
Abstract
In this paper we study how the presence or absence of redundancy on multiple related texts can be used to compute sentence relevance for extractive multi-document summarization. Two types of redundancy can be found: intra-document and inter-document. By experimenting with them, different ideas can be extracted, for example: statements redundant between documents—which can be important by their popularity; statements that are not redundant—which can be important by their novelty; or statements redundant within each document—which can be important by being constantly addressed by a single author. We propose an unsupervised graph-based method that allows to generate summaries based on different strategies of redundancy. We present experiments on two DUC corpora of nine different strategies to extract information depending of how redundancy within a document and in different documents is managed. According to DUC gold standards, we found that a multi-document generic summary should contain the most redundant (popular) information between different sources while avoiding local intra-document redundancy. We implemented a mechanism to enrich sentence rankings with redundancy, improving the evaluation of summaries.
Keywords
Introduction
As information consumers, we face everyday the problem of handling massive amounts of data from the Internet. Much of this information is redundant, which complicates the assimilation of content in a big group of texts when looking for a specific topic. This redundancy is in part caused by the freedom to generate information without virtually any control on its content, which in general is a good thing; however, tools to filter this redundancy would be of great help to people who need to digest all this information.
Apart from being a problem to deal with, this huge amount of data can be highly valuable; information redundancy has two faces: it is a problem, but it is also useful for discriminating information. Multi-document summarization deals with this affluence of information with methods to automatically extract the most important ideas from multiple sources and present them into a final summary. In some cases, summarization algorithms can use some clues to determine importance, such as in query-focused, comparative or update summarization: in these approaches, a sentence is considered important if it matches a specific query (query-focused), if it is the most discriminative sentence by representing the characteristics of a document group (comparative), or if it shows information different from what was previously known (of update).
However, one may need a general panorama of what texts say, i.e., a generic summary. In this setting, the importance of information is determined only with regard to the content of the input itself. So, in this case what should be considered of importance to the final reader? This is why we propose a different perspective to search for information in multiple documents based on redundancy, giving importance to an idea by its level of popularity. In this way, this massive redundancy would be of great help at assigning relevance to an idea.
For the purpose of evaluating the effect of redundancy on summarization, we developed an unsupervised method to automatically summarize multiple documents, providing the flexibility of extracting either popular or novel information from these documents. What differentiates this work from others is the way we deal with redundancy. We first analyzed all possible cases of redundancy that can arise per document, and across documents, within multiple texts. Afterwards, we developed a mechanism to extract different summaries—on the same group of documents—containing sentences generated by experimenting with these cases of intra-document and inter-document redundancy, such as: ideas redundant per author, ideas redundant by different authors, unique ideas that are not redundant, etc.
Studies have been carried on to find out what approach of redundancy humans prefer, leaving inconclusive results because this depends always on the information needs [23]. While some studies have suggested that people prefer to consult sources of information with low redundancy, others have shown that people ignore the redundancy in the sources or, in some cases, even prefer it. By applying the aforementioned mechanism on the DUC corpora and evaluating with the ROUGE measures2, we aim to study redundancy in the ambit of multi-document summarization. In this way, we can provide a general statement on what makes an idea important, considering its redundancy, so that it should be included in a summary.
The rest of this paper is structured as follows. In Section 2 we present an analysis of related work from the point of view of how these works handle redundancy. Section 3 explains our proposed method in full detail. In Section 4, we present our experiments to determine the influence of redundancy on summarization, using the proposed method. Finally, in Section 5 we draw our conclusions, along with possible lines of future work.
State of the art
There have been numerous methods that analyze redundancy when looking for information in multiple sources. For example, back in 1998, Bourbakis et al. [1] proposed a methodology for eliminating redundancy from documents of a database by comparing their paragraphs’ features. Back then, there were no common resources for evaluating these methods, so that now we focus on those works that have used DUC corpora and ROUGE measures; in this way, we can find out how redundancy has influenced the measure of sentences’ relevance in multi-document summarization.
All approaches agree that redundancy should be eliminated from the final summary. Some of them manage redundancy at the phase of sentence selection by selecting the top n non-redundant ranked sentences, i.e., avoiding sentences in the summary if their similarity to the previously selected sentences is greater than a given threshold [5, 18].
The maximum marginal relevance (MMR) approach [7] searches novelty by penalizing the score of sentences according to their similarity with the already selected sentences for the summary. But in the same way they penalize this redundancy, they benefit similarity with regard to a given query. This method is typically applied during the process of sentence selection for query-focused summarization methods [12, 16]. In this way, the top sentences composing the final summary are important to the query and are not redundant between themselves, i.e., are diverse.
Modifications have been proposed on the MMR technique to change the benefit in the formula. Instead of benefiting its similarity with a given query, they favor other aspects related to the method, while the penalization on redundancy remains the same. For example Qiang et al. [19] made an adjustment to benefit the coverage of the sentence on the closed patterns of the documents. Also, Hennig [10] changed the formula to benefit the already computed score of the sentence according to its similarity with not only the query, but other elements of the text as the title of the cluster or the title of the document.
Furthermore, some other techniques penalize redundancy on the computation of the sentence score diferently from the MMR technique. For example Radev et al. [20] penalize a sentence if it overlaps with highest ranked sentences; on the other hand, Toutanova et al. [25] use a discount factor on the computation of each feature value of the sentence, where the magnitude of the discount or penalization is related to the similarity with the first selected sentences for the summary.
Some other authors, instead of penalizing, compensate the non-redundancy or diversity. For example, Parveen and Strube [17] compensate sentences by not sharing the same entities, while Galanis et al. [9] compensate sentences by not sharing the same bigrams through an optimization method pursuing, among other variables, in order to maximize the quantity of different bigrams in the final summary.
A different approach is to deal with redundancy in previous stages. In graph-based methods this is considered from the construction of the graph. For example, Mihalcea and Tarau [15] establish a maximum similarity threshold. In this way, very similar sentences are not linked with an edge and thereby they do not add importance to a node. Other graph-based approach is presented by Shen and Li [22], where the summary is represented by the minimum dominating set on a graph built by representing nodes as sentences and edges as similarities, hence leaving out the redundant sentences by looking for the minimum set.
Clustering methods also have been successful in reducing redundancy and representing diversity by grouping sentences which are highly similar to each other into one cluster, thus generating several clusters. Once sentences are clustered, sentence selection is performed by selecting a sentence from each cluster. At the end some extra measures have to be executed on the selected sentences to ensure non-redundancy on the final summary [5, 20].
As can be seen, none of these methods judges directly the importance of an idea by its absence or presence of redundancy. The usual management of redundancy is mainly focused on precisely avoiding it on their final summary. This is why this work focuses on studying redundancy handling through a flexible framework that allows us to experiment with different redundancy settings. This framework will be explained in the following section.
Proposal
We aim to take advantage of the presence or absence of intra-document and inter-document redundancy as relevant information. Of course, at the end redundancy should be eliminated from the final summary, but this information on sentences is not ignored. This section presents our proposed method for this purpose. The explanation is divided in the three stages of the extractive summarization process: sentence extraction, computing relevance—from redundancy—for each sentence, and the generation of the summary from the most relevant sentences.
Sentence extraction
Starting from a group of texts to be summarized, an appropriate representation to manipulate them is necessary. For this purpose, we represent them in a graph adopting a traditional method, i.e., by mapping all the sentences of the texts as nodes and the similarity between them as edges, that is, edges are weighted with the similarity value. The graph is complete: every node is connected to all other nodes.
A suitable similarity measure is very important. Following Le and Mikolov [11], we implemented a cosine similarity measure on sentences represented on a vector space model (Paragraph Vector—also known as doc2vec), which has shown to give good results in measuring similarity considering context. This measure has proven to be the best among other semantic models—such as LSA, LDA, or Word2Vec—for automatic document summarization [4].
For breaking a text into sentences, we used the standard script provided by NIST for evaluating summaries since DUC 20033. This script takes points, ellipsis, exclamation and question marks as end-of-sentence markers, taking care of not cutting well-known abbreviations and pronouns. To improve this process, the script first does some pre-processing steps on the text to homologate the different writing styles from every newspaper provider. By using this script, we conform to DUC standards to determine what is a sentence and what is not. In addition, a basic pre-procesing was performed on sentences by converting them to lower case and stemming—in order to improve the overlapping and sharing of context of words—and by removing punctuation marks.
Relevance search
After extracting sentences into the graph, nodes are weighted to initially determine sentence importance. This latter is going to be useful for decision making at removing sentences. We are adopting the TextRank [14] value as the initial weight of nodes—relevance of sentences. In an undirected graph, node weights are computed as in PageRank: the more connections the node has with other important nodes, the higher score it has. Moreover, the strength of the connection also accounts for giving it importance, i.e., the stronger the similarities of its edges with others, the more relevant the node.
Formally, the TextRank value can be computed as follows: let G = (V, E) be a directed graph with the set of vertices V and the set of edges E, where E is a subset of V × V. For a given vertex V i , let In (V i ) be the set of vertices that point to it (predecessors), and let Out (V i ) be the set of vertices that vertex V i points to (successors). The TextRank score of a vertex V i is defined as follows
Since our graph is not directed, we treated the output and input edges as equal. After computing the initial relevance value for each node, we obtain a graph with weighted edges and weighted nodes, as depicted in Fig. 1. This figure represents all sentences from n documents, where each document has a variable number of sentences (m sentences for document 1, k sentences for document 2, l sentences for document n, etc.)

Graph representation after weighting edges.
Once we have this graph representation, we are able to experiment with redundancy. Redundancy will be exhibited through similarity: if two sentences are highly similar, then these sentences are redundant.
It is possible to determine the relevance of an idea depending on how redundant it is across documents, i.e., inter-document redundancy, or how redundant it is within each document, i.e., intra-document redundancy. For example: one can say that a statement is important if it is redundant across all documents—such as popular information, see Fig. 2a; or that it is important if it is not mentioned across all documents—as the concept of the inverse document frequency, that if it is mentioned by everyone then it is not relevant because everyone knows about it, see Fig. 2b; or that an statement is important if it is redundant only in one document but not on all of them—if only one author thinks it is important maybe it is, as valuable rare information, see Fig. 2c. All these ideas could be valid on different areas such as medicine, news, geography, politics, etc.
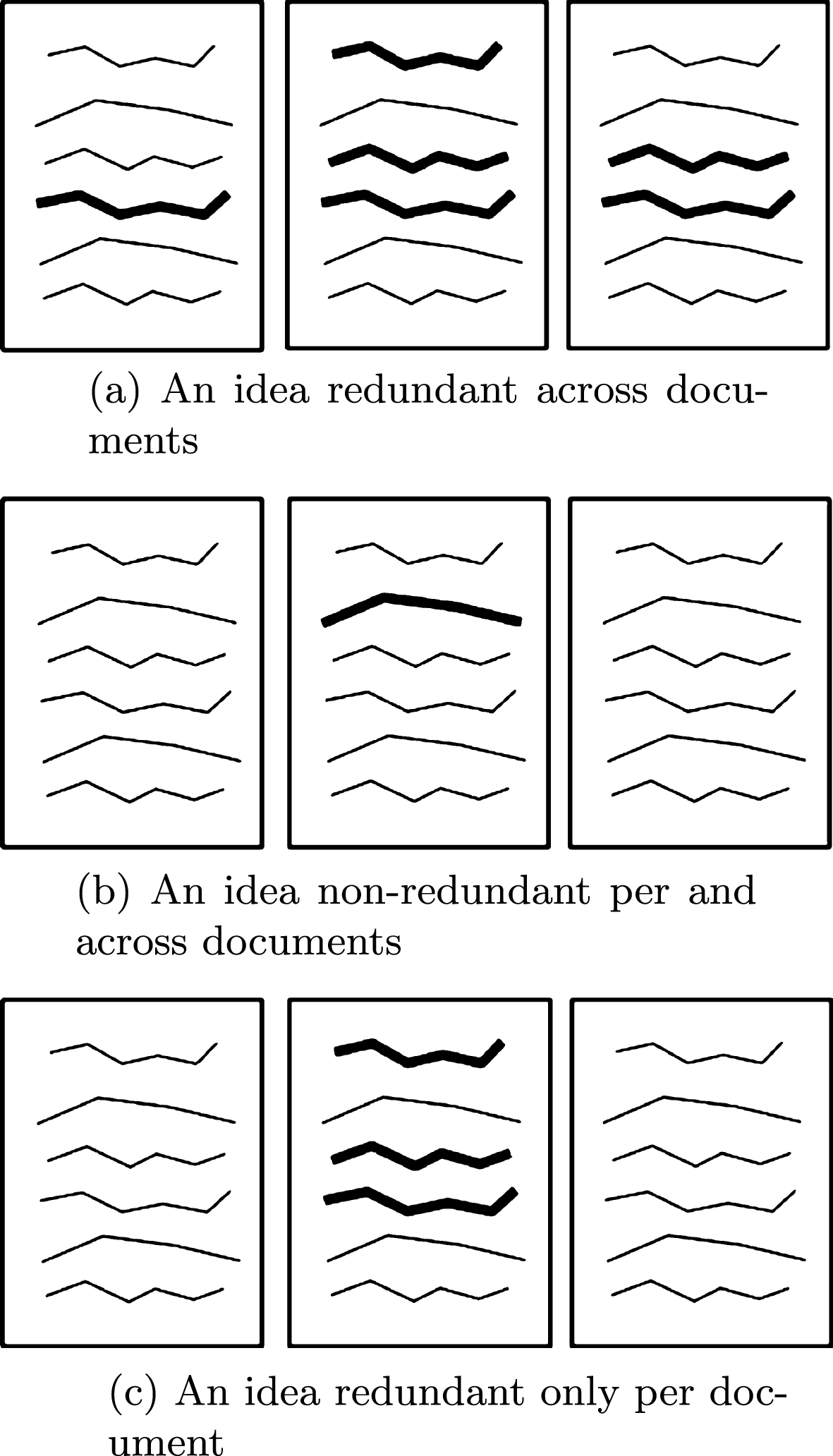
Some strategies to define idea importance according to redundancy.
After considering these notions, we determined nine possible strategies given the combination of intra-document and inter-document redundancy. These strategies establish that a sentence is relevant if: It is redundant per document and redundant across documents. It is redundant per document and not redundant across documents. It is redundant per document. It is not redundant per document and redundant across documents. It is not redundant per document and not redundant across documents. It is not redundant per document. It is redundant across documents. It is not redundant across documents. Redundancy is not taken into account to provide relevance.
Strategies 3 and 6 determine the relevance of a sentence based on intra-document redundancy only, inter-document redundancy is irrelevant. Strategies 7 and 8 are based on intra-document redundancy as well, but consider relevance based on inter-document redundancy, without taking into account intra-document redundancy. Strategy 9 is a combination of these two latter ideas, by ignoring intra-document and inter-document redundancy, so that redundancy is eliminated without taking it into account to determine the relevance of the sentence.
These strategies are more clearly defined based on two parameters:
pd: per-document redundancy parameter, indicating how intra-document redundancy (r.) should be managed, pd = 1 intra-document r. is important, pd = 0 intra-document r. is irrelevant, pd = -1 intra-document r. is undesired. cd: cross-document redundancy parameter, indicating how inter-document redundancy (r.) should be managed, cd = 1 inter-document r. is important, cd = 0 inter-document r. is irrelevant, cd = -1 inter-document r. is undesired.
Having established these strategies, what follows is the merging of similar nodes on the graph, taking care of how the relevance of the nodes is being carried on. To mimic the nature on how documents are processed by human readers, we settled to perform the merging of nodes first by document and then across documents. Starting from the graph with weighted edges and weighted nodes, we present the algorithm for merging, see Algorithm 1.
Merging process
To depict this process, a single merging between two given nodes is shown in Fig. 3. Let us follow the merging process between these two nodes together with the presented algorithm.
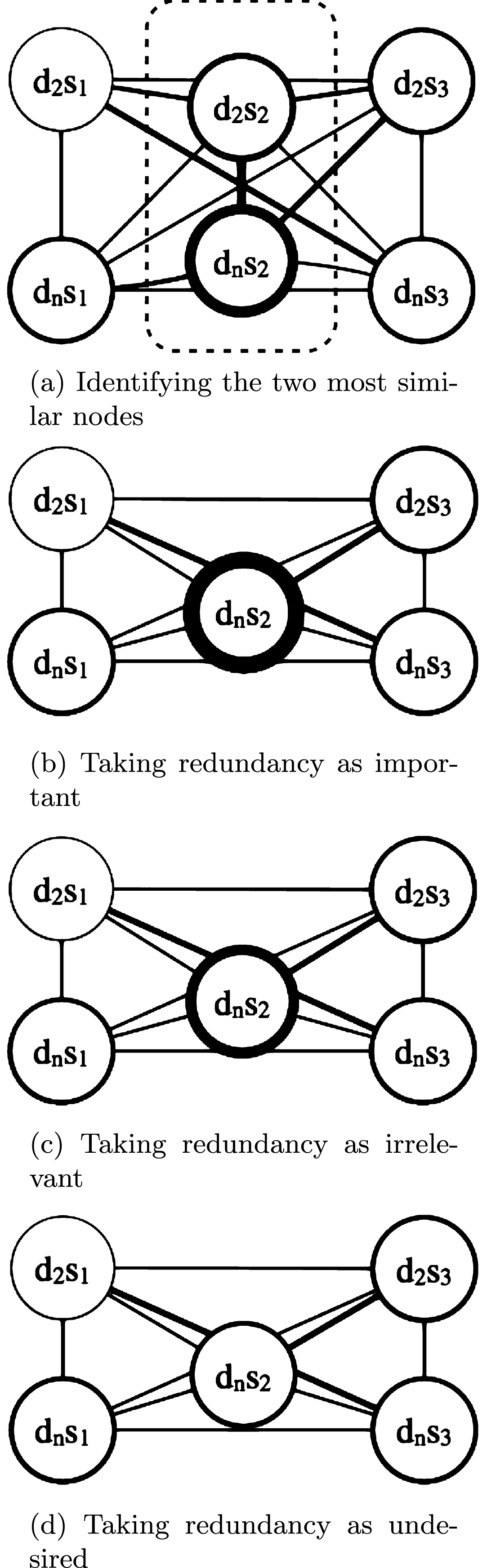
Merging process example of two nodes.
At step 1, the two most similar nodes are detected in Fig. 3a, N+ is d n s2 and N- is d2s2. Next, the merges of these two nodes for step 2 are presented from Fig. 3b to d. For all cases, steps 2.1 and 2.2 of the algorithm are performed in the same way: the text of d n s2 remains, while d2s2 disappears; before disappearing, all the edges of d2s2 are inherited to d n s2 by averaging their weights—this is represented as thickness of the edges. It can be seen how before merging there was no edge between nodes d n s2 and d2s1, which later appears because node d2s2 inherited it to d n s2 before disappearing, with half of its original thickness.
Now we focus on the three possible cases at step 2.3, where the weight of N + is re-computed. Figure 3b shows the resulting relevance of N+ when redundancy is considered as important. Figure 3c shows the resulting relevance of N+ when redundancy is taken as irrelevant, and Fig. 3d shows the resulting relevance of N+ when redundancy is undesired. In this way, the merging process increases, ignores, or penalizes the relevance of the node when it finds a similar sentence, giving the flexibility needed to experiment with the different strategies.
When merging per document, at the first step the two chosen nodes must belong to the same document and the parameter taken into account at step 2.3 is pd. The process finishes when the established intra-document similarity threshold is reached. When merging across documents, at the first step the two chosen nodes must belong to different documents and the parameter taken into account at step 2.3 is cd. The process stops when the established inter-document similarity threshold is reached. Once the algorithm finishes, each sentence will have a computed relevance value according to the selected redundancy strategy.
Once the assignment of relevance to the sentences has finished, a ranking of sentences will result. Usually at this stage, the most relevant sentences compose the final summary, but some measures are implemented to ensure that they are not redundant between each other.
Given that we removed redundancy together with the computing of relevance, no redundancy is expected in the ranked sentences. Therefore, we can simply pick the top relevant sentences and employ them in the final summary until a maximum length is reached, ensuring non-redundancy.
Experiments and results
For our experiments we used the DUC 2004 task 2 and DUC 2007 main task corpora. No data set to train the method was necessary since it is unsupervised. The specifications of these corpora are shown in Table 1.
Specifications of the DUC 2004 and DUC 2007 corpora
Specifications of the DUC 2004 and DUC 2007 corpora
By using DUC corpora, we wanted to study which of the previous stated redundancy strategies are used by gold-standard DUC summaries. Since the majority of works involved in summarization compare their resulting summaries against those summaries provided by DUC, this study will lead us to state the general understanding of what kind of redundancy makes an idea important to become part of a summary—according to DUC gold standards.
For computing the doc2vec-based similarity measure, the Paragraph Vector method was used to create a model and generate vectors of the sentences, later they will be compared using a cosine measure.
We adopted the Distributed Memory Model of Paragraph Vectors (PV-DM) of doc2vec. This is a fully connected multi-layer perceptron with three layers: the input, projection and output layer. As input for the first layer, the one-hot encoded vector of the paragraph and the one-hot encoded vectors of words within this paragraph, must be provided—the number of words is specified by a given sliding window. The number of neurons for this input layer depends on the length of the dictionary of words and paragraphs used for training this neural network. Input vectors are then combined by concatenating them at the projection layer. Finally, at the output layer, a hierarchical softmax with a binary Huffman tree is used to normalize output values and optimize the training process. The training process is made by minimizing the error with the stochastic gradient descent, where the gradient is obtained via backpropagation.
This neural network requires big volumes of texts to be trained. For this requirement, the training was done with the dataset from “One Billion Word Language Modeling Benchmark”4 that has almost 1 billion words. Punctuation marks were removed, so the sentences to be represented afterwards in this vector space model are also processed without punctuation marks. Each resulting vector has a dimension of 100 elements (this is configured at the projection layer of the neural network), the chosen window between the predicted word and context words was of 8 words, we ignored all words with a total frequency lower than 5, and we did 10,000 iterations at the inference stage for computing new sentence vectors.
As doc2vec has proven to outperform other simple similarity measures in different tasks [11], we decided to carry out our experiments based on the doc2vec-based similarity measure.
To exemplify the use of the doc2vec-based similarity measures with the DUC corpora, we present a few sample sentences from a cluster of news of DUC 2002, where the covered topic is the opening of the first McDonald’s in different countries. See Table 2. Consider sentences s3 and s4 as a reference to be compared with the other sentences. Sentence s3 and sentence s8 refer to a similar idea, and sentences s4, s6 and s7 seem to refer to the same fact. Similarity values using doc2vec and the superposition similarity measure—which simply measures the overlapping of words between sentences [14]—are shown in Table 3. doc2vec-based values are between -1 and 1, while similarities of the superposition measure start from 0 having no upper limits—the upper limit depends on the length of the sentence. The highest values reported by the doc2vec-based similarity measure correspond to the most similar ideas, while the superposition similarity measure does not perform well when comparing s3 by giving the highest value to an idea that is not similar. Also note that doc2vec performs better at comparing sentences that are similar but not necessarily by sharing the same words—as the case between s3 and s8.
Examples from DUC 2002 with similarity measures
Examples from DUC 2002 with similarity measures
Similarity values between sentences used for comparison (rounded to the first decimal)
We tested the merging method with all combinations of the parameters described in Section 3.2, yielding nine redundancy strategies. Our method was applied on the graphs built with the clusters of texts from DUC 2004 and DUC 2007 corpora. The resulting summaries were evaluated against summaries provided by DUC with the ROUGE method.
Table 4 presents the results of the experiments performed on the DUC 2004 corpus, while Table 5 presents the results of the experiments performed on the DUC 2007 corpus. Only recall measures are presented for these experiments, and results are ordered by ROUGE-1 in descending order.
Results for redundancy strategies for DUC 2004 texts
Results for redundancy strategies for DUC 2004 texts
Results for redundancy strategies for DUC 2007 texts
Table 4 shows that, for DUC 2004, the strategy that generated the best ROUGE results was number 7, i.e., giving relevance to ideas redundant across documents. The next two best results reinforce the same idea: giving relevance to ideas redundant across documents (cd = 1) is the best strategy. On the other hand, the strategies where an idea is penalized by being redundant across documents (cd = -1) were ranked in the four worst results.
Another interesting pattern to notice is, when the cd parameter is left static, the pd parameter follows the same ranking: first, it is best to ignore intra-document redundancy (pd = 0), a less good strategy is to penalize it (pd = -1), and the worst strategy is to take it into account to provide relevance (pd = 1). A similar case happens when the pd parameter is left static, being the same rank for the cd parameter: the best strategy is to take into account inter-document redundancy (cd = 1), then ignore this redundancy (cd = 0) and being the worst option to penalize it (cd = -1).
The more the inter-document redundancy is considered as favorable, the better results are, whereas intra-document redundancy is irrelevant for the importance of the sentence.
For DUC 2007, Table 5 shows that the best strategy is number 6 or number 4 with a small difference on the scores. Both strategies penalize the relevance of the sentence if it is redundant per document (i.e., intra-document redundancy). Strategy 6 does not take into account inter-document redundancy while strategy 4 does. On the other hand, the worst three strategies, resulted from penalizing inter-document redundancy (cd = -1).
An interesting pattern to observe is that, when the cd parameter is left static: the best option is to penalize intra-document redundancy (pd = -1), then ignore this redundancy (pd = 0) and the worst option is to consider relevance when intra-document redundancy is present (pd = 1).
For the case of DUC 2007, we can say that penalizing redundancy per document yields better results, while statements that are redundant across documents (i.e., inter-document redundancy) are desirable. In other words, statements not biased to a single source are better. We analyzed some clusters of documents where penalizing intra-document redundancy was better and we found that giving importance to this type of redundancy reduces the possibility of taking inter-document redundancy into the final summary, which is more relevant for multi-document summarization.
Finally, the fact that there are strategies that are able to obtain a higher score than strategy 9 (pd = 0, cd = 0), means that considering redundancy to enrich relevance calculation in sentences improves summaries.
Despite the goal of this work is not to outperform the best techniques on multi-document summarization, we present a comparison with other techniques to show that this technique, on its best redundancy strategy for the DUC corpora, is able to outperform well-known baselines. We aimed to leave the method as simple as possible in order to attest the effect of changing redundancy strategies only, while avoiding interference from other improvement stages of the summarization method.
Baseline methods were designed with the purpose of having a reference for comparison that should always be outperformed when a new method is proposed. The most well-known baselines are those required by DUC on their competitions: random, lead and coverage.
We present a comparison between the results of our method with the best redundancy strategy, which was the number 7 (taking ideas redundant across documents) for DUC 2004, and number 4 (taking ideas redundant across documents, but not redundant per document) for DUC 2007—considering its ROUGE-2 and ROUGE-SU4 scores, against baselines and best performing methods. For these comparisons see Tables 6 and 7. We show only the recall measure for ROUGE-1, ROUGE-2 and ROUGE-SU4, because this is the most widely available score for the methods compared.
Comparison with baselines and best methods using DUC 2004 corpus
Comparison with baselines and best methods using DUC 2004 corpus
Comparison with baselines and best methods using DUC 2007 corpus
To verify statistical significance of presented results for all nine strategies, we present in Table 8 for DUC 2004 the results with their confidence interval of 95%, which are provided by the ROUGE script. To decide whether one strategy is better than another, results can be examined by taking the minimum value of the best strategy and comparing it with the average score for every other strategy.
ROUGE-1 results on all strategies of redundancy for DUC 2004 with a 95% confidence interval
ROUGE-1 results on all strategies of redundancy for DUC 2004 with a 95% confidence interval
For DUC 2004, all strategies with cd = 1 have a minimum score greater than the average score of every other strategy. Therefore, we can conclude that the strategies where cd = 1 outperform others with a 95% of confidence. Regarding the strategies where the cd flag varies between 0 and -1, there are not conclusive differences, even when the pd flag is varied between all of its possible values: 1, 0, - 1.
An unsupervised method to summarize multiple documents was presented. This method provides the flexibility to experiment with all variations of intra-document and inter-document redundancy, allowing to generate summaries with popular or rare—which can be viewed also as novel or diverse—information within a cluster of documents. These summaries can be convenient for some areas where popularity or rarity are useful to provide a general idea of what multiple texts talk about.
Using this method, we presented a study of nine different strategies to extract information depending of how redundancy within a document and in different documents is managed. By studying these strategies on DUC corpora, we could establish a general statement about what makes an idea important—in the ambit of news—to be part of a summary, according to DUC gold standards.
We discovered that summaries should convey ideas redundant across documents, whereas taking ideas redundant per document seems to be inconvenient. The main conclusion we obtained, with a confidence greater than 95%, is that a multi-document generic summary should contain the most redundant—popular—information between different sources. These results lead us to conclude that considering inter-document redundancy is better than ignoring it or penalizing it for generic summaries.
We found also that providing relevance to ideas according to their level of redundancy, does improve the summary. For all methods were a final ranking of sentences results as a process of computing sentence relevance, this method can be implemented as a mechanism to eliminate redundancy and at the same time take it into account to improve the ranking.
Summaries for each corpus are different: summaries from DUC 2004 are generic, while those for DUC 2007 are query-focused. Having obtained different strategies for each corpus is an expected result, since different types of summaries should need different redundancy strategies.
As future work, it is possible to enhance the readability of the final summary by identifying the correct order to present the highest ranked sentences. To find this order, it could be possible to add directed edges on the graph according to the order of appearance of the sentences on each document.
In addition, results of this method can be improved to outperform other methods with several techniques. For example, by applying the proposed merging process on the best performing methods at the stage of redundancy reduction; in this way, the presence of redundancy can be used to improve the value of the sentence’s relevance. It is also possible to try more experiments where better similarity measures are obtained; varying the parameters involved on the neural network of Paragraph Vector; adding more data; more types of pre-processing on the text as stemming, removing punctuation marks or stop words, etc.
Finally, the proposed method can be applied on other corpora apart from DUC, to assess how the same redundancy strategies used to build a good summary for news, vary in different areas. Particularly, evaluation methods without summary references will be explored [13, 24].