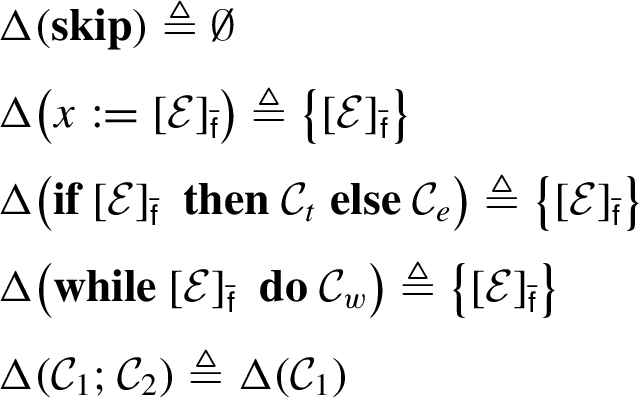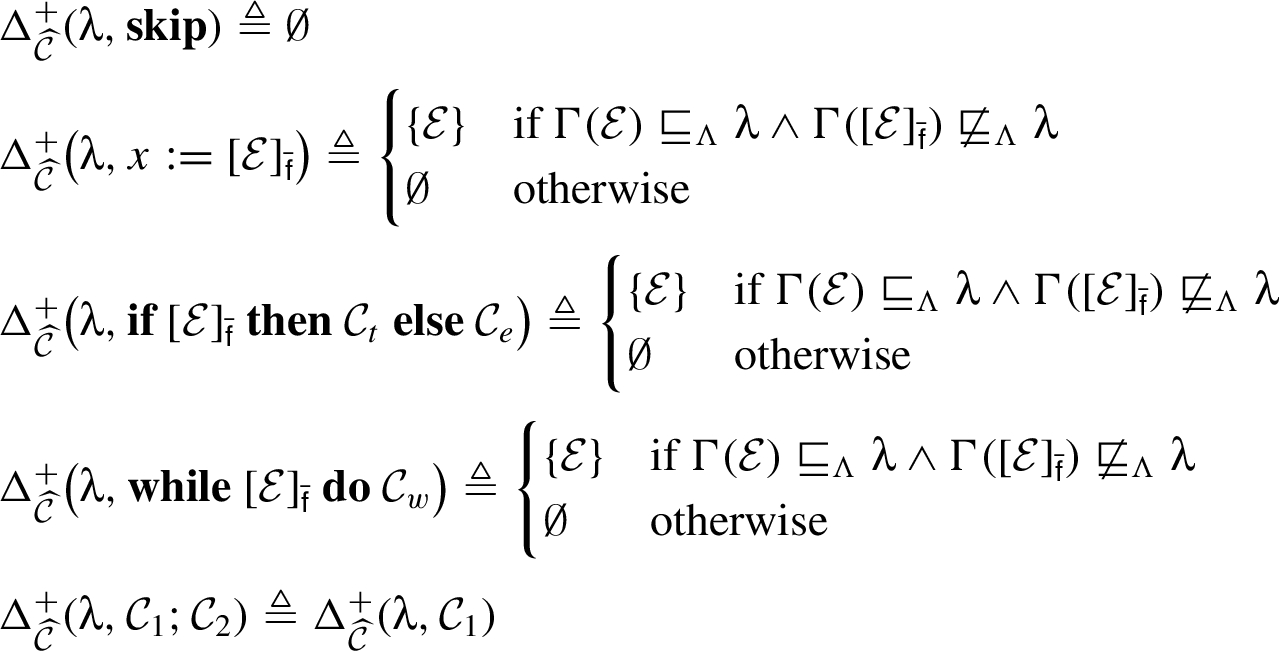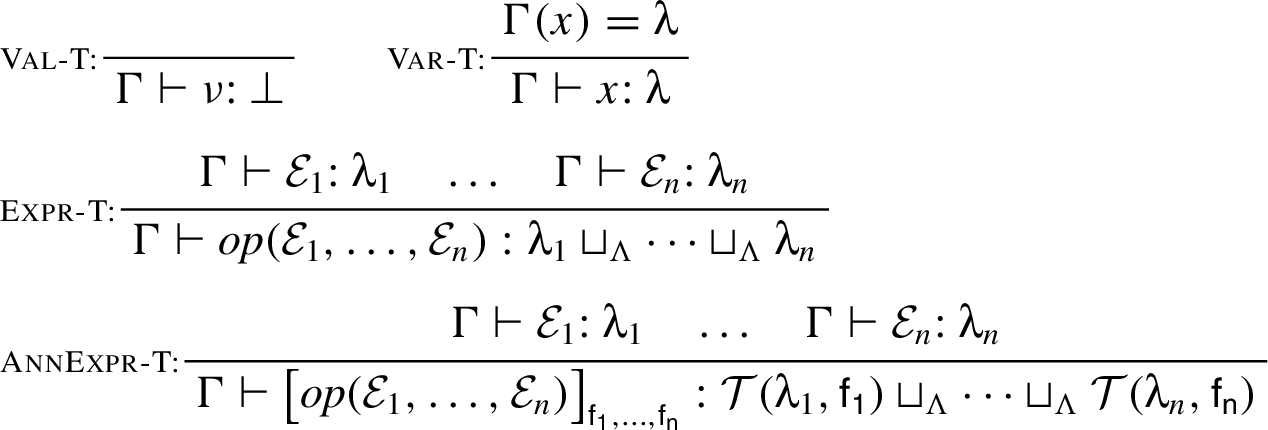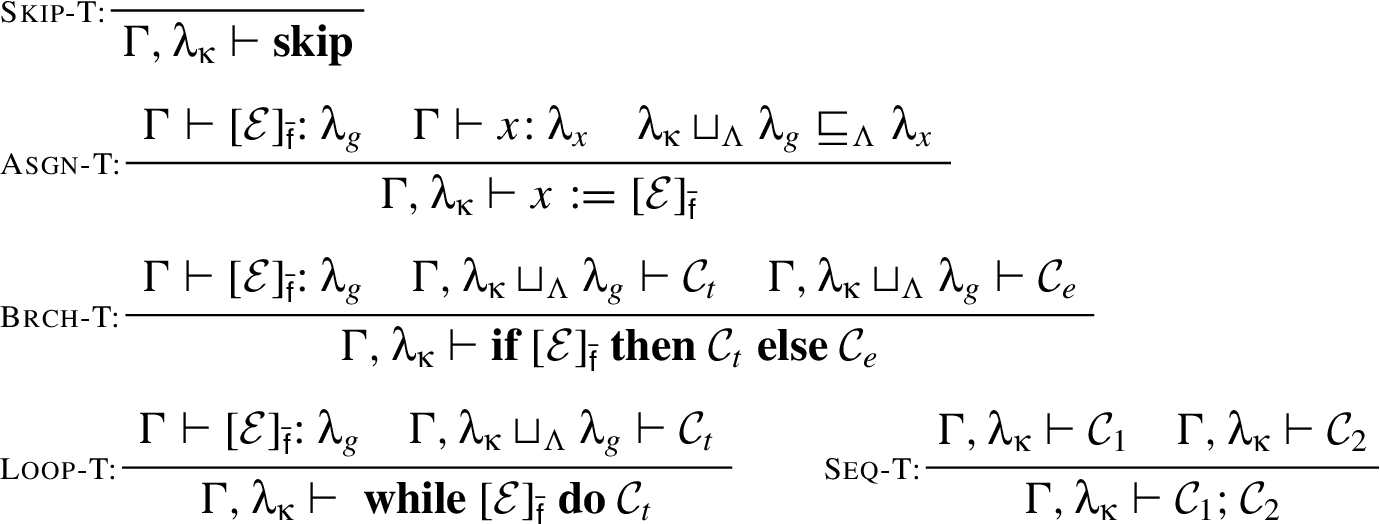Restrictions that a reactive information flow (RIF) label imposes on a value are determined by the sequence of operations used to derive that value. This allows declassification, endorsement, and other forms of reclassification to be supported in a uniform way. Piecewise noninterference (PWNI) is introduced as a fitting security policy, because noninterference is not suitable. A type system is given for static enforcement of PWNI in programs that associate checkable classes of RIF labels with variables. Two checkable classes of RIF labels are described: RIF automata are general-purpose and based on finite-state automata; κ-labels concern confidentiality in programs that use cryptographic operations.
Data is usually accompanied by restrictions about uses. Information flow control [50] has been employed to ensure those restrictions propagate from inputs to the outputs of operations. In Denning’s initial work [21] and in much that has followed – both for confidentiality and integrity – the set of restrictions assigned to the output of an operation is the union of the restrictions associated with its inputs. But by ignoring the operator and the values of inputs, that approach can be too conservative.
The most general formulation of flow-derived restrictions would assign restrictions to the output of an operation according to operator , its inputs , and the restrictions associated with those inputs. That output might warrant fewer restrictions, additional restrictions, or an incomparable set of restrictions than are associated with its inputs.
With an operation that computes the winner of an election, the inputs are votes and the output is the majority. Each input is secret to the principal casting that vote, whereas the output ought to be readable by any principal. So the output should be associated with fewer restrictions than the inputs.
A conference-management system matches papers to reviewers, where that matching is generated by a non-deterministic computation. The inputs – a list of reviewers and a list of submissions – can be read by the entire program committee, but conflicts of interest dictate that only a subset of the program committee learn which reviewers are assigned to any given paper. So, as with other aggregation problems [31], outputs are associated with more stringent restrictions than inputs.
Previous work on information flow control – declassification and erasure policies [16], information flow locks [10,11], typed declassification [24], expressions for declassification (for confidentiality) and endorsement (for integrity) [44,46], and capability-based mechanisms for downgrading security policies [35,49,56] – does not support arbitrary changes in restrictions linked with specific operations. Other approaches (e.g., [30,40,47,48,53]) allow such changes but only between two levels of labels (e.g., public and secret).
Reactive information flow (RIF) labels, which we introduce in §2, seek to address these limitations by allowing stronger, weaker, or incomparable restrictions to be associated with the output of an operation, as determined by the operator and the restrictions on inputs. Piecewise noninterference (PWNI) described in §4 then extends classical noninterference in a way that handles changes to restrictions that RIF labels support. Using terminology introduced by Sabelfeld and Sands [53], PWNI stipulates for programs that associate RIF labels with variables, what information undergoes changes of restrictions and where in the program code. A type system is given in §5 to support static enforcement of PWNI for certain classes of RIF labels. Examples of those classes include RIF automata in §3 and κ-labels in §6. In §7 we discuss how previous work relates to RIF labels and PWNI.
RIF labels
Restrictions. Restrictions are assumed to be elements of a join semilattice .1
A partial order would suffice for the theory of RIF labels developed in this section. A join semilattice becomes useful for certain instantiations of RIF labels, as illustrated in §3 and §6.
For confidentiality, an element of R might identify which principals are allowed to read some value, either by enumerating that set of principals or by giving the name (e.g., public, secret, etc.) for such a set; for integrity, it might identify the set of principals allowed to write that value. But other kinds of restrictions also could be specified using elements in R – use-based privacy [9] is an example.
Relation is satisfied if compliance with restrictions implies compliance with restrictions , so is at least as strong as r or, equivalently, r is at least as weak as . When elements of R denote sets of principals, then for confidentiality we would define to be and define to hold if and only if holds – if allows a principal to read then so does r, but r might also allow other principals to read, too. And, for integrity, we would define to be and define to hold if and only if holds.
Reclassifiers and RIF labels. A reclassifier abstracts how an operation changes the restrictions for an argument.2
The term reclassify is taken from Denning’s thesis [21] where it is used to describe an operation that changes the restrictions imposed on objects.
To associate reclassifiers with operations, we extend a language that defines ordinary expressions: variables and terms , where is an operator and each is an ordinary expression. For ordinary expressions ,
defines a reclassifying expression. It specifies that reclassifier identifies how the restrictions associated with the value of ordinary expression should be changed for constructing the restrictions associated with the value produced by . Notation is used as a shorthand for , and we sometimes abbreviate by or simply if the elided specifics are irrelevant. By convention, the identity reclassifier ϵ causes no changes to restrictions.
When reclassifying expressions are used to compute values, then sequences of reclassifiers offer abstract descriptions for the series of operations that have been applied to values as program execution proceeds. Such a sequence of reclassifiers then provides a basis for determining the set of restrictions associated with a computed value. For example, consider the following program.
Here, restrictions on the value stored in are derived from:
the restrictions on the value stored in and in , changed according to sequence because each of these values flows to through , then flows to through , and finally flows to through .
the restrictions on the value stored in , changed according to sequence , and
the restrictions on the values stored in and , changed according to .
A RIF label λ specifies a set of restrictions for an associated value v as well as for values derived by executing operations on v. Formally, a RIF label maps sequences of reclassifiers to elements of underlying join semilattice of restrictions. This mapping is specified for a set Λ of RIF labels by giving a set of reclassifiers along with two functions and .
maps to the restriction that λ currently imposes:
maps and each reclassifier to a RIF label that should be associated with the value produced by an operation abstracts:
As an example, the restrictions associated with the value of a reclassifying expression (1) will incorporate restrictions derived from RIF label being associated with the value of expression . Note that RIF labels λ and might have and – which makes having indirection between λ and useful.
As is conventional, denotes the set of finite sequences of elements in .
of reclassifiers in the usual way, with identity reclassifier ϵ considered an element of every set of reclassifiers.
Classes of RIF labels. A class of RIF labels can serve as the basis for a join semilattice , where the cardinality of Λ can be infinite. The join operator is used for combining RIF labels; the restrictiveness relation specifies whether one RIF label is at least as restrictive as another. We posit that Λ includes elements ⊥ and ⊤ such that for all : and hold.
Since, by definition, and hold in a join semilattice, a combination of RIF labels is at least as restrictive as any of its constituents. For the examples of RIF labels in this paper, and are related in a way that ensures restrictions imposed by are the same as the combined restrictions imposed by individual RIF labels λ and .4
Reasonable examples of RIF labels do exist where (7) does not hold.
The definition of restrictiveness relation depends on partial order for set R of restrictions, , and :
This definition ensures that if holds, then
current restrictions specified by are at least as strong as what λ imposes because, by definition, and thus , and hold, so (8) implies that , and
restrictions that imposes for any derived value are at least as strong as what λ imposes – if v flows to w then there is a sequence that v flows through, and (8) requires that hold.
The quantification over all sequences in (8) means that this definition for is conservative, since it imposes conditions for sequences of reclassifiers that never arise in a program execution.
Terminology for reclassifications.
(RIF Class).
A class of RIF labels is formed as follows:
The definition of a RIF class is silent about the existence of algorithms for computing or for deciding . We say that a RIF class is checkable if and only if:
There exists an algorithm for computing for all .
There exists a sound, if not complete, test for determining whether holds for all .
The type system we give in §5 is decidable if its RIF labels are from a checkable class.
Reclassifications. A reclassifier triggers a reclassification in a RIF label λ, if holds. In the literature, reclassification is categorized based on the restrictions that new and old labels impose – specifically, whether is weaker than . Figure 1 defines specialized terminology for this categorization, where gives a set of principals that must be trusted not to divulge the value (for confidentiality) or not to have corrupted the value (for integrity). So, according to Fig. 1, reclassifier triggers a declassification if the principals trusted not to divulge the value by the new label (i.e., ) are a superset of those trusted by the old label (i.e., λ); if they are a subset, then triggers a classification. Also, reclassifier triggers an endorsement when the principals trusted not to have corrupted the value by the new label (i.e., ) are a subset of those trusted by the old label (i.e., λ); if they are a superset, then triggers a deprecation.
The approach in this paper, however, involves a finer-grained categorization of reclassifications. That categorization is based on how a new RIF label is related to the old RIF label λ: When holds then we say that triggers a downgrade; when holds then we say that triggers an upgrade. And the reclassifying expressions that appear in a program in conjunction with the RIF labels that tag variables in these expressions, specify what information is being reclassified and where in the program. In particular, given a reclassifying expression at a particular program point, if the RIF label of is different from the RIF label of , then triggers a reclassification: The what dimension of this reclassification is the current value of , and the where dimension is that particular program point (i.e., code locality is employed).
The RIF label for ordinary and reclassifying expressions are deduced as usual from the RIF labels of the variables that appear in those expressions. Starting from a fixed mapping Γ that associates a RIF label with each variable x, define:
Thus, the RIF label associated with a reclassifying expression combines RIF labels obtained after the indicated transitions have been performed.
We give a concrete example of reclassification using program (2) and assuming that the following restrictiveness relation holds:
So reclassifier triggers a downgrade. For the what dimension, the value to be downgraded is the result of applying to the values stored in and at program point “; ” – as opposed to the values stored in and at initialization. For the where dimension: the value of is downgraded at that program point – not earlier. A formal characterization for the security policy satisfied by a program that employs RIF labels and reclassifying expressions is given in §4.
RIF automata
Finite state automata provide the basis for a checkable class of RIF labels, called RIF automata, that have broad practical utility. This class of RIF labels is supported in the JRIF5
JRIF is a variant of the Jif security-typed programming language, which extends Java with support for information flow control.
programming language [34]. We built JRIF to gain practical experience with using RIF automata for specifying security policies and to understand the compiler modifications needed when a programming language that supports ordinary security label types is converted to use RIF automata. The privacy automata used in the Avanance language [9] for specifying use-based privacy are also instances of RIF automata.
Formalization of RIF automata. A finite state automaton can serve as a RIF label by: (i) having the set of reclassifiers be the automaton’s input alphabet, and (ii) associating restrictions with each automaton state. Restrictions imposed by are those associated with the automaton’s current state. Reclassifiers change the automaton’s current state. Thus they cause a (potentially) different set of restrictions to be imposed.
A set comprising RIF automata is defined relative to some join semilattice of restrictions . Each RIF automaton is described by a 5-tuple
where:
Closure is obtained from in the usual way: and .
We require transition function to be total, so any sequence of reclassifiers from causes a sequence of transitions. And for we write to denote the automaton that results when performs the transitions indicated by a sequence of reclassifiers. Automaton thus replaces current state of with ; we define formally by:
and are defined as expected.
Instantiating definition (8) of using these definitions gets:
A computable test for deciding is now given. It is based on constructing a restrictiveness product automaton that is the product of RIF automata and but with unreachable automaton states eliminated.
Restrictiveness product automata are not RIF automata because the signature for in is
whereas a RIF automaton would have to associate a single element of R (rather than a pair of elements) with each automaton state.
Condition (13), which stipulates that all states in are reachable, is straightforward to check with a linear-time depth-first search of the state-transition graph for . And condition (13) implies that for any predicate on states
holds. Therefore a decision procedure for need only check a predicate on the pair of restrictions associated with each state – namely that holds if .
To prove that (15) is equivalent to definition (12) of , observe that
The properties of for RIF automata are satisfied by using a form of product construction that does yield a RIF automaton.
Note that (7) relating and is satisfied by this definition.
Finally, we prove in the Appendix A that is a join semilattice.
RIF automaton for secret ballots.
Examples of RIF automata. A security policy we might associate with the ballot that each participant A casts in an election is: (i) only A may read the ballot’s value and (ii) anyone may read the majority value derived from all of the ballots cast. We formalize this security policy as a RIF automaton , where is the set of principals eligible to learn the election outcome, the join semilattice of underlying restrictions is , and set of reclassifiers includes , which will be associated with calculating the election outcome.
A conventional graphical representation for finite-state automata is used. Circles denote states of the automaton. Arrows between states are labeled with lists of reclassifiers, any of which can trigger the allowed transitions. We will write * to abbreviate the list of all reclassifiers and to denote a list of all reclassifiers not contained in list ℓ. The label inside each state q indicates associated restrictions , and the grey-filled state indicates the current automaton state.
of ; the formal definition is:
Restriction defines which principals can read the value being labeled by :
the value may be read only by A if is in state , because , and
any value derived by using a operation may be read by any principal, because the current state transitions to and hold.
Thus, according to the terminology of Fig. 1, causes declassification.
A programmer would use reclassifying expression to assert that computing the majority of votes in implements the intended effect of a operation. That derived value can be stored in a variable whose RIF label imposes no restriction on readers. Assignment
has exactly that effect if the RIF automaton associated with each variable is in state , and the RIF automaton associated with variable is at least as restrictive as
which happens to be equivalent to for any .
RIF automaton of document excerpting.
A second example sketches RIF automata that enforce integrity policies for a document management system.8
Given is a set of original documents; these are trusted by all principals for all purposes. Operation derives a new document by excerpting from document D according to . Because “creative” excerpting can be used to generate a document that has different meaning from the original, cautious principals should hesitate to use such derived documents for certain purposes. Using the terminology of Fig. 1, excerpting causes deprecation.
One RIF automaton for supporting such a policy might employ a join semilattice of underlying restrictions , where holds; these restrictions indicate whether a document is trusted for all purposes or for limited purposes. would employ a set of reclassifiers that includes , which will correspond to excerpting operations. And would have two automaton states, where:
Figure 3 gives a graphic depiction for a RIF automaton associated with an original document D; the formal definition of is:
RIF automaton would be associated with any document produced by excerpting from D.
Some applications might require a more refined basis for deciding whether a document should be trusted for a specific purpose. One obvious basis for making such trust assessments is the set of principals participating in the document’s derivation. A RIF automaton can specify such policies. There would be an automaton state for each set S of principals corresponding to a subset of . And restrictions being associated with an automaton state would depend on members of S. So the join semilattice of underlying restrictions is . Transitions are facilitated by having a set of reclassifiers contain an element for each principal p that invokes an excerpting operation. Here is the formal definition of an automaton that is associated with a document D that some principal has written:
A security policy for RIF labels
Our security policy for programs that use RIF labels is obtained by extending termination-insensitive noninterference (TINI) [52]. TINI applies to programs comprising deterministic commands, so execution of a command that is started in a memory and terminates in a memory can be described by giving a finite trace
where each state gives a command and a memory . We write ∙ in the final state of a trace to signify further execution is not possible, but ∙ is not considered a command. Thus the trace for a terminating command includes at least two states: one state having command followed by one having ∙.
Memories are represented by functions that map variables x appearing in any command to values . These functions are then extended as usual for mapping ordinary expressions and reclassifying expressions.
An operational semantics for command execution can be given by a partial function Υ, where returns the finite trace corresponding to an execution of that terminates when started in memory , and is undefined if that execution does not terminate.
Observations as a threat model
A mapping Γ, which associates variables with RIF labels, induces equivalence classes of memories that agree on the values in variables allowed to flow to :
where is the domain of a memory .
Our threat model is intended for analyzing systems in which principals are co-resident and able to detect changes (subject to restrictions defined by RIF labels) being made to shared memory or other resources. We formalize this threat model relative to λ by constructing an observation
for each transition that occurs. So observation gives the new value for each variable that was (i) changed by the transition and (ii) has a RIF label at most λ. It is easy to show:
For a RIF label λ, program execution described by a trace τ results in a sequence9
A formal definition of is thus given by the following, where ⇁ is used to delimit observations in the resulting sequence.
of non-empty observations that are derived from the successive transitions in τ, and it induces an equivalence relation on traces
Sequences of observations are the basis for our threat model. Each principal p is assigned a set of restrictions. The threat model stipulates that a principal p sees changes to any variable x satisfying . Thus, principal p sees those sequences of observations where holds.
Piecewise noninterference
In the absence of reclassifications, an illicit λ-flow is witnessed when executing a command in states having different values of a variable with RIF label satisfying results in differences in updates to any variable with RIF label λ or less restrictive. TINI prohibits illicit λ-flows for any join semilattice. To formalize an extension to TINI for accommodating reclassification under our threat model, we require some notation. For τ a non-empty finite trace or subtrace,
and indices i and j satisfying , define
In addition, we write as an abbreviation for and write for . It is convenient to define , , , , and as equivalent to ϵ when does not hold.
We start by formalizing prohibition of illicit λ-flows for commands that do not contain reclassifying expressions. By definition, an illicit λ-flow is not present if executing in memories and satisfying does not result in different updates to a variable that has a RIF label λ or less restrictive.
where
When is then τ and exhibit the illicit λ-flow.
Reclassification. Each transition in a trace involves evaluating some (possibly empty) set of expressions. The operational semantics of commands determines what those expressions are and how their values are computed. We posit that the operational semantics for each command also includes a function that gives the set of reclassifying expressions that command evaluates as part of its first transition.
For example, with a simple imperative programming language and ordinary expressions and we might expect to have
if we are assuming that assignments are executed as a single transition and that an if statement involves a first transition to evaluate its Boolean guard followed by other transitions for the then (or else) parts.
Handling downgrades. A reclassifying expression is considered to perform a λ-downgrade if and hold. The set of expressions that satisfy the definition of a λ-downgrade and are evaluated by to make its transition is given by:
To define our security policy for programs independent of specific programming constructs, we posit that the language semantics includes a function10
The subscript in enables this function to depend on an enclosing program and/or the position of within . For example, the language semantics might omit from if that assignment appears in the scope of an if having a Boolean guard , where holds.
that satisfies:
If holds, then is the reference point11
See [41] for a thorough study of reference points for declassification.
for the corresponding λ-downgrade . The reference point signifies where in program this λ-downgrade is performed and what information is being λ-downgraded – the evaluation of at that program point .
Notice that, by definition, assigning the value of an expression in to a variable having RIF label λ does not constitute an illicit λ-flow. So characterizes illicit λ-flows that have been eliminated by fiat. Trade-offs associated with selecting the content of are discussed at the end of this section.
A generalization of (18) suffices to accommodate λ-downgrades that occur in the first transition of a trace that results from executing command . was defined above in terms of updates to any variable x satisfying . But differences in updates to x that arise when expressions in have different values are, by definition, not considered illicit λ-flows. Therefore, initial memory pairs and that cause expressions in to have different values should be ignored in checking for indistinguishable observations [51]:
where
By construction in (23), and hold. Therefore and
hold too. Thus, ignoring downgraded expressions in the first transition of trace τ (i.e., elements of ), is also ignoring downgraded expressions in the first transition of trace (i.e., elements of ).
To handle traces that perform λ-downgrades after the first transition in , we partition traces into consecutive subtraces starting with transitions that are λ-downgrades. These subtraces are called λ-pieces. To formalize, we introduce operators and . Subtrace is the initial λ-piece of trace τ and subtrace is the rest. Thus, and satisfy the following two properties, for traces and subtraces τ satisfying .
Trace τ splits at a λ-downgrade into and :
There is no λ-downgrade after the first transition within λ-piece :
Here is a schematic representation of and :
Notice that by repeatedly isolating the first λ-piece of the remainder, a trace τ is partitioned into consecutive λ-pieces.
Two λ-pieces and are witnesses of an illicit λ-flow if executing the same command in memories and that satisfy and agree on values of expressions that have already been λ-downgraded, leads to having (i) different commands in their last states, and/or (ii) different updates to a variable x where holds. This is because (i) implies that the next λ-downgrades that are reached by these two λ-pieces are not found at the same program point. So, the reference point of these λ-downgrades is being compromised since it depends on information that is not allowed to flow to λ. When (ii) occurs, updates to x have been compromised because they are influenced by information that is not allowed to flow to λ. In sum, (i) and (ii) expose compromises of what is allowed to flow to λ and where in the program.
In this paper, we avoid these compromises to (i) and (ii) by rejecting certain pairs of λ-pieces and :
By iterating through successive corresponding λ-pieces in two traces τ and , the following formula uses the approach embodied by (27) to identify λ-pieces that evidence an illicit λ-flow and thus provides the formal guarantee associated with downgrades.
().
Notice, if traces τ and each are a single λ-piece (i.e., and for all λ) then is equivalent to (27), since in the consequent of (28) would be , which trivially holds.
A characterization similar to (23) now handles downgrades that appear anywhere in traces that result from executing a command .
Downgrade examples. Some example programs illustrate nuances of (29). These programs use RIF labels with and reclassifiers satisfying and . Assume that and .
The first example program assigns in a value with RIF label to a variable with RIF label without use of a reclassifying expression and, thus, would seem to exhibit an illicit -flow.
Traces for program (30) comprise two -pieces.12
Each trace is also a single -piece. For that case, holds because is equivalent to . The same applies to example programs (31) and (32) to come.
One -piece starts with command , and the other -piece starts with command (and includes ), due to the following.
Checking, we find (29) is satisfied despite our earlier premonition about . A close look shows why the flow to in assignment actually ought to be allowed, as characterization (29) does: is assigning an -downgraded value, since the value of in the right hand side of was an -downgraded value in and has not been changed since and constant 1 imposes no additional restrictions.
Program (30) highlights a difference in how downgrades are treated by PWNI as compared with proposals using memory-reset (e.g., [13]). Under PWNI, a downgraded value remains so for the remainder of the trace; with memory-reset, a downgraded value remains so only until the next reclassification operation. So, program (30) would be considered to exhibit a leak according to the memory-reset approach. Gradual release [3], which does not rely on memory-reset, deems program (30) secure, like PWNI does.
A second example program changes in the value in after the -downgrade in .
Traces for (31) comprise a single -piece that starts with command because:
Program (31) does not satisfy (29), because traces τ and exist that generate observations that are not (but should be) indistinguishable. This is because there exist memories and satisfying and . When alternative executions of are started in these two memories, generates different updates to . And having (29) not satisfied for this program is what we should desire – the value in when executes is not the value that was -downgraded, so in program (31) a value with RIF label that has not been -downgraded is being used to update a variable with RIF label .
We also have examined with respect to downgrades for the examples used by Askarov and Sabelfeld [4] when discussing localized delimited release. Both and localized delimited release yield the same judgments for these examples, although in general the two policies are incomparable.
A final program illustrates the role of conjunct in the consequent of .
Consider traces and , where the following hold: , , and . Trace τ comprises a first -piece that starts with (and includes ), followed by a second -piece that starts with ; trace has a first -piece that starts with (and includes ), followed by a second -piece that starts with :
Program (32) does not satisfy (29) because both and hold, so conjunct in the consequent of does not hold. And having (29) not satisfied is what we should desire, because the choice of or leaks information about the value of to .
Instead of command equality (i.e., ), we could have extended the bisimulation used in [4] to handle downgrades of arbitrary expressions during execution. However, with this bisimulation, we would risk accepting insecure programs. This is because this bisimulation does not seem to set intermediate reference points for the downgrades. For example, consider program (32), which is insecure. A bisimulation that supports downgrades with reference points on intermediate states would accept the program as secure. The case to consider concerns the execution steps and , where . Adapting the bisimulation definition in [4] to support downgrades with reference points on intermediate states, these two execution steps constitute a bisimulation if
iff , and
if , then and states , are bisimilar.
Condition (i) holds because, for any such reachable memories and , both equalities are false. Because these equalities are false, condition (ii) is vacuously true. So these execution steps are (vacuously) bisimulations, and thus this insecure program is accepted as secure. Another form of bisimulation might fare better, but we have not found one.
Handling upgrades. A reclassifying expression is considered to perform a λ-upgrade if and hold. Characterization (29) does not detect illicit λ-flows caused by λ-upgrades. Consider, for example, a program comprising assignment
that uses RIF labels from . Assuming and hold, this program satisfies (29). Yet the program exhibits an illicit -flow: differences in the initial value of an -upgraded expression () with RIF label result in differences in updates to a variable () with RIF label where holds.
In checking for evidence of illicit λ-flows, (29) compares traces τ and that differ in initial values of variables whose RIF labels satisfy . That set of comparisons covers some expressions whose RIF labels satisfy but it does not cover all expressions – it ignores expressions that involve λ-upgrades.
A programming language that supports RIF labels will provide syntax that allows programmers to specify λ-upgrades by using reclassifying expressions. To be independent of language constructs, we posit that the language semantics includes a function that satisfies:
So contains all expressions that satisfy the definition of a λ-upgrade and are evaluated by (within ) to make its transition.
Since (29) correctly identifies illicit λ-flows from variables x for which holds, we transform λ-upgraded expressions to such variables as a way to identify illicit λ-flows for λ-upgraded expressions. Define translation to be the command that results from, in every subcommand of , substituting an expression for every expression where and hold.13
See (36) and (37) below for an example of the translation.
Here, is a fresh variable that stores a list of values that could assume, and successive evaluations of return successive elements of that list. If a program exhibits an illicit λ-flow from a λ-upgraded expression then, by construction, exhibits an illicit λ-flow from . Moreover, because contains no λ-upgraded expressions, it exhibits no illicit λ-flows from upgraded λ-expressions per se. That means we can use (29) to check for illicit λ-flows in by checking for illicit λ-flows. A formal definition of can be found in the Appendix B.
The resulting characterization of piecewise noninterference (PWNI) for a program employs – defined in (28) – by extending (29) to handle λ-flows from λ-upgraded expressions.
(Piecewise Noninterference).
The election example and the conference-management example of §1 both satisfy this definition when coded in a straightforward manner.
Upgrade examples. as defined in (35) considers executions of a translation in which -upgraded expressions are replaced by different fresh variables . So, equivalent expressions within an execution and in different executions of the original program may take different values in executions of the translation. Here is an illustration, where RIF labels are from .
creates translated program ,
where holds. Boolean guard in (36) is always , so execution of (36) produces no traces in which executes. In translated program (37), Boolean guard takes values and , so there are traces of (37) where executes as well as traces where executes. Thus, is not satisfied for (37) due to the illicit -flow from upgraded expression to , even though in program (36) upgraded expression never actually flows to . One way to circumvent this conservatism is to restrict the set of values that a fresh variable can take. In particular, that set can be limited to containing values that the upgrading expression can take during program execution.
Assessing PWNI. Whether a program satisfies depends, in part, on flexibility that (22) allows in the definition of and that (34) allows in the definition of .
is constrained only by (22), so may omit expressions that cause λ-downgrades. With fewer expressions in :
There are more pairs of memories from which execution results in a pair of λ-pieces whose subtraces and must satisfy (27). So the omissions may cause to reject programs that do not actually exhibit illicit λ-flows.
Fewer λ-pieces need to be checked by evaluating . So the omissions may cause to accept more programs that do not exhibit illicit λ-flows.
is constrained only by (34), so may include expressions that do not cause λ-upgrades. The additional expressions are replaced in each by expressions involving list . That means there could be more pairs of memories (i.e., those that differ in ) from which execution results in a pair of λ-pieces whose subtraces and must satisfy (27). So the additions may cause to reject programs that do not exhibit illicit λ-flows.
Absent a widely accepted semantic definition for information flow in the presence of reclassifications – and none has yet appeared in the literature – examples must suffice as a starting point for any discussion of whether definitions being given for and are sensible.
The larger question is whether PWNI constitutes a reasonable approach to defining secure programs when reclassifications are possible, independent of the specific choices for and . Here, besides considering various examples, the declassification principles described in Sabelfeld and Sand [53] offer criteria for evaluation. The principles are:
Conservativity: In programs that do not involve reclassification, satisfying PWNI implies satisfying noninterference. Thus, PWNI satisfies conservativity.
Non-occlusion: PWNI satisfies non-occlusion because declassifications do not allow other secret values to be leaked. The syntactic equality on commands at the end of λ-pieces, which some might find too conservative, is here seen as ensuring PWNI satisfies non-occlusion.
Semantic Consistency: PWNI does not satisfy semantic consistency. Transformation of a declassification-free program in a semantics-preserving way might not preserve PWNI. However, we know of no policy that satisfies semantic consistency and also (i) specifies a where dimension for downgrades, (ii) has the capability to allow downgrades of expressions in the midst of the computation (rather than restricting downgrades to initial values), (iii) does not employ memory-reset (which was already shown problematic for program (30) above), and (iv) satisfies Conservativity and Non-occulusion. An interesting open research problem is to determine whether (i)–(iv) necessarily implies that semantic consistency cannot be satisfied.
Monotonicity of Release: PWNI does not satisfy monotonicity of release, because adding declassification annotations might render a secure program insecure. The example used in [4], which shows that localized delimited release does not satisfy monotonicity of release, applies to PWNI as well.
Static enforcement of PWNI
Type-checking allows static enforcement of when is written in a programming language having a type system based on some checkable class of RIF labels. A simple imperative language provides a vehicle for demonstration.
Language and semantics. Fig. 4 gives a syntax of a simple programming language for defining commands. There, ν ranges over constants, x ranges over program variables, range over ordinary expressions, and range over commands. Note, allowing only reclassifying expressions (rather than ordinary expressions) in the language syntax for commands is not a limitation – due to (5), identity reclassifier ϵ is handled by every RIF label and reclassifying expression has the same value and RIF label as ordinary expression .
Syntax of simple imperative language.
Operational semantics.
Figure 5 gives an operational semantics for the programming language of Fig. 4. We write there to denote a mapping that is identical to except . The rules in Fig. 5 define partial function .
The final part of the semantics for this programming language is definitions for , , and . These are given in Fig. 6 through Fig. 8. In defining , we write to denote the set of target variables in assignments appearing in a command .
excludes λ-downgrades that cannot influence the value being assigned to a variable x where holds. No illicit λ-flow is possible without such an assignment.
for and is the smallest set that satisfies (34). To exclude λ-upgrade guards because an assignment does not appear in the body of an or (as done in the definition of ) would invalidate (34) by decreasing the size of .
Definition of .
Definition of .
Definition of .
Typing rules for expressions.
Typing rules. Fig. 9 gives rules to associate a type with each expression. The rules for ordinary expressions are standard. instantiates (9); is based on (10).
Figure 10 shows the familiar rules to deduce whether a command is type-correct. Judgment signifies that a command is type correct. Parameter in these rules is called pc-label. It is used in checking for implicit flows. A pc-label associates a type with the conjunction of the guards for all of the enclosing conditional commands; is combined with the type of the right hand side of an assignment statement.
Typing rules for commands.
The following theorem states that if a program is type correct, then this program satisfies PWNI.
It was not a coincidence that we could enforce our expressive RIF labels by adapting a type system like the one used in Volpano et al. [59]. The type system in [59] can enforce any set of labels that form a join semi-lattice, and RIF labels form a join semi-lattice. In general, any enforcement mechanism that enforces noninterference for traditional label lattices, should be easily extendable to enforce piecewise noninterference for RIF labels, since piecewise noninterference is the conjunction of noninterference for successive λ-pieces of execution.
κ-Labels: Illustrating leverage from type-checking RIF labels
Although RIF automata are a checkable class of RIF labels, they are not expressive enough to specify allowed flows of information in the presence of cryptographic operations. In this section we give another example of a checkable class of RIF labels: κ-labels. Programs written in terms of a type system based on κ-labels can be checked by a compiler in order to get assurance that a value v flows to only if principals authorized to read are (i) authorized to read v or (ii) unable to reverse some cryptographic operation used in generating from v. So the type system allows us to conclude that encryptions and decryptions are successfully keeping secrets. Our modelling of cryptographic operations follows the symbolic formulation of Dolev and Yao [22].14
Notice that we do not consider a Dovel–Yao attacker. Our threat model is the one defined in Section 4.1.
The starting point for defining allowed flows based on κ-labels is mapping to sets of principals from variables and from cryprographic keys.
is the set of principals allowed to know the initial value of variable x.
is the set of principals allowed to know the value of cryptographic key k, which is considered a constant.
Reclassifiers for κ-labels are associated with cryptographic operations, and rewrite rules for sequences of reclassifiers characterize when cryptographic operations are inverses. Different cryptosystems and cryptographic operations give rise to different reclassifiers along with different sets of rewrite rules.
κ-Atoms. A κ-atom for a value to which v has flowed is a pair , where gives the sequence of cryptographic operations involved in deriving from v, and is a set of principals authorized to read v. Let denote the set of κ-atoms. Reclassifier is associated with a cryptographic operation 𝜃 whose invocation has in its list of arguments, which may be cryptographic keys or other expressions.
A rewrite rule will have form
where and are reclassifiers. This rewrite rule defines to be the complement of and allows appearances of “” to be deleted in a sequence of reclassifiers. Notation will be used to denote the complement of reclassifier . Reclassifiers are not required to have complements, but if complements and both do exist then we require that holds.
To illustrate, we formulate κ-atoms for a symmetric-key cryptosystem having two cryptographic operations – encryption and decryption. produces a ciphertext from plaintext p and key k. Its reclassifiers are defined by regarding appearances of to be instances of reclassifying expression
which posits flows occur from p (associated with reclassifier ) and from k (associated with reclassifier ) to the value that produces. recovers the plaintext iff ciphertext c was previously encrypted using k. It has reclassifiers for the flows from c and from k to the value that produces:
And we assume and satisfy the expected properties.
Property (38) stipulates that the effects of on plaintext can be reversed by using ; it is that basis for rewrite rule
Property (39) further implies that is the only complement of . Thus, (39) stipulates an absence of certain rewrite rules. Finally, (40) prohibits rewrite rules that would define complements for reclassifiers associated with flows from k: and . This prohibition corresponds to forbidding cryptographic functions where a key used as input to that function can be recovered from the output. It also rules out cryptographic systems that admit plaintext attacks.15
A plaintext attack uses plaintext p and corresponding ciphertext c to recover the encryption key k satisfying . The attack can be viewed as having a cryptographic function that satisfies:
This semantics for would lead to rewrite rules – precluded by (40) stipulating that plaintext attacks are infeasible – for the flows from k in :
Reduced sequence denotes the sequence obtained by repeatedly applying some given rewrite rules to sequence of reclassifiers, until no longer possible. By definition, no reclassifier is followed by its complement in a reduced sequence. If the full set of rewrite rules defines at most one complement for each reclassifier then (i) reduced sequence is unique and (ii) the order in which rewrite rules are applied does not matter, so is associative; see [33, Appendix A.3] for proofs.
All reclassifiers in rewrite rule (41) have a single argument k; it is a key. We define set of principals that can recover a value produced by a cryptographic operation associated with a reclassifier as follows.
Set complement thus contains those principals that cannot recover a value produced by the cryptographic operation identified by .
If a value is derived from v by performing a sequence of cryptographic operations described with sequence of reclassifiers then v can be recovered from only by those principals able to perform inverses of all operations mentioned in . So the set of principals that cannot recover a value produced using a sequence of cryptographic operations are those principals that cannot invert at least one of the operations in . We characterize that set formally as follows, writing to indicate that ranges over the reclassifiers appearing in reduced sequence .
κ-atoms concern confidentiality for principals in a set . Subsets are more restrictive, so we use as the join semilattice of underlying restrictions. is defined to be the set of principals to which the value associated with may flow – the set of principals in β along with principals that cannot recover an input to the sequence of cryptographic operations:
And specifies the flows allowed by when its associated value is transformed by some cryptographic operation being identified with reclassifier .
For example, an initial value v that can flow to principals in would be associated with κ-atom . And κ-atom associated with a transformed value potentially changes the set of principals where that transformed value might flow.16
The new set of principals is a superset when extends and holds. It is a subset when is a proper prefix of , and hold. (If is a proper prefix of then is the complement of the final reclassifier in , so contains neither the final reclassifier in nor the being added.)
The definition of restrictiveness relation on κ-atoms is obtained by substituting and for and in definition (8). Notice that for all
and, therefore, an implementation of κ-atoms need only store reduced sequences.
A computable test to decide for κ-atoms can be obtained by extending complement sequences from Dolev–Yao [22], as follows. For any finite sequence of reclassifiers, define maximal complement sequence to be the sequence of reclassifiers that minimizes the length of . can be computed by taking the complement of each element in , starting at the end.
A test for is then given by:
Soundness and completeness proofs for this test are given in [33, Appendix A.3].
κ-Labels. A κ-label is a finite set of κ-atoms. If we adopt the following definitions for , and ,
then κ-labels form a join semilattice where is defined by
and restrictiveness relation is defined by substituting and into definition (8). The RIF class is then characterized by:
Examples of κ-labels. To illustrate, we typecheck a simple command that invokes operations of the symmetric cryptosystem formalized above. Suppose x is allowed to flow to some subset of set of all principals, principals in are authorized to know key k, y is allowed to flow to some subset of , and principals in are authorized to know key :
Here is a command that combines the symmetric-key cryptographic operations discussed above.
A first assignment encrypts x using key k and then a second assignment attempts to decrypt that ciphertext using a key .
Given the assumptions above about x and k, we posit the following type declarations for the variables named in the first assignment of (47). Notice, the type for w corresponds to a value that has been encrypted under key k.
Using these types and typing rule in Fig. 9, we obtain a type for the RHS of the first assignment of (47).
So, according to typing rule in Fig. 10, that assignment is type correct provided the following holds.
Substituting according to type declarations (48), obligation (49) for type correctness simplifies as follows:
The final formula is trivially equivalent to .
Analogous reasoning establishes that the second assignment is type correct provided the following holds.
The validity of (50) depends on whether holds and on the choice of and in the following proposed types for and :
Case : From , we conclude from and that holds. Expanding (50) gets
This final formula is valid provided holds. So we have established that if holds then the assignment is type correct provided holds. This conclusion should not be surprising, since if holds then once w has been decrypted, the value of x (which would now be stored in y) could flow to principals not in (because they are in ).
Case : Expanding (50) yields::
This formula is valid for all values of and since, by definition of ,
because complements and do not exist. Thus, we conclude the assignment is type correct when , for any choices of and . Again, this outcome should not be surprising. With no way to recover x from the value stored in y by the second assignment (since we have assumed that cryptographic operation has no inverse), the second assignment cannot cause a flow violation.
Type-correctness guarantee for κ-labels. The connection between type correctness and flows proved for this example command is an instance of a more-general guarantee about type correctness. To formalize this guarantee, note that any value a principal could read must be tagged with a κ-label satisfying , where
We consider a κ-label to be -low iff holds and to be -high iff holds. Thus the type-correctness guarantee provided by (any) κ-labels can be formulated as limiting what can learn from values that flow from -high to -low – in particular, type correctness ensures that cannot recover a -high value from -low values.
To show why this guarantee persists when using the κ-labels we defined above for the symmetric-key cryptosystem, consider a command that is type correct. Theorem 1 implies will hold and, therefore, if a value flows from -high to -low, then it does so through some operation that performs a -downgrade. Since cryptographic operations and are the sole reclassifying expressions for our κ-labels, we conclude that all -downgrades are caused by these operations. Without loss of generality, let such an operation be described by
which has a flow from (associated with reclassifier ) and a flow from k (associated with reclassifier ) to the value that produces.
By definition, for (51) to exhibit a -downgrade then
must hold. From the first conjunct we get:
To validate the type-correctness guarantee, it suffices to prove that cannot recover either or k from or, equivalently that the following hold.
Establishing .
Establishing . According to (40), has no complement. Thus, by definition, .
Related work
RIF labels specify restrictions that depend on the history of applied operations. And a static type system can ensure that programs using RIF labels will satisfy PWNI, which extends noninterference [27] to accommodate reclassification. Our work thus extends an approach initiated by Volpano et al. [59] – a type system based on Denning’s lattice model [19–21] that enforces noninterference.
We are not the first to explore types that depend on a history of applied operations. Strom and Yemini [57] propose types that incorporate typestate to summarize the history of operations previously applied to an object and to govern the set of operations that may next be invoked. But Hartson and Hsiao [29] seem to be the first to use history in access control. Contemporary uses of history for defining authorization include stack inspection [61] and history-based access control [1].
Reclassification: Specification and enforcement
State based reclassification. A good deal of prior work ties reclassification to changes in state predicates. Chong et al. [16] is closest to RIF labels. There, information flow policies for confidentiality are defined in terms of state predicates that specify when a value may be reclassified. A static type system enforces these declassification and erasure policies. And when a reclassification occurs in the approach of Chong et al. [16], the value and all derived values are reclassified – in contrast, with RIF labels, reclassifications apply only to the single value.
With ClickRelease, Micinski et al. [43] extend the approach in Chong et al. [16] by allowing a more-expressive language for the formulas that specify when values may be declassified. In particular, ClickRelease uses temporal logic formulas over events, in contrast to the state predicates used by Chong et al. [16]
Paralocks [12] formulates a security policy as , where Σ is a set of state predicates and α is a principal. A value associated with such a policy is allowed to flow to α only if all predicates in Σ are true. Changes to state predicates in Σ alter the allowed flows. Paralocks policies are enforced using a static type system.
A policy in Thoth [24] and its successor system SHAI [23] specifies confidentiality and integrity restrictions for data containers called conduits. The policies comprise two layers. The access control layer specifies which principals may read and update the associated conduit and under what conditions. The declassification layer specifies conditions under which policies for data derived from the associated conduit can change. The conditions employed by a Thoth policy are predicates on conduits’ state, which include both data and metadata (including a type) of conduits. Thoth uses dynamic analysis for enforcement, SHAI uses static analysis too.
Jeeves [6] employs faceted values [5] to specify declassification between two levels of confidentiality (i.e., public and secret). A faceted value is a pair comprising a real and a dummy value, guarded by a state predicate. If that state predicate (which itself can be a faceted value) holds, then the real, possibly secret, value is allowed to flow to low outputs. Otherwise, the dummy value flows to low outputs.
All of this prior work thus ties reclassification to changes in state predicates. In contrast, RIF labels tie reclassification to expression evaluation. A comparison of RIF labels with reclassification based on state predicates thus depends first on what state predicates are available and second on whether those state predicates could be incorporated into RIF transition function .
Operation based reclassification. Explicit expressions for declassification (for confidentiality) and endorsement (for integrity) have been proposed [44,46]. However, the approach can be unsatisfying because output restrictions are not connected to input restrictions or to the operation that transforms inputs to outputs. For example, [44,46] allow an arbitrary label to be assigned to the result of evaluating any expression – type-casting has the same flavor.
RIF labels tie reclassification to expression evaluation, but it is not the first work to connect restrictions on outputs to an operation. With FJifP [30], a principal declares trusted methods to declassify input values.17
Trusted methods are similar to trusted subjects, first introduced by Bell and LaPadula [8] to handle declassification.
A FJifP trusted method always performs the same declassification of an input whereas, depending on the RIF label associated with an input value, a specific reclassifier in a reclassifying expression could trigger different changes to the restrictions. So reclassifying expressions (in conjunction with RIF labels) are more expressive than trusted methods.
Rocha et al. [47] propose policy graphs to specify declassification of information from secret to public (as compared to RIF labels, which handle arbitrary reclassification); similar techniques to those presented in [47] are later employed by Hammer et al. [28] and Johnson et al. [32]. In a policy graph, nodes represent variables and edges represent operation identifiers (similar to our reclassifiers). The tail node of an edge is an input of the corresponding operation, and the head node of that edge is an output of that operation. Some of the nodes in a policy graph are defined final. Values in variables of non-final nodes are considered secret, whereas values in variables that correspond to final nodes are declassified and considered public. Data and control-flow analysis is used to check whether some given program satisfies a specific policy graph. Subsequently, Rocha et al. [48] introduce a specification language for defining policies that might also depend on how many times a function is applied to a given value. This specification language seems more expressive than Rocha et al. [47], although the properties being enforced have not been formally characterized. We believe restrictions defined using any of these policy graphs could be described using a set of RIF automata.
Li and Zdancewic [39] suggest that downgrades between two security levels be specified as lambda terms. Apply one of these lambda terms to a value and the result, by definition, is given a downgraded label. (A type system is given to enforce these policies.) This approach to characterizing downgrades is attractive because it is independent from the program code. Enforcement, however, involves a conservative approach to deciding equivalence of functions because that problem is undecidable in general. Also, the approach is not well suited for handling reclassifications based on how a value has been derived, whereas RIF labels do handle that.
Extending noninterference for reclassification
Declassification violates classical noninterference [27], which has prompted researchers to develop alternatives. One example is conditional noninterference [26,27]. It proscribes secret information flows to public information, unless a given predicate is satisfied by (i) the sequence of operations involved in this flow and (ii) the principals invoking those operations. For declassification, conditional noninterference is more expressive than PWNI, because PWNI ignores identities of the principals that invoke operations. PWNI, however, handles reclassification in full generality (i.e., arbitrary lattices of labels and declassification as well as classification), in contrast to conditional noninterference. which only deals with declassification in a 2-level lattice.
Gradual release (GR) [3] dictates that declassification of expressions, encrypted exceptions, and released cryptographic keys are the only execution points where an attacker’s knowledge about initial secret values may increase. Other work (delimited release [51] and relaxed noninterference [39]) specifies what expressions of secret values in the initial state could be declassified, with no restriction about where in the program such expressions are declassified.
PWNI supports declassifications of arbitrary expressions on any secret within the program. For this reason, the program below, which is arguably secure, is accepted by PWNI, but rejected by delimited release [51] (and its extensions, such as localized delimited release [4]):
Delimited release (and its extensions) rejects the above program for the same reason it rejects the following program:
And the reason is to prevent laundering attacks – the declassification of inadvertently causing the declassification of h.
PWNI and RIF labels prevent laundering attacks by construction. If a variable is allowed to be declassified (e.g., in (54)), then this variable will be tagged with a RIF label that specifies declassification; if a variable is not allowed to be declassified (e.g., h in (54)), then this variable will be tagged with a RIF label that does not specify declassification. So, in (54), the RIF label of will not be as restrictive as the RIF label of h, and thus, PWNI will be violated by assignment and the entire program will be rightfully rejected. On the other hand, PWNI rightfully accepts program (53), when all variables , , , h are tagged with a RIF label that specifies such a declassification.
The flexibility that PWNI offers to be able to handle declassifications of any secret expression in the program (and ultimately accept (53)) is a useful advantage. This is because usually the value that we desire to be ultimately declassified is the result of consecutive computations (i.e., an arbitrary expression in the program) – not the result of one clean expression on initial secrets. Those cases can be handled by PWNI, but not by delimited release (and its extensions).
The cost of the flexibility that PWNI offers comes from formally specifying what is being declassified and where in the program (similar targets to localized delimited release). Specifying what is being declassified in terms of initial secrets is in general undecidable when declassifying an arbitrary expression in the program. Consequently we choose to specify what is being declassified with respect to secrets that exist at the program point (i.e., command) where declassification is triggered. So, we set the reference point of the declassification to be the program point where this declassification is triggered. One way to select a program point as a reference point is to demand λ-pieces end and start at that same program point (just as the beginning of a program is regarded as a reference point for noninterference, demanding all executions to start from there). For this reason PWNI requires exact code equality at the ends of λ-pieces. And with exact code equality, the where dimension of the declassification is identified, too, because the program point at which an expression is declassified becomes explicit.
With conditional gradual release [7], as with our approach, any expression in a program may be declassified. However, conditional gradual release allows declassifications to depend on secret guards, causing a declassification to disclose more information than might have been intended. (PWNI does not suffer from this defect, because of the way λ-pieces are defined.)
Non-disclosure policy [42] is a variation of noninterference for handling local declassification constructs. These declassification constructs augment allowed flows during execution of some code M, restoring the previously allowed flows once execution leaves M. To satisfy the non-disclosure policy, noninterference must hold for flow relations that are allowed at every execution step. This policy, then, embodies a different design choice from PWNI about the scope of a declassification – with PWNI the declassification persists to the end of the execution, whereas with the non-disclosure policy it ends when the declassification construct has completed. The same design choice is adopted in [13] for handling flow-locks [11].
Other alternatives to noninterference associate declassification with special commands, such as match queries18
A match query checks whether two objects are equal. For example, a match query is use to check whether a certain string is the password of a given user.
[60], one-way functions [58], or various other cryptographic operations. With computational noninterference (CNI) [36], disclosure of secret values is permitted only when those values are encrypted; CNI is enforced by type systems introduced in Laud et al. [38] for passive and Fournet et al. [25] for active adversaries. Smith et al. [55] propose a variant of noninterference that handles both encryption and decryption, and it is enforced using a type system.
κ-labels demonstrate how RIF labels can handle cryptographic operations by treating these operations as special and translating them into reclassifying expressions. The literature on type checking of cryptographic operations has explored two general approaches [17]: computational and symbolic. κ-labels embrace the symbolic approach, using an analysis approach derived from Dolev–Yao [22]. Cryptographically masked flows [2] also employs a symbolic analysis, and it too is enforced by type systems. Laud [37] shows that type correctness according to [2], together with some additional conditions, imply CNI, thereby establishing a connection between cryptographically masked flows (which is based on symbolic analysis) and CNI (which is based on computational analysis). Cortier et al. [17] generalizes this connection by showing that programs secure according to a symbolic analysis are also secure according to a computational analysis.
Semantic properties have been proposed to handle erasure, too. Del Tedesco et al. [18] use knowledge semantics to express a hierarchy of erasure policies. These erasure policies are categorized based on (i) whether they specify erasure of all or part of the information, and (ii) whether erasure depends on program state (either high or low). Erasure is a form of classification, and thus, can be specified by RIF labels. However, with the RIF labels in this paper, erasure only affects a value being derived and cannot be formulated to depend on program state.
Noninterference and its variations (including PWNI) characterize allowed flows of information; they do not handle required flows. Chong [15] gives a semantic definition for required information release policies and presents a static type system to enforce these policies. A required information release policy specifies what information should be released and how this information can be learned by the authorized observers. The semantics is based on algorithmic knowledge.
Views of the reclassification landscape
The survey by Sabelfeld et al. [53] introduces a four-dimension categorization for declassification policies (though the categorization seems applicable reclassification, too): what information is declassified, who declassifies information, where in the system information is declassified, and when information can be declassified. RIF labels and our reclassifying expressions specify what, where, and when, but not who. The what is the value produced by the expression; where is the position of the reclassifying expression in the program text; when is determined by the program’s control flow.
Nothing prevents the semantics of our reclassifiers from incorporating information about who is evaluating a given reclassifying expression. The decentralized label model (DLM) [44,45] is an obvious starting point for such an extension. According to DLM, a value may be declassified only if the declassification command is executed on behalf of the value’s owner or on behalf of a principal that acts-for that owner. To adopt this approach, we would add an additional input argument to – the identity of the principal undertaking the reclassification. The semantics of would then be extended so that a reclassifier triggers a transition only for certain principals.
Broberg et al. [14] offers an orthogonal view for information flow policies and declassification. It is based on a three-level hierarchy of control. Level 0 control is a set of possible flow relations between information sources (e.g., input variables) and sinks (e.g., output channels). A flow relation indicates that information from the source is allowed to flow to the sink. Level 1 controls select which flow relations are allowed. Level 2 controls constitute a meta policy for controlling the way in which the current flow relations (Level 1 controls) may be changed. RIF label function incorporates aspects of Level 1 and Level 2 controls.
Footnotes
Acknowledgments
We appreciate the comments we received on early discussions of this work from Eleanor Birrell, Michael Clarkson, Josée Desharnais, Michael George, José Meseguer, Brad Martin, Andrew Myers, David Naumann, Karn Seth, Geoffrey Smith, and Nadia Tawbi. Steve Chong and Deepak Garg, in addition, provided detailed and very helpful feedback on an earlier draft of this paper. Diligence by the reviewers and the editor is also appreciated, and a better paper resulted.
This work was supported in part by AFOSR grants F9550-16-0250, F9550-19-1-0264, and NSF grant 1642120. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of these organizations or the U.S. Government.
⟨ Λ RA,,⊑ RA,⊔ RA ⟩ is a join semilattice
To prove that is a join semilattice requires showing (i) , (ii) , and (iii) that is the least upper bound.
To prove (i), it suffices to use decision procedure (15) for , and prove:
because reachability condition (13) for implies that if
holds then . Completing the proof of (55) is just a matter of expanding the definition of .
The proof of (ii) is similar.
The proof of (iii) involves showing that is the least RIF label satisfying
Our proof by contradiction derives from the assumption that a RIF label satisfying , , and exists.
From we have for any ; from we have for any . Since defines a lattice, we conclude
From assumption we conclude (i) and (ii) . But (56) conjoined with (i) contradicts (ii).
Definition of T ( λ,C )
is defined based on a deterministic generator G of fresh variables, which store lists of values. Specifically, sets G to its initial state, and returns the next fresh variable . Each variable stores a list of values with the same type as , and it is tagged with a RIF label that satisfies .
substitutes each upgrading expression in with expression . So, we extend the evaluation and the RIF labels for expressions to accommodate this new expression . In particular, we define successive evaluations to return successive elements of the list stored in . And define to be .
We now give the formal definition for , which employs auxiliary procedures T and S.
There is a reason why upgrading expressions are substituted by variables that store lists of values instead of variables that store ordinary (scalar) values: upgrading expressions in commands. When a command involves an upgrading expression, then this expression might yield as many upgraded values as the number of iterations of that command. All these values should be protected against leaking to certain principals. So, we substitute them with arbitrarily chosen values (which are elements of these lists) and ensure that they do not influence observations of these principals.
Notice that is deterministic, by construction. This means that for the same command , the translated command is always the same. So, comparing traces and in PWNI definition (35) is meaningful, because these traces correspond to the exact same translated command.
References
1.
M.Abadi and C.Fournet, Access control based on execution history, in: Proceedings of the 10th Annual Network and Distributed System Security Symposium, 2003, pp. 107–121.
A.Askarov and A.Sabelfeld, Gradual release: Unifying declassification, encryption and key release policies, in: Proceedings of the IEEE Symposium on Security and Privacy, 2007, pp. 207–221. doi:10.1109/SP.2007.22.
4.
A.Askarov and A.Sabelfeld, Localized delimited release: Combining the what and where dimensions of information release, in: Proceedings of the 2007 Workshop on Programming Languages and Analysis for Security, PLAS’07, ACM, New York, NY, USA, 2007, pp. 53–60. doi:10.1145/1255329.1255339.
5.
T.H.Austin and C.Flanagan, Multiple facets for dynamic information flow, in: Proceedings of the 39th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’12, ACM, New York, NY, USA, 2012, pp. 165–178. doi:10.1145/2103656.2103677.
6.
T.H.Austin, J.Yang, C.Flanagan and A.Solar-Lezama, Faceted execution of policy-agnostic programs, in: Proceedings of the 8th ACM SIGPLAN Workshop on Programming Languages and Analysis for Security, PLAS’13, ACM, New York, NY, USA, 2013, pp. 15–26.
7.
A.Banerjee, D.A.Naumann and S.Rosenberg, Expressive declassification policies and modular static enforcement, in: Proceedings of the IEEE Symposium on Security and Privacy, 2008, pp. 339–353. doi:10.1109/SP.2008.20.
8.
D.Bell and L.La Padula, Secure computer systems: Unified exposition and MULTICS interpretation, Technical Report ESD-TR-75306, Bedford, MA, 1976.
9.
E.Birrell and F.B.Schneider, A reactive approach to use-based privacy, Technical Report 54843, Cornell University, Computing and Information Science, November 2017.
10.
N.Broberg, B.Delft and D.Sands, Paragon for practical programming with information-flow control, in: Proceedings of the 11th Asian Symposium on Programming Languages and Systems, Vol. 8301, Springer-Verlag New York, Inc., New York, NY, USA, 2013, pp. 217–232. doi:10.1007/978-3-319-03542-0_16.
11.
N.Broberg and D.Sands, Flow locks: Towards a core calculus for dynamic flow policies, in: Proceedings of the 15th European Conference on Programming Languages and Systems, ESOP’06, Springer-Verlag, Berlin, Heidelberg, 2006, pp. 180–196. doi:10.1007/11693024_13.
12.
N.Broberg and D.Sands, Paralocks: Role-based information flow control and beyond, in: Proceedings of the 37th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’10, ACM, New York, NY, USA, 2010, pp. 431–444. doi:10.1145/1706299.1706349.
13.
N.Broberg and D.Sands, Flow locks: Towards a core calculus for dynamic flow policies, Technical report, Chalmers University of Technology and Göteborgs University, May 2006.
14.
N.Broberg, B.van Delft and D.Sands, The anatomy and facets of dynamic policies, in: Proceedings of the 28th IEEE Computer Security Foundations Symposium, 2015, pp. 122–136. doi:10.1109/CSF.2015.16.
15.
S.Chong, Required information release, in: Proceedings of the 23rd IEEE Computer Security Foundations Symposium, IEEE Press, Piscataway, NJ, USA, 2010, pp. 215–227.
16.
S.Chong and A.C.Myers, End-to-end enforcement of erasure and declassification, in: Proceedings of the 21st IEEE Computer Security Foundations Symposium, 2008, pp. 98–111. doi:10.1109/CSF.2008.12.
17.
V.Cortier, S.Kremer and B.Warinschi, A survey of symbolic methods in computational analysis of cryptographic systems, J. Autom. Reason.46(3–4) (2011), 225–259. doi:10.1007/s10817-010-9187-9.
18.
F.Del Tedesco, S.Hunt and D.Sands, A semantic hierarchy for erasure policies, in: Proceedings of the 7th International Conference on Information Systems Security, ICISS’11, Springer-Verlag, Berlin, Heidelberg, 2011, pp. 352–369.
19.
D.E.Denning, A lattice model of secure information flow, Commun. ACM19(5) (1976), 236–243. doi:10.1145/360051.360056.
20.
D.E.Denning and P.J.Denning, Certification of programs for secure information flow, Commun. ACM20(7) (1977), 504–513. doi:10.1145/359636.359712.
21.
D.E.R.Denning, Secure information flow in computer systems., PhD thesis, Purdue University, West Lafayette, IN, USA, 1975.
22.
D.Dolev and A.C.Yao, On the security of public key protocols, Information Theory, IEEE Transactions on29(2) (1983), 198–208. doi:10.1109/TIT.1983.1056650.
23.
E.Elnikety, D.Garg and P.Druschel, SHAI: Enforcing data-specific policies with near-zero runtime overhead, Technical report, Max Planck Institute for Software Systems, Saarland Informatics Campus, Germany, January 2018.
24.
E.Elnikety, A.Mehta, A.Vahldiek-Oberwagner, D.Garg and P.Druschel, Thoth: Comprehensive policy compliance in data retrieval systems, in: Proceedings of the 25th USENIX Conference on Security Symposium, SEC’16, USENIX Association, 2016, pp. 637–654.
25.
C.Fournet and T.Rezk, Cryptographically sound implementations for typed information-flow security, in: Proceedings of the 35th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’08, ACM, New York, NY, USA, 2008, pp. 323–335. doi:10.1145/1328438.1328478.
26.
J.A.Goguen and J.Mesegue, Unwinding and inference control, in: Proceedings of the IEEE Symposium on Security and Privacy, 1984, pp. 75–87.
27.
J.A.Goguen and J.Meseguer, Security policies and security models, in: Proceedings of the IEEE Symposium on Security and Privacy, 1982, pp. 11–20.
28.
C.Hammer and G.Snelting, Flow-sensitive, context-sensitive, and object-sensitive information flow control based on program dependence graphs, International Journal of Information Security8(6) (2009), 399–422. doi:10.1007/s10207-009-0086-1.
29.
H.R.Hartson and D.K.Hsiao, Full protection specifications in the semantic model for database protection languages, in: Proceedings of the 1976 Annual Conference, ACM’76, ACM, New York, NY, USA, 1976, pp. 90–95. doi:10.1145/800191.805538.
30.
B.Hicks, D.King, P.McDaniel and M.Hicks, Trusted declassification: High-level policy for a security-typed language, in: Proceedings of the Workshop on Programming Languages and Analysis for Security, PLAS’06, ACM, New York, NY, USA, 2006, pp. 65–74. doi:10.1145/1134744.1134757.
31.
T.H.Hinke, Inference aggregation detection in database management systems, in: Proceedings. 1988 IEEE Symposium on Security and Privacy, 1988, pp. 96–106. doi:10.1109/SECPRI.1988.8101.
32.
A.Johnson, L.Waye, S.Moore and S.Chong, Exploring and enforcing security guarantees via program dependence graphs, in: Proceedings of the 36th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI’15, ACM, New York, NY, USA, 2015, pp. 291–302. doi:10.1145/2737924.2737957.
33.
E.Kozyri, Enhancing expressiveness of information flow labels: Reclassification and permissiveness, PhD thesis, Cornell University, Ithaca, New York, USA, 2018, https://search.proquest.com/docview/2167492985?accountid=10267.
34.
E.Kozyri, O.Arden, A.C.Myers and F.B.Schneider, JRIF: Reactive information flow control for Java, Technical report, Cornell Univarsity, February 2016.
35.
M.Krohn, A.Yip, M.Brodsky, N.Cliffer, M.F.Kaashoek, E.Kohler and R.Morris, Information flow control for standard OS abstractions, in: Proceedings of the 21st ACM SIGOPS Symposium on Operating Systems Principles, SOSP’07, ACM, New York, NY, USA, 2007, pp. 321–334. doi:10.1145/1294261.1294293.
36.
P.Laud, Semantics and program analysis of computationally secure information flow, in: Proceedings of the 10th European Symposium on Programming Languages and Systems, ESOP’01, Springer-Verlag, London, UK, 2001, pp. 77–91, http://dl.acm.org/citation.cfm?id=645395.651928. doi:10.1007/3-540-45309-1_6.
37.
P.Laud, On the computational soundness of cryptographically masked flows, in: Proceedings of the 35th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’08, ACM, New York, NY, USA, 2008, pp. 337–348. doi:10.1145/1328438.1328479.
38.
P.Laud and V.Vene, A type system for computationally secure information flow, in: Proceedings of the 15th International Conference on Fundamentals of Computation Theory, FCT’05, Springer-Verlag, Berlin, Heidelberg, 2005, pp. 365–377. doi:10.1007/11537311_32.
39.
P.Li and S.Zdancewic, Downgrading policies and relaxed noninterference, in: Proceedings of the 32nd ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’05, ACM, New York, NY, USA, 2005, pp. 158–170. doi:10.1145/1040305.1040319.
40.
P.Li and S.Zdancewic, Practical information-flow control in web-based information systems, in: Proceedings of the 18th IEEE Workshop on Computer Security Foundations, CSFW’05, IEEE Computer Society, Washington, DC, USA, 2005, pp. 2–15. doi:10.1109/CSFW.2005.23.
41.
A.Lux and H.Mantel, Declassification with explicit reference points, in: Computer Security – ESORICS 2009, M.Backes and P.Ning, eds, Springer Berlin Heidelberg, Berlin, Heidelberg, 2009, pp. 69–85. doi:10.1007/978-3-642-04444-1_5.
42.
A.A.Matos and G.Boudol, On declassification and the non-disclosure policy, in: Proceedings of the 18th IEEE Computer Security Foundations Workshop (CSFW’05), 2005, pp. 226–240. doi:10.1109/CSFW.2005.21.
43.
K.Micinski, J.Fetter-Degges, J.Jeon, J.S.Foster and M.R.Clarkson, Checking interaction-based declassification policies for Android using symbolic execution, in: Proceedings of the European Symposium on Research in Computer Security, ESORICS 2015, Springer International Publishing, Cham, 2015, pp. 520–538.
44.
A.C.Myers, JFlow: Practical mostly-static information flow control, in: Proceedings of the 26th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’99, ACM, New York, NY, USA, 1999, pp. 228–241. doi:10.1145/292540.292561.
45.
A.C.Myers and B.Liskov, A decentralized model for information flow control, in: Proceedings of the 16th ACM Symposium on Operating Systems Principles, SOSP’97, ACM, New York, NY, USA, 1997, pp. 129–142. doi:10.1145/268998.266669.
46.
A.C.Myers, L.Zheng, S.Zdancewic, S.Chong and N.Nystrom, Jif 3.0: Java information flow, Software release, http://www.cs.cornell.edu/jif, July 2006.
47.
B.P.S.Rocha, S.Bandhakavi, J.den Hartog, W.H.Winsborough and S.Etalle, Towards static flow-based declassification for legacy and untrusted programs, in: Proceedings of the IEEE Symposium on Security and Privacy, 2010, pp. 93–108. doi:10.1109/SP.2010.14.
48.
B.P.S.Rocha, M.Conti, S.Etalle and B.Crispo, Hybrid static-runtime information flow and declassification enforcement, Information Forensics and Security, IEEE Transactions on8(8) (2013), 1294–1305. doi:10.1109/TIFS.2013.2267798.
49.
I.Roy, D.E.Porter, M.D.Bond, K.S.McKinley and E.Witchel, Laminar: Practical fine-grained decentralized information flow control, in: Proceedings of the 30th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI’09, ACM, New York, NY, USA, 2009, pp. 63–74. doi:10.1145/1542476.1542484.
50.
A.Sabelfeld and A.C.Myers, Language-based information-flow security, Selected Areas in Communications, IEEE Journal on21(1) (2003), 5–19. doi:10.1109/JSAC.2002.806121.
51.
A.Sabelfeld and A.C.Myers, A model for delimited information release, in: Proceedings of the International Symposium on Software Security (ISSS’03), LNCS, Vol. 3233, Springer-Verlag, 2004, pp. 174–191.
52.
A.Sabelfeld and D.Sands, A per model of secure information flow in sequential programs, in: Proceedings of the 8th European Symposium on Programming Languages and Systems, ESOP’99, Springer-Verlag, Berlin, Heidelberg, 1999, pp. 40–58. doi:10.1007/3-540-49099-X_4.
53.
A.Sabelfeld and D.Sands, Declassification: Dimensions and principles, J. Comput. Secur.17(5) (2009), 517–548, http://dl.acm.org/citation.cfm?id=1662658.1662659. doi:10.3233/JCS-2009-0352.
54.
F.B.Schneider, K.Walsh and E.G.Sirer, Nexus Authorization Logic (NAL): Design rationale and applications, ACM Trans. Inf. Syst. Secur.14(1) (2011), 8:1–8:28. doi:10.1145/1952982.1952990.
55.
G.Smith and R.Alpízar, Secure information flow with random assignment and encryption, in: Proceedings of the 4th ACM Workshop on Formal Methods in Security, FMSE’06, ACM, New York, NY, USA, 2006, pp. 33–44. doi:10.1145/1180337.1180341.
56.
D.Stefan, A.Russo, J.C.Mitchell and D.Mazières, Flexible dynamic information flow control in Haskell, in: Proceedings of the 4th ACM Symposium on Haskell, Haskell’11, ACM, New York, NY, USA, 2011, pp. 95–106. doi:10.1145/2034675.2034688.
57.
R.E.Strom and S.Yemini, Typestate: A programming language concept for enhancing software reliability, IEEE Trans. Softw. Eng.12(1) (1986), 157–171. doi:10.1109/TSE.1986.6312929.
58.
D.Volpano, Secure introduction of one-way functions, in: Proceedings of the 13th IEEE Computer Security Foundations Workshop, 2000, pp. 246–254. doi:10.1109/CSFW.2000.856941.
59.
D.Volpano, C.Irvine and G.Smith, A sound type system for secure flow analysis, J. Comput. Secur.4(2–3) (1996), 167–187, http://dl.acm.org/citation.cfm?id=353629.353648. doi:10.3233/JCS-1996-42-304.
60.
D.Volpano and G.Smith, Verifying secrets and relative secrecy, in: Proceedings of the 27th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’00, ACM, New York, NY, USA, 2000, pp. 268–276. doi:10.1145/325694.325729.
61.
D.S.Wallach, J.A.Roskind and E.W.Felten, Flexible, extensible Java security using digital signatures, DIMACS Series in Discrete Mathematics and Theoretical Computer Science38 (1996), 59–74. doi:10.1090/dimacs/038/07.


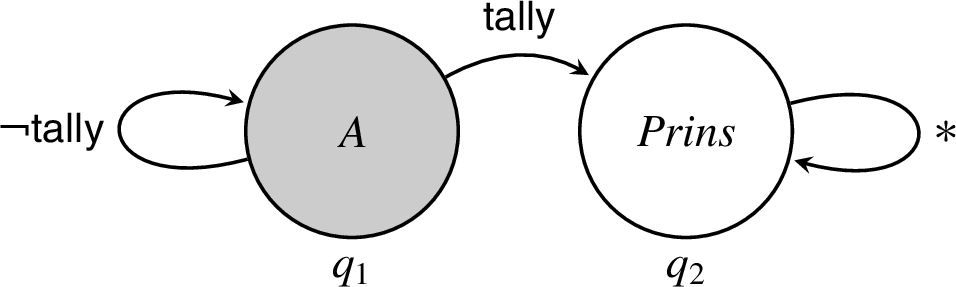
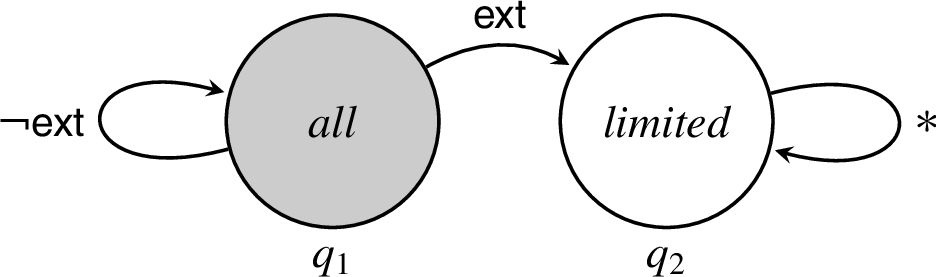
 and
and  . Subtrace
. Subtrace 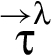 is the initial λ-piece of trace τ and subtrace
is the initial λ-piece of trace τ and subtrace 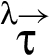 is the rest. Thus,
is the rest. Thus, 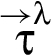 and
and 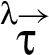 satisfy the following two properties, for traces and subtraces τ satisfying
satisfy the following two properties, for traces and subtraces τ satisfying 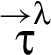 and
and 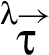 :
:
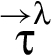 :
:
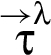 and
and 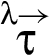 :
: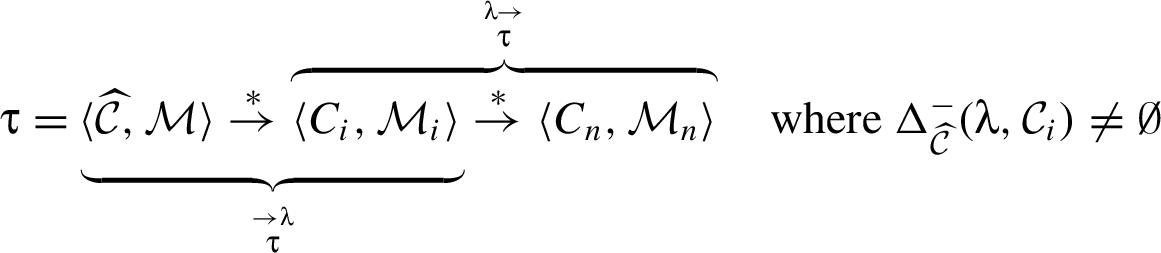
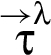 and
and 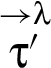 are witnesses of an illicit λ-flow if executing the same command in memories
are witnesses of an illicit λ-flow if executing the same command in memories 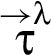 and
and 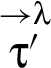 :
: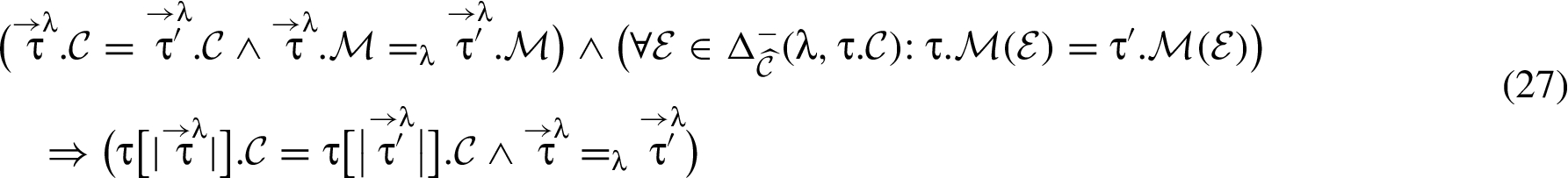
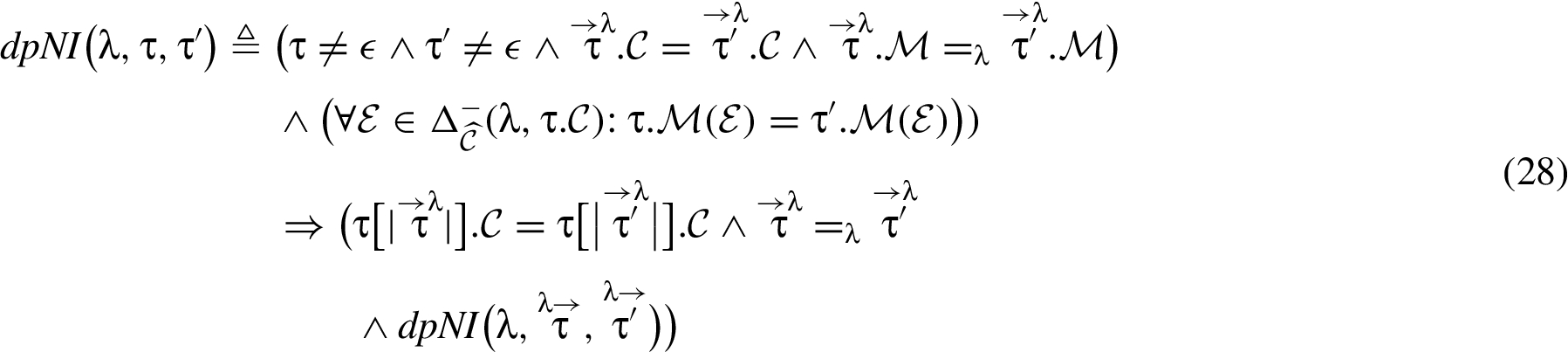
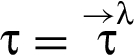 and
and 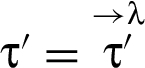 for all λ) then
for all λ) then  in the consequent of (28) would be
in the consequent of (28) would be 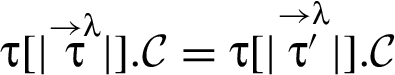 in the consequent of
in the consequent of 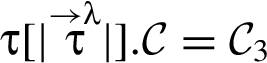 and
and 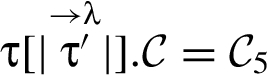 hold, so conjunct
hold, so conjunct 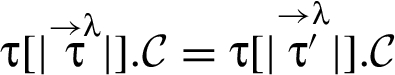 in the consequent of
in the consequent of 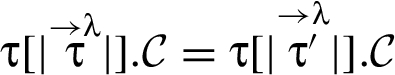 ), we could have extended the bisimulation used in [4] to handle downgrades of arbitrary expressions during execution. However, with this bisimulation, we would risk accepting insecure programs. This is because this bisimulation does not seem to set intermediate reference points for the downgrades. For example, consider program (32), which is insecure. A bisimulation that supports downgrades with reference points on intermediate states would accept the program as secure. The case to consider concerns the execution steps
), we could have extended the bisimulation used in [4] to handle downgrades of arbitrary expressions during execution. However, with this bisimulation, we would risk accepting insecure programs. This is because this bisimulation does not seem to set intermediate reference points for the downgrades. For example, consider program (32), which is insecure. A bisimulation that supports downgrades with reference points on intermediate states would accept the program as secure. The case to consider concerns the execution steps 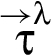 and
and 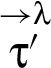 must satisfy (27). So the omissions may cause
must satisfy (27). So the omissions may cause 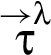 and
and 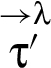 must satisfy (27). So the additions may cause
must satisfy (27). So the additions may cause