
Abstract
Interpolation has been successfully applied in formal methods for model checking and test-case generation for sequential programs. Security protocols, however, exhibit idiosyncrasies that make them unsuitable for the direct application of interpolation. We address this problem and present an interpolation-based method for security protocol verification. Our method starts from a protocol specification and combines Craig interpolation, symbolic execution and the standard Dolev–Yao intruder model to search for possible attacks on the protocol. Interpolants are generated as a response to search failure in order to prune possible useless traces and speed up the exploration. We illustrate our method by means of concrete examples and discuss the results obtained by using a prototype implementation.
Introduction
A number of tools (e.g., [1,2,7,8,13,17,21,30] just to name a few) have been developed for the analysis of security protocols at design time: starting from a formal specification of a protocol and of a security property it should achieve, these tools typically carry out model checking or automated reasoning to either falsify the protocol (i.e., find an attack with respect to that property) or, when possible, verify it (i.e., prove that it does indeed guarantee that property, perhaps under some assumptions such as a bounded number of interleaved protocol sessions [33]). While verification is, of course, the optimal result, falsification is also extremely useful as one can often employ the discovered attack trace to directly carry out an attack on the protocol implementation (e.g., [3]) or exploit the trace to devise a suite of test cases so as to be able to analyze the implementation at run-time (e.g., [5,10,36]).
Such an endeavor has already been undertaken in the programming languages community, where, for instance, interpolation has been successfully applied in formal methods for model checking and test-case generation for sequential programs, e.g., [23,24,26,28], with the aim of reducing the dimensions of the search space. Since a state space explosion often occurs in security protocol verification, we expect interpolation to be useful also in this context. Security protocols, however, exhibit idiosyncrasies that make them unsuitable for the direct application of the standard interpolation-based methods, most notably, the fact that the presence of a Dolev–Yao intruder [16] gives a security protocol a flavor of non-determinism, makes it a non-sequential program (since the intruder, who is in complete control of the network, can freely interleave his actions with the normal protocol execution) and requires taking care of the deduction capabilities of the intruder.
In this paper, we address this problem and present an interpolation-based method for security protocol verification. Our method starts from the formal specification of a protocol and of a security property and combines Craig interpolation [12], symbolic execution [20] and the standard Dolev–Yao intruder model [16] to search for goals (representing attacks on the protocol). Interpolation is used to prune possible useless traces and speed up the exploration. More specifically, our method proceeds as follows: starting from a specification of the input system, including protocol, property to be checked and a finite number of session instances (possibly generated automatically by using a preprocessor), it first creates a corresponding sequential non-deterministic program, according to a procedure that we have devised, and then defines a set of goals and searches for them by symbolically executing the program. When a goal is reached, an attack trace can be extracted from the constraints that the execution of the path has produced; such constraints represent conditions over parameters that allow one to reconstruct the attack trace found. When the search fails to reach a goal, a backtrack phase starts, during which the nodes of the graph are annotated (according to an adaptation of the algorithm defined in [26] for sequential programs) with formulas obtained by using Craig interpolation. Such formulas express conditions over the program variables, which, when implied from the program state of a given execution, ensure that no goal will be reached by going forward and thus that we can discard the current branch. The output of the method is a proof of (bounded) correctness in the case when no goal location can be reached; otherwise all the discovered (one or more) attack traces are produced.
In order to show that our method concretely speeds up the validation, we have implemented a Java prototype called SPiM (Security Protocol interpolation Method). We report here also on some experiments that we have performed: we considered seven case studies and compared the analysis of SPiM with and without interpolation, thereby showing that interpolation does indeed speed up security protocol verification by reducing the search space and the execution time. We also compare the SPiM tool with the three state-of-the-art model checkers for security protocols that are part of the AVANTSSAR platform [1], namely, CL-AtSe [35], OFMC [7] and SATMC [4]. This comparison shows, as we expected, that SPiM is not yet as efficient as these mature tools but that there is considerable room for improvement, e.g., by enhancing our interpolation-based method with some of the optimization techniques that are integrated in the other tools.
Summarizing, we list the contributions of this work as follows.
We define a translation of security protocols into sequential programs and we prove the correctness of this translation.
By adapting existing program analysis techniques, we propose a new approach for security protocol verification that combines Craig interpolation, symbolic execution and the standard Dolev–Yao intruder.
We implement our technique in a tool called SPiM and we show that Craig interpolation produces a speed-up in the verification process up to 70%.
We proceed as follows. In Section 2, we provide some (fairly standard) background on security protocol verification, discussing the algebra of protocol messages, the Dolev–Yao intruder, the two security protocol specification languages ASLan
Background
We provide some (fairly standard) background on security protocol verification and briefly describe the two specification languages ASLan
Messages
Security protocols describe how agents exchange messages, built using cryptographic primitives, in order to obtain security guarantees such as confidentiality or authentication. Protocol specifications are parametric and prescribe a general recipe for communication that can be used by different agents playing in the protocol roles (sender, receiver, server, etc.). The algebra of messages tells us how messages are constructed. Following standard practice (e.g., [7,31]), we consider a countable signature Σ and a countable set
The symbols of Σ that have arity greater than zero are partitioned into the set
We could, of course, quite straightforwardly add other operations, e.g., for hash functions, but refrain from doing so for the sake of simplicity.
In contrast to the public operations, the mappings of
Since the mappings map from constants to constants, we consider a term like
As is often done in security protocol verification, we interpret terms in the free algebra, i.e., every term is interpreted by itself and thus two terms are equal iff they are syntactically equal (e.g., two constant symbols
For concreteness and brevity, we consider here the standard Dolev and Yao [16] model of an active intruder, denoted by i, who controls the network but cannot break cryptography; note, however, that our approach is independent of the actual strength of the intruder and weaker (or stronger, e.g., being able to attack the cryptography) intruder models could be considered.
The intruder i can intercept messages and analyze them if he possesses the corresponding keys for decryption, and he can generate messages from his knowledge and send them under any agent name. For a set
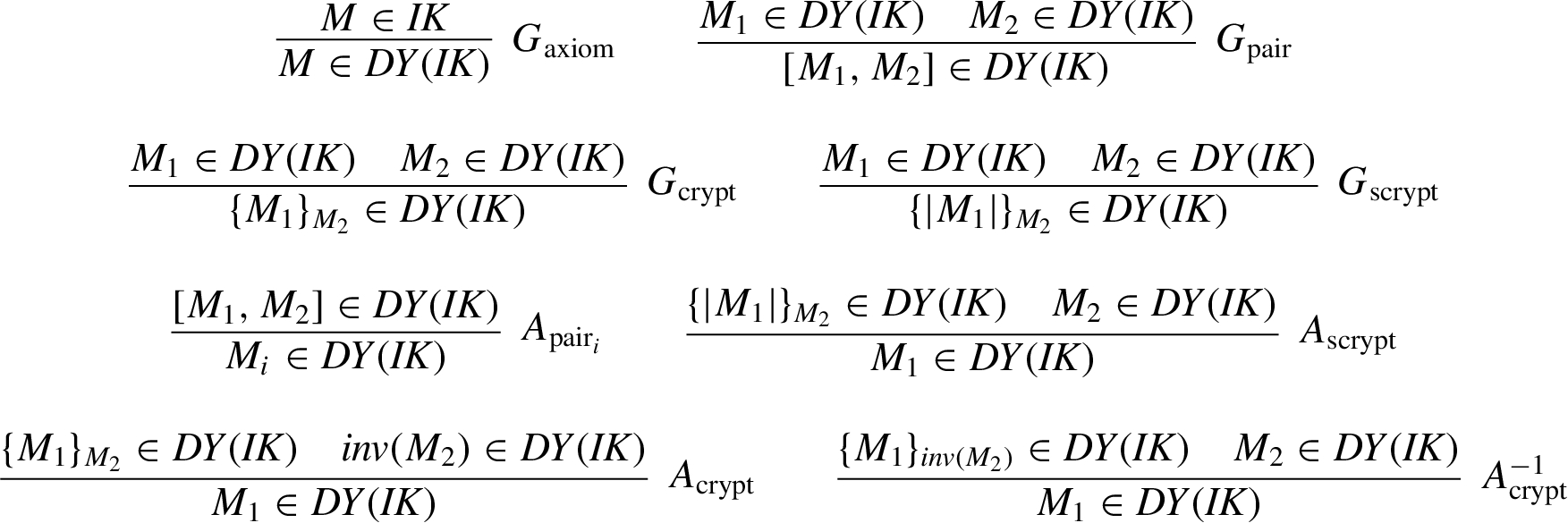
The system
We give here a brief overview of the security protocol specification languages ASLan
ASLan
Hierarchy of entities. An ASLan
The body of an entity. Inside the body of an entity we use three different types of statements: assignment, message send and message receive. An assignment has the form
As a running example, we will use NSL, the Needham–Schroeder Public Key (NSPK) protocol with Lowe’s fix [21], which aims at mutual authentication between A and B:
Man-in-the-middle attack on the NSPK protocol (left), symbolic attack trace at state 15 of the algorithm execution (middle) and instantiated attack trace obtained with our method (right).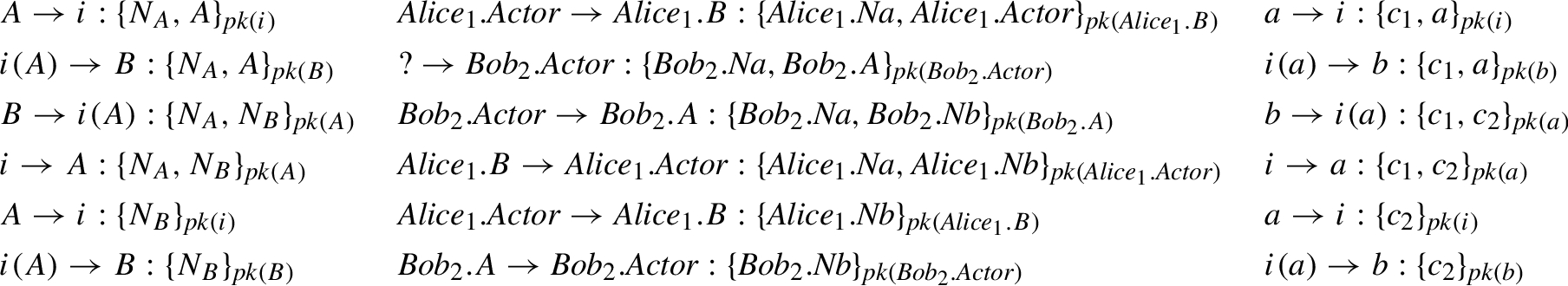
Partial ASLan
We give the complete ASLan
The two roles are
The variable declarations and the behavior of
Description of goals. Finally, we describe here two kinds of protocol goals in ASLan
In the NSL running example, we want to verify whether the man-in-the-middle attack known for the NSPK protocol can be still applied after Lowe’s fix. The scenario we are interested in can be obtained by the following ASLan
In session 1, the roles of
A set of goals needs also to be specified. For simplicity, here we only require to check the authentication property with respect to the nonce of 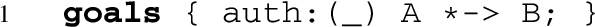
Translation from ASLan
The specifications that we consider in this paper do not use Horn clauses, but rather a so called Prelude file, in which all the actions of the DY intruder are defined as a set H of Horn clauses, is automatically imported during the translation from ASLan
The transition relation → is defined as follows. For all
a rule such that
a substitution
We now define the translation of the relevant ASLan

the predicate
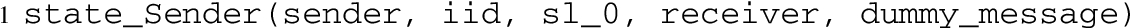
is used in transition rules to store all the informations of an entity, where the ID
Given that an ASLan
A variable assignment statement is translated into a transition rule inside the rules section. As an example, if in the body of the entity
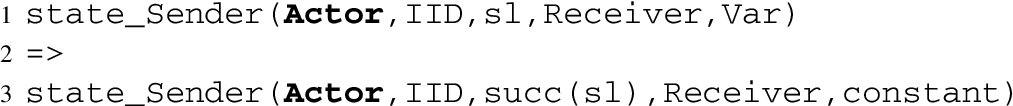
which, for a given entity specified by
In the case of a message exchange (sending or receiving statements) the
The last point we discuss is the translation of goals focusing on authentication and secrecy described above. The label in a send statement (e.g.,

where

where With regard to the NSL example, we show the ASLan specification corresponding to the translation of line 7 of the entity The original ASLan
The SPiM input language SiL
In Fig. 4, we present the full grammar of the SPiM Input Language SiL, a simple imperative programming language that we will use to define the sequential programs to be analyzed by the verification algorithm.
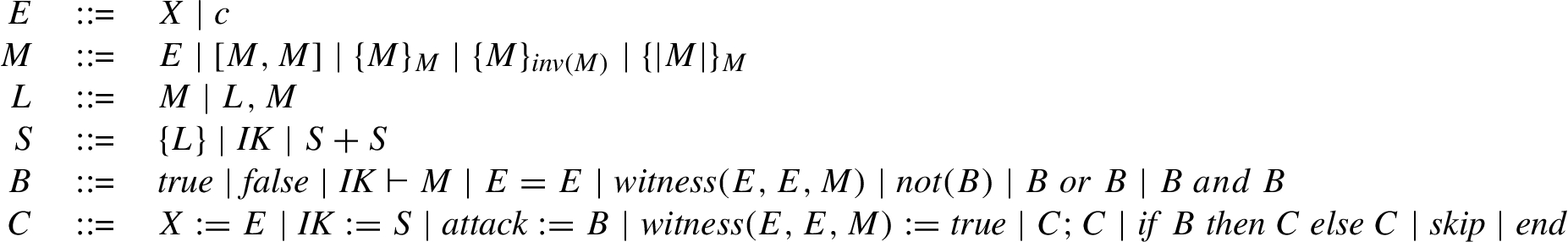
The grammar of SiL.
The SPiM Input Language SiL is defined by the grammar in Fig. 4, where X ranges over a set of variable locations
The basic terms of the language, constants and variable locations, are in the syntactic category E. A message M is a constant, a variable location, a concatenated message or some form of encrypted message.
The category L denotes lists of messages, whereas S stands for a set of messages: here
B denotes the class of Booleans. In addition to the standard Boolean constants and operators, SiL contains two specific predicates:
Finally, the statements of SiL, in the category C, comprise standard constructs (like assignments, conditionals and concatenation) together with mechanisms used to handle specific aspects of security protocols, like the possibility of setting the values of the message set variable
Two remarks are in order. First, for simplicity, we give the syntax in the case of a single goal to be considered; in case of more goals, a distinct
We denote with
Note that here, in order to simplify the presentation, we do not use an explicitly typed model. However, the implementation described in Section 5 does make use of a typed model in order to improve the efficiency of the tool (at the relatively small expense of not being able to find type-flaw attacks, which are anyway often “corrected” when moving from a protocol’s specification to its concrete implementation in a typed programming language).
A (SiL concrete) data state (that we will sometimes refer to only as “state”) is a function
In order to specify the behavior of SiL constructs, we present a big-step structural operational semantics for it. As it is the case for any structural operational semantics, the definition is given by means of a proof system. Rules manipulate judgments of the form
The big-step operational semantics of SiL is defined by the proof system in Fig. 5, where we use the following meta-variables: m ranges over

A big-step semantics for SiL.
The rules for the evaluation of basic terms are quite simple: a constant evaluates to itself and a variable to the value associated to it in a given data state. The rules for compound messages evaluate the single components and then merge the results in a message of the appropriate form. The rules of the third class show how lists are evaluated by concatenating single messages and how sets of messages are built by using lists. In particular, the special set variable
Evaluation of Booleans is standard: constants evaluate to themselves; predicates (equality and witness) evaluate either to
Finally, the rules for statements modify the data state on which they are applied. Assignments modify the state value of the variable considered (be it a generic variable,
Given a protocol
The input of our method is then:
an ASLan a scenario a set of goals (i.e., properties to be verified) in
We will first describe how to obtain a program for a single session and then how to decorate it with goal locations used to verify security properties. In Section 3.3, finally, we will explain how to combine more sessions in a single program.
First of all, we notice that in our translation, and according to the ASLan
For example, the second session of our running example (Example 1), i.e., the one between a and b, is obtained by the composition of two program instances, the first played by a and 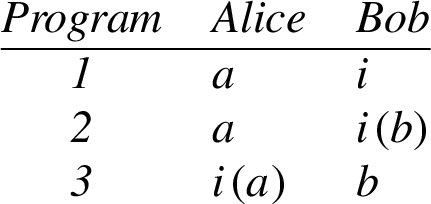
To simplify notation, for the variables and constants of the resulting program we will use the same names as the ones used in the ASLan
The behavior of the intruder introduces a form of non-determinism even within a single session, e.g., related to the construction of a message sent by the intruder, which we capture by letting the program depend on a number of input values, one for each intruder choice. The corresponding input variables are denoted by the symbol Y, possibly subscripted with an index. Finally, symbols of the form
Structure of the program. The exchange of messages in a session follows a given flow of execution that can be used to determine an order between the instructions contained in the different roles. Such a sequence of instructions will constitute the skeleton of the program.
After a first section that concerns the initialization of the variables, the program will indeed contain a proper translation, based on the semantics of ASLan
In the next paragraphs, we will describe more specifically: (i) how variables are initialized and (ii) how each statement is translated.
Initialization of the variables. A first section of the program consists of the initialization of the variables. Let
Sending of a message. The sending of a message
Receipt of a message. Consider the receipt of a message

where
Generation of fresh values. Finally, an instruction of the form
Introducing goal locations. The next step consists of decorating the program with a goal location for each security property to be verified. As it is common when performing symbolic execution [20], we express such properties as correctness assertions, typically placed at the end of a program. Once we have represented a protocol session as a program (or more programs in the case when a session instance is split into more program instances), and defined the properties we are interested in as correctness assertions in such a program, the problem of verifying security properties over (a session of) the protocol is reduced to verifying the correctness of the program with respect to those assertions.
We consider here two common security properties (authentication and confidentiality) and show how to represent them in the program in terms of assertions. They are expressed by means of a statement of the form
Authentication. Assume that we want to verify that
We can restrict our attention to the case when according to the program instance under consideration
A second condition is necessary and concerns the fact that the message M has not been sent by
In NSL, we are interested in verifying a property of authentication in the session that assigns i to 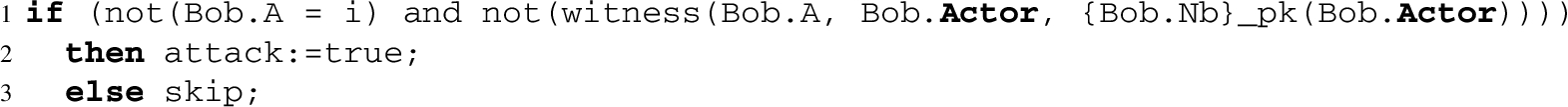
after the receipt of the message.
Confidentiality. Assume that we want to verify that the message corresponding to a variable M, in the specification of a role

where For NSL, assume that we want to verify the confidentiality of the variable at the end of the program. The program instances described in Example 4 give rise to the following three
Program 1
Program 2
Program 3




Now we need to define a global program that properly “combines” the programs related to all the sessions in the scenario. The idea is that such a program allows for executing, in the proper order, all the instructions of all the sessions in the scenario; the way in which instructions of different sessions are interleaved will be determined by the value of further input variables, denoted by X (possibly subscripted), which can be seen as choices of the intruder with respect to the flow of the execution. Namely, we start to execute each session sequentially and we get blocked when we encounter the receipt of a message sent by a role that is played by the intruder. When all the sessions are blocked on instructions of that form, the intruder chooses which session has to be reactivated (by setting the variables X accordingly).
For what follows, it is convenient to see a sequential program as a graph (which can be simply obtained by representing its control flow) on which the algorithm of Section 4 for symbolic execution and annotation will be executed. We recall here some notions concerning programs and program runs.
A (SiL) program graph is a finite, rooted, labeled graph
A (SiL) program path of length k is a sequence of the form
Let
Let
For each
Given a program graph, an intruder location is a location of the program graph corresponding to the receipt of a message.
A block of a program graph
The exit locations of a block
A program graph can simply be seen as a sequence of blocks. Namely, we can associate to the program graph
Intuitively, we decompose a session program graph
Block

Block

The idea is that each such block will occur as a subgraph in the general scenario program graph

An algorithm for building the program graph combining more sessions.
In Fig. 6, we give an algorithm that we have devised to incrementally build the program graph
The first
The resulting program graph
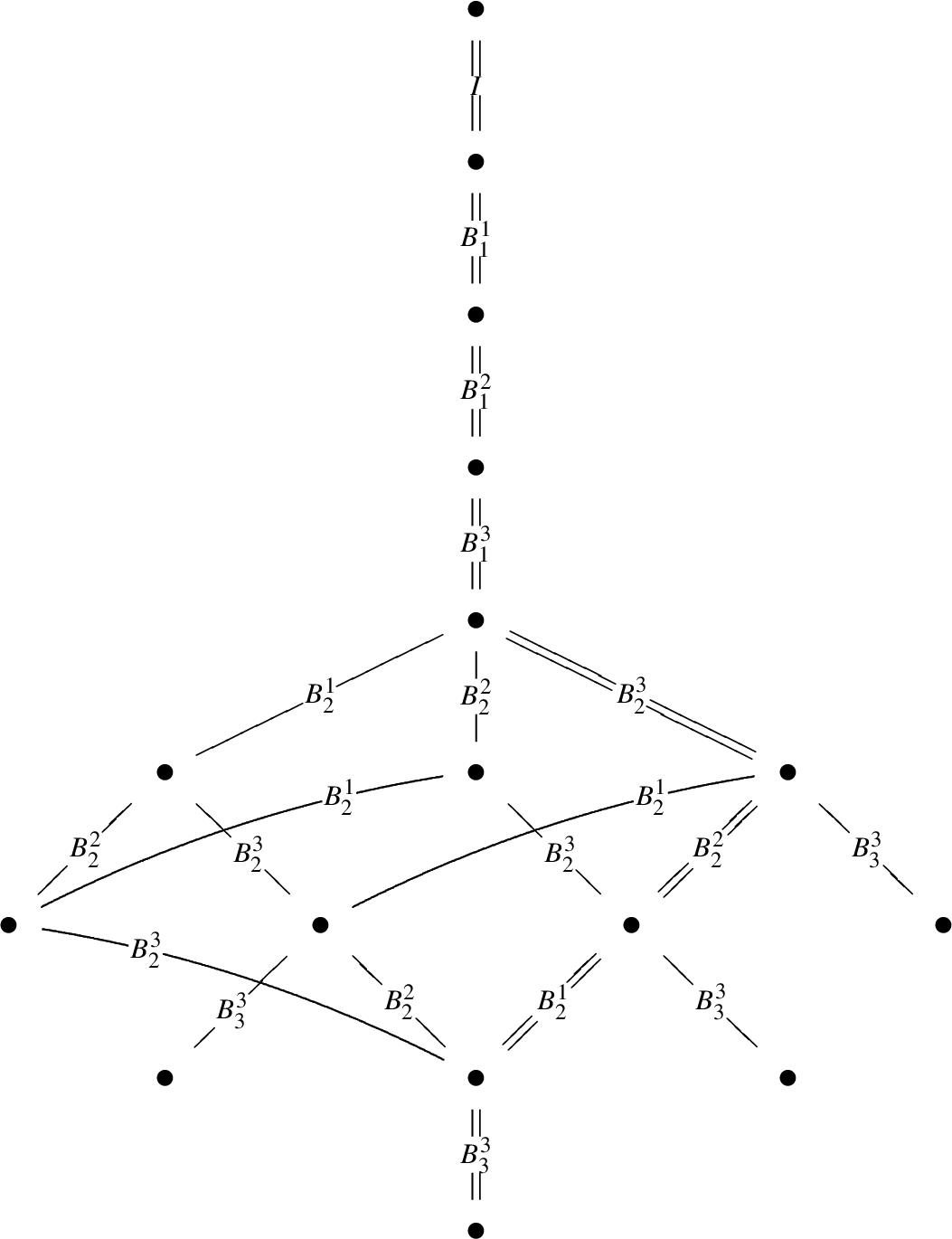
A SiL program graph for NSL.
Figure 10 shows the message sequence chart corresponding to one of the paths of the program graph for NSL, in the scenario described in the previous examples. The entire graph (whose block composition is shown in Fig. 7) is obtained by using the algorithm of Fig. 6 plus some optimization, as described in the text above. The path highlighted in double lines in Fig. 7 is the one shown in Fig. 10.
Now, we show that the translation into SiL, defined in Sections 3.2 and 3.3, preserves important properties of the original specification. In particular, we show that given an ASLan
Equivalence of single steps.
We say that an ASLan term
where ≡ denotes syntactic equality.
In the following, we consider an ASLan
We define a variable mapping as a function
Note that such a function always exists and it is implicitly created at translation time by the translation procedure from ASLan
Let
We say that an ASLan state S and a SiL state ς are equivalent, for each SiL ground term
We notice that while an ASLan transition occurs when there exists a substitution (of values for variables) that makes a rule applicable, in SiL we simulate, and in a sense make more explicit, such a substitution by using the Y input variables. This establishes a correspondence between ASLan substitutions and assignments of values to SiL input variables, which will be important in the following proofs, and that we will handle by means of the following notion of extension of a SiL state.
Given a SiL state ς and a set of input variables
Since the input variables of the form
Let r be an ASLan rule; we will write
Let I be an ASLan
If
If there exists an extension
The proof proceeds by considering all the possible ASLan
Equivalence of runs. We have showed that, starting from equivalent states, the application of ASLan rules and SiL code fragments that have been generated from the same ASLan
In order to compare SiL actions and ASLan rules, a few things need to be taken into account. The goal here is to define things in such a way that a step of execution in SiL corresponds exactly to a step of execution in ASLan. First of all, we note that, strictly speaking, the translation of an ASLan
Assume given a program graph
We define a SiL action run (for
We notice that the definition above does exclude
Assume given a protocol
Given a scenario
An ASLan path (for a protocol scenario for each entity for for
The intuition behind this definition is that, given an ASLan transition system, the set of ASLan paths collects all the “potential” sequences of applications of ASLan rules, i.e., those admissible by only taking care of respecting the order given by the step labels inside the rules, no matter how the rest of the state evolves. The condition on the step labels is used to ensure that rules belonging to a same session are applied in the correct order.
An ASLan run (for a protocol scenario
We say that an ASLan path
Let
It is enough to observe that SiL action paths and ASLan paths follow, for a given program instance, the order in which the actions are executed in the protocol: this is obtained by the definition of the graph construction in the case of SiL, and by using step labels inside the rules in the case of ASLan. Furthermore, in both cases, each possible interleaving between sessions is admitted, i.e., whenever in a SiL path an action of the program instance
For each SiL action run
Let
Finally, we can use the previous theorem to show that an attack state can be found in an ASLan path iff a goal location can be reached in the corresponding SiL path.
Let
Let S be an ASLan attack state, i.e.,
In this section, we present the interpolation-based algorithm that we use for verification and describe, in particular, how we can calculate interpolants in our specific setting.
Our algorithm is a slightly simplified version of the IntraLA algorithm of [26], obtained by removing some fields only used there to deal with program procedures. In a nutshell, the idea underlying our algorithm is as follows. The input of our algorithm is a SiL program graph, as defined in Section 3.3, together with a set of attacks (goals) to search for; the output is either the proof that no attack has been found or an abstract attack trace for each attack found. The algorithm executes symbolically the program graph searching for given goal locations, which in our case represent attacks found on the given scenario of the protocol. In Fig. 8(left), we have depicted a simplified version of a generic program graph, highlighting a location n from which a path leading to a goal location starts. In the case when we fail to reach a goal during a search along an edge (Fig. 8(center)), an annotation, i.e., a formula expressing a condition under which no goal can be reached, is produced by using Craig interpolation. Informally speaking, the annotation,
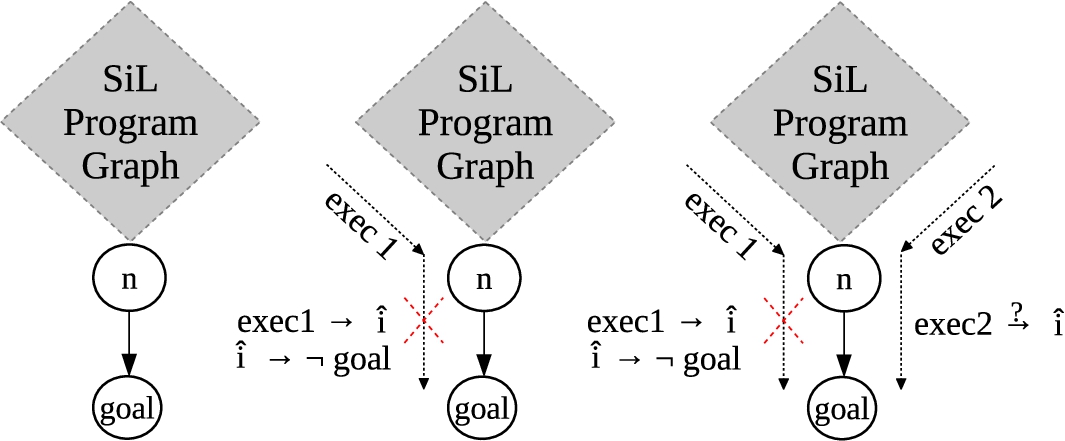
A SiL program graph (left). A first phase of symbolic execution with generation of an annotation (center). A second phase of symbolic execution with annotation check (right).
The annotation language
In what follows, we use a two-sorted first-order logic with equality, in which the graph annotations will be expressed. The signature of the first sort is based on the algebra of messages defined in Section 2, over which we also allow a set of unary predicates
Symbolic execution notions
Before presenting the algorithm, we introduce some notions concerning symbolic execution. In the following, we will assume given a program graph
Let V be the set of program variables. A symbolic data state is a triple
Intuitively, a symbolic data state ξ represents a set of “concrete” (SiL) data states parametrically and it can be characterized by the formula
Note also that E assigns a value (a term) to the program variables, but not to the parameters. It follows that we can associate to each symbolic data state ξ the set
We assume a defined initial symbolic data state
A symbolic state is a pair
Intuitively,
The previous definitions do not define explicitly a symbolic interpreter, but only specify that it has to satisfy some conditions on the semantics of

of Program 3 in Example 7. The symbolic execution of the conditional will consist in adding the pairs
An algorithm state is a triple
During the execution of the algorithm, the set of queries is used to keep track of which symbolic states still need to be considered, i.e., of those symbolic states whose location has at least one outgoing edge that has not been symbolically executed, and the annotation is a decoration of the graph used to prune the search. Formally:
A program annotation is a set of pairs in
We note here that an empty set of annotations
For an edge
Let
An annotation is justified when all its elements are justified.
A justified annotation is inductive and if it is initially justified, then it is an inductive invariant. The algorithm maintains the invariant that A is always justified.
A query
The edge e is blocking the query q when
The algorithm also maintains, as invariants, the facts that no symbolic state (i.e, no query) in Q is blocked and that for all goals l in G, we have
The rules of our algorithm are given in Fig. 9.

Rules of the algorithm IntraLA with corresponding side conditions. Intuitively, the subscripts h and
The first rule applied is always
Symbolic execution steps
The
Backtracking steps
When the symbolic execution using the
The rule
Finally, if some outgoing edge
The
In Section 4.3, we will explain how the formula ϕ can be obtained by exploiting the Craig interpolation lemma.
The generation of interpolants
We have seen in Section 4.2 that the rule
We will first introduce some notions concerning the description of data states and actions in our annotation language and then describe how to obtain, in our case, the formula ϕ as an appropriate interpolant.
Let μ be a term, a formula, or a set of terms or of formulas. We write
In the context of our graphs, the most interesting case is when the action a is represented by a conditional statement, with a condition of the form
The ability of the intruder of generating new messages can be simulated by enriching his initial knowledge with a set of constants not occurring elsewhere in the protocol specification. Since we consider finite scenarios, the size of such a set can also be bounded a priori.
We use formulas of the form
The formula
A theory
Our translation of the program statement
Let M be a ground message,
Now let
The algorithm terminates when no rules can be applied, which implies that the query set is empty. We note that the algorithm always terminates (after a full exploration of the paths in the program graph, in the worst case) as it is just an optimization over the standard symbolic execution algorithm. In [26], the correctness of the algorithm, with respect to the goal search, is proved: the proof given there applies straightforwardly for the slightly simplified version we have given here.
Let
The output of our method can be of two types. If no goal has been reached, i.e.,
Such traces can be inferred from the information deducible from the symbolic data state
Execution of the algorithm on the program graph for the protocol NSL
We continue our running example by showing the execution of the algorithm on some interesting paths of the graph defined in Section 3.2 for the protocol NSL: Table 1 summarizes the algorithm execution.
For readability, we have not reported the evolution of parameters and goals set. We remark that each new parameter is added to the parameters set once used and the goals set is initialized with the goal locations corresponding to the translation of the authentication goal
Message sequence chart for one execution path of the NSL example. The actions executed in 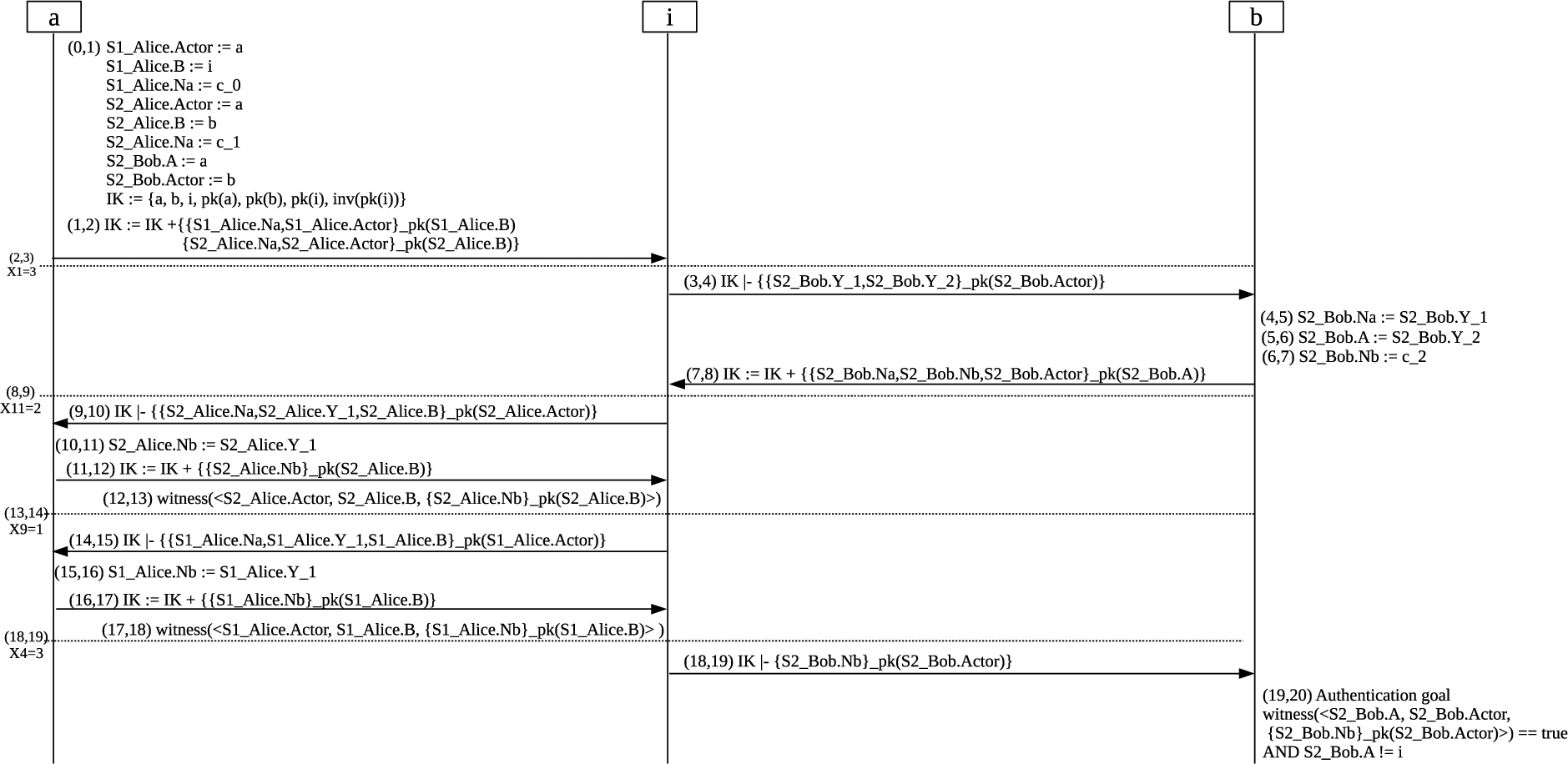
The first path we show (summarized by the message sequence chart in Fig. 10) reaches a goal location with an unsatisfiable state and then annotates it with an interpolant, while the other ones reach the previously annotated path and then block their executions (thus saving some execution steps). The algorithm starts, as described in Table 1, by using the
In step 20, the algorithm blocks its symbolic execution because the edge
We now show how the algorithm calculates an interpolant and how it is propagated annotating the graph (to prevent the execution of paths that will not reach a goal location). Afterwards, we discuss how the constraints imposed by the interpolant translate to the NSL protocol and why it prevents the executions of paths that would not reach the goal location.
NSL sub-graph.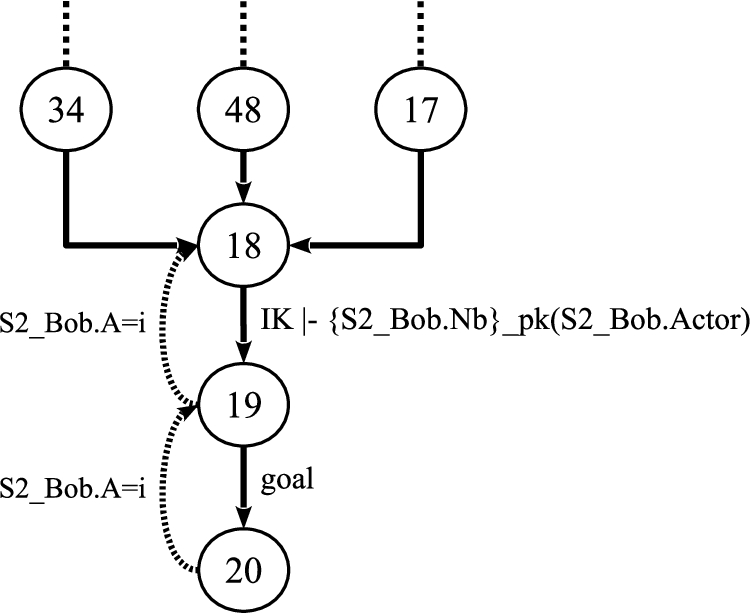
The backtrack phase starts and, until step 33, the algorithm creates interpolants to annotate the program graph and then it propagates annotations up to the location
As shown in Fig. 11, there are two other paths that reach location
Note that, for readability, we have sequentially enumerated the locations encountered in this example. In particular, the locations 17–20 of Fig. 11 correspond, respectively, to the locations
This means that each symbolic state that reaches location
While with NSL the algorithm concludes with no attacks found, if we consider the original protocol NSPK (i.e., remove Lowe’s addition of “B” in the second message of the protocol), then our method reaches the goal location with an execution close to the one we have just provided. In fact, in NSPK, when we compute the step after the 19th, the intruder rules lead to the goal with the inequality
Now, by using the information in
The SPiM tool.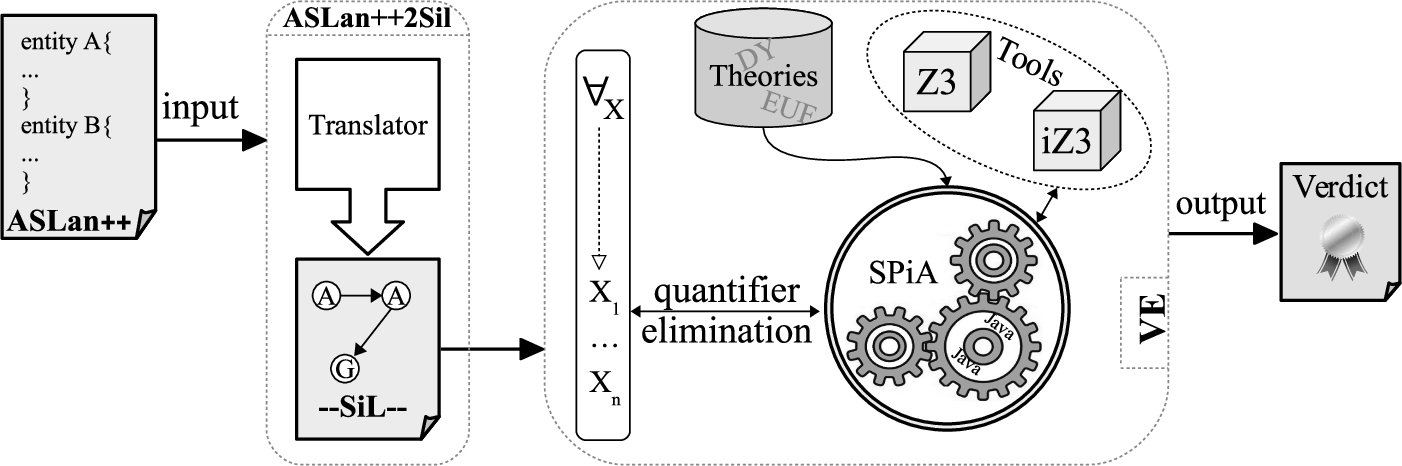
It is also not difficult to extract from this instantiated attack trace a test case, which can then be applied to test the actual protocol implementation. In fact, the constraint set contains a sequence of equalities of the form
In order to show that our method concretely speeds up the validation, we have implemented a Java prototype called SPiM (Security Protocol interpolation Method), which is available at a quantifier elimination module, DY intruder and EUF (Equalities and Uninterpreted Functions) theories and the tools Z3 [15] and iZ3 [27], used for SAT solving and interpolant generation, respectively.
Both Z3 and iZ3 are invoked by SPiA (Security Protocol interpolation Algorithm), which is our implementation of the algorithm in Section 4. Quantifier elimination and the definition of theories are related to the usage of Z3 and iZ3. In fact, as shown in Section 4, our algorithm needs to handle many quantifications and, for performance issues, a module that unfolds each quantifier over the finite set of possible messages has been developed. Moreover, the DY theory has been properly axiomatized (with respect to each formula produced by SPiA) in Z3 and iZ3, which do not support it by default.
More specifically, the VE symbolically executes a program graph. After the execution of an action branching from a node to the next one, it produces a formula, which represents the symbolic state reached. Z3 is then used for a satisfiability check on the newly produced formula. When the symbolic execution of a given path fails to reach a goal, the VE calls iZ3, which generates an annotation (i.e., a formula expressing a condition under which no goal can be reached from the current state) by using Craig’s interpolation. By a backtracking phase, SPiA propagates the annotation through the program graph. Such an annotation is possibly used to block a later phase of symbolic execution along an uninteresting run, as explained in Section 4. SPiM concludes reporting either all the different reachable attack states (from which abstract attack traces can be extracted) or that no attack has been found for the given specification.
Experiments and results
We considered 7 case studies and compared the results obtained by using interpolation-driven exploration (SPiA) and full exploration (Full-explore) of the program graph. Full-explore explores the entire graph checking, at each step, if the state is satisfiable or not. If there is an inconsistency, SPiM blocks the execution of the path resuming from the first unexplored path, until it has explored all paths.5
It would be possible to modify the Full-explore algorithm and check for inconsistencies at the end of the path instead of at any step but this would lead to an unfair comparison. In fact, a similar improvement could have been implemented also for SPiM, but then it would be difficult to distinguish between the steps pruned by interpolation and those pruned by such an improvement.
Table 2 shows the results obtained (with a general purpose computer), by making explicit the time required for symbolic execution steps (applications of
Empirically, the more the program graph grows, the more the annotations prune the search space. This is due to the fact that the number of states pruned by interpolation is usually related to the size of a program graph; this is confirmed by the results in Table 2 and, in particular, by the case studies for which Full-explore has not concluded the execution (marked with an asterisk).
SPiA vs Full-explore
Evaluation performed to show the scaling behavior for 3 sessions.
We have also compared the SPiM tool with the three state-of-the-art model checkers for security protocols that are part of the AVANTSSAR platform [1]: CL-AtSe [35], OFMC [7] and SATMC [4].6
For this comparison, given that all these tools support ASLan
SATMC, CL-AtSe and OFMC
We remark that the aim of SPiM is mainly to show that Craig’s interpolation can be used as a speed-up technique also in the context of security protocols and not (yet) to propose an efficient implementation of a model checker for security protocol verification. In fact, we do not see our approach as an alternative to such more mature and widespread tools, but we actually expect some interesting and useful interaction. For example, CL-AtSe implements many optimizations, like simplification and rewriting of input specifications, and OFMC implements some optimizations at the intruder level as well as a specific technique, called constraint differentiation (CDiff), which considerably prunes the state space (it is more or less equivalent to partial-order reduction techniques typical of model checking, where the reduction is “pushed” to the constraint solving procedure). Moreover, both CL-AtSe and OFMC implement the step compression and protocol simplifications techniques, which merge together some of the actions performed in the protocol.
We do not see any incompatibility in using interpolation together with such optimization techniques. For instance, CDiff prunes the state space by not considering the same state twice, whereas interpolation works on reducing the search space by excluding some paths during the analysis (i.e., it prunes the execution of some of the paths). Moreover, based on the idea that the intruder controls the network, when the intruder sends a message (
The only possible side effect that we foresee in using interpolation together with such optimization techniques is that the number of paths pruned by interpolation could decrease when we use it in combination with other techniques. In general, however, although we don’t have experimental evidence yet, we expect that if enhanced with such techniques, SPiM could then reach even higher speed-up rates. We are currently working in this direction.
The interpolants we have considered so far (with our running example) are quite simplistic for readability reasons. However, the interpolants generated by SPiM can be rather complex formulae (i.e., with hundreds of connectives and variables). In the remainder of this section, in order to give an insight of the kind of information that can occur in an annotation, we describe the details of some of the interpolants generated during the execution of SPiA on the running example. Specifically, an interpolant can be composed of two different types of constraints:
constraints over the knowledge of the intruder; and
constraints over the instantiation of variables (e.g., constraining session instantiations).
Before going into the details of the interpolants, we recall that in the running example we have considered two sessions:
Session 1: Session 2:
Note that when we generate the SiL graph, we consider one program for each role in each session, but we don’t consider programs for the entities played by the intruder. Therefore, we combine three different programs, one for the first session (i.e., considering
P1: Session 1, Role Alice (
P2: Session 2, Role Alice (
P3: Session 2, Role Bob (
For the sake of simplicity, in the remainder of this section we focus on interpolants that either constrain the intruder knowledge or the instantiation of other variables, but nothing prevents an interpolant from combining the two types of constraints.
NSL – SiL path execution
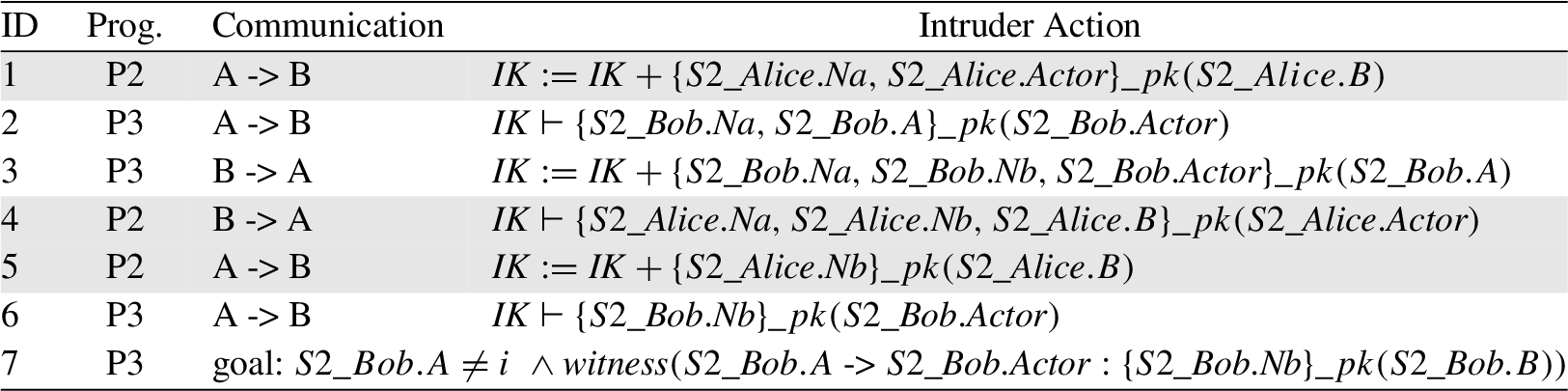
NSL – SiL path execution
Interpolants constraining the intruder knowledge. We illustrate this type of interpolant by considering the execution path of the NSL running example detailed in Table 4. The execution path is the one given in Example 9 (and in Table 1) but it focuses on P2 and P3 for readability. As we already discussed in Section 2, the running example is secure against a MITM attack. Therefore, when SPiM reaches the goal location (with
When we reach the end of the execution of the protocol (i.e., location with
The annotation (of location 6 in Table 4) in Fig. 13(left),7
Note that, for the sake of readability, we refer to the constants of the nonces using the notation
Another similar example is reported in Fig. 13(right). The annotation has been generated by the
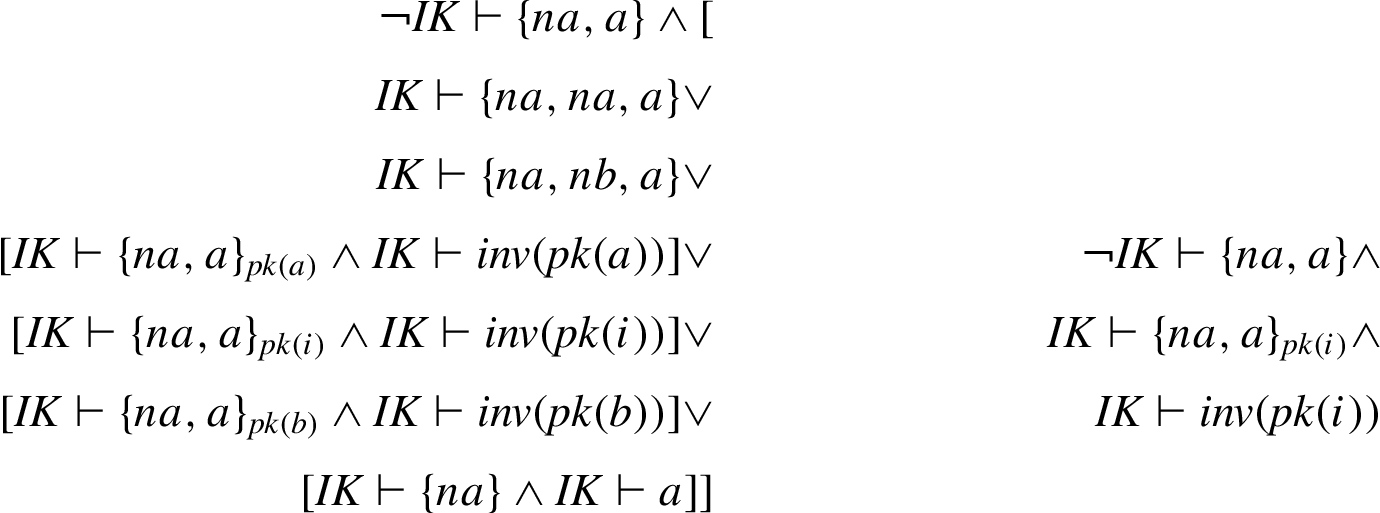
Two examples of interpolants constraining the intruder knowledge.
Interpolants constraining instantiation of variables. The second type of interpolants is the one constraining the instantiation of program variables. For example, the following interpolant constraints the instantiation of the agent’s variables in such a way that a path where the intruder plays the role of Alice will not be (re-)executed since it is (trivially) in contrast with the authentication goal:
To the best of our knowledge, there is no other tool for security protocol analysis that uses a speed-up technique based on Craig’s interpolation. We now discuss some further related work on interpolation, in addition to the works we already considered in detail in the other sections of the paper.
In [26], McMillan presented the IntraLA algorithm that we have used as a basis for this work. However, our application field is network security whereas IntraLA has been developed for software verification, and this has led to a number of substantial differences between the two works. First of all, our case studies are security protocols, and thus parallel programs, whereas IntraLA works on sequential ones. For this reason, we have defined a simple programming language (SiL) with some protocol-oriented features and provided a translation procedure from protocol specifications (expressed in ASLan
Recently, McMillan has proposed in [28] a variation of IntraLA that mainly adapts IntraLA to large-block encoding (LBE). This technique reduces the abstract reachability tree used by the IntraLA algorithm, for example by simplifying the tree produced from very long sequences of if statements. Moving from original trees to the ones produced with LBE is not a trivial task and requires further investigation. Introducing LBE could speed up our tool too but, as we have already discussed in Section 5.1, we implemented SPiM mainly to show that interpolation can concretely be used as a speed-up technique together with the DY intruder model in the context of security protocols. Other works by McMillan that exploit the use of Craig interpolation in model checking are [22,25], but interpolants are used there in a different way, i.e., to apply interpolant-based image approximation.
Besides McMillan’s works on interpolation applied to model checking, there are a number of model checkers that implement different techniques to speed-up the search for goal locations. In particular, for the purpose of the comparison with SPiM and in addition to the tools already considered in Section 5.1, we consider here four security protocol analysis tools that implement the DY intruder theory: Maude-NPA [18], ProVerif [8], Scyther [14] and Tamarin [34].
Besides DY, Maude-NPA supports a wide range of theories such as the “associative-commutative plus identity” theory. Maude-NPA has been implemented with particular focus on performances and in fact, during the analysis, it takes advantage of various state-space reduction techniques. These range from a modified version of the lazy intruder (called “super lazy intruder”) to a partial-order reduction technique. The ideas behind the speed-up techniques of Maude-NPA are very similar to the ones of SPiM: reduce the number of states to explore and try to not explore a state after having the evidence that from this state the model checker will never reach the goal location (i.e., will never reach the initial state given that Maude-NPA performs a backward reachability search). As for all the back-ends of the AVANTSSAR Platform (discussed in Section 5.1), in principle we do not see any incompatibility in combining the interpolation-based technique we have proposed in this paper with the speed-up techniques implemented in Maude-NPA. However, Maude-NPA performs backward reachability analysis whereas our technique has been defined for forward reachability analysis. This does not prevent possible useful interaction between the two approaches but it might require a non-trivial adaptation of the interpolation-based algorithm.
In ProVerif, security protocols are represented using Prolog rules in order to handle multiple executions. It implements an efficient algorithm that, combined with a unification technique along with rule optimization procedures, handles the problem of state-space explosion. Due to the particular nature of the techniques it implements, it is not clear if ProVerif could further improve its performance by integrating an interpolation-based technique.
Scyther uses a pattern-refinement algorithm that provides concise representations of (infinite) sets of traces. It does not use approximation methods nor abstraction techniques and it could thus benefit from including our technique, in particular, when unbounded verification is performed. However, as with Maude-NPA, due to Scyther’s backward searching algorithm, this integration would require further study.
Tamarin uses a constraint-solving algorithm and a symbolic representation of states like SPiM, but supports analysis for an unbounded number of protocol sessions. Intruder capabilities and protocols are specified jointly as a set of (labeled) multiset rewriting rules. Tamarin is particularly well suited for the analysis of protocols that use the Diffie–Hellman key exchange, which SPiM does not handle. One of the main difficulties one might have in implementing our speed-up technique in Tamarin is thus with the Diffie–Hellman key representation. However, since Tamarin uses a (labeled) operational semantics that is similar to the one used in SPiM, it might still be feasible to adapt the interpolation technique successfully.
Concluding remarks
We believe that our interpolation-based method, together with its prototype implementation in the SPiM tool and our experimental evaluation, shows that we can indeed use interpolation to reduce the search space and speed up the execution also in the case of security protocol verification. In particular, as we have shown, we can use a standard security protocol specification language (ASLan
As future work, we plan to increment our experimental results by considering further (and more complex) security protocols, such as those described in [9] and in the standard literature. This will allow us to collect further evidence as to what extent interpolation can indeed increase the performance of SPiM.
More importantly, as we remarked above, we are not aware of any other tool for security protocol verification that uses an interpolation-based speed-up technique, and we believe that actually interpolation might be proficiently used in addition (and not in alternative) to other optimization techniques for security protocol verification. We are thus currently investigating possible useful interactions between interpolation and such optimization techniques, given that there are no theoretical or technical incompatibilities between them. This will allow us to enhance SPiM and promote its performance closer to the level of the more mature tools. Symmetrically, it would be interesting to investigate also whether such mature tools might benefit from the integration of interpolation-based techniques such as ours to provide an additional boost to their performance. This will of course be a much more challenging endeavor to undertake, as it will possibly require some internal changes to already deployed tools, but given our close scientific relations to some of the tool developers, we are hopeful that we will be able to carry out some attempts in this direction.
Footnotes
Acknowledgments
Work partially supported by the FP7-ICT-2009-5 Project no. 257876, “SPaCIoS: Secure Provision and Consumption in the Internet of Services” and the PRIN 2010-11 project “Security Horizons”. Much of this work was carried out while the authors were at the Dipartimento di Informatica, Università di Verona, Italy, and while Marco Rocchetto was at iTrust at the Singapore University of Technology and Design. We thank Giacomo Dalle Vedove, Marco Palamà and Fabio Pettenuzzo.