
Abstract
In recent years, traditional machine learning algorithms have been gradually replaced by deep learning algorithms. In the field of computer vision, convolutional neural network is considered to be the most successful deep learning model. Based on convolutional neural network, the accuracy of image classification has been greatly improved. In this paper, a method for semantic image segmentation based on convolutional neural network is proposed. Firstly, the disparity map is introduced to improve the segmentation accuracy. To obtain the disparity map with more continuous disparity values, an image smoothing method is used to optimize the disparity map. Then, based on the AlexNet network, a fully convolutional network architecture is proposed for semantic image segmentation. The unpooling operation is employed to restore the extracted features to their original sizes. The experimental results demonstrate that the network can achieve high pixel-wise prediction accuracy and that using RGB-D image as the input of the network can reduce the noisy segmentation outputs.
Introduction
Self-driving is a hot area of research in the automobile field. Accurate and effective classification for traffic scene is one of the key technologies to improve the intelligence of self-driving system. Semantic segmentation is considered to be the basic of classification, because the result of semantic segmentation directly affects the effectiveness of subsequent object classification.
At present, the commonly used machine learning algorithms for semantic image segmentation include SVM [1], decision tree [2], random forest [3] etc. These traditional methods require feature engineering that transforms raw image data into features, such as hog feature [4], texture features [5] etc. Good feature engineering is known and proven to be directly influential in building a successful and predictive model. But coming up with features is difficult, time-consuming, and requires expert knowledge. With the advancement of GPU, deep learning algorithms have been widely applied [6] in research for semantic image segmentation. The deep learning methods, such as convolutional neural network (CNN), fully convolutional network (FCN), can automatically extract valuable features from image. This characteristic contributes greatly to improved semantic segmentation accuracy.
Several of the recently proposed network architectures that focus on the semantic image segmentation have achieved good results. Girshick et al. [7] proposed an image segmentation algorithm based on the deep convolutional neural network AlexNet [8]. This algorithm demonstrated that convolutional neural network has better feature learning ability than traditional machine learning methods. But this method does not directly use the convolutional neural network for image pixel-wise segmentation. Hariharan et al. proposed a simultaneous detection and segmentation method [9]. This method achieves good semantic segmentation results by combining detection and segmentation. But this method relies too much on vast region proposals and has high computation complexity and computation time. Long et al. transformed the full connection layers in CNN into convolutional layers, and combined the unpooling method to realize the semantic image segmentation [10]. Chen et al. introduced a fully connected conditional random field into FCN [11]. This method overcomes the poor localization property of deep networks by post-processing the prediction results of FCN. Lin et al. used the context information of image to improve the semantic segmentation of CNN [12]. This method explored ‘patch-patch’ context and ‘patch-background’ context in deep CNN.
Recently, the research of semantic image segmentation based on RGB-D image has gained popularity. Silberman et al. created the RGB-D indoor scene data set NYUv2 [13]. Their experiments demonstrated that the depth map can help improve the object segmentation results. Hft et al. presented a convolutional neural network architecture for semantic scene segmentation [14]. In their works, the depth channel is provided as feature maps. They evaluated the network on the NYUv2 dataset and demonstrated that the depth information can help improve the classification performance. These studies show the importance of depth information for semantic image segmentation.
In this paper, a traffic scene semantic segmentation method is proposed based on convolutional neural network. In order to achieve smooth segmentation results, we take the RGB-D image as the input to the network. Firstly, the semi-global stereo matching algorithm and the method for fast global image smoothing are combined to obtain the high-quality disparity map. The representative traffic scene images are selected from the KITTI dataset [15] and the RGB-D dataset is established for training and testing of the network. Then, a network architecture is presented for semantic image segmentation task. Finally, the performance of the proposed network is evaluated on the RGB-D dataset and RGB dataset. The numerical accuracy and qualitative results are shown in the experimental section. The results show that the proposed network architecture can achieve better semantic segmentation accuracy by fusing RGB image with disparity map.
Disparity map and dataset
Obtaining disparity map
The disparity map contains many object features such as depth, contours, edges etc. These features are important for the convolutional neural network to extract valuable information. Therefore, it is necessary to obtain a smooth disparity map. The commonly used stereo matching algorithms include local matching, semi-global matching and global matching. The local matching algorithm has fast calculating speed while the matching result is rough. The global matching algorithm has high matching accuracy, but it has high computational complexity and matching time. The semi-global matching algorithm is between the local matching and global matching. It has better real-time performance and relatively good matching accuracy. Moreover, the semi-global matching algorithm is less sensitive to the change of the light ray and has a good robustness to noise. Therefore, considering the real-time requirement and the robustness, we use semi-global matching algorithm to obtain the disparity map. The steps of the algorithm are asfollows: Use the window-based local algorithm to compute gray similarity matching cost of each pixel. Establish a global energy function by performing clustering on matching costs based on smoothness constraint in multi-directional scan lines. Use the winner takes all algorithm (WTA) to select the disparity value that minimizes the energy function. Sub-pixel disparity value is estimated by quadratic curve fitting. Eliminate the abnormal points and relieve the error matching due to occlusion. Use the fast global image smoothing method [16] to optimize the rough disparity map and make disparity values more continuous.
Through the first four steps, the rough disparity map that has many noise points can be obtained. The fifth step is used to fill the non-matched pixel points and make the disparity map smoother.
The matching result is shown in Fig. 1. In the disparity map before optimization, the black pixel points are the non-matched points. In the optimized disparity map, the disparity values are more continuous and the edges of objects are also bepreserved.

Matching result.
Many outdoor scene datasets are available for semantic image segmentation [15, 17]. Out of these, the KITTI dataset [15] contains many stereo image pairs, so that the disparity map can be obtained.
Firstly, the representative traffic scene image pairs are selected from the stereo2012 dataset which is a sub-dataset in KITTI. The frequency of each class in the dataset is unbalanced. Sky, building and road pixels dominate the dataset. There are almost no pedestrian and traffic sign pixels in the dataset. It is very hard to manually label the small classes. To assess the performance of the network, the traffic scene is divided into 8 classes: sky, building, road, sidewalk, tree, car, lawn, and traffic sign. The first 6 classes are dominated classes and the last 2 classes are small classes in the dataset. The other classes of the dataset are ignored. Then, the pixels are labeled manually with the left image as the sample. Finally, the acquired disparity maps and the left color images are fused into four-channel images. Note that the image resolution in KITTI is approximately 1226×370 pixels and it is cropped to 480×360 pixels because low-resolution images allow us to train the network in an acceptable period of time. A total of 480 images are selected and divided into training set (350 images), validation set (90 images), and test set (40 images) without overlaps. Training set is used to train the network and build predictive model, validation set is used to verify the segmentation accuracy of the network and test set is used to assess the qualitative performance of the model. These pictures are used to verify the performance of the network as proof-of-concept, although the more the better.
Network architecture and learning scheme
Network architecture
There are many classic convolutional neural networks architectures that have achieved good results in terms of image classification. Among them, AlexNet won the 2012 ImageNet image classification contest. We establish our architecture based on AlexNet network due to its good performance. AlexNet contains 5 convolutional layers, 3 pooling layers and 3 fully connected layers. The output of AlexNet is a 1000 dimensional feature vector corresponding to 1000 different classes. Since the semantic pixel-wise segmentation task requires that the output of the network should have the same size with the input image, the fully connected layers are discarded and the unpooling operation is used to enlarge the size of feature map. The unpooling operation is implemented following the same approach proposed in [18]. It records the locations of maximum feature value in each pooling window during pooling operation. These location information is used to place each feature value back to the corresponding location during unpooling operation. Unlike the pooling operation that reduces the size of feature maps, the unpooling operation restores these feature maps to their original sizes. The process of pooling and unpooling is shown in Fig. 2.

Illustration of max-pooling and unpooling operations.
The detail of the proposed network architecture is shown in Fig. 3. The network consists of an encoder network and a corresponding decoder network. The encoder network is used to extract features from input image. The main function of the decoder network is to produce semantic output through unpooling operations. In order to output higher resolution feature maps at the end of the encoder network, we use a stride of 1 pixel to perform the convolution operations and a 2×2 pixels window to perform the max-pooling operations. The stride of max-pooling operations is 2 pixels with no overlap. A recently-developed normalization method called “batch normalization” is performed after each convolution operation to reduce the internal covariate shift [19], and the local response normalization technique used in the AlexNet is discarded. The batch normalization can also help reduce overfitting during training phase.
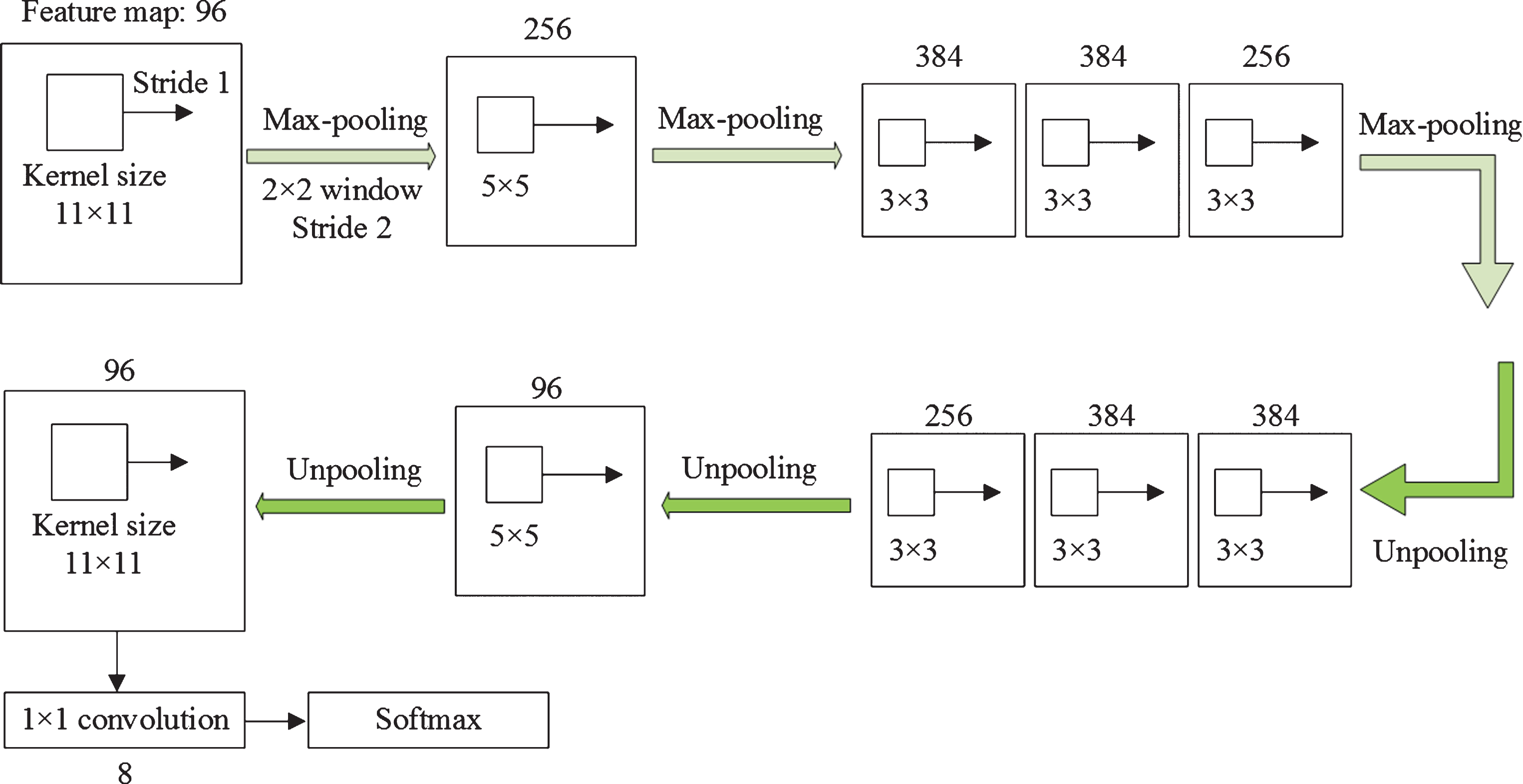
Netwok architecture.
The decoder network consists of five convolutional layers that are the mirrored versions of the encoder network. After decoder network, the 1×1 filters are used to perform the convolution operation to reduce the dimensions of feature maps. The output of 1×1 convolution operation is 8 feature maps of which the resolution has the same size as the input image. These 8 feature maps are fed to a softmax classifier that produces 8-channel class probabilitymap.
The weights and biases in convolutional layers are initialized to Gaussian distribution and zero, respectively. The weights of batch normalization layers are initialized as described in [20]. Stochastic gradient descent (SGD) [21] is used to train the variants of the network. These variants are computed using Equation (1).
The cross-entropy loss function [10] is used to compute the loss between the actual output and the label. The equation is shown in Equation (2).
The number of pixels of each class in the scenes varies greatly. The frequency of certain classes is several times that of other classes. It is important to weight the loss of each class. The median frequency balancing [22] is used to achieve this function. The optimized loss is shown inEquation (3).
In our experiments, we use Ubuntu 14.04 operating system with Intel Xeon E5-2620 CPU and an NVIDIA GeForce GTX TITAN X GPU. We implement the training and testing of the network using the deep learning frame Caffe [23] with cuDNN v2 acceleration.
Global accuracy and class average accuracy are employed to assess the performance of the network. The global accuracy is the ratio of the samples correctly classified to all samples in the dataset, and the class average accuracy is the mean of the predictive accuracy over all classes. The class average accuracy has little actual meaning because the numbers of pixels of each class are unbalanced in the training set. Since the dominant classes occupy most of the pixels in our training set, the accuracy of these classes are higher relatively and vice-versa. A high global accuracy means that the semantic segmentation results are smoother especially for the classes that dominate the dataset. The aim of semantic image segmentation is to get smooth semantic segmentation, so the iteration wherein the global accuracy is highest amongst the evaluations on the validation set is selected as the final predicting model.
The RGB-D image and the corresponding RGB image are used as the input of the network respectively to implement the training and testing. The prediction accuracy of the model on the validation set is obtained after each round of 400 iterations in the training set. The training mini-batch is set to 4 due to the limitation of graphics memory and the maximum number of iterations is set to 10,000. The training loss and validation accuracy curves are shown in Fig. 4. The conclusions are summarized asfollows:
Training loss and validation accuracy curves. The training loss and validation accuracy all obtain the good convergence rates. The validation accuracy using RGB-D image as input is higher than that using RGB image as input.
Numerical validation accuracy
The classes that dominate the training set, such as sky and road, have high segmentation accuracy whether using RGB-D image or RGB image as the input of the network.
The global accuracy using RGB-D image as the input is 3.3% higher than that using RGB image as the input. The class average accuracy is 5% higher than that using RGB image as theinput.
For the classes including sky, building, road, sidewalk, tree, lawn, car, and traffic sign, the segmentation accuracy using RGB-D image as the input of the network improved by 4.0%, 5.5%, 1.1%, 5.4%, 2.1%, 9%, 5.1%, and 7.5%, respectively, than using RGB image as the input of the network.
Through the above analysis and comparison, it can be inferred that using RGB-D image as the input of the network can get higher global accuracy and class average accuracy. There has been a great improvement for the accuracy of the important classes such as building, road, and car in the traffic scene. Figure 5 shows the disparity maps and qualitative results. As is clear from the Fig. 5, the disparity map can help improve the noisy outputs. Moreover, for small objects such as traffic sign, the method using RGB-D image as the input of the network could also help improve the segmentation results. Then the network architecture proposed in [24] is used to implement the training and testing on the RGB-D dataset. The training parameters are the same as that of the proposed network. The global accuracy is 85.6% which is decreased by 0.5% compared to our proposed network architecture. Although it is not obvious, the result reveals that our proposed fully convolutional network architecture has a good performance for semantic image segmentation.

Qualitative assessment on test samples.
This paper proposed a semantic image segmentation method. The optimized disparity map is used to improve the segmentation accuracy. A fully convolutional network is presented for pixel-wise image segmentation based on AlexNet network. The proposed network consists of an encoder network and a decoder network. The encoder network is used to extract the features of the input images. The decoder network uses the unpooling operations to restore the resolution of the feature maps to their original sizes. The network can accept images of any size as input and produce the corresponding predicted output. The stochastic gradient descent is employed to train the network. The experimental results show that the introduction of disparity map can help reduce semantic noise output and that the proposed network architecture achieves good segmentation results.
Footnotes
Acknowledgments
This project is supported by the National Natural Science Foundation of China (Grant Nos. 51775082, 61473057, 61203171) and the China Fundamental Research Funds for the Central Universities (Grant Nos. DUT17LAB11, DUT15LK13).