
Abstract
As far as mobile edge computing is concerned, it is necessary to ensure the data integrity of latency-sensitive applications during the process of computing. While certain research programs have demonstrated efficacy, challenges persist, including the inefficient utilization of computing resources, network backhaul issues, and the occurrence of false-negative detections. To solve these problems, an integrity protection scheme is proposed in this paper on the basis of data right confirmation (DRC). Under this scheme, a two-layer consensus algorithm is developed. The outer algorithm is applied to establish a data authorization mechanism by marking the original data source to avoid the false negative results caused by network attacks from the data source. In addition, blockchain-based mobile edge computing (BMEC) technology is applied to enable data sharing in the context of mobile edge computing while minimizing the network backhaul of edge computing. Based on the Merkle Tree algorithm, the inner layer algorithm is capable not only of accurately locating and promptly repairing damaged data but also of verifying all servers in the mobile edge computing network either regularly or on demand. Finally, our proposal is evaluated against two existing research schemes. The experimental results show that our proposed scheme is not only effective in ensuring data integrity in mobile edge computing, but it is also capable of achieving better performance.
Introduction
With the rapid development of the Internet of Things (IoT) industry, mobile edge computing (MEC) has become a new paradigm [11,13]. It integrates artificial intelligence [7] and advanced communication technology [24] and provides reliable service support for delay-sensitive applications [1] due to its unique low latency and high resource utilization.
Although edge computing provides relatively sufficient resources for terminal devices with poor computing power, due to unpredictable task sizes and numbers of terminal computing devices, there will still be excessive network load due to the edge servers’ computing tasks. With the above challenges, collaborative computing [15,20,23] and edge caching [12,27,33] technology have become effective methods for breaking edge networks’ resource constraints.
Collaborative computing technology and edge caching technology enable an edge server’s computing tasks or services to be shared with other edge servers. These servers can then jointly compute and process data. At present, many studies [8,26,36] assume that edge servers are 100% reliable and secure, which is unreasonable. It is not unreasonable to assume that data in one of the shared edge servers is changed or corrupted during computational processing. This event will directly affect the results of the calculations. It may even cause the task to fail. These calculations will then need to be resubmitted because they returned incorrect parameters. In addition, edge servers using cooperative computing technology will generate some cooperative tasks. Once the cooperative task calculation fails, all edge servers participating in the calculation need to recalculate the subtasks and recheck the integrity of the subtasks. This computational impact is much more significant than that of non-cooperative tasks. In the Appendix, we give a proof. Therefore, for each edge server, ensuring the integrity of computing task data has become a significant challenge in edge computing applications.
Influenced by the data protection strategy of cloud computing, most of the data protection research related to edge computing is based on the challenge-proof strategy [10,37]. In this strategy, the computing device or service provider initially initiates a data check request with the edge server. The edge server that receives the request will perform local computing verification based on the correct data replica digest provided by the computing device. When the verification is successful, the edge server communicates the verification result to the service provider; otherwise, the terminal computing device must resend the computing data. The computation and network backhaul costs are enormous [28] if this method occurs in many edge servers under collaborative computing.
In addition, in the ever-changing edge network environment, it is essential to confirm the rights of the data itself, that is, to record the data usage process. It is assumed that after the terminal computing device generates a computing task, a penetration attack will occur during the request to uninstall the edge server, resulting in the task being tampered with. The terminal computing device sends out an incorrect task, and the edge server will obtain an incorrect calculation result through collaborative or local calculation after receiving the task. This process wastes the computing resources of the edge network and increases the network load.
Therefore, this paper proposes a protection scheme based on data confirmation to solve the above-mentioned problems. The scheme realizes the data right confirmation operation based on the blockchain. When the data replica of an edge server is damaged, it can be tracked to the nearest edge server according to the data information stored on the blockchain to obtain a reliable data replica. At this juncture, the edge server is solely tasked with validating the integrity of the data stored within the blockchain. It does not need to interact with other servers for confirmation, which significantly reduces the number of network backhauls. In addition, we have adopted a new consensus mechanism that can regularly or on-demand verify the data replica in the edge server to ensure the correctness of the edge server’s computing tasks. This avoids the waste of edge server computing resources and solves the problem of false negative detection results. The contributions of this paper are as follows:
We propose a lightweight protection scheme based on data permission confirmation, which is a data-centric scheme. In this scheme, we first innovatively proposed a two-round consensus mechanism based on PoW and expanded two new algorithms to form a complete consensus algorithm. The algorithm can check the calculated data content in time and accurately locate the specific location of the damaged data.
We solve the problem of false-negative data detection results and combine BMEC technology to minimize network backhaul and fully use edge server computing resources.
We evaluate our scheme against some existing advanced schemes. Experimental results and security analysis show that our scheme can achieve a 100% damage detection rate under different data copies and blocks and have relatively low detection delay consumption. This scheme can effectively guarantee data integrity in edge computing and significantly save computing and communication resources of the edge network.
The rest of the paper is organized as follows: In Section 2, we summarize the current data protection schemes for edge computing. In Section 3, we define the general architecture of the related system and discuss the related work in detail. In Section 4, we expound upon the blockchain consensus network, elucidating the pertinent algorithms encompassing both internal and external aspects. In Section 5, we evaluate the performance of the scheme and compare it with other schemes. We then conclude the paper in Section 6.
Related work
BMEC is an innovative architecture for mobile edge computing [18] that will play a vital role in the future development of IoT and 5G/6G communications. MEC can provide devices with rich computing power in a mobile blockchain environment. Moreover, the blockchain can provide a distributed database to store various data, such as transaction content of computing devices, device information, etc. The blockchain packages them into a series of blocks. It reaches a consensus in the mobile edge computing network, which not only solves the resource limitation of the blockchain itself but also provides security such as resource traceability and transaction confirmation to MEC.
At present, many MEC safety studies are using BMEC technology. For example, [30,34,35] implemented an effective mobile device authentication scheme using BMEC technology and [3,5,25] applied BMEC technology to the unmanned aerial vehicle (UAV) network. Some studies [9,16,29,31] also use BMEC architecture for data integrity protection. [9] proposed a dynamic BMEC data integrity protection architecture and a two-layer consensus algorithm for changes in blockchain members. This scheme uses string consensus, data correctness verification and binary consensus to achieve the verification purpose. Since the verification process is random, it may generate many blockchain transactions and waste computing resources. [31] proposed a BMEC security architecture using multiple data stores and blockchain agents to achieve real-time contextual data integrity in IoT environments. [29] proposed a lightweight BMEC framework that supports cross-platform software systems that are easy to deploy, scalable, and cost-effective. This scheme mainly focuses on the data protection process, using authentication and encryption technology to protect the operation of sensitive data without considering the repair stage after data damage. [16] proposed a data integrity protection scheme based on BMEC for a specific industrial Internet of Things, mainly protecting data tasks with less sensor calculation. Therefore, based on the above research, BMEC technology can be used as a promising data integrity protection method.
In addition, some studies [6,14,19,32,37,39] proposed a provable data possession (PDP) scheme for data detection proof and restoration. In PDP, all request verification processes are edge server interaction processes at different stages. This individual checks and interactions method is unsuitable for edge computing networks with strict latency requirements. A similar proof of retrievability (PoR) scheme [2,4,10,38] has also been published. The paper [6] conducted a detailed study and proposed a binary sampling scheme based on homomorphic labelling called ICL-EDI. The ICL-EDI scheme simplifies complex calculation proofs. It uses binary sampling technology to reduce the computational overhead of edge networks significantly and allows terminal computing devices or service providers to perform one-to-many verification. Therefore, the ICL-EDI scheme only accelerates the data verification and certification process of edge computing.
The paper [17] proposed a distributed self-management scheme called CooperEDI. The CooperEDI scheme differs from the above scheme in that it does not require the edge server to always issue a proof of calculation, that is, the correct hash calculation result of the target calculation. The CooperEDI scheme initially determines the edge servers using the correct data through pairwise interactions, and these correct edge servers then become managers in the scheme. When other non-manager data are damaged or tampered with, the manager locates and repairs the damaged data. In the CooperEDI scheme, there is an extensive network backhaul problem in the process of mutual verification between edge servers. If the terminal computing device or server requests too many computing tasks at this time, congestion of the edge computing network may occur. Second, the CooperEDI scheme identifies managers by setting a half-threshold when identifying scheme managers. For example, assuming that a total of n edge servers experience a data attack while determining that the replicas are identical, the number of real replicas is less than
In summary, some current research schemes still have the problem of wasting edge server computing resources, network backhaul, and false-negative data detection results [21]. To solve the above problems, this paper proposes a more novel and flexible BMEC data integrity verification scheme, which performs data integrity verification based on the data source.
System overview

System general architecture.
The scheme proposed in this paper applies to the general architecture of edge computing. As shown in Fig. 1, the general architecture of edge computing consists of a three-layer structure of cloud, edge and terminal. In the cloud layer, service providers can cooperate with cloud data centres and deploy complete service content to cloud data centres. In order to improve the extensiveness of services, cloud data centres generally offload some service content to the edge layer. The edge layer is mainly composed of edge servers. When the edge server receives a service task, it can cooperate with other edge servers or cloud data centres to complete it and return the calculation result to the computing device at the terminal layer. These computing devices must be within the edge server’s communication range. In addition, the edge server and the cloud data centre jointly build a blockchain network and have the exact logical definition; whether it is communication between servers or between the server and the cloud data centre, it will be legally recorded on the blockchain.
Our proposal can be deployed in any mobile edge computing scenario and is applicable to any computing form. For example, Metaverse [22] is an emerging digital Internet application. Metaverse generates a mirror image of the real world based on digital twin technology. Users participate in the Metaverse through a shared edge infrastructure. Service providers usually cache services on nearby edge servers. Therefore, we need to ensure the integrity of the cache service to ensure that it can connect to the virtual world under any conditions.

System model including the first six processing stages.
The general framework used in this paper is shown in Fig. 2. To visualize the data delivery process, we allow service providers to serve only one edge server and the first edge server to deliver to other edge servers for caching. The service provider is represented by
Our work developed a two-layer consensus algorithm consisting of an outer layer consensus algorithm and an inner layer consensus algorithm.
Overview of blockchain
The chain owner
In practical applications, the management right of the blockchain will be owned by the mobile edge computing manager, that is, the chain owner. Each mobile edge server acts as a node in the blockchain. In this research, we set the blockchain nodes as full nodes, that is, each node needs to store the entire blockchain.
Consensus
In this blockchain network, since every full node stores all blocks, all nodes need to participate in the consensus phase for transaction verification, ledger management, and coin rewards. For the transactions generated by the non-cooperative work of nodes, we use a proof of work(POW)-based consensus mechanism to implement. However, due to the complexity of the mobile edge computing environment, there are often tasks that require the cooperation of mobile edge servers to complete. To prevent malicious nodes from tampering, forging, replacing, and deleting some transaction records in the blockchain during the collaboration process, we propose a two-round consensus mechanism based on POW. First, we define a set of cooperative nodes
Outer layer algorithm
The outer layer algorithm serves as the foundation for our work. It provides two primary functions: building a consensus network and a data right confirmation mechanism.
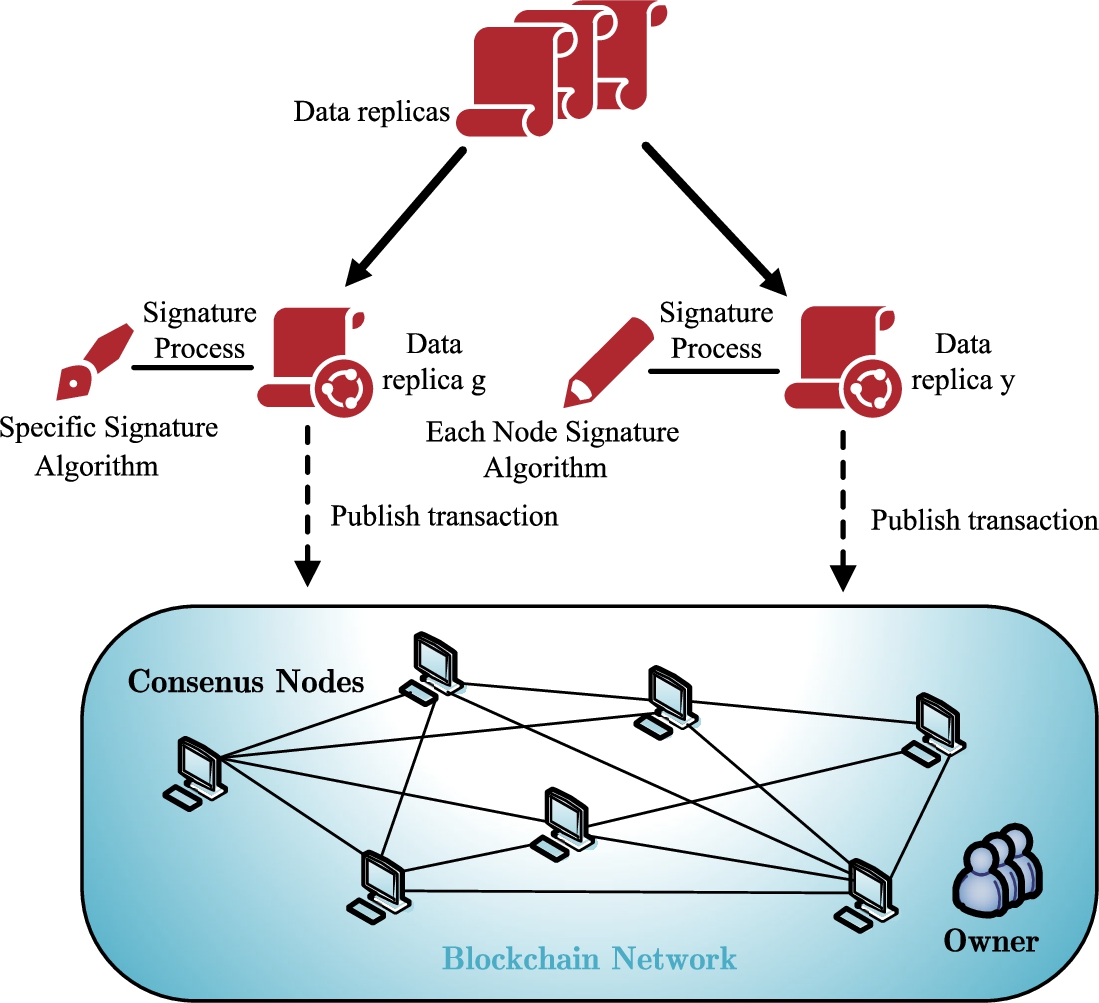
Algorithmic process for establishing a data right confirmation mechanism.

Outer layer algorithm
In summary, Algorithm 1 is an extended algorithm of the above consensus, mainly used to record the authenticity and integrity of blocks during broadcasting. Moreover, check whether the data permission type has changed through two storage tables. The algorithm is implemented through smart contracts, and the input objects are described as computing tasks and edge server ids through pseudocode. The content of the algorithm is mainly initialization work and data permission check work.
The inner layer algorithm is based on the Merkle algorithm and is used to execute two primary tasks: data pre-processing and identifying and fixing corrupted data. In this paper, we adopt the Merkle algorithm to preprocess the data. The Merkle algorithm can process information in segments by using a specific data structure, that is, output a hash result by calculating a multi-part hash algorithm.

Inner layer algorithm
We divide the Merkle algorithm used in Algorithm 2 into three layers, as shown in Fig. 4. First, we need to preprocess each data replica, divide each data replica according to the data block, and then calculate the hash value of the bottom layer, middle layer and vertex layer through the Merke algorithm, and store these values in the block. When a data replica is traded, first check the hash value of the vertex layer of the data replica. If the hash value of the vertex layer changes, the copy of the data has been tampered with. Then continue to check the hash value of the middle layer and trace the hash value of the bottom layer according to the changed hash value of the middle layer. Therefore, we can know which data block has the problem.

Merkle algorithmic process for data preprocessing and data repair.
In summary, this structure empowers the subsequent verification process that pinpoints the exact location of the corrupted copy of the data without having to replace the entire file, significantly improving data repair efficiency. Additionally, the inner algorithm establishes a time-polling and event-triggering framework that enables timely or on-demand verification of all edge servers. The algorithm’s pseudo-code is shown in Algorithm 2.
Experimental overview
In Section 2, we elaborated on the schemes of [6] and [17]. The scheme proposed in [6] is ICL-EDI, which is abbreviated as ICL; the scheme proposed in [17] is CooperEDI, which is abbreviated as CE. In addition, [19] proposed a scheme that uses the Boneh–Lynn–Shacham (BLS) algorithm to implement PDP to ensure data integrity and is abbreviated as P-BLS. Our work compares these three schemes using random sampling detection.
Experimental setup
To determine the experimental settings, we referred to those in [17]. We set seven parameters, which are:
Sampling scale
Data replica scale
Data size
Dat block size
Corruption ratio
Corruption severity
Time polling interval
Among this settings,
Corruption detection rate: this metric is the ratio of the number of detected corrupted edge data replicas over the total number of corrupted edge data replicas. The higher the value is, the better the performance.
Time consumption: this metric is the computation time and communication time taken to complete the data assurance process. The lower the value is, the better the performance.
Specific experimental settings
Specific experimental settings
The simulation experiments were performed on four i9-10900KF computers, each with 64 GB of memory. Five virtual machines were created per PC and randomly mapped to a geographic region to simulate the networked edge servers that constitute the edge caching system in that region, including a cloud server. Each virtual machine has 2 GB RAM and uses the Ubuntu 16.04 operating system. According to the ten application test results of the Amazon cloud server, the network delay between different edge servers is set at 5 ms to 15 ms, and the network delay between the cloud server and the edge network server is set at 120 ms. The experimental scheme is mainly realized through Python and Websockets library. Due to the generality of the data, the data during the experiment is obtained by random generation, and the data size is set, as shown in Table 1.
Furthermore, the blockchain was developed and tested using the Ethereum platform. Our work simulates file corruption by randomly modifying
During the experiment, P-BLS, ICL, CE and DRC were analyzed and compared in terms of their data damage detection and computing time consumption. In the initial experimental settings, the intermediate values were fixed values from

Comparison between the corruption detection rate and time consumption of P-BLS, ICL, CE and DRC.
When
When

Effect of this correlation function and variable on time consumption in DRC.

Average total time spent by these
When
Furthermore, our proposed method was separately tested and analyzed. When
The above four schemes implement the verification process through the edge server, which inevitably generates additional communication overhead. For this reason, this paper tests and compares the network overhead of the four schemes and obtains the detection results according to the adjustment of the data replica scale. As shown in Fig. 8, we can see that the data replica scale significantly impacts the network overhead of the P-BLS, ICL and CE schemes. As the data replica scale increases, the network overhead will also increase. The reason is that P-BLS will need to transmit more data integrity certificates from the edge server to the cloud server, resulting in increased overhead; ICL and CE involve more edge servers for inspection, resulting in more network traffic. The DRC will be tracked to a specific edge server for repair according to the usage information of the data, and the impact is negligible. Therefore, the above results show that DRC can verify and repair many edge data copies without significant communication overhead.

Average communication cost of four schemes.
DRC conducted the theoretical analysis and comparison for [17] in this section. The scheme in [17] is called CE, and it confirms the scheme of administrator by quantity. In CE, the administrator has certain permissions and only administrators can confirm correct data replicas. Furthermore, all edge servers must be replaced with these data replicas under edge computing as soon as the administrator confirms the correct data replicas. However, there are two conditions that must be met to confirm the replicas:
the number of identical false data replicas < the number of identical true data replicas; the number of identical data replicas
Therefore, it must be noted that if the number of identical false data replicas > the number of identical true data replicas, the true data will be overwritten by fake data. What is more serious is that additionally, all data replicas in the edge environments will be replaced with fake data replicas, and the method used by the administrators to confirm the correctness of the data replicas is difficult to control. Once the administrator betrays or misjudges their correctness, the load of an edge computing network will suffer under a serious influence.
Therefore, we assume that there are a total of n pieces of data replicas, and each data replica is assigned to a different edge server. The possibility of successfully tampering with the data replicas in each server is
In the P-BLS scheme, when a damaged edge data replica is detected, the service provider of the application usually needs to transfer a complete data replica from the cloud server to the edge server to replace the damaged data replica. This involves the checking calculation of the edge server, the calculation comparison with the cloud server, the feedback and confirmation from the cloud server to the edge server, and the sending of a complete data replica by the cloud server, which will cause a lot of backhaul communication overhead. The ICL and CE solutions optimize the P-BLS solution and realize data replica restoration by selecting management edge servers. Although the communication with the cloud server is omitted, the selection of the management edge server needs to participate in some edge servers to obtain confirmation, so there is also some backhaul communication overhead. Moreover, if the data replica of the management edge server is damaged, the management edge server needs to be selected again, which will also increase communication overhead. The DRC scheme mainly obtains the information of the data replica by interacting with the blockchain, and each edge server will store the relevant information of the blockchain. When the data replica on an edge server is damaged, there is no need to find a repairable edge server directly. The blockchain can be used to find relevant data and use clues to directly communicate with the edge server with a complete copy of the data, which can better avoid network backhaul.
In addition, DRC does not consider the security of blockchain technology itself, but this characteristic is not the focus of this paper. Second, DRC does not adopt the public chain mode to improve the accuracy of identifying damaged data copies and the efficiency of repairing data copies. The basic idea of DRC is to solve the problem of distributed management by authentic right of data, and this strategy not only avoids some negative problems caused by centralization but also solves the data credibility itself, which ends the problem of false-negative detection results for data replicas from the source.
Conclusion
A lightweight protection scheme, called DRC and based on the authentic right of data, was proposed in this paper. The scheme focuses on realizing a two-layer consensus algorithm and establishing a relatively complete mechanism for the authentic right of data. Based on this right, a time polling mechanism and an event trigger mechanism are used for rapid detection to ensure that damaged data copies can be checked, located, and repaired in time. The experimental results show that DRC can not only effectively ensure the data integrity in mobile edge computing, but also solve the problems of wasted computing resources, network backhaul, and false-negative detection results from data copies. DRC additionally exhibits good performance.
Footnotes
Proof of computation in the Introduction
Assuming that each server has n computing tasks, m tasks from among the n computing tasks are cooperative computing tasks. When the error rate of a task is p and the tasks are in the calculation state in the time t, then the calculation can be obtained in the time t and the error rate of each server’s cooperative task is
Similarly, if the n computing tasks are all non-cooperative tasks, then the overall error probability is
Let