
Abstract
CAPTCHAs are reverse Turing tests that aim to distinguish between human and non-human online participants. CAPTCHAs enable site administrators to determine if a particular user is a legitimate human or a bot, and grant or deny them access to resources accordingly, thus preventing abuse of resources. However, given the incentive to break or circumvent CAPTCHAs, they must also evolve alongside advances in machine learning tools and techniques to continue providing security for online services. In this paper, we present the essential design criteria for building robust CAPTCHAs and thus provide a general framework for evaluating a specific CAPTCHA design. We then develop several new CAPTCHA exemplars, and analyze them from this perspective to show how design decisions impact different evaluation parameters. We also provide an overview of a new security method that can be applied to any image CAPTCHA and present the results of the evaluation of one of the most promising image based CAPTCHAs with a comprehensive user study.
Introduction and related work
With the pervasiveness of the Internet and the World Wide Web, it is increasingly advantageous for attackers to begin abusing web services and online forms for personal and financial gain. Web administrators need a way to curtail or stop the bots’ abuse, while not restricting their human users from accessing the resources they provide.
The CAPTCHA, which stands for Completely Automated Public Turing test to tell Computers and Humans Apart, was invented to discern between a bot and human user online. CAPTCHAs are reverse Turing tests administered by computers designed to keep bots from abusing web services and online forms made for human users. CAPTCHAs rely on hard AI problems to provide the challenge question asked to the user (human or bot). This ensures that the challenge question is one that is difficult for a computer to perform with a high degree of success, yet still remains easy for a human to perform quickly [41]. These types of questions provide the foundation for a vast majority of CAPTCHAs.
Fortunately, CAPTCHAs have been reasonably successful in stopping a majority of bot abuse at the minor inconvenience of users, and as a result, they are widely used around the web today as a practical security measure. Unfortunately, CAPTCHAs have become a “necessary evil” for online services, especially ones that are designed for public use or are free in terms of usage cost and/or registration to the end user. CAPTCHAs are “evil,” in a sense, because they impede service for a user by requiring them to solve a challenge to continue; in essence, they take up system resources (CPU time, bandwidth etc.) that could be spent on enhancing the service they are protecting. Users frequently report becoming angry or not performing an action, such as posting a comment, if they are forced to solve a CAPTCHA to perform that action. However, blackhats and bots continue pumping out spam in all forms: emails, junk comments, link spam etc., whether or not form controls implemented.
Very recently, an important shift in enterprise scale CAPTCHA implementations occurred – Google has begun to move away from text based CAPTCHAs toward image based CAPTCHAs, as they have discovered that deep-learning neural networks for vision tasks were exceptionally well equipped to handle the unique challenges of text based CAPTCHAs [3,17,39]. Despite the best efforts to obfuscate the text with tricks to fool optical character recognition methods and computer vision models (e.g., overlapping characters, boundary color distortions, character warping, additional noise in the form of lines, etc.) the amount of obfuscation required to defeat the deep-learning model reached a level where the CAPTCHA challenges are now too difficult for humans to solve reliably. The regularity and structure of the characters causes the problem, since at a certain point increasing variation in the structure of the characters also makes them incomprehensible to a human. CAPTCHA designers have since begun to migrate to different forms and styles, and away from text based challenges. While deep-learning neural network based models remain primarily academic and exist only in the hands of a small knowledgeable elite (Google, CV & machine learning academics) [17], it will not be long before these tools and techniques reach the computing mainstream. The shift to an image based model presents its own set of obstacles to overcome by both the service provider and the attacker, and soon enough, deep learning models may yet again prove to be powerful enough to overcome previously challenging computer vision related tasks. There is already some evidence that this is the case, with the ability to discern emotion [26] and age [22] from faces, generate image tags based on the content of an image [24], and identify multiple objects in complex scenes [30]. Furthermore, emerging neuroscience research has even provided methods to create human–machine interfaces that allow a computer to read a person’s mind via an analysis of brain waves to determine the category an image belongs to [27]. Also, recent work has been done that demonstrates these types of tools can be used to attack ReCAPTCHA successfully [40], forcing Google to be constantly evolving the platform and its challenge questions. It is easy to see there exists the very real possibility that simple cognitive tasks that are easy for a human to perform will become something that can be accomplished by a computer using a number of different algorithms and learning models to affect this outcome. While we are not the first by any means to attempt to provide a framework for existing CAPTCHA design evaluation [4,20,32], we do provide a view into the path our research took evaluating the existing body of CAPTCHAs, CAPTCHA research, and their various shortcomings into consideration when we were developing the security and design methods detailed in this paper.
There has also been a recent shift away from CAPTCHAs toward what is being termed “strong identity” as a method for providing user privileges and access to online resources. Strong identity as an online security concept is rooted in the leveraging of the verifiable “real world”. The intention behind this idea is that using multiple forms of identification to get a better sense of who the user is and what their behavior will be like when using the service can be useful from a security perspective [14]. For example, when signing up for a new account with an online service, the user can be presented with the option to link to their social media accounts (facebook profile, twitter, linkedin, etc.), and allow them to be scanned by the new service provider. The linked accounts are examined by the service provider’s algorithm that evaluates user behaviors and performs cross validation of content. If the linked accounts appear legitimate, going forward the user will not have to solve a CAPTCHA or wait for an administrator to approve the creation of the account [9]. Social networking sites stand out in particular as service providers who are in favor of this security model [19]. Strong identity takes the form of online service providers encouraging the user to use their real name and provide truthful, accurate information when creating an account; information that can be cross referenced to “official” information sources (e.g. SSN, home address, telephone number etc.) and is unique to an individual.
Socio-behavioral models [35] that correlate with strong identities are also gaining traction as a new method to identify bot behavior. Behavioral models are based around the idea that a typical “legitimate” user performs a set of actions that are considered by the online service provider to be typical of the use of the services provided. Since bots have a fixed set of actions that are usually designed to maximize some type of outcome for an attacker, their behaviors online become an outlier that the service provider can identify and act upon accordingly.
Google, for example, has also started incorporating advanced risk analysis to determine the difficulty of the CAPTCHA presented to a user. This involves gathering and evaluating a number of different data points captured during a browsing session such as speed of link clicks, time spent on page, cookie history, logged into services owned by Google, age of said accounts, browser user agent etc. Behavior in terms of such data is used to determine if the browser/session is exhibiting human or bot like behaviors and to serve a CAPTCHA of corresponding difficulty (or even no CAPTCHA at all). However, while strong identity models sound great in theory, the use of real world information online can result in negative consequences if compromised (ID Theft, stalking/harassment, loss of reputation etc.) and comes at the expense of anonymity and privacy. Indirectly, CAPTCHAs provide a way to allow users to remain anonymous without having to provide real information to prove their humanity. Additionally, such strong identity approaches may not be suitable for all types of web based applications. Thus, it would not be a stretch to say that if you value privacy online, it is in your best interest to support and develop new CAPTCHAs.
In this paper, our goal is to examine the design considerations and requirements for building robust CAPTCHAs, and to use them to analyze several CAPTCHA exemplars, thus providing a future path for designing CAPTCHAs. The paper’s main contributions are the following: 1) Provide a general framework for evaluating a specific CAPTCHA design. 2) Demonstrate how the general framework can be applied to a number of different CAPTCHA designs to see how design decisions can impact different evaluation parameters. 3) Provide an overview of a new security method (SIGNAC) that can be applied to any image CAPTCHA to prevent reverse image search and image similarity search attacks against indexed images, and also provide resistance to computer vision attacks.
The rest of the paper is organized as follows: Section 2 contains an overview of the major design considerations that we believe must be taken into account to create a strong implementation of CAPTCHA, as well as various requirements and challenges that will be faced by site administrators and CAPTCHA designers alike regarding issues of security. Section 3 contains an evaluation of the major styles of CAPTCHA seen online today. Section 4 evaluates a number of CAPTCHA designs we have created and analyzes them according to the design criteria identified in Section 2. Section 5 presents the evaluation from a comprehensive user study carried out over the implemented image based CAPTCHAs and discusses the limitations of CAPTCHAs. We conclude the paper in Section 6.
Design requirements and challenges
We first discuss the CAPTCHA design considerations and the key requirements and challenges faced when developing new CAPTCHAs.
CAPTCHA design considerations
We are primarily interested in three major criteria by which a CAPTCHA’s quality can be judged – usability, scalability, and robustness. The interplay and tradeoffs between these three categories express themselves in the style and design of each CAPTCHA. These criteria provide a general framework for use in considering both the qualitative and quantitative design aspects of a CAPTCHA. Due to the nature of CAPTCHA design, specific quanatative metrics for evaluation criteria frequently must be derived from a particular implementaiton, and they will not be universal in their applicability. The framework we provide is intended to be used as a preliminary guide to determine if it is worthwhile to pursue a hard AI problem converted into a CAPTCHA design before expending the resources to perform a more in-depth evaluation. It is worth noting that novel methods for creating CAPTCHAs are fairly straightforward to come up with (e.g., KittenAuth) [42], as just about any hard AI problem, logic puzzle, mind game or simple cognitive task can be used as the basis for a challenge. These are guaranteed to have a measure of success at stopping bot attacks already in use as long as they avoid or alter the methodology of the CAPTCHA that has previously failed. We present a number of these types of novel examples that we have created in Section 4.1 and use the framework to evaluate each design against the three criteria. Sections 4.2 and 5 demonstrate a more in-depth analysis of a design, including a security reivew. The framework demonstrates its value as it can be applied quickly and effectively to both new designs as well as existing designs when faced with unforeseen threats that evolve out of advances in machine learning and computer vision. [1,12,13,16,25,36,38,44]. This fact only becomes more true as newer and more powerful algorithms and systems are devised over time. [6,15,31]. Therefore, using the design criteria analysis framework provides the tools to take existing and emerging threats into account and evolve a design over time to maintain a reasonable expectation of security, or retire and replace it when necessary.
To this end, the ReCAPTCHA service can be used to provide the benchmarks for usability, scalability and robustness for comparison to other CAPTCHAs, since it is maintained by Google and used across a variety of their own services in addition to third party sites. No other CAPTCHA can compare to its strengths and variety, and none of its weaknesses are so great that it fails to uphold form security to an acceptable degree at its global scale. Its longevity, mutability (change over time), and adoption as the standard for online services/form control speaks to its success and the success of CAPTCHAs in general.
Usability
Usability relates to all of the ways in which a user must interact with the CAPTCHA challenge and provide the solution. This idea can encompass numerous factors, some that are easy to quantify and measure, and some that are more qualitative/subjective. Quantifiable usability metrics include: average user time to solve, average percent correct response, number of new challenges requested, average number of challenges presented before correct response, server CPU time to generate challenge, etc. Qualitative usability metrics include: user reported ease of use on type of challenge presented, input type(s), impact of security methods to user, etc. Each of them plays an important role in the overall usability of a particular CAPTCHA implementation, and the interactions between each of the metrics and how they affect one another as well as the user must be considered. The critical consideration for usability revolves around the subjective question, “How easy is it for the user to solve this CAPTCHA challenge?” which can be measured quantitatively via a user study using the aforementioned quantitative metrics.
Scalability
Scalability is perhaps the most important factor when creating a strong, secure challenge for an enterprise scale web service/form. Scalability refers to the ability to generate a large number of unique, one-off challenges and serve them to users at the rate deemed necessary to serve the userbase of the service provider. A designer should strive to reuse as little information as possible in each challenge, as each bit of information that is the same can be used in an analysis to determine patterns and enhance random guessing. This is ultimately why text based challenges failed against deep learning models – text characters are expressed in a regular fashion and must be so irrespective of security enhancements like adding noise. If the CAPTCHA does not have a large number of challenges, the attacker can simply maintain a database of the challenges and answer them without actually needing to solve the challenge. While this definition might seem simple, it is perhaps the most challenging criterion to successfully achieve when designing a CAPTCHA. A question such as, “how easy is it for my CAPTCHA to generate a unique challenge?” falls within the realm of scalability. Another important factor to consider when evaluating scalability criteria are the databases used to generate the challenge questions. “How are the challenges generated?” is usually the question that should be asked. Populating the database can be done in manual, semi-automated, or fully automated form, which has a large impact on scalability. For example, an object recognition image CAPTCHA requires a database of tagged images to draw upon for challenges. If the tags can be generated automatically, this means that the database can be generated at the rate of high confidence (thresholded) image classification. Semi-automated and manual (mechanical turk) database population can be seen as sub-optimal when trying to scale a CAPTCHA to handle a large number of users. Some quantifiable metrics to measure database needs include: average daily users expected, and number of impressions. Another component considered in the scalability criteria is parallelizeability. This means that the process used to populate the database, generate the challenge, serve the challenge, and score the challenge can be run in parallel. This helps establish a cadence for CAPTCHA challenge serve rate that can be used to gauge how much compute power and time will need to be used by the service before going online.
Robustness
Robustness is a measure of how well a particular type of challenge holds up against the various tools and techniques used to break CAPTCHAs. Is the challenge easy to break with OCR programs? Can a computer vision program accurately classify the images in a challenge? Would a competent scripter be challenged to write something clever that could foil the task posed by the challenge? What techniques or logic is the designer of the CAPTCHA using to hamper or foil these attacks? By logical extension, robustness also covers the degree to which challenges vary between one another within the same category of challenge. This category frequently has the most “turnover” of the three categories, meaning that what is considered robust today could easily be defeated by a new system that comes from new research. For example, it is relatively easy to see that a text based CAPTCHA can provide unique combinations of characters at a particular length that lends itself to an extremely large space complexity. Text based CAPTCHA were believed to have had strong scalability (characters generated on the fly from ascii set) and high robustness (variability in characters presented in each challenge). However, once deep learning models were able to capitalize on the fact that characters are regular in their structure and that they have to be expressed only in a certain way for humans to interpret them, this variability decreased significantly and no amount of noise, warping, or alterations performed on the characters within the limits of human comprehension could stop the deep learning model’s success in solving the challenge. High robustness comes from design choices that foil tools that can be used to reveal information about the challenge from its expression. Some examples of robustness metrics are: resistance to CV, resistance to OCR, resistance to ML, and resistance to AI.
Requirements and challenges
We now discuss the various requirements and challenges in building and deploying CAPTCHAs to secure an online service provider from bot attacks.
Risk analysis based CAPTCHA selection
The appropriate CAPTCHA to use depends on the environmental context and the degree of risk inherent in allowing access. The following questions can guide the CAPTCHA selection process:
What type of service is being provided? Can this service be considered “critical”? What impact will a breach of the form security have on service operations? E.g. Service downtime, expanded operations costs, loss of goodwill from userbase etc. What impact will a breach of the form security have on service’s users? What is the “cost” of supporting spam accounts? Cost can be measured in many ways, such as CPU time, bandwidth, account monitoring (automated and human), etc. What is the level of tolerance built into the service? e.g. system operations-wise (quantifiable) for dealing with negative factors such as user annoyance at CAPTCHA, at spam comments evading controls, loss of service, loss of users etc.
Improved machine learning tools
As time progresses forward, so does technology and algorithms. Computer vision in particular has made great strides in its general performance capabilities – an area where it could be considered lacking in the past, and is now providing new threats to CAPTCHAs. Thanks in part to the rise in GPU computing and cluster computing, compute power density is at an all time high. One recent example is the results from the 2014 Large Scale Visual Recognition Challenge – which focuses on the task of image recognition in particular. The visual systems competing in the challenge for 2014 were tested in six categories based on their ability to detect objects, locate specific items in an object, and classify those images from a labeled dataset of 14 million images already tagged by humans. The average accuracy of entrants doubled from 22.5% to 43.9% while the error rate fell from 11.7% to 6.6% [30]. This level of success was achieved by most teams using an old algorithm – convolutional neural networks, which has been around for some time but were not practical until GPU computation was cheap and publicly available. While these systems are still no match for human analysis, it is easy to see why a CAPTCHA designer should become nervous about these systems. Indeed, the algorithm used in Google Streetview for recognizing the numbers on a house to determine the home address, which was based on deep convolutional neural networks, could equally be used to decipher the hardest category of ReCAPTCHA challenges they were serving, with 99.8% accuracy. Google’s security blog [39] notes that they are moving away from text distortions as their primary method of security in their text based CAPTCHA, and instead have chosen to rely on performing advanced risk analysis – which they do not elaborate on for obvious reasons.
An economic analysis
Motoyama et al. [33] published a seminal paper providing a thorough analysis of CAPTCHA breakers and their evolution into solving services that pay humans to solve CAPTCHAs. They make the argument that CAPTCHAs can increasingly be understood and evaluated in purely economic terms, that is, the market price of a solution compared to the monetizable value of the asset being protected. They examine the market-side of this question in depth, analyzing the behavior and dynamics of CAPTCHA-solving service providers, their price performance, and the underlying labor markets driving this economy. This analysis and the reality of solving/farming/mechanical turks as methods to beat CAPTCHAs at a near perfect rate (by the very definition of CAPTCHA) pose a grave threat to CAPTCHA use and the services they protect. Thus, Motoyama’s paper successfully demonstrates that we must begin to look at the problem of online form security from an economic perspective, instead of a purely technical perspective.
Indeed, CAPTCHA attacks can be abstracted to their logical extreme when an attacker simply pays a mechanical turk (a human via a web service) for the solution to a CAPTCHA. As long as the attacker’s costs remain lower than his profits, he will use that method and by the definition of a CAPTCHA (correct solution to challenge determines human or bot), this “attack” will succeed, simply because a human is providing the solution. We can even humor the scenario where the attacker is content to operate at the break-even point (costs of attack are equal to profits), just to spite the service provider and antagonize legitimate users – a losing proposition for the defender. Given the advances in computational ability to provide near-human cognition [12,15,31,33,43], all CAPTCHAs can and will eventually be defeated by attackers and form security mechanisms will be forced to evolve into something else yet to be developed, or replaced entirely. However, until that day arrives, we must be content with utilizing a risk based framework combined with an economic analysis to select the strongest possible design criterion for CAPTCHAs and accept that pay to play solutions cannot be realistically stopped, short of extreme measures on behalf of the service provider.
Latency
One general problem faced by website providers is the issue of latency – the amount of time required to access the website. Adding in a CAPTCHA increases the latency, thus making it more inaccessible to users. Thus, a general goal in developing CAPTCHAs should always be to match the CAPTCHA requirements to the security needs. Specifically, it is important to ensure that the CAPTCHA employed to protect the resources behind the link produces as little time impact and the minimum amount of bandwidth as necessary to provide the security required to keep bots out. This is a general issue, applicable to all CAPTCHAs.
One option is to design a form in such a way that the CAPTCHA only restricts a specific action and impacts only a small part of the content to be loaded. For example, a comment that a user wants to post on an article can be scoped such that the http post request for submitting the comment be the only thing that is restricted by the CAPTCHA (the rest of the page and other comments load while waiting for the new comment to post). Another option could be perhaps a compressed, encrypted caching of the resources/page could be sent to the client upon initiation of attempting to solve the challenge, so that when successfully solved, it could be quickly decrypted and inflated client-side in the browser with minimal impact to the user. However, should an attacker learn of this, it presents a potential denial of service avenue beyond the constant request for CAPTCHA. It is our opinion that best practice is to use a risk based approach on a website to determine what resources need to be behind a CAPTCHA before loading and minimize it to what the service provider can afford to operate and not drive away users with long load times or using CAPTCHAs in unnecessary places.
An overview of CAPTCHA styles
We now discuss existing CAPTCHA styles as well as some of the emerging alternative CAPTCHA styles.
Existing CAPTCHA styles
There are three major styles of CAPTCHA – each with its own unique angle for presentation to the user and its accompanying underlying methodology. These can then be subdivided based on various methods of implementation and/or various methods of testing for the “humanity” of users. Note that these methods correspond with 2 of the 5 human senses (sight and sound) that are easy to interact with via a computer. The omission of smell and taste being somewhat obvious, however touch is quickly becoming a new area of exploration as the technology to support this has recently moved into mainstream computing. Existing CAPTCHAs use either text, images, audio, or a combination of the above.
Text. This is the de facto standard style of CAPTCHA because it is the easiest to design, implement and use. It consists of a string of characters (letters, numbers, and sometimes special characters) that a user must type in to prove they are human. These are the most common types of CAPTCHA currently in use, due in part to their scalability (easy to generate) and robustness (uniqueness, space complexity). Image. These CAPTCHAs utilize images as a method to provide security. More specifically, they ask users to perform cognitive tasks that involve the images, such as image recognition (e.g. what is being shown in the image) or a categorization task (e.g. select all pictures of cats) based on viewing and comprehending what the images are depicting. These are the second most common type of CAPTCHA. Although they often score high in usability, particular implementations provide shortcomings in the scalability and robustness category, and are weak against certain types of attacks. We will demonstrate some of these shortcomings of image CAPTCHAs in our design overview. Audio. These CAPTCHAs are usually used in tandem with another CAPTCHA (usually text based) to provide accessibility to blind users. The audio CAPTCHA speaks the characters out loud so that blind users can understand. They usually are susceptible to speech to text attacks and can pose some usability problems – namely the protection used (other garbled noise to disguise the characters) to make them more secure causes audio CAPTCHAs to become nearly impossible to decipher for the end user and bots alike. Also, not all computers have speakers or a port accessible for headphones – thus there is no guarantee of sound at any particular computer terminal. Multi-Modal. This method takes two or more existing styles, for example image and text based methods, and combines them to provide enhanced usability [2,8].
Emerging alternative CAPTCHAs
We now provide a quick overview of existing alternative methods of CAPTCHA that are designed to be more robust methods beyond traditional simple text, image, or audio based CAPTCHAs. Many of these styles incorporate nuanced information contained in text or images into the challenge question to provide stronger security.
HIP. Human Interactive Proofs – To be effective, a HIP must be difficult enough to discourage script attacks by raising the computation and/or development cost of breaking the HIP to an unprofitable level [7]. GOTCHA. Generating panOptic Turing Tests to Tell Computers and Humans Apart – these are generated on the fly by a series of mathematical equations and require the users to describe the resulting image with a phrase. This is primarily used as a password replacement system [5]. POSH. Puzzle Only Solveable by Humans – this method has three primary criteria: it can be generated by a computer, it can be consistently answered by a human, and a human answer cannot be efficiently predicted by a computer. The designer suggests that a POSH does not even have to be verifiable by a computer at all [10]. What’s UP. This CAPTCHA uses images that are rotated to various angles. The user must place the images facing up correctly based on their orientation [18]. CORTCHA. Context-based Object Recognition to Tell Computers and Humans Apart – using images gathered from the internet, the designers note that although an object that is segmented by a computer might be poor cognitively, but if the object is surrounded by its original context in the image, then the object is readily recognizable by humans. By exploiting the context, objects segmented by computer can be used in an Image Recognition CAPTCHA (IRC). The use of context solves the dilemma, and an IRC can be designed without labeling any image [45]. SKETCHA. This CAPTCHA uses line drawings of 3D models rotated to a randomized point of view. The goal of the user is to rotate each image until it is upright, choosing among four orientations by clicking on the image. Each line drawing was automatically rendered from a 3D model using a randomized point of view, providing for many possible images from each model [37]. IMAGINATION. IMAge Generation for Internet AuthenticaTION – This CAPTCHA produces controlled distortions on randomly chosen images and present them to the user in the form of a mosaic image. The authors recommend the use of a two step verification process. In the first step, the user clicks near the center of any picture in the mosaic. In the second step, the user is asked to identify a distorted image by selection from a list. This two-round click-and-annotate process makes the CAPTCHA user friendly and very effective [11]. Interactive Games. One example of an interactive game CAPTCHA is FunCAPTCHA. It asks the users to perform two “fun” tasks to prove they are human. These tasks usually take the form of small games, such as selecting the picture of a woman from 9 pictures and drag it to the middle of the CAPTCHA, or rotate the image until it is facing up [21]. Video CAPTCHA. There are a number of video CAPTCHAs available in the market. NuCAPTCHA is one of the more popular implementations where a string of characters is presented to the user within the video. The other style shows the user an advertisement and asks them to type something related to the video advertisement that has been shown to them [23].
Designing new CAPTCHAs
We now elaborate on the methodology for designing new CAPTCHAs and examine how they can be analyzed based on the design criteria discussed earlier. We provide several examples of CAPTCHAs we have thought about implementing and to test out as effective methods of performing reverse Turing tests. We structure each CAPTCHA by type – providing a brief overview of the concept and how to solve the challenge, a discussion of its functionality focused on its usability and its scalability, and its security strengths and weaknesses (robustness). Note that while these CAPTCHAs can work – they can only do so on a very small scale and most would fail in the scalability category for large public facing web services. We present these sample challenges for three reasons: 1) to demonstrate the design criteria framework in action, 2) to show the difficulty in transforming a hard AI problem into a CAPTCHA challenge that satisfies all three criteria to a high level, 3) to show how each style has unique attributes that make in depth security evaluations time consuming when using the framework is sufficient to identify shortcomings in design.
When “Warping” is referred to in the style analysis, it refers to all of the traditional obfuscations that have been used with text based CAPTCHAs in the past. Things such as overlapping characters, distortion of the characters via image filters, additional noise, color blending etc. can all be used to secure text from OCR and CV attacks, at the expense of usability. While the effectiveness of these techniques at reducing attacks is coming under increased scrutiny as tools evolve, it still provides an impediment and can provide benefits when combined with other obfuscations.
A brief note about the “Cambridge effect” that is referenced throughout this section – this refers to the unique ability for humans, English speakers in particular, to read words that are misspelled as long as the first and last letters of the word remain in their correct location within the word. This essentially provides a method to “scramble” words that are 4 or more characters in length, and provide an additional layer of obfuscation for challenge keywords, phrases or sentences. The “Cambridge effect” is actually an old internet hoax, as no research at Cambridge University has been conducted for this topic – nevertheless it serves a useful purpose in our CAPTCHA design framework evaluation as an attempt at a security method that can be quickly evaluated. The following paragraph in italics is the original example of “the Cambridge effect” in action:
“Aoccdrnig to rscheearch at Cmabrigde uinervtisy, it deosn’t mttaer waht oredr the ltteers in a wrod are, the olny iprmoetnt tihng is taht the frist and lsat ltteres are at the rghit pclae. The rset can be a tatol mses and you can sitll raed it wouthit a porbelm. Tihs is bcuseae we do not raed ervey lteter by it slef but the wrod as a wlohe.”
The following sections are divided into two parts. The first section demonstrates how we apply the CAPTCHA design criteria and risk analysis framework to various challenge ideas to perform an analysis of CAPTCHA security. The goal is to demonstrate the process of evaluating ideas from conception to application of design criteria followed by a risk analysis. Note that security analysis portion essentially serves as the criteria evaluation for “robustness” as a category of design. The second group represents challenge ideas and techniques we have designed and implemented to test in a real world use case study. The CAPTCHAs presented in this section demonstrate a specific design methodology we developed for image based CAPTCHAs. The user study functions as a way to test the usability of a design and gather useful real world feedback that can be used to enhance the design, or determine if the CAPTCHA method is a dead end not worth pursuing further.
A design analysis of several new CAPTCHA exemplars
Word change CAPTCHA. This CAPTCHA uses 4 words, where each word differs from another by 1 letter, which alters the meaning of the word. The words are represented by an image. The goal is for the user to be able to determine the sequence of the words and come up with the correct final word. Figure 1 provides an example.
Usability: Image/Object recognition is the primary hard AI task turned into a CAPTCHA challenge. Additional contextual complexity comes from user determining the letter that is different between images and entering in the response as a string in a freeform textbox.
Scalability: Requires a database of labeled images and a dictionary to function. Can benefit from new tools that provide automated image tagging to create image database automatically.
Strengths: Freeform text box makes guessing difficult. Images can apply noise methods to foil CV and ML attacks for enhanced security. Large inter-category variation for images can be used (cartoons, drawings, photos, etc.). Position of the letter that changes varies from challenge to challenge.
Weaknesses: Potential solution space bounded by words in dictionary. May be vulnerable to CV attacks that can filter noise where original image/object can be recognized.

Example of word change challenge.
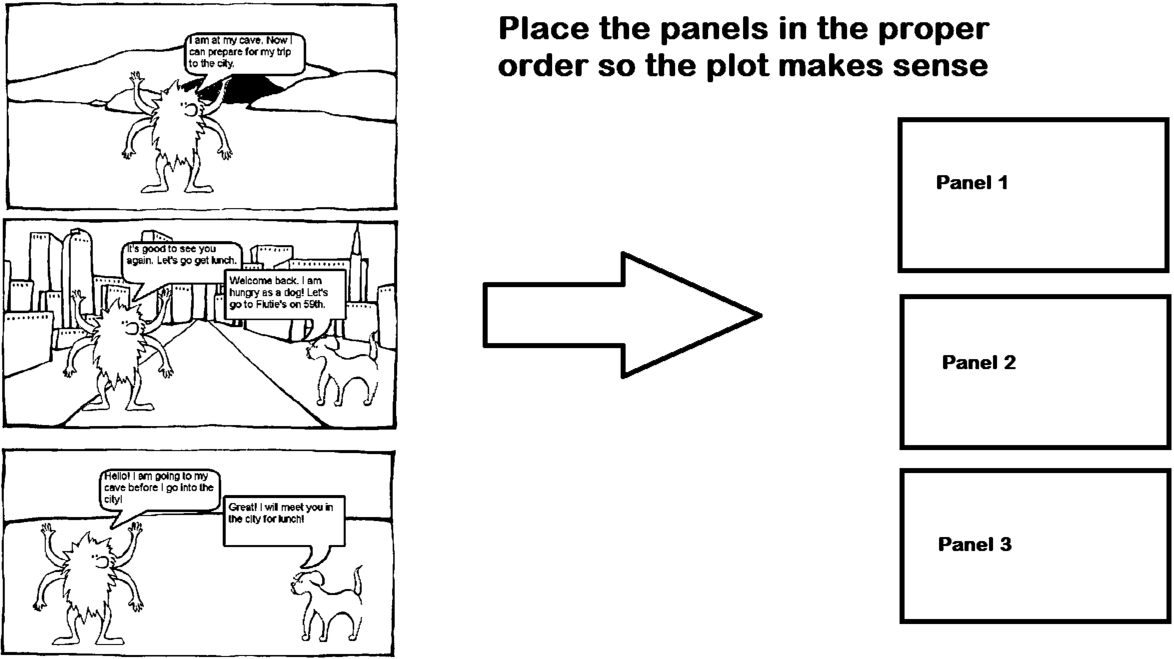
Example of storyboard challenge.
Storyboarding CAPTCHA. In this CAPTCHA the user is presented with a randomized set of panels from a short comic. These panels have a definite order and must be placed in this order. The user needs to drag the panels into the correct order. The CAPTCHA can additionally benefit from Cambridge effect for increased security and complexity. Figure 2 provides an example.
Usability: Context analysis is the primary hard AI challenge in this design with image recognition being a subtask required to analyze the context. Requires additional software to be installed to enable drag/drop functionality. Requires mouse or touch input to enter response.
Scalability: Difficult to scale, as comic strips must be created, segmented, and tagged to ensure the generation algorithm understands the correct order. Potential for automation exists via mining old published strips, but is difficult to achieve without prescreening for meeting requirements. Licensing can also be an issue.
Strengths: Extremely difficult for adversary to comprehend story without advanced NLP and DL reasoning capabilities. Potential to add noise to images to foil CV and ML attacks – specifically for reverse image search (e.g. find original comic strip).
Weaknesses: If using old comic strips, there exists the potential for database attacks and matching attacks. Small number of panels makes correct random guessing easier for attacker.
Consequence & conclusion image CAPTCHA. In this CAPTCHA two images are presented that represent an idea where the final outcome is the result of the two images interacting. Ex: New York City + Hurricane Irene = Flooded city. The user needs to choose the image that represents the correct outcome of the interaction. Figure 3 provides an example.
Usability: The user must make a selection based on their reasoning of what the images are trying to communicate – in this case the hard AI challenge is again contextual (cause-effect) with image recognition being a subtask. The challenge response requires the user to click or tap on the image that best reflects the result of the scenario. Requires mouse or touch to enter response.
Scalability: Requires a database of labeled images and a logic backend (to provide framework for consequence/conclusion) to function. Can benefit from new tools that provide automated image tagging to create image database automatically, specifically contextual image recognition tools (e.g. IBM Alchemy).
Strengths: Difficult for adversary to comprehend challenge without advanced NLP and DL reasoning capabilities. Nothing for OCR to pick up. Images can apply noise methods to foil CV and ML attacks for enhanced security. Large inter-category variation for images can be used (cartoons, drawings, photos, etc.).
Weaknesses: Bounded by size of consequence and conclusion logic database. Potential weakness to database attacks due to limited size of logic database. Small number of choices for challenge solution makes random guessing more successful.

Example of consequence and conclusion challenge.
Pattern completion CAPTCHA. This CAPTCHA is designed to act as a method to counteract OCR and Image recognition techniques. The CAPTCHA requires a user to order a random series of images, words, or numbers in ascending or descending order (also randomized). The user must correctly order the challenges based on the solution dictated by the CAPTCHA. The CAPTCHA may additionally benefit from Cambridge effect for increased security and complexity. Figure 4 provides an example.
Usability: Image/Object recognition is the primary hard AI task turned into a CAPTCHA challenge. Additional contextual complexity comes from user determining the ordering criteria for the images and dragging the images to their appropriate place.
Scalability: Easy to scale as qualifiers can be randomized and the increments generated at random as well. Challenge requires a tagged image database to function.
Strengths: Multiple layers of security from randomized ascending/descending and greatest/least ordering keeps attackers guessing between each challenge. Images and text can apply noise methods to foil CV and ML attacks for enhanced security. Large inter-category variation for images can be used (cartoons, drawings, photos, etc.).
Weaknesses: Potentially vulnerable to CV attacks and OCR attacks, as the indicators can be deciphered with the proper tools and techniques. Text is particularly vulnerable to ML attacks, and a correct text guess can strengthen an attack against a mixed image/text/numbers challenge.
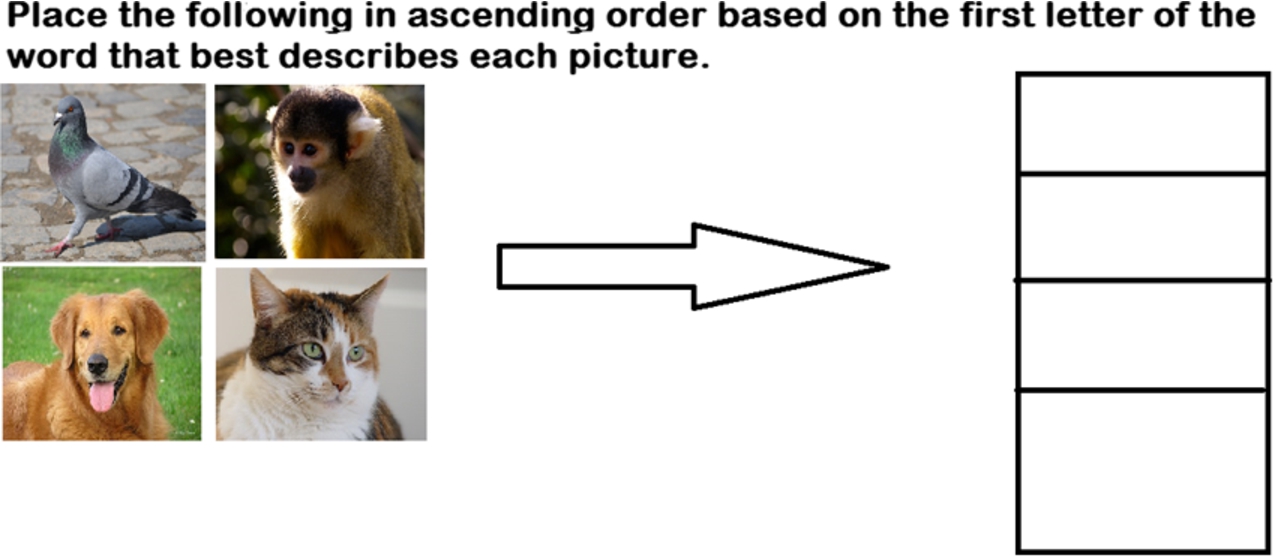
Example of pattern completion challenge.
Pictionary CAPTCHA. In this CAPTCHA the user is presented with a series of images that represent a short English phrase. Ex: I love you communicated by a picture of a human eye, a heart, and a finger pointing toward the user. The user must correctly decipher the phrase and select or type the matching answer. Figure 5 provides an example.
Usability: Image/Object recognition is the primary hard AI task turned into a CAPTCHA challenge. Additional contextual complexity comes from user determining the “idea” communicated by the image (not always a “literal” interpretation). This CAPTCHA is somewhat difficult to use, in that the images used in Pictionary must communicate the idea to the user. There is a high probability of misinterpretation or miscommunication of the idea required to solve the challenge. Requires a keyboard to solve challenge.
Scalability: Easy to scale, as the ideas represented by the images form a sort of symbolic language that can be mixed and matched accordingly.
Strengths: Freeform text box provides no clues for guessing. “Ideas” provide strength against straight image tag matching. Images can apply noise methods to foil CV and ML attacks for enhanced security. Large inter-category variation for images can be used (cartoons, drawings, photos, etc.).
Weaknesses: Vulnerable to a combination image recognition and dictionary attack, as someone could create an equivalency chart for pictures to ideas. Bounded by the size of the symbolic language logic used in the backend to create unique challenges.
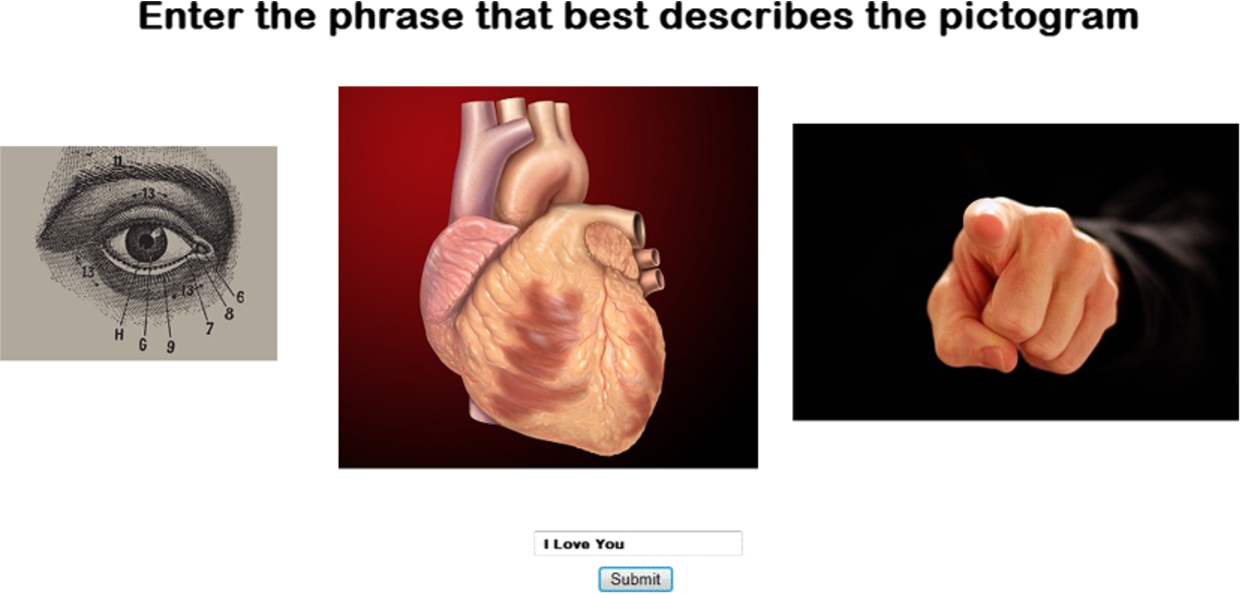
Example of pictionary challenge.

Example of jigsaw puzzle challenge.
Jigsaw puzzle CAPTCHA. In this CAPTCHA an image is cut into 9 or 12 equal squares and scrambled. The user is asked to place the pieces into the framework to correctly reassemble the image within the allotted time. The user must reconstruct the image inside of the frame by dragging the pieces to their correct places. Figure 6 provides an example.
Usability: Image/Object recognition is the primary hard AI task turned into a CAPTCHA challenge. Additional contextual complexity comes from sclicing up the image into puzzle pieces for reassembly. Requires additional software to be installed to enable drag/drop functionality. Requires mouse or touch input to enter response. This CAPTCHA has moderate usability as the person must be able to put the puzzle together in a reasonable amount of time, without making it too easy for an image processing algorithm to do the same.
Scalability: Easy to scale as it only requires an image that meets a certain set of criterion, aligned with the purpose of defeating image/edge detection algorithms. No image tags required to assemble an image database.
Strengths: Strong against OCR, as there are no words to pick up. Depending on the level of the implementation sophistication, provides some resistance against edge detection/segmentation attacks. Images can apply noise methods to foil CV and ML attacks for enhanced security. Large inter-category variation for images can be used (cartoons, drawings, photos, etc.).
Weaknesses: Vulnerable to tagged image database, image recognition, and reverse image search. There are also jigsaw puzzle solving algorithms that are currently in development and performing well on datasets.
Example of Cambridge study used in image CAPTCHA challenge with SIGNAC applied.
Cambridge study CAPTCHA. This CAPTCHA is based on the above mentioned (apocryphal) Cambridge study which notes that as long as the first and last letters of a word are in the correct place, the rest of the word can be scrambled and is still readable to the average English reader. Ex: Cantaloupe to Cnatalupoe. A randomized number of sentences in English are collected and scrambled based on this idea. A word is then removed from the sentences and the user must select the correct word that completes the sentence from the list. Thus, to solve this CAPTCHA the user must correctly decipher the word and pick the appropriate word to fill in the blank in the sentence. An alternative to this is to select and scramble a word and then to present the user with a list of words, where 3 are similar to the scrambled word (synonyms) and 1 is different (antonym), now requiring the user to select only the three synonyms. Figure 7 provides an example, with our additional image obfuscation applied, which will be described in detail later.
Usability: Context is the core hard AI challenge in this CAPTCHA, as the user must comprehend the sentence to complete it correctly. As the study holds true, it should be easy for speakers of English to understand the words, even when scrambled in this fashion. A mouse or touch is required to solve.
Scalability: Easy to scale, as any word that is 4 or more letters long in the English language can be scrambled in this fashion and sentences can be pulled from online libraries, catalogs, etc. Note that the alternative version looks for comprehension of the word, as opposed to just an unscrambling/word match and can pull words from dictionary and thesaurus.
Strengths: Strong against image recognition attacks, since it is a word based challenge focused on context.
Weaknesses: Vulnerable to lexicographical attacks (i.e. scrabble algorithm looking for dictionary hits) and OCR. The alternative version is potentially vulnerable to dictionary attacks and reverse thesaurus lookup (i.e. find the antonym).

Example of compound words challenge.
Compound words CAPTCHA. This CAPTCHA uses compound words to generate two images that represent the requisite two words contained in the images. It is flexible in that you can show the pictures and have the users select the words or show the words and have the users select the pictures. The goal is to get the idea communicated by the word/images and match the idea to the answer. Alternatively, the CAPTCHA can also provide a compound word where the user must select an image associated with another compound word to illustrate the idea of the compound word. Ex: Sunflower represented as two images featuring sunlight and flowerpot as the main focus. In this case the user must select the nuanced compound words that communicate the idea in the displayed word. Figure 8 provides an example.
Usability: The CAPTCHA is easy to use in that it requires the user to select images or words that match with the idea communicated in the two or more images that make up the compound word. The alternative version has moderate usability as the ideas communicated can be too nuanced for the user to easily comprehend. Requires users to extract a word represented by an image. The user then selects the correct images with the constituent parts to make the original compound word.
Scalability: Requires a database of labeled images and a dictionary to function. Can benefit from new tools that provide automated image tagging to create image database automatically.
Strengths: Images can apply noise methods to foil CV and ML attacks for enhanced security. Large inter-category variation for images can be used (cartoons, drawings, photos, etc.). Freeform text box provides no clues for guessing.
Weaknesses: Challenge variation bounded by number of compound words.
In this section, we will briefly discuss the meaning and qualifications of the criteria low, medium, and high for each of the three design categories accordingly.
Usability. Low: Users have a difficult time solving challenges. Challenges frequently require significant amounts of time to solve (e.g. greater than 45 seconds) and users often fail to solve the challenge correctly greater than 50% of the time. Security methods used in the challenge may be too extreme (e.g. too much noise/distortion) that makes comprehension for humans difficult. Challenge comprehension is difficult for average target user in native language, language barriers, and specialized symbol packages/fonts required. Implementation requires specialized browser plugins/extensions/software libraries that may not be widely available or have a large installed userbase and/or could provide security vulnerabilities to users and implementers.
Medium: Users can solve the challenge most of the time (e.g. greater than 75% of the time). Challenges require a moderate amount of time to solve (30 seconds or less). Security methods used in the challenge may occasionally impact comprehension (e.g. too much noise/distortion in less than 25% of challenges) that makes comprehension for humans difficult. Challenge comprehension is easy for average target user in native language, does not require additional fonts/special character packages. Little to no language barrier (beyond directions). Implementation does not require specialized browser plugins/extensions/software libraries that are uncommon (i.e. common ones like javascript are OK).
High: Users have an easy time of solving the challenge quickly (10 seconds or less) and have a success rate of 90%+ for solving the challenges. Security methods do not impact challenge comprehension. Comprehension of challenge transcends languages and cultures and can be easily solved by all humans with a simple explanation in native language. Implementation does not require specialized browser plugins/extensions/software libraries that are uncommon (i.e. common ones like javascript are OK).
Scalability. Low: Datasets used for challenge creation must be crafted manually by a human (e.g. tagging images, drawing panels, labeling scenes etc.), and the task of creation is one that is not easy to farm to a mechanical turk without heavy investment of time and resources. Size of dataset is small enough that repeat challenges can/must occur and an attacker can enumerate the entire database generated from the dataset in a trivial amount of time.
Medium: Datasets used for challenge creation must be crafted in part by a human (e.g. tagging images, drawing panels, labeling scenes etc.), however the core task can be farmed to a mechanical turk service with little investment of time and resources. Size of dataset is directly related to the ability to farm the task to the mechanical turk service. A break-even is achieved when the cost of generating a unique challenge is equal to the cost to pay a solving service to crack it.
High: Datasets used for challenge creation can be generated automatically and requires no human input. Challenges can be created on-demand and in parallel by service provider. Can potentially have no duplicate challenges due to sample space size. The ability to enumerate the challenge database is too difficult for the attacker due to its size/scale.
Robustness. Low: Challenges are easily defeated using existing computer vision and optical character recognition tools. Attacker can successfully solve more than 10% of the challenges using fully automated tools in under 30 seconds. Core challenge does not require any higher level reasoning beyond identification task. Challenges are not unique and repeat frequently.
Medium: Challenges can potentially be defeated by existing computer vision and optical character recognition tools. Attacker must perform more than one additional step to defeat security methods in challenge and automation of attacks requires advanced knowledge of cv algorithms and creation of custom tools e.g. must filter noise from image before an object recognition algorithm can be used to ID object. Challenges require contextual knowledge beyond literal interpretation of challenge presentation.
High: Challenges are immune to most/all known computer vision and optical character recognition attacks. Attacker cannot successfully solve 1% or more in an automated fashion in under 30 seconds. Challenges require contextual knowledge beyond literal interpretation of challenge presentation. Intra-category variation is high (e.g. expressions on images of human faces) among the items in the datasets used in challenge creation. Security methods difficult or impossible to remove without concerted effort on behalf of the attacker.
Table 1 gives a comparison of all of the above CAPTCHAs in terms of the design criteria of usability, scalability, and robustness. Note that as each of these designs is a visual CAPTCHA, they can all use image noise as a security method to improve robustness.
Tradeoffs between each design criterion
Tradeoffs between each design criterion
We now present a number of different image based CAPTCHA styles that we have developed that have been implemented and tested. All of these CAPTCHAs use a technique we have developed in prior work termed SIGNAC [28,29] (after the 19th century neo-impressionist painter Paul Signac), which stands for Secure Image Generation Noise Algorithms for CAPTCHAs. The SIGNAC method is designed to be a broadly applicable security enhancement for any image based CAPTCHAs that use a tagged database of images to generate challenges. The images SIGNAC produces look somewhat like a snowy television image or a painting done in the “pointillism” style. It provides security against reverse image search attacks (using Google or TinEye) and computer vision attacks by adding noise and distorting the image, while allowing a human user to still be able to discern what is depicted in the image. A reverse image search attack is when an attacker can take an image from a CAPTCHA and use an image search engine to find copies of the image somewhere online where metadata related to the image can be used to discern what the image depicts without having to perform image recognition or object recognition tasks. The RIS engines are robust and can handle things like image cropping, rotations, hue changes etc., so defeating them is not a trivial task. It is important to note that the order of applying filters plays a significant factor in contributing to the security of the image produced when testing against reverse image search engine attacks. The process demonstrated in Fig. 9 is an example of a set of operations that performs well in a general use case. While this work we present is not new in its entirety – details on how the methodology functions can be found in [28,29], however a brief overview of the noising technique will provide appropriate context for the CAPTCHA styles we will be demonstrating and analyzing in the user study in Section 5.
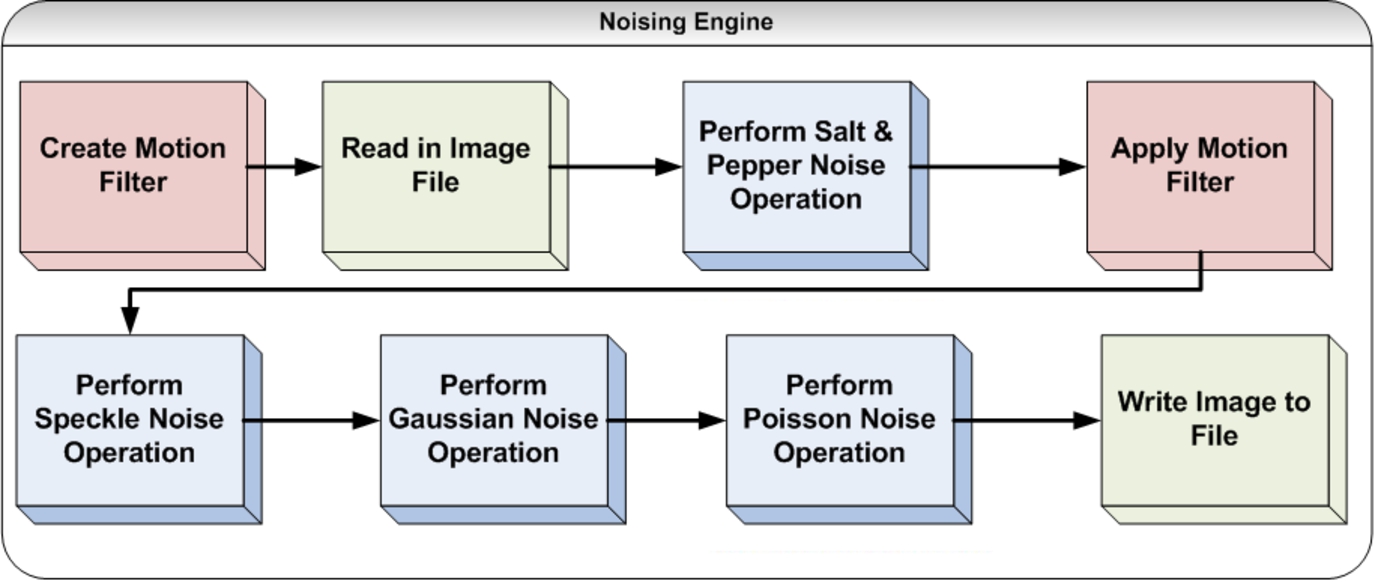
Overview of the SIGNAC Image Generation Process.
We have developed 5 different styles of image based CAPTCHAs, with varying degrees of difficulty. All used noised images from 10 different image categories (airplane (1), bird (2), car (3), cat (4), doll (5), fish (6), flower (7), monkey (8), robot (9), train (10)). A total of 100 noised images were generated with 10 from each category. All 5 CAPTCHA styles have the option to click a link to serve up a new CAPTCHA if the user cannot understand/decipher/solve the one they have been given. In the user study, this is tallied as “no response” by our database. Style 1 displays an image and asks the user to describe it by entering a description (freeform text response). Style 2 displays an image and provides a dropdown box with 4 responses, with 1 of the 4 choices being the correct answer. Style 3 displays a dropdown box with 5 responses, 4 choices and not here. Style 4 asks the user to select the image from 3 images that best represents X, where X is an image category. These four styles which were created in [28,29] are demonstrated in Fig. 10.
Style 5, which is our new style that demonstrates the concept of the “Cambridge effect”, uses a sentence with the “Cambridge effect” applied to it to provide contextual clues for the missing keyword that would complete the sentence that is related to an image depicted in the CAPTCHA challenge. Figure 7 demonstrates this style. The goal of this CAPTCHA is to provide obfuscated contextual clues for the keyword in the form of a sentence that help a human gain an edge over a machine when attempting to solve the challenge. The extra complexity is designed to slow down a machine, however a human should have no problem getting through it. The final version of this style would be an automated system that can use random sentences pulled from various sources and select keywords that match an image in a tagged image database and present it as a challenge while still maintaining enough context in the sentence that a user can complete it. As mentioned before, this style leverages the “Cambridge effect” on a sentence with the keyword omitted to help obfuscate the keyword from attackers and uses the SIGNAC method to provide secure images.
In our opinion, the order of difficulty for the user is (1, 5, 3, 2, 4) from most difficult to least difficult. One final security measure included in our challenges is that the default response is always “Please Select”, which evaluates to an incorrect response if a bot simply tries to guess the first available response and submit it over and over to pass the challenge. A time-to-live is also available (e.g. please solve the challenge within 30 seconds or another challenge will be presented) as an option.

Four alternative image CAPTCHA exemplars.
In this section, we demonstrate an example of an experiment that was structured to test SIGNAC for defeating RIS and CV attacks. We gathered 100 random indexed images from a search engine across 10 categories and applied the SIGNAC method to the images. Note that the image filter types did not change during the course of the experiments, only the mean values of the noise functions. The security method described here is designed to be a general purpose image security method that can be applied to all CAPTCHAs that use images. New research such as DeepCAPTCHA [34] is even more promising, as it provides noise resistant against removal attempts of the noise that is added to the image.
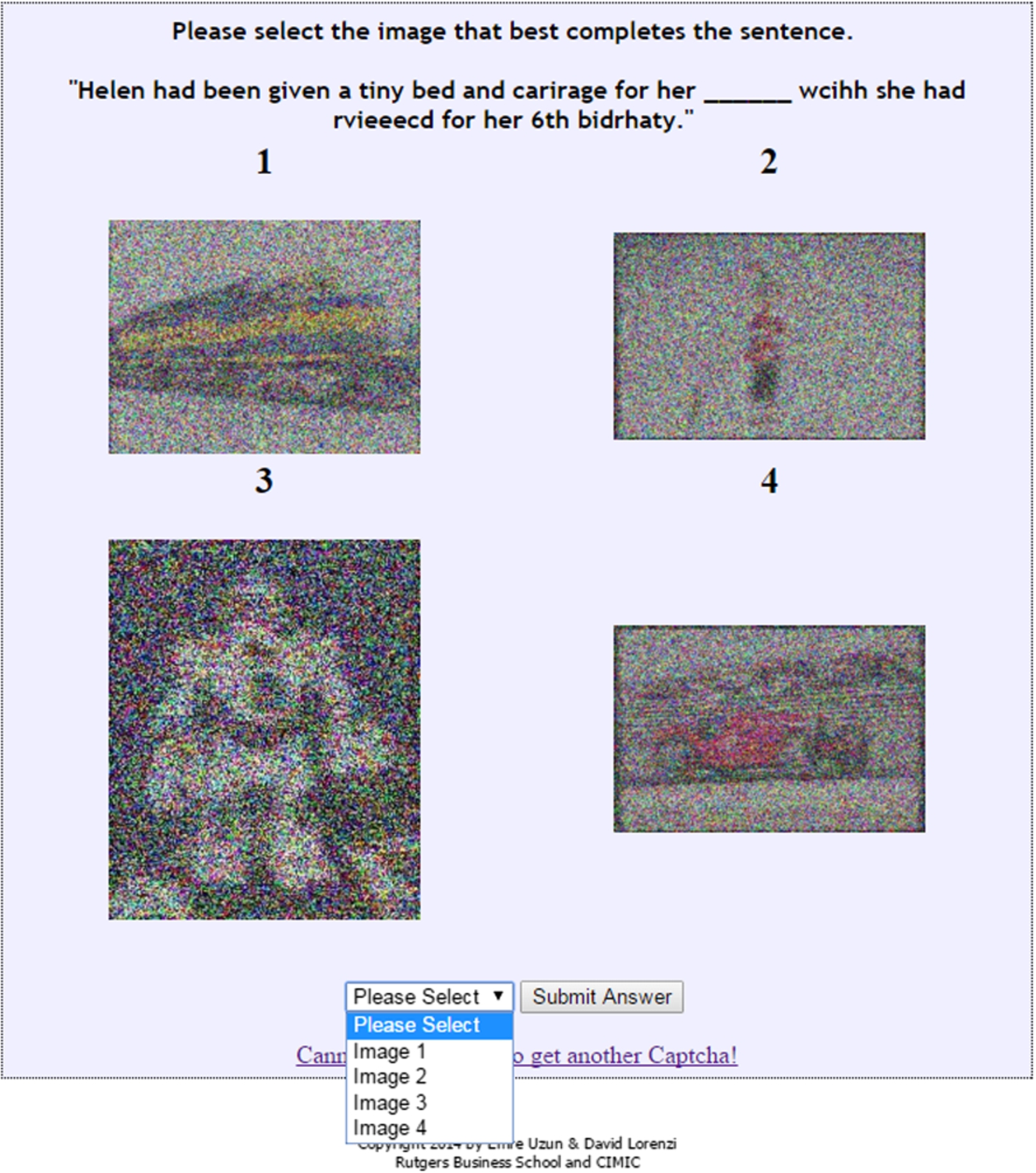
RIS engine testing
The goal of this experiment was to establish a baseline for which a given set of noise functions can provide zero exact matches against both Google (G) and Tineye’s (T) reverse image search engines. The approach described here is more conservative in regards to security, in that many of the images are no longer returning matches at much lower levels of noise overall. We consider even 1 match a failure – thus we do not report specific numbers of matches for each image failure. The number following the search engine designation is the number in the set of 10 for that category, e.g., car contains 10 images total, numbered 21–30 – T22 means that image 22 failed to produce zero matches as matches were found on Tineye (but not Google).
RIS Engine Testing
RIS Engine Testing
Table 2 shows that at 0.25 mean noise, we have 8 out of 100 unique images returning matches. Tineye has one unique hit (T22) and Google has five unique hits (G32, G57, G77, G79, G81). There is overlap on image 84 and 85 as both engines returned matches. This means that out of our random sample of 100 indexed images, 92 out of 100 returned zero matches. At 0.30 mean noise, we have 1 out of 100 unique images returning a match. Tineye and Google both return matches for the same image. This means that out of our random sample of 100 indexed images, 99 out of 100 returned zero matches. At 0.35 mean noise, we have achieved our goal of returning zero matches for our test group of 100 random indexed images. Figure 11 depicts an example output from the noising engine to tune the noise for a particular image. It is important to note that for each image, the noise threshold is different. This particular example had a large number of matches and required a significant amount of noise to return zero matches.

Demonstration of thresholding noise values for security method validation from [28].
While stopping RIS engines was the primary challenge, CV tools are powerful and have been successfully used to defeat image based CAPTCHAs in the past. Thus, we aim to make it as difficult as possible to use them in performing object recognition tasks. One such CV attack case is that of edge detection. This is a key component of object recognition, and being able to foil it will go a long way in stopping any CV attacks from performing this task on an image recognition CAPTCHA challenge. Figure 12 shows the before and after of an edge detection algorithm (Sobel) on an image of a cat that has been noised, effectively destroying the edges in the image while still allowing a human to comprehend the cat that is depicted. Also depicted is the popular SIFT and ASIFT methods for object recognition, and again the noise is effective in stopping the algorithm from functioning properly. These techniques and their methods are detailed in [29].

Demonstration of noise preventing CV-based attacks [29].
We now present a detailed user study1
The user study was carried out with approval from the Rutgers IRB.
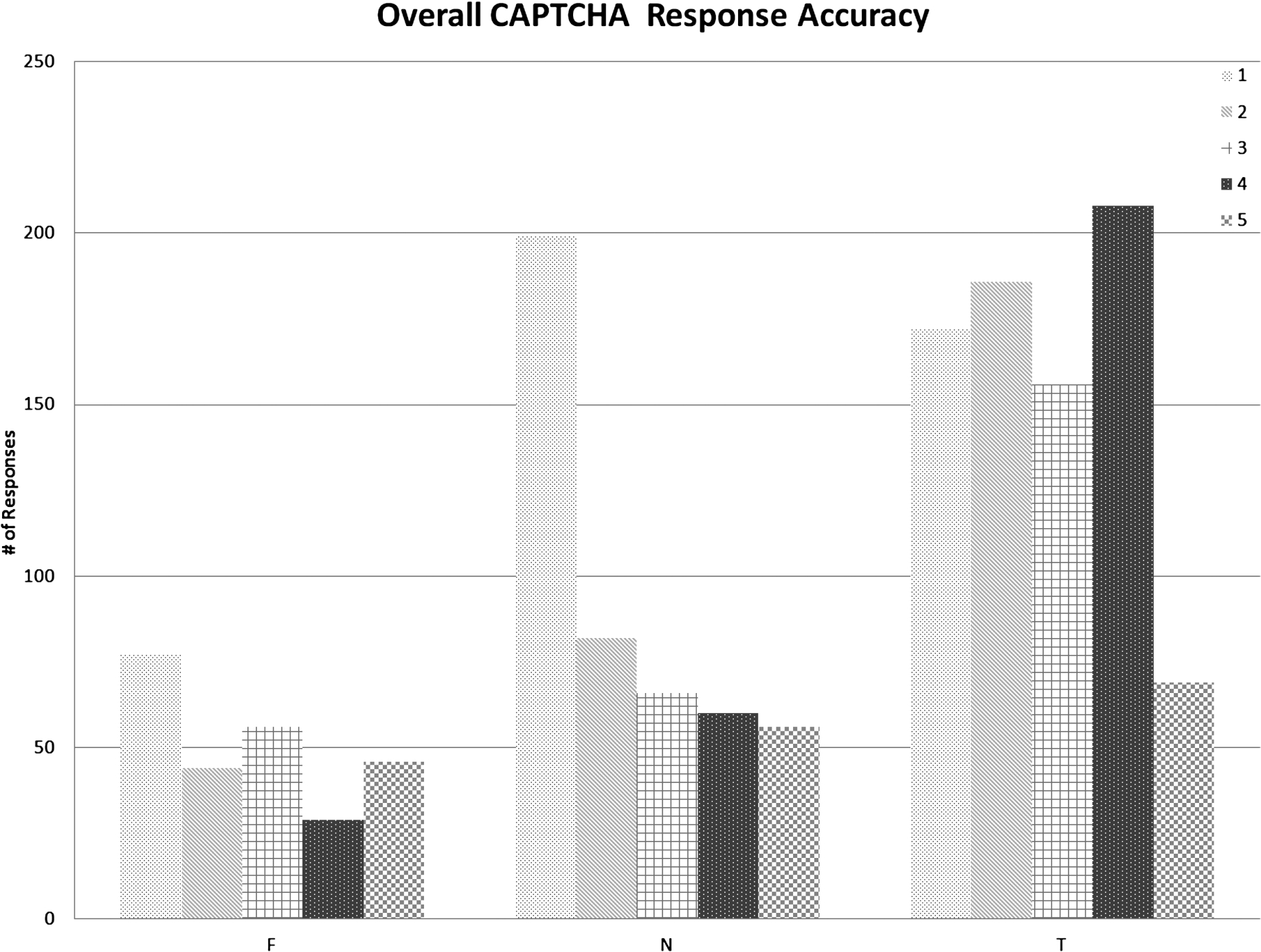
Overall CAPTCHA Response Accuracy − F = Incorrect N = No Response T = Correct.
Figure 13 demonstrates the overall responses gathered from the students, divided into three groups. The F group is incorrect responses related to the challenge of each style. Not surprisingly, the freeform text response (style 1) performed the worst, with the highest number of incorrect answers. Style 4 performed the best with the lower number of incorrect answers. The N group represented when users could not solve the challenge so they clicked the link available at the bottom to get a new challenge – what we termed “No Response”. Again, we see an extreme outlier in the freeform text response (style 1) – more people were unable to answer it than were able to answer it correctly. Somewhat interesting is that style 3, which is not significantly different in design from style 2, has a higher rate of incorrect responses simply by adding in “not here” and introducing ambiguity. Surprisingly, style 5 seems to be on a similar path to style 1, in that it has a large number of no responses and incorrect responses. We speculate this is because we deliberately do not provide an explanation of the “Cambridge effect” in the challenge, the user is simply presented with a scrambled sentence and must make sense of it.
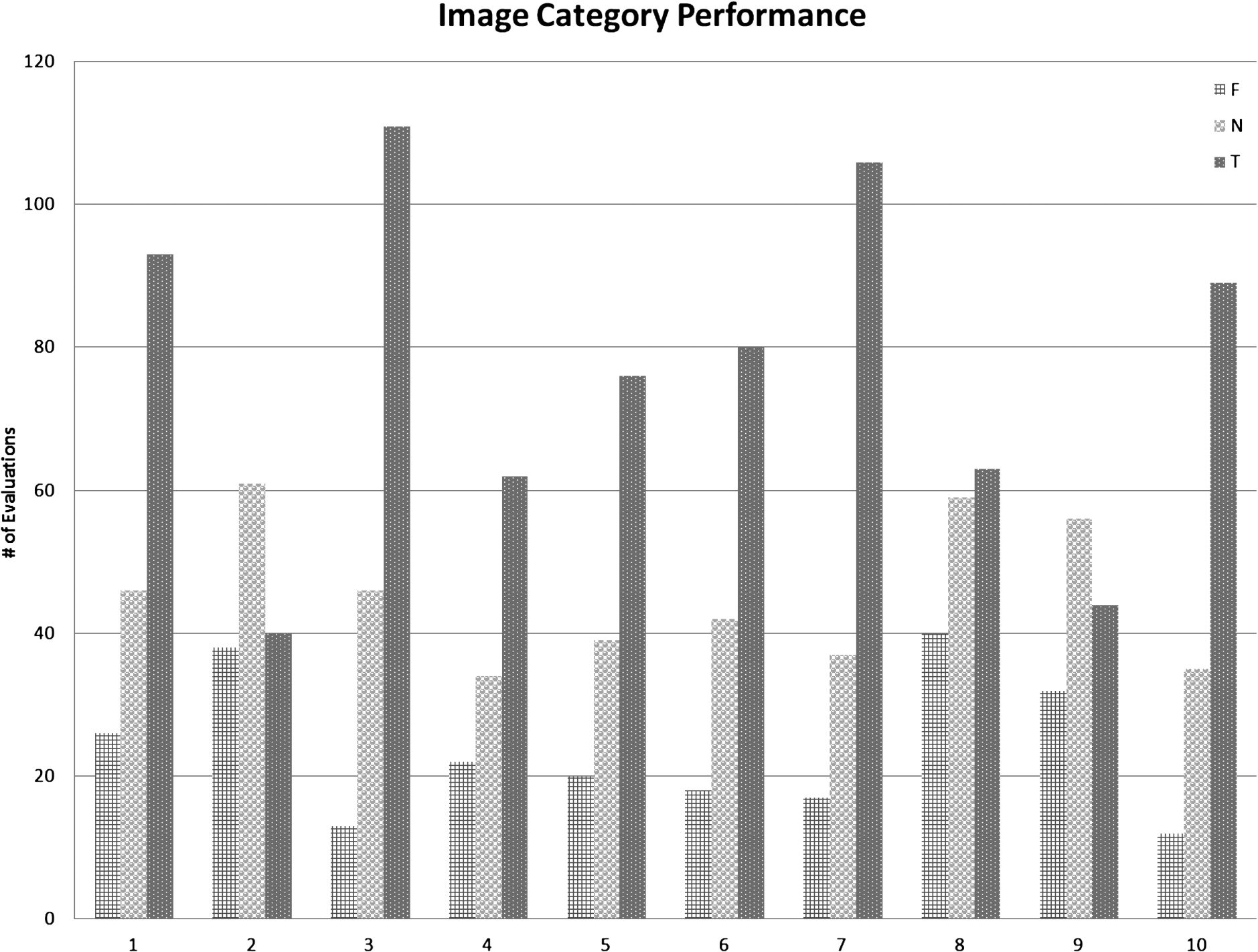
Image Category Performance − F = Incorrect N = No Response T = Correct (airplane (1), bird (2), car (3), cat (4), doll (5), fish (6), flower (7), monkey (8), robot (9), train (10)).
Figure 14 shows how well each image category did. This helps us see which “concrete” categories work well and which ones perform poorly. Three categories that stand out as performing poorly are birds (2), monkeys (8), and robots (9). We speculate that this is due in part to many of the images chosen for this category depict birds and monkeys whose bodies are designed to blend into their natural environments. Thus, when the noising algorithm is applied, it can make it very difficult to discern the animal from the overall background image. The failure of the robots category is most likely due in part to the wide range of styles that a robot can come in – too much ambiguity. We can see that these categories had more “no responses” than they did correct or incorrect answers. Three categories that did well were cars (3), flowers (7), and trains (10). We suspect these categories did well because of the structured nature their designs – cars and trains do not change shape much, and flowers share similar shapes and come in bright and eye catching colors. Fish (6), doll (5), cat (4) and airplane (1) were in the middle of the pack with reasonable performance. Figure 15 shows the successful rate of identification of an image across all styles. Note that total response includes no response as well.
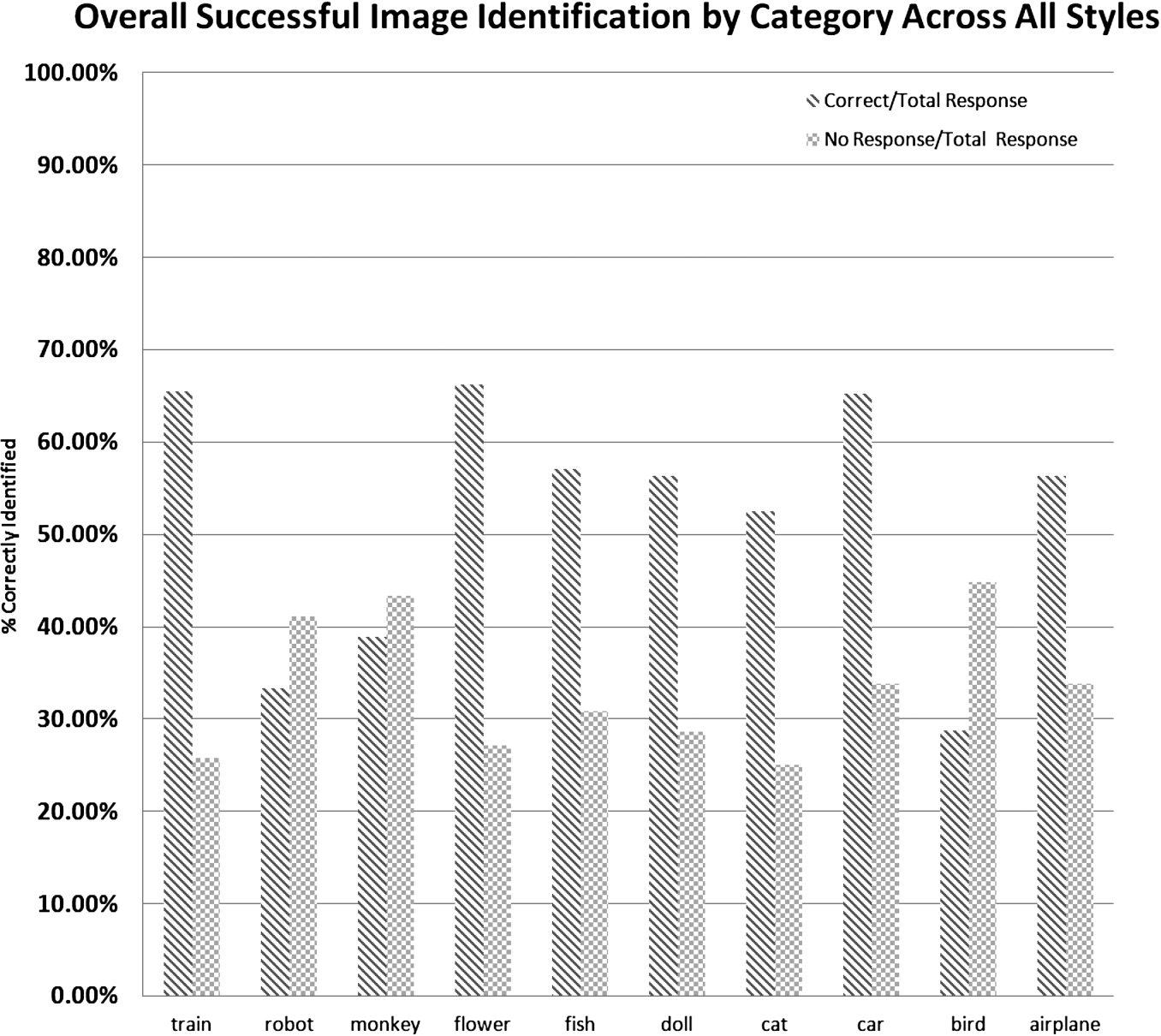
Successful Image Identification Across Styles.

Statistical Summary.
Finally in Fig. 16 we provide a statistical overview of the performance of each style under different circumstances. We examine two scenarios – one where we have classified no response as a “correct” response and one where we have classified no response as an “incorrect” response. Imagine a scenario where a CAPTCHA is guarding a resource that is extremely valuable to the user – for example, their personal email account. Under these circumstances, the user will continue to answer CAPTCHAs until they can gain access to their user account due to the level of importance it has to them. It doesn’t matter if they get frustrated with no responses because they will keep on trying challenges until they gain access. Under these circumstances, by allowing ourselves to classify no response as a success, the rate of success for the various styles increases significantly, with style 4 even reaching 90% success. Now imagine the converse scenario, where the CAPTCHA is guarding a resource that has little to no value to a user, for example, a comment section on a popular news article. When a user is faced with a CAPTCHA challenge, they will be disincentivized to post a comment, because now doing so requires more effort than the user is willing to expend. Under these circumstances, a no response can be viewed in a negative light, the same as a failure. If you are a service provider that wants comments, you will be less likely to use a CAPTCHA like this to secure that service. With failure rates above 50%, very few, if any comments will be posted as users will be too frustrated to bother. Ironically enough, if the CAPTCHA is too severe it could possibly make people comment more to complain about the difficulty in solving the CAPTCHA. Lastly, a review of the no response to total response ratio is worthy of review. Style 1 is quickly approaching 50% chance of a response – terrible from a usability perspective. The styles 2–4 all have somewhat reasonable rates between 20% and 26% respectively, however style 5 has a high rate of no response 33% in spite of the small sample size of tests.
All of the statistics generated from the user study presented in the previous section are meant to be somewhat “tongue-in-cheek’, as straight usability tests like the one conducted here do not capture the true nuances of the human response to form security. One can argue that without actually providing a scarce resource, any user behavior that is observed isn’t an accurate representation of how it would be approached in the wild. Without proper context, it is difficult to accurately gauge the performance in usability of any particular CAPTCHA approach. For example, our test users reported that after they answered a number of challenges for each of the different styles, their accuracy improved once they understood what to look for. Another point to consider is when students were given the “pointillism” pointer, that is, to stand further away from the computer monitor to let your eye blend the pixels in the image so its easier to see, reported an increase in the ability to correctly identify categories. CAPTCHA design is equal parts science and art. We have seen from the many examples we offer the tradeoffs within the three major categories, as well as other implementation based security concerns. Every method will have some failures, and the longer a method remains static, the greater the chance a database attack can be generated or a new technique/algorithm developed to defeat it. In this case, it is best to just enumerate all of the possibilities that exist at the time and create a grid that shows the strengths and weaknesses of each method eliminating the ones that fail to meet whatever set of predefined criteria the service provider has decided upon and quantify them accordingly.
Another point worth noting was that the SIGNAC method used to generate the images was going to have an impact on usability – however this was intentional. We deliberately used a high noise threshold to provide a security guarantee of zero RIS matches, since the images were gathered from online image search engines. This means that the images were significantly more noisy than they needed to be, thus the somewhat unsurprising affected usability performance of the CATPCHA styles. Finally, the users were only able to solve challenges for a short time maybe 5 to 10 minutes. It would be a worthwhile exercise to compare first run results to the same group of users trying the challenges again after they are familiar with all of the styles.
Conclusions and future work
In this paper we have examined several design criteria for developing robust CAPTCHAs. We have posited several examples and implemented a few variants of image based CAPTCHAs. The conducted user study demonstrates the tradeoff between usability and security. In the future we plan to further examine different aspects of CAPTCHA design including establishing user tastes and preferences to CAPTCHA styles so that form designers can have a method that will not detract from their service while providing some measure of security. One aspect of future work we intend to investigate is that of the increasing accuracy and power of image recognition algorithms and their ability to decipher context within an image. Currently these tools are not mature, however they present a compelling avenue for automation – easily generating large, verbose datasets that can be adapted for visual CAPTCHA design. As such, algorithms for obfuscating the images such that automated tools and AI fail to solve/comprehend/process the challenge yet allow humans to do so remains an active research challenge for the CAPTCHA community. Once this barrier is overcome, the reality of robust strong visual AI is certainly not far behind. Generative Adversarial Networks (GANs) present a potentially interesting option for “attacking” image based CAPTCHAs – perhaps by generating solutions to image recognition challenges and performing a probabilistic guess attack using the discriminator network. Through the iterative process of designing and breaking CAPTCHAs, perhaps a new alternative can emerge to displace re-CAPTCHA, or CAPTCHAs altogether. In conclusion, the value of utilizing a risk based framework for evaluating CAPTCHA designs using an analysis of the usability, scalability, and robustness categories along with more fine-grained quantitative and qualitative methods within those categories provides us with the best way to achieve reasonable form security while minimizing service overhead and maximizing user utility and convenience.