
Abstract
Email has sustained to be an essential part of our lives and as a means for better communication on the internet. The challenge pertains to the spam emails residing a large amount of space and bandwidth. The defect of state-of-the-art spam filtering methods like misclassification of genuine emails as spam (false positives) is the rising challenge to the internet world. Depending on the classification techniques, literature provides various algorithms for the classification of email spam. This paper tactics to develop a novel spam detection model for improved cybersecurity. The proposed model involves several phases like dataset acquisition, feature extraction, optimal feature selection, and detection. Initially, the benchmark dataset of email is collected that involves both text and image datasets. Next, the feature extraction is performed using two sets of features like text features and visual features. In the text features, Term Frequency-Inverse Document Frequency (TF-IDF) is extracted. For the visual features, color correlogram and Gray-Level Co-occurrence Matrix (GLCM) are determined. Since the length of the extracted feature vector seems to the long, the optimal feature selection process is done. The optimal feature selection is performed by a new meta-heuristic algorithm called Fitness Oriented Levy Improvement-based Dragonfly Algorithm (FLI-DA). Once the optimal features are selected, the detection is performed by the hybrid learning technique that is composed of two deep learning approaches named Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN). For improving the performance of existing deep learning approaches, the number of hidden neurons of RNN and CNN is optimized by the same FLI-DA. Finally, the optimized hybrid learning technique having CNN and RNN classifies the data into spam and ham. The experimental outcomes show the ability of the proposed method to perform the spam email classification based on improved deep learning.
Keywords
Nomenclature
Grey Wolf Optimization Gray-Level Co-occurrence Matrix False Positive Rate Water Cycle Feature Selection Fitness Oriented Levy Improvement-based Dragonfly Algorithm Artificial Neural Network Negative Selection Algorithm Recurrent Neural Network Ant Lion Optimization Convolutional Neural Network Net Present Value Particle Swarm Optimization Local Outlier Factor Dragonfly Algorithm Random Weight Network Genetic Algorithm Support Vector Machine Term Frequency-Inverse Document Frequency False Negative Rate Combined Clustered NSA and Fruit Fly Optimization K-Nearest Neighbour Matthews Correlation Coefficient Decision Tree Hybrid Kernel based Support Vector Machine Long Short-Term Memory Neural Network Whale Optimization Algorithm Discrete Wavelet Transform Naive Bayes False Detection Rate Gate Recurrent Unit Deep Neural Network Whale Optimization Algorithm
Introduction
Nowadays, cyber crimes are mostly considered as “borderless white collar” crimes. The internet users such as the government, organizations, and individuals are mostly affected by it [23]. Most of the email users are tired of receiving spam daily in their inboxes. Various organizations and individuals broadly use electronic mail (email), and it is important for several types of group connections. In these days, spam email is one of the costly and fast-rising issues connected with the internet. Spam emails are mostly a commercial one, and it consists of attractive links to the prominent websites, but mostly these pave the way for the officious sites [37]. Machine learning plays a vital role in cyber security [26]. Spam is a worldwide email services-linked problem. It is composed of unnecessary and spontaneous emails without a deliberate receiver, and it is intended for various reasons, from marketing to scams and fraud [4,13]. In 2009, nearly 97% of received or sent emails were categorized as spam mails. Hence, in modern times, more concentration is provided for email classification. Currently, conflict occurs between spammers and spam detection tools since each side searches for novel paths of revealing other’s presence [3,31].
Spam is defined as a junk or unwanted message sent to an Internet user’s inbox. Spam is a severe threat to the internet and society [2]. The spam messages cause internet users to face security issues and others to face improper and illegal issues. Additionally, valuable resources such as productivity, bandwidth, and storage are also wasted by spam messages [17]. Hence, more demand arises for automatic email spam filtering [15]. Even though the practitioners and researchers take a constant effort to generate accurate spam detection systems, numerous spam messages are yet received by internet users daily. Spammers send many messages with no aid of cost using botnets, malware, and spam campaigns [17,22]. Therefore, a spam detection system must be used to detect the fraudulent and unsolicited emails that are afflicting the enormous benefits of the emails.
Spam detection compares the non-spam and spam emails, which will help to avoid the spam mail from receiving into the user’s inbox [21,34]. The initial step in the email filtering process is spam detection that prevents junk mails from going into the users’ inboxes. The presence of vast mailing tools increases the spam email count in a fast manner. The spam problems are mostly handled by the spam filters [38]. These filters recognize spam emails on the basis of the analysis of their contents and various additional information [16]. In the initial stage, spam filters are produced on the basis of blacklists of recognized spammers, keyword filtering, and a group of user-defined rules [29,39]. Yet, these methods require to be updated and maintain in a continuous manner since it suffers from the time-consuming and ineffective problem. This technique is called as the knowledge engineering approach. An efficient way for pattern matching is the behavioral characterization in detecting malware [35].
The major development of this paper is enlisted as below.
To improve the email spam detection using the hybrid deep learning algorithms consisting of CNN and RNN by optimizing the hidden neurons for improved cyber security.
To perform the feature extraction for extracting the features with two sets of features like text features and visual features, TF-IDF is extracted for the text features. Then, the color correlogram and GLCM are determined for the visual features.
To introduce a new meta-heuristic algorithm called FLI-DA for improving the optimal feature selection and deep learning process.
To reveal the capability of the developed technique using various performance measures for the spam email classification on the basis of improved deep learning.
The paper organization is arranged in the below manner: Section 1 provides the introduction about email spam detection for improved cybersecurity. The various literature survey works related to email spam detection are listed in Section 2. The proposed model for email spam detection using text and image datasets is described in Section 3. Section 4 describes the text features and visual features adopted for proposed email spam detection. The FLI-DA for optimal feature selection and classification is provided in Section 5. Section 6 explains the text and visual feature classification using hybrid CNN and RNN. The results and discussions are discussed in Section 7. Finally, Section 8 concludes the paper.
Literature survey
Related works
In 2019, Rawashdeh et al. [1] used a novel technique composed of enhancement, comparison quality, assessment, induction, and groundwork. The recommended spam classification was tested using seven datasets. The dataset was validated and trained by cross-validation. The feature selection was made by the meta-heuristic algorithm known as the WCFS and simulated annealing using the three styles of hybridization. The outcomes have displayed that the SVM classifier performed better f-measurement. Additionally, the feature count using simulated annealing and interleaved water cycle was minimized below 50%.
In 2018, Naem et al. [30] suggested a novel predictive technique to handle the spam emails issue based on boosting, and ALO is known as the ALO-Boosting. In this context, the developed technique was used in the different seeking regions to alter the original location of the people. On the basis of the boosting algorithm, the optimum feature subset was obtained for the enhanced classification. Further, the boosting classifier known as the classification technique has described the group of models that altered the soft learners to the powerful learners. For the chosen least value of the features, the optimum features were detected by the presented model. Based on the boosting classifier, spam email classification has attained more precision.
In 2015, Idris et al. [19] introduced an email detection model designed depending on the NSA’s improvement. The random detector generation present in the NSA was improved by applying the PSO. During the NSA’s random detector generation stage, the detectors were generated by the model. The detector was generated as the fitness function by combining the NSA-PSO-used LOF. Once it attained the anticipated spam coverage, the procedure of termination has been stopped. The evaluation of the examination and the application of the techniques were also made. The results displayed that the presented model had generated the best performance when differentiated from the conventional models.
In 2019, Faris et al. [14] developed an intelligent detection model to handle the email spam detection works using the RWN and the GA. The detection procedure was used for detecting the features using an automatic recognition capacity. Depending on the three email corpora, the analysis of the developed method has occurred during the sequence of tests. The outcomes have shown that the presented method has achieved high precision, recall, and accuracy.
In 2019, Olatunji [33] developed an SVM-oriented method for detecting spam. The best performance was attained with the optimal parameters by paying more attention to the successful search. The tests were carried on both the testing as well as the training datasets. This method is not suitable for large datasets. The outputs have revealed that the developed technique was superior to the state-of-the-art techniques. In 2019, Chikh et al. [7] had introduced a novel method of email detection based on an improved NSA known as the CNSA-FFO. The efficiency of the conventional NSA was enhanced by combining the original NSA with the FFO and K-means clustering. The results have shown that the presented model has exceeded the conventional NSA-PSO in positive prediction, complexity, and accuracy.
In 2019, Kumaresan et al. [24] presented a spam classification technique using HKSVM and S-Cuckoo. In the first step, depending on the image and the text, the features were collected from the emails. The textual features have used the term TF frequency. The image features were considered by the wavelet moment and the correlogram. The optimum features were identified by the hybrid features using the hybrid algorithm known as the S-Cuckoo search. Moreover, the recommended classifier did the classification by merging three different kernel functions, and it was used by the SVM classifier in the final step. The results have shown that high accuracy was obtained by the recommended model.
In 2019, Shuaib et al. [40] proposed a meta-heuristic optimization technique for choosing the salient features in the email corpus known as the WOA. The rotation forest technique performs the feature selection using WOA to classify the mail as non-spam and spam. Once the feature selection has been made, the presented algorithm can categorize the emails.
In 2021, Noorizadeh et al. [32] developed the design and implementation of the cyber-physical industrial control system testbed. The Tennesse Eastman process replicates in the PC, and the closed-loop controllers were involved in the Siemens PLC. By using the man-in-the-middle structure, the developed testbed was injected by the false data injection cyber attacks. This method is used for providing privacy for the users. Several cyber-attack detection algorithms were improved in real on the testbed, and performance was related with the other. However, this method makes the system very slow.
In 2020, Samira et al. [12] developed a hybrid approach to spam filtering based on the Neural Network model Paragraph Vector-Distributed Memory (PV-DM). It was used for building the compact representation of email. A comprehensive filter for categorizing the emails was represented in this methodology. The PV-DM and the TF-IDF were taken into account to allot a dual representation vector to each message. This method was resistant to differences in message cohesion and the language system. Anyhow, this method ignored the relationship within the languages.
Review
Although there are some detection models for identifying spam emails, there are still some challenges faced by the people for accessing the spam emails, so a new methodology needs to be implemented for acquiring the spam emails effectively. Some of the features and challenges are mentioned in Table 1. Among them, by using SVM [1], the classification performance acquired was high, and Simulated Annealing [1] was employed for optimizing the outcomes and assessing the spam detection model. Yet, the cost function of simulated annealing is highly expensive. ALO [30] is used for altering the original location of the people present in the different searching regions, and it is performing well in detecting optimum features with the least number of features selected and acquiring more precision. But, it needs to improve the performance when it is used with existing classifiers. NSA-PSO [19] acquired the best accuracy when compared over benchmark NSA model, and it employs LOF as the fitness function for generating detector. Still, parallel hybridization needs to be implemented for detecting email spam in the network. GA [14] can find the significant features of spam emails, and it optimizes the configuration of its core classifiers. However, it needs to examine imbalanced datasets. SVM [33] performs higher, and it is flexible and reliable. This method is not suitable for large datasets. CNSA-FFO [7] has high performance regarding accuracy and computational complexity, and it can detect email spam. But, it has less convergence precision. In HKSVM [24] every kernel function is suitable for some tasks, and it defines the arrangement of huge dimensional space. Yet, the performance needs to be enhanced. Random forest algorithm and WOA [40] have provided a great enhancement, and WOA can shun away from the local optima. Still, it needs to experiment on huge datasets. Hence, it is specified that the above mentioned defects might help upcoming researchers in effectively developing new models for detecting spam emails. The cyberattack detection method [32] is used for providing privacy for the users. This method makes the system slower than before. PV-DM [12] is resistant to differences in message cohesion and the language system. This method ignores the relationship within the languages.
Features and challenges of conventional email spam detection methods for cybersecurity
Features and challenges of conventional email spam detection methods for cybersecurity
Developed email spam detection model
Email is the major economic and reliable communication type. In recent years, the increase in email users resulted in an increase in spam emails. Automatic classification techniques classify spam from the ham mails utilizing text mining techniques. Several researchers have introduced various deep learning and machine learning-oriented strategies such as case-based reasoning, K-NN, NB, NN, SVM, DNN, artificial immune systems, etc. However, these techniques cannot completely handle the problem owing to the constant complexity of spamming software devices. The architecture of the proposed email spam detection for improved cybersecurity is displayed in Fig. 1.

The proposed architecture of email spam detection for improved cybersecurity.
The proposed model comprises four phases: dataset acquisition, feature extraction, optimal feature selection, and detection. In the first step of data acquisition, the benchmark dataset of email is gathered. Here four datasets are gathered, in which three datasets are related to the texts, and one dataset is related to the image. Once the datasets are collected, it is subjected to the next step of feature extraction, consisting of two sets of features such as text features and visual features. The text features are extracted from the text dataset, and visual features are extracted from the image dataset. Here, the text features extract the frequency count of spam words using the TF-IDF. The GLCM and color correlogram are used for the visual features. Initially, the dataset is divided into the training set and the testing set. As the length of the extracted feature vector tends to be long, it undergoes the third step of optimal feature selection to choose the optimal features. The optimal feature selection is made by a new meta-heuristic algorithm known as FLI-DA. Here, 20 features are selected optimally. Once the optimal features are chosen, the final step of detection takes place. The detection is done using two deep learning approaches called RNN and CNN. For enhancing the performance of the traditional deep learning approaches, the number of hidden neurons of both the RNN and CNN are optimized using the same proposed FLI-DA. The optimized hybrid learning technique with CNN and RNN classifies the data into spam and ham.
The benchmark dataset of spam emails is used here that are publically available. Here, four types of datasets are collected. The first three datasets are related to the text features, and the last dataset is related to the image dataset.
Dataset 1: The first text dataset is known as the Ling-spam dataset, and it is collected from the link [8]. It consists of 2893 spam as well as non-spam messages. These messages mostly concentrate on the linguistic interests around the software discussion, research opportunities, and job postings. The information in the header was removed. There exist 2412 legitimate messages and 481 spam messages.
Dataset 2: The second text dataset is called as the spam mails dataset. This dataset is collected from the link [9]. It includes the enron1 folder. This folder is composed of spam and ham. Each of the folders consists of emails.
Dataset 3: The third text dataset is named as the spam-or-ham-email classification. It is gathered from the link [10]. It consists of 71,325 datasets and 2371 tasks.
Dataset 4: The fourth image dataset is named as the image spam dataset. It is gathered from the link [11]. In addition, it is collected from the mailboxes of two real users.
Text features and visual features adopted for proposed email spam detection
Text feature extraction
The text features are extracted for the text dataset. Here, TF-IDF is used to extract the frequency count of spam words from the text dataset. The TF-IDF [43] is a digital statistical technique. The significance of vocabulary is reflected by modelling it to the documents in corpus or clusters. It is commonly employed as a weighting factor in user modelling, text mining, and information retrieval. The value of TF-IDF is proportional to the count of times the word appearing in the document. It is mostly balanced by the frequency of the word present in the corpus. The fact, which describes that few words are normally available in the corpus and are provided more importance, is rejected here. The product of TF and IDF results in producing TF-IDF. The computation for TF-IDF is very simple, and the computation between two documents is made easier by using this TF-IDF. Moreover, The TF-IDF returns all the documents that are related to the queries. The formula for TF is described in Eq. (1) that represents the frequency in which a characteristic appears in a single document.
Here, the denominator represents the total word count in the document
In the above equation, the total count of documents present in the corpus is denoted by E and
If the corpus documents count increases, then the outcome of IDF will be lesser. If the dynamic characteristic team is more, then the distinguishing capability of the characteristic text is very worst. When every document present in a corpus is composed of a characteristic, the weight will be 0. For avoiding zero in the denominator, most practical applications employ a technique of including 1 in the denominator. It is mostly utilized to measure the importance of a word present in the word frequency. The words having high frequency are not significant. The lack of theoretical basis is the significant concept of low frequency words. The common words do not describe the meaningless word. Low frequency words contain better characteristics skills. Few words are evenly distributed in various document categories, and few words may often occur in specific document types. Hence, the latter one is more applicable for describing the document characteristics.
The textual extracted features are described as
Visual feature extraction
The visual features are extracted from the image dataset, which uses GLCM and color correlogram features in the proposed email spam detection.
Energy: It is also known as ‘angular second moment’ or ‘uniformity’. It returns the sum of square elements present in the GLCM matrix. It is computed in terms of homogeneous regions to non-homogeneous regions. Thus, when the frequency of the duplicated image pixel is more, it is also more.
Entropy: The randomness present in the image is computed by entropy. As a result, a homogeneous image returns fewer entropy values.
Contrast: The intensity linking contrast is computed among a pixel of an image and its neighbour.
Correlation: It represents the gray tone linear dependencies present in an image. It describes the correlation of pixel with its neighbour.
Homogeneity: It represents the pixel similarity. The homogeneous image’s GLCM matrix returns the value as 1. Thus, when the image texture needs fewer modifications, it is very less.
Here,
The term σ represents the variance of intensities of all the pixels. It is computed as in Eq. (10).
Here, the term
Initially, the input image is transformed to a color quantization using 64-colors (4 levels for every channel). Then, the colors present in the input ham or spam images are quantized into On the basis of the distance l, a neighbourhood of 3 × 3 is considered for every pixel. The distance is considered on the basis of the original color correlogram, such as
For all the pixels present in the instance, this probability is repeated. It produces a 64-dimensional feature vector that is being utilized as a visual feature vector.
The total number of visual features attained is 3537. Here, both the GLCM and color correlogram are concatenated. Thus, the final visually extracted features are represented as
Optimal feature selection
The feature selection is performed to minimize the inputs for further analysis and processing. It is also used to find the most relevant inputs. Here, optimal feature selection is made with the help of a new meta-heuristic algorithm known as FLI-DA. The total number of textual features attained is 600. The optimally selected textual features are represented by
Features before feature selection
Features before feature selection
Features after feature selection
Objective function
The major objective of the presented email spam detection for improved cybersecurity is to maximize detection accuracy. Here, the optimization of hidden neurons of the CNN and RNN as well as the optimal feature selection, is done by the proposed FLI-DA. The RNN and CNN are used to detect spam emails. The objective function is described as in Eq. (12).
In the above equation
Here,
Encoding of solution
The solution encoding of the proposed email spam detection for improved cybersecurity is displayed in Fig. 2. Here, the optimal feature selection, as well as the hidden neurons of CNN and RNN, is optimized using the FLI-DA. The bounding limit of the number of attributes lies in the range of (1-length of feature). Similarly, the bounding limit of the hidden neurons of both RNN and CNN lies in between the value of (5-255). The bounding limit is nothing but the minimum and maximum ranges of each solution or chromosome variable. The optimization of each variable should be within the bounding limit, which ensures performance. It is user-defined as the input of optimization algorithms is randomly chosen based on the limited ranges. In Fig. 2,
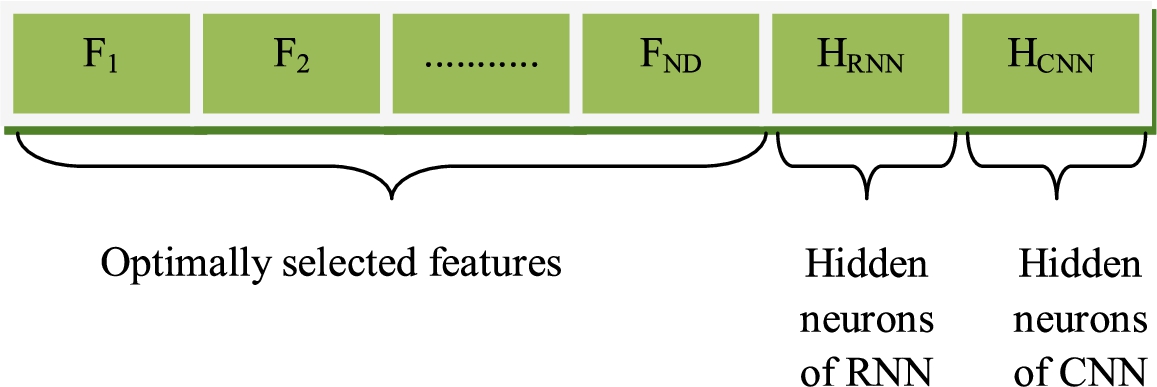
Solution encoding.
The motivation of DA [20] arises from dynamic and static swarming behaviours. These swarming behaviours are identical to the exploitation and exploration phases. In the exploration phase, the dragonflies hunt the remaining flying prey. During the exploitation phase, a huge count of dragonflies migrates in one direction along with long distances. Hence, all the swarms are distracted by the enemies and attracted towards the food. Equation (14) describes the separation of the kth dragonfly
Here, the count of neighbouring individuals is denoted by
In the above equation, the velocity of the lth neighbouring individual is denoted by
Equation (17) computes an attraction towards a food source.
Here, the position of the food source is denoted by
In the above equation, the enemy’s position is denoted by
Here, the iteration counter is denoted by v, the inertia weight is denoted by δ, the enemy’s position of the kth individual is denoted by
Equation (21), Eq. (22), and Eq. (23) are used to update the position of the dragonflies as below.
In the above equations, the constant is denoted by ξ, the two random numbers in the interval range of [0, 1] are denoted by

Conventional DA [20]
The proposed FLI-DA does the optimal feature selection and the hidden neuron optimization of CNN and RNN. The CNN can easily find the important features without the intervention of any humans. CNN performs identification and prediction, and it gives an effective dense network. If the data of the CNN is high, the accuracy will also be high. The RNN can remember information by the time. The RNN can easily predict the time series. RNN can process the input, which can be of any length. The model size does not exceed even if the input size is larger. The optimization algorithms have achieved great attention among researchers. Optimization algorithms are used for handling various engineering-related problems. Using the optimization principles, decision-making systems, as well as expert systems, are generated. Optimization algorithms mostly depend on the performance of classification and prediction. The inspiration of DA [20] arises from the dynamic as well as the static swarming behaviour of the dragonflies for implementing the exploitation and the exploration search spaces.
In the conventional DA, the random walk is improved using the levy flight as in Eq. (16). But, in the proposed FLI-DA, rather than the levy flight, the random walk is performed using the new update formula that is decided by the fitness function
Otherwise, if
In the above equations, b represents a random number, and it lies in between the value of −1 to 1. The pseudo-code of the proposed FLI-DA is displayed in Algorithm 2, and the flowchart of the proposed FLI-DA is displayed in Fig. 3.

Proposed FLI-DA

Flowchart of the proposed FLI-DA.
Visual and textual features are used for the classification of the document image. Textual features efficiently capture emotional semantics based on similarity in words. Also, the textual analysis extracts the meaningful values from the texts related to the image under test. The visual features deliver a great description of their content.
Convolutional neural network
CNN [44] consists of two parts. In part 1, the deep features present in the raw data are produced by the pooling and convolution operations. Next, in part 2, for the classification purpose, the features are joined to an MLP. Every layer is described as given below.
Here, the bias and weight of the sth convolution filter are represented by
In the above equation, the pooling strategy is denoted by h. It does not alter the feature map counts. Equation (30) describes the output of the output layer.
Here, the connection weights among the output and the feature layer are denoted by
Here, q is used to denote
Recurrent neural network
RNN [25] is one of the divisions of ANN. A special kind of LSTM is the GRU. GRU is used to make RNN easier. The forget as well as the output gates are joined by the GRU into a single update gate b. Through linear interpolation, the current state is received. The major benefits are the easier training and the less parameter. The input
Here, the logistic sigmoid function is denoted by σ, and the corresponding weight matrices are denoted by
In the above equation, the element-wise multiplication is denoted by Θ. The
Hybridization of two classifiers
Once the optimal features are selected, it is subjected to the detection phase that consists of a hybrid classifier with RNN and CNN. FLI-DA is used for training hybrid classifier RNN and CNN. So, the hidden neurons were selected optimally. Finally, the outcome of both the RNN and CNN undergoes bit and operation detected whether the data is a ham or spam. The hybrid classifier is diagrammatically represented in Fig. 4.
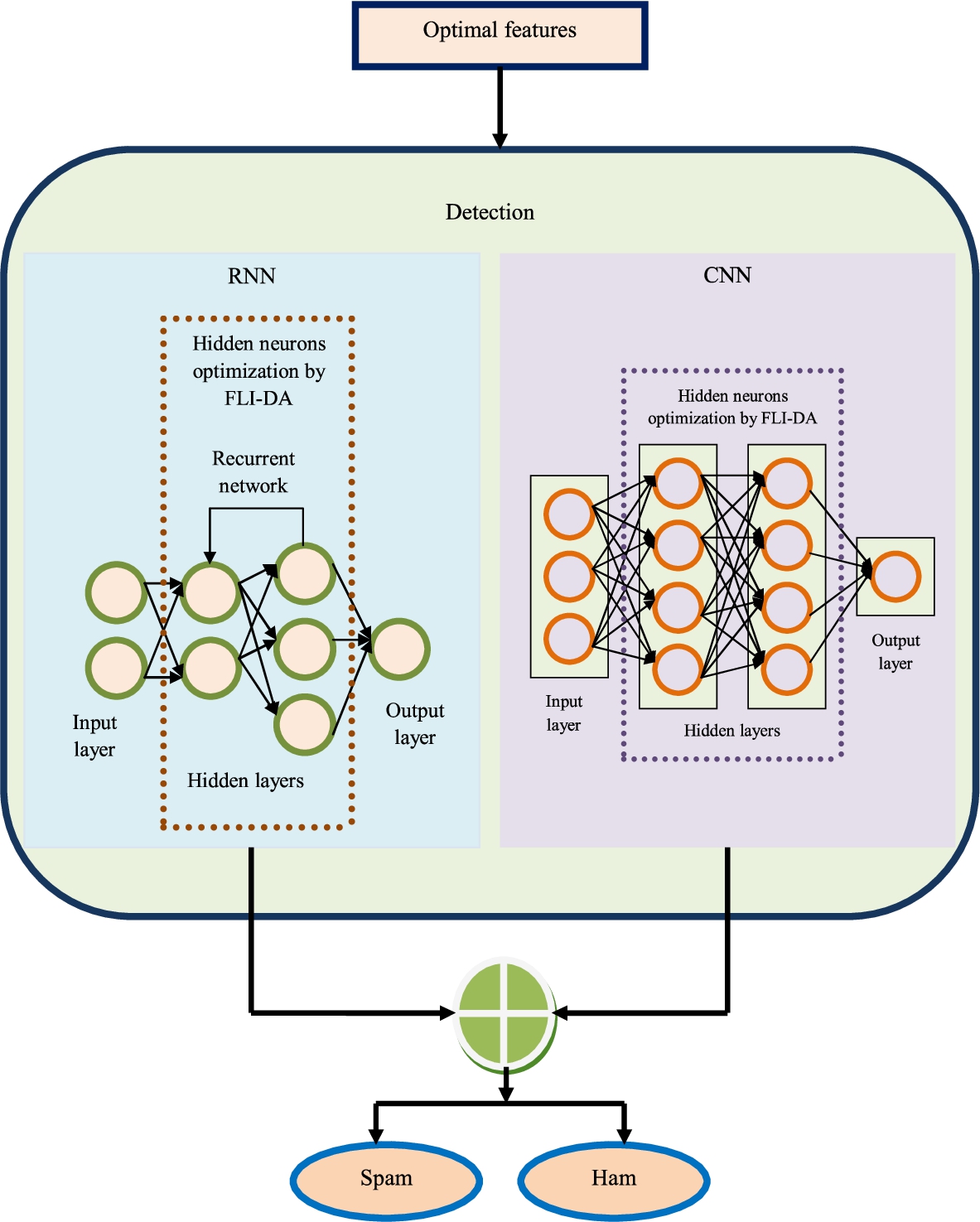
Hybrid classifier to perform email spam detection.
Experimental setup
The implementation environment was the python 3.7 version. The RAM of the system was 8 GB RAM. The proposed email spam detection for improved cybersecurity was implemented in Python, and the analysis of the result was carried out. The population size was taken as 10, and the maximum number of iterations was 25. The total number of datasets used was four, in which the first three datasets resembled the text and the last dataset resembled the image. Here, the performance of the proposed FLI-DA-CRNN was differentiated with several optimization algorithms like PSO-CRNN [42], GWO-CRNN [28], WOA-CRNN [27], and DA-CRNN [20], and deep learning models such as CNN [44], RNN [25], and CRNN [25,44] and machine learning models like DT [41], KNN [18], SVM [6], and NN [5] in terms of Type I measures such as, “accuracy, sensitivity, specificity, precision, NPV, F1 Score, and MCC”, and Type II measures such as “FPR, FNR, and FDR” to determine the superiority of the proposed method. From the analysis, the learning percentage varies from 0.4% to 0.8%. The training percentage is varying from 35% to 85%. Here, when 35% of data is considered for the training, the remaining 65% of data is considered for validation. Similarly, when 40% of data is considered for training, the remaining 60% of data is considered for validation.
Experimental parameters
The experimental parameters were shown in Table 4.
Parameter settings
Parameter settings
The performance is analyzed using ten metrics as described below.
Accuracy: It is clearly described in Eq. (13). Sensitivity: It is defined as “the number of true positives, which are recognized exactly”.
Specificity: It is defined as “the number of true negatives, which are determined precisely”.
Precision: It is defined as “the ratio of positive observations that are predicted exactly to the total number of observations that are positively predicted”.
FPR: It is defined as “the ratio of the count of false-positive predictions to the entire count of negative predictions”.
FNR: It is defined as “the proportion of positives which yield negative test outcomes with the test”.
NPV: It is defined as the “probability that subjects with a negative screening test truly don’t have the disease”.
FDR: It is defined as “the number of false positives in all rejected hypotheses”.
F1 Score: It is defined as “harmonic mean between precision and recall. It is used as a statistical measure to rate performance”.
MCC: It is defined as a “correlation coefficient computed by four values”.
Accuracy of email spam detection using optimized models
The accuracy of the email spam detection using proposed and conventional optimization models by changing the learning percentages for the four datasets is displayed in Fig. 5. It can be seen that the proposed FLI-DA-CRNN achieved better accuracy when compared with several other optimization models. From Fig. 5(a), for dataset 1, at a learning percentage of 85%, the accuracy of the proposed FLI-DA-CRNN is 6.08% better than PSO-CRNN, 4.52% better than GWO-CRNN, 6.56% better than WOA-CRNN, and 3.93% better than DA-CRNN. On considering Fig. 5(b), at a learning percentage of 75% for dataset 2, the accuracy of the proposed FLI-DA-CRNN is 3.42% better than PSO-CRNN, 2.95% better than GWO-CRNN, 2.02% better than WOA-CRNN, and 1.45% better than DA-CRNN. While Fig. 5(c) is taken into account, for dataset 3, at a learning percentage of 85%, the accuracy of the proposed FLI-DA-CRNN is 4.64% improved than PSO-CRNN, 2.67% improved than GWO-CRNN, 3.24% improved than WOA-CRNN, and 5.36% improved than DA-CRNN. In Fig. 5(d), for dataset 4, at a learning percentage of 85%, the accuracy of the proposed FLI-DA-CRNN is 3.2% progressed than PSO-CRNN, 2.03% progressed than GWO-CRNN, 3.32% progressed than WOA-CRNN, and 2.15% progressed than DA-CRNN. Hence, it can be confirmed that the proposed FLI-DA-CRNN performs better email spam detection when it is differentiated from several existing optimization models.

Accuracy of email spam detection using proposed and conventional optimization models by varying learning percentages for (a) Dataset 1, (b) Dataset 2, (c) Dataset 3, and (d) Dataset 4.
The accuracy of the email spam detection for improved security using the deep learning models for four datasets at various learning percentages are given in Fig. 6. For the four datasets, the accuracy of the proposed FLI-DA-CRNN seems to be high in all the varying percentages. In Fig. 6(a), at 85% learning percentage for dataset 1, the accuracy of the proposed FLI-DA-CRNN is 23.29% superior to CNN, 21.62% superior to RNN, and 4.65% superior to CRNN. On seeing Fig. 6(b) for dataset 2, at a learning percentage of 75%, the accuracy of the proposed FLI-DA-CRNN is 23.29% upgraded than CNN, 28.57% upgraded than RNN, and 2.27% upgraded than CRNN. When taking Fig. 6(c), for dataset 3, at a learning percentage of 85%, the accuracy of the proposed FLI-DA-CRNN is 28.57% surpassed than CNN, 25% surpassed than RNN, and 5.88% surpassed than CRNN. While considering Fig. 6(d), at a learning percentage of 85% for dataset 4, the accuracy of the proposed FLI-DA-CRNN is 28.57% advanced than CNN, 32.35% advanced than RNN, and 2.27% advanced than CRNN. Thus, it is revealed that the email spam is detected accurately by the proposed FRI-DA-CRNN.

Accuracy of email spam detection using deep learning models by varying learning percentages for (a) Dataset 1, (b) Dataset 2, (c) Dataset 3, and (d) Dataset 4.
The accuracy of email spam detection using proposed and conventional machine learning models at various learning percentages for four datasets are shown in Fig. 7. This figure describes that the accuracy rises for all the datasets at various learning percentages by the proposed model. In Fig. 7(a), in the case of dataset 1, at a learning percentage of 75%, the accuracy of the proposed FLI-DA-CRNN is 6.02% better than DT, 7.32% better than KNN, 8.64% better than SVM, and 4.76% better than NN. Similarly, from Fig. 7(b) for dataset 2 at 85% learning percentage, the accuracy of the proposed FLI-DA-CRNN is 9.76% improved than DT, 8.43% improved than KNN, 9.76% improved than SVM, and 12.5% improved than NN. At a learning percentage of 75% from Fig. 7(c) for dataset 3, the accuracy of the proposed FLI-DA-CRNN is 7.14% progressed than DT, 9.76% progressed than KNN, 8.43% progressed than SVM, and 9.76% progressed than NN. When Fig. 7(d) is viewed, for dataset 4, at a learning percentage of 75%, the accuracy of the proposed FLI-DA-CRNN is 3.61% superior to DT, 7.5% superior to KNN, 6.17% superior to SVM, and 4.88% superior to NN. These results demonstrate that the proposed FLI-DA-CRNN provides superior email spam detection compared with various machine learning models.

Accuracy of email spam detection using proposed and conventional machine learning models by varying learning percentages for (a) Dataset 1, (b) Dataset 2, (c) Dataset 3, and (d) Dataset 4.
The overall performance analysis on email spam detection using proposed and conventional optimization models, deep learning models, and proposed and conventional machine learning models are listed in Table 5, Table 6, and Table 7. The analysis demonstrates that the Type I measures shows an increased output with the proposed method, and Type II measures show a decreased output with the proposed method, which denotes the superiority of the presented technique. From Table 5, while considering dataset 1, the accuracy of the proposed FLI-DA-CRNN is 6.06% advanced than PSO-CRNN, 4.70% advanced than GWO-CRNN, 6.52% advanced than WOA-CRNN, and 3.81% advanced than DA-CRNN. While from Table 6, for dataset 2, the accuracy of the proposed FLI-DA-CRNN is 17.38% better than CNN, 18.83% better than RNN, and 2.26% better than CRNN. In Table 7, while considering dataset 3, the accuracy of the proposed FLI-DA-CRNN is 14.93% improved than DT, 12.24% improved than KNN, 10.32% improved than SVM, and 12.24% improved than NN. Similarly, for dataset 4, the accuracy of the proposed FLI-DA-CRNN is 8.54% progressed than DT, 11.48% progressed than KNN, 7.37% progressed than SVM, and 7.87% progressed than NNN. The outcomes indicate that better spam detection is performed by the proposed FLI-DA-CRNN compared with the traditional optimization models, deep learning models, and machine learning models.
Overall analysis on email spam detection using proposed and conventional optimization models for four datasets
Overall analysis on email spam detection using proposed and conventional optimization models for four datasets
Overall analysis on email spam detection using deep learning models for four datasets
Overall analysis on email spam detection using proposed and conventional machine learning models for four datasets
The overall analysis of the ensemble approach for four datasets is shown in Table 8. Here, we introduce new classifiers such as Adaboost, Voting_classifier, and LSTM_CNN. Adaboost classifier integrates many classifiers for enhancing the accuracy of the classifiers. Voting_classifier combines many machine learning classifiers for classification and detection. LSTM_CNN is used for detecting fake news.
An overall analysis of the ensemble approach for four datasets
An overall analysis of the ensemble approach for four datasets
The error analysis of the proposed method over the conventional models is shown in Table 9. It is confirmed that the proposed model overcomes the existing models for email-spam detection.
Error analysis of proposed and existing works
Error analysis of proposed and existing works
The analysis of the execution time for the algorithm analysis and the classifier analysis was shown in Table 10, Table 11, and Table 12. From the algorithm analysis, the algorithmic time of the PSO, GWO, WOA, DA, and the proposed FLI-DA-CRNN were 450, 421, 398, 356, and 348 seconds. From classifier analysis 1, the classifier time of the CNN and RNN is 450, 421 seconds. The classifier time of both the CNN and RNN was 398. The classifier time of the proposed FLI-DA-CRNN was 348 seconds. From classifier analysis 2, the classifier time of DT, KNN, SVM, NN, and the proposed FLI-DA-CRNN were 192, 189, 186, 179, and 171, respectively.
Execution time for algorithm analysis
Execution time for algorithm analysis
Execution time for classifier analysis 1
Execution time for classifier analysis 2
A novel spam detection model for improved cybersecurity has been developed in this paper. The benchmark dataset of the email was collected in the first step, which was included with both text and image datasets. Next, the feature extraction was done using text features and visual features. The frequency count of spam words like Term Frequency-Inverse Document Frequency (TF-IDF) was extracted in the text features. The color correlogram and Gray-Level Co-occurrence Matrix (GLCM) were determined in the visual features. Further, the optimal feature selection process was done to minimize the length of the extracted feature vector. The optimal feature selection and the hidden neuron optimization of CNN and RNN are done by the proposed Fitness Oriented Levy Improvement-based Dragonfly Algorithm (FLI-DA). In the next step, the hybrid deep learning technique with RNN and CNN has performed the detection. As an improvement, the count of hidden neurons of both RNN and CNN was optimized by the same FLI-DA. In the final step, the optimized hybrid learning technique with Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) classified the data into spam and ham. From the analysis, the accuracy of the proposed FLI-DA-CRNN is 14.93% better than Decision Tree (DT), 12.24% better than K-Nearest Neighbour (KNN), 10.32% better than Support Vector Machine (SVM), and 12.24% better than Neural Network (NN). The outcomes show that better spam detection is performed by the proposed FLI-DA-CRNN when compared with the other optimization models, deep learning models, and machine learning models. Hence, the experimental results revealed the superiority of the developed method in detecting email spam in a very effective manner.
Future work
Even though the visual and textual features have many advantages, there are some results gets affected because of the proposed classification model. This misclassification will be sought out in the future by developing an innovative and highly performable deep learning model. More image datasets will be considered for experimentation in the future.