
Abstract
Sub-health is the third state featuring a deterioration in physiological function between health and illness, and it has been a global problem received increasing attention. This paper presents a novel computational model for aided diagnosis of sub-health, which is with TCM (Traditional Chinese Medicine) diagnosis as an instance. All the original medical records of sub-health were obtained from the First Affiliated Hospital of Guangzhou University of Chinese Medicine, and these records were divided into training set (training cases) and test set (test cases). Based on rough set and fuzzy mathematics, training set was used to extract important features in different classifications of sub-health and generated fuzzy weight matrixes. The results of test set were achieved with integrated calculation of fuzzy weight matrixes and feature values of sub-health symptom. In order to further evaluate the novel model, it was compared with the linear model, Naive Bayesian classification and fuzzy comprehensive. The results showed that the accuracy of the novel model for the diagnosis of sub-health is higher than the linear model and Naive Bayesian classification, and is a little better than fuzzy comprehensive. So the novel model presented in this study can be used to assist the diagnosis of sub-health and play an active role in intelligent medical inthe future.
Introduction
As a transition state of human body from health to diseases surfaced as life-threatening in humans, sub-health has aroused great attention gradually [1, 2]. To address the computer-aided diagnosis of sub-health, A novel model is presented in this report which describe a case of TCM (Traditional Chinese Medicine). TCM classification of sub-health reflects different symptoms, signs, and living habits [3–6]. The TCM symptoms in different classes of sub-health may be discrete and fuzzy. It’s necessary to find a feasible computational model to diagnose sub-health with symptoms, signs, and living habits. Previous studies demonstrated some simple models in this field [3, 7]. However, the previous models mainly characterize weights with experts’ subjective experiences and perform linear calculations [3], and can not adapt to the fuzzy and discrete symptom of sub-health. Based on Rough Set and fuzzy mathematics, this study presented a novel model for TCM classification of sub-health. Clinical cases of EMR (electronic medical records) were obtained from the First Affiliated Hospital of Guangzhou University of Traditional Chinese Medicines were randomly divided into two groups: training set (training cases) and test set (test cases). Training set was used to extract important features in different classifications of sub-health and generated fuzzy weight matrixes. The results of test set were achieved with integrated calculation of fuzzy weight matrixes and feature values of sub-health symptom. In order to further evaluate the novel model, it was compared with the linear model, Naive Bayesian classification and fuzzy comprehensive. The main frame of this study was shown in Fig. 1.
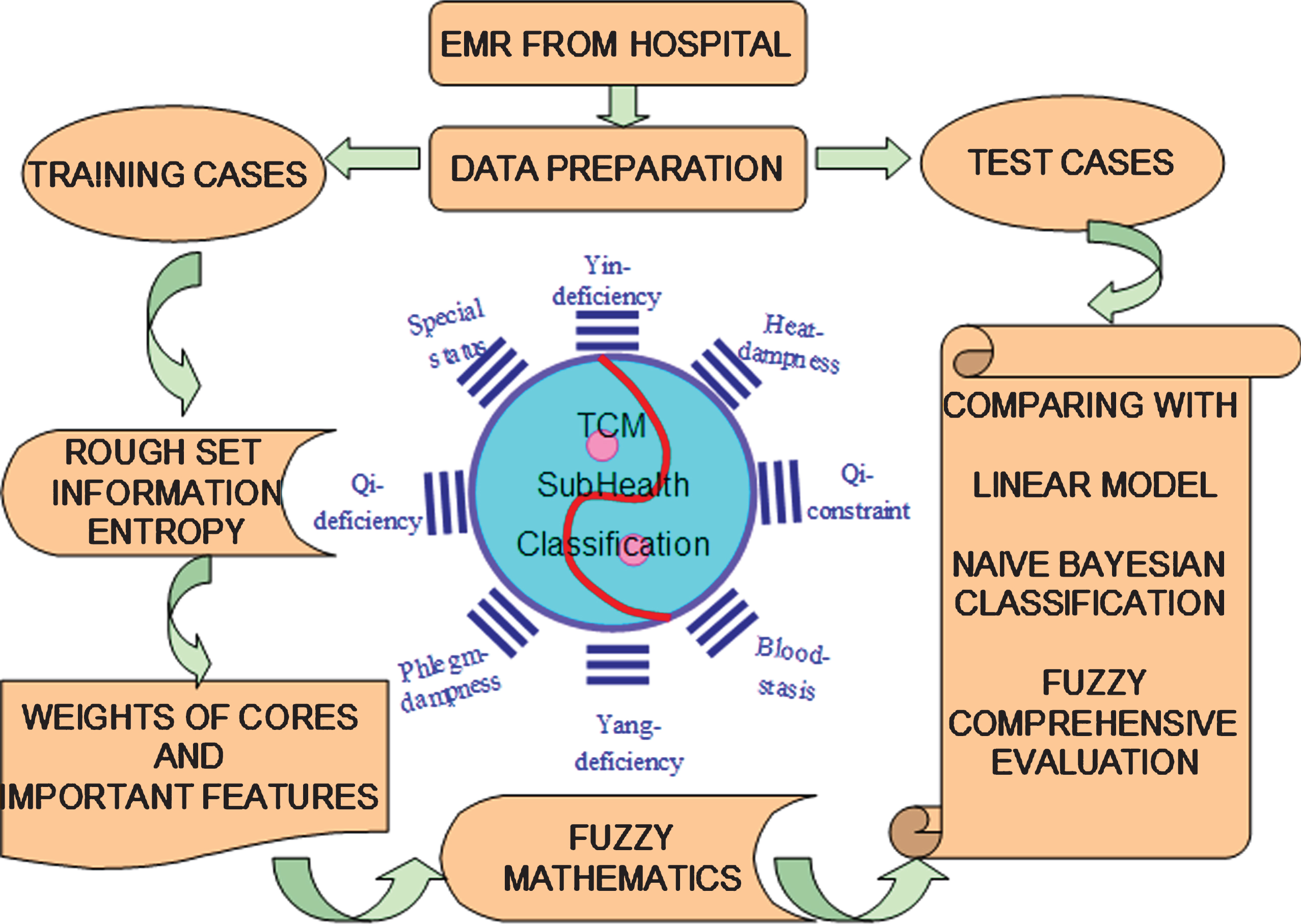
The main frame of this study.
Rough set is an effective mathematical model for incomplete and uncertain knowledge and it is constructed on the basis of indiscernibility relations of attribute sets. According to the approximate concept with elative determinacy, Rough set characterizes upper approximation sets and lower approximation sets [8, 10]. On the view of Rough set, knowledge is usually considered to be an information system which contains object set, condition attribute set, and decision attribute set [11, 12]. Rough set has been used for diagnosing disease and decision-makings in the medical field in recent years [13, 15]. Other decision models, such as information entropy also has been applied to the medical field and bioinformatics [16, 21]. In this study, data of sub-health in medical records is considered to be an information system. The system contains condition attributes and decision attributes for TCM classifications of sub-health. The weights and cords in different TCM classifications of sub-health can be obtained by calculations of training set. And the results of test set were achieved with integrated calculation of fuzzy weight matrixes and feature values of sub-health symptom.
Mathematics model for diagnoses of sub-health
On the view of TCM (Traditional Chinese Medicine), sub-health is described as eight different classifications in the human body: qi-deficiency, yang-deficiency, yin-deficiency, phlegm-dampness, heat-dampness, blood stasis, qi-constraint, and allergies [3]. Each class has different symptom, signs, and living habits. And each class may also share same symptom, signs, and living habits. The diagnosis of sub-health could be converted to a classification problem of sub-health according to symptom, signs, and living habits. Therefore, In the process of classification, symptom, signs and living habits could be considered as the condition attributes and sub-health classes could be considered as the decision attributes. The condition attributes and decision attributes were denoted with two values: 0 and 1. If an attribute existed, its attribute value was 1, otherwise its attribute value was 0. Condition attributes and decision attributes in sub-health medical records can be denoted with formula (1) as follows.
Condition attributes and decision attributes of “Qi-deficiency”
According to the above model, a K-item information system for diagnosis of sub-health can be modeled as follows.
Where U
k
are the record sets in medical records. U
k
= {uk1, uk2, uk3 …}, A
k
denotes the attribute set of symptom in one class of sub-health, A
k
= {ak1, ak2, ak3 …}, V
k
denotes the value set of A
k
. V
k
∈ {0, 1}, F
k
are the mapping values from A
k
to V
k
, F
k
(u
k
, a
k
) → v
k
. The condition attribute sets are represented as C
k
. C
k
= {ck1, ck2, ck3 …}. The decision attribute sets are denoted with T
k
, T
k
= {t}. T
k
∈ {0, 1}, A
k
= C
k
∪ T
k
. If all the attribute values in u
ka
and u
kb
are equal, there are indiscernibility relations between them, which are represented as IND (A
k
). The indiscernibility relations can generate an equivalence class, which is represented as E
Ak
. IND(Ak) and E
Ak
are both dependent under the attribute sets. So the relationships between IND (A
k
) and E
Ak
are as follows.
According to the different values in E
Ak
, the equivalent sets can be given with U
k
, U
k
/A
k
= {EAk1, EAk2 … E
Aki
}. If the distributions of attribute variables are discrete probability distributions, some attribute subsets in A
k
are represented as M, M ⊆ A
k
, U
k
/M = {Em1, Em2 … E
mi
}. The information entropy of M can be calculated with formula (5).
Where S (E mi ) is the quantity of the sub-health records in E mi . S (U k ) refers to the total number of sub-health records. The ratio of them is the distribution probability under U k . Some attribute subsets in A k different from M are represented as N, N ⊆ A k , U k /N = {En1, En2 … E ni }. The information entropy of M to N is calculated with formula (6).
If the information entropy has not changed when an attribute is removed, the attribute can be omitted in the information table, otherwise it is necessary. The core attribute sets generated with all the necessary attributes are as follows.
So the attribute weight of a feature in sub-health diagnosis can be calculated with formula (9).
Where w (c
kx
) is the attribute weight of a feature in one class of sub-health, and it can be obtained according to the above method, the global matrix of decision weights can be obtained. The fuzzy diagnosis formula for sub-health is as follows with integration of feature values and fuzzy weights.
Where μmin is the threshold of diagnosis. v ki and v kj denote the values of the attributes c ki and c kj in the kth class of sub-health, respectively. When S k = 1, the diagnosis of the kth class of sub-health can be confirmed, When S k = 0, the diagnosis of the kth class of sub-health can be denial. When 0 < S k < 1, the diagnosis probability of the kth class of sub-health is S k .
In the novel model presented in this study, training set (training cases) is used to calculate the core symptoms and weights of symptoms in all classifications of sub-health. The test set (test cases) is used to evaluate the accuracies of the novel model. The results of test set can be achieved with the formula (10).
Based on the linear model, test set is used to evaluate the accuracies of the linear model with proper weights given by experts.
Based on the Naive Bayesian model, eight class of sub-health are defined as the classification targets, and symptoms in sub-health medical records are defined as the classification attributes. In this study, training set is used to learn the Bayesian probabilities of symptoms, and test set is used to evaluate the accuracies of Naive Bayesian model with the learned Bayesian probabilities.
Based on the fuzzy comprehensive evaluation, fuzzy subordinate functions describes the probabilities of symptoms in one class of sub-health. Training set is used to calculate the values of the fuzzy subordinate functions, and the values generates a weight matrix. The diagnosis of sub-health can be performed with a fuzzy evaluation formula which is similar to the formula (10). Test set is used to evaluate the accuracies of fuzzy comprehensive evaluation model.
Numerical example
Data preparation
In this study, the sub-health medical records were obtained from the First Affiliated Hospital of Guangzhou University of Traditional Chinese Medicine with simple random sampling. These medical records had been confirmed by clinical experts in the field of sub-health. The incorrect cases and cases with missing data were removed. The information extracted from these medical records included TCM symptom, diagnosis and prescriptions. Symptoms were denoted with two values: 0 and 1. If a symptom existed, it was marked with 1, otherwise it was marked with 0. The diagnosis of sub-health was also denoted with two values: 0 and 1. If a diagnosis was confirmed, it was marked with 1, otherwise it was marked with 0. Prescriptions were described with herbal medicine names without doses. 436 cases are extracted in total and generated a data set. These cases were randomly divided into two groups. 50 percent of them were training set and the rest are test set. The distribution of different TCM classifications of sub-health in testing sets was shown in Fig. 2.
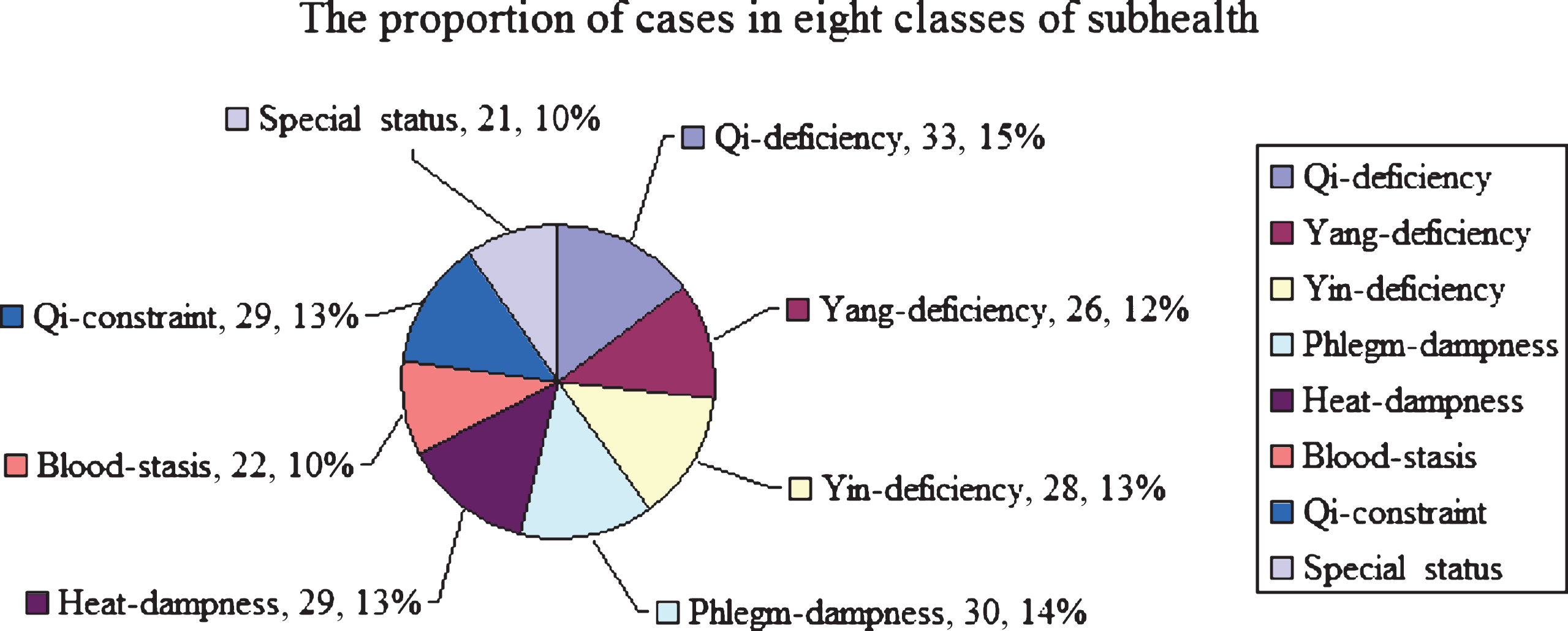
The proportions of cases in eight classes of sub-health.
According to above formulas, the core symptoms and weights of symptoms in all classes of sub-health are shown in Table 2 (only showing the symptoms with top weights) and Fig. 3. The result showed that the core symptoms of “Qi-deficiency” are “Shortness of breath” (weight: 0.104) and “Catch cold easily” (weight: 0.104). It illustrated that “Shortness of breath” and “Catch cold easily” may be the most important factors in the diagnosis of “Qi-deficiency”. The other important symptoms of “Qi-deficiency” also included: “Muscle weakness” (weight: 0.259), “Faint voice” (weight: 0.029), “Fatigue” (weight: 0.259), “Sweat easily” (weight: 0.077), “Pale tongue and weak pulse” (weight: 0.077) and “Introversion” (weight: 0.060), etc.
The core symptoms and weights in all classes of sub-health
The core symptoms and weights in all classes of sub-health

TCM classification of sub-health and some important symptoms.
The accuracies of the novel model comparing to linear model, Naive Bayesian classification, and fuzzy comprehensive evaluation are shown in Fig. 4. The results showed that, the novel model has the highest accuracies in the four models.
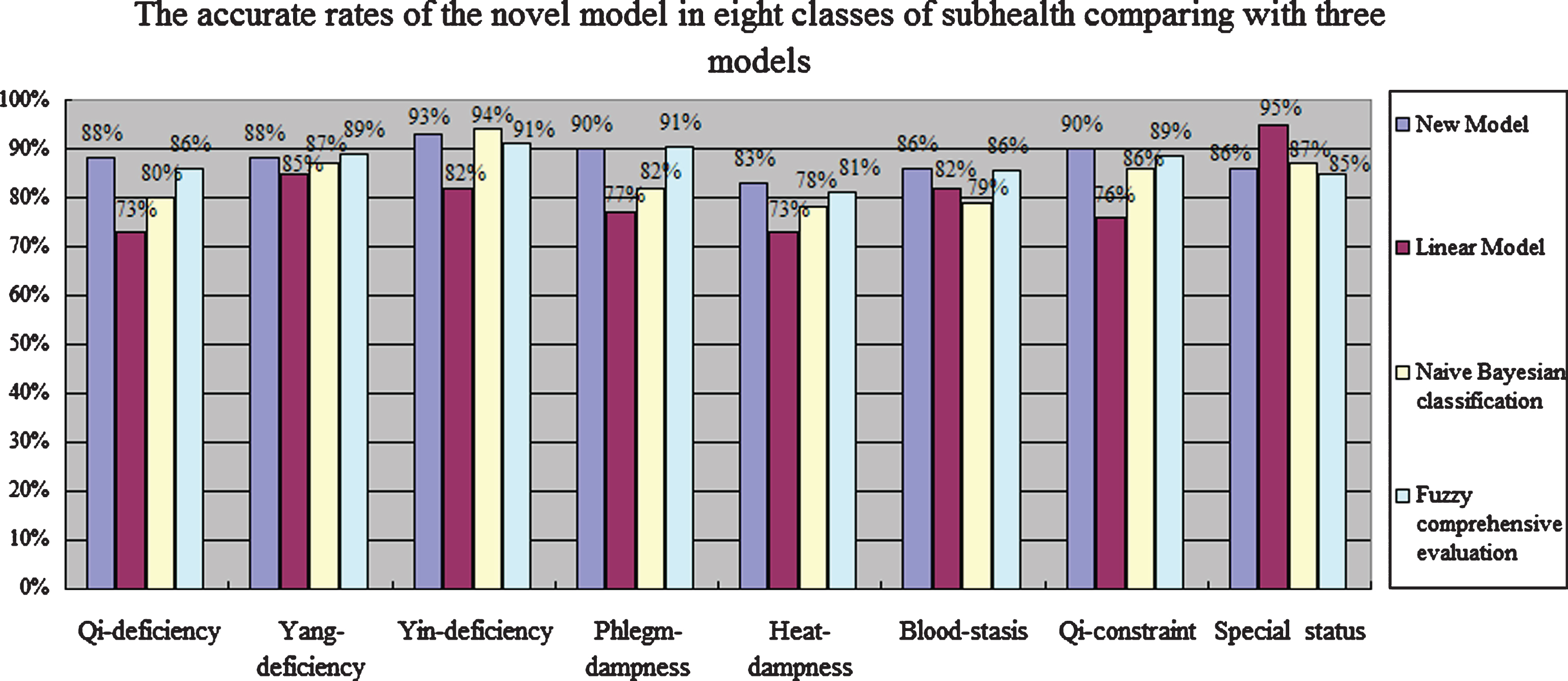
The accuracies in eight classes of sub-health compared to linear model, Naive Bayesian classification and fuzzy comprehensive evaluation.
The novel model works well in global with accuracies from 83% to 93% in all classes of sub-health. And it works best in the diagnosis of “Yin-deficiency” with the highest accuracy of 93%, but works a little poor in the diagnosis of “Heat-dampness” which is only with a lower accuracy of 83%. Compared with linear model, the novel model works well with an average accuracy of 88% than the linear model with an average accuracy of 79%. The novel model has higher accuracy than the linear model in all classes of sub-health except for“allergies”.
Compared with Naive Bayesian classification, the accuracies of Naive Bayesian classification are 78% to 94%. The results shows that the novel model may be more stable than Naive Bayesian classification. In Fig. 4, the accuracies of novel model in all classes of sub-health are higher than Naive Bayesian classification in addition to “Yin-deficiency’ and “allergies”. The accuracy of “Yin-deficiency” in the novel model is 93% compared to Naive Bayesian classification with an accuracy of 94%. The accuracy of “allergies” in the novel model is 86% compared to Naive Bayesian classification with an accuracy of 87%. There are only little differences. Therefore, the novel model has higher accuracies than Naive Bayesian classification in global.
Compared with linear model and Naive Bayesian classification, fuzzy comprehensive evaluation has higher accuracies in most classes of sub-health. Fuzzy comprehensive evaluation has approximate accuracies compared to the novel model in most classes of sub-health. However, the novel model has higher accuracies in all classes of sub-health than fuzzy comprehensive evaluation apart from “Yang-deficiency” and “Phlegm-dampness”. The new model with an accuracy of 88% is a little lower than fuzzy comprehensive evaluation with an accuracy of 89% in “Yang-deficiency”. And the novel model with an accuracy of 90% is a little lower than fuzzy comprehensive evaluation with an accuracy of 91% in “Phlegm-dampness”. So the accuracies of novel model are a little better than fuzzy comprehensive evaluation on the whole level.
The accuracies of the novel model comparing to linear model, Naive Bayesian classification and fuzzy comprehensive evaluation are carried out by the statistical method of Pearson Chi-Square. The detailed data is shown in Table 3. Compared to the new model and linear model, the sig values (significative p values) are less than 0.05 except for “Qi-constraint” (sig = 0.328 = 5.754) and “Special status” (sig = 0.216 = 3.210). “Heat-dampness” has the minimum value (sig = 0.000 = 2.903). The results show that the differences of accuracies between the novel model and linear model in many classes of sub-health are significant. Similarly, Compared to the new model and Naive Bayesian classification, the differences are significant besides of “Heat-dampness” (sig = 0.135 = 4.008) and “Special status” (sig = 0.187 = 7.534). “Blood-stasis” (sig = 0.000 = 2.381) and “Qi-deficiency” (sig = 0.000 = 3.582) are the most significant. Compared to the new model and fuzzy comprehensive evaluation, the differences are significant besides of “Qi-deficiency” (sig = 0.217 = 8.231). And “Phlegm-dampness” (sig = 0.000 = 6.561) is the most significant. Results illustrated that,the accuracies of novel model are credible in global. The fluctuation of curve of accuracies among the four models, are shown in Fig. 5. The results showed that there are some inflection points,the inflection points changed drastically with curves of the neighboring model going. The important symptoms in these classes of sub-health are similar. Specifically, the important symptoms in Yin-deficiency may be more similar and the important symptoms in Qi-constraint may be more discrete.
The differences of accurate cases of the novel model compared to linear model, Naive Bayesian classification and fuzzy comprehensive evaluation
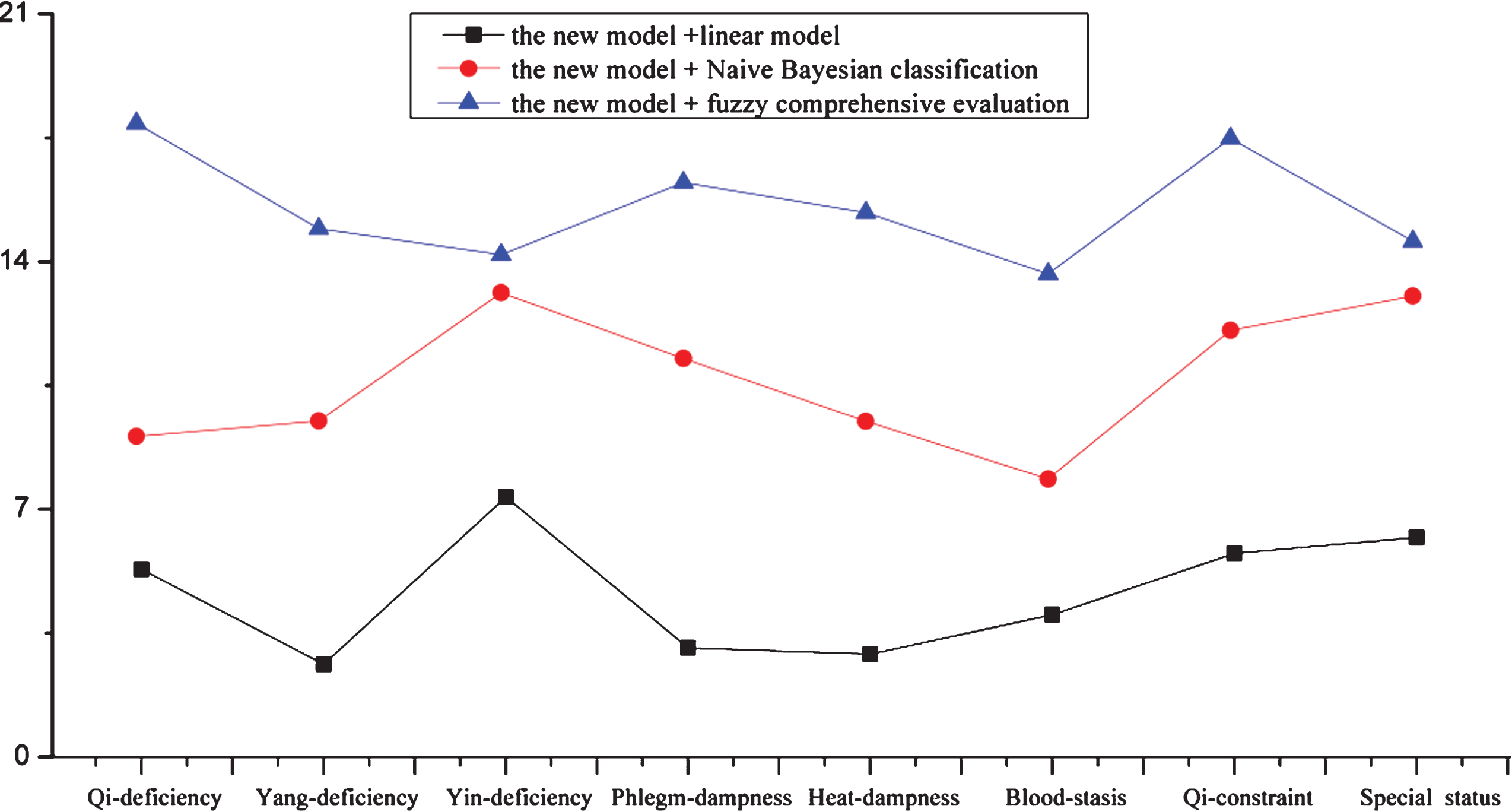
Tthe comparisons of variance volatilities of accuracies among the four models.
Diagnosis of sub-health is a typical problem of classification and decision with priori knowledge and data. However, it’s difficult for us to obtain the accurate weights from the known knowledge. Rough set can help us to find the most important symptom and its weight with indiscernibility relations on attribute sets. It may be a good method to achieve fuzzy weights form a large number of medical records based on rough set. Therefore, a computer-aided diagnosis system can be designed to update weight matrixes from EMRs automatically to perform the intelligent training functions and learning functions.
The linear model [3] characterizes the weights of symptom according to experts’ subjective experiences, calculates the total scores for each class of sub-health with linear summations and gives a primary diagnosis via the maximum total score. In linear model, “allergies” is a class of sub-health which is related to allergy and genetics [3], and related important impact factors such as urticaria has been known. The impact factors (symptoms) of “allergies” are distinctive in all classes of sub-health, so “allergies” can be diagnosed more easily with linear model.
Naive Bayesian classification is a classification mathematics method which obtained the results based on the calculations and comparisons of the conditional probabilities [22]. Naive Bayesian classification considers all the symptoms, including the impact factors and non-impact factors. However, the novel model only considers the impact factors and calculates results with their fuzzy weights. So the novel model might be more close to reflecting the relationships between symptoms and classes of sub-health.
Fuzzy comprehensive evaluation is an effective evaluation mathematical method which determines classification results according to the weights ofinfluence factors and fuzzy subordinate functions [23, 24]. It has been applied to the evaluations of medical researches [23, 24]. However, the range of variables (symptoms) is wide in this study, it may be difficult for the fuzzy subordinate functions to show the importance of some core symptoms and to help obtain high accuracy.
Conclusions
In this study, a novel computational model is presented to diagnose sub-health based on rough set and fuzzy mathematics. Compared with linear model, Naive Bayesian classification and fuzzy comprehensive evaluation, the novel model had higher accuracies in global. Based on the novel model in this study, an intelligent system for aided diagnosis of sub-health can be built in the future. This system can be linked to EMR(electronic medical records) databases in hospital to obtain clinical data and to achieve automatic learning functions and training functions for diagnostic model, to help clinicians to give rapid and objective diagnosis of sub-health. So it can be used to analyze big data of sub-health and play an active role in intelligent medicine in the future and help us to monitor the state of sub-health in human body. However, the priori knowledge in this model depends on the number of medical cases. In order to get the more precise weights, the number of medical training cases should be increased.
Conflict of interests
The authors declare that they have no competing interests.
Footnotes
Acknowledgments
We acknowledge the editors and reviewers to help us to improve this manuscript. The paper is supported by Guangdong science and technology project fund (No. 2014A020221034).