
Abstract
Existing CAPTCHA solutions are a major source of user frustration on the Internet today, frequently forcing companies to lose customers and business. Game CAPTCHAs are a promising approach which may make CAPTCHA solving a fun activity for the user. One category of such CAPTCHAs – called Dynamic Cognitive Game (DCG) CAPTCHA – challenges the user to perform a game-like cognitive (or recognition) task interacting with a series of dynamic images. Specifically, it takes the form of many objects floating around within the images, and the user’s task is to match the objects corresponding to specific target(s), and drag/drop them to the target region(s).
In this paper, we pursue a comprehensive analysis of DCG CAPTCHAs. We design and implement such CAPTCHAs, and dissect them across four broad but overlapping dimensions: (1) usability, (2) fully automated attacks, (3) human-solving relay attacks, and (4) hybrid attacks that combine the strengths of automated and relay attacks. Our study shows that DCG CAPTCHAs are highly usable, even on mobile devices and offer some resilience to relay attacks, but they are vulnerable to our proposed automated and hybrid attacks.
Introduction
The abuse of the resources of online services using automated means, such as denial-of-service or password dictionary attacks, is a common security problem. To prevent such abuse, a primary defense mechanism is CAPTCHA [1] (denoted “captcha”), a tool aimed to distinguish a human user from a computer based on a task that is easier for the former but much harder for the latter.
The most commonly encountered captchas today take the form of a garbled string of words or characters, but many other variants have also been proposed (we refer the reader to [4,20,38] which provide excellent review of different captcha categories). Unfortunately, existing captchas suffer from several problems. First, successful automated attacks have been developed against many existing schemes. For example, algorithms have been designed that can achieve character segmentation with a 90% success rate [21,22,28,40]. Second, low-cost attacks have been conceived whereby challenges are relayed to, and solved by, users on different web sites or paid human-solvers in the crowd [12,13,18]. In fact, it has been shown that [27] such relay attacks are much more viable in practice than automated attacks due to their simplicity and low economical costs. Third, the same distortions that are used to hide the underlying content of a captcha puzzle from computers can also severely degrade human usability [6,39].
Given these problems, there is a need to consider alternatives that place the human user at the center of the captcha design. Game captchas offer a promising approach by attempting to make captcha solving a fun activity for the users. These are challenges that are built using games that might be enjoyable and easy for humans, but hard for computers.
In this paper, we focus on a broad form of game captchas, called Dynamic Cognitive Game (DCG) captchas. This captcha challenges the user to perform a game-like cognitive task interacting with a series of dynamic images. Specifically, we consider a representative DCG captcha category which involves objects floating around within the images, and the user’s task is to match (i.e. drag/drop) the objects with their respective target(s). A startup called “are you a human” [2] has recently been offering such
Besides promising to significantly improve user experience,
This paper is a combination and consolidation of our prior conference publications [17,25,26], which serves to integrate multiple studies in a single archival journal paper. Moreover, we report on two new usability studies. The
Background
We use the term Dynamic Cognitive Game (DCG) captcha to define the broad captcha schemes that form the focus of our work. We characterize a
Security model and design choices
The
For example, target thresholds might limit bot success rates below 0.6% [42], and human user success rates above 90% [8].
A pre-requisite for the security of a DCG captcha implementation (or any captcha for that matter) is that the responses to the challenge must not be provided to the client machine in clear text. For example, in a character recognition captcha, the characters embedded within the images should not be leaked out to the client. To avoid such leakage in the context of DCG captchas, it is important to provide a suitable underlying game platform for run-time support of the implemented captcha. Web-based games are commonly developed using Flash or HTML5 in conjunction with JavaScript. However, both these platforms operate by downloading the game code to the client machine and executing it locally. Thus, if these game platforms were directly used to implement DCG captchas, the client machine will know the correct objects and the positions of their corresponding target(s), which can be used by the bot to construct the responses to the server challenges relatively easily. This will undermine the security of DCG captchas.
The above problem can be addressed by employing encryption and obfuscation of the game code which will make it difficult for the attacker (bot) on the client machine to extract the game code and thus the correct responses. Commercial tools, such as SWF Encrypt [35], exist which can be used to achieve this functionality. This approach works under a security model in which it is assumed that the bot does not have the capability to learn the keys used to decrypt the code and to deobfuscate the code. A similar model where the attacker has only partial control over the client machine has also been employed in prior work [33].
In addition to automated attacks, the security model for DCG captchas (and any other captcha) must also consider human-solver relay attacks [13,27]. In fact, it has been shown that such relay attacks are much more appealing to the attackers than automated attacks currently due to their simplicity and low cost [27]. In a relay attack, the bot forwards the captcha challenges to a human user elsewhere on the Internet (either a payed solver or an unsuspecting user accessing a web-site [14]); the user solves the challenges and sends the responses back to the bot; and the bot simply relays these responses to the server. Unfortunately, most, if not all, existing captcha solutions are insecure under such relay attack model. For example, character recognition captchas are routinely broken via such relay attacks [27]. For DCG captchas to offer better security than existing captchas, they should provide some resistance to such human-solver relay attacks (this is indeed the case as we demonstrate in Section 5).
Due to the legal restrictions on attacking commercial DCG captchas, we proceeded to develop our own animation-based DCG prototypes for the purpose of our study. Using Adobe Flash, we implemented four captcha games that represented a broad class of DCGs. These games are
The DCG captchas implemented for the purpose of this study are shown in Fig. 1. Each DCG captcha can be characterized by the following distinct components.
Answer object – a moving object that should be dragged to the corresponding target object in order to successfully complete the game. For the parking game shown in Fig. 1(c), the orange boat, that can be dragged to the empty dock position to complete the game, is the answer object.
Target object – an object onto which the corresponding answer object should be dragged.
Target area – the area within which the target objects reside.
Activity area – the area within which the foreground objects move.
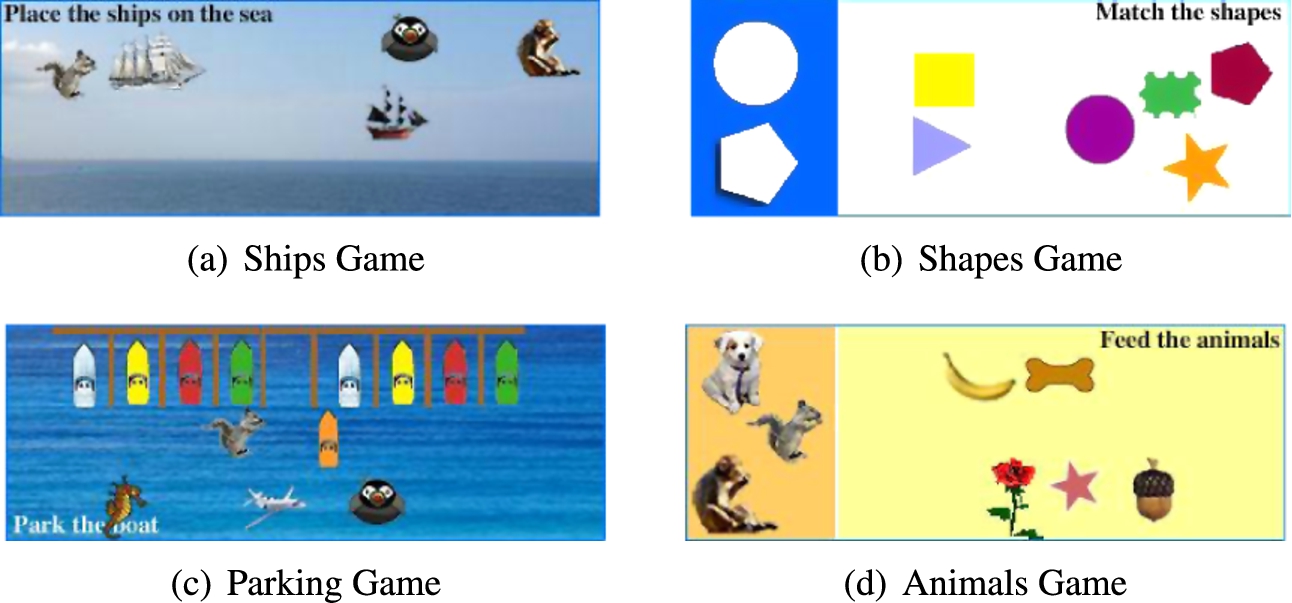
Static snapshots of 4 game instances of a representative DCG captcha analyzed in this paper (targets are static; objects are mobile).
DCG captchas are classified according to the number of target objects. The Ships game (Fig. 1(a)), is a one-target DCG type, where the sea is the target object. So the ships, that are the answer objects, can be dropped anywhere within the sea. The Shape game (Fig. 1(b)) has a circle and a pentagon placed on the left side of the game as the two target objects. The Animal game (Fig. 1(d)) is a three-target instance of DCG captcha. The Parking game (Fig. 1(c)) is a variant of DCG captcha where there is no target object but a target area (the empty parking space) onto which the boat should be dragged.
To complete a DCG captcha game, a user has to drag and drop all answer objects to their corresponding target objects. For example, in the Animal game, the user has to drag the bone to the dog, the acorn to the squirrel, and the banana to the monkey. The game is considered incomplete, and the user is rejected in case the game is not completed within 60 s.
Each foreground object has an initial pre-specified location in the activity area. The direction of movement of objects is randomly chosen from 8 possible directions – north (N), south (S), east (E), west (W), NE, NW, SE and SW. For horizontal and vertical movements, objects move 1 pixel per frame. For diagonal movements, the objects move 1.414 pixels per frame. The frame rate for the games is set at 40 frames per second. Hence, the foreground objects move at an average speed of
For each of the 4 games, we set 5 parameterizations, choosing number of moving objects as (4, 5, 6), and object speed as (10, 20, 40) frames per second (FPS) (These frame rates translate into average object speeds of 12.1, 24.2 and 48.4 pixels/second, resp.). For each game, we used 5 combinations of speed and number of objects: (10 FPS, 4 objects); (20 FPS, 4 objects); (20 FPS, 5 objects); (20 FPS, 6 objects); and (40 FPS, 4 objects). This resulted in a total of 20 games in our corpus.
In this section, we report our usability studies of our representative DCG captcha category. The first study is student based which we used to measure the usability of the DCG captcha with respect to different parameters as explained in Section 2.2. Then, to validate our study results we preformed another study on Amazon Mechanical Turk (MTurk) is which we tested only one variant of each game instance. Finally, we present our mobile-based study that we conduct to evaluate the usability of DCG captchas on mobile devices.
Study design, goals, and process
Demographics of participants in the usability, relay and hybrid attacks studies
Demographics of participants in the usability, relay and hybrid attacks studies
Drag error rates and completion time Lab Usability Study (
Our
The participants were subjected to a consent agreement, and demographics form before the experiment. At the end of the experiment, their experience in solving DCG captchas was recorded using a survey form. The survey contains the 10 System Usable Scale (SUS) standard questions [5], each with 5 possible responses (5-point Likert scale, where 1 represents strongly disagreement and 5 represents strongly agreement).
For our
The
Via our study, our goal was to assess the following aspects of the DCG captchas:
Efficiency: time taken to complete each game.
Robustness: likelihood of not completing the game, and of incorrect drag and drop attempts.
User Experience: participants’ SUS ratings of the games.
In this subsection, we report the study results of the three usability studies we conducted.
Lab-based usability study
All statistical results reported in this paper are at the 95% confidence level.
Next, we calculated the likelihood of incorrect drag and drop attempts (drag error rate). For example, in the Animals game, an incorrect attempt would be to feed the monkey with a flower instead of a banana. We define the drag error rate as the number of incorrect objects dragged to the target area divided by the total number of objects dragged and dropped. The results are depicted in Table 2. We observe that the Shape game yields the smallest average per click error rate of 3%. This suggests that the visual matching task (as in the Shapes game) is less error prone compared to the semantic matching task (as in the other games). The game challenge which seemed most difficult for participants was the Parking game. Since objects in this game are relatively small, participants may have had some difficulty to identify them.
Drag error rates and completion time per object speeds (
Another aspect of the usability analysis included testing the effect of increase in the number of objects (including noisy answer objects) on the overall game performance. Table 4 summarizes the drag error rates and completion time against different number of objects. Here, we can see a clear pattern of increase, albeit very minor, in average completion time and average error rate with increase in the number of objects. This is intuitive because increasing the number of objects increases the cognitive load on the users which may slow down the gameplay and introduce chances of errors. A Friedman’s test revealed statistical difference among the mean completion time corresponding to the three number of objects (
Drag error rates and completion time per # of objects (
Drag error rates, game error rate and completion time MTurk Usability Study
Drag error rates, game error rate and completion time MTurk Usability Study
Drag error rates and completion time Mobile-based Usability Study (
Table 5 summarized the results of MTurk usability study. The second column of Table 5 shows that the average completion time is almost doubled comparing to the lab-based usability study, however, the completion time still less than 15 seconds on average for all the games. A Friedman’s test showed significant difference in the mean timings of all 4 types of games (
The second column of Table 5 shows that the average overall error rate increases from 0% to 3.5% and the average drag error rate increases from 4% to 32%. This is due to the diversity of the MTurk workers over the students who were hired for the first study. Moreover, this variant (40 FPS, 6 objects) is considered harder than the tested variants in the first study, our previous results shows that the completion time increases with increasing the speed and number of the objects.
Table 6 summarized the results of the Mobile-based usability study. The overall error rate is zero – all the participants were able to complete the games successfully. The second column of Table 6 shows the time taken by the participants to complete the games. The time to solve the challenges is in between the time taken by the participants in the lab-based study and Mturk study. Similar to the previous two studies, the maximum time was taken to solve the Animal game. The drag error rate was the minimum for the Shape game and the maximum for Parking game, which is in line with the previous two studies.
User experience of the three studies
Now, we analyze the data collected from the participants during the post-study phase. The average SUS score from the first study came out to be 73.88 (
Automated attacks
Having validated, via our usability study, that it is quite easy for the human users to play our DCG captcha instances, we next proceeded to determine how difficult these games might be for the computer programs. In this section, we present and evaluate the performance of a fully automated framework that can solve DCG captcha challenges based on image processing techniques and principles of unsupervised learning.
Our automated attack and results
Our attack framework involves the following phases:
Learning the background image of the challenge and identifying the foreground moving objects.
Identifying the target area. For example, the area that contains all the animals in the Animals game.
Identifying and learning the correct answer objects. For example, the ships in the Ships game.
Building a dictionary of answer objects and corresponding targets, the background image, the target area and their visual features, and later using this knowledge base to attack the new challenges of the same game.
Continuously learning from new challenges containing previously unseen objects.
Next, we elaborate upon our design and matlab-based implementation per each attack phase as well as our experimental results. We note that, on a web forum [11], the author claims to have developed an attack against “are you a human” captcha. However, unlike our generalized framework, this method is perfected for only one simple game that has one target object and a fixed set of answer objects. It is not known whether or how easily this method can be adapted to handle different games, games with multiple instances that carry different sets of answer objects, and those with multiple target objects. Since only one game is cracked, one needs to keep refreshing the game page until that specific game appears. Since no technical details are provided in [11], we can only doubt if any background learning or object extraction is implemented by observing the short time it takes to finish the attack.
However, one drawback of this preliminary method is that if the moving speed of the foreground objects is too slow, especially when some foreground objects hover over a small area, the dominant color values of most pixels in that area will be contributed by the foreground objects instead of by the background. A shadow of foreground objects may appear as pseudo patches in the background image as shown in Fig. 2(b) for the Shapes game of Fig. 2(a), indicated by the dashed rectangle. Using more sampling frames for initial background learning could alleviate this problem, but resulting in a time-consuming learning procedure. Our preliminary experiment indicates that an average 30.9 s, generated by running the above learning method 15 times per game challenge, is needed for learning a game background completely.
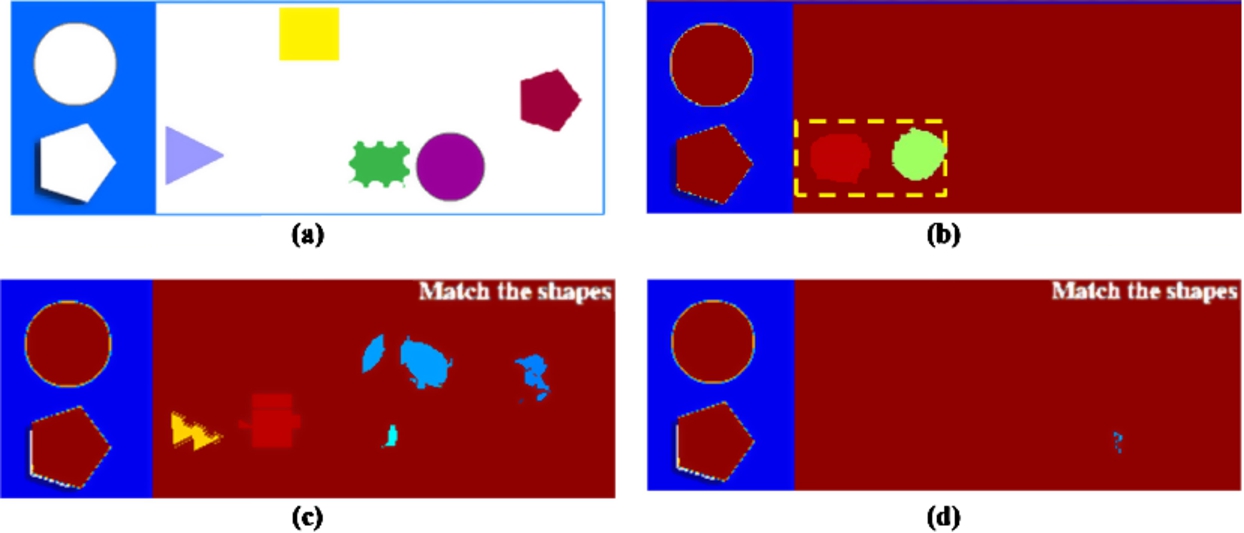
Detected backgrounds. (a) original frame image; (b) detected background with pseudo patches by using preliminary method; (c) detected background with pseudo patches after performing the 1st step of the proposed method; (d) detected background with a minor patch after performing the 2nd step of the proposed method.
In our new method, we overcome the conflict between the number of sampling frames and the pseudo patch effect by actively changing the location of one moving object per sampling frame. In the first step, a few frames
After removing the extracted background from 5–8 equally distant frames from the collected frames, the objects in each of the selected frame are extracted. The objects below a certain size threshold were discarded as noise. The frame with the maximum number of objects was then selected to extract various objects. Using multiple frames for object extraction also helped us discard the frames in which the objects overlapped each other and were hence detected as a single object instead of distinct individual objects.
As the final step as part of this phase, the visual features, coded as color code histograms (a visual feature commonly used to describe the color distribution in an image), of the foreground objects and the background image, are stored in the database, together with some other meta-data such as the object size and dimensions.
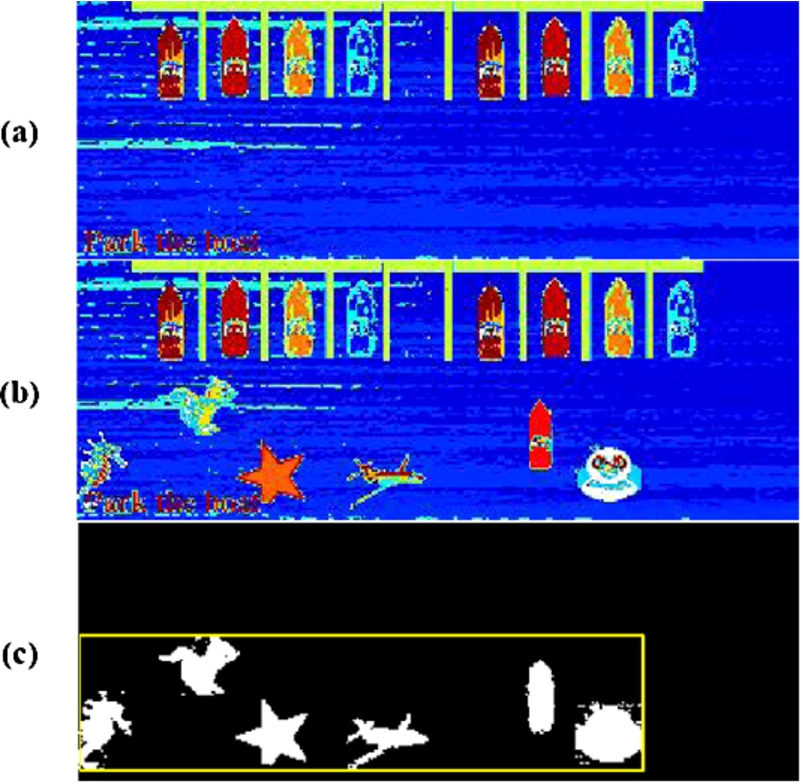
Target Detection. (a) The detected background for the Parking challenge; (b) One sample frame represented in color code; (c) Detected foreground objects from (b) and their MBR.
After the removal of the entire area bounded by
We also implemented alternative methods such as Edge-based and exclusion methods, However, MBR method is more robust.
There are two benefits in the background learning. First, the learned background can be used to quickly extract foreground moving objects. Second, the learned background can be used to locate the target area where foreground answer objects need to be dragged to. The proposed active learning is tested on all 36 game challenges (i.e., 3 (speeds), 3 (# of objects), 4 (game prototypes)).
The adoption of a large image database for each answer object could pose a challenge to our approach since it allows for the creation of many different foreground answer object configurations for the same game. In the worst case, a challenge may contain none of the previously learned answer objects for that particular game. Continuous learning will be activated in such cases and can also be used as a way for auto attacking in the run time. Such cases fall into the category of “known foreground answer objects and known target objects,” and the success rate can be estimated using the number of foreground objects (o), number of answer objects (t), and number of drag/drop attempts allowed for each object (a). For example, if
During attacking, there is a time lapse between selecting a foreground object and verifying whether it is an answer object. Both feature extraction and database lookup (through feature matching) take time. In our implementation, we chose to click and hold a selected object until a match with an answer object in the database is registered. In doing so, we guarantee that an answer object, once verified, can be readily dragged/dropped, thus to avoid dealing with the issue of constantly moving objects. However, this approach may fail if a constraint is added by the captcha implementation that limits the amount of time one can hold an object from moving. A less invasive attacking method would be to utilize parallel processing, in which one thread is created to perform feature extraction and comparison, and another thread is used to track and predict the movement of the object currently under verification.
Relay attacks
Human-solver relay attacks are a significant problem facing the captcha community, and most, if not all, existing captchas are completely vulnerable to these attacks routinely executed in the wild [27]. In this section, we assess DCG captchas w.r.t. to relay attacks.
Difficulty of relaying DCG captchas
The attacker’s sole motivation behind a captcha relay attack is to completely avoid the computational overhead and complexity involved in breaking the captcha via automated attacks. A pure form of a relay attack, as the name suggests, only requires the attacker to relay the captcha challenge and its response back and forth between the server and a human-solver. For example, relaying a textual captcha simply requires the bot to (asynchronously) send the image containing the captcha challenge to a human-solver and forward the corresponding response from the solver back to the server.
In contrast, DCG captchas offer some level of resistance to relay attacks, as we argue in the rest of this section. There appears to be a few mechanisms that can potentially subject DCG captchas to a relay attack. First, if the server sends the game code to the client (bot), the bot may simply ship the code off to the human-solver, who can complete the game as an honest user would. However, in the DCG captcha security model (Section 2.1), the game code is obfuscated and can be enforced to be executable only in a specific domain/host authorized by the server using existing tools [35], which will make this attack difficult, if not impossible.
The second possibility, called Static Relay attack, is very simple and in line with a traditional captcha attack (and thus represents a viable and economical relay attack). Here, the bot asynchronously relays a static snapshot of the game to a human-solver and uses the responses (locations of answer objects and that of the target objects) from the solver to break the captcha (i.e., drag/drop the object locations provided by the solver to the target object locations provided by the solver). However, it is expected to have poor success rates. The intuitive reason behind this is a natural loss of synchronization between the bot and the solver, due to the dynamic nature of DCG captchas (moving objects). In other words, by the time the solver provides the locations of target object and the answer objects within a challenge image (let us call this the nth frame), the objects themselves would have moved in the subsequent, kth, frame (
The third possibility, called Stream Relay, is for the bot to employ a streaming approach, in which the bot can synchronously relay the incoming game stream from the server over to the solver, and then relay back the corresponding clicks made by the solver to the server. Although the Stream Relay attack might work and its possibility can not be completely ruled out, it presents one main obstacle for the attacker. Streaming a large number of game frames over a (usually) slow connection between the bot (e.g., based in the US) and the solver’s machine (e.g., based in China) may degrade the game performance (similar to video streaming over slow connections), reducing solving accuracy and increasing response time. Such differences from an average honest user gameplay session may further be used to detect the attack.
In the rest of this section, we report our Stream Relay attack study and show the ability of detecting such relay attack using our proposed machine learning detection method.
Stream relay attack
Under Stream Relay, the attacker obtains the DCG captcha challenge from the server, just like a legitimate user. The attacker runs a streaming server (such as a VNC server), and the human-solver connects to the attacker machine through a streaming client (such as a VNC client). This streaming software is responsible for delivering the DCG captcha frames to the human-solver and sending the human-solver’s mouse interactions, such as drag/drop, mouse clicks and positions, to the attacker. The attacker then simply forwards the log of this interaction between the human-solver and the game to the server. Finally, the server would run the detection algorithm on this log, and responds back by rejecting (or accepting) the attacker. Due to network latency, our hypothesis is that the human-solver may suffer from degradation of the game quality at his/her end. This degradation would decrease the game performance of DCG captcha. More importantly, it would make the solver interaction with the game distinguishable from the interaction between the legitimate user and the game (as in the normal setting), and thereby make it possible for the server to detect the relay attack.
Study design, goal and process
MTurk workers were hired for the Stream Relay attack study. The MTurk workers (serving the role of human-solvers) were asked to connect to a computer residing at our university and connected to our university wireless network through a VNC java applet (serving the role of the attacker’s machine). The workers were then asked to fill demographics form, play four games (40 FPS, 6 objects) variant of each game instance (ordered based on
We used three different experiments to test various relay attack scenarios, the demographics of the participants are shown in the columns 5 to 7 of Table 1, as described below:
High-Latency Relay: The first scenario involved collecting data from participants residing outside the US. Since in a typical relay attack, the human-solvers are normally hired from sweatshops in remote countries (e.g., India or China) by an attacker residing in the US, this setting reflects a real-life relay attack scenario. We collected data from 40 participants as part of this scenario. Small Game Relay: The second attack scenario involved testing a case when an attacker tries to minimize communication between the attacker and the solvers by reducing the game size. This was achieved by presenting games with Low-Latency Relay: In the last scenario, we tested a setting in which the attacker launches the attack from a machine that is in close proximity to the solvers (e.g., both the attacker and solvers are located in the US). To evaluate this scenario, we collected data from 20 participants located within US.
Study results
In this subsection, we will report the study results and compare them to the MTurk usability study.
Completion times, and error rates in Stream Relay attack scenarios
Completion times, and error rates in Stream Relay attack scenarios
To overcome the issues presented by network latency for the participants outside the US, in the second scenario (Small Game Relay), we reduced the game size by
Our last stream relay experiment, Low-Latency Relay, tested the Stream Relay attack performance when the attacker and the solver reside relatively nearby (both within the US). The results of this experiment are depicted in the third column of Table 7. The results show huge improvement over the previous two scenarios. The time taken to complete the game is on average about 40% lower compared to the time taken by participates in High-Latency and Small Game Relay scenario. Analyzing the data using Mann–Whitney U test with Bonferroni correction, we found statistically significant difference between the mean time of the Ships game and its correspondent in the usability study:
In the previous subsection, we have demonstrated that the DCG captcha game performance (completion timings and error rates) in the usability study setting and the game performance in each of the Stream Relay attack scenarios differs in the average case. In this section, we set out to investigate whether it is possible for the captcha service, based on the different gameplay features and behavioral data, to identify whether an individual gameplay event (captcha solving instance) conducted by a legitimate user or to human-solver in the Stream Relay attack.
A continuous key-press track may not correspond to a drag track when the mouse misses to grab a moving object. Such a key-press track is called an invalid mouse drag. When an invalid mouse drag occurs to a legitimate user, he/she can usually realize it immediately and take appropriate corrective actions. Consequently, an invalid mouse drag track will end relatively quickly, resulting in relatively few timestamps on the track. In contrast, when the same situation happens during Stream Relay attack, the remote human-solver may be slow in response due to the network communication delay, which may be reflected as either a longer invalid mouse drag track, or a slow-motion mouse movement that generates many timestamps, or both.
There are 7 features extracted from the users’ gameplay data, used as input to train a classifier to differentiate legitimate users from relay attackers and tested with different machine learning methods.
PlayDuration: overall gameplay time (in seconds).
Successful drag rate: the ratio of the number of successful drags/drops to the total number of drag/drops.
Number of attempts: the number of times the mouse status changes from “up” to “down”.
Average dragging time: the sum of time duration of drags divided by the number of drags.
The maximum duration among all invalid mouse drags in a gameplay instance.
Number of timestamps in the invalid mouse drag with the longest duration.
The product of Features 5 and 6.
Both Support Vector Machine (SVM) [7] and K-Nearest Neighbors (KNN) [16] are tested on 127 (
In the classification task, the positive class corresponds to a legitimate user and the negative class corresponds to human-solver relay attacker as denoted below:
True Positive (TP): legitimate user correctly classified as legitimate user. True Negative (TN): relay attacker correctly classified as relay attacker. False Positive (FP): a relay attacker misclassified as legitimate user. False Negative (FN): a legitimate user misclassified as a relay attacker.
Three different measures are used to evaluate the classifier’s performance, namely precision, recall, and accuracy, as defined in Equations 1, 2 and 3. Of these, recall is the most important because low recall leads to a high rejection rate of legitimate users, causing user frustrations and compromising usability. The desired classification result should demonstrate a sufficiently high recall and a reasonably high precision.
Results of using the optimal feature subset for each game in classification of legitimate user and (High- and Low-Latency and Small Game) relay attacker
Results of using the optimal feature subset for each game in classification of legitimate user and (High- and Low-Latency and Small Game) relay attacker
To measure the overall classification accuracy and recall of our model, we built a classifier for each of the four game types using all the collected data from usability study and the three relay attack scenarios. The average measurement values are shown in Table 8, suggesting that the best average accuracy and average recall are achieved for the Animal and Ships games, followed by the Shape game and then the Parking game. This suggests that increasing the number of the required drags/drops improves the classification performance.
Relay attacks as shown in Section 5 are easily detectable. Automated attack is effective, however, it has some weaknesses, such as:
The auto-attack framework cannot detect the target area that overlap the activity area. Dragging and dropping a moving object always follows a straight line-path, which doesn’t work for more complex paths. The learning phase requires too many drags/drops which may be detectable by the server.
In this section, we propose two models of hybrid attacks for attacking DCG captcha that combine the strengths of both of the automated and relay attack and overcome their weakness. A key component of both models in our framework is robust object tracking that preserves the synchronization between the game and the bot, which we discuss next.
Real-time object tracking
Real-time tracking on moving objects of a game challenge plays an important role in keeping synchronization between the game and the bot. The tracking efficiency affects whether a timely completion of a game challenge by the bot could be done like human, which becomes one of the key factors that determines the success rate. In this section, we introduce a simple and efficient color code histogram based tracker.
Based on the characteristics of DCG prototypes introduced in Section 2.2, namely, (1) the background is static, and (2) the moving objects have unchanging appearance, we propose a simple and efficient tracking algorithm, named color code histogram based tracker (denoted as CCH) that generates the foreground mask by utilizing the detected background, and associates the track to the same object based on color code features [41]. We used 6-bit color code instead of 8-bit (e.g., gray image) or 24-bit (e.g., RGB/HSV/Lab image), which is an approximate color representation that consists of the top two bits of each RGB channel, in order to reduce the computation cost. Moving objects as well as the game scene are represented as a normalized 64-bin color code histogram. The tracking task is thereby simplified as a histogram matching task in the subsequent frames by using histogram intersection [34] that is known to be robust against scaling and rotation. To alleviate the segment merging problem caused by objects occlusion, CCH will abandon the current foreground mask if fewer segments than the number of tracks can be found. The extent of tolerance to partial occlusion relies on tuning the similarity threshold in histogram intersection.
Such a simple design also exposes two weaknesses: (1) The quality of the foreground mask in each frame completely relies on the quality of the detected background; and (2) Tracking may become inaccurate when multiple objects have similar color histograms. Future research may consider other clues in matching, such as motion, to alleviate this problem.
Auto-attack with offline learning
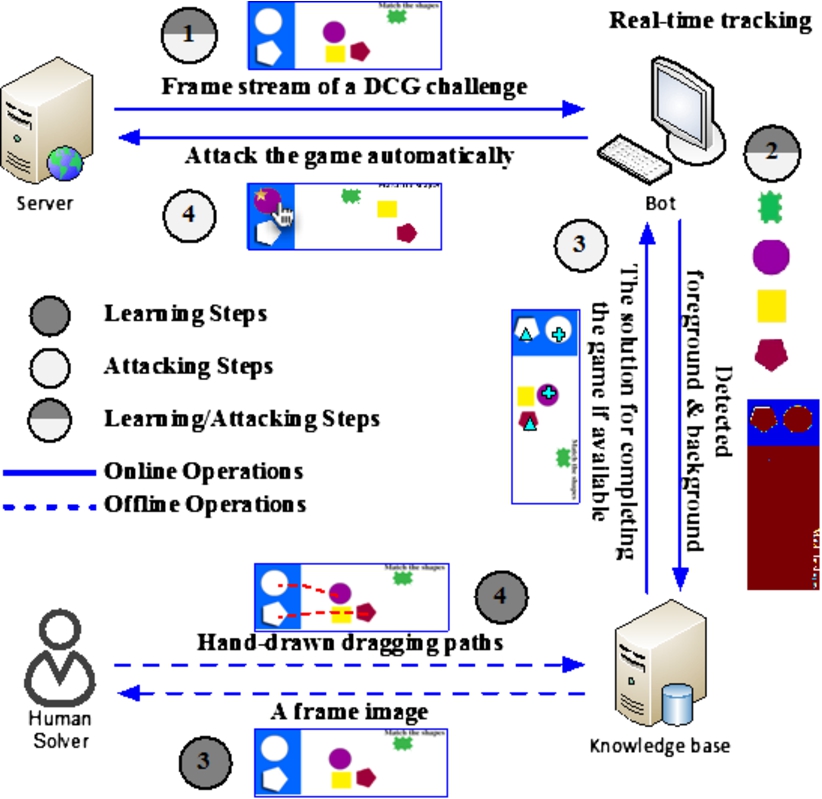
Hybrid attack model I: Auto-attack with Offline human Learning.
Model I of our proposed hybrid attack framework (Fig. 4), Auto-attack with Offline human Learning (AOffL), attacks a known game with the help of real-time tracking and offline knowledge. In the learning phase of AOffL, the necessary knowledge related to a game scene is learned in advance from a remote human-solver.
First, the bot starts the game and keeps scanning the game frame images. Second, the bot performs initial analysis to detect the game background, moving objects and potential target areas, and keeps tracking the moving objects. Third, similar to the relay attack against a text-based captcha, only one frame image is sent from the bot to the human-solver. The solver task is draw line(s) from the answer object(s) to its/their corresponding target object(s). These lines provide several clues for attacking the game: (1) The start and the end points of each line label the locations of the answer object and its corresponding target object, respectively; (2) The end portion of each line (e.g., the portion connected to the target object) can also be used as the basic entry path to the target object if straight-line paths are not workable in this game. For example, 40% of each hand-drawn dragging path (starting from the end point) is treated as the basic entry path. Therefore, an answer object can always be dragged to the start point of the entry path first, and follow the entry path to the target finally. If a complex path, is required, a curvature threshold could be defined to identify those critical turning points with curvatures larger than the threshold, which finds the key points that must be passed in turn in a new path. Finally, the above clues together with the initial analysis, i.e., background and foreground detection, will be recorded in the knowledge base. Answer objects as well as the background are represented in color code histograms. A continuous learning from the game server is required to build an up-to-date dictionary.
The attacking phase consists of the following steps (as shown in Fig. 4). The initial analysis is performed (Step 1) followed by submitting a query to the knowledge base (Step 2). If a match is found, the bot will drag an answer object from its current location provided by the real-time tracking to its corresponding target object (Step 3). The drag/drop attempt iterates until completing the game (Step 4). If a match is not found, which indicates that the game or the answer objects are completely new, the framework will learn the game as the dictionary based auto-attack framework mentioned in Section 4. Moreover, the attacking phase is converted into offline learning just in case that brute-force based learning cannot work out the puzzle.
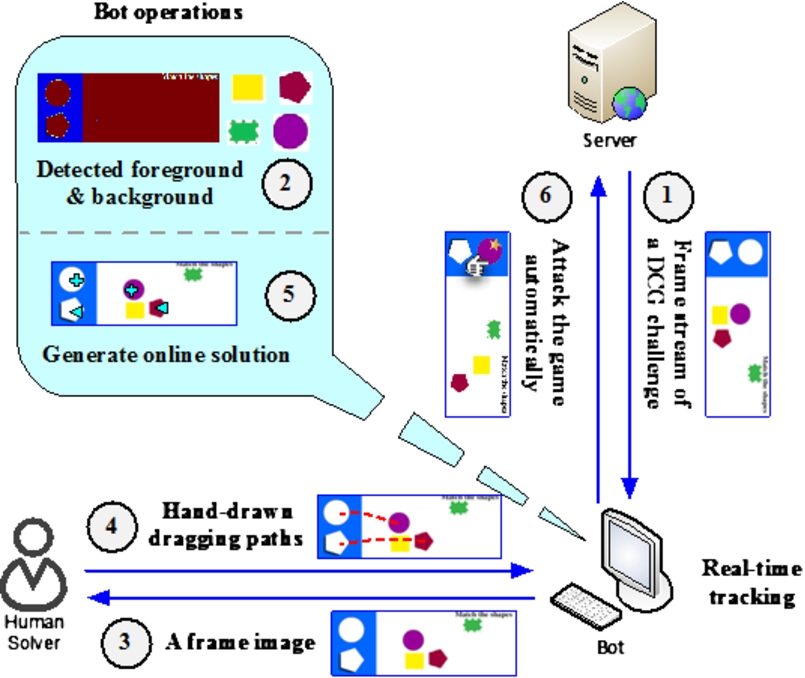
Hybrid attack model II: Auto-attack with Online human Learning.
Model II of our hybrid attack framework (Fig. 5), Auto-attack with Online human Learning (AOnL), attacks any game, seen or unseen, with the help of real-time tracking and online knowledge. Compared with AOffL, a human-solver must be available when the game starts, similar to what is required in relay attacks. Moreover, there is no knowledge base for future attacking as the remote solver provides the required knowledge in real-time.
As indicated in Fig. 5, when attacking a game challenge, the bot keeps receiving frames from the server (Step 1), and performs initial analysis (i.e., detect background and foreground) on the game without drag/drop attempts (Step 2). Meanwhile, it sends one frame image to the solver once the game starts (Step 3). The solver performs the same operation as the learning phase in AOffL (Step 4). Once the solver submits his/her responses, the bot can learn the answer objects and the dragging paths for this particular challenge based on the initial analysis and the solver’s response (Step 5), and complete the game automatically with the help of real-time tracking (Step 6). One concern in AOnL is that the success rate for completing a game relies heavily on correctness and efficiency of the solver’s response (the same concern underlies the relay attack on text-based and DCG captchas).
Study design, goal and process
In order to evaluate the performance for the users’ drawing operation and thereby the performance of our hybrid attack, we conducted a user study in which we recruited 40 MTurk workers. We asked the participants to fill a demographics form, then provide them with 4 static images that represent snapshot to the four DCG explained in Section 2.2 and asked them to draw lines from the answer object(s) to its/their corresponding target(s), the order of representing the images to the participants followed the standard
Study results
In this subsection, we will report the study results and compare them to the MTurk usability study.
Drag error rates, game error rate and completion time Hybrid attack
Drag error rates, game error rate and completion time Hybrid attack
The term captcha was first introduced in 2000 [1], describing a test that can differentiate humans from malicious computer programs. captchas are deployed by many online services, such as account registration, ticket selling, and search engines, to limit the scale of different types of attacks (e.g., denial-of-service or password dictionary attacks) involving automated bots. Most captchas are largely based on visual challenges, such as involving users to identify alphanumeric characters in distorted images, but many other variants have also been proposed [20,38].
A wide variety of captchas have been proposed over the last decade or so. The most commonly utilized captcha involves challenging the users to recognize alphanumeric characters embedded within an image, such as Gimpy, Yahoo, reCapthca [37], Baffle [10], handwritten [30] and PayPal, or within a video such as NuCaptcha and emergent captcha [38]. captchas that challenge the users to recognize or classify objects in images, such as collage captcha [32], implicit captcha [3], Asirra captcha [15], PIX, and ESP-PIX [36], have also been proposed. Some video-based captchas, such as content-based tagging of YouTube videos [23], and audio based captcha, such as Google, eBay, ReCaptcha, Slashdot and Math-function [19] audio captchas, have also been introduced.
Unfortunately, existing captcha technology suffers from several problems. The distortions that are used to hide the underlying content of a puzzle from computers can also severely degrade human usability [6,39]. Challenges based on spoken words suffer from similar issues due to sound distortion [31]. Moreover, captchas are not foolproof, and many captchas used in real-world have been successfully attacked. The task of solving captcha has been made easier by commercial solving services that attackers often utilize [27]. These services offer two categories of attacks: automated attacks and relay attacks. Automated attacks (e.g., [21,22,40]) normally utilize image processing algorithms to solve the captcha, while relay attacks [27] utilize the human intelligence of third-party, remotely located human-solvers.
Relay attack involves outsourcing the captcha solving process to human labor, either opportunistically or via sweatshops [27]. An attacker could launch a website that attracts visitors by providing some free service, and then opportunistically engage them in solving third-party captchas. Alternatively, an attacker could hire people to solve captcha and pay them a certain amount of money per successful attack. A relay attack against a text captcha, for instance, involves the attacker to forward the image that contains the captcha to a human-solver; the solver then solves the captcha in real-time, and provides the solution, which the attacker relays back to the server.
Although automated attacks seem to be a natural option to bypass the security offered by captchas, developing programs to solve captcha with human-like accuracy is often very complicated and costly [27]. In contrast, paid solvers are willing to solve as many as 1000 captchas for just $1, making relay attack an overall more attractive, effective and economical option [27]. While the traditional captcha research has focused mainly on developing, or preventing, automated captcha attacks, attackers in the wild have gone on to break existing captcha schemes via relay attacks [27].
Most, if not all, existing captchas are vulnerable to relay attacks, and do not provide a reliable mechanism to distinguish a remote human-solver from a legitimate user. Subjecting textual captchas to relay attacks is very simple – the attacker simply forwards the challenge image to the solver, who provides the response which the attacker simply forwards to the service. Effectively detecting such attacks does not seem feasible. One way to avoid them is to set a timeout for solving the captcha. However, timing alone is not a robust method for detecting an attack. A comprehensive study on captcha-solving services presented in [27] concludes that 70% of the captcha submissions are correct, and are submitted within 30 seconds, which is well within the captcha timeout set by most websites.
Attacking video captcha [38] is straightforward as well. The captcha video file can be forwarded to a human-solver. Alternatively, a new video can be created by taking multiple snapshots of the video captcha, and sent to the human-solver.
Image-based captchas require users to perform an image recognition task, e.g., selecting only the images of cats in a grid of images. This kind of captcha can also be easily attacked by relaying. The image can be transferred to a solver, and solver can send back the coordinates of the mouse clicks to the attacker. The attacker’s bot can then replicate the action performed by the solver.
The fact that most captchas are static and do not require multiple interactions from a user makes attacking them by relaying to a human-solver an easy task. DCG captcha is perhaps the first step towards creating interactive and dynamic captcha capable of defeating relay attacks. A commercial implementation of DCG captcha, called “are you a human,” [2] is also available.
Conclusions and future work
We investigated the security and usability of game-oriented captchas in general and DCG captchas in particular. Our overall findings are mixed. On the positive side, our results suggest that DCG captchas, unlike other known captchas, offer some level of resistance to relay attacks. We believe this to be a primary advantage of these captchas, given that other captchas offer no relay attack resistance at all. Furthermore, the studied representative DCG captcha category demonstrated high usability. On the negative side, however, we have also shown this category to be vulnerable to a dictionary-based automated attack and hybrid attacks.
An immediate consequence from our study is that further research on DCG captchas could concentrate on making these captchas better resistant to automated attacks while maintaining a good level of usability. One of the main weaknesses of the DCG captcha instances is that the underlying game background is static, which is utilized by our attack framework to extract the foreground objects from the game frames thereby undermining the captcha security. One direction to remedy this problem is to design DCG captchas variations that incorporate different forms of dynamic background. The variations design may involve random noises, objects with dynamically changing color and luminance, object occlusion, and dynamically changing background, and combinations thereof. Such variations would resist our proposed attack, however they may be prune to other more sophisticated attacks as well they may have low level of usability. Further work is needed to investigate the security as well as the usability of such variations.
Further study is also needed to find the best/optimal method for selecting the moving and target objects. For example, an attack can be developed on the challenges that is based on shape matching that can solve the challenges by finding the similarities between the moving and target objects, and then for each of the target objects the moving object with highest similarity could be considered to be its corresponding answer object.
Footnotes
Acknowledgments
We thank: the team of “are you a human” for creating the CAPTCHAs that inspired our work; Wei-Bang Chen for his help in the implementation of the automated-attack framework; John Grimes, John Sloan and Anthony Skjellum for guiding us regarding the ethical aspects of our work; Sonia Chiasson, Fabian Monrose and Gerardo Reynaga regarding early discussions; and various members of the SPIES group at UAB and PreCog group at IIITD for helpful suggestions throughout the study. The work of Mohamed, Georgescu, Gao and Saxena is partially supported by a grant on “Playful Security” from the National Science Foundation CNS-1255919. Van Oorschot holds the Canada Research Chair in Authentication and Computer Security and acknowledges NSERC for funding the chair and a Discovery Grant.