
Abstract
There are a lot of applications of multi-agent systems, such as robot navigation, distributed control, data mining, etc. Reinforcement learning (RL) is a popular method used in multi agent path planning. RL algorithm needs an accurate representation of a small and discrete space. In order to plan multi agents in continuous time, this paper approximate the Q-values with the fuzzy logic, such that the modified RL can work in continuous state space. The fuzzy reinforcement learning proposed in this paper uses fuzzy Q-iteration algorithm and a modified Wolf-PH algorithm. The convergence and existence of the algorithm are proven. The continuous time planning algorithm is applied to a cooperative task of two mobile Khepera robots. The experimental results show the effectiveness of the new path planning method for the multi agents in continuous time.
Introduction
Multi-agent systems are composed of multiple interacting intelligent agents, which can be used to solve problems such as robotics team, distributed control, resource management, collaborative decision, and data mining [1]. A multi-agent system includes several intelligent agents in an environment. Each agent has its independent behavior and should coordinate with others [2]. An important advantage of using the multi-agent system is modeling the cooperation of real-life situations. Multi-agent systems could emerge as the most natural way of looking at a system, or provide an alternative perspective on centralized systems. They include several intelligent agents in an environment, and each agent perceives the environment through sensors and actuators. At the same time, the multi-agent system can also learn new behaviors in order to adapt to the new task and objectives in the environment [3].
The reinforcement learning is one of the most popular method for multi-agent planning. The learning object is to maximize a reward function defined by the environment, such that the agents can interact with the environment and modify the environment in a good manner [4]. At each learning stage, the agent detects the environment by taking actions. For the traffic situation, it gives a new state [5]. The quality of each transition is evaluated by another reward function. In order to give the correct actions to agents, feedback RL can be used [6], which uses less informative than the supervised learning method [7]. The agents are not told what actions should be taken. They only know what actions are most rewarding.
Since RL requires accurate representations of state-action values in the environment and the policies must be in some lookup tables, the solutions are untreatable One of the challenges of the reinforcement learning for multi agents path planning in continuous-time is dimension problem [8]. The states in continuos-time and spaces have to be divided into many cells, such that the discrete-time RL can be applied. The accuracy of this RL is the dimension of one cell. In order to improve the leaning accuracy, the cell number has to be increased. However, for large space problem, the discrete-time RL cannot work well.
Most multi agents path planning approaches have to reduce the working space, or discretize the space into low dimension. However, in the real life applications the state variables have many possible values and even are continuous. RL should be combined with other methods, or be modified. [10] uses function approximation for the discrete states to reduce computation space. [11] applies vector quantization for continuos states. [12] uses normalized Gaussian network to modify Q-learning. [13] uses prediction method for heterogeneous agents. [9] applies neural networks to approximate the unknown space. The above methods are not real continuos-time path planning, because they only divide the working space into small spaces.
In order to plan the multi agents path in continuos-time, the reinforcement learning is modified in this paper. We use fuzzy quantization for the state space of the multi agents. The well known WoLF-PHC algorithm [14] is combined with fuzzy logic, such that the Q-function of the agents are partitioned through a fuzzy state space. The path planning algorithm uses fuzzy Q-iteration model to achieve the sub-optimal policy for the agents. The feasibility of the proposed method is shown with two mobile robots to finish a cooperative job.
Fuzzy reinforcement learning has been applied in the single-agent navigation [15]. From the best of our knowledge, this is the first paper on continuous-time path planning of multi-agent systems. The key technique of this paper is we use fuzzy logic to modify the classical RL to overcome the dimension problem.
Continuos-time path planning with fuzzy reinforcement learning
For multi agent path planning problem, the action set and given tasks are solved in a determined environment. This problem can be modeled as a stochastic game, such as a Markov decision process. The actions at any time consist of each individual agent actions. The multi-agent reinforcement learning process is a generalization of the Markov decision process, called the stochastic game [16].
Providing the joint action set
In discrete time, when the joint action
We define scalar reward for each agent as
The actions are chosen according their own policy
In continuos-time, the above equations are
Since the rewards rt,i of the agents depend of the joint action, their returns depend on the joint policy
Each agent may have its own goal. The multi agent path planning is a full cooperation problem. So the reward for any state is the same for all agents, i.e., ρ1 = ρ2 = . . . = ρ
n
. So the returns for all the agents are also the same,
Determining an optimal joint policy
We define the best response of agent i to the opponent strategies σ
i
with the maximum reward
For a fully cooperative stochastic game, the learning goal is to maximize the common discounted return. The objective can be accomplished by learning the optimal joint-action values Q∗ through value iteration by using a greedy policy [20],
The agents use the greedy policies applied to Q∗ to maximize the common return
The multiple joint actions of some states can be optimal. In the lack of coordination mechanism, different agents could break ties among multiple optimal joint actions in different way.
Q-iteration
We define the Q-function as
The optimal Q-function Q∗ satisfies the Bellman optimally equation [21]
Here Q∗ is a fixed point of H. We can start from an arbitrary Q
o
and update Q in each iteration l by
H is a contraction with factor α < 1 in the infinity norm [22]. For any pair of Q-function Q1 and Q2,
H has a unique fixed point.
Q∗ is a fixed point of H: Q∗ = H (Q∗), and Q-iteration converges to Q∗ as l → ∞ . A optimal policy
The Q-iteration needs to save and update distinct Q-values for each state-action pair. It can only deal with finite set of state and actions, such as discrete sets [23, 24].
When the state space is continuous, the Q-function has to be in an approximated form, because an exact representation of the Q-function could be impractical or intractable [25].
We use a vector φ ∈ R
n
to parameterize the Q-function. The approximator φ is based on a fuzzy partition of the continuos state space, where the action space is assumed to be discrete. There are N fuzzy sets in the fuzzy partition. The membership function is
This membership function can be regarded as a basis function or a feature [26]. The membership function may have linguistic meaning if a prior knowledge about the Q-function is available. It is not necessary in the presented method. The number of membership functions increase with the dimensionality of the state space and the number of the agents.
Triangular functions [27] are used as the fuzzy partition in this paper. For every d exist a unique x
d
(the core of the membership function), such that μ
d
(x
d
) > μ
d
(x) ∀x ≠ x
d
. Since all the others membership functions take zero values in x
d
, we assume that μ
d
(x
d
) = 1. We have N
r
triangular membership functions for each state variable x
r
, r = 1, 2, . .,
We assume that the action space is discretized for all agents. They have the same number of actions available,
There z = nNM elements stored in the fuzzy approximator φ . The membership function-action pair (μ d , u ij ) for each agent corresponds the parameter vector φd,i,j. We construct a nN × M matrix for the elements of the approximator. The first column with the N elements is for the first agent. So the indexes of the parameter approximator φ[i,d,j] means d - th membership functions for j - th action for i - th agent.
The Q-function can be also approximated by multiple-input multiple-output fuzzy rules. The state x is the input of the fuzzy rules. It produces M outputs for each agent, which correspond Q-values of each action. For each agent u ij |i = 1, 2, . ., n j = 1, 2, . . M .
The fuzzy rules can be regarded as a zero-order Takagi-Sugeno rule [28, 29]
The approximate Q-value is calculated by a weighted sum of the parameters φi,d,j
It is a linearly parameterized approximation [30]. This approximator can be denoted by an approximator mapping
Thus we do not need to store great amount of Q-values for every pair (x,
In order to analyze the Q-function, φ is parameterized into a linear function. It is the same as the reinforcement learning, where the approximation F is also linear [32]. So the normalized membership functions can be seen as state-dependent basis functions.
(4) provides an approximate of Q-function. The approximate
Because of triangular membership function and linear parameterized approximation, (7) is a convex quadratic optimization problem [35]. (7) is reduced to
The approximate fuzzy Q-iteration starts with an arbitrary parameter vector φ . This vector in each iteration uses the mapping
It stops when the difference between two consecutive parameters vector φ is greater than threshold ξ,
A greedy policy can be obtained to control the system from φ∗ (which is the parameter vector derived when l→ ∞). An action is calculated by interpolation between the best local actions for every membership function core x
d
In order to implement the update (9), we propose a modified WolF-PHC algorithm [14]. The fuzzy Q-iteration is applied to plan multi-agent path in continuous state space.
The algorithm starts with an arbitrary φ (it can be φ = 0) until a threshold ξ is reached after several iterations. We assume the dynamics f, the reward function ρ, and the discount factor γ are known. The algorithm is as follows: Let α ∈ (0, 1], the learning rate δ
l
> δ
w
∈ (0, 1] s, initialize
Repeat For state x, we select action u according to mixed strategy π (x) with suitable exploration. At each step a random action with probability ɛ ∈ (0, 1) is used. Applying fuzzy Q-iteration, for Membership functions μ
d
d = 1, . ., N and discrete actions U
j
j = 1, . . ., M, the threshold ξ > 0
Until
Update the average Move π to the optimal policy with respect to Q-table
Output:
A greedy policy is obtained to control the system by
(13) corresponds to
So if ||φl+1 - φ∗||∞ < γ||φ
l
- φ∗||∞, induction ||φ
l
- φ∗||∞ < γ
l
||φ0 - φ∗|| for l > 0. According to Banach fixed point, φ∗ is bounded. Since the vector with which the iteration starts is bounded, then ||φ0 - φ∗||∞ is also bounded. Let G
o
= ||φ0 - φ∗||∞ which is bounded and ||φ
l
- φ∗||∞ ≤ γ
l
G0 for l > 0, applying the triangle inequality:
If γ
l
G0 [γ + 1] = ξ,
Applying γ log base on both side of the above expression
In order to validate our fuzzy reinforcement learning method, we setup a multi-agent learning task. Two Khepera robots [36] move in a surface such that both agents reach close to the origin at the same time with minimum time elapsed, see Fig. 1. The Khepera is a small-sized wheeled robot designed to real world applications. It has 5 sensors which are placed around the robot, see Fig. 2. These sensors are pairs of ultrasonic devices. Each pair is composed of one transmitter and one receiver. They are used to reconstruct the odometry and detect natural features in the environment, such as obstacles and other nearby agents.

Two agents move to one point.

Position of the Khepera’s UltraSonic sensors.
The Khepera’s sonar readings is defined as la,c . It has three degrees, 0, 1, 2, representing the amount of closeness to the nearest obstacle or other agents. 0 indicates for obstacles or agents which are near, 1 indicates for obstacles or agents which are in a medium distance and finally, 2 is for obstacles or agents which are relatively far from the sensors.
The parameters d a (the distance to the target or the goal) and p a (the relative angle to the target or goal) are divided in eight degrees (0 -8). Where 0 represents the smallest distance or angle, and 8 represents the greatest relative distance or angle from the current Khepera’s position to the target or goal.
The actions available for the Khepera robot are: Move forward Turn in clockwise direction Turn in counter clockwise direction Stand-Still
The sensor data are inaccurate and fluctuating. In order to avoid these influences for the reinforcement learning and the Q-iteration, the movement of the robots are relatively slow during the learning process. The collisions with other objects or agent are reduced [37].
The state is defined as x = [x1,x2, . . ., x8]
T
. Each agent has the coordinates in two-dimension positions, s
ix
and s
iy
, and velocities in two dimensions,
The continuos time dynamics of the agents are
The aim of the Q-iteration algorithm is to obtain the transition function f. The continuos time system is discretized with a step T = 0.4 s. The dynamics of the system are integrated between the sampling time. The start points are selected randomly. The training iteration is 1000 . If the final goal is not accomplished within 1000 iteration, the experiment is restarted. The magnitude of the state and action variables are bounded and normalized as: s
ix
and s
iy
∈ [- 6, 6] meters,
The control actions for each agent are discrete with 25 levels: U i = [-2 - 0.2 0 0.2 2] × [-2 - 0.2 0 0.2 2], i = 1, 2. They correspond to force in diagonal, left, right, up, down and no force applied.
The membership functions used for the position state and velocity state are triangular, see Fig. 3 [39]. The cores of the membership function for the position domain s is centred at [-6, - 3, - 0.3, - 0.1, 0, 0.1, 0.3, 3, 6] . The cores of the membership function for the velocity domain are: [-3, - 1, 0, 1, 3]. There are 50625 pairs (x,
Triangular fuzzy partition for velocities in X and Y.
The final objective is the agents arrive at the same time in minimum time by the reward function ρ
For the coordination problem, the agents consider each other. They do not use explicit coordination conditions for the other agents. They use explicit coordination or negotiation like social conventions, roles and communication [38]. So our algorithm accomplish an implicit form of coordination where the agents learn to prefer on the equally good solutions. After the Q-iteration is performed, φ∗ is obtained which is a policy can be derived by a interpolation between a the best local action for each agent
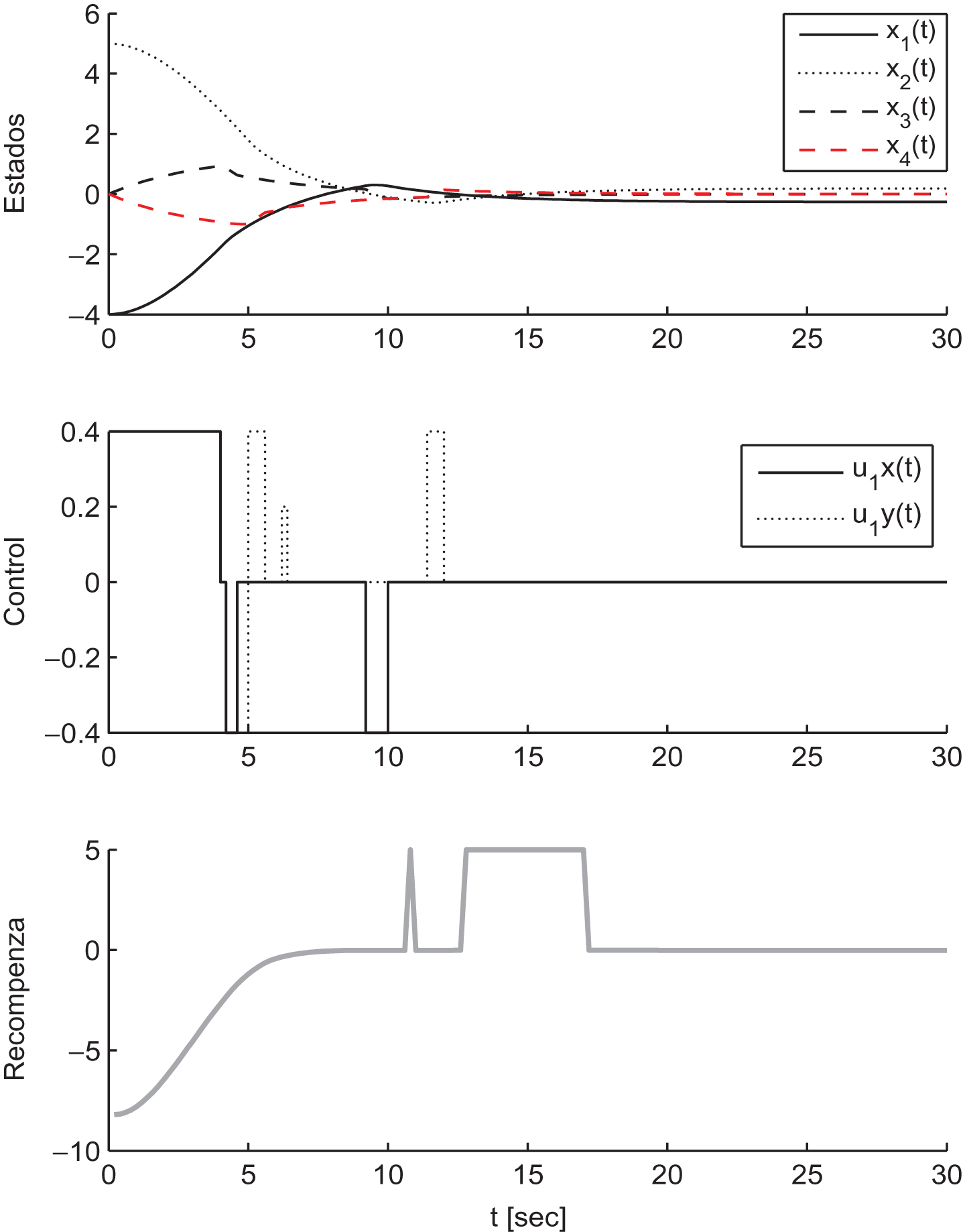
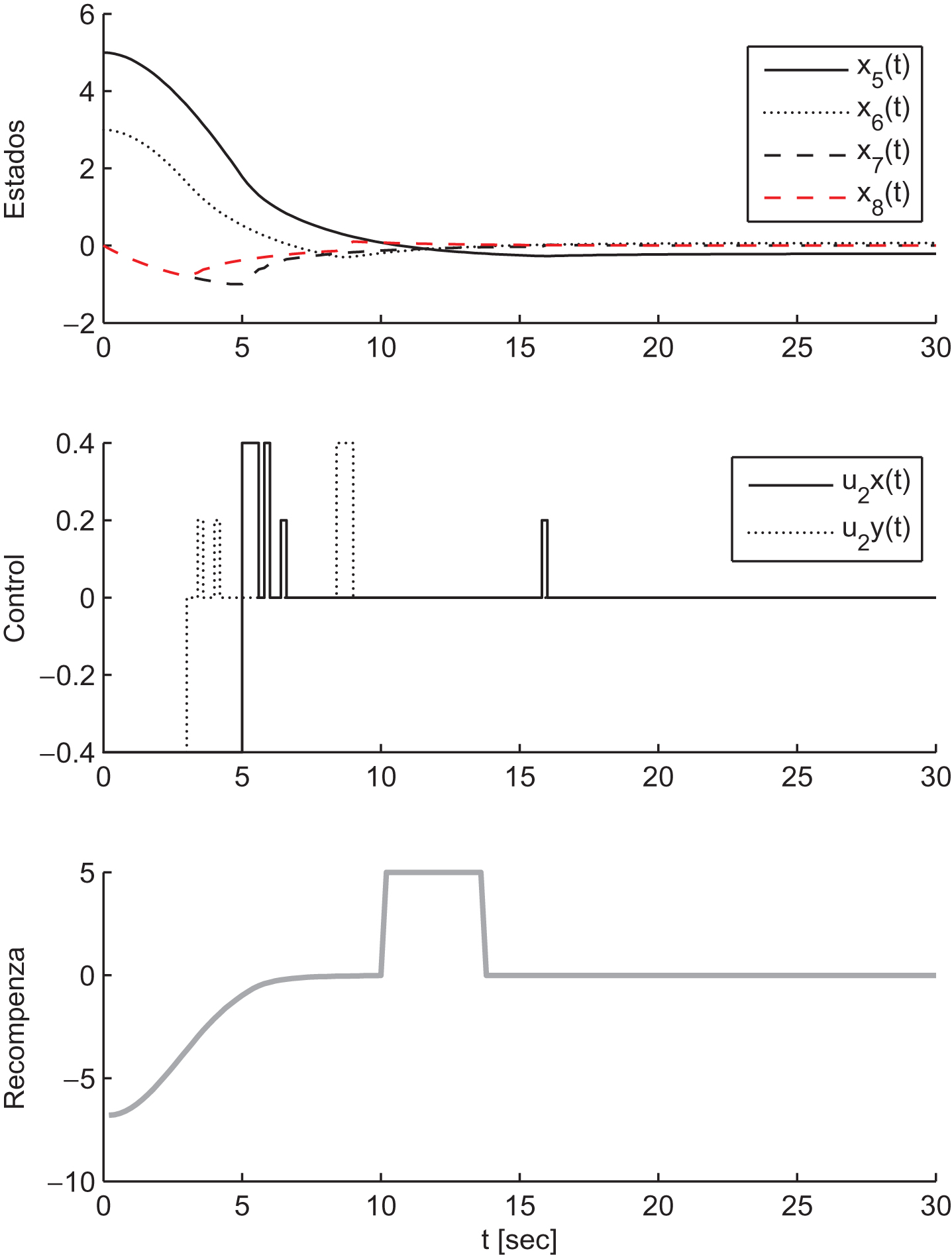
In our experiment the discount factor is γ = 0.96, the threshold is ξ = 0.05, the initial conditions for the experiment is s0 = [-4, - 6, - 2, 2, 5, 3, 2, - 1] . The control signal U1 = [u1x, u1y] and the states of Agent-1 is shown in Fig. 4. Figure 5 shows the results of Agent-2. We can see that they converge after 310 iterations.

States of Agent 1 (second - meter).

States of Agent 2 (second - meter).
The vector approximation parameter φ converges after 330 iterations, the bounded ||φl+1 - φ l || ≤ ξ is reached. The final path are showed in Fig. 6. It is evidently different from the optimal policy, which should drive both agents in a straight line toward the goal.

Final path by Agent 1 and Agent 2 (meter - meter).
Now we use Gaussian membership functions
The two robot are on a tennis court, see Fig. 7. In this experiment the discount factor is γ = 0.8, the threshold is ξ = 0.05m, the initial conditions for the experiment is s0 = [-10, - 12, - 7, 16, 21, 11, 13, - 4] . The control signal U1 = [u1x, u1y] and the states of Agent-1 is shown in Fig. 8. Figure 9 shows the results of Agent-2. We can see that they can converge after 250 iterations in Fig. 10.

Two agents move on a tennis court.
States and signal control for the Agent 1 (second - meter).
States and signal control for the Agent 2 (second - meter).

Final path by Agent 1 and Agent 2 (meter - meter).
The conclusion the triangle functions are more simple, while the Gaussian functions are more effective.
Now we compare our fuzzy Q-iteration with the classical Q-iteration. Because the classicalQ-iteration can be only applied to discrete-time learning, the tennis court is gridded with 7 × 8 cells. The initial position of the two agents are the same as above. Each time, they can move one cell. They will stop if the target cell is arrived. The object is the two robot reach the target at the same time. After 24 trainings trial the Q-tables converge to the Q-values, see Fig. 11.

Performance of the Q- learning.
The learning time is similar as the fuzzyQ-iteration, however the accuracy is the dimension of one cell. It is about 30 cm. The accuracy of fuzzy Q-iteration is the threshold ξ = 5 cm. If the classical Q-iteration wants to obtain the same accuracy, the grid should be 42 × 48, the training time is 6 times more. These results are shown in Table 1.
Training time and accuracy of RL
We can see that, for this tennis court RL problem, 56 cells is good enough for our fuzzy RL algorithm. Both training error and training time are acceptable. However, for the classical RL, the training error is very big (30 cm). We have to use more cells (2016 cells) to improve training accuracy of the classical RL. Now the training time of the classical RL is much more (160 seconds).
In this paper we presents a fuzzy Q-iteration to modify WoLF-PHC algorithm. This fuzzy reinforcement learning can handle multi agent path planning problem in continuous state space. The fuzzy quantization of the states and joint action minimizes the convergence time and avoids huge storage for Q-values and Q-table. The convergence and existence of the algorithm are also proven.
The performance of the fuzzy reinforcement learning is studied by two mobile Khepera robots. The experimental results show the effectiveness of the new path planning method for the multi agents. Future work is to extend this method for model free agents, who can learn itself dynamics in the environment or in the stochastic dynamics.