
Abstract
Microblogging, an internet-based social media application, is well adopted by people to show their ideas and to exchange their minds. It is also a valuable resource to capture people’s interests, thoughts and actions. The contents that people posted are widely spread with distinctive topical feature and contain sentiment-rich information of individuals. In this paper, a microblogging data mining system is developed, which has three functional modules: data preparation, topic analysis and sentiment computing. In data preparation, the microblogging data collecting module is implemented by hadoop and a storm based managing and preprocessing module is designed so that the data is processed effectively and efficiently. For the topic analysis, an LDA based method is adopted to detect topics hidden in microblogs. We also propose a method to calculate the hot degree of each topic and to track the topic evolution. For the sentiment analysis, an integrated method by combining the emotion and the dictionary is introduced to quantify the sentiment. Furthermore, the system is used to make a spatial sentimental analysis on microblogging data from all provinces of China. The sentiment changes with topic or event are also presented with visualization.
Introduction
The explosive growth of online social media (twitter, facebook, microblogs, weixin,...), has attracted enormous people of all ages in this decade. Twitter has over 316 million registered users and over 140 million tweets are published every day. In China, microblogs, a twitter-like broadcast medium launched in 2009, has accumulated more than 212 millions users up to 2015. People involved in such social media often post their thoughts, forward interesting news, or comment on some information. The contents accumulated in social media not only convey the information about hot topics or events, but also reflect the emotional states or sentiments of individuals.
Topics hidden in microblogs often show users’ regular interest, popular events or hot spots. Detecting users’ interested topics enables us to improve the personalized service such as the targeted advertising, the personalized recommendation and so on. Moreover, detecting hot topics automatically, precisely and efficiently is very useful on government’s decision making. For instance, some popular events in real world, like avian flu, the missing of MH370 etc., caused concerns worldwide. The related news has been discussed and propagated in social media and finally has become a hot topic. Furthermore, the topics are often evolved over time. Therefore, the study of topic detection and topic evolution is an interesting and important problem in both computer science and social science.
However, detecting the topics hidden in microblogs is not the only concern of the governments, who usually want to know “whether citizens are happy? Are they satisfied with the current situation?”. The traditional way is to launch a survey by handing out questionnaires or publishing questionnaire online. Microblogs, as an important source of information propagation, provide us with large amount of rich-opinion data. It enables us to reveal the sentiment of individuals from those data automatically.
Therefore, microblogging data mining plays an important role in social media analysis, which could be used in a wide range of potential applications.
The rest of this paper is organized as follows. The related works are reviewed in Section 2 and the framework is presented in Section 3. Section 4 describes how the data preparation is processed. In this section, we propose a time-line based method to collect tencent-microblogging data and we also present a realtime data managing module based on Apache Storm. Section 5 shows the topic analysis based on LDA, including topic detection, topic tracking and hot degree calculation. All the above work are implemented on tencent-microblogging data. Section 6 elaborates on the sentiment analysis based on dictionary. Moreover, the visualization and spatial analysis are shown in this section, too. Finally, we conclude the whole paper in Section 7.
Related work
With the fast development of Internet-based technologies, we are witnessing an exponential growth in data sets, coined as Big Data era. Knowledge, which is hidden in the data, has to be extracted and built to support human decision-making [1]. A large number of novel algorithms, which focus on knowledge mining from large data, have been investigated [2–4]. In this paper, we review the related work from two aspects: topic models and sentiment analysis.
Topic models
Topic models provide a principled and nice way to discover topic structures from documents, especially for the collection of large scale documents [5]. Generally speaking, topic is characterized by a set of informative keywords or terms [6]. During these years, there are a large number of statistical approaches proposed to model the text document, which is useful to detect topics. In the unigram model [7], each document is supposed to follow a multinomial distribution, and words in the document are independently drawn from the above distribution. It is assumed that each document in the text corpus has a distinct topic so that the mixture of unigrams could be developed. The probability latent semantic analysis (pLSA) [8] is also a well adopted method, which assumes that each document is generated by the activation of multiple topics. Each topic follows multinomial distributions over words, thus, it can be regarded as a relaxation of the mixture of unigrams model, the latter considers each document is generated from only one topic. However, the pLSA model uses a distribution indexed by training documents, thus, the number of parameters being estimated in the pLSA model is growing linearly w.r.t. the number of training documents. Therefore, the pLSA model may be prone to overfitting in many practical applications. Latent Dirichlet Allocation (LDA) [9] addresses the overfitting of the pLSA model by using the Dirichlet distribution to model the distribution of topics for each document. Each word is sampled from a multinomial distribution over words which are specific to this topic. As an alternative, the LDA model is a well-defined generative model and can be used to handle new document easily without overfitting.
In reality, topics are often dynamic and evolve over time. Thus, the temporal information is an important aspect in topic analysis. However, most of the previous works on topic analysis ignored the temporal information. To address this problem, some researchers realized the importance of discover dynamics in topic. Mei et al. studied mining evolutionary topics from texts by comparing topics in consecutive time intervals [10]. Wang et al. designed Topic Over Time (TOT) model that treats time stamp as an observed continuous variable generated by topic [11]. This model was designed to capture the temporal features with beta distribution, and confined topics neatly by keeping the temporal components. Some other models were also proposed to study topic changes over time [12, 13].
With the popularity of social media, large volume of data about human interactions becomes available. Some researches investigated the topic analysis on social media data. Qian et al. proposed a multi-modal event topic model (mmETM) [14], which separated the visual-representative topics and non-visual-representative topics by learning the correlations between the textual and the visual modalities.
Sentiment analysis
Sentiment analysis, a.k.a. opinion mining, is to analyze people’s opinions, sentiments, evaluations, appraisals, attitudes, and emotions towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes. Sentiment analysis could help the development of almost all business and social domain. Therefore, a lot of efforts have been made in automated sentiment analysis. Liu gave a brief investigation about the work on sentiment analysis with three levels: document level, sentence level and aspect level [15]. Ravi et al. made a survey on the work published during 2002-2015, which is organized on the basis of sub-tasks to be performed, machine learning and natural language processing techniques used and applications of sentiment analysis [16].
Sentiment analysis is becoming more and more important with the development of social media. Microblogging service, such as twitter, could provide us a rich source of information about products, personalities, and trends, etc. Thus, many researchers focus on the sentiment analysis on microblogs. Pak et al. proposed a methodology for analyzing sentiment of users in Twitter [17]. Ghiassi et al. introduced an approach to supervise feature reduction using n-grams and statistical analysis to develop a Twitter-specific lexicon for sentiment analysis [18]. Kontopoulos et al. investigated the deployment of original ontology-based techniques towards a more efficient sentiment analysis of Twitter posts [19]. Duwairi et al. gave a framework for sentiment detection in Arabic tweets [20]. To have a better understanding and summarization of the opinion mining, the sentiment visualization was well studied in [21].
As mentioned above, a variety of prospective studies have been done on topic analysis and sentiment analysis. However, little work has been performed on Chinese microblogs, especially on topic analysis and sentiment analysis. It is also necessary to develop a system to mine microblogging data so as to do topic analysis and sentiment analysis together.
Framework
In this section, a framework is designed to manage and mine microblogging data. As shown in Fig. 1, the framework contains three functional modules: data preparation, topic analysis and sentiment analysis.
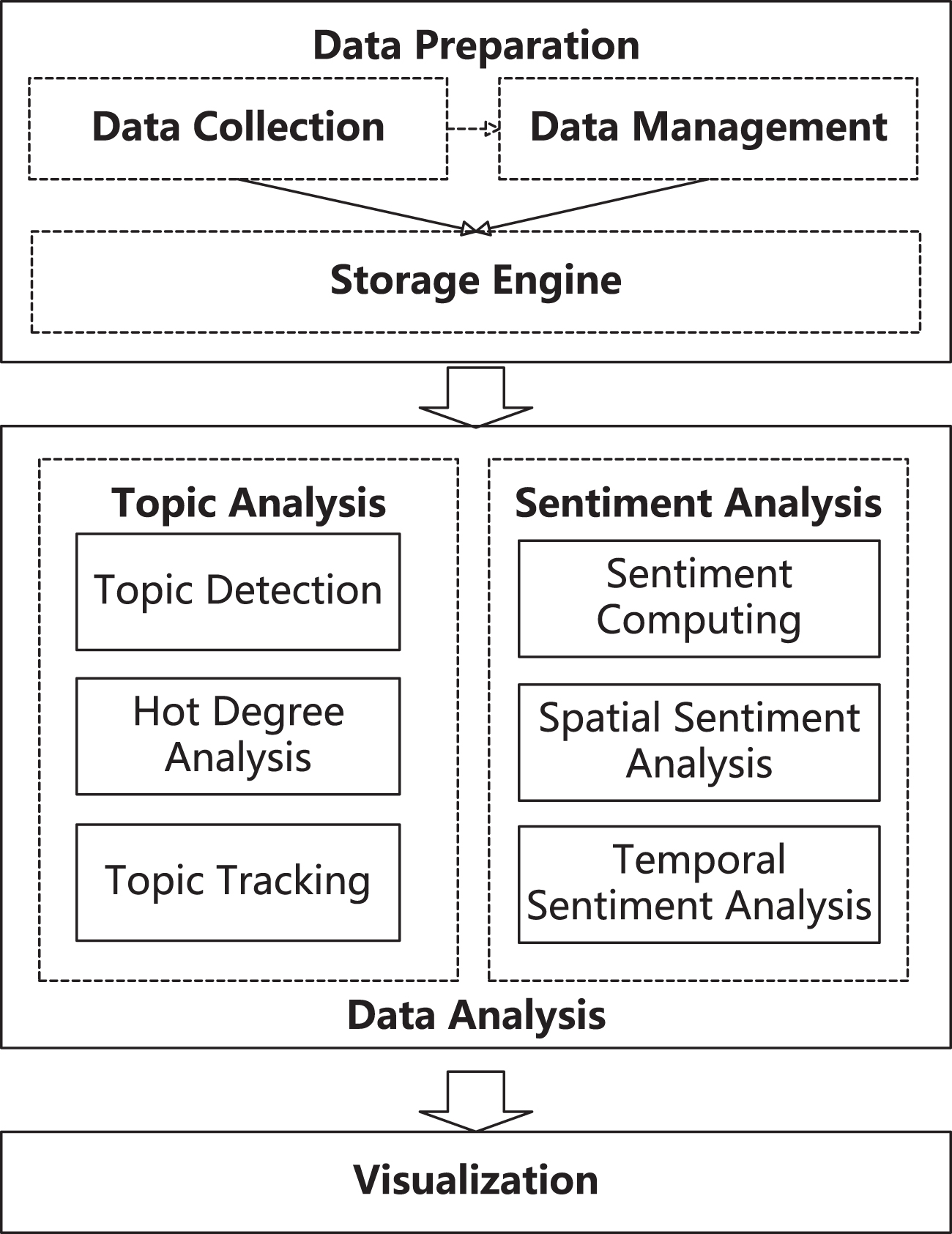
The framework of the microblogging data managing and mining system.
Microblogging data collection
Microblogging platform (such as Tencent microblogs, sina weibo), has become a very popular and widely used social media for information sharing, information propagation, and friends making. People registered in microblogs can post some opinions, browse others’ postings, make some comments, forward some interesting news and follow some friends. Thus, the platform accumulates enormous amount of information about users, which imply many potential applications. The key problem is how to obtain those data effectively and efficiently?
In this paper, we take the microblogging data as an example, design and implement a data collecting system. To improve the efficiency, we propose a time-line tracking technique and present a data collecting method. The flow chart is illustrated in Fig. 2.
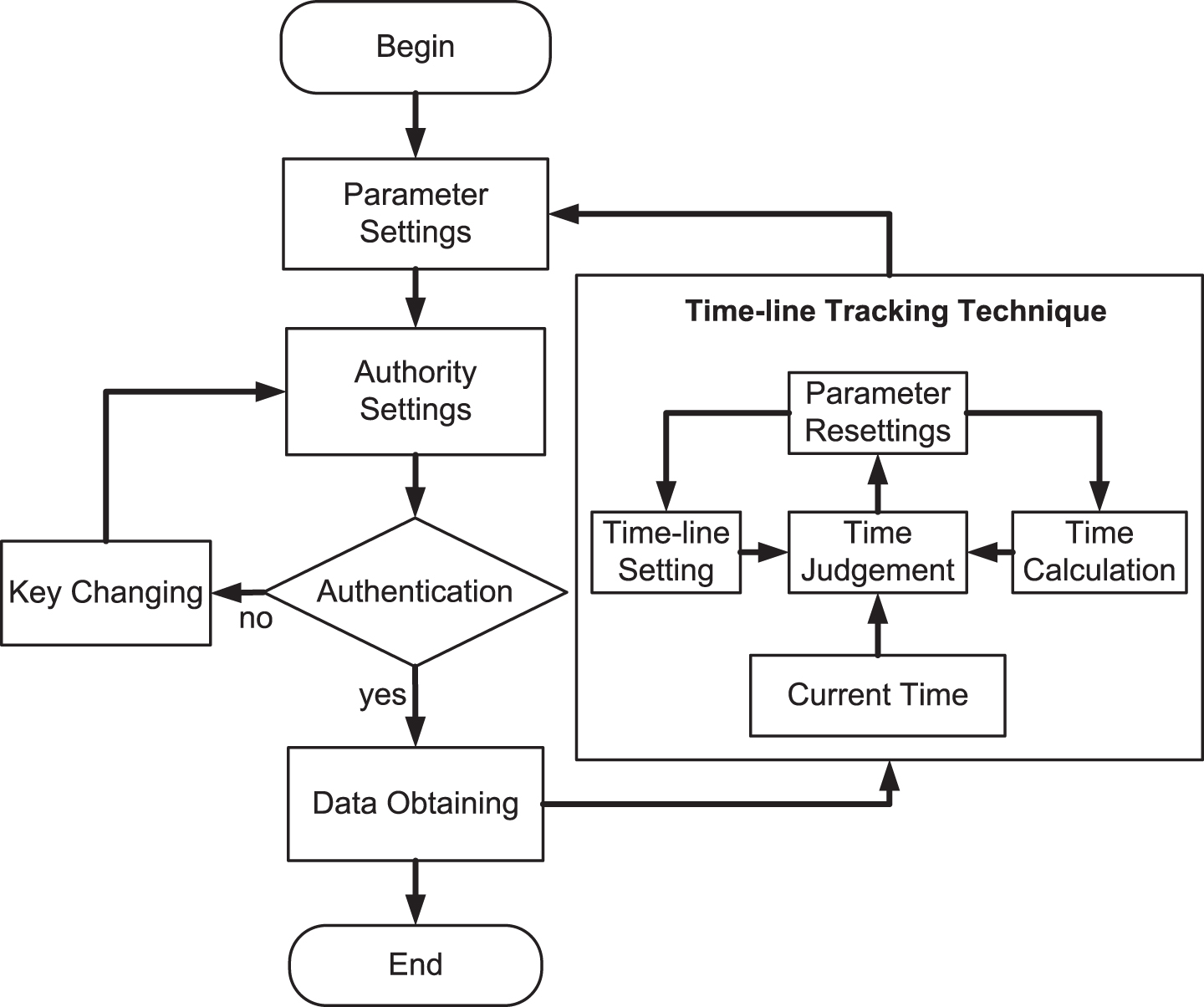
The flow chart for microblogging data collection.
In the data collection module, we use Kafka (http://kafka.apache.org/), a distributed messaging service, to improve the effectiveness and efficiency of the data collection. That’s because, in comparison to most messaging systems, Kafka has better throughput, built-in partitioning, replication, and fault-tolerance, which makes it a good solution for large scale message processing applications. Moreover, Kafka is able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for off-line processing and reporting.
In this section, we present a realtime data managing module based on Apache Storm (http://storm.apache.org/). Apache Storm is a free and open source distributed realtime computation system. Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. The realtime data managing module based on Apache Storm is illustrated in Fig. 3. As shown in Fig. 3, it contains three functional parts.
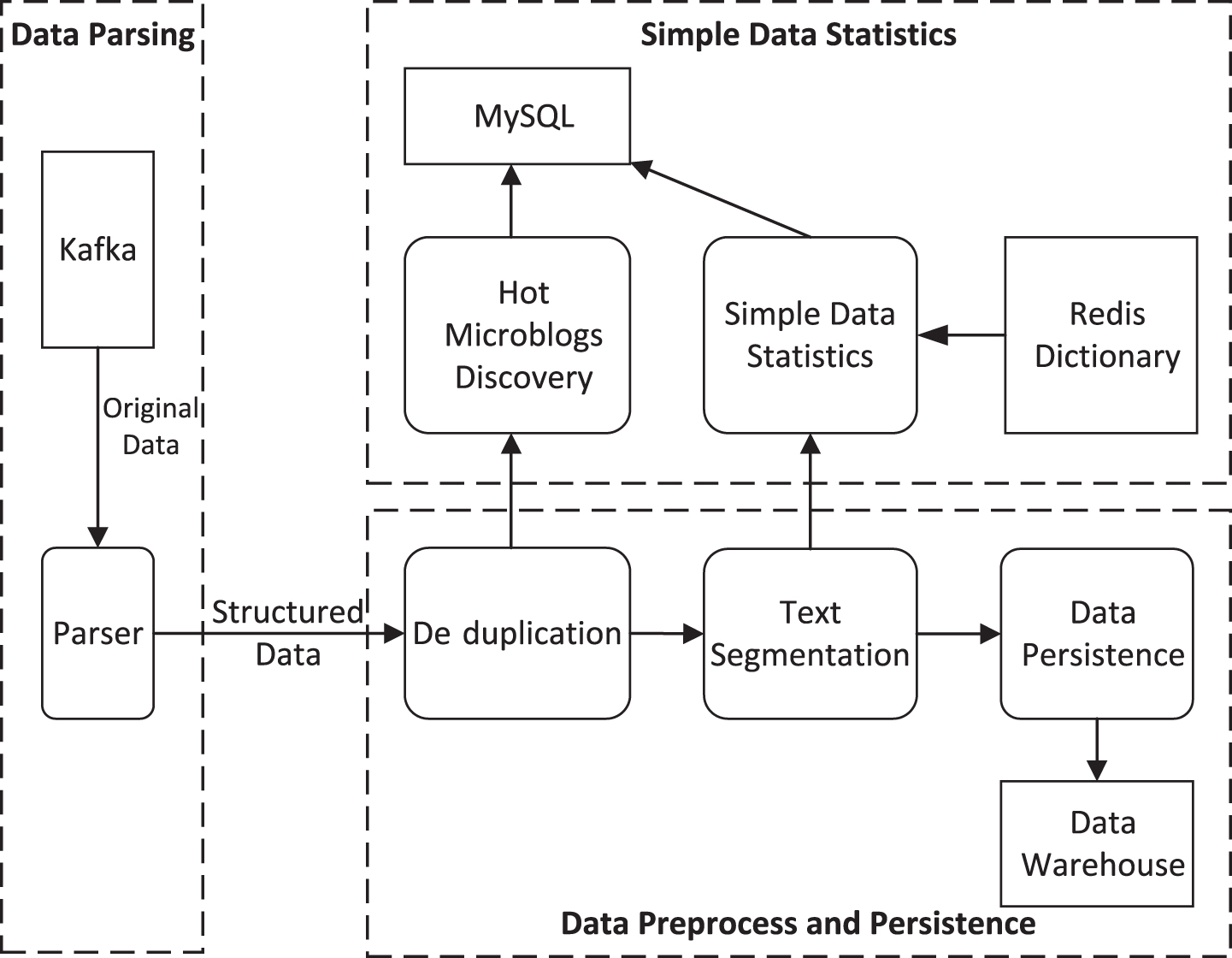
Realtime data managing module based on apache storm.

The simple statistical analysis on Tencent microblogs.
Topic detection
In this system, we adopt Latent Dirichlet Allocation (LDA) Model in place of traditional VSM model, to extract the hidden topics of Tencent microblogs. LDA is an unsupervised generative model which can be used to classify text documents. A document is made up of groups of words which may belong to different topics. A topic is represented as a collection of words, with corresponding probabilities of each word belonging to a particular group. LDA is a process that tries to backtrack from the documents to find a set of topics that are likely to have been generated by the collection. The main idea of LDA topic modelling is that the words that appear together many times in the documents are assumed to be related or present similar meaning, therefore they are more likely to be assigned to the same topic. The approach can be more efficient and objective than manually classifying the text subjectively.
With LDA algorithm, we get the distribution between microblogs and topics Lm×n, where l
ij
denotes the probability of the microblog i belonging to topic j.
We propose a method to calculate the hot degree for each topic, which is formulated as the vector . The definition is given as follows.
n denotes the number of the topics; m denotes the number of the microblogs; is a n dimensional vector, which denotes the hot degree of topics; is a m dimensional vector, which denotes the hot degree of microblogs; Lm×n is a matrix got from LDA algorithm, which denotes the distribution between microblogs and topic;
The hot degree of microblogs is defined as a vector , where d
i
denotes the hot degree of the microblog i. It is calculated asfollows.
where c
i
denotes the number of clicking on the microblog i; f
i
denotes the number of forwarding on the microblog i; r
i
denotes the number of replying on the microblog i;
α, β, γ are parameters to adjust the weight of each term, and α + β + γ = 1;
With the above LDA, we are able to get the distribution between microblogs and topics, denoted by , for the period of t
k
.
In order to track the topic evolution, we adopt the cos distance to measure the similarity of two topics, which could help us to determine which topic is the continuation of the last one. The ith column and jth column of are first selected and then transposed to form the topic vectors. The vectors for the topic i and j are shown as follows: , . The similarity between two topics (i, j) from continuous time slices (t
k
, tk+1) is presented as follows. If the similarity between two topics is higher than a threshold δ, they are considered as the same topic evolution.
We perform the work of topic analysis on 4-node hadoop cluster, shown in Fig. 5. Each machine is equipped with 4 Quad-Core AMD Opteron CPU, 32 GB Memory and 12T Disk Storage. We install CentOS 6.4×86 as the operating system. The software environment is described in Table 1.
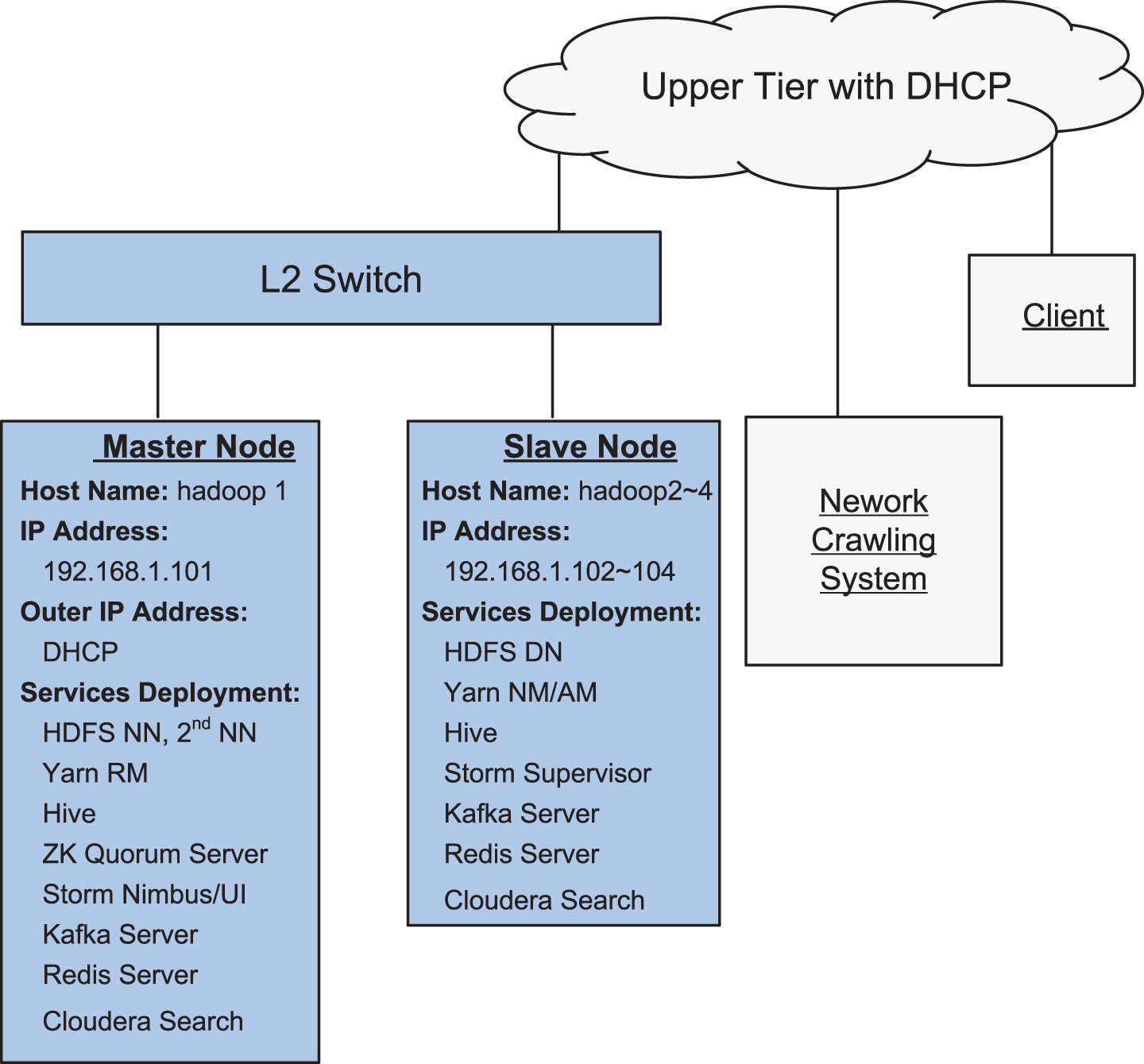
The organization of the 4-node hadoop cluster.
The software environment of our system
As to the hot degree calculation, the parameters α, β, andγ should be determined first. As it is not a supervised learning, thus the parameters cannot be learned automatically. In this paper, we set the parameters manually according to our experience. When we evaluate the hot degree of a topic, we have to take all the microblogs into consideration. For a microblog posted by one user, it could be browsed or clicked, forwarded and replied by others. All those factors imply the hot degree to some extent. According to public opinion analysis theory, if one posting is of great importance, most people will click to browse and propagate this message by forwarding it. Some person who are interested in it may reply it with some comments. That is, the behavior of forwarding is playing a more import role than browsing in determining the popularity of a microblogs. Likewise, the browsing behavior often counts more than replying. According to the above analysis, we set α = 0.3, β = 0.5, andγ = 0.2 in the implementation of hot degree calculation.
We design a web-based results visualization system. Some results about topic detection, topic tracking, hot topic computation are shown in Fig. 6.
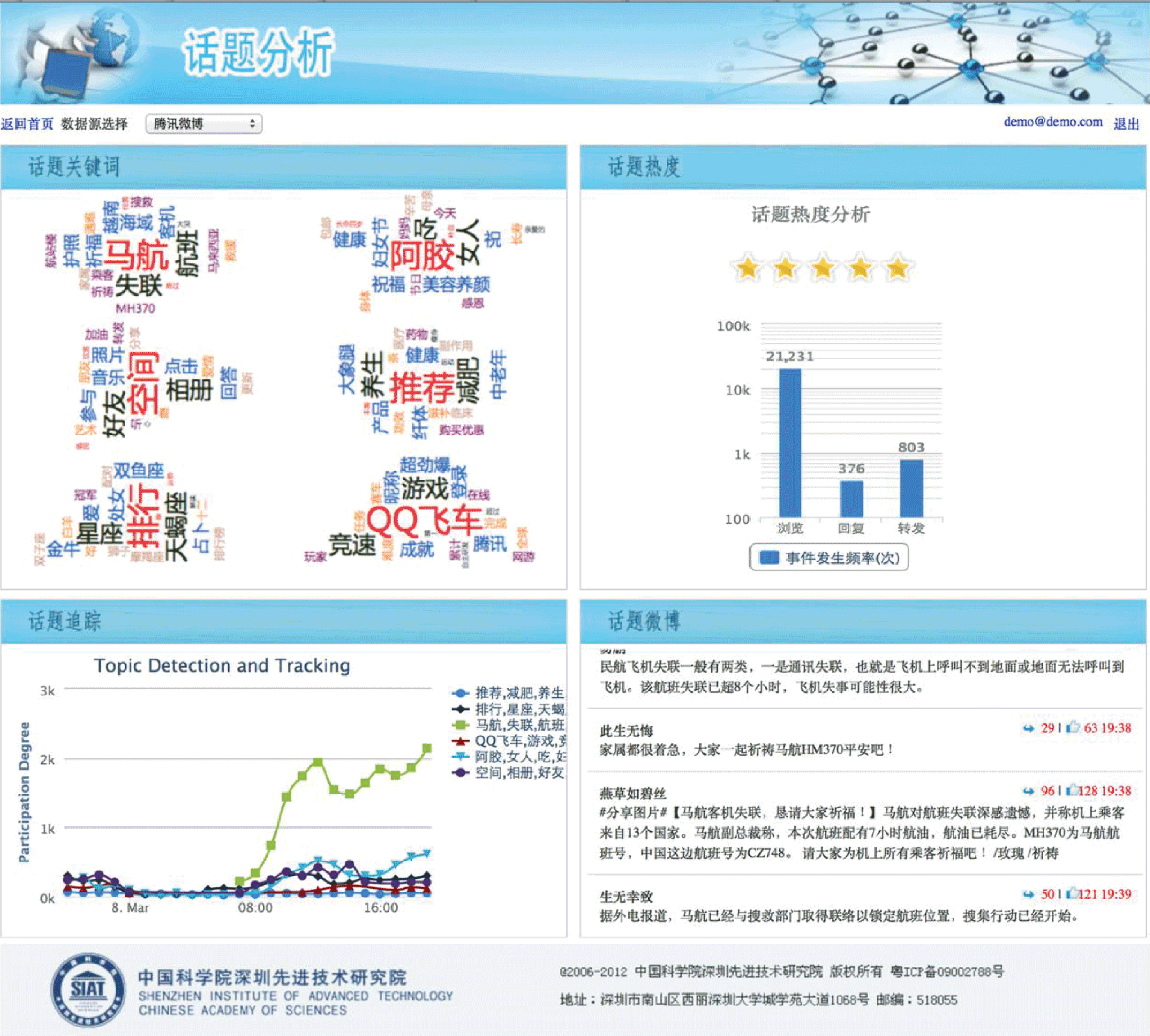
Some results on topic analysis.
As shown in Fig. 6, there are 6 hot topics which are characterized as ‘MH370 Lost of Contact’, ‘E-jiao’, ‘QQ Zone’, ‘Health’, ‘Horoscopes’ and ‘QQ Games’. We click one of them, then we can get the hot degree. The evolution of the above 6 hot topics are shown in the left bottom of the page, from which we can find that the topic ‘MH370 Lost of Contact’ has been attracted great attention and lasted a long time.
Sentiment calculation
At the beginning of the sentiment analysis, a microblog is split into emotions and terms(segments). During that process, the N-Pat tree based method is adopted to detect new popular phrases [22]. Data filtering is also performed by removing stopwords.
In this paper, we take three kinds of opinions (positive, neutral and negative) into consideration. A dictionary based approach is proposed to quantify the sentiment on microblogs. Three kinds of dictionary are given as follows in this section.
An integrated method is proposed to determine the sentiment of each microblog. The quantitative formula to calculate the kth microblog is defined as:
α, β are parameters to adjust the weights of the two factors; e
i
denotes the ith emotion existed in the microblog d
k
; num (e
i
) denotes the total number of emotions existed in the microblog d
k
; p (e
i
) denotes the sentiment of the emotion e
i
; s
j
denotes the jth term (word segments) in the microblog d
k
, it could be a feature or a popular phrase; num (s
j
) denotes the total number of the terms existed in the microblog d
k
; p (s
j
) denotes the sentiment of the term s
j
;
In the implementation of sentiment computing, the parameters α and β are set to be 0.5 respectively. That means, the emotion and word segments are considered to be equally in determining the sentiment of a microblog in this paper. In this paper, we also analyze people’s sentiment on each topic. With the sentiment of each microblog, we can get the sentiment of each topic t
j
as follows. If p (t
j
) >0, we consider it to be positive; else, we consider it to be negative.
With the proposed method and large data, a quantitative spatial analysis on public sentiment is performed. Some results are shown in Fig. 7. The main view (in the left) shows the distribution of public sentiment in different provinces. If the sentiment of a province is positive, it means people here are happy. That is, people are satisfied with their current situation. Otherwise, if the sentiment value shows negative, it means that people in that province are unhappy (or sad). That is, people are dissatisfied with their present condition. In this paper, we use five kinds of colors to distinguish the different degree of sentiment. The redder the color is, the happier the people are. The sentiment distribution is changing over time. That changes of values are shown at the bottom of the view space. On the right side of the view space, terms representing people’s sentiment are emerging with its frequency.
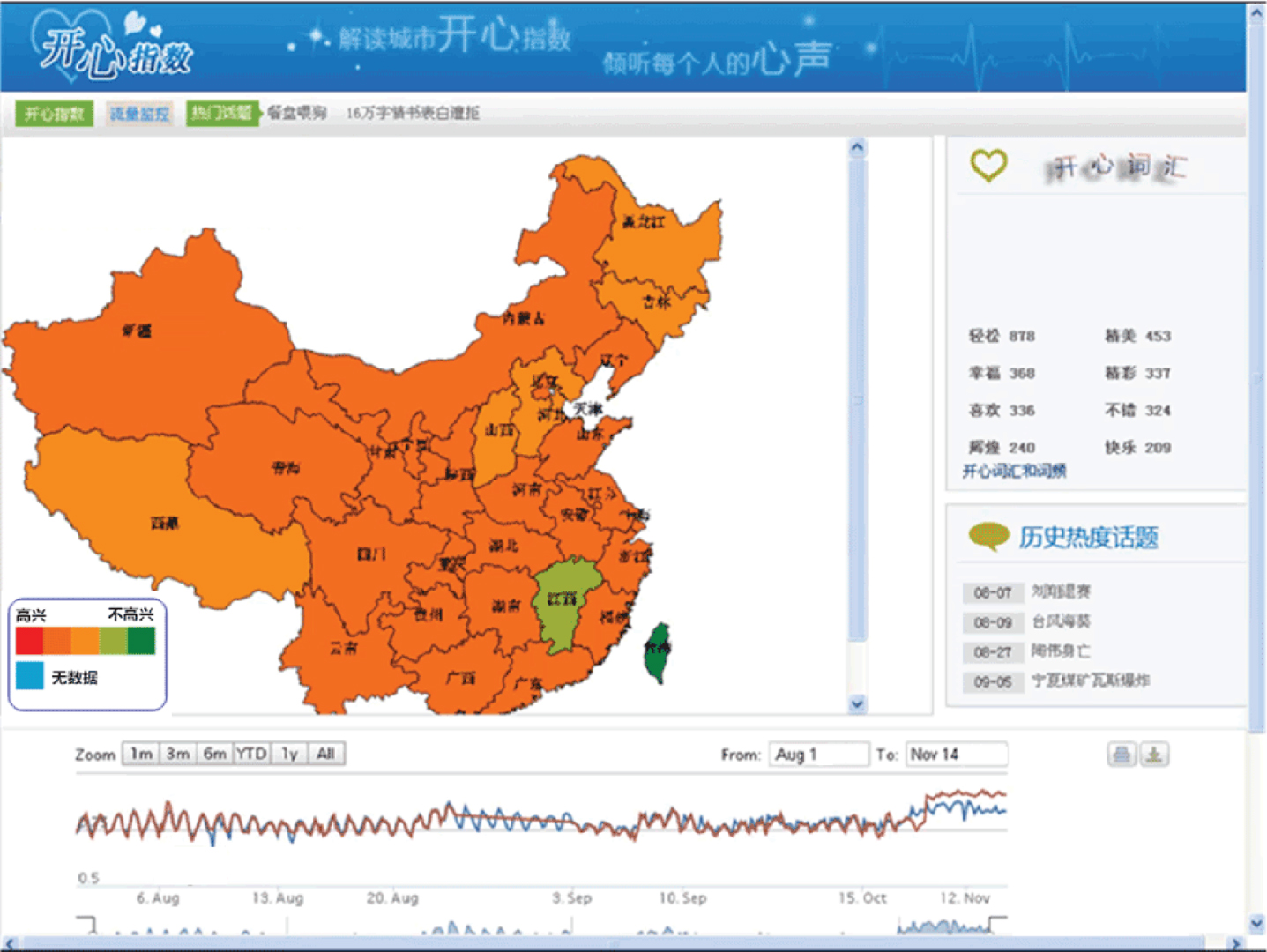
The visualization of public sentiment hidden in microblogging data in China.
Besides the above general analysis, we also analyze the spatial sentiments with topic or event evolution. The following three figures (Figs. 8, 9 and 10) have shown us the public sentiment changes on a certain topic of “Liu Xiang’s losing complication”.

Public sentiment when the news arrived that Liu Xiang would attend the olympic games in London.
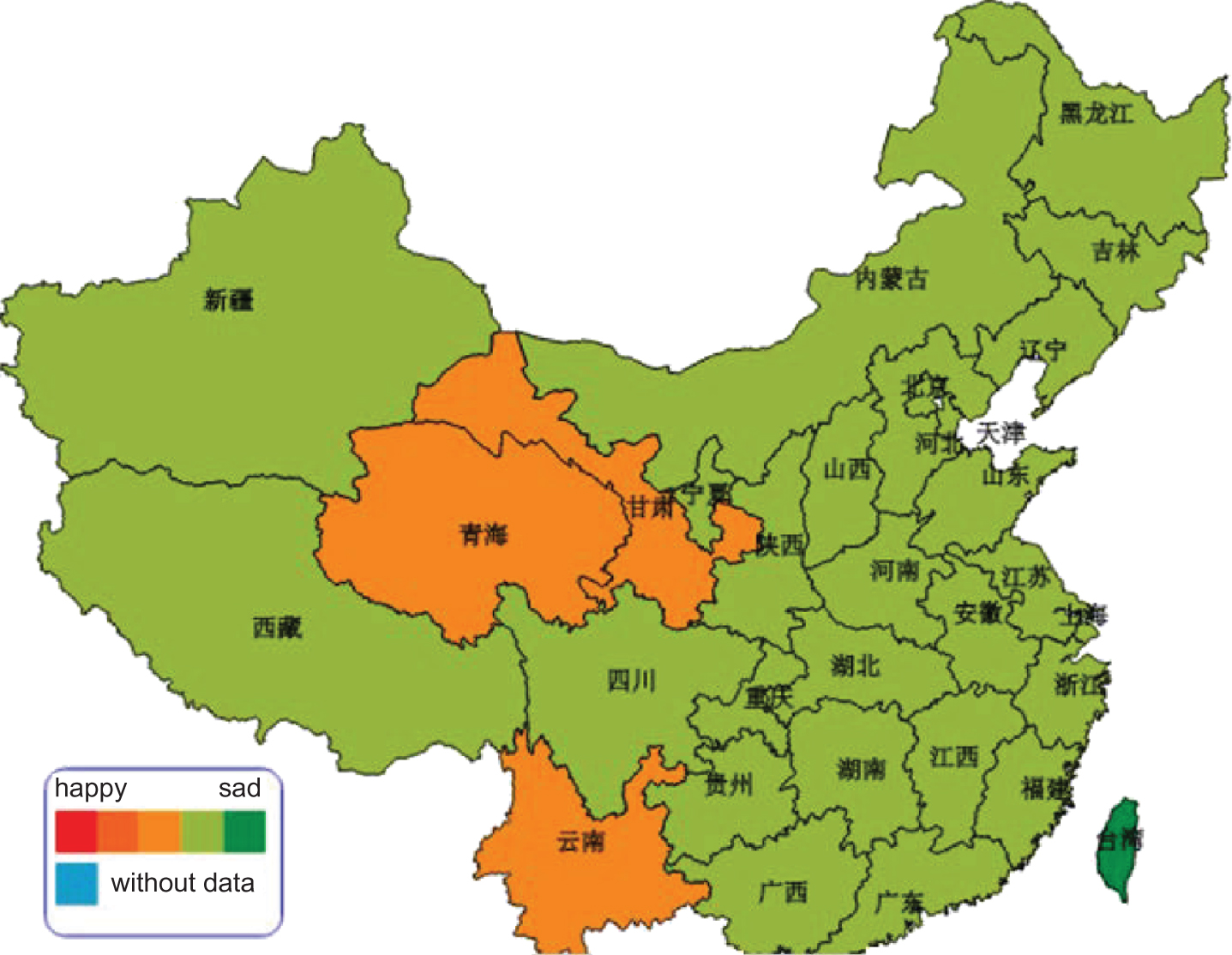
Public sentiment during Liu Xiang’s complication.

Public sentiment after the news released that Liu Xiang fell down.
Liu Xiang, who has been a China’s 110 m hurdle athlete, attracted large attention in the past decade. Figure 8 shows public sentiment when the news arrived that Liu Xiang would attend the olympic games in London. According to the visualizing results, we could find that Chinese people were very happy and excited. That was because they were expecting the winning of Liu Xiang. Figure 9 shows public sentiment during the Liu Xiang’s complication. According to Fig. 9, we can see that people in most provinces rapidly turned sad. We tracked the source and found the reason that Mr Liu hammered into the top of the first barrier with his leg and tumbled to the ground in the first heat of the 110m hurdles. Figure 10 shows the public sentiment after the news of Mr. Liu’s falling down released. People in all provinces turned sad because they are so disappointed.
Thanks to the high-speed development of information technology, people gradually enjoy the internet-based social media and the data is increased with tremendous speed. Social media analysis is an ongoing hot topic in both theory and practice. Due to the variety of the social media, how to precisely and efficiently determine and trace the evolution of the topics in different applications are big challenges. In this paper, we develop a system to collect and manage data effectively based on Hadoop and Storm. Furthermore, we make some analysis on Chinese microblog, which is very popular in China but the research on topic and sentiment analysis is not too much.
This paper is an extension of our previous work [23]. The main extension lies in the sentiment analysis. The approach to calculate the sentiment degree is elaborated in this paper, which is based on three kinds of dictionary. Moreover, a spatial analysis on public sentiment is performed over topic evolution. In addition, the framework and organization are also improved. Our work not only gives the result for Tencent microblogging data analysis, but also could attract more researches on this topic so as to have a deep understanding on microblogging data.
Footnotes
Acknowledgments
This research is partly supported by the National Natural Science Foundation of China (Grant Nos. 61303167, 61433012, U1435215 and 61402461), Project of Education Ministry for the Development of Liberal Arts and Social Sciences (Grant No. 16YJCZH041), Natural Science Foundation of Guangdong Province (Grant No. 2015A030310364), Shenzhen basic research (Grant No. JCYJ20160229195940462), The National Key Research and Development Program of China (Grant No. 2016YFB0201401) and Scientific Research Foundation of SDUST for Recruited Talents (Grant No. 2015RCJJ069).