
Abstract
The isolation of security critical components from an untrusted OS allows to both protect applications and to harden the OS itself. Virtualization of the memory subsystem is a key component to provide such isolation. We present the design, implementation and verification of a memory virtualization platform for ARMv7-A processors. The design is based on direct paging, an MMU virtualization mechanism previously introduced by Xen. It is shown that this mechanism can be implemented using a compact design, suitable for formal verification down to a low level of abstraction, without penalizing system performance. The verification is performed using the HOL4 theorem prover and uses a detailed model of the processor. We prove memory isolation along with information flow security for an abstract top-level model of the virtualization mechanism. The abstract model is refined down to a transition system closely resembling a C implementation. Additionally, it is demonstrated how the gap between the low-level abstraction and the binary level-can be filled, using tools that check Hoare contracts. The virtualization mechanism is demonstrated on real hardware via a hypervisor hosting Linux and supporting a tamper-proof run-time monitor that provably prevents code injection in the Linux guest.
Introduction
A basic security requirement for systems that allow software to execute at different levels of security is memory isolation: The ability to store a secret or to enforce data integrity within a designated part of memory and prevent the contents of this memory to be affected by, or leak to, parts of the system that are not authorised to access it. Without the usage of special hardware, trustworthy memory isolation is dependent on the OS kernel being correctly implemented. However, given the size and complexity of modern OSs, the vision of comprehensive and formal verification of commodity OSs is as distant as ever.
An alternative to verifying the entire OS is to delegate critical functionality to special low-level execution platforms such as hypervisors, separation kernels, or microkernels. Such an approach has some significant advantages. First, the size and complexity of the execution platform can be made much smaller, potentially opening up for rigorous verification. The literature has many recent examples of this, in seL4 [33], Microsoft’s Hyper-V project [34], Green Hills’ CC certified INTEGRITY-178B separation kernel [42] , and the Singularity [29] microkernel Second, the platform can be opened up to public scrutiny and certification, independent of application stacks.
Virtualization-like mechanisms can also be used to support various forms of application hardening against untrusted OSs. Examples of this include KCoFi [15] based on the Secure Virtual Architecture (SVA) [17], Overshadow [10], Inktag [28], and Virtual Ghost [14]. All these examples rely crucially on memory isolation to provide the required security guarantees, typically by virtualizing the memory management unit (MMU) hardware. MMU virtualization, however, can be exceedingly tricky to get right, motivating the use of formal methods for its verification.
In this paper we present an MMU virtualization API for the ARMv7-A processor family and its formal verification down to the binary level. A distinguishing feature of our design is the use of direct paging, a virtualization mechanism introduced by Xen [7] and used later with some variations by the SVA. In direct paging, page tables are kept in guest memory and allowed to be read and directly manipulated by the untrusted guest OS (when they are not in active use by the MMU). Xen demonstrated that this approach has better performance than other software virtualization approaches (e.g. shadow page tables) on the x86 architecture. Moreover, since direct paging does not require shadow data structures, this approach has small memory overhead. The engineering challenge inherent to this project is to design a minimal API that (i) is sufficiently expressive to host a paravirtualized Linux, (ii) introduces an acceptable overhead and (iii) whose implementation is sufficiently small to be subject to pervasive verification for a commodity CPU architecture such as ARMv7.
The security objective is to allow an untrusted guest system to operate freely, invoking the hypervisor at will, without being able to access memory or processor resources that the guest has not received static permission for. In this paper we describe the design, implementation, and evaluation of our memory virtualization API, and the formal verification of its security properties. The verification is performed using a formal model of the ARMv7 architecture [22], implemented in the HOL4 interactive theorem prover.
The proof strategy is to establish a bisimilarity between the hypervisor executing on a formal model of the ARMv7 instruction set architecture and the top level specification (TLS). The TLS describes the desired behaviour of the system consisting of handlers implementing the virtualization mechanism and the behaviour of machine instructions executed by the untrusted guest. The specification of the MMU virtualization API involves an abstract model state that is not represented in memory and thus by design invulnerable to direct guest access. Due to the direct paging approach, however, the page tables that control the MMU are residing in guest memory and need to be modelled explicitly. Hence, it is no longer self-evident that the desired memory isolation properties, no-exfiltration and no-infiltration in the terminology of [27], hold for guests in the TLS, and an important and novel part of the verification is therefore to formally validate that these properties indeed hold.
To keep the TLS as simple and abstract as possible, the TLS addresses page tables directly using their physical addresses. A real implementation cannot do this, but must use virtual addresses instead, in addition to managing its internal data structures. To this end an implementation model is introduced, which uses virtual addresses instead of physical ones and stores the abstract model state explicitly in memory. This provides a very low-level C-like model of handler execution, directly reflecting all algorithmic features of the memory subsystem virtualization implemented by the binary code of the handlers, on the real ARMv7 state, as represented by the HOL4 model. We exhibit a refinement from the TLS to the implementation model, prove its correctness, and show, as a corollary, that the memory isolation properties proved for the TLS transfer to the implementation model. This constitutes the second part of the verification.
The next step is to fill the gap between the verification of this low-level abstraction and the binary level. To accomplish this an additional refinement must be established. Using the same approach as [20], we demonstrate how this can be achieved using a combination of theorem proving and tools that check contracts for binary code. The machine code verification is then in charge of establishing that the hypervisor code fragments respect these contracts, expressed as Hoare triples. Pre and post conditions are generated semi-automatically starting from the specification of the low-level abstraction and the refinement relation. They are then transferred to the binary analysis tool BAP [9], which is used to verify the hypervisor handlers at the assembly level. Several tools have been developed to support this task, including a lifter that transforms ARM code to the machine independent language that can be analysed by BAP and a procedure to resolve indirect jumps. The binary verification of the hypervisor has not been completed yet. However, we demonstrate the methodology outlined above by applying it to prove correctness of the binary code of one of the API calls. The scalability of the approach has been shown in [19], where it was used to verify the binary code of a complete separation kernel.
An alternative approach would be to focus the code verification at the C level. First, such an approach does not directly give assurances at the ISA level, which is our objective. This can be partly addressed by a certifying compiler such as CompCert [35]. However, system level code is currently not supported by such compilers. Moreover, this type of code is prone to break the standard C-semantics, for example by reconfiguring the MMU and changing the virtual memory mapping of the program under verification as is the case here.
The verification highlighted three classes of bugs in the initial design of the virtualization mechanism:
Arithmetic overflows, bit field and offset mismatches, and signed operators where the unsigned ones were needed. Missing checks of self referencing page tables. Approval of guest requests that cause unpredictable behaviours of the ARMv7 MMU.
Moreover, the verification of the implementation model identified additional bugs exploitable by requesting the validation of physical blocks residing outside the guest memory. This last class of bugs was identified because the implementation model takes into account the virtual memory mapping used by the handlers. Finally, the binary code verification identified a buffer overflow.
We report on a port of Linux kernel 2.6.34 and demonstrate the prototype implementation of a hypervisor for which the core component is the verified MMU virtualization API. The complete hypervisor augments the memory virtualization API by handlers that route aborts and interrupts inside Linux. Experiments demonstrate that the hypervisor can run with reasonable performance on real hardware (Beagleboard-xM based on the Cortex-A8 CPU). Furthermore an application scenario is demonstrated based on a trusted run-time monitor. The monitor executes alongside the untrusted Linux system, enforces the
Scope and limitations
The binary verification of the hypervisor has not been completed yet. However, we demonstrate the methodology outlined above by applying it to prove correctness of the binary code of one of the API calls. The scalability of the approach has been shown in [19], where it was used to verify the binary code of a complete separation kernel. In Section 9.5 we comment on the tasks that are not automated and need to be manually accomplished to complete the verification.
Related work
The size and complexity of commodity OSs make them susceptible to attacks that can bypass their security mechanisms, as demonstrated in e.g. [31,47]. The ability to isolate security critical components from an untrusted OS allows non critical parts of a system to be implemented while the critical software remains adequately protected. This isolation can be used both to protect applications from an untrusted OS as well as to protect the OS itself from internal threats. For example, KCoFI [15] uses Secure Virtual Architecture [17] to isolate the OS from a run-time checker. The checker instruments the OS and monitors its activities to guarantee the control-flow integrity of the OS itself. Related examples are application hardening frameworks such as Overshadow [10], Inktag [28], and Virtual Ghost [14]. In all these cases some form of virtualization of the MMU hardware is a critical component to provide the required isolation guarantees.
Shadow page tables (SPT) is a common approach to MMU virtualization. The virtualization layer maintains a shadow copy of page tables created and maintained by the guest OS. The MMU uses only the shadow pages, which are updated after the virtualization layer validates the OS changes. The Hyper-V hypervisor which uses shadow pages on x86, has been formally verified using the semi automated VCC tool [34]. Related work [2,41] uses shadow page tables to provide full virtualization, including virtual memory, for “baby VAMP”, a simplified MIPS, using VCC. This work, along with later work [1] on TLB virtualization for an abstract mode of x64, has been verified using Wolfgang Paul’s VCC-based simulation framework [13]. Also, the OKL4-microvisor uses shadow paging to virtualize the memory subsystem [26]. However, this hypervisor has not been verified.
Some modern CPUs provide native hardware support for virtualization. The ARM Virtualization Extensions [3] augment the CPU with a new execution mode and provide a two stage address translation. These features greatly reduce the complexity of the virtualization layer [48]. XHMF [49] and CertiKOS [24] are examples of verified hypervisors for the x86 architecture that control memory operations of guests using virtualization extensions. The availability of hardware virtualization extensions, however, does not make software based solutions obsolete. For example, the recent Cortex-A5 (used in feature-phones) and the legacy ARM11 cores (used in home network appliances and the 2014 “New Nintendo 3DS”) do not make use of such extensions. Today, the Internet of Things (IoT) and wearable computing are dominated by microcontrollers (e.g. Cortex-M). As the recent Intel Quark demonstrates, the necessity of executing legacy stacks (e.g. Linux) is pushing towards equipping these microcontrollers with an MMU. Quark and the upcoming ARMv8-R both support an MMU and lack two stage page-tables. Generally, there is no universal sweet spot that reconciles the demands for low cost, low power consumption and rich hardware features. For instance, solutions based on FPGAs and soft-cores such as LEON can benefit from software based virtualization by freeing gates not used for virtualization extensions to be used for application specific logic (e.g. digital signal processing, software-defined radio, cryptography).
A virtualization layer provides to the guest OS an interface similar to the underlying hardware. An alternative approach is to execute the commodity OS as a partition of a microkernel, by mapping the OS threads directly to the microkernel threads, thus delegating completely the process management functionality from the hosted OSes to the microkernel (e.g. L4Linux). This generally involves an invasive and error-prone OS adaptation process, however. The formal verification of seL4 [33] demonstrated that a detailed analysis of the security properties of a complete microkernel is possible even at the machine code level [44]. Similarly, the Ironclad Apps framework [25] hosts security services in a remote operating system. Its functional correctness and information flow properties are verified on the assembly level.
In order to achieve trustworthy isolation between partitions, more light-weight solutions can also be employed, namely formally verified separation kernels [8,19,42] and Software Fault Isolation (SFI) [50,52]. The latter has the advantage over the former in that it is a software-only approach, not relying on common hardware components such as MMU and memory protection units (MPU). Nevertheless, both mechanisms are generally not equipped with the functionality needed to host a commodity OS. Conversely, formally verified processor architectures specifically designed with a focus on logical partitioning [51] and information flow control [6] can be used to achieve isolation.
Contributions
We present a platform to virtualize the memory subsystem of a real commodity CPU architecture: The ARMv7-A. The virtualization platform is based on direct paging, a virtualization approach inspired by the paravirtualization mechanism of Xen [7] and Secure Virtual Architecture [17]. The design of the platform is sufficiently slim to enable its formal verification without penalizing the system performance. The verification is performed down to a detailed model of the architecture, including a detailed model of the ARMv7 MMU. This enables our threat model to consist of an arbitrary guest that can execute any ARMv7 instruction in user mode. We prove complete mediation of the MMU configurations, memory isolation of the hosted components, and information flow correctness. Additionally, we present our methodology for the binary verification of hypervisor code and report on first results. So far, one handler has been verified on the binary level. Completing the binary verification for all handlers is work in progress. The viability of the platform is demonstrated via a prototype hypervisor that is capable of hosting a Linux system while provably isolating it from other services. The hypervisor supports BeagleBoard-xM (a development board based on ARM Cortex-A8) and is used to benchmark the platform on real hardware. As the main application it is shown how the virtualization mechanism can be used to support a tamper-proof run-time monitor that prevents code injection in an untrusted Linux guest.
Verification approach
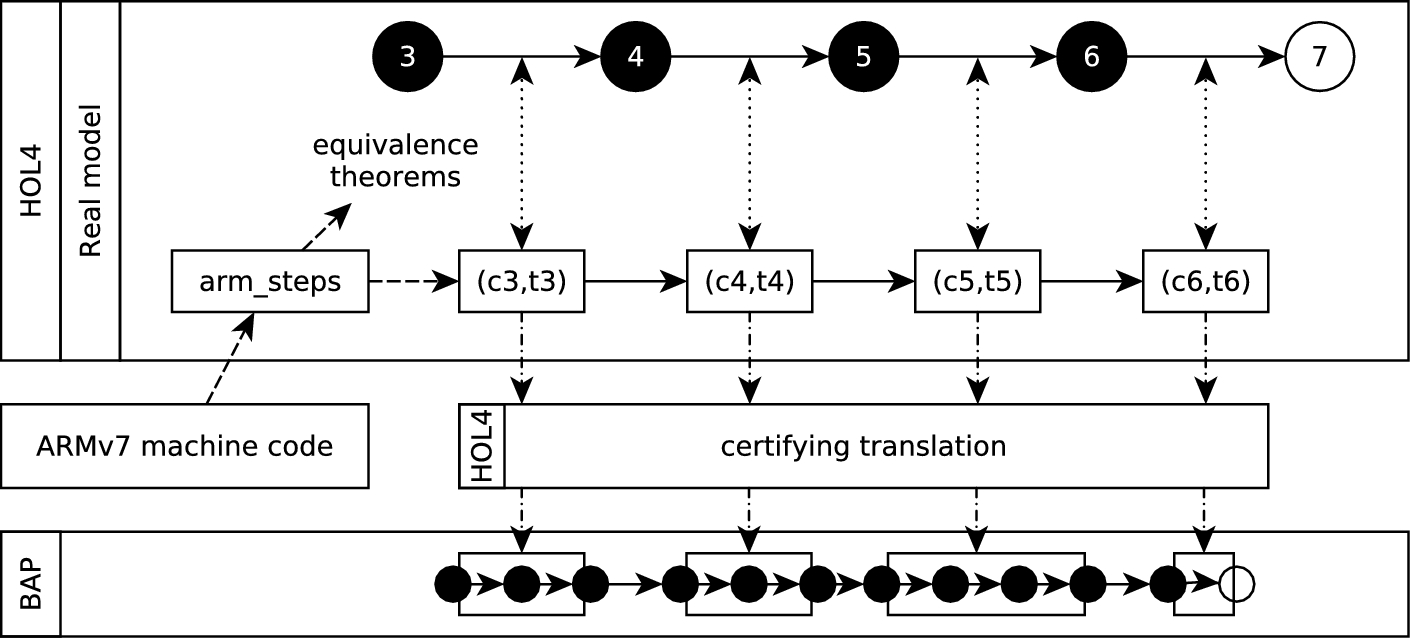
In Fig. 1 we give an overview of the entire verification flow presented in this paper. In particular it depicts the different layers of modelling, how they are related, and the tools used. This is discussed in more detail in Section 3.6.
Our MMU virtualization API is designed for paravirtualization and targets a commodity CPU (ARMv7-A). In such a scenario, the hosting CPU must provide two levels of execution: privileged and unprivileged. The hypervisor is the only software component that is executed at the privileged level; at this level the software has complete control of the underlying hardware. All other software components (including operating system kernels, user processes, etc.) are executed in unprivileged mode; direct accesses to the sensitive resources must be prevented and all transitions to privileged mode are controlled through the use of exceptions and interrupts.
In addition to the MMU virtualization API itself, as part of the hypervisor, the system is intended to support two types of clients:
An untrusted commodity OS guest (Linux) running non-critical software (e.g. GUI, browser, server, games).
A set of trusted services such as controllers that drive physical actuators, run-time monitors, sensor drivers, or cryptographic services.
An example computation of such system is shown in the row labelled “Real model” of Fig. 1. White circles represent states in unprivileged execution level where the untrusted guest (either its kernel or one of its user processes) are running. Gray circles represent unprivileged states where one of the trusted services are in control. Finally, black circles represent states in privileged level where the hypervisor is active. Transitions between two unprivileged states (e.g.
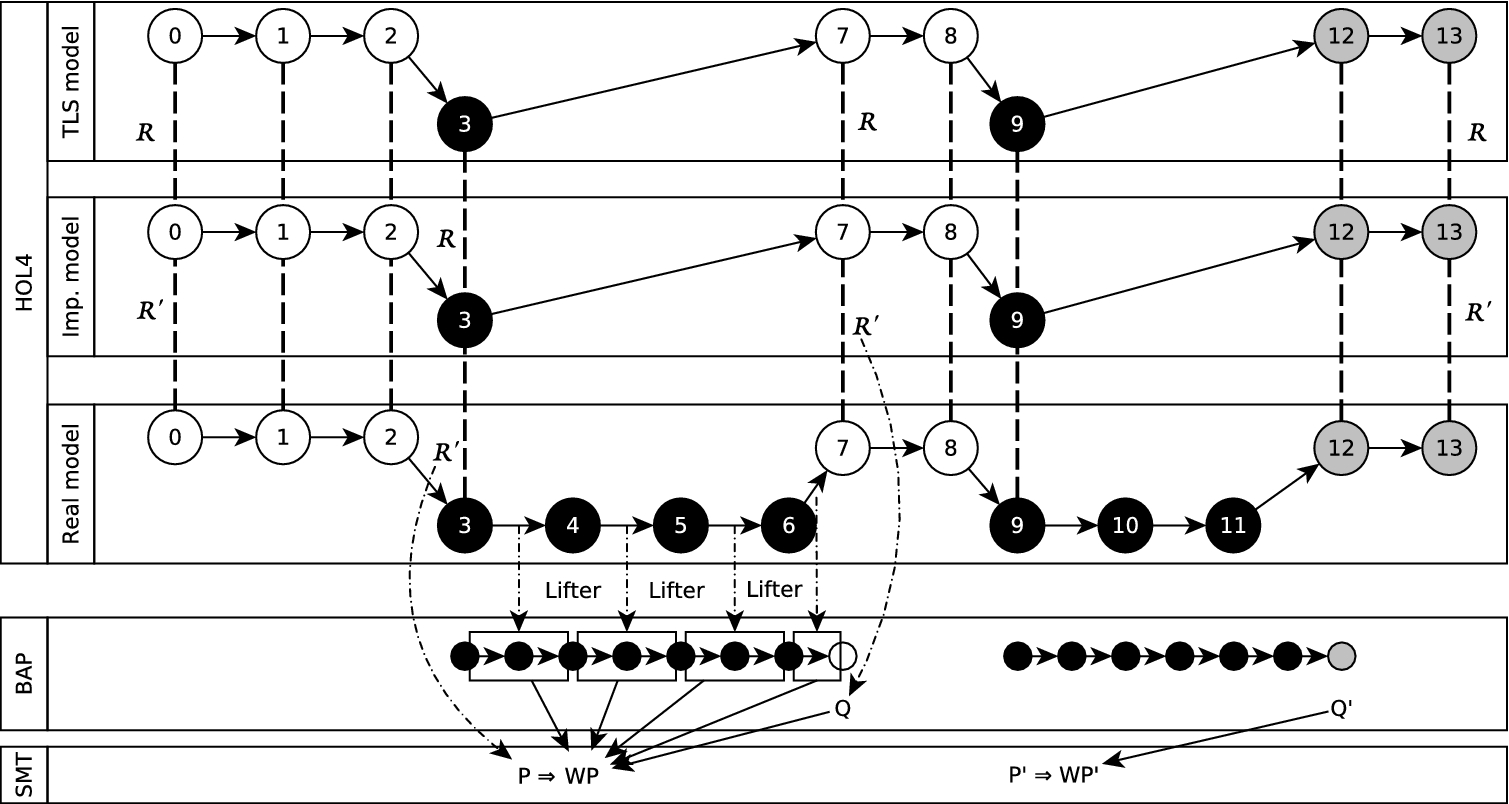
Executions of a real machine (middle), the implementation model (above), and the Top Level Specification (top) and the relations between them. In addition the dependencies of the binary verification methodology (bottom) are depicted.
Due to the size and complexity of a complete Linux system, a realistic adversary model must consider the Linux partition compromised. For this reason, the attacker is an untrusted paravirtualized Linux kernel and its user processes, that maliciously or due to an error may attempt to gain access to resources outside the guest partition. Thus, the attacker is free to execute any CPU instruction in unprivileged mode; it is initially not able to directly access the coprocessor registers, and all attacker memory accesses are initially mediated by the MMU. However, by exploiting possible flaws in the hypervisor the attacker may during the course of a computation gain such access to the MMU configuration, something our security proof shows is in fact not possible. In this work, we assume absence of external mechanisms that can directly modify the internal state of the machine (e.g. external devices or physical tampering). The analysis of temporal partitioning properties (e.g. timing channels as investigated in [12]) is also deliberately left out of this work.
Security goals
The verification must demonstrate that the low level platform does not allow undesired interference between guest and sensitive resources. That is:
The hypervisor must play the role of a security monitor of the MMU settings. If complete mediation of the MMU settings is violated, then an attacker may bypass the hypervisor policies and compromise the security of the entire system. We show this by proving that neither the untrusted guest nor the trusted services can directly change the MMU configuration.
Executions of an arbitrary guest cannot affect the “trusted world”, i.e. the parts of the state the guest is not allowed to modify, such as memory of trusted services, system level registers and status flags, and the hypervisor state. This is an integrity property, similar to the no-exfiltration property of [27].
Absence of information flow from the trusted world to the guest, i.e. confidentiality, similar to no-infiltration of [27].
Note that these properties, as in [27], are qualitatively different: The integrity property is a single-trace property, and concerns the inability of the guest to directly write some other state variables. Since it is under guest control when and how to invoke the virtualization API, there are plenty of indirect communication channels connecting guests to the hypervisor. For instance, a guest decision to allocate or deallocate a page table affects large parts of the hypervisor state, without ever directly writing to any internal hypervisor state variable. Enforcing this is in a sense the very purpose of the hypervisor. On the other hand, the only desired effects of hypervisor actions should be to allocate/deallocate, map, remap, and unmap virtual memory resources, leaving any other observation a guest may make unaffected, thus preventing the guest from extracting information from inaccessible resources even indirectly. This is essentially a two-trace information flow property, needed to break guest-to-guest (or guest-to-service) information channels in much the same way as intransitive noninterference is used in [38] to break guest-to-guest channels passing through the scheduler in seL4.
In this work we establish these properties via successive refinements that add more details (that in turn can highlight different misbehaviour of the system) to the virtualization API, starting from an abstract model refining down to the binary code of the low level execution platform. We first demonstrate that the intended security property holds for the most abstract model. At each refinement, the proof consist of (i) identifying a relation that is strong enough to transfer the security property from the higher abstract model to the more real one (we call this a candidate relation) and (ii) demonstrating that the candidate relation actually satisfies the properties required from a refinement relation. For the first task it turns out that one needs a bisimulation relation in order to transfer higher-order information flow properties like confidentiality. The latter task is reduced to subsidiary properties, which have natural correspondences in previous kernel verification literature [27,42]:
A malicious guest cannot violate isolation while it is executing. Executions of the abstract vs the more real model preserve the candidate bisimulation relation.
These two tasks are qualitatively different. The former task, due to our use of memory protection, is really a noninterference-like property of the hosting architecture rather than a property of the hypervisor. This property must hold independently of the hosted guest, which is unknown at verification time since the attacker can take complete control of the untrusted Linux. By contrast, the latter task consists in verifying at increasing levels of detail the functional correctness of the individual handlers.
Top level specification
The first verification task focuses on establishing correctness of the design of the virtualization API. With this goal, in Section 6.1 we specify the desired behaviour of the virtualization API as a transition system, called the Top Level Specification (TLS). This specification models unprivileged execution of an arbitrary guest system on top of a CPU with MMU support, alternating with abstract handler events. These events model invocations of the hypervisor handlers as atomic transformations operating on an abstract machine state. Abstract states are real CPU states extended by auxiliary (model) data that reflect the internal state of the hypervisor. We refer to this auxiliary data as the abstract hypervisor state. Handler events represent the execution of several instructions at privileged level, in response to exceptions or interrupts. Modelling handler effects as atomic state transformations is possible, since the hypervisor is non-preemptive, i.e. nested exceptions/interrupts are ruled out by the implementation.
Since in direct paging the guest systems can directly manipulate inactive page tables, the TLS needs to explicitly model page tables in memory. This contrasts simpler models such as the one presented in [19] where the hypervisor state was represented in the TLS using abstract model variables only. For this reason, establishing complete mediation, integrity, and confidentiality for the TLS is far from trivial.
Implementation model
Extending the security properties to an actual implementation, however, requires additional work, for the following reasons:
The TLS uses auxiliary data structures (the abstract hypervisor state) that are not stored inside the system memory. The TLS accesses the memory directly using physical addresses.
As is common practice, the virtualization code executes under the same address translation as the guest (but with different access permissions), in order to reduce the number of context switches required. For this approach it is critical to verify that all low-level operations performed by the hypervisor correctly implement the TLS specification; these operations include reads and updates of the page tables, and reads and updates of the hypervisor data structures. To show implementation soundness we exhibit a refinement property relating TLS states with states of the implementation. The refinement relation is proven to be preserved by all atomic hypervisor operations; reads and updates of the page tables, reads and updates of the hypervisor data structures. In particular it is established that these virtual memory operations access the correct physical addresses and never produce any data abort exceptions. Moreover, it is shown that the refinement relation directly transfers both the integrity properties and the information flow properties of the TLS to the implementation level.
Binary verification
The last verification step consists in filling the gap between the implementation and the binary code executed on the actual hardware. This requires to exhibit a refinement relation between the implementation model and the real model of the system (i.e. where each transition represents the execution of one binary instruction).
Intuitively, internal hypervisor steps cannot be observed by the guests, since during the execution of the handler no guest is active. Moreover, as the hypervisor does not support preemption, then the execution of handlers cannot be interrupted. These facts permit to disregard internal states of the handlers and limit the refinement to relate only states where the guests are executing.
Thus, the binary verification can be accomplished in three steps: (i) verification that the refinement relation directly transfers both the isolation properties to the real model, (ii) verification of a top level theorem that transforms the relational reasoning into a set of contracts for the handlers and guarantees that the refinement is established if all contracts are satisfied, and (iii) verification of the machine code. The last step establishes if the hypervisor code fragments respect the contracts, expressed as Hoare triples
List and first appearance of models, theorems and tools
List and first appearance of models, theorems and tools
We use Fig. 1 and Table 1 to summarise the models, theorems and tools that are described in the following sections. We use three transition systems; the TLS (Section 6.1), the Implementation Model (Section 6.2) and the ARMv7 model (Section 4). These transition systems have been defined in the HOL4 theorem prover and differ in the level of abstraction they use to represent the hypervisor behaviour. The three transition systems model guest behaviour identically (e.g. transitions
We use HOL4 to verify that the security properties hold for the TLS (Theorems 1, 2, 3, 4 and 5 of Section 6.1). The reasoning used to implement the proofs in the interactive theorem prover is summarised in Section 7.
The refinement (
The refinement (
The verification of the refinement (Theorem 7 of Section 6.3) is only partial: we demonstrate the verification of the binary code of the hypervisor only for a part of the code-base and we rely on some assumptions in order to fill the semantic gap between HOL4 and the external tools. We prove Theorem 7 for non-privileged transitions in HOL4 (i.e. transitions not involving the hypervisor code such as
For the hypervisor code, we show that the task can be partially automated by means of external tools. For this purpose we use the HOL4 model of ARMv7 to transform the binary code of the hypervisor (e.g. the code executed between states 3 and 7 in the real model) to the input language of BAP (represented in the figure by arrow labelled “Lifter”). The usage of HOL4 for this task allows us to reduce the assumptions needed to fill the gap between the HOL4 ARMv7 model and BAP, as described in Section 9. The methodology to complete the verification is the following: given a hypervisor handler whose code has been translated to the BAP code C, we use a HOL4 certifying procedure that generates a contract
The ARMv7 CPU
ARMv7 is the currently dominant processor architecture in embedded devices. Our verification relies on the HOL4 model of ARM developed at Cambridge [22]. The use of a theorem prover allows the verification goals to be stated in a manner which is faithful to the intuition, without resorting to approximations and abstractions that would be needed when using a fully automated tool such as a model checker. Furthermore, basing the verification on the Cambridge ARM model lends high trustworthiness to the exercise: The Cambridge model is well-tested and phrased in a manner that retains a high resemblance to the pseudocode used by ARM in the architecture reference manual [5]. The Cambridge model has been extended by ourselves to include MMU functionality. The resulting model gives a highly detailed account of the ISA level instruction semantics at the different privilege levels, including relevant MMU coprocessor effects. It must be noted that the Cambridge ARM model assumes linearizable memory, and so can be used out of the box only for processor and hypervisor implementations that satisfy this property, for instance through adequate cache flushing as discussed in Section 5.5.
We outline the HOL4 ARMv7 model in sufficient detail to make the formal results presented later understandable. An ARMv7 machine state is a record
System behaviour is modelled by the state transition relation
The ARMv7 MMU uses a two level translation scheme. The first level (L1) consists of a 4096 entry table that divides up to 4 GB of memory into 1 MB sections. These sections can either point to an equally large region of physical memory or to a level 2 (L2) page table with 256 entries that maps the 1 MB section into 4 KB physical pages. MMU behaviour is modelled by the function
In the ARM architecture domains provide a discretionary access control mechanism. This mechanism is orthogonal to the one provided by CPU execution modes. There are sixteen domains, each on activated independently in one of the coprocessor registers
The state transition relation queries the MMU whenever a virtual address is accessed, and raises an exception if the requested access mode is not allowed. To describe the security properties guaranteed by an ARMv7 CPU we introduce some auxiliary definitions.
(Physical memory access rights).
The predicate
The ARMv7 MMU mediates accesses to the virtual memory, enabling or forbidding operations to virtual addresses. Intuitively, a physical address
(Write-derivability).
We say that a state
According with the MMU configuration in σ, only a subset of physical addresses are writable (
(MMU-equivalence).
We say that two states are MMU-equivalent if for any virtual address
Informally, two states are MMU-equivalent if their MMUs are configured exactly in the same way.
(MMU-safety).
Finally, a state is MMU-safe if it has the same MMU behaviour as any state with the same coprocessor registers whose memory differs only for addresses that are writable in
A state is MMU-safe if there is no way to change the MMU configuration (i.e. the page tables) by writing into addresses that writable in non-privileged mode. That is the MMU configuration prevent non-privileged SW to tamper the page tables.
An ARMv7 processor that obeys the access privileges computed by the MMU satisfies the following two properties:
(ARM-integrity).
Assume
Note, that the MMU-safety prerequisite is not redundant here, because single instructions in ARM may result in a series of write operations, e.g., for “store pair” and unaligned store instructions. If the MMU configuration was not safe from manipulation in unprivileged mode, then such a series of writes could lead to an intermediate MMU configuration granting more write permissions than the initial one and the resulting state would not be write-derivable from σ.
(ARM-confidentiality).
Let
Intuitively, Property 2 establishes that in MMU-safe configurations unprivileged transitions only can access information stored in the registers and in the part of memory that is readable in
The memory virtualization API
The memory virtualization API is designed for the ARMv7-A architecture1
In practice, the presented design also supports the ARMv6 and ARMv5 architectures.
Isolation of memory resources used by the trusted components.
Virtualization of the memory subsystem to enable the untrusted OS to dynamically manage its own memory hierarchy, and to enforce access restrictions.
The virtual memory layout is defined by a set of page tables that reside in physical memory. The configuration of these page tables is security critical and must not be directly manipulated by untrusted parties. At the same time, the untrusted Linux kernel needs to manage its memory layout, which requires constant access to the page tables. Hence the hypervisor must provide a secure access mechanism, which we refer to as virtualizing the memory subsystem.
We use direct paging [7] to virtualize the memory subsystem. Direct paging allows the guest to allocate the page tables inside its own memory and to directly manipulate them while the tables are not in active use by the MMU. Once the page tables are activated, the hypervisor must guarantee that further updates are possible only via the virtualization API to modify, allocate and free the page tables.
Physical memory is fragmented into blocks of 4 KB. Thus, a 32-bit architecture has data: the block can be written by the guest. L1: contains part of an L1 and is not writable in unprivileged mode. L2: contains four L2 and is not writable in unprivileged mode.
The virtualization API shown in Fig. 2 is very similar to the MMU interface of the Secure Virtual Architecture [17] and consists of 9 hypercalls that selects, creates, frees, maps, or unmaps memory blocks or page tables.
Figure 3 indicates the address translation procedure and the connection between components of memory subsystem.

The virtualization API of the hypervisor to support direct paging.
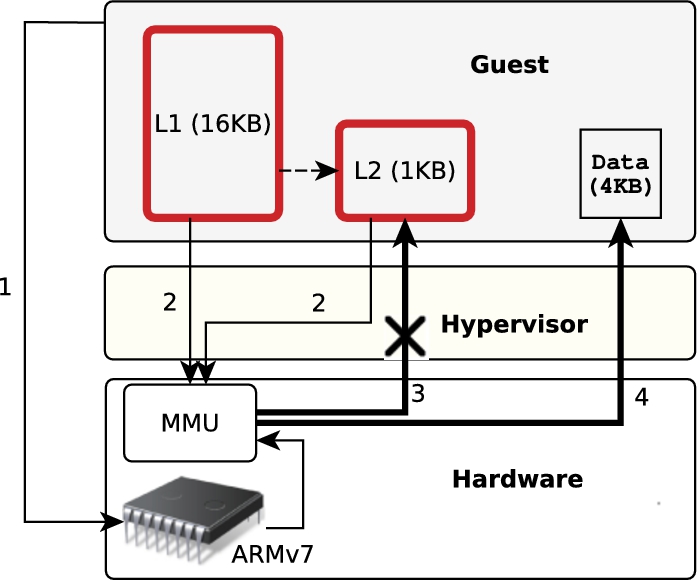
Direct paging: 1) guest writes to virtual memory are mediated by the MMU as usual; 2) page tables are allocated in guest memory; 3) the hypervisor prevents writable mappings to guest memory regions holding page tables, forbidding the guest to directly modify them; 4) the hypervisor allows writable mappings to data blocks in guest memory.
Each API call needs to validate the page type, guaranteeing that page tables are write-protected. This is illustrated in Fig. 4. The table in the centre represents the physical memory and stores the virtualization data structures for each physical block; the page type (
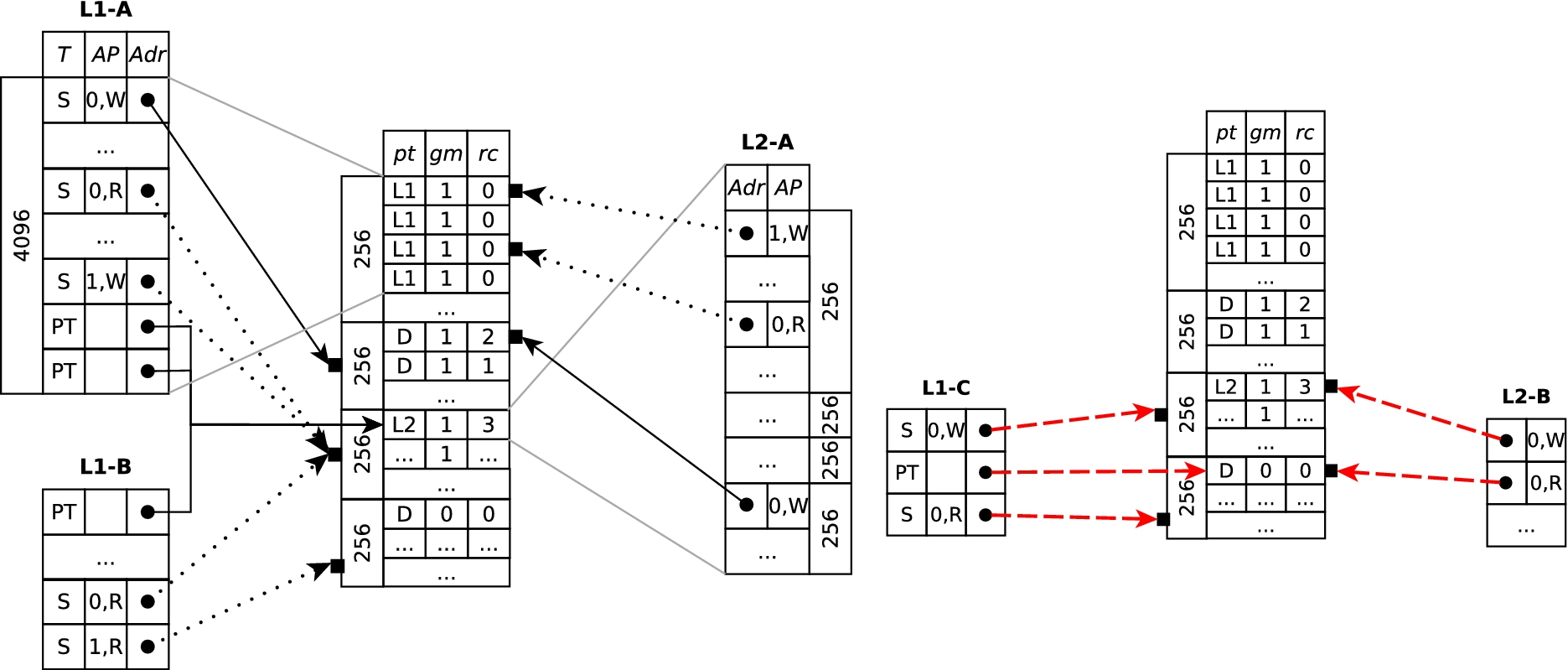
Direct-paging mechanism. We use solid arrows to represent the L2 page table references and unprivileged write permissions, dotted arrows to represent other allowed references, and dashed arrows for references violating the page table policy.
The four top most blocks contain an L1 page table, whose 4096 entries are depicted by the table L1-A. The top entry of the page table is a section descriptor (
The API calls manipulating an L1 enforce the following policy: Any section descriptor that allows the guest to access the memory must point to a section for which every physical block resides in the guest memory space. Moreover, if a descriptor enables a guest to write then each block must be typed
The figure depicts two additional L1 page tables; L1-B and L1-C. The type of a physical block containing L1-B can be transformed to L1 by invoking L1create. On the other hand, a block containing L1-C is rejected by L1create since the block contains three entries that violate the policy. In fact,
the first descriptor grants guest write permission over a section which has at least one non data block, in this case L2, the second section descriptor allows the guest to access a section of the physical memory in which there exists a block that is outside the guest memory, and the third entry is a PT-descriptor, but points to a physical block that is not typed L2.
The first setting clearly breaks MMU-safety, since the guest is now able to write directly to a page table, circumventing the complete mediation of MMU configurations by the hypervisor. The second situation compromises confidentiality and possible integrity of the system if the guest has write access to the block outside its own memory. The third issue may again break MMU-safety if the referenced block is a writable data block. In case the referenced block contains (part of) another L1 page table this setting can lead to unpredictable MMU behaviour, since the L1 page table entries have a different binary format than the expected L2 entries.
The table L2-A depicts the content of a physical block typed L2 that contains four L2 page tables, each consisting of 256 entries. Each hypercall that manipulates an L2 enforces the following policy: If any entry of the four L2 page tables grants access permission to the guest then the pointed block must be in the guest memory. If the entry also enables guest write access then the pointed block must be typed
A naive run-time check of the page-type policy is not efficient, since it requires to re-validate the L1 page table whenever the switch hypercall is invoked. To efficiently enforce that only The number of descriptors providing writable access in user mode to the block. The number of PT-descriptors that point to the block.
The intuition is that a hypercall can change the type of a physical block (e.g. allocate or free a page table) only if the corresponding reference counter is zero. Lemmas 5 and 6 in Section 7 demonstrate that this approach is sound and that the page table policy described above is sufficient to guarantee MMU-safety.
Spawning a new process using the virtualization API. The guest (1) requests a writable mapping of four physical blocks to allocate a new L1 page table. After (2) setting up the table in memory (not shown), it asks (3) to remove the writable mapping, (4) to interpret the blocks as an L1 table, and (5) to make this one the new active L1 page table (not shown).
In Fig. 5 we exemplify how an OS can use the API to spawn a new process. The OS selects four blocks from its physical memory to allocate a new L1 page table. We assume that initially the OS has no virtual mapping that enables it to access this part of the memory (i.e. the reference counter Using L2map, the OS requests to change an existing L2 page table, establishing a writable mapping to the four blocks. The hypercall increases the reference counter accordingly (i.e. Without any mediation of the hypervisor, the OS uses the new mapping to write the content of the new L1 page table. Using L2unmap, the guest removes the mapping established in (1) and decreases the reference counters (i.e. The guest invokes L1create, requesting the page table to be validated and the block type changed to L1. The request is granted only if the reference counter is zero, guaranteeing that there does not exist any mapping in the system that allows the guest to directly write the content of the page table. Finally, the OS invokes switch to perform the context switch and to activate the new L1.
The example demonstrates some of the principles used to design the minimal API: (i) the address of the page tables are chosen by the guest, thus we do not need to change the OS allocators, (ii) the preparation of the page table can be done by the OS without mediation of the hypervisor, (iii) the content of the page table is not copied into the hypervisor memory, thus reducing memory accesses and memory overhead and not requiring dynamic allocation in the hypervisor, (iv) tracking the reference counter is used to guarantee the absence of page tables granting the guest write access to another page table, thus we can allow context switches among all created L1s without needing to re-validate their content.
When an exception is raised, the CPU redirects execution flow to a fixed location according to the exception vector. In ARMv7, subsequent instructions are executed in privileged mode but under the same virtual memory mapping as the interrupted guest. The hypervisor must enforce that the memory mapping of the exception vector, handler code, and hypervisor data structures is accessible during an exception without being modifiable by the guests. To this end, the hypervisor maintains its own static virtual memory mapping in a master page table and mirrors the corresponding regions to all L1s of the guest (with restricted access permissions).
Hypervisor accesses to guest page tables
The hypervisor APIs must be able to read and write the page tables allocated by the guest, in order to check the soundness of the requests and to apply the corresponding changes. The naive solution requires the hypervisor to change the current page table, enabling a hypervisor master page table whenever the guest memory must be accessed and then re-enabling the original page table before the guest is restored. This solution is expensive as it requires to flush TLB and caches. A solution tailored for Unixes can rely on the injective mapping built by the guest, which can be used by the hypervisor to access the guest kernel memory. In our settings the hosted guest is not trusted, thus this solution cannot guarantee that the injective mapping is obeyed by the guest. Some ARMv7 CPUs support special coprocessor instructions for virtual-to-physical address translation. These instructions can be used to validate the guest injective mapping at run-time. However, this approach is platform dependent and can result in nested exceptions that complicate the architecture and verification of the hypervisor. Instead, our design reserves a subset of the virtual address space for hypervisor use. The hypervisor master page table is built so that this address space is always mapped according to an injective translation (1-to-1) allowing the hypervisor to easily compute the virtual address for each physical address in the guest memory, similar to the direct memory maps supported by FreeBSD [36] and Linux [21]. As with the hypervisor code and data structures, these regions are mirrored in all guest L1 tables.
Memory model and cache effects
Hypervisors are complex software interacting directly with many low level hardware components, like processor, MMU, etc. Furthermore, there are hardware pieces that, while being invisible to the software layer, still can affect the system behaviour in many aspects. For example, the memory management unit relies on a caching mechanism, which is used to speed up accesses to page table entries. Basically, a data-cache is a shared resource between all partitions and it thus affects and is affected by activities of each partition. Consequently, data-caches may cause unintended interaction between software components running on the same processor, which can lead to cross-partition information leakage.
Moreover, for the ARMv7 architecture cache usage may cause sequential consistency to fail if the same physical address is accessed using different cacheability attributes. This opens up for TOCTTOU2
TOCTTOU – Time Of Check To Time Of Use.
As an example (Fig. 6), the guest can use an uncacheable virtual alias of a page table entry in physical memory to bypass the page type constraints and install a potentially harmful page table. If the cache contains a valid page table entry PTE A for the physical address from a previous check by the hypervisor and this cache entry is clean (i.e., it will not be written back to memory upon eviction), the guest can (1) store an invalid (i.e. violating the page table policy) page table entry PTE B in a data page and (2) request the data page to become a page table. If the guest write is (3) directly applied to the memory, bypassing the cache using a uncacheable virtual address, and (4) the hypervisor accesses the same physical location through the cache, then the hypervisor potentially validates stale data (5). At a later point in time, the validated data PTE A is evicted from the cache and not written back to memory since it is clean. Then (6) the MMU will use the invalid page table containing PTE B instead and its settings become untrusted.
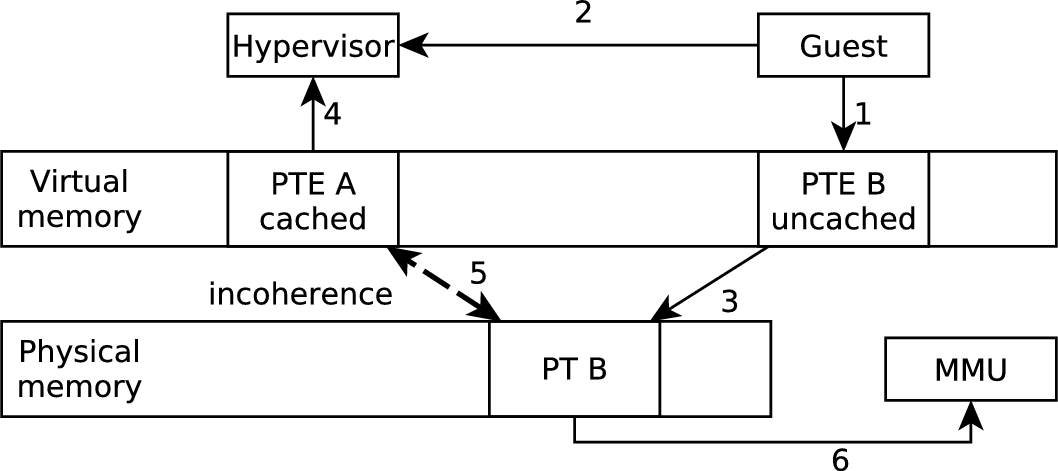
Integrity threat due to incoherent memory caused by mismatched cacheability attributes. PTE A is validated by the hypervisor (4) but PTE B will be used as a page table entry for the guest (6).
This kind of behaviour undermines the properties assured by formal verification that assumes a sequentially consistent model. In this paper, to counter this threat we use a naive solution; we prevent memory incoherence by cleaning the complete cache before accessing data stored by the guest. Clearly, this can introduce a substantial performance overhead, as shown in Section 10.2. In [18], we demonstrate more efficient countermeasures to such threats and propose techniques to fix the verification.
The top level specification
A state of the Top Level Specification (TLS) is a tuple
The TLS interleaves standard unprivileged transitions with abstract handler invocations. Formally, the TLS transition relation If If
In our setup the trusted services and the untrusted guest are both executed in unprivileged mode. To distinguish between these two partitions, we use ARM domains. We reserve the domains 2–15 for the secure services.
(Secure services).
Let
Intuitively, guaranteeing spatial isolation means confining the guest to manage a part of the physical memory available for the guest uses. In our setting, this part is determined statically and identified by the set of physical addresses
(Invariant preserved).
Let
Section 7 elaborates the definition of the invariant and summarises the proof of the Theorem.
Complete mediation (MMU-integrity) is demonstrated by showing that neither the guest nor the secure services are able to directly change the content of the page tables and affect the address translation mechanism.
(MMU-integrity).
Let
We use the approach of [27] to analyse the hypervisor data separation properties. The observations of the guest in a state
The remaining part of the state (i.e. the content of the memory locations that are not part of the guest memory, banked registers) and, again, the coprocessor registers constitute the secure observations
The following theorem demonstrates that the context switch between the untrusted guest and the trusted services is not possible without the mediation of the hypervisor. The proof is straightforward, since S only depends on coprocessor registers that are not accessible in unprivileged mode.
(No context switch).
Let
The no-exfiltration property guarantees that a transition executed by the guest does not modify the secure resources:
(No-exfiltration).
Let
If
The no-infiltration property is a non-interference property guaranteeing that guest instructions and hypercalls executed on behalf of the guest do not depend on any information stored in resources not accessible by the guest.
Let
If
(No-infiltration).
The implementation model
A critical problem of verifying low level platforms is that intermediate states of a handler that reconfigures the MMU can break the semantics of the high level language (e.g. C). For example, a handler can change a page table and (erroneously) unmap the region of virtual memory where the handler data structure (or the code) are located. For this reason we introduce the implementation model, that is sufficiently detailed to expose misbehaviour of the hypervisor accesses to the observable part of the memory (i.e. page tables, guest memory and internal data structures). The implementation interleaves standard unprivileged transitions and hypervisor functionalities. In contrast to the TLS, these functionalities now store their internal data in system memory, accessed by means of virtual addresses. In practice, in the implementation model the hypervisor functionalities are expressed as executable specifications, yet they are very close to the execution of the actual hardware at instruction semantics level. We demonstrate these differences by comparing two fragments of the TLS and the implementation specifications.
The TLS models the update of a guest page table entry as

where
The implementation can fail to match the TLS for two reasons: (i) the current page table can prevent the hypervisor from accessing the computed virtual address, and then the implementation terminates in a failing state (denoted by ⊥), (ii) the current address translation does not respect the expected injective mapping, thus
The next example shows the difference between accesses to the reference counter in the TLS and at implementation level. The TLS models this operation as

This representation is directly reflected in the hypervisor code. For each block, the page type (two bits) and the reference counter (30 bits) are placed contiguously in a word. These words form an array, whose initial virtual address is
The handlers are represented by a HOL4 function
Then, the state transition relation
If
If
To show implementation soundness we exhibit a refinement property relating abstract states
(Implementation refinement).
Let
If
If
Finally we show that the security property of the TLS and the refinement relation directly transfer the mmu-integrity/no-exfiltration/no-infiltration to the implementation. We use
Let
if
if
if
(Implementation security transfer).
Binary code correctness
In the ARMv7 model of Section 4 the untrusted guest, the trusted services and the hypervisor share the CPU, and the hypervisor behaviour is modelled by the execution of its binary instructions.
Intuitively, internal hypervisor states cannot be observed by the guest, since (i) during the execution of the handler the guest is not active, (ii) the hypervisor does not support preemption and (iii) the handlers do not raise nested exceptions. For this reason, we introduce a weak transition relation, which hides states that are privileged. We write
Our goal is to exhibit a refinement property relating implementation states
(Real refinement).
Let
If
If
Finally one must show that the security properties are transferred to the real model.
Let
if
if
if
(Real security transfer).
Execution safety and end-to-end information flow security
Note that we do not prove explicitly execution safety. The reason is that the transition relations of the ARM CPU and the TLS are left-total. Left-totality for the ARM CPU depends on the fact that the physical CPU never halts (with the exception of the privileged “wait” instruction that is never used by the hypervisor). Left-totality for the TLS holds because the virtualization API is modelled by HOL4 total functions over TLS states; every function is equipped with a termination proof, which is either automatically inferred by the theorem prover or has been manually verified. The only transitions that can yield a dead state (⊥) are the hypervisor transitions of the implementation model, due to incorrect memory accesses. Proving that this model can never reach the state ⊥ is part of the proof of Theorem 6. It makes use of Lemma 9, which shows that all hypervisor memory accesses are correct.
We do not prove standard end-to-end information flow properties because their definitions depend on the actual trusted services. This is often the case when two components are providing services to each other. For example, if the trusted service is the run-time monitor of Section 12, then it should be able to directly read the memory of the untrusted Linux (to compute the signatures). Additionally, the trusted service can be allowed to affect the behaviour of the guest, for example by rebooting it or by changing its process table if a malware is detected.
However, our verification results enable the enforcement of end-to-end security by properly restricting the capability of the trusted services. In fact, these services are executed non-privileged, thus their execution is constrained by Properties 1 and 2. Moreover, their memory mapping is static, is configured in the master page table of the hypervisor, and is independent of the guest configuration. If complete isolation is needed, it is sufficient to configure these entries of the master page table properly, use Properties 1 and 2 together with Theorem 2 to prove that the trusted services cannot affect and are independent of the guest resources. This enables the trace properties to be established and consequently to obtain end-to-end security.
TLS consistency
We proceed to describe the strategy for proving the TLS consistency properties of Section 6.1. To this end we summarise the structure of the system invariant. The system invariant consists of two predicates: one (
The reference counter is sound (i.e.
if b is a data block and i is a page table, i.e.
if b is a L2 page table and i is a L1 page table then
if i is not a page table, i.e.
A system state is well typed (
The proofs of the theorems of Section 6.1 have been obtained using the HOL4 theorem prover and the lemmas are described in the following.
(Invariant implies MMU-safety).
If
Lemma 1 demonstrates an important property of the system invariant; a state that satisfies the invariant has the same MMU behaviour as any state whose memory differs only for addresses that are writable in unprivileged mode. The proof of the lemma depends on the formal model of the ARMv7 MMU (but not on its instruction set); there the MMU behaviour is determined by coprocessor registers and the contents of the active L1 and referenced L2 page tables. The invariant guarantees that the active L1 page table of σ resides in four consecutive blocks that have type L1 and every page table descriptor in this table points to a block typed L2. Moreover, only data blocks may be writable in unprivileged mode and write attempts to other blocks will be rejected. We examine a state
To demonstrate MMU-integrity the ARM-integrity property is used. By definition of the TLS transition relation, if
Let
The proof of Lemma 2 uses the formal ARMv7 MMU model and directly follows from the invariant. In particular, part (iii) of predicate
Similar to the proof of Theorem 2, the definition of the transition relation and Lemma 1 yield that
We proceed separately for unprivileged and privileged transitions. For unprivileged transition the ARM-confidentiality property is used. As proven above, from the definition of the transition relation, Lemma 1,
The proof of the Theorem 5 for hypervisor transitions has been obtained by performing relational analysis. The function
Finally, we prove Theorem 1 by showing that the invariant is preserved first by guest transitions (Lemma 3) and then by the abstract handlers (Lemma 4). □
Let
This lemma demonstrates that the invariant is preserved by guest transitions. Its proof depends on the ARM-integrity property. It is straightforward to show that the invariant only depends on the content of the physical blocks that are not typed D and the hypervisor data (i.e. h and
(Invariant vs hypervisor).
Let
The lemma demonstrates that the invariant is preserved by the handler functionalities and shows the functional correctness of the TLS design. By definition, if
This verification task requires the introduction of several supporting lemmas. The idea is that according to the input request, the abstract handler only changes a small part of the system state. For instance, when
Let h and
Changing the type of a block can affect the soundness of page tables that reference that block. The following lemma expresses the key property that soundness of page tables is preserved for all type changes of other blocks, as long as the reference counters of that blocks are zero:
Assume
The proof of Lemma 5 hinges on the fact that type changes can only break parts (ii) and (iv) of the page table soundness condition. However, if the type is only changed for blocks that are not referenced by any page table, soundness is preserved trivially.
We exemplify the usage of Lemma 5 when proving Lemma 4. Assume that
Similarly, the following lemma shows that, if the page type is changed only for blocks with zero references, then for all other page tables, the number of references is unchanged.
Assume
Finally we use the following lemma to show that the well-typedness of a block and its counted outgoing references are independent from the content of the other physical blocks.
Let
For every functionality of the virtualization API (see Fig. 2), Lemmas 5, 6 and 7 help to limit the proof of Lemma 4 to only checking the well-typedness and soundness of the reference counter for the blocks that are affected by
To verify the implementation refinement relation (i.e. prove Theorem 6) we proved two auxiliary lemmas:
(Real MMU).
Let
The Lemma shows that TLS and implementation states have the same MMU configuration. Its proof uses that the system invariant requires page tables to be allocated inside the guest memory, whose content is the same in the TLS and implementation states. Moreover, coprocessor registers contain the same data.
(Hypervisor page tables).
Let
For all
For every block b and access request
The lemma shows that the implementation is always able to access the guest memory and the hypervisor data structures, and that the computed physical addresses match the expected values. To prove that the refinement is preserved by all possible transitions we verify independently the guest and hypervisor transitions. For guest transitions, Theorem 4 (No-exfiltration) and Lemma 1 (MMU-safety) guarantee that the guest can change neither the memory outside The proof depends on the fact the relation
Binary analysis is key requirement to ensure security of low-level software platform, like hypervisors. Machine code verification obviates the necessity of trusting the compilers. Moreover, low level programs mix structured code (e.g. implemented in C) with assembly and use instructions (e.g. mode switches and coprocessor interactions) that are not part of the high level language, thus making difficult to use verification tools that target user level code.
For our hypervisor the main goal of the verification of the binary code is to prove Theorem 7. This verification relies on Hoare logic and requires several steps. The first step (Section 9.2) is transforming the relational reasoning into a set of contracts for the hypervisor handlers and guaranteeing that the refinement is established if all contracts are satisfied. Let C be the binary code of one of the handlers, the contract
Then, we adopt a standard semi-automatic strategy to verify the contracts. First, the weakest liberal precondition
The second verification step (computation of weakest preconditions) can be performed directly in HOL4 using the ARMv7 model. However, this task requires a significant engineering effort. We adopted a more practical approach, by using the Binary Analysis Platform (BAP) [9]. The BAP tool-set provides platform-independent utilities to extract control flow graphs and program dependence graphs, to perform symbolic execution and to perform weakest-precondition calculations. These utilities reason on the BAP Intermediate Language (BIL), a small and formally specified language that models instruction evaluation as compositions of variable reads and writes in a functional style.
The existing BAP front-end to translate ARM programs to BIL lacks several features required to handle our binary code: Support of ARMv7, management of processor status registers, banked registers for privileged modes and coprocessor registers. For this reason we developed a new front-end, which is presented in Section 9.3, that converts an ARMv7 assembly fragment to a BIL program.
The final verification step consists of checking that the precondition P implies the weakest precondition. This task can be fully automated if the predicate
An alternative approach for binary verification is to use the “decompilation” procedure developed by Myreen [39]. This procedure takes an ARMv7 binary and produces a HOL4 function that behaves equivalently (i.e. implements the same state transformation). This result allows to lift the verification of properties of assembly programs to reasoning on HOL4 functions. However, the latter task can be expensive due to the lack of automation in HOL4.
Soundness of the verification approach
The procedure described here to establish the functional correctness of the hypervisor code relies on four main arguments.
The HOL4 procedures that evaluate the effects of a given instruction in the ARMv7 model specify the updates to the processor state correctly. We use the ARMv7 step theorems to guarantee the correctness of this task. The lifter transforms this state update information into an equivalent list of single-variable assignments in BIL. The correctness of this part of the lifter is an assumption for now. The expressions in each update of a processor component are correctly translated to BIL expressions in the list of assignments, preserving their semantics. This has been proven for our lifter. The binary code fragment that is lifted is actually executed on the ARMv7 hardware.
The last argument relies on the fact that the boot loader places the unmodified hypervisor image to the right place in memory. This is another assumption since we do not verify our boot loader. Furthermore there must not be self-modifying code. The easiest way to enforce this is to partition the hypervisor memory via its page table into data and code region and prove an invariant that the first is non-executable but the latter is non-writeable. There is no such protection against self-modifying code in the hypervisor at the moment. Finally, one needs to show that the binary code is not interrupted, thus proving that the hypervisor is in deed non-preemptive. We do not have a full proof of the statement, but there are provisions in the lifter to show the absence of ARMv7 interrupts and exceptions.
For system call and unknown instructions, the lifter generates BIL statements that always fail, i.e., one can only verify programs in BAP that do not use such instructions. We follow the same approach for fetches, jumps, and memory instructions accessing constant addresses which are not mapped in the hypervisor’s static page table. Thus such operations cannot produce pre-fetch or data aborts. Additional care has to be taken to distinguish data and code regions to avoid permission faults due to writes to the code region or fetches from the data region, however there are no such checks at the moment. Indirect jumps are solved dynamically based on the lifted BIL program (see Section 9.4) and for any jump to a location that is not defined in the program, i.e., not in the region accessible by the hypervisor, analysis with BAP will give an error. For dynamic memory accesses the lifter is able to insert assertions that the corresponding address is mapped, however the feature is currently not activated automatically. At last, the reception of external interrupts should not be re-enabled during hypervisor execution. Currently this invariant is not checked in the code verification but it could be easily added as an assertion between every instruction.
Generation of the contracts
Let C be the binary code of one of the handlers, we define the precondition P and the postcondition Q such that the contract subsumes the refinement:
These contracts are not directly suitable for the verification of the binary code because the contracts quantify on states (
This procedure makes heavy use of the simplification rules and decision procedures of HOL4. We informally summarise how this procedure works for the memory resource. The precondition
For the postcondition
For every address
For every address
When the symbolic execution is too complex (e.g. too many outcomes are possible according to the initial state), we split the verification by generating multiple contracts
Translation of ARMv7 to BIL
The target language of the ARMv7 BAP front-end is BIL, a simple single-variable assignment language tailored to model the behaviour of assembly programs and developed to be platform independent. A BIL program is a sequence of statements. Each statement can affect the system state by assigning the evaluation of an expression to a variable, (conditionally or unconditionally) modifying the control flow, terminating the system in a failure state if an assertion does not hold and unconditionally halting the system in a successful state. The BIL data types for expressions and variables include boolean, words of several sizes and memories. The main constituent of BIL statements are expressions, that include constants, standard bit-vector binary and unary operators, and type casting function. Additionally, an expression can read several words from a memory or generate a new memory by changing a word in a given one.
We developed the new front-end on top of the HOL4 ARM model (see Section 4), so that the soundness of the transformation from an ARM assembly instruction to its corresponding BIL program relies on the correctness of the ARM model used in HOL4 and not on a possibly different formalization of ARMv7. Our approach is illustrated in Fig. 7.
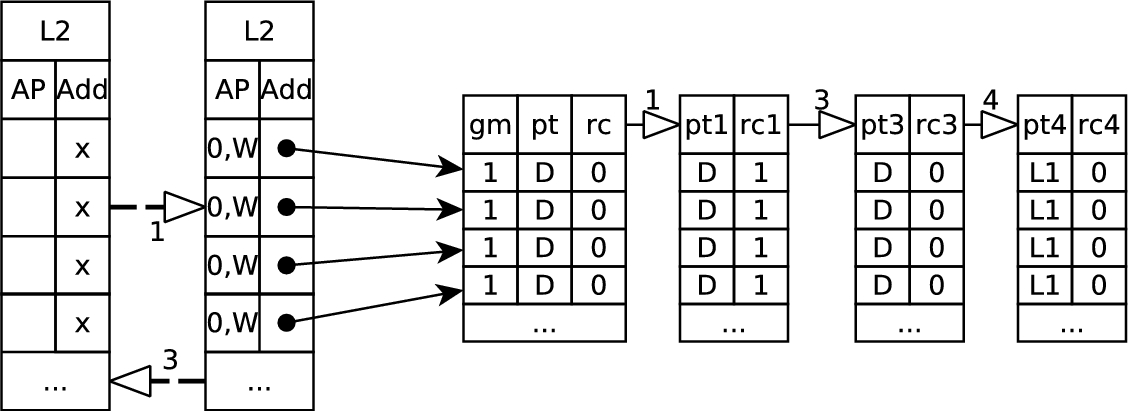
Lifting machine code to BIL using the HOL4 ARMv7 model. The
The HOL4 model provides a mechanism to statically compute the effects of an instruction via the
The translation procedure involves the following steps, (i) mapping HOL4 ARM states to BIL states and (ii) for each instruction of the given assembly fragment producing the BIL fragment that emulates the
To transform an ARM instruction to the corresponding BIL fragment we need to capture all the possible effects of its execution in terms of affected registers, flags and memory locations. The generated BIL fragment should simulate the behaviour of the instruction executed on an ARM machine. Therefore, to obtain a BIL fragment for an instruction we need to translate the predicates
The described lifting procedure is straightforward. However, its soundness depends on the correct transformation of HOL4 terms (e.g.
In order to dynamically generate the certifying theorem, the translation procedure is implemented in ML, which is the HOL4 meta language. The translation syntactically analyses and deconstructs the input expressions to select the theorems to use in the HOL4 conversion and rewrite rules. For terms composed by nested expressions the procedure acts recursively.
To compute the weakest precondition of a program is necessarily to statically know the control flow graph (CFG) of the program. This means that the algorithm depends on the absence of indirect jumps. Even if the hypervisor C-code avoids their explicit usage (e.g. by not using function pointers), the compiler introduces an indirect jump for each function exit point (e.g. the instruction at the address The CFG of the of C fragment is computed using BAP. From the CFG, the list L of reachable addresses containing an indirect jump is extracted. For each address let the indirect jump is substituted with an assertion, which requires The new fragment has no indirect jump; the weakest precondition The SMT solver searches for an assignment of the free variables (including all If the SMT solver discovers a counterexample which involves the indirect jump at the address a, then it also discovers a possible target for this jump via selected assignment of the variable If the SMT solver does not find a counterexample, then every indirect jump is either unreachable or all its possible targets have been discovered. The fragment C is transformed by substituting every indirect jump with an assertion that always fails ( The procedure is restarted. Note that the inserted conditional statements prevent that the discovered assignments of
In order to handle the greater complexity of the hypervisor code respect to the separation kernel verified in [19], we re-engineered this tool as a BAP plug-in. A particular problem that we face is that the CFG can contain loops if the same internal function of the hypervisor is called twice from different points in the program. Integrating the procedure with BAP allowed us to reuse the existing loop-unfolding algorithms to break these artificial loops.

Indirect jump example.
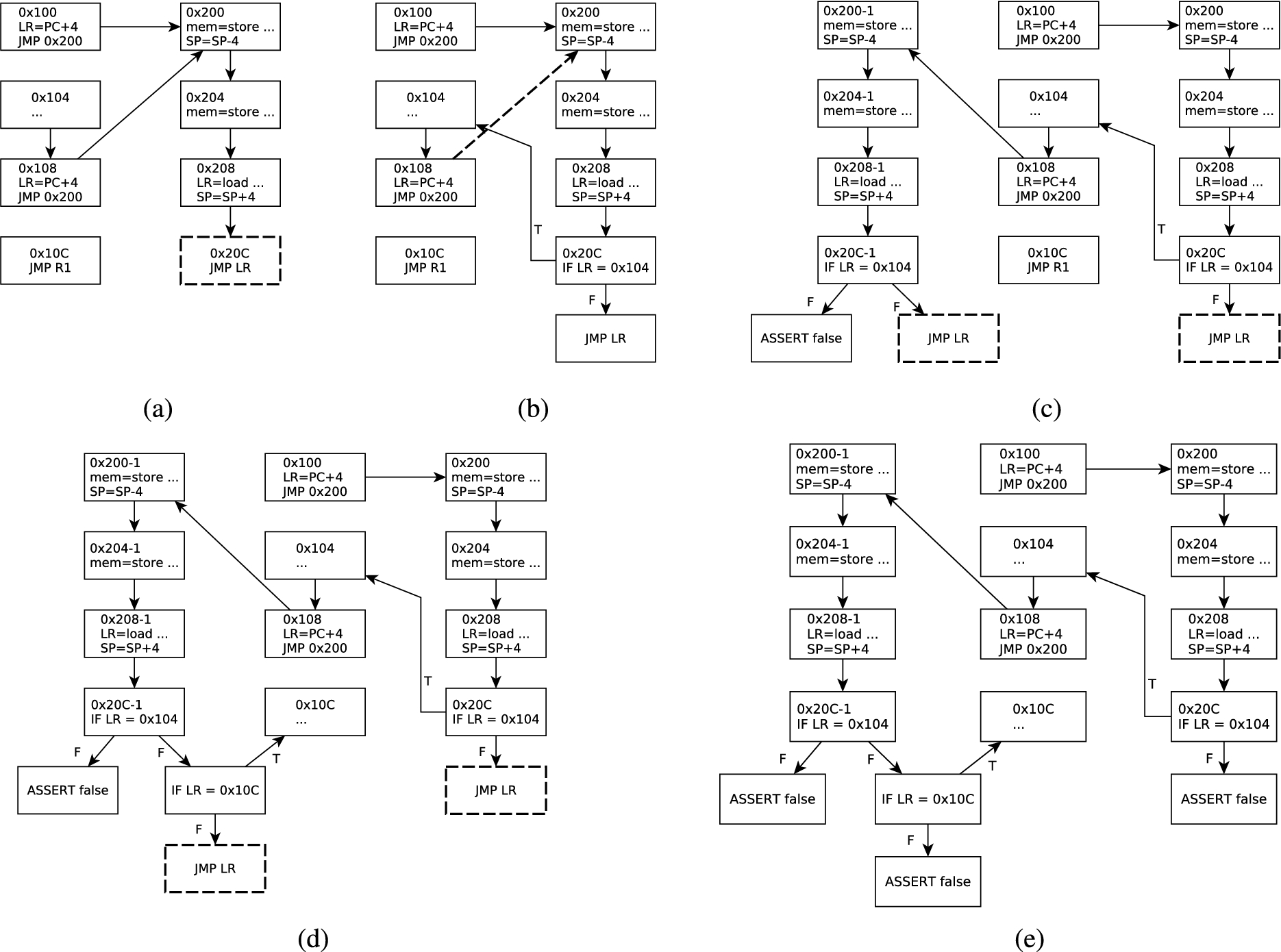
Execution of the indirect jump solver.
We use Figs 8 and 9 to demonstrate the algorithm. The assembly program (Fig. 8(a)) contains a function at
In addition to solving indirect jumps, effective application of the verification strategy required the implementation of several tools and optimisation of the weakest precondition algorithm of BAP. Weakest preconditions can grow exponentially with regard to the number of instructions. Even though this problem cannot be solved in general, we can handle the most common case for ARM binaries, namely the sequential composition of several conditionally executed arithmetical instructions. This pattern matches the optimisation performed by the compiler to avoid small branches. We improved the BAP weakest precondition algorithm by adding a simplification function that identifies these cases. For some fragments of the code this straightforward strategy strongly reduced the size of the precondition; e.g. for one fragment consisting of 27 C lines compiled to 35 machine instructions the size of the precondition has been reduced from 8 GB to 15 MB.
Furthermore, machine code (and BIL) lacks information on data types (except for the native types like word and bytes) and represents the whole memory as a single array of bytes. Writing predicates and invariants is complex because their definition depends on location, alignment and size of data-structure fields. Moreover, the behaviour of compiled code often depends on the content of static memory used to represent constant values of the high level language. We developed a set of tools that integrate HOL4 and GDB to extract information from the C source code and the compiled assembly. With the support of these tools we are able to write the invariants and contracts of the hypervisor independently of the actual symbol locations and data structure offsets produced by the compiler.
Figure 10 summarises the work-flow of our binary verification approach.
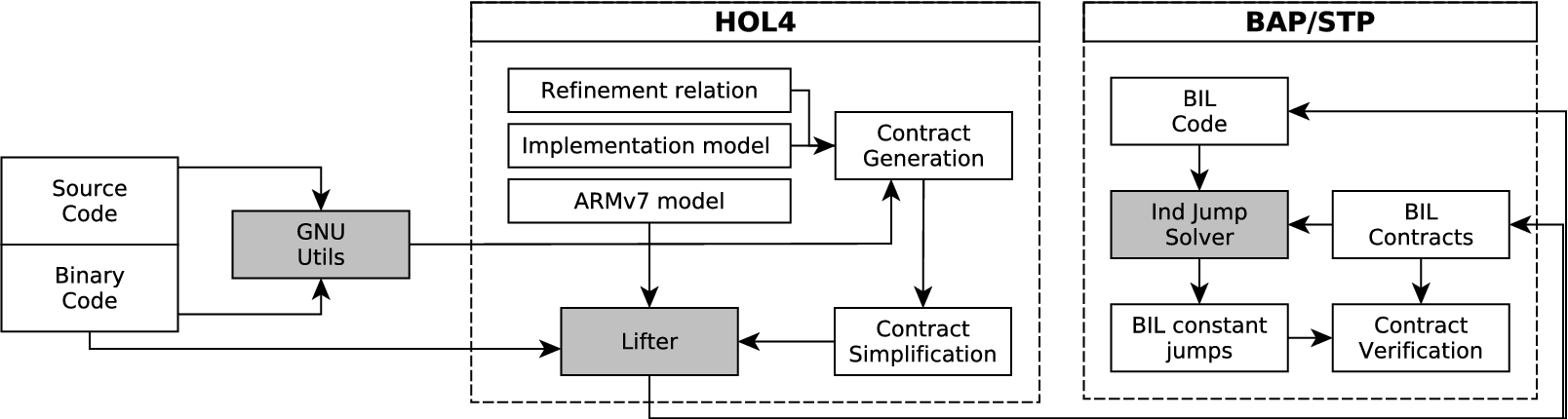
Binary verification work-flow: Contract Generation, generating pre and post conditions based on the specification of the low-level abstraction and the refinement relation; Contract Simplification, messaging contracts to make them suitable for verification; Lifter, lifting handlers machine code and the generated contracts in HOL4 to BIL, Ind Jump Solver, procedure to resolve indirect jumps in the BIL code; BIL constant jumps, BIL fragments without indirect jumps; Contract Verification using SMT solver to verify contracts. Here, grey boxes are depicting the tools that have been developed to automate the verification as much as possible.
The binary verification of the hypervisor has not been completed yet due to some time consuming tasks that require better automation. First, the inference procedure of Section 9.2 uses the HOL4 simplification rules and decision procedures, however it is not completely automatic and must be adapted for every handler. Without taking into account the specificity of each handler, a naive procedure can easily generates contracts that cannot be handled by SMT solvers. For every handler, we manually specialize the procedure to generate contracts that have no quantifier in the precondition and only universal quantifiers in the postcondition.
Further complexity arises due to presence of loops. In theory, loops can be automatically handled by unfolding, since all loops in the hypervisor code iterate over fixed and limited ranges (e.g. the number of descriptors in a page table). Practically, this increases the size of the code (1024 times for handlers working on L2, and up to
By design, every loop in the hypervisor is also present in the specification. Let
that is, a new refinement relation/invariant
Implementation
The implementation of the hypervisor demonstrates the feasibility of our approach. The actual implementation targets BeagleBoard-xM (which is equipped with an ARM Cortex-A8) and supports the execution of Linux as the untrusted guest. The hypervisor executes both the untrusted guest and the trusted services in unprivileged mode, and their execution is cooperatively scheduled. Theorems 1, 2 and 3 guarantee that the main security properties of the system (i.e. the correct setup of the page tables) cannot be violated by either the guest or the trusted services. Moreover, the untrusted guest cannot directly affect the trusted services or directly extract information from their states (Theorems 4 and 5). This isolation is achieved by the complete mediation of the MMU settings and the allocation of the ARM domains 2–15 to the secure services. This approach limits the number of secure services to fourteen. However, this mechanism has the benefit of using the same page tables for both the guest and the trusted services (by reserving an area of the hypervisor virtual memory for the latter). This reduces the cost of context switch, since TLB and caches do not need to be cleaned. If more trusted services are needed, a separate page tables can be used.
The core of the hypervisor is the virtualization of the memory subsystem. This is provided by the handlers that are the subject of the verification and that are modelled by the transformations
Linux support
The Linux kernel 2.6.34 has been modified to run on top of the hypervisor. This task required modification of architecture-dependent parts of the Linux kernel like execution modes, low-level exception routines and page table management. High-level OS functions such as process, resource and memory manager, file system, and networking did not require any modifications. This also introduce the additional handlers of the hypervisor that are not part of the formal verification.
CPU privilege modes. In the absence of hardware supports, like virtualization extension, the target CPU includes only two execution modes: privileged and unprivileged (user). As for other approaches based on paravirtualization, since the hypervisor executes as privileged, the Linux kernel has been modified to execute as unprivileged. To separate kernel and user applications, the hypervisor manages two separate unprivileged execution contexts: virtual user and virtual kernel modes. In x86 these virtual modes can be implemented by segmentation. This approach is not possible for CPUs that do not provide this feature (e.g. x86 64-bit and ARM). Instead, we reserve the ARM domain 0 for the kernel virtual mode. Whenever the guest kernel requests a switch to virtual user mode (invoking the dedicated hypercall) we disable the domain 0, thus any access to the kernel virtual addresses generates a fault.
Note that the main security goal here is not to guarantee this OS-internal isolation, but to maintain the separation between the virtualized components (such as the Linux guest vs secure data or services residing in non-guest memory).
CPU exceptions. CPU exceptions such as aborts and interrupts change the processor mode to privileged. These exceptions must therefore be handled in the hypervisor, which after validation can forward them to the unprivileged exception handlers of the Linux kernel. The hypervisor supplies the kernel exception handlers with some privileged data needed to correctly service an on-going exception (e.g. for pre-fetch abort, the privileged fault address and fault status registers are forwarded to the guest). The exception handlers in the Linux kernel have thus been slightly modified to support this. Among the exceptions that are forwarded to the Linux kernel there are the hardware interrupts delivered by the timer. This allows Linux to implement an internal time based scheduler.
Memory management. To paravirtualize the kernel, we modified the architecture dependent layer of its memory management. In the modified Linux all accesses to the coprocessor registers or to the active page tables are done by issuing the proper hypercalls. The architecture independent layer of the memory management has been left unmodified. In order to speed up the execution of Linux, a minimal emulation layer has been moved from the Linux kernel into the hypervisor itself. This layer reduces the overhead by translating a guest request into a sequence of invocations of the APIs that virtualize the MMU. Since the emulation layer accesses page tables only through the virtualization API, showing memory safety of this component is sufficient to extend the coverage of the verification.
Run-time overhead
The port of the Linux kernel 2.6.34 on the hypervisor allows us to present a rough comparison of our approach with existing paravirtualized hypervisors for the ARM architecture [30]. The purpose of the evaluation is more to demonstrate that our approach actually runs with reasonable efficiency. A serious evaluation is out of scope of this work. It requires a more optimised implementation, and a more comprehensive evaluation.
The run-time evaluation is done using LMBench [37] running on Linux 2.6.34 with and without virtualization. The outcome, measured on an ARMv7-A Cortex-A8 system (BeagleBoard-xM [46]), is presented in Table 2. The significant virtualization overhead for the fork benchmarks is due to a large number of simple operations (in this case, write access to a page-table) being replaced with a large number of expensive hypercalls. It may be possible to reduce this overhead with minimal optimisation (e.g. batching). In Table 2 we also report measures from [30], where the authors compare several existing hypervisors for ARM. We point out that these performance numbers have been obtained from different sources, testing different ARM cores, boards and hosted Linux kernels. Hence we do not claim to be able to draw any hard conclusions from these figures about the relative performance of the hypervisors or their underlying architectures.
With the purpose of demonstrating that the hypervisor can run efficiently real applications, in Table 3 we report the overhead introduced when executing tar, dd and several compression tools. The second column reports the latency for the version of the hypervisor that aggressively flushes the caches (i.e. the caches are completely clean and invalidated whenever an exception or an interrupt is raised, while the hypervisor in the first column limits cache flushes to the cases of context switch). This naive approach guarantees that the actual CPU respects the fully sequential memory model, but introduces severe performance penalties especially in the application benchmarks. Less conservative approaches (e.g. evicting only the necessary physical addresses or forcing the page tables to be allocated in memory regions that are always cacheable) can be adopted for some processor implementations, but they require a more fine-grained modelling including caches and an adaptation of the verification approach for their justification, as discussed in [18].
Latency benchmarks. LMBench micro benchmarks for the Linux kernel v2.6.34 running naively on BeagleBoard-xM, paravirtualized on the hypervisor without cache flushing (Hypervisor), with aggressive flushing (Aggressive cache flushes), and the other hypervisors (L4Linux, Xen, OKL4). Figures in the three last columns have been obtained from different ARM cores, boards and hosted Linux kernels
Latency benchmarks. LMBench micro benchmarks for the Linux kernel v2.6.34 running naively on BeagleBoard-xM, paravirtualized on the hypervisor without cache flushing (Hypervisor), with aggressive flushing (Aggressive cache flushes), and the other hypervisors (L4Linux, Xen, OKL4). Figures in the three last columns have been obtained from different ARM cores, boards and hosted Linux kernels
Latency benchmarks. Application benchmarks for the Linux kernel v2.6.34 running natively on BeagleBoard-xM, paravirtualized on the hypervisor without cache flushing (Hypervisor), with aggressive flushing (Aggressive cache flushes)
Memory footprint. Comparison of memory usage of Shadow page table and direct paging
The main difference between our proposal and the existing verified hypervisors is the MMU virtualization mechanism. The direct paging approach requires a table which contains at most
It should be noted that on ARMv7, most operating systems including Linux dedicate one L1 page to each process and at least three L2 pages to map the stack, the executable code and the heap. Then the OS itself has a minimum footprint of
Evaluation
The hypervisor is implemented in C (and some assembly) and consists of 4529 lines of code (LOC). Excluding platform dependent parts, the hypervisor core is no larger than 2066 LOC. The virtualization of the memory subsystem consists of 1200 LOC. To paravirtualize Linux we changed 1025 LOC of its kernel, 950 in the ARM specific architecture folder and 75 in init/main.c. The paravirtualization is binary compatible with existing userland applications, thus we do not need to recompile either hosted applications or the libc. For comparison, the only other hypervisor that implements direct paging is the Xen hypervisor, which consists of 100 KLOC and its design is not suitable for verification. Instead, the small code base of our hypervisor makes it easier to experiment with different virtualization paradigms and enables formal verification of its correctness. The formal specification consists of 1500 LOC of HOL4 and intentionally avoids any high level construct, in order to make the HOL4 model as similar as possible to the C implementation, at the price of increasing the verification cost. The complete proof consists of 18,700 LOC of HOL4.
The verification highlighted a number of bugs in the initial design of the APIs: (i) arithmetic overflow when updating the reference counter, caused by not preventing the guest to create an unbounded number of references to a physical block, (ii) bit field and offset mismatch, (iii) missing check that a newly allocated page table prevents the guest to overwrite the page table itself, (iv) usage of the signed shift operator where the unsigned one was necessary and (v) approval of guest requests that cause unpredictable MMU behaviour. Moreover, the verification of the implementation model identified three additional bugs exploitable by the guest by requesting the validation of page tables outside the guest memory. Finally, the methodology described in Section 9 has been experimented in the verification of the binary code of one of the hypercalls. This experiment identified a buffer overflow in the binary code that was missing in implementation model. The HOL4 model uses a 10-bit variable to store an untrusted parameter which is later used to index the entries of a page table. The binary code uses a 32-bit registers to store the same parameter, thus causing an overflow when accessing the L2 page table if the received parameter is bigger than 1023. The bug has been fixed by sanitising the input using the mask
The project was conducted in three steps. The design, modelling and verification of the APIs for MMU virtualization required nine person months. Here, the most expensive tasks have been the verification of Theorems 1 and 6. The C implementation of the APIs and the Linux port has been accomplished in three person months. While the implementation team was completing the Linux port the verification team started the verification of the refinement, which has taken three months so far. This work is continuing, in order to complete the verification from the HOL4 implementation level down to assembly.
Applications
Applications of the hypervisors include the deployment of trusted cryptographic services and trusted controllers. In the first scenario, the hypervisor core is extended with the handlers required to implement message passing. These handlers allow (i) Linux to send a message to the trusted service, (ii) the trusted service to reply with an encrypted message and (iii) the two partitions to cooperatively schedule themselves. The isolation properties guarantee that the untrusted guest cannot access the cryptographic keys stored in the memory of the trusted services. The second scenario includes a device (e.g. a physical sensor) whose IO is memory mapped. The guest is forbidden to access the memory where the IO registers are mapped, thus guaranteeing that the trusted controller is the only subject capable of directly affecting the device. The complete Linux system can be used to provide a rich and complex user interface (either graphical or web based) for the controller logic without affecting its security.
The MMU virtualization solution demonstrated here can be used by other ARM-based software platforms than the hypervisor reported above. A fully fledged hypervisor (e.g. XEN) can use our approach to support hardware that lacks virtualization extensions (e.g. Cortex-A8, Cortex-A5, ARM11). The mechanism can also be used by compiler-based virtual machines and unikernels, which need to monitor the memory configuration and protect it from the rest of the system (e.g. SVA uses a non-verified implementation of direct paging). Customers of cloud infrastructures can also benefit from our approach (see Fig. 11(a)). In this setting, if the virtualization extensions are available, the most privileged execution mode is controlled by the software platform managed by the cloud provider (e.g. a hypervisor). Thus, these extensions cannot be used by the customer to isolate its untrusted Linux from its own trusted services. In this setup, our mechanism can be used to fulfil this requirement.
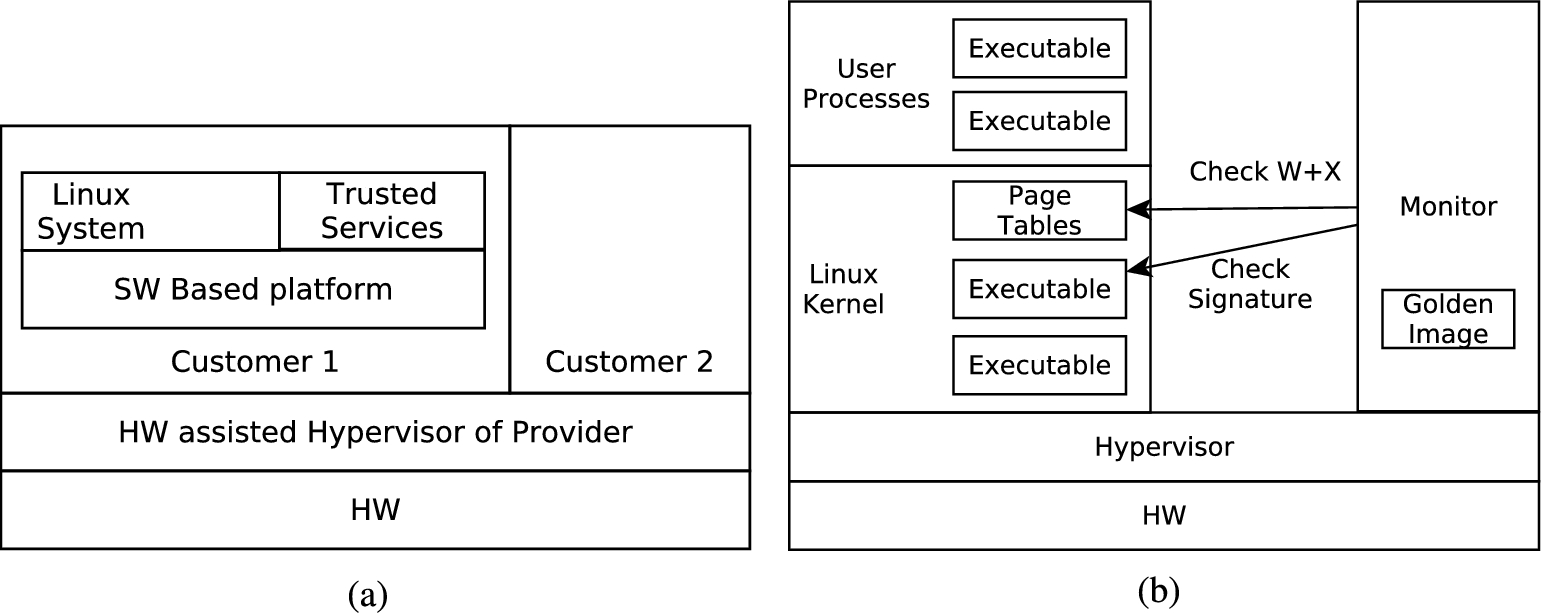
Applications of the secure virtualization platform. (a) Usage of SW-based virtualization in a cloud platform. (b) Deployment of a run-time monitor preventing code injection.
An interesting application of isolating platforms is the external protection of an untrusted commodity OS from internal threats, as demonstrated in [15]. Trustworthy components are deployed together and properly isolated from the application OS (see Fig. 11(b)). These components are used as an aid for the application OS to restrict its own attack surface, by guaranteeing the impossibility of certain malicious behaviours. In [11], we show that this approach can be used to implement an embedded device that hosts a Linux system provably free of binary code injection. Our goal is to formally prove that the target system prevents all forms of binary code injection even if the adversary has full control of the hosted Linux and no analysis of Linux is performed.
The system is implemented as a run-time monitor. The monitor forces an untrusted Linux system to obey the executable space protection policy (usually represented as
We configured the hypervisor to support the following interaction protocol:
For each hypercall invoked by a guest, the hypervisor forwards the request to the monitor. The monitor validates the request based on its validation mechanism. The monitor reports to the hypervisor the result of the hypercall validation.
Since the hypervisor supervises the changes of the page tables, the monitor is able to intercept all the memory layout modifications. This makes the monitor able to know whether a physical block is writable: if there exists at least one virtual mapping pointing to such block and having writable access permission. Similarly it is possible to know which physical block is executable.
Then the signature checking is implemented in the obvious way: whenever Linux requests to change a page table (i.e. causing to change the domain of the executable code) the monitor (i) identifies the physical blocks that can be made executable by the request, (ii) computes the block signature and (iii) compares the result with the content of the golden image. This policy is sufficient to prevent code injection that is caused by changes of the memory layout setting, due to the hypervisor forwarding to the monitor all requests to change the page tables.
Figure 11(b) depicts the architecture of the system; both the run-time monitor and the untrusted Linux are deployed as two guests of the hypervisor. Using a dedicated guest on top of the hypervisor permits to decouple the enforcement of the security policies from the other hypervisor functionalities, thus keeping the trusted computing base minimal. Moreover, having the security policy wrapped inside a guest supports both the tamper-resistance and the trustworthiness of the monitor. In fact, the monitor can take advantage from the isolation properties provided by the hypervisor. This avoids malicious interferences coming from the other guests (for example from a process of an OS running on a different partition of the same machine). Finally, decoupling the run-time security policy from the other functionalities of the hypervisor makes the formal specification and verification of the monitor more affordable.
The formal model of the system (i.e. consisting of the hypervisor, the monitor and the untrusted Linux) is built on top of the models presented in Section 6.1. Here we leave unspecified the algorithm used to sign and check signatures, so that our results can be used for different intrusion detection mechanisms. The golden image
To formalize the top level goal of our verification we introduce some auxiliary notations. The “working set” identifies the physical blocks that host executable binaries and their corresponding content. Let σ be a machine state. The working set of σ is defined as
By using a code signing approach, we say that the integrity of a physical block is satisfied if the signature of the block’s content belongs to the golden image. Let
The system state is free of malicious code injection if the signature check is satisfied for the whole executable code. That is: Let σ be a machine state,
Finally, in [11] we demonstrate our top level goal: No code injection can succeed.
If
We implemented a prototype of the system. The monitor code consists of 720 lines of C and 100 lines have been added to the hypervisor to support the needed interactions among the hosted components.
We have presented a memory virtualization platform for ARM based on direct paging, an approach inspired by the paravirtualization mechanism of Xen [7], and the Secure Virtual Architecture [17]. The platform has been verified down to a detailed model of a commodity CPU architecture (ARMv7-A), and we have shown a hypervisor based on the platform capable of hosting a Linux system while provably isolating it from other services. The hypervisor has been implemented on real hardware and shown to provide promising performance, although the benchmarks presented here are admittedly preliminary. The verification is done with respect to a top-level model that augments a real machine state with additional model components. The verification shows complete mediation, memory isolation, and information flow correctness with respect to the top-level model. As the main application we demonstrated how the virtualization mechanism can be used to support a provably secure run-time monitor for Linux that provides secure updates along with the
The main precursor work on formally verified MMU virtualization uses the simulation-based approach of Paul et al. [1,2,41]. In [2,41] shadow page tables are used to provide full virtualization, including virtual memory, for “baby VAMP”, a simplified MIPS, using VCC. Full virtualization is generally more complex than the paravirtualization approach studied in the present paper, but the machine model is simplified, information flow security is not supported by the simulation framework, and neither applications nor implementation on real hardware are reported. In [1] the same simulation-based approach is used to study TLB virtualization on an abstract version of the x64 virtual memory architecture. Other related work on verification of microkernels and hypervisors such as seL4 [33] or the Nova project [45] does not address MMU virtualization in detail. It may be argued that the emergence of hardware based virtualization support makes software MMU virtualization obsolete. We argue that this is not the case. First, many platforms remain or are currently in development that do not yet support virtualization extensions, second, many application hardening frameworks such as Criswell et al. [16], KCoFi [15], Overshadow [10], Inktag [28] and Virtual Ghost [14] rely on some form of MMU virtualization for their internal security, and third, some use cases, e.g. in cloud scenarios, could make good use of software based MMU virtualization to harden VMs without relying on cloud provider hardware.
Our results are not yet complete. The MMU virtualization approach does not support DMA. To securely enable DMA the behaviour of the specific DMA controller must be formally modelled (in [43] the authors describe a framework for such extensions and establish Properties 1 and 2 for the resulting model) and the hypervisor must (i) mediate all accesses to the memory area where the controller’s registers are mapped, (ii) enable a DMA channel only if the pointed physical blocks is data and (iii) update the reference counters accordingly. Several embedded platforms are equipped with IOMMUs, that provide HW support to isolate/confine external peripherals that use DMA. However SW based isolation of DMA is still interesting since it can be used in the scenarios where these HW extensions are not available (e.g. CortexM microcontrollers), they are not accessible (e.g. when they are managed by a cloud provider), or in time critical applications since the page walks introduced by the IOMMU can slow down the peripheral and make worst case execution time analysis more difficult.
A tricky problem concern the treatment of unpredictable behaviour in the ARMv7 architecture. The Cambridge ISA model [22] maps transitions resulting in unpredictable behaviour to ⊥. We ignore this for the following reason. Our verification shows that unpredictable behaviour never arises during hypervisor code execution. This is so since the ARMv7 step theorems used by the lifter are defined only for predictable instructions, and since our invariant guarantees that the MMU configuration is always well defined. As a result unpredictable behaviour can arise only during non-privileged execution, the analysis of which we have in effect deferred to other work [43].
Finally more work is needed to properly reflect caches, TLBs, and, further down the line, multi-core. The soundness of the current implementation depends on the type of data cache, and on flushing the cache when needed, in order to support a linearizable memory model. To enable more aggressive optimisation, and to fully formally secure our virtualization framework on processors with weaker cache guarantees, the model must be extended to reflect cache behaviour.
Footnotes
Acknowledgments
We thank the anonymous reviewers for their extensive comments. Work partially supported by framework grant “IT 2010” from the Swedish Foundation for Strategic Research, and the CERCES grant from the Swedish Civil Contingencies Agency.