
Abstract
Nowadays, online services, like e-commerce or streaming services, provide a personalized user experience through recommender systems. Recommender systems are built upon a vast amount of data about users/items acquired by the services. Such knowledge represents an invaluable resource. However, commonly, part of this knowledge is public and can be easily accessed via the Internet. Unfortunately, that same knowledge can be leveraged by competitors or malicious users. The literature offers a large number of works concerning attacks on recommender systems, but most of them assume that the attacker can easily access the full rating matrix. In practice, this is never the case. The only way to access the rating matrix is by gathering the ratings (e.g., reviews) by crawling the service’s website. Crawling a website has a cost in terms of time and resources. What is more, the targeted website can employ defensive measures to detect automatic scraping.
In this paper, we assess the impact of a series of attacks on recommender systems. Our analysis aims to set up the most realistic scenarios considering both the possibilities and the potential attacker’s limitations. In particular, we assess the impact of different crawling approaches when attacking a recommendation service. From the collected information, we mount various profile injection attacks. We measure the value of the collected knowledge through the identification of the most similar user/item. Our empirical results show that while crawling can indeed bring knowledge to the attacker (up to 65% of neighborhood reconstruction on a mid-size dataset and up to 90% on a small-size dataset), this will not be enough to mount a successful shilling attack in practice.
Introduction
The world’s most valuable resource is no longer oil but data. Nowadays, many companies base most of their business on the data they own about users. The companies usually leverage this knowledge to build a user profile which is then used to provide a personalized experience. Advertising, for example, is one of the many applications in which designing good user profiles is crucial [16]. Another example is recommender systems (RSs), i.e., services that help users in finding what they want/like [17,21,35,41]. For instance, e-commerce sites like amazon.com invest significant resources in building accurate RSs to increase sales.2
State-of-the-art recommendation algorithms are based on the concept that similar users tend to be interested in similar products, for some notion of similarity. This similarity is often computed based on the history of the purchases/rates (called interactions in general) of the users with items. This approach is known as collaborative filtering (CF). The system must consider as much historical knowledge about the user as possible to get reliable similarities. Famous and successful companies (e.g., Amazon [35], Pinterest [21], or Netflix [17]) base their recommendation on information about the users-items interaction collected through the years among millions of users.
Although valuable for the companies, some of this information about users is disclosed through the web. Usually, this is done to improve the user experience. For instance, amazon.com publishes the users’ ratings and comments to allow users to get a better idea about the products. Additionally, other forms of aggregated information may be publicly available, such as the total number of reviews or an item’s average rating.
On the other hand, being public, this knowledge can be accessed by anyone who has an Internet connection. Thus, competitors can leverage it to improve their services. Potentially, a competitor can design a mechanism to collect as much public information as possible at almost zero cost and then use such “stolen” knowledge to its advantage. In an ideal case, this scenario could represent a substantial competitive advantage.
In this paper, we investigate whether collecting public information can be considered a real threat. Specifically, we design a straightforward and almost cost-free attack pipeline analyzing in what conditions it can be potentially successful and to which extent. To measure the value of the collected data, we compare how well we can estimate the similarity between users in the target system. We employ two different standard similarity measures [31,43], namely Pearson’s correlation and cosine similarity. Our analysis particularly stresses the data collection phase, which is often overlooked or given for granted by most of the literature about attacks on RSs [14,36], i.e., they assume knowing the full user-item rating matrix.
The described attack represents only one possible attack to RSs. The profile injection attack (also known as the shilling attack) is undoubtedly the most discussed type of attack in literature [23,29,38]. As the name suggests, the profile injection attack seeks to mislead the RS by injecting well-crafted fake users into the system. The type of damage provoked by fake user profiles depends on the attacker’s goal. There are three common goals:
This paper aims to fill the gap between the potential threat and the actual feasibility of a concrete attack to a recommendation service. We first examine different ways to collect public information through web crawling, assessing which strategies are the most efficient and effective. Considering the way items are displayed online, we also propose a crawling strategy, called
This paper is an extension of a recent work [1]. Specifically, this extended version adds the following contributions:
We added a new shilling attack, i.e., the sampling attack. This attack showed very different behaviors with respect to the other considered attacks, which led to new interesting considerations;
We included three new datasets in our analysis, namely
We improved several aspects of the experimentation procedure:
The rest of the paper is structured as follows. Section 2 presents the notation we use and crawling approaches. Section 3 describes the related work underlining the main differences with our analysis. Section 4 describes the methodology and assumptions used in our analysis. Section 5 describes the details of the datasets we used and presents our experimental results, along with a thorough discussion. Finally, Section 6 wraps up the main results of the paper with some insights about possible future research directions.
In this section, we summarize the notation (Section 2.1) and the background knowledge on crawling (Section 2.2) used throughout the paper.
Notation
We refer to the set of users of an RS with
Crawling a recommendation-based website
Personalized recommender systems are usually offered by online services, such as e-commerce (e.g., Amazon), streaming services (e.g., Netflix, Spotify), or social networks (e.g., Facebook, Instagram). The information about users, items, and ratings own by these services are usually (partially) publicly available. For example, in amazon.com, we can browse through the products’ pages and see the users’ reviews. It is also possible to visit the user page and check his/her previous public reviews. This allows a malicious user to automatically collect (for example, via a crawling bot) such information to design an attack against the recommendation service. Today’s online services are aware of this concern, and they defend their websites against automatic crawling. The most gentle countermeasure is responding with a control web page to check whether the requests come from a human or a machine. These control pages usually contain a captcha-based query [47], or tasks that are very simple for humans but “hard” for a bot.3
On the other hand, attackers can try to circumvent such defenses by using, e.g., VPN, proxy, and TOR.4
Nonetheless, maximizing the knowledge does not simply mean collecting as much data as possible but gathering the most informative data for the attacking purposes. This further adds complexity to the crawling task.
In the most general case, the crawling problem has already been studied by researchers in the context of search engines [13]. Even though the final aim is different, the optimization problem is the same. This problem can be seen as an unconstrained Travel Salesman Problem with incomplete information (i.e., partial knowledge of the graph). Thus, it is safe to assume that it is NP-hard. However, there are heuristic-based algorithms that allow crawling the graph efficiently. In particular, Cho et al. proposed the following crawling strategies [13]:
Related works
In this section, we discuss the related works regarding web crawling and the shilling attack.
Crawling
Crawling the web is almost as old as the World Wide Web itself [6,11,13,32]. The automatic algorithm that systematically browses the World Wide Web is called a web crawler, or spider/spiderbot. Search engines have been the first technology to rely on such an algorithm to index the web. The term crawler comes from the first search engine: the “WebCrawler”. Since their first appearance, many efforts have been devoted to increasing the crawling procedure’s efficiency and effectiveness [2,18,33]. Focused web crawling [10] is one of the main strategies to improve the crawling quality in specific contexts. Focused web crawling is a procedure that collects Web pages satisfying some specific properties by prioritizing the so-called crawl frontier. The crawl frontier is the set (usually implemented as a queue) of known but not yet visited web pages. However, it is not always easy or feasible to define properties that can help focus the crawling. Since our analysis focuses only on the graph’s structure, one of the most promising properties is the PageRank [37] of a page. Unfortunately, PageRank is useful when computed on a complete graph, while on a partially known graph is not so accurate [26,27].
Crawling algorithms have also been influenced by artificial intelligence (AI). iRobot [9] has been one of the first crawler-based on AI technologies. iRobot uses clustering combined with a Prim-like algorithm [20] to reconstruct the sitemap and select optimal traversal paths. The optimal traversal path is defined in terms of the informative content of the pages. Other examples of “intelligent” crawlers are ACHE [3] and HIFI [4]. Our analysis focuses on classical crawling strategies because of their universality and fast (and thus cheap) implementation.
Shilling attack
The profile injection attack (also known as the shilling attack) is by far the most popular attack against recommender systems [23,38,42]. A shilling attack consists of the injection of well-crafted fake users into the system. The goal of the attacker is usually one of the following:
The literature also offers studies about the effectiveness of shilling attacks under different constraints or scenarios. Burke et al. made an analysis related to the one we propose in this paper [7]. In their study, the attacker has limited knowledge about a target user. Our results confirm some of the drawn conclusions in [7]. Still, our analysis is broader and with a different goal. Moreover, we also cover a new attack scenario, which includes a potential competitor aiming to take advantage of the target system’s collected knowledge. In [28], a cost-benefit analysis about a shilling attack is performed. However, the only conclusion the authors draw is that the higher the number of available items in the catalog, the higher the attack cost. Nevertheless, some of our conclusions support their results. It is worth mentioning that we have taken into account the considerations made in [28] when we designed the experiment. The size of the attacks, which is directly related to the cost, has been calibrated to mimic a real-world case. Deldjoo et al. studied the attack’s effectiveness on different groups of users (more/less active) [15]. They had quite different results on the two tested datasets, namely Movielens and Yelp. Still, they found that BPR-MF [40] seems to be more resistant than the other tested recommendation approaches.
Finally, there is a large body of research devoted to studying methods to detect shilling attacks. Our analysis does not directly focus on profile injection detection. However, we also conducted some experiments about the detectability of the performed attacks. For a comprehensive study on the detection traits of shilling attacks, we refer the reader to [44].
Methodology
We will consider two main attack scenarios that can threaten a recommender system. These two attacks are independent of each other, but both rely on the information gathered through a starting crawling phase (Section 4.1). The two considered type of attacks are:
(Section 4.2) the standard profile injection attack. The attacker crafts the fake profiles exclusively using the crawled information. The attacker aims to promote (push) or demote (nuke) a specific target item; (Section 4.3) the attacker aims at collecting valuable information about the system. The collected information may be valuable for the attacker to improve its own business or simply study its competitors. We assess the informative content of the crawled data by reconstructing the neighborhood of a target node. The higher the overlap w.r.t. the actual neighborhood (computed with the complete knowledge of the graph), the more effective the crawling process. Besides the quality, we also assess the quantity of information each crawling strategy can collect.
Crawling
Besides the classical crawling techniques described in Section 2, we propose a variation of the backlink strategy. In this new strategy, called
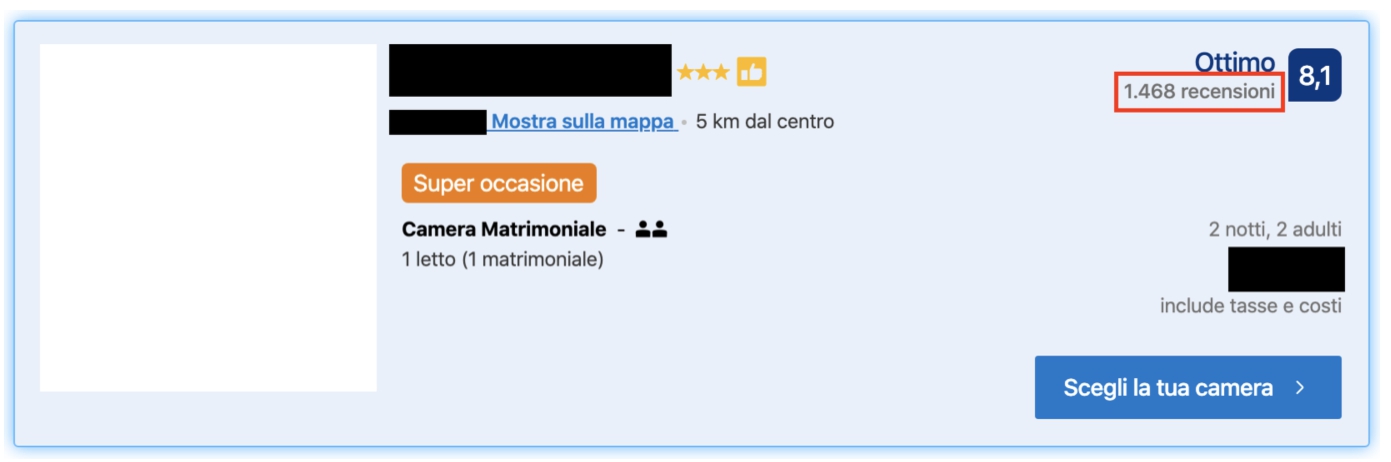
Example from booking.com of the availability of the (full) public degree information (the red box) before requesting the item webpage.
Figure 2 shows an example of the application of all the strategies mentioned in Section 2, including

Example of exploration strategies on a bipartite (recommendation) graph. All the explorations start from the target node
The crawling phase for collecting the rating information is performed starting from a target node (either a user or an item). Figure 2 shows an example of crawling starting from the item

Crawling procedure
In our simulation, a node in the (unknown) user-item rating graph (excluding the starting node) passes through three states (depicted in Fig. 3):
The node exists in the whole graph but is currently unknown.
The node has been discovered through another just visited node linked to it. Discovered but not visited nodes can be considered in the frontier of the graph exploration. A discovered node may carry information about its out-degree.
Possible states of a node (with the exception of the starting node) during the crawling procedure. U = unknown, D = discovered, and V = visited.
The node has been visited, allowing the discovery of (potentially) new nodes. The visiting of a node simulates the request of its web page.
The core difference between profile injection attacks lies in the way fake profiles are designed. The injected profiles must be carefully designed to avoid being detected. Profiles that highly differ from the “average” profile can be easily spotted and marked as suspicious (or even blocked), making the attack harmless. The number of fake profiles injected into the targeted system is usually called the
the set of target items,
set of items
set of items,
all the remaining set of items for which the fake profile does not give any rating
We tested five shilling attacks [23,38] in our analysis:
The way user profiles are crafted in the attacks above is summarized in Table 1.
Summary of the diverse attack models. Note that the filler size (f) and the selection size (s) are attack parameters.
and
respectively indicate the average rating over all items, and the average rating of i over all users.
and
are the corresponding standard deviations. pop stands for popular items, and
is a random sampling function over X of dimension n. The items in the set
are associated to a missing rating (i.e., null)
Summary of the diverse attack models. Note that the filler size (f) and the selection size (s) are attack parameters.
In competitive scenarios, collecting as much data as possible may not be the most effective and efficient strategy. It might be more useful to collect less but more informative data. To this end, we try to assess the quality of the collected knowledge by comparing how close are the most similar users/items computed with the crawled data w.r.t. the ones computed with the whole dataset. This comparison is based on the fact that the most popular recommendation engines are neighborhood-based [31,41,43]. Neighborhood-based systems rely on the concept of users/items similarity to compute the recommendations. Thus, if the neighborhood reconstruction is accurate enough, we can affirm that the collected knowledge has a competitive value. For example, if a competitor can match one of its users’ identities with one of the target systems, it can use the knowledge about the user’s neighborhood to improve the personalization quality, or it can be used to avoid the cold-start problem [41].
Similarity measures
The neighborhood of a node (user/item) is determined in terms of a similarity measure between nodes. Our analysis employed two of the most widely used similarity measures in the recommender system community [41]: Pearson’s correlation and cosine similarity. These measures are formally defined as follows:
user-based
item-based
where
user-based
item-based
In our experiments, to avoid any bias, similarities have been computed only between users/items with support greater or equal than 5, that is, given
The detailed description of the neighborhood reconstruction procedure is summarized in Algorithm 2.

Neighborhood reconstruction evaluation
Given the data crawled by a specific crawling strategy, the similarity matrix between users/items is computed and compared with the same matrix computed on the entire dataset. The reconstruction quality is measured in terms of the size of the overlap between the set of the k most similar users/items computed with the crawled data and the whole dataset. The higher the overlap’s size, the higher the value of the crawled information.
We assume the following attacker’s capabilities:
The attacker can access only the public (e.g., accessible through the system’s website) information of the target service. The data collection is performed by crawling the website, as described in Section 2.2. The crawling methods leverage only information about the user-item rating graph ignoring all side information like figures, description, or comments. The information of a user/item is gathered when the corresponding page is requested (i.e., visited). A page’s visit also discloses the linked/rated items (users) but not their details. A discovered item, i.e., an item linked by a user/item’s page, also carries information about its out-degree (see Section 4.1); The attacker targets a particular node in the graph (either user or item), which is also its starting node for the crawling. The attacker has the resources to perform a (push) shilling attack. The size of the attack is calibrated concerning the size of the target system.
Experiments and results
Each phase of the described methodology has been extensively tested. Specifically:
we compare the crawling policies in terms of how much they cover, i.e., number of discovered nodes, the recommendation graph after visiting a fixed number of nodes; we assess whether standard shilling attacks based on the crawled information are effective in practice (Section 5.3). We test both the effectiveness as well as the detectability of the injected user profiles; we measure the value of the crawled data in understanding the underlying recommendation model. Assuming the system is based on a k-nearest neighbor algorithm, we try to reconstruct a target node’s neighborhood, either user or item. If the reconstruction is similar to the one computed over all the graph, then the collected information has collaborative value, and competitors might maliciously leverage it (Section 5.4).
Datasets
In our experiments, to emulate a real e-service (e.g., e-commerce) recommendation-based website, we use seven small- to large-scale datasets commonly used as a benchmark in the RSs community [41] (details are summarized in Table 2). In particular:
It is a small dataset crawled from the entire FilmTrust website in June 2011. Filmtrust uses a 5-star rating system. Dataset collected by Cai-Nicolas Ziegler in a 4-week crawl in 2004 from the Book-Crossing community. The dataset has been pre-processed to keep only users with at least ten ratings. This
This dataset contains reviews and ratings (5-stars) from the Goodreads book review website.
this is the user-movie (5-stars) ratings data from the Netflix Prize.6
Datasets information: number of users, number of items, number of interactions (i.e., ratings), average number of ratings per user, and number of ratings per item
To mimic a real attacking scenario, we test the crawling algorithms assuming that only a small subset of nodes can be visited. We fixed this number of nodes with respect to the size of the datasets. The experiments have been performed on the datasets described in Table 2. The results reported in Fig. 4 show the coverage of each crawling algorithm in terms of how many nodes they can discover. We do not report the PageRank algorithm because of its computational complexity, making it less reasonable to be used in practice.
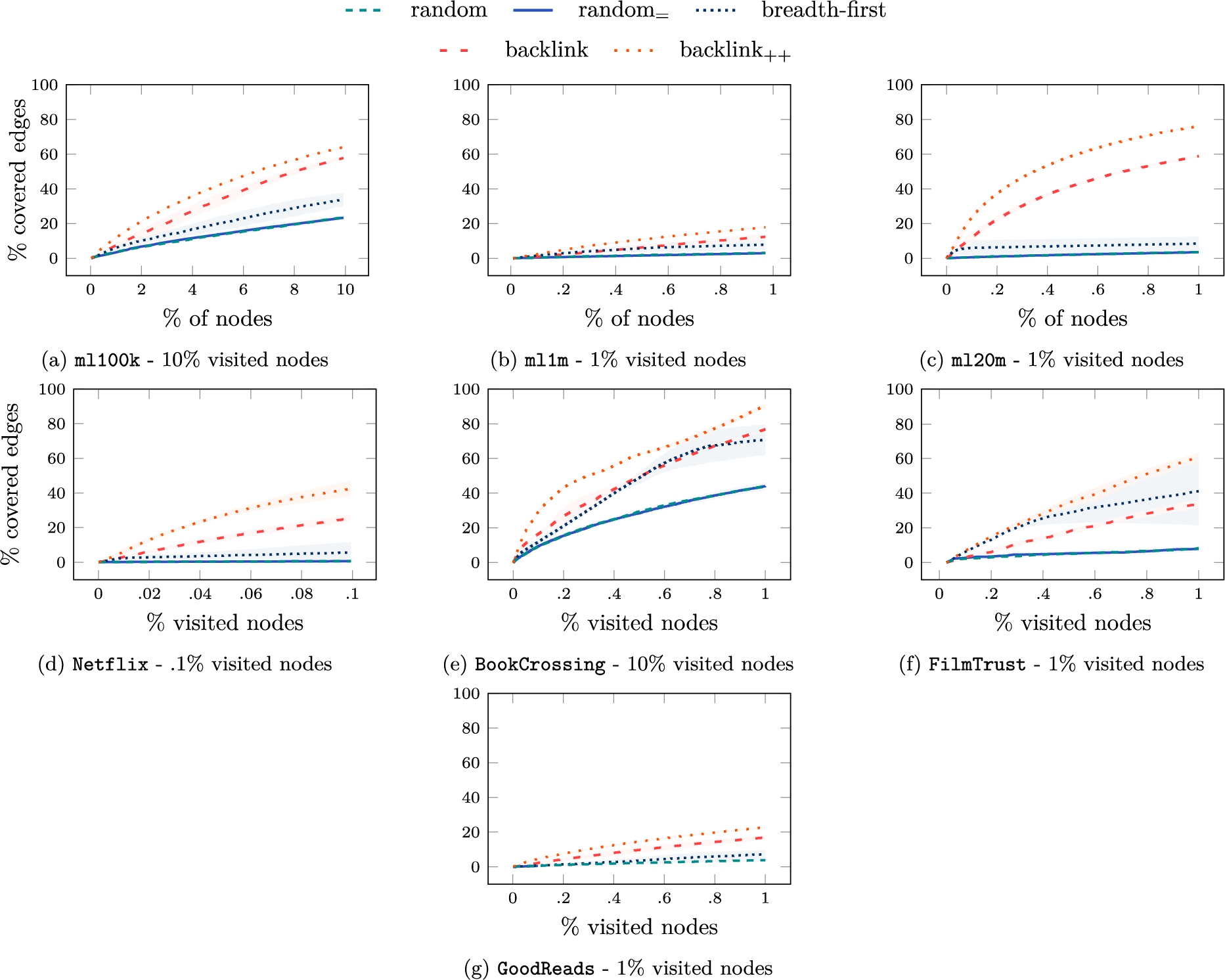
Graph coverage (% of discovered nodes) of the crawling algorithms across different datasets.
In all datasets, both random and
Regarding the backlink strategy, both the standard and the
It is worth noticing that the percentage of nodes visited is not a direct indicator of how much the crawling procedure can cover the graph. A clear example is the difference between
This set of experiments aim to assess whether performing a shilling attack using crawled information is as effective as using the entire dataset. In particular, we test whether crafting malicious user profiles using crawled data harms standard shilling attacks’ effectiveness. To run these tests, we needed to build a recommendation engine. We chose to employ the popular k-nearest neighbor [41] recommender (
We report the results on the smallest datasets, namely

Comparison of different (push) shilling attacks based on data crawled using different algorithms (and the full dataset). Reported results are in Hit@10 overall percentage users that did not rate the target item. Target item has been randomly selected from the 2nd quintile of the most popular items. On the x axis, bwr means Bandwagon Random, bwa means Bandwagon Average, and samp stands for the Sampling attack.
It is evident from the figure that, in general, in terms of hit@10, having the full knowledge of the rating matrix increases the attack’s effectiveness. However, on really small and dense datasets (e.g.,
In terms of prediction shift, all attacks consistently achieve about a 1 point push. Nonetheless, it is not enough to get the target item in the top-10 position of the recommendation in most cases. The
In general, the new set of experiments show that shilling attack can be very successful in small size recommendation systems, especially if the rating matrix is relatively dense and not extremely long-tailed.
After performing the attack, regardless of the success or not, we checked whether the injected profiles were easy to detect using standard statistical detection mechanisms [5,48]. In particular, we implemented the following detection strategies:
measure of rating deviation of a user on a set of target items concerning other users, combined with the inverse rating frequency of these items [12].
is usually used to detect average attacks. It computes the mean-variance between all the filler items and the overall average. A low variance would indicate the possibility of an average attack [8].
In the experiments, a fake user profile is considered detected if either its MeanVar or RDMA is significantly different from the average computed over all the training users. Tables 3, 4, and 5 show the detection percentage of the injected profiles.
Fake profile detection percentage (%) on ml1m
Fake profile detection percentage (%) on
Fake profile detection percentage (%) on
Fake profile detection percentage (%) on
In both MovieLens and Filmtrust, almost all the crafted profiles have been detected for all attacks except the sampling attack. By design, sampling attack is based on true statistics, and it seems that even using a subset (from the crawling) helps the attack be successful, at least in terms of the number of undetected fake profiles. On
In general, considering both the success rate and the detectability of the attacks, these results further support that performing a shilling attack on crawled data can hardly be effective in large-scale scenarios.
With these last set of experiments, we want to test if the crawled information is enough to be considered valuable in terms of competitive knowledge about the underlying recommendation engine. Clearly, different recommender systems use collaborative information in very different ways. Still, the underlying core concept is related to the number of ratings shared by the users (or items). For this reason, we argue that reconstructing the neighborhood gives a good estimate of what we know about the system.
These experiments have been performed following the procedure described in Section 4.3. We tested both user-based and item-based recommendations, using cosine similarity and Pearson correlation.
Neighborhood reconstruction on user-based recommenders
Figures 6 and 7 show the overlap percentage of the neighborhood reconstruction using a user-based KNN based on Pearson’s correlation and cosine similarity, respectively.
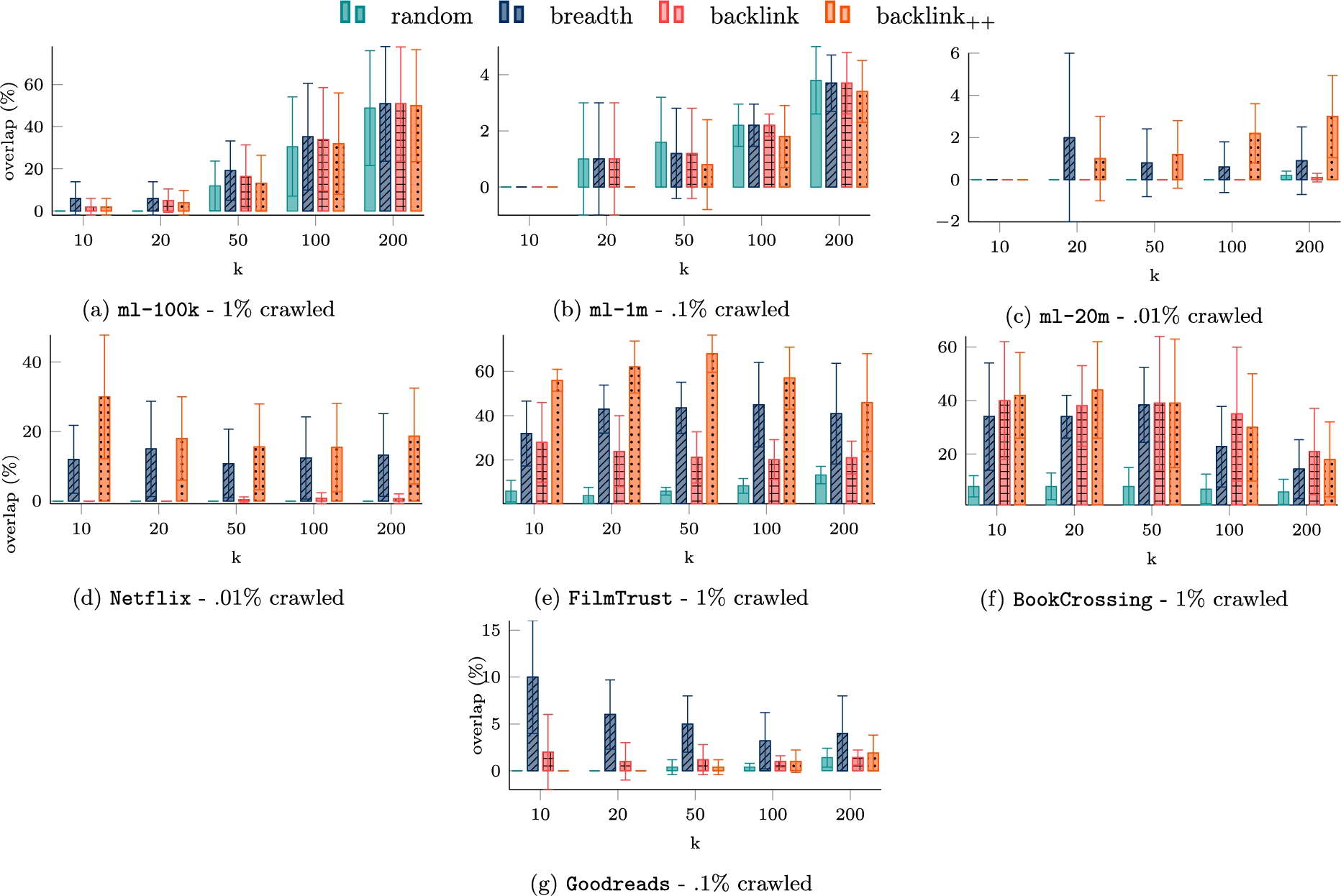
Neighborhood reconstruction using user-based Pearson’s correlation. The results are the average (± standard deviation) over five randomly selected users. k on the x-axis is the dimension of the considered neighborhood.

Neighborhood reconstruction using user-based cosine similarity. The results are the average (± standard deviation) over five randomly selected users. k on the x-axis is the dimension of the considered neighborhood.
As expected from the crawling experiments results, the random strategies do not allow any kind of reconstruction. This is intuitively reasonable since this strategy does not consider any properties of the nodes/graph to prioritize the nodes.
Contrary, in all but one dataset (i.e.,
Surprisingly, breadth-first that has shown not to be a good method in terms of coverage, achieves comparable results w.r.t.
Figures 8 and 9 show the overlap percentage of the neighborhood reconstruction using an item-based KNN based on Pearson’s correlation and cosine similarity, respectively. In these experiments, we increased the crawling percentage on
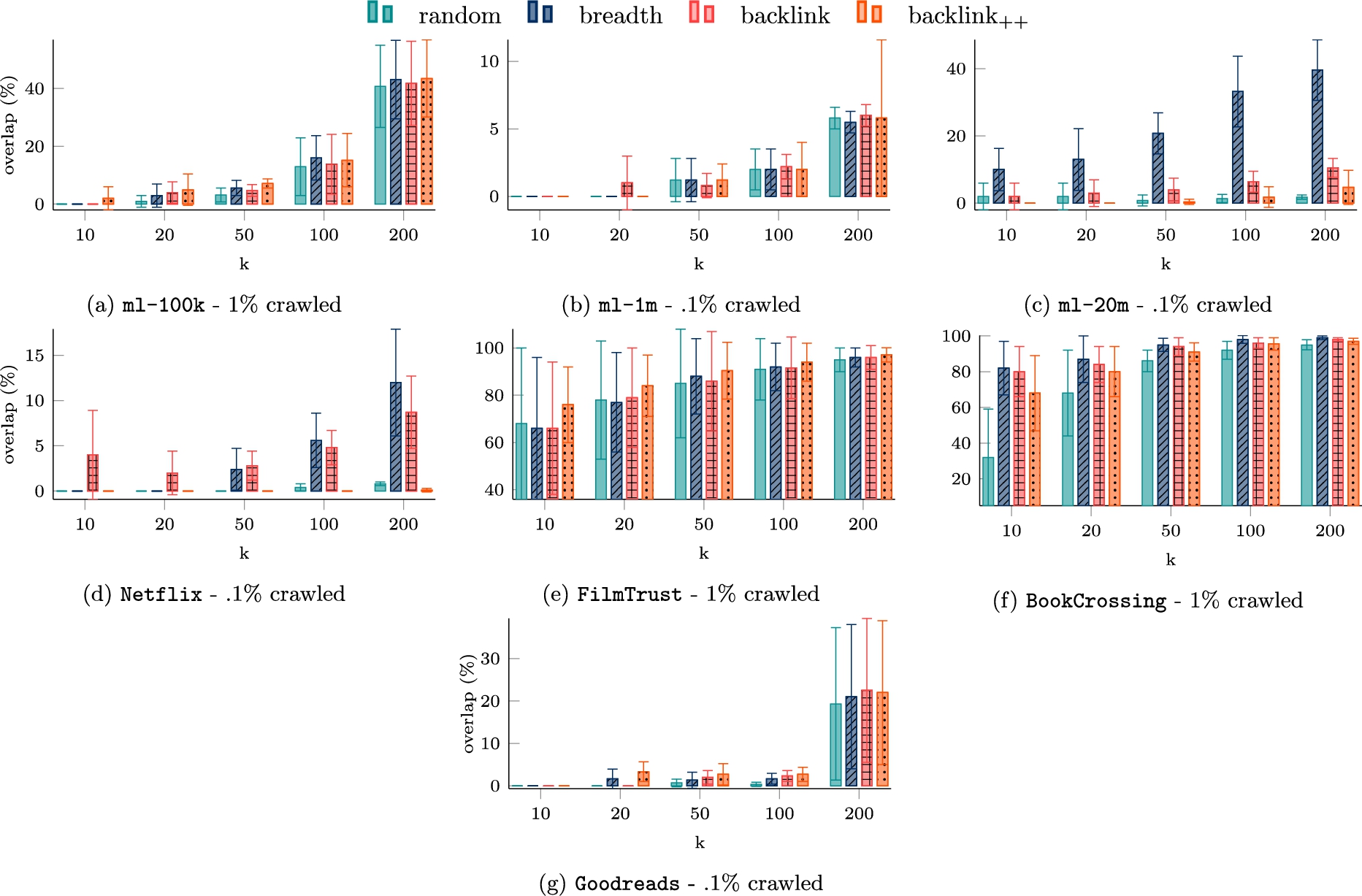
Neighborhood reconstruction using item-based Pearson’s correlation. The results are the average (± standard deviation) over five randomly selected average popular items. k on the x-axis is the dimension of the considered neighborhood.

Neighborhood reconstruction using item-based cosine similarity. The results are the average (± standard deviation) over five randomly selected average popular items. k on the x-axis is the dimension of the considered neighborhood.
The need to increase the crawling percentage underlines the fact that it is harder to reconstruct an item’s neighborhood on big systems. This can be due to a longer tail in the long tail distribution. However, on small datasets, the reconstruction is possible even with the random crawling strategy. This is reasonable since we targeted popular items, and hence the crawling has more chance of covering useful nodes.
It is further confirmed that breadth-first works pretty well, except for
We want to emphasize that, on average, the reconstruction over the cosine similarity seems easier than with Pearson’s correlation, while in terms of absolute value, the neighborhood reconstruction has a slightly higher rate of success in the user-based setting.
Wrapping up, in general, we can state that a competitor can collect useful knowledge crawling a target e-service, especially in the case of a small size target system. In general, the rate of success highly depends on the size of the target site and available resources to perform the crawling. Empirically, it seems that a standard breadth-first strategy does the job nicely, but when possible, using more information to prioritize the crawling frontier (e.g.,
Profile injection attacks are by far the most common kind of attacks to recommender systems. In principle, they are easy to apply and have only a limited cost. However, when dealing with real-world, large-scale systems, many challenges must be faced to perform such an attack. This work showed that the first challenge is to gather data to start mounting the attack. We empirically demonstrated strategies to effectively collect a good amount of information (backlink and
In future work, we aim to expand this analysis to other types of attacks. Moreover, it will be worth investigating new crawling policies that also use the content information about the items rather than the graph’s mere structural information. Besides, new and more advanced attacking techniques should also be compared with ad-hoc detection mechanisms.