
Abstract
Finding community structures in online social networks is an important methodology for understanding the internal organization of users and actions. Most previous studies have focused on structural properties to detect communities. They do not analyze the information gathered from the posting activities of members of social networks, nor do they consider overlapping communities. To tackle these two drawbacks, a new overlapping community detection method involving social activities and semantic analysis is proposed. This work applies a fuzzy membership to detect overlapping communities with different extent and run semantic analysis to include information contained in posts. The available resource description format contributes to research in social networks. Based on this new understanding of social networks, this approach can be adopted for large online social networks and for social portals, such as forums, that are not based on network topology. The efficiency and feasibility of this method is verified by the available experimental analysis. The results obtained by the tests on real networks indicate that the proposed approach can be effective in discovering labelled and overlapping communities with a high amount of modularity. This approach is fast enough to process very large and dense social networks.
Keywords
Introduction
Community detection and analysis reveal the structure, organization and evolution of social networks. Although the study of community detection is not new, social networking portals have proliferated in recent years through development of web2.0-based portals. As the size and the number of social portals increase, community detection techniques have become more intriguing to many researchers [1–3]. The objective of this article is to present a method for detecting communities according to the properties of the relationships between users.
There is no universally accepted definition for a community. In this study, a social community is defined as a group of people who have a high level of interaction within their community and lower level of interaction outside their community [1]. Most state-of-the-art community detection algorithms are influenced by the following two drawbacks: 1) Many community detection algorithms adopt clustering methods to detect communities on social networks based merely on structural criteria [4]. Thus, they assign each node to only one community. However, it is clear that social actors could belong to more than one community of interest. For example, a user could belong a family community as well as to a sporting community of sport and may well have two or more sport communities of interest, such as football and soccer. 2) Most of the community detection algorithms do not pay attention to the semantic information gathered by the social actors of the network when they post and comment on it.
Thus, the objective of this article is to present a new approach to detect overlapping communities according to social activities and semantic data, which are available in Resource Description Format (RDF), of social networks. RDF is known to be a rich graph of social networks, which have become more pronounced with the growth of web.2.0. Due to the development of web2.0-based portals, according to the popularity of various interests, semantic social network analysis has become the focus of many researchers in recent years [5–10]. Social network analysis could be performed using additional semantic information from comments written by members of social networks. Moreover, this proposed semantic community detection approach detects overlapping communities that allow community members to take part in more than one community.
Two distinct types of methods for overlapping community detection are the crisp and fuzzy methods [11]. In crisp overlapping community detection, each node has full membership in all of the communities to which belongs to. For example, in the Facebook social network, suppose person A belongs to three communities of interest in different topics, such as family, football and soccer. Fuzzy overlapping community detection assigns a different membership coefficient for each of the different communities that the node belongs to. In this example, person A may have a 0.5 membership coefficient to belong to family community, 0.2 to football and 0.3 to soccer.
Fuzzy methods for detecting overlapping communities have a significant effect on the performance of overlapping community detection algorithms and have recently attracted the attention of many researchers [11]. In the approach proposed here, the fuzzy relation method is applied to the community detection algorithm and to defining the relations between tags and users. As previously mentioned, there is a collection of tags that is generated by users through folksonomy, with no universally managed approach to the clustering of the collection. The proposed approach finds relations between tags and enriches this collection with respect to fuzzy relations. This is because users of a social network are linked to each other based on fuzzy relations. After this infrastructure construction phase, a consistent community detection algorithm must be applied to detect communities. The Label Propagation Algorithm (LPA) for community detection [12] could be one of the best algorithms for applying semantic knowledge because of its consistency in semantic analysis and its simple adaptability in detecting overlapping communities. Thus, the proposed community detection approach presented here utilizes the LPA method as a basic component of the approach and extends it to adopt both semantic networks and detecting overlapping communities. The LPA is an algorithm in which nodes iteratively update their labels according to the most used label in their neighbourhood, leading to communities that are formed by grouping nodes of the same labels.
This article is organized as follows: the available approaches in finding communities in networks and covering some related literature are presented in Section 2. The proposed community detection method is discussed in Section 3. The experiments and the results are discussed in Section 4 and the conclusion is drawn in Section 5.
Related works
Most common algorithms for detecting communities ignore overlapping issue which is an important fact in real-world networks [13]. Palla [13] is one of the beginner researchers in overlapping community detection who propose CPM algorithm based on clique percolations [14]. The idea is based on assumption a network consists of fully connected subgraph and searching for adjacent clique in order to find overlapping communities. An extension version of CPM has been presented for weighted graph [15].
Another class of detecting overlapping communities is based on local expansion. LFM and EAGLE are two famous algorithm based on local maximizing [16–18].
LPA is a dynamic algorithm for community detection which commonly use to deal with overlapping property of the social networks [12]. Because of the nearly-linear time consuming and easy implementation, LPA could be a good basic for efficient community detection methods [19]. LPA is also a good choice to apply semantic community detection. COPRA is a direct extension of the LPA to detect overlapping communities by allowing nodes to select more than one label from neighbours’ labels [20]. Zhou has proposed a heuristic approach utilizing ant colony strategy to propagate labels with ants through the network and finding overlapping communities [21].
In the last decades, a few researches have tried on applying fuzzy theory to detect overlapping communities. Zhang has proposed a method based on approximation mapping of network nodes into Euclidean space and fuzzy c-means clustering [22]. Psorakis has presented a probabilistic method utilizing a Bayesian non-negative matrix factorization model to extract overlapping communities from a network [23]. Wang has applied fuzzy c-means on a network which has node’s similarity obtained by random walk algorithm [24]. Gregory has investigated the effect of fuzzy method to detect overlapping communities instead of crisp methods and has found the fuzzy methods has a strong effect on the performance of community detection methods [11]. In the proposed approach here Fuzzy clustering by Local Approximation of MEmberships (FLAME) is used to combine with LPA algorithm in order to extract overlapping communities. Although methods for identifying overlapping which are considered in this section have been proposed in the past, identifying meaningful communities in real-world networks has proven to be a challenging task. Semantic web and its applications could be a good choice as a tool for detecting meaningful communities from real-world and online social networks. Wimmics 1 team is one of the main research groups who works on semantic analysis of the social networks [5]. They have proposed the Semtagp community detection algorithm based on semantic analysis and label propagation algorithm but with no consideration of overlapping problem [25]. The proposed approach here considers the overlapping communities through semantic social network analysis and focus on user activities in order to detect meaningful communities.
Proposed method
This community detection algorithm is used in the Fuzzy Semantic Overlapping community detection method (FuSeO) proposed in this paper. The objective of this approach is to allow the social network members to belong to more than one community. This approach is applied to the content generated by users in posts to improve community detection and apply fuzzy clustering to detect overlapping communities. The architecture of this method has two main parts, as shown in Fig. 1. The first main part extracts an interaction graph as an appropriate semantic infrastructure, and the second main part designs an applicable community detection algorithm on this infrastructure through fuzzy clustering to detect overlapping communities.
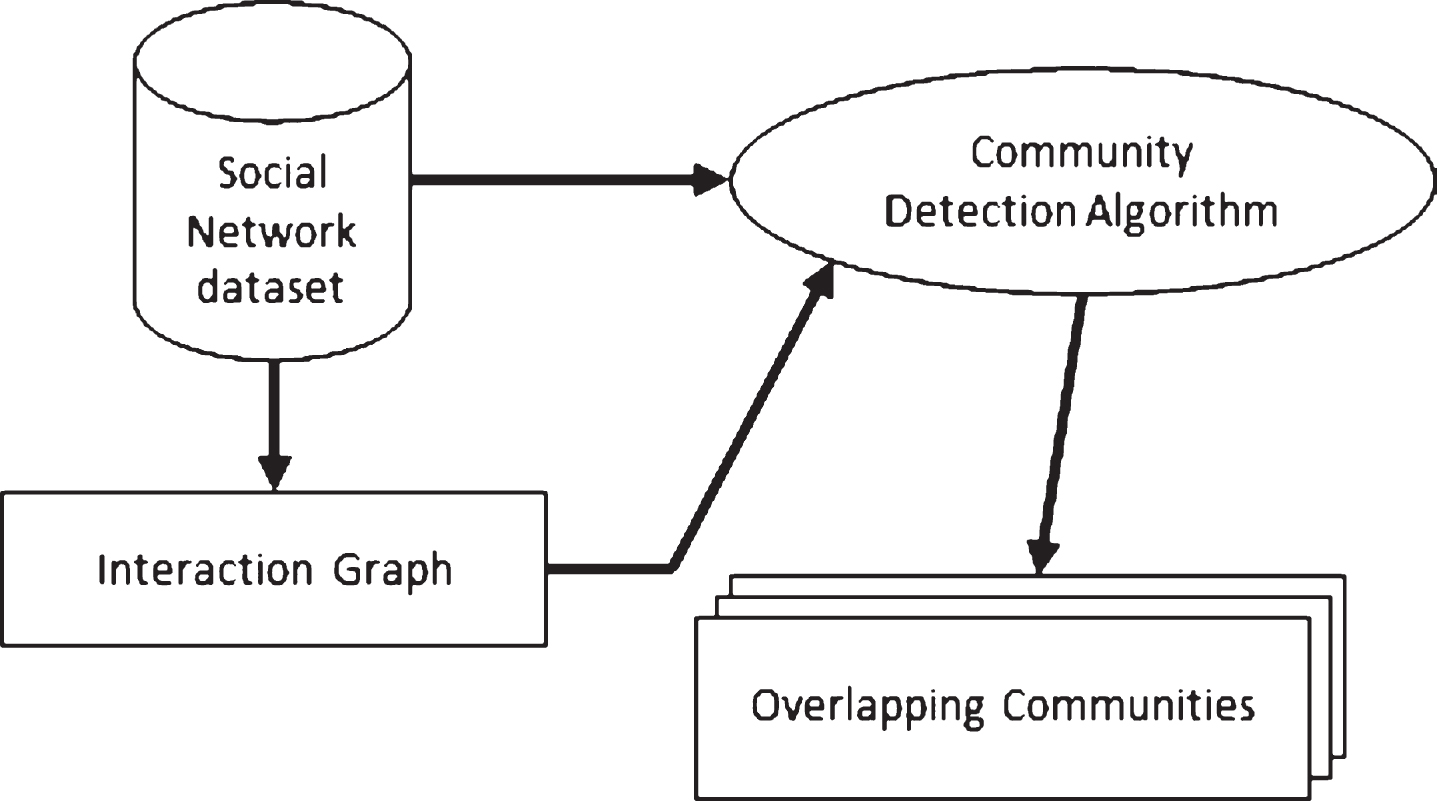
The general phases of the proposed approach.
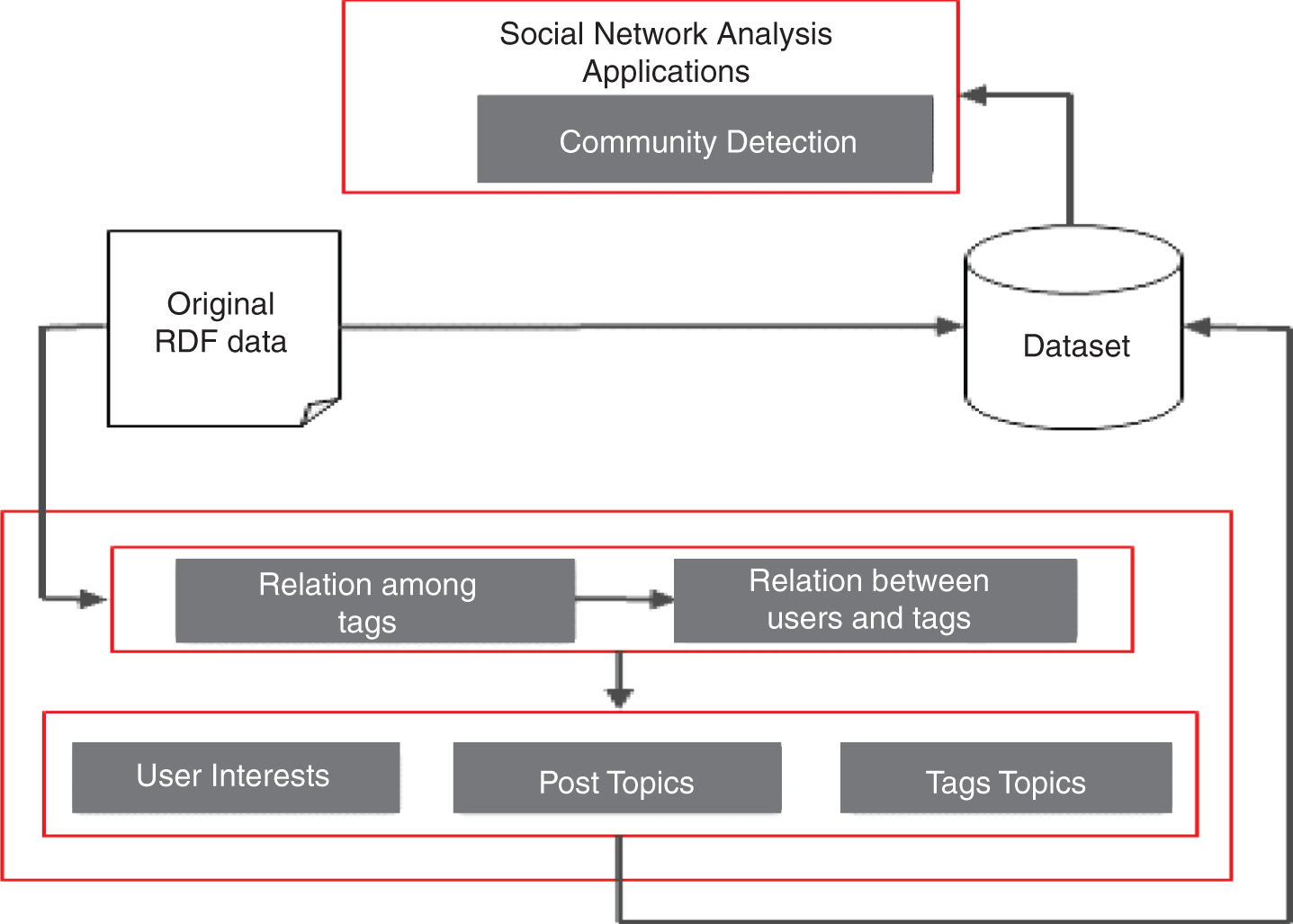
The architecture of the semantic social network analysis presented in [7] is adopted here to implement the two parts of this proposed approach (Fig. 2).

The general semantic social network analysis architecture.
The user-content social media (UCSM) ontology is necessary for this approach and has to be established for each social network. An overview of UCSM is presented in Fig. 3.
The overall view on UCSM architecture.
Online forums for posting provide a platform where users interact by sharing their interests on different levels. To construct a graph of the interactions (which we call the interaction graph), it is reasonable to set nodes representing users and edges representing their interactions. The process of extracting the interaction graph from RDF is shown in Fig. 4. The main step in this process is to find a method for connecting users, and then, after ascertaining the graph topology, consider the user interactions determined by this topology.
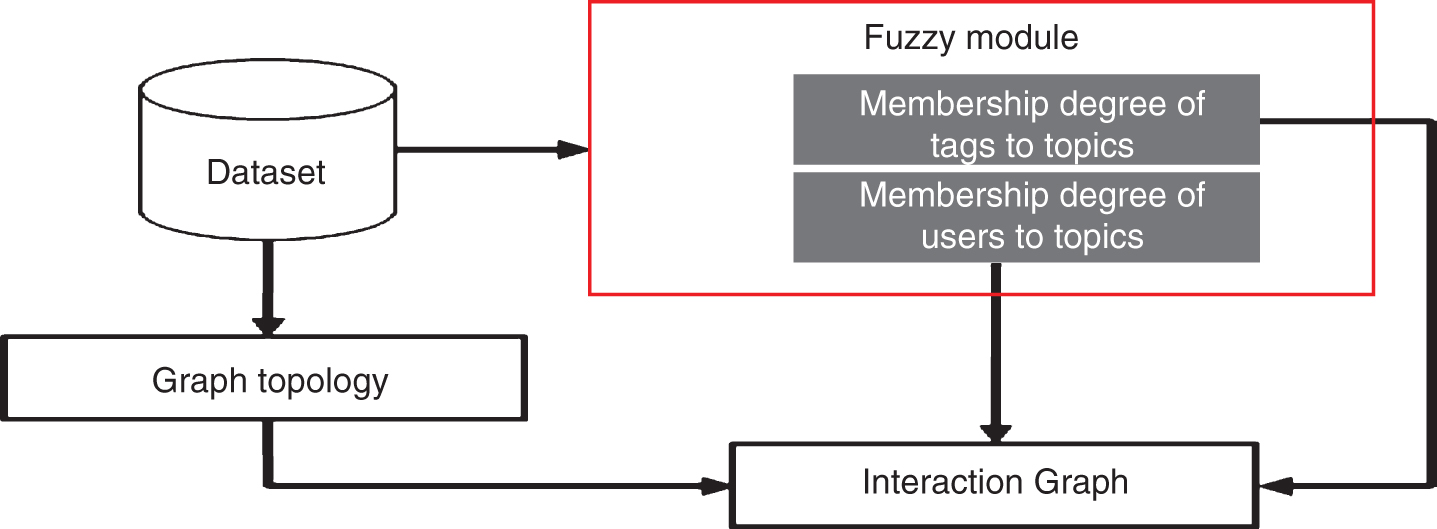
The architecture of Graph Configuring.
This graph topology indicates which users are connected, that is, which two users exchange at least one message directly. However, it does not indicate whether the two corresponding users are actually in the same community. Here, each user may have a large number of contacts with other users, but only a limited number of stable correlations 2 . The number of stable correlations of a user is called the Dunbar number [26]. For example, suppose that the Dunbar number for a user is 10 in Facebook and that she/he participates in more than 100 posts. It could be deduced that the edges in the network have various relation degrees that would be modeled by a weighting strategy to show how information diffuses over the network.
To assign weights to the edges, the stability degree for each edge should be computed using semantic information generated by users in posts. The interests of users and the relations between tags are determined in UCSM ontology, but determining the degrees of these relations is important for defining the degrees of relations between users in this study.
In conclusion, the interaction graph needs to answer the following three questions to be considered. How are users connected and how are their interactions considered? What are the users’ interests and what are the degrees of the interests? What are the relation degrees between users?
The topology of the interaction graph can be characterized by answering the first question. There are three solutions for considering users and their interactions according to replying schema [27]. All-previous-reply: every post in a thread is a response to all of the previous posts in this thread. Accordingly, each node connects to any node representing a previous replier in the common interest thread. Last-reply oriented: every post in a thread is a response only to the previous post in this thread. Thus each node only connects to the node corresponding to the previous replier in the common interest thread. Created-oriented: every post in a thread is a response to the user who created the thread. Accordingly, each node connects only to the node of the user who created the thread.
Three graph representations of a sample thread that contains four comments posted by four members, m1, m2, m3 and m4, are shown in Fig. 5. M1 creates the thread and m4 posted the last comment on the thread.
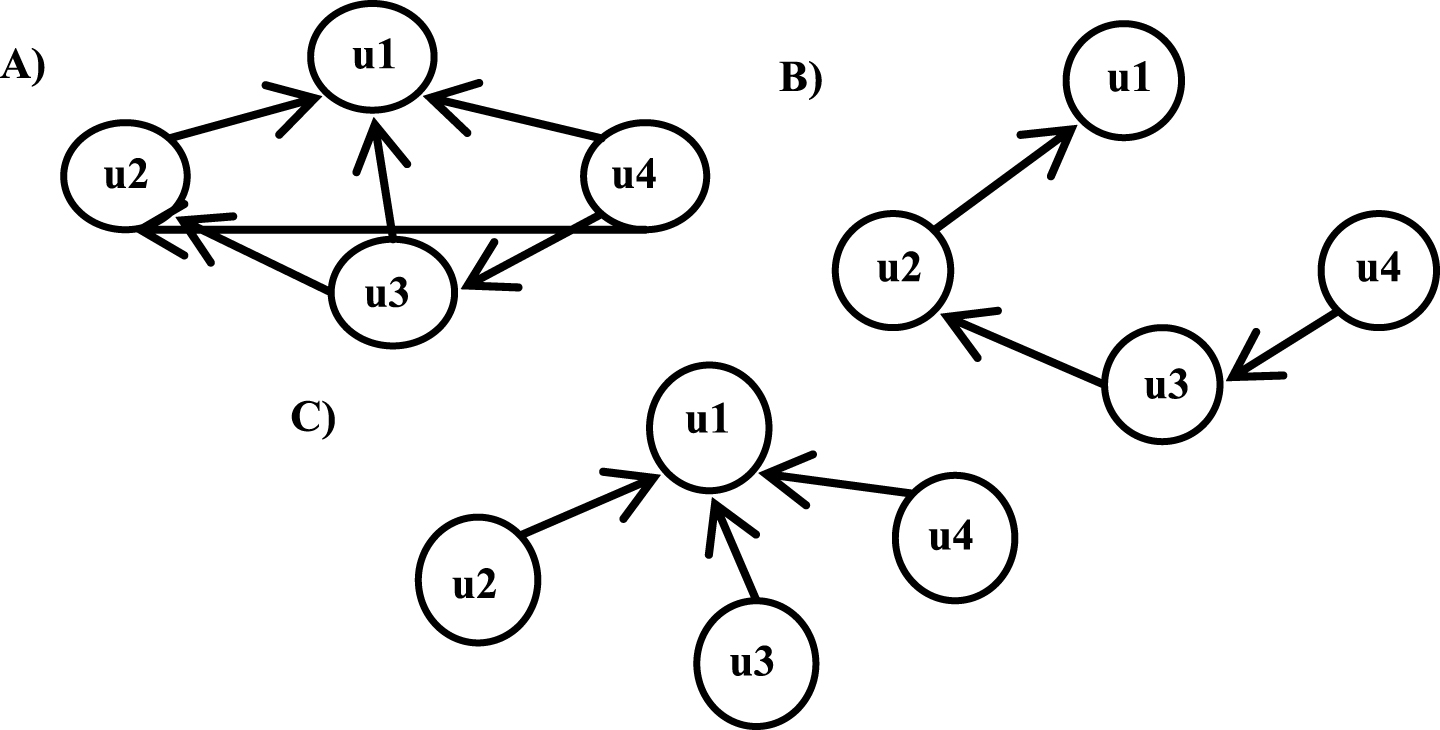
Three graph representations of social network post activity where ui represents useri as a node of the graph: A is related to all-previous-reply, B is related to reply-oriented and C is related to creator-oriented.
If the density is measured by the number of edges in the graph, the created-oriented representation has the lowest density, while the All-previous-reply representation is the most dense graph. The created-oriented representation is proposed here for the following reasons: The created-oriented representation has the lowest density among the representations, so it is less complicated to run community detection algorithms based on it. With the created-oriented representation, the most important links—the links between the creator of a thread and all of the repliers—are considered. Like the all-previous-reply representation, the created-oriented representation creates a path between all pairs of repliers in the same thread; however, this path is different from the path between repliers and the creator. All repliers have a common neighbor: the creator of the thread. This plays an important role when combined with the community detection algorithm in finding communities, and it will be more clearly explained in section 4.3.
Online forums for posting enable a user to submit a post and assign to it 1–5 tags indicating the key topics of the post. Other users who are interested in this topic may provide answers or comments. As tags are generated by users 3 and are not named using classical and professional titles, it is possible that the network contains different tags corresponding to the same topic. Moreover, more than one tag may be assigned to a post to indicate its topic. To solve the problem of detecting topics from posts’ tags and detecting users’ interest topics, UCSM should be created for any given dataset. UCSM 4 is a light-weight ontology based on Social Network Analysis (SNA) for the management of the two main resources in social network sites: users and content. The two main properties of UCSM for this method are user-interest and topic-tag to provide the interest topics for each user.
A user may have more than one interest topic, each with a different level of interest. The level could be computed by using the semantic properties of posts, such as the number of LIKEs, the number of DISLIKEs, the content of the post, the title of the post, and the number of votes. The most influential property is the number of votes, which is obtained from Equation [28]. Equation 2 defines how the number of VOTEs is used here to compute users’ levels of interest.
I (u, t) denotes the fuzzy interest degree of user u on topic t, P
u
denotes the posts in which user u participates in and the sigmoid function is used as a squashing function Equation 1. m (tag
i
, t) denotes the fuzzy degree of belonging tagi to topic t. m (tag
i
, t) can be computed by considering the rate of occurrence of tagi in topic t. To find tag relations, the similarity between two tags is computed based on the cosine similarity in Equation 3.
Users in post service share their interests to interact with others and comment and vote on others’ interests. As the amount of interaction among users increases, the similarities between them grow stronger, and vice versa. To find fuzzy relation degrees between users, the similarities between users are calculated using Equation 6.
The proposed overlapping community detection strategy involves three main steps, as illustrated in Fig. 6.
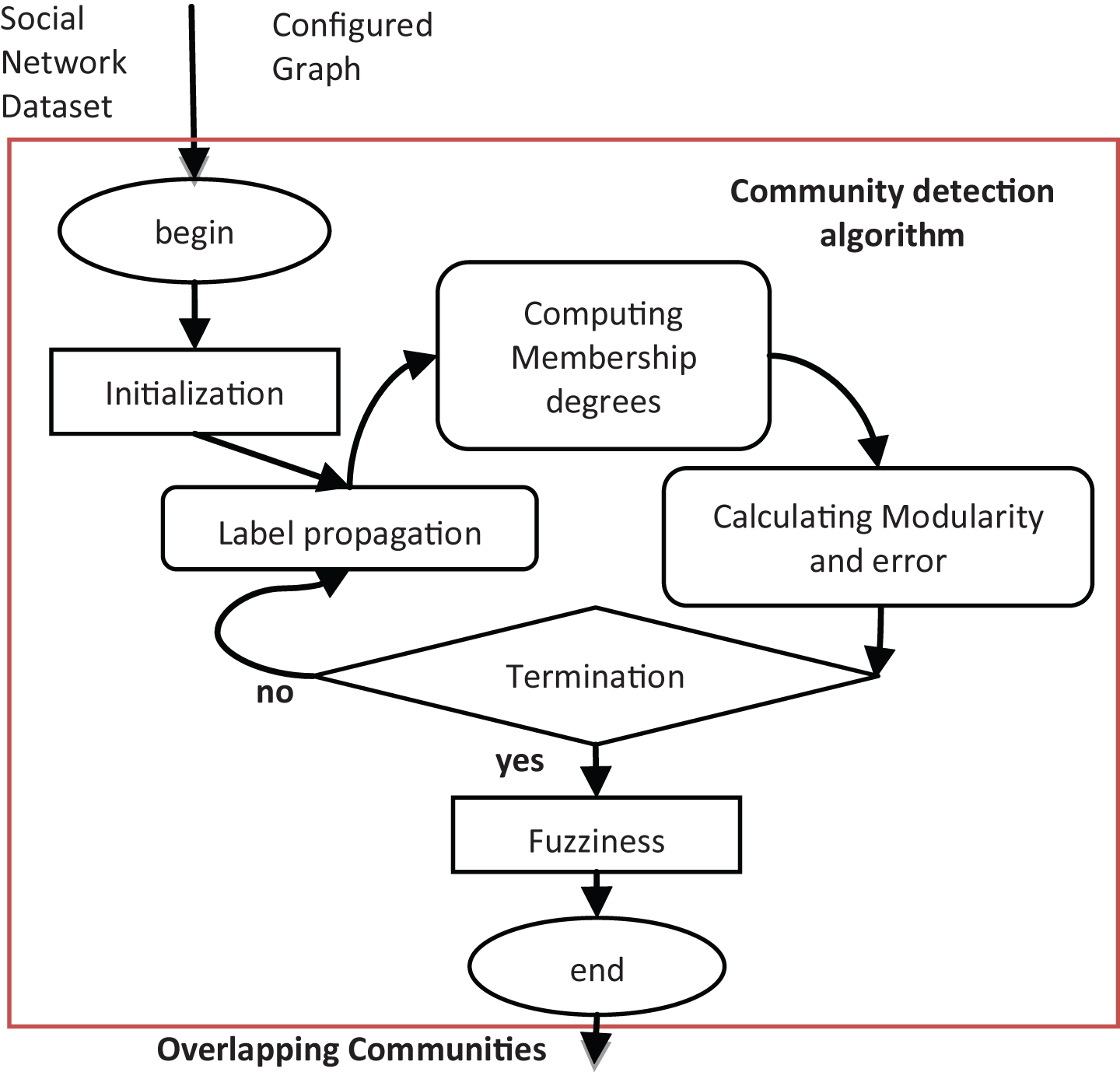
The proposed community detection chart.
The first step is initialization and the extraction of the structure of the network, which is described in 3.1. The second step is the assignment of fuzzy membership, inspired by the FLAME clustering algorithm (Fuzzy clustering by Local Approximation of MEmberships) [30]. The third step is the iterative process to reach a stable situation in which communities are detected.
Because of the simplicity, the consistency of the label propagation algorithm [12] with the network structure, and the simple adaptability for detecting the overlapping communities, the LPA may be the best algorithm for application to semantic knowledge. The LPA is an algorithm in which nodes iteratively update their labels by the most commonly used label in their neighborhood, leading to the formation of communities by grouping nodes with the same labels.
The main idea of the label propagation algorithm is that the community of each node is determined based on the communities of its neighbors. Every node is initialized by a unique label and propagates its labels through the network iteratively. As the labels propagate, densely connected groups of nodes quickly reach a consensus on a unique label. When many such dense groups are created throughout the network, they continue to expand outwards until it is no longer possible to do so. At the end of the propagation process, nodes that have the same labels are grouped together as one community.
Pure LPA performs this process iteratively: at every step, each node updates its label based on the labels of its neighbors. Labels can be propagated in either a synchronous or an asynchronous manner. In synchronous propagation, labels at the current time depend on the labels from a previous time, while in asynchronous propagation, nodes are placed in a queue and their labels are replaced sequentially.
Propagating semantic labels
The LPA initially assigns a label to each node and then propagates the labels by iteration: in the next step, each node chooses the most frequently used labels in its neighborhood. To propagate semantic labels, labels are collected from tag sets generated by users in folksonomy [25]. In this study, the LPA is run with semantic labels provided by social activities instead of with user-defined or random labels. Each node tends to keep its connection with a community to which most of its neighboring nodes belong. As tags are generated by users in folksonomy and are not named using classical and professional titles, it is possible that the network contains different tags corresponding to the same community. To solve this problem, UCSM ontology should be created to extracting topics and related tags for each social network site. Thus, the topic of each tag, rather than the tag itself, should be used.
Extending to overlapping communities
In the LPA algorithm, a node label identifies a single community to which the node belongs. If communities overlap, each node may belong to more than one community. Therefore, any method for finding overlapping communities needs to allow a node label to contain more than one community identifier. As a first attempt, a node label might be a set of all topics. Initially, each node would be labelled by the most interested topic, and each propagation step would copy all of x’s neighbors’ topics of interests into x’s set. This clearly will not work because every node would ultimately be labelled with the set of all topics.
To solve the problem, each node x is labeled with a set of pairs (c, M
c
), where c is a community identifier and M
c
is the membership degree of x to community c, such that all membership degrees for x sum to 1. As communities are identified with topics here, each node initializes its label with a set of pairs containing interested topics and corresponding degrees of interest (I(x,c)). Each propagation step sets x’s label to the union of its neighbors’ labels, taking the weighted sum of the membership degrees of the communities over all neighbors. More precisely, assume that there is a function that maps a node x and community identifier c to its membership degree in iteration t:
Synchronous updating is used here, partly because it seems to provide better results than asynchronous updating [20]: in our algorithm, the label of a node in iteration t is always based on its neighbors’ labels in iteration t − 1.
A method of retaining more than one topic in each label without keeping all of them is required. The method uses the membership degree for this purpose: during each propagation step, each node constructs its label as above and then deletes the pairs whose membership degree is less than some threshold.
It is possible that all pairs in a node label have a belonging coefficient that is lower than the threshold. If so, only the pair that has the greatest membership degree remains, and all others are deleted. If more than one pair has the same maximum belonging coefficient below the threshold, the pair that has a more general topic than others could be selected. The number of posts under a topic indicates the topic’s generality, which is computed with a query.
After each iteration, normalization is performed by multiplying the membership degree of each remaining pair by a constant so that they sum to 1.
The algorithm’s termination refers to the termination of the propagation phase. Ideally, the propagation phase terminates when all nodes have the same labels in successive iterations. The propagation phase does not always converge to a state in which no changes occur with a further iteration. To ensure that the algorithm is terminated, there are three alternative termination criteria: When every node has a label that is used by a maximum number of neighbours. When the Modularity measure has negligible changes at two continuous times: |Modularity(t) – Modularity (t–1)| < ∈ and t = k (k is a constant number that limits the iteration). When the approximation error for membership degrees is negligible: E(M) = < ∈.
Semantic modularity calculation
Modularity metric introduced by Newman and Girvan [31] is defined as the difference between inside and outside edges of the detected communities Equation 9.
The modularity is implemented by querying the RDF graph with SPARQL queries which calculate the different parts of the Equation 4. A few queries are designed by Erétéo et al. to queries to retrieve different network measures and calculate m [6]. Here, this calculation is done with applying suitable queries with combine to programming [25].
The modularity metric introduced by Newman and Girvan [31] is defined as the difference between the inside and outside edges of the detected communities Equation 9.
where m is the number of edges of the network, A ij is the number of edges between node i and node j and C is the community of node i. We make use of the directed modularity on RDF directed graphs to measure the quality of the community partition obtained after each propagation iteration. In a high modularity partitioned network, there are more connections between nodes within each community than between nodes from different communities [31]. The modularity in a directed network is defined in [32] by Equation 11 where and are the in-degree and out-degree of node i, respectively.
The modularity is implemented by querying the RDF graph with SPARQL queries that calculate the different parts of Equation 4. A few queries were designed by Erétéo et al. to retrieve different network measures and calculate m [6]. Here, this calculation is performed by applying suitable queries, combined with programming [25].
Experimental results
Methodology
To evaluate the performance of the FuSeO approach to discover the structure of overlapping communities, a dataset of the StackOverFlow 5 site is used. The StackOverFlow5 site is a question and answer site that is a real-world network with no friendship framework. From this dataset, a RDF graph of post activities has been extracted that includes the folksonomy of tags and semantic features of edges. As in real-world networks because the ground truth of community structures is not known, and the modularity measure [31] is employed to assess the quality of a partition. Q simply refers to the modularity measure.
In addition to measures of solution quality, this section measures: #communities: the total number of communities. #overlap: the overlap, which is the average number of communities to which each node belongs. This is the sum of the sizes of all communities (including singletons) divided by the number of vertices, n. Convergence point: the number of iterations needed to reach maximum modularity.
These properties are measured to experimentally determine both fuzzy and crisp overlapping communities. As mentioned in Section 3, the extracted interaction graph is a fuzzy network and the FuSeO community detection algorithm is a fuzzy algorithm. To perform experiments with crisp overlapping communities, an extended version of COPRA algorithm is applied which is named SemCopra.
This section describes experiments on a three subnetworks of the StackOverFlow dataset to evaluate the approach. These three datasets are named as NetOD, NetDF and NetFA which are of October 20th to December 20th 2008, December 21th to February 20th 2009 and February 21th to April 20th 2009 respectively. The StackOverFlow dataset is provided as a relational dataset with no friendship framework network. In StackOverFlow, users submit a question and then assigns some tags to indicate the key topics of the question. Other interested users may provide answers to the question and make comments or vote on other answers. Table 1 introduces the properties used in these datasets and their descriptions. The semantic tag enrichments presented in this article are applied to generate a namespace te (tag enrichment), where te:followed indicates the tag most used after another tag and te:is and te:isa indicate the similar and subset tags, respectively. By applying semantic analysis on the dataset, the statistics of the experimental subnetwork are listed in Table 2.
The properties in the RDF description format of the datasets
The properties in the RDF description format of the datasets
Properties of the dataset
Here we show the results of experiments that are designed to evaluate the behavior of the proposed algorithm with the previously described measures. We also check the effect of varying the maximum admissible community for each node using parameter v. This reveals the main differences between this overlapping community detection and one with no overlap (v = 1). First, the algorithm was run on the dataset for several values of v from 1 to 10, and the modularity was computed after each iteration.
As shown in Fig. 7, the modularity of the solution increases with the number of iterations and reaches a maximum. The figure shows the impact of the parameter v on modularity, which is more accurately observable in Fig. 8. Figure 8 shows a plot of the final modularity obtained at each v. Overall, the modularity increases as the parameter v varies from 2 to 10. However, in detail, v = 6 gives a higher value than v = 7 and v = 8 gives a higher value than v = 9. The best modularity is obtained when v = 7 in this dataset because the modularity of the solution corresponding to v = 7 is the closest to 1. It is clear that the best value for the modularity is 1, and modularity close to 1 is related to better detected communities.
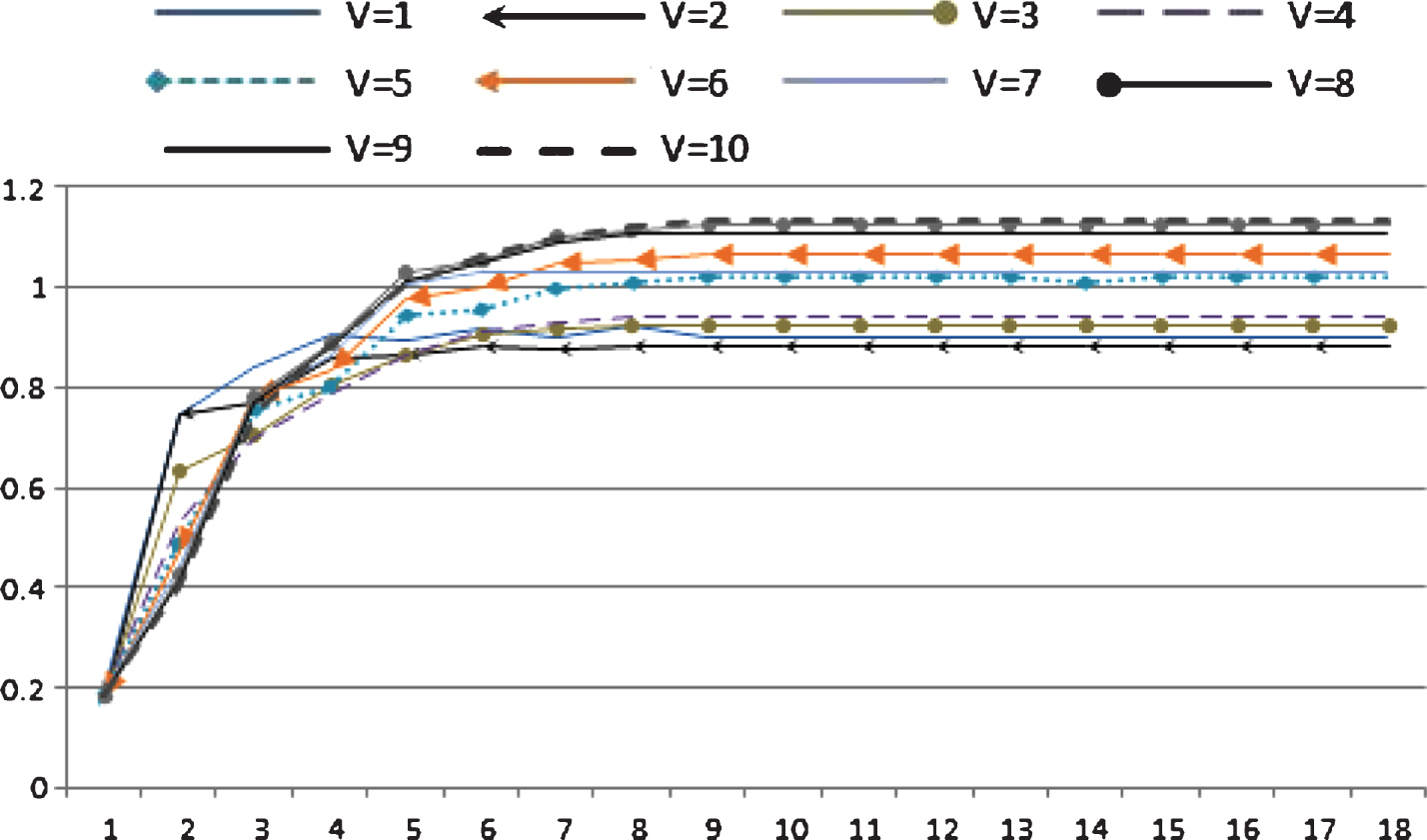
Modularity of FuSeO for verity of v.
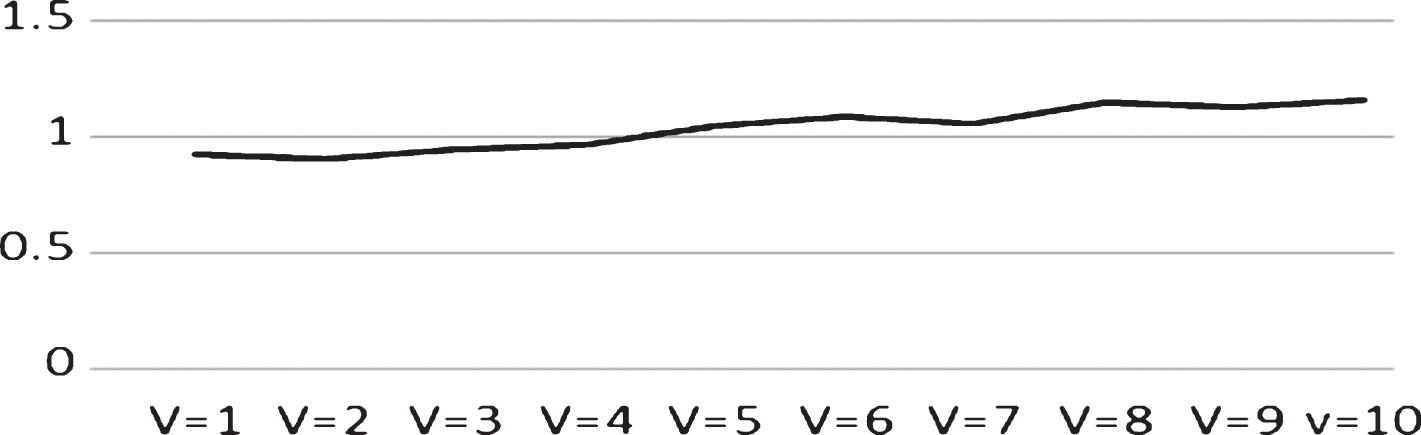
The final modularity relate to each v.
Another result that stands out from Fig. 7 involves the normal termination point. This is the iteration at which the modularity reaches its maximum. Figure 9 gives a better picture of this result. The figures show that the algorithm converges earliest when v = 2 or v = 7. The median value of the normal convergence point for different values of v from 1 to 10 is 10 in this dataset.
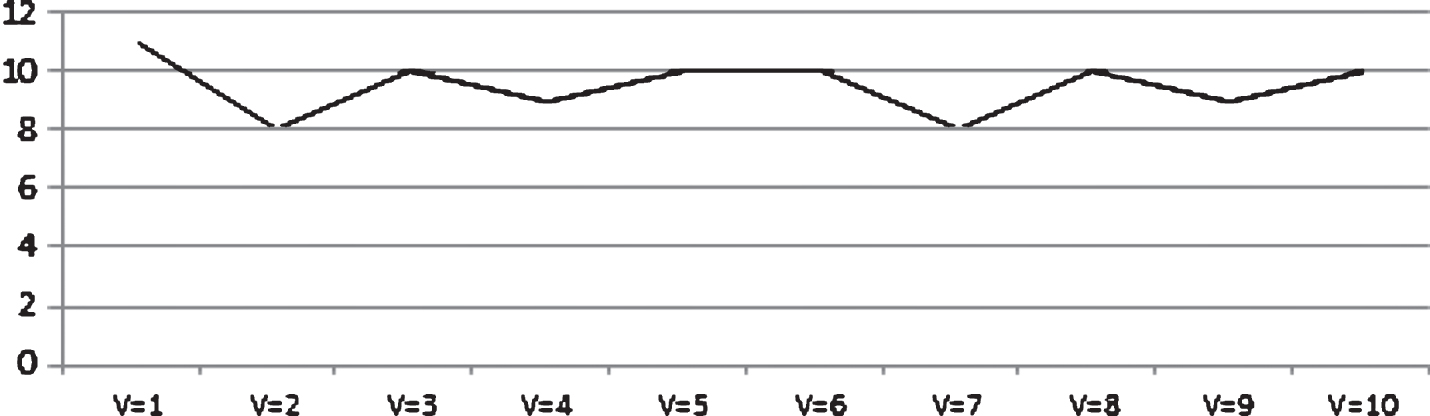
The normal convergence point relate to each v.
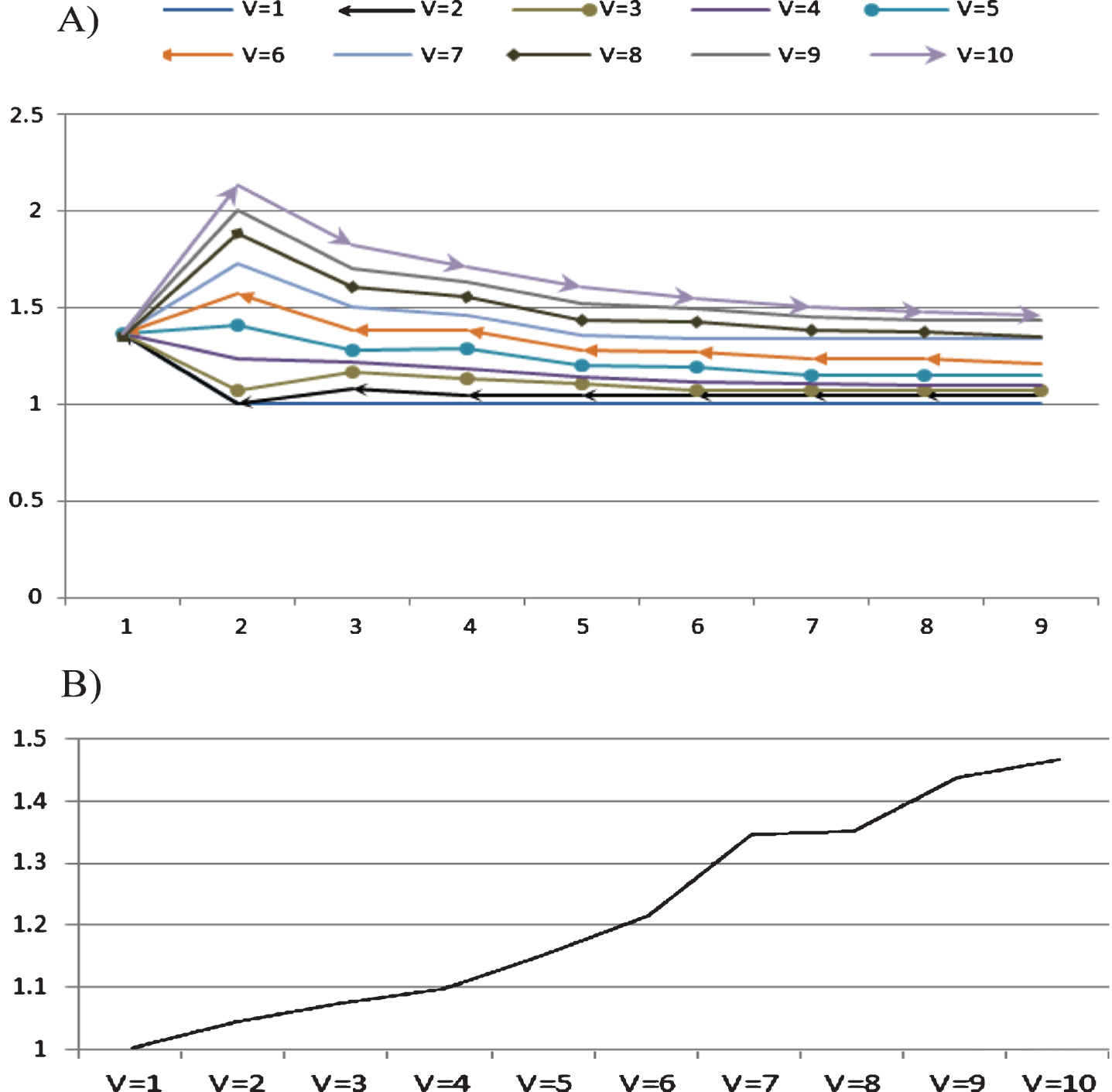
The amount of overlap relates to each v, A: for each iteration and B: is in final detected communities.
To understand the effect of v on the number of detected communities and the amount of overlap between them, see Figs. 10 and 14. Figure 10(A) indicates that the overlap changes in 10 iterations for various value of v from 1 to 10. It is observed that the overlap number in the beginning of the algorithm is particularly high and decreases to reach a stable number at the end of graph. Figure 10(B) is a chart showing the changes of the final overlap with respect to various values of parameter v. This chart indicates the increasing trend of the final average overlap with increasing v.
To understand the effect of v on the number of detected communities and the amount of overlap between them, Figs. 10 and 14 are depicted. Figure 10(A) indicates the overlap changes in 10 iterations for various value of v from 1 to 10. It is observed that the overlap number in the beginning of the algorithm is partly high and decrease to reach a stable number at the end of graph. Figure 10(B) is a chart to show the changes of the final overlap with respect to various value in parameter v. This chart indicates the increasing trend of the final average overlap by increasing v.
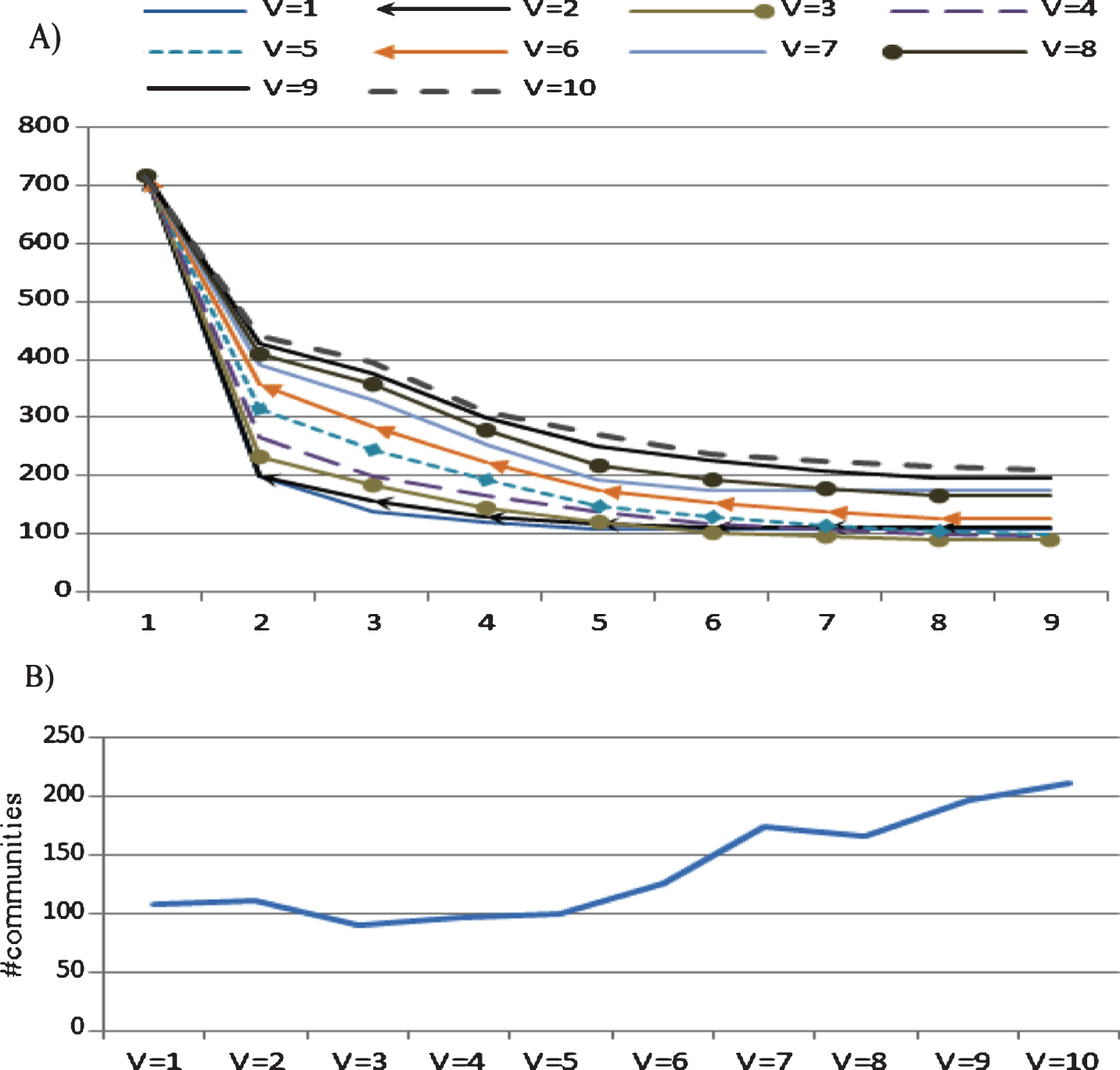
The amount of overlap relates to each v, A: for each iteration and B: is in final detected communities.
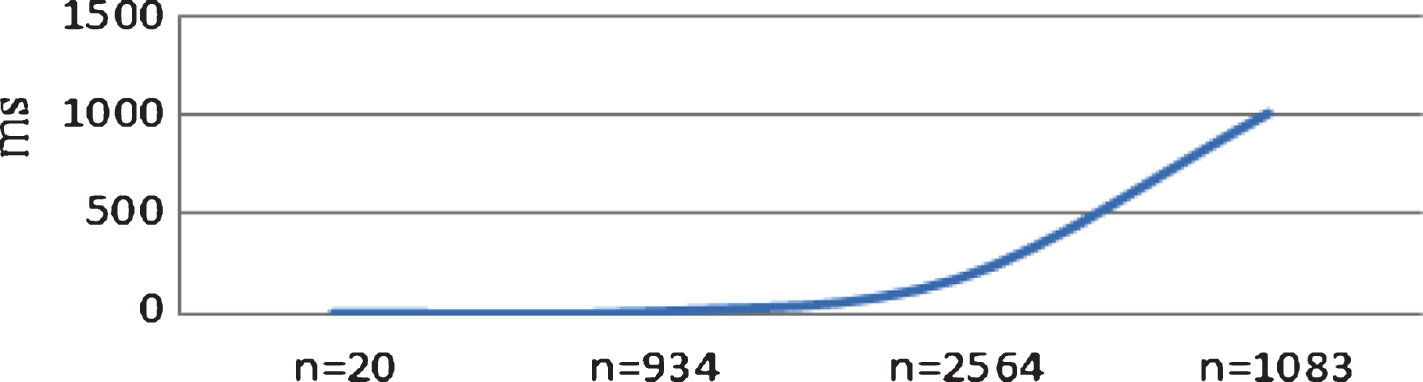
The time complexity for various node numbers n.
Figure 12 show an experiment similar to that shown in Fig. 11, but related to the number of detected communities. Figure 12 shows that the time complexity has near square order, based on the number of nodes in the network. With respect to Section 3.2.6, it is clear that the time complexity is influenced by more than just the number of nodes.
Figure 12 is a similar experiment to Fig. 11 but it is relate to number of detected communities.
Finally, we experimentally evaluate the convergence rate. This depends on both the the number of iterations and the v parameter. Section 3.2.6 predicted that the worst-case time per iteration is O(vnm log (vm/n)), but did not attempt to predict the number of iterations required. Figure 12 shows the number of iterations needed to converge to the final modularity is 10. By increasing the size of the data-set, the convergence point increases but for this experiment 10 iterations are needed to calculate the time complexity regardless the convergence point. Also it is obvious that the time complexity increases with v, so the v is constant to 5 here.
Figure 12 shows that the time has near square order, based on the number of nodes in the network. With respect to Section 3.2.6, it is clear that the time complexity is influenced by more than just the number of nodes.
In this section, the performance of the proposed approach is compared with two other algorithms: COPRA [20] and LPA [12]. To perform these algorithms on the experimental dataset, the adapted version of each algorithm is used: SemCOPRA: Semantic COPRA is a semantic version of COPRA, adapted for application to an interaction graph that is a semantic network of social users. TagP: TagP is a version of the label propagation algorithm, which is adapted for application to an interaction graph. The main difference between TagP and LPA is the use of tags, instead of numeral labels, as meaningful labels to propagate. Thus TagP is a semantic label propagation algorithm without any overlap consideration.
In this experiment, the evolution of the modularity of the detected communities is analyzed by three algorithms: FuSeO, SemCOPRA, and TagP. The trends of the evolution of modularity are compared to observe the effect of added fuzzy theory and semantic UCSM architecture. Figure 13 presents the curves of the evolution of the modularity after applying the three algorithms at each iteration point.
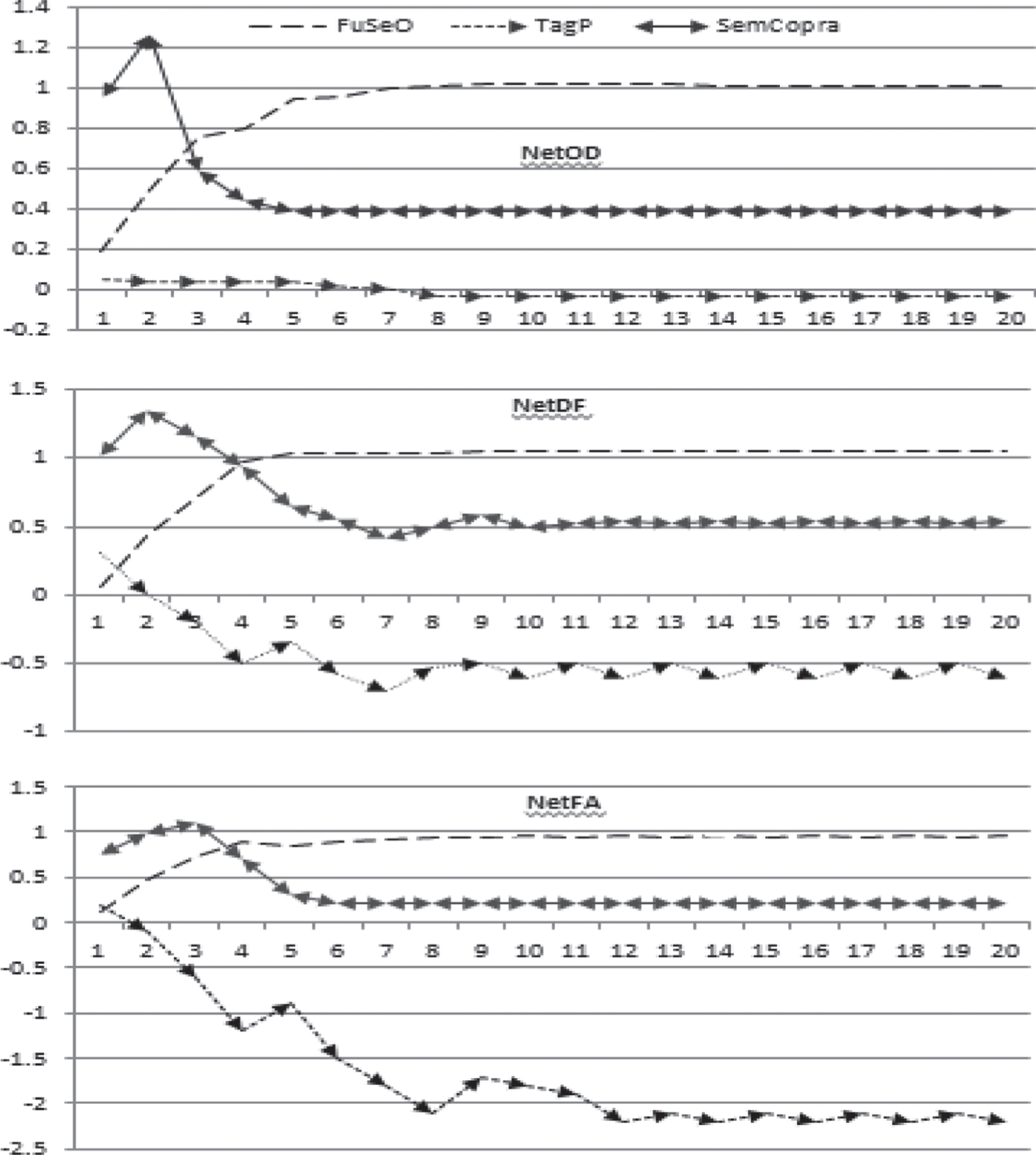
Modularity trend of FuSeO compare to TagP and SemCOPRA.
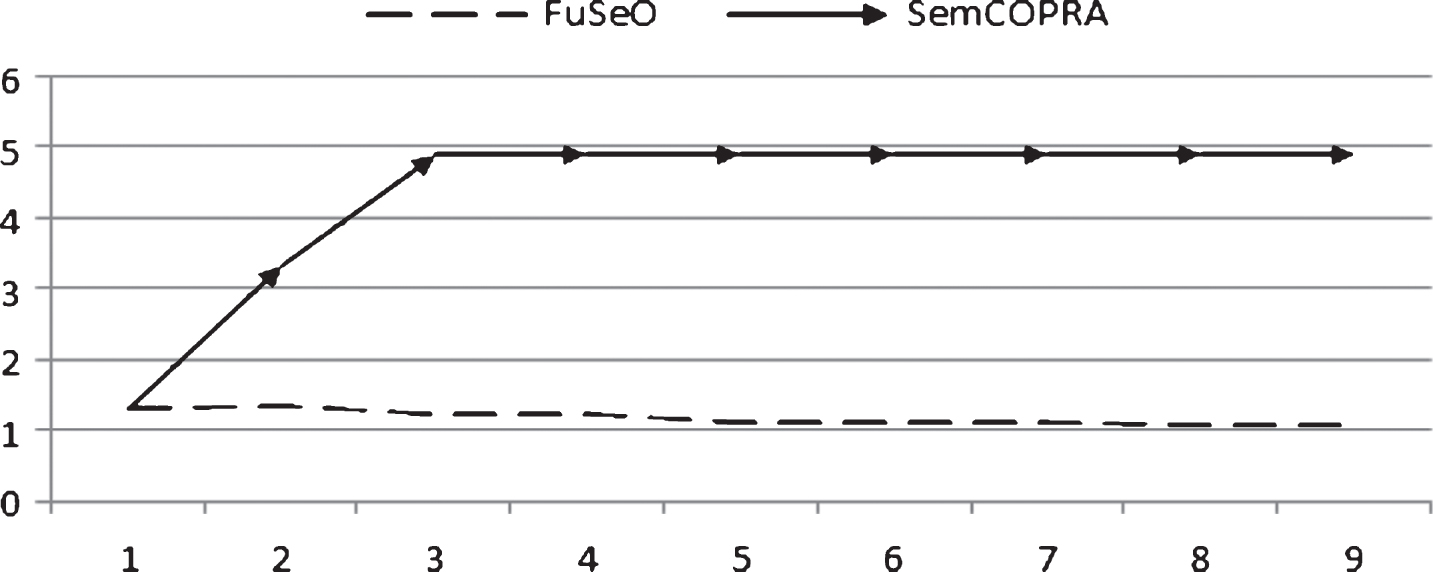
Compare the overlap in FuSeO and SemCOPRA.
In these datasets, it is observed that the FuSeO algorithm detects a community partition with higher modularity than the others and that the TagP algorithm detects the weakest community partition. FuSeO has an increasing trend with iteration progress, but TagP and SemCOPRA have downtrends. Because of the overlapping community structure and the semantic nature of the experimental dataset, the TagP gives an unacceptable result, as indicated by the low and negative obtained value for modularity. SemCOPRA and FuSeO have significantly better modularity than TagP. This is due to the very broad tags that act like numbers in LPA and also due to the overlapping nature and density of the dataset. Although the SemCOPRA give a positive modularity value and better results than TagP, it is also inefficient. SemCOPRA has a good start but its downtrend causes it to become inefficient. This is due to the different level of belonging to overlapping communities which is equal to fuzzy membership function.For a better explanation of this comparison, Fig. 14 depicts the overlap measure of both SemCOPRA and FuSeO. It is observed that SemCOPRA allows nodes to belong to more communities than FuSeO in average. This is the problem that prevents SemCOPRA from acting well on this dataset.
FuSeO is a new overlapping community detection approach proposed in this article. It uses the advantages of both semantic web and fuzzy theory to reveal the meaningful and overlapping communities among users. The FuSeO approach derives a semantic interaction network from the RDF of the social network to: 1- reduce the number of passive nodes and edges existing in the large topological network of friendship social networks; 2- establish a network structure for non-friendship social networks. It also extracts fuzzy relations among users with respect to the semantic UCSM structure and uses fuzzy theory to differentiate between the intensities of the relations. Then, an extended version of the overlap label propagation algorithm is applied on this fuzzy interaction network. FuSeO extend the overlapping label propagation to initializing semantic topics and propagation with fuzzy belonging factors.
The results of the experiments performed on a real-world (StackOverFlow) dataset show that the proposed fuzzy semantic approach is able to significantly improve the modularity in comparison to two other algorithms, COPRA and TagP. The maximum allowable number of communities for each node is an important factor that has different impacts on different aspects of the proposed community detection approach. This factor has a direct impact on the overlap, but the modularity has an increasing trend with increasing factor, up to a maximum value, and then changes its trend.
As for future work, we plan to apply the algorithm to other online social networks and implement multi-thread FuSeO to reduce time consumption.
Web instrumented man-machine interactions, communities and semantics.
Correlations that are active in the exchange of information for period of time [26].
In folksonomy.
A sample UCSM ontology was created for the StackOverFlow dataset by Meng et al. in 2014.
Question answer.