
Abstract
In recent years, a modern networking paradigm called Software-Defined Networking (SDN) has been introduced to manage the large networks and datacenters. This paradigm was introduced to keep pace with the rapid growth rates on the Internet and to support advanced network applications. SDN uses an open standard protocol called OpenFlow to manage the network traffic. In OpenFlow switches, the software control plane has been decoupled from the hardware data plane and placed in a controller which has a network-wide view. OpenFlow process all incoming packets that have the same characteristics (lie in the same class) in the same manner. In this paper, we propose and use a generalized extension of BR-tree data structure called AMQ-R tree to organize the rule-sets in a multi-dimensional tree integrated with approximate membership query data structures including Bloom, Quotient and Cuckoo filters in order to get higher quality packet classification performance. Three types of approximate membership query filters integrated with the R-tree have been designed and implemented. Also, a multi-threading technique has been used to accelerate the packet classification by querying the tree in a parallel manner. The experimental results using simulated rule-sets show that this technique can classify incoming packets in up to 1.4 MPPS (Mega Packet per Second) with very small memory requirements.
Keywords
Introduction
Software Defined Networking (SDN) is a modern networking paradigm based on the OpenFlow (OF) protocol [30] that decouples the network software control plane from the hardware data forwarding plane [7]. In SDN, the network applications are equipped with a global network view so as to support complex implementations, such as fault tolerance, network verification, quality-of-service (QoS), access control, and network security. To support modern network applications, SDN needs a kernel network function called packet classification.
Unlike the traditional packet classification problem that concerts in forwarding packets according to five fields (source/destination IP addresses, source/destination port numbers, and protocol type), in OpenFlow packet classification, to route a packet, network global view are required at each network switch to decide the behavior of the packet, where the packet behavior is a set of switch actions on that packet [22]. The OpenFlow contains a set of predefined rules called rule-set, depending on the OpenFlow version, each rule in that rule-set contains a set of matching fields. OpenFlow version 1.4 supports up to 40 matching fields [37], these fields have arbitrary size and required different types of match. In the SDN packet classification, more than 15 fields in the incoming packet header fields are required to check against the rule-set in order to decide the packet behavior, hence it called many-field packet classification. The same behaviors are set to all incoming packets that belong to the same rule in a rule-set [14]. Recent rule-sets contain thousands or more of 18 fields’ rules, which make classifying packets against such rule-sets at the line speed a challenging problem [14].
In recent years, a large group of researchers made their interest to develop solutions to improve packet classification performance. Many hardware and software OpenFlow packet classification solutions have been proposed. The most of the hardware solutions use parallel lookup techniques to perform high-speed classification. They use a special type of high-speed memory such as ternary content addressable memory (TCAM) devices to perform their solutions, but using such hardware devices may limit the size of rule-sets [39]. To address the scalability problems, software solutions have been proposed [8,10]. Software solutions need more resources and they are more scalable such that they affect the classification performance significantly. Software solutions can be classified into several classes. The solutions that use tree data structures have a good memory accesses rate per classification, but they duplicate the classification rules among the tree more than one time, hence they suffered from high memory requirements [9,36]. Recently, the approximate membership query (AMQ) data structures have become an important component in much research area [15]. AMQ is a data structure used in many databases, routers, and storage system to handle the large amounts of data that they process. An AMQ data structure represents a large set of elements in a small amount of memory and supports a membership query with small false positive probability. In this work, we propose a generalized extension of BR-tree for many-field packet classification using the rectangular tree (R-tree) to speed up the classification throughput integrated with an approximate membership query data structure to minimize the memory requirements. R-tree requires only
The Bloom filter based R-tree (BR-tree) has been used, and two new extensions of BR-tree including the Quotient filter based R-tree (QR-tree) and the Cuckoo filter based R-tree (CR-tree) have been proposed in this work and then used in the many-field packet classification. In this work, we call the R-tree that integrated with an approximate membership query data structure as AMQ-R-tree. The AMQ data structure (filter) uses a little amount of memory to represent large rule-sets, also the AMQ data structure can handle the arbitrary size of rule fields. Using the R-tree data structure for packet classification provides high classification throughput, but it needs additional memory requirements to store metadata in the internal nodes. Hence, the AMQ data structures have been used to reduce the memory requirements, and to eliminate the redundant R-tree search at the similar branch of the tree. In the performance evaluation section, we perform a performance comparison with the other well-known many-field packet classification algorithms. Our proposed solution achieves better search performance and memory requirement than other many-field packet classification algorithms in the most cases. The main contributions of this paper are as follows:
Proposing of two new extensions of BR-tree including Quotient filter based R-tree (QR-tree) and Cuckoo filter based R-tree (CR-tree), that we name them AMQ-R-trees.
Using AMQ-R-trees for many-field packet classification.
Evaluating three variants of AMQ-R-tree (Bloom filter based R-tree, Quotient filter based R-tree, and Cuckoo filter based R-tree).
Performing a performance comparison with other many-field packet classification algorithms.
The rest of this paper is organized as follows. The related works are discussed in Section 2. The approximate membership query and BR-tree data structures concept are described in Section 3. The proposed AMQ-R-tree is introduced in Section 4, and the proposed AMQ-R-tree in many-field packet classification is presented in Section 5. A performance evaluation and simulation results are described in Section 6, and a conclusion about the paper is presented in Section 7.
Related works
Packet classification is an important network kernel function, therefore, it takes a big attention from the network developers. The classical packet classification is the network function that used by the traditional network devices to deal with forwarding packet according to 5 packet header fields only. Many-field packet classification is the network function that used to classify packets into flows according to a large predefined set of rules called rule-set. Each rule in that rule-set contains up to 18 matching fields. In the following sections, we will describe the current classical and many-field packet classification techniques briefly.
Classical packet classification
Many of hardware and software solutions for the classical packet classification problem have been proposed. Hardware solutions such as Ternary Content Addressable Memory (TCAM) [27] and Bitmap Intersection [26,39] provide a good classification performance by using a parallel lookup, but using hardware resources limit the size of the forwarding tables and rule-sets. Hence, the software solutions are required to solve the scalability problem. Software solutions use extendible data structures to store the rule-sets and forwarding tables. The current classical packet classification solutions can be classified as:
Basic Search Algorithms: This group contains the simplest solutions for packet classification such as Linear Search, Hierarchical Tries (H-Tries), and Hierarchical Binary Search Tree. The linear search algorithm uses a simple list to store the rules in decreasing priority order and searches for matching in that list in a sequential manner. Hierarchical tries use the prefixes to recursively build two-dimensional trie, and then, for each incoming packet, it traverses that trie looking for matching rule. The solutions that belong to this group store the rule-sets in a basic data structure with a small amount of memory, but it suffers from the scalability problem.
Heuristic algorithms: This group contains solutions such as the Recursive Flow Classification (RFC) [16], and Distributed Cross-producing of Field Labels (DCFL) [40]. The classification query is divided into a number of exact match queries. RFC solution can be used for classical and many-field packet classification. It divides the rule-set into a smaller set and performs the same single-field matching over several phases. This group requires more preprocessing time to perform rule-sets and query dividing.
Decomposition-based algorithms: In this group, the rule-sets are divided into several single-field rule sets, and then lookup for incoming packet fields has performed separately. The results are then combined from all fields. Field Split Bit-Vector (FSBV) [23] is an example of this group solution. This group spends more additional memory and processing time to merge the fields results in order to obtain the final result.
Decision Tree-Based Algorithm: In decision tree-based solutions, each header field is defined as a search space, and then, these spaces are divided into smaller sub-spaces and so on. To classify incoming packet, it performs a linear search on these sub-spaces. The HyperCuts [36,46] algorithm generates a shorter decision tree by performing multiple field cutting per step, to form shorter decision tree. It has high scalability and low rule-set dependency. The main Decision-tree-based solutions drawback is its high memory requirement.
Some researchers have turned their research on finding alternative ways to provide the packet classification services. The authors in [13] studied the non-linear dynamics of some specified traffic flow types and proposed a traffic classification approach. They based their analysis on non-linear statistics of the IP traffic flows that are not affected by payload encryption or dynamic port change. The non-linear analysis can be considered as an eminent alternative to linear analysis of traffic data. The authors in [11] use a cuckoo hashing for field-programmable gate arrays-based IP address filtering. Their proposed hash function is pipelined reconfigurable and supports parallel computation. They achieved a constant worst case lookup by using cuckoo hashing instead of the classical hashing in FPGAs. The classical hash functions have linear lookup and may map many IP addresses to a single table position while Cuckoo hashing guaranteed mapping each IP address to a unique hashing table position. The authors in [21] use neural network based on training function to perform packet classification. In their work, they used Artificial Neural Network (ANN) with combination of hidden layer neuron and training functions as an effective tool for packet classification. The authors in [28] study the existing decision-tree algorithms and their cutting schemes weaknesses and propose a new cutting schemes, they call their scheme BitCuts. BitCuts generates a decision-tree algorithm performs bit-level cutting and achieves 2.0×–2.2× the throughput of HyperCuts.
Many-field packet classification
Recently, the researchers focus in their works on many-field packet classification problem that classifies the incoming packets according to the rule-sets of more than 15 fields in each of their rules. We will list a group of the most recent works that try to accelerate the packet classification from different directions. A new approach to identify properties of the many-field packet classifier has been proposed in [25]. This approach has a linear space and logarithmic time complexity. It can classify packets with fields of more types including range type, but this approach uses a hardware device (TCAM). These devices are expensive and have a limited size that prevents to scale such approach to work on large rule-sets. Many software many-field packet classification algorithms had been proposed, many of these algorithms use tree structures to represent the rulesets, some of them use a probabilistic data structures to accelerate querying these trees. The authors in [20] proposed a packet classification algorithm using Bloom filter in a leaf-pushing area-based quad-tree. They hash the tree nodes in Bloom filter that stored in on-chip memories. Another Bloom search solution has been proposed in [42], using the GPU-accelerated implementation. The authors in [29] proposed a decision-tree based solution for many-field packet classification, they called their solution Binary search on levels (BSOL). They represent the rules as a hyper-rectangle in a two-dimensional address space, and then they generate a binary decision tree and associate each tree node with space. The space of each node is divided between its two children. They associate each node with a filter list. They concluded that their solution has a high classification speed. The authors of [9] employed a replication control scheme on the Binary search on levels (BSOL) algorithm to minimize the memory requirements, and the processing latency, they call the new algorithm as (BSOL-RC). The memory requirement is still high because they have to store the entire rule-set plus many additional data in their tree. A two-dimensional pipelined method for many-field packet classification has been proposed in [35], they used a two-dimensional array of Processing Elements (PEs). The array works as horizontal and vertical pipeline at the same time, and its PEs can access their memory locally and can support prefix, and exact match. Their method requires a special high-performance processing elements.
The authors in [34] proposed many-field packet classification approach using range-tree [45,47] and hash table [33] to build an efficient search algorithm. Firstly, they construct a range tree or hash table for each filed according to on the field’s type. Next they query their data structure for each field of the incoming packets independently. Later they merge the partial searching results to compute the final result. This approach also requires large preprocessing time and need high processing latency including the time required to reach in the range trees, the time required to search in the hash tables and the merging time.
In our previous work [2], we used the classical R-tree for packet classification. In this work, we introduce a generalized extension of BR-tree called AMQ-R-tree that integrates AMQ data structure with R-tree. We use this AMQ-R-tree in many-field packet classification, first, we use the Bloom filter based R-tree structure (BR-tree), and then we introduce and use two new data structures named Quotient filter based R-tree (QR-tree), and Cuckoo filter based R-tree (CR-tree). In the proposed solution, we avoid all the factors that restrict the scalability of the classifier and we shift the tree construction to the off-line phase to avoid the preprocessing time that is needed by the most of the classification methods that described in this section.
Approximate membership query and BR-tree data structures concepts
In this section, we will provide a general background about all of the data structures that we need in our work.
BR-tree
A BR-tree [19] is d-dimensional tree data structure. Each node in the BR-tree is R-tree node in the combination with Bloom filter array. Figure 1 depicts an example of a simple BR-tree data structure. In BR-tree of M degree, each node can contain between (m and M) d-dimensional entries,
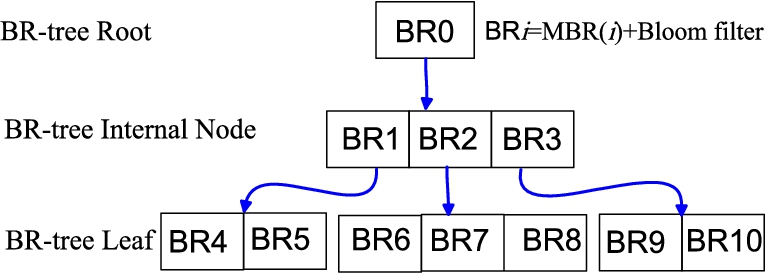
An example of Bloom-filter-based R-tree data structure.
BR0 is the root node and contains a big range to represent all possible attributes. In BR-tree of M degree, each internal node can contain m
The approximate membership query (AMQ) data structures use a small amount of memory and have the ability to identify whether an item has a match in a large previously programmed dictionary or not. The AMQ data structures can answer the item is definitely not in the set or it may be in the set with high probability [6]. In this work, three types of AMQ filters have been used. In the next sections, we will introduce a summary of the filters that used in this work for approximate membership query purpose.
Bloom filter
Bloom filter (BF) [24] proposed by Burton Howard Bloom in 1970 is a probabilistic data structure, used to query about the elements membership. When querying BF about an item if it in a set, the result will be possibly in the set, with some error probability (false positive), or definitely not in the set without any false negative. The classical BF is a bit-array structure, where the items can be hashed to the BF, but cannot remove. Advanced BF versions (such as Counting BF) have the ability to remove items. The BF contains an array of m bits all set to 0, to add n new items to a BF of size m, first, feed each of these items to K different hash functions. These hash functions return K array positions, and set these positions in the BF array to 1. To query BF for an item, first feed that item to the same K hash functions, if all the K positions that returned from hash functions are already set to 1 in the BF array, then the item possibly in the set. If any of the K positions is 0 in the BF array, then the item is definitely not in the set. The size of the BF m, and the number of hash functions k are related to the required false positive rate. Also adding more items to BF increase the probability of false positive. BF false positives probability
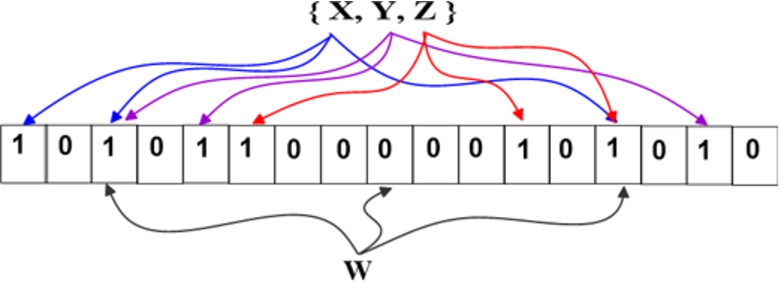
A simple example to add three items
Figure 2 depicts a simple example to add three items
A Quotient Filter (QF) is a probabilistic data structure proposed by Bender et al. in 2011 [4]. Like Bloom filter, QF has the ability to reply either the queried item is definitely not in the set or it possibly in the set. QF has better false positive rate than BF. There is a trade-off between the false positive rate and the filter size. Also adding more items to fixed size QF increases the false positive rate. In addition to insertion and query operations, QF can perform removing operation without affects the storage or the false positive rate. Also, the resize and merge operations can perform without needing of additional storage or re-hashing operations. Unlike the BF, an empty QF is a set of m slots, each slot contains a key and three additional meta-data bits. QF uses only one hash function to generate a fingerprint of p- bits from the inserted item. It uses r least significant bits called the remainder as a key, and the quotient
QF uses three meta-data bits to deal with collisions (when different items got the same keys and the same slot number). The quotient filter defines a
The look up for an item X in a quotient filter is performed as follows. First, we hash the item X using a hash function to produce the
Cuckoo filter
A Cuckoo Filter (CF) [43] is another probabilistic data structure. Its idea was originated from Cuckoo hashing, which was proposed by Pagh et al. [32]. CF can perform the usual probabilistic data structures operations (insertion, and query), as well as removing, re-size, and merging. An empty CF is an array of buckets, each bucket can store K fingerprints. CF usually uses two hash functions to generate a key and two positions. If the CF fails to insert the key in the first position (the slot already contains k keys), then it will try to insert it to the second position. If the alternative position is also full, then the CF uses specific operation called reallocation operation to deal with such situations. An advanced version of CF uses only one position to insert the element’s key, and if it fails to insert the key in that position, then it generates another position using the key in order to accelerate the reallocation operation. CF has better query performance and fewer memory requirements than both BF and QF. Figure 3 depicts a Cuckoo filter with size of 8 buckets, each bucket can store k=1 item. Initially, the items b and c are already in the Cuckoo filter. Figure 3(a) depicts how to add element “a” into the filter,
To lookup Cuckoo filter for a given item x, first calculate x’s fingerprint
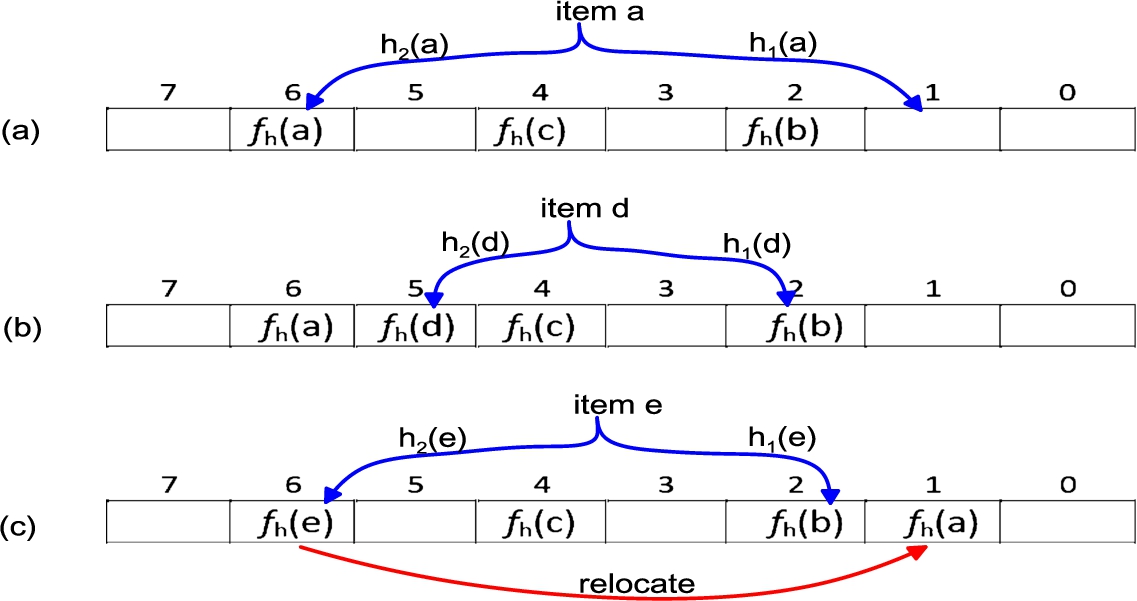
(a) Inserting “a” at bucket (6). (b) Inserting “d” at bucket (5). (c) Inserting item “e” at bucket (6).
In this section, we propose AMQ-R-tree, which is a new extension of the BR-tree that uses the rectangular tree with integrated AMQ filters in its nodes. The AMQ-R-tree data structure is a combination of root, internal nodes, and leaves. Figure 4 shows the main structure of the AMQ-R-tree. Each node in AMQ-R-tree is an R-tree node integrated with an AMQ filter where an AMQ filter is a small data structure that hashes a set with n items by applying k hash functions on that set. In AMQ-R-tree, the root node’s entries (e.g., AMQ-R1, and AMQ-R2) hash all possible attributes. Let M be the degree of AMQ-R-tree (the maximum number of the entries of each node), the root node contains (1 to M) entries, internal nodes and leaves contain m entries
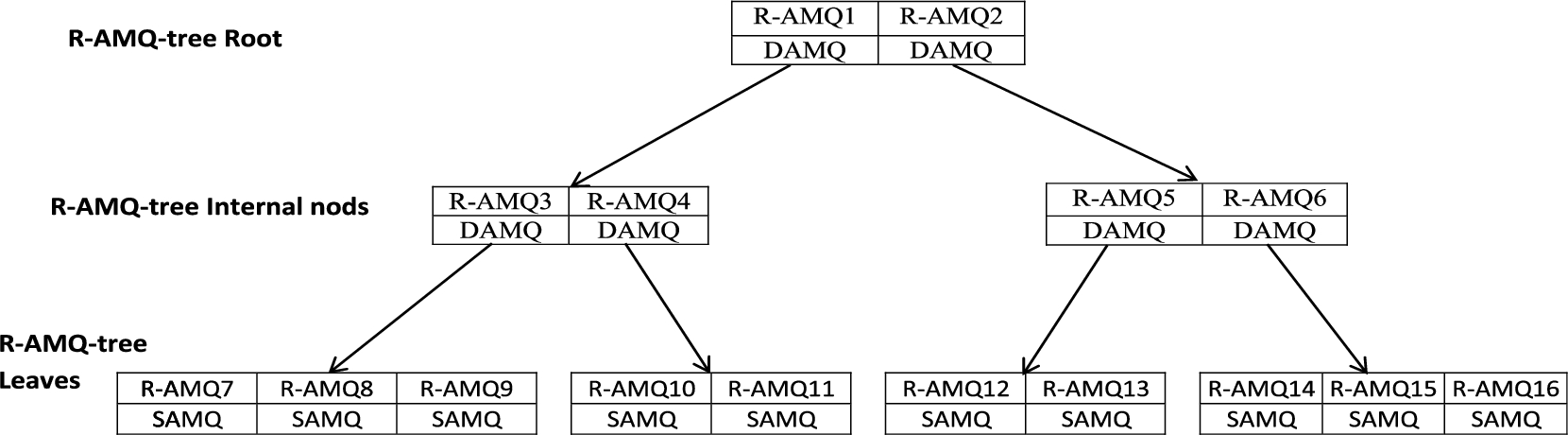
An example of AMQ-R-tree data structure.
To insert a new entry to an AMQ-R-tree, subsequent steps should be followed. We describe the insertion process in a simple example depicted in Fig. 5 that shows how to insert the objects of Table 1. In this table there is a set of objects, each object has one multidimensional attribute (
A simple example of 8 objects, each object with one multidimensional attribute and two identities
A simple example of 8 objects, each object with one multidimensional attribute and two identities
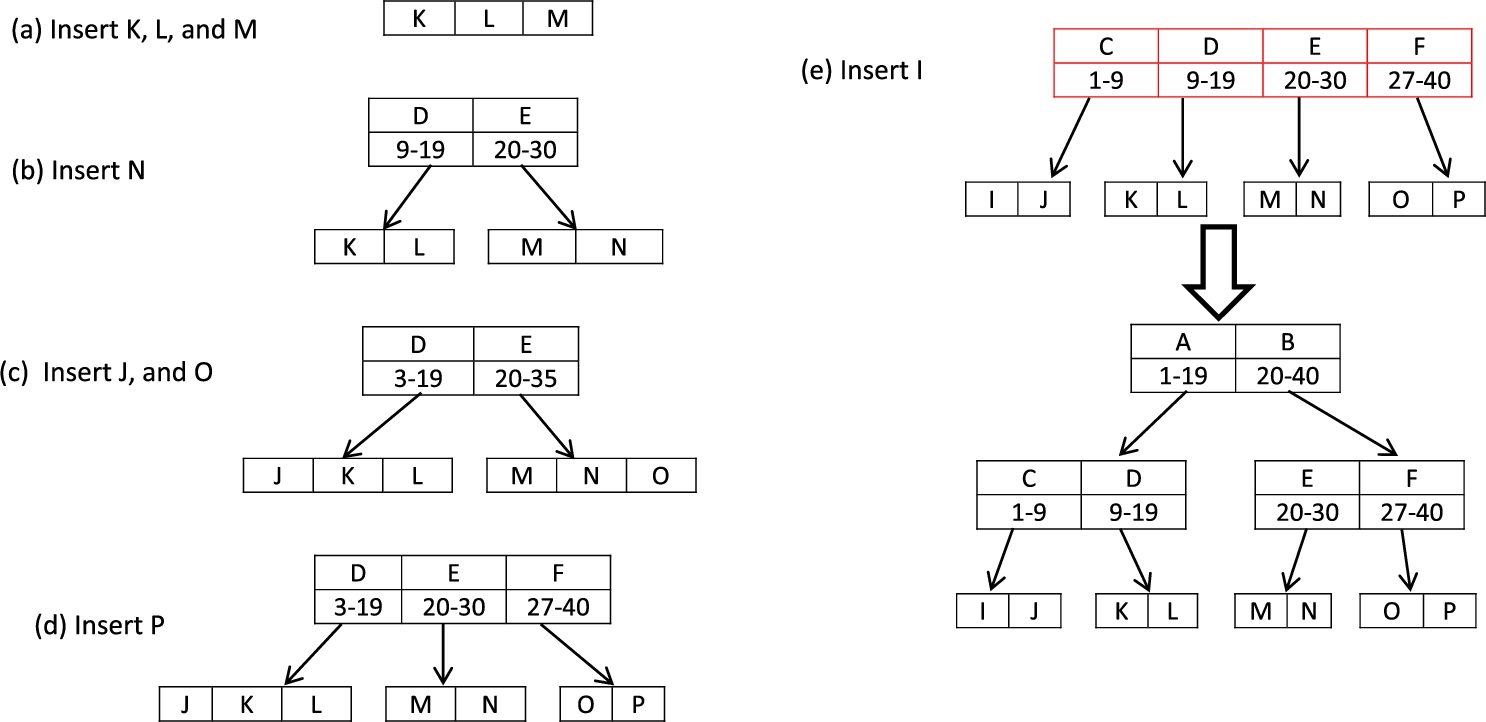
The full steps of generating R-tree from the objects in Table 1.
In the case of the selected leaf is already full, then splitting operation is performed on the selected leaf (Figs 5(b) and (d)). The splitting operation is performed by selecting two seeds (
The second step to construct AMQ-R-tree is to add an AMQ filter for each node’s entry. The AMQ filter is a small data structure which stores all hashed attributes of the corresponding entry. In the AMQ-R-tree root and internal nodes, the AMQ filter stores the hashed attributes of all the nodes in the lower levels that belong to its corresponding entry. In our implementation of AMQ-R-tree, a dynamic length AMQ filter at each tree level has been used, starting from the leaves. We select the static size m of required AMQ filter in order to insert all of node entries’ item identities with false positive rate less than decided upper bound of false positive probability. Then group all leaf entries AMQ filters in one larger dynamic length AMQ filter to hash them at the next upper level AMQ filters, so that the size of AMQ filter in the next upper level can hold all AMQ filters for the entries that bounded by that node entry.
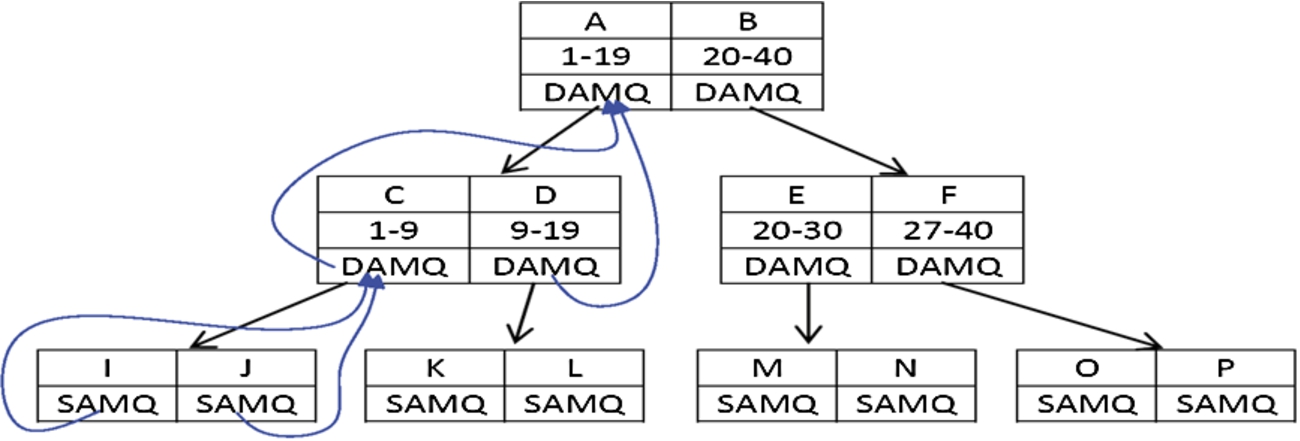
An example of how to add AMQ filters to R-tree nodes, SAMQ shows the static AMQ filter and DAMQ shows dynamic AMQ filter.
To program AMQ filter, we use a set S of hash functions, each hash function returns insertion position with P bits, the number of P bits depends on the used AMQ filter. To insert a new item to the AMQ filter, we feed it to all of these S hash functions, each of the S hash functions returns P bits, since the size of the AMQ filters is variable at each tree level. We select a d bits from these P bits to fit the size of the AMQ filters at the corresponding level. Figure 6 shows a simple example of how to add AMQ filters to R-tree nodes. After constructing the R-tree, we start from the leaves and hash all the item identities in a static length AMQ filter. We select a d bits from the P bits that generated by the S hash functions. In the next upper level, we hash all the item identities in a dynamic length AMQ filter of the parent node, and so on till the root. To hash the item identities in the dynamic length AMQ filter of the parent node, we use
To query AMQ-R-tree for an item, first we should create MBR from that item’s multi-dimensional attributes and feed its identities to the same S hash functions that used at AMQ filters programming, then the AMQ-R-tree will traverse from the root to the leaves. At each level, we select the appropriate node entry that its MBR covers the queried MBR with minimum area, and its filter gives a positive result to the query identities. When querying the AMQ filters, we select appropriate number from the bits returned from the S hash functions according to the AMQ filter size at that level. At the leaves level, if the queried MBR matches any leaf entry and the AMQ filter gives a positive result for all the query attributes, we report that leaf’s entry (or entries) as a matching result.
Many-field packet classification using AMQ-R tree
Figure 7 depicts the main structure of our proposed classifier.
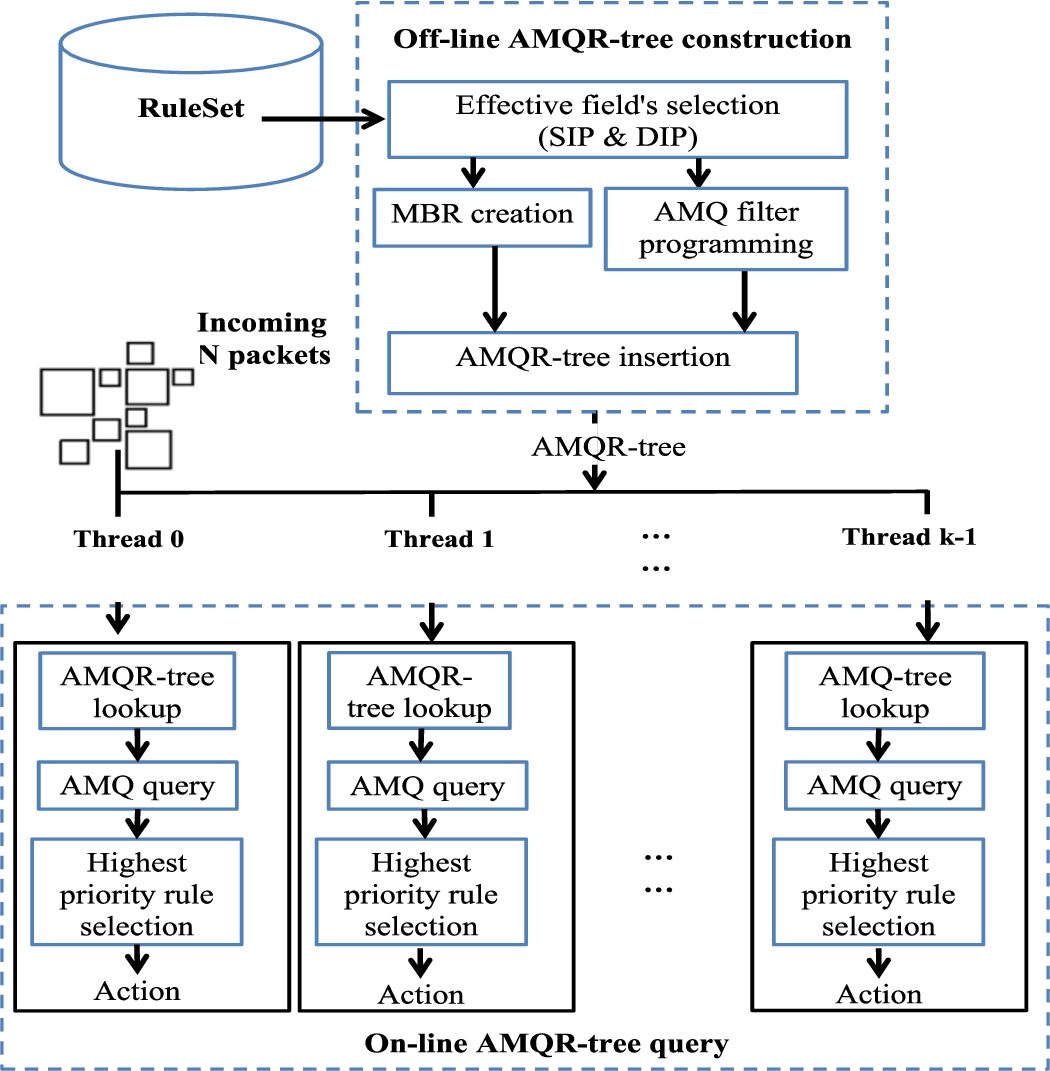
The proposed approximate membership query-based R-tree (AMQ-R-tree) data structure.
As it can be observed, the proposed classifier classifies incoming packets using the proposed AMQ-R-tree in two main phases:
Phase 1: Off-line AMQ-R-tree construction, in this phase, the proposed AMQ-R-tree maps the rule-set into an R-tree based on the source and destination address prefixes (SIP & DIP), then appends a static length AMQ filter for each leaf node entry and programs all the remaining fields from each rule to its corresponding AMQ filter. After that, the AMQ-R-tree creates a dynamic length AMQ filter for each node entry at the next upper level to describe all of the leaves that it covers. Subsequently, performs the same procedure until reaching the root, so that the AMQ filters at the root node entries hash all the rule-set. Phase 2: On-line AMQ-R-tree query, in this phase, the proposed algorithm classifies N incoming packets by using K threads. The tree from phase 1 is used to accelerate classification process.
The Bloom Filter (BF), Quotient Filter (QF), and Cuckoo Filter (CF) have been used as AMQ filters to create AMQ-R-trees. The following subsections describe the proposed classifier in details.
For each rule in the rule-set, we generate one MBR as the tree entry. To create MBR, first we convert the SIP & DIP from each rule into range values, and represent these ranges as MBR, then describe the similar objects with bigger MBR in the next higher level. The converting of prefixes into ranges is performed by representing the minimum allowed value for the corresponding prefix as the start of the range, and the maximum allowed value as the end of the range. Table 2 depicts a simple example of 13 rules with SIP & DIP and their corresponding MBRs after conversion. Figure 8(a) depicts the corresponding MBRs for Table 2 after representing them in the geographic coordinate system. The dotted blue rectangles (R3-R7) represent the upper-level rectangles that AMQ-R-tree define, and the dotted black rectangles (R1, and R2) represent the root rectangles that AMQ-R-tree define. Figure 8(b) shows the corresponding AMQ-R-tree for Fig. 8(a).
A simple example of 13 rules with SIP & DIP length = 8 and their corresponding ranges after conversion
A simple example of 13 rules with SIP & DIP length = 8 and their corresponding ranges after conversion
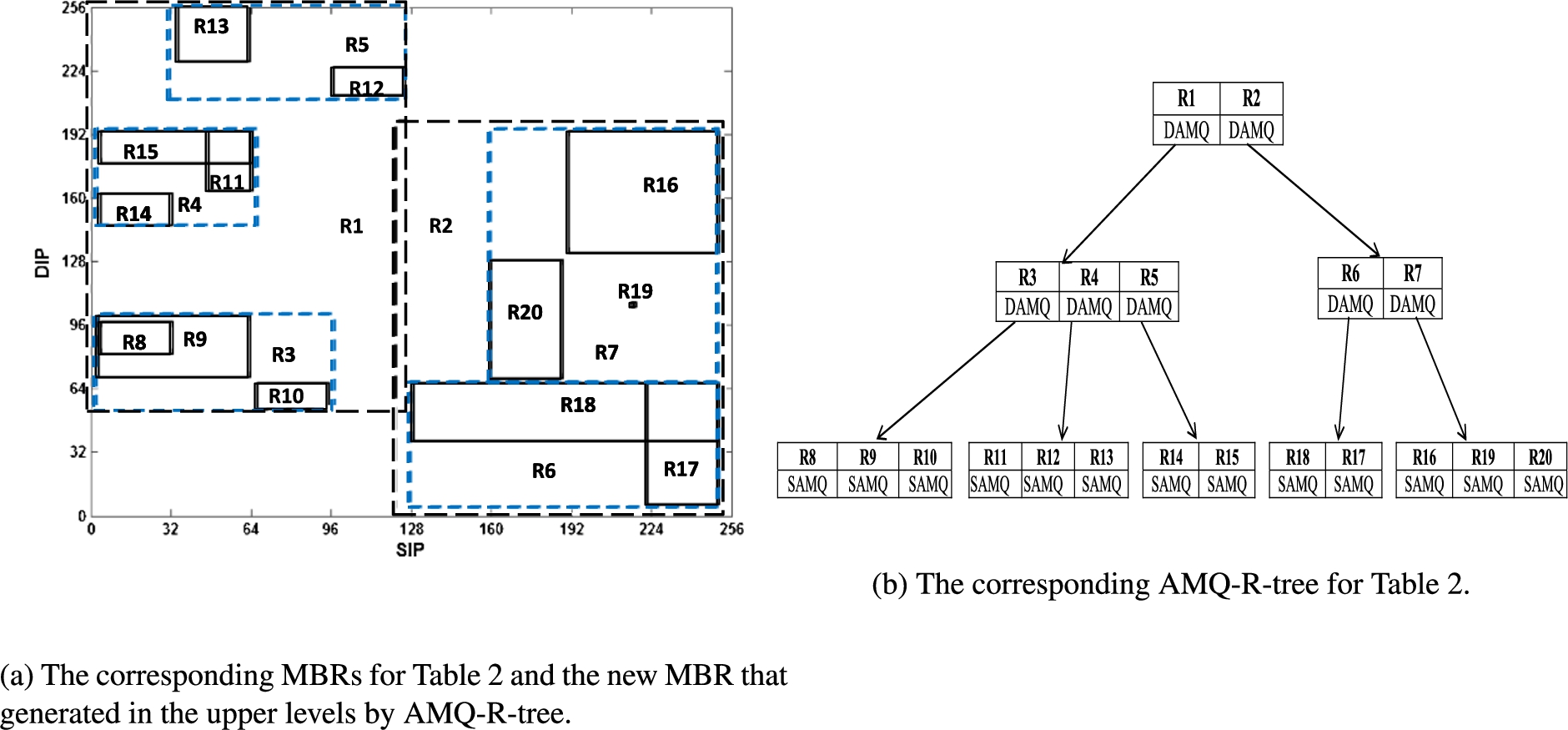
Minimum bounding rectangles (MBRs) creation & AMQ-R-tree construction.
In our implementation of AMQ-R-tree, three different types of AMQ filters (Bloom Filter (BF), Quotient Filter (QF), and Cuckoo Filter (CF)) have been used to generate three different types of AMQ-R-tree that we named them BR-tree, QR-tree, and CR-tree. To insert a new rule to an AMQ-R-tree, first we generate an MBR from SIP & DIP, and then traverse the tree from the root node to the leaves, and perform the insertion operation as described in Section 4. After that, the remaining fields from each rule is hashed in AMQ filter. Each of the proposed trees adopts different standards for the programming operation. The following sections describe the programming operation for each of the proposed trees.
BR-tree programming
In our implementation of BR-tree, a dynamic length Bloom filter has been used in each node entry, and a set S of different hash functions have been used. Each leaf in BR-tree contains m
QR-tree programming
In our implementation of QR-tree, we use a variable number of slots as needed in the QF for each tree node. We use Murmurhashing2 [38] to generate P-bits fingerprint. QF takes the R (remainder) least significant bits of these P-bits as the insertion position, and
At each leaf, we insert the reminder fields in the node by using the fingerprint bits that is generated by the hash function. These fingerprints are generated one time only and used the same number of R-bit and a variable number of quotient bits depending on the size of the QF at the corresponding level. The small QFs from each leaf has been represented by one larger QF at the next upper-level nodes to insert these fields, and so on until reaching the root. Table 3 depicts a simple example to show the size and value of the R, and Q bits when the word “TCP” in RQ-tree with 5 levels using Murmur hash function is inserted. After that Murmur hash function returns “110100110011110010001110” as a fingerprint. From Table 3, it can be seen that the QF at the root node has
A simple example to show the size and value of the remainder bits (R), and quotient bits (Q) when hashing the word “TCP” in a leaf node at the proposed RQ-tree with 5 levels using Murmur hash function
A simple example to show the size and value of the remainder bits (R), and quotient bits (Q) when hashing the word “TCP” in a leaf node at the proposed RQ-tree with 5 levels using Murmur hash function
The Cuckoo filter (CF) is a table of buckets, that each bucket stores M keys. CF uses two hash functions to provide two possible locations in the buckets table for each key, and one hash function to generate the key. In our implementation of CR-tree, we use a variable size CF’s buckets table at each tree level. In each location of buckets table, we use a bucket that can store eight keys. In general case, we use only two hash functions, one to set location and the other for generating item key. In the case of the set position bucket is already full, we perform XOR operation between the two hash function results (location XOR key) to get a new position. In the case of that new location’s bucket also is already full, we put the new key in that location and give one of the old items as an alternative location by performing XOR between its current location and its key. The operation of setting alternative location to an item is called reallocation operation. In our implementation, we perform the reallocation operation 150 times if required. If there are a need to performing more than 150 reallocation operations to insert an item, then we decide that the CF is full, and extend the size of CF to insert the remaining items.
The insertion operation in CR-tree is very similar to QR-tree insertion. We use increasing size CF’s buckets table at each tree level. To insert a rule’s field to the CF, we calculate the hash functions for all rule fields one time only at the leaves and insert all remainder fields keys at that node’s CF at locations commensurate with the size of the current node’s CF size by selecting a set of bits from positions bits. Then move to the next upper levels until reaching the root. At each level, we insert these rule’s fields at the corresponding node’s entry.
On-line AMQ-R-tree query
To classify N incoming packets, K independent threads have been used, where each thread is responsible for classifying
Each thread, to classify an incoming packet (test whether it maps a rule in the rule-set), first it creates the query’s MBR from the incoming packet’s SIP & DIP, and feeds the remaining fields to the hash functions to get the keys and locations. Then the thread performs two queries simultaneously, one is MBR query, and the second is reminder fields approximate membership query. The MBR query is the same query at each of the proposed trees, where the thread will query the AMQ-R-tree by traversing it from the root to the leaves. At each level, it selects an appropriate node that its MBR covers the queried MBR with minimum area, then it moves the search to the next tree level and so on until reaching the leaves. At the leaves, it performs a matching between the queried MBR and the selected node’s MBRs and reports the corresponding rule as a primary search result, if there is any match. The thread will report these results as final results if it is a success at the remainder fields approximate membership query too. To perform the remainder fields approximate membership query, there are three cases:
Using Bloom filter based R-tree (BR-tree): We feed each of the remaining fields to K hash functions to get k array positions for each field, then traverse the BR-tree from the root to the leaves at each level. We map the array positions to the Dynamic Bloom filter DBF integrated at the appropriate node entry (the same node entry that resulted from the MBR query at the current level). If any of the bits at these positions is 0 and it mentioned as not wild-card field in wild-card register then the packet definitely not matches any rule in that rule-set, and we end the search (if it was, then all the bits would have been set to 1 when it was programmed). If all bits are 1 and the MBR query success at that level, we move the search to next tree level and so on until reaching the leaves. At the leaves, we perform the array position mapping with BF.
Using Quotient Filter based R-tree (QR-tree): The query in QR-tree is very fast and simple. For each incoming packet first, we generate MBR and calculate the fingerprints for the incoming packet fields and then we traverse the tree from root to leaves. At each level, we select all node entries that can cover the queried MBR and its QF gives a positive result for all the remaining fields taking into account the appropriate length for quotient bits at every level. If there are no node entries that can cover the queried MBR or any of fields get a negative result in QF query, then the QR-tree reports a negative result for the queried packet, otherwise moves the search into the next level and repeats these steps until reaching the leaves.
Using Cuckoo Filter based R-tree (CR-tree): To query an incoming packet in CR-tree, we calculate the MBR and hash functions for all incoming packet fields at the beginning and traverse the tree from root to the leaves. At each level, we choose the node entry that can cover the rule’s MBR in a smaller area, and map all remainder fingerprints with that node’s CF. Taking into account the appropriate position at every level that commensurates with the size of the current node’s CF size by ignoring a set of bits from previous level positions. Note that when query CF for an item, we should try in its alternative position if we fail to find its fingerprint in its position’s bucket. If any of incoming packet’s fields gives a negative result in CF, we will try in other node entries that can cover the queried MBR. If there are no node entries that can cover the queried MBR and query fails in its CF, then the RC-tree reports a negative result for the queried packet. Otherwise, we move the search into the next level and repeat these steps until reaching the leaves.
If there is more than one rule in the result, then the rule with the highest priority is selected, and the results from each thread are added to the answer set.
Theoretical analysis
In this section, we use the most commonly used two metrics in literature including query time, and memory consumption.
Query time analysis
Query time (T) is the amount of time that the classifier needed to classify single packet theoretically. It has been proved in [18] that the maximum height (h) for an R-tree that stores N items (rules) and has m minimum number of entries at each node is:
Since we use one AMQ filter at each node’s entry, then we need to query m filters at each level. Bloom filter requires
Quotient filter requires
Memory consumption analysis
Memory consumption M is the amount of memory needed to store the rule-set in the proposed structure. Since we store the whole rule-set fields in the AMQ filters at each tree level, and the R-tree has
Performance evaluation
In this Section, we will evaluate our work in term of different performance metrics. Simulation using Embarcadero RAD Studio 2010 (Delphi 2010) at Core-i7 machine with 8 GB RAM has been performed. For this simulation, we have created a number of rule-sets by using Classbench tool [1,41]. These rule-sets have similar characteristics to the real rule-sets and have different types (access control list (ACL), firewall (FW), and IP chain (IPC)), with different size (about 1K, 5K, and 10K rules) for each type. Table 4 depicts the simulated rule-sets and the tracing data size and specifications.
The simulation rule-set and tracing data type, size, and specifications
The simulation rule-set and tracing data type, size, and specifications
Performance comparison in terms of the required storage, and number of memory accesses in both average and worst cases using variable size and type of rule-sets for our proposed trees and other packet classification algorithms
The search speed is highly depended on AMQ filter performance and the number of memory accesses. In this evaluation, the memory access has been considered as the most time-consuming operation. We have used the dynamic size AMQ filters for each of our proposed trees (BR-tree, QR-tree, and CR-tree), then the average of memory access number to classify packets using each of the proposed data structures have been counted. In Table 5, we show performance comparison in terms of the required storage, and the number of memory accesses in both average and worst cases using variable size and type of rule-sets for our proposed trees against three many-field packet classification algorithms (A Decomposition-Based Approach for Scalable Many-Field Packet Classification on Multi-core Processors (DBAMCP) [34] , Binary Search on Levels with Replication Control (BSOL-RC) [9], and Packet Classification Using a Bloom Filter in a Leaf-Pushing Area-based Quad-Trie (BF-AQT) [20]). We have chose these algorithms because they related to our proposed algorithm so that they use tree structures in their solutions. In [20] they use a tree structure combined with a bloom filter.
As can be seen, the performance of the proposed classification algorithm for all the simulated rule-sets is distinctly better or similar to the other solutions. In BSOL-RC, each node in the tree has a filter list, these filters overlap the spaces of the corresponding nodes. The filters of each node are inserted to the child that overlaps its space. In the case of the parent space overlap both of its two children, insert the filter in both of its two children. However, inserting the parent space in both of its two children causes a memory expansion. Also, when the number of replicated filters became unacceptable due to the high decision tree, they divide the filter set into multi-subsets, and they generate a hash table for each tree level contains a leaf, this may generate a large set of hash tables and affects the classification performance. The range tree in DBAMCP has empty nodes and more tree levels than CR-tree in our approach. Also, it uses separated filters to stores the remainders fields. Hence, it required more memory accesses and storage memory. The BF-AQT builds a leaf-pushing Area base Quad Tree by assigning codewords for
Table 5 shows that the performance of the proposed solution on the IPC rule-sets type is better than other types in terms of worst and average number of memory accesses. Since IPC type has a small number of the overlapped rules, the more overlapped rules lead to more tree overlapped MBRs, which make the internal tree nodes have the minimum allowed number of entries that affect the tree height, and increases the required number of memory access. In case of FW type, it has worst performance, since it has many overlapped rules that affect the tree height and needs more number of memory accesses to traverse the tree. The number of memory accesses that required in the ACL type is between two other rule-sets. Our proposed trees show very good performance in comparison to the other packet classification algorithms, especially CR-tree that requires storing single fingerprint for each entry, and one or two memory access only. CR-tree performs as the best data structure of our proposed data structures and almost the best one between all the other techniques.
CR-tree has high scalability and low memory storage as we describe in Section 6.4 comparing to other many-field packet classification. BSOL-RC stores the replicated filters in a new decision tree, and this will increase its memory usage and memory accesses. DBAMCP uses unbalanced range tree with many empty unused nodes to stores prefixes and ranges fields, these nodes cost more memory storage and memory accesses. BF-AQT needs to store large number of rules to represents small rulesets, and huge number of rule to represents big rulesets especially for those rulesets that contain
Processing latency
The processing latency (L) is defined as average processing time to classify a single packet. We assume that all 15 field of the packet header is already available for use. To measure the processing latency, we use rule-sets of type IPC with variable size (1K, 2K, 4K, 8K, 16K, 32K, and 64K) rules. Then we compare the processing latency of our approach with the many-field packet classification in [9] (BSOL-RC), [34] (DBAMCP), [20] (BF-AQT). Each of these approaches uses rule-sets generated by the same tool (Classbench tool) that we use to generate our rule-sets. The DBAMCP uses range-tree and hashing to search the fields of the input packet header in parallel. It merges the partial results from all the fields in rules ID to produce the final match results. BSOL-RC enhances the binary search on levels BSOL [44] by employing a replication control scheme. The range tree in DBAMCP has more empty nodes and more tree level than R-tree in our approach. Also, it uses a separated filters to store the remainders fields. The overall processing latency of DBAMCP contains range tree search, filter query, and partial results merging process. Hence, as can be seen in Fig. 9, the proposed approaches latency outperform the DBAMCP approach. CR-tree outperforms the DBAMCP approach by (2×) times with respect to various rule-set sizes. The BSOL-RC constructs an unbalanced binary search tree and uses a set of hash tables to store the leaves nodes for every tree level that contains a leaf. Moreover, in BSOL-RC, the rule-set may divide into more than two sub-rule-sets because that single decision tree may not be scalable for large rule-sets. Also BSOL-RC dynamically stores replicated filters in a new decision tree to result in fewer memory requirements. Hence, as can be seen in 9, the BSOL-RC outperforms the DBAMCP only in the small rule-sets, and increasing the rule-sets size increases BSOL-RC latency rapidly. Also, the proposed approaches outperform BSOL-RC and BF-AQT with respect to various rule-set sizes.
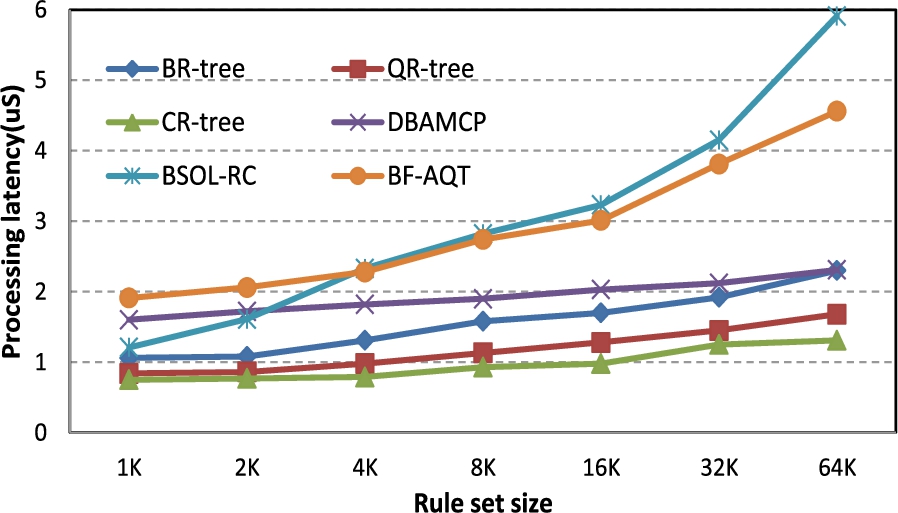
Processing latency comparison with respect of various rule-set sizes.
To evaluate the throughput for our proposed approaches, we define classification throughput as the number of the incoming packets that our system can classify in a second measured as Mega packet per second (MPPS). We have generated variable size of rule-sets, for each type (100, 1k, 5k, and 10k) rules. Then we perform the tree query for N incoming packets using a variable number of threads, at each time. We have used a varied number of tracing data as incoming packets. We have generated the tracing data by the same tool that we use to generate the simulated rule-sets. The results show that the best number of the threads should be used in our machine is 32. For example Fig. 10(a), (b), and (c) show the throughput of our proposed BR-tree, QR-tree, and CR-tree, respectively. All of these trees were built for IPC rule-sets using a different number of threads to classify a different number of the incoming packets. The best number of threads to be used for classification is highly depends on the used machine specifications, and it is variable from machine to other.
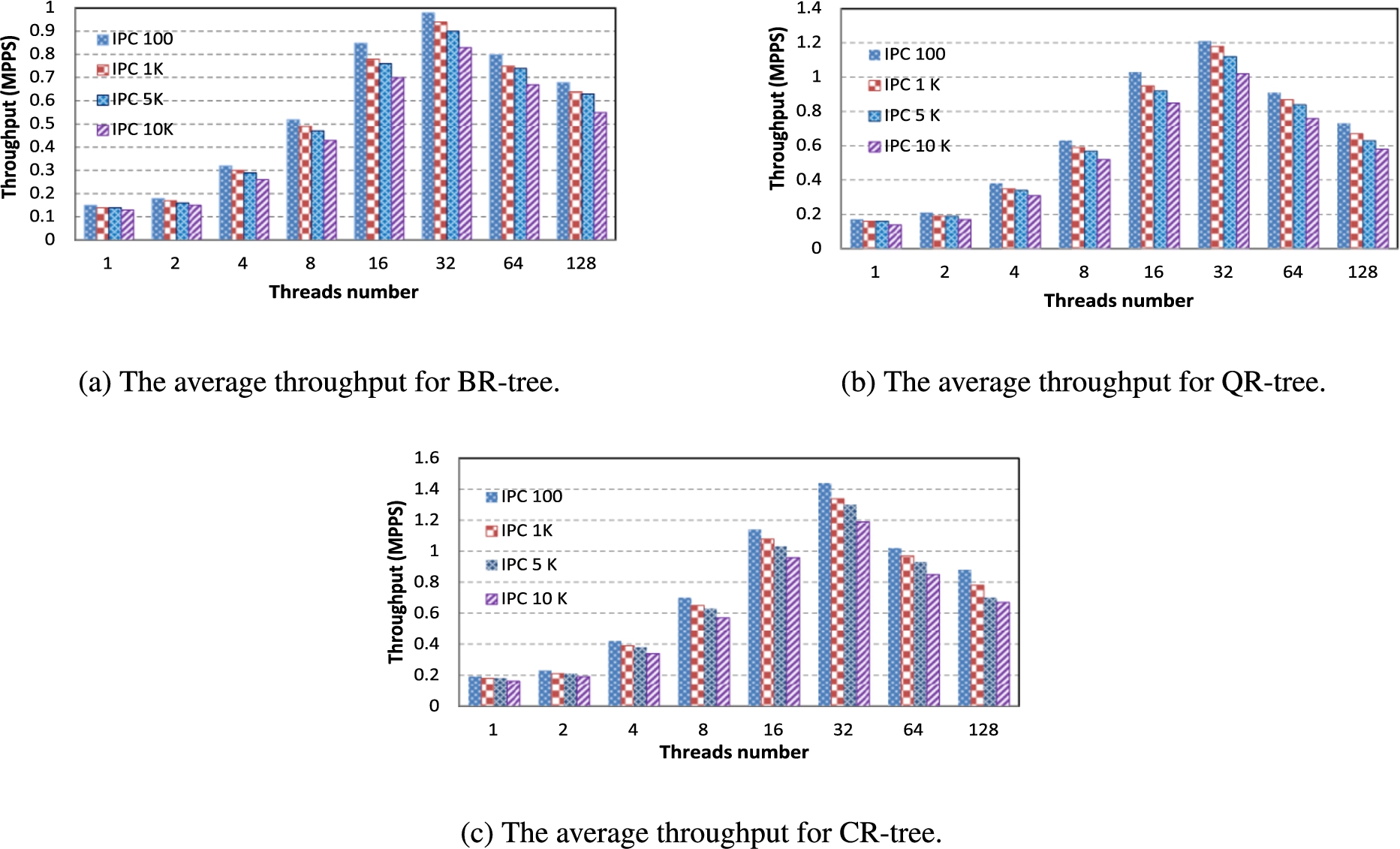
The average throughput for BR-tree, QR-tree, and CR-tree using a different number of threads.
As can be seen in Fig. 10(a) that BR-tree can classify the incoming packets in up to 1 MPPS when working on rule-set of type IPC with size 100 rules, and up to 0.830 MPPS when working on the rule-set of type IPC with size 10K rules. For QR-tree and CR-tree, we get the same results about the number of threads. Figure 10(b) shows the average throughput for QR-tree using a different number of threads to query IPC rule-set. Figure 10(c) shows the average throughput for CR-tree using a different number of threads to query IPC rule-set. From this results, we conclude that the best number of threads to classify packets in our proposed trees in our machine was 32 threads. In the rest of this paper, we will use 32 threads to measure all of the proposed data structures performance. Figure 11 shows our proposed trees throughput for different types of rule-sets using 32 threads.
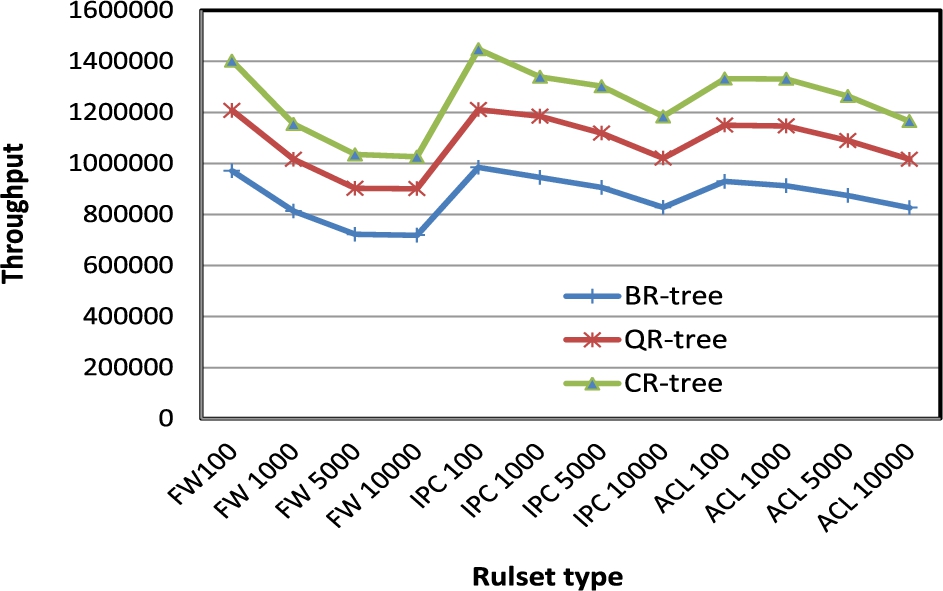
The proposed data structures throughput for different types of rule-sets using 32 threads for querying.
As can be seen from Fig. 11, the throughput of our three trees have same patterns, and this is because the throughput highly depends on the R-tree height multiplied by the number of memory access required to query each node’s AMQ filters. The main R-tree was built independently from the AMQ filters, that means the R-tree height is not affected of what type of AMQ filter used in it, and the number of nodes that required to be visited is fixed. The only difference of the performance of our three trees is how many memory access required to matching the incoming packets in each tree level at query operation. The CR-tree presents the best classification performance among our other proposed trees because it requires the minimum number of memory accesses. BR-tree requires more memory accesses because it uses more hash functions. QR-tree uses two hash functions, but it needs more processing overhead to check up additional bits to mention the exact location of stored items. On its best case, CR-tree can classify up to 1.42 MPPS on rule-sets of size 100 rules and up to 1.2 MPPS on rule-sets of size 10K rules. In comparing to BR-tree and QR-tree, the best throughput that BR-tree can perform was 0.98 MPPS and the best throughput that QR-tree can perform was 1.21 MPPS.
To evaluate the scalability of the proposed data structures from the respects of storage requirements and the average number of memory accesses. We have generated 15 large rule-sets with different size (from 20K rules to 100K rules) and characteristics. Since this experiment uses rule-sets with different size, we use Bytes per rule (BpR) to provide a better evaluation of proposed data structures scalability [44]. BpR is equal to the total required storage to represent the entire rule-set in the proposed data structures divided by the number of rules.
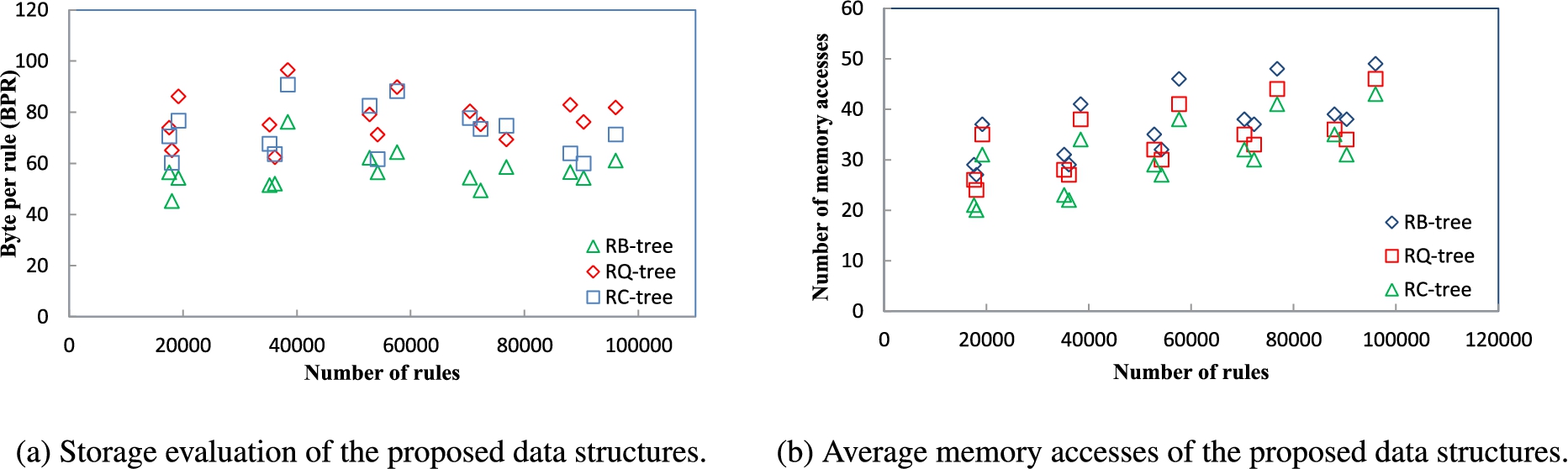
Storage evaluation using Bytes per rule, and throughput evaluation of the proposed data structures.
Figure 12(a) shows the required Bytes per rule (BpR) for the proposed data structures. As can be seen, the proposed data structures require 40 to 96 Bytes to store each rule for rule-sets of size 20K to 100K. As a result, the proposed data structures do not incur any exponentially increased storage. Moreover, the average required storage of the proposed data structures is only 70 Bytes for rule-sets with size of up to 100K rules. The proposed data structures are rectangular trees integrated with AMQ data structures, and these data structures are balanced and semi-full trees. The main factor to increase the BpR in such trees is the tree height. Increasing the tree height by one required to represent each rule in one more AMQ data structure in the new level. For large rule-sets, it requires adding a large number of rules till the tree became full or semi-full to increase the tree height one more time. Also, the bigger AMQ filters in the internal levels can hash relatively larger number of rules. Therefore, the proposed data structures could maintain the required storage without being affected by the growing size of rule-sets. Figure 12(b) shows the average number of memory accesses for the proposed data structures with variable size rule-sets. For each rule, up to one million packets have been used as tracing data to measure the average number of memory accesses. The proposed data structures require 20 to 49 memory accesses to classify each packet with average memory access equal to 34 for rule-sets of size up to 100K rules. The average required memory accesses increases only when the tree height increases. Hence, the average required memory accesses increases moderately in very slow rate with the growing size of rule-sets.
In our experimental scalability evaluation, the results show that the proposed data structures could obtain regular storage requirement and reasonable memory accesses for 15 different rule-sets, and provide good scalability in terms of variable sizes and characteristics of rule-sets.
In our proposed system, we have used a set of space-efficient probabilistic data structures. These data structures provide false positive in a very small probability, but they do not provide false negatives. In other words, when querying such data structures, the result will be either “possibly in the set” or “definitely not in set”. The false positive rate in such data structures is not a constant value, instead of that, it has a probability depends on a set of factors, such as the number of items to be inserted, the size of the data structure, the number of hash functions, and the size of the fingerprints. Each of the AMQ data structures that used in the proposed solution has a standard equation to calculate the false positives probability. The Bloom filter, Quotient filter, and Cuckoo filter have been used with R-tree data structure. To insert n elements, if k is the number of hash functions, m is the number of bits in the filter array, f is the fingerprint bits, and b is bucket size, then:
False positive probability of the proposed structures using up to one million packets as a tracing data
False positive probability of the proposed structures using up to one million packets as a tracing data
The results in Table 6 show that our proposed solutions have false positive rates (
In this paper, a generalized extension of BR-tree integrated with approximate membership query data structures has been proposed and used in many-field packet classification. In addition, multi-threading technique has been used to classify multiple packets in a parallel manner. Three types of the approximate membership query filters have been used separately in this tree, for each type, and performance evaluation has been performed using simulated rule-sets generated by Classbench tools. In addition, the scalability and the accuracy of the packet classification have been practically measured. From the results, we concluded that the best number of threads to be used in our machine was 32 threads to get the best result. The proposed technique can classify packets in up to 1.4 MPPs using Cuckoo filter based R-tree (CR-tree) with very small memory requirements. It can classify packets in up to 1 MPPS and 1.2 MPPS using Bloom filter based R-tree (BR-tree) and Quotient filter based R-tree (QR-tree), respectively. In the performance comparison with the other well-known packet classification, we concluded that our proposed techniques have less memory accesses and less memory requirements in most cases. Also, we performed performance comparison with two modern 15-fields packet classification approaches from respect of the processing latency. The results showed that the proposed approaches outperformed these approaches in more than 2× times.