
Abstract
This paper proposes a dynamic workload’s threshold-based scheduling and load balancing algorithm for distributed computing systems. It takes into account the dynamicity and heterogeneity of available system resources, and tasks. It automatically updates the workload thresholds upon any significant change of any resource workload and balances the system’s workload using the new thresholds. Unlike most of the current scheduling and load balancing algorithms, the proposed algorithm uses the resource’s load as a workload index instead of number of tasks. The number of tasks is not a good workload index especially when the weights of tasks are different. A node can be overloaded even if it has a number of tasks less than that in an under-loaded node. A simulation model is built to evaluate the performance of the proposed algorithm. The performance of the proposed algorithm is evaluated and compared with that of Min–Min, and Ant Colony scheduling algorithms using mean task response time, average utilization of processing nodes, and load balancing level as performance metrics. The results show that the proposed algorithm reduces the task mean response time, improves resources utilization, and load balancing level compared with the other two studied algorithms in the range of system’s parameters values examined.
Keywords
Introduction
Grid computing is a new emerging computing paradigm which provides massive heterogeneous resources for solving very large applications in science and engineering [31,36]. It enables coordinated resource sharing, independently of their physical type and location, in dynamic virtual organizations consisting of individuals, institutions, and resources, for solving computationally intensive scientific and engineering applications. Such applications include, but not limited to meteorological simulations, molecular dynamics, data intensive applications, protein biosynthesis, research of DNA sequences, and nanomaterials. The grid users do not have to worry about where their computations are being performed [8–10,13,14,19–21,23,30,36]. One of the main motivations of grid computing systems is the ability to provide grid users and applications with pervasive and seamless access to vast high performance computing resources by creating an illusion of a single system image [3,7,10,14,15,19,35,36,38]. The servers and the processing nodes (PNs) in the grid computing system offer variety of services such as computation services, application services, data services, information services, and knowledge services.
The grid resources are typically heterogeneous in the sense that they have different processor speeds, memory capacities, and I/O bandwidths [8–10,15,36]. Users dynamically submit their tasks with uneven task arrival patterns. Also, grid resources can be freely added or withdrawn at any time according to the owner’s discretion. So, the performance of grid PNs and their load frequently change with respect to time. Such environments may lead to a situation where some PNs are over-loaded while other PNs are under-loaded or even idle during their operations. This situation leads to degrading system performance. To avoid this situation, it is desirable to transfer some tasks from the over-loaded PNs to the idle or under-loaded ones in the grid computing system to utilize available grid resources efficiently and hence improve system performance. The process of load redistribution is known as load balancing [8–10,13,19–21,23,26,30,31,36].
Generally, load balancing algorithms can be classified into two categories namely: static and dynamic [7–9,11,12,18–20,30]. In static load balancing algorithms, the load balancing decisions are made deterministically or probabilistically at compile time and remain constant during runtime. They are not affected by the runtime system state. In contrast, dynamic load balancing algorithms attempt to use the runtime system state information to make more informative load balancing decision. In [18], the authors in turn classified the dynamic load balancing algorithms into centralized or decentralized (distributed) in terms of the location where the load balancing decisions are made.
In centralized load balancing algorithm, only a single resource (controller) is responsible for collecting and using the parameters necessary for making the load balancing decisions. That is only one resource acts as the central controller and all the remaining resources act as slaves. Arriving tasks to the system are sent to controller, which distributes them among the slaves to minimize the overall system mean task response time. The centralized policies are more beneficial when the communication cost is less significant, as in the case of shared-memory multi-processor systems. Many authors argue that this approach is not scalable because the load balancing decision maker may become the bottleneck of the system and the single point of failure as the system size increases [7,11,12,18].
On the other hand, in the decentralized load balancing algorithms, all PNs in the system are involved in making the load balancing decisions. Many researchers believe that the decentralized load balancing algorithms are more scalable and have better fault tolerance because of the localization of load balancing decisions making process. They also believe that these algorithms are very costly from the communication time point of view as every PN in the system obtains the global system state information. Hence, in the decentralized mechanisms, usually, each PN accepts the local task arrivals and makes decisions to send them to other PNs on the basis of its own partial or global information of the system workload distribution [7,11,12,21].
The load balancing problem in traditional distributed systems has been intensively studied [7,11,12]. As a result, a huge number of scheduling load balancing algorithms for traditional distributed environments have been developed. Unfortunately, these algorithms cannot work directly in grid environments, because grids have a lot of specific characteristics like heterogeneity, autonomy, and dynamicity which make the load balancing problem more complicated [8–10,19,20,30,31,36]. Therefore, in the grid environment, it is essential to consider the impact of various dynamic characteristics on the design and analysis of grid scheduling and load balancing policies [9,20,23].
The two major parties in grid computing, namely, users who submit various applications, and resources providers who share their resources, usually have different motivations when they join the grid computing system. The grid users are mainly concerned with the performance of their applications while the resource providers are mainly concerned with the performance of their resources in a particular period. So, the objective functions for any scheduling algorithms can be classified into two categories [6,15,30], application-centric and resource-centric. The goal of application-centric objective function is to optimize the performance of each application using any of the application’s performance metrics such as the Makespan or task response time. On the other hand, Resource-Centric objective function aims to optimize the performance of resources using any of the resource’s performance metrics such as throughput (the number of completed jobs in a given period) or utilization (the percentage of time when the node is busy).
In this paper, we propose a dynamic decentralized workload’s threshold-based scheduling and load balancing algorithm for grid and distributed computing systems. Unlike most of the current scheduling algorithms; instead of using the number of tasks as a workload index in taking load balancing decisions; the proposed algorithm takes the load balancing decisions at all levels based on the current node (processing node or cluster manager) workload. Workload is the ratio between the sum of lengths (represented in millions of instructions MI) for all tasks waiting in the ready queue at the node, and the node processing capacity (represented in millions of instructions per second MIPS). The main objective of the proposed algorithm is to minimize the mean task response time and the communication overhead. It provides the following unique characteristics of practical grid computing environment:
The proposed threshold-based load balancing algorithm (TBLBA) runs on a grid computing system with two-level hierarchical architecture. The hierarchical structure is a natural choice since the grid computing system can encompass a large number of high performance computing resources that are located across different domains and continents, it is difficult for centralized model to address communication overhead and administration of remote workstations.
In each level of the hierarchy, the proposed algorithm uses two workload’s thresholds for making load balancing decisions. The two thresholds are updated only upon any significant change in PNs workloads to reduce the amount of immigrated tasks, and hence minimize the communication overhead that is considered as a bottleneck for most of the current load balancing algorithms.
It takes into account the heterogeneity of grid resources. The grid resources are heterogeneous in nature; they may have different hardware architectures, operating systems, computing power, resource capacity, and network bandwidth between them.
It focuses on applications that are computationally intensive as it is more common in today’s real life applications.
As in [2,8,9], we focus on the steady-state mode, where the number of tasks submitted to the grid is sufficiently large and the arrival rate of tasks does not exceed the total grid processing capacity. That is the grid traffic intensity is less than one. The class of problems addressed by the proposed load balancing algorithm is computation-intensive consisting of totally independent tasks with no communication between them.
The rest of the paper is organized as follows: Section 2 presents related work. Section 3 describes the architecture of grid model. Section 4 introduces the proposed threshold-based load balancing algorithm. In Section 5, the simulation environment and results are discussed. Finally, Section 6 summarizes this paper.
Related works and motivations
In this section, we summarize some of the recent scheduling and load balancing algorithms designed for improving grid and high performance distributed computing systems performance. In [25], the authors presented a load balancing algorithm for the computational grid environment in which the grid scheduler selects computational resources based on the task requirements, task characteristics and information provided by the resources. Their algorithm objective was to minimize the Total Time to Release (TTR) for an individual task. TTR includes processing time of the task, waiting time in the queue, as well as transfer of input and output data to and from the resource. The algorithm computes TTR, and then the tasks are arranged in descending order based on TTR value. Tasks are scheduled in the sorted order. The algorithm performance is evaluated and compared with First Come First Serve and Min–Min algorithms. Their results show that the algorithm gives a better performance than First Come First Serve and Min–Min algorithms. The load balancing algorithms presented in [17] introduce a task migration mechanism to balance the workload when any of the processing elements become over-loaded, but they do not consider the resource and network heterogeneity which are main characteristics of grid computing systems. In [16], the authors presented the Min–Min algorithm which calculates the expected completion time for all tasks at all processing nodes. Task with minimum expected completion time is allocated to a machine which has minimum completion time. This algorithm failed to consider idleness of the processing nodes. In [35], the Max–Min algorithm is presented. It is similar to Min–Min algorithm. It finds the task with maximum expected completion time from a set of unallocated tasks and allocates it to processing node which has minimum completion time for the job.
In [33] the authors proposed a ring topology for the grid managers which are responsible for managing a dynamic pool of processing elements. Their load balancing algorithm was based on the real computers workload which is not applicable because of its huge communication overhead cost. A cost optimization scheduling algorithm to optimize the execution cost of tasks is described in [4]. The algorithm also minimizes task execution time. But the authors did not consider the failure rate of the resources and user deadline of tasks. In [31], the authors proposed a dynamic hierarchical load balancing approach which considers the load of each resource in taking load balancing decisions. It minimizes the response time of the tasks and improves the utilization of the resources in grid environment. In contrast to the algorithm proposed in [4], their algorithm considers the failure rate of the resources and user deadline of tasks. But their algorithm can be only applied to batch jobs since it uses batch mode of scheduling, and it also asks every resource provider to determine the available time of his resource at the joining time to the grid which is impractical. In [22], the authors presented an application demand aware scheduling algorithm which considers application demand of tasks for scheduling. It produces better user satisfaction but does not consider the fault rate of the resources. In [32], a prioritized user demand scheduling algorithm is proposed. The algorithm considers user deadline for allocating jobs to different heterogeneous resources from different administrative domains. It produces better Makespan and more user satisfaction but data movement is not considered.
In [27,37] the authors presented a tree-based model that maps any grid architecture into a tree structure. The model takes into account the heterogeneity of resources and it is completely independent of any physical grid architecture. However, their model did not provide any task allocation procedure and also, it did not consider the communication cost between clusters. In their model, the resource management policy is based on a periodic collection of resource information by a central entity (grid Manager or global Scheduler), which might be communication consuming and also a bottleneck for the system.
Most of grid applications are data-intensive ones and during their execution they may require moving between geographically distributed grid resources in certain time ranges. Therefore the author in [28] discussed the communication support problem in the grid environments and developed a grid methodology that supports the needed connectivity services. In their methodology, the load balancing decisions are affected by the network-related information. Their connectivity solution is offered as services for the grid nodes. On the same line, for Metropolitan area grids, the authors in [29] discussed the resource management, and network-control design challenges critical to provide network-assisted extensible grid services. These services can improve the performance of single domain administrated grid computing system that built on optical transport networks. They proposed a methodology that considers the communication infrastructure as the grid main enabling factor. It unifies various geographically distributed computing resources into a virtual site aiming to cooperatively work as if they were in the same Server or LAN.
In [5,24], two new distributed swarm intelligence inspired load balancing algorithms are proposed. The first one is based on ant colony optimization, while the second algorithm is based on particle swarm optimization. Also, in our previous work [10], an Ant colony based load balancing algorithm (ACLBA) for the grid computing environment is proposed. The pheromone level in the proposed algorithm is associated with resources rather than paths. The pheromone level for a resource depends on communication bandwidth, workload status, and processing capacity. Experimental results showed that the proposed algorithm can perform very well on the grid computing environments. In [1], a load balancing algorithm combined with intelligent agents and a multi-agent approach is proposed. This algorithm assumed two grids levels, local and global. In local grid, each agent is responsible for scheduling and load balancing, and in global grid, agent acts as service provider. The authors in [34], proposed a hybrid scheduling and load balancing policy. In the allocation phase, this policy hierarchically clusters available resources into groups. Process execution is conducted in two levels. The first one assigns processes to resources groups while the second schedules processes on their assigned groups of resources. The performance of their policy is evaluated and investigated, using CloudSim tool, in terms of load-balancing, cost savings, and computational efficiency.
In our previous work [8], we presented a two-level load balancing policy that takes into account the heterogeneity of the grid computational resources. It distributes the system workload based on the resources processing capacity which leads to minimize the overall mean task response time and maximize the grid utilization and throughput at the steady state. Also in our previous work [9], a fully decentralized two-level load balancing algorithm for computationally intensive tasks on a heterogeneous multi-cluster grid environment was presented. It distributes the grid workload based on the resources occupation ratio and the communication cost. The grid overall mean task response time is considered as the main performance metric that is needed to be minimized. The simulation results showed that the proposed load balancing policy improves the grid overall mean task response time. The model presented in [8,9] overcomes the bottleneck of the models presented in [27,30–32,37] by removing the grid manager node which centralizes the global load information of all the grid resources but it also does not consider the communication cost between clusters.
Almost all of the algorithms previously discussed use the number of tasks as a workload index in taking load balancing decisions. Unfortunately, the number of tasks is not a good workload index when the weights of tasks are different. A node can be over-loaded even if it has a number of tasks less than that in an under-loaded node. Unlike these algorithms, this paper proposes a dynamic decentralized threshold-based load balancing algorithm for high performance distributed computing systems. At any level, the manager automatically updates two workload thresholds to be used in taking load balancing decisions. The thresholds are computed based on the current resource’s workload status upon request from any resource if the resource suffers from a significant workload. This leads to minimize the communications overhead and improve resource utilization. Using mean task response time, average utilization of PNs, and load balancing level as performance metrics, the performance of the proposed algorithm is evaluated and compared with that of the benchmark scheduling algorithm Min–Min, and ACLBA. The simulation results show that the proposed algorithm has a lower mean task response time, higher resource utilization and load balancing level than the other two studied algorithms in the range of examined system parameters.
Grid computing model architecture
Generally, a grid computing environment consists of geographically distributed heterogeneous resources (computational power, data storage and network resources) which are owned by multiple administrative domains or clusters. These resources are logically aggregated to serve as a unified computing resource. In this research paper, we consider a large-scale multi-cluster grid computing service model which is based on a hierarchical decomposition structure as shown in Fig. 1.

Grid computing model architecture. (Colors are visible in the online version of the article;
The proposed grid computing model architecture is mainly composed of the following components:
User, a person or a program that submits jobs in the form of gridlets for execution on the available grid resources.
Portal node, that provides grid applications to remote users through the Internet.
Grid Information Server (GIS), responsible for collecting necessary grid information such as grid workload, network traffic, …, etc. that are needed by Grid Scheduler (GS) for efficiently balancing the grid’s workload between the clusters.
Grid Scheduler (GS), responsible for balancing the grid workload from user’s tasks among all the cluster managers based on the grid’s acquired information at the GIS and the proposed load balancing strategy that utilizes all the available grid resources efficiently to satisfy user’s demands.
Cluster, an autonomous entity composed of one or multiple PNs (resources), and a cluster manager (CM). Every PN may have one or more CPUs, and I/O devices. PNs machines are responsible for executing user jobs. In every cluster, there is one CM which is responsible for managing and balancing its assigned rate of grid workload among all PNs in its pool. All PNs in each cluster are locally connected by high speed, and low latency communication links, while cluster managers (CMs) are connected by switches via the global network or WAN with low speed, and high latency properties. Hence, the proposed grid computing model is constructed as a two-level hierarchical model as illustrated in Fig. 1. It can be explained as follows:
Level 1: Local level
This level is composed of clusters (PNs linked to their corresponding CM). Any public, private PC or workstation can join the grid computing system by sending a join request to the nearest CM and offer its resources to be used by the grid users. When a PN joins the grid, it should first run the grid computing service (GCS) which will report the CM about the needed information of the available resources in the newly joining PN such as number of CPUs, total CPUs speed, memory size, available software, and all other hardware specifications. This information will be used by the local load balancing algorithm located at the CM to efficiently and effectively distribute its rate of grid user’s tasks among the PNs in its pool.
Grid users can submit their tasks for remote processing (remote tasks) through the available website browsers using the GCS on the portal nodes to the GS. The GS distributes the arriving tasks to the CMs according to a load balancing policy based on the available information about the CMs. Also, any local site or cluster user can submit his computing tasks (local tasks) directly to the PNs in his domain or cluster. Hence, any PN may have two kinds of arriving tasks namely, remote tasks arriving from its associated CM and local tasks submitted directly to the PN by the local users. This makes the task submission process easy and accessible to any number of clients (remote or local).
As it is illustrated in Fig. 1, there are two types of nodes in this level, PNs nodes and CMs nodes.
Every PN is responsible for the following:
Maintaining its workload information and sending it instantaneously to its CM upon any significant change. The load balancer at the CM will use this information to utilize all active PNs in its pool efficiently.
Executing assigned user’s tasks and returning back the results.
Migrating tasks to its CM if it is over-loaded.
Also, in this level, each CM is responsible for the following:
Managing a pool of PNs (computers or processors) which is dynamically configured (i.e., PNs may join or leave the pool at any time).
Registering new joining PNs to the cluster.
Removing registration data of the leaving PNs from the cluster.
Allocating incoming remote tasks to any PN in its pool according to a specified load balancing algorithm.
Receiving workload information from all active PNs in its cluster, manipulating this information to estimate its cluster workload, and sending the estimated cluster workload to the GS. The GS will use this information to distribute grid workload among all available clusters efficiently.
Receiving immigration orders from the GS, and executing them.
Executing the local load balancing procedure in case of detecting any unbalanced behavior in its cluster.
Level 2: Grid level
In this level, the system has two nodes namely GIS and GS. They are static nodes i.e., they cannot leave the system. The dynamic nature and heterogeneity of the grid resources make the workload state information of available resources very important for a GS in taking schedule decisions. The role of GIS is to provide such information to GS.
GIS is responsible for the following:
Collecting the CMs information, such as total CPU processing capacities of the cluster (equals summation of all CPUs capacities of processing nodes in the cluster) expressed in millions of instructions per second (MIPS), similarly, memory size, network bandwidth, software availabilities and cluster workload expressed in millions of instructions (MI).
Maintaining workload information of all CMs in the system.
The GS is responsible for:
Receiving workload information of clusters from GIS.
Executing load balancing algorithm in case of imbalance behavior occurring among CMs.
Sending its load balancing decisions to the corresponding CM for execution.
The Local Scheduler (LS) at the CMs in turn is responsible for distributing the arriving tasks from the GS on the PEs in its pool according to a load balancing policy. When the execution of the tasks is finished, the GCS notifies the users by the results of their tasks.
As it could be seen from this decomposition, adding or removing CMs or PEs becomes very easy, flexible and serves both the openness and the scalability of the proposed grid computing model.
Any CM acts as a web server for the grid computing system. Clients (users) submit their computing tasks to the GS using the web browser. Upon a task arrival, according to the available CM’s workload information, the GS distributes the incoming task to any of the CMs. After receiving tasks, based on the PN’s workload information, the CMs distribute them for processing on any of the available PNs. After processing any task, the PNs use the GCS to inform the users by the results of their tasks.
A PN may fail or simply, its owner may shut it down. For reliability reasons, every CM monitors the tasks that have been sent for execution and sets a timeout limit for each one. If any task reaches the timeout limit, the CM resends it to other PN for execution.
To be close to reality, the proposed grid computing model has two types of users, namely remote and local. Remote users can submit their tasks for processing to the grid computing system using the Internet via portal node. Local users, submit their tasks directly for processing at the grid computing system to the PNs in their local clusters. The proposed model utilizes the FCFS scheduling policy for all tasks waiting in queues at any level in the system. It is noticed from similar models presented for example in [8,9,27,37] that these models suffer from communication overhead. In the proposed grid computing system, to minimize the communication overhead, we assume that local tasks will be executed at any of the available PNs in the cluster in which they have been submitted as long as the anticipated local processing time is less than or equal to the communication time plus the anticipated remote processing time plus an error rate δ. For the same reason, we also assume that a transferred task from cluster i to cluster j for remote processing receives its service at cluster j and is not transferred to other cluster (i.e., each task is forwarded at most once).
Remote/Local users submit their tasks in the form of Gridlets. A Gridlet is an entity which contains information such as task length expressed in millions of instructions (MI); task size expressed in megabytes (MB), and ID of the user who submits the task. This information will be used to calculate the expected task execution time and also transfer time if needed in case of remote processing. The length of the gridlet is calculated based on the number of instructions in the user task.
The proposed algorithm aims to effectively utilize the available system resources and minimize the user’s tasks response time. Many of the current load balancing algorithms [1,8–10,16,27,36,37] use the number of tasks in the ready queue of the PN as a workload index in taking the load balancing decisions. It is known that if the weights of tasks are different, a node can be over-loaded even if it has a number of tasks less than that in an under-loaded node. Hence, the system performance may degrade if the load balancing decisions are taken using only the number of tasks as a workload index. To avoid system performance degradation, the proposed algorithm uses the load as a workload index in taking the load balancing decisions.
Notations. Using the grid computing model presented in Fig. 1, the following notations are used in the load balancing algorithms:
Task parameters:
Processing node parameters:
Cluster parameters:
Grid parameters:
G: grid.
The proposed TBLBA works at two levels namely: Cluster manager level and grid level. The details of these levels are explained as follows.
Cluster manager level
As mentioned earlier, a cluster’s local user can submit his/her tasks directly to any PN in the cluster, in addition to the remote tasks coming from GS or transmitted from any PN at another cluster. This may lead to imbalance workload situations among cluster’s PNs. Unlike most of the current load balancing algorithms [8,9,21,25,36], only if a significant workload change occurs at any PN, instead of periodically, the PN automatically impulses its CM to run the local scheduler (LS) for redistributing the cluster’s workload among the PNs in its cluster. This minimizes the communications and computations overhead at the CM. Also, the CM has to run LS upon receiving remote tasks from the GS. Since the CM and the PNs in its domain are in close communications, it collects the PNs workload information instantaneously at the time of invoking the LS.

In-cluster load balancing
Hence the LS, at the CM in any cluster, will be invoked in the following two cases:
Case 1: The CM receives a remote task from the GS for processing in its cluster.
Case 2: Significant workload change occurs at any PN in the cluster.
If any of these cases occurs, the CM will utilize Algorithm 1 as a load balancing algorithm to distribute its workload among the available PNs in its cluster.
Using the upper and lower thresholds, the CM utilizes Algorithm 2 in classifying the workload states of all PNs in its cluster into three categories; lightly loaded, naturally loaded, and over-loaded.

PNs states allocation
Then, the CM uses the lists LL, and OL resultant from Algorithm 2 in matching the immigration pairs between PNs and balancing the workloads between them using Algorithm 3.

Immigration pairs selection and load balancing
The GIS periodically collects the workload information from each cluster in the grid. This information is utilized by the GS when needed to eventually distribute the global grid workload on its clusters. A task can only be transferred if the sum of its completion time in the receiver cluster and transfer cost is less than its completion time on the source cluster. This assumption is made to avoid making useless task migration. To minimize communication overhead, we assume that a transferred task from a source to a receiver cluster receives its service at receiver cluster and is not further transferred to other cluster (i.e., each task is forwarded at most once). Based on the collected information, the GM estimates the upper and lower cluster processing time thresholds. It then uses these thresholds to analyze the current grid workload. According to the result of this analysis, the GM decides whether to start the grid load balancing algorithm or not. It invokes the load balancing algorithm if any of the following two cases occurs:
Case 1: The GM receives a task from the grid users for processing at any cluster in the grid.
Case 2: Significant workload change occurs at any cluster in the grid as a result of local task arrival.
If any of these two cases occurs, the GM will utilize Algorithm 4 as a load balancing algorithm to distribute the grid workload among the clusters.

Grid load balancing

Clusters states allocation
Using the grid upper and lower processing time thresholds, the GM utilizes Algorithm 5 in classifying the workload states of all clusters in the grid into three categories; lightly loaded, naturally loaded, and over-loaded.
Then, the GM uses the lists LLC, and OLC resultant from Algorithm 5 in matching the immigration pairs between clusters and balancing the workloads between them using Algorithm 6.

Selection of clusters immigration pairs and load balancing
The performance of the proposed load balancing algorithm is evaluated using the following performance metrics:
Mean response time
The length of time between the instant from the task arrival time to the grid and the instant when it leaves the grid, after all processing and communication are over is referred to as the task response time. Let
Average node utilization rate
The ith processing node
Hence, the average utilization rate U of all processing nodes is computed by:
Load balancing level
It is known that higher average resource utilization does not guarantee a good load balancing strategy [30]. Hence, the mean square deviation d of PNs utilization rate
The smaller the mean square deviation is, the more effective load balance obtained.
Hence, the relative deviation α of d over U that describes the load balancing level of the grid is given by:
The small values of the mean square deviation d lead to higher relative deviation which indicates that the entire system workload is balanced among processing nodes (i.e. a good load balancing level). The best load balancing level is achieved when d equals zero and α equals 100%. This means that, the smaller the mean square deviation is, the more effective load balance obtained.
The previously explained performance metrics are applied to the grid computing system environment and they are correlated. For example, if the grid workload is balanced among the PNs, the resource utilization rate will be high and as a result, the task’s response time will be minimized.
Simulation results and discussion
Simulation tool environment
To evaluate the performance of the proposed load balancing algorithm, a heterogeneous grid environment model is built using the java based simulation tool GridSim 5.0 [36]. GridSim is used to analyze scheduling and load balancing algorithms on large distributed computing systems of heterogeneous resources. It provides facilities for modelling and simulating entities in such environments. These entities include users, heterogeneous resources, applications, and resource load balancers which are used in designing and evaluating load balancing algorithms. In our simulation model, tasks are modeled as Gridlet objects which contain all the information related to the task and the execution management details. All of the needed information about the available grid resources can be obtained from the grid information service entity that keeps track of all resources available in the grid environment. All simulation experiments have been performed on a PC (Dual Core Processor, 3.2 GHz, 4 GB RAM) running on Windows 7.
Simulation setup and assumptions
The simulated grid environment contains 16 clusters which is a benchmark for scheduling algorithms to evaluate their efficiency [26]. Number of PNs in every cluster is randomly assigned and is ranging from 1 to 5. The cluster’s PNs have different characteristics, configurations, and capabilities. Every PN may have 1 or 2 processing element(s) (processor(s)). The FCFS scheduling policy is utilized at all scheduling levels. The experiment focuses on gridlets which are computationally intensive tasks as it is more common in today’s real life applications [13,21]. Gridlets arrive sequentially and randomly to the system following a Poisson process with rate λ. Simultaneous arrivals are excluded. The inter-arrival times are independent, and exponentially distributed. The service times of tasks are assumed to follow the exponential distribution with rate μ. Gridlets are mutually independent that is, there is no dependences or communication between them and can be executed at any PN that satisfies their requirements. Each processing element can execute a single gridlet at a time. Gridlets are not preemptable that is, the execution of a task cannot be interrupted or moved to another PN during execution. Gridlet length is a uniformly distributed random number in the range of (5,000 to 10,000) Millions of Instructions (MI) units. The CPUs speed, ranging from 0 to 4 MIPS, are randomly assigned to the processing elements. LAN (WAN) link bandwidth is ranging from 500 to 1,000 (200 to 500) Mbps. For reliability issue, each result presented is the average value obtained from 5 simulation runs with different random numbers seeds. All time units are in seconds.
The average system traffic intensity factor in the simulation is denoted by ρ, which is the average task arrival rate divided by the average task processing rate. Using this definition, the tasks service time’s μ are adjusted to get the desired system traffic intensity. To study the performance of the proposed load balancing algorithm under different system parameters setting, the system traffic intensity factor is varied during the simulation, and results are collected from experimental runs. The final results of the simulations are presented on an average basis.
Experimental results
In this section, the performance of the proposed TBLBA is evaluated and compared with that of the well-known benchmark scheduling algorithm Min–Min discussed in [20], and ACLBA which is discussed in our previous work [10]. The performance measurements of these algorithms rely on three metrics: average task response time, utilization of PNs, and load balancing level.
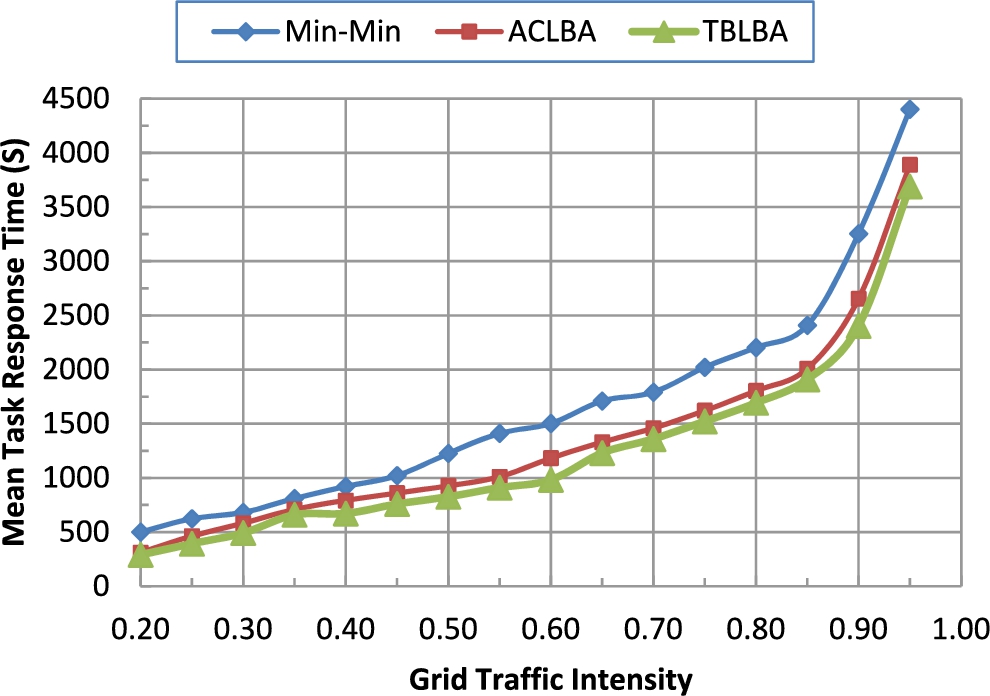
Mean task response time of proposed TBLBA vs Min–Min, and ACLBA. (Colors are visible in the online version of the article;
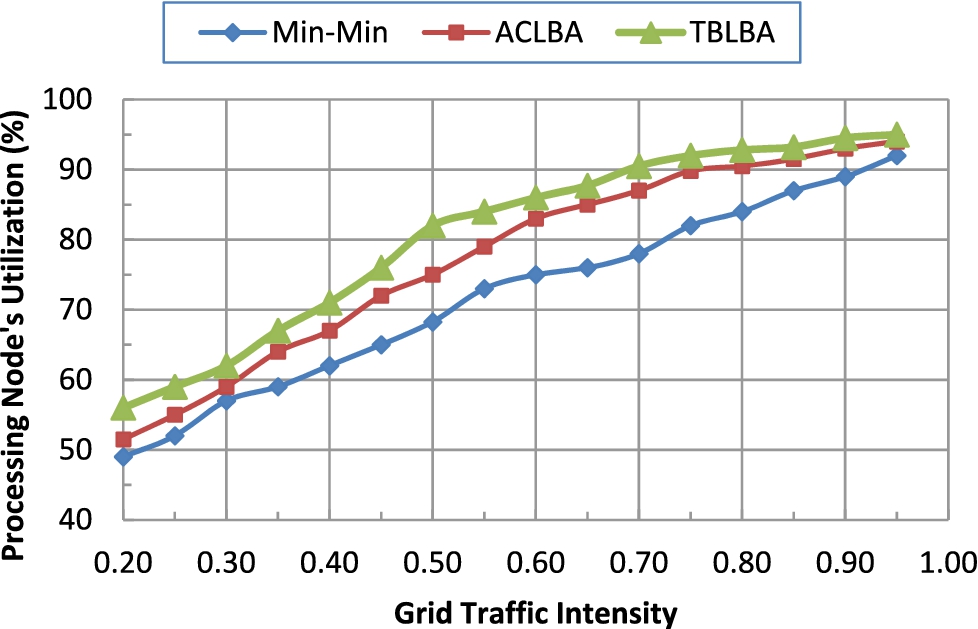
Average processing node utilization. (Colors are visible in the online version of the article;
The Min–Min algorithm accepts tasks only through grid scheduler. It does not allow local task submission as our models do. Hence, to be able to compare the performance of the Min–Min algorithm with our algorithms ACLAB, and TBLBA, in this experiment, the local task arrival rate is scaled down to 0 (i.e., no local task arrival is allowed). Figures 2–5 compare the performance of the proposed TBLBA for various system traffic intensity against that of Min–Min, and ACLBA. Figure 2, compares the mean task response time of these load balancing algorithms while varying system traffic intensity from 0.2 to 0.95. Note that, for the system to be stable; its traffic should be less than one. From this figure; one can notice that the proposed TBLBA outperforms the other two algorithms in terms of mean task response time. Also from that figure, it is noticed that the response times of the three algorithms increase dramatically as the system traffic intensity (
Figures 3 and 4 illustrate the average node utilization, and mean square deviation of PNs for various grid workload using Min–Min, ACLBA, and proposed TBLBA respectively. From these figures, it is noticed that the average PNs utilization (mean square deviation) obtained using the three algorithms increases (decreases) as the grid workload increases. However, the utilization (mean square deviation) of PNs under the proposed TBLBA is always higher (lower) than that of both Min–Min, and ACLBA which means that, the performance of the proposed TBLBA is better than that of the other two algorithms. This ensures the results presented earlier in Fig. 2.
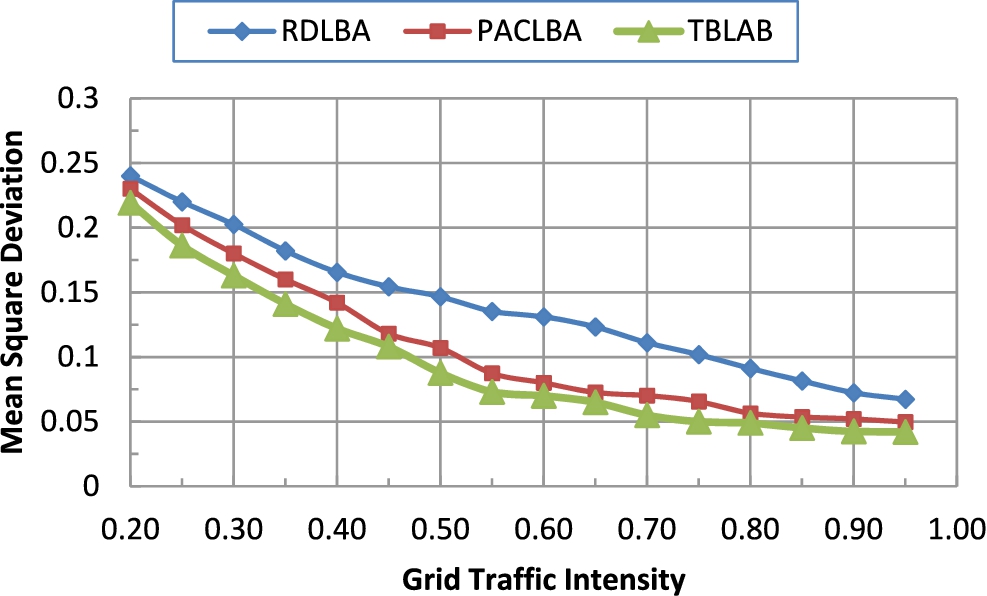
Mean square deviation. (Colors are visible in the online version of the article;
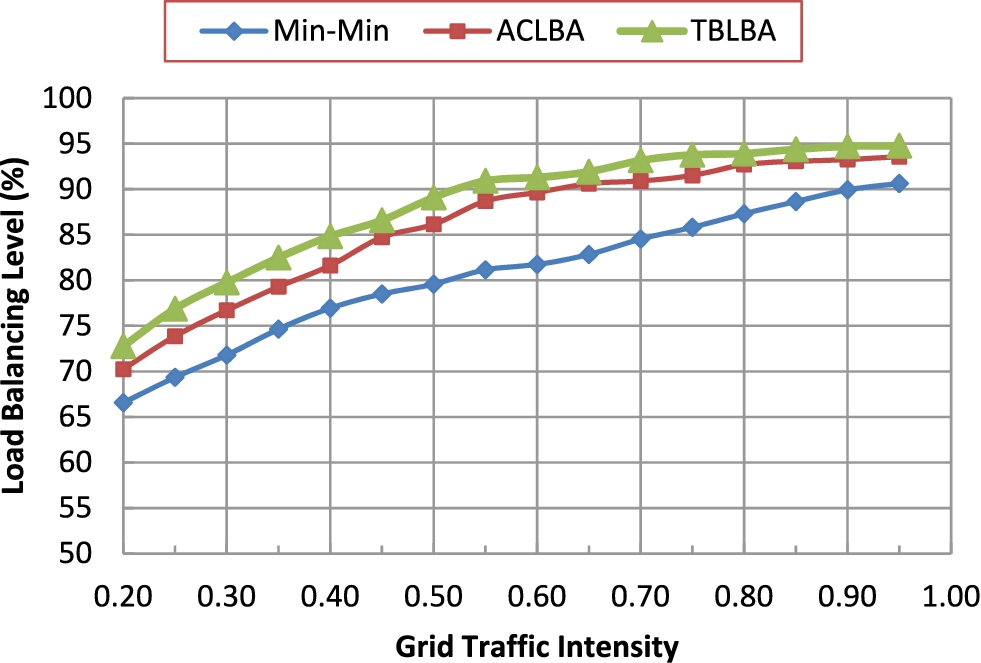
Load balancing level. (Colors are visible in the online version of the article;
Figure 5 presents the load balancing level of the three studied algorithms for various grid workloads. From that figure, it is noticed that the load balancing level obtained using the proposed TBLBA is always higher than that of the Min–Min, and ACLBA in all cases which again ensures the previously presented results. In view of the previously presented results, we can say that the proposed TBLBA outperforms both of the Min–Min, and ACLBA scheduling algorithms.
This experiment is carried out to study the effect of the local task arrival rate on the performance of the proposed TBLBA. Since the Min–Min algorithm does not allow local task arrivals, in this experiment only the performance of the proposed TBLBA, and that of ACLBA is compared, as the two algorithms allow local task arrivals. The same setting of grid parameters for the previous experiment is used. The only difference is the arrivals rate. This experiment is repeated twice by setting the local task arrival rate to 20%, and 40% from the total tasks arrived to the system respectively. As shown in Fig. 6, the mean task response time obtained by the two algorithms decreases as the ratio of the local task arrival rate increases. This result is obvious since most of the local arrivals are executed locally and do not suffer from any transmission delay which leads to decreasing task response time.

Mean task response time obtained by ACLBA, and proposed TBLBA for different ratios of local task arrival rate. (Colors are visible in the online version of the article;
In this paper, a dynamic threshold-based load balancing algorithm for high performance distributed computing systems is proposed. The proposed algorithm takes into account the dynamicity and heterogeneity of available system resources. It automatically updates the workload thresholds upon any significant change of any resource workload and balances the system’s workload using the new thresholds. Unlick most of the current load balancing algorithms which use the number of tasks in a PN’s waiting queue as a workload index in taking load balancing decisions, the proposed algorithm uses the real PN’s load as a workload index in taking load balancing decisions. The number of tasks is not a good workload index when the weights of tasks are different. A node can be over-loaded even if it has a number of tasks less than that in an under-loaded node. By using the real load as a workload index in taking the load balancing decisions, the proposed algorithm efficiently utilize all of the available resources in the system. A simulation model is built to evaluate the performance of the proposed algorithm. Using the performance metrics; average task response time, utilization of PNs, and load balancing level, the performance of the proposed TBLBA is evaluated and compared with that of Min–Min, and ACLBA scheduling algorithms. The simulation results show that the proposed algorithm has a good response time against the other two algorithms in the range of examined system parameters. In the future, this algorithm could be extended to deal with user demands such as task deadline, and execution cost. Also, it could be improved from the reliability point of view by considering some fault tolerance measures.