
Abstract
Support vector machine (SVM) is a supervised binary classifier with good generalization ability and excellent computational properties. It has been widely used in many fields such as image recognition, bioinformatics and so on. However, the traditional SVM requires the input data to be clear and knowable, while in the actual application process, there will be many cases that the input data is uncertain. In order to solve this problem, a new SVM model is proposed in this paper by combining the uncertainty theory with the SVM theory. The uncertainty theory was proposed by Liu in 2007, and it is often used to describe the uncertainty of things. The uncertain set in uncertainty theory is often used to model unsharp concepts. Therefore, this paper regards each uncertain data as an uncertain set and establishes a SVM model with uncertain chance constraints. However, the uncertain chance constraints are non-convex. Therefore, this paper gives the equivalent transformation process of constraint conditions when the input data are triangular uncertain sets. Finally, the non-convex constraint conditions are transformed into the linear constraint conditions, so that the model is transformed into a nonlinear programming model. In the numerical experiment, the Particle Swarm Optimization (PSO) algorithm is used to solve the problem, which proves the feasibility of the model.
Introduction
In the 1960s, Vapnik et al. [1] first proposed the SVM model. Since then, the theory has been continuously improved and developed. Until the 1990s, Vapnik et al. [2] proposed a complete traditional SVM model and applied it to handwritten character recognition. Since then, SVM has been widely concerned and gradually applied to image recognition, bioinformatics and many other fields [3, 4].
As SVM is more and more applied to practical problems, people gradually find some shortcomings of this model. One of them is that the traditional SVM requires that the input data is clearly known, but there are many cases that the input data is uncertain in real life. In view of this problem, many scholars have carried out relevant research and obtained many achievements. One of the most popular ideas to solve this problem is to combine the fuzzy set theory proposed by Zadeh [5]. Among them, there are three main methods in the idea of combining fuzzy set theory. The first one is to add membership attribute to the sample point, which is used to describe the degree that the sample point belongs to the class, so that different input points have different contributions to the learning of decision surface, which can be used to reduce the influence of outliers and noise in data points. In this way, Lin et al. [6] proposed the fuzzy SVM (FSVM) model. Later, Wang et al. [7] further proposed a new FSVM for credit risk evaluation and Hao et al. [8] further studied it based on fuzzy sets. An et al. [9] proposed a new membership function considering the intra-class scattering information of samples. Fan et al. [10] combined entropy with fuzzy membership function and proposed a FSVM based on entropy to solve the problem of imbalanced datasets. It is not difficult to see that the model obtained by this method is essentially a weighted model, and scholars focus on the construction of membership function. The second method is by combining fuzzy set theory with Hausdorff distance and applying it to support vector machine theory. Wu et al. [11] applied the Hausdorff distance of real numbers to the space of triangular fuzzy sets and proposed the fuzzy support vector regression (FSVR) machine with Gaussian penalty noises. Further Wu [12] set each input data as a symmetric triangular fuzzy number and proposed a FSVN with hybrid penalty noises. The third is to treat the sample points as fuzzy variables, and then the constraint conditions are transformed by using the possibility measure in the fuzzy theory, so as to establish the SVM model with fuzzy constraints. Based on this, Ji et al. [13] assumed that the input data were triangular fuzzy numbers, and then proposed a fuzzy support vector machine model with fuzzy constraints. However, the research results of this method are relatively few. Bessides, Elkan et al. [14] pointed out that there are certain contradictions in the fuzzy set theory and possibility measure. In 2007, Liu [15] proposed uncertainty theory, which is often used to deal with the uncertainty of things. After the theory was put forward, many scholars have studied it and applied it to many fields and obtained many achievements. SVM based on uncertainty theory is an emerging research direction in recent years. In 2022, Qin et al. [16] proposed a SVM with uncertain chance constraints based on uncertain distribution. And in 2022, Li et al. [17] proposed a hard interval SVR with uncertain chance constraints through the same idea. Besides, in 2022, Zhang et al. [18] proposed a ɛ-SVR with expected value constraints.
In this paper, the uncertain set theory is used to build the model innovatively. In 2010, Liu [19] proposed uncertain set theory, which is also used to deal with unsharp concepts. Compared with fuzzy set theory, there are many differences in measure, membership function, computational logic and so on. Therefore, although they are similar in some forms, they are two completely different theories, and there is no contradiction in uncertain set theory. Therefore, after the uncertain set theory is proposed, there is another method to solve the problem of uncertain input data in SVM.
In this paper, the uncertain set theory and SVM are combined, each uncertain input data is regarded as an uncertain set, the traditional constraints are transformed into uncertain constraints through uncertain measure, and an uncertain SVM model based on the uncertain set theory is proposed. In Section 2, this paper introduces some basic knowledge of uncertain set theory. In Section 3, the construction process of the model is given, and the corresponding equivalent transformation form of the model is given for calculation by taking the input data as triangular uncertain set as an example. In Section 4, a numerical example is given as an application of the model. In Section 5, the conclusion and further work are given.
Preliminary
Liu [15] established uncertainty theory in 2007, which is a theory about belief degree analysis. The uncertainty theory axiomatizes the uncertain measure through three axioms: the normality axiom (Axiom 2.1), the duality axiom (Axiom 2.2) and the subadditivity axiom (Axiom 2.3).
And Liu [15] called the set function
Around the uncertainty belief degree, Liu et al. have done a lot of research and put forward a lot of theoretical results, and the uncertain set theory is one of them. In 2010, Liu [19] proposed the uncertain set theory for modelling unsharp concepts that are essentially sets with unclear boundaries. And an uncertain set is a set-valued function which is defined as follows:
After that, Liu [15] gave the fundamental relation between uncertain sets and crisp sets:
In addition, it is different from the fuzzy set theory, the uncertain set theory conforms to the following two laws:
A set can be described by its eigenfunction, and similarly, an uncertain set can be described by its membership function, which is defined as follows:
In addition, the relationship between the membership function and the belief degree is as follows:
In the process of uncertain set calculation, the inverse membership function is often used for convenience, and its definition is as follows:
Besides, Liu innovatively put forward the concept of independence in uncertain set theory, which is very important in many definitions and theorems.
Through membership function and independence, the arithmetic operational of uncertain set can be obtained as follows:
It is worth noting that When there is no solution to f (x1, x2, ⋯ , x n ) = x for some values x, Liu set λ (x) =0.
Another important concept in uncertainty theory is the concept of expected value. Its specific content is shown in the following definition:
In the formula of expected value, there are two important parts, which are calculated as follows:
In the process of modeling in this paper, the concept of distance is very important. In the uncertain set theory, the definition of distance is as follows:
Uncertain support vector machine model
Model building
When the input data of sample
When the sample set is linearly separable, according to the principle of correct classification and interval maximization, the linearly separable uncertain support vector machine model is given as follows:
It is easy to know that the above model (1) is a non-convex constrained problem, but when the membership function is known, we can obtain its equivalent transformation form with good mathematical properties by the following theorem.
The second measureinversion formula was used in the above proof. Similarly, we can obtain:
When facing the linear non-separable problem, this paper combines the above model (1) with the idea of soft interval, and then according to Theorem 3.1 we can get:
For a sample S = {
Based on the above model, the equivalent solution model can be obtained after the specific expression of membership function μ
il
is given. In the uncertain set, the triangular uncertain set and the trapezoidal uncertain set are common. Since the triangular uncertain set has good computational properties, it is relatively clear to use the triangular uncertain set to demonstrate the algorithm, so this paper assumes that the input data is the triangular uncertain set. When the input data
Similarly, the sum ξ + d of a triangular uncertain set ξ and a constant d is also a triangular uncertain set, as follows:
After that, this paper obtain a crisp equivalent form of its linearly separable uncertain support vector machine model by the following theorem.
when
when
After obtaining the membership function λ
i
(x) of the uncertain set
when y
i
= +1,
It is easy to know that
Similarily, when y
i
= -1,
So we can get the objective function is:
According to the above Theorem 3.4, at this time, the constraint conditions are transformed from uncertain constraints to linear constraints, and the objective function is transformed into a special piecewise function. According to the above proof process, we can get:
The expression of the slack variable τ i in the Corollary 3.2 is slightly different from that of the traditional SVM, but the geometric meaning expressed by them is similar. The diagram of slack variable τ i is shown in the Fig. 1.
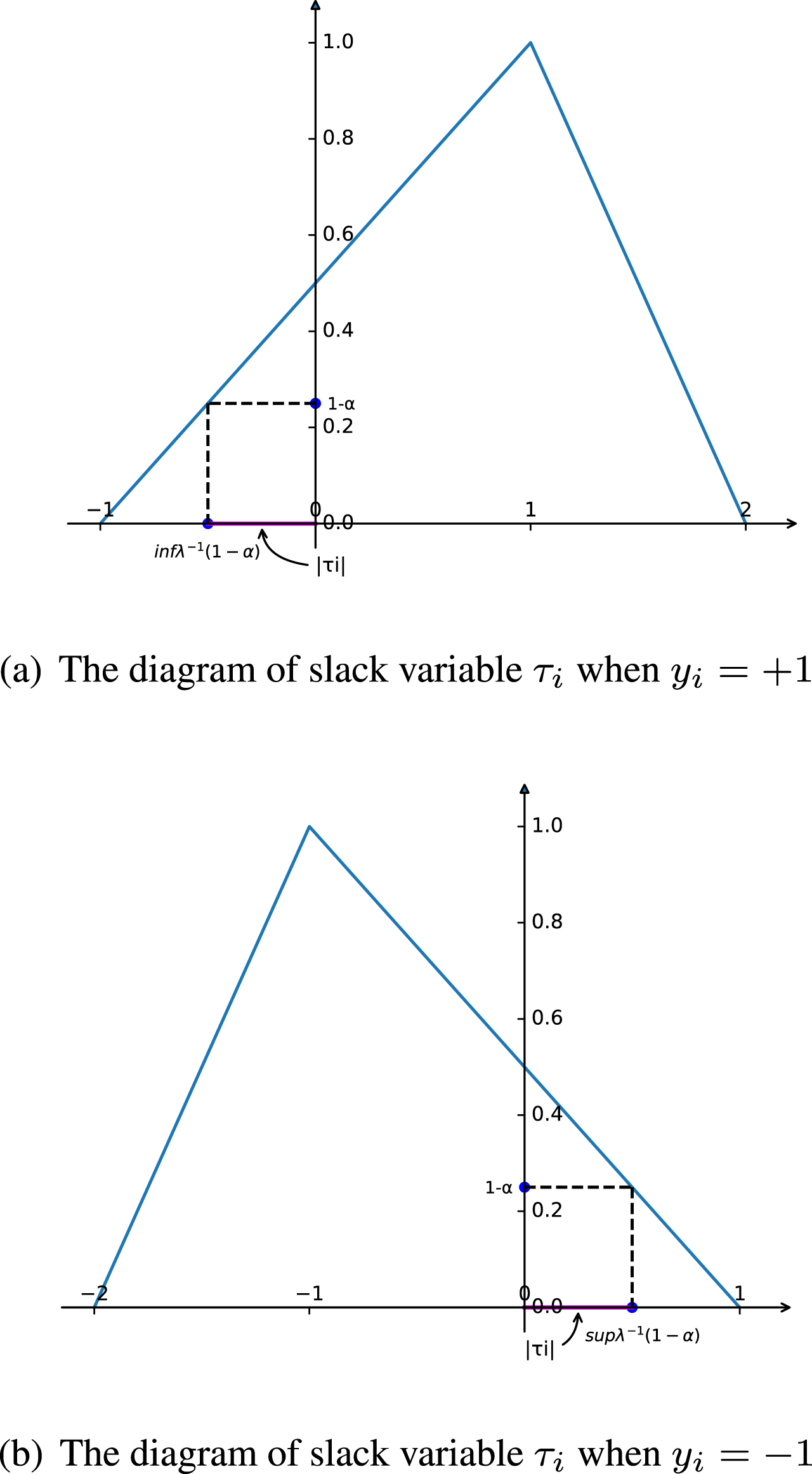
The diagram of slack variable τ i .
From the geometric point of view, what the variable τ i does is, when the constraints in Theorem 3.4 cannot be satisfied, it makes the constraints true by a translation transformation.
The original problem becomes a nonlinear optimization problem after the equivalent transformation. However, because the objective function is a complex piecewise function, some gradient-based algorithms are no longer applicable, so PSO algorithm is adopted in this paper. It is worth noting that PSO algorithm solves the minimum value of the objective function, while the objective function of the original problem is to solve the maximum value. Therefore, in the calculation of PSO algorithm, the original objective function is multiplied by -1, so that the maximum problem is transformed into the minimum problem. Besides, PSO algorithm is often used to compute unconstrained optimization problems. In the face of constrained optimization problems, it is necessary to transform constrained optimization problems into unconstrained optimization problems. The transformation method adopted in this paper is to add constraints into the objective function as a penalty term. If the constraint conditions are met, the penalty term is zero, otherwise it is not zero. In addition, in order to prevent the influence of outliers, it is necessary to normalize the penalty term. After the above transformation process, the model in Theorem 3.4 can be transformed into the fitness function in the PSO algorithm:
In this section, a numerical example is given to illustrate the application process of the model. In this numerical example, this paper modified the iris data set to make each data a triangular uncertain set.
Each sample point in the iris data set contains four features (sepal lengt, sepal width, petal length and petal width). For the convenience of calculation, the first two features (sepal length, sepal width) are selected as input features in this paper. Then, the original feature data of each sample is used as the value of b ij in the triangular uncertain set, while the value of a ij and c ij are randomly selected, and the final data set is shown in Table 1.
The sample data
The sample data
According to the Table 1, we can get the geometric diagram of two-dimensional accurate data and the geometric diagram of two-dimensional uncertain set data respectively which are shown in Fig. 2.
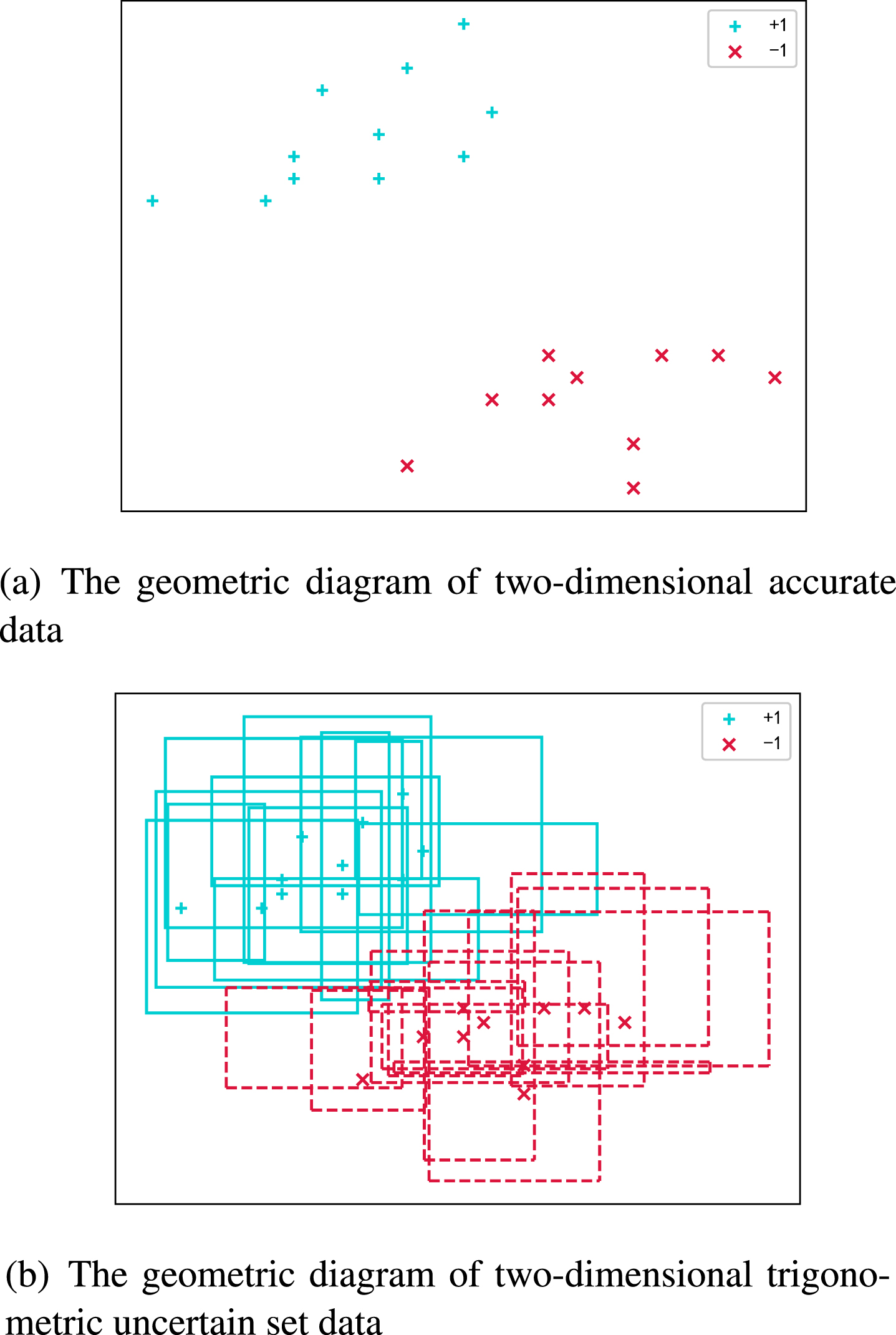
The geometric diagram of two-dimensional accurate data and two-dimensional trigonometric uncertain set data.
According to the Fig. 2, each accurate data is an accurately knowable point, while each inaccurate data conforming to the triangular uncertain set can be approximately regarded as a rectangular region constrained by membership function. Furthermore, ideally, each accurate data point is contained in a corresponding rectangular area. That means we don’t know what the real data is, we just know where the real data might be. The traditional SVM model can only solve the data whose geometric diagram is shown in the Fig. 2(a), while the model proposed in this paper can solve the data whose geometric diagram is shown in the Fig. 2(b).
The above data set was brought into the model in Theorem 3.4 as a training set, and PSO algorithm was used for training. There are some key parameters in PSO algorithm, in this paper, the maximum number of iterations is set to 100, the maximum speed is set to 0.5, and the population size is set to 10. Then, the iterative process under different belief degrees is obtained as shown in the Fig. 3.
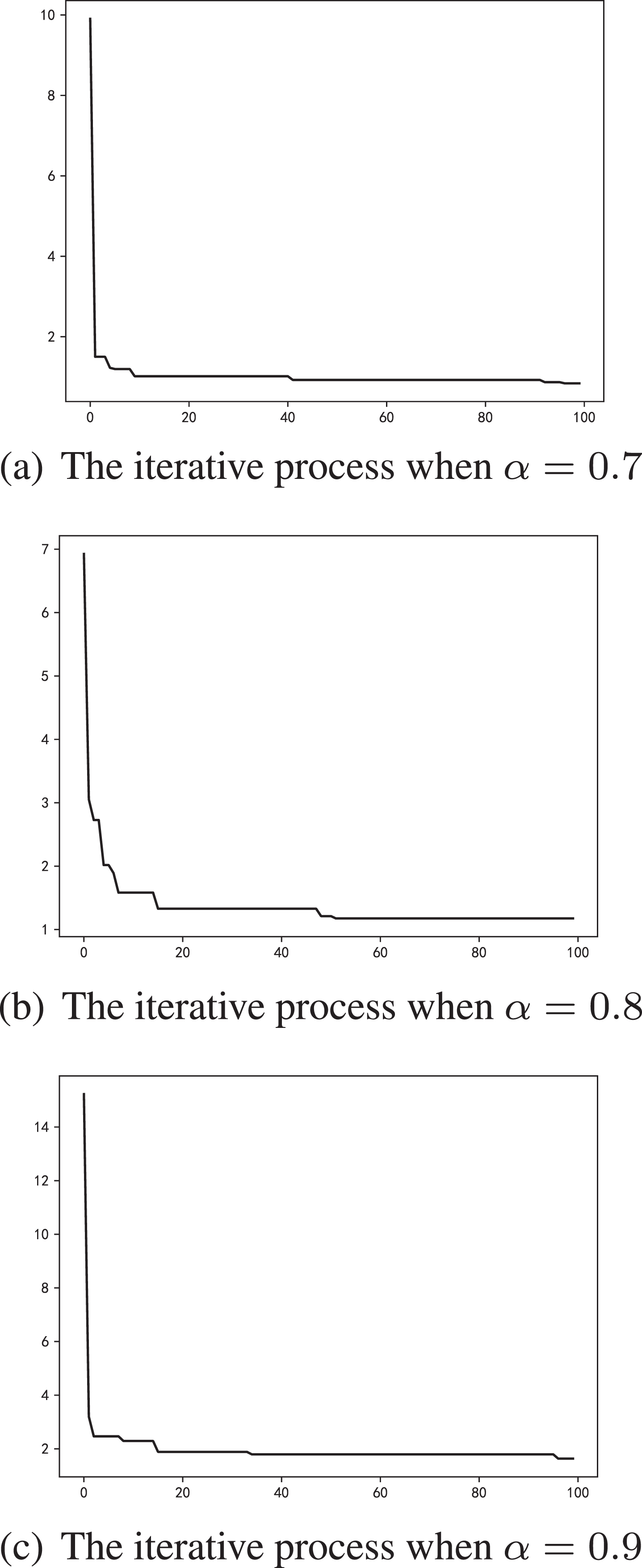
Iterative process under different degree of belief.
In the Fig. 3, the vertical axis represents the value of the function (3) and the horizontal axis represents the number of iterations. As can be seen from the Fig. 3, the result obtained by iteration is not necessarily the global optimal solution, which is mainly related to the selection of algorithm parameters. The larger the number of particles and the more times of iteration, the easier it is to get the global optimal solution. Of course, the corresponding algorithm complexity will be higher and the operation time will be longer. Due to hardware limitations, the parameters selected in this paper are relatively small, but the results are sufficient to prove that the model is solvable and the algorithm is feasible. The final result is shown in the Table 2:
The training results
In order to solve the problem of uncertain input data, this paper assumes that each input data which cannot be known exactly is an uncertain set, and then combines the theory of uncertain set with the idea of SVM, replacing the distance concept in traditional SVM with the distance concept which is subject to the uncertain set, and then puts forward the corresponding uncertain chance constraints. However, it is difficult to calculate the uncertain chance constraints directly, so this paper gives the equivalent transformation form of the model, and takes the input datas as triangular uncertain sets for example, gives a clear equivalent formula for calculation. In the clear equivalent formula, the constraint is transformed from the uncertain chance constraints to the linear constraints, which transforms the original problem into a nonlinear optimization problem with relatively complex objective function. This paper uses the PSO algorithm to solve this problem, and gives a numerical example to show the application of the model to prove its feasibility of the model.
However, this paper only presents the model in the linear case, and the nonlinear case can be further studied in the future. In addition, the complexity of the algorithm used to solve the model in this paper is high, and the algorithm can be optimized in the future.
Footnotes
Acknowledgment
This work was funded by the National Natural Science Foundation of China (Grant Nos. 12061072 and 62162059) and the Xinjiang Key Laboratory of Applied Mathematics (Grant No. XJDX1401).