
Abstract
Web archives store born-digital documents, which are usually collected from the Internet by crawlers and stored in the Web Archive (WARC) format. The trustworthiness and integrity of web archives is still an open challenge, especially in the news portal domain, which face additional challenges of censorship even in democratic societies. The aim of this paper is to present a light-weight, blockchain-based solution for web archive validation, which would ensure that documents retrieved by crawlers are authentic for many years to come. We developed our archive validation solution as an extension and continuation of our work in web crawler development mainly targeting news portals. The system is designed as an overlay over a blockchain with a proof-of-stake (PoS) distributed consensus algorithm. PoS was chosen due to its lower ecological footprint compared to proof-of-work solutions (e.g. Bitcoin) and lower expected investment in computing infrastructure. We based our prototype on the open-source Nxt blockchain and implemented it in Python. The prototype was tested on web archive content crawled from Hungarian news portals at two different timestamps with more than 1 million articles in total. We concluded that the proposed solution is accessible, usable by different stakeholders to validate crawled content, deployable on cheap commodity hardware, tackles the archive integrity challenge and is capable to efficiently manage duplicate documents.
Introduction
Web archives are snapshots of web content collected by processes called crawlers. The contents of such web archives are trusted only as much as the institutions or individuals who created them, e.g. we can (mostly) trust the archives stored by national archives in democratic societies are unaltered and stored as they were crawled in the past. These repositories may become targets of hacking attempts aiming to reduce consensual trust and cause confusion in order to increase the value of certain preferred, ‘alternative’ information sources. This is an open societal challenge, as there is broad consensus about the significance of being able to research and access web content which was available five, ten or even more years ago. Unfortunately, there are various reports about attempts to alter web archives or the original content (i.e.’cancel culture’). If a content sought to be removed is still available in the archives and can be used as proof, soon the archives will be the next target. That is an additional reason warranting the development of solutions which distribute trust and allow different stakeholders (e.g. archive holders and researchers) to participate in the validation of at least the archived content.2
As the number of content providers is orders of magnitude greater than the number of memorial institutions, it is easier to develop and test a standard workflow and extend it to the scale of the content providers.
Our goal is therefore to propose a blockchain-based web archive validation solution which tackles trust, is simple and cheap to implement. It should be accessible to different web archive stakeholders, e.g. national archives, research institutions and groups, as well as the general public. Essentially it can be one piece of a puzzle allowing future generations to enjoy and research the Internet as it was in the past.
Born digital (cultural) heritage can be regarded as an unwanted orphan: most undertakings in the domain face lack of financial resources (i.e. formal funding) and entirely rely on the competence and enthusiasm of the human element involved [26]. Web archives are used for long-term storage of (usually static) born-digital documents harvested from the web [11,12,15,16,42]. They allow content to be replayed in the future in close resemblance to their original versions at the time of capture [4,5]. The Internet Archive’s (IA) Wayback Machine [17] is the largest web archive.3
Internet Archive, https://archive.org/.
The above initiatives aim to address real-life threats of censorship and tampering in web content with trusted archives, which is a justified research and development effort, as there were reports about manipulated web content (e.g. politically-correct (PC) speech and ‘cancel culture’ in general) and even archives, e.g. blog posts in the Wayback Machine [8]. Lernet et al [23] go one step ahead and present proof-of-concept attacks for showing deliberately modified resources to users without tampering with the archive content itself.
Additional important challenges in web archives are duplicates, as well as inaccurate or missing metadata and unwanted boilerplate text [13,24,27,33]. Countering the above-listed challenges in the web archival domain is a task which is yet to be fully solved. Currently trust is reputation-based, which means that we either trust an institution or individual maintaining a web archive, or we do not.4
Trust in the institution can therefore be easily manipulated by pulling emotional strings and reduce its popularity and therefore the trust within.
Based on the above we concluded that data acquisition, storage, retrieval, analysis, indexing/searching and visualization are the key topics and challenges both practitioners and researchers active in the web archival domain try to face. Conservation and preservation are on the radar but defined as concepts of lesser relevance. Security in general with topics such as trust, integrity (i.e. protection against alteration), censorship and other forms of unwanted filtering and modification are seldom addressed issues in digital heritage in general and web archives specifically [26, Fig. 14].
As we stated above, researchers and practitioners of web archiving prioritize practical problems of storing and searching web crawled data to more complex activities of heritage curation as conservation and preservation. There is also an obvious lack of trust in the research communities which in many respect goes back to the complexity to handle web crawled material as well as to the way memory institutions curate their collections. Within this context we specifically focus on stakeholder trust in web archival solutions on the metadata, document and political levels.
Metadata level
Although certain efforts aim to standardize the process and shape future web archives, they are confined to the metadata level [1]. The textual level of web content curation is not standardized, and this drawback is the main reason that born-digital material, and, more specifically web archives, are underrepresented in current scientific research compared to analogue or digitized sources. The fact that there are certain efforts to standardize the metadata describing crawled documents does not mean that there are adequate amounts of high quality metadata available to researchers. A scientific citation of a source must contain stable authorship and temporal metadata to fulfil scientific standards and these are most often lacking in the case of born-digital sources [39].
The Internet mostly consists of discrete documents (scientific papers, news articles, forum posts, product descriptions and ratings, etc.), which contain (at least implicitly) metadata. These metadata are often treated as secondary if it comes to maintaining or standardising them to facilitate usage in (internal) archives or global search engines.5
Such big companies have the resources to handle diverse documents at scale therefore they can quickly become the target of censorship and prone to lose trust.
Documents crawled from the web lack three other important features which hinder their use in research as trusted sources. (1) There are identical or, what is worse, nearly-identical versions of the “same” document available in a web archive crawled at different timestamps. In current web applications, an HTML document can be different in a crawl done within seconds as it is generated on the fly by portal engines. (2) The textual integrity of a born-digital object is far more complex than that of an analogue one, as the distinguishing between dirt (boilerplate) and the actual content is often more than a simple technical decision. (3) As web documents are easily alterable, it is very hard to track the actual agent and the motivation of the changes, which, in many cases are done by purely technical actors, sometimes by the authors/editors themselves for various reasons and extent, and sometimes by malicious algorithms or personae.
Luckily, there are good examples of versioned, collaboratively edited, born digital knowledgebases e.g. Wikipedia and its derivatives. They adhere to most of the aforementioned technical requirements. There is also Wordpress an open source CMS system which owns more than half of the market in 2021.6
https://www.tooltester.com/en/blog/cms-market-share/ last accessed, 2021/10/01.
Traditional archives have always been embedded in a context of power, channelling access to the past, in more ways than one. On the one hand, by regulating the entry of documents into the archives, and on the other, by organising the archive’s material in a way that determined what was searchable in the sea of documents. Thirdly, by regulating who has access to the documents.
This complex system, which Cornelia Vismann describes so thoroughly [35], has only become more complex as culture, as Manuel Castells puts it, is now being digitally mediated [9]. Over the two-decades-long history of web archiving [38], the stakeholders directly involved in the archiving process have become increasingly heterogeneous. The first and most pressing problem is that a good part of the web communication to be archived today is in the hands of companies whose services have themselves become archives. However, they are even less able than traditional archives and international or national web archives to meet the strict principles of archiving and curation: reliability, stability and transparency. There are a great number of well-documented examples of such data destruction or loss, as the closure of GeoCities by Yahoo! in 2009 or the data loss from MySpace following “a server migration”7
Chokshi, N. (2019). Myspace, once the king of social networks, lost years of data from its heyday. New York Times. https://www.nytimes.com/2019/03/19/business/myspace-user-data.html last accessed, 2021/10/01.
The delicate and precarious balance between service providers, content producing institutions and individuals, international and national web archiving initiatives, and the growing number of audiences (academics, politicians, companies, individuals) who use the results of web archiving is also threatened by the uncertainty of the legal environment. One symbolic example is the attack by publishers on the Internet Archive.8
https://blog.archive.org/2020/07/29/internet-archive-responds-to-publishers-lawsuit/ last accessed, 2021/10/01.
But it is not only political power that can be confronted with the practice of web archiving but also the private sphere of the individual. This is illustrated by the case of Tumblr’s decision to delete 700,000 blogs classified by the AI tool as containing prohibited sexual content. Volunteers made a desperate attempt to archive the material,9
Captain, S. (2018). The frantic, unprecedented race to save 700,000 NSFW Tumblrs for posterity. Fast Company. https://www.fastcompany.com/90279321/the-frantic-unprecedented-race-to-save-700000-nsfw-tumblr-for-posterity last accessed, 2021/10/01.
It is even possible that civil initiatives with an otherwise obviously indispensable memory policy function, such as Documenting the Now, which aims to archive the social media presence of social movements, will confront the global web archiving institution, the Internet Archive, in order to protect the security of individuals [28].
One of the many challenges facing web archiving and maybe one of the largest is responsiveness. The CODIV-19 pandemic has shown that the centuries-old policy architecture of traditional archives is unsustainable in a born-digital culture and that documenting sudden environmental and social changes requires archivists to react with a speed previously unimaginable. The difficulties of web archiving at the data and policy level mean that it is almost impossible to maintain a stable consensus among all stakeholders, which would be a prerequisite for building trust in web archives and for embedding the whole practice in society. We, therefore, argue that, in addition to the trust that can be achieved discursively, greater emphasis should be placed on achieving trust through technical means. Therefore it is very complicated, maybe even impossible to provide solutions for each of the above problems. In the following, we summarize the threats faced by web archives and propose a blockchain-based solution which solves at least some of the challenges identified.
In threat modelling one attempts to think like an attacker and identify threats to different assets of a system, taking into consideration assumptions about the capabilities of the potential threat sources (i.e. attackers). In most threat modelling approaches it is necessary to create an inventory of relevant assets, list potential threat sources (attackers) and utilize a proper framework for identifying threats [7]. Microsoft’s STRIDE is commonly used to group threats into six broad categories from whose names it obtained its abbreviation, namely: spoofing identity, tampering with data, repudiation threats, information disclosure, denial of service and elevation of privileges [32].
The assets we aim to protect with the WARChain system are born-digital documents. In the context of our specific analysis, we focused on the protection of newspaper articles published by news portals. We performed an attacker-centric threat modelling and identified the following categories of threat sources, which were actually the usual suspects targeting most types of infrastructures, but with different motives in our specific context:
Nation states – either democratic or autocratic states which push propaganda or target content which is not aligned with their national interests, e.g., criticism against a certain government.
Affected external individuals e.g., influential politicians or businessmen intent on hiding or modifying content published about their activities.
Criminal organizations, which are either hired by nation states or individuals to perform attacks, or are intent to modify born-digital articles for their own purposes.
Companies, mainly multi-nationals intent on covering up or shaping facts published by independent journalists.
Insiders employed by the news portals or their subcontractors motivated by financial rewards, revenge or ego.
We analyzed the current ecosystem of online news portals and their usual data management and backup policies and identified the following most important threats grouped into the STRIDE categories:
Spoofing: (1) Hide or alter the true identity of the original author or entity modifying a news article;
Tampering: (2) Data integrity attacks against accessible news articles (e.g., tampering with news portal data), (3) backup or historical data integrity attacks (e.g., modifying a news entry in the Wayback machine) or (4) fake news generation and insertion.
Repudiation: (5) Claim that a news entry was created or modified by somebody else.
Information disclosure: (6) Disclose author information for articles with sensitive content e.g., criticism against an authoritarian government, potentially leading to arrests and prosecution.
Denial of service: (7) Intentional harm caused to data storage devices in a data center or backup facility with the ultimate goal to render certain born-digital documents unavailable for good.
Elevation of privilege: (8) News portals back office access and privilege escalation or (9) the same attack in backup systems used to store historical newspaper article data. These threats can results in (often) untraceable spoofing, tampering, repudiation or information disclosure. Essentially this threat category is an enabler for other threat categories in our specific context.
We will show that our proposed solution successfully tackles a significant subset of the challenges identified in this section. More specifically, it will be a valuable asset in countering spoofing, tampering and repudiation threats.
Solution
We propose to introduce a system architecture shown in Fig. 1, which consists crawlers, validators, archived content storage and consumers. Crawlers, storage and consumers are components in existence and out of scope for this paper. Crawlers harvest document from the web [18], stored in archives (depicted by the WARC [15] Store processes) and subsequently used by consumers. The key novel elements of the proposed WARChain (this name was coined as a combination of the words’web archive’ and’blockchain’) system are the validator processes. The task of these proposed nodes is to participate in a distributed consensus algorithm with the goal to validate each new web archive entry deposited by the crawlers, as well as to certify the validity of each entry when requested by peer nodes or archive consumers depicted by the laptops in the bottom right of Fig. 1. This solution is intended to replace similar, informal validation systems based on document hashes and institutional document repositories (e.g. in Zenodo communities10
Zenodo, https://zenodo.org/.
We consider crawlers, storage nodes and validators as trused elements of the global web archival ecosystem, which might be targeted by the diverse threat sources identified in Section 4. Consumers are not necessarily trusted and might be considered as potential threat sources. We further propose that the validators reach distributed consensus by relying on a proof-of-stake (PoS) blockchain and majority voting. We advocate for the use of PoS as opposed to proof-of-work (PoW) solutions, which consume significant amounts of computing power and electricity, thereby increasing their ecological footprint i.e., they are dirty solutions. The ‘stake’ in such a system would not be measured by the size of financial deposits, but instead by the trust placed in the institutions participating in the system which host the validator nodes. The trusted systems are depicted in Fig. 1 by the icons of academic and government institutions, which can be national archives, universities or other trusted institutions. One such participating institution could host different node types, e.g. a university or other research outfit might host a crawler, a storage node, one or more validators and customers, who in this context would be the researchers accessing the trusted web archives.
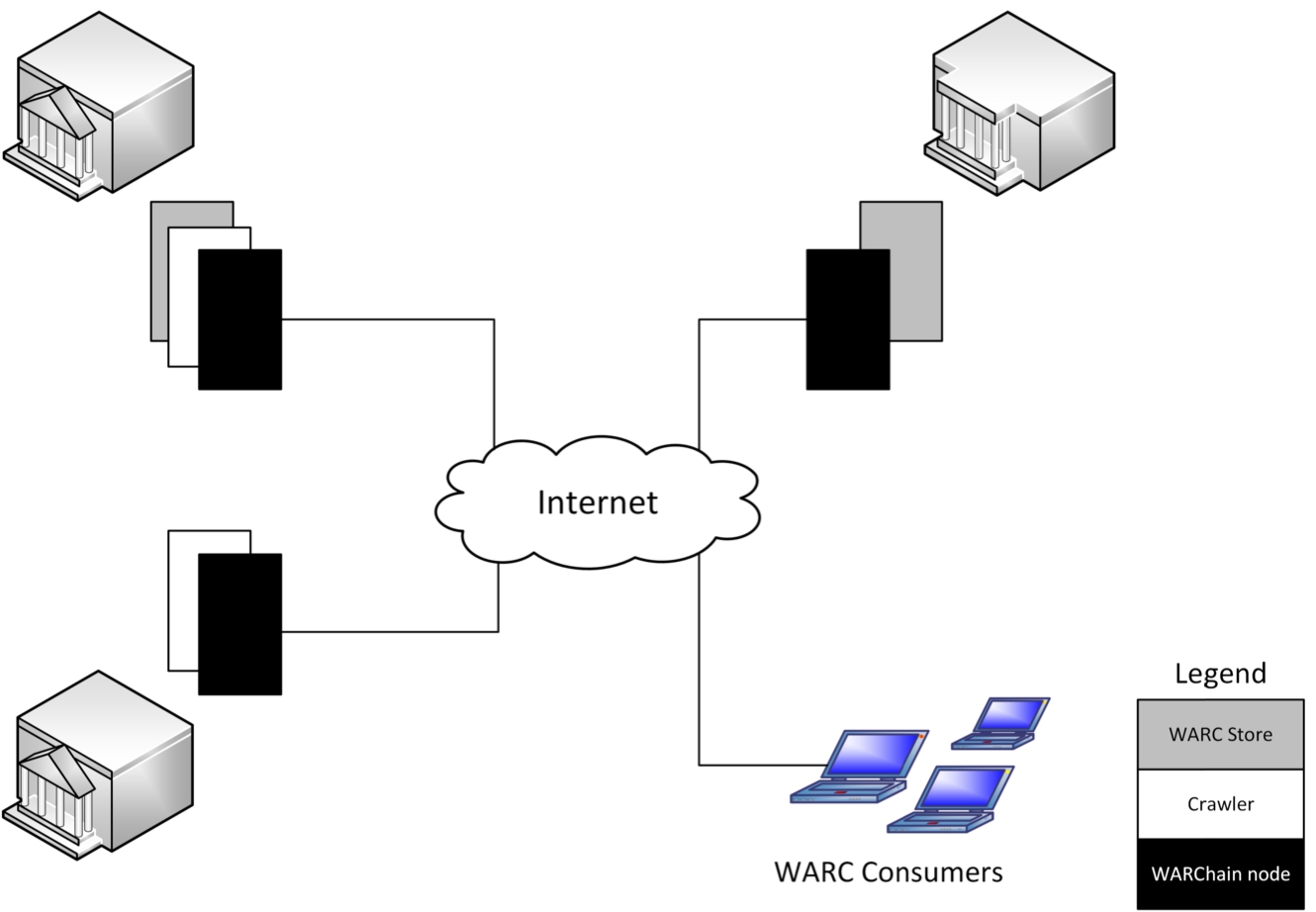
WARChain system architecture.
In our proposed architecture not all node types participate in the PoS blockchain, more specifically only the WARChain validator nodes participate in it. Validators might be hosted only by trusted institutions, which stake the public trust put in them while participating. Ideally, only national archives and highly respected higher education and research institutions would be allowed to delegate validator nodes to the system, thereby making it a semi-private blockchain used for a specific purpose. This is different from the general-purpose blockchains usually utilized by cryptocurrencies and other common usage scenarios. The authors of the ARCHANGEL solution [10] present a somewhat similar solution, but with the notable difference of relying on a public proof-of-work blockchain, which wastes significant amounts of energy as well as not formally introducing the different node types shown in Fig. 1.
Essentially, we propose an extension of the existing systems in which web archives are crawled and stored in storage nodes utilizing on-premise or cloud-based glacier storage which can be rented even on a limited budget. The novel processes participating in the WARChain are used only for storing the limited information necessary for web archive validation. We propose a system in which trusted crawlers harvest documents from the web, persist them into the storage nodes as well as generate tuples of additional validation information consisting of the following pieces of information:
Crawler process or institution identifier. Storage complexity: up to 128 bits for a globally unique identifier.
Crawl date. The timestamp of document crawl. Storage complexity: up to 64 bits for a Unix timestamps.
URL hash. A hash of the URL of the crawled document. Storage complexity: 256 bits (if SHA256 is used).
Document hash. A hash of the document harvested from the URL specified. Storage complexity: 256 bits.
The above tuple ensures that each raw document stored in the storage archive has a unique and irrefutable link to its corresponding block and/or transaction within the blockchain, i.e. the crawler identifier, crawl date and URL hash uniquely identify a web document crawled by a specific crawler at a specific time.
We propose to use strong one-way hashing functions (e.g. SHA256) which are expected to be available and secure for many years to come. Additionally, the chosen hashing function should be ready for the coming age of quantum computers, i.e. able to resist hacking attempts performed on novel quantum computers of ever increasing strength.
The storage complexity of this solution is limited as for each (id, timestamp, URL hash, document hash) tuple we propose to introduce up to 704 bits (128 + 64 + 256 + 256 bits) of additional data per web document. Considering that the Bitcoin block-chain’s size exceeded 350 GB in November 2021,11
an equally sized WARChain would be able to contain a theoretical maximum amount of information about up to 0.535 billion documents, which is about 14% of the actual size of the currently indexed Web (3.8 billion pages).12 Obviously, an implemented version would have slightly higher storage consumption, but would still be able to contain validation information about large portions of the indexed Web, while having a similar storage complexity to Bitcoin. Based on the above calculation we theorize that WARChain could theoretically contain validation information for web archives containing the entire indexed web, while running on a general-purpose personal computer with storage devices available today, e.g. on a few disk drives with 1–2 TB capacity.In Fig. 1 we visualized crawlers, storage, validators and consumers. Our team implemented and experimented with all of the listed components. We discussed crawlers and storage in [13] and [14]. As a proof-of-concept we implemented the WARChain as an overlay over the open-source Nxt proof-of-stake blockchain and published our prototype on Github.13
In this section we discuss the implementation of the WARChain and its underlying infrastructure in more detail.Instead of the EduPoS blockchain prototype utilized in reference [22], this research was based on the Nxt proof-of-stake blockchain.14
Nxt was chosen as it is easy to install, it is open source, has an easy-to-use web-based application programming interface and implements a proof-of-stake distributed consensus algorithm which is less energy intensive compared to proof-of-work solutions like Bitcoin.Nxt’s private blockchain evaluation kit15
is an Nxt bundle which is easy-to-deploy and suitable for academic research and evaluation. A notable potential drawback of Nxt in our use case is that it is published under the Jellurida Public License (JPL). JPL is an extended version of GPL with the addition of an airdrop requirement if a developer decides to create an Nxt fork and use it as a cryptocurrency.16 Fortunately, this limitation did not materialize in our case, as we did not use our Nxt-based blockchain for cryptocurrency.The Nxt evaluation kit comes with ten genesis blocks which allowed us to start experimenting with an empty blockchain, but with multiple usable and well-funded accounts. The existence of funds was relevant as both cryptocurrency transfers and sending messages incur fees in Nxt.
Each WARChain validator node was an Nxt peer, i.e. a full member of the Nxt blockchain. Our additional code implemented the following domain-specific functionality:
A searchable dictionary of (URL hash, document hash) pairs.
A counter and reporting capabilities for duplicate entries.
Detection and reporting of potentially tampered-with documents which are reachable via a shared URL, but differ between crawls.
The validator nodes worked with (crawler id, crawl time, URL hash, document hash) tuples. One example tuple serialized to JSON is shown in Listing 1.

Document hash representation in JSON
The document and URL hashes were created with the SHA256 cryptographic one-way function with an empty salt value in this example. SHA256 is considered a strong one-way function, which will most probably remain secure for an extended period of time.
As we intended to work with large WARC files [15] and switch between different versions of our prototypes, we needed an efficient way to experiment with real-life WARC files. Therefore, we decided to implement a crawler simulator in Python. Stage one of the simulator works with WARC files by relying on the WARCIO streaming library.17
It extracts URL and article data and saves them to easily accessible Excel and comma separated formats. We decided to extract the newspaper articles from archives we worked with, i.e. we focused only on article text and removed the HTML markup and media files by relying on existing functionality in the BeautifulSoup library18 and our own custom WARC content filtering.Stage two of the simulator loads the cleaned URL and article data, creates transactions and pushes them into the WARChain. This part of the simulator was wrapped as a console application.
We started our experiments with the assumption that the implementation of the underlying Nxt proof-of-stake blockchain was correct and that it inherently supported distributed consensus and immutability of blocks. Further, we assumed that the data stored inside the chain is unchangeable even in the presence of one or more malicious participants in the system depicted in Fig. 1. Instead of checking the functionality of the underlying blockchain, our intention was to show that the proposed WARChain system can run effortlessly on commodity computer hardware and that it manages duplicate entries and integrity checking in the web archival context. Along this line of thought, our first experiment focused on the efficiency and ease of use of the system, followed by the verification of the system‘s strong integrity validation and duplicate management capabilities.
Overview of the experimental setup
Overview of the experimental setup
We conducted our experiments in a setup which consisted of the following elements (see Table 1 for a summary):
One or more crawler simulators implemented in the Python programming language. The simulators extracted articles from WARC files which contained web pages crawled from a newspaper portal [14]. The WARC content was crawled at two different dates and the two archives contained 467115 and 592896 article entries.
The WARChain consisted of a varying number of nodes.
As an efficient way to compare both article text and URL values between the two archives, we hashed them with SHA256 and compared those hash values when looking for exact URL/article matches.
We ran the Nxt private evaluation kit with default, out-of-the-box settings – we configured only the known peers. The experiments were run on a high-end personal computer with an Intel i7-9750 CPU, 16 GB RAM and a pair of non-raid SSD drives.
The specific goal of our first experiment was to show that the proposed solution is not just easy to deploy, but also able to run on commodity personal computers, thereby allowing any stakeholder with limited funds to install it on any computer with an appropriate network connection. The starting point of the experiment was a WARChain system with of a single validator node. We populated the validator node by running one crawler simulator, taking the smaller WARC file (467 thousand entries) as input. For simplicity, our experimental setup did not include any storage nodes. This setup was similar to a situation in which a single institution implemented a single WARChain node which was then populated by document descriptions created by a single crawler process. It is important to note that we started this experiment with a completely empty ledger (i.e. blockchain).
We did not explicitly control the process in which Nxt grouped transactions into blocks. We serialized the tuples corresponding to separate web documents to JSON and experimented with different numbers of such descriptions in a single message submitted via Nxt’s SendMessage API function. We listed a subset of messages sent in this manner in Nxt’s web-based graphical user interface and include it in Fig. 2.
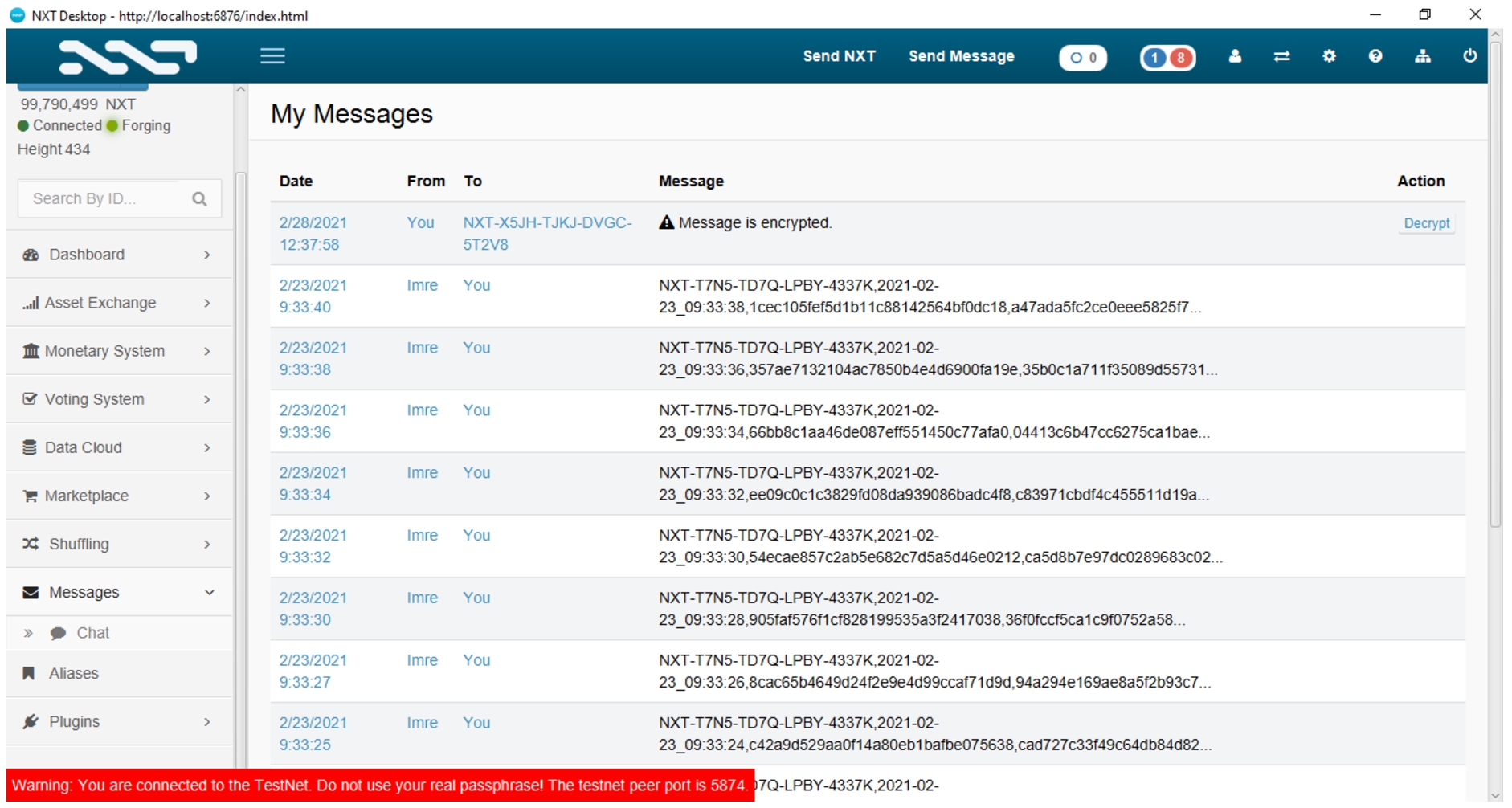
JSON-serialized document descriptions in the Nxt user interface.
We sent the messages to a well-known genesis account which comes as part of the default Nxt private blockchain evaluation kit. For simplicity, we did not use message encryption in our experimental setting. This configuration can be changed if necessary as it would be sufficient that trusted, legitimate blockchain users knew the passphrase corresponding to the account and could load its messages for web archive validation purposes.
As one JSON was roughly 200 bytes long and SendMessage allowed prunable19
Prunable messages are moved from the blockchain to long-term storage after a specified time.
We measured the memory and time complexity of populating a single WARChain node. Our measurements are shown in Table 2. Memory consumption was measured as the memory used by the single validator node running on the high-end personal computer we used during our tests. Memory use was moderate considering that Nxt is implemented in Java.
Memory consumption and average transaction time
The average transaction time was measured via the time necessary to submit 100 tuples created for the documents in the input archive and serialized to JSON. We were somewhat perplexed by the fact that sending a message to the Nxt blockchain took two seconds on average, regardless of message size, which we varied between JSON strings corresponding to 1 through 35 documents as stated above. We attributed this seemingly sluggish performance to the default Nxt configuration we used in this experiment and did not attempt to tweak the performance of the underlying blockchain. As in this experiment we had only a single validator node, our time complexity measurements did not include the overhead caused by the communication infrastructure and the distributed consensus algorithm. Considering that an actual deployment of the WARChain would consist of a smaller number of nodes, the time to validate transactions can and should be significantly lower than the currently measured 5–10 minutes available in Bitcoin20
or Ethereum.21Based on our first experiment we concluded that the WARChain is easy to deploy, the validation code can be quite simple (at least in the context of the Nxt PoS blockchain), as well as that time and computing complexity are limited. This experiment also showed that the WARChain is able to act as an immutable platform for storing information about web crawls conducted by different actors, guaranteeing the integrity of documents potentially crawled in the past and no longer available.
We were surprised that Nxt was somewhat slow when running it with its default configuration and we intend to investigate this further as part of our future work. Even if it turned out in the future that Nxt could not perform better, we expect that there will be other similar solutions with higher throughput to which we could easily port the WARChain system.
The specific goal of our second experiment was to test the system’s capability to efficiently detect and report alterations in web documents collected by crawlers at different timestamps and by different WARChain stakeholders. We started by repeating experiment #1 and followed that up by running the crawler simulator on the second, extended dataset collected from the same news portal at a different timestamp. This second web archive consisted of 592,896 entries as mentioned above. Again, and similarly to the previous experiment, we submitted Nxt messages consisting of 35 document descriptions encoded in JSON (see Section 1 for details). We expected the system to be capable to discern the following types of document entries:
New entries which were included only in the second archive.
Modified entries which existed in both archives, but were different.
Removed entries which were inside the first, smaller dataset, but not included in the second, larger WARC file.
We found that the overlap between the two archives was only partial as 173,784 URLs were shared between the two archives (about 37% overlap). We did not find document discrepancies between the two datasets which would point to possible integrity issues caused by either planned corrections, tampering or censoring. More specifically, this meant that we found 173,784 shared URL hashes between the two datasets and the corresponding article hashes were (also) equal. Thereby we concluded that there were no alterations made to documents between the collection times of the two web archives we used in our experiments. Table 3 summarizes these findings.
Document validation across multiple web archives
Document validation across multiple web archives
We were surprised to see a smaller than expected overlap between the two archives, which we intend to investigate in the future, i.e. we intend to find out why only 37% of the articles were shared between the archives collected at different times from the same news portal. It was either caused by a change in the crawler implementation, or there might be more sinister reasons behind this finding.
We decided against measuring the average time it took to perform a single integrity check, as we reckoned that it is near zero compared to the length of other tasks performed in the system, e.g., the crawling process and reaching distributed consensus in the underlying proof-of-stake blockchain.
In our third experiment we wanted to assess the merits of the proposed solution in duplicate document detection. We initialized a slightly different experimental environment with a blockchain consisting of two validator nodes and ran two crawler simulators which were inserting validation information at two different WARChain nodes – Table 4 contains the list of processes involved in this experiment. When looking at Fig. 1, this can be understood as if there were two black processes (validators) and two white processes (crawlers). We deployed this system on the mobile workstation specified in Table 1 and a different general-purpose workstation running the same version of the Nxt private blockchain. We configured the well-known peers for both blockchain nodes, thereby creating a single system. It is obvious that this setup could be easily scaled further by using cloud-based, containerized solutions or multiple workstations and/or servers.
Duplicate detection environment
Duplicate detection environment
With this experiment we tested the way the system would behave in a more realistic setting in which multiple web crawlers collect documents from potentially overlapping parts of the web. As the blockchain is not designed to perform update and delete operations, we allowed each crawler to create new transactions for each batch of crawled documents. This way the blockchain contained numerous (see Table 1 for a quantitative measure) transactions essentially describing the same archived content by different crawlers, i.e. there were duplicate transaction entries in the blockchain which differed only in the crawler identifier and/or crawl timestamp of the JSON representation shown in Listing 1. If the system were implemented on a global scale with participation of many validators and crawlers, then the above described duplicate data entry feature of the system would be quite useful in detecting duplicate crawling efforts carried out by different organizations and teams worldwide, as well as allowing cross-validation between the duplicate content crawled.
Another significant aspect of duplicate management are storage nodes and the duplicate storage of overlapping contents crawled by different digital archival projects. In this context we propose the WARChain to be used towards handling that sub-problem of duplicate management by allowing web crawling projects to check in the WARChain who crawled their target content and when, thereby allowing them to make decisions against storing duplicate content available in multiple locations. We intend to investigate this feature as part of our future research.
We stated that the long-term authenticity of web content by archives is an open scientific challenge. We approached this challenge by identifying the system’s key assets and common threat sources. We continued by applying the STRIDE methodology to pinpoint the most likely threats grouped into the spoofing, tampering, repudiation, information disclosure, denial of service and escalation of privilege threat categories. We then proposed to mitigate the majority of identified threats with WARChain, a light-weight, blockchain-based solution for web archive validation. The WARChain was implemented as an overlay on the Nxt proof-of-stake blockchain, thereby requiring less computing power compared to proof-of-work solution, like Bitcoin. Due to the high cost of storing data in any blockchain, we separated archive storage from the blockchain-based archive validation. The nodes participating in the WARChain store only tuples consisting of crawler identifier, archive date, URL hash and document hash. We thereby rely on two layers of cryptography, one to hash the URLs and documents, and the other to hash the blocks in the blockchain and thereby add immutability and authenticity to the web archival process.
We implemented the WARChain in Python and as an overlay over the Nxt proof-of-stake blockchain. We validated the solution by testing it on two medium-sized web archives crawled from a news portal and consisting of approximately 500,000 entries each. We extracted the article texts from the archived documents and worked with hashed URL and article values.
The experiments conducted showed that the system can run on cheap commodity hardware, it is capable to validate vast amounts of archived web content and is able to manage duplicate entries resulting from multiple overlapping crawls. If a similar system were deployed at multiple digital archives worldwide, we could distribute technological trust between those participants, who would ideally be national archives and research institutions. That kind of distributed trust and non-repudiation would ensure that the web archives created by crawlers are not tampered with and available for validation even many years in the future.
As future work, we intend to experiment with additional web archives, port the system to work on mainstream proof-of-stake blockchains as they become available (e.g. Ethereum Casper) and to implement a more fine-grained duplicate detection solution based on minhashing, i.e. to split the article texts into sentences or bags of words and store multiple hash values for each text document. As any PoS-based solution needs to somehow penalize misbehavior of nodes, which we still need to explore and experiment with in the future. On the deployment side we intend to package our solution as Docker image(s) and thereby ease its deployment on personal computers, servers or in the computing cloud.
Footnotes
Acknowledgment
This research was supported by the Institutional Excellence Program for Higher Education (FIKP) of the Republic of Hungary.