
Abstract
In recent years, UNet and its derivative networks have gained widespread recognition as major methods of medical image segmentation. However, networks like UNet often struggle with Point-of-Care (POC) healthcare applications due to their high number of parameters and computational complexity. To tackle these challenges, this paper introduces an efficient network designed for medical image segmentation called MCU-Net, which leverages ConvNeXt to enhance UNet. 1) Based on ConvNeXt, MCU-Net proposes the MCU Block, which employs techniques such as large kernel convolution, depth-wise separable convolution, and an inverted bottleneck design. To ensure stable segmentation performance, it also integrates global response normalization (GRN) layers and Gaussian Error Linear Unit (GELU) activation functions. 2) Additionally, MCU-Net introduces an enhanced Multi-Scale Convolution Attention (MSCA) module after the original UNet’s skip connections, emphasizing medical image features and capturing semantic insights across multiple scales. 3)The downsampling process replaces pooling layers with convolutions, and both upsampling and downsampling stages incorporate batch normalization (BN) layers to enhance model stability during training. The experimental results demonstrate that MCU-Net, with a parameter count of 2.19 million and computational complexity of 19.73 FLOPs, outperforms other segmentation models. The overall performance of MCU-Net in medical image segmentation surpasses that of other models, achieving a Dice score of 91.8% and mIoU of 84.7% on the GlaS dataset. When compared to UNet on the BUSI dataset, MCU-Net shows an improvement of 2% in Dice and 2.9% in mIoU.
Introduction
In recent years, healthcare professionals have gained the capability to perform rapid bedside ultrasound examinations using handheld devices known as Point-of-Care Ultrasound (POCUS). These devices are more portable compared to traditional ultrasound equipment [1]. POCUS has demonstrated remarkable clinical efficacy in detecting various conditions, including pneumonia, pleural effusion, and dyspnea caused by pericardial effusion [2], as well as assessing pre- and post-resuscitation conditions following cardiac arrest [3]. POCUS’s application can also be found in home healthcare settings, enabling medical assessments through the linkage of a portable ultrasound device with a cell phone [4]. On the other hand, the field of MRI is also progressing toward POC applications [5]. With the ongoing advancement of POC medical devices, the prevailing trajectory of future research lies in the analysis of examination findings through artificial intelligence [6]. Using techniques like image segmentation and image classification within the domain of deep learning on such devices can significantly expedite the diagnostic process for both patients and doctors. However, the majority of POC devices face limitations in terms of computational performance and memory. Consequently, designing a model that strikes a balance between model complexity and computational efficiency remains a formidable challenge in this domain.
POC application demonstration (shown in the image as POCUS).
Presently, prevalent solutions for medical image segmentation tasks widely apply UNet [7] and its diverse derivative networks. These networks include UNet++ [8], AttentionUNet [9], V-Net [10], UNet3+ [11], and ResUNet [12] etc. Notably, there has been a recent integration of the self-attention mechanism from Vision Transformers [13] into the UNet framework. This innovation has led to the creation of Transformer-based UNet derivative image segmentation models such as TransUNet [14], TransBTS [15], MedT [16], Swin UNet [17], and more. However, while the aforementioned studies tend to introduce more complex networks into UNet to enhance model performance, the practicality of deploying such segmentation networks with a large number of parameters on bedside devices is limited. These devices often face constraints in computational performance and memory [18]. Particularly, Transformer-based UNet derivative image segmentation models exhibit outstanding performance due to their excellent modality fusion capabilities and the self-attention mechanism that effectively captures global information. However, Transformer-based UNet derivative networks exhibit increased model complexity, a higher number of parameters, extended network training durations, and a demand for advanced computational devices such as GPUs. These attributes are a result of the strong emphasis on performance enhancement.
Recently, the ConvNeXt network [19] demonstrated that a pure convolutional network can outperform Transformer-based networks, highlighting the effectiveness of convolutional neural networks. Taking that into consideration, we have decided to employ a pure convolutional neural network approach to address the aforementioned problem. Referring to ConvNeXt’s improvement of the original ResNet, we have proposed the MCU Block as a replacement for the original convolution module in UNet. This modification enables our model to prioritize the target region by acquiring global information. At the same time, model parameters and computational complexity are reduced through the use of depth-wise (DW) convolution [20]. To enhance the model’s feature extraction capabilities across multiple scales of information, we have introduced Multi-scale Convolutional Attention (MSCA) [21] after the jump connection. The convolutional channels within MSCA have been adjusted, and its structure has been optimized specifically for the medical image segmentation task. We have employed convolution to replace the original pooling layer to prevent information loss during downsampling pooling. Additionally, we have added batch normalization (BN) [22] during both the upsampling and downsampling stages to ensure the stability of the training process.
The main contributions of this paper are as follows:
We propose MCU-Net, an efficient network model tailored for medical image segmentation. We introduce the MCU Block, which enhances the model’s capability to acquire global information in medical image segmentation. Additionally, we incorporate a convolutional attention module (MSCA) to improve multi-scale feature extraction. The structure of the upsampling and downsampling layers is redesigned for better performance. Both the MCU Block and MSCA utilize depth-separable convolution to optimize network model complexity. We conduct extensive experiments on GlaS and BUSI datasets, demonstrating the exceptional performance of our proposed network in terms of both model complexity and segmentation performance.
The remaining sections of this paper are structured as follows: In Section 2, we provide an overview of the current state of progress in related work. Section 3 details the methodology of MCU-Net and its constituent modules. Section 4 is dedicated to presenting the experimental details, and Section 5 showcases the experimental results. In Section 6, we discuss the limitations of the research presented in this paper and outline prospects. Finally, the whole paper is summarised in Section 7.
Previous UNet-based approach
FCN (Fully Convolutional Network) [23] is a pioneer of image segmentation that employs complete convolutions for feature extraction. UNet, introduced as a typical method of medical image segmentation networks, addressed information loss by introducing jump connections between the original encoder and decoder of FCN. UNet achieved significant success in medical image segmentation applications, establishing itself as a benchmark model in the field. Zhou et al. [8] introduced U-Net++, which redesigned jump connections to create a network that aggregates features with different semantic scales on the decoder sub-network. This innovative approach efficiently addresses the challenge of unknown network depth by integrating U-Nets with different depths. Building upon the foundation laid by U-Net++, Huang et al. [11] proposed U-Net3+, which further enhanced the model by employing full-scale jump connections, deep supervision, and a combination of hybrid loss functions and classification bootstrap modules. Jha et al. [24] introduced the DoubleU-Net, utilizing a stacked UNet approach by adding UNet at the base of the original UNet architecture. Concurrently, they employed Atrous Spatial Pyramid Pooling (ASPP) to capture contextual information within the network. In a separate endeavor, Anita et al. [12] enhanced the UNet model by introducing a residual structure, resulting in the ResUNet. They replaced conventional convolutions in the model with Res-blocks to significantly boost network performance. Oketay et al. [9] introduced the Attention-UNet, which incorporates an attention module into the jump connection of the U-Net framework. This approach utilizes Attention Gate implicit learning to effectively suppress irrelevant regions in the input image while emphasizing crucial features for segmentation tasks. While these various methods enrich and broaden the potential applications and research scope of UNet-type networks, they also introduce heightened complexity in network structures and algorithms, posing challenges for practical applications that should not be underestimated. In Table 1, we provide a comprehensive summary of the evaluation criteria, advantages, and disadvantages of the aforementioned networks.
Advantages, disadvantages, and evaluation metrics of UNet-based networks
Advantages, disadvantages, and evaluation metrics of UNet-based networks
The attention mechanism represents a specialized form of neural network that assigns distinct weights to various segments of the input data, guided by the demands of a specific task. This mechanism effectively steers the network’s attention toward regions of interest, resulting in a notable enhancement in performance. Hu et al. [25] introduced SE-Net, which features the Squeeze and Excite (SE) module. This module facilitates the transformation from spatial features to global features, thus better capturing intricate inter-channel relationships. Woo et al. [26] proposed CBAM, a feed-forward convolutional neural network attention module. CBAM seamlessly combines cross-channel and spatial information, effectively extracting informative features. Huang et al. [27] introduced CCNet, featuring a crossing attention mechanism. This mechanism adeptly captures both horizontal and vertical information, strategically weighting the features of target pixel points through correlation analysis to attain comprehensive global contextual information. In contrast, ECA-Net [28] refines the excitation module of SE-Net, underscoring the significance of bypassing dimensionality reduction in channel attention. It emphasizes that suitable cross-channel interactions can substantially mitigate model complexity while preserving performance. On the other hand, SA-Net [29] integrates the Shuffle Attention (SA) module. Diverging from conventional spatial and channel attentions, SA-Net employs a shuffle attention approach, utilizing a permutation matrix to reorganize the feature map. This restructuring fosters the exchange of feature information, bolstering visual transmission and elevating model performance. Remarkably, the attention mechanism engenders performance enhancement with only a minor portion of model parameters and computational resources, which serves as an encouraging prospect for our pending problem. However, it’s important to acknowledge that the attention mechanisms aforementioned might not excel in the domain of multi-scale feature extraction. Refer to Table 2 for a summary of the advantages and disadvantages of the attention mechanisms.
Advantages and disadvantages of attention mechanism
Advantages and disadvantages of attention mechanism
Recently, Convolutional Neural Networks (CNNs) have made a comeback as ConvNeXt [19], a pure convolutional network, achieved superior performance in segmentation tasks by drawing inspiration from the successful experiences of Vision Transformer and re-designing the ResNet50/200 convolutional models. Based on the research of ConvNeXt, Zhang et al. [30] introduced BCU-Net. This model redesigns ConvNeXt into a form of encoder-decoder. At the same time, BCU-Net will allow parallel input of advanced ConvNeXt and UNet. Finally, the Multilabel Recall Loss (MRL) module will facilitate the deep integration of local and global pathology semantics between the two heterogeneous branches. Chen et al. [31] proposed an improved UNet network for oral therapy, among which the DCN Block applies a dual ConvNeXt Block and proposes an attention module using multi-filter and self-attention techniques. Although the above networks are based on ConvNeXt for network design, none of them are investigated in the direction of model light-weighting, thus making it difficult to meet the medical needs of POC applications. Inspired by ConvNeXt, Han et al. [32] designed ConvUNeXt. This innovative design reconfigures the convolutional blocks within UNet and introduces a lightweight attention mechanism that hones in on the target region. Concurrently, UNeXt [33] stands as a streamlined segmentation model that simplifies the conventional UNet structure and elevates its standard MLP by introducing a Tokenized MLP layer. Refer to Table 3 for a comprehensive overview of the evaluation criteria, advantages, and limitations of the networks mentioned.
Advantages, disadvantages, and evaluation metrics of further evolved convolutional networks
Advantages, disadvantages, and evaluation metrics of further evolved convolutional networks
MCU-net overall network architecture
The UNet architecture is divided into three key components: encoder, decoder, and skip connections. When it comes to the encoder, a sequence of convolutions and consecutive downsampling operations are employed to extract semantic information at various stages of the network. While the decoder involves upsampling the extracted features. During this process, the semantic information obtained from different stages in the encoder is integrated with the high-resolution semantic information derived from the upsampling through jump connections. This integration aims to alleviate the spatial information loss caused by downsampling.
MCU-Net adopts the U-shaped structure of the UNet as its core architecture. Unlike UNet, MCU-Net replaces the conventional convolution blocks in the encoder-decoder sections with MCU Blocks. MCU Block simplifies the UNet model and improves network performance. However, it should be noted that this alteration might lead to a limitation in the local feature extraction capability of the network. Consequently, MCU-Net introduces the Multiscale Convolutional Attention (MSCA) module following the skip connection within the UNet structure. The primary purpose of the skip connection in UNet is to extract distinct levels of semantic information for subsequent upsampling operations. In contrast, from different scales, MSCA processes semantic information obtained through skip connections. This adjustment empowers the model to distribute more weights on local features within the target region. Furthermore, adaptations are made to the upsampling and downsampling layers within the encoder-decoder framework to ensure the stability of the training process. The comprehensive architecture of our proposed MCU-Net is visually depicted in Fig. 2.
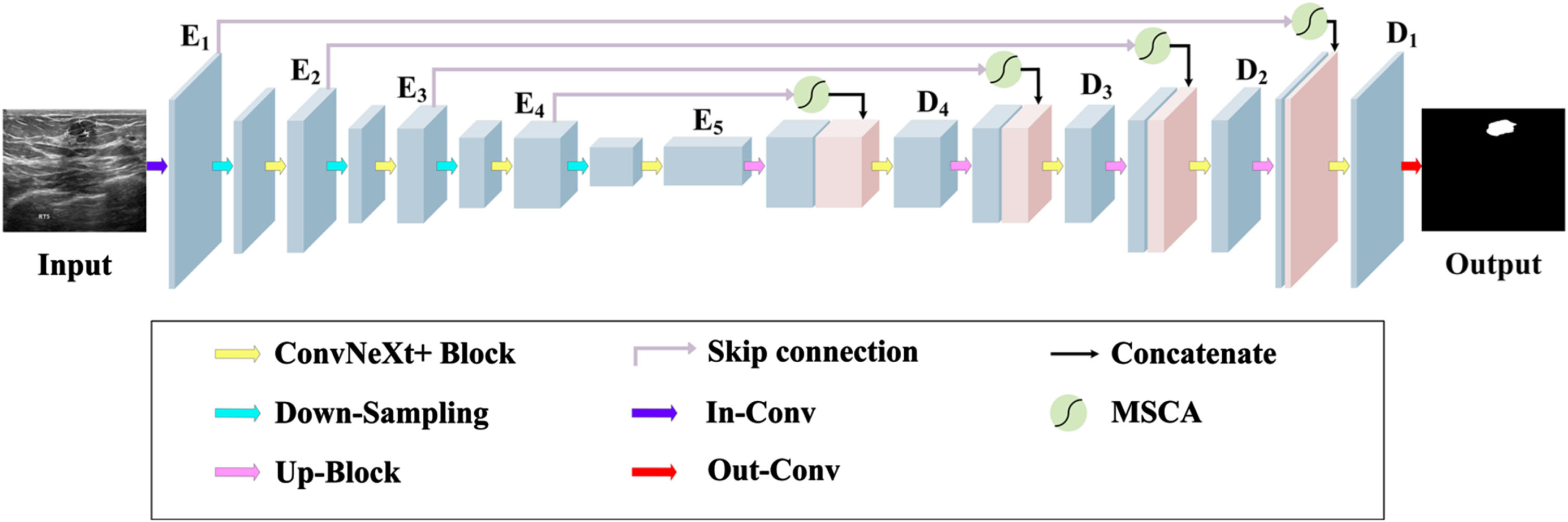
Overall network architecture of MCU-Net based on UNet.
MCU-Net consists of Encoder, MSCA Block, Decoder, and Skip Connections. The Encoder in MCU-Net consists of five MCU Blocks and four downsampling layers. The outputs from the five encoder layers are denoted as E1, E2, E3, E4, and E5. The Decoder is constructed with four MCU Blocks and four upsampling layers. The outputs from the four decoder layers are labeled D1, D2, D3, and D4. The MSCA module connects the results from the skip connections with the upsampling outputs within the decoder. For reference, the inputs and outputs of MCU-Net are presented in Table 4.
We show in detail the inputs and outputs of each module in MCU-Net. Econv denotes the encoder module and Dconv denotes the decoder module
ConvNeXt, building upon the foundation of the standard ResNet [34], refined the design of the Vision Transformer and delved into crucial components that contribute to enhancing model performance. ConvNeXt conducted in-depth exploration across various aspects, encompassing macro-level design, ResNeXt, large kernel convolutions, inverted bottlenecks, and micro-level design, surpassing Transformer’s performance. When incorporating the ConvNeXt Block into the UNet architecture, we observed an enhancement in the performance of UNet. Consequently, MCU-Net adopts the ConvNeXt Block as the major convolutional module. Furthermore, to optimize the ConvNeXt Block’s performance within the medical image segmentation domain, we introduced the MCU Block after refining it to meet the specific requirements.
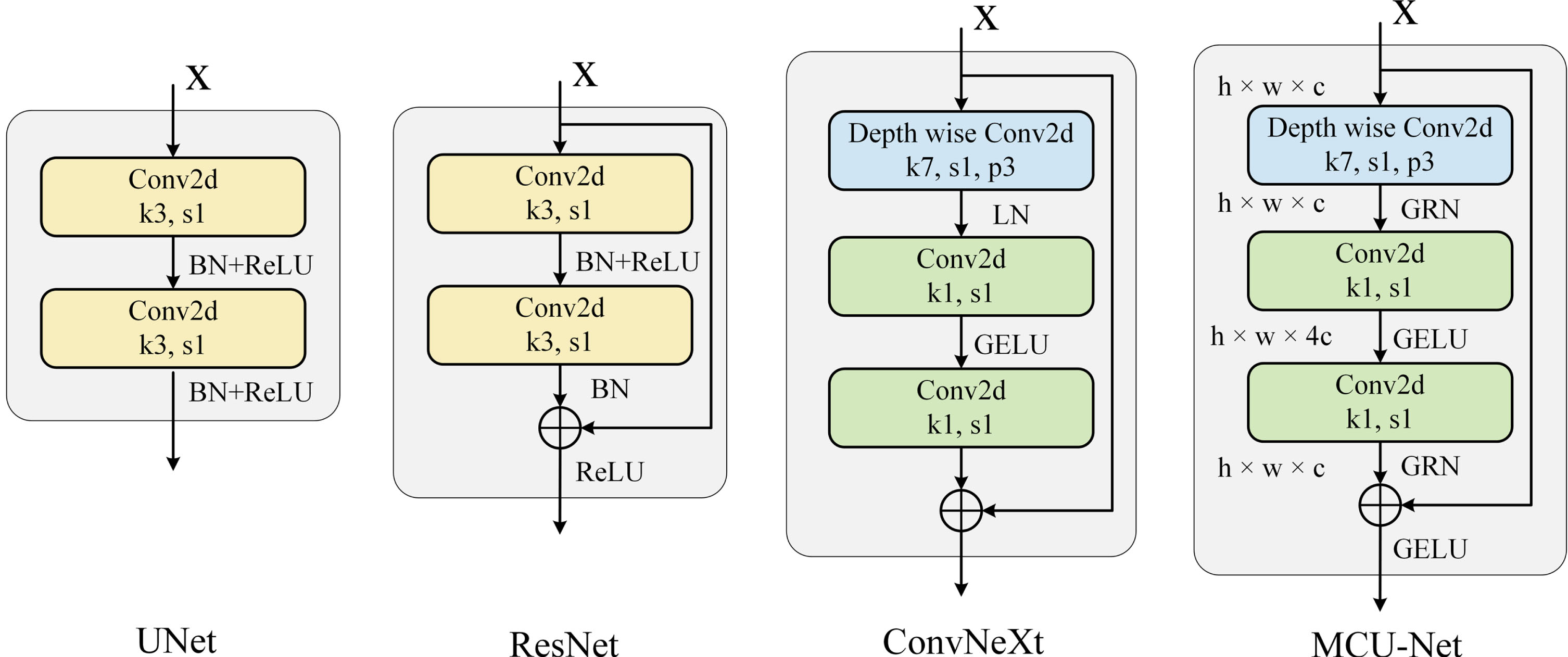
Implementation details of convolutional modules for UNet, ResNet, ConvNeXt, and MCU-Net.
In U-Net, the global max pooling layer serves as the method for downsampling. However, global max pooling lacks adjustability and doesn’t possess learnable parameters. In contrast, convolution operations are equipped with learnable parameters that can cater to data-specific adjustments, rendering the downsampling effect more tailored to actual requirements. Consequently, we substituted the original downsampling approach with a 2×2 convolution kernel and a stride of 2. This change avoids potential information loss that could arise from global maximum pooling. We have not adjusted the downsampling module and still use Bilinear Interpolation for upsampling, but we have added Batch Normalization [22] before both the upsampling and downsampling modules. This approach curtails the network’s sensitivity to significant parameter shifts during inverse computations, rendering the network’s parameter updates more stable. This step ensures training process stability and standardizes data throughout the upsampling and downsampling procedures. The implementation details of upsampling and downsampling are shown in Fig. 4.
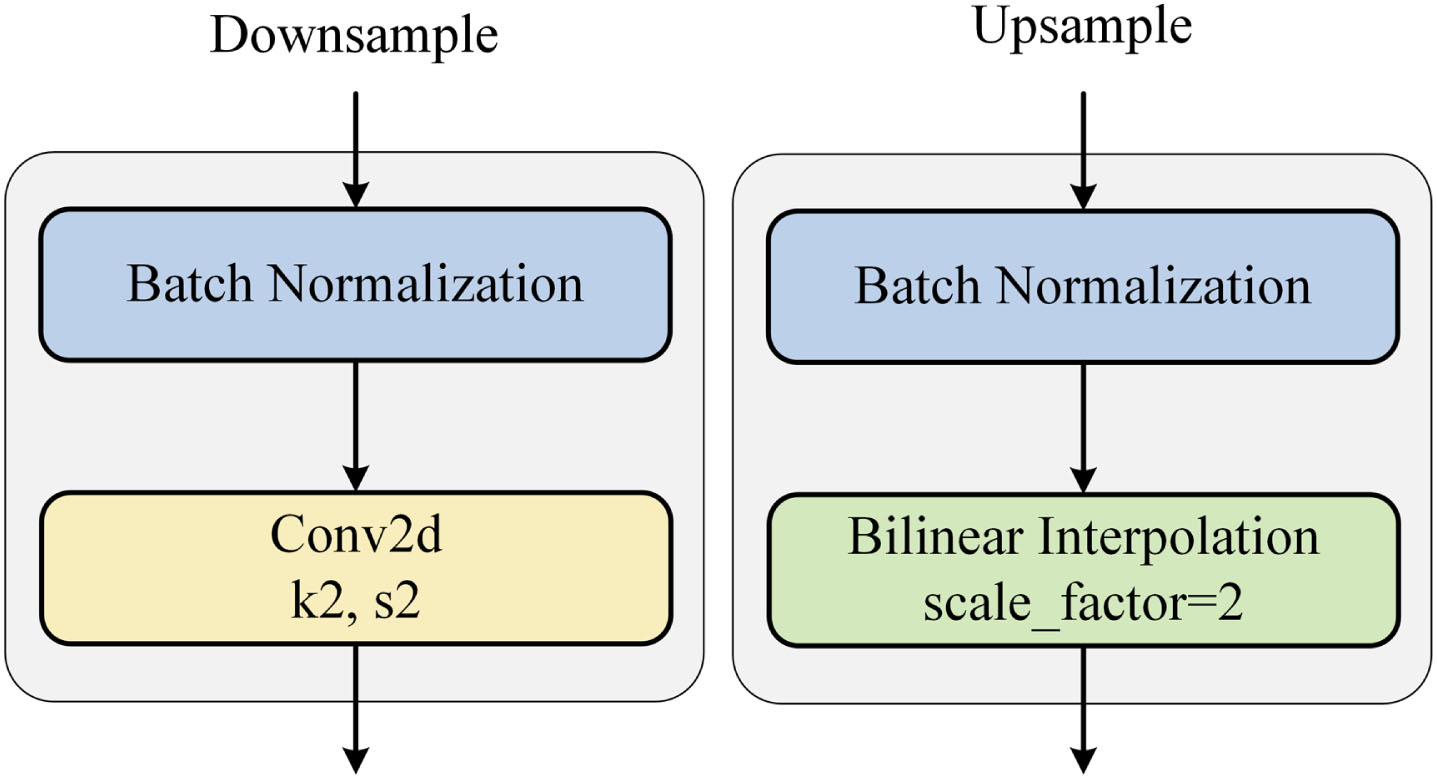
Up-sampling and down-sampling adjustment details.
After adding the MCU Block, we observed a reduction in the overall model complexity. However, we also identified a shortfall in effectively capturing local information during the image segmentation process. To address this limitation, we opted to integrate an attention mechanism to enhance the model’s capabilities. The Multi-scale Convolutional Attention (MSCA) [21] module emerged as a novel form of attention mechanism, harnessing an economical convolutional attention approach. Compared to previous attention mechanisms, MSCA uses deep convolution that aggregates local information, which can lead to a significant reduction in the computational cost of the attention network. MSCA introduces an innovative multi-branch depth-banded convolution scheme for capturing multi-scale context. This approach incorporates three distinct convolution kernel sizes: 7, 11, and 21. It further restructures conventional convolution into a pair of banded convolutions, where a single pair of 7×1 and 1×7 convolutions effectively replace a standard 7×7 convolution [39]. This banded convolution design achieves dual objectives: It enables the extraction of semantic information with minimal computational cost and parameters while complementing mesh convolution to facilitate the extraction of banded features, such as blood vessels and muscle cells, in the medical domain. Simultaneously, the utilization of three convolutions with varying scales empowers MSCA to capture information across multiple scales, enriching the semantic information accessible to MCU-Net. This enhancement encompasses fine-grained features that were previously less perceptible to the network.
In this study, our objective was to enhance MCU-Net’s capacity for capturing intricate semantic information within medical image segmentation. To achieve this, the convolution kernel dimensions were adjusted from 7, 11, 21 to 5, 7, 11. Additionally, a 1×1 convolution was incorporated preceding the MSCA module. This addition of a 1×1 convolution corresponds to a fully connected computational process, augmenting the network’s depth without expanding the receptive field. Subsequently, a GELU activation function was integrated to heighten the nonlinearity of the network. This augmentation enables the network to encapsulate more intricate features and ultimately improves the overall performance of the final model. From a mathematical perspective, the MSCA can be represented as Equation (1):
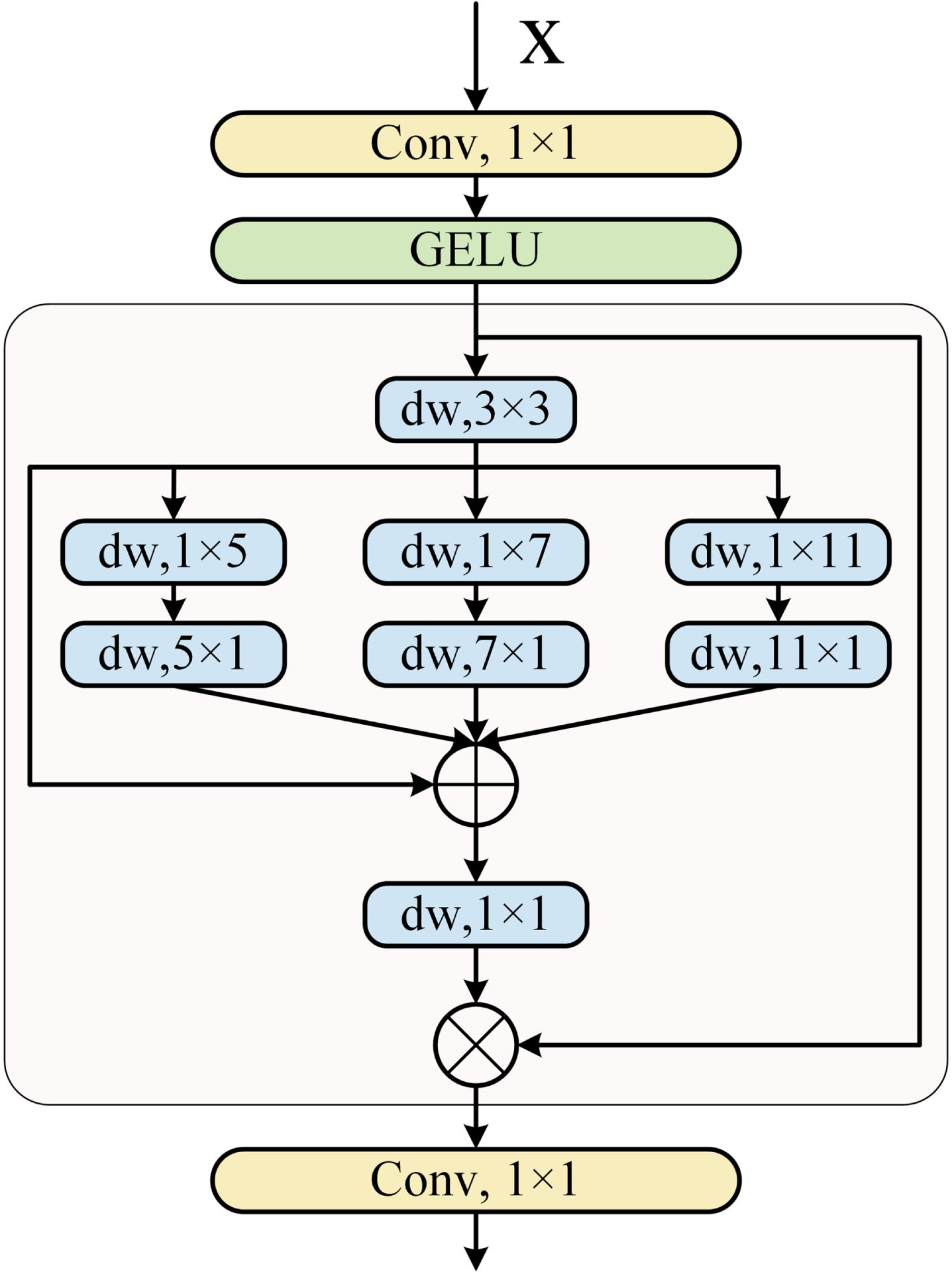
Multi-scale convolutional attention module (MSCA).
Dataset
We utilized two datasets for our experiments: the Gland Segmentation dataset (GlaS) [40] and the Breast Ultrasound Images dataset (BUSI) [41]. Figure 6 shows the data set used in our experiments.
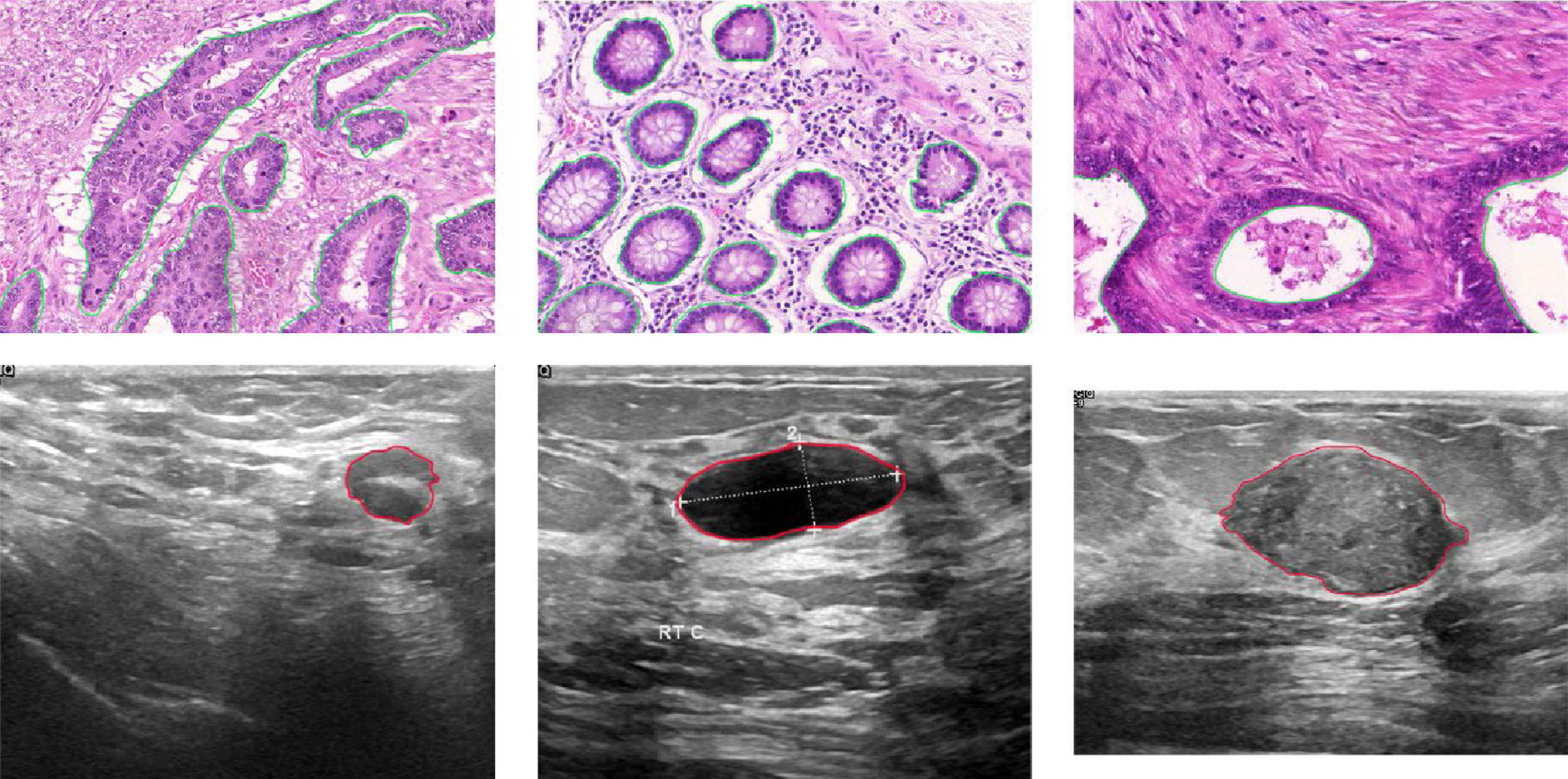
The experimental data set is shown, where the first row is the Gland segmentation dataset (the green outline is the segmentation area) and the second row is Breast Ultrasound Images (the red outline is the segmentation area).
Furthermore, medical segmentation frequently grapples with limited data availability. In this paper, we address this challenge by augmenting the image data through various techniques, including random horizontal and vertical flipping, center cropping, random cropping, and random aspect ratio cropping. These augmentation strategies serve to bolster the model’s generalization capacity and enhance its overall robustness.
To assess the performance of various methods, we employ the Dice coefficient (Dice) and Mean Intersection over Union (MIoU) as our evaluation metrics.
The Dice coefficient, which is widely used in medical image classification tasks, measures the similarity between two samples and ranges between 0 and 1. A higher Dice coefficient value indicates a greater similarity between the predicted and true labels. Mathematically, the Dice coefficient is defined as follows:
Furthermore, the mIoU metric calculates the average intersection ratio of the true and predicted values across all samples. It provides a comprehensive evaluation of the overlap between the predicted and true segmentation. The mIoU can be calculated using the following formula:
Here, TP represents the predicted medical image segmentation region correctly identified as the true medical image segmentation region, TN denotes the predicted background region correctly identified as the true background region, FP signifies the predicted medical image segmentation region falsely identified as the true medical image segmentation region, and FN indicates the predicted background region falsely identified as the true background region.
In the evaluation of deep learning models, two critical metrics are the number of parameters (Params) and the floating point operations per second (FLOPs). The parameter count represents the total number of trainable parameters in the model, providing insight into the model’s computational and spatial complexity. On the other hand, FLOPs quantify the computational time complexity, reflecting the number of floating point calculations the model can perform in a unit of time. By comprehensively considering these two metrics, a more comprehensive assessment of a deep learning model’s complexity can be achieved, facilitating guidance for model optimization efforts.
We implemented the MCU-Net model using PyTorch on a single NVIDIA RTX 3090 GPU card with 24 GB of RAM. During training, we did not utilize any initial training weights for MCU-Net. For the GlaS dataset, we set the batch size to 4, while for the BUSI dataset, it was set to 8. The input size for both datasets was uniformly defined as 480×480, with a weight decay of 5e-5. To train the MCU-Net model, we employed the Adam W optimizer [42] with an initial learning rate of 0.0015. With BCE and dice loss, the loss function
It is important to note that the same training settings and loss functions were utilized for training all baseline models, ensuring a fair and consistent evaluation across all methods.
Comparison with state-of-the-art
To validate the overall segmentation performance of MCU-Net proposed in this paper, we conducted comparative analyses with other state-of-the-art methods on the GlaS and BUSI datasets. The considered methods encompass UNet, UNet++, AttUNet, ResUNet, and ConvUNeXt. Tables 5 and 6 present contrasting results across these algorithms in terms of Dice and mIoU metrics after testing the GlaS and BUSI datasets, the evaluation metrics for model complexity (Params and FLOPs), as well as the time taken for training over 300 epochs.
Metrics of Different Methods on GlaS Dataset
Metrics of Different Methods on GlaS Dataset
Metrics of different methods on BUSI dataset
In terms of model performance, our method has the best metric scores in Dice and mIoU. Specifically, in the GlaS dataset, Dice is 1 over UNet and 0.4 over ConvUNeXt, and mIoU is 1 over U-Net and 0.2 over ConvUNeXt. According to the BUSI dataset, Dice is 2 above U- Net and 0.5 above UNeXt, while mIoU is 2.9 above U-Net and 0.3 above ConvUNeXt. The performance evaluation metrics of UNet++ and AttUNet perform consistently in all datasets; while ResUNet performs slightly worse than the other models.
Furthermore, our approach not only excels in segmentation performance but also demonstrates leadership in terms of model complexity. MCU-Net’s parameters in Params and FLOPs are 2.19M and 19.73Grespectively. This accomplishment primarily stems from our strategic utilization of DW convolution throughout MCU-Net, encompassing both the MCU Block and MSCA. This judicious integration effectively reduces the computational complexity and parameter count of the model. In comparison, the nearest contender, ConvUNeXt, incorporates an attention mechanism that has not been fine-tuned to optimize Params and FLOPs, thereby positioning us ahead in terms of model complexity. Figure 7 illustrates the correlation between mIoU and Params, as well as mIoU and FLOPs. The mIoU used here corresponds to the GlaS dataset. It is clear from the graph that MCU-Net has achieved outstanding results in terms of model complexity.
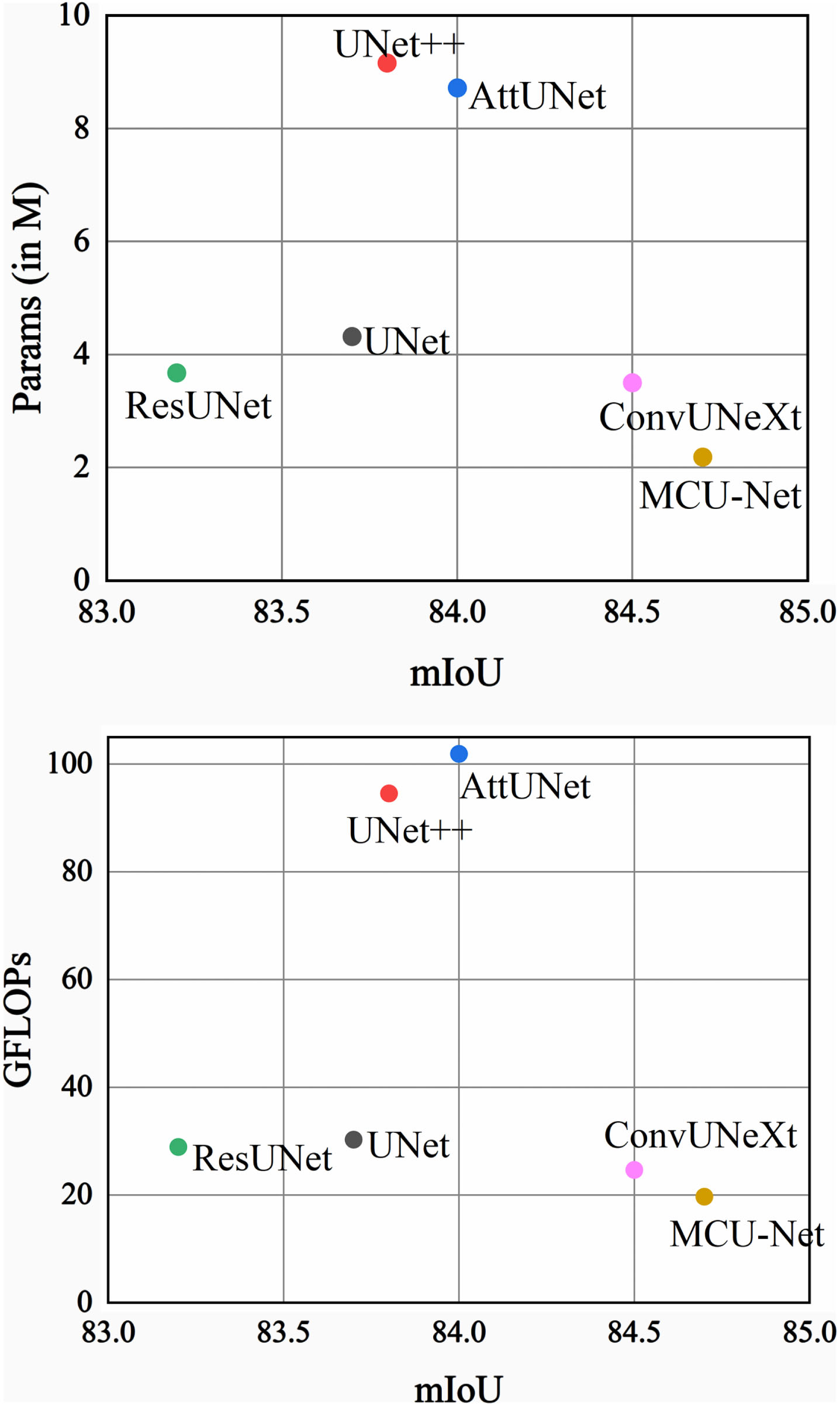
Comparison plot. The X-axis corresponds to the mIoU (higher is better). The Y-axis corresponds to the number of parameters, and GFLOPs (lower is better), respectively.
Finally, in terms of training time, UNet and ResUNet only took 20 minutes and 23 minutes on the GlaS dataset, and 103 minutes and 110 minutes on the BUSI dataset. This is mainly because UNet and ResUNet do not utilize attention mechanisms, while MCU-Net incorporates the MSCA attention mechanism. Benefiting from its fully convolutional design, MCU-Net achieved training times of 19 minutes on GlaS and 100 minutes on BUSI. On the other hand, both AttUNet and ConvUNeXt employ attention mechanisms, yet their training times surpass that of MCU-Net. This observation underscores the fact that the MSCA attention mechanism introduces lower model complexity. Moreover, due to the intricate nature of its skip connections, UNet++ exhibited a training time of up to 208 minutes on the BUSI dataset.
In Figs. 8 and 9, we showcase the visual segmentation results obtained from various methods on the GlaS and BUSI datasets. In Fig. 8, the H&E-stained tissues of colorectal adenocarcinoma present complex semantic information, exhibiting low contrast with the surrounding tissues, unclear boundaries, and the presence of numerous cluttered regions that require simultaneous segmentation. In certain scenarios, other networks display varying degrees of under-segmentation and a lack of sensitivity to the recognition of local semantic information. Notably, in the red box of Fig. 8, UNet and ConvUNeXt struggle to effectively extract local semantic information in this region. Conversely, MCU-Net demonstrates heightened segmentation accuracy, with its image segmentation results closely approximating the Ground Truth. In Fig. 9, the visualization of the BUSI dataset underscores disparities among the segmentation outcomes produced by different methods for cancer tissue section images. Cancerous and normal tissues share morphological and color similarities, thereby amplifying the challenges associated with accurate segmentation. However, MCU-Net’s focus on capturing local information enables precise delineation of lesion boundaries, yielding superior results compared to other algorithms.
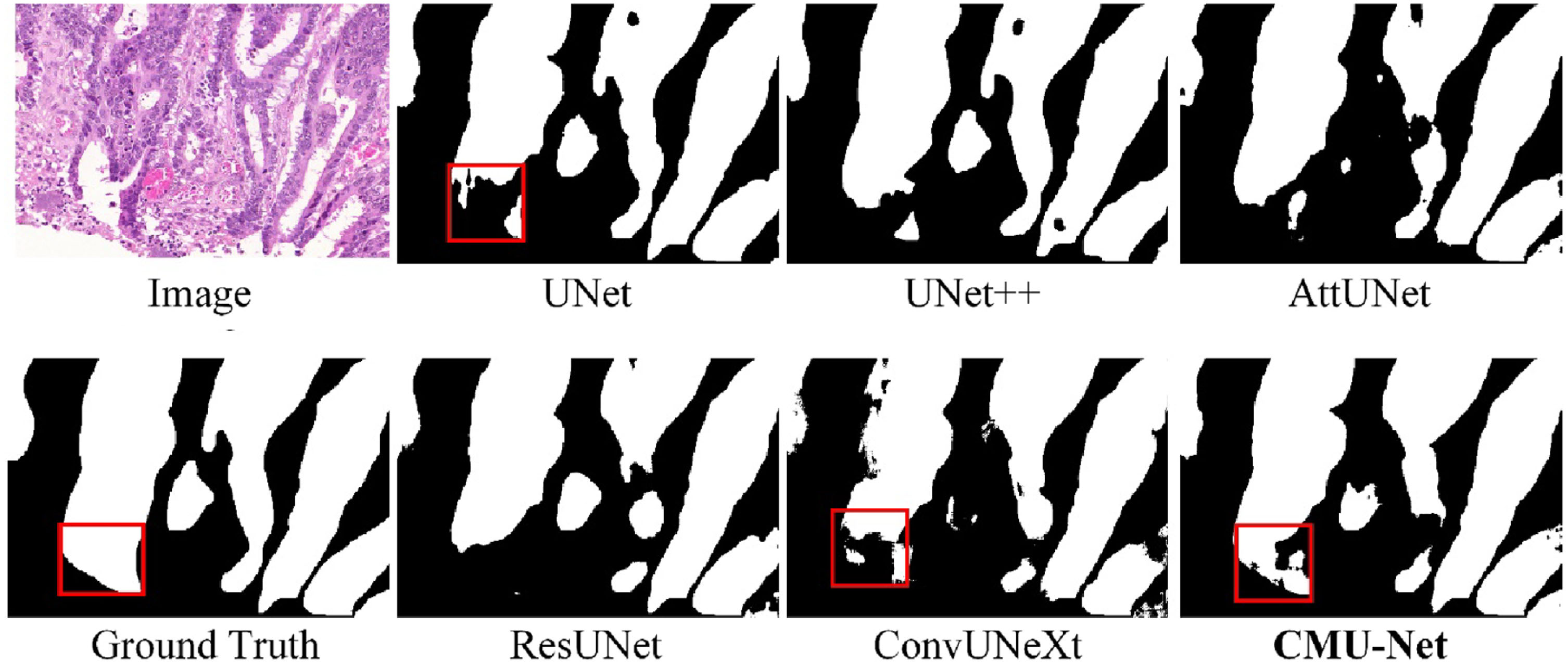
Visual detail results on the GlaS dataset.

Visual detail results on the BUSI dataset.
To verify the effectiveness of MCU Block, Improved upsampling and downsampling, and Improved MSCA in the MCU-Net proposed in this paper, we design several different sets of network models, and the results of each set of ablation experiments are obtained by comparing them on the GlaS dataset, and the results of the ablation experiments are shown in Table 7.
Presentation of ablation study results
Presentation of ablation study results
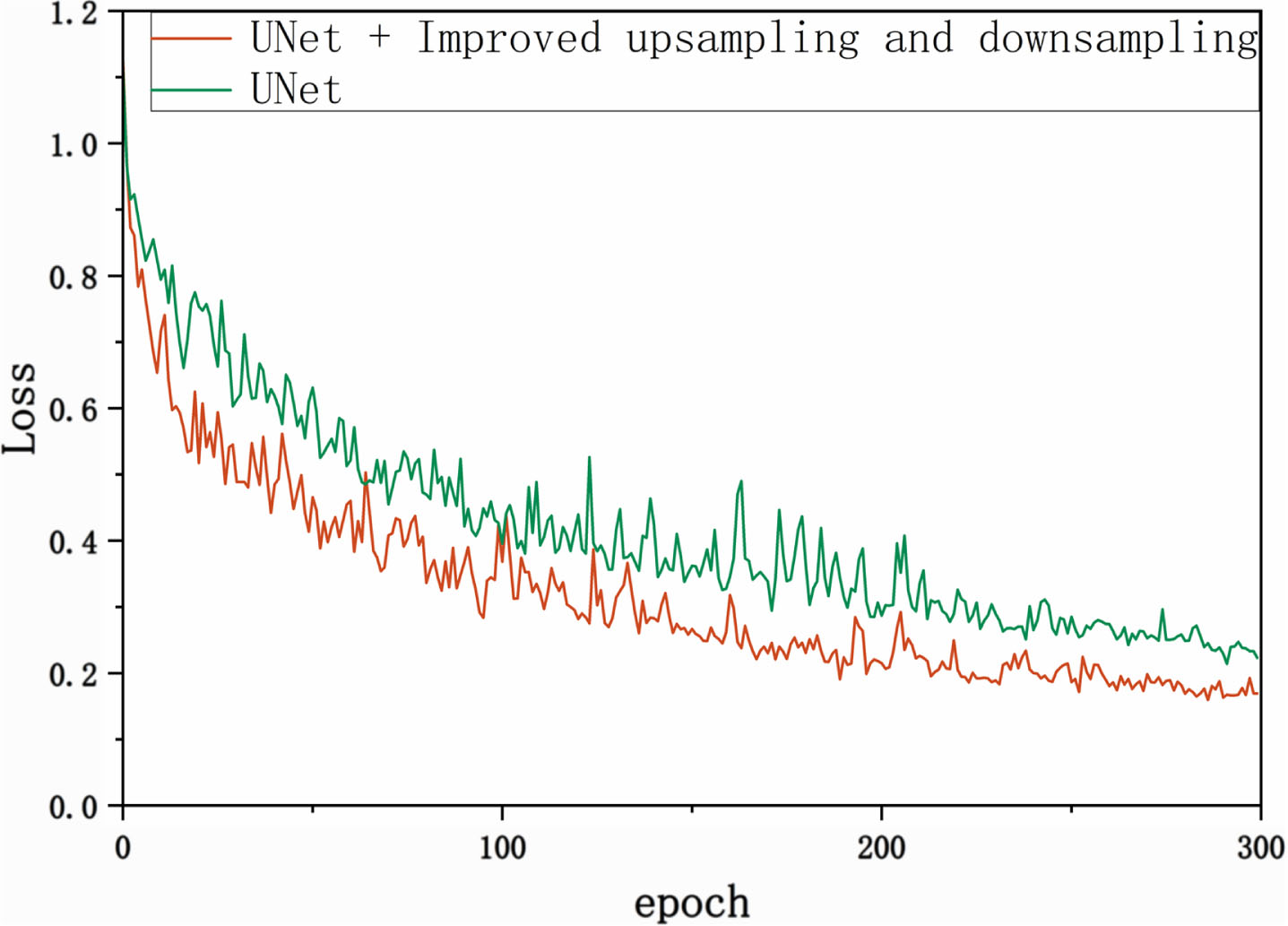
Loss fluctuation graphs for Experiment 1 and Experiment 2.
This study introduces an efficient convolutional neural network named MCU-Net, which is based on ConvNeXt to improve UNet. MCU-Net employs DW convolution and large convolutional kernels in both the encoder-decoder structure and the attention mechanism, aiming to reduce the overall model complexity. To address the potential reduction in segmentation accuracy due to decreased model complexity, we modified the original ConvNeXt Block. In doing so, we incorporated a GRN normalization layer and the GELU activation function to maintain segmentation precision during the task. Simultaneously, in the process of upsampling and downsampling, we replaced pooling layers with convolutional layers and integrated BN layers. This approach mitigates the network’s sensitivity to significant parameter changes during backpropagation, ensuring the stability of parameter updates throughout training. Additionally, we introduced the Multiscale Convolutional Attention (MSCA) module, which captures local features across multiple scales, thereby enhancing the overall segmentation accuracy of the network.
MCU-Net was validated on two publicly available datasets, including GlaS and BUSI. Comparative experiments showed that the algorithm outperformed existing state-of-the-art algorithms in terms of the model performance metrics Dice and mIoU, the model complexity metrics Params and FLOPs, as well as the training time, demonstrating that MCU-Net not only possesses excellent segmentation accuracy, but also that it has a lower model complexity. Notably, our ablation experiments revealed that the addition of MCU Block, the MSCA attention mechanism, and the modified up-and-down sampling module had a positive impact on the model’s performance.
Indeed, our approach has its limitations. In comparison to the classical UNet architecture, our method hasn’t significantly reduced training time. This can be attributed to the addition of the GRN normalization layer in the MCU Block to maintain segmentation accuracy. If a more concise convolutional module with high performance could be introduced, the lightweight nature of the network would be further enhanced. Furthermore, when compared to traditional desktops or servers, mobile devices operate within diverse operating systems and software environments. Adaptations and optimizations are necessary to ensure seamless execution of the model on mobile devices. Therefore, a crucial direction for future work is the ongoing refinement and enhancement of model performance, ensuring that segmentation algorithms can be successfully deployed and executed smoothly on embedded devices.
Conclusion
In instant POC applications, large image segmentation networks are not efficiently deployed to portable devices with limited clinical computing resources. To address this challenge, based on a conventional convolution neural network and attention mechanism, we propose MCU-Net, a deep learning network with simplicity, low parameter count, and low computational complexity. The MCU Block has been re-engineered, featuring the incorporation of a GRN normalization layer and the integration of a GELU activation function, building upon the foundation of the ConvNeXt Block. The MCU Block yields a substantial reduction in model parameters while upholding consistent segmentation performance. Within the upsampling layers, MCU-Net substitutes convolutions for pooling and integrates BN layers to enhance training stability. Additionally, we introduce the Multiscale Convolutional Attention module (MSCA) after the skip connections, further refining the MSCA’s structure and convolutional channels. The enhanced MSCA captures more local features across multiple scales, resulting in superior performance. Comparative experiments and visualization studies on the GlaS and BUSI datasets can demonstrate that we achieve more competitive results in terms of the balance between parameters, computational complexity, and performance. In the future, we aim to further optimize our model’s performance, reducing training time and parameters. We also plan to embark on the deployment of the model on embedded devices.
Footnotes
Acknowledgments
The research was supported by the CAMS Innovation Fund for Medical Sciences (CIFMS) (2022-I2M-C&T-B-035). National High Level Hospital Clinical Research Funding, 2022-PUMCH-A-121.