
Abstract
Multi-document summarization aims to produce a concise summary that contains salient information from a set of source documents. Many approaches use statistics and machine learning techniques to extract sentences from documents. In this paper, we propose a new multi-document summarization framework based on sentence cluster using Nonnegative Matrix Tri-Factorization (NMTF). The proposed framework employs NMTF to cluster sentences using inter-type relationships among documents, sentences and terms, and incorporate the intra-type information through manifold regularization. The most informative sentences are selected from each sentence cluster to form the summary. When evaluated on the DUC2004 and TAC2008 datasets, the performance of the proposed framework is comparable with that of the top three systems.
Keywords
Introduction
The exponential growth in the volume of documents available on the Internet brings the problem of finding out whether a single document can meet a user’s complex information need. In order to solve this problem, multi-document summarization, which reduces the size of documents while preserves their important semantic content is highly demanded. Most of the summarization work done till date follow the sentence extraction framework, which ranks sentences according to various pre-specified criteria and selects the most salient sentences from the original documents to form summaries [1].
Though traditional feature-based ranking approaches and graph-based approaches employ quite different techniques to rank sentences, they have at least one point in common, i.e., all of them focus on sentences only, but ignore the information beyond the sentence level. Actually, in a given document set, there usually exist a number of themes (or topics) with each theme represented by a cluster of highly related sentences [2]. These theme clusters are of different size and especially different importance to assist users in understanding the content in the whole document set. The cluster level information is supposed to have foreseeable influence on sentence ranking.
In order to enhance the performance of summarization, cluster-based ranking approaches have been explored in the literature [3]. Normally these approaches apply a clustering algorithm to obtain the theme clusters first and then rank the sentences within each cluster or by exploring the interaction between sentences and obtained clusters. So the sentence ranking performance is inevitably influenced by the sentence clustering result.
The key part in sentence clustering is to estimate the similarity between two sentences [4]. Intuitively, many similarity measures traditionally used for document clustering cannot be directly applied to sentence clustering. The solutions that rely on term overlaps can be effective when dealing with documents because the documents about the same topic may share many terms in common. However, the sentences with very similar meanings do not necessarily share enough terms, owing to the short length and the limited content that they contain. Inevitably, the similarity measures based on term overlaps alone fail to perform well in sentence clustering. To help alleviate this problem, Nonnegative Matrix Factorization (NMF), which utilizes relationship between sentences and terms or sentences and documents, has been used in sentence clustering [5]. However, there also exist relationships between sentences and sentences, terms and terms, documents and documents, documents and terms, documents and sentences.
In this paper, we propose a new multi-document summarization framework based on sentence cluster using Nonnegative Matrix Tri-Factorization (NMTF). One of the benefits of the framework is that inter-type relationships between three text objects, i.e., documents, sentences and terms, can be fully utilized, moreover intra-type information between documents and documents, sentences and sentences, terms and terms can be also incorporated through manifold regularization. So the sentence cluster performance can be further enhanced via these relationships.
The main contributions of this paper are three fold. (1) Nonnegative Matrix Tri-Factorization based sentence clustering framework is developed; (2) two sentence clustering approaches are developed, which allow term and/or document plays an explicit role in sentence clustering as an independent text object so that sentence clustering can benefit from inter-relationship and intra-relationship among them; and (3) thorough experimental studies are conducted to verify the effectiveness of the proposed framework.
The rest of this paper is organized as follows. Section 2 reviews related work. Section 3 presents Nonnegative Matrix Tri-Factorization based sentence clustering framework that enhances sentence clustering using inter-type relationships among documents, sentences and terms, and incorporates the intra-type information through manifold regularization. Section 4 addresses other issues in theme-based summarization. Section 5 addresses experiments and evaluations. Conclusions are presented in Section 6.
Related work
A variety of summarization approaches have been proposed in the literature. These approaches are either extractive or abstractive. Extractive summarization assigns a significance score to each sentence and extracts the sentences with highest scores to form the summaries. Abstraction summarization, on the other hand, involves a certain degree of understanding of the content conveyed in the original documents and creates the summaries based on information fusion and/or language generation techniques [6]. Like most researchers in this field, we follow the extractive summarization framework [7] in this work.
Under the framework of extractive summarization, sentence ranking [8] is the issue of most concern. Beyond that, when the given documents are all supposed to be about the same topic, they are very likely to repeat some important information in different documents or in different places in the same document. Therefore, effectively clustering the sentences with the same or very similar content is necessary. Recently it has been successfully applied in cluster-based summarization [2, 3]. These cluster-based summarization approaches utilize the clustering results to select the representative sentences in order to generate summaries. Alternatively, the clustering results could be used to improve or refine the sentence ranking results. Wan and Yang [9] proposed two models to incorporate the cluster-level information into the process of sentence ranking for generic multi-document summarization, namely ClusterCMRW and Cluster-HITS. The ClusterCMRW (Cluster-based Conditional Markov Random Walk) model incorporates the cluster-level information into the text graph and manipulates clusters and sentences equally, the Cluster-HITS model treats clusters and sentences as hubs and authorities in the HITS algorithm. Zheng et al. [10] proposed a novel approach for multi-document summarization based on sentence clustering, which detects redundancy when selecting representative sentences. Zhang et al. [11] proposed a density peaks sentence clustering approach for multi-document summarization, which measures representativeness, diversity and conciseness at the same time.
Steinberger et al. [12] proposed a LSA-based multi-document summarization approach. Li et al. [13] extended generic multi-document summarization using LSA to query-based document summarization. Zha [14] proposed generic summarization using sentence clustering and the mutual reinforcement principle (MRP). Their method clusters sentences of documents into several topical groups. Sentences are extracted from each topical group by their saliency scores which are computed using the MRP, this is a modified LSA method. This method guarantees that the elements of a singular vector with respect to semantic feature values will be only positive values, even though the semantic features do not necessarily identify subtopics. Yeh et al. [15] proposed a document summarization method using LSA and a text relationship map (TRM). Their method uses LSA to derive the semantic matrix of a document and uses semantic representation of a sentence to construct a semantic text relationship map. TRM is constructed using the similarity between semantic representations, and important sentences are extracted by using the number of links in the TRM. This method does not consider subtopics for document summarization.
Wang et al. [13] proposed a language model to simultaneously cluster and summarize documents. Nonnegative factorization is performed on the term-document matrix using the term-sentence matrix as the base so that the document-topic and sentence-topic matrices could be constructed, from which the document clusters and the corresponding summary sentences are generated simultaneously. Lee et al. [5] proposed an unsupervised method using Non-negative Matrix Factorization (NMF) to select sentences for automatic generic document summarization. Park et al. [16] used relevance feedback (RF) and NMF to distill the contents of the documents with respect to a given query, to generate a document summarization. The approach can reduce the semantic gap between the low level feature representation in vector model and the high level user’s perception by means of iterative relevance feedback. Shen et al. [17] proposed Bi-mixture PLSA with sentence bases to simultaneously cluster and summarize the documents utilizing the mutual influence of the document clustering and summarization procedures. Tan et al. [1] proposed a joint matrix factorization and manifold-ranking framework for topic-focused multi-document summarization, which aims at learning better sentence similarity scores and better sentence ranking scoressimultaneously.
These approaches either utilize topic information and sentence itself information or utilize inter-relationships between sentences and terms, sentences and documents, ignoring intra-relationships among them. We propose Nonnegative MatrixTri-Factorization based sentence clustering framework, which uses not only inter-relationships between sentences and terms, sentences and documents, terms and documents, but also intra-relationships among documents, sentences and terms.
Non-negative matrix tri-factorization based sentence clustering framework
Problem formulation
First of all, let’s introduce the document-sentence-term tri-type graph model for a set of given documents, based on which the sentence clustering framework is developed. Let G =< V, E, R, W >, where V is the set of vertices that consists of the document set D = {d1, d2, …, d
b
}, the sentence set S = {s1, s2, …, s
n
} and the term set T = {t1, t2, ⋯ , t
m
}, i.e., V = D ∪ S ∪ T, b is the number of documents, n is the number of sentences and m is the number of terms. Each term vertex is the sentence that is given in the WordNet as the description of the term. It extracts the first sense used from WordNet instead of the term itself
1
. E is the set of edges that connect the vertices in V, i.e., E = {< v
i
, v
j
|v
i
, v
j
∈ V >}. R is a set of inter-type relationship matrices that consists of
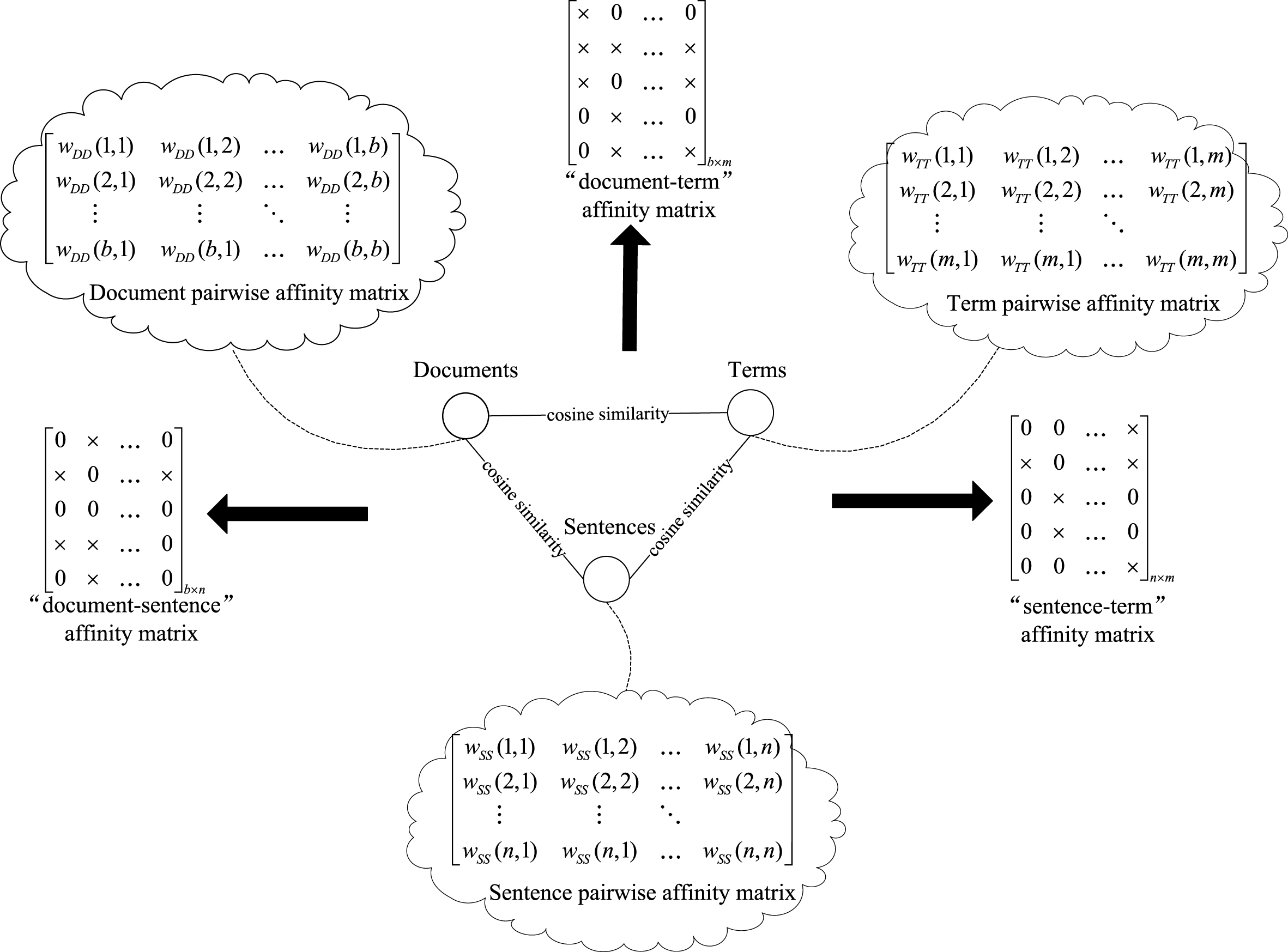
The tri-type graph is composed of documents, sentences and terms, involving (1) Inter-type relationships (solid lines): the relations between objects in different types. (2) Intra-type relationships (dashed lines): the relations between different text objects in a same type.
Using inter-type relationships
Let us first consider clustering sentences via relationships between sentences and terms. The close connection between Nonnegative Matrix Factorization (NMF) and clustering provides the potential theory to develop the method. Ding et al. proposed to use NMTF [19] to simultaneously cluster the rows and columns of an input nonnegative relationship matrix by decomposing it into three nonnegative factor matrices. We apply it to R ST matrix, which minimizes the following objective:
Simultaneous clustering on S and T is then achieved by solving Equation (1). As the rows of G S (with normalization) can be interpreted as the posterior probability for clustering on S [19], the cluster label of s i is obtained by
Let us move to clustering sentences using inter-type relationship between sentences and documents. We replace R ST with R SD . Likewise, we use the equation similar to Equation (1) to solve the problem.
The optimization objective in Equation (1) only involves the inter-type relationships of two types of text objects, whereas the intra-type information which is deemed important in sentence clustering [20] has not been used. In this section, we incorporate the intra-type information through Laplacian regularization. For the two types of text objects, i.e. sentences and terms, given the intra-type information in form of the pairwise affinity matrices W SS and W TT , we can incorporate them into Equation (1) as follow:
In the following, we will present the solution to Equation (3). As we see, minimizing Equation (3) is with respect to X
ST
, G
T
and G
S
, and we cannot give a closed-form solution. We will give an alternating scheme to optimize the objective. In other words, we will optimize the object with respect to one variable while fixing the other variables. This procedure repeats until convergence.
Optimizing Equation (3) with respect to X ST is equivalent to optimizing
Optimizing Equation (3) with respect to G T is equivalent to optimizing
We introduce the Lagrangian multiplier
Using the Karush-Kuhn-Tucker condition [22] α
ij
G
T
(i, j) =0, we get
Introduce
Equation (10) leads to the following updating formula
Optimizing Equation (3) with respect to G S is equivalent to optimizing
Similar with the computation of G
T
, we introduce the Lagrangian multiplier
Setting
Using the Karush-Kuhn-Tucker complementarity condition [35] β
ij
G
S
(i, j) =0, we get
Introduce
Equation (16) leads to the following updating formula
The number of iterations of the sentence clustering using inter-relationships and intra-relationships with sentences and terms approach is denoted as N1. The input data R
ST
is an n × m matrix. The cost of Equation (5) is O (nN1C
S
C
T
), the cost of Equation (11) is O (mC
T
) and the cost of Equation (17) is O (nC
S
). The cost of obtaining initial sentence cluster is
We also normalize the final matrix G S , the cluster label of s i is obtained by Equation (2). Convergence proof of the algorithm please refers to [24]. Clustering sentences using inter-type relationship between sentences and documents and their intra-type relationship is similar to the above solution.
Sentence clustering using three types of text objects
Using inter-type relationships
When adding specific term semantics or the document context can enhance sentence clustering, we believe that using both of them should be able to bring us the further boosted clustering performance. To go one step further, we cluster sentences using documents, sentences and terms information. This time, we generalize the objective in Equation (1) to simultaneously cluster three text objects, that is to solve the following optimization problem [25]:
However, it is not straightforward to solve Equation (18) by generalizing existing iterative multiplicative NMTF solution algorithms. Motivated by [26] that deals with bipartite graph, we propose to solve the optimization problem in Equation (3) by solving an equivalent Symmetric NMTF problem.
We first present the following lemma.
Based on Lemma 1, we have the following theorem.
Theorem 1 presents a general framework via NMTF to simultaneously cluster three types of text objects using the inter-type relationship matrices. So cluster label of s i can be obtained byEquation (2).
Under R, X and G defined in Equation (22), we denote
We approach sentence clustering using information of three types of text objects by solving the following optimization problem:
We introduce the Lagrangian multipliers 4Λ and minimize the Lagrangian function as follows:
Fixing G, letting ∂L/ - ∂X = 0, from Equation (27) we get
Before computing G, we first introduce two lemmas which have been proved in [27].
Based on the above lemmas, we prove the following theorem.
Then the following function
The algorithm of sentence clustering using inter-relationships and intra-relationships among three types of text objects via NMTF is presented in Table 2. The final cluster labels of s i are obtained from the resulted G S using Equation (32).
Cluster quality evaluation on the DUC2004 dataset
Sen = sentence; Doc = document; LSA = Latent Semantic Analysis.
Cluster quality evaluation on the TAC2008 dataset
Sen = sentence; Doc = document; LSA = Latent Semantic Analysis.
The number of iterations of the sentence clustering using inter-relationships and intra-relationships among sentences, documents and terms approach is denoted as N2. The input data G is a (n + m + b) × (C
S
+ C
W
+ C
D
) matrix. The cost of Equation (28) is O ((n + m + b) 2 × (C
S
+ C
W
+ C
D
)), the cost of Equation (32) is O ((n + m + b) 3 × (C
S
+ C
W
+ C
D
)). The cost of obtaining initial sentence cluster is
Theme-based summarization
Cluster number estimation
Our aim is to cluster sentences and select sentences in each cluster to form a summary. Note that our proposed NMTF-based sentence clustering framework requires predefined cluster number c S , c T and c D . To avoid exhaustive search for a proper cluster number for each document set, we employ the spectra approach introduced in [28] to predict the number of the expected clusters. Based on the sentence similarity matrix W SS using the normalized 1-norm, for its eigenvalues β i (i = 1, 2, …, n), the ratio φ i = βi+1/ - β2 (i ≥ 1) is defined. If φ i - φi+1 > 0.05 and φ i is still close to 1, then set c S = i + 1. Similarly, we can set the term cluster number c T and the document cluster number c D in the same way.
Summary generation
In multi-document summarization, the number of documents to be summarized can be very large. This makes information redundancy appear to be more serious in multi-document summarization than it is in single-document summarization. Redundancy control is necessary. Two popular techniques for avoiding redundancy in summarization are maximal marginal relevance (MMR) [29] and clustering [3]. In MMR, the determination of redundancy is based mainly on the textual overlap between the sentence that is about to be added to the output and the sentences that are already in the output. MMR has been modified by many researchers [30]. On the other hand, clustering offers an alternative that the summarization system clusters the input textual units before starting the selection process. This step allows analyzing one or a few number of representative units from each cluster instead of all textualunits.
We combine the aforementioned two methods to generate document summarization as follows: We get sentence clusters based on the proposed framework at first. Then we define a coefficient θ
k
to evaluate the importance of each cluster C
k
(1 ≤ k ≤ c
S
), which is formulated as the normalized cosine similarity between a theme cluster and the whole document set for generic summarization, or between a theme cluster and a given query for query-based summarization, θ
k
∈ [0, 1] and
Experiments and evaluations
Experiment setup
In order to compare our proposed clustering framework, we use surface word matching as the baseline of the experiments. We apply WordNet, LSA and context-based matching to test the influence of sentence representation for sentence clustering [20]. We further apply the proposed NMTF-based sentence clustering framework to test whether sentence clustering results can be improved when inter-relationships and intra-relationships among terms, sentences and documents are used.
We conduct a series of experiments on the DUC 2004 generic multi-document summarization dataset and TAC2008 query-focused summarization datasets. According to the task definitions, systems are required to produce a concise summary for each document set (without or with a given query description) and the length of summaries is limited to 665 bytes in the DUC2004 and 100 words in TAC2008.
Evaluation methods
Intrinsic cluster quality evaluation
In order to evaluate the sentence cluster quality, we need to construct a sentence graph model G1 (S, E
S
) at first, where S = {s1, s2, ⋯ , s
n
} is the set of vertices representing sentences in document sets, E
S
is the set of edges connecting two sentences, every edge in E
S
is associated with a weight measuring the cosine similarity between the corresponding two sentences. Newman et al. [31] define modularity measure Q as follow:
Our final aim is to generate more accurate summarization. We use ROUGE evaluation toolkit [32] to evaluate the generated summarization, which has long been adopted by DUC for automatic summarization. It measures summary quality by counting overlapping units between system-generated summaries and human-written reference summaries. We report three common ROUGE scores in this report, namely ROUGE-1, ROUGE-2 and ROUGE-SU4, which base on Uni-gram match, Bi-gram match and Skip-Bi-gram match, respectively. Documents and queries are pre-processed by segmenting sentences and splitting words. Stop words 2 are removed and the remaining words are stemmed using Porterstemmer 3 .
Performance of sentence clustering based on different measures
We first do the experiment on the DUC 2004 dataset: We vary the parameter λ from 0.1 to 0.9 with stepsize 0.05, and verify when λ = 0.1, the NMTF-based sentence clustering using inter-relationships and intra-relationships among two kinds of text objects can achieve the best performance. Then, NMTF-based sentence clustering using inter-relationships and intra-relationships among three kinds of text objects also achieves best when λ = 0.1. We set λ = 0.1 in the TAC2008 datasets. The evaluations of cluster quality based on the different measures on the DUC2004 and TAC2008 datasets are shown in Tables 1 and 2. From the two tables, we can easily see the performance of each measure. We list reasons for the performance of different sentence clustering measures in Table 3.
Reasons for the performance of different sentence clustering measures
Reasons for the performance of different sentence clustering measures
We further conduct the paired t-test evaluation using the ROUGE-2 recall scores, the primary DUC evaluation criterion, on all 50 DUC 2004 document sets and 48 TAC 2008 document sets. The hypothesis is that “the first algorithm is equal to or inferior to the second one in ROUGE-2,” and the significance level was 5%. The p-values presented in Table 4 suggest that all the hypotheses were rejected, which means the first algorithm is superior to the second one. The evaluation results further confirm that our analysis is correct.
Hypothesis testing (paired t test) on the DUC2004 and TAC2008 datasets
The aim of the NMTF-based sentence clustering framework is to generate more accurate sentence clusters by iteratively refining two text objects clustering (i.e., sentence clustering and term clustering, or sentence clustering and document clustering) or iteratively refining three text objects clustering (i.e., sentence clustering, term clustering and document clustering).
Figure 2 plots the values of Q (the sentence cluster quality) in each iteration of the four proposed NMTF-based sentence clustering algorithms on the DUC2004 dataset, the Q values corresponding to the iterations greater than zero illustrate the qualities of the sentence clusters generated by the four new NMTF-based sentence clustering algorithms (i.e., using inter-relationships between sentences and terms, using inter-relationships and intra-relationships between sentences and terms, using inter-relationships among documents, sentences and term and using inter-relationships and intra-relationships documents, sentences and terms, respectively). The curves clearly show that the quality of sentence clustering using inter-relationships between sentences and terms is much lower than the other three approaches. The increase of Q indicates the improvement of the cluster quality.
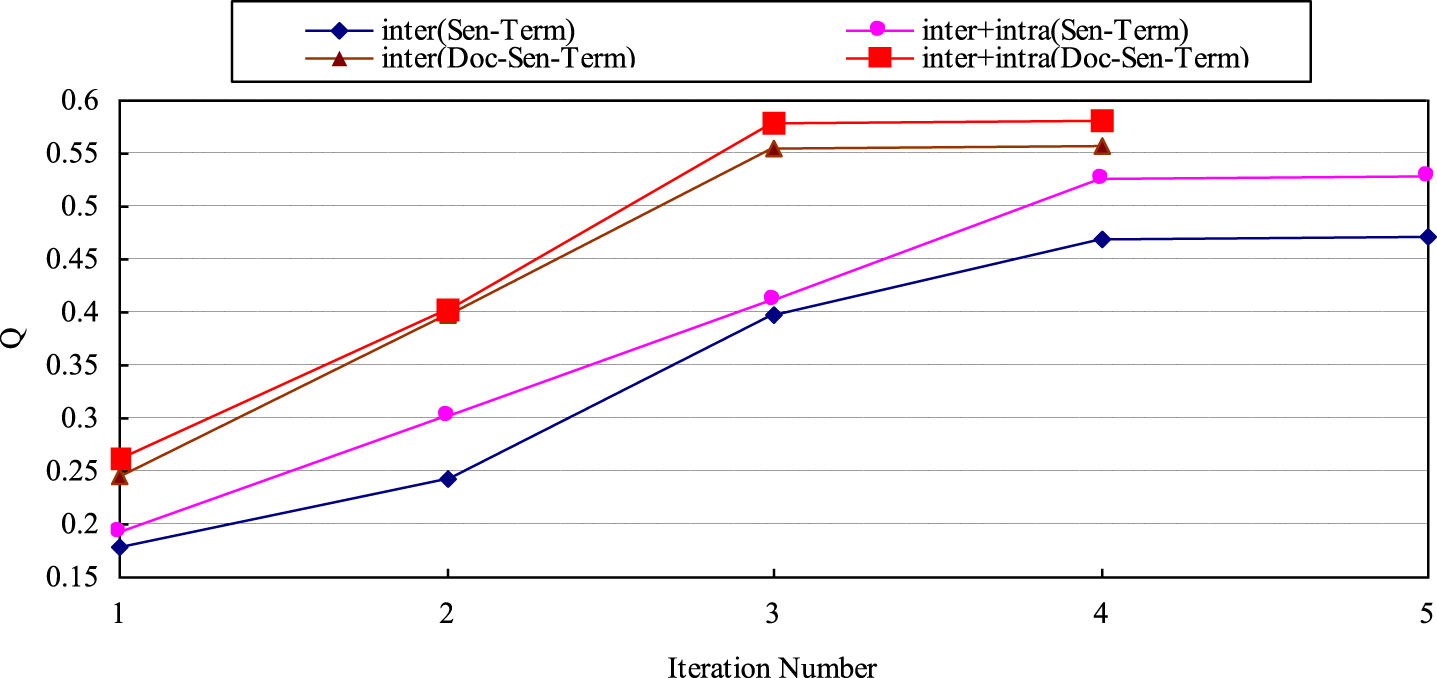
Trends of the cluster quality with increased iteration numbers on the DUC2004 dataset.
While Q directly evaluates the quality of the generated clusters, we also were interested in knowing whether the improved quality of clusters can further enhance the quality of sentence ranking and thus raise the performance of summarization. Therefore, we also evaluated the ROUGEs in each iteration of the four algorithms. Figure 3 illustrates the increase of ROUGE-1, ROUGE-2, and ROUGE-SU4 results on the same dataset mentioned earlier. The figure further shows that the performance of the generated summaries using inter-relationships between sentences and terms is inferior to the performance of the other three algorithms. For fair comparison, except the clustering algorithms, all the other processes involved (i.e., preprocessing, redundancy control, and summary generation) remained the same. Figure 3 demonstrates the significant role of the proposed NMTF-based sentence clustering algorithms in summarization.
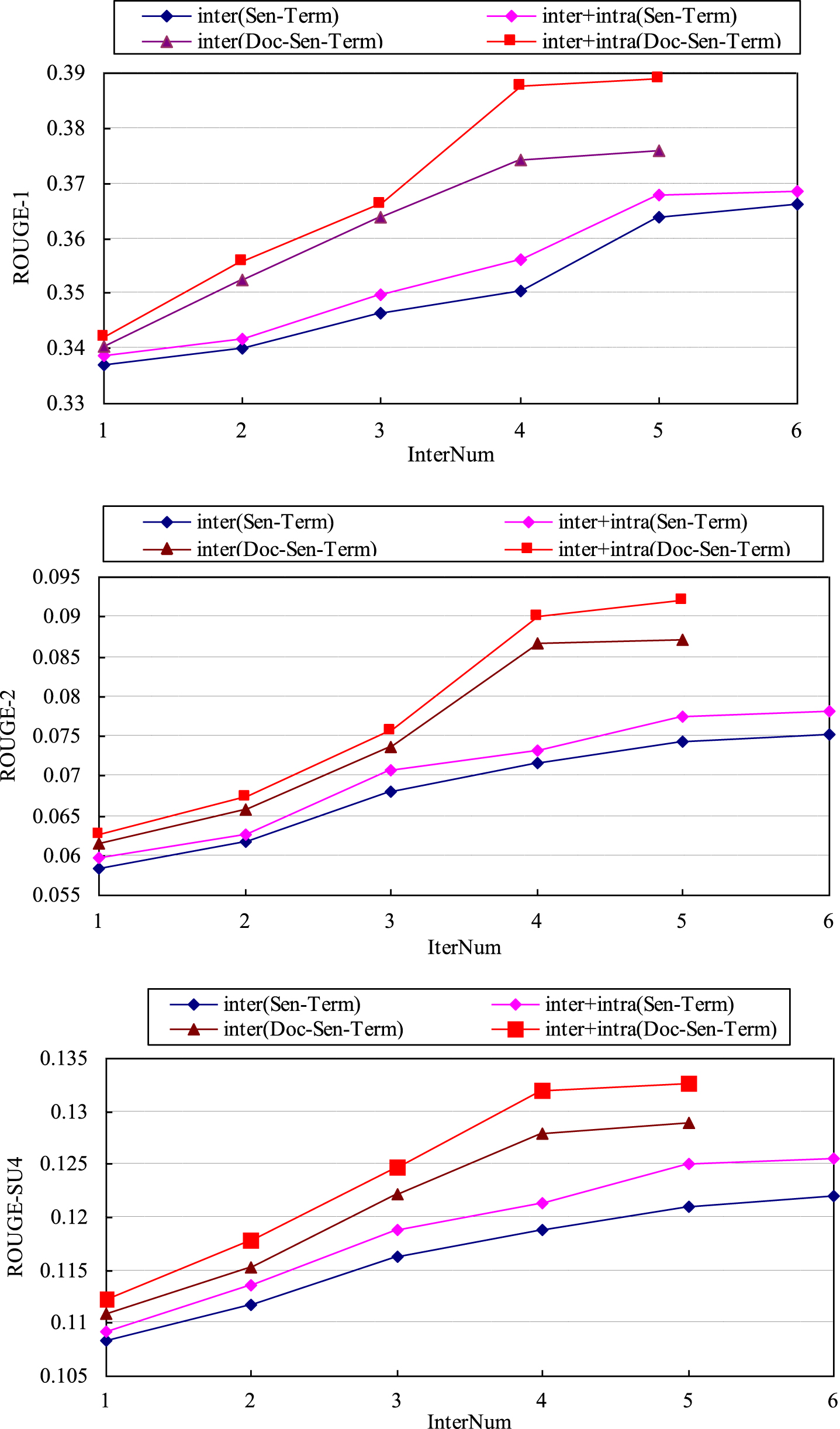
Trends of ROUGEs with increased iteration numbers on DUC2004 Dataset.
Sentence clustering relies heavily on sentence similarity methods, but the sentences with similar meaning always share few common words, so traditional bag-of-words cosine similarity is no longer suitable for measuring sentence similarity. In this paper, we propose a new multi-document summarization framework based on sentence cluster using Nonnegative Matrix Tri-Factorization (NMTF). The proposed framework employs NMTF to cluster sentences using inter-type relationships among documents, sentences and terms, and incorporate the intra-type information through manifold regularization. Experimental results show that the framework is able to generate more reasonable sentence clusters, which in turn lead to more meaningful summarization performance. In future studies, we will focus on the influence of other proper context definitions besides terms and documents on sentence clustering to further enhance the performance of sentence clustering.
Footnotes
The senses of words in WordNet are ranked according to frequency. The first sense is more likely than the second, the second is more likely than the third, etc. So we use the first sense of each word from WordNet.
Words which are filtered out prior to, or after, processing of natural language data (text).
http://tartarus.org/ martin/PorterStemmer/index.html
Acknowledgments
The work described in this paper was supported by China Postdoctoral Science Foundation Funded Project (No. 2017M613205), Basic Research Project Funded by Shenzhen Science and Technology Innovation Committee (No. 201703063000511) and Scientific Research Foundation of Northwestern Polytechnical University (Nos. 3102016QD009 and 3102016QD010).