metaprogramming [3]. Given a number (in this case 5), it generates code for a function that takes an argument and raises it to that power. This can be useful in performance-critical situations, as it avoids the overhead of using a loop. While it is unlikely that anyone would use JavaScript in such a situation, the ubiquity of the example demands that we should be able to handle it.
Note that, in general, any program that only uses constant code strings (with no concatenation or any attempts to perform intensional operations) and does not feature nested uses of
From SLamJS to JavaScript applications
The application that guided our work is information flow analysis for JavaScript in Web applications. We now consider some of the features of this scenario that we have not addressed and how they have been handled by others. We claim that most of the problems have been addressed, although combining them into a single analysis system would require further effort.
Handling of Primitive Datatypes As demonstrated in some of our examples, our analysis models its primitive datatypes (such as strings and booleans) very coarsely; our abstract domains are too simple. Fortunately, more refined abstractions for these datatypes have been well-studied [6].
Precision of 0CFA JavaScript has several features not found in SLamJS, including typical imperative control flow features (such as
Associative Arrays as Objects One of the most challenging features of JavaScript from a static analysis perspective is its objects, which are really associative arrays. (In other scripting languages these are called hashes or dicts.) In particular, as any string can be used as a field name, it is difficult to determine whether two distinct reads or writes might refer to the same field. Our analysis is deliberately coarse in its handling of objects, so that we can focus on
JavaScript Semantics A bigger problem in producing a sound analysis of JavaScript is the complexity and quaintness of its semantics [33]. Guha et al. attempt to simplify this problem by producing a much simpler “core calculus” for JavaScript called
Code Strings vs Staged Code Perhaps the most relevant difference between JavaScript and SLamJS is our metaprogramming constructs: JavaScript
Reactive Systems A practical Web application is not simply a program that takes inputs, runs once, then gives output: it may interleave input and output throughout its execution, which might not terminate. Bohannon et al. consider the consequences of this for information security in their work on reactive noninterference [4].
Infrastructural Issues In applying an information flow analysis to a Web application, several infrastructural issues need to be addressed. Would the code be analysed before being published by on a webserver, in the browser running it or by some proxy in between? Will the entire code be available in advance, or must it be analysed in fragments [9]? Who would set the security policies that the analysis should enforce? Li and Zdancewic argue that noninterference alone is too strict a policy to enforce and that a practical policy must allow for limited declassification [31].
Information flow analysis
Early work on information flow security focused on monitoring program execution, dynamically marking variables to indicate their level of confidentiality [13]. However, the study of static analysis for information flow security can essentially be traced back to Denning, who introduced a lattice model for secure information flow and critically considered both direct and indirect flows [10]. Denning and Denning developed a simple static information flow analysis that rejected programs with flows violating a security policy [11].
Noninterference Goguen and Meseguer introduced the idea of noninterference [15] (the inability of the actions of one party, or equivalently data at one level, to influence those of another) as a way of specifying security policies, including enforcement of information flow security. Noninterference and information flow security became almost synonymous, although Pottier and Conchon were careful to emphasise the distinction between the two [39].
Security Type Systems Security type systems became a common way of enforcing noninterference policies and proving the correctness of noninterference analyses, progressing from a reformulation of Denning and Denning’s analysis [51] to Simonet and Pottier’s type system for ML [40]. Unfortunately, the requirement that the program analysed follow a strict type discipline makes it impractical to apply these ideas to dynamically typed languages such as JavaScript. Perhaps as a consequence, information flow in untyped and dynamically typed languages is relatively poorly understood.
Dynamic Analyses Dynamic information flow analysis circumvents the need for a type system or other static analysis by tracking information flow during program execution, and enforcing security policies by aborting program execution if an undesired flow is detected; examples of such analyses for JavaScript are presented by Just et al. [25] and Hedin and Sabelfeld [19]. Indeed, the problems they address and their motivations are very similar to ours, but our methods are very different.
Dynamic vs Static A dynamic analysis only observes one program run at a time, so dynamic code generation is easy to handle. However, care has to be taken to track indirect information flow due to code that was not executed in the observed run. Strategies to achieve this include, for instance, the no-sensitive upgrade check [52], which aborts execution if a public variable is assigned in code that is control dependent on private data. As a rule, however, such strategies are fairly coarse and could potentially abort many innocuous executions; thus it is commonly held that static analyses are superior to dynamic ones in their treatment of indirect flows [44]. Note that this is in contrast to analysis of safety properties, where static analyses may generate “false positives” because they need to approximate flow control and other complex behaviours within a program.
Nonetheless, there has been a resurgence of interest in dynamic analyses [45]. From a practical perspective, dynamic analyses are usually significantly simpler than static analyses, which means that they can be developed more easily for complex languages like JavaScript. They can also be deployed in situations where there is no opportunity to analyse the code before running it, for example because it is being supplied by a third-party advertiser on a website. In terms of speed, dynamic analyses incur no computational cost during development, but typically slow down execution of a program by a roughly constant factor, so there is often a focus on making them more efficient [38]. Static analyses can be slow to run during development, but cost nothing at run-time. Thus, provided the analysis scales reasonably with the size of the program, optimisation is less important, as it has no impact on the user.
But ultimately, dynamic and static approaches are fundamentally different in that static analyses enforce information flow policies by alerting the developer before a program is deployed, allowing the program to be fixed before it causes problems for a user. Although dynamic approaches are also able to enforce information flow policies, they do so by terminating the offending program, inconveniencing its user.
Hybrid Approaches As a compromise, Chugh et al. [9] propose extending a static information flow analysis with a dynamic component that performs additional checks at runtime when dynamically generated code becomes available. The static part of their analysis is similar to ours (minus staging), although they do not formally state or prove its soundness. Their study of JavaScript on popular websites suggests the static part is precise enough to be useful. Because the additional checks on dynamically generated code occur at runtime, they must necessarily be quick and simple to avoid performance degradation. Consequently, these checks are limited to purely syntactic isolation properties, with a corresponding loss of precision. Our fully static analysis does not suffer from these limitations.
Going in the other direction, Austin and Flanagan [2] have proposed faceted execution, a form of dynamic analysis that explores different execution paths and can thus recover some of the advantages of a static analysis.
Static analysis of staged metaprogramming
Many different approaches to staged metaprogramming have been proposed. Our language’s staging constructs are modelled after the language
Control flow analysis for a two-staged language has been investigated by Kim et al. [27]. Their approach is based on abstract interpretation, putting particular emphasis on inferring an over-approximation of all possible pieces of code to which a code quotation may evaluate. This information is not explicitly computed by our analysis, so it is quite possible that their analysis is more precise than ours. However it does not seem to have been implemented yet.
Choi et al. [7] propose a more general framework for static analysis of multi-staged programs, which is based on an unstaging translation that replaces staging constructs with function abstractions and applications. Under certain conditions, analysis results for the unstaged program can then be translated back to its staged version. This method allows existing static analyses for the unstaged language to be used on the staged language, requiring only the specification of a “projection function” that describes how analysis results for the translated program relate to the original program.
There are some limitations to their work. Most significantly, many interesting programs, such as the one mentioned earlier, are not valid in
Furthermore, as shown in Examples 18–20, the precision of the resulting combined analysis is highly sensitive to the target language encoding used in the translation and the behaviour of the target language analysis. While their approach is useful as a quick way of adding staging to an existing language and analysis, we argue that staging constructs are sufficiently important and complex that we should aim to analyse them directly.
Inoue and Taha [23] consider the problem of reasoning about staged programs; in particular, they identify equivalences that fail to hold in the presence of staging, and develop a notion of bisimulation that can be used to prove extensionality of function abstractions, and work around some of the failing equivalences. Their language differs from ours in that it avoids name capture.
Some work on analysing metaprogramming focuses on its application to optimising compilation of programs with metaprogramming. For example, Smith et al. [48] consider using static analysis to optimise compilation in a cut-down version of Cyclone, a type-safe, C-style language with run-time code generation. Their analysis is based around a relatively coarse over-approximation of control flow between code blocks in a program, but this suits their application because their language does not have first-class functions.
We have mainly considered homogeneous metaprogramming, in which the code manipulated and executed is written in the same language as the code that manipulates it. In heterogeneous metaprogramming, the two languages are different. This is particularly relevant for web applications that construct database queries, which are often written in SQL. Schoepe et al. [46] extend an idea from Cheney et al. [5] to produce an ML-like language in which database queries can be built using staged metaprogramming. They develop a type system for analysing information flows within the language and the database, including flows that result from the program reading information through a database query and later writing it with a different query.
Analysing eval
There has been relatively little work on analysing
A different approach is taken by Meawad et al. [34]. Their tool Evalorizer uses a proxy to intercept and log uses of JavaScript
Conclusions
We have presented a fully static information flow analysis based on 0CFA for a dynamically typed language with staged metaprogramming, implemented it and formally proved its soundness. We have shown how to apply our analysis to a language with string-based
Progressing from here, there are two obvious lines of work. The first is to improve the precision of the analysis by applying its ideas to CFA2 or using results from abstract interpretation. The second is to extend the language to handle more features, such as imperative control flow and exceptions.
All the pieces are now in place for an interesting, sound and principled analysis of JavaScript with
Footnotes
Acknowledgments
We thank our anonymous reviewers for their comments and suggestions.