With the popularity of cloud computing, an increasing number of institutions outsource their data to a third-party cloud system which could be untrusted. The institutions encrypt their data before outsourcing to protect data privacy. On the other hand, data mining techniques are used widely but computationally intensive, especially for large datasets. Combining data from different institutions for a big and varied training set helps enhance data mining performance. Therefore, it is important to make the cloud system which has powerful computing abilities run data mining algorithms on the encrypted data from multiple institutions. Two challenges need attention – how to compute on encrypted data under multiple keys and how to verify the correctness of the result. There are no existing methods that solve the two challenges at the same time. Elastic net is a useful linear regression tool to find genomic biomarkers. In this paper, we propose the first privacy-preserving verifiable elastic net protocol based on reduction to support vector machine using two non-colluding servers. We construct a homomorphic cryptosystem that supports one multiply operation and multiple add operations under both single key and different keys. We allow the involved institutions to verify the correctness of the final result. The collaboration between multiple institutions is made possible without jeopardizing the privacy of data records. We formally prove that our protocol is secure and implement the protocol. The experimental results show that our protocol runs reasonably fast, and thus can be applied in practice.
Cloud computing is gaining popularity in academia and industry. Cloud computing can be classified to IaaS (Infrastructure as a Service), PaaS (Platform as a Service), SaaS (Software as a Service) and DaaS (Data as a Service). It provides resource-constrained users with cost-efficient, convenient and high-speed services. More and more institutions (i.e., hospitals with huge volume medical records) are motivated to upload their storage to the cloud (IaaS). Traditionally, data are stored locally and kept within the institutions’ trust domains. Outsourcing means data owners lose control over the data stored in the cloud. However, the institutions’ data usually contains sensitive or valuable information. For example, hospitals keep an electronic medical record for every patient which includes sensitive information such as genetics and mental health. The patients are unwilling to disclose such sensitive information to unauthorized users. As a result, outsourcing storage incurs security and privacy concerns. We should transform or encrypt the original data to maintain confidentiality and integrity before outsourcing to the cloud. Geometric transformation (i.e., rotation/translation) perturbs the content of instances by transforming data to a new vector space [11]. Encryption is the process of encoding a message so that only authorized parties with the correct secret key can access it. Different institutions might choose the same cloud service provider (i.e., Amazon, Google, and Microsoft). Their outsourced data is also likely to be stored on the same cloud server. No matter geometric transformation or encryption is used, different institutions must keep private information to preserve data confidentiality. To be specific, different institutions should choose different perturbation matrices for geometric transformation. For encryption, different institutions should pick different secret keys. Otherwise, the records of one institution will be revealed to other institutions. As encryption provides higher security level than transformation, we focus on encryption-based schemes in this paper.
On the other hand, data mining techniques such as classification (e.g., support vector machine), regression (e.g., linear regression), and clustering (e.g., k-means) have wide applications in real-life scenarios. For example, regression can be applied to predict the trend of stock price or recommend drug doze for patients, etc. Regression falls under the family of supervised learning algorithms, which first build models on the labeled training data and then use those models to predict the output of new data. Data mining algorithms are usually computationally intensive, especially for large datasets. For example, the complexity of solving a typical regression model () is with matrix inversion where n is the number of training samples. Due to the popularity of data mining techniques, cloud service providers start to offer such service to the users. Considering the cloud service providers have powerful computing abilities, the integration of data mining techniques with cloud computing is a promising solution. Furthermore, combining data from different institutions for a big and varied training set helps enhance data mining performance. To avoid jeopardizing data privacy, the cloud servers should run data mining algorithms on encrypted data. However, there are two challenges during the process of collaborative data mining on encrypted data in the cloud. The first one is how to compute on encrypted data as traditional encryption method would not work. Besides that the data is in encrypted form, an additional difficulty of this problem is that records are encrypted under different keys. Homomorphic encryption allows computation on encrypted data. There indeed exists a multikey fully homomorphic encryption primitive that allows computation on data encrypted under multiple keys [40]. However, its efficiency is still far from practice, and it requires interactions among all the medical institutions during the decryption phase. The second challenge is how to verify the correctness of the result returned by the cloud. The computation procedures at the cloud server are not transparent to the users. The cloud might return false result due to malicious attacks or software failures. It is also possible that the cloud returns a random result to save computation resources instead of performing intensive computations honestly. Multi-client verifiable computation was first introduced in [12]. Current verifiable computation schemes are formally based on Probabilistically Checkable Proofs (PCPs) [34] or Fully Homomorphic Encryption (FHE) [8], they are hard to be utilized in practice due to high computation and storage costs.
Elastic net is a popular linear regression tool, which is particularly useful when the number of training samples n is much less than the dimension of training samples m. For example, a typical microarray dataset has many thousands of genes and often fewer than 100 samples. For ease of understanding, we give a specific application example – biomarker discovery application (see Section 3.1). Elastic net regression was found to be the most accurate predictor [32] for biomarker discovery among existing approaches. We concentrate on designing a privacy-preserving verifiable elastic net among multiple institutions, which has not been studied before. Our goal is to ensure that the cloud learns nothing about the original data beyond what is revealed by the final result of elastic net regression.
Why encrypted by different keys? A typical input for biomarker discovery is a gene expression profile which is a vector recording the degrees of activation of different genes. It is well recognized that genomic information such as DNA is particularly sensitive and must be well protected [20]. The privacy of gene expression has been overlooked until Schadt et al. pointed out that gene contents can be inferred based on expression profiles alone [44]. Even worse, some expression data is strongly correlated to critical personal indexes such as body mass index and insulin levels. It is likely that an entire profile can be derived and linked to a specific individual. Therefore, gene expression profiles stored in the cloud should also be encrypted. As medical institutions need to retrieve expression profiles when implementing personalized treatment, profiles from different medical institutions would be encrypted using different keys to avoid leaking the details of the records to other medical institutions.
Why two non-colluding servers? It has been proved that completely non-interactive multi-party computation cannot be achieved in the single server setting when user–server collusion might exist [50]. Thus, we need at least two non-colluding servers [13] if we want to keep the medical institutions offline. This two non-colluding servers model makes sense in the practical community (e.g. [13,19]). For example, we set up two cloud servers which belong to Amazon Web Services (AWS) cloud service and Google Cloud Platform (GCP) respectively. Considering the consequences of legal action for breach of contract and bad reputation, the two cloud servers are unwilling to collude. Therefore, it is reasonable for us to assume the existence of two non-colluding servers.
Difficulties of the problem: The two challenges for running data mining algorithms on encrypted data for multiple institutions in the cloud still exist – how to compute on encrypted data under multiple keys and how to verify the correctness of the result. Besides, the state-of-the-art solution (e.g. glmnet [22]) for the elastic net is based on an iterative algorithm, which requires information of one training sample in each iteration. It is not clear how to perform these iterations if all data records are encrypted. Other existing solutions (e.g. Least Angle Regression (LARS) [61], computing the Euclidean projection onto a closed convex set [39] and using proximal stochastic dual coordinate descent [45]) suffer from a similar problem.
Ideas of our proposed solution: Instead of using the iterative algorithms to solve the elastic net problem directly, it has been proved that elastic net regression can be reduced to support vector machine (SVM) [60]. An identical solution as glmnet [22] up to a tolerance level can be obtained with a solver for SVM. Our main idea is to transform the encrypted training dataset of the elastic net to that of SVM, based on which we compute the gram matrix.1
A matrix that contains dot product of any two training samples.
Then the gram matrix will be used as input to a modern SVM solver. Once obtaining the solution to SVM, we reconstruct the solution to the elastic net. We make sure that the cloud server cannot recover patients’ expression profiles based on the gram matrix, for which we provide a security proof in this paper. To reduce the communication overhead between the two non-colluding servers, we utilize a framework to enable additively homomorphic encryption to support one multiplication [9]. We choose the BCP Cryptosystem [6] as the underlying additively homomorphic encryption and modify it to support multikey homomorphism. In this way, we successfully remove the need to transform the ciphertexts to those under the same key, while it is a must in [43,51,52]. To remove the constraint that medical institutions need to be online during decryption phase, we divide a medical institution’s secret key s into two shares , , and distribute them to the servers. Final decryption is obtained after two rounds of partial decryption. To verify the correctness of the result returned by the cloud, we make use of the fact that the gradient of the objective function of the elastic net regression must be close to zero at the correct solution.
Our contributions can be summarized as follows:
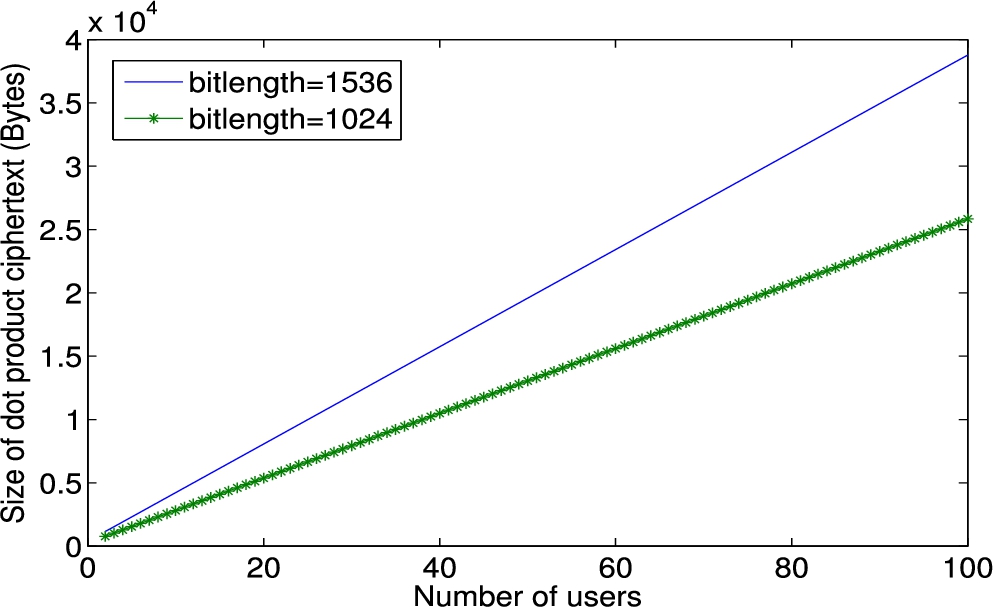
Using two non-colluding servers, we construct a homomorphic cryptosystem that supports one multiply operation and multiple add operations under both single key and different keys. Compared with the BCP cryptosystem, our scheme only doubles the encryption time. With 1024-bit security parameter, an add operation takes less than one millisecond while a multiply operation takes about 16 milliseconds. The size of ciphertext increases linearly from 6138 B to 26 KB with the number of involved users rising from 2 to 100. Overall speaking, the proposed scheme is practical.
We propose the first privacy-preserving verifiable protocol to solve the elastic net on gene expression profiles encrypted by different encryption keys for cancer biomarker discovery, which encourages cooperation between medical institutions. Through reduction from the elastic net to SVM, we demonstrate how to train SVM securely based on the gram matrix. The solution to the elastic net is reconstructed based on the solution to SVM. Our solution can allow users (medical institutions) to stay offline except for the initialization phase. As for verifying the correctness of the final result, we either let the multiple institutions cooperate with each other or shift the verification task to one of the cloud servers to compute the gradient of the objective function of the elastic net regression. If the gradient is close to zero, the correctness of the result is verified.
http://www.cancerrxgene.org, accessed on 10 Aug 2016.
for drug sensitivity in cancer cell lines [54]. We want to point it out that our scheme is not restricted to the elastic net regression. The homomorphic cryptosystem constructed in this paper can be used to solve not only SVM but also lasso regression based on a similar reduction from lasso to SVM [31]. Therefore, our scheme provides a solution to two hot data mining topics (classification and regression) simultaneously. By contrast, existing schemes use different encryption methods for privacy-preserving classification or regression.
The rest of the paper is organized as follows. Section 2 discusses the related work. Section 3 introduces the preliminary information. The building blocks of our scheme and the concrete construction are clarified in Section 4. Then we conduct security analysis in Section 5 and experimental evaluation in Section 6. Finally, we conclude this paper in Section 7.
Related work
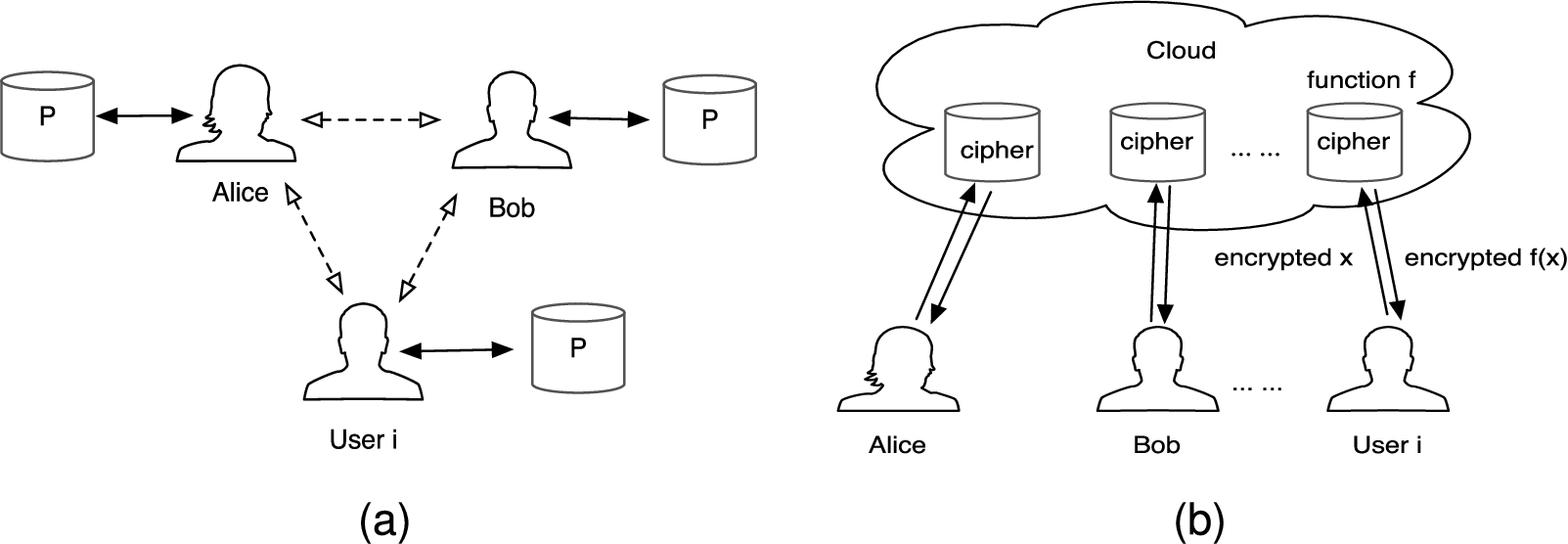
There are mainly two ways to achieve privacy-preserving SVM. One is the perturbation based approach. Data sent to the cloud is perturbed by a random transformation [36], which considers only one user (i.e., medical institution). The other is the cryptography based approach, such as secret sharing [35], Oblivious Transfer (OT) [35,47] and Fully Homomorphic Encryption (FHE) [35,37]. The cryptography based approach provides a higher level of privacy compared to perturbation based approach but incurs higher computation/communication overhead. Most of the previous work focused on distributed databases [35,47,49,55,56], while we consider a centralized outsourced encrypted database under multiple keys. We show two collaborative data mining models – the distributed model and the outsourced model in Fig. 1(a) and Fig. 1(b), respectively. Under the distributed model, each user not only stores the data locally but also computes locally, and interacts with others to finish the data mining task. Under the outsourced model, each user should outsource the data to a cloud server first and then the cloud is responsible for running data mining algorithms. Liu et al. proposed a secure protocol based on FHE for outsourced encrypted SVM [37], but it requires the users to be online during the whole process. Zhang et al. [58] trained SVM efficiently for multiple institutions based on integer vector encryption [59]. Although the integer vector encryption scheme supports addition, linear transformation and weighted inner product on ciphertexts, we cannot derive the training set for SVM given the training set for the elastic net on encrypted domain. The reason is that reduction from the elastic net to SVM leads to the exchange of rows and columns (see Section 3.2.2). Both [37] and [58] require one cloud server and assume that there is no user–server collusion. However, it has been proved that completely non-interactive multiple party computation cannot be achieved in the single server setting when user–server collusion might exist [50]. Thus, we need at least two non-colluding servers if we want to keep the institutions offline. According to [17], each user can secret-share its data between the two non-colluding servers. Then the two servers compute on the shares of the input interactively and send the shares of the result to the users to reconstruct the final output. Although the secret sharing based approach is better regarding computation cost, it incurs higher communication cost [42] and cannot deal with data encrypted under multiple keys. Moreover, oblivious transfer focuses on the single key setting, which is not suitable for the case of multiple keys. Consequently, we focus on homomorphic encryption based approach in this paper. There indeed exists a multikey FHE primitive that allows computation on data encrypted under multiple keys [40]. However, its efficiency is still far from practice and it requires interactions among all the institutions during the decryption phase. Peter et al. came up with a scheme that transforms the ciphertexts under different keys into those under the same key [43], incurring a massive amount of interactions between the servers. To reduce communication overhead, proxy re-encryption [4] can be utilized to transform ciphertexts [51,52]. However, the amount of interactions is still substantial. Because they used partially homomorphic encryption – if the underlying cryptosystem is additively homomorphic, they need joint work between the two servers to compute multiplication and vice versa. Therefore, the interactions between the servers are still heavy. We aim to further reduce communication overhead between the servers in this paper. Zhang et al. [57] proposed a privacy-preserving elastic net protocol based on two non-colluding servers, but they require the servers to be honest-but-curious. In our paper, we allow one server to be malicious and discuss how to verify the correctness of the result.
Two collaborative data mining models. (a) The distributed model. (b) The outsourced model.
The problem of verifiable computation has been extensively studied such as [1,3,7,14,21,27,29,34,41,46]. A lot of solutions (i.e., [3,29,34,41]) focus on general function. However, they depend on Probabilistically Checkable Proofs (PCPs) [34] or Fully Homomorphic Encryption (FHE) [8], they are hard to be utilized in practice due to high computation and storage costs. Other work [1,14,21] achieve improved performance but are still not efficient enough to be deployed in practice. Some solutions are comparably efficient but function-specific [7,27,46]. A verifiable computation scheme under multi-client setting was first proposed in [12], followed by a stronger security guarantee scheme [26]. Both [12] and [26] are based on FHE and thus are not practically efficient.
Preliminaries
What’s biomarker discovery?
The current cancer treatment based on doctors’ empirical knowledge can be described as “one-size-fits-all” – almost all the patients diagnosed with same cancer will receive similar treatment. Under this situation, some patients are likely to be under-treated while others are over-treated. Even worse, not all patients will benefit from the treatment, a proportion of them may suffer from severe side effects. By contrast, personalized medicine aims at treating patients differently with different drugs at the right dose [18]. To achieve personalized treatment for cancer, we need biomarkers (i.e., a set of genes) to predict a patient’s response to anticancer drugs (e.g., sensitivity and resistance). Cancer Genome Project (CGP) [2] and Cancer Cell Line Encyclopedia (CCLE) [24] are examples showing the analysis results for discovering biomarkers using genomic features derived from human tumor samples against drug responses. A typical input for genomic features is a gene expression profile which is a vector recording the degrees of activation of different genes. The number of genes can be up to tens of thousands. A patient’s response is usually measured by GI50 value (log of drug concentration for 50% growth inhibition) [15]. Given n gene expression profiles (e.g., from n patients) of which the dimension is m (), elastic net regression was found to be the most accurate predictor [32] for biomarker discovery among existing approaches.
Elastic net regression
Let the input dataset be , where each is a column vector representing a gene expression profile, and is the GI50 value.3
GI50 denotes the log of the drug concentration for 50% growth inhibition.
Let be a matrix containing all gene expression profiles (the transposed ith row of X is ), and the column vector (ith element of y is ) are the responses, the goal of linear regression analysis is to find a column vector such that can be approximated by . The ordinary least squares (OLS) regression works by minimizing the residual sum of squares . There are some situations where OLS is not a good solution, for example, when m is large, or the columns of X are highly correlated. One way to handle this problem is to introduce a penalization term. Ridge regression uses -norm penalization (), while lasso regression uses -norm penalization (). Ridge regression cannot produce a sparse model. By contrast, owing to the nature of penalty, lasso is able to generate a sparse model. Nevertheless, lasso has some limitations – it selects at most n variables in the case, picks out only one variable from a group of correlated variables not caring which one is selected (the robustness issue: we want to identify all related variables). In our application, since and genes may be highly correlated, lasso regression is not the ideal method in this situation and elastic net penalty () is introduced, which is a convex combination of the lasso and ridge penalty [61]. It performs well under the situation of and correlated variables. The elastic net regression can be represented as follows.
where is the -regularization constant and is the -norm budget.
Support vector machine with squared hinge loss
Given that we have a dataset where and , we aim at finding a separating plane () to classify the training samples into two classes. There exist many eligible separating planes. For the sake of robustness, support vector machine maximizes the margin () between two classes, which is equivalent to minimize . However, sometimes the training dataset is linearly inseparable. One solution is to allow SVM to make mistakes on some samples. We use the squared hinge loss to measure the error of sample , which needs to be minimized. Therefore, the linear SVM with squared hinge loss can be represented as follows.
where C is the penalty parameter of the error term. The above is the primal form of SVM, which is often solved in its dual form:
where and each is the coefficient for . Q is a matrix with . Gram matrix K is defined as. Once we get α by solving (3), we can further compute .
Reduction from elastic net to SVM
Zhou et al. demonstrated that elastic net regression could be reduced to SVM [60]. They do not include any bias item b (they assume that the separating hyperplane passes through the origin). After a series of transformations, (1) and (3) can be changed to (4) and (5) respectively.4
Here we use to differentiate from , β can be derived from .
We do not provide the transformation steps (Please refer to [60] for details).
where , and ( is an identity vector).
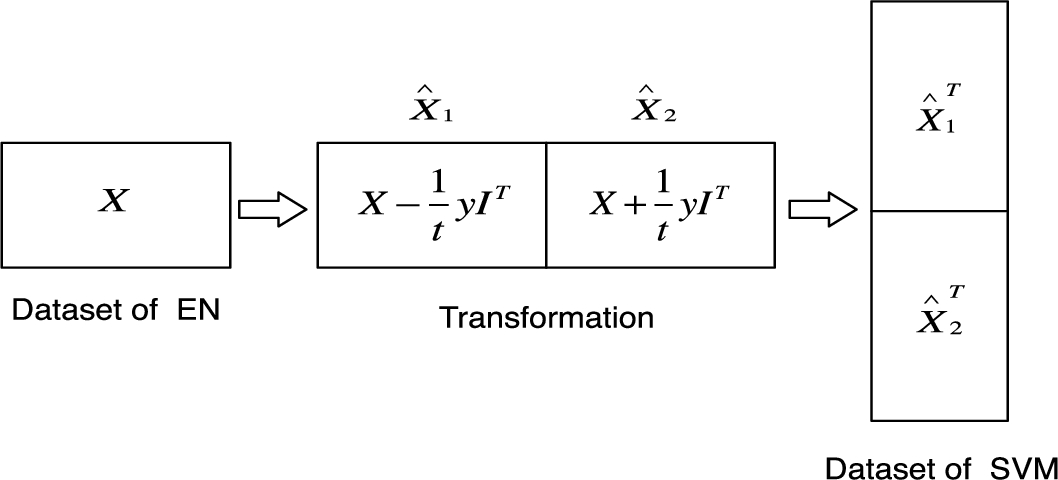
where , and is the optimal solution. Comparing (4) and (5), we notice that they have similar form except for two differences. The first one is that the class labels in elastic net are real valued but binary in SVM. As shown in Fig. 2, to transform the training dataset X of the elastic net to that of SVM, we compute as subtracting each column of X by and calculate as adding each column of X by , then concatenate and together and transpose it. The first m training samples of SVM are of class , and the remaining are of class . The second difference is that they have different scale. The optimal solution can be represented by the optimal solution as . Finally, the optimal solution β to the elastic net (see (1)) can be recovered from according to , where t is the -norm budget and denotes a vector consisting of elements of from index i to j.
Dataset Transformation from Elastic Net to SVM.
System model
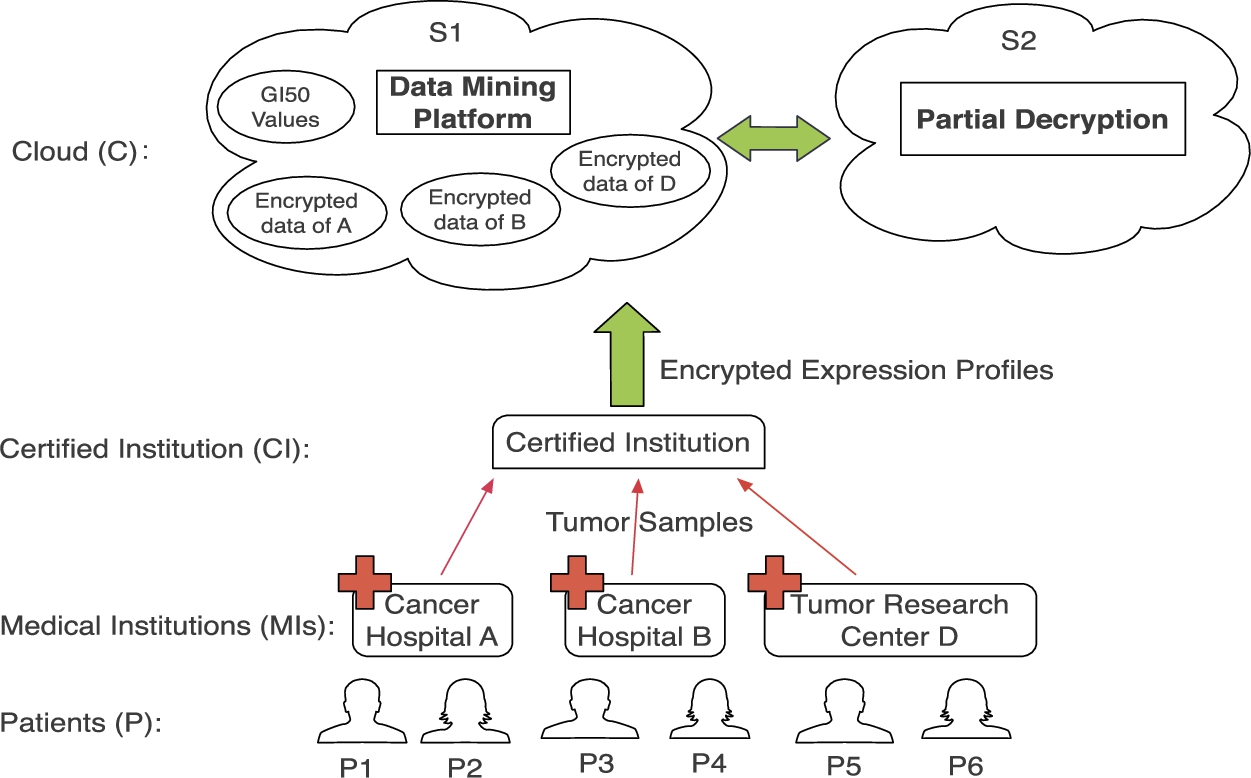
In this paper, we propose a collaborative model for privacy-preserving biomarker discovery for anticancer drugs using encrypted expression profiles extracted from the tumor samples of patients. As shown in Fig. 3, the involved parties are patients, medical institutions, certified institution and the cloud.
System model for genomic biomarker discovery through collaborative data mining.
Patients (P). Cancer patients go to the medical institutions to receive personalized treatment. We list six patients here labeled as .
Medical institutions (MI). There are different MIs (e.g., cancer hospitals, tumor research centers) in our model. Each MI can extract tumor samples from the patients, observe the effect of 72 hours of anticancer drug treatment on them, and upload the GI50 values to the cloud. On the other hand, MI sends the tumor samples to the certified institution.
Certified Institution (CI). CI is responsible for performing gene expression profiling. CI encrypts the gene expression profiles from different MIs with different encryption keys and sends the encrypted profiles to the cloud. Only the MI that holds the correct private key can decrypt the encrypted profiles.
Cloud (C). It consists of two non-colluding servers and , which is responsible for storage and extensive computation.
Threat model
CI is a trusted party. It follows the algorithm correctly and is trusted to keep the data safe. It does not record input or output.
is untrusted. It may deviate from the algorithm instructions. It may return wrong/random result to the user and try to escape from being detected.
MI and are honest-but-curious. They follow the algorithm correctly but secretly record all the input and output, attempting to recover the original private data.
There is no collusion between and , but there might exist collusion between an MI and . However, none of the medical institutions will collude with . We consider three types of potential attacks:
An honest-but-curious attacker at MI tries to know the expression profiles of other MIs.
A malicious attacker at attempts to get the expression profile of MIs.
An honest-but-curious attacker at aims at recovering gene expression profiles through observing the input, intermediate or final results.
Our scheme
The main steps of our scheme.
Fully homomorphic encryption can be used to compute arbitrary polynomial functions over encrypted data. However, the high computational complexity and communication cost preclude its use in practice. If only focusing on those operations of interest to the target application, more practical homomorphic encryption schemes are possible. For example, Zhou and Wornell [59] proposed an integer vector encryption scheme which supports addition, linear transformation and weighted inner product on ciphertexts. Nevertheless, the reduction from elastic net to SVM leads to changes of the training dataset. To be specific, one gene expression profile of a patient across all genes (i.e., one row) is a training sample of elastic net. But one training sample of SVM (see Fig. 2) can be considered as gene expression values of a particular gene among all the patients (i.e. one column). Therefore, if we encrypt gene expression profiles using the integer vector encryption, there is no way to construct ciphertexts for the training dataset of SVM. As a result, we restrict our attention to cryptosystems encrypting one element of the profile at a time instead of encrypting the whole profile.
We show the main steps of our scheme in Fig. 4. To avoid iterative training of the elastic net (Step 1), we first make a reduction from the elastic net to SVM (Step 2). In our setting of collaborative data mining in the cloud, the training dataset of the elastic net is horizontally partitioned (different institutions holding different records with the same set of attributes) while the training dataset of SVM is vertically partitioned (records are partitioned into different parts with different attributes after the transformation). Once we get the solution to SVM (Step 4), we can reconstruct the solution to the elastic net (Step 5). We use gram matrix (Section 3.2.1) as input to train SVM (Step 3, Section 4.2). The basic operations for computing gram matrix are homomorphic addition and multiplication. We thus need a cryptosystem that supports one multiply operation and multiple add operations under both single key and different keys. Indeed, the BGN cryptosystem [5] can compute one multiplication on the ciphertexts using bilinear maps. However, it does not support multikey homomorphism. Is it possible to achieve both homomorphic addition and homomorphic multiplication without fully homomorphic encryption? When it comes to multikey homomorphism, can we construct such a cryptosystem? Is there a way to decrypt the encrypted gram matrix while keeping the involved institutions offline? We give affirmative answers to these questions. Firstly, we utilize a framework proposed in [9] to make an additively homomorphic encryption scheme support one homomorphic multiplication (Step 3a, Section 4.1.1). Secondly, we show how to modify an additively homomorphic encryption scheme (BCP cryptosystem) to achieve multikey homomorphic addition (Step 3b, Section 4.1.2). Thirdly, we use secret sharing to authorize one server (i.e., ) to decrypt the encrypted gram matrix without knowing the secret key of any institution (Step 3c, Section 4.1.3). We keep medical institutions stay offline except for the initialization phase.
Building blocks
Framework to enable one multiplication on cihphertexts
Catalano and Fiore [9] showed a framework to enable existing additively homomorphic encryption schemes (i.e. Paillier, ElGamal) to compute multiplication on ciphertexts. We use to denote the underlying additively homomorphic encryption. The idea is to transform a ciphertext into “multiplication friendly”. To be specific, we use (where is a random number) to represent the “multiplication friendly” ciphertext. Given two “multiplication friendly” ciphertexts and , we compute multiplication as .
To decrypt , we will add to the decryption of α where , is retrieved from , . The addition of two ciphertexts after multiplication works by adding the α components and concatenating the β components. Therefore, the β component will grow linearly with additions after performing a multiplication. To remove this constraint, two non-colluding servers are used to store and respectively. In this way, can throw away the β component after performing a multiplication, because will operate on the ’s in plaintext. Therefore, the ciphertext contains only the α component after performing a multiplication. This framework has a nice property that it inherits the multikey homomorphism of the underlying additively homomorphic encryption.
Multikey homomorphism of the BCP cryptosystem
The BCP Cryptosystem.
The BCP cryptosystem (also known as Modified Paillier Cryptosystem) is an additively homomorphic encryption scheme under single key [6]. We briefly review the BCP cryptosystem in Fig. 5 and discuss how to modify it to support multikey homomorphism at the expense of expanding the ciphertext size. Supposed that is under key , is under key , then where denotes a ciphertext related to key and can be computed as
The ciphertext size only depends on the number of involved medical institutions (i.e., keys). There are two MIs with key and respectively in this example, the addition of their ciphertexts is a 3-tuple. If n MIs cooperate together, the addition of their ciphertexts should be a -tuple. To decrypt , the secret key and are required.
Incorporating the above modified the BCP cryptosystem to the framework that enables additively homomorphic encryption to support one multiplication, we obtain our final encryption scheme .5
denotes the framwork and denotes the underlying cryptosystem.
Keep institutions offline
We leverage ’s proxy re-encryption property, which inherits from the underlying the BCP cryptosystem (see (10)). To keep and offline, we split the secret key s of each involved medical institution into two shares. Specifically, we have and . holds , and holds , . Supposed that we have a ciphertext where and are two training samples of SVM, will first decrypt the ciphertext partially with and .
Then will send and to . will compute and return , , to afterwards. Finally, is able to decrypt completely and get in plaintext.
Gram matrix computation
Gram matrix K is defined as where and are any two training samples (see Section 3.2.1). Recall that the original training dataset X of elastic net regression is transformed to the training dataset of SVM during the reduction process (see Section 3.2.2), we use to denote the transformed dataset. After dataset transformation, the horizontally partitioned dataset of the elastic net is converted to a vertically partitioned dataset of SVM. The gram matrix of is computed as follows.
For ease of description, we first consider the case of two medical institutions denoted as and . Assume that the cloud store n gene expression profiles, among which records are from and records are from . Then in the transformed dataset of SVM, for each training sample, the first elements are encrypted under key , and the remaining elements are encrypted under key . Assume that we have two training samples and of SVM, their dot product can be computed as follows and their ciphertexts are denoted as , .
Supposed that the ciphertext of and are and respectively,6
will abandon the and component after a multiplication.
then will compute , as follows. The computation of or only requires single key homomorphism.
As and are encrypted under different keys, adding them together requires multikey homomorphism.
Observing that the gram matrix in (17) is symmetric, we only need to compute the upper triangular half. Section 4.1.3 shows how to decrypt to get . In a similar way, can get the gram matrix K in plaintext. If there are more than two medical institutions, we can easily extend (18), (19) and (21) to handle the case of multiple medical institutions. The size of ciphertext of increases linearly with the number of involved medical institutions. Likewise, the communication overhead also increases linearly during the decryption phase.
Our construction
Given the encrypted gene expression profiles derived from multiple medical institutions, the cloud runs privacy-preserving elastic net on it to discover biomarkers to predict a patient’s response to anticancer drugs. As it is not clear how to design a privacy-preserving protocol based on iterative algorithms to solve the elastic net. We resort to reduction to shift our attention from elastic net to SVM. In Algorithm1, we first demonstrate how to transform the encrypted dataset of the elastic net to that of SVM (see Section 3.2.2). Performing such transformation on the dataset in plaintext is easy. However, once it is encrypted, we need to rely on the homomorphic properties of our cryptosystem to finish the transformation. Next, we compute the encrypted gram matrix of the transformed training dataset (see Section 4.2). Gram matrix plays a role as intermediate dataset based on which SVM model can be generated correctly without breaching the privacy of patients’ gene expression profiles. To keep medical institutions offline, we authorize to decrypt . Based on K, we train SVM and obtain the solution α. Finally, we use α to reconstruct β, which is the solution to the elastic net.
Protocol for Privacy-preserving Elastic Net.
Train SVM
We do not include any bias item in this paper, according to Section 3.2.2. The dual coordinate descent method [30] seems to work. It is efficient, and its main idea is to optimize one variable once at a time, reducing memory requirements. However, coordinate descent methods are inherently sequential and hard to parallelize. To utilize the parallel properties of SVM, we also seek to find a solution which can be parallelized [48]. As shown in [10], optimizing on either the primal problem or the dual problem is in fact equivalent. Linear SVM can be considered as non-linear SVM with a linear kernel and an associated Reproducing Hilbert Space .
According to the representer theorem, the minimizer of (22) can be represented by . Note that these coefficients are different from the Lagrange multipliers in standard SVM literature. The relationship between and is . (22) can be rewritten as
where K is also the gram matrix with and is the row of K. The Newton optimization algorithm of the above problem can be expressed as dense linear algebra operations. When combined with highly optimized libraries such as Intel’s MKL for multicores, Jacket, and CuBLAS for GPUs, we can largely speedup the training of SVM.
Model assessment
In Algorithm 1, there are two parameters: -norm constraint t and -regularization parameter λ. It is not known beforehand which t and λ are best for the elastic net. For different combinations of , the predictive power of the derived solution varies. We do “grid search” on t and λ using k-fold cross validation [23] to assess the goodness-of-fit of our model under different parameters. The grid-search is straightforward. We specify the range of t and λ respectively. Then we try various pairs of . As it might be time-consuming to do a complete grid-search, we recommend using a coarse grid first. Once a “better” region is identified, we will conduct a finer grid search on that region. We divide our training dataset into k subsets satisfying , (). We use where as the validation set and the remaining subsets as the training dataset each time. To measure the performance of regression, we choose Rooted Mean Squared Error (RMSE). An RMSE value closer to 0 indicates the regression model is more useful for prediction. In the setting of k-fold cross-validation, we need to compute the average of k RMSE values. Supposed that there are d samples in the validation set, the predicted GI50 value of gene expression profile is and the true value is , then RMSE is computed as
Recall that each gene expression profile is encrypted, we can compute the ciphertext of the predicted GI50 value as where β is the solution to the elastic net. To get in plaintext, we make the two non-colluding servers work together. reveals β to . returns to . Then computes . For each pair, computes RMSE with each predicted value . Finally, will pick the optimal which achieves the smallest RMSE and get the optimal solution .
Verify the correctness of the result
As is untrusted and may deviate from the algorithm instructions, it may return wrong/random result to the user. Consequently, we need a method to verify the correctness of the returned result. We observe that the correct β is a minimizer of the objective function (F) given by (1).
The gradient of the objective function (25) must attain a value close to zero at the correct β. Recall that we assume that data are horizontally partitioned among different medical institutions, X and denote the training dataset of the elastic net and SVM, respectively. In order to compute , we need to compute the dot product of samples not only from the same institution (single key) but also from different institutions (multiple keys). Dot product of samples from the same institution can be computed with the framework in Section 4.1.1. To compute dot product from different institutions, we need to modify the multiplication operation under single key (6) to the setting of two keys. The idea is to incorporate the multikey homomorphism (11) to the multiplication. Given two ciphertexts (under key ) and (under key ), we compute multiplication as .
Therefore, is able to compute the encrypted result of . Next, and interact with each other to get the plaintext of (see Section 4.1.3). λ and β are known to and can be revealed to . We thus get and can also be calculated easily. As for , we have two choices to handle with it. Assume that we use and to denote the training dataset and class labels belonging to institution i, is responsible for computing the encrypted . The first option is to send each to the corresponding institution. Finally, the institutions decrypt the encrypted and cooperate with each other to add up all the to get . The second option is to shift the verification workload to which is honest-but-curious in our model. can obtain as it stores all the . Adding up the three parts – , and , we get the final verification proof (gradient ).
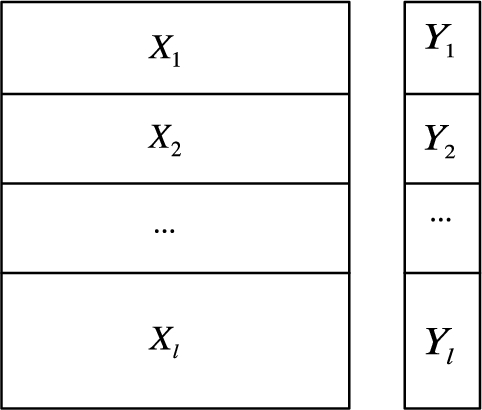
Horizontally partitioned dataset.
Correctness. We want to prove that where l is the number of involved institutions. We show one horizontally partitioned dataset in Fig. 6 where , , …, and , , …, . We also have , and .
Further optimizations
An alternative to the BCP cryptosystem. In our scheme, we rely on the BCP cryptosystem which is additively homomorphic. We demonstrated how to modify it to support multikey homomorphism in Section 4.1.2. We provide you with an elliptic curve based cryptosystem which offers shorter ciphertext and faster computing speed – Additively Homomorphic Elliptic Curve-based El Gamal (AH-ECC) [16] in this section. Considering 112-bit security parameter, each BCP ciphertext is a pair of 4096-bit group elements. On the contrary, each AH-ECC ciphertext is a pair of 193 bits. On the same platform, the computing speed of AH-ECC is faster than BCP by two orders of magnitude.
: On input a security parameter τ, select an approporiate elliptic curve E and public generators on E (generating a group of order q). Choose a random private key , define the public key as , and output public parameters () and private key x.
: Message m is encrypted by drawing a random element and computing two EC-points as . The ciphertext is .
: Decryption is performed by computing the element . Then a pre-computed table of discrete logarithms may then be used to recover m from (which is practical for small ranges of m).
Supposed that we have two ciphertexts and , we should perform pairwise point addition of ciphertexts to get their sum . To be specific, , and . If we aim to achieve multikey homomorphism, we should modify it in a similar way as how we change the BCP cryptosystem. Given two ciphertexts under different keys, such as under key () and under key (), we have , . The ciphertext of is a triple .
The main drawback of AH-ECC is that decryption requires a pre-computed table of discrete logarithms. Although can help maintain this table, AH-ECC is not practical when the range of values in the gene expression profiles is large.
Combination with MapReduce. MapReduce is a popular programming model for parallel and massive processing. Considering one dot product job, we can separate it into a bunch of sub-jobs. Each sub-job is performed on a Map function. Afterwards, all the outputs of the Map functions are imported into the Reduce function, which computes the summation. Liu et al. proposed one protocol for secure dot product in MapReduce in [38]. They rely on fully homomorphic encryption and thus need re-encryption with the same key when handling with multiple users. However, we can replace their scheme with the cryptosystem we put forward in this paper to accelerate the computation of gram matrix.
Security analysis
We assume that all the medical institutions and are honest-but-curious. They follow the algorithm correctly, but secretly record all the input and output. They attempt to recover the original private data. But is untrusted. It may deviate from the algorithm instructions. It may return wrong/random result to the user and try to escape from being detected. There might exist collusion between a medical institution and . We analyze the security of our model with the Real and Ideal paradigm and Composition Theorem [25]. The main idea is to use a simulator in the ideal world to simulate the view of a malicious adversary in the real world. If the view in the real world is computationally indistinguishable from the view in the ideal world, then the protocol is believed to be secure. According to the Composition Theorem, the entire scheme is secure if each step is proved to be secure.
In Algorithm
1
, it is computationally infeasible forto distinguish the gene expression profiles encrypted under multiple keys as long asis semantically secure and the two servers are non-colluding.
We discuss the security of each step in Algorithm 1.
Step 1. Dataset transformation: Given , it requires the homomorphic addition to compute and . Therefore, we need to prove the security of addition over ciphertexts against a malicious adversary in the real world. We set up a simulator in the ideal world to simulate the view of . Considering one operation , the view of in this step includes input and output . Without loss of generality, we assume that simulator computes and where and . Then the simulator computes and returns to . Since the view of are ciphertexts generated under cryptosystem and has no knowledge of the private key. If could distinguish the real world from the ideal world, then it indicates can distinguish ciphertexts generated by , which contradicts to the assumption that is semantically secure. Therefore, is computationally infeasible to distinguish the real world from the ideal world.
For the case where a medical institution (denoted as ) colludes with , we use to denote the corresponding adversary. cannot learn anything beyond gene expression values of .
Step 2. Gram Matrix computation: Recall that the basic operation of gram matrix computation is the dot product of two training samples and . The security of addition has been proved in step 1. As for the security of multiplication, computing α component is implemented over ciphertexts on (see (26)). Similar to the proof above, we can prove the security of multiplication with the real and ideal paradigm. Moreover, the multikey homomorphic addition of the BCP Cryptosystem is based on ciphertexts (see (11)). As long as the BCP Cryptosystem is semantically secure, the multikey homomorphic addition is secure. As for decrypting the encrypted dot product, interacts with . sends and to (see (13)). returns , to . Based on the hardness of computing discrete logarithm, it is infeasible for to deduce or . Therefore, cannot recover or .
For the case of collusion between and , and are both revealed to . Even though the adversary can know , the value of and remains unknown. According to Theorem 3, it is secure to reveal gram matrix to .
Step 3. Train SVM: Given the gram matrix K, we train SVM to get α. cannot infer anything about gene expression profiles based on α.
Step 4. Reconstruct β based on α: If gene expression profiling microarray is known to the public, then will know which genes are picked out as biomarkers corresponding to non-zero elements of β. We can remedy this vulnerability by permuting the gene expression profile before uploading. □
No encryption scheme is secure against known-sample attack if dot products are revealed.
We define known-sample attack as an attacker obtaining the plaintexts of a set of records of the encrypted database but not knowing the correspondence between the plaintexts and the encrypted records. According to [53], no encryption scheme is secure against known-sample attack if distance information is revealed. As distance computation can be decomposed into dot products, revealing dot products equals to revealing distance. Given n encrypted samples whose dimension is m, if an attacker knows the plaintexts of m linearly independent samples, the attacker can obtain the plaintext of any encrypted samples even without the decryption key. The idea is to construct m linear equations, whose unique solution corresponds to the desired sample. □
Fortunately, in the following theorem, we show that it is impossible for the attackers to make use of Theorem 2 to launch the attack.
cannot reconstruct gene expression profile of a patient with gram matrix K known, considering the impossibility that an attacker collects enough samples of SVM to launch the attack mentioned in Theorem
2
.
According to Section 3.2.2, one gene expression profile of a patient across all genes (i.e., one row) is a training sample of the elastic net. But the training sample of SVM can be considered as gene expression values of a particular gene among all the patients (i.e., one column). If colludes with , it only brings minor advantage that some of the elements from of a training sample are revealed. Unless the attacker cracks our cryptosystem and obtains all the private keys of the involved medical institutions, he cannot set up linear equations to launch the known-sample attack. □
Experimental evaluation
The configuration of our PC is Windows 7 Enterprise 64-bit Operating System with Intel(R) Core(TM) i5 CPU (4 cores), 3.4 GHz and 16 GB memory. We use a public database for drug sensitivity in cancer cell lines [54]. To provide platform independence, we use Java to implement our scheme together with open-source IDE. We use BigInteger class which offers all basic operations we need to process big numbers. We utilize SecureRandom class to produce a cryptographically strong random number. As for the generation of safe prime numbers, we use the probablePrime method provided by BigInteger class. The probability that a BigInteger returned by this method is composite does not exceed . The performance of our scheme depends heavily on the size of modulus N, and the number of additions and multiplications performed. During the initialization phase, public and private key pair are generated. The runtime of creating a key pair varies with the bit length of N, as it depends a lot on the random number generator. A typical value for N is 1024, and it takes about 2 second in average to generate one key pair.
Encryption time.
Dot product time.
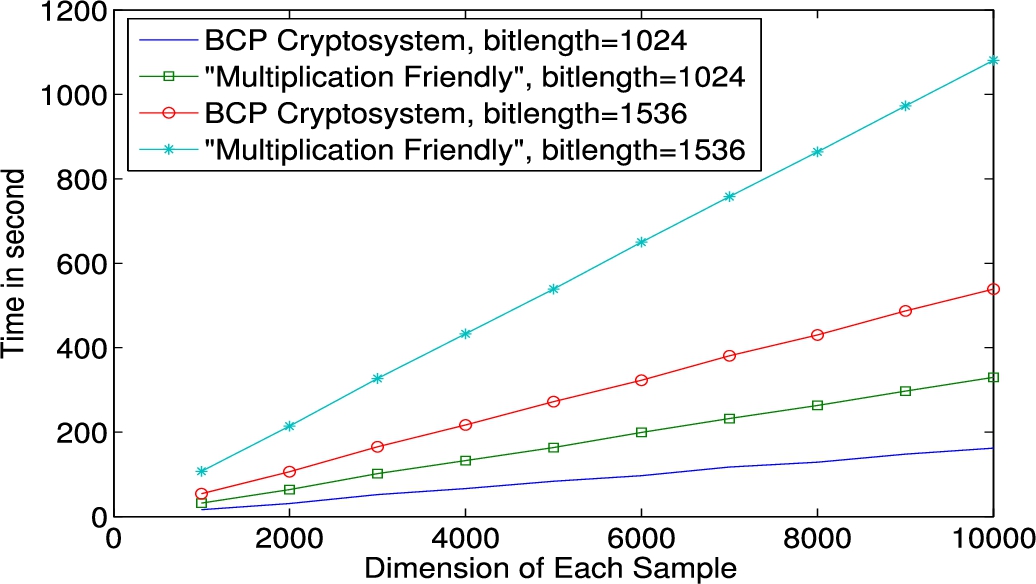
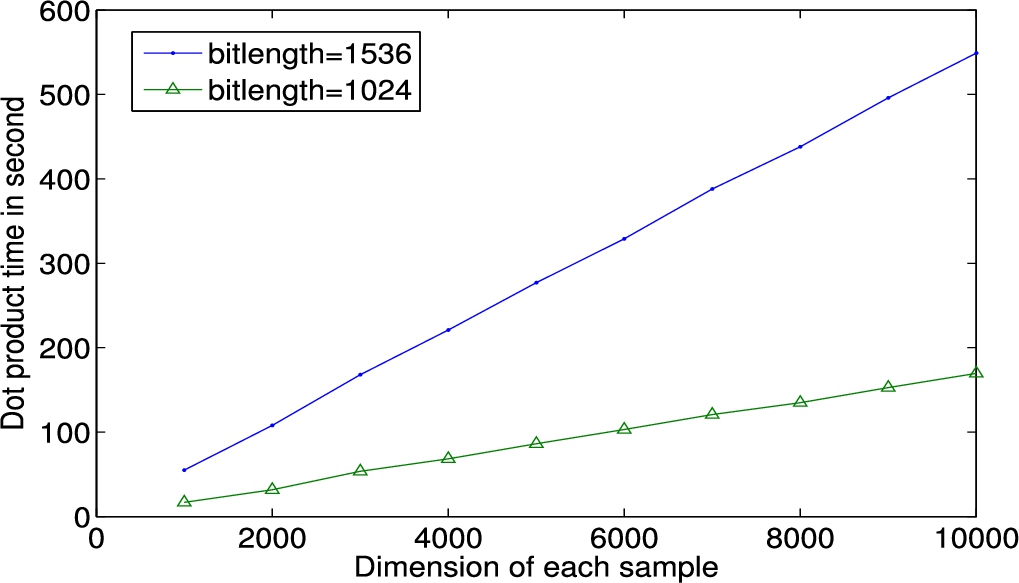
We first compare the encryption time of two training samples when using the BCP Cryptosystem and our proposed cryptosystem . We vary the dimension of each sample from 1000 to 10,000. The bit length of modulus N is set to 1024 and 1536 respectively (following the same setting as in [43]). As shown in Fig. 7, the encryption time scales linearly as the dimension increases. We use and where b is a random number to denote the ciphertext of x under BCP and cryptosystem respectively. Leveraging the framework proposed in [9], the encryption time of doubles that of the BCP Cryptosystem. The additional encryption time is caused by generating the random number b. Moreover, we measure the time to compute the dot product of two encrypted training samples. We focus on a vertically partitioned dataset of SVM. To facilitate understanding, we encrypt the first half (belonging to Alice) of a sample using secret key and the second half (belonging to Bob) using secret key . We show the runtime of dot product computation on the ciphertexts in Fig. 8. Similarly, time to calculate dot product increases linearly with the dimension of samples. For vectors of dimension m, one dot product operation includes m multiplications and additions, among which one addition is multikey homomorphic. It takes only 1 millisecond to run a multikey homomorphic addition. For operations under the single key, addition is much faster than multiplication. With a 1024-bit modulus, the runtime of additions is less than 1 second. The runtime of multiplications varies from 16 seconds to 185 seconds with the dimension of a sample increasing from 1000 to . Therefore, multiplications are the bottleneck of dot product computation. To decrypt one encrypted dot product, it takes 285 milliseconds and 572 milliseconds with and without secret sharing separately. Recall that the multikey homomorphism property is achieved at the expense of expanding ciphertext size, we also measure the effect of the number of involved users on the increase of ciphertext size. As shown in Fig. 9, the ciphertext size increases linearly from 6138 B to 26 KB when the number of involved users increasing from 2 to 100.
Size of dot product ciphertext.
The public database for drug sensitivity in this paper consists of 1002 cancer cell lines, 265 anticancer drugs. For each drug, GI50 values of around 300 to 1000 cell lines are available. As for gene expression profiling, it contains the RMA-normalized expression values of 17737 genes of 1018 cell lines. We preprocess them in MATLAB, keeping those cell lines that belong to the intersection of gene expression profiles and GI50 values. For example, considering drug -0325901, we get 843 expression profiles and GI50 values. As our cryptosystem only supports operations on the integer domain, we need to preprocess the database. To be specific, we first select a system parameter p to represent the number of bits for the fractional part of expression values. We next multiply each expression value by to get its integer value. Then, we need to divide each element of the gram matrix by to remove the influence of scaling up. After running our privacy-preserving elastic net, we successfully pick out 165 genomic biomarkers.
Comparison with existing schemes: We focus on the homomorphic encryption based schemes [37,43,51,52], of which the setting is outsourced encrypted database under multiple keys. According to the experimental evaluation of [9], using their proposed framework to enable one multiplication on additively homomorphic ciphertexts outperforms the BGV homomorphic encryption [28] (in terms of ciphertext size, time of encryption/decryption/homomorphic operations). As shown in the experiments above, modification to the BCP Cryptosystem for multikey homomorphism only doubles the encryption time. Therefore, addition and multiplication can be run more efficiently in our scheme compared to [37], which deals with only two users (i.e. keys). Besides, they require the users to be online while we keep the users offline in this paper. Under two non-colluding servers model, the schemes in [43,51,52] can be used to compute addition/multiplication. The main drawback of their schemes is that they have to transform the ciphertexts under multiple keys to those under the same key, which is a heavy workload for the cloud server. Moreover, computing multiplication incurs interactions between the two servers. By contrast, our cryptosystem enables calculating multiplication without interactions. Multi-client verifiable computation was first introduced in [12]. Current verifiable computation schemes are formally based on Probabilistically Checkable Proofs (PCPs) [34] or Fully Homomorphic Encryption (FHE) [8], they are hard to be utilized in practice due to high computation and storage costs.
Discussion and conclusions
In practical scenarios, a gene expression profile typically has a dimension of order . We can only collect hundreds of patients’ profiles of different cancers. If we store gram matrix K in the memory, it is of order in our case, which requires a lot of memory. Keerthi et al. [33] proposed to restrict the support vectors to some subset of basis vectors in order to reduce the memory requirement. This method requires space where . However, the derived α using this method can be different from the one we get using the entire gram matrix K. It is a trade-off between accuracy and efficiency. For genomic biomarker discovery, it is obviously more important to pick out accurate biomarkers. Therefore, it makes sense to maintain the gram matrix in memory.
To conclude, in this paper, by assuming the existence of two non-colluding servers, we proposed a privacy-preserving collaborative model to conduct the elastic net regression through reduction to SVM on encrypted gene expression profiles and GI50 values of anticancer drugs. To compute the gram matrix on ciphertexts, we successfully construct a cryptosystem that supports one multiply operation and multiple add operations under both single key and different keys. Besides, we use secret sharing to allow one of the cloud server to get the gram matrix. To verify the correctness of the final result, we base our scheme on the fact that the gradient of the objective function at the correct solution should be close to zero. Our scheme keeps the medical institutions offline and is proved to be secure. The experimental results highlight the practicability of our scheme. The proposed protocol could also be applied to other applications that use support vector machine, elastic net, lasso (classification or regression). Our current scheme assumes that only is untrusted and is honest-but-curious. Our future work is to extend our scheme to handle the case when both and are malicious.
Footnotes
Acknowledgments
This project is partially supported by the Seed Funding Programme of HKU (201511159034), NSFC/RGC Joint Research Scheme (N_HKU 729/13), and National High Technology Research and Development Program of China (2015AA016008), and the collaborative research fund (CRF) of RGC of Hong Kong (Project No. CityU C1008-16G).
References
1.
M.Backes, D.Fiore and R.M.Reischuk, Verifiable delegation of computation on outsourced data, in: Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, ACM, 2013, pp. 863–874.
2.
J.Barretina, G.Caponigro, N.Stransky, K.Venkatesan, A.A.Margolin, S.Kim, C.J.Wilson, J.Lehár, G.V.Kryukov, D.Sonkinet al., The Cancer Cell Line Encyclopedia enables predictive modelling of anticancer drug sensitivity, Nature483(7391) (2012), 603–607. doi:10.1038/nature11003.
3.
S.Benabbas, R.Gennaro and Y.Vahlis, Verifiable delegation of computation over large datasets, in: Advances in Cryptology – CRYPTO 2011, 2011, pp. 111–131.
4.
M.Blaze, G.Bleumer and M.Strauss, Divertible protocols and atomic proxy cryptography, in: EUROCRYPT’98, Springer, 1998, pp. 127–144. doi:10.1007/BFb0054122.
5.
D.Boneh, E.-J.Goh and K.Nissim, Evaluating 2-DNF formulas on ciphertexts, in: Theory of Cryptography Conference, Springer, 2005, pp. 325–341. doi:10.1007/978-3-540-30576-7_18.
6.
E.Bresson, D.Catalano and D.Pointcheval, A simple public-key cryptosystem with a double trapdoor decryption mechanism and its applications, in: Advances in Cryptology – ASIACRYPT 2003, Springer, 2003, pp. 37–54. doi:10.1007/978-3-540-40061-5_3.
7.
M.Cafaro and P.Pelle, Space-efficient verifiable secret sharing using polynomial interpolation, IEEE Transactions on Cloud Computing (2015). doi:10.1109/TCC.2015.2396072.
8.
D.Catalano and D.Fiore, Practical homomorphic MACs for arithmetic circuits, in: Annual International Conference on the Theory and Applications of Cryptographic Techniques, Springer, 2013, pp. 336–352.
9.
D.Catalano and D.Fiore, Using linearly-homomorphic encryption to evaluate degree-2 functions on encrypted data, in: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, ACM, 2015, pp. 1518–1529.
10.
O.Chapelle, Training a support vector machine in the primal, Neural Computation19(5) (2007), 1155–1178. doi:10.1162/neco.2007.19.5.1155.
11.
K.Chen, G.Sun and L.Liu, Towards attack-resilient geometric data perturbation, in: Proceedings of the 2007 SIAM International Conference on Data Mining, SIAM, 2007, pp. 78–89. doi:10.1137/1.9781611972771.8.
12.
S.G.Choi, J.Katz, R.Kumaresan and C.Cid, Multi-client non-interactive verifiable computation, in: TCC, Lecture Notes in Computer Science, Vol. 7785, Springer, 2013, pp. 499–518.
13.
S.S.Chow, J.-H.Lee and L.Subramanian, Two-party computation model for privacy-preserving queries over distributed databases., in: NDSS, 2009.
14.
K.-M.Chung, Y.T.Kalai and S.P.Vadhan, Improved delegation of computation using fully homomorphic encryption, in: CRYPTO, Lecture Notes in Computer Science, Vol. 6223, Springer, 2010, pp. 483–501.
15.
D.G.Covell, Data mining approaches for genomic biomarker development: Applications using drug screening data from the Cancer Genome Project and the Cancer Cell Line Encyclopedia, PloS ONE10(7) (2015), e0127433.
16.
G.Danezis and E.De Cristofaro, Fast and private genomic testing for disease susceptibility, in: Proceedings of the 13th Workshop on Privacy in the Electronic Society, ACM, 2014, pp. 31–34.
17.
D.Demmler, T.Schneider and M.Zohner, ABY – A framework for efficient mixed-protocol secure two-party computation, in: NDSS, 2015.
18.
M.J.Duffy and J.Crown, A personalized approach to cancer treatment: How biomarkers can help, Clinical Chemistry54(11) (2008), 1770–1779. doi:10.1373/clinchem.2008.110056.
19.
Z.Erkin, T.Veugen, T.Toft and R.L.Lagendijk, Generating private recommendations efficiently using homomorphic encryption and data packing, IEEE Transactions on Information Forensics and Security7(3) (2012), 1053–1066. doi:10.1109/TIFS.2012.2190726.
20.
Y.Erlich and A.Narayanan, Routes for breaching and protecting genetic privacy, Nature Reviews Genetics15(6) (2014), 409–421. doi:10.1038/nrg3723.
21.
D.Fiore and R.Gennaro, Publicly verifiable delegation of large polynomials and matrix computations, with applications, in: Proceedings of the 2012 ACM Conference on Computer and Communications Security, ACM, 2012, pp. 501–512.
22.
J.Friedman, T.Hastie and R.Tibshirani, glmnet: Lasso and elastic-net regularized generalized linear models, R package version 1, 2009.
23.
T.Fushiki, Estimation of prediction error by using K-fold cross-validation, Statistics and Computing21(2) (2011), 137–146. doi:10.1007/s11222-009-9153-8.
24.
M.J.Garnett, E.J.Edelman, S.J.Heidorn, C.D.Greenman, A.Dastur, K.W.Lau, P.Greninger, I.R.Thompson, X.Luo, J.Soareset al., Systematic identification of genomic markers of drug sensitivity in cancer cells, Nature483(7391) (2012), 570–575. doi:10.1038/nature11005.
25.
O.Goldreich, Foundations of Cryptography: Volume 2, Basic Applications, Cambridge University Press, 2004. doi:10.1017/CBO9780511721656.
26.
S.D.Gordon, J.Katz, F.-H.Liu, E.Shi and H.-S.Zhou, Multi-client verifiable computation with stronger security guarantees, in: Theory of Cryptography Conference, Springer, 2015, pp. 144–168. doi:10.1007/978-3-662-46497-7_6.
27.
L.Guo, Y.Fang, M.Li and P.Li, Verifiable privacy-preserving monitoring for cloud-assisted mHealth systems, in: 2015 IEEE Conference on Computer Communications (INFOCOM), IEEE, 2015, pp. 1026–1034. doi:10.1109/INFOCOM.2015.7218475.
28.
S.Halevi and V.Shoup, An implementation of homomorphic encryption, https://github.com/shaih/HElib.
29.
S.Hohenberger and A.Lysyanskaya, How to securely outsource cryptographic computations, in: Theory of Cryptography Conference, Springer, 2005, pp. 264–282. doi:10.1007/978-3-540-30576-7_15.
30.
C.-J.Hsieh, K.-W.Chang, C.-J.Lin, S.S.Keerthi and S.Sundararajan, A dual coordinate descent method for large-scale linear SVM, in: Proceedings of the 25th International Conference on Machine Learning, ACM, 2008, pp. 408–415.
31.
M.Jaggi, An equivalence between the lasso and support vector machines, in: Regularization, Optimization, Kernels, and Support Vector Machines, 2014, pp. 1–26.
32.
I.S.Jang, E.C.Neto, J.Guinney, S.H.Friend and A.A.Margolin, Systematic assessment of analytical methods for drug sensitivity prediction from cancer cell line data, in: Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing, 2014, p. 63.
33.
S.S.Keerthi, O.Chapelle and D.DeCoste, Building support vector machines with reduced classifier complexity, Journal of Machine Learning Research7 (2006), 1493–1515.
34.
J.Lai, R.H.Deng, H.Pang and J.Weng, Verifiable computation on outsourced encrypted data, in: European Symposium on Research in Computer Security, Springer, 2014, pp. 273–291.
35.
S.Laur, H.Lipmaa and T.Mielikäinen, Cryptographically private support vector machines, in: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2006, pp. 618–624. doi:10.1145/1150402.1150477.
36.
K.-P.Lin and M.-S.Chen, Privacy-preserving outsourcing support vector machines with random transformation, in: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2010, pp. 363–372.
37.
F.Liu, W.K.Ng and W.Zhang, Encrypted SVM for outsourced data mining, in: 2015 IEEE 8th International Conference on Cloud Computing, IEEE, 2015, pp. 1085–1092. doi:10.1109/CLOUD.2015.158.
38.
F.Liu, W.K.Ng and W.Zhang, Secure scalar product for big-data in MapReduce, in: 2015 IEEE First International Conference on Big Data Computing Service and Applications (BigDataService), IEEE, 2015, pp. 120–129. doi:10.1109/BigDataService.2015.9.
39.
J.Liu, S.Ji, J.Yeet al., SLEP: Sparse learning with efficient projections, Arizona State University, 2009.
40.
A.López-Alt, E.Tromer and V.Vaikuntanathan, On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption, in: Proceedings of the Forty-Fourth Annual ACM Symposium on Theory of Computing, ACM, 2012, pp. 1219–1234.
41.
B.Parno, M.Raykova and V.Vaikuntanathan, How to delegate and verify in public: Verifiable computation from attribute-based encryption, in: TCC, Lecture Notes in Computer Science, Vol. 7194, Springer, 2012, pp. 422–439.
42.
T.B.Pedersen, Y.Saygın and E.Savaş, Secret charing vs. encryption-based techniques for privacy preserving data mining, 2007.
43.
A.Peter, E.Tews and S.Katzenbeisser, Efficiently outsourcing multiparty computation under multiple keys, IEEE Transactions on Information Forensics and Security8(12) (2013), 2046–2058. doi:10.1109/TIFS.2013.2288131.
44.
E.E.Schadt, S.Woo and K.Hao, Bayesian method to predict individual SNP genotypes from gene expression data, Nature Genetics44(5) (2012), 603–608. doi:10.1038/ng.2248.
45.
S.Shalev-Shwartz and T.Zhang, Accelerated proximal stochastic dual coordinate ascent for regularized loss minimization, in: ICML, 2014, pp. 64–72.
46.
W.Sun, B.Wang, N.Cao, M.Li, W.Lou, Y.T.Hou and H.Li, Verifiable privacy-preserving multi-keyword text search in the cloud supporting similarity-based ranking, IEEE Transactions on Parallel and Distributed Systems25(11) (2014), 3025–3035. doi:10.1109/TPDS.2013.282.
47.
T.Tassa, A.Jarrous and Y.Ben-Ya’akov, Oblivious evaluation of multivariate polynomials, Journal of Mathematical Cryptology7(1) (2013), 1–29. doi:10.1515/jmc-2012-0007.
48.
S.Tyree, J.R.Gardner, K.Q.Weinberger, K.Agrawal and J.Tran, Parallel support vector machines in practice, Preprint, arXiv:1404.1066, 2014.
49.
J.Vaidya, H.Yu and X.Jiang, Privacy-preserving SVM classification, Knowledge and Information Systems14(2) (2008), 161–178. doi:10.1007/s10115-007-0073-7.
50.
M.Van Dijk and A.Juels, On the impossibility of cryptography alone for privacy-preserving cloud computing., HotSec10 (2010), 1–8.
51.
B.Wang, M.Li, S.S.Chow and H.Li, Computing encrypted cloud data efficiently under multiple keys, in: 2013 IEEE Conference on Communications and Network Security (CNS), IEEE, 2013, pp. 504–513. doi:10.1109/CNS.2013.6682768.
52.
B.Wang, M.Li, S.S.Chow and H.Li, A tale of two clouds: Computing on data encrypted under multiple keys, in: 2014 IEEE Conference on Communications and Network Security (CNS), IEEE, 2014, pp. 337–345.
53.
W.K.Wong, D.W.Cheung, B.Kao and N.Mamoulis, Secure kNN computation on encrypted databases, in: Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, ACM, 2009, pp. 139–152. doi:10.1137/1.9781611972795.
54.
W.Yang, J.Soares, P.Greninger, E.J.Edelman, H.Lightfoot, S.Forbes, N.Bindal, D.Beare, J.A.Smith, I.R.Thompsonet al., Genomics of Drug Sensitivity in Cancer (GDSC): A resource for therapeutic biomarker discovery in cancer cells, Nucleic Acids Research41(D1) (2013), D955–D961. doi:10.1093/nar/gks1111.
55.
H.Yu, X.Jiang and J.Vaidya, Privacy-preserving SVM using nonlinear kernels on horizontally partitioned data, in: Proceedings of the 2006 ACM Symposium on Applied Computing, ACM, 2006, pp. 603–610. doi:10.1145/1141277.1141415.
56.
H.Yu, J.Vaidya and X.Jiang, Privacy-preserving SVM classification on vertically partitioned data, in: Advances in Knowledge Discovery and Data Mining, Springer, 2006, pp. 647–656. doi:10.1007/11731139_74.
57.
J.Zhang, M.He and S.-M.Yiu, Privacy-preserving elastic net for data encrypted by different keys – With an application on biomarker discovery, in: IFIP Annual Conference on Data and Applications Security and Privacy, Springer, 2017, pp. 185–204.
58.
J.Zhang, X.Wang, S.-M.Yiu, Z.L.Jiang and J.Li, Secure dot product of outsourced encrypted vectors and its application to SVM, in: Proceedings of the Fifth ACM International Workshop on Security in Cloud Computing, ACM, 2017, pp. 75–82. doi:10.1145/3055259.3055270.
59.
H.Zhou and G.Wornell, Efficient homomorphic encryption on integer vectors and its applications, in: 2014 Information Theory and Applications Workshop (ITA), IEEE, 2014, pp. 1–9.
60.
Q.Zhou, W.Chen, S.Song, J.R.Gardner, K.Q.Weinberger and Y.Chen, A reduction of the elastic net to support vector machines with an application to GPU computing, in: Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015.
61.
H.Zou and T.Hastie, Regularization and variable selection via the elastic net, Journal of the Royal Statistical Society: Series B (Statistical Methodology)67(2) (2005), 301–320. doi:10.1111/j.1467-9868.2005.00503.x.