
Abstract
The use of GPU computing is today an active research field due to the enormous parallel processing power of GPU. For more calculation efficiency, we integrate the GPU computing into an agent-based distributed computing, the result being a multi-agent model for distributed GPGPU computing. The computation distribution is based on a multi-agent system designed in accordance with the standards of the Foundation for Intelligent Physical Agents (FIPA). The interactions between the agents are based on Agent Communication Language (ACL). These agents are deployed into a multitude of interconnected computing nodes where each node is accelerated by a GPU chip. This multi agent system is implemented with the Java Agent DEvelopment Framework (JADE). Additionally, we provide a Java programming library to allow programmers to easily use this system to optimize their algorithms. An illustrative example with a K-means algorithm is given to show how cumbersome algorithms can be accelerated by this model.
Introduction
The researchers in the High-Performance Computing (HPC) field are faced with two forms of applications. The first is compute-intensive applications like weather or financial forecasts, scientific simulations: Mechanical, Aerodynamic, Electrical, Molecular Biology, etc. This form of applications covers the execution of programs across multiple processors on the same or multiple machines. It focuses on executing different operations in parallel to fully utilize the available computing resources in the form of processors and memory. The second is data-intensive applications like image or video processing, video games, big data, etc. This form of applications focuses on the distribution of data sets across multiple computation programs. In this form of applications, the same operations are performed on different parallel computing processors on the distributed data sub set. Thu, for the both kinds of applications, researchers created models that best meet the needs of these applications in computation and storage resource management. These models were developed by considering a strategy for dividing the data and tasks, and applying a suitable strategy to reduce interactions.
In literature, there are two categories of HPC models. The first category is the massively parallel models, examples of such models are 2D or 3D reconfigurable mesh [27], FPGA and recently GPU [17, 18]. The second category is the massively distributed models, as examples, grid computing, clusters [13, 14, 25], the cloud computing [25], agent-based distributed computing [29]. In this research work, we have focused on GPU computing and agent-based distributed computing.
In GPU computing, one of the most important advances is the Nvidia CUDA solution. The Nvidia TITAN X is a fastest GPU at the time of writing this paper. This GPU has 3584 shader units also called CUDA cores or elementary processors; it has 1417 MHz as base clock which can be boosted to 1531 MHz, and 12 Gbits of GDDR5 memory with 480 Gbits/s of memory bandwidth. To have more computational power, four TITAN X GPUs can be interconnected with Nvidia’s Scalable Link Interface (4-way SLI), the result being a powerful GPU with 14336 CUDA cores and 48 Gbits GDDR5 memory which in collaboration with the Intel Core i7 5960X CPU can give an interesting optimization in many areas of applications. Unfortunately, in some cases, the use of multi-GPU systems is not sufficient to achieve a high-performance computing in certain scientific or engineering applications. Specifically, in the case where these applications have to process a large amount of data and perform complex tasks, as for instance, in medical imaging, performing an analysis on a stream of MRI cerebral images using image-processing techniques such as the K-means clustering algorithm. In addition, the scalability is not guaranteed and strongly depends on the evolution of the GPU and CPU hardware proposed by Nvidia, AMD and Intel. Thus, using a multi-GPU system on single node is constrained by hardware limitations. In other words, the computing and data communications capabilities of the processing environment become the dominating bottleneck. To overcome these limitations, we studied distributed programming libraries with the aim to combine GPU computing and distributed computing paradigms.
In the distributed computing paradigm, we found a set of distributed programming libraries and standards, as for instance MPI (Message Passing Interface) [30, 31], OpenMP (Open Multi-Processing) [32, 33], or HPX [29]. These librairies were used to design parallel and distributed computing models [34, 35]. All these researches agree that the challenge is to design a model which provides an ease of programming with a high level programming language as Java (without memory management or other low-level programming routines), and best performance exploitation of hardware. Unfortunately, these two goals are contradictory due to the fact that some researchers obtained best performance by using low-level communication libraries known to be error-prone like MPI (Message Passing Interface) or OpenMP (Open Multi-Processing) [22], Others researchers [23] have designed a model using a high-level programing language which ensures simplicity of programming and portability of the code, although bringing a loss of performance and preventing an efficient access to CPU and GPU due to high-level abstractions of the hardware.
To tackle these problems, we developed a model of distributed Multi-Agent System (MAS) for GPU computing called DAG. It runs cumbersome applications which have parallel components targeted for execution on GPUs.
This paper presents the role of the MAS on asynchrony distribution of data and tasks between remote GPUs across interconnected nodes, and show the programming library called dag.jar developed for programmers who want to use DAG to optimize their algorithms. This paper explains how this library grant an ease of programming by replacing the C/C
Literature review
In the last years, the most used parallel computing trend is the GPGPU (General-Purpose computing on GPU) which is based on graphics chips, these graphics chips became increasingly programmable, which allowed computer scientists, along with researchers in various fields such as medical imaging and electromagnetics, started using GPUs to accelerate a range of scientific applications. In the beginning, the challenge was that GPGPU required the use of graphics programming libraries like OpenGL (Open Graphics Library) and DirectX to program the GPU. Developers had to make their scientific applications looking like graphics applications and map them into problems that drew triangles and polygons. This limited the accessibility to the tremendous performance of GPUs for science. This cumbersome translation was obviated by the advent of general-purpose programming languages and APIs such as Sh/RapidMind, Brook. After that, Nvidia which is actually the world leader in Visual Computing Technologies realized the potential of bringing this performance to larger scientific community and invested in modifying the GPU to make it fully programmable for scientific applications. In addition, it added support for well-suited languages like C, C
In the other hand, the distributed computing paradigm is in full swing due to rapid network technology evolution; as instance, the Fiber Distributed Data Interface (FDDI), with 1 Gbits/s; or the IEEE 802.3 gigabit Ethernet, with 10 Gbits/s (e.g. 1000Base-LX or 1000Base-SX series. In distributed computing literature, we found the agent-based distributed computing trend [29] characterized by the distribution and parallel execution of tasks based on agents. This trend used for experiments with large agent numbers [37], especially so in Social Learning (SL) experiments with Multi Agent Systems (MAS) [36].
Tacking account that GPGPU and distributed computing have received a great amount of attention from the research community. Several projects have been proposed [24, 38, 42, 44] to build powerful computers based on these two computing paradigm.
CUDASA [44] is an extension of the CUDA platform which extends parallelism to multi-GPU systems and GPU-cluster environments. rCUDA [46, 47, 13] is a distributed implementation of the CUDA platform that enables shared remote GPGPU in HPC clusters. PIMA(GE)2 [21] is an library able to exploit traditional clusters through MPI, GPU device through CUDA.
Besides CUDA-based approaches, also OpenCL solutions have been proposed to simplify distributed GPU systems programming. Kim et al. [38] proposed the SnuCL that extends the original OpenCL semantics to heterogeneous cluster environments. SnuCL relies on the OpenCL language with few extensions to directly support collective patterns of MPI. Indeed, in SnuCL, it is the programmer responsibility to take care of the efficient data transfers between nodes. In that sense, end users of the SnuCL platform need to have an understanding of MPI collective calls semantics in order to be able to write scalable programs.
Bednarek et al. propose the bobox [40] designed to support development of data-intensive application in a single node. Indeed, in the bobox routine, program is expressed in a form of oriented graph called execution plan. Vertices of the execution plan (denoted boxes) perform individual data processing operations and each operation is implemented as a sequential routine in C
In the context of agent-based programming, other works have investigated the problem of integration of the GPU in MAS. Hermellin et al. propose a literature review [43] reporting on contributions which are at the intersection between MAS and GPGPU and identifies the most promising directions for the combination of the GPU and multi agent paradigms. This review conclude that the GPGPU can bring much to the field of SMA and vice-versa.
DAG architecture.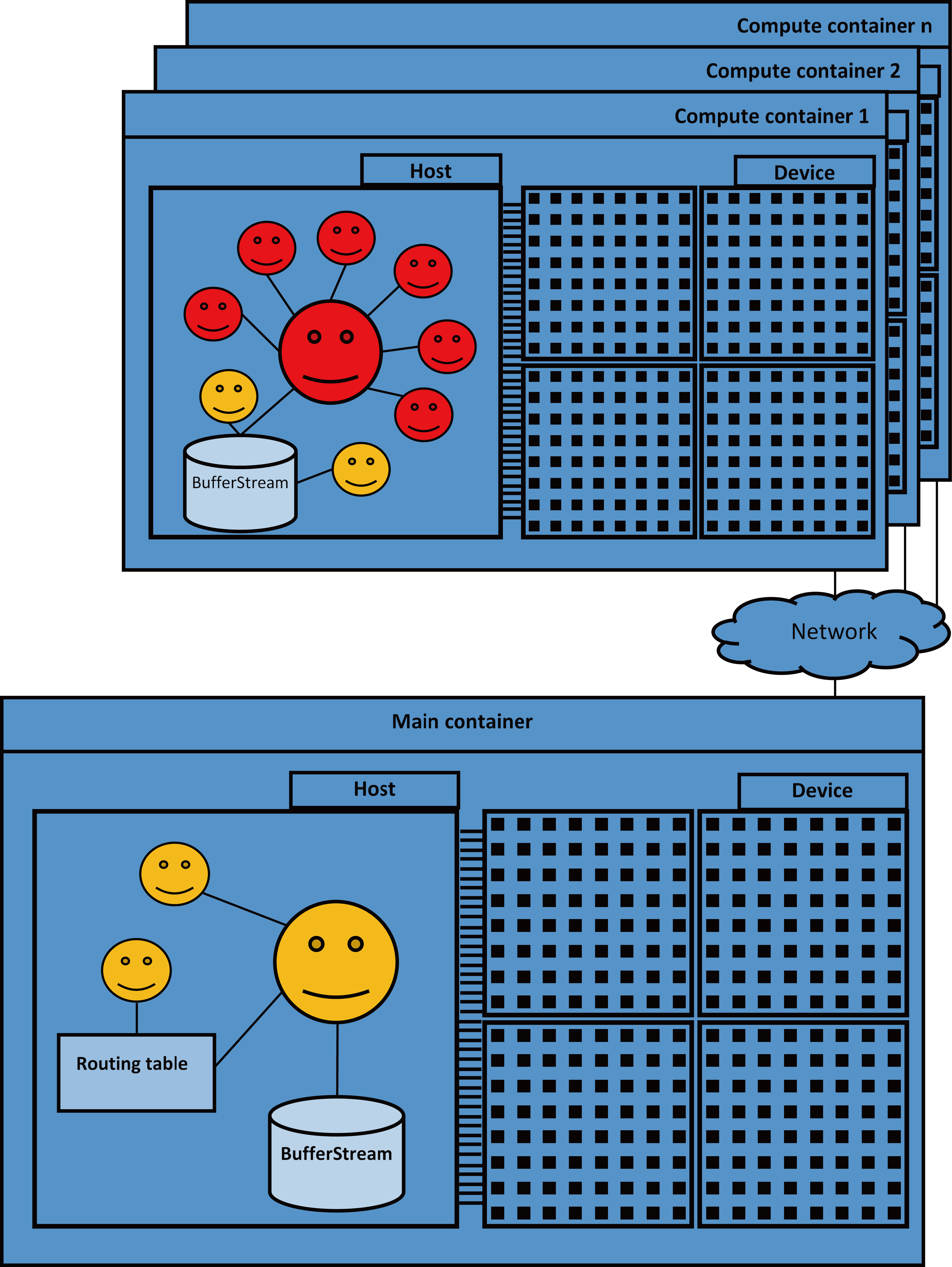
Architecture
The DAG system aims at high resource utilization and high scalability. The computation distribution is based on the agent interactions within MAS deployed on multiple heterogonous nodes. The used MAS was implemented by JADE [20] in accordance with the standards of the Foundation for Intelligent Physical Agents. The interactions between the agents are based on asynchronous communication mechanisms in accordance with the ACL.
Cscs Each running instance of the JADE runtime environment is called a container as it can contain several agents. The JADE platform is a set of active containers distributed on heterogeneous computer nodes. JADE agents are identified by a unique name and, provided they know each other’s name, they can communicate transparently regardless of their actual location: same container or different containers in the same platform.
As shown in Fig. 1, the DAG consist of two types of containers:
Main container: Is exactly a JADE main container which must always be active in a platform and all other containers register with it as soon as they start. Note that only one main container must be launched at first to start the JADE platform. The main container has the ability of accepting registrations from other non-main containers. A main container holds two special agents, automatically started when the main container is launched. The first one is the AMS (Agent Management System) that provides the naming service (i.e. ensures that each agent in the platform has a unique name) and represents the authority in the platform (for instance it is possible to create/kill agents on remote containers by requesting that to the AMS). The second one is the DF (Directory Facilitator) that provides a Yellow Pages service by means of which an agent can find other agents providing the services he requires in order to achieve his goals. Additionally, the main container holds a routing agent, scheduler agent, serializer agent.
Compute containers: Are JADE normal (‘non-main’) containers, each compute container register with main container as soon as it starts and must “be told” where to find (host and port) its main container. In compute containers, we find serializer agent, scheduler agent, team leader agent and worker agents.
The DAG multi agent system.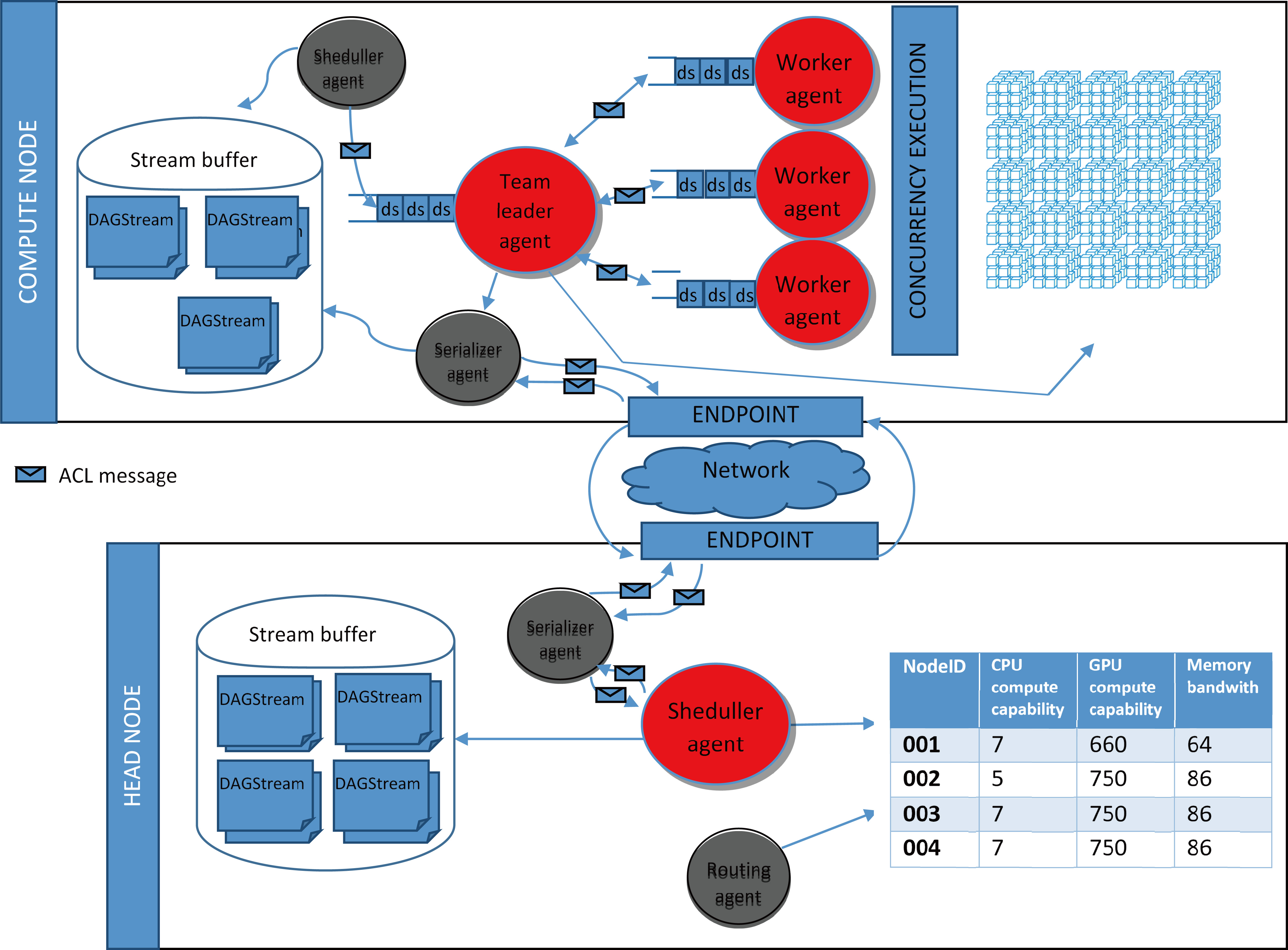
In this section, we show how an algorithm is performed within DAG, and how agents interact between each other across nodes to achieve efficient tasks and data communications.
As shown in Fig. 2, the main concept of DAG is lightweight programs so-called DAGStream designed to be executed concurrently on the GPU devices of DAG. DAGStreams are forwarded across the distributed multi agent system which is responsible for dispatching tasks and for transparently and efficiently moving data across the nodes. At the beginning, the DAG compiler parses the algorithm written with dag.jar library and splits it into DAGStreams. These latter are stacked into the Stream Buffer (SB). The programmer gives to each DAGStreams a priority and a weight number, the first allows the programmer to sort DAGStreams by priority for a concurrent access to a computational device, for instance, when two DAGStreams are ready to be performed on the same available GPU device, the second is a kind of estimation number defined by the programmer which indicates the weight of the DAGStream, relative to GPU kernel launch and memory copy (Host to Device, Device to Host).
Head node workflow.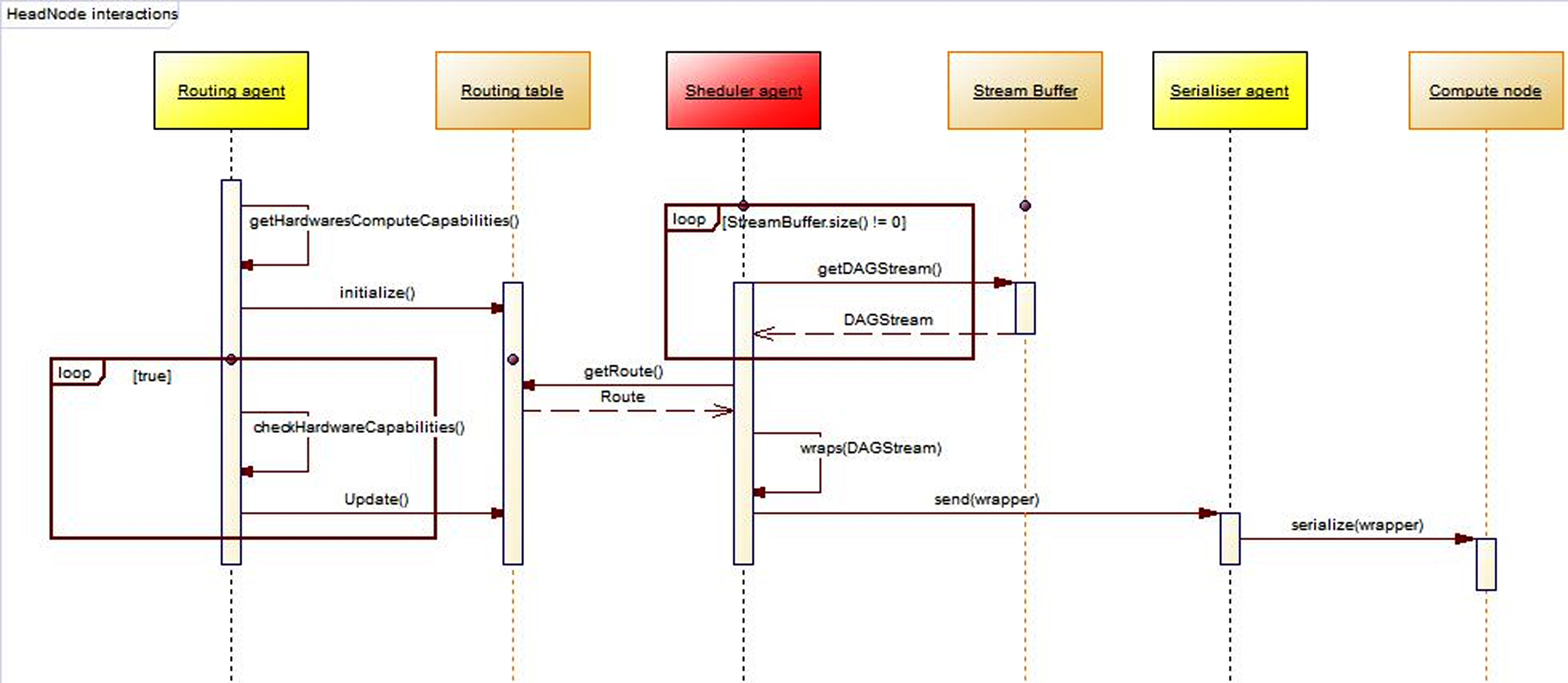
As shown in the Fig. 3, in the head node, the head scheduler agent which represents the backbone of the DAG multi-agent system fetches continuously DAGStream from SB. Optionally the SB can be organized by a queue, thus the head scheduler agent will fetch the DAGStream by the FCFS (for First Come First Served) algorithm. Indicates this option during the compilation time, alert the head scheduler agent to perform DAGStreams by their arrival time into the SB.
The routing table in the head node are generated in two steps, by the initiation routines, and synchronized regularly by the routing agent. The letter is an agent which acts on the routing table, it modifies the runtime system during its decision-making process. Its responsibility is to pick up information and calculate the so-called compute capabilities of the compute nodes. In each node, the CPU and GPU compute capabilities are measured by FLOPS (for Floating-point Operations Per Second) and relative to cores numbers, frequency and operation per cycle. Obviously, GPUs are fast in terms of theoretical computational power and, furthermore, note that compute nodes can have multiple GPU connected via SLI which theoretically increase the node compute capability.
When the head scheduler agent fetches a given DAGStreams from SB, it decodes its content and – depending on the routing table and the targeted device – dispatches the task and data of the DAGStream to the correct compute node. In addition, whether the weight indicator are specified by the programmer, the decision of the head scheduler agent is influenced by the mathematical difference between the weight indicator of the DAGStream and the compute capability.
Once the decision-making of routing process is done by the head scheduler agent, it wraps DAGStream into wrapper which contains descriptors and information necessary for routing and execution through the DAG. To be portable across nodes, wrappers are objects identified, by a unique WID. Each wrapper prepared is delegated to the serializing agent which serialize the wrapper content, then dispatches them to the node hosting the requested GPU device.
The serializing agents have as principal goal: transparent and efficient moving of compressed data across the nodes. In detail, the serializing agents uses a fast and efficient object graph serialization frameworks.
On the other side, in the compute nodes, as shown in Fig. 4 the serializer agent receives and de-reserializes wrappers, then copy DAGStreams to SB. Continuously, the scheduler agent on the compute nodes read DAGStream with the aim to sort and stack them in the stream queue of the so-called team lead agent. The DAGStream are shortened in the system in two way, either by Priority based scheduling if the priority of the stream was specified by the programmer, or else by the Sort Job First (SJF) scheduling.
Each team lead agent in the different nodes dequeues DAGStream from its local queue. Tacking account that the team leader agent checks continuously the state of the GPU, it posts DAGStream for the so-called worker agent in its queue.
Compute node workflow.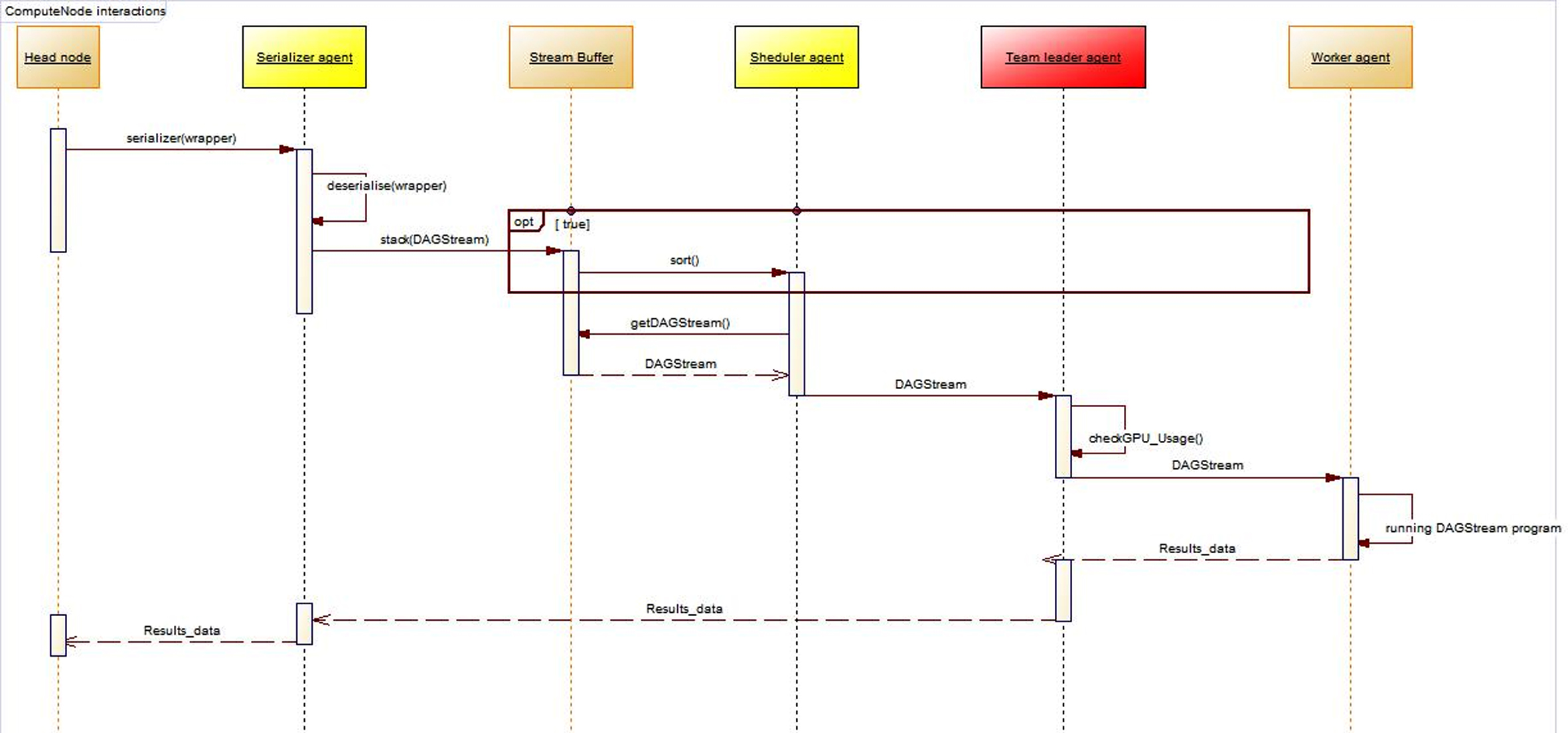
As mentioned before in this section, DAGStream is a set of tasks and data created with the aim to divide a given cumbersome problem to sub problems. These formers contain DAG host code and C CUDA GPU code. They are delegated to the worker agents which collaborate with the GPUs using CUDA stream to perform computational tasks.
The CUDA streams used by the worker agents run asynchronously on the same device or multiple devices. In addition DAGStreams run in parallel across the DAG, this abstraction hide the complexity of multi-GPU programming, i.e. the DAG appears like if he have one super GPU device.
Direct programming with CUDA on multi-GPU require using unmanaged C
In this section we show the library (dag.jar) proposed for programmers who seeks to use the DAG for implementing their algorithms. The dag.jar is a java based library which guarantees the simplicity of programming and increase productivity using java annotation.
While maintaining the notion of host and device code, dag.jar extends the CUDA programming library. This library simplifies the development of distributed GPU applications. To do this we use Java binding for CUDA (JCUDA API) which wraps the C/C
Additionally, dag.jar let the programmer to use the CUDA C to write device code (kernel) separately in files, the lasts will be compiled by NVCC (for Nvidia CUDA Compiler) with the aim to generate assembler-like language named PTX files dispatched and executed on GPU devices across the DAG system.
The library dag.jar exposes a very simple programming objects:
Device: Represents a compute device. i.e. GPU allowing concurrent execution of multiple kernel.
Buffer: Represents an object which contains the DAGStream sub-programs.
Kernel: Is a component targeted to be performed on the GPU devices.
Memory: Represents the object of manipulated data, it have the following features:
MemoryType: Represents the type of memory manipulated during CUDA routines, it can be DEVICE (for device memory), HOST_PINNED (for host Pinned memory), HOST_PAGEABLE_ ARRAY (for pageable memory in form of a Pointer.to (array)) or HOST_PAGEABLE_DIRECT (for pageable memory in form of a Pointer.to (directBuffer)). Pointer: An auto managed object which contain a memory address to the actual memory. FloatBuffer: The buffer for the memory, if it is no device memory.
DAGStream: Is typical sequence of operations for a CUDA program, note that the proposed DAGStream can launch multiple CUDA streams to achieve overlapping between data transfers and other operations. Each DAGStream contain operations for the declaration and allocation of host and device memory, initializing of the host data, transferring data from the host to the device, executing one or more kernels and transferring results from the device to the host.
Furthermore, the DAG have its own compiler which is a wrapper about Java host compiler for the host code, it use the native java compiler to split the java methods surrounded with the annotation @ParallelExec to DAGStreams. Each DAGStream is surrounded with @DAGStream annotation, it contain host code written with Java using JCUDA.
The host code manages the execution of device code which is written with C exactly in same way as it is done for CUDA C/C
K-means application on the proposed system
We will present across this section, an illustrative example of use the DAG to encode a clustering algorithm called K-means which has been applied for the image segmentation. K-means was applied on 3 streams of MRI cerebral images. After that to show the efficiency of the DAG for massive data processing, we compare the total time running of the segmentation of all images of each streams using classic GPU-based K-means with the total time running of the segmentation of all images of each streams using DAG-based K-means version.
K-means flow chart.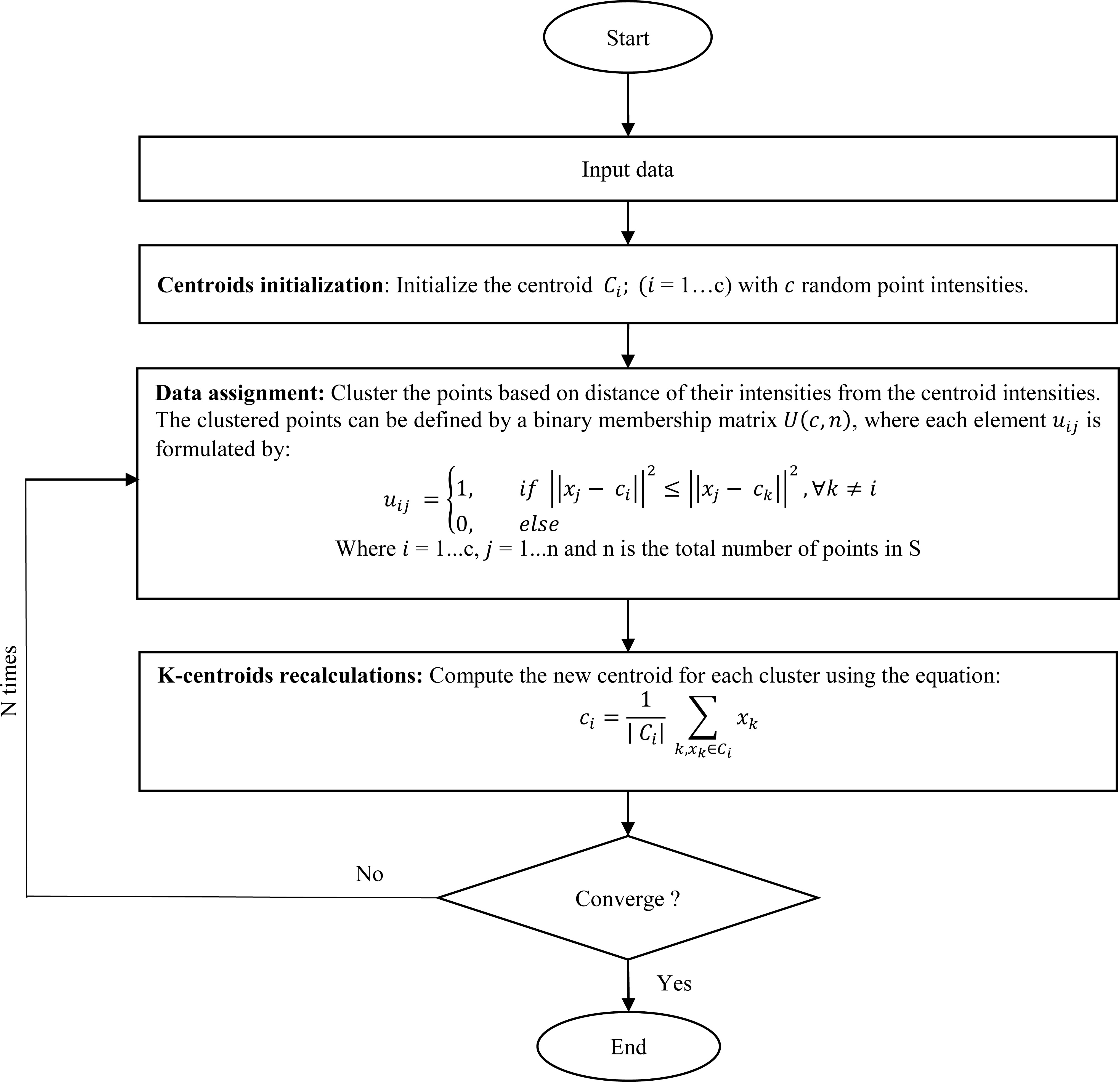
The K-Means [1] is an unsupervised clustering algorithm that classifies the input data points
Where
As described in MacQueen paper [1], an initial clustering
In this application, the clustering k-means algorithms is used for the image segmentation; thus, the flow chart of the algorithm is illustrated by the Fig. 5, it takes a 2-dimensional image as data in input, each point (pixel) of this image have an intensity.
In brief, k-means chooses the centroid smartly and it compares centroid with the data points based on their intensity and characteristics and finds the distance, the data points which are similar to the centroid are assigned to the cluster having the centroid. New
Steps and agents interactions during the DAG-based k-means execution.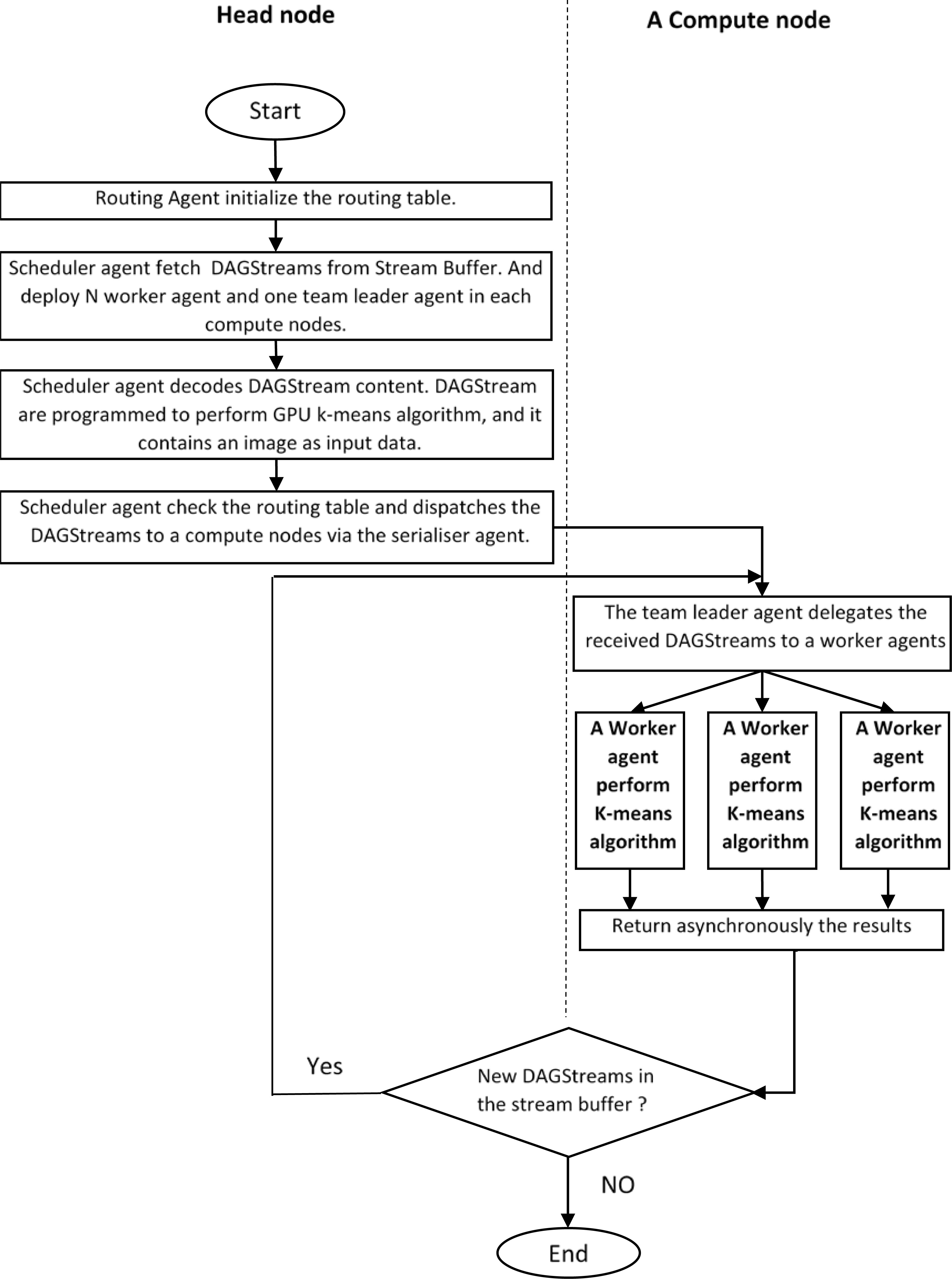
DAG-based K-means performed by worker agents.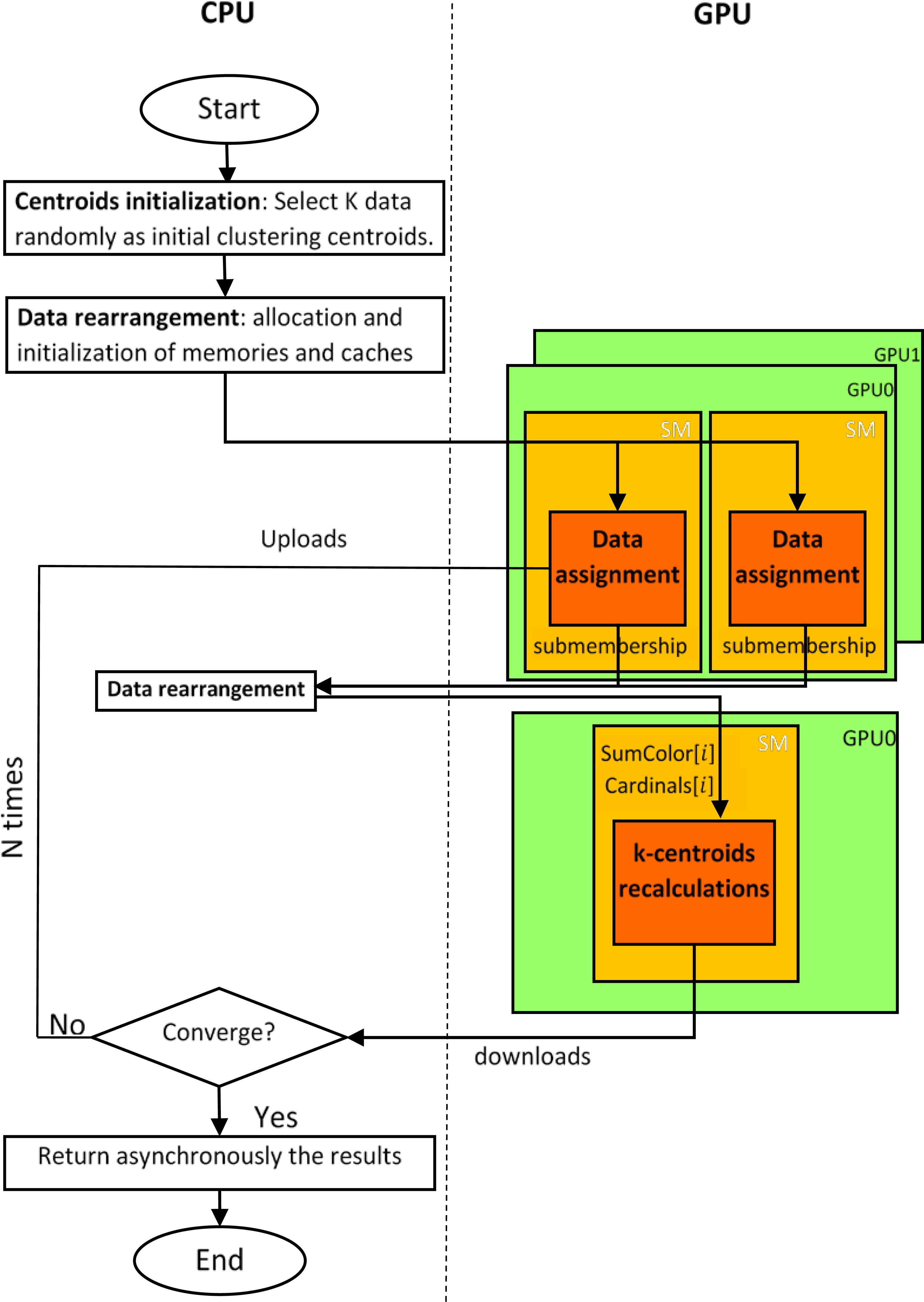
DAG-based k-means clustering algorithm are performed on streams of images on independent GPU computing units i.e. Streaming Multiprocessor (SM). For each image of the streams to process, the SMs of the GPUs have its own queue used to collaborate with a worker agent. The Fig. 6 illustrates the steps and interactions established within the DAG multi-agent system during DAG-based k-means application on images streams.
The purpose of these interactions is to send the DAGStreams to the worker agents. the former performs K-means algorithm, as show in the Fig. 7. The initiation routine, data rearrangement and the convergence test steps are performed by worker agents CPUs. The data assignment, and k-centroids recalculations steps are performed by worker agents SMs on GPU devices.
The source code of the DAG-based K-means is accessible on the repository called DAG-based-K-means on github. The code is surrounded by the annotation: @ParallelExec(node
In fact, the method public void kmeans(){...} are summarized in the following:
Centroids initialization: The worker agent select
Data assignment: The GPU calculates the distance between each points and centroids, and clusters the points using these distances. Each point data sets will be delegated to a processor in GPU.
Data rearrangement: The membership structures are downloaded from the GPU memory to the host (CPU) memory, and the host rearranges all data, and calculates SumColor [
K-centroids recalculation: The GPU recalculate the new centroids of each cluster; every thread block is responsible for a new centroid.
In brief data assignment, K-centroids recalculation are parallel performed on the SMs of GPU using CKE, in the other side the worker agent is responsible for centroids initialization, data rearrangement and controlling iteration process.
Comparison between total time proccessing of C-means and P-means applied on streams of brain MRI images; (a) Speed up results (b).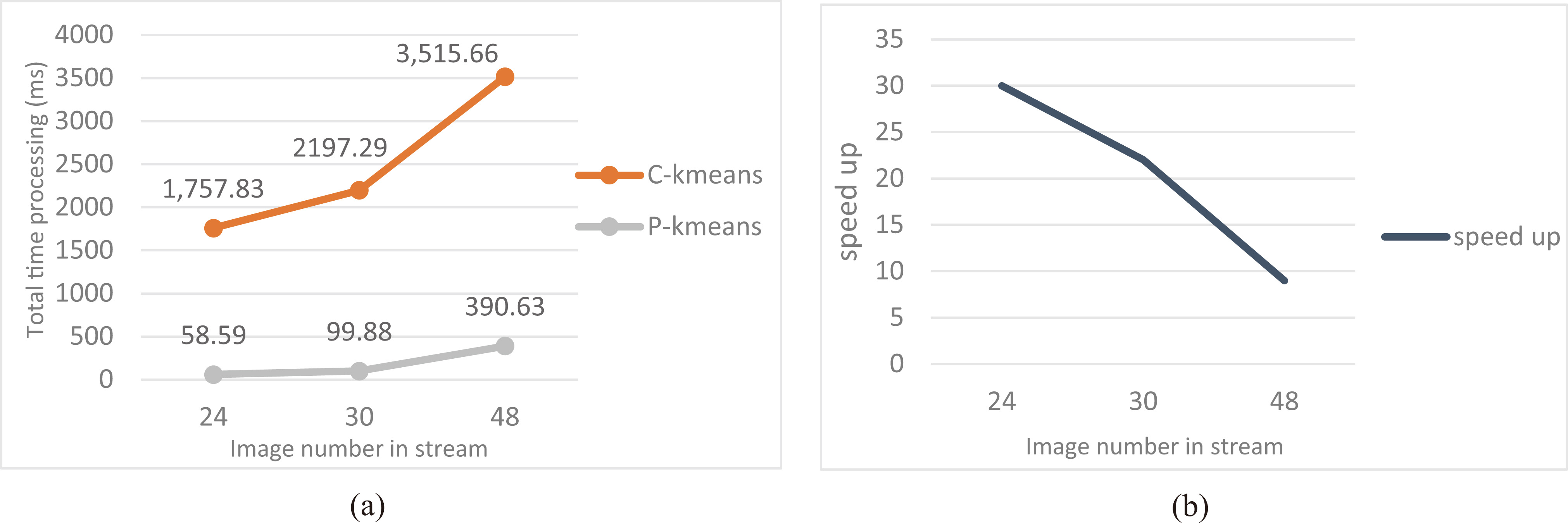
In this section, we use a stream of 24, 30 and 48 brain MRI images which have the dimension: 400*300, to compare the total time processing all images of a stream using the classic GPU-based k-means denoted by C-Kmeans, with the total time processing all images of a stream using DAG-based k-means which is denoted by P-Kmeans. All experiments were performed with 4 nodes that have an Intel Core i7-3610 QM CPU 2.30 GHz (8 CPUs), 8 GB main memory and GeForce GTX 660 M, 835 MHz engine clock speed, 2048 MB GDDR5 of device RAM, and 384 stream processors, organized into 3 multiprocessors. Additionally, we add an external GPU GeForce GTX 750Ti to the node 3, this GPU are connected by PCIe x16 using a PE4C V2.1 connectors, the system was assembled and tested in our laboratory. The GTX 750Ti have 1020 MHz engine clock speed, 2048 MB GDDR5 of device RAM, and 640 stream processors, organized into 5 multiprocessors.
As shown in Fig. 8, we compare C-Kmeans with P-Kmeans. The speed of P-Kmeans could reach from 9 to 30 of the C-Kmeans and highly depending on data throughput. We found that the total time processing decrease as
This performance improvement benefits from the massively parallel computing model of the GPUs and agent-based distributed computing. In GPUs used for the tests, 384 processor for GeForce GTX 660 M or 684 processors for GeForce GTX 750Ti are all indistinctive, and not distinguished by pixel and vertex, so that they can run at same time without idle situation.
Discussion
The DAG model which is based on agent-based distributed computing and GPU computing solves the problem of hardware limitations in GPU computing, specifically the number of elementary processors and storage capacity. Also the dag.jar library overcome difficulty of programming distributed systems which use low-level libraries currently available like MPI or OpenMP which can be error-prone in some complex cases such as massively image processing.
The K-means application on DAG show the advantages of easily encoding compute-intensive and data-intensive algorithm such as K-means algorithm applied for the segmentation of streams of MRI cerebral images using high-level programming language (java) hiding the complexity of HPC models. Unlike CUDASA, rCUDA and Bobox, the end user which is a java programmer don’t take care of the data transfers between nodes. In the background, the multi-agent systems of the DAG is responsible to distributes data and tasks between remote GPUs across interconnected nodes. i.e. the programmer don’t need to have an understanding about agent programming semantic to use the DAG; it just need to understand the CUDA semantic.
Despite of the great performance of PIMA(GE)2 library, specifically for the massively image processing, end users need to understand the low level MPI library in order to be able to write scalable programs, which in this case will be a mixture between MPI and CUDA code.
The performance evaluation shows the flexibly of the execution DAG-based K-means application on massive data across multiple interconnected nodes having low-cost GPU chips. Our results show that the speedups could rich from 9 to 30 relatives to our own classic GPU K-means. Thus, GPU based k-means [2, 3, 4, 20] applied for massive data clustering can be rewritten using DAG with java (for host code) and C (for device code). By doing so, researchers can benefit from the power of DAG for massive data processing and easily send data and tasks to distributed GPU devices across nodes using java.
Conclusion
In this paper, we presented the DAG system which integrate GPU computing in the agent-based distributed computing. The proposed DAG system can runs cumbersome applications which have parallel components targeted for execution on GPUs. The features of the DAG presented in this paper are:
A model of distributed multi-agent system which asynchronously distributes data and tasks between remote GPUs across interconnected nodes. A programming library (dag.jar) for developers who want to use DAG to optimize their algorithms. This library extends the CUDA standards by replacing the C/C
Actually, the DAG represents in our laboratory a useful tool to validate and accelerate all the elaborated parallel algorithms by the parallel image processing team.
Despite its great performance, the developed model and the complexities of the given systems and real phenomena, we plan to improve our tool using new load balancing strategy, and new data communication strategy to accelerate time execution of the implemented parallel programs.
Footnotes
Authors’ Bios