
Abstract
Community detection from networks is one of the long standing and challenging tasks in the field of complex network research. Detection of communities poses numerous challenges in terms of their overlapping and hierarchical nature, dynamics of networks and underlying communities, scalability of detection algorithms on large scale networks to mention a few. Traditional community detection methods are not readily scalable to large networks mainly due to the computation of global network metrics. This paper presents a novel scalable overlapping community detection approach for large scale networks by presenting a
Introduction
Network systems are ubiquitous in nature and society, and form the basic structure representing interactions among various related entities. Some important network systems include (i) real-world social networks like human proximity networks, friendship networks, terror networks, and crime/gang networks, (ii) biological networks like protein-protein interaction networks and gene regulatory networks (iii) computer and computer-generated networks like Internet and WWW (iv) online social networks like
Social Network analysis (SNA) is a multi-disciplinary field dedicated to the analysis and modelling of relations and diffusion processes between various objects of network structures found in nature and society, and other information/knowledge processing entities. The aim of SNA is to understand how the behaviour and interaction of such entities translate to large-scale social network systems. SNA is one of the important techniques which finds significant application in anthropology, physics, mathematics, biology, communication networks, economics, geography, and computing. The application of SNA includes but not limited to transport planning, dealing with organized crime in adversary networks, community detection and tracking, sentiment analysis and opinion mining, node influence analysis, link prediction, and highlighting functionally coherent groups of proteins and predict the level of functional homogeneity within these protein groups or communities.
One of the important challenges in the field of SNA addressed in the existing literatures and along the lines of which the current proposal is directed, is the detection of communities and tracking their temporal evolution. Actors in a social network tend to form groups and the task of community detection is to identify such groups (communities) through the study of network structures and topologies. Community detection from social networks is a long standing and challenging task because communities can often be closely related to the functional units of a system, e.g., they may represent functionally coherent groups of proteins, people discussing similar topics and sharing an ideology (e.g. relating to a political party, government initiatives, election campaigns and so on), criminals linked to a particular crime, group of people involved in money laundering in a financial transaction network, web pages related to similar topics and so on. Identification of such groups, clusters, or communities in a social network forms the basis for many other social network analysis tasks. Further, communities may overlap and have a hierarchical structure. Moreover, community structures change with the changing dynamics of the underlying network. These properties further complicate the process of community detection. It thus becomes important to devise novel methods to address community detection challenges in a unified manner.
This paper presents a novel approach to solve the scalability issue of earlier overlapping community detection methods for large networks. It provides a distributed implementation of a density-based overlapping community detection method proposed in [2] via
The rest of the paper is organised as follows. Section 2 presents a brief review of literature on existing parallel and distributed implementations of community detection algorithms. This section also presents significant differences of closely related methods with the proposed approach. Section 3 presents detailed description on the implementation of proposed approach. Some preliminary results are summarized in section 4. Section 5 finally concludes the paper.
Related works
Although many techniques and methods for detecting communities from social networks have been proposed in literature [4–12, 36], none of them aims to address all the multifaceted challenges inherent in the field, but instead deal with a single objective. Identifying communities poses numerous challenges which include dealing with their overlapping and hierarchical nature [30, 35], tracking their evolution in dynamic networks [2, 40], and scaling the community detection methods for large-scale social networks, besides dealing with directed and weighted properties of the underlying networks. A comprehensive summary and review of various challenges and solutions to the community detection problem is presented in [40]. It is also often difficult to have consensus on the evaluation methods of identified community structures with the underlying ground truth [32–34]. Recently, community detection methods based on both structure and semantics/content of online social networks (like [44]) have also been proposed. Methods which include both the structure and content related data for detection and analysis of communities in online social networks may help in providing important insights on concepts related to the influence and diffusion in online social networks. In this line of work, [42, 43] have highlited the significance of communities and their dynamic behavior in online social networks for collaborative decision making and opinion formation.
Presently, huge size of social networks has created a great need for scalabe community detection methods. Earlier methods fail to address this issue in their present state and very few possess characteristics that can be exploited for scaling the methods via parallelization and distributed computing, which is the backbone for addressing scalability issues over big data. Traditional community detection methods based on modularity optimization [22, 36] and hierarchical clustering methods [23] are generally considered non-scalable to large-scale networks as they are based on global network metrics and thus difficult to parallelize. Some of the recent parallel algorithms proposed for detecting disjoint communities include [13–15]. These methods are mainly based on shared memory architectures, and multi-core processors and GPUs. The
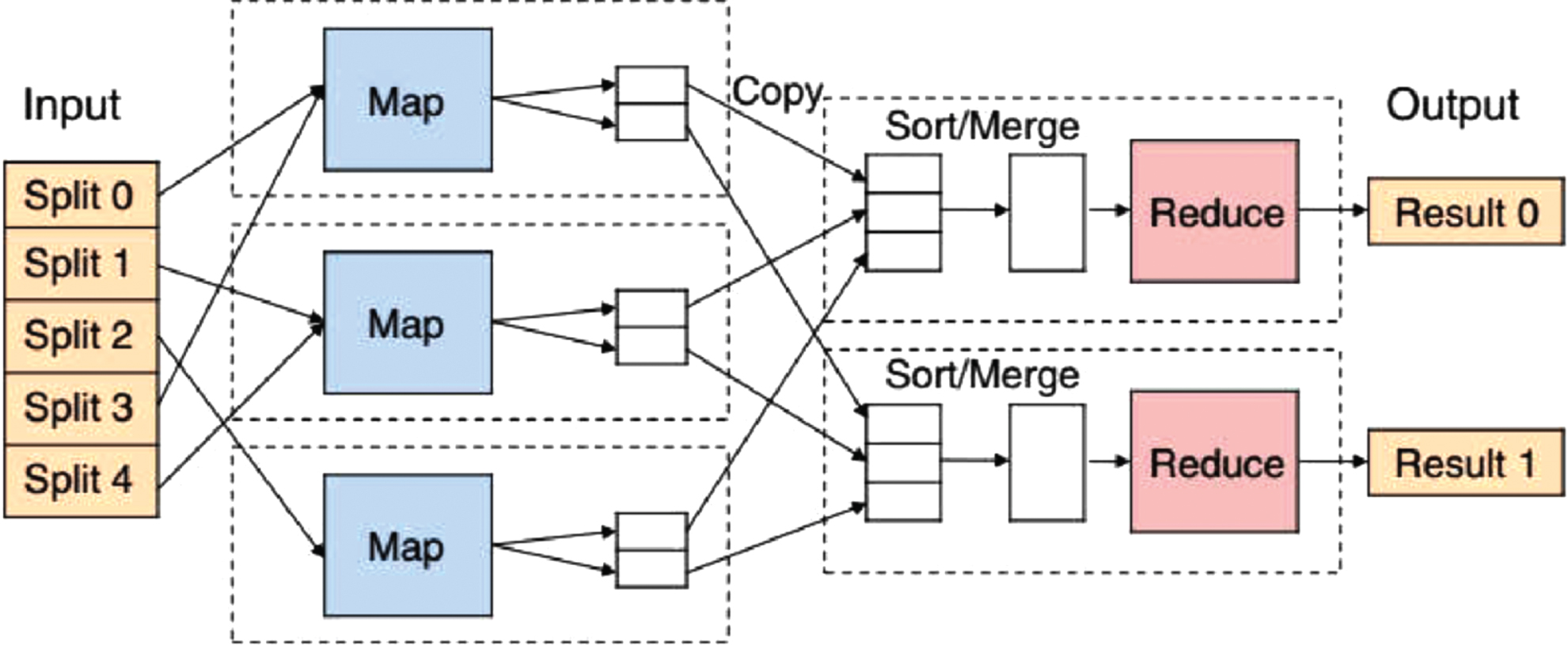
Basic processing architecture of
The popularity of
The main objective of this work is to scale the previous work of the authors [2], a novel density-based overlapping community detection method, using a distributed computation approach implemented over
The proposed approach is based on a local density based distance function, which can be efficiently parallelized via
It should be noted that the distance is measured only between those node pairs that are directly linked and have reciprocating interactions as they are expected to be less distant (more similar). In case of undirected networks, each link is considered to be reciprocating by treating it as a set of two oppositely directed links with the same weight as the original link. Given these considerations, the first layer of the distance function for two reciprocating nodes p and q is represented by Equation 1, where V p and V q are sets of nodes to which nodes p and q have outgoing links/interactions respectively, and V pq is the set of common nodes to which both p and q have outgoing links in the network.
In Equation 1, Δ (p, q) represents the layer-2 of the distance function which will be discussed shortly and η (0 < η ≤ 1) is an input parameter which specifies the resolution at which communities need to be identified. In simple terms, the first layer of the distance function ensures that the distance between two reciprocating nodes p and q is computed at the second layer only if the fraction of their commonly interacted nodes forms a significant fraction of the total outreached nodes of either p or q, i.e., min (|V p |, |V q |). Otherwise, the distance between p and q is taken as 1 (maximum).
The second layer of the distance function takes the intensity of interactions between nodes (link weights) into consideration. It is based on the assumption that if a node p has outgoing links (interactions) to a node q and a set of nodes V
pq
(to which q also has outgoing links) then the similarity/distance between p and q can be measured in terms of proportion of response from q and nodes in V
pq
to the interactions of p and vice versa. Formally, the response of node q and the nodes in V
pq
to the interactions of node p is measured as the average of per-node reciprocated interactions (edge weights) of q and the nodes in V
pq
towards p, represented by δ (p, q), as given in Equation 2, where
Finally, symmetric distance between two nodes p and q, Δ (p, q), is taken as the maximum of their mutual directed-response (or minimum of the reciprocals of their mutual directed-response) values normalized by their respective total weight of outgoing interactions (represented by
The dual-layer distance function thus defined measures the amount of maximum average reciprocity among two nodes p and q and their common neighbors, provided the overlap of their neighbors is significant. Smaller values of Δ (p, q) represent higher response between nodes p and q and translates to more closeness between p and q.
Given a distance measure, we need to specify a neighborhood threshold to mark the boundary for any given node as required by density-based methods. However, instead of manually specifying the threshold value, we determine a local neighborhood threshold for a node p as the average per-receiver reciprocated interaction score of p with all its outreached neighbors. Formally, the local neighborhood threshold of a node p (ɛ
p
) is defined using Equation 4, where V
p
represents the set of nodes to which p has out-links,
Based on the distance function dist (p, q) and local neighborhood threshold ɛ p , we define a local ɛ p -neighborhood of a node p as the subset of p’s out-linked nodes (i.e., V p ) with which its distance is less than or equal to ɛ p . Formally, the local ɛ p -neighborhood of a node p can be defined using Equation 5.
In simple terms, we can state that N p contains those neighbors of p in the network that have a significant topological overlap with p and an above-average interaction intensity with p in the network neighborhood. This approach thus aims to find areas of higher structural density (than the surrounding) to constitute a community.
Formally, for a given resolution fraction (η), a density-based community is realized by the following two key definitions.
The basic aim is to find all maximal sets of connected core nodes such that for each pair of nodes in a maximal set there exists a chain of nodes v1, v2, …, v n such that v i and vi+1 are mutual-cores for all i ranging from 1, 2, …, n - 1. The set of all such connected core nodes forms the mutual-core connected maximal subgraph (MCMS) of a community. A community is then defined as the union of an MCMS (backbone of the community) and local ɛ p -neighborhoods of each core node p in the MCMS. The set of all such possible communities identified forms the community structure of an underlying network.
As mentioned earlier, the main objective of this paper is to create a parallelized implementation of our earlier community detection method in [2] over a distributed computation platform (
Stage 1: Computation of density-based neighbourhoods and formation of mutual-core network
The initialization process of this stage involves a mapper and reducer pair, which computes local metrics to establish the density-based local neighbourhoods of each node in the network as shown in Fig. 2.
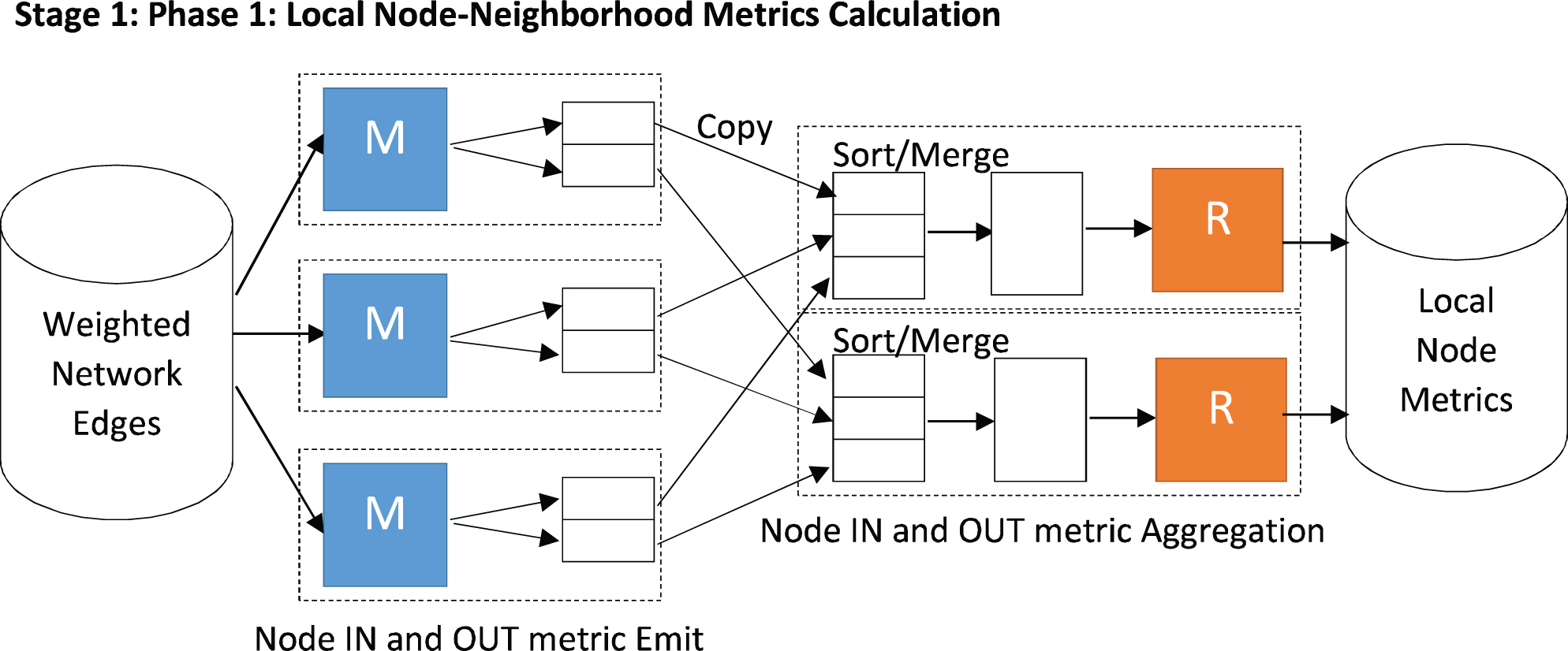
MapReduce phase 1 for computing local metrics.
The input to this phase is the network edges in the form of <

Record format emitted by the mapper function of the first phase of Stage 1.
The reducer function of this phase accepts this information in aggregated form for each node as shown in Fig.4. This information is used by the reducer function to compute various local metrics for each node which include

Records aggregated at the reducer function of the first phase of Stage 1.
For each node (record read by the reducer), the reducer emits this aggregated local information in the format shown in Fig. 5. The field out_reciprocated in the value of the emitted record for a node p is a set containing elements in the form <q:
The second phase of this stage involves computing layer-1 and layer-2 components of the distance function as mentioned earlier to identify density-based neighbourhood of each node. The overview of this phase is shown in Fig. 7. The mapper function of this phase takes input from the reducer of the previous phase in the format shown in Fig. 5. For each node, it emits multiple records for ordered pairs of nodes in the format shown in Fig. 6.

Record format emitted by the reducer function of the first phase of Stage 1.

Record format emitted by the mapper function of the second phase of Stage 1.
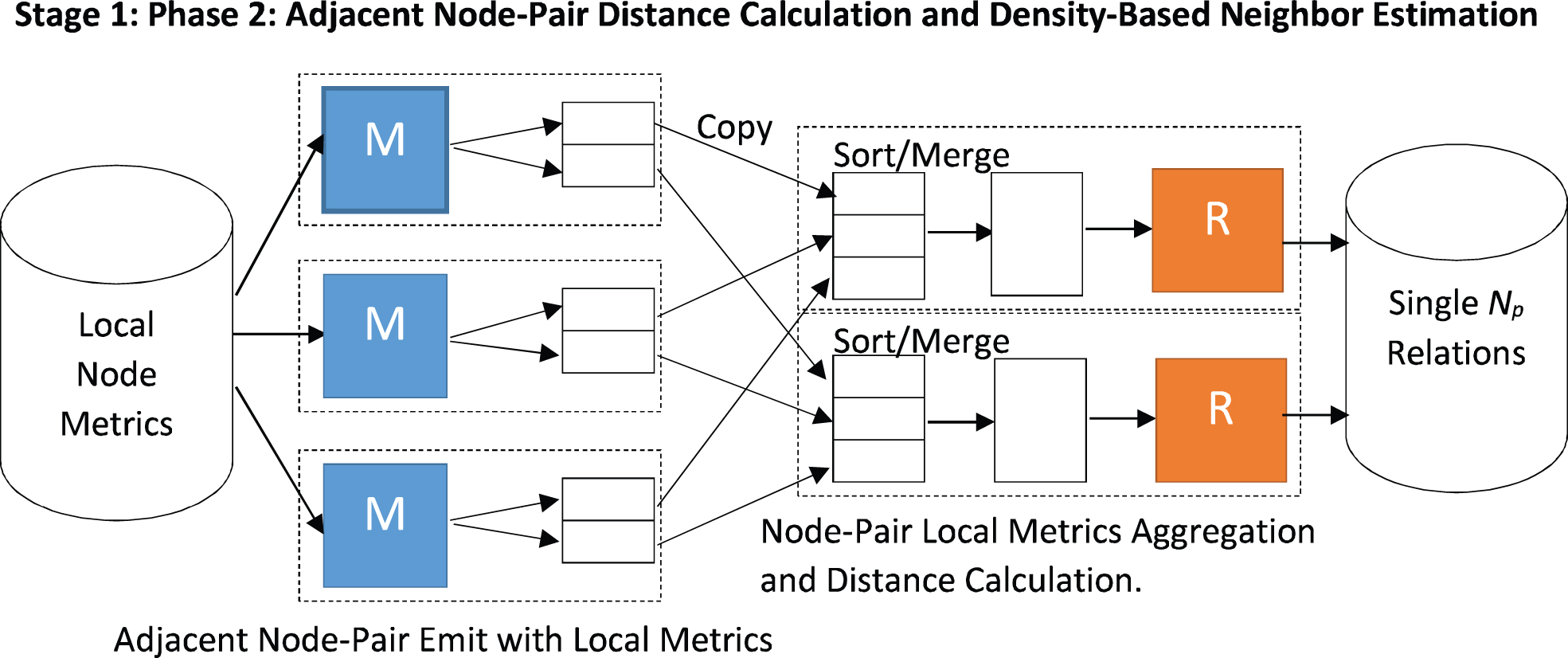
MapReduce phase 2 for computing density-based neighbours.
To emit the records for a key node p, the mapper takes each node q from V
p
only for which
The reducer function of this phase aggregates these records on the key, thus completing the value part for each node pair emitted by the mapper. That means reducer has local metrics computed by the first phase for both the nodes of the node pair which are sufficient to compute the distance between this pair of nodes as discussed in the first part of section 3. For each record thus read, the reducer computes the distance between the pair of nodes in the key part of the record from the information in the value part of the record. It emits 0, 1 or 2 records with key equal to the ID of one of the nodes in the node pair and the value equal to the ID of the other (along with |V
p
| of the key node) depending upon the following conditions: 1. Record with key = s and value = ‘t: |V
s
| ’ is emitted if dist (s, t) < ɛ
s
, and 2. Record with key = t and value = ‘s:|V
t
| ’ is emitted if dist (s, t) < ɛ
t
. Each record thus emitted represents that the node present in the value part of the record belongs to the density-based local neighbourhood of the node in the key part. To find the complete density-based local neighbourhood N
p
of each node p as given in Equation 5, these records simply need to be aggregated on the key which is done by the third MapReduce phase of this stage. In the third phase, the mapper only emits the records (identity mapper) for the reducer to aggregate N
p
for each node p. Upon aggregation of N
p
the reducer function uses Equation 6, with the value of resolution parameter η passed as a configuration parameter, to determine whether the key node p is a core-node or not. If node p is found to be a core-node, the reducer performs two actions. First, it creates a separate file in HDFS named p with contents equal to the list of nodes in N
p
(to be used later in the second stage). Second, the reducer takes each node q from N
p
and emits records for the node pair p andq with key in the ordered form <s:t> such that s = min(p,q) and t=max(p,q) and value equal to 1. These records are emitted by the reducer for fourth and last

MapReduce phase 3 for aggregating density-based neighbourhoods.
The last MapReduce phase of this stage involves an identity mapper which simply emits the records from the previous reducer. The reducer function of this phase aggregates the value field of these records, wherein an aggregated value of 2 for a node pair represents a mutual-core relation between the two. For each mutual-core pair <s:t> thus found, the reducer emits a record with key = s and value = t thus forming the edges of the mutual-core network of the underlying social network as illustrated in Fig. 9.
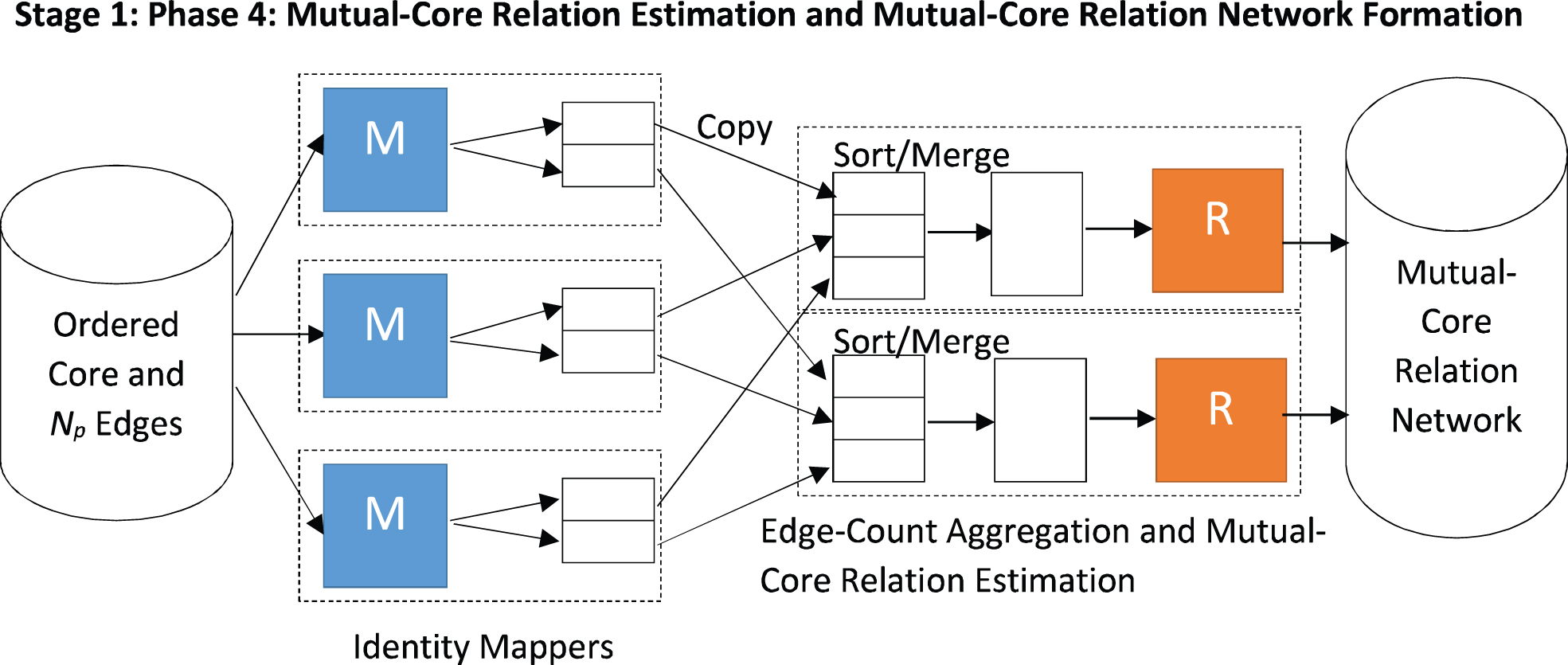
MapReduce phase 3 for aggregating density-based neighbourhoods.
The connected components of the mutual-core network constructed in the previous stage represent the MCMSs of various communities in the underlying network. For a connected component in the mutual-core network, its full community is identified by taking the union of density-based local neighbourhood N p of each node p in the connected component. This becomes a trivial task once a connected component is extracted as the N p of each core-node p has already been saved in separate files on the HDFS in the previous stage.
The important task in this stage thus is to extract the connected components from the mutual-core network. Many
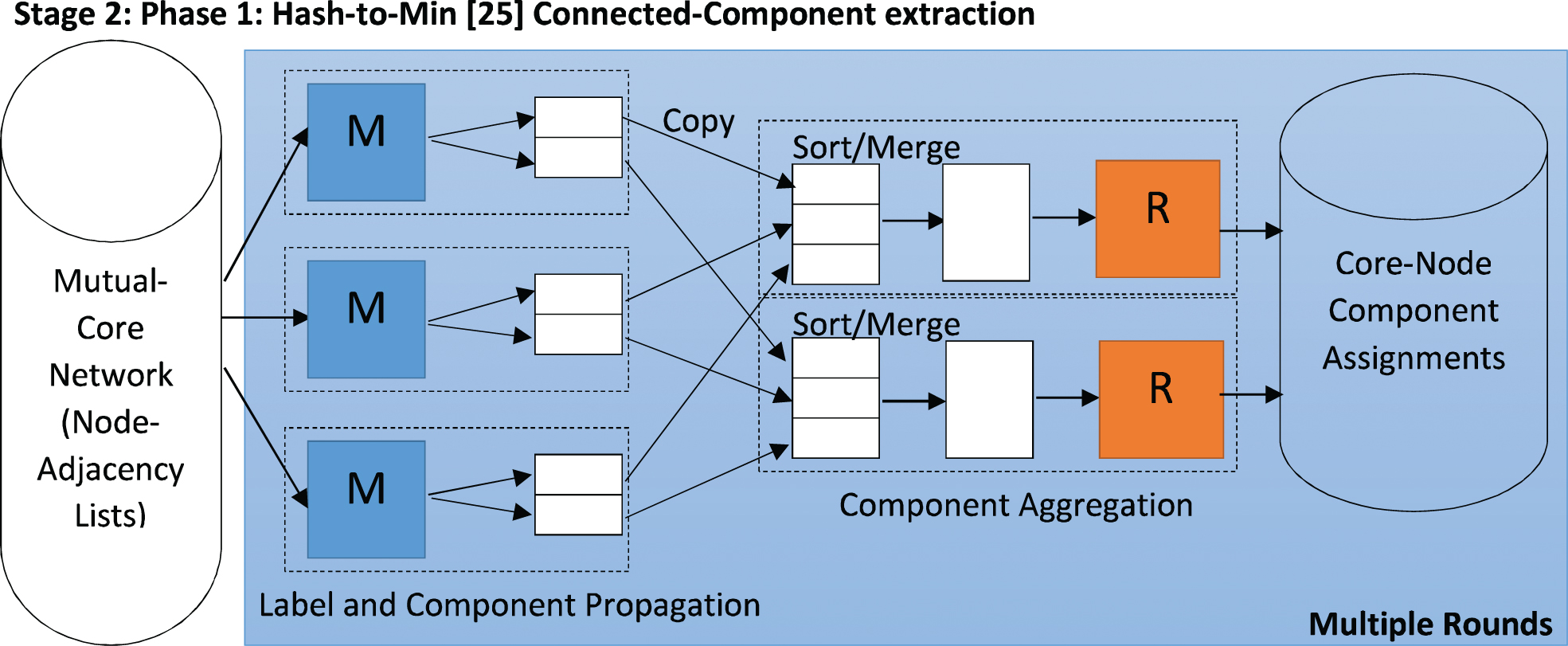
Hash-to-Min [25] connected-component extraction.
At this stage, there are two alternative ways of representing and using the connected components. One way is to use the records emitted by Hash-to-Min in the form <C
v
min
, C> wherein the key = C
v
min
is the smallest ID of the node in the connected component (representing the connected component ID) and value = C is the list of all the node IDs belonging to the connected component. In order to extract the complete communities, finally a single mapper function is used which reads a <core-node
min
, connected-component-list> record and performs the following tasks for each such record: Create a new directory on HDFS labelled with the connected-component ID i.e. C
v
min
in the key part of the record. Move all the existing files containing the N
p
of each core-node p ∈ C in the value part of the record (already saved on HDFS in the previous stage) to the directory created in the previous step.
Alternatively, the last round of the Hash-to-Min method can be modified such that the last reducer also emits C
v
min
= {v
min
}. Thus the <key, value>format output of Hash-to-Min method becomes such that the key is a node ID (core-node in this case) and the value is the connected-component ID to which the node belongs. Finally, to extract the complete communities, a single mapper function is used which reads a <core-node, connected-component ID> record and performs the following tasks for each such record: Create a new directory on HDFS labelled with the connected-component ID in the value part of the record if it doesn’t exist already. Move the existing file containing the N
p
of the core-node p in the key part of the record (already saved on HDFS in the previous stage) to the directory labelled with the connected-component ID in the value part of the record.
These two steps of the last mapper ensure that a community consisting of at least one pair of mutual-core nodes is represented by a separate directory containing files representing its core-nodes and each such file containing N p i.e. the density-based local neighbourhood of each core-node p. Moreover, a community consisting of a single core-node p is simply represented by a separate file labelled p containing its N p . These are those files which were not moved by the last mapper to any directory as the core-nodes represented by these files did not have mutual-core relations with any other core-nodes and thus did not appear in the mutual-core network as illustrated in Fig. 11.
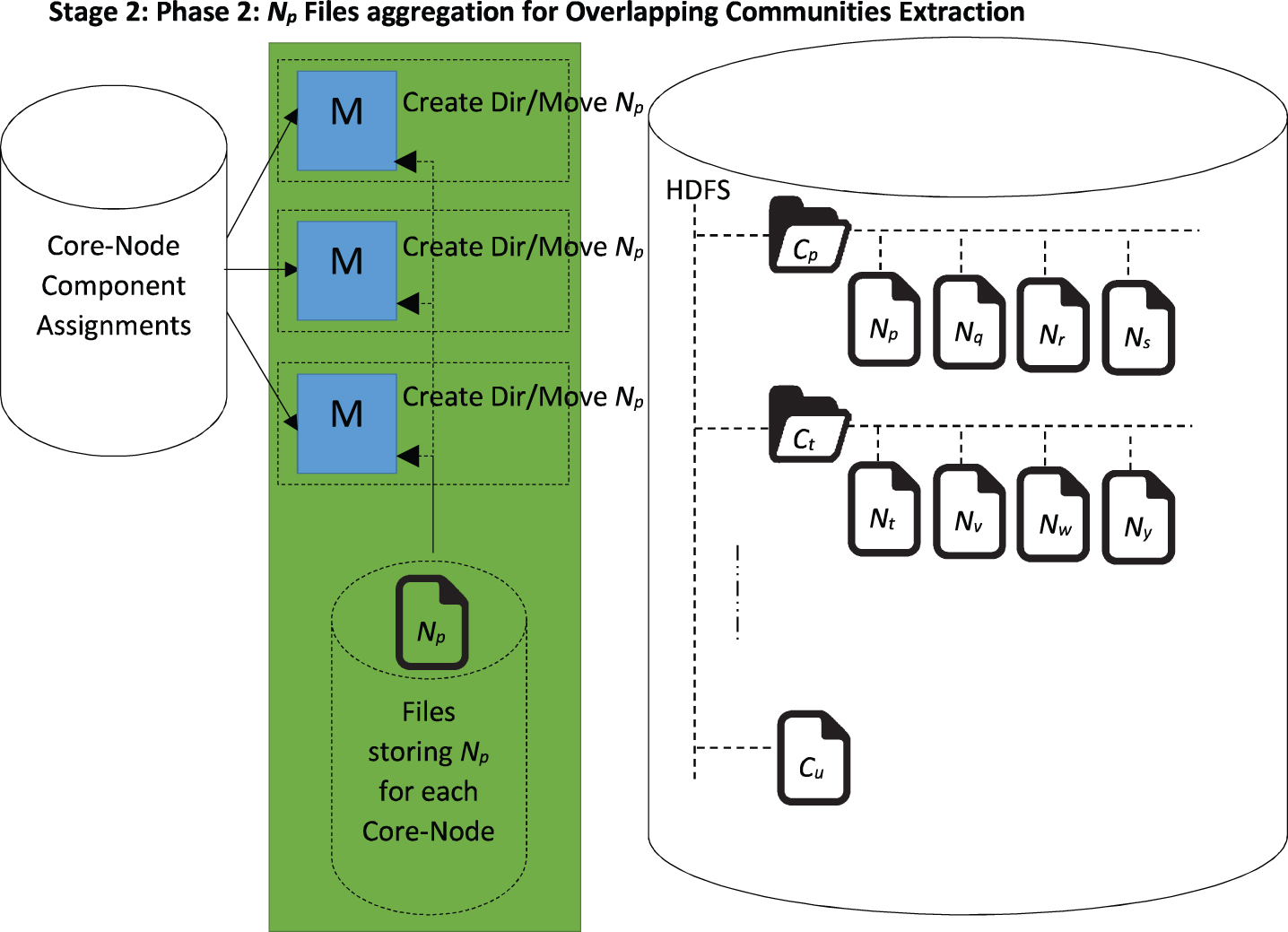
Extracting communities by grouping N p neighbourhoods of mutual-core nodes.
To present some basic characteristics of the proposed method, this paper uses two network datasets. One is a large interaction graph of the most popular online social network in Slovakia, namely,
The quality of communities identified by the proposed community detection method has already been evaluated in [2] for a centralized implementation of the same. The distributed implementation of the method via
For the current distributed implementation, η affects the computation overhead in terms of disk I/O operations, involved for creating files for core-nodes in the last phase of the first stage. It also dictates the overall complexity of the second stage for finding connected components as the size of input for this stage depends on the number of core-nodes identified in the first stage. Figure 12 illustrates the fraction of nodes identified by the proposed method as core-nodes in both the input networks at different values of η . It can also be observed from this figure that generally the number of core-nodes identified by the method is much smaller than the actual size of the network by a large magnitude. It can be thus concluded that the disk I/O overhead caused due to creation of core-node files in the first stage is a large magnitude less than as required for all nodes in input network.

Fraction of nodes identified as core-nodes from the two input graphs in Stage 1.
Moreover, the number of
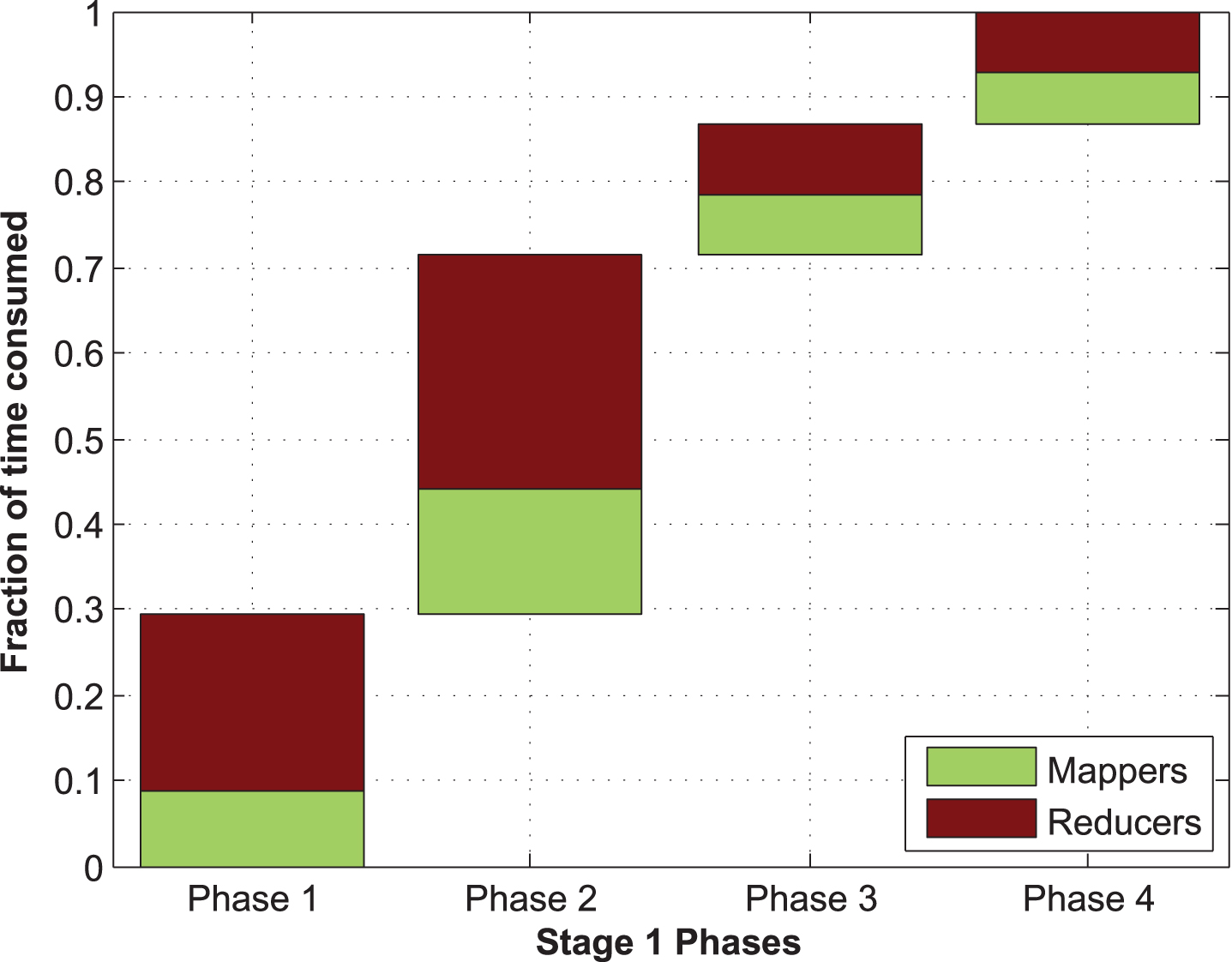
Average time consumption of the Mappers and Reducers of Stage 1.
From Fig. 13, it can be seen that the majority of the time required by the first stage is at phases 1 and 2. That is where the neighbourhood aggregation and distance computation is performed. Moreover, most of the time is consumed at the Reducer stages due to the requirement of copying and sorting the data at various nodes of the cluster. The number of
We have presented a novel