
Abstract
The machine learning technique has been used to increase cloud management’s intelligence. Effective resource provisioning also preserves the environment. Manual cloud management has some difficult problems, such as complexity in cloud systems and scale issues. Hence, this paper introduces a new task for managing the resources in the cloud using deep learning. The aim is to predict the overall workload and server status prediction to the cloud resource management. Initially, performance monitoring is performed to keep aware of the performance of the application and guarantee the cloud application’s performance. In the suggested work, the required data is collected for the resource utilization on multiple Virtual Machine (VM) metrics. The VM provisioning is performed next to rectify the issues of resource provisioning. After that, the workload and server status prediction is conducted, where the Weighted Recurrent Neural Network (W-RNN) is adopted. After attaining the predicted workload, the VM placement module is carried out. Here, the virtual resource’s quantity is attained. Moreover, the multi-objective functions like resource utilization; cost, energy, time, and Quality of Service (QoS) are derived in this phase with the help of the Improved Rain Optimization Algorithm (IROA). Subsequently, the VM recycling is performed in the suggested work. Here, a resource collector is given for the virtual resources recycling task. It scans the applications of the cloud in the data centre and processes the VM recycling for every application. While considering the statistical analysis of the IROA-W-RNN-based resource management system achieved a mean of 56.27% than JAYA-W-RNN, 21.09% than SCO-W-RNN, 60.2% than MFOA-W-RNN, and 16.74% than DA-W-RNN for configuration 4. Finally, the numerical analysis is conducted to validate the presented resource management task with the aid of various conventional tasks.
Keywords
Introduction
One of the popular subjects in computer science over the recent decades has been cloud computing. Users can utilize applications in the data center of the cloud using cloud computing. It also saves maintenance costs and money on purchasing physical transportation [30]. People are starting to install their applications in clouds or public data centers rather than purchasing infrastructure [5]. A growing number of consumers are mostly using their web applications in the cloud because of the low cost, high scalability, affordability, and availability of cloud services [7]. As cloud data centers are used more frequently, researchers are focused more on cloud-related issues. Resource management is very difficult due to the storage issue, server power consumption, and resource utilization in data centers or the cloud [15]. The majority of availability is used to schedule and provision cloud resources without taking other essential factors like the server’s thermal characteristics or resource consumption [10]. One of the key technologies needed by businesses to extract knowledge from their business data is cloud computing, but it requires more computational power [28]. Companies are struggling to identify the optimal resources inside their business operations while using cloud computing services to process Big Data. The incorrect calculation of the required resources has an explicit impact on their budget [11].
The rapid growth of cloud data centers has been increased by the development of cloud computing. Simultaneously, the problems of high carbon emissions, high energy usage, and high cost are affecting the performance of the implementation. These elements are affecting the development of cloud computing technologies [2]. Cloud service providers employ virtual machines rather to offer users storage, computing, and other services as a result of virtualization technology applications. As a result, academia has extensively investigated the scheduling techniques in the cloud as well as virtual machines [22]. The majority of the recent cloud resource management strategies have increased CPU utilization by reducing the cloud or data center’s power consumption. The conventional technique is mainly focused on enhancing CPU usage through the integration of virtual machines [1]. Millions of data servers are currently hosted by cloud computing frameworks, and these servers make use of various virtual machines as cloud computing resources. It takes a lot of energy for Cloud Data Center (CDC) infrastructures to provide large-scale computational services [14]. Additionally, computational nodes produce a lot of heat, which necessitates cooling equipment to counteract its effects. As a result, the CDC’s overall energy usage for servers and cooling systems significantly increases [3]. The effect of temperature is not currently taken by workload distribution policies and simulating the thermal characteristics of CDCs is difficult. A thermal-aware model is required to simulate and predict the characteristics of nodes and monitor the crucial performance characteristics.
The high extensibility and availability of applications and services are ensured by resource management auto-scaling in cloud computing services [6]. The Horizontal Pod Auto Scaling (HPA) has the drawback that is direct scaling. In addition, allocating surplus resources prevents slow performance because it is challenging to determine how many resources are needed for certain applications and services [21]. The authors employed a linear program to determine the best allocation of cloud resources. They offered a CloudSim simulation and a timed automatic network to increase the accuracy of constrained resources [32]. This strategy is used to improve the loss of virtual machines during migration. The majority of traditional algorithms focus on CPU usage, which causes a high waste of resources. A Recurrent Neural Network (RNN) related deep learning technique is used in resource utilization to forecast the time series of multivariate information [31]. Moreover, “Bidirectional Long Short-Term Memory (Bi-LSTM)” is one of the deep learning techniques that are used to extract the context data in both directions [16]. However, the gradient vanishing problem causes more information to be lost in the last forecast state of the Bi-LSTM. Therefore, they implemented resource management in cloud applications using VM provisioning, placement, and recycling to solve the above issues.
The noteworthy objectives of the suggested resource management system are given below.
To implement a valuable resource management system for managing the resources in the cloud network to reduce traffic bursts, overruns, and costs effectively.
To develop an effective IROA from the conventional ROA by modifying the random parameter using the best and fitness values to assign the tasks for the machines that highly enhance the overall performance.
To design a W-RNN-based workload and server status prediction model to scale the level of active server resources based on the incoming workloads for decreasing the undesirable energy level, where the weight optimization takes place to minimize the RMSE and MAE.
To develop a VM placement strategy utilizing IROA, which assigns the tasks for the VMs based on the predicted workload and active server state with respect to objective functions like cost, energy, resource utilization, execution time, and QOS.
To ensure the efficiency of the recommended resource management system in the cloud over traditional approaches and heuristic strategies with some performance measures.
The details of the suggested resource management system are given in the following sections. In part 2, the existing system’s advantages and demerits are given. The suggested system explanation and developed algorithm description are specified in part 3. VM provisioning and method of prediction description are provided in part 4. VM placement and multi-objective function explanation are included in part 4. In part 5, the offered system experimental outcome is given. The conclusion is described in part 6.
Literature survey
Related works
In 2016, Zhang et al. [33] have suggested a structure for managing dynamic virtual resources. It was needed to handle the network traffic in cloud environments. The forecasting of the increase in workload was managed using this developed model. It was used to decrease the implementation cost and increase the web application’s availability in the cloud. Their experiments demonstrated high accuracy by comparing their workload forecasting method with others. Their experiment analysis used the World Cup workload dataset that demonstrated the applicability of the methodology in various traffic burst conditions. Additionally, an experiment analysis was performed in the suggested management model. The suggested model recognized various modifications in workload intensity. However, that work had taken over time and allocated numerous virtualized IoT while predicting the changes in the cloud. At last, this developed system provided low-cost and high-availability outcomes.
In 2023, Raghavendar et al. [26] designed a system for identifying factors using resource provisioning techniques in distributed systems. This developed resource management model’s major goal was to improve the data skew rate, approximation amount rate, and minimization rate. Additionally, the complexities and difficulties of hybrid optimization for effective capital allocation in the cloud using IoT were also highlighted. That developed system was contrasted with other traditional models, and it provided better performance.
In 2023, Simic et al. [29] suggested a resource management system using an optimization strategy to optimize the cloud resources. The capabilities of the system were first demonstrated using a real-time data flow. Then, they were assessed using workflows like 13, 52, and 104. The outcomes demonstrated that the implemented model was suitable for optimizing the deployment of cloud resources and calculating the run-time distribution. The business process model was used in the workflows for big data processing. This study was compared to traditional systems by providing crucial information about their most important business processes.
In 2023, Jeong et al. [13] suggested a proactive auto-scaling, which reacted right away to irregular workloads and minimized over overutilization of resources. Proactive auto-scaling applied a deep learning technique integrated with an attention mechanism for the usage of identifying memory usage and future Central Processing Unit (CPU). Vertical Scaling reduced the additional utilization of resources by adjusting the over-allocation of resources within a pod based on anticipated resource usage. Finally, resource scaling was performed using prevention overload with pod auto-scaling in terms of pod data and usage of resources. Proactive auto-scaling was performed more efficiently than traditional pod auto-scaling in terms of memory usage and CPU during the initial resource allocation. As compared to traditional HPA, the developed system did not show overload.
In 2020, Gholipour et al. [8] proposed a new way of managing cloud resources based on multi-criteria decisions that utilized simultaneous container migration and virtual machines. The efficiency of the developed approach was contrasted to other heuristic algorithms, and that significantly decreased the migration frequency, SLA violation, and energy usage. These work simulations were conducted using the Container Cloudsim simulator.
In 2020, Gill et al. [9] developed a lightweight framework and simulation system for thermoSim resource management in cloud computing infrastructures. ThermoSim was used to detect the temperature using deep learning. This strategy was effectively used in the cloud settings for light resource management. The CloudSim was used to evaluate the performance of numerous important factors while managing the cloud resources for the execution of workloads, including temperature, energy consumption, service level agreement violation rate, and number of virtual machine migrations. Additionally, the proposed framework was utilized to validate various thermal and energy-aware resource management strategies over current framework performance. The investigated system effectively reduced the cost, energy consumption, memory usage, accuracy, and time usage. The validation outcomes showed that the suggested framework had the capability to model and simulate the thermal behavior.
In 2020, Liang et al. [20] offered a resource allocation system with physical machines and virtual machines. The data center’s virtual machines, cloud tasks, and physical machines were modeled in this developed system. The mapped rule was implemented by taking the memory characteristics and CPU of the cloud. The memory-aware resource management strategy for low-energy cloud data centers was developed based on the rule. This developed model accomplished the goal of lowering the overall cost for cloud users and energy use. The efficacy of the suggested strategy in this work was much more extensive than the comparison algorithm for the overall cost of cloud users and consumption of energy sources.
In 2020, Li et al. [17] implemented a resource management approach to analyze the edge cloud’s workload demands. This suggested system was used to decrease the cost of the rented nodes. In addition, the replica management method was investigated using the consistency preservation and replica allocation strategies. It was suggested to utilize a dynamic replica allocation scheme to enhance the experience of the user while lowering storage overheads. The replica consistency preservation technique was suggested to ensure the consistency and accuracy of the data. Finally, a real-world dataset was used as the basis for comprehensive experimentation. The recommended resource management technique might dramatically lower the total rented nodes’ cost, and increase CPU usage and the SLA default rate, Additionally, the proposed replica allocation approach could successfully decrease the data transmission time and storage overhead.
Problem statement
Cloud resource management is the operation of handling the resource utilities in the cloud sector. This contains estimated network resources, storage resources, and other resources such as memory and CPU. Resource management enhances profitability and also estimates job costs. Various approaches have been presented to perform resource management in the cloud effectively. However, these approaches still demand for improvements. Table 1 presents several conventional cloud resource management task’s advantages and complexities. VM Provisioning Procedure [33] rectifies the issues of resource provisioning. It allocates the VMs for the tasks accurately. However, it is hard to set up and manage. It consumes more memory. IoT [26] improves the personalized experience. It provides effortless data communication. But, it is prone to data privacy and security. It is a very complex approach. Big data processing workflow [29] detects the fundamental risks. It enhances efficiency and cost-effectiveness. Yet, it requires more hardware resources. It is a very slow approach. Bi-LSTM [13] offers faster scaling and effectively performs a burst workload. It estimates the future memory and CPU usage. However, it loses more data because of the vanishing gradient issue. It demands more computational resources. Containerization [8] has the ability to interconnect the containers. It simplifies the tasks for the single clusters. But, it requires high training data. It has high infrastructure costs. RNN [9] accurately forecasts the temperature of the cloud hosts. It can process any kind of data. But it updates the data very slowly. It has exploding gradient issues. Cloud task mapping [20] utilizes the memory and CPU features for the cloud tasks. It supports to deploy the VMs. However, it lacks of flexibility. It has resource limitations and back-off errors. Dynamic replica allocation strategy [17] minimizes the storage overheads hence satisfies the user experience. It adjusts the replica count of each file. But, it raises the inconsistency and complexity. It requires more storage speed. Hence, a new methodology has been implemented for precise resource management in the cloud sector utilizing modern approaches.
Features and challenges of conventional cloud resource management systems
Features and challenges of conventional cloud resource management systems
Proposed resource management scheme in cloud environment
The traditional resource management system contains many disadvantages to allocating a VM. It doesn’t have the capacity to handle the heavy workload. A combination of high and low resource use in the application provides inefficient resource utilization. It is struggled to assign suitable VMs in data centers for various applications with various resource requirements. Also, it is a very challenging task for the conventional system. Furthermore, a lot of VM placement solutions just take the current resource use, such as CPU. Most of the traditional systems does not use the CPU. Continuously, the workload problem does not solve. Cloud network bandwidth is becoming into another difficult challenge in effective resource management in data centers. Cloud computing would result in increased internet traffic, which would also have an impact on the cloud network. It also has an impact on the utilization of resources and time in the cloud data center [4]. Therefore, the developed resource management system is suggested to rectify these challenges. The structural view of the resource management system using deep learning is shown in Fig. 1.
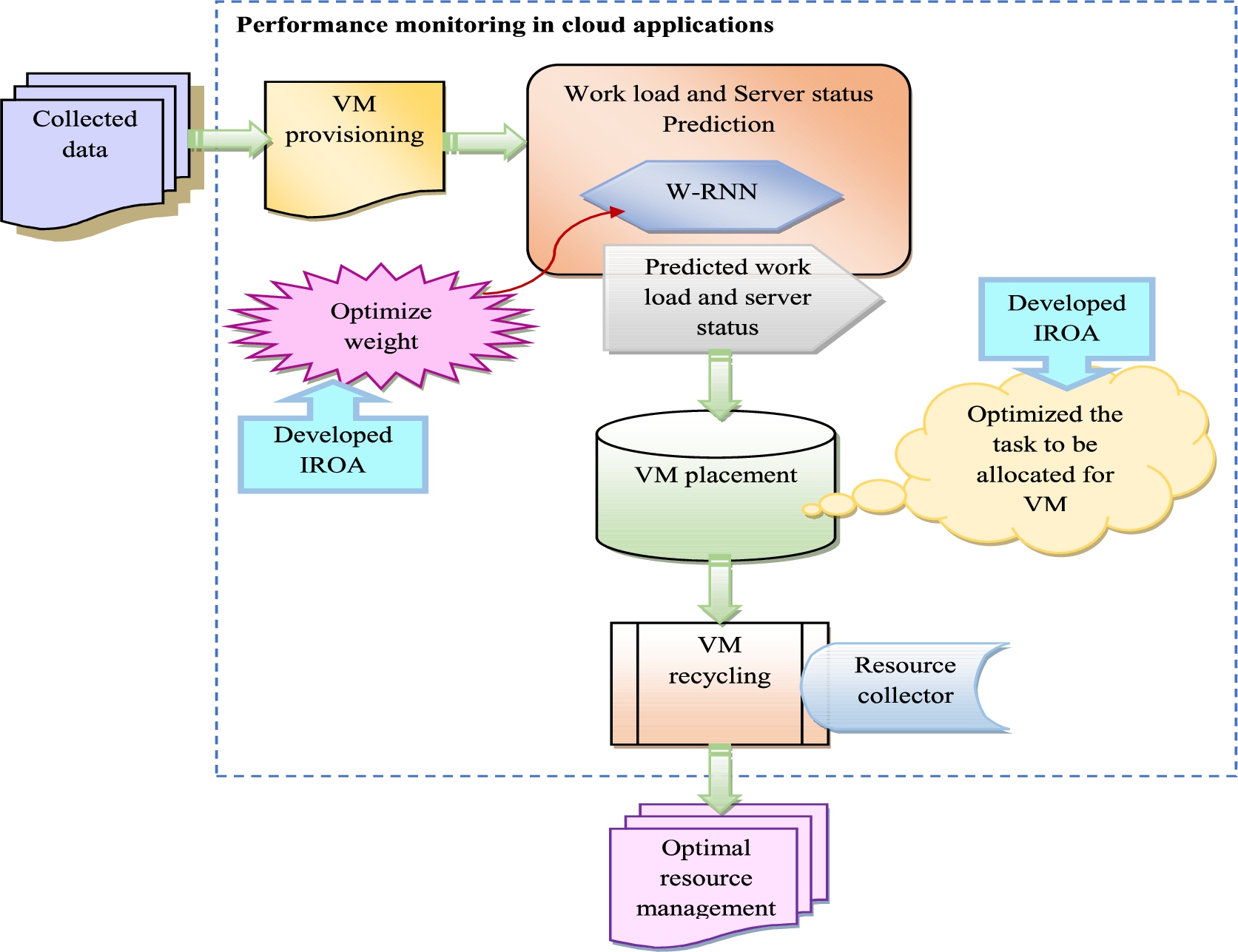
Structural view of resource management system using deep learning.
A newly developed resource management system is used to reduce the traffic burst, overruns, and costs for effectively managing the resources in the cloud. The resources are monitored using resource provisioning, placement, and resource recycling. Performance monitoring is performed to keep aware of the performance of the application and guarantee the cloud application’s performance. Additionally, it is used to assess whether the application has access to sufficient virtual resources. The performance monitor in a cloud environment is necessary. Because they effectively manage the hosts in traffic and run frequently. The developed model’s aim is to predict the overall workload and server status. The prediction of overall workload and server status is used to improve the effectiveness of the developed system in the cloud network. The required data is collected for the resource utilization on multiple VM metrics. Firstly, the VM provisioning process is performed to decrease the VM provisioning issues like high storage cost, capacity utilization, and time. Then, the workload and server status prediction is performed using the W-RNN model. Here, the implemented IROA is used to optimize the weights to decrease RMSE and MAE. Then, the VM placement process is carried out based on the predicted server status and workload. Here, the implemented IROA is used to optimize the VM that is allocated for a specific task from VM placement for minimizing the cost, energy, resource utilization, execution time, and maximizing the QOS. At last, the VM recycling process is performed. It is done by the resource collector with the VM instance’s usage and the associated PM’s workload. It scans the data center’s cloud applications and then performs the VM recycling process. The numerical analysis is performed to ensure the performance of the developed resource management system.
Several initialization parameters are used for the developed resource management system. Cursor sharing, memory area sizes, the number of concurrent processes, and work area size are all variables that have an impact on system performance. Some of the network initialization attributes like available CPU, available memory, processing time, CPU clock speed, reaction time, memory need, priority of all tasks, completion time, and CPU requirement are used in the suggested resource management system. These attributes vary by the number of nodes like 50, 100, 50, and 200.
Developed IROA
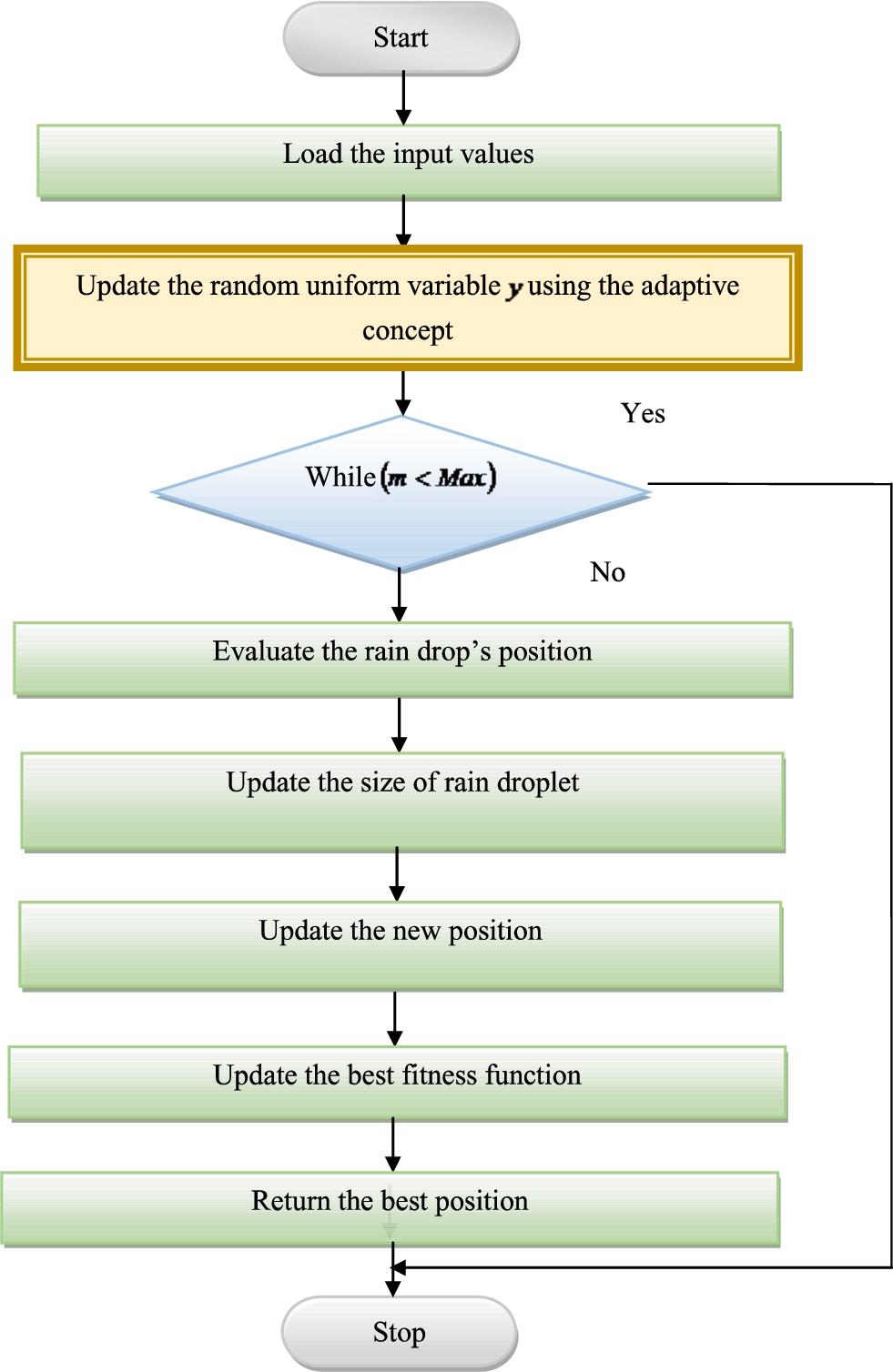
The implemented IROA is utilized to enhance the efficacy of the resource management system in the cloud environment. It performs the weight optimization from W-RNN during server status and workload prediction to minimize the RMSE and MAE. In addition, the tasks to be assigned for the particular VMs are also carried out with the help of this suggested IROA. This task allocation-based VM placement process improves effective resource utilization and resources. Moreover, the optimal allocation of resources to the VM minimizes the cost, energy, resource utilization, and execution time and maximizes QOS. The ROA optimization increases the solution quality. Also, it effectively monitors the loss function. But, it struggles to handle the computational complexity. It consumes more time for the computation. It provides a high convergence rate. It initializes more parameters. Hence, it affects the performance of the model. The designed IROA is used for resolving the recent issues in ROA. From the traditional ROA, the random uniform variable y is upgraded to improve the solution optimization performance. The random uniform variable y is updated based on best fitness and mean fitness in IROA. The upgraded random variable y is calculated by Eq. (1).
Here, the term y is the updated random uniform number in IROA. The term
ROA [27]: The rain behavior is inspired to implement the ROA optimization. Every solution is attained by using the raindrop behavior. The raindrops are randomly generated in the search space based on their problems. The ROA mainly focused on the raindrop’s radius. Because the radius of raindrops is changed based on the time.
The raindrops are connected to other drops. The neighborhood raindrop’s size and radius are needed to determine the solution during the iteration. The droplets contain constant parameters and it is indicated by o. In the first stage, the radius of the raindrop is determined using the upper and lower limit of variables. If the first and second droplets are nearest to each other, they can make the new droplet. The new radius of the raindrop is measured by using Eq. (2).
Here, the term S is the radius and it is generated randomly. The droplet variable is signified by o. The terms
Here, the term β is the volume percentage based on the soil. In the second stage, the two variable’s endpoints are still tested to determine the final variable. In the third stage, the raindrop cost is updated based on the reduced cost function. The droplet’s local maximum and minimum variables are calculated using the egg-crate function. The eggcrate’s operation is measured by Eq. (4).
Here, the term y is the random uniform parameter. The droplet’s global minimum variables are determined using the Rosenbrock function. The rosenbrock’s operation is calculated using Eq. (5).
Here, the term

Improved IROA
Structural view of VM placement using developed IROA.
VM provisioning
The process of configuring or developing a VM in a cloud platform or physical server is known as VM provisioning. Virtualized environments can manage the physical disk storage of a VM using VM provisioning. The workload prediction effectively handled the network traffic. Hence, virtual resources are used to prevent a sudden fall in performance and resource insufficiency in advance. Thus, the forecasted workload is used to solve issues of resource provisioning. VM provisioning problems are decreased by resource provisioning. The initial process is the VM provisioning. After, the workload is predicted using the W-RNN method. The current performance data and the predicted workload for the upcoming time period are gathered by the VM scheduler. The amount of virtual resources that could be provided to a certain cloud application is the key problem of VM provisioning. The application model performance issue is solved using queuing theory. The conventional system’s VM provisioning does not explain how these virtual resources are distributed among all of the PMs in the data center. But, this process overcomes the above issues in the cloud.
W-RNN model
The W-RNN [25] is used to learn the present term dependencies. Present-term dependencies are very crucial for predicting the server status and system workload. The W-RNN is very helpful for predicting the status with time series. The RNN prediction performance depends on the activation function. The RNN technique uses the “Feed-Forward Network (FFN)”. These loops act as the short-term memory for storing and retrieving past data spanning time scales and performing temporal tasks. The RNN shared the values when working with a target sequence of any length to avoid generalization. The prediction of RNN is calculated via Eq. (6).
The weight of RNN is indicated by
The present weight in the RNN is calculated using Eq. (8).
Here, the term F is the error. The previous state weight is denoted by X. The weight changes in back propagation are given in Eq. (9).
Here, the count is denoted by o. The summation of the error rate is indicated by
Work load and server status prediction using W-RNN
The workload and server status predictions have significant real-world implications for cloud providers. The service components of the application are hosted in one or more Virtual Machines (VMs) when enterprise users deploy their apps in the cloud. A SLA is typically signed by the cloud providers. The SLA provides the applications with sufficient resources to prevent SLA violations. Typically, each VM hosted by the service receives the initial resources from the cloud providers. It can lead to poor performance in service quality when the workload increases or takes over time. Conversely, a decrease in workload is used to reduce the utilization of resources. The cloud system is necessary to manage the resources to decrease the operating cost and resource usage.
The conventional W-RNN has many advantages like it takes minimum time for implementation. It provides time series prediction. However, it is difficult to handle various inputs during the VM placement. It suffers from complex problems. So, the developed W-RNN is implemented to resolve these issues. Here, the recommended IROA is used to optimize the weights for minimizing the RMSE and MAE. The objective function of minimized RMSE and MAE is given in Eq. (10).
Here, the term
Here, the term k is the variable. The missing data variables are noted by P. The term
Here, the term l is the number of data points. The term
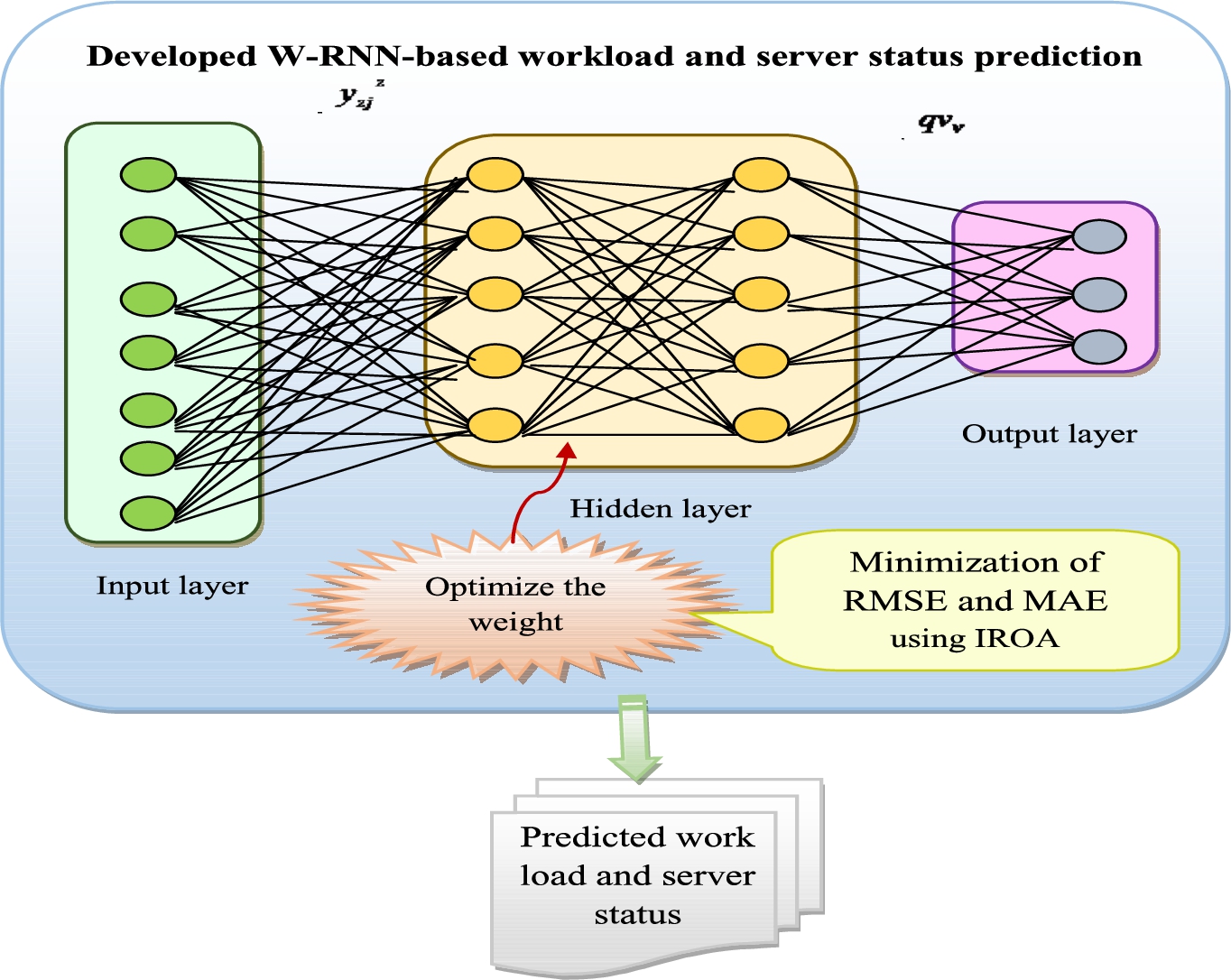
Structural view of W-RNN-based workload and server status prediction.
VM placement
The VM placement is the process of making the decision for mapping the VM to PM after the workload and status of the server are predicted. The desired amount of virtual resources has been acquired. VM scheduler stores the information for each application as well as various availability zones in this cloud data center. So, the VM placement procedure is used to increase the performance of the system. The VM placement strategy is used to find the best location for the virtual machine instances. Subsequently, the cloud will get the instructions such as adding an instance for an application.
The objective function of minimized resource utilization, cost, energy, execution time, and maximized QOS is given in Eq. (13).
Here, the term
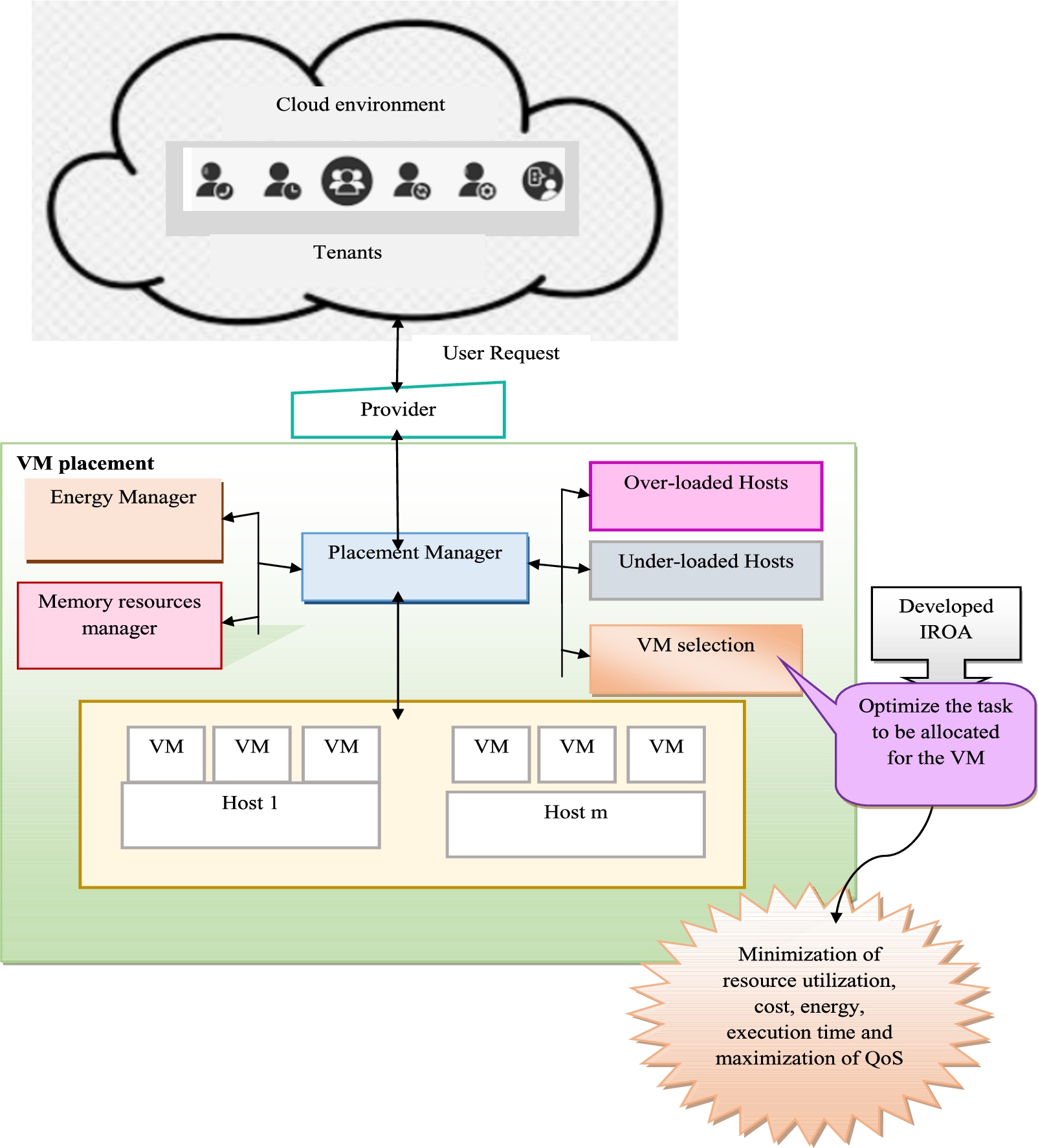
Structural view of VM placement using developed IROA.
Multi-objective functions of the developed resource management system, like resource utilization, cost, energy, execution time, and QOS explanation, are given below.
Resource utilization: The ratio of a resource’s overall uptime to the execution time of a workload carried out by that resource is known as resource utilization. It is measured by Eq. (14).
Here, the term o is the number of resources. The total execution time is denoted by
Cost: The total cost of cloud users is calculated using
Here, the term t is the running time of the VM. The total number of created VMs is noted by Q. The CPU cores are indicated by
Execution time: The overall running time of VM placement is said to be execution time. It measures the total time of VM placement. It is measured by Eq. (16).
In the cloud environment, the number of active physical machines is indicated by P. The term
Energy consumption: The amount of energy utilization in a cloud network is said to be energy consumption. It is measured by Eq. (17).
Here, the terms
VM recycling
They also offer a resource collector to deal with cost-effective considerations in over provisioning scenarios. It is a low-priority activity that is only carried out in the absence of regular scaling-up procedures inside the framework. As a result, the resource collector does not take action during the traffic. The primary goal of the developed system is to handle greater traffic and maintain high availability. Virtual resource recycling is done by the resource collector with the VM instance’s usage and the associated PM’s workload. It scans the data center’s cloud applications and performs the VM Recycling process. It achieves the goal of cost-effectiveness by performing the VM Recycling.
Results and discussions
Experimental setup
Python was utilized to offer an IROA-W-RNN-based resource management system. The developed system was conducting performance analysis via various performance measures. A population rate was fixed as 10, a chromosome length was fixed as 5 and an iteration gap was fixed as 250 in this analysis. The heuristic algorithms like the Jaya Optimization Algorithm (JAYA) [23], “Sand Cat Swarm Optimization (SCO) [19], Moth-Flame Optimization Algorithm (MFOA) [18], and Dragonfly Algorithm (DA) [24]” were used. Also, the techniques such as DBN [12], LSTM [13], RNN [9], and W-RNN [25] were utilized for the experimental analysis.
There are five configurations have been considered for performing experiments that included details like the number of sources, memory size, and CPU. The detailed description of the five types of configurations is illustrated in Table 2.
Configuration description of the proposed optimal task scheduling in a cloud environment
Configuration description of the proposed optimal task scheduling in a cloud environment
Several performance measures are used to validate the developed resource management system.
Performance evaluation on the suggested server status and workload prediction
The performance comparison of the implemented resource management system over the recent system’s methods and algorithms is depicted in Fig. 5 and Fig. 6, respectively. The IROA-W-RNN-based resource management system specified less MAE of 6.05% than DBN, 1.60% than LSTM, 2.17% than RNN, and 7.02% than W-RNN at the sigmoid function. The developed IROA-W-RNN-based resource management system had given less RMSE and MAE compared than recent systems.
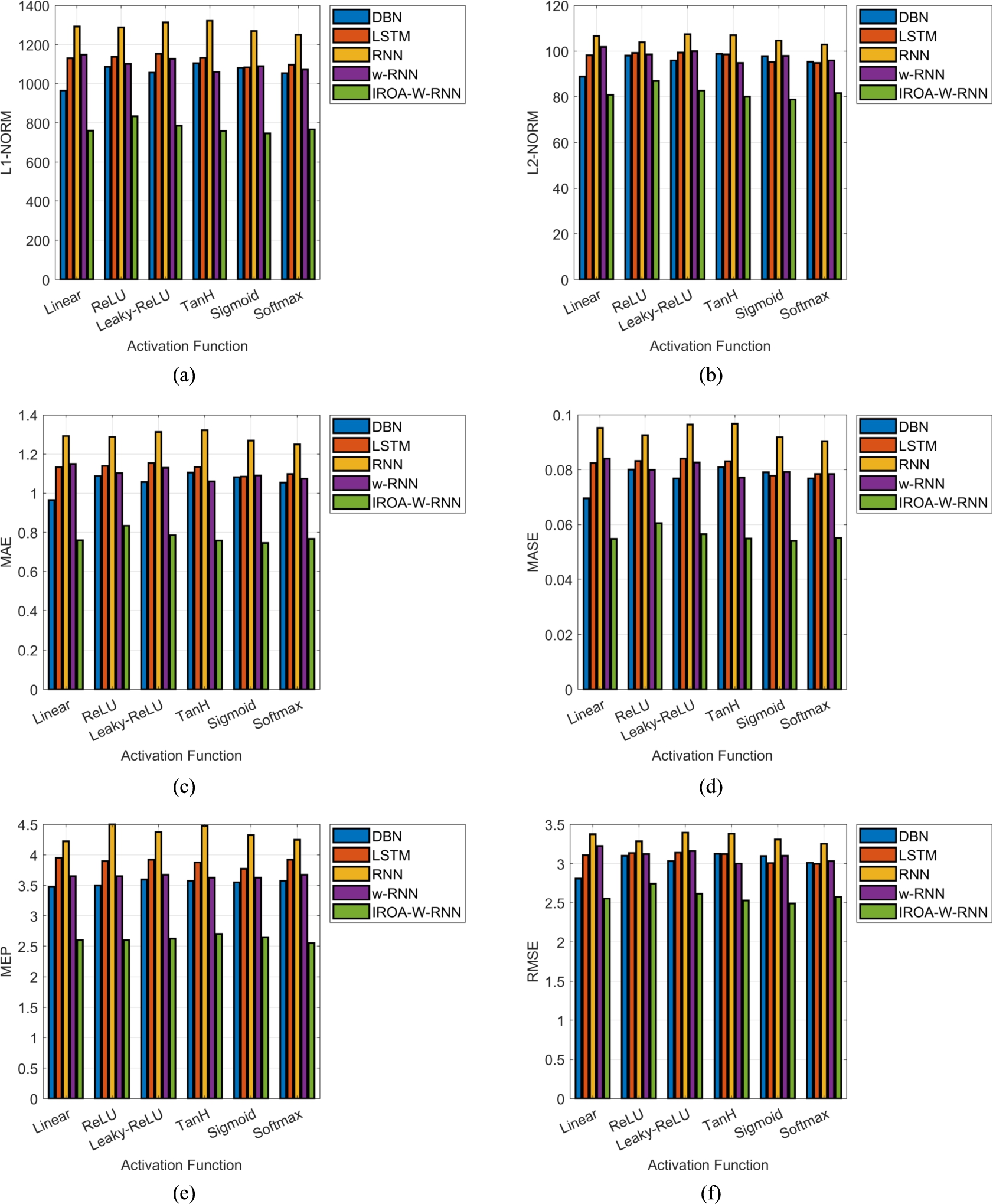
Performance validation of the designed resource management system in the cloud among various methods in regards with “(a) L1-NORM (b) L2-NORM (c) MAE (d) MASE (e) MEP (f) RMSE and (g) SMAPE”.
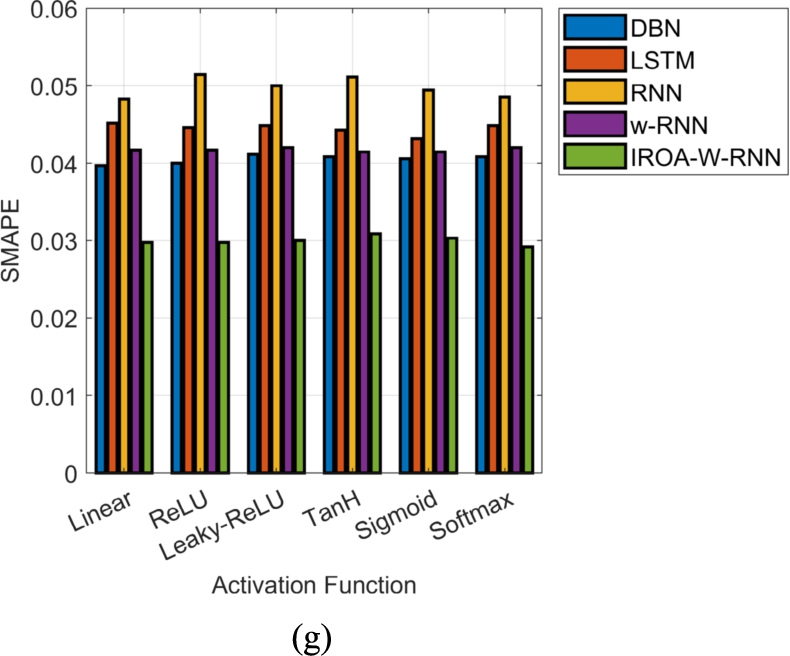
(Continued.)
The efficacy analysis on the VM placement in the suggested resource management system is displayed in Fig. 7. The IROA-W-RNN-based resource management system had given less resource utilization of 5.11% than JAYA-W-RNN, 54.20% than SCO-W-RNN, 8.50% than MFOA-W-RNN, and 12.48% than DA-W-RNN at configuration 2. The suggested system showed greater performance than existing models.
Cost function analysis on the offered system
The cost function analysis of the suggested resource management system is displayed in Fig. 8. At configuration 3, and the IROA-W-RNN-based resource management system proved less cost function of 7.37% than JAYA-W-RNN, 11.49% than SCO-W-RNN, 10.3% than MFOA-W-RNN, and 7.14% than DA-W-RNN. The IROA-W-RNN-based resource management system achieved less cost function than conventional methods.
Overall analysis of the recommended model
The effectiveness examination of the designed system over various algorithms is depicted in Table 3. In Table 4, the efficacy of the designed system over various methods is given. The IROA-W-RNN-based resource management system proved less MEP of 7.37% than JAYA-W-RNN, 11.49% than SCO-W-RNN, 10.3% than MFOA-W-RNN, and 7.14% than DA-W-RNN. The investigated system provided better performance than other heuristic strategies and existing methods.
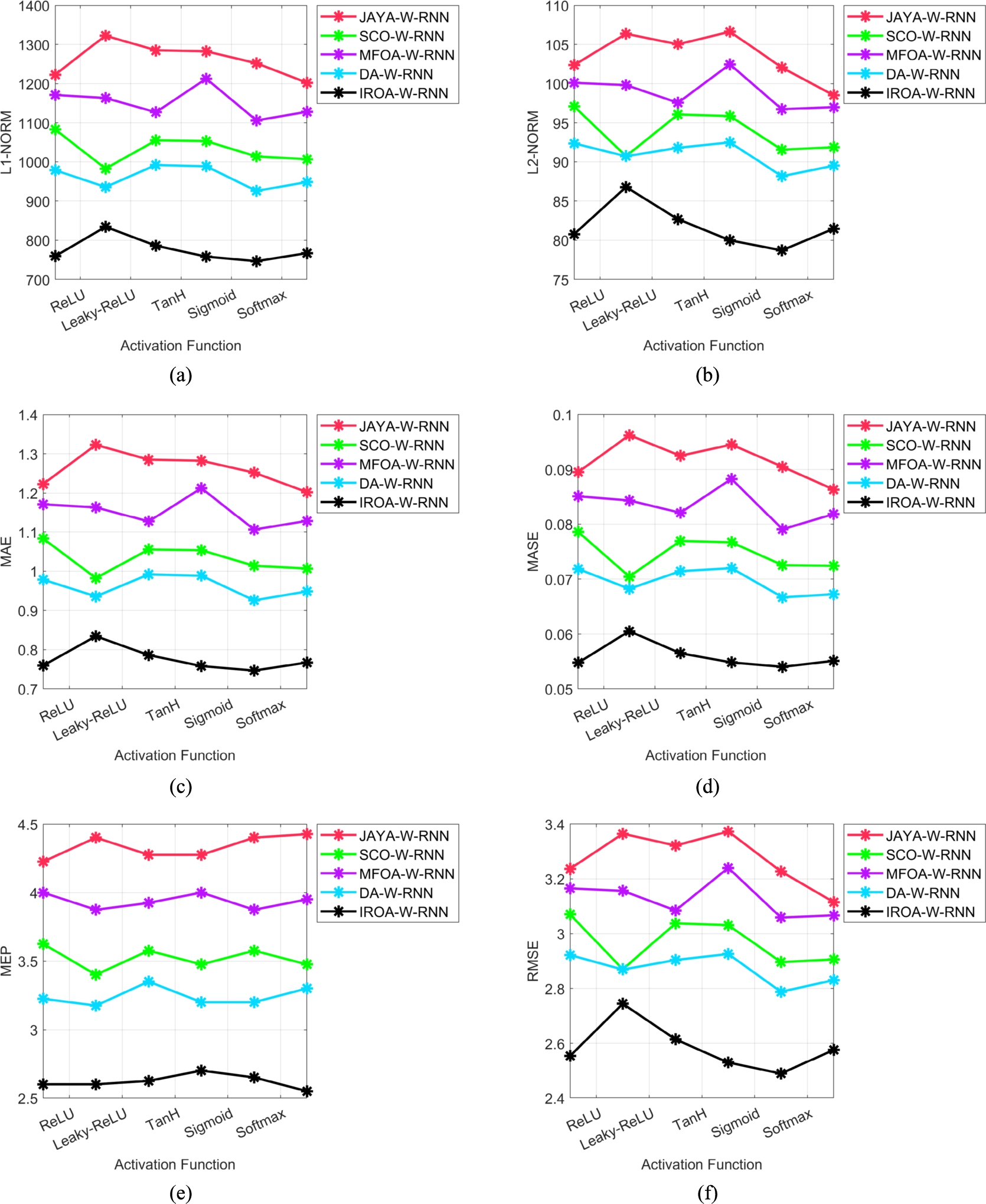
Performance analysis of the proposed resource management system in the cloud among various heuristic strategies in terms of “(a) L1-NORM (b) L2-NORM (c) MAE (d) MASE (e) MEP (f) RMSE and (g) SMAPE”.
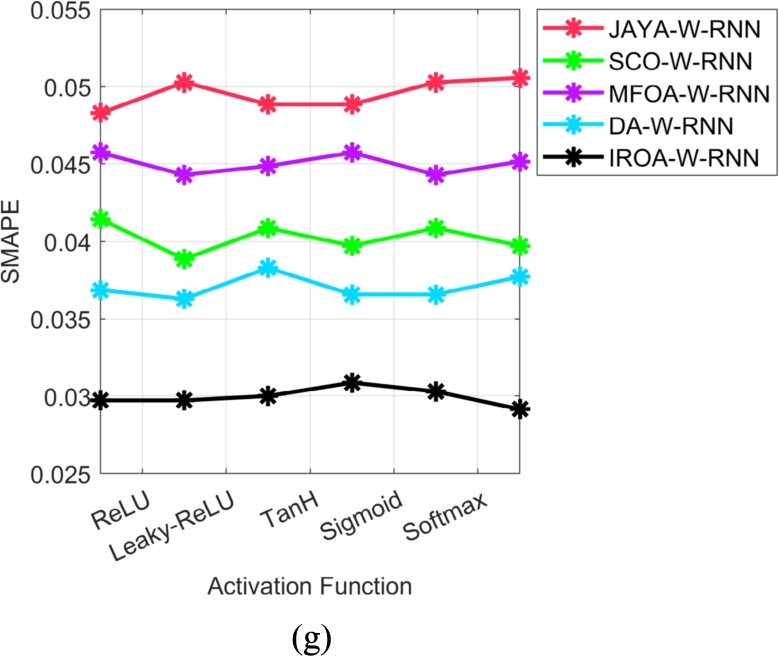
(Continued.)
The suggested resource management system’s statistical analysis among several algorithms is depicted in Table 5. The IROA-W-RNN-based resource management system achieved a mean of 56.27% than JAYA-W-RNN, 21.09% than SCO-W-RNN, 60.2% than MFOA-W-RNN, and 16.74% than DA-W-RNN for configuration 4. The designed system provided greater performance than other heuristic algorithms.
Conclusion
A newly developed resource management system was used to reduce the traffic burst. The required data was collected for the resource utilization on multiple VM metrics. Firstly, the VM provisioning process was performed to decrease the VM provisioning issues like high storage cost, capacity utilization, and time. Then, the workload and server status prediction was performed using the W-RNN model. Here, the recommended IROA was used to optimize the weights to minimize the RMSE and MAE. Then, the VM placement process was carried out. Here, the implemented IROA was used to optimize the VM that was allocated for a specific task from VM placement for minimizing the cost, energy, resource utilization, execution time, and maximizing the QOS. At last, the VM recycling process was performed. It was done by the resource collector with the VM instance’s usage and the associated PM’s workload. It scanned the data center’s cloud applications and then performed the VM Recycling process. The suggested IROA-W-RNN-based resource management system proved less MASE of 5.07% than JAYA-W-RNN, 10.19% than SCO-W-RNN, 7.23% than MFOA-W-RNN, and 9.04% than DA-W-RNN. The numerical analysis was conducted to validate the performance of the developed resource management system. However, it needs more investigation about the (SLA-aware autonomic Technique for Allocation of Resources) STAR approach which will help to enhance the constraints like LA violation, availability, reliability, and latency QoS parameters. In the future, the designed model will be extended using the given STAR approach. It can be utilized to enhance the efficacy of the developed model and also prevent the cyber-attacks.
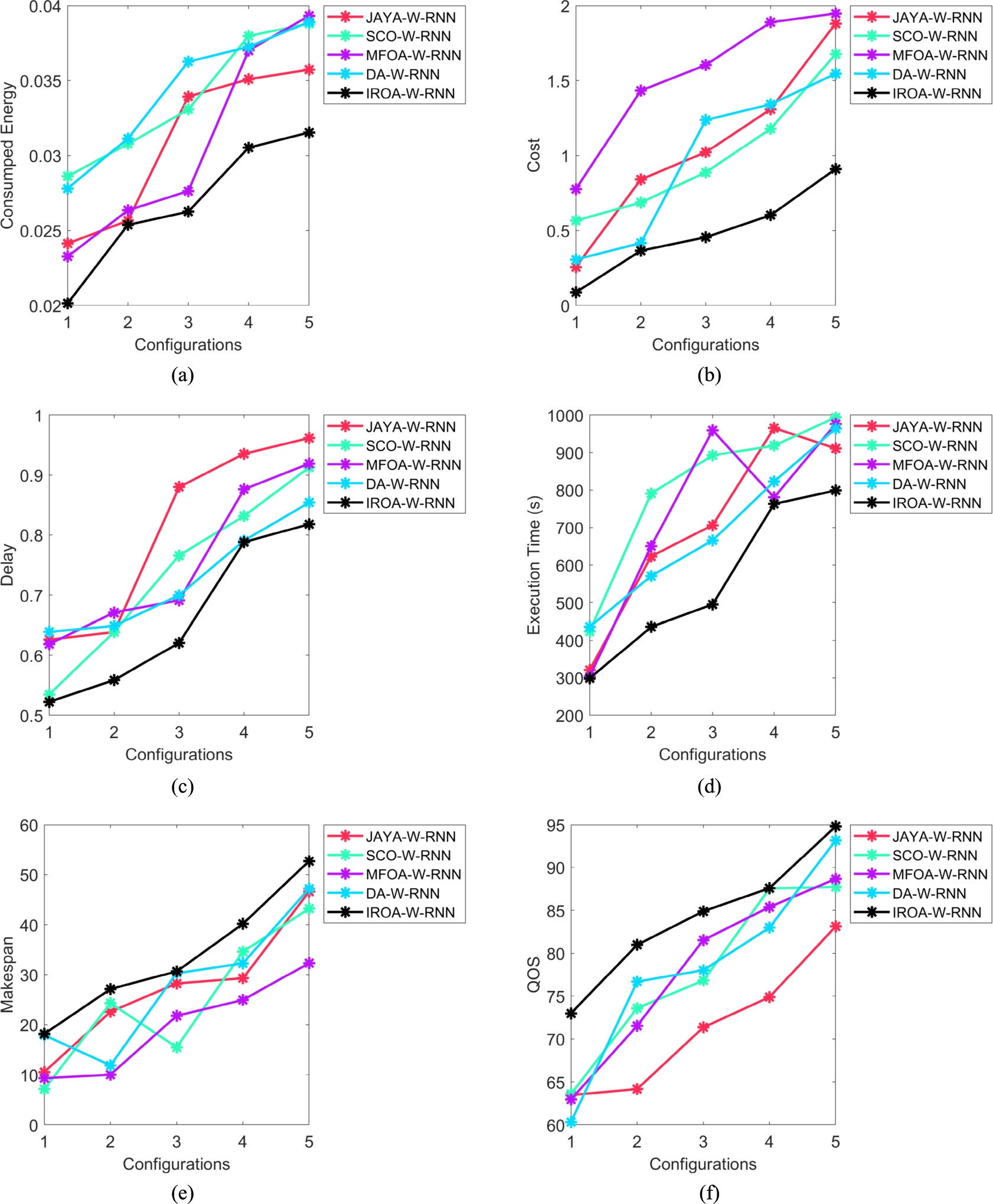
Performance analysis of the recommended resource management system in the cloud among various heuristic algorithms for “(a) consumed energy (b) cost (c) delay (d) execution time (e) makespan (f) QOS (g) resource utilization (h) success rate (i) throughput”.
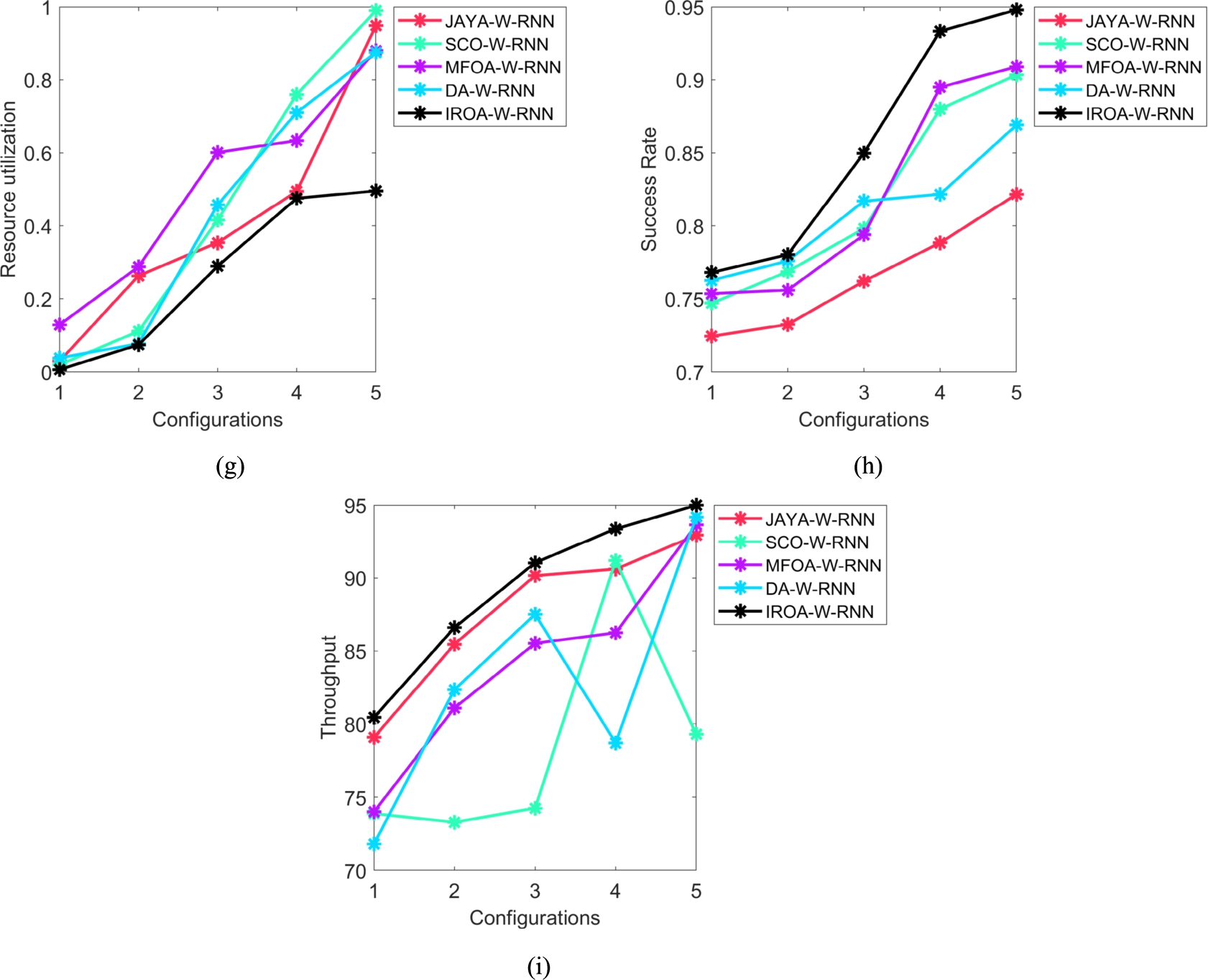
(Continued.)

Cost function analysis of the suggested resource management system in the cloud over various heuristic algorithms for “(a) configuration 1 (b) configuration 2 (c) configuration 3 (d) configuration 4 and (e) configuration 5”.
Performance evaluation of suggested resource management system in the cloud with various heuristic algorithms
Performance analysis of suggested resource management system in the cloud with different existing methods
Performance analysis of suggested resource management system in the cloud with various heuristic algorithms
Conflict of interest
The authors have no conflict of interest to report.