
Abstract
Recommender Systems (RSs) are largely used nowadays to generate interest items or products for web users of diverse nature. Therefore, this work focuses on using fuzzy logic to accommodate diversity and uncertainty in user choices and interest. This would help in generating better recommendations with different tastes that correspond to different interest choices of the user. In this paper, a fuzzy hybrid multi-agent recommender system is designed and developed. The novelty of our approach is the use of interval type-2 fuzzy sets to create user models capable of capturing the inherent ambiguity of human behavior related to diverse users’ tastes. In the due course, we also extended an existing, well known hybrid recommendation method, by integrating the proposed fuzzy approach into the recommendation process. As a result, a new RS approach was developed, which was capable of improving the prediction accuracy of system and at the same time reducing errors by being able to extract more information from the available dataset. Experimental study and analysis was conducted using two case studies namely book purchase and shopping women apparels. As a result, the proposed recommendation approach was found to perform considerably well as compared to its counterparts, even under data sparsity conditions.
Introduction
Recommender Systems (RSs) are programs that help the user in navigating large volumes of information available, attempting to provide a solution to the user’s needs or suggesting items that the user may like [10]. Most common techniques used in their implementation are: collaborative filtering (CF), where user ratings for objects are used to perform an inter-user comparison and then propose the best rated items [12]; content-based filtering (CBF), where measures of similarity between item’s content are used to find the right selection [26]; and hybrid versions of these, where combination of these techniques is used to overcome their individual limitations [30]. The extent to which users find the recommendations satisfactory is, ultimately, the key feature of RSs, and the accuracy of modeling dynamic user preferences personalized according to their tastes is of key importance to this goal [8]. Traditional techniques used to create user models are usually too rigid to capture the inherent uncertainty of human behavior. Soft computing techniques and particularly, fuzzy sets and fuzzy logic systems can handle and process uncertainty in human decision-making. Thus, using them in user modeling can be advantageous, as it will result in recommendations closely meeting user preferences. The purpose of such personalization is to adjust strategies of product recommendation (to fit user interests) modeled according to users’ preferences, profile and needs [23].
Soft Computing (SC) techniques provide an approximate solution to the problems handling vague and imprecise information. Hence, it can be used in an environment where users having different profiles may have different needs to be satisfied while using the recommendation system [21]. Amongst various SC techniques, the fuzzy logic field has grown considerably in a number of applications across a wide variety of domains for product recommendations [37]. The fuzzy logic theory has been the subject of interest to researchers in the recommender systems’ field as well [14]. This is because of its proven efficiency for solving problems of fuzzy nature in all areas. This theory can be used to solve problems of such systems by giving a sort of intelligence to them [35].
The most appropriate paradigm for designing and implementing such complex systems is the Multi Agent System (MAS) technology [34]. A multi-agent system is comprised of multiple agents working together to solve a problem. It is a computational system consisting of intelligent agents, which work in conjunction with each other to achieve some individual or collective task [25]. The agents in a multi-agent system have several important characteristics like autonomy, contains local views and decentralization. The multi-agent systems are being used in an increasingly wide variety of applications, ranging from comparatively small systems for personal assistance to open, complex, mission critical systems for industrial applications [2]. The proposed system has been developed over a multi-agent architecture. This approach enabled us to distribute the workload amongst agents which were designed to work on behalf of users i.e. one agent corresponding to one user. Multi-agent systems also allow different users to interact when they are online. Online users can interact directly by asking questions related to product features or giving suggestions to other users.
The major objective of the proposed multi-agent fuzzy hybrid recommender system is to model diverse users’ tastes. This would in turn improve the quality of recommendation by making the system flexible while capturing the user preferences. Hence, we borrowed concepts from the area of fuzzy logic (specifically, type-2 fuzzy systems) to handle the inherent uncertainty related to personalization and changing tastes of the users. We put forward the main contributions of the paper as: (1) management of uncertainty related to diverse users’ tastes by increasing the domain flexibility for recommendations; (2) in turn a novel recommendation algorithm FFCH (Fuzzy Feature Combination Hybridization Method) is developed by extending the traditional “Feature Combination Hybridization Method”. This has been achieved by application of Fuzzy C-Means (FCM) Clustering and Interval Type-2 (IT2) fuzzy sets; (3) eventually; we developed a recommender system to realize our proposal.
The organization of this paper is as follows. Section 2 reviews the related work in this area. We discuss the need of using fuzzy sets in modeling user requirements as per different user profiles. Section 3 explains the basic concepts in brief. The proposed notion is described in Section 4 with examples. In section 5, we extend an existing, hybrid recommendation method, by integrating the proposed fuzzy approach for modeling user preferences into the recommendation process; and then present an overview of the multi-agent recommender system implemented to realize the same. The approach is evaluated in Section 6 by comparing against the standard Resnick’s CF and type-1 fuzzy approaches for recommendation. Finally, Section 7 concludes this work and briefly mentions the future work.
Related work
The search for new progress of fuzzy modeling application to recommender systems based on content was initially presented by Ronald Yager [32], who considered methods for constructing recommender systems. The methods proposed by Yager were based only on the preferences of the person concerned by the recommendation, and did not use the preferences of other collaborators. In a work by Chris Cornelis [3], the user/item similarities as fuzzy relations to resolve data sparsity problem were modeled. In this context, Cane, Stephen and Fu-lai Chung [4] presented a collaborative filtering framework based on fuzzy association rules and multi-level similarity. They extended the existing techniques by using fuzzy association rules to address data sparseness and non-transitive associations. For static systems and on the basis of user interactions with the system, Yukun Cao and Li [37] proposed a fuzzy based system for consumer electronics to find the best products for the consumer. Also, Adnan et al. made use of fuzzy logic to recommend relevant news to its users [27] whereas Myszkorowski and Zakrzewska used fuzzy logic for recommending groups in E-Learning Systems [19]. Maatallah and Seridi [24] used fuzzy logic to classify users in several classes to offer them recommendations corresponding to their different preferences in order to solve the stability problemof RSs.
All researches cited above, used fuzzy logic to classify items in several classes or to model fuzzy similarities and relations between users and items in the system. Only [24], classified users in several classes and offered him recommendations corresponding to their different preferences. But a major limitation of their work is that, they used type-1 fuzzy sets which have no uncertainty associated with them. Hence, the system lacks in the proper handling of fuzziness due to the unstable nature of user’s preferences and dependability on varying user needs.
Moreover Guerrero and Moreno [17, 18] used 2-tuple fuzzy linguistic logic in order to provide qualitative recommendations to the concerned user. Besides this, 2-tuple fuzzy linguistic logic has been used effectively in computing with words in decision making as well Martinez and Herrera [9, 22]. The 2-tuple FLM (Fuzzy Linguistic Model) is a continuous model of representation of information which reduces the loss of information typical of other fuzzy linguistic approaches [6]. But the limitation remains the same as stated above, that the basic underlying fuzzy modeling approach of 2 tuple FLM is also grounded on type-1 fuzzy sets.
Therefore, we put forward the suggestion of using IT2 (interval type-2) fuzzy sets for modeling of user’s preferences. This is because a type-2 fuzzy set supports a non-crisp, fuzzy membership function.
Jerry Mendel [15] elaborates the need to use type-2 fuzzy logic systems to model and minimize the effects of a broad range of uncertainties that can occur in a system requiring any kind of decision making task. Even, Ashraf and Nilavu, and have made use of type-2 fuzzy logic to provide better recommendations to their users. Ashraf and Nilavu also state that type-2 fuzzy logic is better in handling uncertainty than type-1 fuzzy logic [1, 5]. Interval type-2 fuzzy logic systems provide a way to handle knowledge uncertainty. They have the potential to solve problems related to selection and decision making in the presence of uncertainty. A type-2 fuzzy logic system has more design degrees of freedom than does a type-1 fuzzy logic system because the former one is described by more parameters or factors than the latter. This suggests that a type-2 fuzzy system has the potential to outperform a type-1 fuzzy system in minimizing uncertainties, because of its additional number of design degrees of freedom [16]. The effects of uncertainties can be minimized by tuning and optimizing the parameters of the type-2 fuzzy sets during a training process [15]. An interval type-2 fuzzy set provides this measure of dispersion and is therefore valuable to the design of systems that include linguistic or numerical uncertainties that translate into inference rules.
The main advantage of using interval type-2 fuzzy sets is that the interval type-2 (IT2) fuzzy sets generalize type-1 fuzzy sets so that more uncertainty can be handled. Membership function of a type-1 fuzzy set has no uncertainty associated with it, as membership value is crisp. But, an IT2 fuzzy set lets us incorporate uncertainty about the membership function into fuzzy set theory (as output of membership function is an interval rather than a crisp value). And, if there is no uncertainty, then an IT2 fuzzy set reduces to a type-1 fuzzy set. In general, uncertainty comes in many forms and three of them are [14]: fuzziness (or vagueness), which results from the imprecise boundaries of fuzzy sets; non-specificity (or information-based imprecision), which is connected with sizes (cardinalities) of relevant sets of alternatives; strife (or discord), which expresses conflicts among the various sets of alternatives. In our recommender system, we are mainly concerned with uncertainty due to fuzziness and strife.
Basic concepts: Fuzzy sets
Fuzzy sets are the sets whose elements have degrees of membership (rather than a crisp value 0 or 1); as given in Equation (1). A type-1 fuzzy set denoted as A is characterized by a type-1 membership function μA (x) where x ∈ X (set of values to be mapped into type-1 fuzzy sets), and μA (x) : X → [0, 1]. So, type-1 fuzzy set A = {(x, μA (x)) , x ∈ X, μA (x) ∈ [0, 1]}; where
The Fig. 1 given below represents a type-1 membership function. The membership function takes on a single value at a specific value of x (say x′) where the vertical line meets the triangle. In the case study which we refer in this paper, μA (x) is represented by Uik (as shown in Fig. 1 given below).
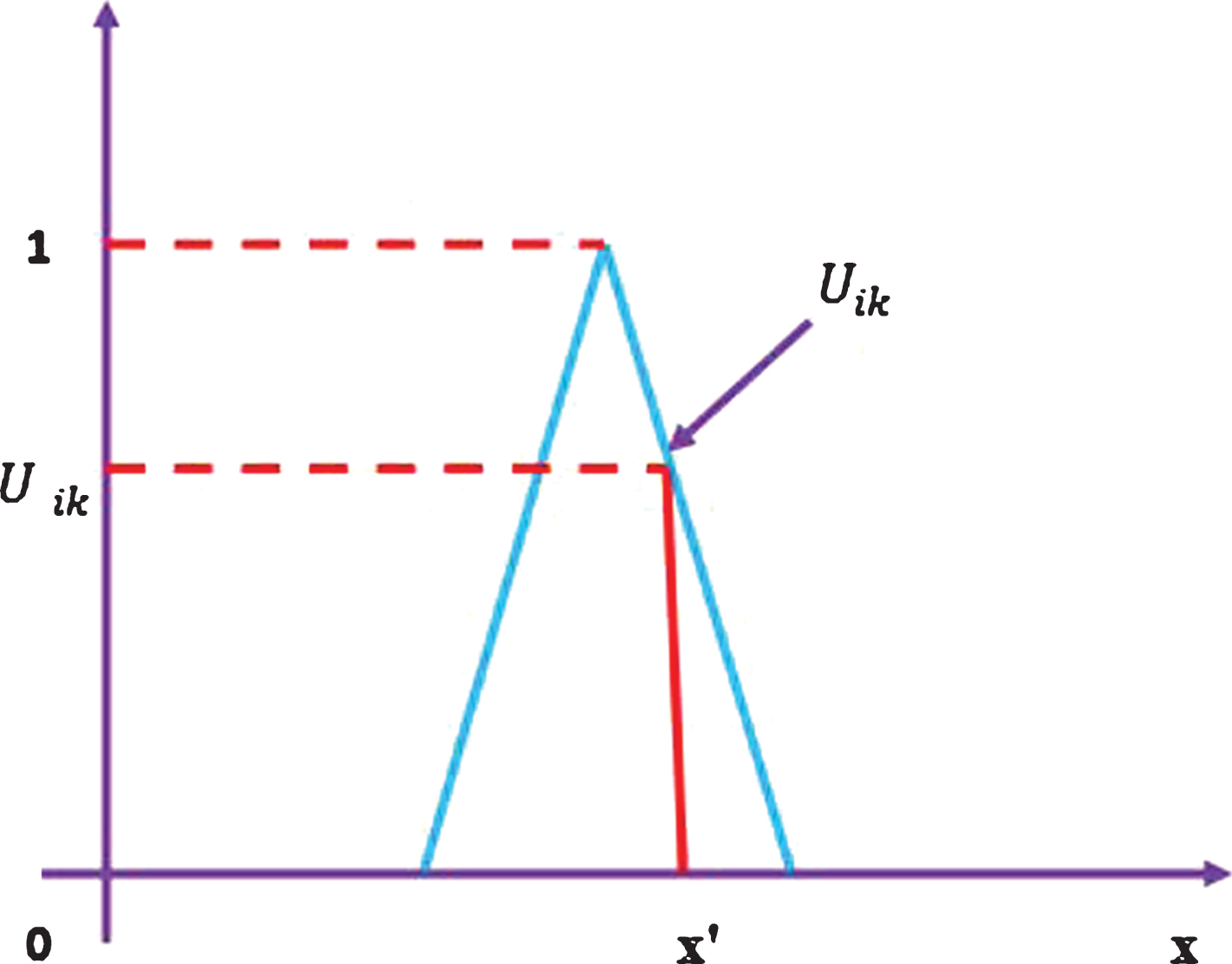
Type-1 membership function.
An interval type-2 fuzzy set denoted as is characterized by a type-2 membership function where x ∈ X (set of values to be mapped into type-2 fuzzy sets) and u ∈ Jx ⊆ [0, 1]; as shown in Equation (2) and Fig. 2. Here, Jx is called the primary membership of x, where Jx ⊆ [0, 1], ∀x ∈ X. A type-2 fuzzy-set is mathematically defined as:

Type-2 membership function.
For other definitions of , meant for continuous and discrete values of x and Jx, please refer [14a]. In Equation (2), the first restriction that ∀u ∈ Jx ⊆ [0, 1] is consistent with the type-1 constraint that 0 ≤ μA (x) ≤1, i.e., when uncertainties disappear a type-2 membership function must reduce to a type-1 membership function. The second restriction that is consistent with the fact that the values taken by a type-2 membership function should lie between or be equal to 0 and 1. Also, the foot of uncertainty (explained below) is defined as: [14]. The Fig. 2 represents an interval type-2 fuzzy membership function. The Fig. 2 has been obtained by blurring the triangular type-1 membership function (as depicted in Fig. 1), by shifting the points on the triangle either to the left or to the right (not necessarily by the same amounts). The shifting of the points is determined due to application of Equation (6). The type-2 membership function is no longer a single value; instead, it takes on an interval of values i.e. known as the (the shaded region) as shown in Fig. 2) [29]. is upper membership function marked as , is lower membership function marked as in Fig. 2 (refer Equation (3 and 4)). Please note that, for this case study, μA (x) is represented by Uik, therefore we have:
Fuzzy logic is a form of many-valued logic. It deals with reasoning that is approximate rather than fixed and exact and hence incorporates uncertainty which is inherent in human decision making. Therefore, we used fuzzy techniques like interval type-2 fuzzy sets, fuzzy membership functions, fuzzy inference rules and fuzzy clustering in the proposed RS. We modeled user preferences using fuzzy logic techniques.
Modeling user preferences
To justify and explain the use of interval type-2 fuzzy sets for user preferences, we proceed with an example taken from the case study of recommendation for book purchase. Please note that our users for this work belong to academia. They are students, researchers and professors of the university. To illustrate the concept, consider modeling of user preferences (as per their profile) for cost of an item (book). In case of cost defined using type-1 fuzzy sets, let ‘ρ’ (a crisp value) be some threshold value defined for membership of a book in a particular cost category (low [300, 500], medium [400–600], high [550 & above]). Then system will recommend those books to the user whose membership degree in a cost category is greater than the threshold value ‘ρ’. This includes all the cost categories which are lower in range as compared to the category chosen by a user. For example, if a user chooses medium category, then the membership value will be considered for all low and medium range books or if a user go for high category, then the membership value will be considered for all low, medium and high range books Also, type-1 membership function due to fuzzy c-means clustering is defined as in Equation (5), givenbelow:
Here, Uik is the membership of kth user in the ith cluster. As α and β are the scaling factors that vary from one user to another (depending on three different user profiles), thus modeling ‘cost’ using type-2 fuzzy sets provides more personalized recommendations to the user. Determination of values for parameters α and β is discussed in detail in the following sub-section 4.2.
Now coming back to the example; for such cases, it is probable that a book may found to be suitable for a professor and not for a student even under similar kinds of circumstances and preferences (depending upon user chosen category for cost and profile). This situation can be modeled by applying type-2 fuzzy membership function (as given in Equation (6)), as the membership can deviate by some value ±ɛ (ɛ is some real number between [0, 1]). Also, this deviation in membership value will provide flexibility and diversity to the domain of books to be recommended to the user and thus it gives recommender system more choices in selecting relevant books to be recommended to a user. So the uncertainty related to the user’s perspective of “What is expensive and what is not!” is handled in a better way in case of type-2 fuzzy sets. For the same scenario as described above under type-1 fuzzy sets, the book “Introduction to Computer Graphics” will be recommended to an earning person (as membership value is increased from 0.351 to 0.436) and not to a non-earning person (as the membership value is decreased from 0.351 to 0.28) (refer Table 1). We have summarized this generation of recommendations customized to user profile and preferences using type 2 fuzzy approach in Fig. 3. Similarly, the user’s preferences for another item attribute like: the year of book publication can also be modeled using IT2 fuzzy sets as different users may have different view towards “Oldness of a book due to its publication year!”.

Generating recommendations customized to user profile and preferences using type 2 fuzzy approach.
Estimation of type-1 membership values and interval type-2 membership values for medium cost range
Moreover our second case study, which is based on the shopping of women apparels, also considers the item attribute price. As already explained, attribute price has an inherent uncertainty associated with it, so we have modeled price using IT2 fuzzy sets over here.
For the sake of completeness, we analyzed the proposed approach on a variety of datasets. We also studied the standard MovieLens dataset (the dataset was elicited from http://grouplens.org/datasets/movielens/) and explored that the user preferences in it can also be modeled using type-2 fuzzy sets. For this we chose to fuzzify user category (over the attribute user’s age) and movie category (over the attribute movie type). Users are categorized on the basis of age, for example: children, teenagers, youngsters, middle aged people and old aged people. Various movie categories are: action, adventure, drama, romance, comedy, horror etc. But a movie may contain various elements like action, comedy and romance each with a certain degree of percentage. So, different movie types can be combined to make a group. For example: romance, comedy, drama can be combined to make a group, similarly another group can be action, adventure, romance. These groups of movie types have each element with a degree of percentage and each user category may have different choices of these movie groups with varying degree of preference for each group element. So, there is a degree of uncertainty associated with movie choice and we can handle this uncertainty using type 2 fuzzy sets.
Therefore, we can put forward the claim that the proposed approach is generic. It can be applied to any suitable database requiring fuzzy modeling of user preferences.
The user’s perspective of features like cost, publication oldness, age, movie type etc. has an inherent uncertainty associated with it. As a result we model such features using type-2 fuzzy sets. Initially for instance, using fuzzy c-means clustering we determine the cluster(s) to which a selected book can belong in the given book dataset. A book may have multiple memberships. Each membership is denoted by Uik (membership of ith book in kth cost category). Using type-2 fuzzy sets, each book is associated with one or more intervals like (), such that Uik∈ (). For every Uik and a particular user profile (professor/researcher/student) the fuzzy system assigns values to parameters α and β in [0, 1] where α and β are scaling factors and their value vary for each user category. Therefore we have: (αp, βp) as scaling factors for professor; (αr, βr) as scaling factors for researcher; and (αs, βs) as scaling factors for student. The system determines typ2ik for each Uik against a particular book. In case of multiple memberships, corresponding to single user category, denoted by μL (representation of membership of a book in low (L) cost category), μM (representation of membership of a book in medium (M) cost category), and μH (representation of membership of a book in high (H) cost category); the book is said to belong to the category scoring the maximum typ2ik (obtained from Equation 6). We have considered three user and three cost categories, so we have 9 rules in total. Finally, the membership value for the item is determined by combining all typ2ik’s obtained as a result of application of multiple fuzzy inference rules based on uncertainty related to user’s view towards various item attributes. We combine these; by taking simple average of all values to defuzzify the output. The obtained value is used further to determine suitability of the item for recommendation. In case the item appears in the recommendation list, it may get a feedback. Depending on this feedback (whether like or dislike) the parameter values for α and β can be updated (or adjusted) in the fuzzy logic system. We used the fuzzy inference rules stated in Fig. 4 to determine the parameters according to the customer’s purchasing power.

Fuzzy Inference rules.
We would now explain how these parameters or factors (α’s and β’s) were tuned in the system. A fuzzy logic system contains many design parameters whose values can be optimized by the designer before the system is operational. There are many ways to do this, and all make use of a set of data, usually called the training set. This set consists of input–output pairs for the system. We identified a feasible set of parameters for the given inference rules. These were all α’s and β’s (see Fig. 4). Given input–output training samples, we wished to update the scaling parameters so that errors were minimized for training samples. A general method for doing this is to initialize all the parameters including the parameters in antecedent and consequent of the rules and then apply suitable optimization methods implemented for an artificial neural network [20]. When neural networks are used to model a set of existing data, so that predictions can be made on new data, the main challenge is to find the set of weight and bias values that generate the outputs that best match the existing data. Optimization methods for doing this have been extensively studied [36].
The most common technique for estimating optimal neural network weights and biases is called back-propagation [31]. Hence, the parameters α and β were also attuned by back-propagation optimization method using MATLAB Neural Network version 8.0. The method used in back propagation is gradient descent. We preferred to apply this algorithm due to its simplicity and speed. Several hundreds of such runs were executed taking variety of training samples such that all the 2×3 = 6 parameter values for all α’s and β’s are selected and executed multiple times. This helped in estimation and adjustment of the parameter values essential in testing the suitability of an item for recommendation.
The back-propagation program started by splitting the data set of 300 instances. It divided data into a training set of 240 instances (80%) and a test set of 60 instances (20%). Then the program created a neural network with four input nodes (one for each numeric input), four hidden nodes and two output nodes (one for each boundary (lower and upper) of the output intervals for α’s and β’s respectively). This neural network is based on the hyperbolic tangent (tanh) function for hidden node activation, and the softmax function for output node activation [33]. The neural network’s weights and bias values were initialized to small random values (between 0.002 and 0.0002). Then the back-propagation algorithm was used to search for weights and bias values that generated neural network outputs that most closely matched the output values in the training data. Training with back-propagation is an iterative process. The training process stops after 1,700 iterations, or when a mean squared error term drops below 0.002 and then training dataset is used to compute α’s and β’s for test data. The output values for α’s and β’s are approximated according to the study and analysis related to the ‘customer purchasing power’ done in the work by Watson [13]. The authors in their work examined the relationship between customer income, desire to purchase and aspects of economic psychology. The research was designed to investigate how people with differing levels of income and materialism vary in their propensity to spend and/or save. The results indicated that highly earning people are more likely to view themselves as spenders and have more favorable attitudes toward purchasing. Therefore, we assumed the output values for α’s and β’s to be: αP = 1, βP = 2; αR = 1, βR = 1; αS = 2 and βS 1. These values were then used in the execution of test runs while training a back propagation neural network to compute intervals for the estimation of α’s and β’s for various user profiles.
On the completion of the training procedure, the program demonstrated the values of the weights and biases (intermediate calculations) in the neural network. These were determined by the training procedure. The process finishes by computing appropriate parameter values for α’s and β’s. The parameter settings obtained by training neural net are as follows: αP∈ (0.8, 1.2) and βP∈ (1.6, 2.1); α R , βR ∈ (0.9, 1.1); αS ∈ (1.8, 2.3) and βS (0.7, 1.0). The correctness of the obtained parameter values for α’s and β’s was investigated on the basis of the surveys and analysis in [13, 17]. It was observed experimentally, that the performance of the proposed RS approach changed with respect to different parameter settings for α and β for each user category. Also, the performance of the proposed recommendation approach improved noticeably when the gap between parameter values for various user categories was increased; as compared to the instances when this gap was allowed to decrease.
Our recommender system is built on a multi-agent based methodology as the key tasks of a personalized recommender system can be distributed amongst several agents and performed with coordination. These tasks include: gathering customer’s personal interests, constructing a model to describe the information collected, handling customer’s information and providing suitable recommendations to individuals. Hence, we give a framework for the proposed personalized agent-based recommender system (as shown in Fig. 5). Under this arrangement each agent performs a given work.
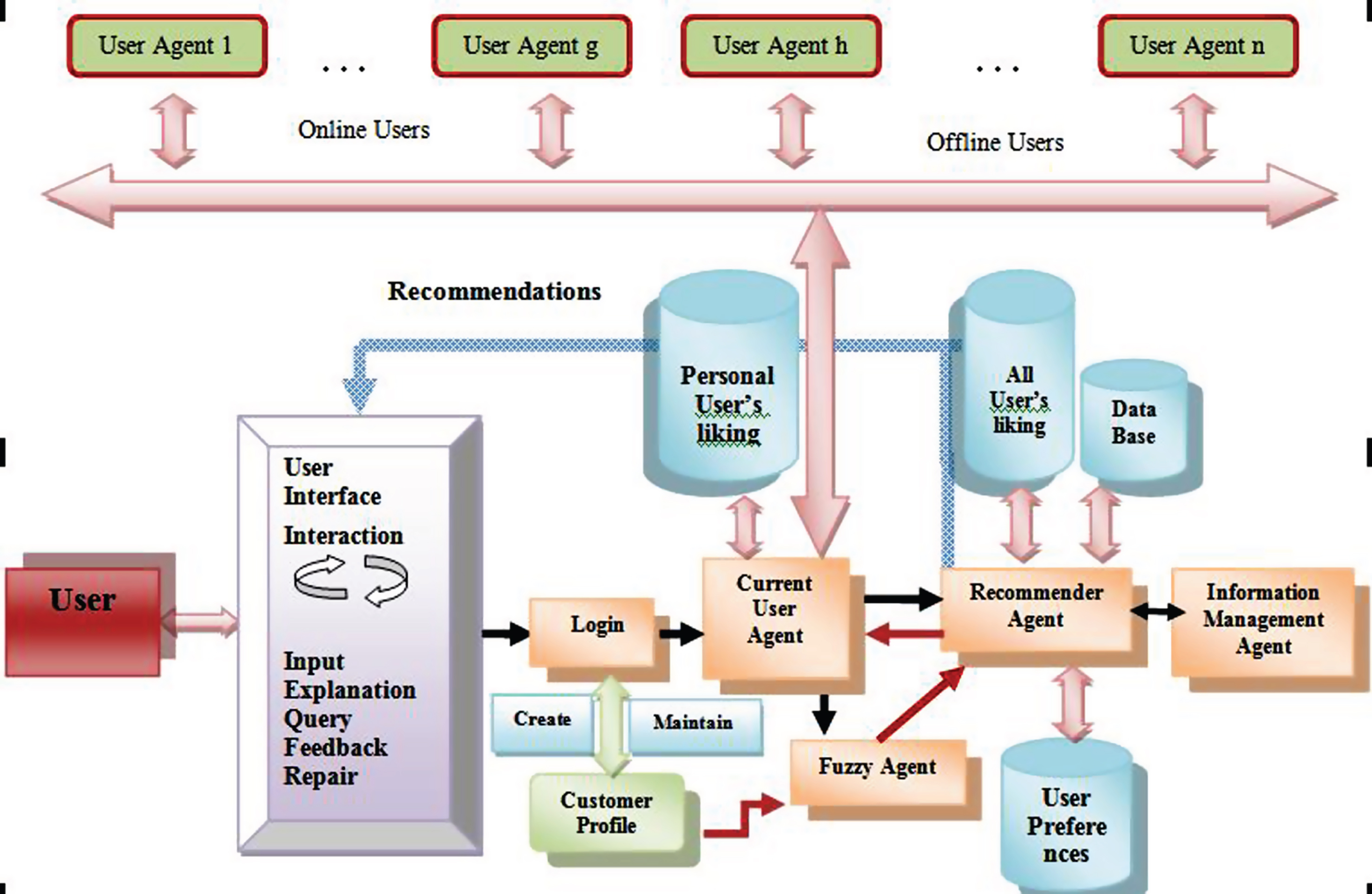
Framework for the proposed agent-based recommender system.
Our proposed framework consists of three phases: the modeling phase, the recommendation phase and the feedback phase. In the modeling phase, a user agent (UA) is activated when a customer logs into the system (after authenticating a user). User agent is responsible for collecting the user likes and dislikes for items of different categories. These ratings are then maintained by the information management agent or IMA. The ratings are used to determine similar users and preferred items by using collaborative filtering (CF) technique performed by a virtual contributing recommender (a module in the recommender agent itself). Fuzzy techniques are applied to refine the output gained due to CF approach. The obtained refined output is fed as an input for the primary recommendation technique (i.e. content based filtering or CBF). In the recommendation phase, the recommender agent (RA) works to generate preference-based recommendations for the user. The recommender agent is activated whenever a customer enters into the system. With the learnt product preferences from the customer (where fuzziness in the preferences is handled by the fuzzy agent or FA), this agent can decide whether to recommend a specific item to the corresponding customer or not. These recommended items are obtained from the filtered preferred items by using content based filtering (CBF) in which the recommendations are generated on the basis of the product’s attributes. Then, in the feedback phase, the user can like or dislike the recommended items (on Likert rating scale from –2 to +2) and these changes in ratings are also reflected in the user_liking relation in the database. In case of any conflicts or dislikes, the RA is capable of storing and using feedbacks for improving recommendations in future iterations.
Two-part hybrid recommender systems are quite successful, but under certain domain and data characteristics different hybrids might achieve unlike results. For our intended recommendation system, we decided to use the feature combination strategy [30a] making use of a virtual contributing recommender that provides supplementary features for the actual recommender. The feature combination hybrid is not a hybrid in the sense, because there is only one recommendation component. The idea is to inject features of one source (such as collaborative recommendation) into an algorithm designed to process data with a different source (such as content-based recommendation). In our case, user rating data (to determine preferred items amongst masses) were combined with the item features (based on user’s likes, dislikes and past interactions). The system has only one primary content based recommender component, but the content is drawn from a knowledge source associated with collaborative recommendation. To be more specific, collaborative filtering features are utilized to strengthen content based recommendation.
Though many recommendation systems combine collaborative and content-based filtering techniques to improve rating prediction, however, our approach is unique. In this work, we unify user-item ratings and content features in a single model (Feature Combination); and then extend the basic approach, to allow data exploitation by fuzzy c-means clustering and interval type-2 fuzzy techniques to handle uncertainties related to diverse user preferences. The major advantage of using this approach is its simplicity and computational ease. There is one wholesome recommender with independent yet interconnected modules. In a multi-agent set up like ours, we used different agents to handle different modules and the agents connected with each other via communication messages.
Fuzzy feature combination hybridization (FFCH) method
Our proposed recommendation algorithm offers an extension to a well-known existing “feature combination hybridization method” in which output from one filtering technique is used as an input feature to another [30]. The traditional feature combination method is a two stage process. In the first stage, new features (preferred items) are generated by applying collaborative filtering method. In second stage, content-based filtering method is applied on the obtained features (preferred items) in which user’s preferences are considered to recommend the most relevant items to the user. Proposed recommender system uses “
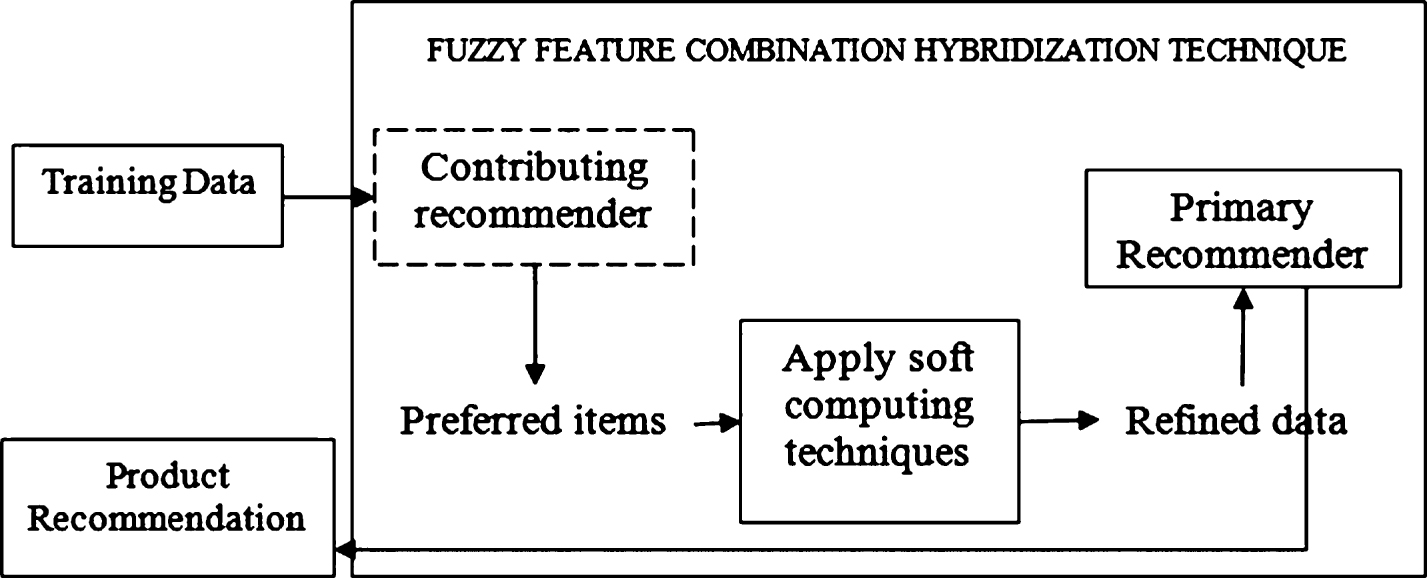
A block diagram depicting the FFCH technique.
We will analyze in this step, modeling of user’s preferences for cost considering the content and profile of the target user in the system. This is to prove the system’s ability in identifying appropriate clusters for providing recommendations relevant to the user’s preferences (in this case for cost preference and the user category as professor). After identifying the similarities (in the form of membership values Uik) with different clusters, we obtained the following results (as seen in Table 2).
Computation of similarities between a user and clusters
Computation of similarities between a user and clusters
From results, both clusters G1 and G2 had the greatest similarity values. We find that the similarities with the clusters are very close (difference in similarity <0.1). We can say in this case, that the user favors G1’s items to the same favorite degree of G2’s items. But in case of Resnick’s CF approach (1994), which is non-fuzzy, an item belongs to a single cluster group G1 only and this fact is quite evident. For the type-1 fuzzy approach, though similarity is high but the group G2 does not meet the threshold requirement ‘ρ’, hence G2 is omitted from the recommendation generation process; whereas in the type-2 fuzzy approach, considering the user’s profile content and his personal likes and dislikes, the membership values can be varied for different user categories. Like here, in case of a user who is a professor by occupation, the clusters G1 and G2 both get selected for recommendation generation but the same phenomenon was not observed for other user categories, i.e. student and researcher. A professor is a full-time earning user and can supposedly afford a book towards higher range as well (considering that same may not be true for other non-earning or part time earning user categories). Therefore, for this reason, the system assigned a professor (user) these two clusters (G1 for medium cost and G2 for high cost), hence increasing the recommendation domain for this user. Next, we carry out the recommendation process normally in each cluster group, for users of various profiles, experiences and selecting in each time a given ‘N’ number of items with the highest scores.
The objective of this experiment is to perform evaluation of recommendation accuracy and errors. We need to quantify how much the items recommended by the proposed RS are preferred by the target user. Our goal is to evaluate the recommenders’ ability to recommend user’s preferred items (where a user can belong to any profile). In this paper, we use precision, recall, F-measure, confusion matrices and RMSE as evaluation metric [7] to assess the performances of different recommender approaches. We compared the proposed interval type-2 fuzzy based FFCH recommendation algorithm against a baseline algorithm, i.e. Resnick’s CF approach and a type-1 fuzzy based FFCH approach (where the fuzzy agent applies only type-1 fuzzy sets and FCM clustering approaches) to generate recommendations.
Our baseline algorithm is the user-based collaborative filtering (CF) approach (which uses the well-known Resnick’s standard prediction formula as given below) for generating recommendations. Resnick’s [28a] standard prediction formula is reproduced below as Equation (7); see also. In this formula c (i) is the rating to be predicted for item i in consumer profile c and p (i) is the rating for item i by a producer profile p who has rated i. In addition, and refers to the mean ratings for c and p respectively. The weighting factor sim (c, p) is a measure of the similarity between profiles c and p, which is traditionally calculated as Pearson’s correlationcoefficient.
To carry out the experiments, we set up a recommendation scenario; where agents are provided with an initial training datasets. To show how our proposal works in such situations to provide more accurate recommendations; we have implemented the said set-up for an agent-based Recommender System workable over any suitable dataset. We implemented three kinds of recommender system prototypes responsible for generating recommendations for multiple user agents (for CF/ type-1 FFCH/type-2 FFCH approaches). These agents were built using JADE 4.3 for a multi-agent set up (a freeware available at http://jade.tilab.com). The agents were programmed in Java language and the required essential features were incorporated into them.
Recommendation is viewed as an information retrieval task. Particularly, it is required to retrieve (recommend) all items which are predicted to be good or relevant. Therefore, it is specially a task necessitating high precision as defined below.
Precision: is defined as a measure of exactness or accuracy. It determines the fraction of relevant items retrieved out of all items retrieved. That is, precision represents the proportion of recommended items that are relevant and actually liked by the user (see Equation 8).
Recall: (also known as sensitivity) is the fraction of relevant instances that are retrieved. Recall determines the fraction of relevant items retrieved out of the number of relevant items that should have been returned. That is, recall represents the proportion of relevant items that are recommended and all relevant items actually available refer Equation 9).
F-measure: is a measure that combines precision and recall. It is the harmonic mean of precision and recall as given in Equation 10.
Confusion Matrix: a table of confusion (sometimes also called a confusion matrix), is a table with two rows and two columns that reports the number of false positives, false negatives, true positives, and true negatives.
Root Mean Squared Error: also known as RMSE. It is a frequently used measure of the differences between values (sample and population values) predicted by a model or an estimator and the values actually observed. It is calculated using Equation (11) and places greater emphasis on larger errors by penalizing more when errors are significant.
The principal reason for using this metric is that these errors can have the greatest impact on the user decision. For example, on a 5-point scale, a 1-point error may not be perceptible by the user (items rated with either 4 or 5 points are good recommendations), while with a 4-point error, the algorithm could be recommending a very bad item.
We executed offline evaluation over two datasets based on (i) book purchase and (ii) shopping women apparels. The book dataset was elicited from http://csl.du.ac.in/, the official website of Delhi University for its Central Science Library (CSL). It is a huge repository of thousands of books for several academic disciplines. Presently, we concentrated only on the computer science books for building a book dataset for the prototype. CSL provides a book issue facility for 6507 titles under the discipline ‘Computer Science’. For the experimental study, 30 different relevant user profiles from various categories were created, who actually rated over 100 books on the five selected book attributes (type, author, publisher, publication year (oldness) and cost) on the Likert rating scale from –2 to +2. For all the recommendation runs performed (10 runs performed per user), the number of top N recommendations was fixed at 10. Therefore in all, the total number of final recommendations generated by using a given RS equals almost 30×10×10 i.e. 3000 ratings. This dataset was then used for evaluation purpose as detailed in this section.
Similarly we had worked over another product domain i.e. shopping for women apparels. The product descriptions were collected by running the web crawler Visual Web Ripper (http://www.visualwebripper.com/) over the shopping website www.Amazon.com. The collected data were preprocessed in order to map text associated with the item to a set of attributes and values. Various item attributes collected were: item name, type, size, color, price, discount and other additional features were listed down in special features column. Various user profiles are children, teenagers, middle aged people and old aged people. Here, the user profile attribute ‘age’ and the item attribute ‘price’ has an inherent uncertainty associated with it, so this could also be modeled using fuzzy logic (here fuzzy c-means clustering and IT2 fuzzy sets were applied to the respective attributes). Training and evaluation data are computed in a manner similar to that of book purchase dataset. These datasets are used for computing recommendations for the user. For the experimental study in case of shopping apparels dataset, 35 different relevant user profiles from various categories were created, who actually rated over 100 items (women apparels) on the above mentioned attributes on the Likert rating scale from –2 to +2. For all the recommendation runs performed, the number of top N recommendations was fixed at 10. Therefore in all, the total number of final recommendations generated by using a given RS equals almost 35×10×10 i.e. 3500 ratings. This dataset was then used for evaluation purpose for measuring precision and errors as explained below.
Offline evaluation is one of the most popular approaches in the recommender system studies. It can be used for measuring precision as well as computing errors by comparison. It is based on a dataset that is divided into two subsets: training and evaluation. The training subset is the data the algorithm knows, that is, the data the algorithm uses to compute the recommendation or rating predictions. These are then compared with the data in the evaluation subset. The experiments were performed by dividing the dataset into two groups, a training subset and an evaluation subset. The first set corresponds to the data used to train the algorithm. With such information, the algorithm computes the recommendation (and generates prediction ratings) that will be later compared with the original data present (actual user ratings) in the evaluation subset for computing errors. We have followed a random approach for selecting the training subset. The training subset is constructed from a percentage of the available ratings, randomly chosen. For our tests we used all the following percentages: 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, and 90%. Initially, the evaluation subset was composed by randomly selecting 10% of the dataset. Obviously, ratings that appear in the evaluation subset were never included in the training subset. With high percentages of ratings in the training set, we can evaluate the behavior of the algorithm under relatively high density conditions. In contrast, a small percentage allows evaluating the algorithm under sparsity conditions, common in the initial phases, or in domains with a large number of users and/or items. Data sparsity is a major challenge in recommender systems applying collaborative filtering [38] Sparsity refers to the fact that some observed ratings in a user-item rating matrix are too few. Undoubtedly, the most challenging situation belongs to the sparsity conditions prevailing when the training dataset is comprised of only 10% data. Therefore it is imperative to perform accuracy evaluation under data sparsity conditions using the most popular metrics in the literature. We have computed precision, recall and F-measure for training dataset formed of various lower percentages of data. Though in this paper, we have included only the results with training dataset formed of 10% data to avoid repetition of results. Evidently, it was seen that performance of various algorithms decreased with decrease in the density of the rating matrix and increased in the opposite situation. Moreover, error computation using RMSE has been depicted graphically for all the different percentages of data used in the training set. Each test was repeated 10 times, so the results presented in the next sub-section refer to their means.
Results and analysis
We studied the evolution of accuracy of different recommendation algorithms (CF, Type-1 fuzzy logic and type-2 fuzzy logic approaches) for two different datasets: book purchase dataset and shopping women apparels dataset, when the percentage of data used as training set was changed. The results for the book dataset with around 3000 ratings are shown in Tables 3–5 and for the women apparels dataset with around 3500 ratings are shown in Tables 6–8. Also, to determine how many correct items are recommended or not to the user, both recommended items and user’s feedback have been analyzed and the results of the analysis are shown as confusion matrices. Confusion matrices for book purchase and shopping women apparels datasets are depicted in Tables 3–5 and Tables 6–8 respectively. True positives represent the number of items that were correctly recommended by the system, false positives are items that were recommended by the system but user considered them to be irrelevant, false negatives are items that should have been recommended but the system did not recommend them, and true negatives are items which were correctly detected as not relevant (hence not recommended) for the corresponding user. Analyzing the results from all the tables, we have observed that type-2 fuzzy based approach is outperforming both CF and type-1 fuzzy based approach for both the datasets. Also, in all three confusion matrices, higher value of true positives and true negatives depict that the system has been able to successfully determine relevant and irrelevant recommendations for the user.
Confusion Matrix for Book purchase dataset (CF)
Confusion Matrix for Book purchase dataset (CF)
Confusion Matrix for Book purchase dataset (Type-1 fuzzy)
Confusion Matrix for Book purchase dataset (Type-2 fuzzy)
Confusion Matrix for Shopping women apparels dataset (CF)
Analyzing the results from Tables 3–8, the error rate for various recommendation approaches like CF, fuzzy type-1 and fuzzy type-2 on Book purchase dataset is 0.14, 0.11 and 0.08 respectively. For the experimentation performed on same approaches for Shopping Women Apparels dataset, error rate was found to be 0.16, 0.14 and 0.09 respectively. Similarly, the accuracy rate determined using approaches CF, fuzzy type-1 and fuzzy type-2 is 0.85, 0.88 and 0.92 respectively (on Book Purchase Dataset) and 0.84, 0.86 and 0.90 respectively (on Shopping Women Apparels Dataset).
Confusion Matrix for Shopping women apparels dataset (Type-1 fuzzy)
Confusion Matrix for Shopping women apparels dataset (Type-2 fuzzy)
Furthermore, the measures precision, recall and F1 have been calculated during experimentation for all the approaches (CF, fuzzy type1 and fuzzy type2). However, to optimize space utilization, comprehensive calculations have not been included here. In this case, the average of precision, recall and F1 for the recommended items of the Book Purchase dataset are 61%, 65%, 63% (using CF approach), 65%, 69%, 67% (using fuzzy type-1 approach) and 73%, 75%, 74% (using fuzzy type-2 approach) respectively. Similarly, average values of precision, recall and F1 of recommended women apparels are 63%, 67%, 65% (using CF approach), 67%, 71%, 69% (using fuzzy type-1 approach) and 73%, 76%, 74% (using fuzzy type-2 approach) respectively. Above results clearly signifies that fuzzy type-2 approach is outperforming both fuzzy type-1 and Resnick’s CF approach. Also, the system performance can be considered as quite successful.
As observed, in case of precision, recall andF-measure metrics, type-2 FFCH surely outperforms other algorithms (Resnick’s CF and type-1 FFCH) for both datasets; especially in case of data sparsity conditions (the instances of results depicted here are meant for the training set formed out of 10% data only).
Recommender evaluations using RMSE metrics are shown in Figs. 7 and 8 for Book purchase dataset and Shopping women apparels dataset respectively. It could clearly be seen in both the figures that type-2 fuzzy approach is performing better than type-1 fuzzy and CF approaches. RMSE in case of type-2 fuzzy approach for recommendation is the least of all. In fact we observe that, with a training set of 80% data, the variation amongst the three algorithms for RMSE is less. While with the training set of 10% data, the gap in RMSE results between the proposed algorithm and its counterparts is quite significant. Also, all three algorithms improve as the percentage of training data increases. This behavior is just as expected; by increasing the percentage of data in the training set, we are increasing the density of the rating matrix and, therefore, the algorithm has more information to compute the prediction. Similarly, as the density of the information increases, a slight decrease in the differences among algorithms is observed. Most of them present similar results under relatively high density conditions, while their differences are accentuated as density diminishes.
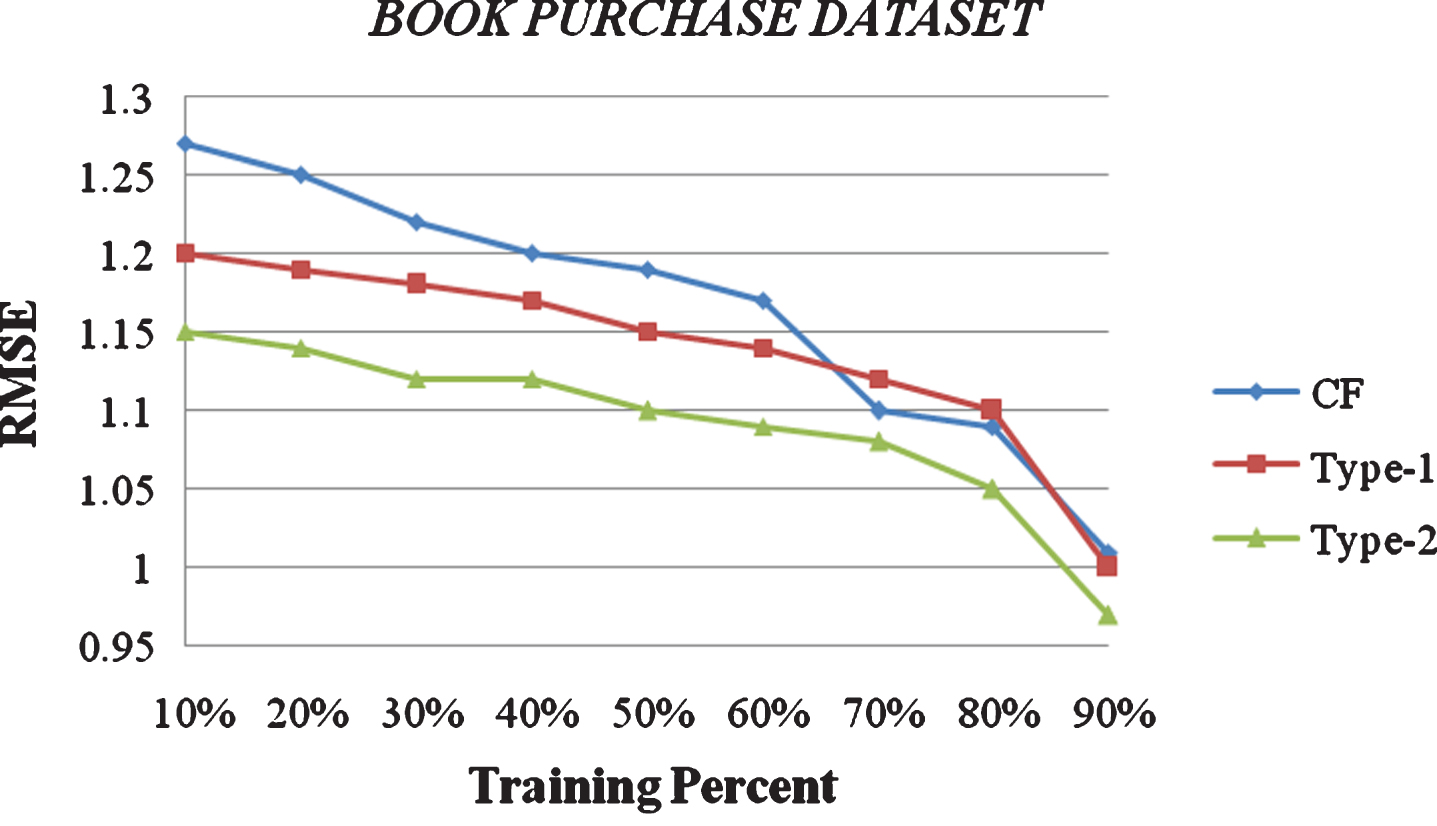
Recommender evaluations using RMSE metrics for Book purchase dataset.
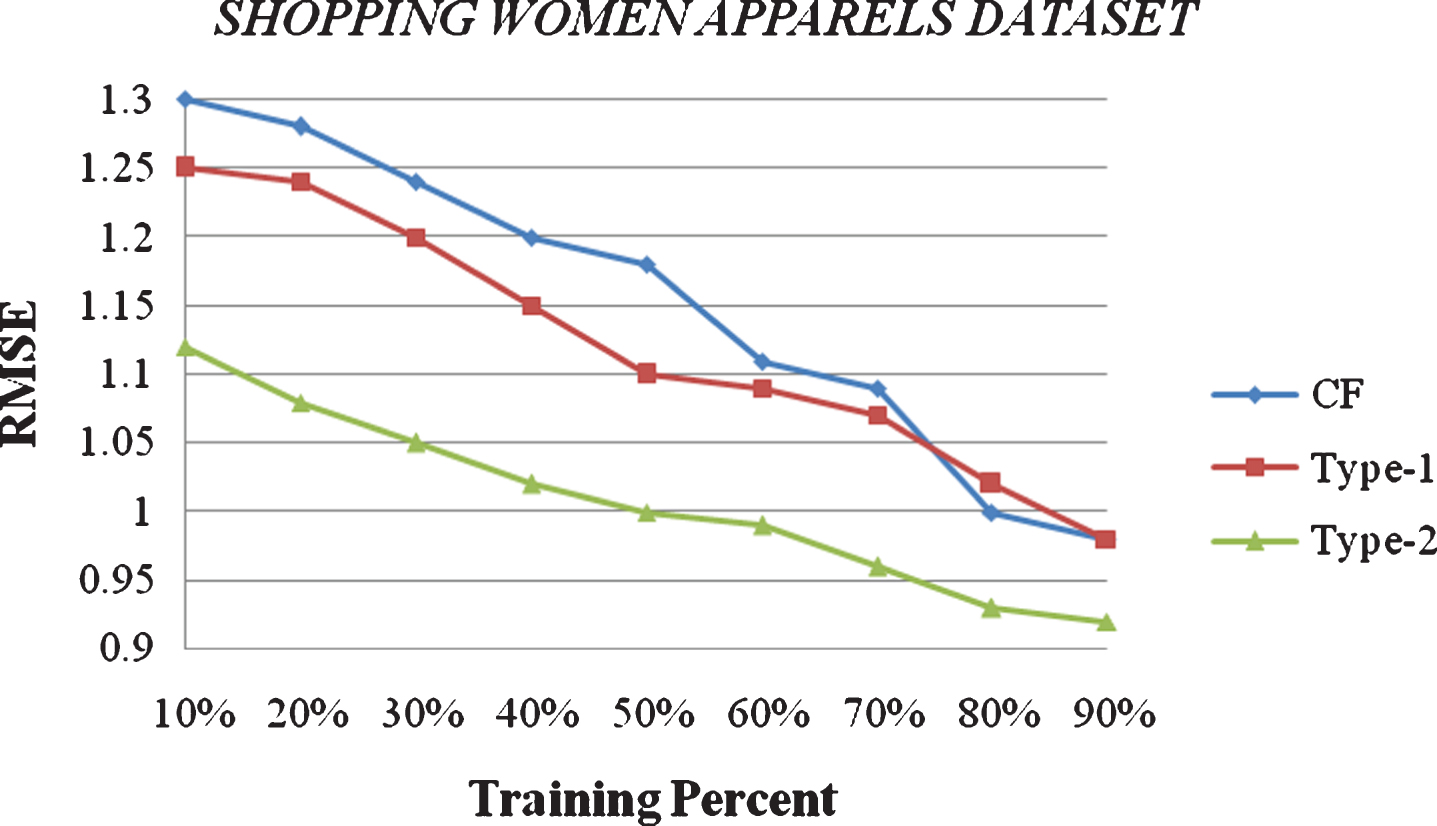
Recommender evaluations using RMSE metrics for Shopping women apparels dataset.
The greatest limitation an algorithm is subjected to is the lack of information. In other words, the accuracy of a prediction is limited by the amount of information that can be obtained from the rating matrix [7]. As observed, the results under high density conditions are pretty good in all the algorithms, although this changes when the density decreases. The tests under sparsity environments are good indicators of the ability of algorithms to extract more information from the rating matrix. As observed in the experimental results the proposed interval type-2 FFCH algorithm performed considerably well.
Summarizing, in this paper, we presented an IT2 based fuzzy technique (called FFCH) for generating recommendations which improved the quality of recommenders by making the system flexible in capturing user preferences thereby ensuring that the algorithm extracts more information from the available dataset. The system dealt with the uncertainty related to user preferences by increasing the domain flexibility and diversity for recommendations. The approach improved prediction accuracy and reduced errors of the RS as the recommendations produced were found to be more accurate with lesser number of errors.
Uncertainty related to diverse users’ tastes was handled using interval type-2 (IT2) fuzzy sets by increasing the domain flexibility for recommendations. The IT2 based fuzzy technique for generating recommendation improved the quality of recommendation by enabling the system to capture diverse user preferences and at the same time reducing errors by being able to extract more information from the available dataset. A novel recommendation algorithm (Fuzzy Feature Combination Hybridization Method) was developed as well. The experiments done on various datasets show that the presented IT2 fuzzy logic based technique is generic and effective in improving the prediction accuracy of RSs. In fact, the proposed interval type-2 FFCH recommendation approach was found to perform considerably well as compared to its counterparts, even under sparse data conditions.
This work can be enhanced further, by augmenting the proposed recommendation algorithm with trust. This will provide us with a two-fold advantage: (i) development of a new trust model; (ii) integration of trust will enable trust based CF in the recommender system hence improving the recommendation quality. Besides this, we are also working towards the design of an automated learning process (based on the user feedback over recommendations) for tuning the scaling parameters specific to various user profiles.